科研快讯 | 14篇论文被信号处理领域顶级国际会议ICASSP录用
ICASSP 2023
近日,2023年IEEE声学、语音与信号处理国际会议(2023 IEEE International Conference on Acoustics, Speech, and Signal Processing,ICASSP 2023)发布录用通知,清华大学人机语音交互实验室(THUHCSI)有14篇论文被录用。
ICASSP是由IEEE电气电子工程师学会主办的信号处理领域的顶级国际会议,在国际上享有盛誉并具有广泛的学术影响力。 本年度会议的主题是“人工智能时代下的信号处理”。
此次被录用的14篇论文涉及智能语音交互领域的诸多研究方向,包括语音合成、歌唱合成、数字人生成、舞蹈生成、语音识别、关键词识别、说话人识别、语音增强、语音分离、说话人提取、自然语言处理等。 论文工作将学术科研与产业应用紧密结合,合作伙伴包括: 香港中文大学、腾讯、元象、小米、地平线、华为、平安、传音、好未来等。
1. Context-aware Coherent Speaking Style Prediction with Hierarchical Transformers for Audiobook Speech Synthesis
作者: Shun Lei, Yixuan Zhou, Liyang Chen, Zhiyong Wu, Shiyin Kang, Helen Meng
合作伙伴: 元象科技有限公司、香港中文大学
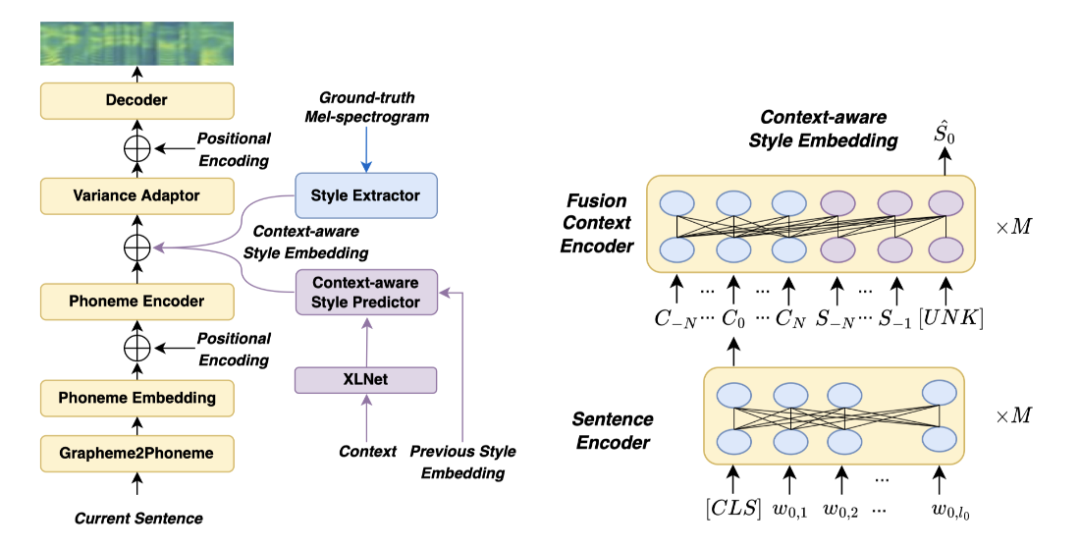
如何为有声读物中多句连续文本生成符合上下文语境且具有连贯性的说话风格,对提升有声读物合成语音的表现力至关重要。 本文为有声读物合成提出了一种结合多模态、多句子上下文信息的说话风格预测方法。 我们设计了一个基于层级变换器(Hierarchical Transformer)的上下文感知风格预测器,在混合注意力掩码机制的帮助下同时考虑文本侧的上下文信息和语音侧的历史语音风格信息,以更好地预测上下文中每句话的说话风格。 在此基础上,我们提出的模型可以逐句生成具有连贯说话风格和韵律的长篇语音。 实验表明,该方法可以为单一句子和多个连续句子生成比基线更具有表现力和连贯性的语音。

2. LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-Speech
作者: Jie Chen, Xingchen Song, Zhendong Peng, Binbin Zhang, Fuping Pan, Zhiyong Wu
合作伙伴: 地平线信息技术有限公司、WeNet开源社区、香港中文大学
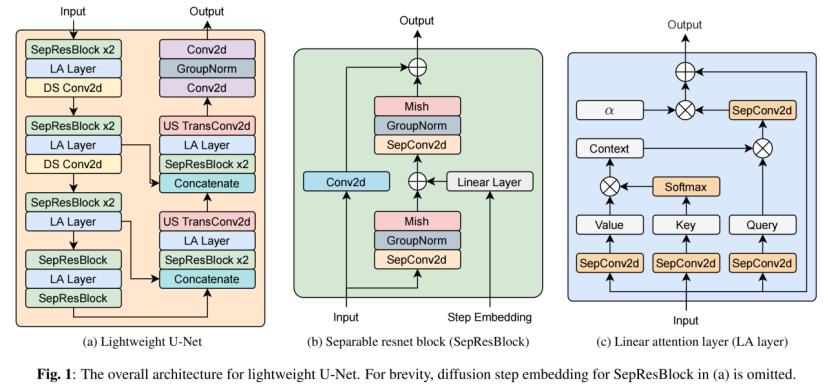
本文提出了基于扩散概率模型的轻量化语音合成声学模型LightGrad。 如今,大量语音合成模型被部署在云端以向客户提供语音合成服务。 基于云服务的语音合成服务存在高延迟、泄露隐私的问题。 将轻量化语音合成模型部署在终端设备可以有效解决上述问题。 但是,将基于扩散概率模型的语音合成声学模型部署在终端设备需解决两个问题: (1)现有的扩散概率模型参数量较多; (2)现有的扩散概率模型推理时需要较多的去噪步数,推理时延较高。 本文提出了一个轻量化U-Net扩散解码器,同时应用了一个无需重新训练模型的快速采样方法,有效降低了基于扩散概率模型的语音合成声学模型的参数量和模型推理时延。 除此之外,LightGrad中还引入了流式合成以进一步降低推理时延。 在中文和英文数据集上的实验表明,与Grad-TTS相比,LightGrad在减少了62.2%的模型参数和65.7%的推理延时的同时,保持了合成语音的质量。

3. A Synthetic Corpus Generation Method for Neural Vocoder Training
作者: Zilin Wang, Peng Liu, Jun Chen, Sipan Li, Jinfeng Bai, Gang He, Zhiyong Wu, Helen Meng
合作伙伴: 传音科技有限公司、北京世纪好未来教育科技有限公司、香港中文大学
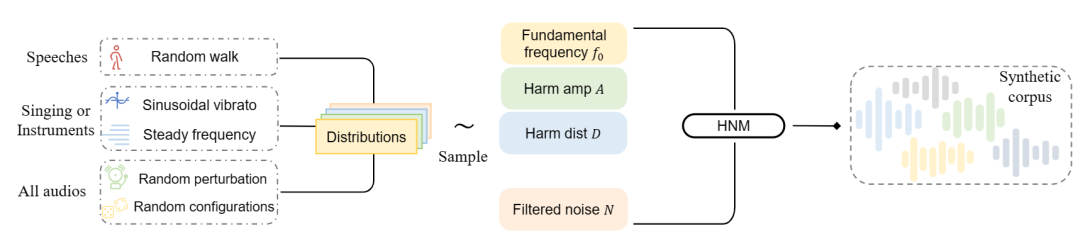
神经声码器因其合成高保真音频的能力而受到青睐。 然而,训练一个神经声码器需要大量高质量的真实音频语料库,且音频录制过程往往需要大量的人力物力财力。 为此,我们提出了一种用于神经声码器训练的合成语料库生成方法,它可以在几乎没有成本的情况下轻松生成数量不限的合成音频。 我们同时对多个目标领域的音频的先验特征进行建模(例如演讲、歌唱的声音和器乐作品等),使生成的音频数据具备这些特征。 通过该方法,在不需要任何真实音频的情况下,使用我们的合成语料库训练神经声码器就可以取得非常有竞争力的合成结果。 为了验证我们所提出方法的有效性,我们对语音和音乐语料进行了主观和客观指标的实证实验。 结果表明,用我们的方法产生的合成语料库所训练的神经声码器可以泛化到多个目标场景,并具有出色的歌唱声音(MOS: 4.20)和器乐作品(MOS: 4.00)的合成结果。

4. Enhancing the Vocal Range of Single-Speaker Singing Voice Synthesis with Melody-Unsupervised Pre-Training
作者: Shaohuan Zhou, Xu Li, Zhiyong Wu, Ying Shan, Helen Meng
合作伙伴: 腾讯科技有限公司、香港中文大学
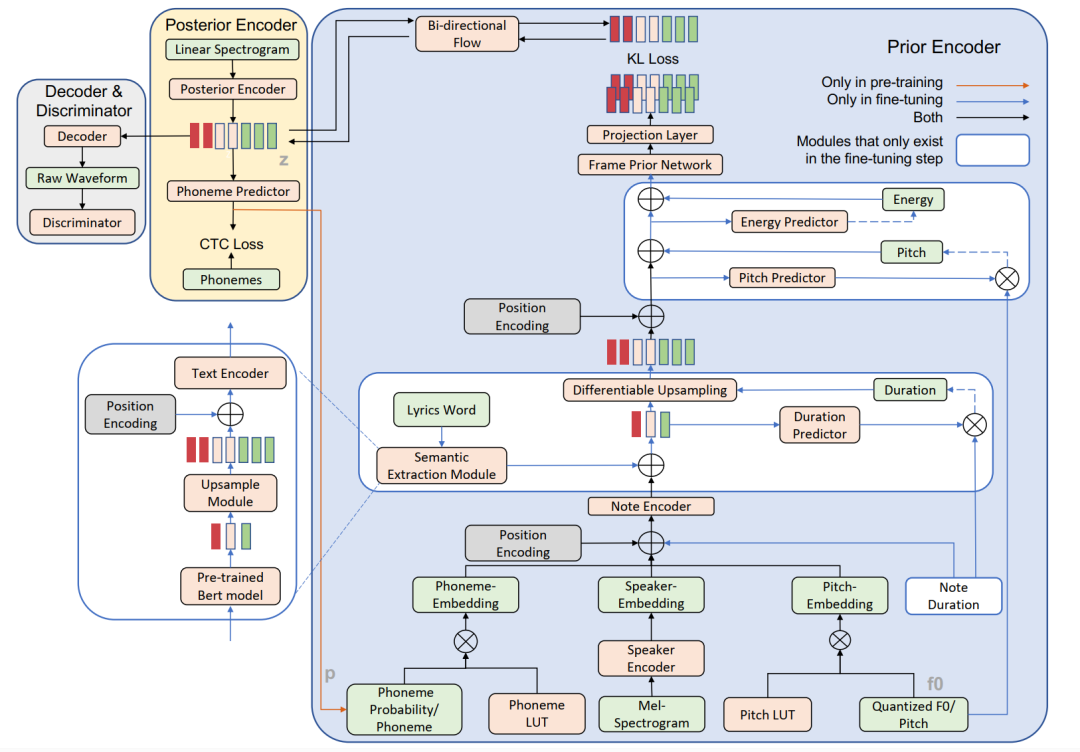
基于单歌手数据所训练出来的歌声合成模型往往受限于单歌手的音域范围,无法较好地合成音域之外的歌声。 我们的工作提出了一种在多歌手数据集上进行旋律无监督预训练的方法,以提高单歌手的歌唱音域范围,同时不降低音色的相似度。 具体来说,在预训练阶段,我们设计了一个音素预测器来预测帧级别的音素信息,一个说话人编码器用于建模不同歌手的声音,并且直接从音频中预测f0值以提供音高信息。 这些预先训练好的模型参数作为先验知识被送入到微调阶段,以提高单歌手的音域范围。 此外,我们的工作还有助于提高合成歌声的声音质量和韵律自然度: 通过首次引入一个可微分的时长调节器来提升韵律自然度,以及一个双向流模型来提高声音质量。 实验结果表明,所提出的歌声合成系统在更高的音域范围上其歌声质量和自然度方面都优于基线模型。

5. WavSyncSwap: End-to-End Portrait-Customized Audio-Driven Talking Face Generation
作者: Weihong Bao, Liyang Chen, Chaoyong Zhou, Sicheng Yang, Zhiyong Wu
合作伙伴: 平安科技(深圳)有限公司
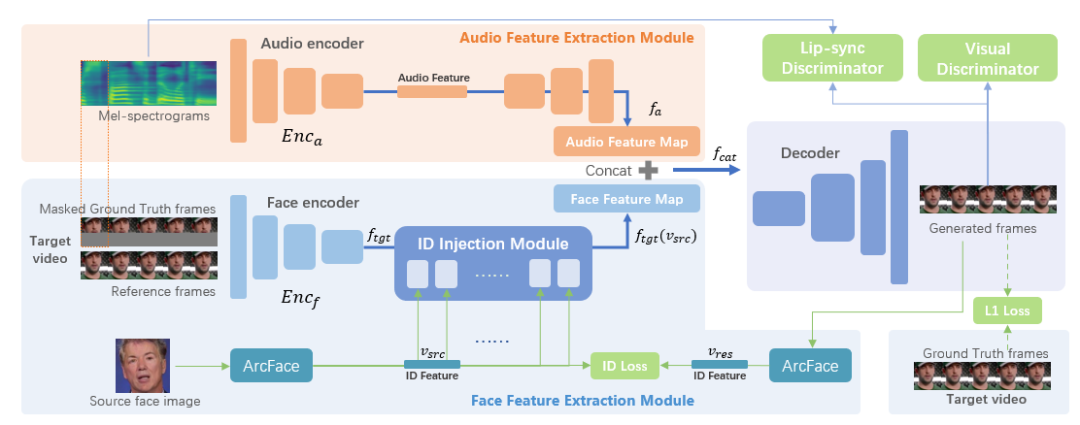
具有肖像定制功能的音频驱动虚拟数字人生成,可以增强数字人在不同场景下 应用 的灵活性,如在线会议、混合现实和数据生成等。 在现有方法中,音频驱动虚拟数字人生成和换脸通常被视为两个不同的独立任务,其通过级联的方式以实现相应的目标。 在使用最新的Wav2Lip和SimSwap方法来实现该目标的过程中,我们遇到了一些问题: 受影响的口型同步、丢失的纹理信息和缓慢的推理速度等。 为了解决这些问题,我们提出了一种结合了两种方法优点的端到端模型。 所提方法借助预训练的语音-口型同步判别器生成高度同步的口型。 此外,我们引入ArcFace和ID注入模块以提供身份信息,因为它与面部纹理具有很强的相关性。 实验结果表明,我们的方法实现了与真实视频相当的口型同步准确度,并且相比级联方法保留了更多的纹理细节,并提高了推理速度。

6. GTN-Bailando: Genre Consistent Long-Term 3D Dance Generation based on Pre-trained Genre Token Network
作者: Haolin Zhuang, Shun Lei, Long Xiao, Weiqin Li, Liyang Chen, Sicheng Yang, Zhiyong Wu, Shiyin Kang, Helen Meng
合作伙伴: 元象科技有限公司、香港中文大学
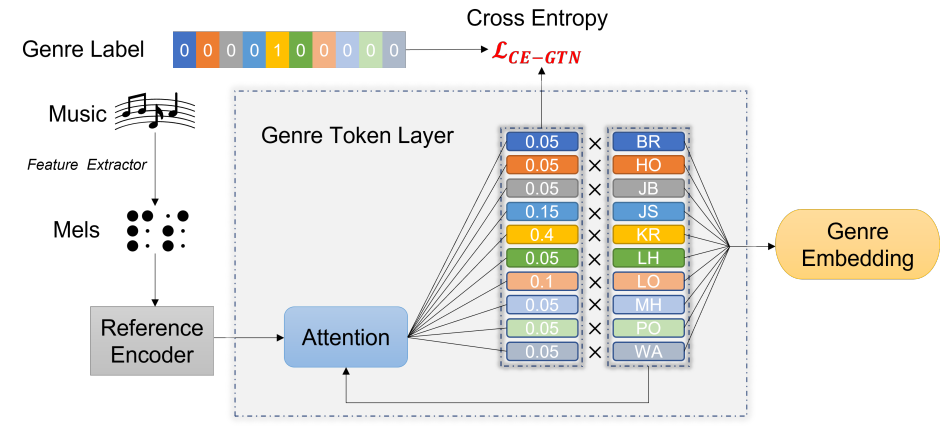
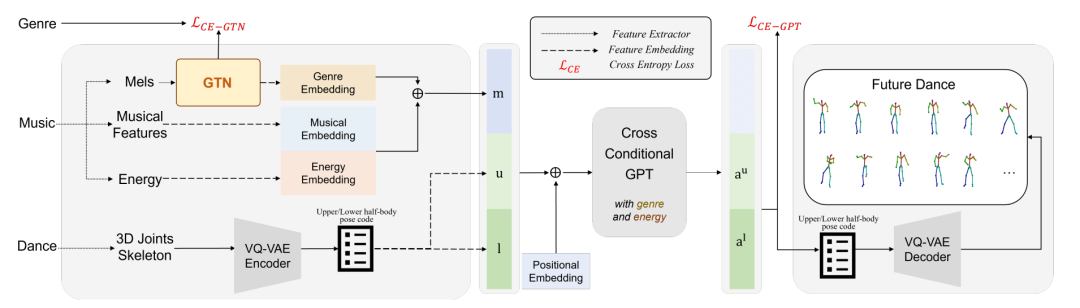
音乐驱动的3D舞蹈生成是 近 年来 热门的研究方向。 现有大多数的舞蹈生成方案缺乏对于舞蹈流派信息(Genre)的考虑,导致生成的舞蹈动作中流派不一致,影响观感。 此外,舞蹈流派与音乐之间的相关性也没有被考虑。 为了解决该问题,我们提出了一个新颖的舞蹈生成框架GTN-Bailando。 具体来说,首先,我们提出流派令牌网络(Genre Token Network),其可以从音乐推断流派,并将所推断出的流派信息引入至舞蹈生成框架中,以满足生成舞蹈的流派一致性。 其次,为了提升流派令牌网络的泛化能力,我们对其采用了预训练和微调的策略。 在AIST++数据集上的实验结果表明,所提出方案在舞蹈质量和流派一致方面皆优于现有最佳的舞蹈生成方案。

7. TrimTail: Low-Latency Streaming ASR with Simple but Effective Spectrogram-Level Length Penalty
作者: Xingchen Song, Di Wu, Zhiyong Wu, Binbin Zhang, Yuekai Zhang, Zhendong Peng, Wenpeng Li, Fuping Pan, Changbao Zhu
合作伙伴: 地平线信息技术有限公司、WeNet开源社区

本文提出剪尾(TrimTail)这一简单粗暴却有效的技巧,不需任何额外的对齐信息,可与任意训练损失(如Transducer损失及CTC损失)或任何模型架构在任意数据集使用,可成为解决ASR领域标签延迟问题的“通解”。 剪尾 (TrimTail) ,具体而言,是指对原始音频的末尾进行一定长度的修剪,对应地,剪头(TrimHead)指对原始音频的头部进行修剪,拓尾(PadTail)指在原始音频的尾部补一段值为零的序列,而拓头(PadHead)是在头部补一段值为零的序列。 本文提出一个观点,认为修剪这个操作可以压缩语音-文本的对齐空间,剪尾可迫使预测标签与先前的语音帧对齐,将对应的概率峰向前“挤”,如此可有效削减延迟。 剪头虽然也可以压缩空间,但是由于开头信息被剪导致缺失,致使语音-文本失配严重。 拓头、拓尾的实验结果(与剪尾相比,严格遵循了单一变量法则)表明延时增加,由于拓头、拓尾相当于拓增了对齐空间,延迟增加也反向证明了所提观点/解释的正确性。 实验结果表明,相比于原模型,经过剪尾训练的模型,能够在保持词错率基本不变或性能微掉的情况下,在中文普通话ASR数据集AISHEEL-1及英文ASR数据集Librispeech上取得约0.1至0.2s的延迟削减。
8. CB-Conformer: Contextual Biasing Conformer for Biased Word Recognition
作者: Yaoxun Xu, Baiji Liu, Qiaochu Huang, Zhiyong Wu, Shiyin Kang, Helen Meng
合作伙伴: 元象科技有限公司、香港中文大学
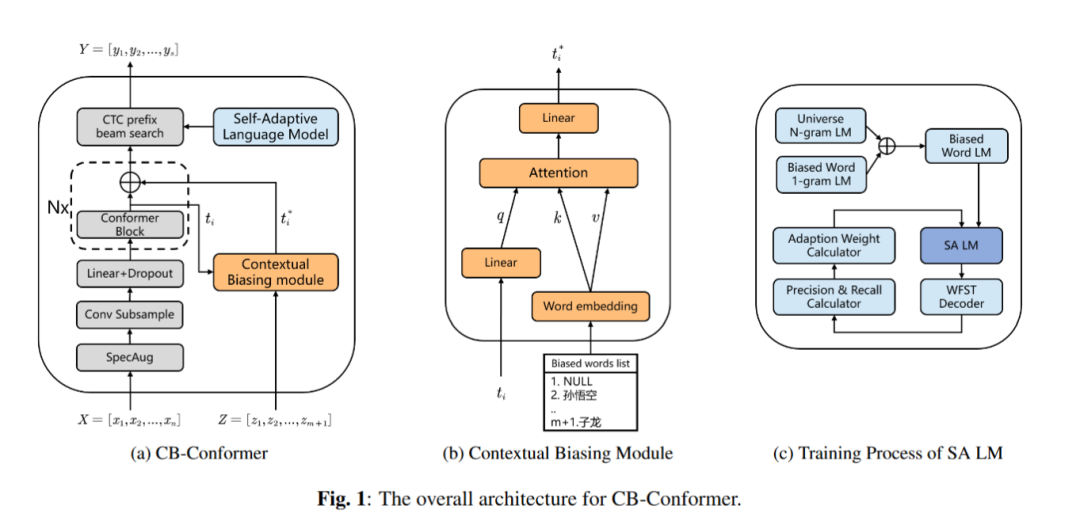
由于源域和目标域不匹配的问题,如何充分利用热词信息(biased word)对提升语音识别模型的性能至关重要。 在本工作中,我们提出了CB-Conformer,通过在传统Conformer中引入上下文偏置模块和自适应语言模型来提高热词识别的性能。 上下文偏置模块结合了音频片段和上下文信息,参数量只占原始Conformer模型参数的0.2%。 自适应语言模型根据热词召回率和精确度修改热词在语言模型内部的权重,从而更加专注于热词识别; 与普通的固定权重的语言模型相比,所提的自适应语言模型与原始语音识别模型更为契合。 此外,我们基于WenetSpeech数据集构建并开源了一个普通话热词数据集。 实验表明,与Conformer相比,所提出的方法的语音识别字错误率降低了15.34%,热词识别召回率提高了14.13%,热词识别F1-score提高了6.80%。
9. Keyword-Specific Acoustic Model Pruning for Open Vocabulary Keyword Spotting
作者: Yujie Yang, , Kun Zhang , Zhiyong Wu, Helen Men
合作伙伴: 华为诺亚方舟实验室语音语义组、香港中文大学
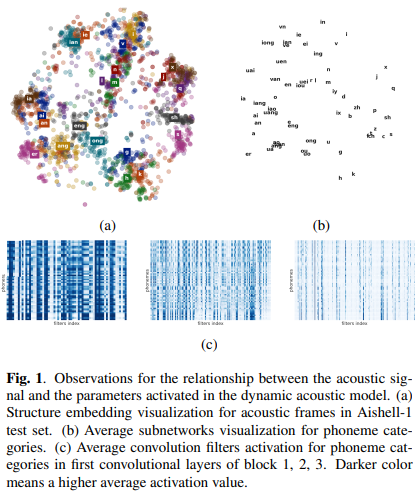
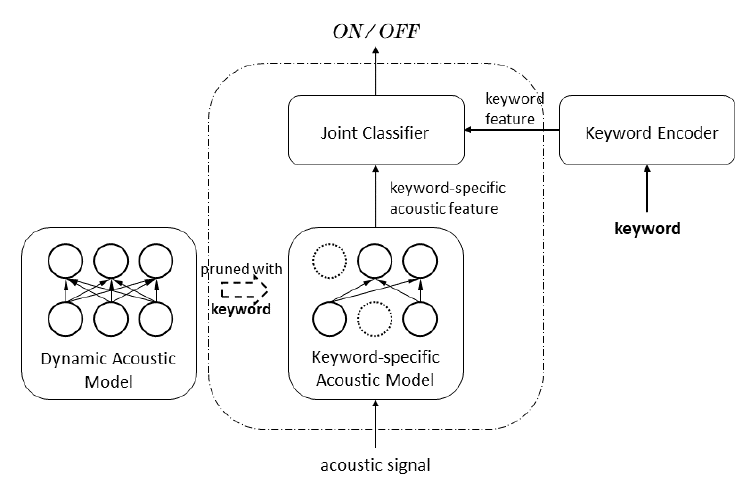
开放词汇语音唤醒系统允许用户自定义唤醒词,但由于语音唤醒需要被部属在端侧,其应用急需轻量化的模型设计。 为了识别所有可能的唤醒词,声学模型需要具有识别人类所有发音的能力,但对特定的唤醒词,声学模型过剩的表达能力必然存在冗余的参数。 我们的工作旨在裁剪掉声学模型中对识别关键词无贡献的参数。 为此,我们设计了一个动态声学模型,其参数与输入有关。 我们首次发现,动态声学模型会使用相似的子网络来处理具有相似发音的声学信号,不同的参数有助于识别不同的音素。 基于这一观察,我们在音素识别任务中,进一步约束具有相同音素伪标签的子网络之间的结构相似性,从而可以修剪出识别不同音素的独立子网络。 应用于端到端语音唤醒系统中时,仅有识别关键词中音素的子网络将被合并为一个识别当前关键词的声学模型,而那些对识别关键词没有贡献的参数将被修剪掉。 实验表明,在开放词汇语音唤醒任务中,我们的针对唤醒词的声学模型剪枝方法可以减少80%的声学模型参数而不会导致唤醒系统性能下降。
10. DASA: Difficulty-Aware Semantic Augmentation for Speaker Verification
作者: Yuanyuan Wang, Yang Zhang, Zhiyong Wu, Zhihan Yang, Tao Wei, Kun Zou, Helen Meng
合作伙伴: 平安科技(深圳)有限公司、香港中文大学
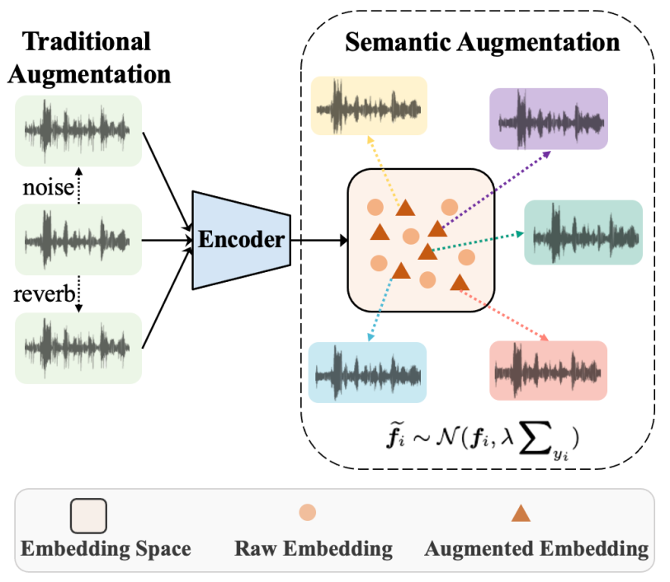
数据增强对于提升深度神经网络模型的泛化能力和鲁棒性是至关重要的。 目前说话人识别中常用的增强方法大都是直接在语音信号级别上进行数据增强,不但耗时,而且增强的样本缺乏多样性。 在本文中,我们针对说话人识别提出了一种基于难度感知的数据增强(DASA)方法。 该方法可以在说话人特征空间中生成多样化的训练样本,同时引入的额外计算成本可以忽略不计。 首先,我们从说话人相关的协方差矩阵中获得增强方向,以此扰动说话人特征来增加训练样本。 其次,在训练过程中为了估计出更准确的协方差矩阵,我们引入了DAAM-Softmax来获得更鲁棒的说话人特征。 最后,我们假设增强的样本数量达到无穷大,并结合DAAM-Softmax推导出DASA的封闭上界形式,从而实现了更好的兼容性和更高的效率。 我们进行了充分的实验,结果表明所提出的方法可以显著改进说话人识别的性能。
11. Inter-SubNet: Speech Enhancement with Subband Interaction
作者: Jun Chen, Wei Rao, Zilin Wang, Jiuxin Lin, Zhiyong Wu, Yannan Wang, Shidong Shang, Helen Meng
合作伙伴: 腾讯天籁实验室、香港中文大学
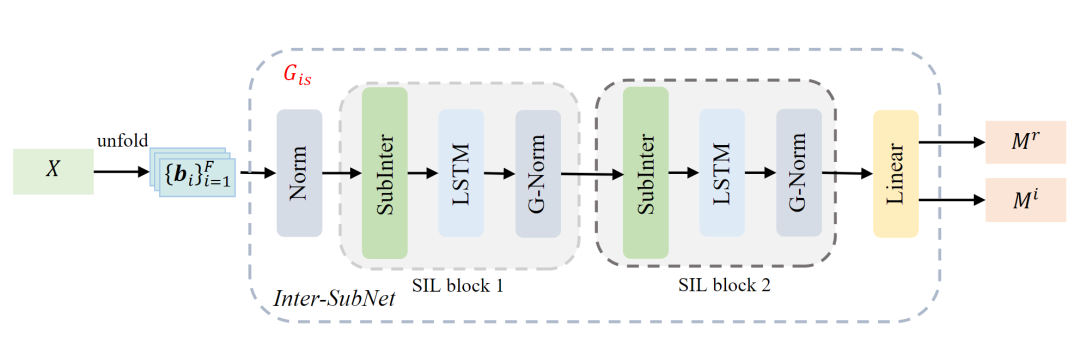
基于子带的语音增强方法通过共享参数的模型并行处理子带,以学习局部频谱的共性,进而达到降噪的目的。 通过这种方式,它们以较少的参数取得了显著的降噪效果。 然而,在一些复杂的声学环境中,由于缺乏全局频谱信息,这些基于子带的语音增强方法的性能会出现严重的下降。 为此,在本文中,我们提出了子带交互方法(Subband Interaction)作为一种补充全局频谱信息(如跨频带依赖和全局频谱模式)的新方式,并在此基础上提出了一个新的轻量级单通道语音增强框架,称为Inter-SubNet。 在DNS Challenge - InterSpeech 2021数据集上的实验结果表面,我们所提出的InterSubNet相较于子带模型性能有了巨大的提升,并超过了其它最先进的语音增强方法。 这证实了我们所提出的子带交互方法的有效性。

12. AV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
作者: Jiuxin Lin, Xinyu Cai, Heinrich Dinkel, Jun Chen, Zhiyong Yan, Yongqing Wang, Junbo Zhang, Yujun Wang, Zhiyong Wu, Helen Meng
合作伙伴: 小米科技有限公司、香港中文大学
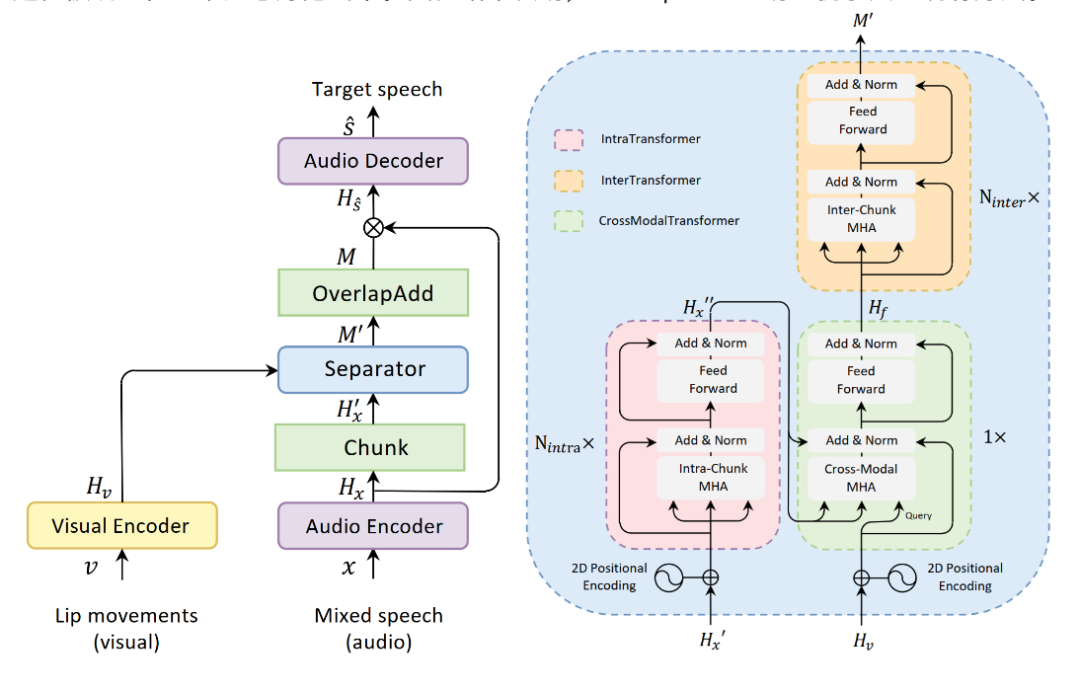
视觉信息可以作为目标说话人提取的一个有效线索,对提高提取性能至关重要。 在本文中,我们提出了AV-SepFormer,一个基于SepFormer的双尺度注意力模型,利用交叉和自注意力融合和建模来自音频和视觉的特征。 AV-SepFormer将音频特征分割成若干块,使其分辨率与视觉特征相当,然后采用交叉与自注意力来对多模态特征进行建模。 此外,我们还使用了一种新型的二维位置编码,该编码引入了块间和块内的位置信息,并获得了比传统位置编码更显著的收益。 我们的模型有两个优点: 音频分块后特征的时间分辨率与视觉特征相同,这缓解了音频和视频采样率不一致带来的危害; 通过结合交叉和自注意力,特征融合和语音提取过程被统一在一个注意力范式中。 实验结果表明,AV-SepFormer明显优于其它现有方法。

13. TFCNet: Time-Frequency Domain Corrector for Speech Separation
作者: Weinan Tong, Jiaxu Zhu, Jun Chen, Zhiyong Wu, Shiyin Kang, Helen Meng
合作伙伴: 元象科技有限公司、香港中文大学
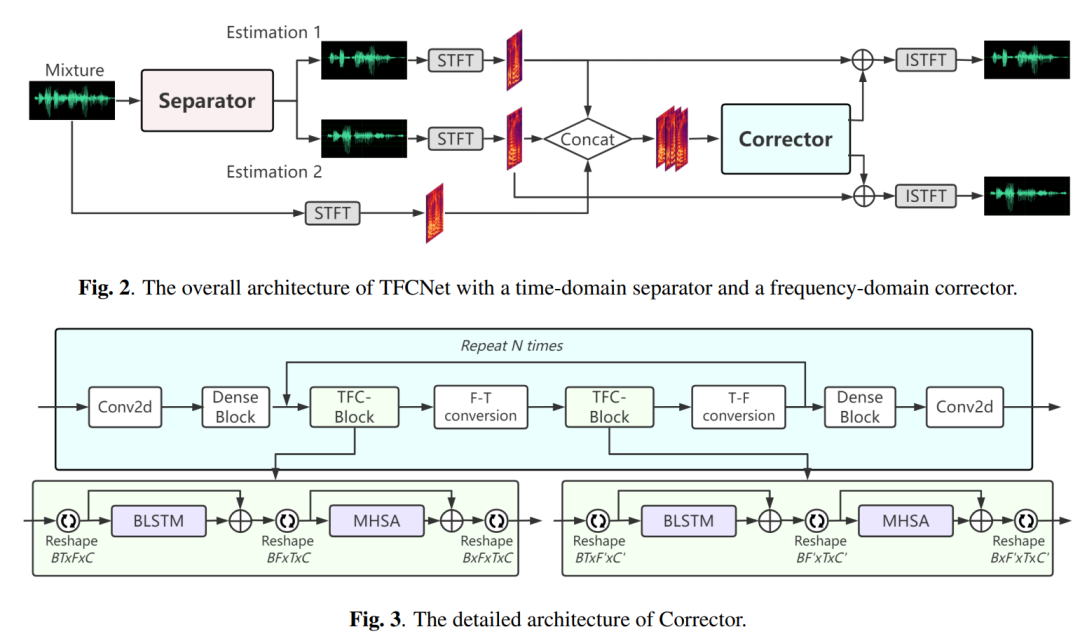
目前主流的语音分离方法是基于时域的方法,即直接使用神经网络模型对语音波形信息进行编码,提取特征,最终解码得到分离后的语音。 虽然时域方法在语音分离上取得突出的性能,但它在编码上存在着不稳定性。 这主要是因为时域方法在编码中用可学习的卷积代替了语音信号处理中的快速傅里叶变换(STFT),这种方法虽然能学习到一定的隐藏频谱空间,但不一定和真实的频谱空间一致,导致分离的语音和真实的语音在频谱上存在幅度及相位误差。 在本文中,我们提出了TFCNet,其由时域的分离器和频域的校正器构成。 频域校正器针对时域分离器的不足而特别进行设计,以便从幅度和相位两部分纠正错误的频谱信息。 在WSJ0-2mix和Libri-2mix数据集上的实验结果表明,加入校正器后分离性能有了巨大提升,超过了之前最先进的语音分离方法。
14. Lexicon-Injected Semantic Parsing for Task-Oriented Dialog
作者: Xiaojun Meng,Wenlin Dai,Yasheng Wang,Baojun Wang,Zhiyong Wu,Xin Jiang,Qun Liu
合作伙伴: 华为诺亚方舟实验室语音语义组
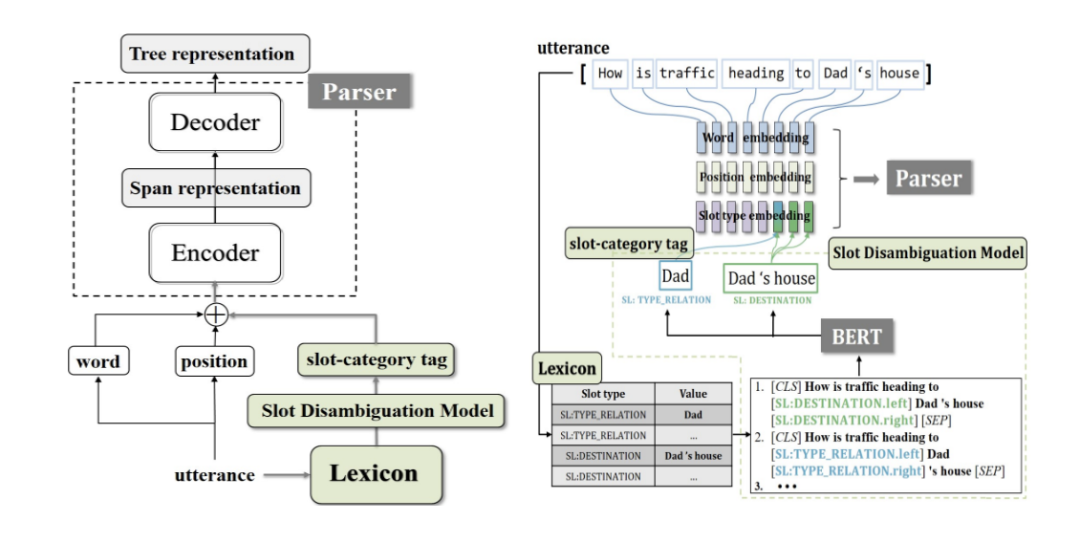
对话系统使用基于层次表征的语义解析已经引起了广泛的关注。 面向任务的解析(TOP)是一种以意图和槽值作为嵌套树节点标签的树表示方法,被用于解析用户的话语,以分析用户意图等。 之前的TOP解析方法在利用词典信息方面受到了限制,而词典信息通常用于指导真实的对话系统。 为了解决这个问题,我们首先提出了一种新的基于跨度解析器的跨度分割表示,它的性能优于现有的表示方法; 然后提出了一种新的基于词汇注入的语义解析器,它收集树表示中语句词语的槽值标签作为词典,并将槽值标签作为特征注入到解析器的跨度表示中。 模型的槽值消歧模块使用基于BERT预训练的二分类模型,对匹配结果进行正/误分类,删除词典中不适当的跨度匹配。 实验表明,我们的解析器在TOP数据集上得到了最好的解析精度(87.62%),也证实了我们提出的基于词汇注入的解析器和槽值消歧模型的有效性。

相关文章:
科研快讯 | 14篇论文被信号处理领域顶级国际会议ICASSP录用
ICASSP 2023 近日,2023年IEEE声学、语音与信号处理国际会议(2023 IEEE International Conference on Acoustics, Speech, and Signal Processing,ICASSP 2023)发布录用通知,清华大学人机语音交互实验室(TH…...
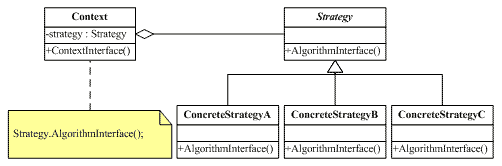
设计模式—策略(Strategy)模式
一、概述策略模式的用意是针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化使用策略模式可以把行为和环境分割开来。环境类负责维持和查询行为类,…...

STM32 触摸屏移植GUI控制控件
目录 1、emWin 支持指针输入设备。 2、 模拟触摸屏驱动 3、实现触摸屏的流程 3.1 实现硬件函数 3.2 实现对GUI_TOUCH_Exec()的定期调用 3.3 使用上一步确定的值,在初始化函数LCD_X_Config()当中添加对GUI_TOUCH_Calibrate()的调用 4、…...
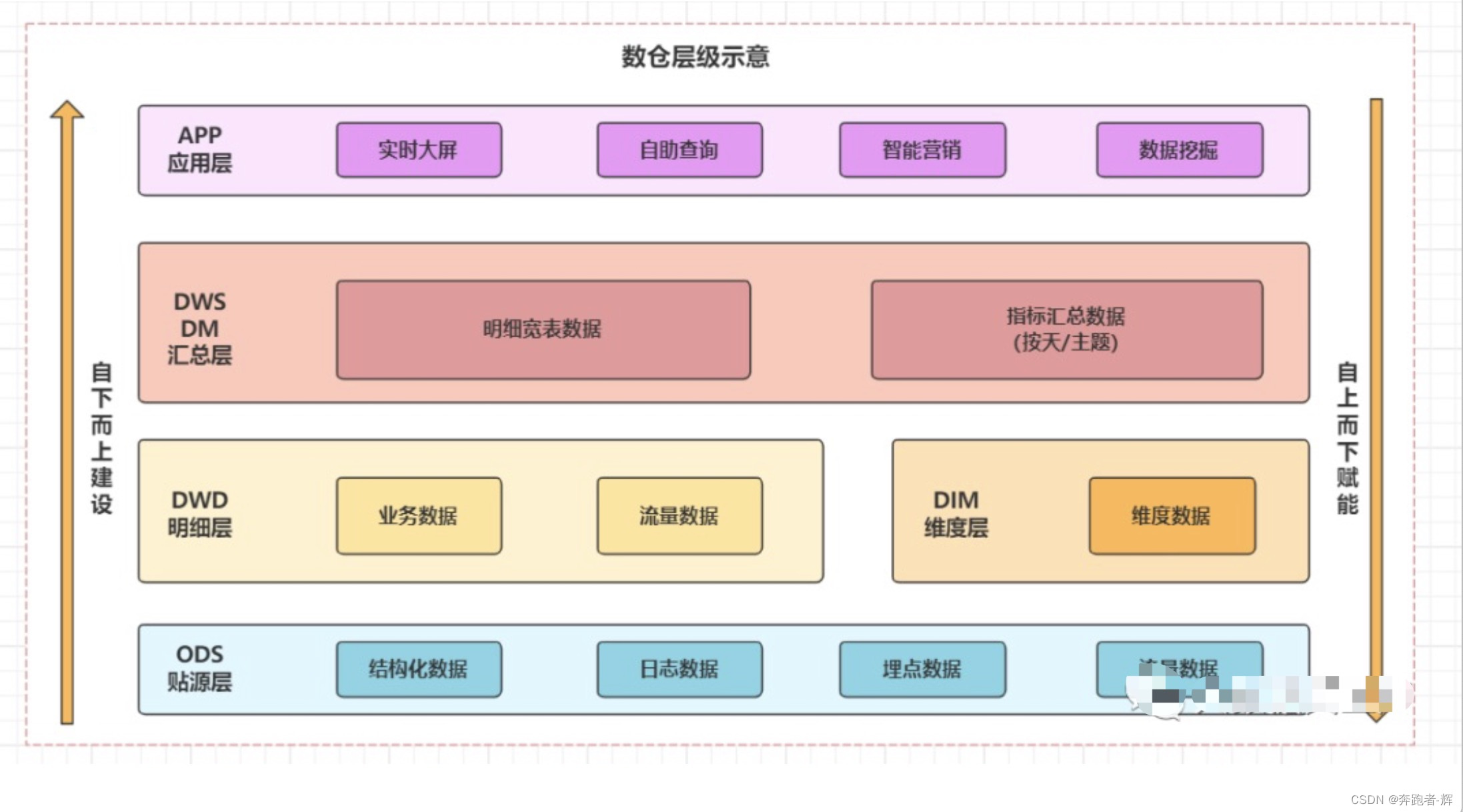
数仓模型之维度建模
目录 1、数仓架构原则 2、如何搭建一个好的数仓 2.1 建模方法 2.2 建模解决的痛点 2.3 数仓系统满足的特性 2.4 数仓架构设计 3、维度建模 4、案例 5、问题讨论 今天我们来聊聊在数仓模型中举足轻重的维度建模。 简单而言,数据仓库的核心目标是为展现层提…...
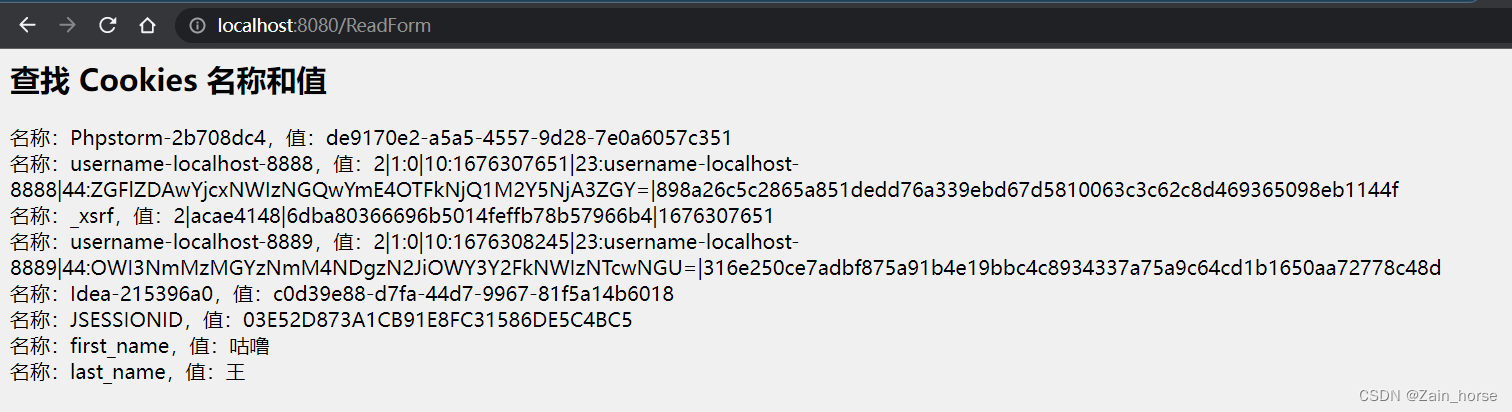
Servlet笔记(9):Cookie处理
一、Cookies处理 1、Cookies概念 Cookies是存储在客户端计算机上的文本文件,并保留各种跟踪信息。 识别返回用户的三个步骤 服务器脚本向浏览器发送一组Cookies。例如姓名、年龄或识别号码等。浏览器将这些信息存储在本地计算机上。当下一次浏览器向Web服务器发送…...

骨传导耳机是怎么传声的,选择骨传导耳机的时候需要注意什么?
骨传导耳机之所以能够成为当下最火的耳机,骨传导技术将声音转化为震动感,通过骨头进行传播,不会堵塞耳朵,就不会影响到周围环境音。这种技术也让骨传导耳机比传统入耳式耳机更安全,无需入耳式设计,避免了…...
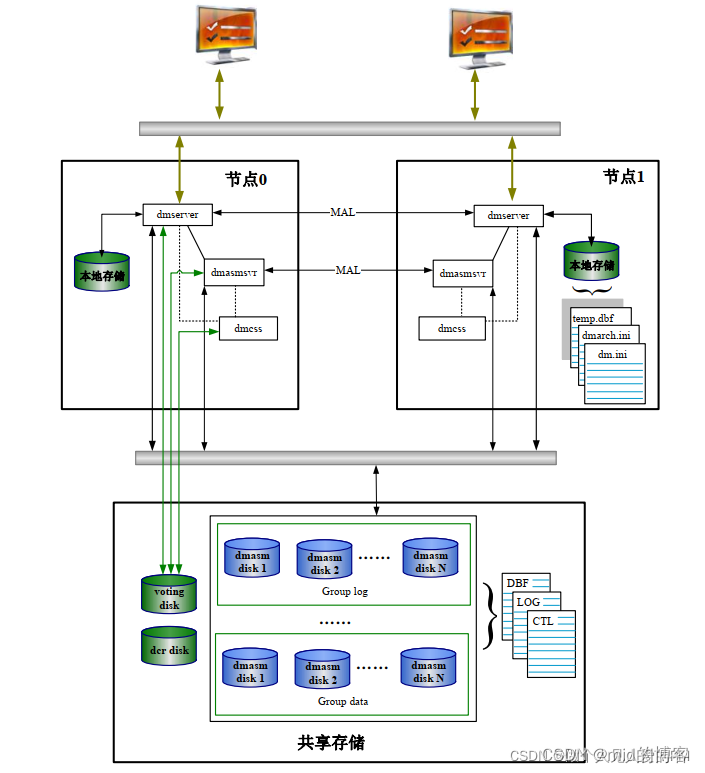
达梦数据库DSC集群部署
一、概述 1.1 DSC 集群架构 1.2 架构说明 1、DMDSC 集群是一个多实例、单数据库的系统。 多个数据库实例可以同时访问、修改同一个数据库的数据。 2、数据文件、控制文件在集群系统中只有一份,不论有几个节点,这些节点都平等地使用这些文件, 这些文件保存在共享存储上。 3…...
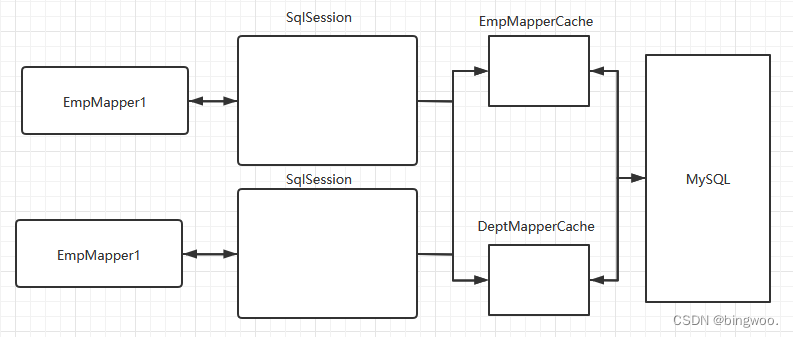
java 系列之Mybatis
java 系列文章 文章目录java 系列文章前言一、Mybatis 入门1.1 认识 框架(了解)1.2 认识 ORM(要知道)1.3 认识 Mybatis(要知道)二、Mybatis 使用2.1 创建maven项目并导入依赖2.2 准备数据库,包和…...

OBS 进阶 之 摄像头操作
目录 一、摄像头 1、win-dshow插件中,摄像头枚举操作 1)、视频源ID 2)、注册视频源信息...
Linux操作系统基础知识命令参数详解
Linux操作系统 RAID分组 RAID JBOD RAID JBOD的意思是Just a Bunch Of Disks,是将多块硬盘串联起来组成一个大的存储设备,从某种意义上说这种类型不被算作RAID,在维基百科里JBOD同时也被归入非RAID架构。RAID JBOD将所有的磁盘串联成一个单…...

Rust中一些K/V存储引擎
K/V存储引擎的由来可以追溯到20世纪70年代的Berkley DB,而近年来,随着互联网应用的发展,KV存储引擎因其简单高效、可扩展性和适合缓存应用等特点,在分布式存储领域得到了广泛应用。而使用Rust编写KV存储具有内存安全、高性能、并发…...
202302-第四周资讯
山川软件愿为您提供最优质的服务。 您的每一个疑问都会被认真对待,您的每一个建议都将都会仔细思考。 我们希望人人都能分析大数据,人人都能搭建应用。 因此我们将不断完善我们的DEMO、文档、以及视频,期望能在最大程度上快速帮助用户快速…...

九方财富冲刺上市:付费用户开始减少,退款金额飙升至4.9亿元
日前,九方财富控股有限公司(下称“九方财富”)通过港交所上市聆讯,并披露了聆讯后招股书。据贝多财经了解,九方财富最早于2021年8月31日在港交所递表,后在2022年3月、9月分别进行了更新。 据每日经济新闻报…...
SSM+HTML搭建(小白教学)
最近做项目,觉得还是有意义记录以下前后端框架是怎么搭建的,今天给大家介绍介绍SSM:SpringBootSpringMVCMyBatis后端搭建:SpringBoot快速搭建的网站(Spring Initializr)选择创建之后,会下载到一个zip压缩包,对压缩包进行解压(包地址一般选择后端项目的放的文件夹中)用idea打开项…...
【知识蒸馏】知识蒸馏(Knowledge Distillation)技术详解
参考论文:Knowledge Distillation: A Survey 1.前言 近年来,深度学习在学术界和工业界取得了巨大的成功,根本原因在于其可拓展性和编码大规模数据的能力。但是,深度学习的主要挑战在于,受限制于资源容量࿰…...

公司新招了个腾讯5年经验的测试员,让我见识到什么才是真正的测试天花板····
5年测试,应该是能达到资深测试的水准,即不仅能熟练地开发业务,而且还能熟悉项目开发,测试,调试和发布的流程,而且还应该能全面掌握数据库等方面的技能,如果技能再高些的话,甚至熟悉分…...

(一维、二维)数组传参,(一级、二级)指针传参【含样例分析,新手易懂】
目录数组传参一维数组传参二维数组传参指针传参一级指针传参二级指针传参我们在写代码的时候难免要把数组或者指针传给函数,那函数的参数该如何设计呢? 数组传参 一维数组传参 我们首先来看下面代码的几个例子: #include <stdio.h>…...

for循环中的setTimeout以及var let作用域
看了很多解释,感觉都不好理解。这个文章是我自己的理解,可以做个参考,如果我理解的不对,欢迎在评论区指正: var:使用var声明的变量具有全局作用域 (循环中每次声明的是同一个变量) l…...
有限差分法求解不可压NS方程
网上关于有限差分法解NS方程的程序实现不尽完备,这里是一些补充注解 现有的优秀资料 理论向 【1】如何从物理意义上理解NS方程? - 知乎 【2】NS方程数值解法:投影法的简单应用 - 知乎 【3】[计算流体力学] NS 方程的速度压力法差分格式_…...
Android入门第66天-使用AOP
开篇这篇恐怕又是一篇补足网上超9成关于这个领域实际都是错的、用不起来的一个知识点了。网上太多太多教程和案例用的是一个叫hujiang的AOP组件-com.hujiang.aspectjx:gradle-android-plugin-aspectjx。首先这些错的文章我不知道是怎么来的,其次那些案例真的运行成功…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...
Mysql故障排插与环境优化
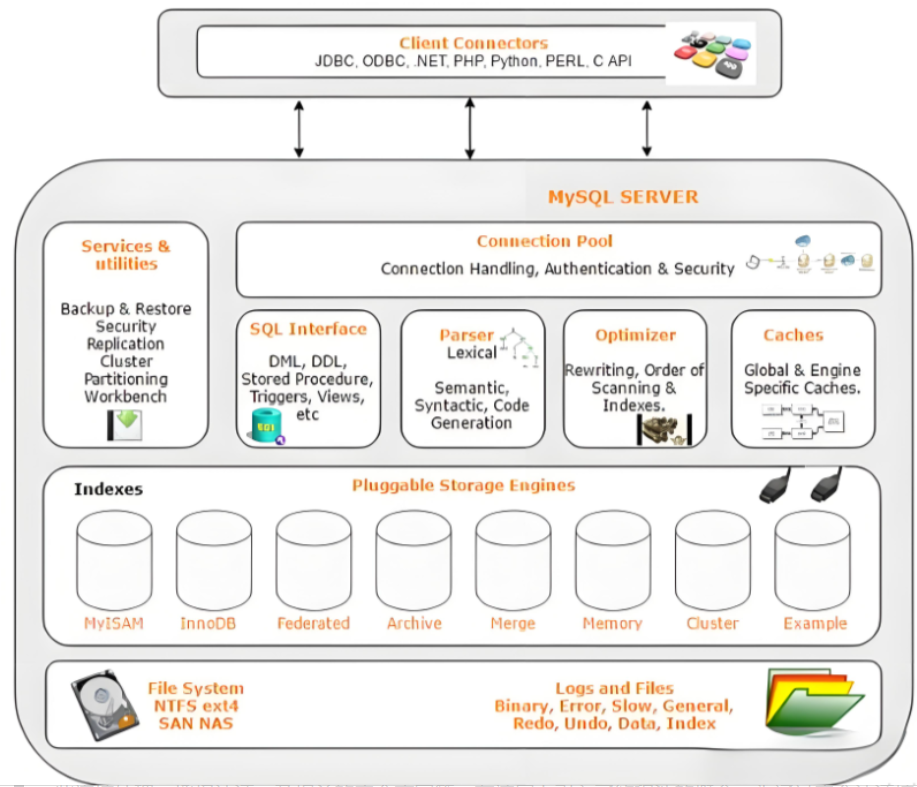
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...