数据分析--观察数据处理异常值
引包:
import pandas as pd
import numpy as np读取文件:
df=pd.read_csv('./HR.csv')文件见绑定资源(来自kaggle的HR.csv)
处理过程:
一、从df中拿出处理对象
二、找出缺失值的位置并删除
s1_s=df['satisfaction_level']
# s1_s.isnull()
#查找空值
print(s1_s[s1_s.isnull()])
# 查看空值的具体情况
print(df[df['satisfaction_level'].isnull()])
# 删除空值
s1_s=s1_s.dropna()
# print(s1_s)
三、观察数据组成情况
(均值。中位数、最大值最小值、标准差、偏度和峰度.......)
print(s1_s.mean())#均值
print(s1_s.median())#中位数
print(s1_s.std())#标准差
print(s1_s.max())#最大值
print(s1_s.min())#最小值
print(s1_s.quantile(q=0.25))#下四分位数
print(s1_s.quantile(q=0.75))#上四分位数
print(s1_s.skew())#偏度=-0.4763...为负偏--均值偏小,大部分数大于均值
print(s1_s.kurt())#峰度=-0.67...-->相对于正态分布来说属于比较平缓的状态
(获取离散化的分布用numpy.histogram)
获取离散化的分布用numpy.histogram
s=np.histogram(s1_s.values,bins=np.arange(0.0,1.1,0.1))# series的值 bins:切分的临界
print(s)
# 输出: (array([ 195, 1214, 532, 974, 1668, 2146, 1972, 2074, 2220, 2004],# dtype=int64), array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]))其他列的数据也是同上三部的操作代码如下:
(多了一个删除异常值)
le_s=df['last_evaluation']
print(le_s[le_s.isnull()])print(le_s.mean())#均值
print(le_s.std())#标准差
print(le_s.max())#最大值
print(le_s.min())#最小值
print(le_s.median())#中位数
print(le_s.skew())#偏度
print(le_s.kurt())#峰度
print(df['last_evaluation'].describe())
print(df.describe())q_low=le_s.quantile(q=0.25)
q_high=le_s.quantile(q=0.75)
q_interval=q_high-q_low
k=1.5
le_s=le_s[le_s<q_high+k*q_interval][le_s>q_low-k*q_interval]
print(le_s)
print(np.histogram(le_s.values,bins=np.arange(0.0,1.1,0.1)))#处理number_project
np_s=df['number_project']
print(np_s[np_s.isnull()])np_s=np_s.dropna()
print('====')
print(np_s)
# print(np_s.skew())k=1.5
np_s1=np_s.quantile(0.25)
np_s2=np_s.quantile(0.75)
np_ss=np_s2-np_s1
np_s=np_s[np_s<np_s2+k*np_ss][np_s>np_s1-k*np_ss]
print(np_s)
print(np_s.describe())
# 查看数据的个数
print(np_s.value_counts())
# 查看各个数据所占的比例
print(np_s.value_counts(normalize=True))
# normalize:输出占比比例
# 按照index排序和values排序
print(np_s.value_counts(normalize=True).sort_index())
print(np_s.value_counts(normalize=True).sort_values())# 处理average_montly_hours
amh_s=df['average_montly_hours']
# print(amh_s)
print(amh_s[amh_s.isnull()])
amh_s=amh_s.dropna()
# print('===\n',amh_s[amh_s.isnull()])
# print(amh_s)
# print(amh_s.describe())
Upper_q=amh_s.quantile(q=0.75)
Lower_q=amh_s.quantile(q=0.25)
q=Upper_q-Lower_q
amh_s=amh_s[amh_s<=Upper_q+q*1.5][amh_s>=Lower_q-q*1.5]
print(amh_s)
# 输出偏度和峰度
print(amh_s.skew(),amh_s.kurt())
观察数值的分布情况
使用了histogram和可视化两个方法
# 方法一
print(np.histogram(amh_s.values,bins=10))
# print(np.histogram(amh_s.values,bins=np.arange(amh_s.min(),amh_s.max()+10,10)))
# # 方法二:画图--利用直方图来观察数据的分布情况
# import matplotlib.pyplot as plt
# plt.hist(amh_s.values,np.arange(amh_s.min(),amh_s.max()+10,10))
# plt.show()其他列的简单操作大部分都是删除空值
tsc_s=df['time_spend_company']
# print(tsc_s)
x=tsc_s[tsc_s.isnull()]
# print(x)
tsc_s=tsc_s.dropna()
# print(tsc_s)
print(tsc_s.min(),tsc_s.max(),tsc_s.kurt(),tsc_s.skew(),tsc_s.std())
uper_q=tsc_s.quantile(q=0.75)
lower_q=tsc_s.quantile(q=0.25)
q=uper_q-lower_q
tsc_s=tsc_s[tsc_s<uper_q+q*1.5][tsc_s>lower_q-q*1.5]
print(tsc_s)
print(tsc_s.min(),tsc_s.max(),tsc_s.kurt(),tsc_s.skew(),tsc_s.std())
print(tsc_s.value_counts().sort_index())
print(np.histogram(tsc_s.values,bins=np.arange(tsc_s.min(),tsc_s.max()+1,1)))wa_s=df['Work_accident']
print(wa_s)
wa_s.value_counts()
wa_s=wa_s[wa_s==0.0]
print(wa_s)lf_s=df['left']
print(lf_s)
lf_s=lf_s[lf_s==1.0]
print(lf_s)
print(lf_s.value_counts())pro_s=df['promotion_last_5years']
print(pro_s)
pro_s=pro_s[pro_s==0.0]
print(pro_s)
print(pro_s.value_counts())s_s=df['salary']
print(s_s)
s_s=s_s.dropna()
print(s_s)
print(s_s.value_counts())dpt_s=df['sales']
print(dpt_s)
dpt_s=dpt_s.dropna()
print(dpt_s)
dpt_s.where()
print(dpt_s.value_counts())say_s=df['salary']其实删除空值只需一行代码上面是为了一列一列的观察数据查看还有没有其他的异常值:
df=df.dropna(axis=0,how='any')意思是删除只要有空值的行。
对比分析:
(将不同列放在一起观察并分析数据)
这里的代码类似与sql的DQL代码
df=df.dropna(axis=0,how='any')
# print(df)df1=df.groupby('sales').min()
print(df1)
df2=df.loc[:,['satisfaction_level','sales']].groupby('sales').mean()
print(df2)
print('=====')
# 输出极差
df3=df.loc[:,['average_montly_hours','sales']].groupby('sales')['average_montly_hours'].apply(lambda x:x.max()-x.min())
print(df3)
print(df['salary'].value_counts())
print(len(df['salary'].value_counts()))简单的可视化操作:
这里用到的是matplotlib
import matplotlib.pyplot as plt
plt.title('salary')
plt.xlabel('salary_zhonglei')
plt.ylabel('shuliang')
plt.xticks(np.arange(len(df['salary'].value_counts())),df['salary'].value_counts().index)
# bottom=['low','medium','high']
plt.axis([-1,3,0,10000])
plt.bar(np.arange(len(df['salary'].value_counts())),df['salary'].value_counts(),width=0.4)
for x,y in zip(np.arange(len(df['salary'].value_counts())),df['salary'].value_counts()):plt.text(x,y,y,ha='center',va='bottom')# ha = 'center', va = 'bottom'
plt.show()相关文章:

数据分析--观察数据处理异常值
引包: import pandas as pd import numpy as np 读取文件: dfpd.read_csv(./HR.csv) 文件见绑定资源(来自kaggle的HR.csv) 处理过程: 一、从df中拿出处理对象 二、找出缺失值的位置并删除 s1_sdf[satisfactio…...

vue3+elementPlus el-input的type=“number“时去除右边的上下箭头
改成 代码如下 <script lang"ts" setup> import {ref} from vue const inputBtn ref() </script> <template><el-input type"number" v-model"inputBtn" style"width: 80px;" class"no_number">…...
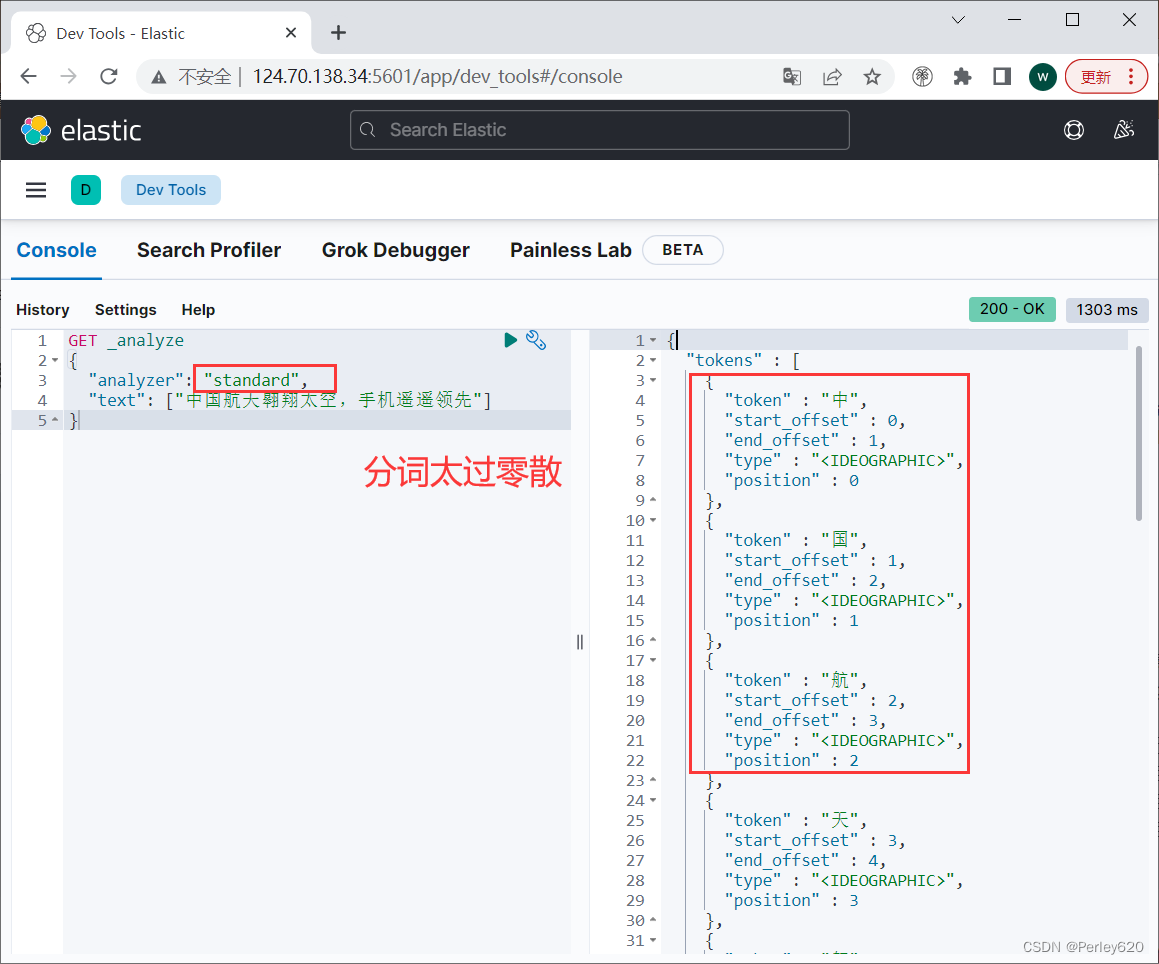
华为云云耀云服务器L实例评测|Elasticsearch的可视化Kibana工具安装 IK分词器的安装和使用
前言 最近华为云云耀云服务器L实例上新,也搞了一台来玩,期间遇到各种问题,在解决问题的过程中学到不少和运维相关的知识。 本篇博客介绍Elasticsearch的可视化Kibana工具安装,以及IK分词器的安装和使用。 其他相关的Elasticsea…...
)
加密货币交易技巧——人和(一)
交易原则 本篇主要讲述加密货币交易人需要注意的几个原则。 1.不能贪心,具体表现在做好仓位管理。第一,不要重仓进去,一定要轻仓。第二,开仓就想好本次要赚多少钱,不要太贪,到了预期点就止盈。第三&am…...

数学建模:最优化问题及其求解概述
数学建模:最优化问题及其求解概述 最优化问题定义分类离散优化问题连续优化问题 求解 此博客围绕运筹学以及最优化理论的相关知识,通俗易懂地介绍了最优化问题的定义、分类以及求解算法。 最优化问题 定义 数学优化(Mathematical Optimiza…...

企业办理CS资质,怎么选择办理等级?
信息系统建设和服务能力等级证书(Information system construction and service—Capability assessment system,简称:CS),由中国电子信息行业联合会组织开展的第三方评估活动,是根据《信息系统建设和服务能…...

华为云云耀云服务器L实例评测|Huawei Cloud EulerOS 自动化环境部署
[toc] Huawei Cloud EulerOS 自动化环境部署 云耀云服务器L实例【Huawei Cloud EulerOS 2.0 64bit】 Python Git Google Chrome Chromedriver Selenium More… 1. Python 镜像创建后自带。 2.Git 拉取项目。 sudo yum install git3. Google Chrome 使用root权限或sudo权…...
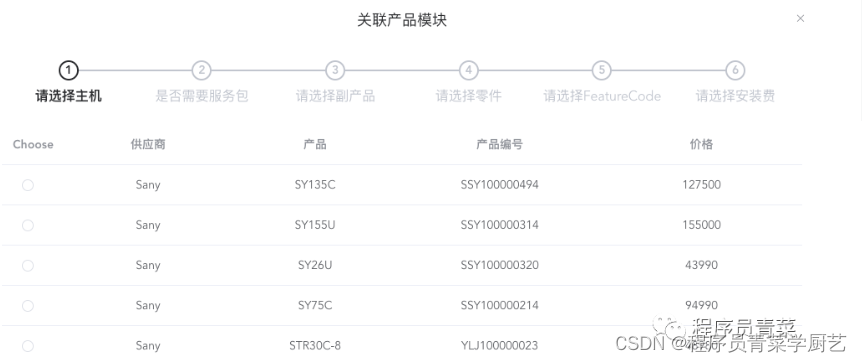
从一张表格开始做挖机报价系统
一、前言 历时4个月的挖机销售报价系统进入收尾阶段,由我直接负责与业务方对接,这中间各种折腾真是一言难尽,项目开发过程中还要维护POS系统以及牛奶配送系统,本项目我们采用的是迭代开发,今天讲一下具体的开发过程以…...
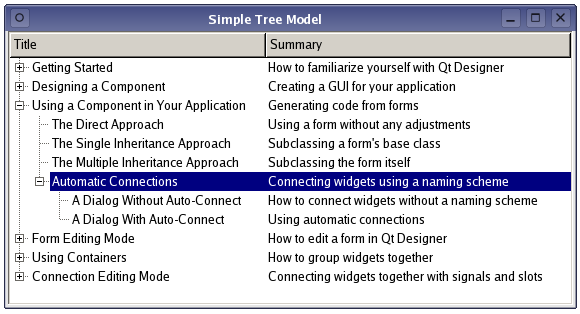
Qt扫盲-QTreeView 理论总结
QTreeView 理论使用总结 一、概述二、快捷键绑定三、提高性能四、简单实例1. 设计与概念2. TreeItem类定义3. TreeItem类的实现4. TreeModel类定义5. TreeModel类实现6. 在模型中设置数据 一、概述 QTreeView实现了 model 中item的树形表示。这个类用于提供标准的层次列表&…...

BF算法详解(JAVA语言实现)
目录 BF算法的介绍 图解 JAVA语言实现 BF算法的时间复杂度 BF算法的介绍 BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继…...

零基础转行网络工程师,过来人给的一些建议
最近收到好多同学的一些提问,零基础没经验,能不能转行到网络工程师?薪资能有多少?发展前景怎么样? 应该有不少朋友都有这个疑问,那么,今天我尽量给大家做出一个详细的解答,希望能有…...

Vue中如何进行分布式搜索与全文搜索(如Elasticsearch)
在Vue中实现分布式搜索与全文搜索(使用Elasticsearch) 分布式搜索和全文搜索在现代应用程序中变得越来越重要,因为它们可以帮助用户快速查找和检索大量数据。Elasticsearch是一种强大的分布式搜索引擎,它可以用于实现高性能的全文…...
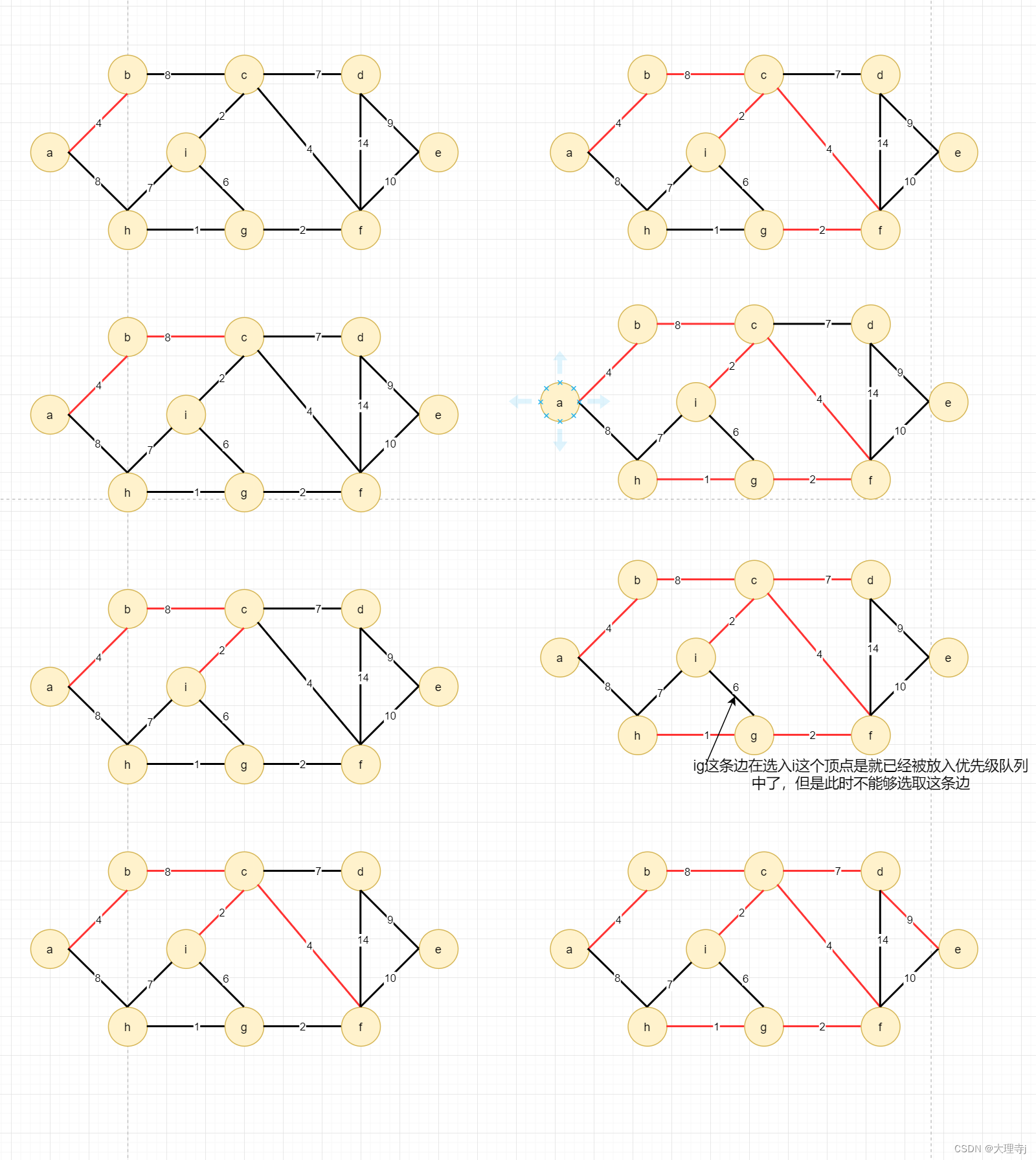
数据结构-图-最小生成树问题
最小生成树 并查集定义举例说明查找某个元素属于哪个集合代码实现路径压缩 Kruskal算法原理代码实现 Prim算法原理代码实现 并查集 定义 🚀在一些应用问题中,需要将n个不同的元素分成一些不相交的集合。开始时,每个元素自成一个单元素集合&…...
使用vite+npm封装组件库并发布到npm仓库
组件库背景:使用elementplusvue封装了一个通过表单组件。通过JSX对el-form下的el-input和el-button等表单进行统一封装,最后达到,通过数据即可一键生成页面表单的功能。 1.使用vite创建vue项目 npm create vitelatest elementplus-auto-form…...

85.最大矩形
单调栈,时间复杂度o(mn),空间复杂度o(mn) class Solution { public:int maximalRectangle(vector<vector<char>>& matrix) {int mmatrix.size();if(m0){return 0;}int nmatrix[0].size();//记录矩阵中每个元素左边连续1的数量vector<…...
Windows服务器 开机自启动服务
1、新建txt,并粘贴下面脚本 start cmd /k "cd /d D:\ahjd&&java -jar clips-admin.jar" start cmd /k "cd /d D:\ahjd\dist&&simple-http-server.exe -i -p 8000"说明,脚本格式为:start cmd /k “cd /d…...

《算法通关之路》chapter17一些通用解题模板
《算法通关之路》学习笔记,记录一下自己的刷题过程,详细的内容请大家购买作者的书籍查阅。 1 二分法 1.1 普通二分法 # 查找nums数组中元素值为target的下标。如果不存在,则返回-1def bs(nums: list[int], target: int) -> int :l, h …...
常用求解器安装
1 建模语言pyomo Pyomo是一个Python建模语言,用于数学优化建模。它可以与不同的求解器(如Gurobi,CPLEX,GLPK,SCIP等)集成使用,以求解各种数学优化问题。可以使用Pyomo建立数学优化模型…...
)
第三章:最新版零基础学习 PYTHON 教程(第一节 - Python 运算符)
在Python编程中,运算符一般用于对值和变量进行操作。这些是用于逻辑和算术运算的标准符号。在本文中,我们将研究不同类型的Python 运算符。 运算符:这些是特殊符号。例如- + 、 * 、 / 等。操作数:它是应用运算符的值。目录 Python 中的运算符类型 Python 中的算术运算符…...
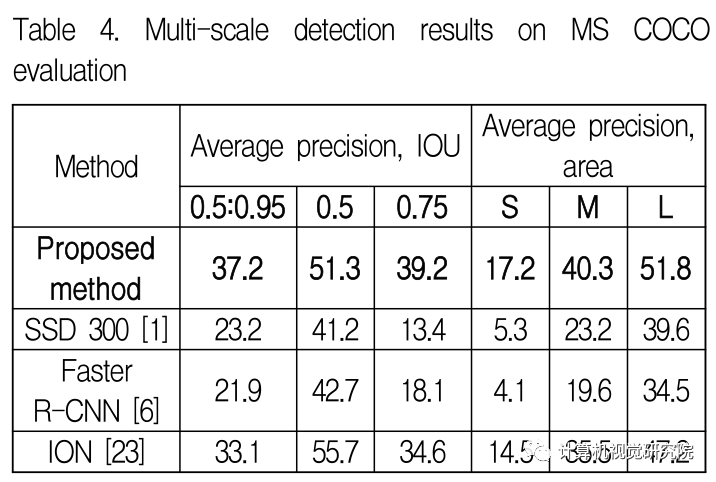
细粒度特征提取和定位用于目标检测:PPCNN
1、简介 近年来,深度卷积神经网络在计算机视觉上取得了优异的性能。深度卷积神经网络以精确地分类目标信息而闻名,并采用了简单的卷积体系结构来降低图层的复杂性。基于深度卷积神经网络概念设计的VGG网络。VGGNet在对大规模图像进行分类方面取得了巨大…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...