豆瓣图书评分数据的可视化分析

导语
豆瓣是一个提供图书、电影、音乐等文化产品的社区平台,用户可以在上面发表自己的评价和评论,形成一个丰富的文化数据库。本文将介绍如何使用爬虫技术获取豆瓣图书的评分数据,并进行可视化分析,探索不同类型、不同年代、不同地区的图书的评分特征和规律。
概述
本文的主要步骤如下:
- 使用scrapy框架编写爬虫程序,从豆瓣图书网站抓取图书的基本信息和评分数据,保存为csv格式的文件。
- 使用亿牛云爬虫代理服务,提高爬虫效率和稳定性,避免被豆瓣网站屏蔽或封禁。
- 使用pandas库对爬取的数据进行清洗和处理,提取出需要的字段和特征。
- 使用matplotlib库对处理后的数据进行可视化分析,绘制各种类型的图表,展示不同维度的评分分布和关系。
正文
爬虫程序
首先,我们需要编写一个爬虫程序,从豆瓣图书网站抓取图书的基本信息和评分数据。我们使用scrapy框架来实现这个功能,scrapy是一个强大而灵活的爬虫框架,可以方便地定义爬虫规则和处理数据。我们需要定义一个Spider类,继承自scrapy.Spider类,并重写以下方法:
- start_requests:该方法返回一个可迭代对象,包含了爬虫开始时要访问的请求对象。我们可以从豆瓣图书首页开始,获取所有分类的链接,并构造请求对象。
- parse:该方法负责处理start_requests返回的请求对象的响应,并解析出需要的数据或者进一步的请求。我们可以使用scrapy自带的选择器或者BeautifulSoup等第三方库来解析HTML文档,提取出图书列表页的链接,并构造请求对象。
- parse_book:该方法负责处理parse返回的请求对象的响应,并解析出图书详情页的数据。我们可以使用同样的方式来提取出图书的基本信息和评分数据,并将其保存为字典格式。
- close:该方法在爬虫结束时被调用,我们可以在这里将抓取到的数据保存为csv格式的文件。
为了提高爬虫效率和稳定性,我们还需要使用亿牛云爬虫代理服务,该服务提供了大量高质量的代理IP地址,可以帮助我们避免被豆瓣网站屏蔽或封禁。我们只需要在settings.py文件中设置代理服务器的域名、端口、用户名和密码,以及启用中间件HttpProxyMiddleware即可。
首先配置爬虫代理,你可以按照以下步骤在Scrapy项目的settings.py文件中进行配置:
确保已经安装了Scrapy以及相关依赖。然后,打开你的Scrapy项目的settings.py文件,并添加以下配置:
# 启用HttpProxyMiddleware中间件
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 1,
}# 设置亿牛云 爬虫代理服务器的配置
HTTPPROXY_AUTH_ENCODING = 'utf-8' # 编码格式# 亿牛云 爬虫代理服务器的域名、端口、用户名和密码
HTTPPROXY_HOST = 'www.16yun.cn'
HTTPPROXY_PORT = 12345
HTTPPROXY_USER = '16YUN'
HTTPPROXY_PASS = '16IP'以下是爬虫程序的代码:
# -*- coding: utf-8 -*-
import scrapy
import csvclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['book.douban.com']start_urls = ['https://book.douban.com/']# 定义保存数据的列表data = []def start_requests(self):# 从豆瓣图书首页开始yield scrapy.Request(url=self.start_urls[0], callback=self.parse)def parse(self, response):# 解析首页,获取所有分类的链接categories = response.xpath('//div[@class="article"]/div[@class="indent"]/table//a')for category in categories:# 构造分类页面的请求对象url = category.xpath('./@href').get()yield scrapy.Request(url=url, callback=self.parse_book)def parse_book(self, response):# 解析分类页面,获取图书列表books = response.xpath('//li[@class="subject-item"]')for book in books:# 构造图书详情页的请求对象url = book.xpath('./div[@class="info"]/h2/a/@href').get()yield scrapy.Request(url=url, callback=self.parse_detail)# 获取下一页的链接,如果存在则继续爬取next_page = response.xpath('//span[@class="next"]/a/@href')if next_page:url = next_page.get()yield scrapy.Request(url=url, callback=self.parse_book)def parse_detail(self, response):# 解析图书详情页,获取图书的基本信息和评分数据item = {}item['title'] = response.xpath('//h1/span/text()').get() # 标题item['author'] = response.xpath('//span[contains(text(),"作者")]/following-sibling::a/text()').get() # 作者item['publisher'] = response.xpath('//span[contains(text(),"出版社")]/following-sibling::text()').get() # 出版社item['pub_date'] = response.xpath('//span[contains(text(),"出版年")]/following-sibling::text()').get() # 出版年item['price'] = response.xpath('//span[contains(text(),"定价")]/following-sibling::text()').get() # 定价item['rating'] = response.xpath('//strong/text()').get() # 评分item['rating_num'] = response.xpath('//a[contains(@href,"rating")]/span/text()').get() # 评分人数item['tags'] = response.xpath('//div[@id="db-tags-section"]/div[@class="indent"]/span/a/text()').getall() # 标签# 将数据添加到列表中self.data.append(item)def close(self, spider, reason):# 爬虫结束时,将数据保存为csv格式的文件with open('douban_books.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.DictWriter(f, fieldnames=self.data[0].keys())writer.writeheader()writer.writerows(self.data)
数据清洗和处理
接下来,我们需要对爬取的数据进行清洗和处理,提取出需要的字段和特征。我们使用pandas库来实现这个功能,pandas是一个强大而灵活的数据分析和处理库,可以方便地读取、操作和转换数据。我们需要做以下几个步骤:
- 读取csv文件,将数据转换为DataFrame对象。
- 去除空值和重复值,保证数据的完整性和唯一性。
- 对部分字段进行类型转换,如将评分和评分人数转换为数值类型,将出版年转换为日期类型。
- 对部分字段进行拆分或合并,如将作者拆分为中文作者和外文作者,将标签合并为一个字符串。
- 对部分字段进行分组或分类,如根据评分区间划分为高分、中等、低分三类,根据出版年划分为不同的年代。
以下是数据清洗和处理的代码:
# -*- coding: utf-8 -*-
import pandas as pd# 读取csv文件,将数据转换为DataFrame对象
df = pd.read_csv('douban_books.csv')# 去除空值和重复值,保证数据的完整性和唯一性
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)# 对部分字段进行类型转换,如将评分和评分人数转换为数值类型,将出版年转换为日期类型
df['rating'] = pd.to_numeric(df['rating'])
df['rating_num'] = pd.to_numeric(df['rating_num'])
df['pub_date'] = pd.to_datetime(df['pub_date'])# 对部分字段进行拆分或合并,如将作者拆分为中文作者和外文作者,将标签合并为一个字符串
df[‘tags’] = df[‘tags’].apply(lambda x: ‘,’.join(x))# 对部分字段进行分组或分类,如根据评分区间划分为高分、中等、低分三类,根据出版年划分为不同的年代
df[‘rating_level’] = pd.cut(df[‘rating’], bins=[0, 7, 8.5, 10], labels=[‘低分’, ‘中等’, ‘高分’])
df[‘pub_year’] = df[‘pub_date’].dt.year
df[‘pub_decade’] = (df[‘pub_year’] // 10) * 10
#数据清洗和处理完成,保存为新的csv文件
df.to_csv(‘douban_books_cleaned.csv’, index=False)数据可视化分析
最后,我们需要对处理后的数据进行可视化分析,绘制各种类型的图表,展示不同维度的评分分布和关系。我们使用matplotlib库来实现这个功能,matplotlib是一个强大而灵活的数据可视化库,可以方便地创建各种风格和格式的图表。我们需要做以下几个步骤:
- 导入matplotlib库,并设置中文显示和风格。
- 读取清洗后的csv文件,将数据转换为DataFrame对象。
- 使用matplotlib的子模块pyplot来绘制各种图表,如直方图、饼图、箱线图、散点图等。
- 使用matplotlib的子模块axes来调整图表的标题、标签、刻度、图例等属性。
- 使用matplotlib的子模块figure来保存图表为图片文件。
以下是数据可视化分析的代码:
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import pandas as pd# 导入matplotlib库,并设置中文显示和风格
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
plt.style.use('ggplot') # 设置风格# 读取清洗后的csv文件,将数据转换为DataFrame对象
df = pd.read_csv('douban_books_cleaned.csv')# 绘制直方图,显示不同评分区间的图书数量
plt.figure(figsize=(8, 6)) # 设置画布大小
plt.hist(df['rating'], bins=20, color='steelblue', edgecolor='k') # 绘制直方图
plt.xlabel('评分') # 设置x轴标签
plt.ylabel('数量') # 设置y轴标签
plt.title('豆瓣图书评分直方图') # 设置标题
plt.savefig('rating_hist.png') # 保存图片# 绘制饼图,显示不同评分等级的图书占比
plt.figure(figsize=(8, 6)) # 设置画布大小
rating_level_counts = df['rating_level'].value_counts() # 计算不同评分等级的图书数量
plt.pie(rating_level_counts, labels=rating_level_counts.index, autopct='%.2f%%', colors=['limegreen', 'gold', 'tomato']) # 绘制饼图
plt.title('豆瓣图书评分等级饼图') # 设置标题
plt.savefig('rating_level_pie.png') # 保存图片# 绘制箱线图,显示不同年代的图书评分分布
plt.figure(figsize=(8, 6)) # 设置画布大小
decades = df['pub_decade'].unique() # 获取不同年代的列表
decades.sort() # 对年代进行排序
ratings_by_decade = [df[df['pub_decade'] == decade]['rating'] for decade in decades] # 获取每个年代对应的评分列表
plt.boxplot(ratings_by_decade, labels=decades) # 绘制箱线图
plt.xlabel('年代') # 设置x轴标签
plt.ylabel('评分') # 设置y轴标签
plt.title('豆瓣图书不同年代评分箱线图') # 设置标题
plt.savefig('rating_by_decade_box.png') # 保存图片# 绘制散点图,显示评分和评分人数的关系
plt.figure(figsize=(8, 6)) # 设置画布大小
plt.scatter(df['rating'], df['rating_num'], color='steelblue', alpha=0.5) # 绘制散点图
plt.xlabel('评分') # 设置x轴标签
plt.ylabel('评分人数') # 设置y轴标签
plt.title('豆瓣图书评分和评分人数散点图') # 设置标题
plt.savefig('rating_num_scatter.png') # 保存图片
结语
本文介绍了如何使用爬虫技术获取豆瓣图书的评分数据,并进行可视化分析,探索不同类型、不同年代、不同地区的图书的评分特征和规律。通过本文,我们可以学习到以下几点:
- 如何使用scrapy框架编写爬虫程序,从豆瓣图书网站抓取图书的基本信息和评分数据,保存为csv格式的文件。
- 如何使用亿牛云爬虫代理服务,提高爬虫效率和稳定性,避免被豆瓣网站屏蔽或封禁。
- 如何使用pandas库对爬取的数据进行清洗和处理,提取出需要的字段和特征。
- 如何使用matplotlib库对处理后的数据进行可视化分析,绘制各种类型的图表,展示不同维度的评分分布和关系。
希望本文能够对你有所帮助,如果你对爬虫技术或者数据可视化有兴趣,可以继续深入学习和探索。谢谢你的阅读!
相关文章:
豆瓣图书评分数据的可视化分析
导语 豆瓣是一个提供图书、电影、音乐等文化产品的社区平台,用户可以在上面发表自己的评价和评论,形成一个丰富的文化数据库。本文将介绍如何使用爬虫技术获取豆瓣图书的评分数据,并进行可视化分析,探索不同类型、不同年代、不同…...
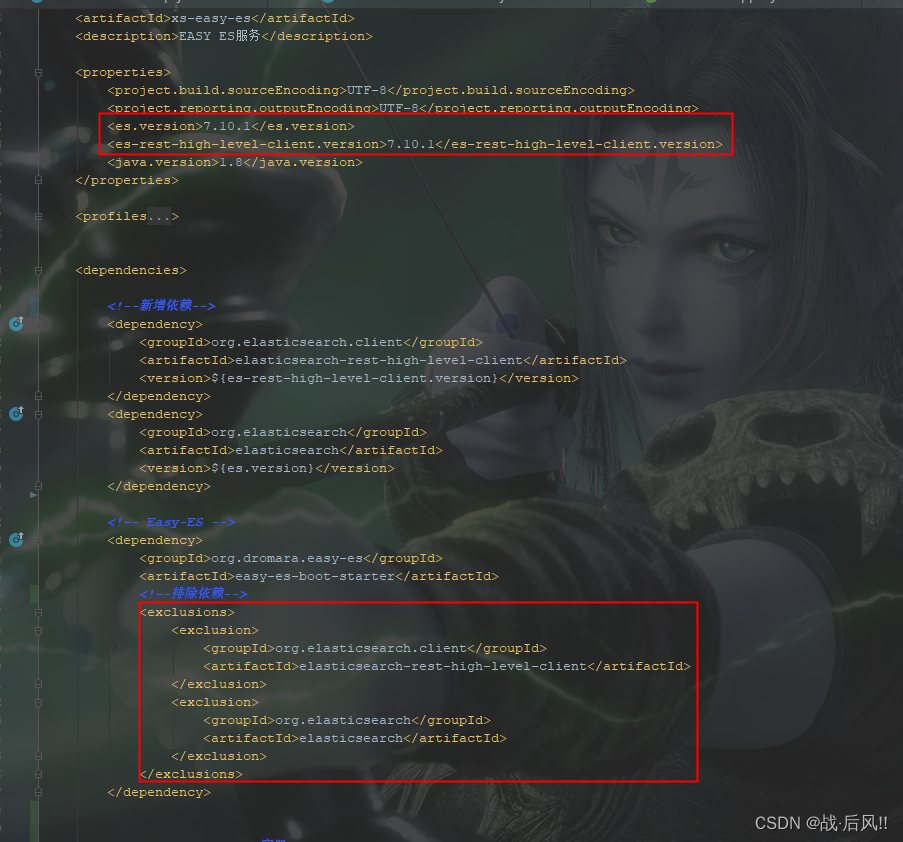
SpringBoot整合Easy-ES操作演示文档
文章目录 SpringBoot整合Easy-ES操作演示文档1 概述及特性1.1 官网1.2 主要特性 2 整合配置2.1 导入POM2.2 Yaml配置2.3 EsMapperScan 注解扫描2.4 配置Entity2.5 配置Mapper 3 基础操作3.1 批量保存3.2 数据更新3.3 数据删除3.4 组合查询3.5 高亮查询3.6 统计查询 4 整合异常4…...
IDEA控制台取消悬浮全局配置SpringBoot配置https
IDEA控制台取消悬浮 idea 全局配置 SpringBoot(Tomcat) 配置https,同时支持http 利用JDK生成证书 keytool -genkey -alias httpsserver -keyalg RSA -keysize 2048 -keystore server.p12 -validity 3650配置类 Configuration public class TomcatConfig {Value(&quo…...

MySQL8--my.cnf配置文件的设置
原文网址:MySQL8--my.cfg配置文件的设置_IT利刃出鞘的博客-CSDN博客 简介 本文介绍MySQL8的my.cnf的配置。 典型配置 [client] default-character-setutf8mb4[mysql] default-character-setutf8mb4[mysqld] #服务端口号 默认3306 port3306datadir /work/docker…...

Qt基于paintEvent自定义CharView
Qt基于paintEvent自定义CharView 鼠标拖动,缩放,区域缩放, 针对x轴,直接上代码 charview.h #ifndef CHARVIEW_H #define CHARVIEW_H#include <QWidget> #include <QPainter> #include <QPaintEvent> #inclu…...
Mac FoneLab for Mac:轻松恢复iOS数据,专业工具助力生活
如果你曾经不小心删除了重要的iOS数据,或者因为各种原因丢失了这些数据,那么你一定知道这种痛苦。现在,有一个名为Mac FoneLab的Mac应用程序,它专门设计用于恢复iOS数据,这可能是你的救星。 Mac FoneLab for Mac是一种…...

代码随想录二刷day30
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、力扣332. 重新安排行程二、力扣51. N 皇后三、力扣37. 解数独 一、力扣332. 重新安排行程 class Solution {private LinkedList<String> res;private Li…...
工业检测 ocr
采用OpenCV和深度学习的钢印识别_菲斯奇的博客-CSDN博客采用OpenCV和深度学习的钢印识别[这个帖子标题党了很久,大概9月初立贴,本来以为比较好做,后来有事情耽搁了,直到现在才有了一些拿得出手的东西。肯定不会太监的。好…...

LVS负载均衡群集
这里写目录标题 LVS负载均衡群集一.集群cluster与分布式1.特点:2.类型1)负载均衡群集 LB2)高可用群集 HA3)高性能运输群集 HPC 3.分布式1)特点 二.LVS1.lvs的工作原理2.lvs的三种工作模式1)NAT 地址转换2&a…...

安卓截屏;前台服务
private var mediaProjectionManager: MediaProjectionManager? nullval REQUEST_MEDIA_PROJECTION 10001private var isstartservice true//启动MediaService服务fun startMediaService() {if (isstartservice) {startService(Intent(this, MediaService::class.java))iss…...
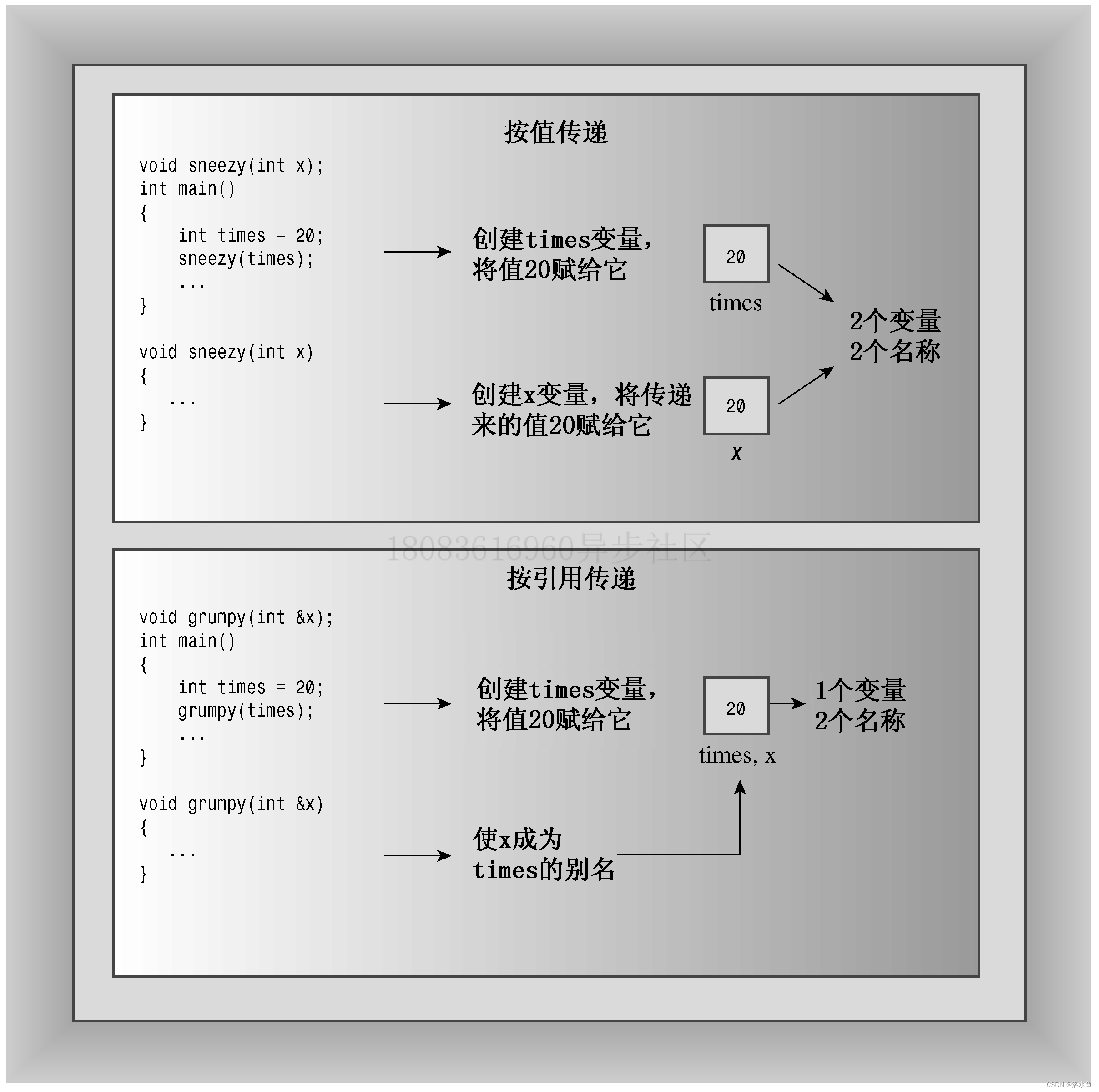
C++ PrimerPlus 复习 第八章 函数探幽
第一章 命令编译链接文件 make文件 第二章 进入c 第三章 处理数据 第四章 复合类型 (上) 第四章 复合类型 (下) 第五章 循环和关系表达式 第六章 分支语句和逻辑运算符 第七章 函数——C的编程模块(上ÿ…...
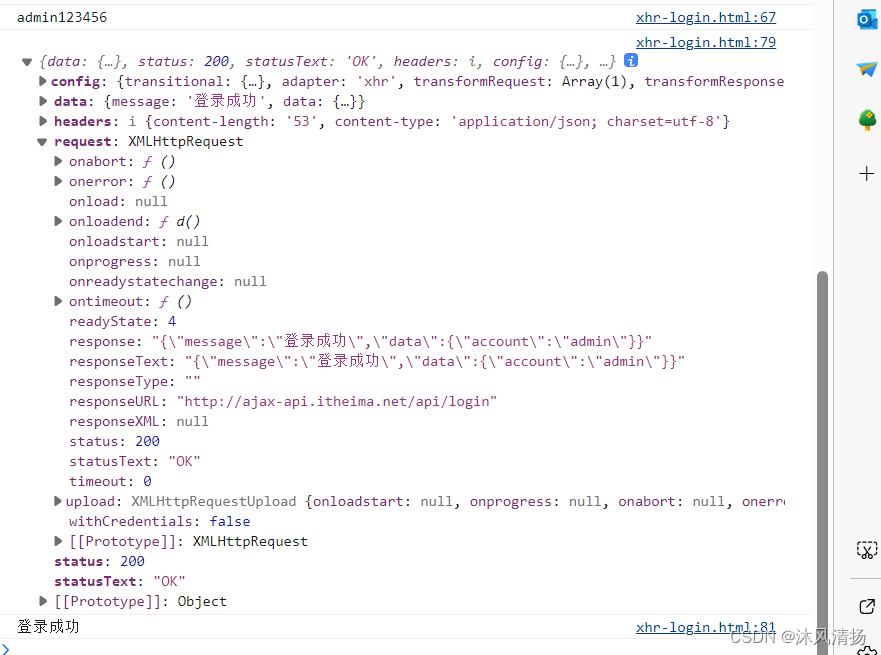
JavaScript-Ajax-axios-Xhr
JS的异步请求 主要有xhr xmlHttpRequest 以及axios 下面给出代码以及详细用法,都写在了注释里 直接拿去用即可 测试中默认的密码为123456 账号admin 其他一律返回登录失败 代码实例 <!DOCTYPE html> <html lang"en"> <head><…...

怎样查看kafka写数据送到topic是否成功
要查看 Kafka 写数据是否成功送到主题(topic),可以通过以下几种方法来进行确认: Kafka 生产者确认机制:Kafka 提供了生产者的确认机制,您可以在创建生产者时设置 acks 属性来控制确认级别。常见的确认级别包…...

腾讯mini项目-【指标监控服务重构】2023-08-16
今日已办 v1 验证 StageHandler 在处理消息时是否为单例,【错误尝试】 type StageHandler struct { }func (s StageHandler) Middleware1(h message.HandlerFunc) message.HandlerFunc {return func(msg *message.Message) ([]*message.Message, error) {log.Log…...

PTA:7-3 两个递增链表的差集
^两个递增链表的差集 题目输入样例输出样例 代码 题目 输入样例 5 1 3 5 7 9 3 2 3 5输出样例 3 1 7 9代码 #include <iostream> #include <list> #include <unordered_set> using namespace std; int main() {int n1, n2;cin >> n1;list<int&g…...

智能合约漏洞案例,DEI 漏洞复现
智能合约漏洞案例,DEI 漏洞复现 1. 漏洞简介 https://twitter.com/eugenioclrc/status/1654576296507088906 2. 相关地址或交易 https://explorer.phalcon.xyz/tx/arbitrum/0xb1141785b7b94eb37c39c37f0272744c6e79ca1517529fec3f4af59d4c3c37ef 攻击交易 3. …...
Attention is all you need 论文笔记
该论文引入Transformer,主要核心是自注意力机制,自注意力(Self-Attention)机制是一种可以考虑输入序列中所有位置信息的机制。 RNN介绍 引入RNN为了更好的处理序列信息,比如我 吃 苹果,前后的输入之间是有…...
Hdoop伪分布式集群搭建
文章目录 Hadoop安装部署前言1.环境2.步骤3.效果图 具体步骤(一)前期准备(1)ping外网(2)配置主机名(3)配置时钟同步(4)关闭防火墙 (二)…...

java临时文件
临时文件 有时候,我们程序运行时需要产生中间文件,但是这些文件只是临时用途,并不做长久保存。 我们可以使用临时文件,不需要长久保存。 public static File createTempFile(String prefix, String suffix)prefix 前缀 suffix …...

C++中的<string>头文件 和 <cstring>头文件简介
C中的<string>头文件 和 <cstring>头文件简介 在C中<string> 和 <cstring> 是两个不同的头文件。 <string> 是C标准库中的头文件,定义了一个名为std::string的类,提供了对字符串的操作如size()、length()、empty() 及字…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...