JavaEE初阶(5)多线程案例(定时器、标准库中的定时器、实现定时器、线程池、标准库中的线程池、实现线程池)
接上次博客:JavaEE初阶(4)(线程的状态、线程安全、synchronized、volatile、wait 和 notify、多线程的代码案例:单例模式——饿汉懒汉、阻塞队列)_di-Dora的博客-CSDN博客
目录
多线程案例
定时器
标准库中的定时器
实现定时器
线程池
标准库中的线程池
实现线程池
多线程案例
定时器
定时器(Timer)是软件开发中用于在特定时间点或时间间隔之后执行预定任务的重要组件。它类似于一个计时器或闹钟,约定一个时间,时间到达之后,执行某个代码逻辑。
定时器非常常见,尤其在进行网络通信的时候。

定时器可以用于调度和执行各种任务,它的主要作用包括:
-
延迟执行任务:定时器可以在一段时间之后执行任务,例如,你可以设置一个定时器在5秒后执行某个特定的代码块。
-
周期性执行任务:除了延迟执行,定时器还可以周期性地执行任务,例如,每隔一定时间执行某个任务,这在周期性任务处理中非常有用。
-
任务调度:定时器还可用于将任务按照预定的时间表调度执行。这对于需要按照特定顺序或时间表执行任务的应用程序非常重要。
-
定时任务:定时器通常用于执行定时任务,例如在每日特定时间运行备份、清理数据等操作。
在Java中,如前面所述,有两种常见的方式来实现定时器功能:Timer 类和ScheduledExecutorService 接口。这些工具使得在Java应用程序中创建和管理定时任务变得相对容易。同时,在其他编程语言和框架中也有类似的定时器或调度器实现,用于满足各种定时需求。
总之,定时器是软件开发中的一个关键组件,它允许开发人员按照时间表执行任务,从而实现各种应用程序中的定时操作。无论是执行单次任务、周期性任务还是按照特定时间表执行任务,定时器都提供了强大的功能来满足这些需求。
标准库中的定时器
"定时器"通常指的是Java的 Timer 类或 ScheduledExecutorService 接口,这些工具允许我们在指定的时间间隔或延迟之后执行任务。这些定时器通常用于执行周期性任务、调度任务或延迟执行任务。
在标准库中,也有定时器的实现:
它来自这个包。我们以前学过的很多的类都是包含在里面的。
package Thread;import java.util.Timer;
import java.util.TimerTask;public class Demo18 {public static void main(String[] args) {Timer timer = new Timer();//给定时器安排了一个任务,预定在……时间去执行timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("执行定时器的任务");}}, 3000);System.out.println("程序启动!");}
}
你会发现我们一共导入了两个包:
import java.util.Timer;
import java.util.TimerTask;它们分别是什么?有什么区别?
Timer 和 TimerTask 都是 Java 中用于执行定时任务的类,但它们之间有一些重要的区别。
-
Timer:
- Timer是一个定时器类,用于安排在未来的某个时间点执行任务。它是一个较早期的 Java 类,存在一些限制和问题,因此在更现代的 Java 应用中可能不再推荐使用。
- Timer 允许你安排单个任务或重复性任务的执行。
- Timer 的任务执行是基于绝对时间的,这意味着你需要指定任务应该在何时执行,例如在某个具体的日期和时间。这可能会导致与系统时间的不同步问题,特别是如果系统时间发生更改或任务执行时间不准确。
- Timer 不处理异常,如果任务抛出未捕获的异常,将会中断 Timer 的线程。
-
TimerTask:
- TimerTask是一个抽象类,用于定义要由Timer 执行的任务。你需要继承 TimerTask 并实现其 run 方法来定义你的任务逻辑。
- TimerTask可以用于在未来的某个时间点执行任务,也可以用于重复性任务。
- TimerTask提供了更灵活的任务调度选项,你可以使用 schedule 方法指定相对时间(多少毫秒后执行)或 绝对时间(在某个日期和时间执行)来安排任务的执行。
- TimerTask 可以捕获并处理任务中的异常,以防止任务中的异常中断 Timer 的线程。
主线程指向 schedule 方法的时候, 就是把这个任务给放到 Timer 对象中了,与此同时, 定时器内部会有一个专门的线程(通常称为"扫描线程"或"工作线程")来扫描任务队列,检查任务的执行时间是否到了。如果任务的执行时间已经到了,扫描线程将执行该任务。
这意味着整个进程不会在主线程结束时立即终止,因为定时器的扫描线程仍在运行,等待任务的执行。只有当所有任务都被执行完毕或者定时器被显式地关闭时,整个进程才会结束。
这是因为定时器通常是一种长期运行的服务,用于执行周期性或延迟任务,而不是临时性的一次性操作。所以,确保定时器内部的扫描线程可以继续执行任务直到所有任务都完成是很重要的。
仔细观察可以发现,整个进程其实没有结束,因为Timer 内部的线程组织了进程的结束:

Timer 里面是可以安排多个任务的:
package Thread;import java.util.Timer;
import java.util.TimerTask;public class Demo18 {public static void main(String[] args) {Timer timer = new Timer();//给定时器安排了一个任务,预定在……时间去执行timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("2000ms");}}, 2000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("3000ms");}}, 3000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("1000ms");}}, 1000);System.out.println("程序启动!");}
}
不管安排任务的顺序,最大的执行时间的最晚出来。
其实我们有两个方法运用定时器:
1、Timer类: java.util.Timer 是Java中的一个类,它允许我们安排在一定时间后或以固定的时间间隔重复执行任务。我们可以创建一个Timer 实例,然后调用其 schedule 方法来安排任务的执行。
import java.util.Timer;
import java.util.TimerTask;public class MyTimerTask extends TimerTask {public void run() {// 在此处定义要执行的任务System.out.println("定时任务执行了!");}
}public class Main {public static void main(String[] args) {Timer timer = new Timer();TimerTask task = new MyTimerTask();// 在1000毫秒后开始执行任务,然后每隔2000毫秒重复执行一次timer.schedule(task, 1000, 2000);}
}
请注意,Timer在多线程环境中可能存在一些问题,因为它是单线程执行的,如果一个任务的执行时间过长,可能会影响其他任务的执行。
我们有不同类型的schedule方法,这些方法用于安排任务的执行。
以下是一些常见的schedule方法,它们可用于不同的定时需求:



2、ScheduledExecutorService接口:
java.util.concurrent.ScheduledExecutorService接口提供了更灵活和强大的任务调度功能,它允许我们创建线程池,以便在多线程环境中更好地管理定时任务。我们可以使用ScheduledExecutorService的schedule和scheduleAtFixedRate方法来执行任务。
当然,线程池这个概念我们现在还没涉及,马上就会提到,先放一放,往后看~
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;public class Main {public static void main(String[] args) {ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);Runnable task = () -> {// 在此处定义要执行的任务System.out.println("定时任务执行了!");};// 在延迟1秒后执行任务,然后每隔2秒重复执行一次scheduler.scheduleAtFixedRate(task, 1, 2, TimeUnit.SECONDS);}
}
使用ScheduledExecutorService通常是推荐的方式,因为它更适合多线程环境,并提供了更多的灵活性和控制选项。
实现定时器
实现定时器我们需要先有一个大致思路:
- Timer 中需要一个线程,扫描时间是否到时间可以执行了?
- 需要有一个数据结构,把所有的任务的保存起来。
- 还需要创建一个类,通过类的对象来描述任务(包含任务内容和时间)。
那么我们具体使用一个什么样的数据结构比较好?
假设使用数组(ArrayList),此时扫描线程就需要不停的遍历数组中的每个任务,判定每个任务是否到达执行时间。上述遍历过程就比较低效。
所以我们最好使用一个优先级队列:因为队列中的任务都有各自的执行时刻 (delay),最先执行的任务一定是时间最小的。 使用带优先级的队列就可以高效的把这个执行时刻最小的任务找出来。它可以使用 O(1)的时间来获取最小的时间
所以定时器的构成: 一个带优先级的队列。
确定好之后就可以开始码代码了!
出师不利,一开始就碰到了一个让人犹豫的问题:
我们定义一个任务的时候,需要传入一个执行任务的时间,这个时间应该是绝对时间(时间戳)还是相对时间呢?
答案其实上面提到,Java库中这个类用的是绝对时间。
其实不难理解,一般你设定任务应该都是会给一个具体的日期和时间点然后执行吧?

既然决定用绝对时间,那么后续扫描线程,我们应该如何去判定当前这个任务是否要执行呢?
- 扫描到当前的时间戳;
- 再获取到任务要执行的时间戳
- 对比两个时间戳,如果时间未到,就不能执行
所以在这里用绝对时间来判定是比较好的,如果是相对时间你还要先换算一下才可以判断。
这样就构造出了要执行任务的绝对的时间戳:

还有一个地方:我们的任务应该怎样定义?
private Runnable runnable;我们声明了一个私有成员变量 private Runnable runnable;,这种写法通常用于保存对实现 Runnable 接口的对象的引用。
这种写法的主要目的是允许我们在类中存储一个可以在后续操作中执行的任务。这在多线程编程中非常有用,因为我们可以将任务的逻辑封装在 Runnable 接口的实现中,然后将这个任务对象存储在类的成员变量中,以便在需要时执行该任务。
当我们声明一个成员变量为 private Runnable runnable; 时,这个成员变量可以引用任何实现了 Runnable 接口的对象。因为 Runnable 接口是一个函数式接口,它只包含一个抽象方法 run(),所以任何实现了 run() 方法的类都可以用来创建一个 Runnable 对象。
因此,我们可以将任何实现了 Runnable 接口的对象赋给 runnable 变量,然后在需要执行任务的时候,调用 run() 方法来执行该任务。这种方式允许我们灵活地在不同的上下文中使用不同的任务逻辑,而不需要修改类的结构。
举个例子,我可以创建多个不同的类实现 Runnable 接口,每个类代表不同的任务,然后根据需要将这些任务对象分配给 runnable 变量。
当前,我们的一个大致框架就构建出来了。但是现在的代码还有一个非常严重的问题:
import java.util.PriorityQueue;class MyTimerTask{//要有一个要执行的任务private Runnable runnable;//要有一个执行任务的时间private long time;//此处的delay就是schedule方法传入的“相对时间”public MyTimerTask(Runnable runnable,long delay){this.runnable=runnable;this.time=System.currentTimeMillis()+delay;}}class MyTimer{//使用一个数据结构保存所有要安排的任务private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();public void schedule(Runnable runnable,long delay){queue.offer(new MyTimerTask(runnable,delay));}}
public class Demo19 {}当前的代码需要自定义优先级队列里面的比较方法。对于优先级队列来说,要求里面的元素务必是可以比较的!
我们的MyTimerTask 是不可以比较的,所以我们的得实现Comparable接口,重写compare to方法:
class MyTimerTask implements Comparable<MyTimerTask>{//要有一个要执行的任务private Runnable runnable;//要有一个执行任务的时间private long time;//此处的delay就是schedule方法传入的“相对时间”public MyTimerTask(Runnable runnable,long delay){this.runnable=runnable;this.time=System.currentTimeMillis()+delay;}@Overridepublic int compareTo(MyTimerTask o) {//这样的写法就是让队首元素是最小时间的值return (int)(this.time-o.time);//如果是想让队首元素是最大时间的值//return o.time-this.time;}}现在我们来写扫描线程的代码:
//搞个扫描线程public MyTimer (){//创建一个扫描线程Thread t = new Thread(()->{//扫描线程,需要不停的扫描队首元素,看是否到达时间while (true){if(queue.isEmpty()){}MyTimerTask task=queue.peek();//比较一下看看当前队首元素是否已经可以执行了}});t.start();}如果发现队列为空该咋办?也就是上面代码的条件语句什么逻辑?
好的方法就是阻塞等待,等到队列不为空为止 -----> 阻塞队列
你还记得 wait 吗?要想使用 wait ,需要搭配 synchronized,不能单独使用!
wait 进行的操作有三个:
- 释放锁:前提是拿到锁;
- 等待通知;
- 通知到来之后,唤醒,重新获取锁
所以此时我们要加锁,这是很必要的,而且:
现在这个定时器代码基本上就是可用的了:
package Thread;import java.util.PriorityQueue;class MyTimerTask implements Comparable<MyTimerTask>{//要有一个要执行的任务private Runnable runnable;//要有一个执行任务的时间private long time;//此处的delay就是schedule方法传入的“相对时间”public MyTimerTask(Runnable runnable,long delay){this.runnable=runnable;this.time=System.currentTimeMillis()+delay;}@Overridepublic int compareTo(MyTimerTask o) {//这样的写法就是让队首元素是最小时间的值return (int)(this.time-o.time);//如果是想让队首元素是最大时间的值//return o.time-this.time;}public long getTime() {return time;}public Runnable getRunnable(){return runnable;}}//我们自己搞的定时器class MyTimer{//使用一个数据结构保存所有要安排的任务private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();//使用这个对象作为锁对象private Object locker = new Object();public void schedule(Runnable runnable,long delay){synchronized (locker){queue.offer(new MyTimerTask(runnable,delay));locker.notify();}}//搞个扫描线程public MyTimer (){//创建一个扫描线程Thread t = new Thread(()->{//扫描线程,需要不停的扫描队首元素,看是否到达时间while (true){try{synchronized (locker) {//不要使用 if 作为 wait 的判定条件,应该用 while//使用 while 的目的是为了在wait被唤醒的时候,再次确认一下条件。while(queue.isEmpty()) {//使用wait进行等待。//这里的 wait 的需要由另外的线程唤醒//添加了新的任务,就应该唤醒locker.wait();}MyTimerTask task = queue.peek();//比较一下看看当前队首元素是否已经可以执行了long curTime =System.currentTimeMillis();if(curTime>=task.getTime()){//当前时间已经达到了任务时间,就可以执行任务了task.getRunnable().run();//任务执行完了,就可以从队列中删除了queue.poll();}else {//当前时间还没到任务时间,暂时不执行任务//暂时先啥都不干,等待下一轮的循环判定}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}}
public class Demo19 {}这个程序到这里,其实还有一个严重的问题——“忙等”:

当时间没到的时候,此处的循环会快速的循环很多次。忙等的过程确实是在等,但是也消耗大量CPU资源,怎么做能够避免忙等?
当任务时间没到的时候,就 wait 阻塞(线程不会在CPU上调度,也就把CPU资源让出来给别人了)。
所以我们在条件里面再加一个wait,这里的 wait 引入带参数的版本(带有超时时间的那个),把时间间隔作为wait的等待时间。
if(curTime>=task.getTime()){//当前时间已经达到了任务时间,就可以执行任务了task.getRunnable().run();//任务执行完了,就可以从队列中删除了queue.poll();
}else {//当前时间还没到任务时间,暂时不执行任务//暂时先啥都不干,等待下一轮的循环判定locker.wait(task.getTime()-curTime);
}另外,此处为啥用 wait ,使用 sleep 行不?
这里wait是更好的,因为有一种情况,可能在等待的过程中,主线程调用 schedule 添加了一个新的任务,新的任务执行时间比刚刚的任务更早,恰好使用刚才 schedule 中的 notify 就可以唤醒这里的 wait 让循环再执行一遍,重新拿到队首元素,接下来wait的时间就会更新。同时也就可以避免因为 wait 没被唤醒而错过新的任务。
之所以我们的代码使用的是 PriorityQueue,而不是 PriorityBlockingQueue,其实就是因为要处理两个 wait 。使用阻塞版本的优先级队列,不方便实现这样的两处等待。
这样,我们的定时器就大功告成了!
import java.util.PriorityQueue;class MyTimerTask implements Comparable<MyTimerTask>{//要有一个要执行的任务private Runnable runnable;//要有一个执行任务的时间private long time;//此处的delay就是schedule方法传入的“相对时间”public MyTimerTask(Runnable runnable,long delay){this.runnable=runnable;this.time=System.currentTimeMillis()+delay;}@Overridepublic int compareTo(MyTimerTask o) {//这样的写法就是让队首元素是最小时间的值return (int)(this.time-o.time);//如果是想让队首元素是最大时间的值//return o.time-this.time;}public long getTime() {return time;}public Runnable getRunnable(){return runnable;}}//我们自己搞的定时器class MyTimer{//使用一个数据结构保存所有要安排的任务private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();//使用这个对象作为锁对象private Object locker = new Object();public void schedule(Runnable runnable,long delay){synchronized (locker){queue.offer(new MyTimerTask(runnable,delay));locker.notify();}}//搞个扫描线程public MyTimer (){//创建一个扫描线程Thread t = new Thread(()->{//扫描线程,需要不停的扫描队首元素,看是否到达时间while (true){try{synchronized (locker) {//不要使用 if 作为 wait 的判定条件,应该用 while//使用 while 的目的是为了在wait被唤醒的时候,再次确认一下条件。while(queue.isEmpty()) {//使用wait进行等待。//这里的 wait 的需要由另外的线程唤醒//添加了新的任务,就应该唤醒locker.wait();}MyTimerTask task = queue.peek();//比较一下看看当前队首元素是否已经可以执行了long curTime =System.currentTimeMillis();if(curTime>=task.getTime()){//当前时间已经达到了任务时间,就可以执行任务了task.getRunnable().run();//任务执行完了,就可以从队列中删除了queue.poll();}else {//当前时间还没到任务时间,暂时不执行任务//暂时先啥都不干,等待下一轮的循环判定locker.wait(task.getTime()-curTime);}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}}我又加了几行代码,使得该定时器可以在完成任务后停止程序:
package Thread;import java.util.PriorityQueue;class MyTimerTask implements Comparable<MyTimerTask>{//要有一个要执行的任务private Runnable runnable;//要有一个执行任务的时间private long time;//此处的delay就是schedule方法传入的“相对时间”public MyTimerTask(Runnable runnable,long delay){this.runnable=runnable;this.time=System.currentTimeMillis()+delay;}@Overridepublic int compareTo(MyTimerTask o) {//这样的写法就是让队首元素是最小时间的值return (int)(this.time-o.time);//如果是想让队首元素是最大时间的值//return o.time-this.time;}public long getTime() {return time;}public Runnable getRunnable(){return runnable;}}//我们自己搞的定时器class MyTimer{//使用一个数据结构保存所有要安排的任务private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();//使用这个对象作为锁对象private Object locker = new Object();public void schedule(Runnable runnable,long delay){synchronized (locker){queue.offer(new MyTimerTask(runnable,delay));locker.notify();}}private volatile boolean isRunning = true; // 添加标志位来控制线程运行// 新增一个方法来停止定时器线程public void stop() {synchronized (locker) {isRunning = false;locker.notify(); // 唤醒等待中的线程,以便它们可以退出}// 中断线程以确保它可以退出if (t != null) {t.interrupt();}}private Thread t; // 将线程对象声明为成员变量//搞个扫描线程public MyTimer (){//创建一个扫描线程t = new Thread(()->{//扫描线程,需要不停的扫描队首元素,看是否到达时间while (isRunning){try{synchronized (locker) {//不要使用 if 作为 wait 的判定条件,应该用 while//使用 while 的目的是为了在wait被唤醒的时候,再次确认一下条件。while(queue.isEmpty()) {//使用wait进行等待。//这里的 wait 的需要由另外的线程唤醒//添加了新的任务,就应该唤醒locker.wait();}MyTimerTask task = queue.peek();//比较一下看看当前队首元素是否已经可以执行了long curTime =System.currentTimeMillis();if(curTime>=task.getTime()){//当前时间已经达到了任务时间,就可以执行任务了task.getRunnable().run();//任务执行完了,就可以从队列中删除了queue.poll();}else {//当前时间还没到任务时间,暂时不执行任务//暂时先啥都不干,等待下一轮的循环判定locker.wait(task.getTime()-curTime);}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}}
public class Demo19 {public static void main(String[] args) {MyTimer myTimer = new MyTimer();// 创建并安排两个任务myTimer.schedule(() -> {System.out.println("Task 1 executed.");}, 2000); // 任务1将在2秒后执行myTimer.schedule(() -> {System.out.println("Task 2 executed.");}, 3000); // 任务2将在3秒后执行// 等待一段时间,以便观察定时任务的执行try {Thread.sleep(5000); // 等待5秒} catch (InterruptedException e) {e.printStackTrace();}// 创建并安排一个额外的任务myTimer.schedule(() -> {System.out.println("Additional Task executed.");}, 1000); // 额外任务将在1秒后执行// 等待一段时间,以便观察额外任务的执行try {Thread.sleep(2000); // 等待2秒} catch (InterruptedException e) {e.printStackTrace();}// 停止定时器线程myTimer.stop();}} 
还记得我们之前提过使用 wait 要注意它是通过 notify 唤醒还是通过 Interrupt 唤醒的,如果是后者还需要进行一次判断……所幸我们写的是while。
那么如果我们用的是PriorityBlockingQueue优先级阻塞队列,代码又会有怎样的变动呢?
import java.util.concurrent.*;class MyTimerTask implements Comparable<MyTimerTask> {private Runnable runnable;private long time;public MyTimerTask(Runnable runnable, long delay) {this.runnable = runnable;this.time = System.currentTimeMillis() + delay;}@Overridepublic int compareTo(MyTimerTask o) {return (int) (this.time - o.time);}public long getTime() {return time;}public Runnable getRunnable() {return runnable;}
}class MyTimer {private PriorityBlockingQueue<MyTimerTask> queue = new PriorityBlockingQueue<>();private volatile boolean isRunning = true;public void schedule(Runnable runnable, long delay) {queue.offer(new MyTimerTask(runnable, delay));}public void stop() {isRunning = false;}public MyTimer() {Thread t = new Thread(() -> {while (isRunning) {try {MyTimerTask task = queue.take();long curTime = System.currentTimeMillis();if (curTime >= task.getTime()) {task.getRunnable().run();} else {queue.offer(task); // 未到时间,重新放入队列Thread.sleep(task.getTime() - curTime);}} catch (InterruptedException e) {// 捕获线程被中断的异常// 这里可以添加需要的处理}}});t.start();}
}public class Demo19 {public static void main(String[] args) {MyTimer myTimer = new MyTimer();myTimer.schedule(() -> {System.out.println("Task 1 executed.");}, 2000);myTimer.schedule(() -> {System.out.println("Task 2 executed.");}, 3000);try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}myTimer.schedule(() -> {System.out.println("Additional Task executed.");}, 1000);try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}myTimer.stop();}
}
我们来对PriorityQueue实现的定时器和PriorityBlockingQueue实现的定时器做一个对比吧:
-
数据结构:
- 第二个代码示例使用了PriorityBlockingQueue,这是一个线程安全的队列,无需额外的同步措施即可在多线程环境中使用。它用于存储定时任务,并根据任务的执行时间进行排序。
private PriorityBlockingQueue<MyTimerTask> queue = new PriorityBlockingQueue<>(); - 第一个代码示例使用了PriorityQueue,这也是一个队列,但不是线程安全的。为了在多线程环境中使用,它使用了一个对象 locker 来进行同步,以确保线程安全性。
private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>(); private Object locker = new Object();
- 第二个代码示例使用了PriorityBlockingQueue,这是一个线程安全的队列,无需额外的同步措施即可在多线程环境中使用。它用于存储定时任务,并根据任务的执行时间进行排序。
-
线程同步:
- 第二个代码示例的 MyTimer 使用了PriorityBlockingQueue,无需显式的锁和 wait/notify,因为PriorityBlockingQueue 自身已经处理了线程同步。
public void schedule(Runnable runnable, long delay) {queue.offer(new MyTimerTask(runnable, delay)); } - 第一个代码示例的 MyTimer 使用了PriorityQueue和一个额外的同步对象
locker,在添加和移除任务时使用了 synchronized 块,并在条件不满足时使用 wait 进行等待,然后在有任务进入队列时使用 notify 唤醒等待线程。public void schedule(Runnable runnable, long delay) {synchronized (locker) {queue.offer(new MyTimerTask(runnable, delay));locker.notify();} }
- 第二个代码示例的 MyTimer 使用了PriorityBlockingQueue,无需显式的锁和 wait/notify,因为PriorityBlockingQueue 自身已经处理了线程同步。
-
停止定时器:
- 在第二个代码示例中,停止定时器的方式是将 isRunning 标志设置为 false ,这会导致扫描线程退出。
public void stop() {isRunning = false; } - 在第一个代码示例中,停止定时器的方式是设置 isRunning 为 false 并使用 locker.notify() 唤醒等待的线程,并且还在 stop 方法中中断了扫描线程。
public void stop() {synchronized (locker) {isRunning = false;locker.notify();}if (t != null) {t.interrupt();} }
- 在第二个代码示例中,停止定时器的方式是将 isRunning 标志设置为 false ,这会导致扫描线程退出。
-
使用 PriorityQueue 的方法:
优势:
- 简单:相对于 PriorityBlockingQueue,这种实现更简单,不需要处理阻塞和唤醒。
- 自定义控制:我们可以更灵活地控制定时器线程的行为,例如添加额外的逻辑来处理任务执行之前的准备工作。
劣势:
- 需要额外的等待和唤醒逻辑:使用 PriorityQueue 需要我们自己处理等待和唤醒线程的逻辑,这可能会引入潜在的错误和复杂性。
-
使用 PriorityBlockingQueue的方法:
优势:
- 线程安全: PriorityBlockingQueue 是线程安全的,不需要手动处理等待和唤醒,使得代码更简洁和可靠。
- 无需自定义控制:不必担心线程的等待和唤醒逻辑,使得代码更容易维护和理解。
劣势:
- 复杂性:虽然不需要自己实现等待和唤醒逻辑,但我们需要引入更多的并发编程概念,如 take() 方法可能会阻塞线程,需要处理 InterruptedException 。
哦,对了,这里要提到一个关于线程调试的小问题。
虽然使用调试器可以调试多线程程序,但是我们一般不太建议使用调试器来调试。
因为调试器的断点就会影响到某些线程的执行顺序,导致调试的时候,执行的效果和不调试的时候执行的结果可能不一样。(正常运行有bug,调试的时候bug不能重现)(观察手段影响到了实验结果,就像物理学著名的“测不准原理”)
-
线程交互问题:在多线程程序中,线程可能以不确定的顺序执行,这可能会导致在调试器中设置断点时线程之间的交互问题。这种情况下,断点可能会影响到线程的执行顺序,使得问题难以重现。
-
并发问题的时序性:许多并发问题涉及到时序性,例如竞态条件或死锁。使用调试器可能无法捕获这种时序性问题,因为调试器通常会暂停线程,改变了线程的执行时间表。
-
难以复现问题:一些多线程问题可能是概率性的,只在特定条件下才会发生。使用调试器进行单步调试可能难以复现这些问题,因为调试会改变程序的执行路径。
-
性能开销:在高并发环境中,使用调试器可能会引入显著的性能开销,因为它需要监视和暂停多个线程。这可能会导致问题难以重现,因为问题在生产环境中可能不会出现。
那么不用调试器,我们如何找问题?打印日志是更靠谱的办法。
使用日志是调试多线程程序的一种常见且可行的方法。服务器程序往往也是需要日志来调试的。使用调试器一般只能解决一些小的“必然重现”的问题,对于更复杂的“概率出现问题”,使用日志是更靠谱的做法。 通过在关键代码路径上记录日志,我们可以了解程序的执行流程,查看线程活动,以及在问题发生时跟踪线程的状态。这种方式对于发现并排查潜在问题非常有帮助,尤其是在生产环境中。
综上所述,调试多线程程序需要谨慎,需要考虑到线程交互、时序性问题和性能开销。使用日志可以提供更好的可追踪性和生产环境中问题的排查能力。
线程池
线程诞生的意义是因为进程的创建/销毁太重量了,比较慢。
但是有对比才有伤害。和进程相比,线程是快,但是如果进一步提高创建销毁的频率,线程的开销也就不能忽视了!
两种典型的办法进一步提高效率:
-
协程(轻量级线程):相比于线程,把系统的调度的过程给省略了(程序猿手工调度)
- 协程是一种当下比较流行的并发编程的手段,在Java圈子里,协程还不够流行。使用协程更多的是 Go 和 python 。
- 协程是一种轻量级的并发编程方式,它允许在单线程内模拟多个执行线程,而不需要创建多个操作系统级别的线程。这可以大大减小线程管理开销。
- 在Java中,虽然标准库没有原生支持协程,但可以使用第三方库(如Quasar、Project Loom等)来实现协程。这些库提供了协程的支持,允许开发者在代码中编写协程任务,而不必担心线程的管理和调度。
- 但是!如果你的项目已经广泛使用线程了,你是否要将它替换成看起来似乎更好的协程呢?是否要将线程替换为协程需要谨慎考虑,因为这取决于项目的特性和需求。如果项目已经广泛使用线程,并且性能已经足够好,那么迁移到协程可能会引入不必要的复杂性。但对于某些特定的场景,如高并发和高吞吐量的网络应用程序,使用协程可能会提供更好的性能和资源利用率。
-
线程池:使线程不至于那么慢。
-
“池”这个词是计算机中比较重要的思想方法,比如进程池、内存池、连接池……它们的含义都是类似的。
- 线程池是一种管理和重用线程的机制,它可以减小线程的创建和销毁开销。线程池在需要执行任务时从池中获取线程,执行完任务后将线程放回池中,以便以后重用。(线程池就是在使用第一个线程的时候提前把 2、3、4、5……线程提前创建好,后续如果想使用新的线程,就不必重新创建了,直接拿过来就用!此时创建线程的开销就被降低了。)
- 在Java中,java.util.concurrent 包提供了 ThreadPoolExecutor 等线程池相关的类,它们可以方便地创建和管理线程池。
- 使用线程池是一种有效的方式来降低线程管理开销,并且可以更好地控制并发度。我们可以设置池的大小,限制同时执行的线程数量,避免资源竞争等。
-
为什么从池子里面取线程的效率比创建新的线程效率更高?
从池子里取这个动作是纯粹用户态的操作。创建新的线程这个动作则是需要用户态+内核态相互配合完成的操作。(如果一段程序是在系统内核中执行,此时就称为“内核态”;如果不是,则称为“用户态”)
操作系统是由内核+配套的应用程序构成,内核是系统最核心的部分,创建线程的操作就需要调用系统API,进入内核,按照内核态的方式完成一系列动作。操作系统内核是要给所有进程提供服务的,当你要创建新的线程的时候,内核会帮你做,但是做的过程中难免也会要做一些其他的事情。这个过程是不可控的。
所以,从池子中获取线程的效率比创建新的线程效率更高的一个重要原因是涉及到用户态和内核态的切换成本。
-
用户态 vs. 内核态:在操作系统中,用户态和内核态是两种不同的执行模式。用户态是应用程序的执行模式,而内核态是操作系统内核的执行模式。当应用程序需要执行一些特权操作(例如创建新线程),它必须通过系统调用进入内核态,这会引入额外的开销。
-
创建新线程的操作:创建新线程通常涉及系统调用,需要进入内核态。内核必须为新线程分配资源、设置线程上下文、分配堆栈等等,这些操作都需要内核的介入。这些额外的操作会导致较大的开销,尤其是在需要频繁创建线程的情况下。
-
线程池的优势:线程池在应用程序启动时通常会预先创建并初始化一组线程。这些线程会一直保持在用户态,而不需要频繁地进入内核态。当需要执行任务时,线程池只需从池中取出一个空闲线程,这是一个纯粹的用户态操作,不需要涉及内核。这个线程会执行任务并在任务完成后回到池中等待下一个任务。这种方式避免了不必要的内核态切换和线程创建的开销。所以线程池最大的好处就是减少每次启动、销毁线程的损耗。
总结起来,线程池的优势在于它通过预先创建和维护一组线程,避免了频繁的线程创建和销毁操作,减少了用户态到内核态的切换开销,从而提高了线程的获取效率。这对于需要高并发处理任务的应用程序来说非常有利,因为它能够更高效地利用系统资源并提高性能。
标准库中的线程池
在Java库中也有线程池,具体的实现。

如下:
ExecutorService executorService = Executors.newCachedThreadPool();//Executors ———— 工厂类
//newCatchedThreadPool() ————工厂方法
线程池对象不是咱们直接new的,而是通过了一个专门的方法,返回了一个线程池对象。
这里就涉及到了 “ 工厂模式(设计模式之一)” 。
工厂模式是一种常见的设计模式,用于创建对象并封装对象的创建逻辑。它通过将对象的创建过程封装到一个独立的工厂类中,使得客户端代码可以通过调用工厂类的方法来获取所需的对象,而不必直接使用构造函数来创建对象。这有助于提高代码的灵活性和可维护性。
通常我们创建对象会使用new,这个new关键字就会触发类的构造方法。但是构造方法存在一定的局限性。所以工厂模式就是给构造方法填坑的。
填的什么坑?
很多时候构造一个对象我们希望有多种构造方式,多种方式就需要使用多个版本的构造方法来分别实现,但是构造方法要求方法的名字必须是类名,用重载的方式来区分(参数类型或个数不同)
但是如果有两个构造方式刚好必参数类型或个数恰好相同呢?就会编译失败。
所以我们使用工厂设计模式解决问题。使用普通方法代替构造方法完成初始工作。普通方法就可以使用方法的不同名字来区分,不用再受到重载的规则制约了。
实践中,一般单独搞一个类,给这个类搞一些静态方法,由这样的静态方法负责构造出对象。
-
构造方法的局限性: 构造方法是用来创建对象的一种机制,但它有一些局限性:
- 构造方法的方法名必须与类名相同,这意味着无法通过方法名来明确表示不同的构造方式。
- 构造方法的参数列表必须不同,通过参数的类型或数量来区分不同的构造方式。但有时候,两种构造方式可能刚好有相同的参数类型和数量,这会导致编译错误。
-
工厂模式填补构造方法的不足: 工厂模式是一种创建对象的设计模式,它通过提供一组静态或非静态方法来代替构造方法,从而解决了构造方法的局限性问题。这些方法可以有自己的名称,因此可以根据方法名来明确表示不同的构造方式,而不需要依赖参数类型或数量。
例如,假设我们有一个类 Car,它有多种初始化方式,可以通过工厂模式创建不同类型的汽车对象,而不仅仅是依靠不同的构造方法。
-
静态工厂方法: 工厂模式通常使用静态方法来创建对象。这些静态方法属于工厂类,负责根据客户端的需求创建适当的对象。这种方式提供了更灵活的对象创建机制,使得代码更易于维护和扩展。
总之,工厂模式是一种创建对象的设计模式,通过提供具有自定义方法名的静态或非静态方法,以解决构造方法的局限性问题。这种模式使得对象的创建更加灵活,同时能够提供更多的构造方式,并且更易于代码的维护和扩展。
举个例子:
class Point {private double x;private double y;public Point(double x, double y) {this.x = x;this.y = y;}// Getters and setters for x and ypublic double getX() {return x;}public void setX(double x) {this.x = x;}public double getY() {return y;}public void setY(double y) {this.y = y;}@Overridepublic String toString() {return "Point [x=" + x + ", y=" + y + "]";}
}class PointFactory {public static Point makePoint_byXY(double x, double y) {return new Point(x, y);}public static Point makePoint_byRA(double r, double a) {double x = r * Math.cos(Math.toRadians(a));double y = r * Math.sin(Math.toRadians(a));return new Point(x, y);}
}public class FactoryPatternExample {public static void main(String[] args) {// 使用工厂方法创建点对象Point point1 = PointFactory.makePoint_byXY(2.0, 3.0);Point point2 = PointFactory.makePoint_byRA(5.0, 45.0);// 打印点的坐标System.out.println("Point 1: " + point1);System.out.println("Point 2: " + point2);}
}
总之,工厂模式是一种非常有用的设计模式,特别是在需要创建多个相关对象并希望将对象创建过程封装起来时,它可以帮助简化代码并提高可维护性。
好了,介绍完工厂模式,我们来看看线程池的创建:
- 使用 Executors.newFixedThreadPool(10) 能创建出固定包含 10 个线程的线程池
- 返回值类型为 ExecutorService
- 通过 ExecutorService.submit 可以注册一个任务到线程池中
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadPoolExample {public static void main(String[] args) {// 创建一个包含10个线程的固定大小线程池ExecutorService executorService = Executors.newFixedThreadPool(10);// 提交任务到线程池for (int i = 0; i < 20; i++) {final int taskId = i;executorService.submit(() -> {// 执行任务的代码System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());});}// 关闭线程池executorService.shutdown();}
}
Executors 创建线程池的几种方式:
以下是 Executors 类中常用的线程池创建方式(这些方法基本上都是对 ThreadPoolExecutor 类的封装,提供了不同的配置选项以满足不同的需求):
-
newFixedThreadPool(int nThreads): 创建一个固定线程数的线程池,该线程池包含指定数量的线程,这些线程一直存在,如果一个线程死掉,就会被新的线程替代。适用于需要控制并发度的情况,例如,限制同时执行的任务数量。
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;public class FixedThreadPoolExample {public static void main(String[] args) {int nThreads = 3; // 指定线程数ExecutorService executorService = Executors.newFixedThreadPool(nThreads);// 提交任务for (int i = 0; i < 10; i++) {final int taskNumber = i;executorService.submit(() -> {System.out.println("Task " + taskNumber + " is running.");});}// 关闭线程池executorService.shutdown();} } -
newCachedThreadPool(): 创建一个线程数目动态增长的线程池,该线程池的线程数量会根据任务的数量自动调整,空闲线程会被回收,新任务到来时会创建新线程。Cached:缓存,用过之后不着急释放,先留着备用。此时构造出来的线程池对象有一个基本特点:线程数目是能够动态适应的。随着往线程池里面添加任务,这个线程池中的线程会根据需要自动被创建出来,创建出来之后也不会着急销毁,会在池子里面保留一定的实践以备随时取用。适用于需要处理大量短期异步任务的情况,线程数会根据任务负载自动扩展和收缩。
-
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;public class CachedThreadPoolExample {public static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();// 提交任务for (int i = 0; i < 10; i++) {final int taskNumber = i;executorService.submit(() -> {System.out.println("Task " + taskNumber + " is running.");});}// 关闭线程池executorService.shutdown();} } -
newSingleThreadExecutor(): 创建一个只包含单个线程的线程池,保证任务按照提交的顺序依次执行。适用于需要按顺序执行任务的场景,例如,顺序处理任务队列。
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;public class SingleThreadExecutorExample {public static void main(String[] args) {ExecutorService executorService = Executors.newSingleThreadExecutor();// 提交任务for (int i = 0; i < 10; i++) {final int taskNumber = i;executorService.submit(() -> {System.out.println("Task " + taskNumber + " is running.");});}// 关闭线程池executorService.shutdown();} } -
newScheduledThreadPool(int corePoolSize): 创建一个定时任务线程池,可以延迟执行命令,或者定期执行命令,类似于进阶版的 Timer,不是一个扫描线程负责执行任务,而是多个线程执行时间到了的任务。
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;public class ScheduledThreadPoolExample {public static void main(String[] args) {int corePoolSize = 3; // 指定核心线程数ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(corePoolSize);// 延迟执行任务scheduledExecutorService.schedule(() -> {System.out.println("Delayed task is running.");}, 3, TimeUnit.SECONDS);// 定期执行任务scheduledExecutorService.scheduleAtFixedRate(() -> {System.out.println("Periodic task is running.");}, 1, 2, TimeUnit.SECONDS);// 关闭线程池scheduledExecutorService.shutdown();} }
上述这几个工厂方法生成的线程池本质上都是对一个类进行的封装—— ThreadPoolExecutor。
这个类功能非常丰富,提供了很多参数。标准库上述的几个工厂方法其实就是给这个类填写了不同的参数用来构造线程池了。
参数?什么参数?
ThreadPoolExecutor是Java中用于创建自定义线程池的类,相比于Executors类提供的工厂方法,它提供了更多的可选参数,允许我们更精细地配置线程池的行为。
简单介绍一下ThreadPoolExecutor提供的可选参数以及它们的作用:
- corePoolSize: 这是线程池的核心线程数,它指定了线程池中一直保持存活的线程数量。这些线程会一直存在,即使它们是空闲的。这个参数允许您控制线程池的基本容量。
- maximumPoolSize: 这是线程池的最大线程数,它指定了线程池中允许的最大线程数量。当任务数量超过核心线程数时,线程池可以创建新的线程,但不会超过这个最大值。
- keepAliveTime 和 TimeUnit: 这两个参数一起使用,指定了当线程池中的线程数量超过核心线程数时,多余的空闲线程等待的最长时间,超过这个时间就会被终止并移出线程池。
- ThreadFactory: 这个参数允许您提供自定义的线程工厂,用于创建线程。这可以用来自定义线程的命名规则、优先级等属性。
- RejectedExecutionHandler: 这个参数定义了当线程池无法接受新任务时的处理策略。例如,可以选择将任务丢弃或者将任务交给调用者来执行。
- workQueue: 这是一个任务队列,用于存储等待执行的任务。不同的队列类型(如有界队列或无界队列)会影响线程池的行为。
通过调整这些参数,我们可以根据具体的需求来细化线程池的行为,例如,控制线程池的大小、处理超过核心线程数的任务、定义线程的创建方式和命名规则,以及处理任务队列满时的策略等。这种灵活性使得ThreadPoolExecutor更加适用于各种不同的多线程应用场景。
详细来说:
在我们刚刚提到的线程池创建方式中,newFixedThreadPool, newCachedThreadPool, newSingleThreadExecutor, 和 newScheduledThreadPool 都是 Executors 类的静态工厂方法,而不是 ThreadPoolExecutor 的方法。
这些工厂方法是 Executors 类提供的便捷方式,用于创建不同类型的线程池。但是这些方法在内部实际上调用了 ThreadPoolExecutor 的构造函数,以根据给定的配置参数创建相应类型的线程池。
例如,Executors.newFixedThreadPool(10) 实际上会创建一个 ThreadPoolExecutor 对象,并设置核心线程数和最大线程数都为 10,以及使用一个无界队列来存储任务。但是,使用 Executors 工厂方法能够更方便地创建线程池,而无需手动配置所有参数。
所以这些线程池创建方式是 Executors 类的方法,但它们在内部使用 ThreadPoolExecutor 来实现。因此,它们提供了更简单的方式来创建和配置线程池,而不必直接使用 ThreadPoolExecutor 的构造函数。
如果我们要使用ThreadPoolExecutor来构造:
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;public class CustomThreadPoolExample {public static void main(String[] args) {int corePoolSize = 10; // 核心线程数int maxPoolSize = 20; // 最大线程数long keepAliveTime = 60; // 空闲线程的存活时间(秒)ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, // 核心线程数maxPoolSize, // 最大线程数keepAliveTime, // 空闲线程的存活时间TimeUnit.SECONDS, // 存活时间的时间单位new LinkedBlockingQueue<>() // 任务队列);// 提交任务到线程池threadPoolExecutor.submit(() -> {System.out.println("Task is running in custom ThreadPoolExecutor.");});// 关闭线程池threadPoolExecutor.shutdown();}
}
在上述示例中,我们直接使用了ThreadPoolExecutor 的构造函数来创建自定义的线程池。通过传递核心线程数、最大线程数、空闲线程的存活时间、时间单位和任务队列等参数,我们可以更灵活地配置线程池的行为。
要创建不同类型的线程池,只需根据需求调整这些参数,例如设置核心线程数和最大线程数相等就可以创建一个固定大小线程池,或者使用不同的队列类型来创建有界或无界队列线程池。然后,我们可以使用 submit 方法将任务提交到线程池中,最后别忘了关闭线程池。
啧啧,所以你看看,是不是很复杂?
ThreadPoolExecutor 的核心任务就两个:
1、构造:
- ThreadPoolExecutor 的构造任务是在创建线程池对象时执行的任务。构造任务的目的是设置线程池的各种参数,例如核心线程数、最大线程数、任务队列、拒绝策略等。
- 构造任务的目标是配置线程池,以便它可以根据应用程序的需求来管理线程的创建、销毁和执行。不同的构造参数可以创建不同类型的线程池,如固定大小的线程池、可缓存的线程池等。
![]()
这里放了一些与“并发编程”相关的内容(Java中,并发编程最主要的体现形式就是多线程)



刚刚其实已经有提到过,再来一遍吧:
- corePoolSize(核心线程数):这是线程池中一直保持存活的线程数量。线程池会保持至少这么多数量的线程,即使它们是空闲的。如果提交的任务数少于核心线程数,线程池不会创建额外的线程。
- maximumPoolSize(最大线程数):这是线程池允许的最大线程数量。当提交的任务数超过核心线程数时,线程池可以创建新的线程,但不会超过这个最大值。(既可以满足效率的要求,又可以避免过多的系统开销,还挺灵活)
- keepAliveTime(空闲线程的存活时间):这是一个时间值,表示空闲线程的存活时间。如果线程池中的线程数量超过核心线程数,并且它们在一段时间内没有执行任务,那么这些空闲线程将会被回收,直到线程数量等于核心线程数。
- unit(时间单位):这是与 keepAliveTime 参数一起使用的时间单位,例如,秒、毫秒、微秒等。
- workQueue(任务队列):这是一个用于存储等待执行的任务的阻塞队列。任务队列可以是有界的或无界的,具体取决于传递的实现类。有界队列限制了队列中等待执行的任务数量,无界队列不做限制。我们可以根据需要灵活设置这里的队列,比如:我们需要优先级,就可以设置PriorityBlockingQueue;如果不需要优先级,并且任务数目相对恒定,就可以使用ArrayBlockingQueue;如果不需要优先级,并且任务数目变动较大,就可以使用LinkedBlockingQueue。
- threadFactory(线程工厂):这是一个用于创建新线程的工厂,工厂模式的体现。此处使用ThreadFactory作为工厂类,有这个类负责创建线程。使用工厂类创建线程,主要是为了在创建过程中对线程属性作出一些设置。如果手动创建线程就得手动设置这些属性,比较麻烦,这时我们就可以使用工厂方法封装一下。通常情况下,我们可以使用默认的线程工厂,但如果需要自定义线程的名称、优先级等属性,可以传递自定义的线程工厂。
- handler(拒绝策略):当任务无法被执行时,该策略决定了应该如何处理这种情况。例如,任务队列已满并且线程池中的线程数量已经达到最大线程数时,继续添加,拒绝策略可以决定是否抛出异常、调用者自己执行任务,或者丢弃任务等。
“核心线程数”如何理解?
核心线程是线程池中的一部分线程,它们在线程池创建后会立即启动并一直存在,不会被线程池回收,即使它们处于空闲状态也是如此。核心线程的存在主要用于处理瞬时到来的任务,以降低任务启动和线程创建的开销。核心线程数是线程池的一个重要参数,决定了线程池中始终存在的线程数量。
核心线程的主要特点包括:
-
一直存在:核心线程在线程池创建后就立即启动,并且一直保持存活状态,不会被销毁,直到线程池关闭。
-
处理任务:核心线程主要用于处理提交给线程池的任务,当任务到达时,核心线程会被用来执行任务。
-
无限制:核心线程的数量可以根据线程池配置而确定,通常可以在创建线程池时指定核心线程数,但核心线程数可以是零或更多,具体取决于应用程序的需求。
核心线程的存在有助于提高线程池的响应速度,因为它们减少了任务提交和执行之间的延迟。然而,核心线程数不会动态扩展或收缩,如果任务量超过核心线程数,线程池可能需要创建额外的线程来处理任务。要注意的是,核心线程数不会限制线程池中的总线程数量,只是保证了至少有这么多线程一直存在。
如果把线程池理解为一个公司,那么公司里的正式员工(有编制的)数目就可以理解为核心线程数,最大线程数量就是正式员工数量+实习生(无编制的)数量。
使用线程池,我们需要设置线程的数目,数目设置多少合适?
设CPU核心数(逻辑核心数)是 N, 那么我们设置啥?2N/1.5N/N+1/N-1?
都不科学!只要你回答出一个具体的数字,一定都是错的!因为在接触到实际的项目代码之前,我们是无法确定的。
确定线程池的合适大小通常是一个涉及性能和资源利用之间权衡的问题,没有一个固定的答案,因为它取决于多种因素,包括应用程序的性质和硬件环境。
一个线程执行的代码主要有两类:
1、CPU 密集型任务:如果你的任务主要是 CPU 密集型的,例如执行大量的计算,那么通常线程池的大小可以设置为接近或等于 CPU 核心数。这样可以充分利用 CPU 资源,但不会超出系统的承受范围。代码里主要的逻辑是在进行算术运算 / 逻辑判断;
2、I/O 密集型任务:如果你的任务主要是 I/O 密集型的,例如大量的文件 I/O、网络请求等,那么通常线程池的大小可以设置更大,可能是 CPU 核心数的两倍或更多。这可以帮助充分利用等待 I/O 操作完成的时间,从而提高效率。代码里主要进行的是IO操作。
- 假设一个线程的所有代码都是CPU 密集型的,这时线程池的数量不应该超过N(设置N就是极限了),设置得比N大也无法提高效率,因为CPU已经满了,此时更多的线程反而增加调度的开销。
- 假设一个线程的所有代码都是 IO 密集型的,这个时候不吃CPU,这时设置的线程池的数量就可以是超过N的,是一个较大的值。一个核心可以通过调度的方式来并发执行。
总之,代码不同,线程池的线程数目设置不同。无法知道一个代码具体多少内容是CPU密集,多少内容是IO密集。
正确做法是:根据具体需求调整。使用实验的方式对程序进行性能测试,我们可以尝试不同大小的线程池,测试过程中尝试修改不同的线程池的线程数目,然后基于性能指标(例如响应时间、吞吐量)来确定最佳大小,看哪种情况下最符合要求。
总之,线程池大小的合适性取决于应用程序的性质,可以通过测试和性能监测来确定最佳大小。常见的起点是根据 CPU 核心数来估算,但在实际应用中可能需要根据特定情况进行调整。
注册任务(添加任务):
- 执行任务是线程池的核心功能之一。一旦线程池创建完成并初始化(不论是哪种方式初始化的),它可以接受任务的提交并安排线程来执行这些任务。
- 任务可以是实现了 Runnable 或 Callable 接口的对象,线程池会通过 submit() 方法来提交任务并安排线程执行这些任务。
- 线程池负责管理线程的生命周期,包括创建、启动、执行任务以及根据需要回收或销毁线程。线程池还会根据任务的数量和线程池的配置来决定是执行任务还是将任务放入任务队列等待执行。
executorService.submit(new Runnable() {@Overridepublic void run() {}});
实现线程池
接下来我们就通过代码来模拟实现一个简单的线程池:
import java.util.ArrayDeque;
import java.util.Timer;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;class Pool{//任务队列private BlockingDeque<Runnable> queue = new LinkedBlockingDeque<Runnable>(1000);//通过这个方法把任务添加到队列中。public void submit(Runnable runnable) throws InterruptedException {//此处我们的拒绝策略,相当于第5种策略阻塞等待。下策~queue.put(runnable);}public Pool(int n ){//创建出n个线程,负责执行上述队列中的任务。for(int i = 0;i < n; i++){Thread t = new Thread(()->{//让这个线程从队列中消费任务,并执行try {Runnable runnable = queue.take();runnable.run();} catch (InterruptedException e) {throw new RuntimeException(e);}});t.start();}}
}
public class Demo {public static void main(String[] args) throws InterruptedException {Pool pool=new Pool(5);for (int i =0;i<1000;i++){int id = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("执行任务"+id);}});}}
}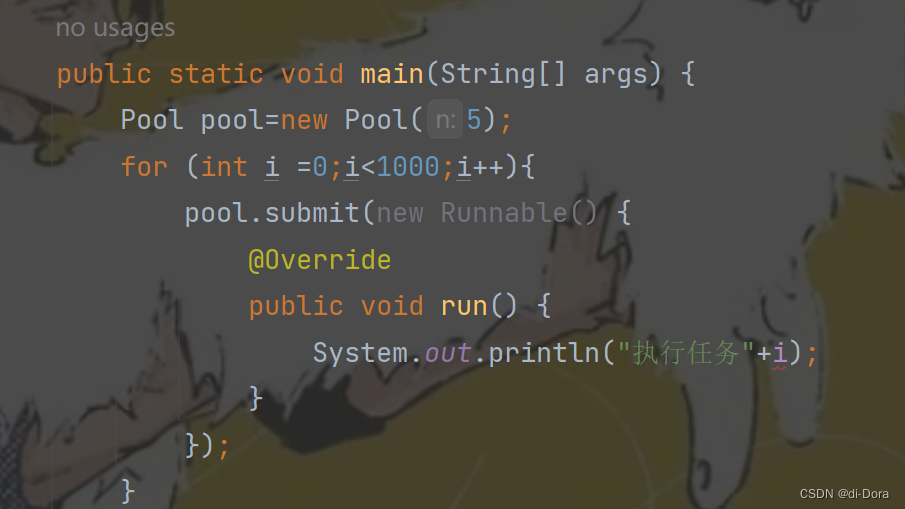
为什么这里编译出错了?应该怎么改正?
这里run方法内部的 i 是在匿名内部类中的,捕获了外部类中的变量 i ,变量捕获只能捕获 final 或者事实final的变量。
“改变成员变量绕开变量捕获”这确实是一个方法,但是不够elegant。
i 变量本事是一个局部变量,它应该只出现在main方法中,把它变成成员变量其他方法也就能够访问到它了。作用域增大,也容易出现一些意想不到的错误!
还有没有更好的方法?
for (int i =0;i<1000;i++){int id = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("执行任务"+id);}});}此时我们捕获的就是 id 不是 i 了。id 有人修改吗?没有!
还有一个比较复杂的版本:
核心操作为:
- submit, 将任务加入线程池中
- 使用 Worker 类描述一个工作线程
- 使用 Runnable 描述一个任务
- 使用一个 BlockingQueue 组织所有的任务
- 每个 worker 线程要做的事情: 不停的从 BlockingQueue 中取任务并执行
- 指定一下线程池中的最大线程数 maxWorkerCount; 当当前线程数超过这个最大值时, 就不再新增线程了
import java.util.concurrent.LinkedBlockingQueue;class Worker extends Thread {private LinkedBlockingQueue<Runnable> queue = null;public Worker(LinkedBlockingQueue<Runnable> queue) {super("worker");this.queue = queue;}@Overridepublic void run() {try {while (!Thread.interrupted()) {Runnable runnable = queue.take(); // 从任务队列中取出任务runnable.run(); // 执行任务}} catch (InterruptedException e) {// 线程被中断时退出循环}}
}public class MyThreadPool {private int maxWorkerCount = 10;private LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();public void submit(Runnable command) throws InterruptedException {if (Thread.activeCount() < maxWorkerCount) {// 当前 worker 数不足, 就继续创建 workerWorker worker = new Worker(queue);worker.start(); // 启动工作线程}// 将任务添加到任务队列中queue.put(command);}public static void main(String[] args) throws InterruptedException {MyThreadPool myThreadPool = new MyThreadPool();myThreadPool.submit(new Runnable() {@Overridepublic void run() {System.out.println("吃饭"); // 任务内容}});Thread.sleep(1000); // 休眠以等待任务执行完成}
}相关文章:
JavaEE初阶(5)多线程案例(定时器、标准库中的定时器、实现定时器、线程池、标准库中的线程池、实现线程池)
接上次博客:JavaEE初阶(4)(线程的状态、线程安全、synchronized、volatile、wait 和 notify、多线程的代码案例:单例模式——饿汉懒汉、阻塞队列)_di-Dora的博客-CSDN博客 目录 多线程案例 定时器 标准…...
SpringCLoud——Nacos配置中心
Nacos实现配置管理 统一配置管理 配置更新热更新 统一配置的创建是在UI界面中完成的: 首先我们点击【配置管理】然后点击【配置列表】: 然后我们就看到了配置管理界面,但是此时这里是空的,我们可以创建一些配置文件:…...
05目标检测-区域推荐(Anchor机制详解)
目录 一、问题的引入 二、解决方案-设定的anchor boxes 1.高宽比(aspect ratio)的确定 2.尺度(scale)的确定 3.anchor boxes数量的确定 三、Anchor 的在目标检测中是怎么用的 1、anchor boxes对真值bounding box编码的步骤 2、为什么要回归偏移量…...
SpringBoot如何保证接口安全?
对于互联网来说,只要你系统的接口暴露在外网,就避免不了接口安全问题。如果你的接口在外网裸奔,只要让黑客知道接口的地址和参数就可以调用,那简直就是灾难。 举个例子:你的网站用户注册的时候,需要填写手…...

构建可扩展的应用:六边形架构详解与实践
面试题分享 云数据解决事务回滚问题 点我直达 2023最新面试合集链接 2023大厂面试题PDF 面试题PDF版本 java、python面试题 项目实战:AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮…...

error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413 解决方案
error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413 解决方案 使用Git提交时报错,代码如下: $ git push -u origin "master" Counting objects: 100% (95/95), done. Delta compression using up to 12 threads Compressing ob…...
基于ssm智能停车场031
大家好✌!我是CZ淡陌。一名专注以理论为基础实战为主的技术博主,将再这里为大家分享优质的实战项目,本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目,希望你能有所收获,少走一些弯路…...
【Git】万字git与gitHub
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理在git和GitHub时的笔记与感言 🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以关注一下🫰&…...

C++版本的OpenCV实现二维图像的卷积定理(通过傅里叶变换实现二维图像的卷积过程,附代码!!)
C版本的OpenCV库实现二维图像的卷积定理过程详解 前言一、卷积定理简单介绍二、不同卷积过程对应的傅里叶变换过程1、“Same”卷积2、“Full”卷积3、“Valid”卷积 三、基于OpenCV库实现的二维图像卷积定理四、基于FFTW库实现的二维图像卷积定理五、总结与讨论 前言 工作中用…...
打开深度学习的锁:(1)入门神经网络
打开深度学习的锁 导言PS:神经网络的训练过程一、导入的包和说明二、数据的预处理2.1 数据集说明2.2 数据集降维度并且转置2.3 数据预处理完整代码 三、逻辑回归3.1 线性回归函数公式3.2 sigmoid函数公式 四、初始化函数五、构建逻辑回归的前向传播和后向传播5.1 损…...

02- pytorch 实现 RNN
一 导包 import torch from torch import nn from torch.nn import functional as F import dltools 1.1 导入训练数据 batch_size, num_steps 32, 35 # 更改了默认的文件下载方式,需要将 article 文件放入该文件夹 train_iter, vocab dltools.load_data_time_…...

算法课作业1
https://vjudge.net/contest/581138 A - Humidex 模拟题 题目大意 给三个类型数字通过公式来回转化 思路 求e的对数有log函数,不懂为什么不会出精度错误,很迷,给的三个数字也没有顺序,需要多判断。 #include<cstdio>…...

linux文本处理 两行变一行
linux简单文本处理 [rootkvm ~]# cat test 1.1.1.1 test1 2.2.2.2 test2 3.3.3.3 test3 192.168.1.2 test4 10.23.9.19 test5 cat test | awk /^[0-9]/{T$1;next;}{print T,$1}1.1.1.1 test1 2.2.2.2 test2 3.3.3.3 test3 192.168.1.2 test4 10.23.9.19 test5 cat test | …...

第二次面试 9.15
首先就是自我介绍 项目拷打 总体介绍一下项目 谈一下对socket的理解 在数据接收阶段,如何实现一个异步的数据处理 谈一谈对qt信号槽的理解 有想过如何去编写一个信号槽吗 你是如何使用CMAKE编译文件的 C11特性了解些啥 shared_ptr 和 unique_ptr 的运用场景 …...
基于matlab实现的平面波展开法二维声子晶体能带计算程序
Matlab 平面波展开法计算二维声子晶体二维声子晶体带结构计算,材料是铅柱在橡胶基体中周期排列,格子为正方形。采用PWE方法计算 完整程序: %%%%%%%%%%%%%%%%%%%%%%%%% clear;clc;tic;epssys1.0e-6; %设定一个最小量,避免系统截断误差或除零错…...
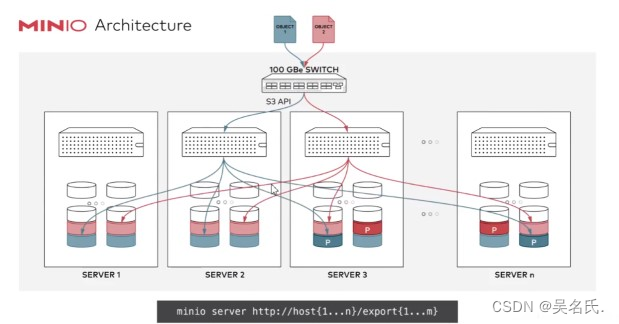
Minio入门系列【2】纠删码
1 纠删码 Minio使用纠删码erasure code和校验和checksum来保护数据免受硬件故障和无声数据损坏。 即便丢失一半数量(N/2)的硬盘,仍然可以恢复数据 1.1 什么叫纠删码 纠删码是一种用于重建丢失或损坏数据的数学算法。 纠删码(e…...
基于永磁同步发电机的风力发电系统研究(Simulink实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
5.后端·新建子模块与开发(自动模式)
文章目录 学习资料自动生成模式创建后端三层 学习资料 https://www.bilibili.com/video/BV13g411Y7GS?p11&spm_id_frompageDriver&vd_sourceed09a620bf87401694f763818a31c91e 自动生成模式创建后端三层 首先,运行起来若依的前后端整个项目,…...
这样而不是data:{}这样?)
vue的data为什么要写成data(return{})这样而不是data:{}这样?
在Vue.js中,为什么要将data写成一个返回对象的函数data()而不是一个普通的对象data: {} 为什么? 因为Vue.js的组件实例是可复用的,而且它们可以在应用中多次实例化。通过将data定义为一个返回对象的函数,可以确保每个组件实例都…...

MySQL基础运维知识点大全
一. MySQL基本知识 1. 目录的功能 通用 Unix/Linux 二进制包的 MySQL 安装下目录的相关功能 目录目录目录binMySQLd服务器,客户端和实用程序docs信息格式的 MySQL 手册manUnix 手册页include包括(头)文件lib图书馆share用于数据库安装的错…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...