(2023,LENS 视觉模型 LLM)迈向可见的语言模型:通过自然语言的镜头来看计算机视觉
Towards Language Models That Can See:
Computer Vision Through the LENS of Natural Language
公众号:EDPJ(添加 VX:CV_EDPJ 进交流群获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
2.1 大语言模型能力
2.2 解决视觉和语言任务的对比模型
2.3 用于视觉应用的大型语言模型
2.3.1 图像标题(Captioning)生成
2.3.2 视觉和语言任务
3. 方法
3.1 视觉词汇
3.2 LENS 成分
3.3 提示设计
4. 实验
4.1 数据集
4.2 实现细节
4.3 结果
4.4 LENS 组件消融
5. 结论
6. 局限性
参考
S. 总结
S.1 主要思想
S.2 方法
0. 摘要
我们提出了 LENS,这是一种利用大语言模型 (LLM) 的力量来解决计算机视觉问题的模块化方法。 我们的系统使用语言模型对一组独立且高度描述性的视觉模块的输出进行推理,这些模块提供有关图像的详尽信息。 我们在纯计算机视觉设置(例如零样本和少样本目标识别)以及视觉和语言问题上评估该方法。 LENS 可以应用于任何现成的 LLM,并且我们发现采用 LENS 的 LLM 在更大、更复杂的系统中表现出很强的竞争力,而无需任何多模态训练。 我们在 https://github.com/ContextualAI/lens 开源我们的代码并提供交互式演示(https://lens.contextual.ai/)。
1. 简介

近年来,大型语言模型(LLM)彻底改变了自然语言理解,在语义理解、问题回答和文本生成方面展示了卓越的能力 [42,10,6],特别是在零样本和少样本设置中。 如图 1(a)所示,已经提出了几种利用 LLM 来完成视觉相关任务的方法。 一种技术涉及训练视觉编码器将每个图像表示为一系列连续嵌入的序列,从而能够被 LLM [55] 理解。 另一种方法采用冻结视觉编码器,该编码器经过对比训练,同时将新层引入冻结的 LLM,随后从头开始训练 [47,52,2]。 此外,另一种方法建议使用冻结视觉编码器(预先训练对比)和冻结 LLM 通过训练轻量级 transformer 来对齐它们 [35,27,63]。
尽管我们在上述研究方向上取得了进展,但与额外的预训练阶段相关的计算费用仍然是一个挑战。 此外,需要包含图像/视频和文本的大型数据集,以便在现有 LLM 的基础上调整视觉和语言模式。 Flamingo [2] 就是一个例子,它将新的交叉注意力层引入到 LLM 中,以结合视觉特征,然后从头开始进行预训练。 尽管使用预训练的图像编码器 [5] 和预训练的冻结 LLM [19],多模态预训练阶段仍然需要惊人的 20 亿个图像文本对以及 4300 万个网页 [64, 32],这项工作可以持续 大约15天。 相反,如图 1(b) 所示,我们可以从视觉输入中提取信息,并使用一组不同的“视觉模块”生成详细的文本表示(例如标签、属性、动作、关系等),然后将其输入信息直接发送给 LLM,避免额外的多模态预训练。
我们引入增强可见的大型语言模型(Large Language Models ENnhanced to See,LENS)一种模块化方法,利用 LLM 作为 “推理模块” 并在独立的 “视觉模块” 上运行。 在 LENS 方法中,我们首先使用预训练的视觉模块(例如对比模型 [47, 50, 13, 5] 和图像-标题(captioning)模型 [34, 35])提取丰富的文本信息。 随后,文本被输入 LLM,使其能够执行对象识别以及视觉和语言 (V&L) 任务。 LENS 无需额外的多模态预训练阶段或数据,以零成本弥合模态之间的差距。 通过集成 LENS,我们获得了一个开箱即用(out of the box)的跨域工作模型,无需任何额外的跨域预训练 [24,20,2,35]。 此外,这种集成使我们能够开箱即用地利用计算机视觉和自然语言处理方面的最新进展,最大限度地发挥这些领域的优势。
总之,我们的贡献如下:
- 我们提出了 LENS,这是一种模块化方法,通过视觉输入的自然语言描述,利用语言模型的少样本(few-shot)、上下文学习能力来解决计算机视觉任务。
- LENS 使任何现成的 LLM 都能够拥有视觉功能,而无需辅助训练或数据。 我们利用冻结的 LLM 来处理对象识别和视觉推理任务,而不需要额外的视觉和语言对齐或多模态数据。
- 实验结果表明,我们的方法实现了零样本(zero-shot)性能,与 Kosmos 和 Flamingo 等端到端联合预训练模型相媲美或优于它们。
2. 相关工作
2.1 大语言模型能力
LLM 在自然语言理解和推理方面表现出了卓越的能力。
- GPT-3 [6] 是此类模型的一个显着例子,它可以在零样本或少样本设置中准确地解决包括翻译、自然语言推理和常识推理在内的复杂任务。
- 最近,更强大的版本(例如 GPT-3.5 和 GPT-4 [45])被设计用于理解、交互和生成类似人类的响应 [43]。 这些模型还因其通过在提示中显示一些示例来执行各种任务的能力而闻名 [6]。
- 最近还努力开发可以与 GPT-3 竞争的开源 LLM,例如 BLOOM [56]、OPT [62]、LLaMA [54]、FlanT5 [7] 等。 然而,所有这些模型都不能直接解决需要根据视觉输入刺激进行推理的任务。
- 我们的工作利用这些 LLM 作为冻结语言模型,并为他们提供从 “视觉模块” 获得的文本信息,使他们能够执行对象识别和 V&L 任务。
2.2 解决视觉和语言任务的对比模型
诸如 [47,50,23,13,61] 之类的基础模型已经证明了基于外部词汇指定任何视觉概念的能力,而不受监督模型中呈现的类或标签的限制。 然而,之前的工作 [49]、[26] 表明这些对比模型无法直接解决零或少量样本设置中的任务。 为了解决这个问题,[51] 提出了一种在 VQA 任务中使用 CLIP 的方法,将问题转换为 CLIP 可以回答的掩码模板,但他们的方法需要进行微调,以将模型的功能扩展到其他任务,例如视觉蕴涵(visual entailment) [58]。 在我们的工作中,我们建议利用对比模型的功能,并将其与众包(crowdsourced)开源词汇相结合,以分配图像中存在的标签和属性,与冻结的 LLM 相结合可以解决各种 V&L 任务。
2.3 用于视觉应用的大型语言模型
2.3.1 图像标题(Captioning)生成
近年来,图像字幕领域出现了显着的增长,其目标是为图像生成自然语言描述。 为此,人们提出了各种深度学习模型。
- 值得注意的是,最近的模型包括 BLIP [34] 和 BLIP-2 [35],它们在 NoCaps [1] 和 COCO [36] 上取得了很好的性能。
- 同时,ChatGPT 与 BLIP-2 一起被用来生成更丰富的视觉描述 [44]。
- 在另一项工作中,苏格拉底(Socratic)模型 [60] 和视觉线索 [59] 也使用文本数据来弥合视觉语言模型和语言模型之间的领域差距。 特别是,视觉线索使用结构化文本提示(包括图像标签、对象属性/位置和标题)构建图像的语义表示。 该方法利用 GPT-3 大语言模型来生成图像说明。
- 我们的工作受到视觉线索的启发,但我们的目标不是生成标题,而是利用冻结 LLM 来使用原始引人注目的视觉信息解决视觉任务。
2.3.2 视觉和语言任务
LLM 可以通过多种方式利用来执行 V&L 任务,这些主要分为两个部分。
多模态预训练。 这些方法以不同的方式对齐视觉和语言模态。
- 例如,Tsimpoukelli 等人 [55] 选择仅微调视觉编码器并生成送入冻结的 LLM 中的嵌入。
- 其他的,例如 Flamingo [2],训练额外的交叉注意层以进行对齐。
- BLIP2 [34] 和 Mini-GPT4 [63] 等工作可以减少额外层和预训练轻量级模块的大小,同时冻结视觉编码器。
- 然而,在所有情况下,视觉和语言的联合对齐都需要大量的计算资源和训练数据,这使得利用最先进的 LLM 变得具有挑战性。 此外,这些方法可能会阻碍 LLM 闻名的推理能力。
语言驱动的模态对齐:这些方法将 LLM 与不同的模块结合起来,以对齐视觉和语言模式。
- Guo 等人 [17] 同时期工作使用现成的 LLM 来解决纯视觉问答任务,例如 VQA 2.0 [16] 和 OK-VQA [39]。相比之下,LENS 扩展了 LLM 的能力来解决对象识别任务,而且它不涉及任何问题引导的信息提取。
- 另一项工作 PromptCap [21],使用 GPT-3 的合成示例来训练问题感知字幕模型,以解决 VQA 任务。 相比之下,LENS 利用“视觉模块”,无需任何额外的预训练阶段。
- 同样,ViperGPT [53] 也利用 Instruct GPT 和 Codex 等黑盒 LLM 在不同的 VQA 基准上取得出色的结果,但严重依赖 BLIP2,后者需要额外的多模态预训练轮次。
- 此外,所有上述方法都依赖于“自上而下”的方法,其中注意力机制由非视觉或特定任务上下文驱动。 然而,我们提出的方法与这些方法不同,因为我们采用 “自下而上” 的方法 [3]。 我们的方法不涉及任何问题引导的信息提取,这是一项更具挑战性的任务。 尽管如此,LENS 仍取得了与这些问题感知模型相当的显着结果。
3. 方法

我们提出了一种名为 LENS 的新颖框架(图 2),旨在增强冻结的 LLM 的能力,使他们能够在现有的自然语言理解能力之上处理视觉以及视觉和语言任务。 与现有方法相比,LENS 提供了一个统一的框架,有助于 LLM 的 “推理模块” 对从一组独立且高度描述性的 “视觉模块” 中提取的文本数据进行操作。更重要的是,它消除了对齐文本的计算开销。 通过对多模态数据进行额外的联合预训练,将视觉域与文本域结合起来,这是解决 V&L 任务的先前工作 [2,35,63,15,27] 的要求。
总而言之,给定图像 I,我们利用视觉模块来提取可以描述图像的所有可想象的文本信息 T,包括对象、属性和标题,而不将其限制为特定的任务指令。 随后,冻结的 LLM 可以处理与特定任务提示连接的通用提示 T,并执行目标识别或视觉推理任务。 在本节中,我们介绍 “视觉模块” 的本质,概述 LENS 的主要组件,然后讨论提示设计。
3.1 视觉词汇
对于 LENS,视觉词汇充当将图像转换为文本信息的桥梁,然后可由现有 LLM 处理。 我们为常见对象和属性开发词汇表。
标签:为了为对比模型的图像标记创建多样化且全面的标签词汇,我们从各种来源收集标签。 其中包括多个图像分类数据集,例如 [48,33,8,46,41,4,57,28],目标检测和语义分割数据集 [18,36,31] 以及视觉基因组(genome)数据集 [29]。
属性:遵循 Menon 和 Vondrick [40] 中提出的方法,我们采用大型语言模型 GPT-3 来生成视觉特征的描述,以区分对象词汇中的每个目标类别。
3.2 LENS 成分
LENS 由 3 个不同的视觉模块和 1 个推理模块组成,每个模块根据手头的任务服务于特定目的。 这些组件如下:
标签模块。 给定图像,该模块识别图像并将标签分配给该图像。 为了实现这一目标,我们采用视觉编码器 (CLIP) 为每个图像选择最合适的标签。 在我们的工作中,我们采用一个常见的提示:“A photo of {classname}”来进行对象标记,以使我们的框架跨域灵活,而不需要手动/整体提示调整[47]。 我们使用 3.1 节中构建的目标词汇表作为我们的类选项。
属性模块。 我们利用该模块来识别图像中存在的目标并将相关属性分配给图像中的目标。 为此,我们采用了一种称为 CLIP 的对比预训练视觉编码器,同时结合了 [40] 中概述的特定于任务的提示。 视觉编码器根据 3.1 节中生成的属性词汇对目标进行分类。
强化标题。 我们利用称为 BLIP 的图像标题模型,并应用随机 top-k 采样 [12] 来为每个图像生成 N 个标题。 这种方法使我们能够捕获并包含图像中视觉内容的各个方面。 然后这些多样化的标题不经任何修改直接传递到 “推理模块”。
推理模块。 我们采用冻结的 LLM 作为推理模块,它能够根据视觉模块提供的文本描述以及特定于任务的指令生成答案。 LENS 可与任何黑盒 LLM 无缝集成,简化了向其添加视觉功能的过程并加快了整体速度。
3.3 提示设计
利用从视觉模块获得的文本信息,我们将它们组合起来构建完整的LLM提示。 我们将标签模块格式化为 Tags: {Top-k Tags},将属性模块格式化为 Attributes: {Top-K attribute},将强化标题模块格式化为 Captions: {Top-N Captions}。 特别是,对于仇恨模因(hateful-memes)任务,我们将 OCR 提示合并为 OCR:this is an image with written "{meme text}" on it。 最后,我们在最后附加具体问题提示:Question: {task-specific prompt} \n Short Answer。 您可以在我们的 demo 中看到此提示的实际效果。
4. 实验
在本节中,我们进行了大量的实验和分析来展示 LENS 的功效。 首先,我们将 LENS 与目标识别中其他最先进的模型 [47] 进行比较。 然后,我们还评估了 LENS 在视觉和语言推理任务上的表现,并将其与多模态基础模型进行比较 [2, 22]。 我们还对重要的设计选择进行消融研究,例如每个任务的提示组件和提示图样。
4.1 数据集
对于目标识别,我们使用[47]中提出的 9 个基准数据集进行实验。 我们检查了我们的方法在零样本、1 样本和 3 样本设置中的性能,旨在展示冻结的 LLM 在结合情境学习方面的能力 [6]。对于视觉和语言推理,我们专注于零样本基准,因为我们在少样本设置中评估 LENS 时没有看到任何改进。 我们在 VQA 2.0 数据集 [16] 和 OK-VQA 数据集 [39] 测试集的测试-开发(test-dev)分割上评估我们的方法。 我们还探讨了 LENS 在 Hateful Memes 数据集 [25] 的开发集和测试集(test-seen)以及 Rendered SST2 [47] 测试集上的性能。 有关每项任务的详细概述,包括数据集大小、类别数量以及所采用的具体评估指标,请参阅补充材料中的表 6。

4.2 实现细节
我们使用 OpenCLIP-H/14 和 CLIP-L/14 作为标签和属性模块中的默认视觉编码器。 我们在强化标题模块中采用了在 COCO [36] 上微调的 BLIP-large 标题检查点。 在此模块中,我们执行 top-k 采样 [12],其中 k 表示所需的标题数量,并为每个图像生成最多 k = 50 个标题。 最后,我们采用 Flan-T5 模型作为我们默认的冻结 LLM 系列 [37]。 为了生成符合评估任务的答案,我们采用波束搜索,波束数量等于 5。此外,我们应用等于 -1 的长度惩罚,鼓励生成简洁的答案,如 [35] 中所示。 这些实验是在 8 个 NVIDIA A100 (40GB) GPU 上进行的。
我们对 LENS 执行特定于任务的优化,以实现最佳性能。 对于目标识别,我们利用标签模块,该模块对每个数据集对应的类进行操作。 此外,我们使用属性模块,它利用属性词汇表。 根据我们的初步实验,我们跳过了强化标题模块。 在 VQA 任务中,我们仅使用强化标题模块,因为我们的实验表明标签和标题没有提供显着的改进。 对于 Hateful Memes [25] 和 Rendered-SST2 数据集,我们合并了标签、属性和标题模块。 我们使用宽度为 5 的波束搜索仅生成一个标题。
4.3 结果
我们评估 LENS 的视觉、视觉 & 语言任务。 对于视觉,我们评估了 8 个基准,并将它们与样本和少样本设置下的物体识别 [47] 中最先进的模型进行比较。 对于视觉和语言,我们评估了视觉问答的四个代表性任务,并将它们与采用冻结 LLM 以及需要额外预训练阶段和用于对齐视觉和语言模态的配对数据集大型语料库的最先进模型进行比较 。 在这些任务中,我们只报告零样本结果,因为我们在采用上下文学习时没有观察到改进。

目标识别:在表 1 中,我们观察到,在零样本情况下,由 ViT-H/14 [11] 组成的 LENS 作为视觉主干,并以 Flan-T5xxl 作为冻结的 LLM,其平均性能优于同等大小采用通用提示的 CLIP +0.7% 。 有趣的是,我们的实验表明,对于对象识别任务,冻结的 LLM 的大小和分类性能之间似乎没有直接关系。 然而,我们确实观察到标签器架构(ViT 主干)的大小和性能之间的对应关系。

在图 3 中,我们绘制了除 ImageNet(由于其尺寸较大)之外的所有数据集上的平均视觉性能,并观察到更多样本有助于提高视觉主干和冻结 LLM 的任意组合下的性能。 此外,我们再次观察到,更好的冻结 LLM 与性能之间没有直接关系。 然而,我们确实看到更好的视觉骨干有助于提高平均视觉表现。

视觉和语言:表 2 列出了 LENS 与其他系统的性能比较分析。我们的实验获得的结果清楚地表明了 LENS 的高度竞争性,即使与 Flamingo [2]、BLIP-2 [35] 和 Kosmos [22] 等更大、更复杂的系统相比也是如此。
具体来说,我们的研究结果表明,在 VQA 2.0 [16] 上,
- LENS Flan-T5XXL 的性能比 Flamingo9B 和 Kosmos-1 分别高出 11% 和 15%。
- LENS 的性能比 Flamingo 最强大的变体高出 6 个点。
- 我们的强化标题模块采用 ViT-L 视觉编码器,与采用 ViT-G 作为视觉编码器的最大 BLIP-2 架构相当。
- 我们最好的 LENS 模型在 Hateful Memes [25] 上超越了 Flamingo 的多个版本,并且在 Rendered-SST2 基准测试中与 Kosmos 相比表现出更好的性能。
- 我们的方法在 Rendered SST2 上表现如此出色也许并不特别令人惊讶,其中需要一个良好的语言模型来理解从图像中提取的文本的情感。 这样,Rendered SST2 不仅仅是将图像特征直接链接到文本;而是将图像特征直接链接到文本。 它还涉及解释该文本的实际含义。
在 OK-VQA 上,我们的模型的性能与 Flamingo 不匹配,可能是因为 Flamingo80B 中使用的 70B Chinchilla 语言模型拥有比我们最好的推理模块更大的知识库,正如 [35] 中所建议的。
4.4 LENS 组件消融


目标识别:在表 3 中,我们使用 Flan-T5XL 和 CLIPH/14 对 LENS 的目标识别组件进行了消融研究,如第 4.3 节中所述。 我们展示了基准测试的平均准确度。 通过仅使用标签模块,我们完全依赖 CLIP,并观察到与表 1 中的 CLIP-H/14 类似的性能。但是,我们注意到仅使用属性模块时性能下降。 与标签结合使用时,属性显着有助于将 LENS 的性能提高 +0.4%。 这表明,与仅使用 CLIP 等单一视觉模块相比,LENS 可以作为可靠的基准。 有关每个数据集的详细概述,见表 7。

视觉推理:对于 VQA 2.0 数据集(Goyal 等人,2017),我们使用我们的模型(配备了 Flan-T5XXL)在最小分割上进行了消融。 如表 5 所示,我们注意到,强化标题模块生成的标题数量的增加导致性能逐渐提高。 然而,它最终达到了饱和点,这表明该模块只能提供有关图像的有价值的信息,但达到一定的阈值。

我们还使用 Hateful-Memes 基准 [25] 的开发集对 LENS 组件进行了消融研究。 表 4 表明,全局标题、标签和属性模块的组合对于实现此任务的高性能至关重要。 具体来说,我们观察到,与 OCR 结合使用时,与全局标题模块相比,标签和属性对性能改进的贡献更大。 然而,值得注意的是,所有这些组件都是必要的,它们的组合使用可以带来最佳性能。 我们还在图 4 中展示了 LENS 的几个定性示例,通过回答有关复杂场景和场景的问题来说明其推理能力。
5. 结论
我们引入了 LENS,这是一种通用且计算高效的方法,使冻结的 LLM 能够有效协调视觉模块,即使与更大的多模态预训练系统相比,也能获得具有竞争力的性能。 LENS 提供对各种开源或黑盒语言模型的适应性,无论其预训练或多模态数据如何,从而为社区内未来的性能改进提供灵活性和可扩展性。
通过利用 LLM 的优势和我们的模块化方法,LENS 展示了任务解决方面的重大进步,而无需额外的预训练。 其与多种视觉任务的无缝集成展示了其多功能性和广泛应用的潜力。
在未来的工作中,一个有趣的探索方向是通过将 LENS 纳入涉及不同模式的任务来扩展 LENS 的适用性。 例如,将 LENS 集成到音频分类或视频动作推理任务中可以产生有价值的见解。 这种扩展将涉及协调法学硕士的角色并将其与补充模块集成。
在未来的工作中,一个有趣的探索方向是通过将 LENS 纳入涉及不同模式的任务来扩展 LENS 的适用性。 例如,将 LENS 集成到音频分类或视频动作推理任务中可以产生有价值的见解。 这种扩展将涉及协调 LLM 的角色并将其与补充模块集成。
6. 局限性



与任何研究工作一样,LENS 有其自身的局限性。 我们的目标是在本节中解决其中的一些问题。 首先,LENS 的视觉能力很大程度上依赖于其底层视觉组件,即 CLIP 和 BLIP。 尽管这些模型已显示出显着的性能改进,但通过利用其优势并将其与 LLM 相结合,仍有进一步增强的空间。 我们在图 5 中展示了 LENS 的一些失败案例。 未来的研究应该探索有效整合这些模型的方法,并利用视觉和语言组件之间的协同作用,以在不同的任务中实现更好的性能。
其次,重要的是要认识到使用 LENS 模型进行评估实验需要大量的计算资源。 例如,我们的实验是使用 8*A100 进行的,这可能会给中小型实验室以及获得此类资源的机会有限的代表性不足的社区带来挑战。 然而,值得注意的是,与评估 LENS 模型相关的计算成本相对低于大型视觉语言模型(例如 Flamingo)的广泛训练要求,后者可能需要超过 50 万 TPU 小时。 尽管如此,仍应努力使计算资源更容易获取,并探索在保持 LENS 有效性的同时减轻计算负担的方法。
参考
Berrios W, Mittal G, Thrush T, et al. Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language[J]. arXiv preprint arXiv:2306.16410, 2023.
S. 总结
S.1 主要思想
本文提出了增强可见的大型语言模型(Large Language Models ENnhanced to See,LENS),这是一种利用大语言模型 (LLM) 解决计算机视觉问题(例如,零样本和少样本目标识别,视觉和语言问题)的模块化方法:使用预训练视觉模块获得有关图像的详尽信息,使用语言模型对其进行推理。
LENS 可以应用于任何现成的 LLM,并且采用 LENS 的 LLM 在更大、更复杂的系统中表现出很强的竞争力,而无需任何多模态训练。
虽然 LENS 模型进行评估实验需要大量的计算资源,但相对低于大型视觉语言模型(例如 Flamingo)的训练要求,后者可能需要超过 50 万 TPU 小时。
S.2 方法
LENS 的框架如图 2 所示。给定图像 I,我们利用预训练视觉模块(例如,CLIP 和 BLIP)来提取所有可以描述图像的文本信息 T,包括对象、属性和标题。 随后,冻结的 LLM 可以处理与特定任务提示连接的通用提示 T,并执行目标识别或视觉推理任务。
相关文章:
(2023,LENS 视觉模型 LLM)迈向可见的语言模型:通过自然语言的镜头来看计算机视觉
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language 公众号:EDPJ(添加 VX:CV_EDPJ 进交流群获取资料) 目录 0. 摘要 1. 简介 2. 相关工作 2.1 大语言模型能力 2.2 解决视觉和…...

线段树上树剖再拿线段树维护:0914T4
cp 一种常见套路: 如果在线段树上进行一段区间修改,那么必然是一段右节点一段左节点 这个过程其实就是zkw的本质 下面都要用zkw来理解 考虑原题,有一棵不规则的线段树 类似zkw,在这类题目中,我们要先把开区间变成闭…...
互联网医院系统|互联网医院探索未来医疗的新蓝海
随着互联网技术的飞速发展,互联网医院应运而生,为人们带来全新的医疗体验。本文将深入探讨互联网医院的开发流程、系统优势以及未来发展方向,带您领略医疗领域的新蓝海。互联网医院的开发流程是一个结合技术、医疗和用户需求的复杂过程。首先…...

Acrel-2000系列监控系统在亚运手球比赛馆建设10kV供配电工程中的应用
安科瑞 崔丽洁 摘要:智能化配电监控系统是数字化和信息化时代应运而生的产物,已经被广泛应用于电网用户侧楼宇、体育场馆、科研设施、机场、交通、医院、电力和石化行业等诸多领域的高/低压变配电系统中。安科瑞自研的Acrel-2000系列监控系统可监控高压开关柜、低压…...

c++中遇到一个不了解的函数,查看能用的接口功能
在C中,您可以使用几种方法来查找函数的接口和使用方式。下面是一些常用的方法: 查阅官方文档:每个常见的C库都应该配有官方文档,其中包含所有可用函数和其接口的详细说明。您可以从官方网站或下载的文档中查找所需函数的接口和使用…...
windows linux子系统 docker无法启动
windows安装Linux子系统后,使用sudo service docker start启动后,再使用sudo service docker status查看docker状态,docker无法启动,使用sudo dockerd查看错误信息如下: failed to start daemon: Error initializing …...

【Redis】深入探索 Redis 的数据类型 —— 无序集合 Set
文章目录 一、Set 类型介绍二、Set 类型相关命令2.1 添加元素和检查成员2.2 移除元素2.3 集合运算求交集求并集求差集 2.4 Set 相关命令总结 三、Set 类型编码方式四、Set 使用场景 一、Set 类型介绍 Set(集合)是 Redis 数据库中的一种数据类型…...

可变参数JAVA
public class Main {public static void main(String[] args) {//方法形参的个数是可以变化的//格式:属性类型...名字System.out.println(getSum(1,2,3,4,5,6,7,8));}//通过键值对对象来遍历;public static int getSum(int a,int...args){//可变参数;int…...
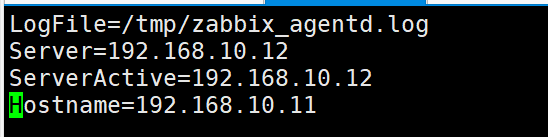
Zabbix监控平台部署流程
Zabbix WEB、Zabbix Server、Zabbix Database放在一台服务器;(192.168.10.12)Zabbix Agent部署在被监控服务器上 (192.168.10.11)Zabbix Porxy 单独部署在一台服务器上(被监控服务器少于500台可以不部署&am…...

重磅!文晔以38亿美元收购富昌电子 | 百能云芯
文晔微电子股份有限公司(文晔科技)于9月14日正式宣布已完成对富昌电子公司(Future Electronics Inc.)100%股权的收购,该交易以全现金方式完成,总交易价值高达38亿美元。 文晔科技的董事长兼首席执行官郑家强…...

Multimodel Image synthesis and editing:The generative AI Era
1.introduction 基于GAN和扩散模型,通过融入多模态引导来调节生成过程,从不同的多模态信号中合成图像;是为多模态图像合成和编辑使用预训练模型,通过在GAN潜在空间中进行反演,应用引导函数,或调整扩散模型…...
Linux——(第十章)进程管理
目录 一、概述 二、常用指令 1.ps查看当前系统进程状态 2.kill 终止进程 3.pstree 查看进程树 4.top 实时监控系统进程状态 5.netstat 监控网络状态 一、概述 (1)进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体&#…...
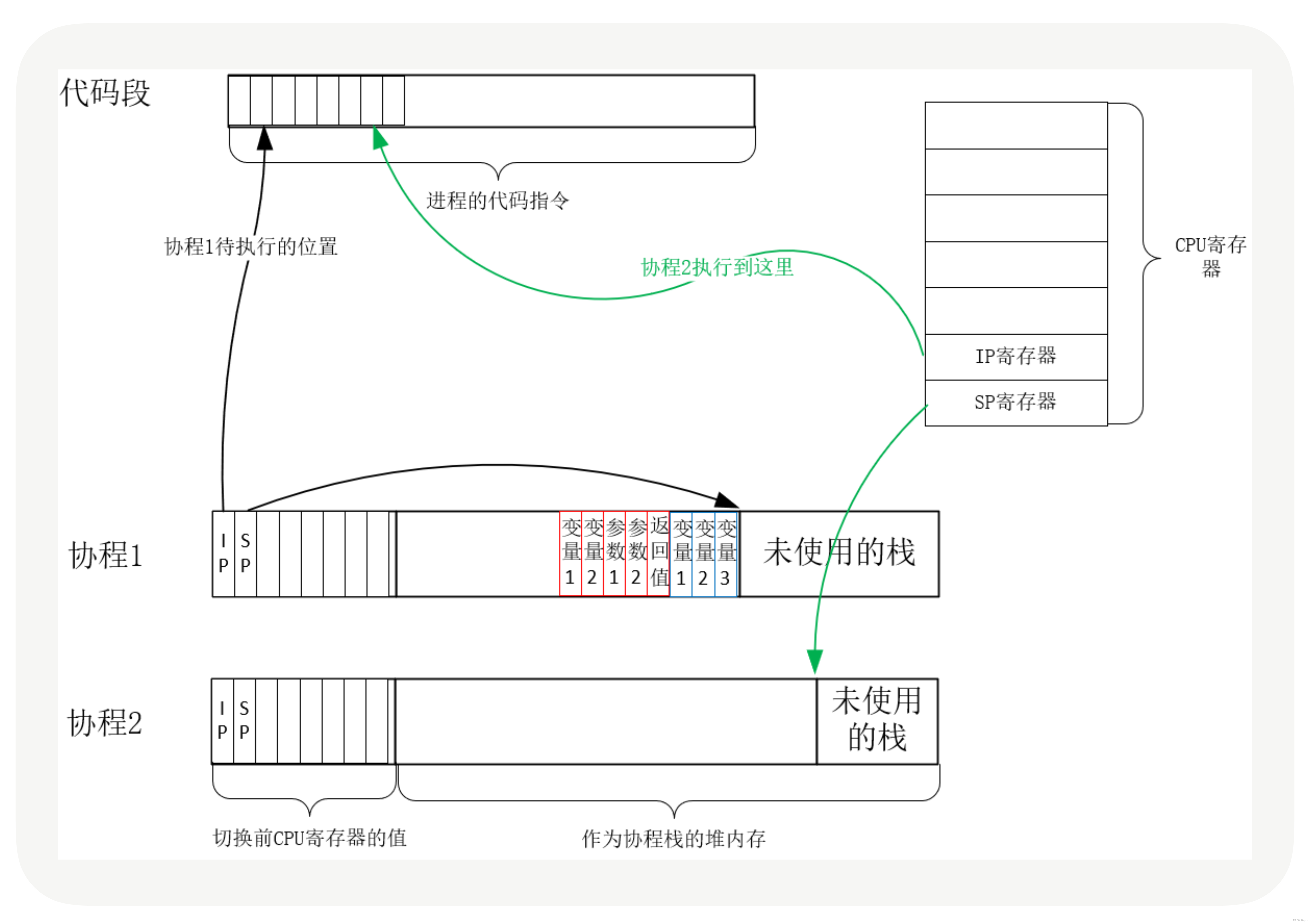
【操作系统】聊聊协程为什么可以支撑高并发服务
在实际的业务开发中,比如针对一个业务流程,调用三方,然后存储数据,从oss上获取数据。其实都是进行的同步调用,说白了就是A完成之后,B在继续完成。如果整个过程中A、B、C 分别耗时100、300、200毫秒。那么整…...
)
算法leetcode|80. 删除有序数组中的重复项 II(rust重拳出击)
文章目录 80. 删除有序数组中的重复项 II:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 80. 删除有序数组中的重复项 II: …...

Vite 完整版详解
1. 打包构建: Vite 使用 Rollup 作为默认的构建工具。通过运行 npm run build 命令,Vite 会将应用程序的源代码打包成一个或多个优化的静态文件,以便在生产环境中进行部署。Vite 的构建过程会根据需要进行代码拆分、压缩和优化,以…...

AI入门指南:探索人工智能的基础原理和实际应用
引言 介绍AI的基本概念:什么是人工智能,为什么它如此重要。 引出博客的主要内容,即AI的基础原理和实际应用。 第一部分:AI的基础原理 什么是人工智能: 解释AI的定义和范畴。 介绍AI的历史和发展。 机器学习入门&#x…...
使用 Webpack 从 0 到 1 构建 Vue3 项目 + ts
使用 Webpack 从 0 到 1 构建 Vue3 项目 1.初始化项目结构2.安装 webpack,补充智能提示3.初步编写 webpack.config.js3.1设置入口文件及出口文件3.2 指定 html 模板位置 4.配置 运行/打包 命令,首次打包项目5.添加 Vue 及相关配置5.1安装并引入 vue5.2 补…...

【Git】Git 分支
Git 分支 1.分支简介 为了真正理解 Git 处理分支的方式,我们需要回顾一下 Git 是如何保存数据的。 或许你还记得 起步 的内容, Git 保存的不是文件的变化或者差异,而是一系列不同时刻的 快照 。 在进行提交操作时,Git 会保存一…...
.NET Upgrade Assistant 升级 .NET MAUI
.NET Upgrade Assistant 是一种可帮助您将应用程序升级到最新的 .NET版本 的工具,并且您可以使用这个工具将您的应用程序从旧平台(例如 Xamarin Forms 和 UWP)迁移到新的平台。此外,这个新版本的工具,可以让您在不更改…...
记一次诡异的Cannot find declaration to go to,Cannot resolve method
记一次诡异的 Cannot find declaration to go to, Cannot resolve method getOnExpressions in Join 对于项目中通常问题,清除缓存,重启idea,或者仔细检查语法通常都能解决问题,但是这次却失效了,以下是原…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...