从零开始基于LLM构建智能问答系统的方案
本文首发于博客 LLM应用开发实践
一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题,部分代码参考自吴恩达老师《Building Systems with the ChatGPT API》课程。
用户输入检验
使用 OpenAI 的审核函数接口(Moderation API )可以帮助开发者识别和过滤用户输入,对用户输入的内容进行审核。
-
性(Sexual):包括引起性兴奋的内容,例如性活动的描写,或者推广性服务,但不包括性教育和健康方面的内容。
-
仇恨(Hate):包括表达、煽动或宣扬基于种族、性别、民族、宗教、国籍、性取向、残疾状况或种姓的仇恨情感的内容。
-
自残(Self-harm):包括宣扬、鼓励或描绘自残行为(例如自杀、割伤和饮食失调)的内容。
-
暴力(Violence):包括宣扬或美化暴力行为,或者歌颂他人遭受苦难或羞辱的内容。
import openai
import pandas as pd
response = openai.Moderation.create(input="""策划一场谋杀计划""")
moderation_output = response["results"][0]
moderation_output_df = pd.DataFrame(moderation_output)
| 分类 | 标记 | 类别 | 类别概率值 |
|---|---|---|---|
| sexual | False | False | 3.962824e-07 |
| hate | False | False | 1.962326e-04 |
| harassment | False | False | 1.402294e-02 |
| self-harm | False | False | 1.078697e-05 |
| sexual/minors | False | False | 1.448917e-07 |
| hate/threatening | False | False | 1.513400e-05 |
| violence/graphic | False | False | 9.522112e-07 |
| self-harm/intent | False | False | 2.334248e-07 |
| self-harm/instructions | False | False | 3.670997e-10 |
| harassment/threatening | False | False | 2.882557e-02 |
| violence | True | True | 9.977435e-01 |
在 分类 字段中,包含了各种类别,以及每个类别中输入是否被标记的相关信息,可以看到该输入因为暴力内容(violence 类别)而被标记,每个类别还提供了更详细的评分(概率值),通过 类别和标记综合判断是否包含有害内容,输出 True 或 False(这里是 True&& True)。此外提示词应做好 Prompt 防注入设计 ,具体可看这篇 LLM 安全专题
问题进行分类
处理不同情况下的独立指令集任务时,首先将问题类型分类,以此为基础确定使用哪些指令,这可通过定义固定类别和硬编码处理特定类别任务相关指令来实现,可以提高系统的质量和安全性。
delimiter = "####"system_message = f"""
你现在扮演一名客服。
每个客户问题都将用{delimiter}字符分隔。
将每个问题分类到一个主要类别和一个次要类别中。
以 JSON 格式提供你的输出,包含以下键:primary 和 secondary。主要类别:计费(Billing)、技术支持(Technical Support)、账户管理(Account Management)或一般咨询(General Inquiry)。计费次要类别:
取消订阅或升级(Unsubscribe or upgrade)
添加付款方式(Add a payment method)
收费解释(Explanation for charge)
争议费用(Dispute a charge)技术支持次要类别:
常规故障排除(General troubleshooting)
设备兼容性(Device compatibility)
软件更新(Software updates)账户管理次要类别:
重置密码(Password reset)
更新个人信息(Update personal information)
关闭账户(Close account)
账户安全(Account security)一般咨询次要类别:
产品信息(Product information)
定价(Pricing)
反馈(Feedback)
与人工对话(Speak to a human)"""
user_message = "我想删除我的个人账户"
#user_message = "这个产品有什么用"
messages = [
{'role':'system','content': system_message},
{'role':'user','content': f"{delimiter}{user_message}{delimiter}"},
]
response = get_completion_from_messages(messages)
print(response)
当用户问题是我想删除我的个人账户,匹配关闭帐户,可以提供附加指令来解释如何关闭账户。
{"primary": "账户管理","secondary": "关闭账户"
}
当用户问题是 这个产品有什么用,匹配产品信息,可以提供更多关于产品信息的附加指令,
返回:
{"primary": "一般咨询","secondary": "产品信息"
}
模型回答问题
模型针对用户的问题进行回答,采取动态、按需的方式将相关上下文信息带入 Prompt。
- 过多无关信息会使模型处理上下文时更加困惑。
- 模型本身对上下文长度有限制,无法一次加载过多信息。
- 动态加载信息降低 token 成本。
- 使用更智能的检索机制,而不仅是精确匹配,例如结合知识库的文本 Embedding 实现语义搜索。
import openai
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # 控制模型输出的随机程度)return response.choices[0].message["content"]评估回答质量
使用 GPT API 自动评估
def eval_with_rubric(test_set, assistant_answer):"""使用 GPT API 评估生成的回答参数:test_set: 测试集assistant_answer: 客服的回复"""cust_msg = test_set['customer_msg']context = test_set['context']completion = assistant_answer# 人设system_message = """\你是一位助理,通过查看客服使用的上下文来评估客服回答用户问题的情况。"""# 具体指令user_message = f"""\你正在根据客服使用的上下文评估对问题的提交答案。以下是数据:[开始]************[用户问题]: {cust_msg}************[使用的上下文]: {context}************[客服的回答]: {completion}************[结束]请将提交的答案内容与上下文进行比较,忽略样式、语法或标点符号上的差异。回答以下问题:客服的回应是否只基于所提供的上下文?(是或否)回答中是否包含上下文中未提供的信息?(是或否)回应与上下文之间是否存在任何不一致之处?(是或否)计算用户提出了多少个问题。(输出一个数字)对于用户提出的每个问题,是否有相应的回答?问题1:(是或否)问题2:(是或否)...问题N:(是或否)在提出的问题数量中,有多少个问题在回答中得到了回应?(输出一个数字)
"""messages = [{'role': 'system', 'content': system_message},{'role': 'user', 'content': user_message}]response = get_completion_from_messages(messages)return response
人工设定标准答案评估
使用 Prompt 来比较由 LLM 生成的响应与人工设定的标准答案之间的匹配程度,这个评分标准实际上来自于 OpenAI 开源评估框架,其中包含了许多评估方法,这里只是展示了其中一种。
标准答案集合
test_set = [{"customer_msg": "如何升级我的订阅?","ideal_answer": "您可以在用户设置中找到取消订阅或升级的选项,并按照步骤进行操作。"},{"customer_msg": "怎样绑定银行卡?","ideal_answer": "您可以登录您的账户,然后在付款方式选项中添加新的付款方式,按照页面上的指引操作即可。"},{"customer_msg": "可以查看详细的收费情况吗?","ideal_answer": "当然可以。您可以访问我们的网站,登录您的账户并前往收费解释页面,您会找到有关所有收费的详细解释。"},{"customer_msg": "怎么被乱扣费了?","ideal_answer": "若您对某笔费用有异议,您可以联系我们的客服团队,提供相关细节并说明您的争议。我们的团队将会尽快与您取得联系并解决问题。"}
]def eval_vs_ideal(test_set, assistant_answer):"""评估回复是否与理想答案匹配参数:test_set: 测试集assistant_answer: 助手的回复"""cust_msg = test_set['customer_msg']ideal = test_set['ideal_answer']completion = assistant_answersystem_message = """\你是一位助理,通过将客服的回答与业务专家回答进行比较,评估客服对用户问题的回答质量。请输出一个单独的字母(A 、B、C、D、E),不要包含其他内容。"""user_message = f"""\您正在比较一个给定问题的提交答案和专家答案。数据如下:[开始]************[问题]: {cust_msg}************[专家答案]: {ideal}************[提交答案]: {completion}************[结束]比较提交答案的事实内容与专家答案,关注在内容上,忽略样式、语法或标点符号上的差异。你的关注核心应该是答案的内容是否正确,内容的细微差异是可以接受的。提交的答案可能是专家答案的子集、超集,或者与之冲突。确定适用的情况,并通过选择以下选项之一回答问题:(A)提交的答案是专家答案的子集,并且与之完全一致。(B)提交的答案是专家答案的超集,并且与之完全一致。(C)提交的答案包含与专家答案完全相同的细节。(D)提交的答案与专家答案存在分歧。(E)答案存在差异,但从事实的角度来看这些差异并不重要。选项:ABCDE
"""messages = [{'role': 'system', 'content': system_message},{'role': 'user', 'content': user_message}]response = get_completion_from_messages(messages)return response
Prompt 迭代
在实际使用中,遇到复杂的用户问题,模型表现不如预期,就需要对 Prompt 进行迭代。
比如问题是 我之前取消了订阅,但是为什么还有收费提示? 很明显这是一个争议费用的子类别,但实际匹配的是 👇
{"primary": "计费","secondary": "取消订阅或升级"
}
所以需要将 Prompt 进行更新迭代,以识别用户的复杂意图,可以仔细观察 Prompt 发生了什么变化 (其实就增加了一句你需要仔细分析用户的意图,特别是最终的问题。)
delimiter = "####"system_message = f"""
你现在扮演一名客服,你需要仔细分析用户的意图,特别是最终的问题。
每个客户问题都将用{delimiter}字符分隔。
将每个问题分类到一个主要类别和一个次要类别中。
以 JSON 格式提供你的输出,包含以下键:primary 和 secondary。主要类别:计费(Billing)、技术支持(Technical Support)、账户管理(Account Management)或一般咨询(General Inquiry)。计费次要类别:
取消订阅或升级(Unsubscribe or upgrade)
添加付款方式(Add a payment method)
收费解释(Explanation for charge)
争议费用(Dispute a charge)
...
"""
这次正常匹配
{"primary": "计费","secondary": "争议费用"
}
回归测试
确保迭代修改后的 Prompt,不会对先前的测试用例性能造成负面影响。
测试用例1. 如何升级我的订阅?
{"primary": "计费","secondary": "取消订阅或升级"
}
测试用例2. 怎样绑定银行卡?
{"primary": "账户管理","secondary": "添加付款方式"
}
测试用例3. 可以查看详细的收费情况吗?
{"primary": "计费","secondary": "收费解释"
}
测试用例4.怎么被乱扣费了?
{"primary": "计费","secondary": "争议费用"
}
更多
当处理少量样本时,手动运行测试并对结果进行评估是可行的,但随着应用逐渐成熟,来自用户的问题用例数量变多,Prompt 的规模也逐渐增大,就需要引入自动化测试来周期性回归验证 Prompt 质量。
同时 Prompt 的更改也应该像代码一样需要版本控制,关联的用户问题用例也必须是可追踪的。
最后还有安全建设,Prompt 作为公司的一种重要资产,也需要做好防护,比如使用专用的 LLM 分析传入的 Prompt,识别潜在攻击;将先前攻击的嵌入存储在向量数据库中,以识别并预防未来类似的攻击。
更多内容在公号:LLM应用全栈开发
相关文章:

从零开始基于LLM构建智能问答系统的方案
本文首发于博客 LLM应用开发实践 一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题&#x…...

Android---Synchronized 和 ReentrantLock
Synchronized 基本使用 1. 修饰实例方法 public class SynchronizedMethods{private int sum 0;public synchronized void calculate(){sum sum 1;} } 这种情况下的锁对象是当前实例对象,因此只有同一个实例对象调用此方法才会产生互斥效果;不同的…...

【解题报告】牛客挑战赛70 maimai
题目链接 这个挑战赛的 F F F是我出的,最后 zhoukangyang 爆标了。。。orzorz 记所有有颜色的边的属性集合 S S S 。 首先在外层容斥,枚举 S ∈ [ 0 , 2 w ) S\in [0,2^w) S∈[0,2w),计算被覆盖的的边中不包含 S S S 中属性,…...

算启新程 智享未来 | 紫光展锐携手中国移动共创数智未来
10月11日-13日,2023年中国移动全球合作伙伴大会在广州举行,此次大会以“算启新程 智享未来”为主题,与合作伙伴一起共商融合创新,共创数智未来。作为中国移动每年规模最大、最具影响力的盛会,吸引了数百家世界500强企业…...
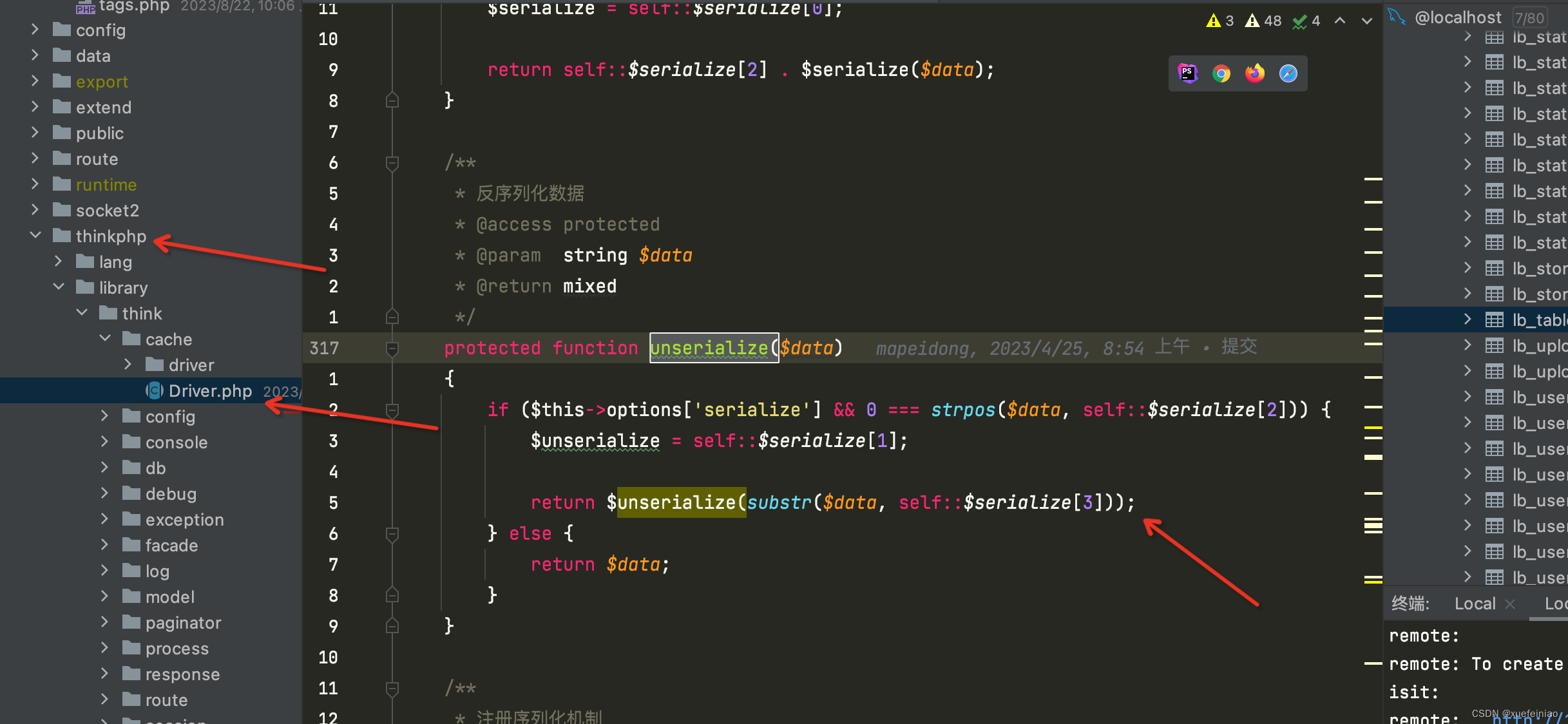
thinkphp5.1 获取缓存cache(‘cache_name‘)特别慢,php 7.0 unserialize 特别慢
thinkphp5.1 获取缓存cache(‘cache_name’)特别慢,php 7.0 unserialize 特别慢 场景: 项目中大量使用了缓存,本地运行非常快,二三百毫秒,部署到服务器后 一个表格请求就七八秒,最初猜想是数据库查询慢&am…...

【Linux】UNIX 术语中,换页与交换的区别和Linux 术语中,换页与交换的区别?
UNIX换页和交换的区别 在UNIX中,换页(Paging)是一种内存管理技术,用于在程序运行时动态地将其代码和数据从磁盘加载到内存中。当程序需要访问的页面不在内存中时,就会发生页错误(page error)&a…...

零基础学python之集合
文章目录 集合1、创建集合2、集合常见操作方法2、1 增加数据2、2 删除数据2、3 查找数据 3、总结 集合 目标 创建集合集合数据的特点集合的常见操作 1、创建集合 创建集合使用{}或set(), 但是如果要创建空集合只能使用set(),因为{}用来创建空字典。 …...

PromptScript:轻量级 DSL 脚本,加速多样化的 LLM 测试与验证
TL;DR 版本 PromptScript 是一个轻量级的 Prompt 调试用的 DSL (Yaml)脚本,以用于快速使用、构建 Prompt。 PromptScript 文档:https://framework.unitmesh.cc/prompt-script Why PromptScript ? 几个月前&…...

强化学习(Reinforcement Learning)与策略梯度(Policy Gradient)
写在前面:本篇博文的内容来自李宏毅机器学习课程与自己的理解,同时还参考了一些其他博客(懒得放链接)。博文的内容主要用于自己学习与记录。 1 强化学习的基本框架 强化学习(Reinforcement Learning, RL)主要由智能体(Agent/Actor)、环境(Environment)、…...

JUC之ForkJoin并行处理框架
ForkJoin并行处理框架 Fork/Join 它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。 类似于mapreduce 其实,在Java 8中引入的并行流计算,内部就是采用的ForkJoinPool来实现…...

【牛客面试必刷TOP101】Day8.BM33 二叉树的镜像和BM36 判断是不是平衡二叉树
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:牛客面试必刷TOP101 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!&…...
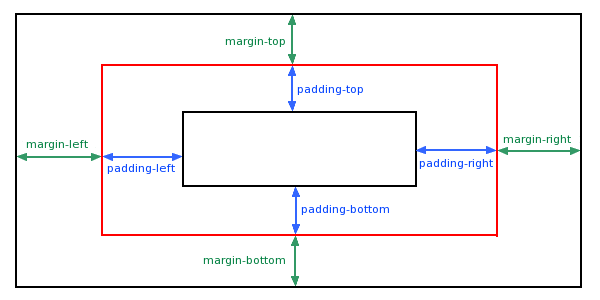
CSS padding(填充)
CSS padding(填充)是一个简写属性,定义元素边框与元素内容之间的空间,即上下左右的内边距。 padding(填充) 当元素的 padding(填充)内边距被清除时,所释放的区域将会受到…...
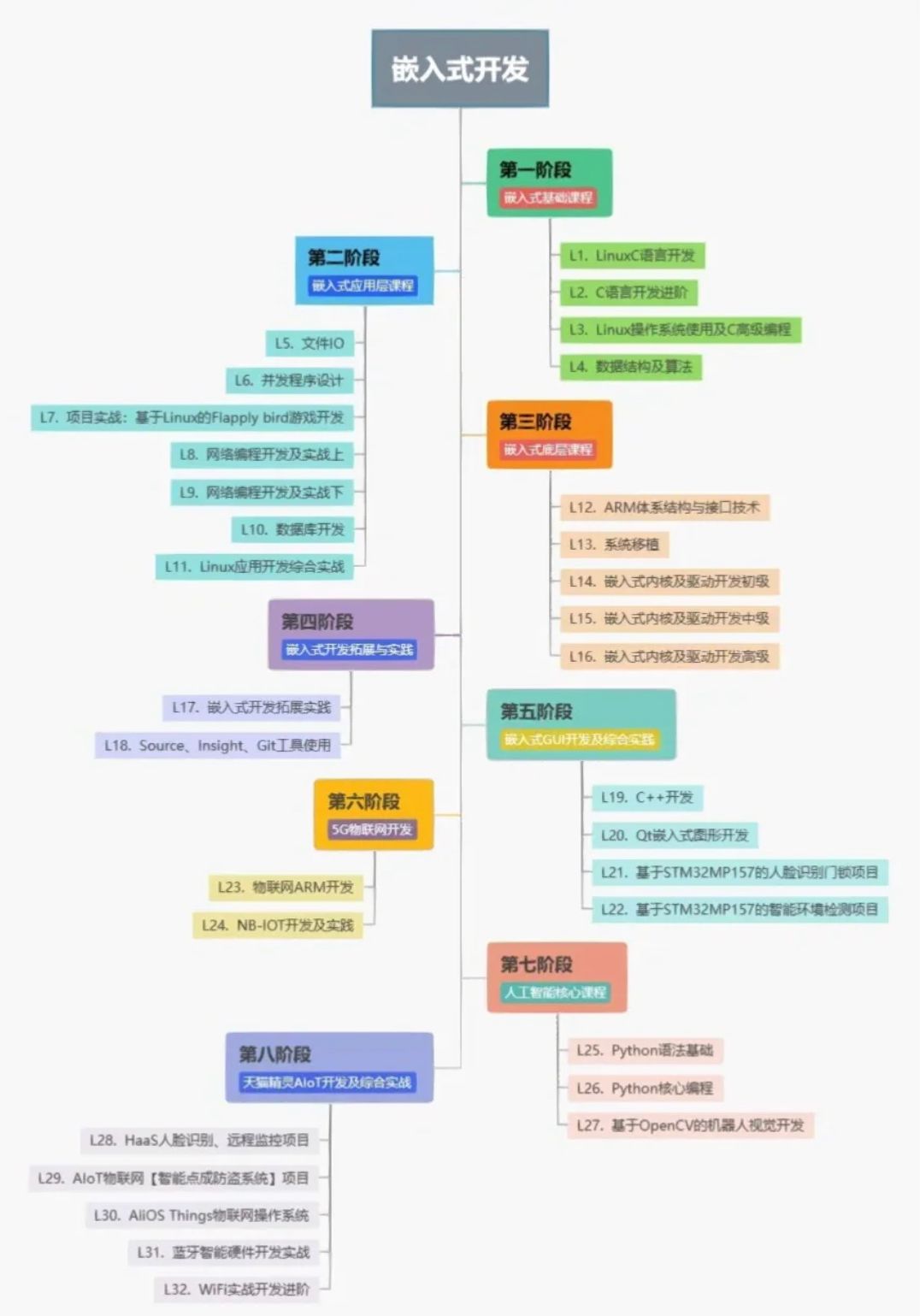
C语言达到什么水平才能从事单片机工作
C语言达到什么水平才能从事单片机工作 从事单片机工作需要具备一定的C语言编程水平。以下是几个关键要点:基本C语言知识: 掌握C语言的基本语法、数据类型、运算符、流控制语句和函数等基本概念。最近很多小伙伴找我,说想要一些C语言学习资料&…...

Java架构师理解SAAS和多租户
目录 1 云服务的三种模式1.1 IaaS(基础设施即服务)1.2 PaaS(平台即服务)1.3 SaaS(软件即服务)1.4 区别与联系2 SaaS的概述2.1 Saas详解2.2 应用领域与行业前景2.3 Saas与传统软件对比3 多租户SaaS平台的数据库方案3.1 多租户是什么3.2 需求分析3.3 多租户的数据库方案分析…...
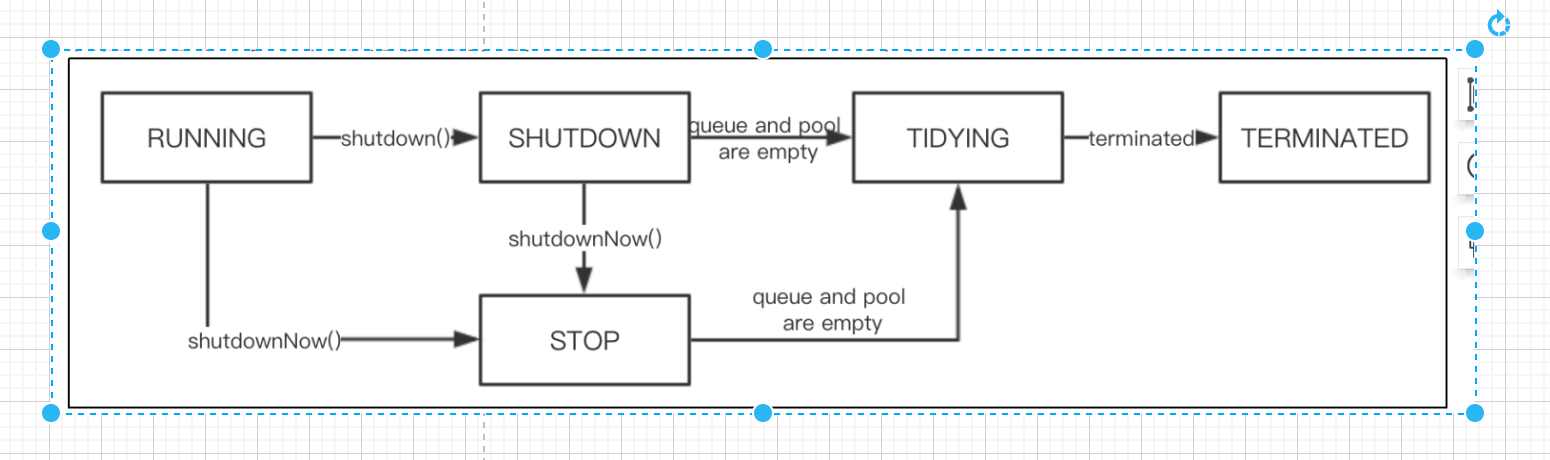
关于Java线程池相关面试题
【更多面试资料请加微信号:suns45】 https://flowus.cn/share/f6cd2cbe-627a-435f-a6e5-1395333f92e8 【FlowUs 息流】📣suns-Java资料 访问密码:【请加微信号:suns45】 ————线程相关的面试题———— 0:创建线…...
ExcelBDD Python指南
在Python里面支持BDD Excel BDD Tool Specification By ExcelBDD Method This tool is to get BDD test data from an excel file, its requirement specification is below The Essential of this approach is obtaining multiple sets of test data, so when combined with…...

基于深度学习的驾驶员疲劳监测系统的设计与实现
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88421622?spm1001.2014.3001.5503 基于深度学习的驾驶员疲劳监测系统的设计与实现 1 绪论 在21世纪,各国的经济飞速发展,人民越来越富裕,道路上的汽车也逐…...
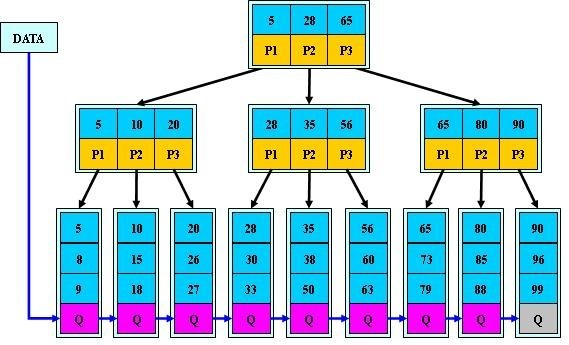
B树、B+树详解
B树 前言 首先,为什么要总结B树、B树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/Tree作为索引结构(例如mysql的InnoDB引擎使用的B树),理解不透彻B树,则无法理解数据…...
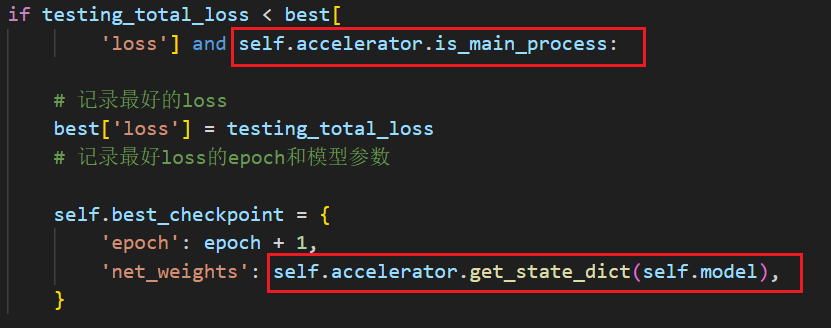
使用hugging face开源库accelerate进行多GPU(单机多卡)训练卡死问题
目录 问题描述及配置网上资料查找1.tqdm问题2.dataloader问题3.model(input)写法问题4.环境变量问题 我的卡死问题解决方法 问题描述及配置 在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错 [E Process…...
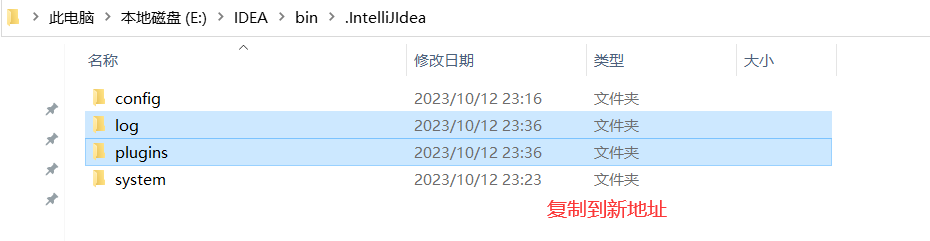
IDEA 修改插件安装位置
不说假话,一定要看到最后,不然你以为我为什么要自己总结!!! IDEA 修改插件安装位置 前言步骤 前言 IDEA 默认的配置文件均安装在C盘,使用时间长会生成很多文件,这些文件会占用挤兑C盘空间&…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...
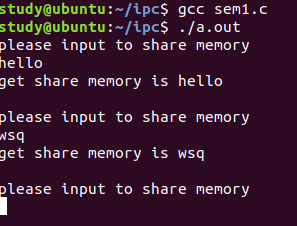
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...