并发编程-学习总结(上)
目录
1、线程基础
1.1、线程实现方法
1.2、如何正确停止线程
1.3、Java线程的六种状态
1.4、wait/notify/notifyAll注意事项
1.4.1、为什么 wait 、notify、notifyAll必须在 synchronized 保护的同步代码中使用?
1.4.2、为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
1.4.3、wait/notify 和 sleep 方法的异同?
1.5、实现生产者-消费者模式的方法
1.5.1、BlockingQueue
1.5.2、Condition
1.5.3、 wait/notify
2、线程安全
2.1、3种线程安全问题
2.1.1、运行结果问题
2.1.2、发布和初始化导致线程安全问题
2.1.3、活跃性问题
2.2、哪些场景需要注意线程安全问题
2.3、为什么多线程会带来性能问题
3、线程池
3.1、线程池的好处
3.2、创建线程池各参数的含义
3.3、线程池执行流程
3.4、默认四种拒绝策略
3.4.1、拒绝时机
3.4.2、拒绝策略
3.4、常见线程池
3.5、ForkJoinPool
3.5.1、功能
3.5.2、父类
3.5.3、自定义Task类
3.5.4、创建线程池
3.5.5、任务运行原理
3.6、线程池常用的阻塞队列
3.6、为什么不要通过Executors创建线程池
3.7、合适的线程数量
3.7.1、CPU密集型任务:
3.7.2、耗时IO型任务:
3.8、如何正确关闭线程池
3.9、如何设计线程池
4、锁
4.1、锁分类
4.1.1、偏向锁/轻量级锁/重量级锁
4.1.2、可重入锁/非可重复锁
4.1.3、共享锁/独占锁
4.1.4、公平锁/非公平锁
4.1.5、悲观锁/乐观锁
4.1.6、自旋锁/非自旋锁
4.1.7、可中断锁/不可中断锁
4.2、synchronized的monitor锁
4.2.1、同步代码块
4.2.2、同步方法
4.3、如何选择synchronized和Lock
4.3.1、相同点
4.3.2、不同点
4.3.3、如何选择
4.4、Lock的常用方法(ReentrantLock)
4.5、公平锁和非公平锁
4.5.1、为什么有非公平锁
4.6、读写锁ReadWriteLock
4.7、读写锁升降级
4.7.1、非公平锁下的读写操作
4.7.2、读写锁的降级
4.7.3、不支持读写锁的升级:读锁->写锁。
4.7.4、锁降级中读锁的获取是否必要呢?
4.8、自旋锁
4.9、JVM对synchronized的优化
4.9.1、自旋
4.9.2、锁消除
4.9.3、锁粗化
4.9.4、锁升级策略
4.10、锁升级策略
4.10.1、无锁
4.10.2、无锁->偏向锁
4.10.3、偏向锁升级为轻量级锁
4.10.4、轻量级锁->重量级锁
4.10.5、适用场景
4.10.6、锁的优缺点比较
5、并发容器
5.1、HashMap为什么线程不安全
5.2、ConcurrentHashMap
5.3、为什么Map桶中超过8个才转为红黑树
5.4、ConcurrentHashMap 和 Hashtable 的区别
5.5、CopyOnWriteArrayList
5.5.1、适用场景
5.5.2、特点
5.5.3、原理
5.5.4、缺陷
6、阻塞队列(BlockingQueue )
6.1、阻塞队列
6.2、常用方法
6.3、常见的阻塞队列
6.4、并发安全原理
6.5、如何选择阻塞队列
6.5.1、线程池对应的阻塞队列
6.5.2、如何选择
7、原子类
7.1、原子类如何利用CAS保证线程安全
7.1.1、原理
7.1.2、原子类
7.2、如何解决AtomicInteger在高并发下的性能问题
7.2.1、原因
7.2.2、解决方案
7.2.3、适用场景
7.3、原子类和volatile
7.4、AtomicInteger 和 synchronized 的异同点?
7.5、Java 8 中 Adder 和 Accumulator 有什么区别?
8、ThreadLocal
8.1、适用场景
8.2、ThreadLocal是用来解决共享资源的多线程访问问题吗?
8.3、多个ThreadLocal在Thread的threadlocals里是如何存储的?
8.4、内存泄露
8.4.1、key的内存泄露
8.4.2、value的内存泄露
8.4.3、避免内存泄露
1、线程基础
1.1、线程实现方法
- 实现Runnable接口(无返回值)
- 继承Thread类
- 线程池创建线程
- 实现Callable接口(有返回值)
1.2、如何正确停止线程
- interrupt()方法:请求中断,设置中断标志(推荐)
若线程处于正常状态,则会将该线程的中断标志设置为true,之后线程将继续正常运行,不受影响。
若线程处于被阻塞状态,或由正常状态变为阻塞状态(sleep()、wait()),线程将立刻退出被阻塞状态,并抛出一个InterruptedException异常。可以通过捕获异常然后return。
- stop():停止线程(不推荐)
直接把线程停止,影响数据完整性
- suspend():暂停线程(不推荐)
暂停线程,但不会释放锁,可能会导致死锁
- resume():恢复因suspend挂起的线程(不推荐)
- volatile变量(推荐)
在存在循环的线程run方法中进行判断是否退出线程
但在某些特殊的情况下,比如线程被长时间阻塞的情况,就无法及时感受中断,所以 volatile 是不够全面的停止线程的方法。
1.3、Java线程的六种状态
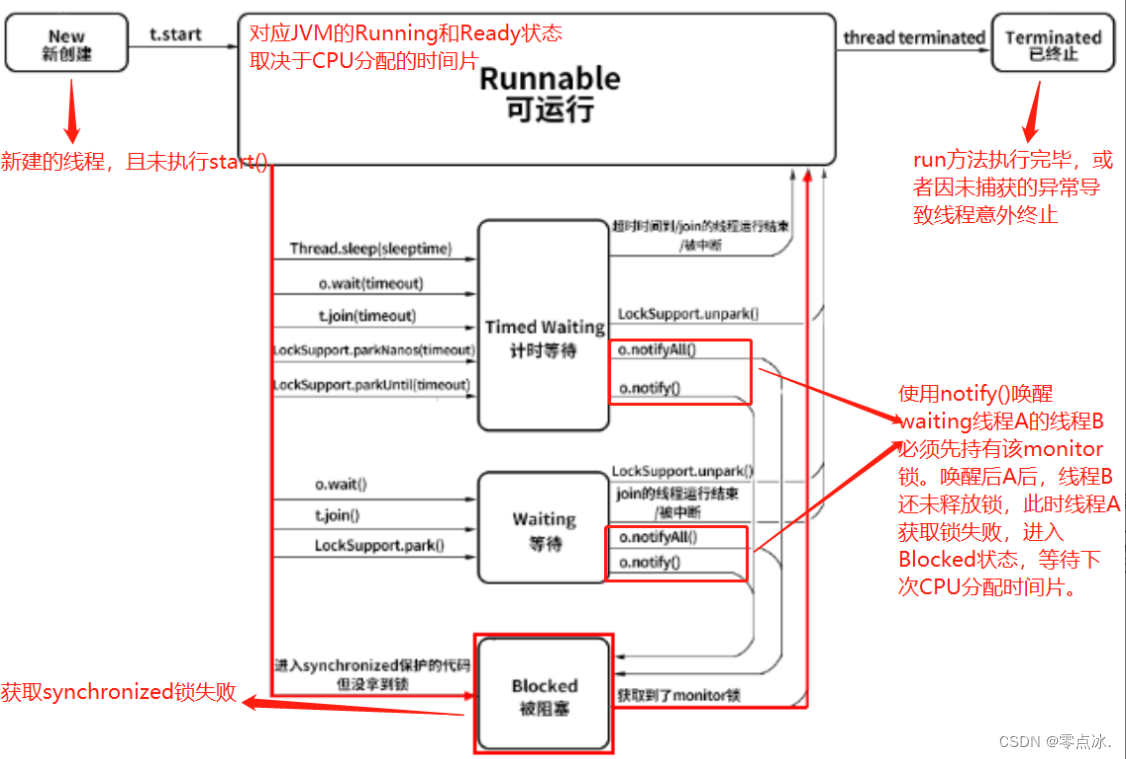
- New(新建):已创建线程,但还未执行start()
- Runnable(就绪):对应操作系统的Running和Ready状态(CPU分配时间片)
- Blocked(被阻塞):进入 synchronized 保护的代码时没有抢到 monitor 锁
- Waiting(等待):执行没有设置timeout参数的Object.wait()、Thread.join()方法
- Timed Waiting(计时等待):执行设置了timeout参数的Object.wait()、Thread.join()、Thread.sleep()方法
- Terminated(终止):run()方法执行完毕;或者出现未捕获的异常,导致意外终止
注意:waiting和Timed Waiting两种状态的线程,在被其他线程使用notify/notifyAll唤醒时,会先进入到Blocked状态。因为唤醒 Waiting 线程的线程如果调用 notify() 或 notifyAll(),要求必须首先持有该 monitor 锁,所以处于 Waiting 状态的线程被唤醒时拿不到该锁,就会进入 Blocked 状态,直到执行了 notify()/notifyAll() 的唤醒它的线程执行完毕并释放 monitor 锁,才可能轮到它去抢夺这把锁,如果它能抢到,就会从 Blocked 状态回到 Runnable 状态。
1.4、wait/notify/notifyAll注意事项
1.4.1、为什么 wait 、notify、notifyAll必须在 synchronized 保护的同步代码中使用?
预防饥饿线程:在以下消费者-生产者模式代码中,生产者执行give方法,消费者执行take方法。如果执行顺序如下所示,且没有其他生产者,那么可能导致消费者线程长久处于wait()状态。

1.4.2、为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
每个对象都有一个monitor锁,锁是对象级别的,而非线程级别的操作。wait、notify、notifyAll都是锁级别的操作,所以将这三个方法定义在Object类中(Object是所有对象的父类)
而sleep的作用是休眠线程,是线程级别的,不会操作对象锁,所以直接放在Thread类中。
1.4.3、wait/notify 和 sleep 方法的异同?
相同点:
都会阻塞线程、都可以响应interrupt中断--->抛出异常
不同点:
- wait/notify必须放在synchronized中,sleep不用;
- wait阻塞线程会释放锁,sleep不会释放锁;
- wait的线程必须等待notify唤醒,而sleep可设置休眠时间恢复自动唤醒线程;
- wait/notify是Object类的方法,sleep是Thread类方法。
1.5、实现生产者-消费者模式的方法
1.5.1、BlockingQueue
public static void main(String[] args) {BlockingQueue<Object> queue = new ArrayBlockingQueue<>(10);Runnable producer = () -> {while (true) {queue.put(new Object());}};
new Thread(producer).start();
new Thread(producer).start();Runnable consumer = () -> {while (true) {queue.take();}
};
new Thread(consumer).start();
new Thread(consumer).start();
}1.5.2、Condition
public class MyBlockingQueueForCondition {private Queue queue;private int max = 16;private ReentrantLock lock = new ReentrantLock();private Condition notEmpty = lock.newCondition();private Condition notFull = lock.newCondition();public MyBlockingQueueForCondition(int size) {this.max = size;queue = new LinkedList();}public void put(Object o) throws InterruptedException {lock.lock();try {while (queue.size() == max) {notFull.await();}queue.add(o);notEmpty.signalAll();} finally {lock.unlock();}}public Object take() throws InterruptedException {lock.lock();try {while (queue.size() == 0) {notEmpty.await();}Object item = queue.remove();notFull.signalAll();return item;} finally {lock.unlock();}}
}1.5.3、 wait/notify
class MyBlockingQueue {private int maxSize;private LinkedList<Object> storage;public MyBlockingQueue(int size) {this.maxSize = size;storage = new LinkedList<>();}public synchronized void put() throws InterruptedException {while (storage.size() == maxSize) {wait();}storage.add(new Object());notifyAll();}public synchronized void take() throws InterruptedException {while (storage.size() == 0) {wait();}System.out.println(storage.remove());notifyAll();}
}2、线程安全
2.1、3种线程安全问题
2.1.1、运行结果问题
多线程情况下,多次执行同一段代码,运行结果不同。
2.1.2、发布和初始化导致线程安全问题
新建一个线程用于对象初始化,在初始化操作完成之前,另一个线程使用该对象,对象的属性可能就不是预期的初始化后的值。
2.1.3、活跃性问题
- 死锁:两个线程互相持有对方需要的资源(锁),但又互不相让。
- 活锁:线程未阻塞,但线程运行异常,报错时无限重试。导致线程处于活跃状态却永远得不到结果。
- 饥饿:一个线程长时间在等待资源:比如1个低优先级的线程,和1000000个高优先级线程(不断生产),此时这个低优先级线程就可能没机会运行,导致饥饿。
2.2、哪些场景需要注意线程安全问题
- 访问共享变量或资源
- 多线程下依赖时序的操作
if (map.containsKey(key)) {map.remove(obj)
}- 对方没有声明自己是线程安全的(比如ArrayList)
2.3、为什么多线程会带来性能问题
- 上下文切换:上下文切换会挂起当前正在执行的线程并保存当前的状态,然后寻找下一处即将恢复执行的代码,唤醒下一个线程,以此类推,反复执行
- 缓存失效:线程切换后,CPU高速缓存会失效
- 多线程间协作开销大
3、线程池
3.1、线程池的好处
- 池中有固定线程,复用线程,避免频繁创建销毁线程,减少线程生命周期的开销,提高性能
- 根据配置和任务数量控制线程数量,避免线程过多导致资源浪费
- 统一管理池中的线程
3.2、创建线程池各参数的含义

new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
->
new ThreadPoolExecutor(核心线程数,最大线程数,非核心线程存活时间,时间单位,缓冲队列,创建线程使用的工厂,任务拒绝策略)。
3.3、线程池执行流程
new ThreadPoolExecutor(corePoolSize, maxPoolSize, keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
核心线程数->缓冲队列->最大线程数->拒绝策略。
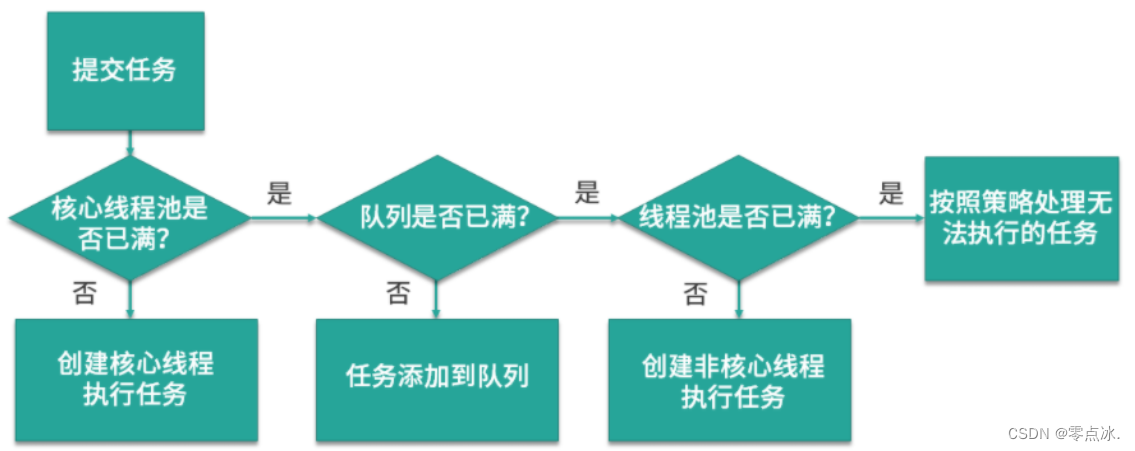
流程:
- 核心线程数未满时,每次来任务就会创建新的核心线程来执行任务;
- 核心线程满了,队列未满,则将任务放到队列中;
- 核心线程满了,队列满了,线程未达到最大线程数,创建非核心线程数执行线程;
- 核心线程满了,队列满了,线程已达到最大线程数,此时线程池工作饱和,执行线程池的拒绝策略。
3.4、默认四种拒绝策略
3.4.1、拒绝时机
- 调用shutdown等方法关闭线程池后,正在执行线程池内剩余的线程,此时再向线程池提交任务,就会遭到拒绝。
- 线程池已经没有能力处理新的任务:队列已满、线程池已满。
3.4.2、拒绝策略
- AbortPolicy:直接抛出异常
- DiscardPolicy:直接丢弃新来的任务,用户无法感知
- DiscardOldestPolicy:丢弃队列中存活时间最长的任务,用户无法感知
- CallerRunsPolicy:把新来的任务直接交个调用者线程运行
3.4、常见线程池
FixedThreadPool:固定线程池:核心线程数 = 最大线程数
CachedThreadPool:可缓存线程池:线程数可以无限增加,并可对闲置线程进行回收
ScheduledThreadPool:定时/周期性线程池:支持定时或周期性执行任务(多数情况下可用Timer类代替)
SingleThreadExecutor:单线程线程池
3.5、ForkJoinPool
3.5.1、功能
将一个大任务拆分成多个小任务后,使用fork可以将小任务分发给其他线程同时处理,使用join可以将多个线程处理的结果进行汇总
3.5.2、父类
RecursiveAction:用于没有返回结果的任务(类似Runnable)
RecursiveTask:用于有返回结果的任务(类似Callable)
3.5.3、自定义Task类
class CountTask extends RecursiveTask<Integer> { private static final int THREADHOLD = 2;private int start;private int end;/*** @Description: 最小的一个任务单元,以及它要处理的范围* @param:* @return:*/public CountTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected Integer compute() {int sum = 0;boolean canCompute = (end - start) <= THREADHOLD;if (canCompute) {for (int i = start; i <= end; i++) {sum += i;}} else {//继续将任务细分int middle = (start + end) / 2;CountTask leftTask = new CountTask(start, middle);CountTask rightTask = new CountTask(middle + 1, end);//执行子任务leftTask.fork();int rightValue = rightTask.compute();//合并结果sum = leftTask.join() + rightValue;}return sum;}3.5.4、创建线程池
public static void main(String[] args) throws ExecutionException, InterruptedException {ForkJoinPool forkJoinPool = new ForkJoinPool(2);CountTask sumTask1 = new CountTask(0, 4);ForkJoinTask task1 = forkJoinPool.submit(sumTask1);System.out.println(task1.get());}3.5.5、任务运行原理
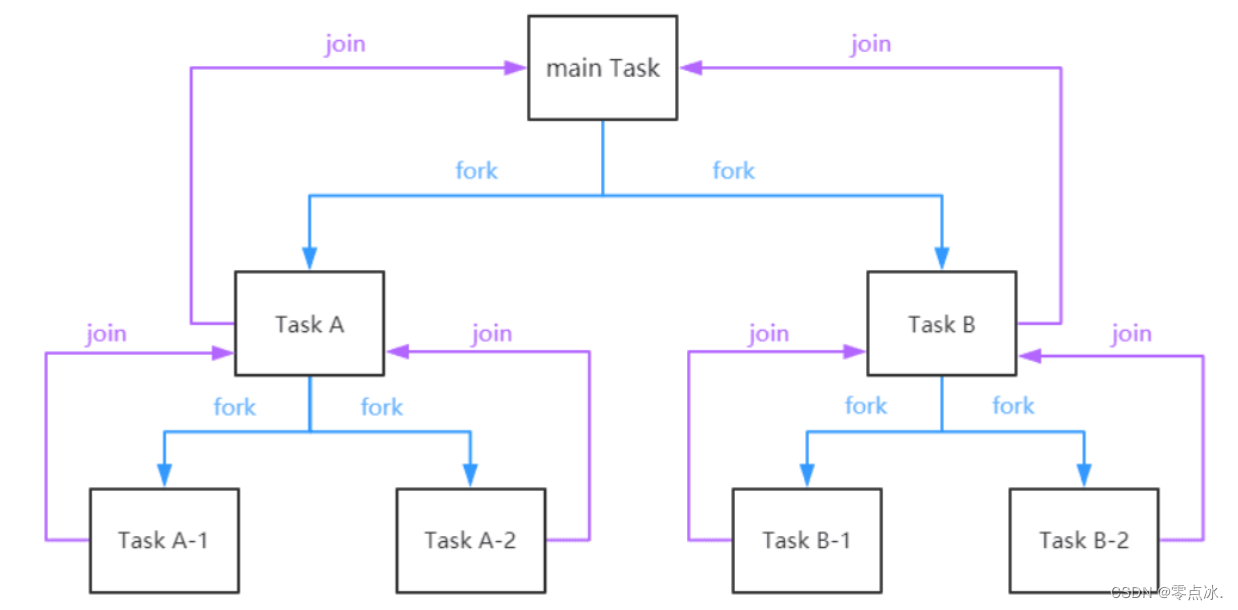
3.6、线程池常用的阻塞队列
LinkedBlockingQueue:无界队列
核心线程数固定的线程池,需要一个没有容量限制的阻塞队列。
FixedThreadPool、SingleThreadExector
SynchronousQueue
容量为0,一旦有任务进入队列,就立刻将任务提交给线程池,所以需要线程池有足够的线程数
CachedThreadPool
DelayedWorkQueue
该队列把任务按照延时时间长短进行排序,方便任务进行
ScheduledThreadPool
3.6、为什么不要通过Executors创建线程池
- 内存溢出:newFixedThreadPool、newSingleThreadExecutor
- OOM:newCachedThreadPool
- 通过使用new ThreadPoolExecutor()手动创建线程池,根据实际情况选择合适的队列、拒绝策略、线程数等,避免资源耗尽的风险。
3.7、合适的线程数量
目的:合适的线程数量可以更好地使用CPU和内存等资源,从而最大限度地提升程序的性能。
3.7.1、CPU密集型任务:
- 线程数 = CPU核心数的1~2倍
- 线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
计算任务重,单个任务耗时长,如果线程数过多,会造成不必要的上下文切换,降低系统性能。
3.7.2、耗时IO型任务:
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
IO 读写速度相比于 CPU 的速度而言是比较慢的,如果我们设置过少的线程数,就可能导致 CPU 资源的浪费。而如果我们设置更多的线程数,那么当一部分线程正在等待 IO 的时候,它们此时并不需要 CPU 来计算,那么另外的线程便可以利用 CPU 去执行其他的任务,互不影响,这样的话在任务队列中等待的任务就会减少,可以更好地利用资源。
3.8、如何正确关闭线程池
- shutdown()-推荐
拒绝新任务的提交,执行完当前线程池中正在执行的任务及队列中的任务后,关闭线程池。
- isShutdown()
判断线程池是否已经开始了关闭工作;
当调用shutdown()或shutdownNow()方法后返回为true;
为true仅表示关闭流程开始,不一定已经关闭。
- isTerminated()
线程池已关闭,且池中和队列中所有线程已执行完毕时,返回true
- awaitTermination()
线程等待一段指定的时间,如果在等待时间内,线程池已关闭并且内部的任务都执行完毕了,那么方法就返回 true,否则超时返回 fasle。
- shutdownNow()-推荐
给所有线程发送中断信号,然后会将队列中正在等待的所有任务转移到一个 List 中并返回,我们可以根据返回的任务 List 来进行一些补救的操作。
3.9、如何设计线程池
- 考虑线程池中的个数是固定的还是动态变化的。
- 考虑队列大小:无界队列(可能导致内存耗尽);有界队列(队列满了拒绝策略)
- 每次提交新任务,是直接放入队列,还是开启新线程
- 没有任务时,线程是睡眠一段时间还是进入阻塞
4、锁
4.1、锁分类
4.1.1、偏向锁/轻量级锁/重量级锁
特指synchronized锁的状态。在对象头中的mark word来表明锁的状态。
偏向锁:不加锁,加标记。
轻量级锁:不阻塞,通过自旋和CAS获取锁。
重量级锁:阻塞,互斥锁。
锁升级:无锁→偏向锁→轻量级锁→重量级锁
4.1.2、可重入锁/非可重复锁
已经持有锁,是否能在不释放当前锁的情况下,再次获取当前锁。
4.1.3、共享锁/独占锁
是否可被多个线程同时获取锁。典型为读写锁。
4.1.4、公平锁/非公平锁
线程是否按照先来先到的原则获取锁。
4.1.5、悲观锁/乐观锁
悲观锁:获取资源前,必须先获得锁,锁住资源,synchronized。
乐观锁:获取资源前,不用获得锁,不会锁住资源,CAS。
适用场景:
悲观锁:并发写入多、临界区代码复杂、竞争激烈等场景。
乐观锁:大部分是读取,少部分是修改的场景,也适合虽然读写都很多,但是并发并不激烈的场景。
4.1.6、自旋锁/非自旋锁
是否利用循环,不停地尝试获取锁。
4.1.7、可中断锁/不可中断锁
可中断锁:一旦申请锁,就只能拿到锁后才能做其他操作(synchronized)。
不可中断锁:线程申请锁后,可中断获取锁的流程(ReentrantLock)。
4.2、synchronized的monitor锁
javac xxx.java:产生xxx.class
javap -verbose xxx.class:生成class文件的反汇编内容
4.2.1、同步代码块
monitorenter(加锁)、monitorexit(释放锁)指令:每个对象头有一个记录着锁次数的计数器
4.2.2、同步方法
ACC_SYNCHRONIZED标识符:如果方法有该标识符,那么在调用方法时会先判断获取对象的monitor锁,方法执行之后释放monitor锁。
4.3、如何选择synchronized和Lock
4.3.1、相同点
- 保证线程安全;
- 保证可见性(前一个加锁操作结果对后一个加锁操作可见);
- 可重入锁。
4.3.2、不同点
synchronized
- 自动加锁和释放锁。
- 加解锁顺序:加锁Lock1->加锁Lock2->解锁Lock2->解锁Lock1。
- 申请锁后,只有获得锁后才能继续其他操作,否则会永远等待。
- 只能被一个线程拥有。
- 不可设置公平锁/非公平锁。
- Java5之前,性能低;Java6之后,增加自旋锁、轻量级锁、偏向锁,性能提高
Lock
- 必须显示lock()和unlock()
- 加解锁顺序:可自由控制加解锁顺序
- 申请锁后,可中断退出。
- 可被多个线程拥有。
- 可设置公平锁/非公平锁。
4.3.3、如何选择
- 最好的情况是两者都不用,优先使用并发工具包来加解锁;
- 尽量使用synchronized由于lock,因为synchronized可自动加解锁;
- 需要使用到尝试获取锁、锁中断、超时功能时,才使用Lock。
4.4、Lock的常用方法(ReentrantLock)
- lock()
获取锁,不能被中断,死锁->永久等待。必须在finally中unlock解锁。
- tryLock()
尝试获取锁,获取成功,返回true;否则返回false。可根据是否获得锁决定后续程序的行为。
- tryLock(long time, TimeUnit unit)
与tryLock类似,区别在于获取锁失败后会等待一段时间,一段时间后还获取不到锁,再返回false。
- lockInterruptibly()
获取锁,能获取则直接返回,不能获取则一直尝试获取锁,可响应中断。
- unlock()
释放锁,必须写在finally块中。
4.5、公平锁和非公平锁
- 公平锁:按照线程请求顺序分配锁。慢,吞吐量小,唤醒阻塞线程开销大。
- 非公平锁:在一定情况下,允许插队,但不是随意插队。快,吞吐量大,有可能产生饥饿线程。
- 通过new ReentrantLock(false) 来设置公平锁/非公平锁。
4.5.1、为什么有非公平锁
示例:A,B,C三个线程,A持有锁,B阻塞等待获取锁
A释放锁时,刚好C来获取锁,非公平锁就可把锁给C。
(B处于阻塞状态,唤醒B需要很大开销)
新线程都会先获取锁,获取不到,再讲线程放到队列尾,之后按顺序唤醒线程获取锁。
4.6、读写锁ReadWriteLock
- 读读共享,读写互斥、写写互斥。读锁可以被多个线程获取,而写锁不会。
- 读写锁适用于读多写少的场景。
4.7、读写锁升降级
4.7.1、非公平锁下的读写操作
- 写锁允许插队:在没有其他线程持有读锁、写锁的时候,能插队成功;插队失败进行等待队列。
- 读锁不允许插队(防止饥饿线程)
4.7.2、读写锁的降级
在不释放写锁的情况下,直接获取读锁,然后再释放写锁。(区别于直接释放写锁之后再获取读锁---中间有时间差,其他线程可能获得锁)
长时间持有写锁,浪费资源,此时会禁止其他线程的读取。
4.7.3、不支持读写锁的升级:读锁->写锁。
场景:升级时,需要等待所有读锁都释放。
示例:A、B两个线程持有读锁,且都想升级为写锁,且A、B都在等待对方释放读锁,此时就会发生死锁现象。
4.7.4、锁降级中读锁的获取是否必要呢?
答案是必要的。主要是为了保证数据的可见性,如果当前线程不获取读锁而是直接释放写锁, 假设此刻另一个线程(记作线程T)获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新。如果当前线程获取读锁,即遵循锁降级的步骤,则线程T将会被阻塞,直到当前线程使用数据并释放读锁之后,线程T才能获取写锁进行数据更新。
4.8、自旋锁
在java1.5及以上的并发包中,AtomicXXX等原子类基本都是自旋锁的实现。
定义
- 自旋锁:不会放弃CPU时间片,不停地尝试获取锁,直到获取成功为止。
- 非自旋锁:获取锁失败后,线程休眠、释放CPU资源。
好处
阻塞和唤醒线程需要高昂开销,自旋锁可避免上下文切换,节省线程状态切换带来的开销。
缺点
如果锁一直被其他线程持有,那么就会一直自旋,白白浪费处理器资源。
4.9、JVM对synchronized的优化
自旋、锁消除、锁粗化、偏向锁、轻量级锁
4.9.1、自旋
自适应的自旋锁:会根据最近自旋尝试的成功率、失败率等因素来决定自旋时间,以解决自旋锁长时间进行无用自旋的问题。
4.9.2、锁消除
如果某些对象不可能被其他对象访问到,就可以把他们当成栈上数据,只能被当前线程访问,绝对线程安全。此时,编译器就会把synchronized给消除,省去加锁和解锁的开销。
4.9.3、锁粗化
举例说明:
有三个连续的同步代码块,每执行一个同步代码块时,都要进行加锁和解锁操作。因为连续,此时可以把三个同步代码块,合并为一个同步代码块,增大了同步区域,即为锁粗化。
减少了中间无意义的加锁和解锁过程。
如果循环场景使用锁粗化功能,会导致其他线程长时间无法获得锁,所以锁粗化功能仅适用于非循环的场景。
4.9.4、锁升级策略
无锁->偏向锁->轻量级锁->重量级锁
4.10、锁升级策略
- 锁升级:无锁->偏向锁->轻量级锁->重量级锁
- Java对象头 = Mark Word + 指向类的指针 + 数组长度(只有数组对象才有)
- Mark Word记录对象和锁有关的信息,根据锁标志位来确定当前对象是什么锁状态。
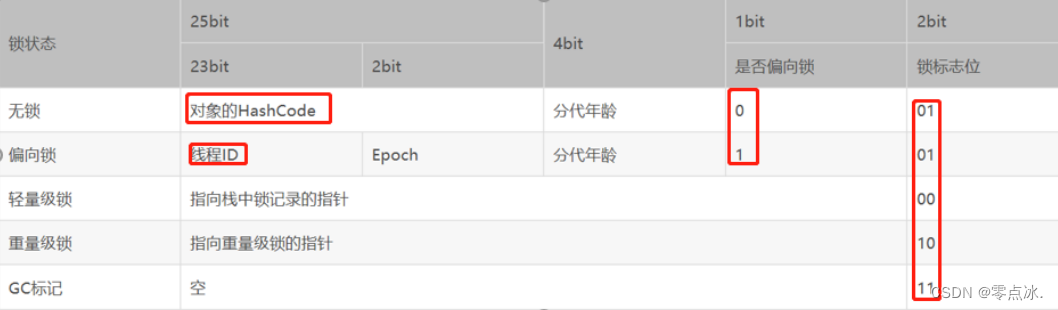
4.10.1、无锁
锁标志位 = 01,是否偏向锁 = 0,存储对象的hashcode值。
当对象没有被当成锁时,Mark Word记录的是对象的hashcode。
4.10.2、无锁->偏向锁
锁标志位 = 01,是否偏向锁 = 1,存储占有偏向锁线程的线程id。
当对象被当成同步锁并且线程A通过CAS抢到锁时,进入偏向锁状态,将线程A的线程id写入Mark Word。
当线程A再次试图获取锁时,JVM发现同步锁为偏向锁,且偏向锁中的线程id值等于线程A的id,就可以直接执行同步锁的代码块;
当线程B来试图获取锁时,JVM发现同步锁为偏向锁,且偏向锁中的线程id值不等于线程B的id,线程B就会通过CAS去尝试获取锁:如果获取成功,则将Mark Word中的偏向锁的线程id修改为线程B的id;如果获取失败,则将同步锁升级为轻量级锁;
4.10.3、偏向锁升级为轻量级锁
出现锁竞争(CAS获取锁失败)时,偏向锁升级为轻量级锁。
锁标志位 = 00,存储指向栈中锁记录的指针。
JVM在当前线程的栈帧中开辟一块独立空间,用以保存指向对象锁Mark Word的指针,同时Mark Word保存指向栈帧中独立空间的指针。
如果保存成功,则当前线程获取该对象的轻量级锁,执行同步代码;
如果保存失败,则当前线程自旋,不断尝试获取锁(尝试N次,由JVM决定),如果抢锁成功,执行同步代码;如果抢锁失败,则将轻量级锁升级为重量级锁。
4.10.4、轻量级锁->重量级锁
轻量级锁自旋超过JVM指定次数时,升级为重量级锁。
锁标志位 = 10,存储指向重量级锁的指针。
未抢占到锁的线程会被阻塞,抢到锁的线程在释放锁的同时会唤醒那些阻塞的线程。
重量级锁下,线程之间的切换需要从用户态到内核态,成本较高。
4.10.5、适用场景
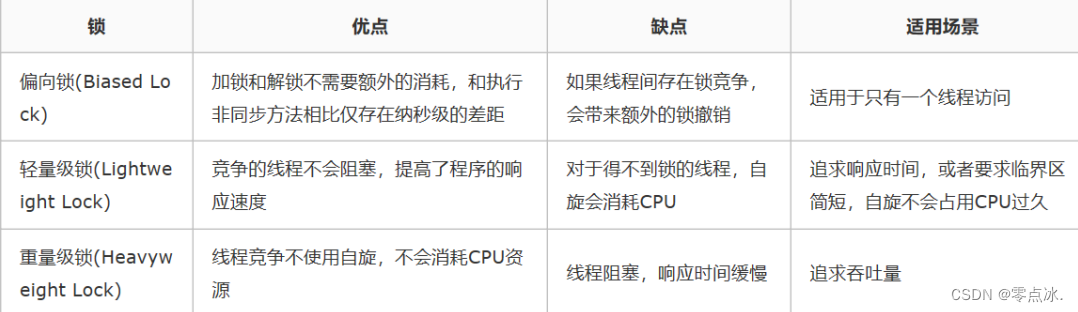
- 偏向锁:只有一个线程在临界区执行,无需操作系统介入;
- 轻量级锁:多个线程交替进入临界区,竞争不激烈,就算有冲突,线程自旋几次就能获取锁;
- 重量级锁:多个线程出现激烈竞争。
4.10.6、锁的优缺点比较
5、并发容器
5.1、HashMap为什么线程不安全
- 扩容期间取出的值不准确
扩容时会创建一个新的Entry数组,然后遍历原Entry数组,把所有的Entry重新Hash到新数组。
在这个过程中另一个线程从HashMap取数据,就有可能取出null。
- 循环链表(死循环)
原因:并发+头插
Jdk1.7在高并发下,HashMap产生死循环,造成CPU100%负载:HashMap在存储时,若size超过当前最大容量*负载因子时,会增加桶的数目,进行HashMap数组扩容(resize()),在resize过程中,会调用transfer()方法将链表转换成新链表,在多线程情况下可能导致链表回路,从而导致死循环。
扩容时,会调用transfer方法将旧的元素重新hash后放到新的table中。
Jdk1.8中HashMap的put元素操作由1.7的头插改为尾插,避免了死循环问题。
5.2、ConcurrentHashMap
- JDK1.7
Segment锁分段技术
segment数组(存储锁)+hashEntry数组
采用锁分段技术来保证线程安全,将数据分为一段一段的,给每段数据各分配一把锁,不同数据段之间的读写互不影响,效率高
最大并发个数就是 Segment 的个数,默认是 16
- JDK1.8
Node数组+链表/红黑树
并发控制使用 synchronized 和 CAS 来操作
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍
5.3、为什么Map桶中超过8个才转为红黑树
- 链表长度>=8,且容量>=MIN_TREEIFY_CAPACITY(默认为64)时,链表转为红黑树
- 链表长度<=6时,红黑树转为链表
单个TreeNode需要占用的空间大约是普通Node的两倍。所以使用红黑树,就是用空间换时间。
泊松分布:
在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率
5.4、ConcurrentHashMap 和 Hashtable 的区别
- Hashtable
synchronized -锁整个Map
不允许在迭代期间修改内容
- ConcurrentHashMap
CAS + synchronized + Node-锁一个Node
允许在迭代期间修改内容
5.5、CopyOnWriteArrayList
5.5.1、适用场景
- 对读操作性能有要求,对写操作性能没要求;
- 读多写少。
5.5.2、特点
写入不会阻塞读取操作,可以在写入的同时读取。打破了读写锁读写互斥的限制
5.5.3、原理
- 在写入操作时,先复制一份容器的副本;
- 在副本中进行写操作,并行的读操作依然在原容器中进行;
- 修改完成后,将原容器的引用指向副本容器。
5.5.4、缺陷
- 占用内存,在写操作时,会同时存在两个对象占用内存;
- 容器元素较多时,复制开销大;
- 写入操作会先写入副本,对其他线程来说,数据不能保证可见性。
6、阻塞队列(BlockingQueue )
6.1、阻塞队列
特点:线程安全。
阻塞功能使得生产者和消费者两端的能力得以平衡,当有任何一端速度过快时,阻塞队列便会把过快的速度给降下来。(take()、put())
适用场景:常用于生产者-消费者模式
常用实现类:
ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、DelayQueue、PriorityBlockingQueue 和 LinkedTransferQueue
6.2、常用方法
抛出异常
add:往队列里添加一个元素,如果队列满了,抛出异常;
remove:删除元素,如果队列为空,抛出异常;
element:返回队列的头部节点,但不删除,如果队列为空,抛出异常。
返回结果但不抛出异常
offer:插入一个元素,插入成功返回true,插入失败(队列已满)返回false;
poll:移除并返回队列头节点,队列为空,则返回null;
peek:返回队列的头节点但不删除,队列为空,则返回null。
阻塞
put:插入一个元素,如果队列满了,则阻塞;
take:获取并移除队列头节点,如果队列为空,则阻塞。
6.3、常见的阻塞队列
- ArrayBlockingQueue
底层为数组,有界队列,利用ReentrantLock实现线程安全。可设置容量和是否公平。
- LinkedBlockingQueue
底层为链表,无界队列。
- SynchronousQueue
该队列容量为0,内部不存放任何数据吗,数据直接传递;
每次放数据都会阻塞,直到有消费者来取数据;
每次取数据都会阻塞,直到有生产者来存放数据。
- PriorityBlockingQueue
自定义排序(元素必须支持比较大小),支持优先级的无界阻塞队列。
自定义类实现compareTo()方法指定元素排序规则;
初始化算构造器参数comparator指定排序规则。
- DelayQueue
具有延迟功能的无界队列;
根据延迟时间的长度,决定元素在队列中的位置;
越靠近队列头的代表越早过期。
6.4、并发安全原理
- 阻塞队列(ArrayBoockingQueue为例)
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull; 读操作和写操作都需要获得lock独占锁才能进行下一步操作;
读操作时如果队列为空,线程就会进入到读线程专属的 notEmpty 的 Condition 的队列中去排队,等待写线程写入新的元素;
写操作时如果队列已满,此时写操作的线程会进入到写线程专属的 notFull 队列中去排队,等待读线程将队列元素移除并腾出空间。
- 非阻塞队列(ConcurrentLinkedQueue为例)
死循环 + 乐观锁
6.5、如何选择阻塞队列
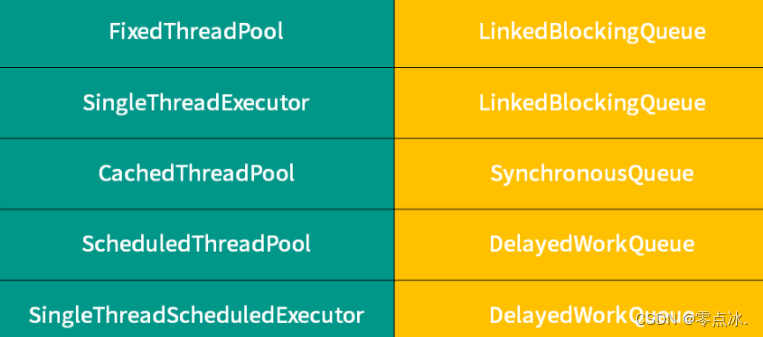
6.5.1、线程池对应的阻塞队列
根据线程池的容量和队列的容量来选择
6.5.2、如何选择
- 功能:排序、延迟等;
- 容量:容量固定、容量无限、容量为0;
- 能否扩容:考虑是否需要动态扩容;
- 内存结构:数组、链表;
- 性能:SynchronousQueue(直接传递,无需保存,性能高);LinkedBlockingQueue(两把锁)、ArrayBlockingQueue(一把锁),并发程度高时,LinkedBlockingQueue性能更好。
7、原子类
7.1、原子类如何利用CAS保证线程安全
7.1.1、原理
循环 + CAS; Unsafe 类是 CAS 的核心类。
CAS操作包括了3个操作数(多个操作,原子性由硬件层面保证):
需要读写的内存位置(V)
进行比较的预期值(A)
拟写入的新值(B)
CAS操作逻辑如下:如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
Unsafe类中的getAndAddInt方法:
public final int getAndAddInt(Object var1, long var2, int var4) {int var5;do {var5 = this.getIntVolatile(var1, var2);} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));return var5;
}7.1.2、原子类
- Atomic* 基本类型原子类
AtomicInteger、AtomicLong、AtomicBoolean
以AtomicInteger为例:
public final int get() //获取当前的值
public final int getAndIncrement() //获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值更新为输入值(update)- Atomic*Array 数组类型原子
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
数组里的元素,都可以保证原子性
- Atomic*Reference 引用类型原子
AtomicReference、AtomicStampedReference、AtomicMarkableReference
让一个对象保证原子性
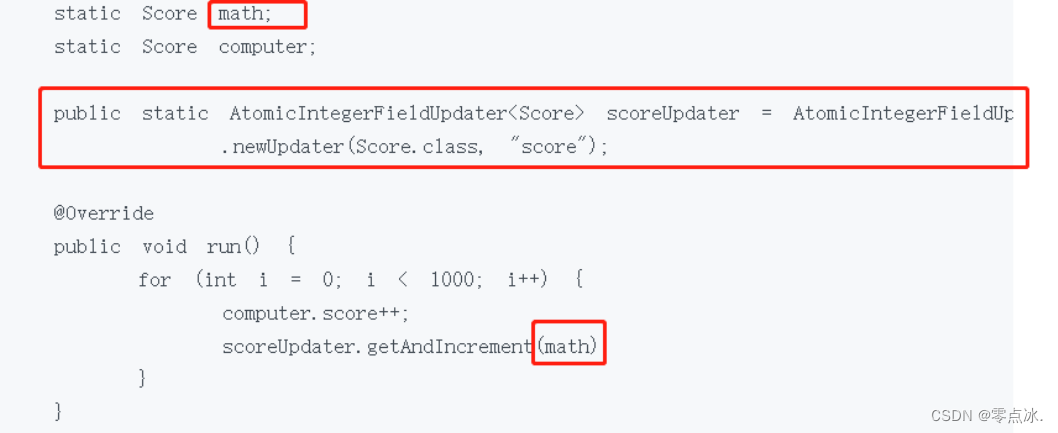
- Atomic*FieldUpdater 升级类型原子
AtomicIntegerfieldupdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater
把一个普通变量升级成原子类。
场景:
1、历史代码变量,已经被声明为普通变量并广泛应用,修改成本高,可升级成原子类保证线程安全;
2、每天大部分时间,该变量不需要保持原子性,只有在少数一两次操作时,需要保证原子性。(原子类比普通变量更耗费资源)
- Adder 累加器
LongAdder、DoubleAdder
- Accumulator 积累器
LongAccumulator、DoubleAccumulator
7.2、如何解决AtomicInteger在高并发下的性能问题
7.2.1、原因
高并发下,本地内存和共享内存间的数据同步会耗费大量资源。

7.2.2、解决方案
LongAdder:分段累加
内部有两个参数参与计数:第一个叫作 base,它是一个变量,第二个是 Cell[] ,是一个数组。
低并发时:base变量
可直接将累加结果修改到base变量上;
高并发时:Cell数组
LongAdder 会通过计算出每个线程的 hash 值来给线程分配到不同的 Cell 上去,每个 Cell 相当于是一个独立的计数器,这样一来就不会和其他的计数器干扰,Cell 之间并不存在竞争关系,所以在自加的过程中,就大大减少了刚才的 flush 和 refresh,以及降低了冲突的概率。
最后会执行 LongAdder.sum() ,把各个线程里的 Cell 累计求和,并加上 base,形成最终的总和。
7.2.3、适用场景
- LongAdder:场景仅仅是需要用到加和减操作的话。
- AtomicLong:需要利用 CAS 比如 compareAndSet 等复杂操作。
7.3、原子类和volatile
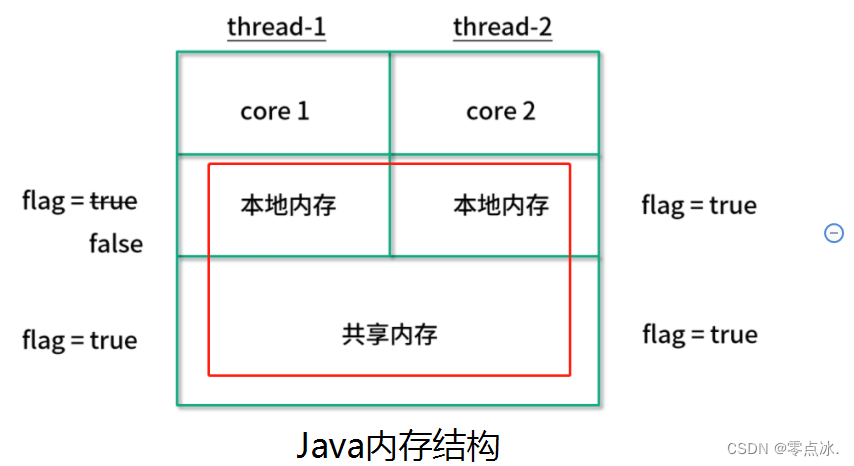
- volatile:保证变量可见性,变量每次修改会直接写入共享内存。
- 原子类:保证i++等复合操作的原子性。
- synchronized:既能保证原子性,也能保证可见性。
7.4、AtomicInteger 和 synchronized 的异同点?
- AtomicInteger:
CAS保证线程安全;
只能修饰一个对象;
性能:乐观锁,开销随着时间增加,逐步上涨。
- synchronized:
monitor 锁保证线程安全;
可以锁方法或代码块;
性能:悲观锁,开销固定。JDK6之后的锁升级会提升性能。
7.5、Java 8 中 Adder 和 Accumulator 有什么区别?
- Adder:
分段锁(降低冲突)。base(低并发),Cell[]数组(高并发)。
在高并发下 LongAdder 比 AtomicLong 效率更高
- Accumulator:
Accumulator 就是一个更通用版本的 Adder。
LongAdder 的 API 只有对数值的加减,而 LongAccumulator 提供了自定义的函数操作。
8、ThreadLocal
8.1、适用场景
用作保存每个线程独享的对象,为每个线程都创建一个副本。
每个线程需要独立保存信息,以便当前线程内其他方法使用。类似于线程内的全局变量。
省去一步步传参的步骤。
示例:simpleDateFormat对象;
1000个线程,共享一个simpleDateFormat对象------不安全。
1000个线程,每个线程创建一个simpleDateFormat 对象------占用内存大,性能低;
线程池,容量为16,设置simpleDateFormat为每个线程的ThreadLocal变量,一共就16个simpleDateFormat对象。8.2、ThreadLocal是用来解决共享资源的多线程访问问题吗?
不是。ThreadLocal存储的对象是线程独享的,不是共享资源。
注意:当放入ThreadLocal中的对象是static修饰的,那么ThreadLocal并不能解决线程安全问题。
ThreadLocal 是通过让每个线程独享自己的副本,避免了资源的竞争。
synchronized 主要用于临界资源的分配,在同一时刻限制最多只有一个线程能访问该资源。
8.3、多个ThreadLocal在Thread的threadlocals里是如何存储的?
Thread>ThreadLocalMap>ThreadLocal
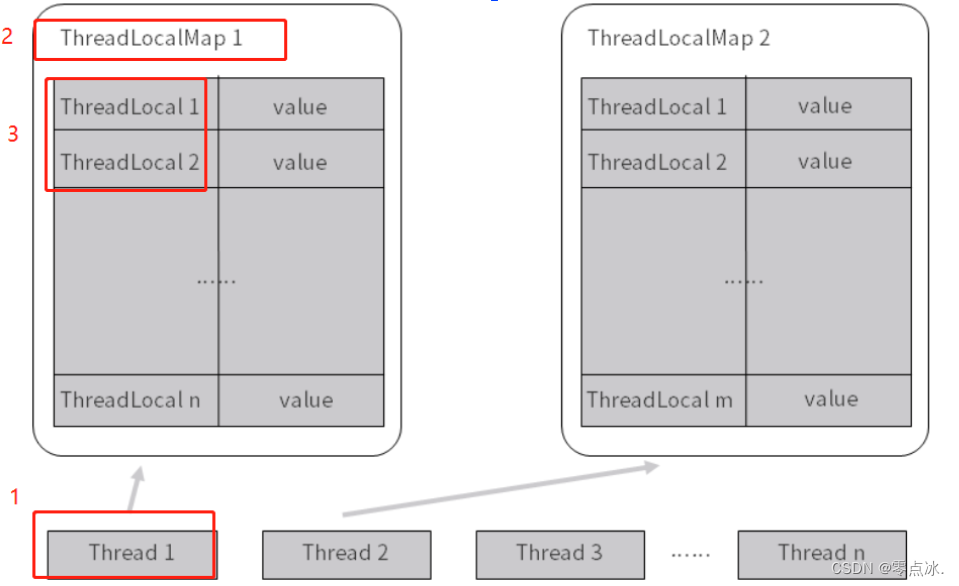
一个 Thread 里面只有一个ThreadLocalMap ,而在一个 ThreadLocalMap 里面却可以有很多的 ThreadLocal,每一个 ThreadLocal 都对应一个 value。
如果在一个想在Thread中保存多个ThreadLocal对象,那么直接new多个ThreadLocal存储对象即可。
ThreadLocal threadLocal1 = new ThreadLocal();
threadLocal1.set("string1");
ThreadLocal threadLocal2 = new ThreadLocal();
threadLocal2.set("string2");8.4、内存泄露
8.4.1、key的内存泄露:
ThreadLocalMap里的Entry中的key是弱引用。
如果在Entry中强引用了ThreadLocal,尽管执行 ThreadLocal instance = null,
根据可达性分析算法,该ThreadLocal对象仍然是可达的,就不会被回收。
8.4.2、value的内存泄露:
正常情况下,当线程终止,key 所对应的 value 是可以被正常垃圾回收的,因为没有任何强引用存在了。但是有时线程的生命周期是很长的,如果线程迟迟不会终止,那么可能 ThreadLocal 以及它所对应的 value 早就不再有用了。在这种情况下,我们应该保证它们都能够被正常的回收。
8.4.3、避免内存泄露:
调用 ThreadLocal 的 remove 方法。调用这个方法就可以删除对应的 value 对象,可以避免内存泄漏。
以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。
相关文章:
并发编程-学习总结(上)
目录 1、线程基础 1.1、线程实现方法 1.2、如何正确停止线程 1.3、Java线程的六种状态 1.4、wait/notify/notifyAll注意事项 1.4.1、为什么 wait 、notify、notifyAll必须在 synchronized 保护的同步代码中使用? 1.4.2、为什么 wait/notify/notifyAll 被定义…...
QT之OpenGL混合
QT之OpenGL混合1. 概述2. 实现2.1 丢弃片段2.1.1 Demo2.2 混合2.2.1 相关函数2.2.2 排序问题2.2.3 Demo1. 概述 OpenGL中,混合(Blending)通常是实现物体透明度(Transparency)的一种技术。 2. 实现 2.1 丢弃片段 在某些情况下,有些片段是只需要设置显…...

【1255. 得分最高的单词集合】
来源:力扣(LeetCode) 描述: 你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。 请你帮忙计算玩家在单词拼写游戏中所能获…...

nginx模块介绍
新编译前,在对应的nginx原编译文件夹 如:nginx-1.23.0 下,要 make clean 清空以前编译的objs文件夹,实际上就是执行了rm objs文件夹。 很多要用到git,先yum install git -y echo-nginx-module 让nginx直接使用echo的…...
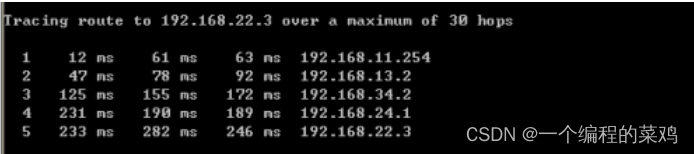
排错工具ping和trace(电子科技大学TCP/IP实验四)
一.实验目的 1、了解网络连通性测试的方法和工作原理 2、了解网络路径跟踪的方法和工作原理 3、掌握 MTU 的概念和 IP 分片操作 4、掌握 IP 分组生存时间(TTL)的含义和作用 5、掌握路由表的作用和路由查找算法 二.预备知识 …...

node.js中ws模块创建服务端和客户端
一、WebSocket出现的原因 1、Http协议发布REST API 的不足: 每次请求响应完成之后,服务器与客户端之间的连接就断开了,如果客户端想要继续获取服务器的消息,必须再次向服务器发起请 求。这显然无法适应对实时通信有高要求的场景…...

kubernates-1.26.1 kubeadm containerd 单机部署
k8s1.26 kubeadm containerd 安装 kubeadm init 时提示 containerd 错误 failed to pull image “k8s.gcr.io/pause:3.6” 报错日志显示containerd pull时找不到对应的pause版本,而不是registry.k8s.io/pause:3.9 [rootk8s-master containerd]# kubeadm init --k…...
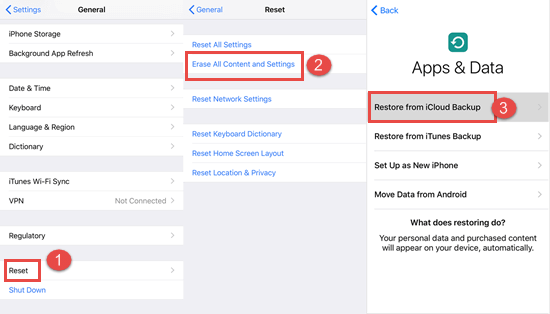
如何在 iPhone 上恢复已删除的通话记录/通话记录
您的通话记录/通话记录可能很重要,尤其是当您想要拨打之前联系过但未保存的号码时。如果您碰巧删除了通话记录(有意或无意),本指南将帮助您了解如何检索它们并找回您需要使用的所有记录。我们将根据您的情况和您拥有的工具讨论不同…...
Canonical为所有支持的Ubuntu LTS系统发布了新的Linux内核更新
导读Canonical近日为所有支持的Ubuntu LTS系统发布了新的Linux内核更新,以解决总共19个安全漏洞。新的Ubuntu内核更新仅适用于长期支持的Ubuntu系统,包括Ubuntu 22.04 LTS(Jammy Jellyfish)、Ubuntu 20.04 LTS(Focal F…...
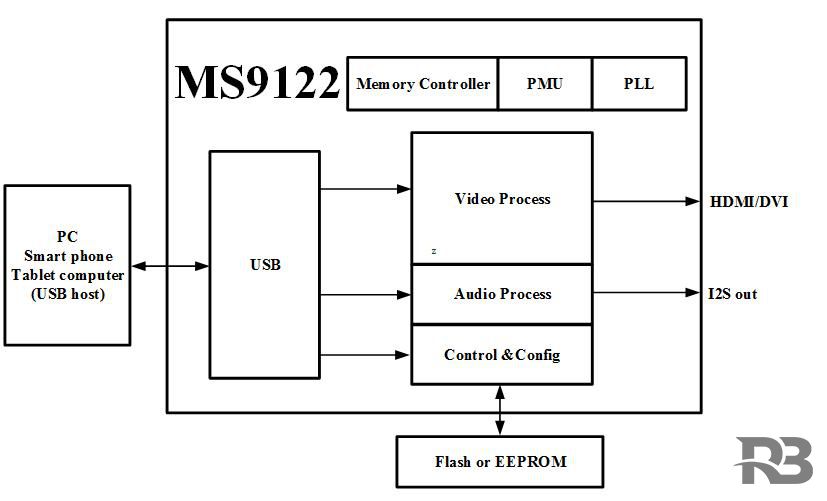
MS9122是一款USB单芯片投屏器,内部集成了USB2 0 控制器和数据收发模块、HDMI 数据接口和音视频处理模块。MS9122可以通过USB接口显示
MS9122是一款USB单芯片投屏器,内部集成了USB2.0 控制器和数据收发模块、HDMI 数据接口和音视频处理模块。MS9122可以通过USB接口显示或者扩展PC、智能手机、平板电脑的显示信息到更大尺寸的显示设备,支持HDMI视频接口。 主要功能特征 HDMI v1.4兼容 最大…...

C++学习笔记-数据抽象
简单的说,数据抽象是用来描述数据结构的。数据抽象就是 ADT。一个 ADT 主要表现为它支持的一些操作,比方说 stack.push、stack.pop,这些操作应该具有明确的时间和空间复杂度。另外,一个 ADT 可以隐藏其实现细节,比方说…...

【Android】Android开发笔记(一)
【Android】Android开发笔记(一) 在Android Studio中import module和delete moduleimport moduledelete moduleAndroid Studio中App(Module)无法正常运行在实机上测试App一些基本概念App的工程结构结语在Android Studio中import m…...

C语言数据结构(二)—— 受限线性表 【栈(Stack)、队列(Queue)】
在数据结构逻辑层次上细分,线性表可分为一般线性表和受限线性表。一般线性表也就是我们通常所说的“线性表”,可以自由的删除或添加结点。受限线性表主要包括栈和队列,受限表示对结点的操作受限制。一般线性表详解,请参考文章&…...
线程安全之synchronized和volatile
目录 1.线程不安全的原因 2.synchronized和volatile 2.1 synchronized 2.1.1 synchornized的特性 2.1.2 synchronized使用示例 2.2 volatile 我们先来看一段代码: 分析以上代码,t1和t2这两个线程的任务都是分别将count这个变量自增5000次ÿ…...

量子计算对网络安全的影响
量子计算的快速发展,例如 IBM 的 Quantum Condor 处理器具有 1000 个量子比特的容量,促使专家们宣称第四次工业革命即将实现“量子飞跃”。 量子计算机的指数处理能力已经受到政府和企业的欢迎。 由于从学术和物理原理到商业可用解决方案的不断转变&am…...
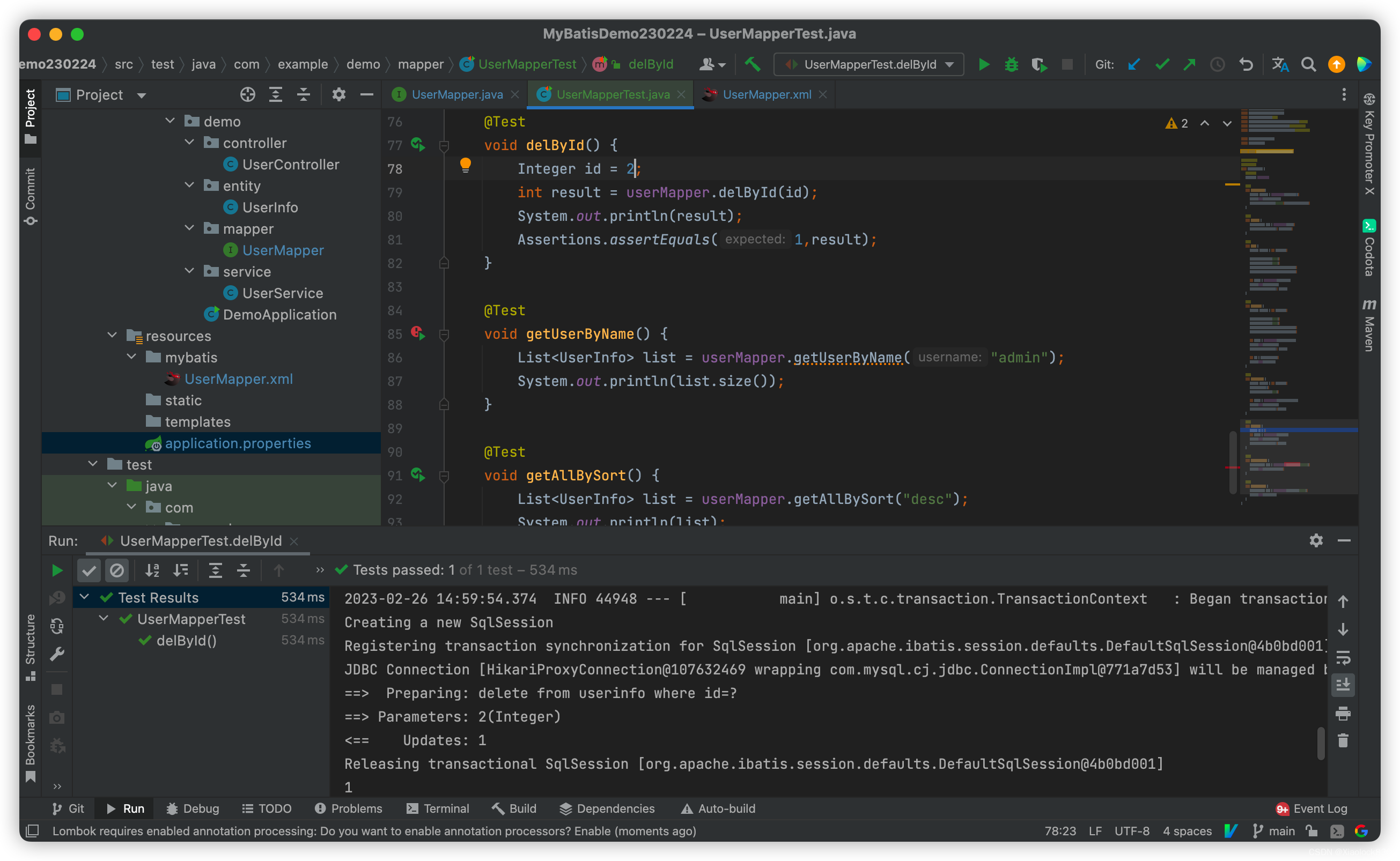
MyBatis——增删改查操作的实现
开启mybatis sql日志打印 可以在日志中看到sql中执行的语句 在配置文件中加上下面这几条语句 mybatis.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl logging.level.com.example.demodebug查询操作 根据用户id查询用户 UserMapper: User…...
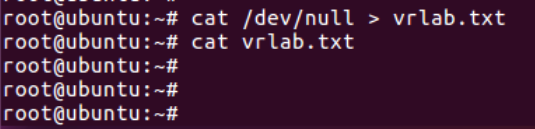
【7】linux命令每日分享——cat查看文件内容
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...

新氧2023年财务业绩预测:退市风险大幅降低,收入增长将放缓
来源:猛兽财经 作者:猛兽财经 公司进展 与新氧(SY)有关的两个重要积极进展值得一提。 第一个积极进展是新氧的退市风险已在很大程度上降低。 2023年1月6日,新氧披露,它已经“重新符合纳斯达克规定的股价每…...

C++使用shared_ptr与weak_ptr轻松管理内存
智能指针之shared_ptr与weak_ptr前言智能指针实例分析前言 C与其他语言的不同点之一就是可以直接操作内存,这是一把双刃剑,直接操作内存可以提高开发的灵活度,开发人员在合适的时机申请内存,在合适的时机释放内存,减少…...

Buuctf reverse [FlareOn4]IgniteMe 题解
一. 查壳 无壳32位程序 二. ida打开 GetStdHandle函数根据微软官方文档可以得知是获取标准输入/输出/错误的句柄 参数里的 0xFFFFFFF6转换一下是4294967286, 对应(DWORD) -10 所以这里的WriteFile函数实际上是实现了printf的功能 sub_4010F0()函数 其功能是通过ReadFile函数读取…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

ubuntu中安装conda的后遗症
缘由: 在编译rk3588的sdk时,遇到编译buildroot失败,提示如下: 提示缺失expect,但是实测相关工具是在的,如下显示: 然后查找借助各个ai工具,重新安装相关的工具,依然无解。 解决&am…...