BIT-7文件操作和程序环境(16000字详解)
一:文件
1.1 文件指针
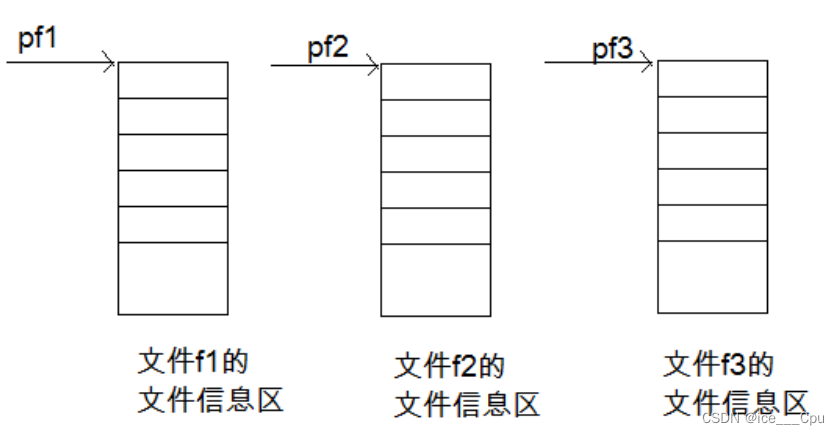
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统声明的,取名FILE.
例如,VS2013编译环境提供的 stdio.h 头文件中有以下的文件类型申明:
struct _iobuf {//文件信息区char *_ptr;int _cnt;char *_base;int _flag;int _file;int _charbuf;int _bufsiz;char *_tmpfname;};
typedef struct _iobuf FILE;
一般来说,我们是通过文件指针来维护这个文件信息区的
下面我们可以创建一个FILE*的指针变量:
FILE* pf;//文件指针变量
定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联的文件。
如图所示:
1.2文件的打开和关闭
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件的关系。
当在C语言中操作文件时,我们通常使用fopen函数来打开文件,并使用fclose函数来关闭文件。
fopen函数用于打开一个文件,并返回一个指向文件的指针。它的原型如下:
FILE *fopen(const char *filename, const char *mode);
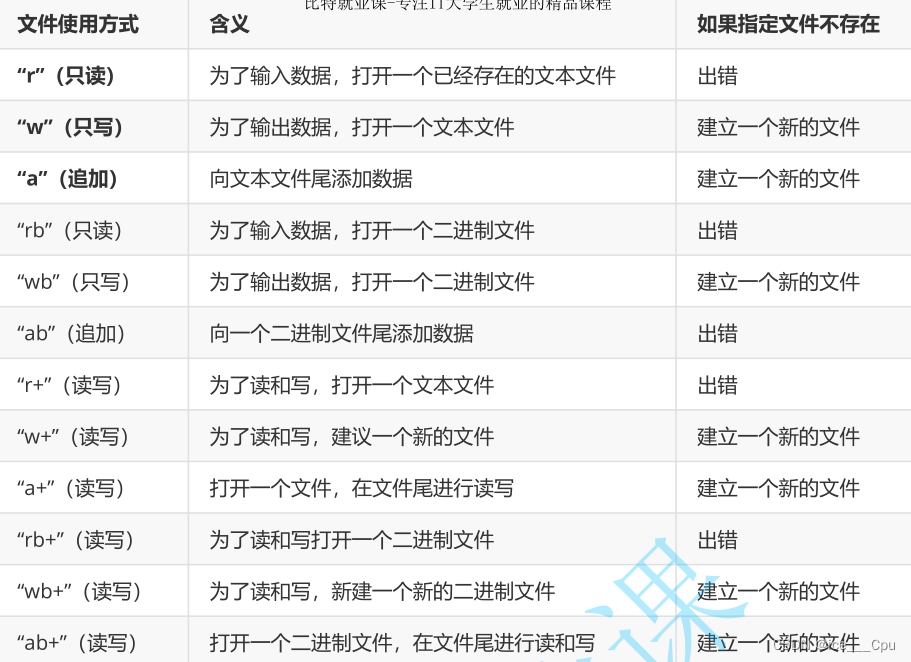
filename参数是一个字符串,表示要打开的文件名称。mode参数是一个字符串,用于指定文件的打开模式。
下面是一些常见的打开模式:
示例代码:
#include <stdio.h>int main() {FILE *file;char *filename = "example.txt";char *mode = "r";file = fopen(filename, mode);if (file == NULL) {printf("无法打开文件!\n");return 1;}// 做一些文件操作...fclose(file);return 0;
}
在上面的示例中,我们声明了一个指向FILE类型的指针file,然后指定了要打开的文件的路径和名称,以及打开模式。然后,我们使用fopen函数打开该文件,并将返回的文件指针赋值给file。
fopen函数的返回值是一个指向FILE类型的指针,如果打开文件失败(比如文件不存在),则返回NULL。
在完成文件操作后,我们使用fclose函数来关闭文件。这个函数负责将文件指针指向的文件关闭,并释放与该文件相关的资源。关闭文件后,我们就不能再对其进行读写操作了。
需要注意的是,打开文件后,我们必须在不再需要使用文件时及时关闭它,以便释放系统资源。
1.3 scanf printf fscanf fprintf sscanf sprintf
scanf:
scanf是一个标准输入函数,用于从标准输入设备(键盘)中读取格式化输入并将其存储在指定的变量中。它允许以指定的格式读取不同类型的数据,如整数、浮点数、字符等。
printf:
printf是一个标准输出函数,用于将格式化的数据输出到标准输出设备(屏幕)。它允许以指定的格式输出不同类型的数据,如整数、浮点数、字符等。
fscanf:
int fscanf(FILE *file, const char *format, argument_list)
file:要读取的文件指针。format:格式字符串,指定了输入的预期格式。argument_list:读取值的变量列表。
fscanf函数从给定的文件中按照指定的格式读取数据,并将读取的值存储到指定的变量中。它会根据格式字符串中的格式说明符逐个读取输入,并将读取的值与相应的变量进行匹配。
fscanf是一个文件输入函数,用于从文件中读取格式化输入并将其存储在指定的变量中。与scanf函数类似,但fscanf从指定的文件中读取数据而不是从键盘。
fprintf:
int fprintf(FILE *file, const char *format, argument_list)
file:要写入的文件指针。format:格式字符串,指定了输出的格式。argument_list:要写入的变量列表。
fprintf函数将指定的变量根据格式字符串的要求进行格式化,并将格式化后的内容写入到给定的文件中。
fprintf是一个文件输出函数,用于将格式化的数据输出到指定的文件中。与printf函数类似,但fprintf将数据写入指定的文件而不是输出到屏幕。
sscanf:
sscanf函数用于从一个字符串中读取数据并按照指定的格式转换。它的函数原型如下:
int sscanf(const char *str, const char *format, ...)
str是要读取的字符串。format是格式字符串,定义了读取数据的规则。...是可变参数列表,用于接收读取的数据。
sscanf是一个字符串输入函数,用于从一个字符串中读取格式化输入并将其存储在指定的变量中。与scanf类似,但sscanf从一个字符串中读取数据而不是从标准输入设备或文件中。
sprintf:
sprintf函数用于将格式化的数据写入一个字符串中。它的函数原型如下:
int sprintf(char *str, const char *format, ...)
str是目标字符串的指针,用于存储格式化的数据。format是格式字符串,定义了写入数据的规则。...是可变参数列表,用于提供需要格式化的数据。
sprintf是一个字符串输出函数,用于将格式化的数据输出到一个字符串中。与printf类似,但sprintf将数据写入一个字符串而不是输出到屏幕或文件中。
这些函数的区别在于输入/输出的来源或目标不同。scanf和printf用于标准输入输出,fscanf和fprintf用于文件输入输出,sscanf和sprintf用于字符串输入输出。
下面是一些示例代码:
#include <stdio.h>int main() {int num;char str[100];// 从键盘输入一个整数printf("请输入一个整数:");scanf("%d", &num);// 将该整数写入文件FILE *file = fopen("data.txt", "w");fprintf(file, "%d", num);//将一个整数num格式化为字符串,并将其写入到指定的文件file中。fclose(file);// 从文件中读取整数file = fopen("data.txt", "r");fscanf(file, "%d", &num);//从打开的文件file中读取一个整数,并将其存储在num变量中。fclose(file);// 将整数转换为字符串sprintf(str, "%d", num);//将一个整数num转换为字符串,并将结果存储在字符数组str中。// 从字符串中读取整数sscanf(str, "%d", &num);//从一个字符串str中读取一个整数,并将其存储在num变量中// 输出整数和字符串printf("整数:%d\n字符串:%s\n", num, str);return 0;
}
1.4 文件的顺序读写
fgetc fputc fgets fputs fread fwrite 是c语言中常用的顺序读写函数(fscanf和fprintf也是),下面我们一 一介绍
fgetc函数:
int fgetc(FILE *stream)函数用于从指定的文件流中读取一个字符,并返回该字符的ASCII码值。它的参数是一个指向FILE类型的指针,指向要读取的文件流。函数执行成功时将返回读取的字符,若已到达文件末尾或读取失败,则返回EOF(-1)。
下面是一个使用fgetc函数读取文件的示例代码:
#include <stdio.h>int main() {FILE *file = fopen("input.txt", "r");int character;while ((character = fgetc(file)) != EOF) {printf("%c", character);}fclose(file);return 0;
}
fputc函数:
int fputc(int character, FILE *stream)函数用于将指定的字符写入到文件中,并返回写入成功的字符。它的第一个参数是要写入的字符,第二个参数是指向FILE类型的指针,指向要写入的文件流。函数执行成功时将返回写入的字符,若写入失败,则返回EOF(-1)。
下面是一个使用fputc函数写入文件的示例代码:
#include <stdio.h>int main() {FILE *file = fopen("output.txt", "w");char character = 'A';fputc(character, file);fclose(file);return 0;
}
注意:fgetc函数在读取到文件末尾或读取失败时返回EOF(-1),而fputc函数在写入失败时返回EOF(-1)。
fgets函数:
fgets 函数用于从文件中读取一行文本。它的声明如下:
char *fgets(char *str, int n, FILE *stream);
- str:指向用于存储读取数据的字符数组的指针;
- n:要读取的字符的最大数量(包括空字符,所以实际数量要-1),通常使用数组的大小;
- stream:指向要读取的文件的指针。
fgets 会读取文件中的一行文本并存储在 str 中,直到达到以下情况之一:
- 读取到了n-1个字符(读取的字符个数不是n,而是n-1)
- 读取到换行符 ‘\n’;(读到\n会把\n保存进去)
- 到达文件的末尾;
- 发生错误。
fgets 会自动在读取到的文本末尾添加空字符 ‘\0’,因此 str 数组必须足够大以容纳该字符串。
示例代码:
#include <stdio.h>int main() {// 打开文件以供读取FILE *file = fopen("file.txt", "r");if (file) {char str[100];// 从文件中读取一行文本while (fgets(str, sizeof(str), file)) {printf("%s", str); // 打印读取的文本}fclose(file); // 关闭文件}return 0;
}
fputs函数:
fputs 函数用于将字符串写入文件。它的声明如下:
int fputs(const char *str, FILE *stream);
- str:要写入文件的字符串;
- stream:指向要写入的文件的指针。
fputs 会将 str 中的内容写入 stream 所指向的文件,直到遇到空字符 ‘\0’。写入成功时,它会返回一个非负值;否则,返回 EOF。
示例代码:
#include <stdio.h>int main() {// 打开文件以供写入FILE *file = fopen("file.txt", "w");if (file) {char str[] = "Hello, World!";// 将字符串写入文件fputs(str, file);fclose(file); // 关闭文件}return 0;
}
注意:
fgets 返回的是读取到的字符串的指针,fputs 的返回值是一个非负整数(表示写入的字符数)或 EOF(表示写入失败)。
fread函数:
fread函数用于从文件中读取数据。其声明如下:
size_t fread(void *ptr, size_t size, size_t count, FILE *stream);
ptr:指向接收数据的缓冲区的指针。(读到哪去的地址)size:要读取的每个元素的大小(以字节为单位)。count:要读取的元素的个数。stream:指向要读取的文件的指针。
fread 函数的返回值表示成功读取的元素数。
示例代码:
#include <stdio.h>int main() {FILE *file = fopen("data.txt", "rb");if (file == NULL) {printf("Unable to open the file.\n");return 1;}int numbers[5];size_t elements_read = fread(numbers, sizeof(int), 5, file);fclose(file);printf("Read %zu elements: ", elements_read);for (int i = 0; i < elements_read; i++) {printf("%d ", numbers[i]);}printf("\n");return 0;
}
在上面的示例中,我们打开一个名为 “data.txt” 的二进制文件,然后使用 fread 函数从文件中读取 5 个整数,并将它们存储在 numbers 数组中。最后,我们遍历数组并将读取的元素打印出来。
fwrite函数:
fwrite函数用于向文件中写入数据。其声明如下:
size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream);
ptr:指向要写入的数据的指针。size:要写入的每个元素的大小(以字节为单位)。count:要写入的元素的个数。stream:指向要写入的文件的指针。
fwrite 函数的返回值表示成功写入的元素数。
示例代码:
#include <stdio.h>int main() {FILE *file = fopen("data.txt", "wb");if (file == NULL) {printf("Unable to open the file.\n");return 1;}int numbers[] = {1, 2, 3, 4, 5};size_t elements_written = fwrite(numbers, sizeof(int), 5, file);fclose(file);printf("Written %zu elements to the file.\n", elements_written);return 0;
}
在上面的示例中,我们打开一个名为 “data.txt” 的二进制文件,然后使用 fwrite 函数将整数数组 numbers 的内容写入文件。最后,我们打印出成功写入的元素数。
注意:fread 函数的返回值表示成功读取的元素数,而 fwrite 函数的返回值表示成功写入的元素数。
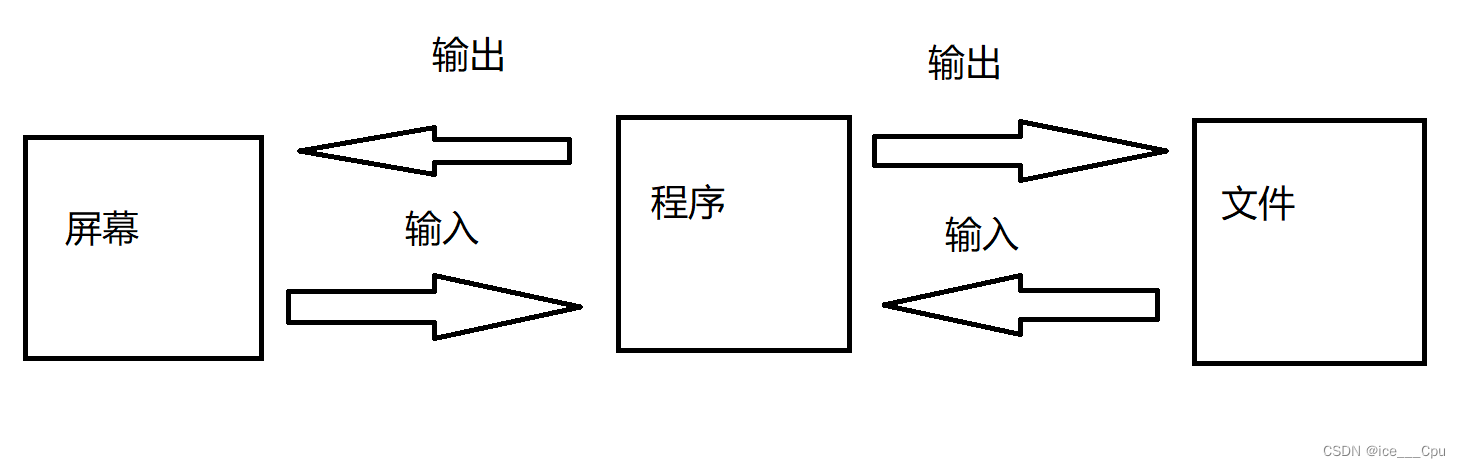
对于c语言中输入输出都是相对于程序来说的,如图所示:
1.4.1 c语言stdin流 stdout流 stderr流
在c语言中,只要c语言程序运行起来,就会默认打开3个流
-
stdin流
-
stdout流
-
stderr流
这三个流的指针都是FILE*
所以对于fputc(‘a’,stdout);来说,就相当于把a打印在屏幕上
对于int ch = fgetc(stdin);来说,就相当于从键盘上读一个字符
1.5 文件的随机读写
1.5.1 fseek
fseek 是 C 语言标准库中的一个函数,用于在文件中移动文件指针的位置。它的原型如下:
int fseek(FILE* stream, long int offset, int origin);
fseek 函数接受三个参数:
stream:指向FILE类型的指针,表示要移动文件指针的文件流。offset:移动的偏移量,单位为字节。origin:指示移动起点的位置,可以是以下三个常量之一:SEEK_SET:从文件开头开始计算。SEEK_CUR:从当前位置开始计算。SEEK_END:从文件末尾开始计算。
fseek 的返回值为 0 表示成功,非 0 值则表示出错。
下面是一个示例代码,演示了 fseek 函数的用法:
#include <stdio.h>int main() {FILE* file = fopen("example.txt", "r");if (file == NULL) {printf("无法打开文件。\n");return 1;}// 定位到文件结尾fseek(file, 0, SEEK_END);// 获取文件大小long int size = ftell(file);printf("文件大小为 %ld 字节。\n", size);// 重新定位到文件开头fseek(file, 0, SEEK_SET);// 读取文件内容char buffer[256];while (fgets(buffer, sizeof(buffer), file) != NULL) {printf("%s", buffer);}fclose(file);return 0;
}
在这个例子中,程序打开了一个名为 example.txt 的文本文件。首先,我们使用 fseek(file, 0, SEEK_END) 将文件指针移动到文件末尾,然后使用 ftell(file) 获取文件大小(以字节为单位)。接下来,我们使用 fseek(file, 0, SEEK_SET) 将文件指针重新定位到文件开头。最后,我们使用 fgets 函数从文件中逐行读取内容,并将其打印到控制台。
1.5.2 ftell
C 语言中的 ftell 函数用于获取文件指针的当前位置。它返回一个 long 类型的值,表示文件指针相对于文件起始位置的偏移量。下面是对 ftell 函数的详细解释以及一个代码示例。
ftell 函数的原型如下:
long ftell(FILE *stream);
ftell函数接受一个指向FILE结构体的指针作为参数,该指针指向要获取偏移量的文件。ftell函数返回一个long类型的值,表示文件指针的当前位置相对于文件开始位置的字节偏移量。如果发生错误,函数返回EOF(-1)。
下面是一个示例代码,演示了如何使用 ftell 函数:
#include <stdio.h>int main() {FILE *file;long filesize;// 打开文件file = fopen("example.txt", "r");if (file == NULL) {printf("无法打开文件。\n");return 1;}// 定位文件指针到文件尾部fseek(file, 0, SEEK_END);// 获取文件指针相对于文件开头的偏移量filesize = ftell(file);printf("文件大小为 %ld 字节。\n", filesize);// 关闭文件fclose(file);return 0;
}
在这个示例中,我们打开一个名为 example.txt 的文本文件,并将文件指针定位到文件末尾。然后,使用 ftell 函数获取文件指针相对于文件开头的偏移量,并将结果存储在 filesize 变量中。最后,打印文件大小。
请注意,fseek 函数用于定位文件指针的位置,而 ftell 函数用于获取这个位置的偏移量。
1.5.3 rewind
rewind 是 C 语言标准库 <stdio.h> 中的一个函数,用于将文件指针重新定位到文件的起始位置。它可用于将文件指针移动到文件开头,以便再次读取文件内容或重新从起始位置写入数据。
下面是 rewind 函数的原型:
void rewind(FILE *stream);
该函数接受一个指向已打开文件的指针作为参数,并将文件指针重置到文件起始位置。函数不返回任何值。
下面是一个使用 rewind 函数的示例代码:
#include <stdio.h>int main() {FILE *file = fopen("example.txt", "r"); // 以只读模式打开文件if (file == NULL) {printf("无法打开文件!\n");return 1;}// 读取文件内容char ch;while ((ch = fgetc(file)) != EOF) {printf("%c", ch);}rewind(file); // 将文件指针重置到文件起始位置printf("\n重新读取文件内容:\n");while ((ch = fgetc(file)) != EOF) {printf("%c", ch);}fclose(file); // 关闭文件return 0;
}
上述代码打开了一个名为 example.txt 的文件,并使用 fgetc 函数逐个字符地读取文件内容并输出。然后,在文件指针被重置到起始位置后,再次读取文件内容并输出。
1.6 文本文件和二进制文件
根据数据的组织形式,数据文件被称为文本文件或者二进制文件。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件。
如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。
一个数据在内存中是怎么存储的呢?
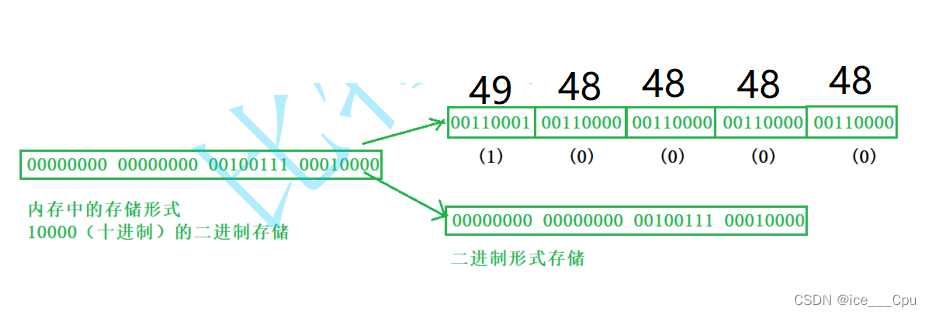
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而二进制形式输出,则在磁盘上只占4个字节(VS2013测试)。
1.7 文件读取结束的判定
feof函数是C语言中用于检测文件结束的函数。下面是关于该函数的详细解释:
函数声明:
int feof(FILE *stream);
函数参数:
stream:指向文件的指针,该文件必须已被打开。
函数返回值:
- 如果
stream指向的文件已经到达文件结尾,则返回非零值(1)。 - 如果
stream指向的文件尚未到达文件结尾,则返回零值(0)。
使用feof函数时,我们首先需要使用fopen函数打开文件,然后通过feof函数来确定文件是否已经结束。
下面是一个示例代码,演示了如何使用feof函数来判断文件是否结束:
#include <stdio.h>int main() {FILE *file;char ch;file = fopen("example.txt", "r");if (file == NULL) {printf("无法打开文件!");return 1;}while (!feof(file)) {ch = fgetc(file);if (!feof(file)) {printf("%c", ch);}}fclose(file);return 0;
}
在上述示例中,我们首先使用fopen函数打开名为example.txt的文件,并将返回的文件指针赋值给file变量。如果文件无法打开,将输出提示信息并返回1。
然后,我们通过一个循环来读取文件中的字符,直到feof函数返回非零值,即文件结束。在每次循环中,我们首先使用fgetc函数从文件中读取一个字符,并将其赋值给变量ch。然后,我们使用feof函数来判断文件是否结束,如果没有结束,将输出该字符。
最后,我们使用fclose函数关闭文件,并返回0表示程序执行成功。
请注意,在文件读取过程中,feof函数的返回值表示的是上一次读取操作是否成功。当文件读取结束时,feof函数的返回值可能是EOF(文件结束符),也可能是非零值(读取失败)。因此,直接使用feof函数的返回值来判断文件是否结束是不准确的。
原因是,文件的结束可能有多种情况。例如,在使用C语言的标准库函数进行文件操作时,当文件遇到文件末尾时,feof函数会返回非0值,但并不表示是文件读取失败。实际上,只有在上一次读取操作失败(如读取错误或出现其他异常情况)时,feof函数才能真正地指示出读取失败。
因此,在文件读取过程中,更好的做法是使用读取函数的返回值进行判断。
下面是对文本文件和二进制文件文件结束的可靠判断:
- 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
fgetc 判断是否为 EOF .
fgets 判断返回值是否为 NULL . - 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
fread判断返回值是否小于实际要读的个数。
1.8 文件缓冲区
文件缓冲区(File Buffer)是在C语言中用于文件输入和输出的一种机制。它主要用于提高文件的读写效率。当我们打开一个文件进行读取或写入操作时,操作系统会为该文件分配一个缓冲区,通过该缓冲区来进行数据的读取和写入。
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译系统决定的。
如图所示:
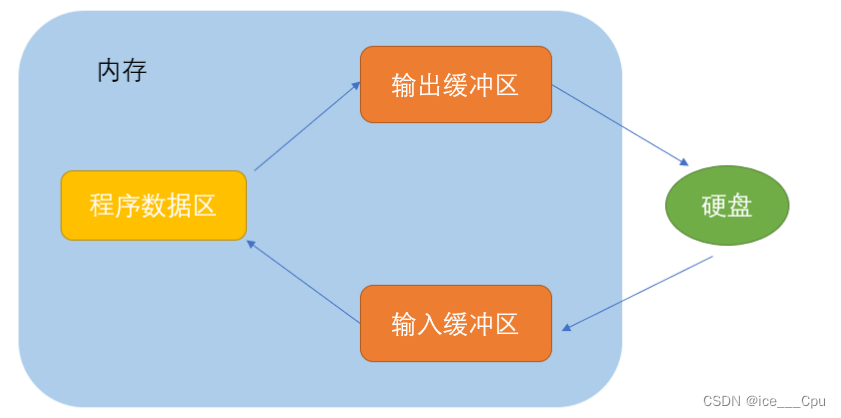
注意:fclose在关闭文件的时候,也会刷新缓冲区,因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。如果不做,可能导致读写文件的问题。
二:程序环境
在ANSI C的任何一种实现中,存在两个不同的环境。
- 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令
- 第2种是执行环境,它用于实际执行代码
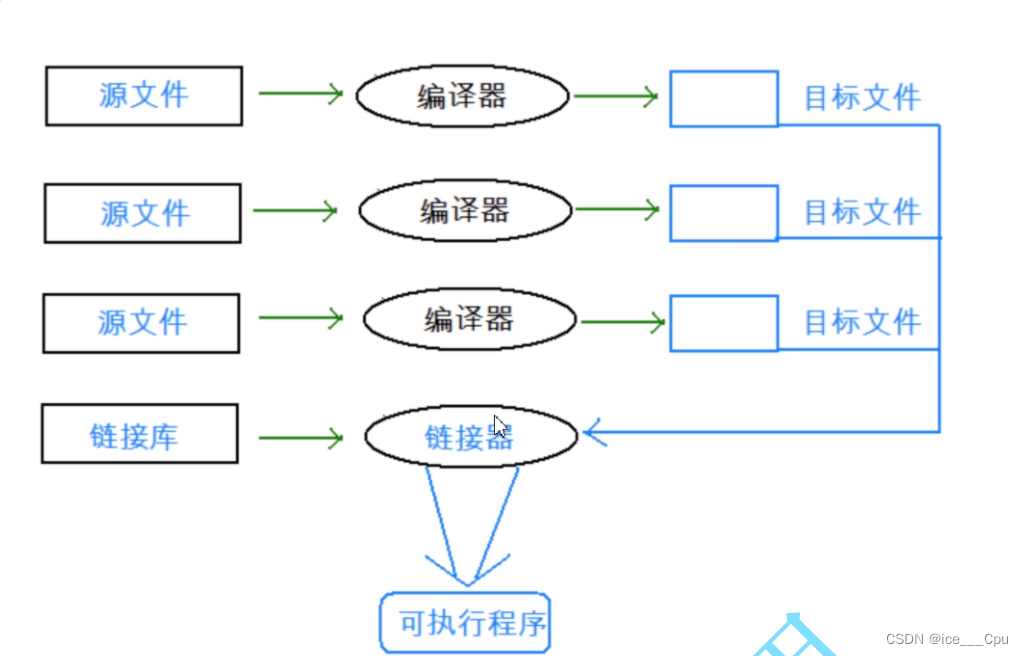
2.2 翻译环境
翻译环境如图所示:
下面是一个简图:
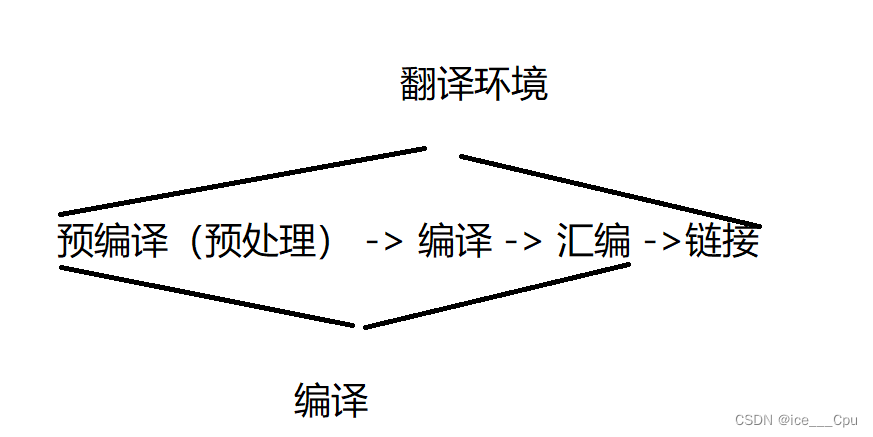
在C语言中,编译器将源代码转换成可执行的机器码的过程分为预编译、编译、汇编和链接四个阶段。下面对这四个阶段进行详细解释:
-
预编译阶段:
- 移除注释:移除源代码中的所有注释。
- 处理预处理指令:处理以
#开头的预处理指令,如宏定义、头文件包含等。 - 展开宏定义:将源代码中的宏展开为相应的代码片段。(宏替换)
- 处理条件编译:根据条件编译指令(如
#if、#ifdef、#ifndef等)判断编译哪些部分的代码。 - 生成修改后的源文件:将预处理后的代码保存为一个新的文件供下一阶段使用。
-
编译阶段:
- 词法分析和语法分析:将源代码分析成词法单元,并根据语法规则构建语法树。
- 语义分析:检查代码的语义正确性,如变量声明与使用是否匹配,函数调用参数是否正确等。
- 中间代码生成:将语法树转换成中间代码(如三地址码、虚拟机指令等)。
- 优化:对中间代码进行各种优化,如常量折叠、公共子表达式消除、循环展开等。
- 目标代码生成:将优化后的中间代码翻译成目标机器代码。
-
汇编阶段:
- 将目标代码转换成汇编语言表示,即将机器指令和操作数用助记符表示。
- 汇编器通过符号表解析符号,并为每个符号分配相应的内存地址。
- 生成可重定位的机器代码文件(目标文件)。
-
链接阶段:
- 解析引用:将不完整的目标文件(包含对其他模块的引用)与其他模块的目标文件进行符号解析,找到引用的符号所在的地址。
- 重定位:将目标文件的各个模块的绝对地址转换成最终的绝对地址。
- 符号解析:将符号引用与符号定义进行匹配,并进行地址重定向。
- 内存分配:将各个模块的目标代码和数据分配到内存的不同区域。
- 生成可执行文件:将链接后的目标文件生成可执行文件,包含所有的符号引用和定义。
2.1 运行环境:
程序执行的过程:
-
程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
-
程序的执行便开始。接着便调用main函数。
-
开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
-
终止程序。正常终止main函数;也有可能是意外终止(断电,卡死,崩溃)
三:预处理
3.1预定义
预定义符号:
- FILE //进行编译的源文件
- LINE //文件当前的行号
- DATE //文件被编译的日期
- TIME //文件被编译的时间
- STDC //如果编译器遵循ANSI C,其值为1,否则未定义
这些预定义符号都是语言内置的。
举个栗子:
printf("file:%s line:%d\n", __FILE__, __LINE__);//打印文件路径和行号
3.2 define定义标识符和宏
在C语言中,#define指令可以用于定义标识符和宏。
在C语言中,#define是一个预处理指令,用于定义常量和宏。
-
define定义标识符常量:
#define MAX 1000 -
define定义宏
#define ADD(x, y) ((x)+(y))
和标识符常量类似,宏也会被替换,比如
- #define ADD(x, y) ((x)+(y))
ADD(x,y)就会被替换为((x)+(y)),
注意ADD(x, y) 是由#define定义的宏,而不是函数,请注意区分
下面通过一个简单代码例子来说明宏的作用:
#define ADD(x, y) (x)+(y)
#include <stdio.h>int main()
{int sum = ADD(2, 3);printf("sum = %d\n", sum);sum = 10*ADD(2, 3);printf("sum = %d\n", sum);return 0;
}
宏定义是使用#define关键字指定的,宏的名称是ADD,宏的替换体是(x)+(y)。这个宏定义表示在代码中使用ADD(x, y)时,会将其替换为(x)+(y)。
在main函数中,有两个使用了宏的行。
- 第一行int sum = ADD(2, 3);,
表示将宏ADD中的x替换为2,y替换为3,得到的替换结果是(2)+(3),这个结果为5。然后将计算结果赋值给变量sum。
- 第二行sum = 10*ADD(2, 3);,
表示将宏ADD中的x替换为2,y替换为3,得到的替换结果是(2)+(3)。
请注意! sum = 10*ADD(2, 3); 中的ADD(2,3)被替换后 式子变成了10 * (2)+(3)这个结果等于23,请不要误以为是2和3相加后再乘10,宏只是简单的进行替换,并不运算
关于宏的替换规则,当使用ADD(x, y)时,预处理器会将其替换为(x)+(y)。在替换过程中,预处理器会将参数x和y直接替换到宏定义中的对应位置。这种替换是简单的文本替换,没有类型检查或计算。因此,在使用宏时要确保参数和替换体的正确匹配,并注意避免出现意料之外的错误。
注意:对于字符串里的符号,宏是不会替换的
3.3# 和 ##用法
当我们在C语言中定义宏时,有时候我们需要把宏参数转化为对应的字符串。在C语言中,我们可以使用#运算符来实现这个目标。
下面是一个示例代码,演示了如何使用#运算符将宏参数转化为字符串:
#include <stdio.h>#define PRINT_STRING(x) printf("String: %s\n", #x)int main() {char str[] = "Hello, world!";PRINT_STRING(str);return 0;
}
在这个示例中,我们定义了一个宏PRINT_STRING,它接受一个参数x。使用#运算符,我们可以在宏的定义中将参数x转化为对应的字符串。在main()函数中,我们传递一个字符串str给宏PRINT_STRING,它将打印出字符串"String: Hello, world!"。
另外,还有一个特殊的运算符##,称为连接运算符或者拼接运算符。它用于将两个宏参数组合成单个标识符,或者拼接成一个更大的标识符。
下面是一个示例代码,演示了如何使用##运算符进行参数拼接:
#include <stdio.h>#define CONCAT(a, b) a ## bint main() {int num1 = 10;int num2 = 20;int result = CONCAT(num, 1) + CONCAT(num, 2);printf("Result: %d\n", result);return 0;
}
在这个示例中,我们定义了一个宏CONCAT,它接受两个参数a和b。使用##运算符,我们将参数a和b拼接成一个新的标识符。在main()函数中,我们使用CONCAT宏将num1和num2拼接成num1和num2,然后将它们相加,得到结果30。最后,我们使用printf函数打印结果。
通过使用#和##运算符,我们可以在C语言中更灵活地操作宏参数,并且能够实现一些特定的功能。
3.4 宏和函数的对比
宏通常被应用于执行简单的运算。比如在两个数中找出较大的一个。那为什么不用函数来完成这个任务?
原因有二:
- 用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和速度方面更胜一筹。
- 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏怎可以适用于整形、长整型、浮点型等可以用于>来比较的类型。宏是类型无关的。
宏的缺点:当然和函数相比宏也有劣势的地方:
3. 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
-
宏是没法调试的。
-
宏由于类型无关,也就不够严谨。
-
宏可能会带来运算符优先级的问题,导致程容易出现错。
宏和函数的一个对比:

命名约定:
一般来讲函数的宏的使用语法很相似。所以语言本身没法帮我们区分二者。那我们平时的一个习惯是:
- 把宏名全部大写
- 函数名不要全部大写
3.5 #undef
#undef 是 C 语言中的一个预处理指令,用于取消定义(或者称为取消宏定义)。当我们使用 #define 定义了一个宏之后,如果需要取消这个宏的定义,就可以使用 #undef 进行操作。
#undef 的语法形式为:
#undef 宏名
其中,宏名 是要取消定义的宏的名称。
下面我们来通过一个代码示例来说明 #undef 的使用:
#include <stdio.h>#define PI 3.14159int main() {printf("PI的值为:%f\n", PI);#undef PIprintf("取消宏定义后,PI的值为:%f\n", PI); // 这里会报错,因为 PI 已经被取消定义了return 0;
}
在上述代码中,我们首先使用 #define 定义了一个名为 PI 的宏,将其值设置为 3.14159。然后在 main 函数中,我们通过 printf 输出了宏 PI 的值。
接着,我们使用 #undef 取消了宏 PI 的定义。所以在下一个 printf 中,我们尝试输出 PI 的值时,编译器会提示错误,因为 PI 已经被取消定义。
需要注意的是,一旦使用 #undef 取消了宏定义,那么在后续代码中就无法再使用该宏了,否则会导致编译错误。
#undef 可以在任何地方使用,不一定要紧跟在宏定义的后面。它的作用范围仅限于当前文件,不会影响其他文件。
3.6 文件包含
在C语言中,#include <> 和 #include "" 是用于包含头文件的预处理指令,它们之间有一些区别。
#include <> 是用于包含系统标准库的头文件。当使用#include <>时,编译器会在系统的标准库路径下搜索指定的头文件。示例代码如下:
#include <stdio.h> // 标准输入输出头文件int main() {printf("Hello, World!");return 0;
}
#include "" 是用于包含自定义的头文件或者用户创建的头文件。当使用#include ""时,编译器首先在当前目录下搜索指定的头文件,如果找不到,则在编译器的包含路径中搜索。示例代码如下:
#include "myheader.h" // 自定义头文件int main() {// 调用自定义函数myFunction();return 0;
}
需要注意的是,#include <> 和 #include "" 的使用是有规范的,开发者应该根据具体的情况选择正确的包含方式。一般来说,系统提供的标准库使用#include <>,自定义的头文件使用#include ""。这样可以提高代码的可读性和维护性。
对于库文件也可以使用 “” 的形式包含,但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
3.7 条件编译
条件编译是C语言中的一种预处理指令,它允许在编译过程中根据指定的条件选择性地包含或排除一部分代码。条件编译经常用于根据不同的编译选项或目标平台来选择性地编译代码。
条件编译使用以下指令:
#if:如果给定的条件为真,则编译下面的代码块。#elif:如果前面的条件为假,并且给定的条件为真,则编译下面的代码块。#else:如果前面的条件都为假,则编译下面的代码块。#endif:表示条件编译的结束。
下面是一个简单的示例,演示如何使用条件编译:
#include <stdio.h>#define VERSION 2int main() {#if VERSION == 1printf("这是版本1\n");#elif VERSION == 2printf("这是版本2\n");#elseprintf("这是其他版本\n");#endifreturn 0;
}
在上面的示例中,根据定义的VERSION宏的值来选择性地编译不同的代码块。如果VERSION的值是1,则输出"这是版本1";如果VERSION的值是2,则输出"这是版本2";如果VERSION的值既不是1也不是2,则输出"这是其他版本"。
通过改变VERSION的值,可以选择不同的代码路径进行编译。
使用条件编译可以根据需要去掉或者包含一些代码,从而实现在不同条件下的灵活编译。这在处理不同平台的特定代码或者根据编译选项选择性地编译某些功能时非常有用。
#if defined(symbol)//这两种写法是等效的
#ifdef symbol
#if !defined(symbol)//这两种写法是等效的
#ifndef symbol
3.7嵌套文件包含
如果出现这样的场景:
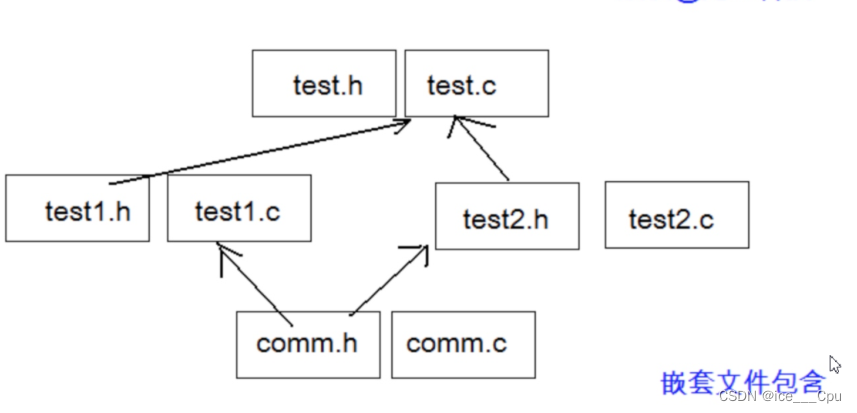
comm.h和comm.c是公共模块。
test1.h和test1.c使用了公共模块。
test2.h和test2.c使用了公共模块。
test.h和test.c使用了test1模块和test2模块。
这样最终程序中就会出现两份comm.h的内容。这样就造成了文件内容的重复
如何解决这个问题?
答案:条件编译。
每个头文件的开头写:
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__
或者
#pragma once
就可以避免头文件的重复引入。
相关文章:
BIT-7文件操作和程序环境(16000字详解)
一:文件 1.1 文件指针 每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统声明…...

冥想第九百二十八天
1.今天周三,今天晚上日语课上了好久,天气也不好, 2.项目上全力以赴的一天。 3.感谢父母,感谢朋友感谢家人,感谢不断进步的自己。...

深入浅出,SpringBoot整合Quartz实现定时任务与Redis健康检测(一)
目录 前言 环境配置 Quartz 什么是Quartz? 应用场景 核心组件 Job JobDetail Trigger CronTrigger SimpleTrigger Scheduler 任务存储 RAM JDBC 导入依赖 定时任务 销量统计 Redis检测 使用 编辑 注意事项 前言 在悦享校园1.0中引入了Quart…...
Lucene-MergePolicy详解
简介 该文章基于业务需求背景,因场景需求进行参数调优,下文会尽可能针对段合并策略(SegmentMergePolicy)的全参数进行说明。 主要介绍TieredMergePolicy,它是Lucene4以后的默认段的合并策略,之前采用的合并…...

数据的加解密
文章目录 分类特点业务的使用补充 分类 对称加密算法非对称加密算法 特点 对称加密算法 : 加密效率高 !加密和解密都使用同一款密钥 但是有一个问题 : 密钥如何从服务端发给客户端? (假如你直接先将密钥发给对方,要是在过程中被黑客技术破解了,那后面的消息也就泄漏了) (后…...

【Spring】更简单的读取和存储对象
更简单的读取和存储对象 一. 存储 Bean 对象1. 前置工作:配置扫描路径2. 添加注解存储 Bean 对象Controller(控制器存储)Service(服务存储)Repository(仓库存储)Component(组件存储&…...
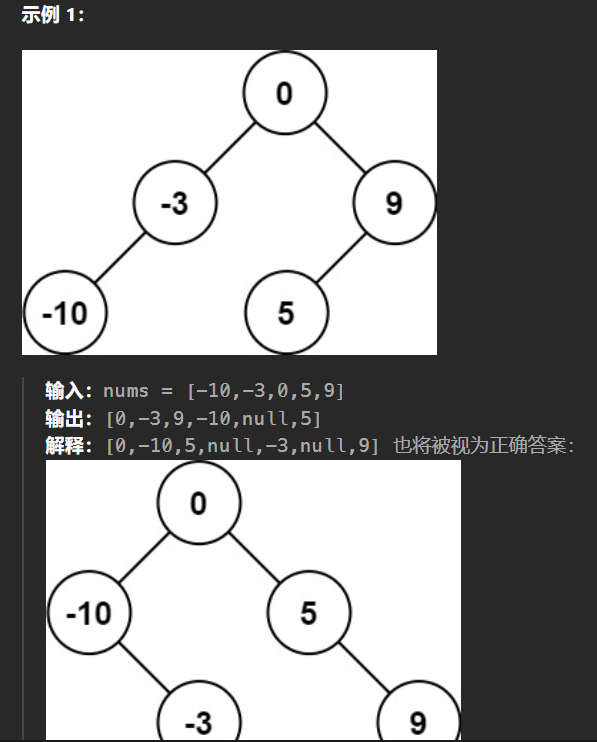
【LeetCode热题100】--108.将有序数组转换为二叉搜索树
108.将有序数组转换为二叉搜索树 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。 高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。 二叉搜索树的中序遍历是升序…...

Redis学习笔记(下):持久化RDB、AOF+主从复制(薪火相传,反客为主,一主多从,哨兵模式)+Redis集群
十一、持久化RDB和AOF 持久化:将数据存入硬盘 11.1 RDB(Redis Database) RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。 备份…...

【智能家居项目】裸机版本——设备子系统(LED Display 风扇)
🐱作者:一只大喵咪1201 🐱专栏:《智能家居项目》 🔥格言:你只管努力,剩下的交给时间! 输入子系统中目前仅实现了按键输入,剩下的网络输入和标准输入在以后会逐步实现&am…...

[Linux]记录plasma-wayland下无法找到HDMI接口显示器的问题解决方案
内核:Linux 6.5.5-arch1-1 Plasma 版本:5.27.8 窗口系统:Wayland 1 问题 在前些时候置入了一块显示器,接口较多,有 HDMI 接口,type-C 接口。在 X11 中可以找到外接显示器,但是卡顿明显…...

【计算机网络】高级IO之select
文章目录 1. 什么是IO?什么是高效 IO? 2. IO的五种模型五种IO模型的概念理解同步IO与异步IO整体理解 3. 阻塞IO4. 非阻塞IOsetnonblock函数为什么非阻塞IO会读取错误?对错误码的进一步判断检测数据没有就绪时,返回做一些其他事情完整代码myt…...

如何设计一个高效的应用缓冲区【一个动态扩容的buffer类】
文章目录 前言一、为什么需要设计应用层缓冲区必须要有 output buffer目的问题output buffer的解决方案: 必须要有 input buffer总结 二、设计要点三、buffer设计思路基础函数关于iovec与readv readfd如何实现动态扩容 问题 前言 在上一个博客,我们介绍…...

图像处理初学者导引---OpenCV 方法演示项目
OpenCV 方法演示项目 项目地址:https://github.com/WangQvQ/opencv-tutorial 项目简介 这个开源项目是一个用于演示 OpenCV 方法的工具,旨在帮助初学者快速理解和掌握 OpenCV 图像处理技术。通过这个项目,你可以轻松地对图像进行各种处理&a…...
管道-匿名管道
一、管道介绍 管道(Pipe)是一种在UNIX和类UNIX系统中用于进程间通信的机制。它允许一个进程的输出直接成为另一个进程的输入,从而实现数据的流动。管道是一种轻量级的通信方式,用于协调不同进程的工作。 1. 创建和使用管道&#…...

【JavaEE基础学习打卡08】JSP之初次认识say hello!
目录 前言一、JSP技术初识1.动态页面2.JSP是什么3.JSP特点有哪些 二、JSP运行环境配置1.JDK安装2.Tomcat安装 三、编写JSP1.我的第一个JSP2.JSP执行过程3.在IDEA中开发JSP 总结 前言 📜 本系列教程适用于JavaWeb初学者、爱好者,小白白。我们的天赋并不高…...
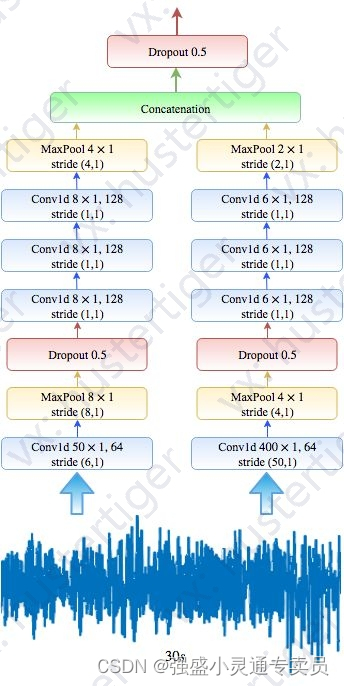
使用序列到序列深度学习方法自动睡眠阶段评分
深度学习方法,用于使用单通道脑电图进行自动睡眠阶段评分。 def build_firstPart_model(input_var,keep_prob_0.5):# List to store the output of each CNNsoutput_conns []######### CNNs with small filter size at the first layer ########## Convolutionnetw…...
【算法】排序——选择排序和交换排序(快速排序)
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法头疼记:算法专栏…...
Docker 容器监控 - Weave Scope
Author:rab 目录 前言一、环境二、部署三、监控3.1 容器监控 - 单 Host3.2 容器监控 - 多 Host 总结 前言 Docker 容器的监控方式有很多,如 cAdvisor、Prometheus 等。今天我们来看看其另一种监控方式 —— Weave Scope,此监控方法似乎用的人…...

Spring Boot集成redis集群拓扑动态刷新
项目场景: Spring Boot集成Redis集群,使用lettuce连接Cluster集群实例。 问题描述 redis其中一个节点挂了之后,springboot集成redis集群配置信息没有及时刷新,出现读取操作报错。 java.lang.IllegalArgumentException: Connec…...

COCI2022-2023#1 Neboderi
P9032 [COCI2022-2023#1] Neboderi 题目大意 有一个长度为 n n n的序列 h i h_i hi,你需要从中选择一个长度大于等于 k k k的子区间 [ l , r ] [l,r] [l,r],使得 g ( h l h l 1 ⋯ h r ) g\times (h_lh_{l1}\cdotsh_r) g(hlhl1⋯hr)最小&…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...