学习网络编程No.7【应用层之序列化和反序列化】
引言:
北京时间:2023/9/14/19:13,下午刚刚更完文章,是一篇很久很久以前的文章,由于各种原因,留到了今天更新,非常惭愧呀!目前在上学校开的一门网络课程,学校的课听不了一点,还没有我自己看书来的快,并且因为我们对网络基础知识已经有了一定能的理解,当然这部分理解是我们对网络概念框架的理解,比较宽泛,没有书本上那么丰富(细节),但是已经足够我们使用,因为我们对其的理解是从整体框架出发,本质还是那句话,学校的课听不了一点,咱直接开摆。然后这几天经历的事情还是比较丰富的,在之后的引言中我们慢慢回顾,最重要的还是在前几天学校开学啦!目前给我的感觉就是困意十足,中午睡觉睡的是真舒服,根本醒不来,哈哈哈!有待加强身体锻炼,剩余就是积极更文,并且在今天我找到了一个白嫖书的好方法,那就是帮图书馆推销有关计算机方面的书籍,只要到达1000浏览量,我们就能白嫖一本自己想要的书啦!感情真不错,哈哈哈!积极更文我能行,该篇博客就让我们来学习一下有关应用层方面的知识,序列化与反序列化。

学习应用层相关知识
在上篇博客中,我们对服务端中的日志概念和守护进程概念进行了理解,并且自己实现了相应代码,最后让服务端执行相应代码,让服务端成为了一个含有日志的守护进程,从而实现服务端持续运行和记录日志的功能。搞定了这些知识之后,无论是服务端的多执行流运行,还是服务端的网络通信或者数据处理,亦或者是客户端的网络通信,数据传输,我们都有了一定的理解,所以有关网络套接字相关的知识,当然也就是上述服务端、客户端、网络通信的知识,我们就讲到这里,并且因为我们一直使用的都是TCP/UDP协议,也就是一直处于网络模型中的传输层,此时对于传输层相关的知识,我们也就学习到这,该篇博客以及之后的博客,我们重点讲解的都是应用层相关知识,当然重点也就是应用层相关协议,如:HTTP/HTTPS,当然不止如此,在讲解应用层协议相关知识时,我们还会穿插讲解有关序列化和反序列化相关的知识,具体有待下述深入学习。
回顾之前知识,强调相关注意点
在之前传输层学习有关套接字网络通信时,我们对IP地址以及端口号都有了很强的认识,然后慢慢的我们了解了网络字节序和点分十进制相关知识,最终一点一点铺垫,对无论是套接字整体框架,还是套接字细节知识我们都有了自己的理解,相比于套接字整体框架接口(UDP/TCP)socket、bind、recvfrom、sendto/socket、bind、listen、accept(connect)、read(recv)、write(send),此时我们对细节知识,也就是网络字节序和点分十进制相关知识也有了一定的了解,其中对于网络字节序,也就是主机序列和网络序列的转换,我们知道可以使用的接口有:htons、ntohs、htonl、ntohl、inet_addr、inet_ntoa、inet_aton,当然我们知道,前者一般是提供给端口号(16位/32位)使用,后者一般是提供给IP地址使用,因为IP地址除了需要将主机序列转化为网络序列之外,它还需要将点分十进制的数据(“124.71.57.104”)转换为二进制数据,当然其中inet_addr和inet_aton是一样的,都是将IP地址从点分十进制转换为二进制序列,反之inet_ntoa同理。
回顾了上述有关使用套接字进行网络通信的基础知识,当然不包括有关多执行流进行数据处理相关知识,此时我们对套接字就又有了一定的认识(脑子是一个健忘的东西),所以此时我们对地址转换函数,也就是inet_ntoa和inet_aton要进行一个注意点强调,本质也就是因为inet_ntoa接口,在我们获取点分十进制的IP地址时,它的返回值是一个指向静态数组的字符指针,那么此时问题就来了,其一:为什么返回的一定是一个静态数组?其二:为什么不能返回一个静态数组?首先第一个问题,在C语言中,不存在字符串类型(当然C++中的字符串类型,本质只是一种利用堆空间对字符进行的封装处理而已),所以如果想要存储字符串,在C语言中就只有三个方法(栈/堆/静态),一个是使用字符数组(缓冲区),另一个是使用堆空间,还有一个就是使用静态存储;明白了这点之后,我们就知道,如果我们想要获取到点分十进制的IP地址,那么在inet_ntoa接口中,它就需要将转换完成的IP地址存放到堆区或者是静态区上,否则就会导致数据(点分十进制IP地址)随着函数栈帧的销毁而销毁,而又因为如果是将数据存放到堆区上,会增加用户对该接口(inet_ntoa)的使用成本,需要用户自己进行堆区的释放,防止内存泄露问题,所以最终该接口是将数据存放到了静态区上(static),也就是它的返回值是一个静态数组的指针,此时因为该接口的返回值是一个静态存储数据,那么该接口此时就有可能存在线程安全问题,虽然在服务端场景下,该接口不会被多线程访问,但是在其它场景下,就有可能会因为多线程同时访问该接口,造成线程安全问题,最后导致程序异常,所以类似于这种,我们需要将某种数据转换为某种数据的过程,一般都会存在线程安全问题,本质在于该接口内部是否进行线程安全处理(互斥锁/同步机制/信号量),当然此时inet_ntoa接口中可能就没有进行线程安全处理,所以当以后我们碰到这一类场景时,就可以使用inet_ntop接口,具体参看使用说明,反之因为inet_aton使用的是我们自己提供的字符数组(&buffer),直接将返回值写入到对应的缓冲区中,所以不存在静态存储问题,不存在线程安全问题。
了解TCP协议下客户端和服务端的一般连接流程
对于这块知识,目前我们只是简单理解,只是为了引出“三次握手和四次挥手”的概念,然后对其有一定的认识而已,当然此时我们是在对TCP版本下的服务端/客户端进行了解,而不是UDP版本服务端/客户端,本质原因也就是TCP需要先建立连接,而UDP不要,并且我们在进行套接字网络通信代码编写时,使用的都是操作系统提供给我们的系统调用接口,并没有很好的从底层去理解网络通信的过程,所以此时为了深入了解有关知识,我们就可以参考下图,通过图示我们来深入了解一下服务端和客户端之间建立连接的过程。
客户端和服务端的三次握手过程
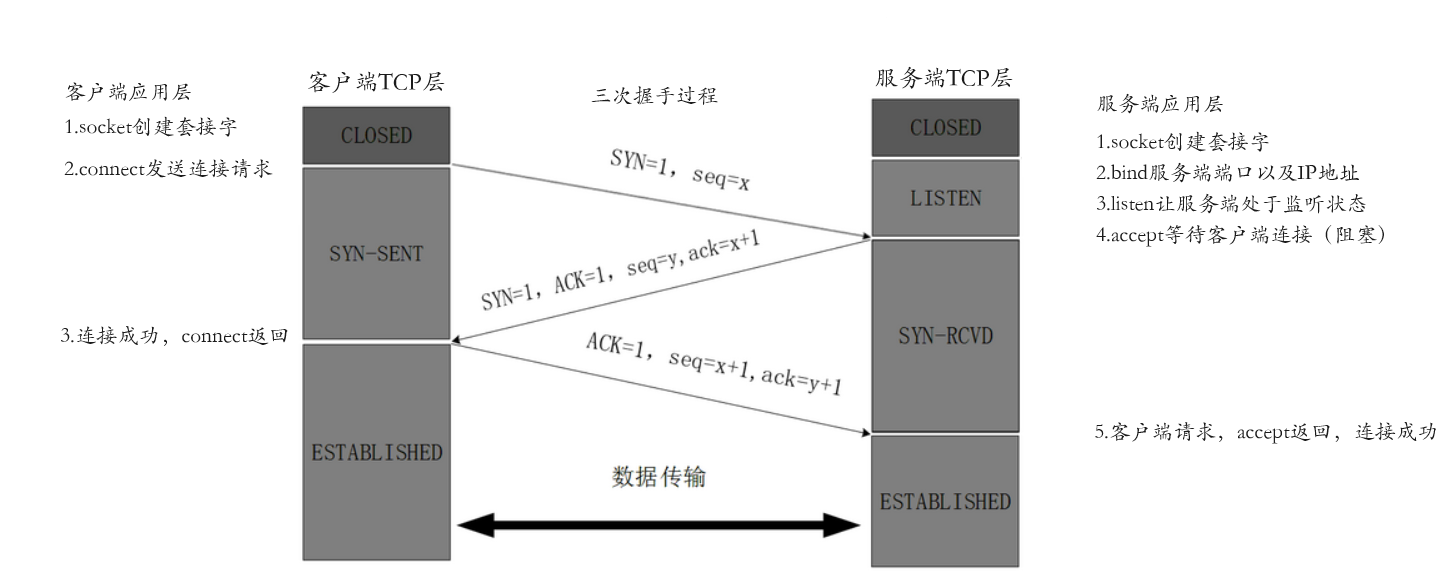
ok,此时有了图示,对于三次握手的理解,我们就有了很强的抓手,对于引出一些概念也较为轻松,从上图我们可以看出,当初我们在进行套接字网络通信编码的过程是一个应用层场景,而客户端和服务端的三次握手是一个传输层场景,所以此时根据我们对TCP/IP网络协议栈的理解,我们明白,只有当我们在上层(应用层)完成了套接字的创建(向系统申请了对应资源),并且调用了connect接口,此时客户端操作系统才会帮我们进行后序的一系列操作,当然具体过程也就是上图中所示,首先操作系统会将SYN(标志位)和seq(客户端初始序列号)封装到TCP数据报中(进入SYN_SENT状态),然后该数据报经过网络协议栈发送到远端服务器上,当远端服务器监听到该连接请求,服务器就会停止accept阻塞状态,然后同理将SYN标志位和自己的seq(服务端初始序列号)封装到TCP数据报中,只不过此时服务端还会将ACK(确认标志位)也封装到TCP数据报中(进入SYN_RCVD状态),然后同理将该数据报发送回客户端,最终客户端接收到之后,也将ACK确认标志位和自己的初始序列号、服务端的初始序列号发送回去,服务端应用层accept返回,服务端与客户端连接成功(两者都进入ESTABLISHED 状态)。
客户端和服务端的四次挥手过程
当客户端和服务端都处于ESTABLISHED 状态,也就是完成客户端和服务端之间的连接时,此时客户端和服务端就可以进行数据传输,并且此时服务端和客户端就可以利用对应客户端和服务端的序列号(seq)和确认号(ack)来保证数据传输的可靠性啦!当客户端和服务端完成数据传输之后,它们就会进行四次挥手过程,具体如下图所示:
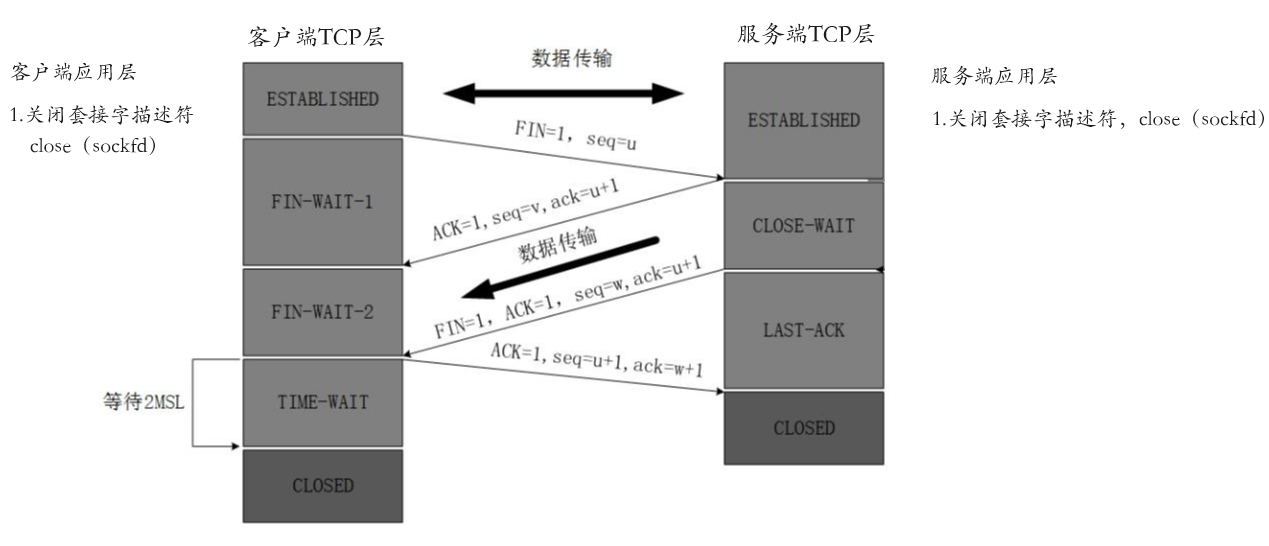
同理,如图所示,此时服务端和客户端任何一方在应用层调用close接口之后,都可以向对方发送一个封装了FIN标志位的数据报,假如此时是客户端先向服务端发送FIN标志位,那么此时客户端就会进入FIN-WAIT-1状态,停止发送数据,但依然可以收到服务端数据,然后当对方接收到对应数据报之后,进入CLOSE-WAIT状态,然后同理向对方发送一个封装了ACK确认标志位的数据报,客户端进入FIN-WAIT-2状态,最后服务器再次发送封装了FIN标志位的报文,表示服务端向客户端发送断开连接请求,服务端进入LAST-ACK(最后确认态),客户端接收到之后,进入TIME-WAIT(时间等待)状态,之所以不是关闭状态,本质是因为客户端的TCP连接还没有释放,只有经过2*MSL(最长报文段寿命)的时间后,客户端才会被真正关闭,最终客户端和服务端之间的连接彻底关闭。
总结:上述就是有关服务端和客户端之间的一般连接流程,其中涉及到的大多是应用层和传输层之间的知识,感兴趣的同学,可以参考该篇博客,深入理解相关知识,TCP协议流程详解
正式进入该篇博客的主题,有关序列化和反序列化相关的知识
明白了上述有关TCP协议下服务端和客户端的一般连接流程,当然也就是服务端和客户端的三次握手以及四次挥手的知识,此时我们对数据传输过程的建立就有了一个更加全面的认识,当然在之后讲解有关TCP/IP等协议时,我们还会深入了解,不过在该篇博客中,此时我们重点来看看有关序列化和反序列化的知识。
什么是序列化和反序列化呢?
简简单单,学习一个新知识同理三步走,是什么/为什么/如何实现,所以对于应用层中有关序列化和反序列化相关的知识,我们就从这三个角度来学习,同理每次对于新知识我都是从是什么/为什么出发,最后再将其用代码实现,而对于博主我的这个学习过程,本质就是一个模板化过程,一个我自己规定好了的过程,所以同理对于序列化和反序列化来说,它们也就是在对某个或者某种过程进行模板(协议)的定制。当明白了这点之后,假如此时该过程是一个网络数据传输过程,那么我们就可以以最常见的服务器和客户端为例,来看看服务端和客户端在进行网络数据传输时,如何对数据进行序列化和反序列化了。王炸直接丢出来,该假设也就是该篇博客的重点,也就是后序代码实现的关键。所以此时我们明白序列化和反序列化过程是一个对网络传输数据的处理过程,并且从服务端和客户端角度来看,序列化和反序列化就是一个对客户端请求数据和服务端响应数据的处理过程,如:我们想要将客户端请求数据发送给服务端,那么此时无论你发送的是何种结构何种类型的数据,最后服务端接收到的一定是一串字节流数据(无TCP/UDP区分),当然也就是二进制数据,反之同理,客户端接收到的数据也一定是字节流数据,所以此时这个将数据转化为字节流的过程,我们就称为序列化过程,反之当服务端或者客户端接收到对应字节流,将其转化为对应数据(解码)的这个过程我们就称为反序列化过程。当然此时有的同学就会想,那我自己在实现客户端或者服务端的时候,是不是就要把对应的数据搞成一个二进制数据,然后把二进制数据通过系统调用接口发送出去,或者是接收到某个二进制数据,我就要把这个二进制数据搞成对应十进制数据或者是对应十进制数据的编码数据,有这个想法没有任何问题,因为这个过程是的的确确存在的,只不过这个过程计算机(操作系统)默认就会帮我们完成而已,谈上述字节流式的序列化和反序列化过程,只是帮助我们更好的理解什么是序列化和反序列化罢了,从底层出发,明白序列化和反序列化的重要性和最基本使用场景。有了上述知识的铺垫,我也就不唯唯诺诺了,本质还是同理,序列化和反序列化就是在对某过程进行规定(协议),上述双方将数据转化为字节流的过程,本质也就是序列化和反序列化的精髓,字节流就是规定,就是协议,就是标准。所以基于应用层而言,序列化和反序列化就是在将某种类型、某种格式的数据转化为一种统一的格式,将某种统一的格式转化为某种类型、某种格式。最后明白,基于目前而言,应用层一般的序列化和反序列化格式已经有标准协议供给我们使用,当然也就是大部分的服务端和客户端使用的都是对应协议,其中有:Json/Xml/Protocol Buffers/MessagePack,所以当服务端和客户端使用了这些协议,无论是服务端还是客户端,它们的数据首先就会被序列化或者反序列化为对应协议规定的格式,如下就是Json中两种不同的协议格式:

从图中可以看出,对于Json而言,它在对数据进行格式控制时,使用的是哈希[Key/Value]的方式,并且外部都使用大括号括起来,这样实现的好处就在于进行数据提取时,非常方便,具体后续详谈。
为什么要进行序列化和反序列化呢?
对序列化和反序列化是什么的概念有了一定的理解之后,我们的三步走就成功走出了第一步,好比冬天来了,春天还有远吗?当然前两步都是基于概念理解,在没有真正见过代码之前, 序列化和反序列化依旧是在扯淡,只不过是扯的详细了点而已,哈哈哈!并且对于上述直接理解、灌输序列化和反序列化的概念,目前给我的感觉除了比较抽象之外,还有就是为什么要进行序列化和反序列化呢?在没有解决这个问题之前,序列化和反序列化给我的感觉就像是无根之萍,非常的漂浮,所以此时为了让我们对其概念有更加全面的认识,我们就需要一个强有力的抓手,搞清楚为什么服务端和客户端在进行网路数据传输时,一定要有序列化和反序列化过程。
在搞清上述问题之前,我们需要明白一个点,客户端在向服务端发送消息时,发送的不单单只有消息内容,伴随着对应的消息内容还存在非常多的其它数据,如:发送时间、用户信息等… ,所以当我们在发送数据时,发送的不仅仅只是一个字符串数据,而应该是一个结构化数据。本质同理使用结构化数据的原因就在于结构化数据不仅支持嵌套更加复杂的数据结构,在结构化数据需要修改时还可以直接添加或者删除某个字段(维护),使发送数据这个过程的灵活性和扩展性大大提高。明白了上述知识,此时对于数据传输过程为什么进行序列化和反序列化我们就有了切入点,本质因为传输的是结构化数据,所以此时就会导致在不同的应用程序中结构体字段大不相同,而因为结构体字段不同,此时就有可能会导致不同的数据格式表示相同数据的问题,最终导致被传输数据无法被接收方正确解析和处理,数据传输失败。 所以因为该问题,此时我们就需要对传输数据进行序列化和反序列化,这也就是我我们进行序列化和反序列化的重要原因之一,因为序列化和反序列化带来的好处并不止于此,如:将数据序列化和反序列化之后,该数据就可以进行跨语言和跨平台传输,本质同理因为我们可以自己定制协议(格式)或者是使用已经存在的标准协议,将数据转化为一个可以被所有平台和语言解析使用的通用格式。当然序列化和反序列化还可以增强数据的封装性和安全性等…,本质也就是我们在定制序列化和反序列化协议的时候,不止可以定制一种格式控制协议,还可以定制一种数据安全协议,如:对数据进行加密处理,对数据添加报头,对数据进行分隔符控制等…。
深入理解序列化和反序列化
行文来到此处,我们对序列化和反序列化的知识就有了一定的了解,并且也有了抓手,明白对数据进行序列化和反序列化的本质目的就是让接收方接收到数据的同时,可以正确的解析识别数据而已。同理上述概念中有关字节流的说法,将数据序列化成字节流,再发送到远端,本质的目的也就是让远端可以接收并识别该数据而已,因为远端也一定是某种计算机,协议规定该计算机只能接收字节流。所以同理,当该字节流被解析为特定数据之后,上层某应用程序想要读取该数据,那么该应用程序首先需要对该数据进行反序列化操作,而该应用程序想要进行反序列化操作,它同理需要有一个抓手(依赖),当然聪明的我们很快能反应,这个抓手一定和发送数据时进行的序列化过程是相同的,最终该应用程序凭借这个依赖,成功的将对应数据读取。再本质一些理解,也就是应用程序在反序列化数据时,一定要知道什么东西代表的是什么东西, 如:我们将数据序列化成一个string或者是vector(数组)亦或者是Hash(映射),在反序列化时,我们就需要知道对应string前后字符代表的是什么,vector对应下标代表的是什么,Hash对应Key值代表的是什么,然后根据这个已知,将数据读取出来,所以这个已知就是我们序列化和反序列化的抓手,而这个定义已知,根据已知进行序列化和反序列化的过程,我们就称为定制协议的过程。
总而言之: 序列化和反序列化并不是什么问题,无论是我们自己定制协议,还是使用标准化协议,结合上述知识,从代码角度去看,只不过就是定义一个头文件,在头文件中实现一个类(C++),类内除了必要的成员变量之外,还含有两个成员函数,一个俗称序列化函数,一个俗称反序列化接口,而在序列化接口中,我们将类内成员变量进行特定格式的控制(天生知道),在反序列化接口中依据序列化格式,将数据重新提取到对应成员变量中,当然具体在这两个过程中是否存在加密等操作我们不关心。最后在客户端中包含该头文件,调用其中的序列化接口,在服务端中同理包含该头文件,调用其中的反序列化接口。形成了一个让客户端和服务端看见同一份资源(类),然后客户端和服务端直接通过该资源传输数据的假象,好比客户端初始化类内成员变量,服务端就可以直接读取类内成员变量的一个过程。 所以这也就是序列化和反序列化的顶级好处,完美的确保了数据的一致性和可靠性。
从代码分析序列化和反序列化
在上述,三步走中的两步走我们已经走完了,同理,无论你理论多么详细,在没看见代码之前,一切都是浮云,所以接下来就让我们进入该篇博客的最后一个知识点,也是有关序列化和反序列化的最后步骤,自己使用代码实现序列化和反序列化过程,当然同理上述所说,该过程目前已经有非常多标准供给我们直接使用(头文件),但我们为了更加全面的认清该过程,此时我们就打算自己实现一次,当然肯定只是简单实现。只不过在进行序列化和反序列化之前,我们需要一个场景,所以此时我们就以一个网络版本计算器为场景,来看看具体如何实现数据的序列化和反序列化吧!
网络版本计算器代码实现
简简单单,在实现网络版本计算器之前,我们需要先理清思路,明白大致的实现过程以及基本步骤,此时第一步同理上述深入理解当中所说,我们需要定义一个头文件(agreement.h),然后在该头文件中定义对应的结构化数据(类),同理因为该结构化数据需要被序列化和反序列化处理,所以此时在该类中除了结构化数据(成员变量)之外,还需要伴随两个接口,一个负责将成员变量序列化,便于传输,一个负责将成员变量反序列化,便于接收,当然具体如何序列化/反序列化,序列化成何种格式,这都有待于在深入学习过程中从代码发现,这里不重点强调,此时我们需要明白的是,在网络版本计算器中,当客户端向服务端发送数据之后,服务端需要根据客户端请求,完成某些任务,然后将对应数据的处理结果响应回给客户端,所以在agreement.h头文件中,我们就需要有两套协议,一个表示请求协议,一个表示响应协议,一个负责传输需处理数据,一个负责传输结果数据。明白了这些之后,此时我们就可以进入代码实现啦!
注意: 因为此时该部分代码涉及非常多细节方面的知识,如果我们想要在理解序列化和反序列化的过程中,将这些细节知识解决,我们就需要一部分一部分的来看相关代码,不然会导致代码非常多,许多细节无法深入透彻,所以此时我们首先将其分为三大块,第一块知识为服务端客户端使用套接字通信过程,当然这块在之前我们已经深入理解过,所以此次我们基于回顾并且带有一定创新的角度看代码;第二块知识为分析服务端客户端中包含头文件以及调用接口,当然该部分就是为了之后的序列化和反序列化协议定制做准备;第三块知识为规定结构化数据和序列化反序列化接口,当然这块知识身为该篇博客重点中的重点,它其中涉及的知识较为复杂,有待深入理解。此时有了这三大块知识的前后联系,对于整块代码我们就有了一定的抓手,清楚接下来我们如何一步一步的执行代码,不会因为任意调用接口导致混乱,下面就让我们来分别看看这三块知识吧!
第一块:服务端和客户端使用套接字进行网络通信代码
当然这块代码在之前学习网络套接字相关知识时,我们已经重点强调且频繁理解过了,而正是因为我们频繁理解过这块知识,所以此时我们对其有了一定新的认识,那就是将其进行封装,好处不言而喻,这样我们就不需要每次都对套接字相关接口进行初始化过程,而是直接传参式调用对应封装接口完成调用,具体代码如下图所示:

此时从上述代码中,我们就可以看出,当我们使用头文件自己封装了一个Sock套接字类时,下次我们无论是在客户端,还是服务端中进行代码编写,都可以直接包含该头文件,直接使用类对象的方式进行传参式调用对应套接字通信接口,再也不需要进行繁琐的失败/成功判断以及sockaddr_in结构体的初始化工作,大大提高了我们的编码效率。并且值得注意的是:要明白服务端建立连接会返回新的套接字,而客户端不会,本质是因为服务端需要确保多客户端同时访问,而客户端不要,所以客户端在进行网络通信时,一直使用的都是唯一的套接字,并不像服务端,连接之后,会有新的套接字供给其使用,而从这一点出发,此时我们需要明白,创建套接字的本质除了是向系统申请网络通信请求以及资源之外,更重要的是它还是对TCP缓冲区的一个抽象,当然具体有关TCP缓冲区相关知识我们后续还会深入,这里只要明白,TCP缓冲区就是被接收数据和待发送数据的存储的空间就行。下述接着让我们回顾一下有关服务端和客户端之间通信的代码。
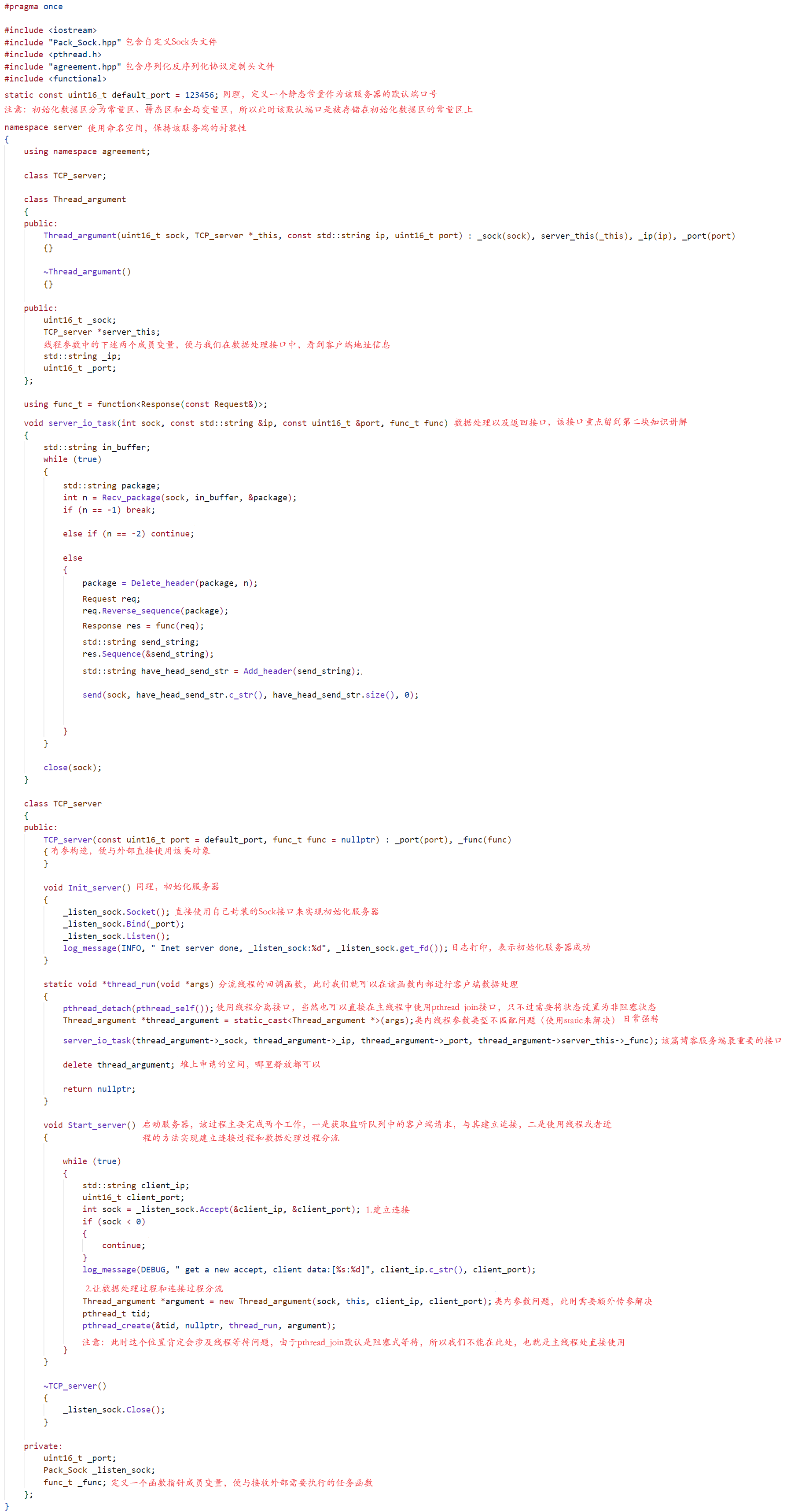
上述代码本质还是一份服务端通信代码,我们重点想要回顾的就是服务端对多执行流的处理过程,以及线程参数等问题的解决方式,当然无论是多执行流还是线程参数等问题,我们在之前的博客中都有详细介绍,所以这里我们也不重点讲解,我们的目标是搞定有关数据处理和返回接口,也就是上述的server_io_task接口,当然本质也就是因为该接口中的知识涉及的就是序列化和反序列化的知识,所以此时让我们进入第二块知识,一起来看看该接口中具体调用了那些头文件中的那些接口吧!
第二块:分析客户端和服务端中使用的头文件以及接口
搞定了上述有关套接字API的封装,以及服务端多执行流和线程参数问题的回顾,此时我们对服务端和客户端利用套接字进行网络通信又有了很好的认识,所以此时我们就可以在此基础上,对服务端和客户端进行进一步的理解,当然也就是上述所说的有关数据接收处理和结果返回的知识(server_io_task),所以下面就让我们来看看,服务端和客户端分别是如何对数据进行处理,从而到达数据传输的可靠性和完整性。
首先是客户端
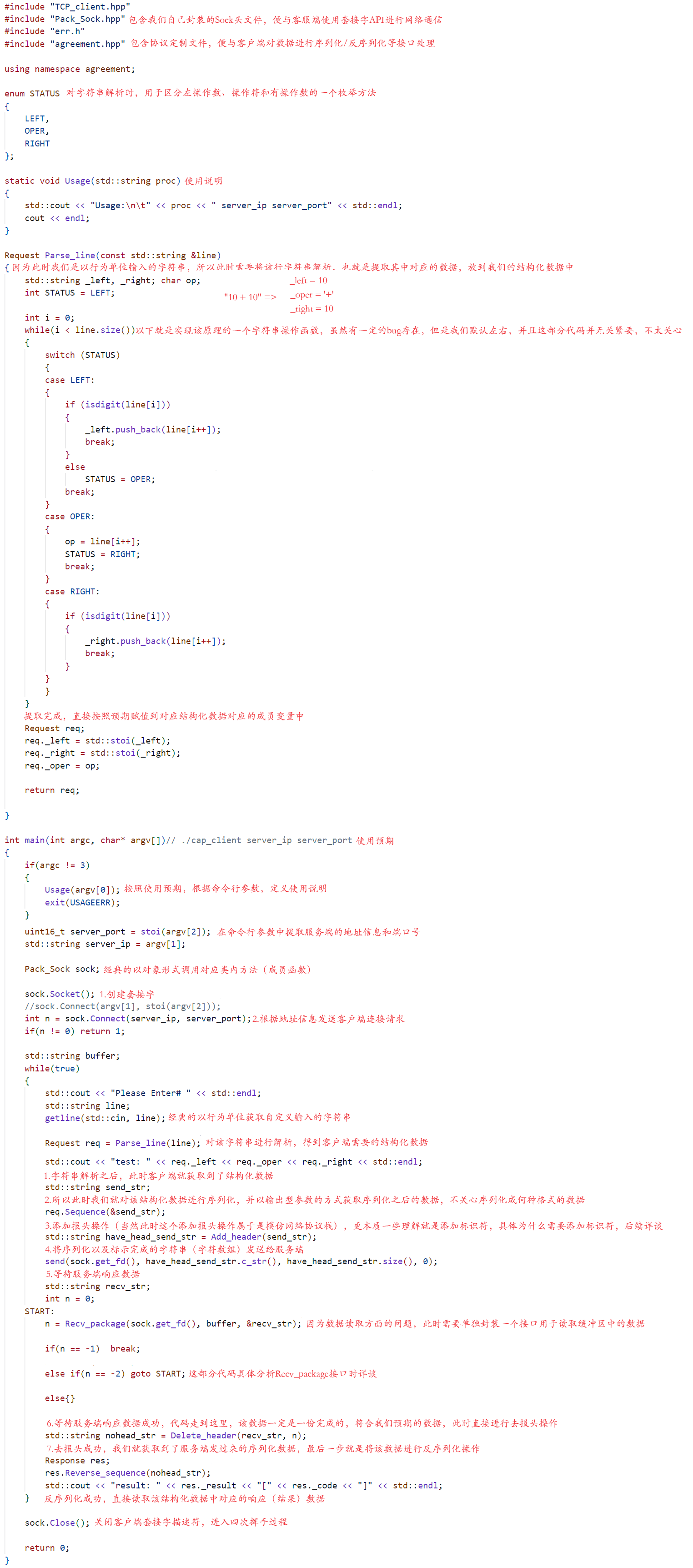
从上述代码中我们可以看出,在实现网络版本计算机的基础上,我们的客户端首先利用了我们自己封装好的Sock套接字API类,实现了网络通信的基础,然后又以行的形式获取到了我们自定义输入的计算表达式(字符串),然后对该计算表达式进行解析,提取出它的左操作数、操作符和有操作数,并将其赋值给Request结构体(客户端请求结构体),再然后客户端利用客户端请求结构体中的序列化接口将客户端请求数据序列化成某规定格式,在序列化完成之后,因为服务端从缓冲区进行数据读取方面的问题,此时还需要对序列化数据加上一定的标识符,当客户端将需发送数据序列化以及标示完成之后,调用send接口发送给某指定服务器,客户端传输工作全部完成。紧接着客户端只需要等待服务端响应结果数据,然后对结果数据进行去报头和反序列化操作即可,注:此时的反序列化操作是与服务端响应数据结构体中的反序列化结构体挂钩。当然可想而知,服务端传输数据和接收数据流程与客户端应该是大致相同的,添加标示的原因也是相同的,具体如下代码所示:
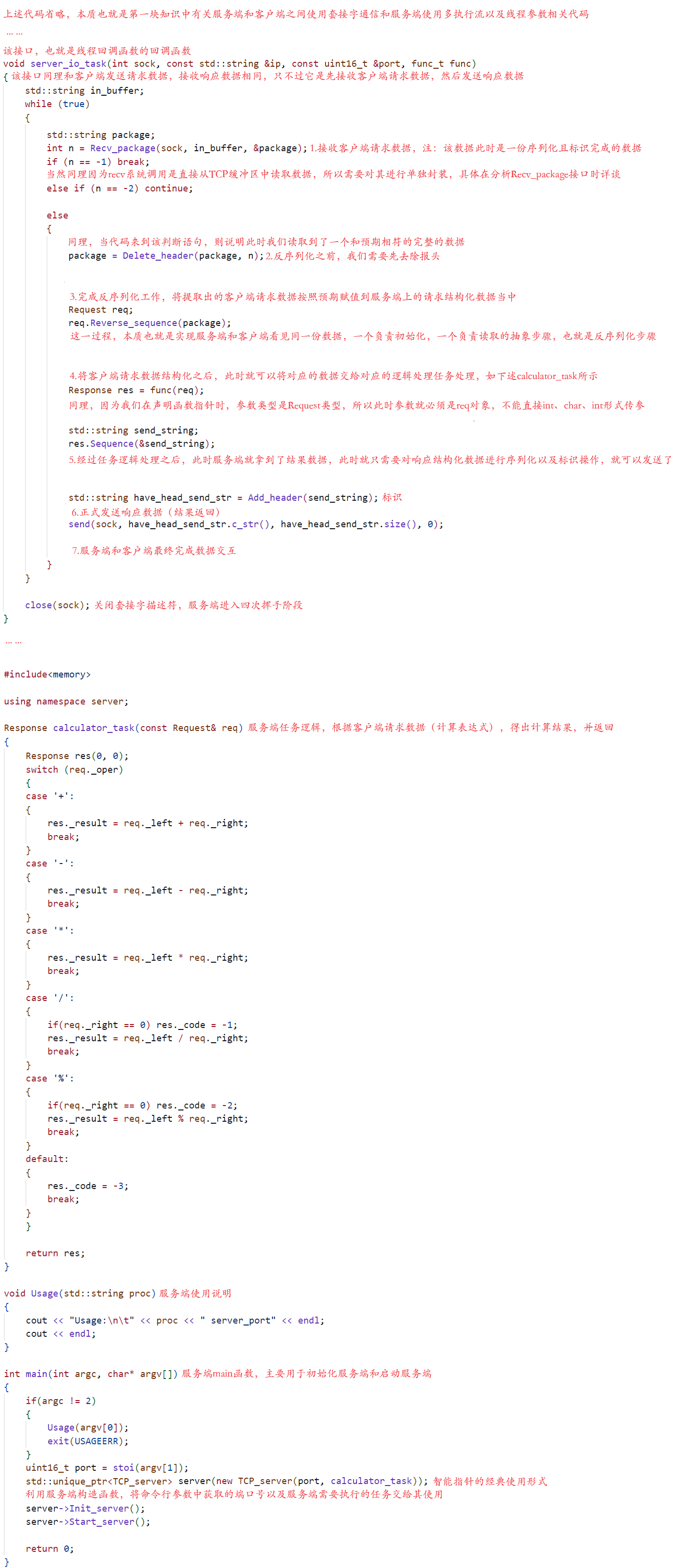
从上述服务端代码,我们可以看出,服务端除了使用套接字实现网络通信和实现多执行流之外,最重要的是它需要对客户端请求数据进行处理,并且返回响应数据,而在这个接收数据和返回数据的过程,序列化和反序列化工作必不可少,因为它可以让服务端和客户端在进行数据交互时,保证数据的可靠性和完整性,实现一种客户端初始化,服务端直接读取的场景,所以我们对传输数据进行序列化和反序列化本质就是想要实现该场景,从而达到TCP协议所说的可靠传输。具体过程与客户端大致相同,本质就是接收,去标识,反序列化,逻辑处理获取结果,对结果进行序列化和标识,最终返回结果,这里不过多赘述。目前我们需要解决的问题还有很多,其中包括将结构化数据序列化成那种格式,添加报头时如何标识以及添加标识的本质原因。所以为了解决这些问题,此时就让我们一起来看看第三块知识的代码。
第三块:规定结构化数据和序列化反序列化接口
在上述介绍什么是序列化和反序列化时,我们谈到对于应用层而言,它的本质就是将某种结构化数据转化为某种规定格式,再由该规定格式转化为结构化数据的一个过程,并且这个过程可以是按照自己的预期完成,也可以是使用已经存在的标准序列化反序列化协议(Json/Xml/Protocol Buffers)完成,而为了更加深入理解这块知识,我们选择的是按照自己的预期来实现,当然在自己实现之后,我们会尝试使用Json标准进行序列化和反序列化工作。所以下述代码就是我们基于网络版本计算器场景下定制的一个服务端和客户端使用协议,并且根据我们的预期和想法,针对服务端和客户端数据需求的不同,我们还分为了请求协议和响应协议,本质也就是客户端使用的是请求协议的序列化过程,而服务端使用的是请求协议的反序列化过程,而因为服务端还需要将数据响应回客户端,所以服务端还需要使用响应协议的序列化过程,客户端使用响应协议的反序列化过程,最终通过这样的方式,让服务端和客户端双方都拿到自己想要的数据,具体如下代码所示:
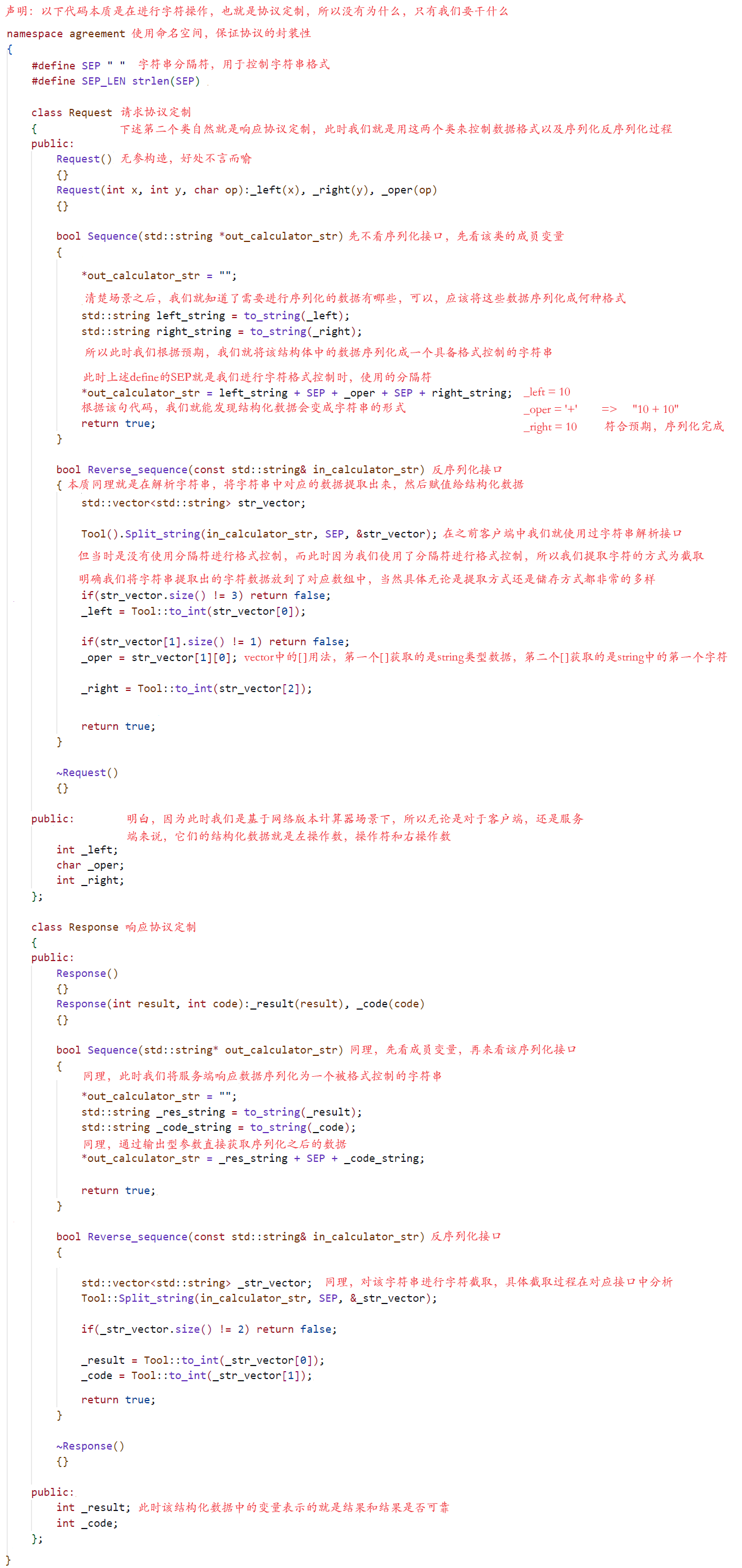
此时通过对上述代码的编写,我们就拥有了对客户端请求数据和服务端响应数据这两种结构化数据的序列化和反序列化的能力,然后就只需要在对应的客户端,对应的服务端中包含对应的头文件(协议),并且在合适的位置和时机下调用对应的接口,我们就很好的构建出了一个客户端/服务端初始化结构化数据,服务端/客户端直接读取数据的场景,确保了数据传输的可靠性和完整性。当然本质上述代码,因为我们规定序列化格式为字符串的形式,所以在序列化和反序列化过程中进行的都是一系列的字符串操作,具体我们不详谈,然而对于我们来说更重要的是,我们在将结构化数据序列化成字符串时,对该字符串我们是可以进行格式控制的,也就是说这个字符串最终是什么形式也是包含在协议定制当中的,是受到规定的,而恰好这一原理与我们添加报头,也就是添加字符串标识是不谋而合的,所以接下来我们就再看看传说中如何对序列化数据添加标识(报头)吧!

如上述代码中所示,此时我们就可以很好的为序列化数据和反序列化数据添加报头和去除报头,当然同理上述所说,添加报头的目的是为了便于recv接口向TCP缓冲区中读取数据时,拥有读到完整数据的能力,当然此时这个完整数据指的是预期服务端每次应该拿到的数据,所以当我们对一个序列化数据添加报头之后,服务端/客户端就可以根据该数据的报头获取到自己想要的数据,也就是“完整数据”,当然也就意味着该完整数据可以是不带报头的有效数据,也可以是带有报头的组合数据,总之就是要有依赖,根据这个依赖读取到自己预期之中的完整数据,如下代码所示:

通过上述先读取报头中有效数据长度的方法,我们就可以很好的将一个完整的预期报文从TCP缓冲区中读取出来,避免了数据的不确定性和不完整性。但是此时我们会发现一个问题,也就是为什么无论是服务端还是客户端在使用recv接口或者read接口从TCP缓冲区中读取数据,都有可能会读取到不完整的数据呢?本质原因非常简单,因为当数据在进行网络传输时,它需要满足网络协议栈的要求,对发送数据包进行分片,从而便于数据在网络中传输,而因为数据包被分片,那么此时就可能会因为网络问题导致部分数据片段被延迟或者是丢失,从而导致接收数据不完整或者是不确定。所以当我们想要从TCP缓冲区中读取到特定预期数据时,我们就需要使用报头的形式来进行标识。
使用Json标准协议完成序列化和反序列化工作
行文来到此处,此时无论是序列化反序列化的概念、原理,还是代码实现我们都有了一定的理解,抛开客户端服务端通信方面的知识不谈,单纯的从发送数据和接收数据来看,序列化和反序列化并没有任何的难点,值得注意的反而是如何根据报头从TCP缓冲区读取出完整的数据,如何对数据进行格式控制和标识。所以上述无论是将结构化数据序列化成字符串的操作,还是将序列化数据提取出来赋值给结构化变量的操作,它本质是一个我们自定义的过程,目的只是为了清楚序列化和反序列化的过程如何完成,本质没有太大的作用。并且这个过程对于目前而言,已经有非常多的标准供给我们使用,所以下述我们就来看看Json的使用方式。

如上代码所示,就是Json标准化协议的使用方式,通过代码原理可以发现,本质和我们自己实现序列化反序列化过程没有太大区别。上述自定义实现序列化和反序列化的工作以后我们就可以直接使用标准化协议直接代替,不需要在麻烦的自己去定制协议,以上就是有关序列化和反序列化的全部知识。
总结:有关应用层序列化和反序列化相关的知识如上所述,非常非常的详细啦!See you。
⭐好书推荐

《C++从入门到精通》

【内容简介】
《C++从入门到精通》从初学者的角度出发,以通俗易懂的语言,配合丰富的实例,详细讲解了C++语言的基础知识。 本书包括4篇18章:第1篇是基础知识,包括了绪论,数据类型,表达式与语句,条件判断语句,循环语句,函数,数组、指针和引用,构造数据类型;第2篇是核心技术,包括了面向对象编程、类和对象、继承与派生;第3篇是高级应用,包括了模板、STL标准模板库、RTTI与异常处理、程序调测、文件操作、网络通信;第4篇为项目实战,结合图书管理系统,依照软件工程的开发流程,讲述如何进行实际开发。
📚 京东购买链接:【C++从入门到精通】
📚 当当购买链接:【C++从入门到精通】
相关文章:
学习网络编程No.7【应用层之序列化和反序列化】
引言: 北京时间:2023/9/14/19:13,下午刚刚更完文章,是一篇很久很久以前的文章,由于各种原因,留到了今天更新,非常惭愧呀!目前在上学校开的一门网络课程,学校的课听不了一…...
小谈设计模式(10)—原型模式
小谈设计模式(10)—原型模式 专栏介绍专栏地址专栏介绍 原型模式角色分类抽象原型(Prototype)具体原型(Concrete Prototype)客户端(Client)原型管理器(Prototype Manager…...

用《斗破苍穹》的视角打开C#3 标签与反射(人物创建与斗技使用)
随着剧情的发展,主线人物登场得越来越多,时不时跳出一个大佬,对我张牙舞爪地攻击。眼花缭乱的斗技让我不厌其烦,一个不小心,我就记不清楚在哪里遇上过什么人,他会什么斗技了。这时候,我就特别希…...

c语言进阶部分详解(详细解析字符串常用函数,并进行模拟实现(下))
上篇文章介绍了一些常用的字符串函数,大家可以跳转过去浏览一下:c语言进阶部分详解(详细解析字符串常用函数,并进行模拟实现(上))_总之就是非常唔姆的博客-CSDN博客 今天接着来介绍一些&#x…...

一文看懂光模块的工作原理
你们好,我的网工朋友 光模块有很多类别,是我们经常要用到的PHY层器件。虽然封装,速率,传输距离有所不同,但是其内部组成基本是一致的。 以太网交换机常用的光模块有SFP,GBIC,XFP,X…...

基于SpringBoot的桂林旅游景点导游平台
目录 前言 一、技术栈 二、系统功能介绍 用户信息管理 景点类型管理 景点信息管理 线路推荐管理 用户注册 线路推荐 论坛交流 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实…...

【小程序 - 加强】自定义组件、使用npm包、全局数据共享、分包_05
目录 一、自定义组件 1. 组件的创建与引用 1.1 创建组件 1.2 引用组件 1.2.1 局部引用组件 1.2.2 全局引用组件 1.2.3 全局引用 VS 局部引用 1.2.4 组件和页面的区别 2. 样式 2.1 组件样式隔离 2.2 组件样式隔离的注意点 2.3 修改组件的样式隔离选项 2.4 styleIso…...

Vue.js3学习篇--Vue模板应用
目录 一,模板基础 1.模板插值 (1)基础插值 (2)HTML代码插值 (3)标签属性插值 2.模板指令 (1)定义 (2)指令参数 二.条件渲染 1.使用v-if指令渲染 2.使…...
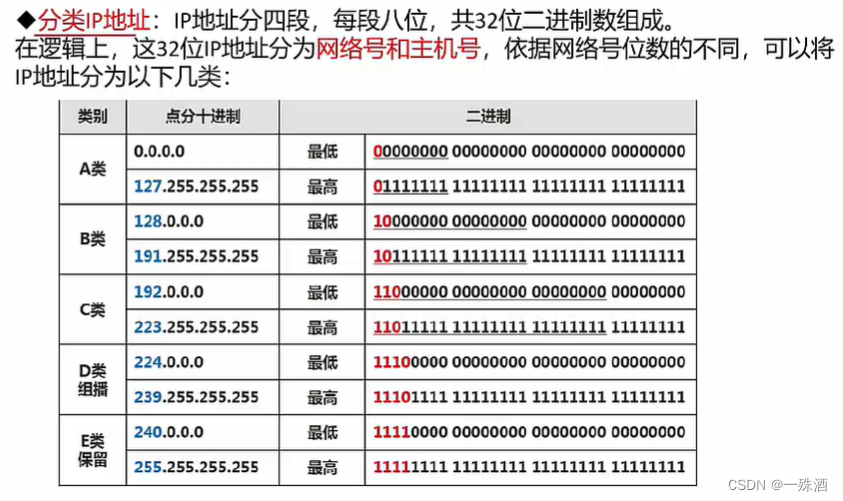
【软考】5.2 传输介质/通信方式/IP地址/子网划分
《传输介质》 双绞线:网线;传输距离在100m以内 无屏蔽双绞线:UTP;可靠性相对较低屏蔽双绞线:STP;屏蔽怕干扰;可靠性相对较高;一般用于对传输可靠性要求很高的场合 网线:…...

软件测试银行项目网上支付接口调用测试实例
公司最近有一个网站商城项目要开始开发了,这几天老板和几个同事一起开着需求会议, 讨论了接下来的业务规划和需求策略,等技术需求一下来还要讨论技术需求, 确认后再慢慢的进入开发阶段,趁着闲暇时间新造的人想总结一…...

w806 adc 中断扫描通道采集
用到了该芯片adc 扫描4个adc 通道,官方的死循环等待非常浪费时间,这里改用adc 中断采集方式,记录一下 int32_t adcFilterSum[4]{0}; int32_t detec_adc_value[4]{0};//mV int16_t detec_convt_ok[4]{0};/*is OK*/ ADC_HandleTypeDef hadc;vo…...

使用CSS的Positions布局打造响应式网页
在当今移动互联网的时代,响应式网页设计已经成为了一个必备的技能。通过使用CSS Positions布局,我们可以轻松地实现一个响应式的网页,使网页能够在不同的屏幕尺寸下自动适应。本文将介绍如何使用CSS Positions布局来打造一个响应式网页&#…...
模型训练环境相关(CUDA、PyTorch)
模型训练环境相关(CUDA、PyTorch) 1. 查看当前 GPU 所能支持的最高版本的 CUDA2. 如何判断是否安装了 CUDA3. 安装 PyTorch3.1 创建虚拟环境3.2 激活并进入虚拟环境3.3 安装 PyTorch 1. 查看当前 GPU 所能支持的最高版本的 CUDA 打开 NVIDIA 控制面板&a…...

链动2+1模式:社交电商行业的新型商业模式与营销手段
链动21模式是近年来在社交电商行业中崭露头角的一种新型商业模式和营销手段。在经历了多年的发展之后,社交电商行业已经进入了一个竞争激烈、用户获取成本高昂的阶段。在这个阶段,如何迅速吸引用户并增加他们的留存率和复购率成为了亟待解决的问题。 为了…...
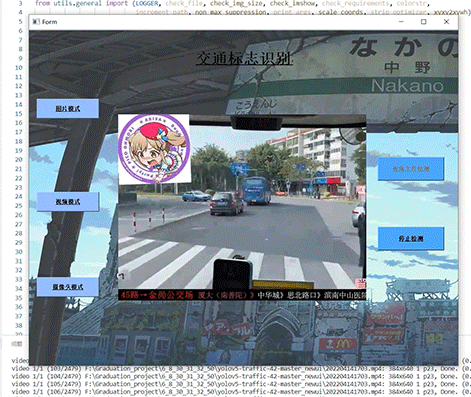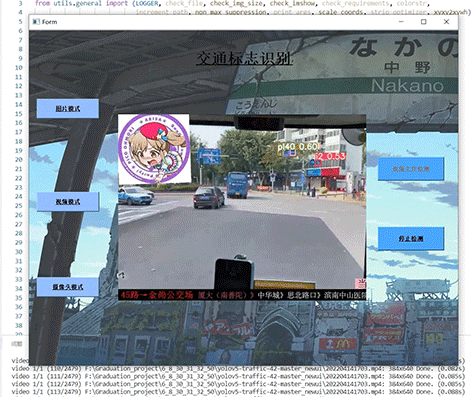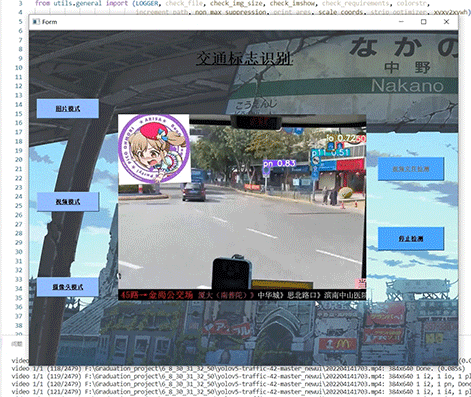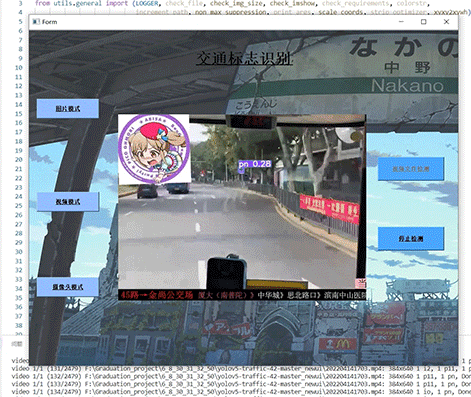
竞赛选题 深度学习 opencv python 实现中国交通标志识别
文章目录 0 前言1 yolov5实现中国交通标志检测2.算法原理2.1 算法简介2.2网络架构2.3 关键代码 3 数据集处理3.1 VOC格式介绍3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式3.3 手动标注数据集 4 模型训练5 实现效果5.1 视频效果 6 最后 0 前言 🔥 优质…...
-- fskv - kv数据库,掉电不丢数据)
LuatOS-SOC接口文档(air780E)-- fskv - kv数据库,掉电不丢数据
示例 -- 本库的目标是替代fdb库 -- 1. 兼容fdb的函数 -- 2. 使用fdb的flash空间,启用时也会替代fdb库 -- 3. 功能上与EEPROM是类似的 fskv.init() fskv.set("wendal", 1234) log.info("fskv", "wendal", fskv.get("wendal"))--[[ fs…...

一篇文章教你Pytest快速入门和基础讲解,一定要看!
前言 目前有两种纯测试的测试框架,pytest和unittestunittest应该是广为人知,而且也是老框架了,很多人都用来做自动化,无论是UI还是接口pytest是基于unittest开发的另一款更高级更好用的单元测试框架出去面试也好,跟别…...
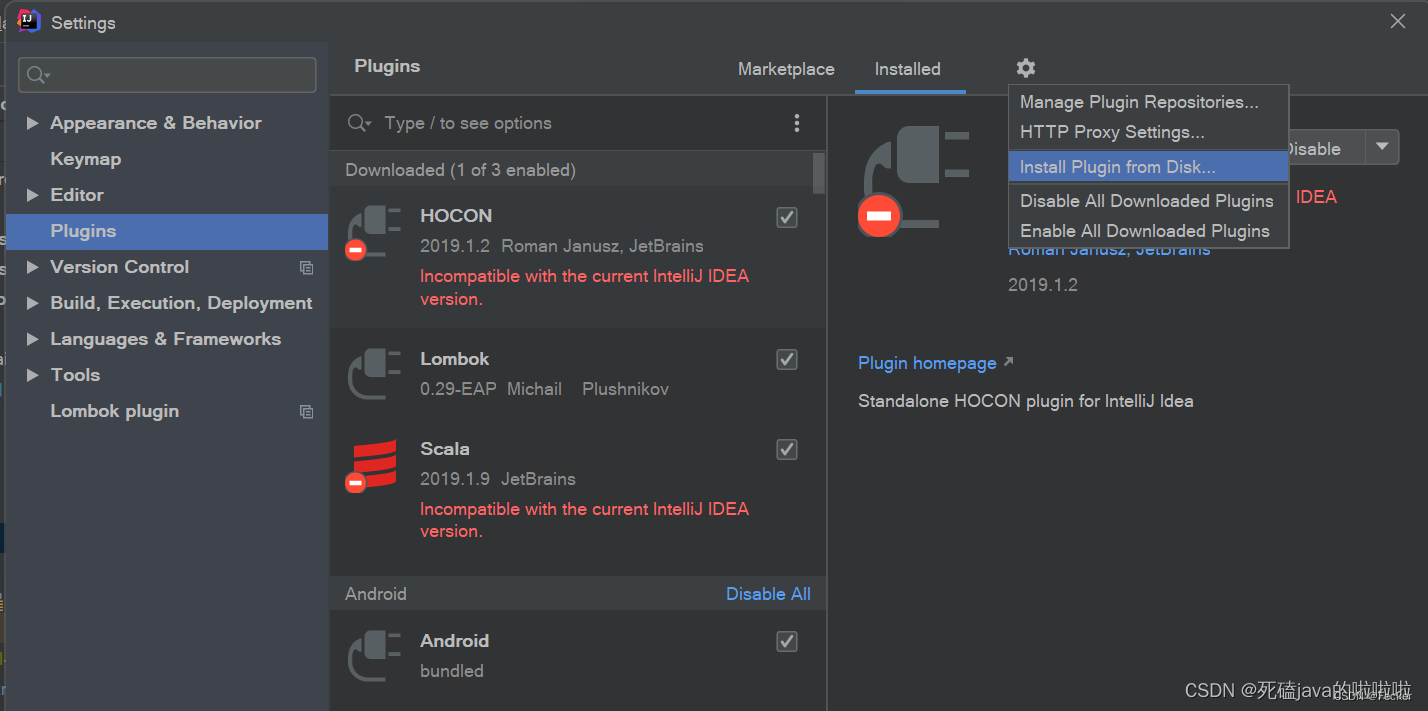
SpringBoot项目:Cannot find declaration to go to
SpringBoot项目get,set方法总报Cannot find declaration to go to 搜了很多答案,没解决 后来仔细一想,原来是我的idea软件重装了,lombok插件没重新安装导致。 安装步骤: 1、下载地址:https://plugins.jetbrains.com…...

【高并发】多线程和高并发提纲
文章目录 三大源头两个主要问题三大解决方案 最近正在面试,对多线程和高并发相关问题整理了一个简单的提纲。 个人感觉这三大部分由底向上,足够引出对并发编程中大部分问题的讨论~ 三大源头 线程切换带来的原子性问题。 原子操作:利用CPU提…...

vue.js处理数组对象中某个字段是否变为两个字段
一、场景: 产品要求做一个时间步骤条,使用目前后端已返回的数据进行操作实现。时间步骤条要求日期和时间分开显示且相同日期只显示第一个日期。 图左边为实现效果,右边为后台返回的接口。接口中current字段表示当前到达第几步,从…...

每日极客日报 · 2026年04月21日
每日极客日报 2026年04月21日 今日精选 20 条 IT 科技热点,覆盖 AI、开源、云原生、硬件等领域。 🔥 今日头条 宁德时代举办2026"超级科技日",发布钠电、凝聚态、快充等技术 4月21日,宁德时代举办主题为"极域之…...

网盘下载革命:八大平台直链解析的终极解决方案
网盘下载革命:八大平台直链解析的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

星链4SAPI中转枢纽深度技术解构:架构优势、工程实践与演进脉络
在当下的技术圈层中,围绕大模型接口调用、API密钥管理与中转网关的讨论热度居高不下。几乎每隔一段时间,就会有关于“黑盒优化”或“算力调度霸权”的新观点浮现。这背后的技术实体——星链4SAPI所代表的模型接口聚合层,正成为开发者工具链中…...

VSCode + Clangd:打造Linux内核与嵌入式开发的智能代码导航环境
1. 为什么选择VSCode Clangd组合 作为一名长期深耕嵌入式开发的工程师,我经历过各种代码编辑器的折磨。从早期的Source Insight到Eclipse,再到后来的Vim配置大战,直到遇见VSCode Clangd这个黄金组合,才算真正找到了开发Linux内核…...

WindowsCleaner:当C盘告急时,我是如何从手动清理到自动化专家的
WindowsCleaner:当C盘告急时,我是如何从手动清理到自动化专家的 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 那天下午,我正…...

手把手教你用MATLAB仿真5G NR中的DM-RS与PT-RS:从序列生成到信道估计
5G NR参考信号深度实践:从MATLAB仿真到相位噪声补偿实战 在毫米波通信和Massive MIMO技术快速发展的今天,5G NR参考信号的设计与实现成为无线通信工程师必须掌握的核心技能。不同于传统LTE系统中"一刀切"的CRS参考信号,5G采用了更加…...

ADK WinPE定制进阶:除了Explorer,我的PE里还集成了这些轻量级必备工具
ADK WinPE定制进阶:打造轻量高效的PE工具生态 在系统维护与部署领域,一个精心定制的WinPE环境就像技术人员的瑞士军刀——不在于功能繁多,而在于每项工具都能精准解决实际问题。当大多数现成PE系统要么功能冗余要么过于简陋时,掌握…...

《后端开发全栈工具安装踩坑指南 经验沉淀手册》
《后端开发全栈工具安装踩坑指南 & 经验沉淀手册》这份汇总,是日常开发、环境搭建、中间件部署过程中,一步步踩坑、反复调优攒下来的实战级工具安装 & 配置沉淀。覆盖了编程语言运行环境、版本控制、数据库全家桶、Nginx/Kafka 等主流中间件、远…...

Markdown写作进阶:Typora + PicGo打造无缝图文体验
Markdown写作进阶:Typora PicGo打造无缝图文体验 在数字化写作时代,Markdown以其简洁高效的特性成为内容创作者的利器。传统Markdown工具常面临图片管理繁琐、排版实时性不足等问题。本文将介绍如何通过Typora与PicGo的组合,实现从写作到发…...

当智能眼镜遇上了AI——使用灵珠搭建【镜中食谱】智能体
今天带大家沉浸式体验 Rokid 自研的 AI 开发平台——【灵珠平台】! 🌟 零代码、零门槛,手把手教你搭建一个专属的【镜中食谱】智能体,让 Rokid Glasses 解决你的吃饭难题! 本文智能体基于Rokid AI Glasses和灵珠AI平…...