大数据NiFi(二十):实时同步MySQL数据到Hive

文章目录
实时同步MySQL数据到Hive
一、开启MySQL的binlog日志
1、登录mysql查看MySQL是否开启binlog日志
2 、开启mysql binlog日志
3、重启mysql 服务,重新查看binlog日志情况
二、配置“CaptureChangeMySQL”处理器
1、创建“CaptureChangeMySQL”处理器
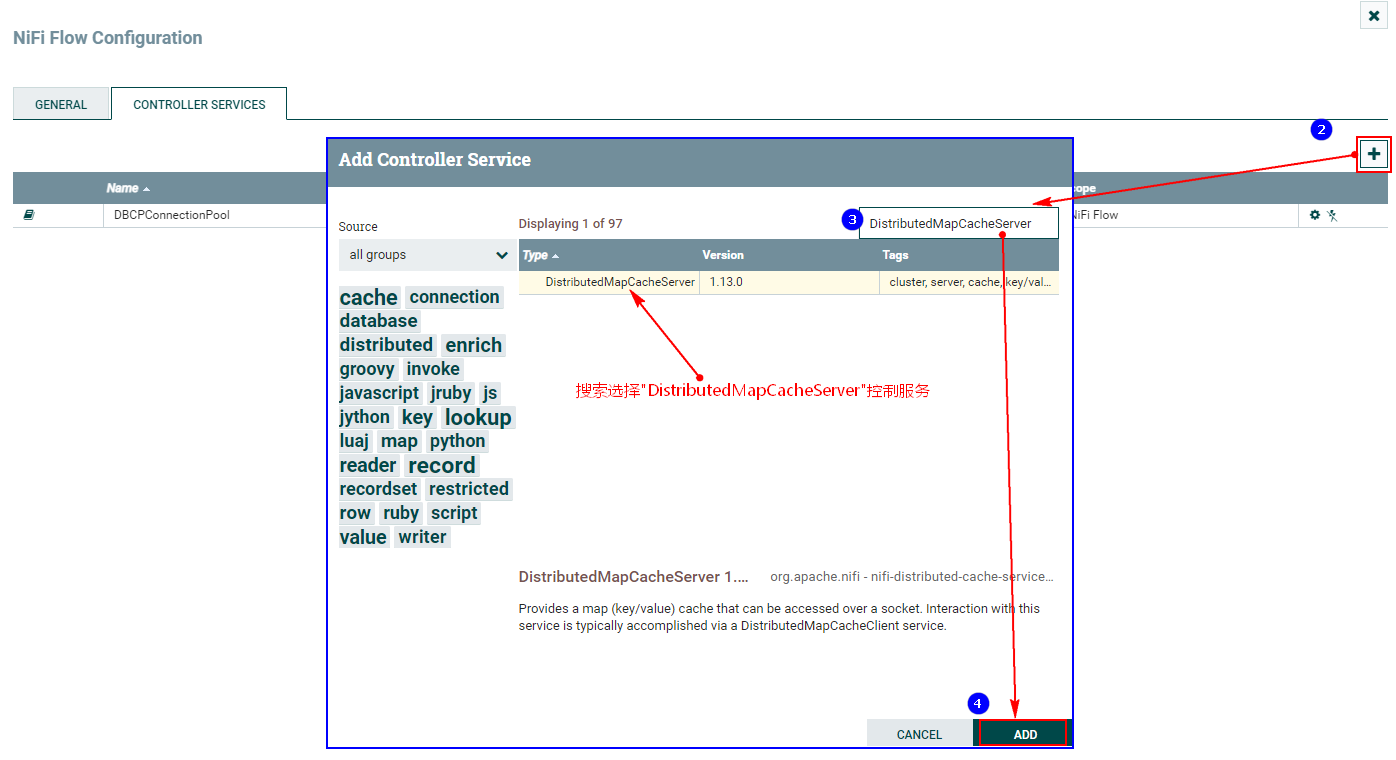
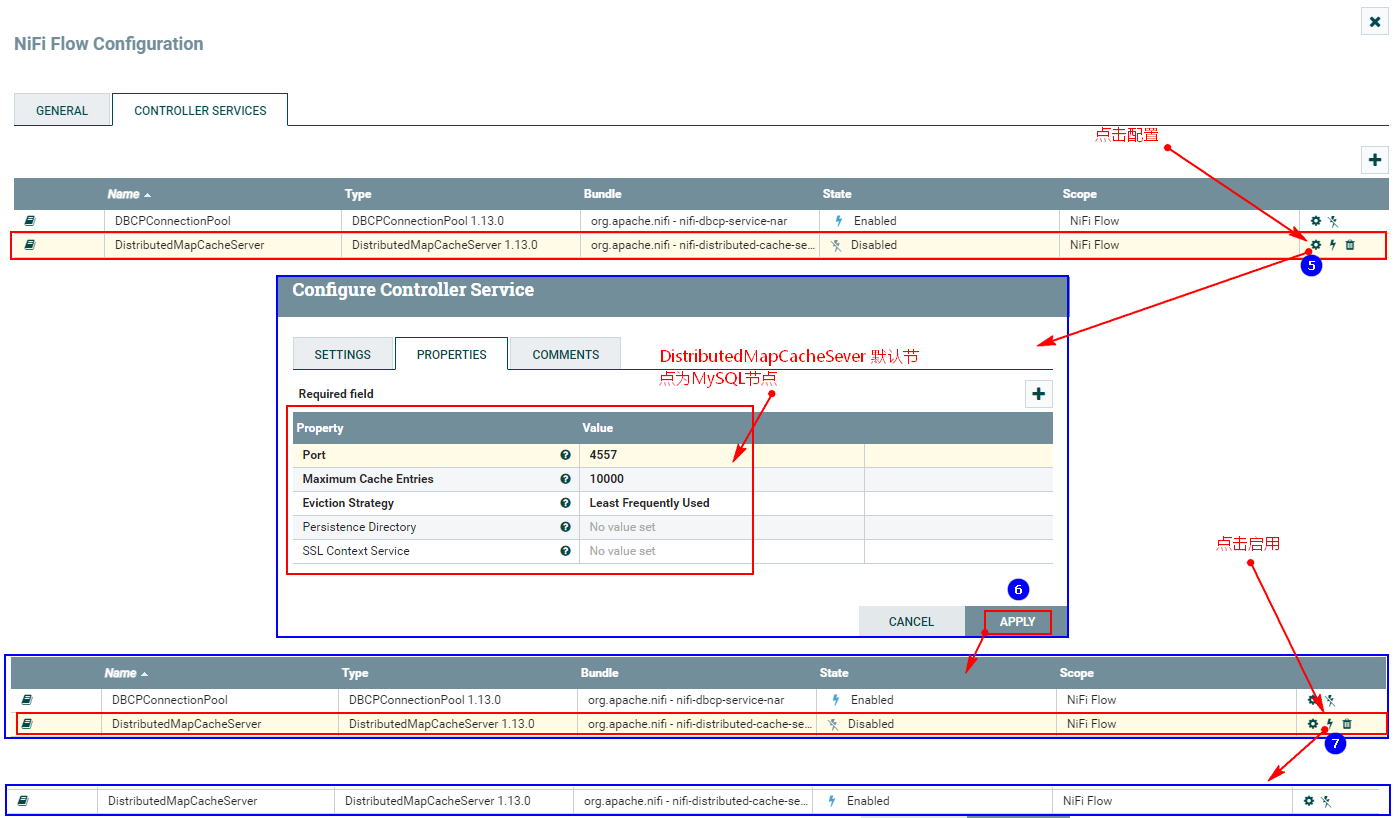
2、配置“DistributeMapCacheServer”控制服务
3、配置“SCHEDULING”
4、配置“PROPERTIES”
5、启动MySQL,创建表“test2”测试“CaptureChangeMySQL”处理器
三、配置“RouteOnAttribute”处理器
1、创建“RouteOnAttribute”处理器
2、配置“PROPERTIES”自定义属性
3、连接“CaptureChangeMySQL”处理器与“RouteOnAttribute”处理器
四、配置“EvaluatejsonPath”处理器
1、配置“EvaluatejsonPath”的“PROPERTIES”属性
2、连接“RouteOnAttribute”处理器和“EvaluatejsonPath”处理器
五、配置“ReplaceText”处理器
1、配置“RelaceText”处理器“PROPERTIES”属性
2、连接“EvaluatejsonPath”处理器与“ReplaceText”处理器
六、配置Hive 支持HiveServer2
1、在Hive服务端配置hive-site.xml
2、在每台Hadoop 节点配置core-site.xml
3、重启HDFS ,Hive ,在Hive服务端启动Metastore和HiveServer2服务
4、在客户端通过beeline连接Hive
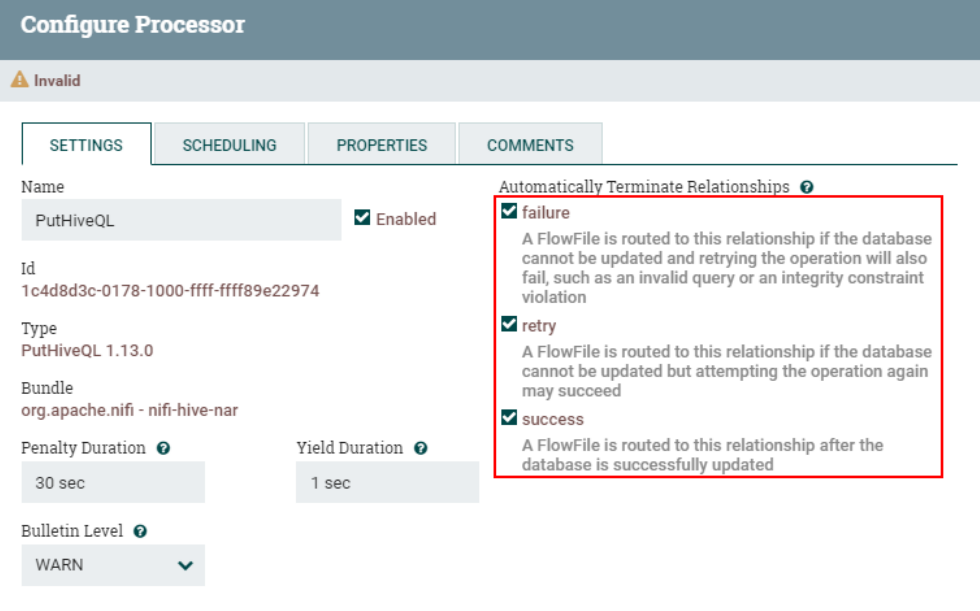
七、配置“PutHiveQL”处理器
1、创建“PutHiveQL”处理器
2、 配置“PROPERTIES”
3、连接“ReplaceText”处理器与“PutHiveQL”处理器并设置关系
八、运行测试
1、在Hive中创建表“test2”
2、启动NiFi处理数据流程,向MySQL中写入数据,查看Hive中表数据
实时同步MySQL数据到Hive
案例:将mysql中新增的数据实时同步到Hive中。
以上案例需要用到的处理器有:“CaptureChangeMySQL”、“RouteOnAttribute”、“EvaluateJsonPath”、“ReplaceText”、“PutHiveQL”。
首先通过“CaptureChangeMySQL”读取MySQL中数据的变化(需要开启MySQL binlog日志),将Binlog中变化的数据同步到“RouteOnAttribute”处理器,通过此处理器获取上游数据属性,获取对应binlog操作类型,再将想要处理的数据路由到“EvaluateJsonPath”处理器,该处理器可以将json格式的binlog数据解析,通过自定义json 表达式获取json数据中的属性放入FlowFile属性,将FlowFile通过“ReplaceText”处理器获取上游FowFile属性,动态拼接sql替换所有的FlowFile内容,将拼接好的sql组成FlowFile路由到“PutHiveQL”将数据写入到Hive表。
一、开启MySQL的binlog日志
mysql-binlog是MySQL数据库的二进制日志,记录了所有的DDL和DML(除了数据查询语句)语句信息。一般来说开启二进制日志大概会有1%的性能损耗。这里需要开启MySQL的binlog日志方便后期使用“CaptureChangeMySQL”处理器来获取MySQL中的CDC事件。MySQL的版本最好是5.7版本之上。
1、登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';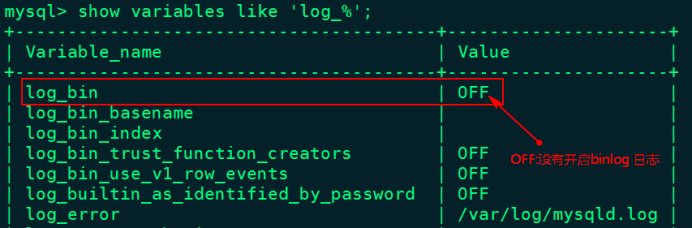
2 、开启mysql binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
#随机指定一个不能和其他集群中机器重名的字符串
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin3、重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';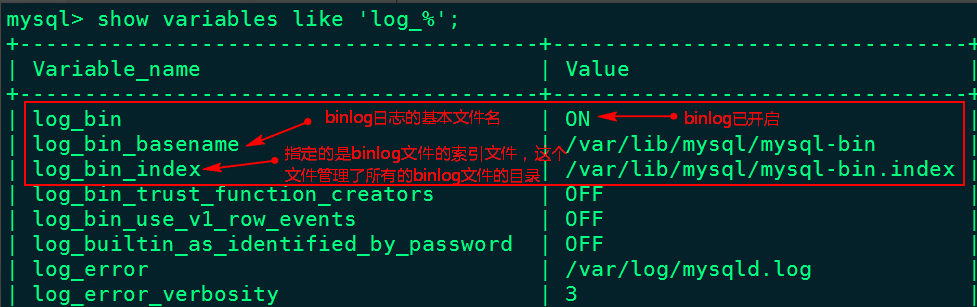
二、配置“CaptureChangeMySQL”处理器
“CaptureChangeMySQL”主要是从MySQL数据库捕获CDC(Change Data Capture)事件。CDC事件包括INSERT,UPDATE,DELETE操作,事件按操作发生时的顺序输出为单独的FlowFile文件。
关于“CaptureChangeMySQL”处理器的“Properties”主要配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
| MySQL Hosts (MySQL 节点) | MySQL集群节点相对应的主机名/端口项的列表。多个节点使用逗号分隔,格式为:host1:port、host2:port…,处理器将尝试按顺序连接到列表中的主机。如果一个节点关闭,并且群集启用了故障转移,那么处理器将连接到活动节点。 | ||
| MySQL Driver Class Name (MySQL驱动名称) | com.mysql.jdbc.Driver | MySQL数据库驱动程序类的类名。 | |
| MySQL Driver Location(s) (MySQL驱动的位置) | 包含MySQL驱动程序包及其依赖项的文件/文件夹和/或url的逗号分隔列表(如果有),例如"/var/tmp/mysql-connector-java-5.1.38-bin.jar文件"。 | ||
| Username (用户名) | 访问MySQL集群的用户名。 | ||
| Password (密码) | 访问MySQL集群的密码。 | ||
| Database/Schema Name Pattern (匹配数据库/Schema) | 用于根据CDC事件列表匹配数据库(或模式,具体取决于RDBMS类型)的正则表达式。正则表达式必须与存储在RDBMS中的数据库名称匹配。如果未设置属性,则数据库名称将不会用于筛选CDC事件。 | ||
| Table Name Pattern (匹配表) | 用于匹配影响匹配表的CDC事件的正则表达式(regex)。regex必须与存储在数据库中的表名匹配。如果未设置属性,则不会根据表名筛选任何事件。 | ||
| Max Wait Time (最大连接等待时长) | 30 seconds | 允许建立连接的最长时间,零表示实际上没有限制。 | |
| Distributed Map Cache Client (分布式缓存客户端) | 指定用于保存处理器所需的各种表、列等信息的分布式映射缓存客户端控制器服务。如果未指定,则生成的事件将不包括列类型或名称等信息。 | ||
| Retrieve All Records (检索所有记录) | true | ▪true ▪false | 指定是否获取所有可用的CDC事件,而不考虑当前的binlog文件名或位置。 如果处理器状态中存在binlog文件名和位置值,则忽略此属性的值。 这允许4种不同的配置: 1).如果处理器State中存在binlog数据,则State用来确定开始位置,并忽略Retrieve All Records的值。(目前NiFi版本测试有问题) 2).如果处理器State中不存在binlog数据,此值设置为true意味着从头开始读取Binlog 数据。 3).如果处理器State中不存在binlog数据,并且没有指定binlog文件名和位置,此值设置为false意味着从binlog尾部开始读取数据。 4).如果处理器State中不存在binlog数据,并指定binlog文件名和位置,此值设置为false意味着从指定binlog尾部开始读取数据。 |
| Include Begin/Commit Events (包含开始/提交事件) | false | ▪true ▪false | 指定是否发出与二进制日志中的开始或提交事件相对应的事件。如果下游流中需要开始/提交事件,则设置为true,否则设置为false,这将抑制这些事件的生成并可以提高流性能。 |
| Include DDL Events (标准表/列名) | false | ▪true ▪false | 指定是否发出与数据定义语言(DDL)事件对应的事件,如ALTER TABLE、TRUNCATE TABLE。如果下游流中需要DDL事件,则设置为true,否则设置为false。为false时这将抑制这些事件的生成,并可以提高流性能。 |
配置步骤如下:
1、创建“CaptureChangeMySQL”处理器
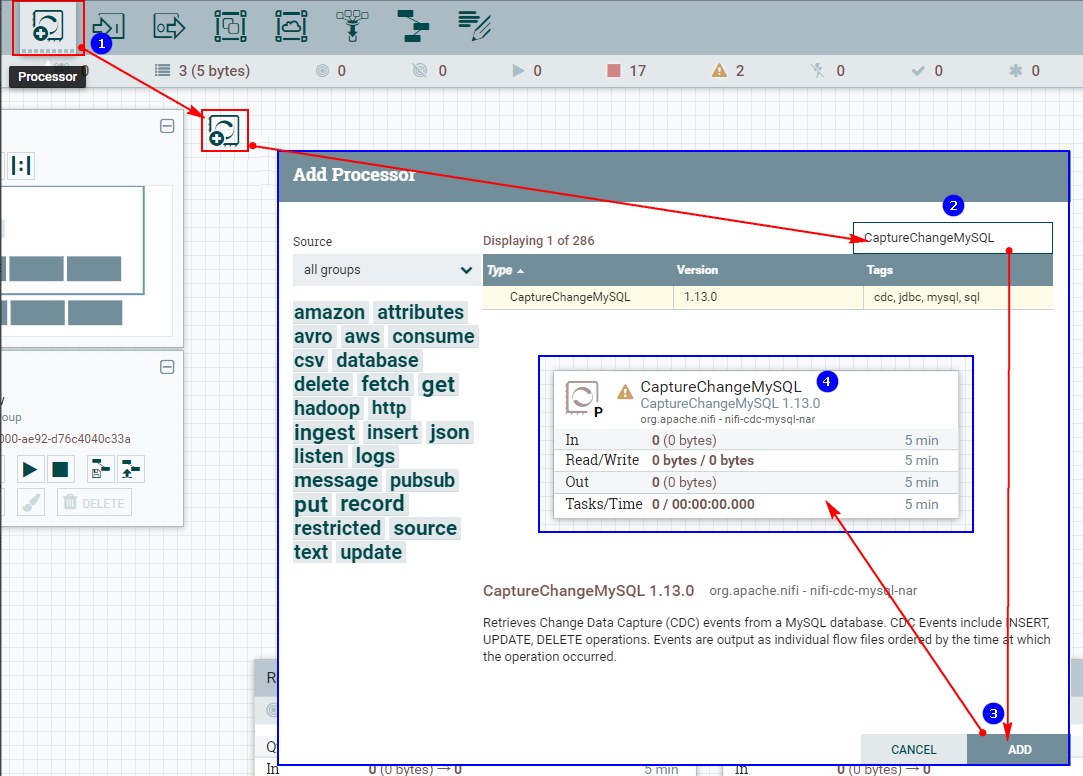
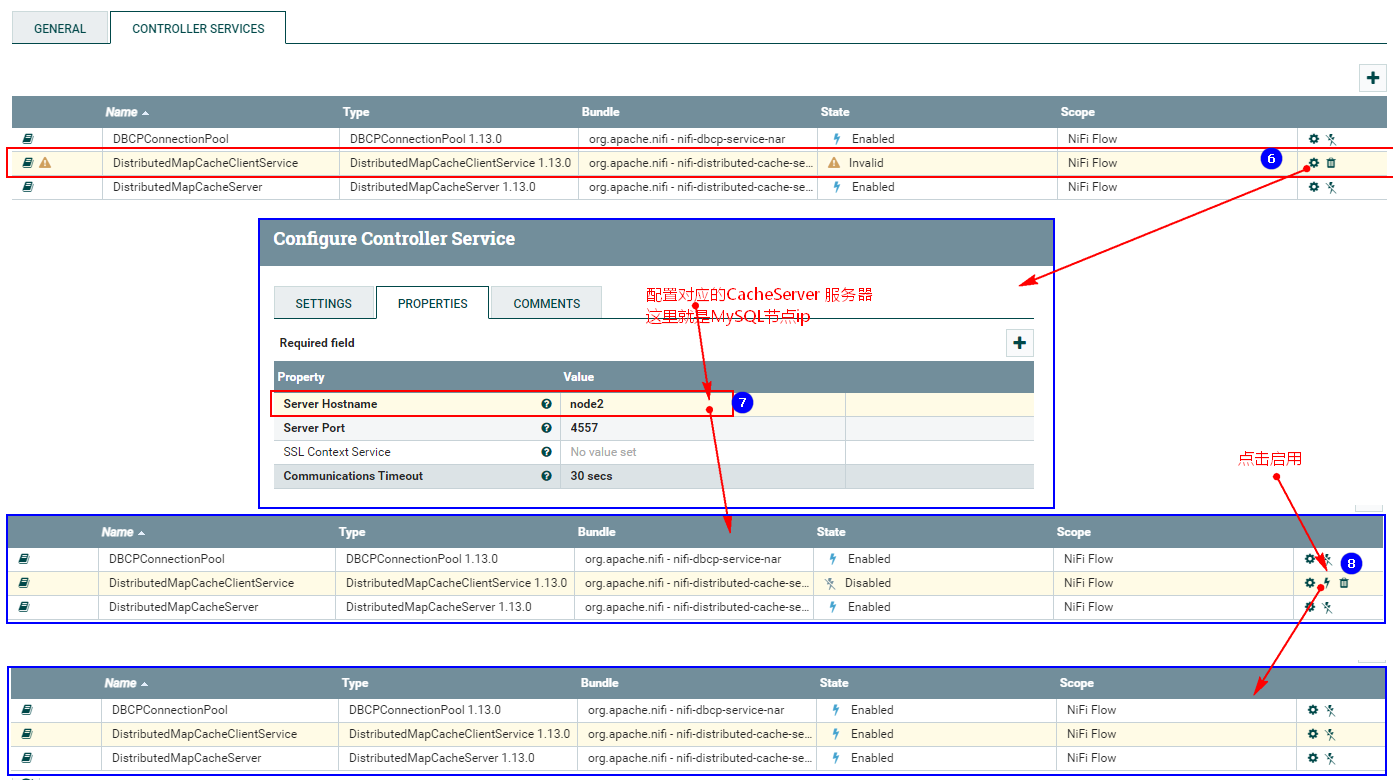
2、配置“DistributeMapCacheServer”控制服务
监控mysql变化需要设置“DistributedMapCacheClient”控制服务,其对应的Server中存储处理器所需的各种表、列等信息,所以这里需要首先配置“DistributeMapCacheServer”控制服务。
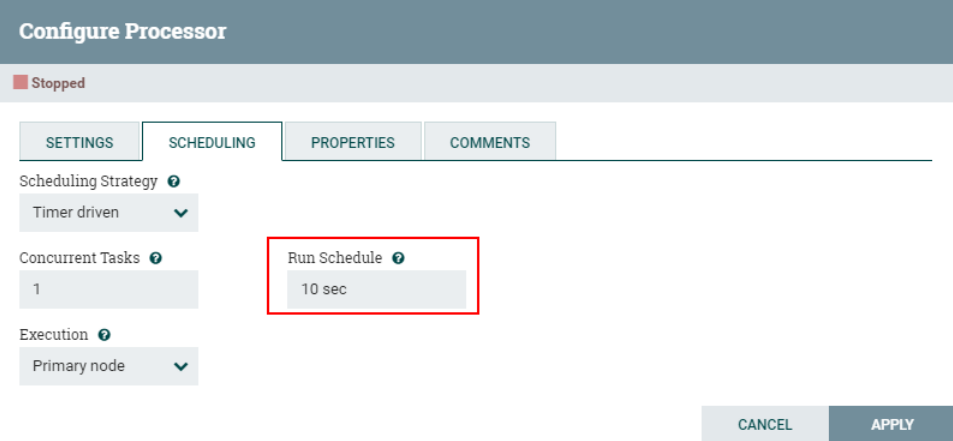
3、配置“SCHEDULING”
由于这里使用“CaptureChangeMySQL”处理器监控“MySQL”中的数据,所以设置调度访问周期为“10s”,防止一直监听MySQL binlog数据,带来性能消耗。
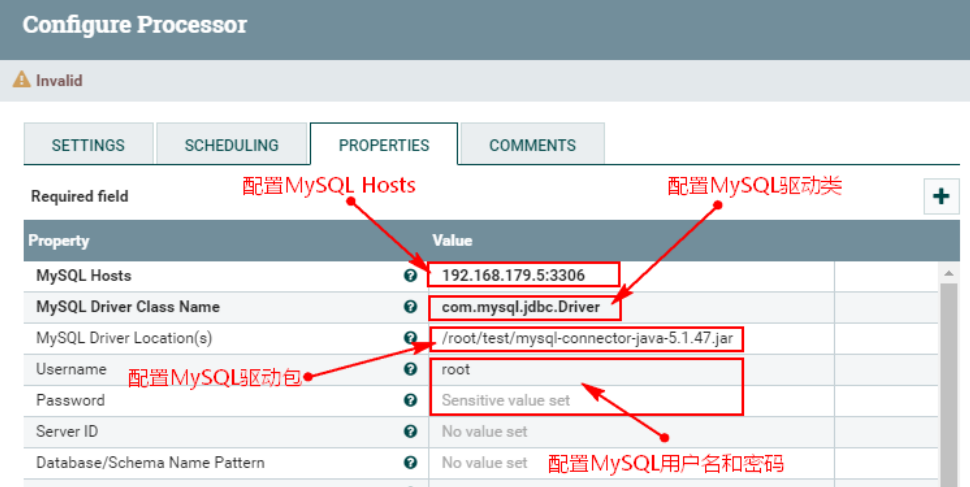
4、配置“PROPERTIES”
在“CaptureChangeMySQL”处理器中配置“PROPERTIES”,配置如下:
- MySQL Host : 192.168.179.5:3306
- MySQL Driver Class Name:com.mysql.jdbc.Driver
- MySQL Driver Location(s):/root/test/mysql-connector-java-5.1.47.jar
注意:这里需要在每台NiFi节点上创建对应目录,上传mysql驱动包。
https://download.csdn.net/download/xiaoweite1/87490406
“PROPERTIES”配置如下:
此外,在“PROPERTIES”中还需要配置“Distributed Map Cache Client”控制服务,来读取“DistributeMapCacheServer”控制服务中的缓存数据:
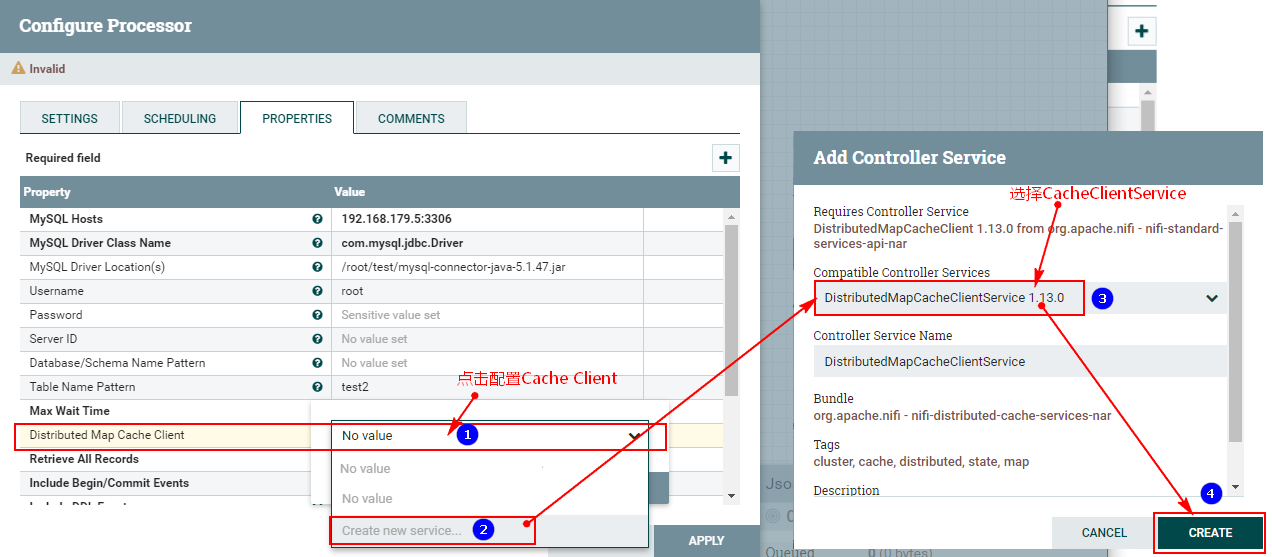
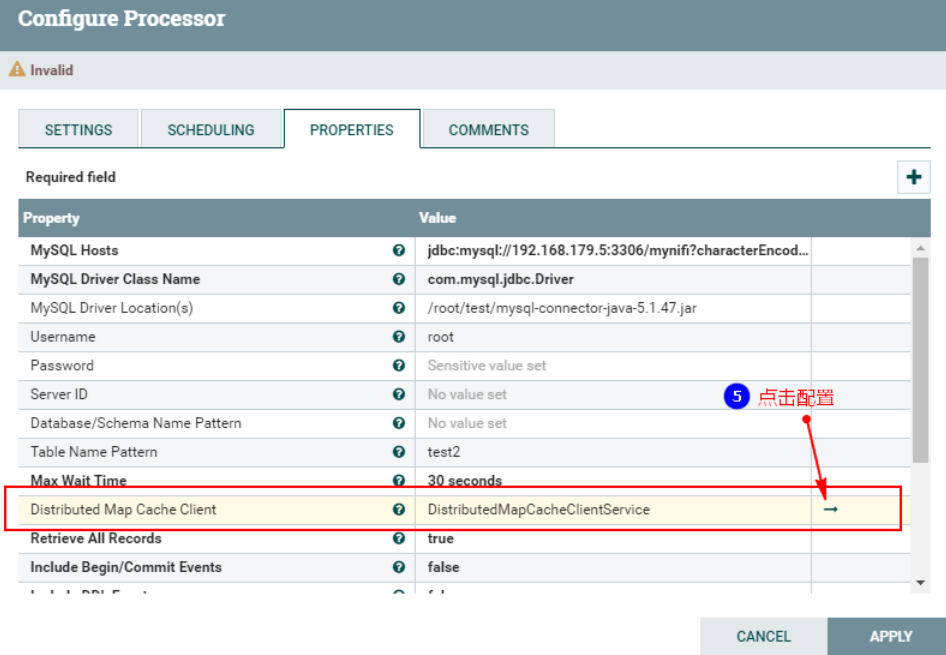
另外,这里我们只是监控表“test2”对应的CDC事件,这里设置匹配表名为“test2”,最终“PROPERTIES”的配置如下:
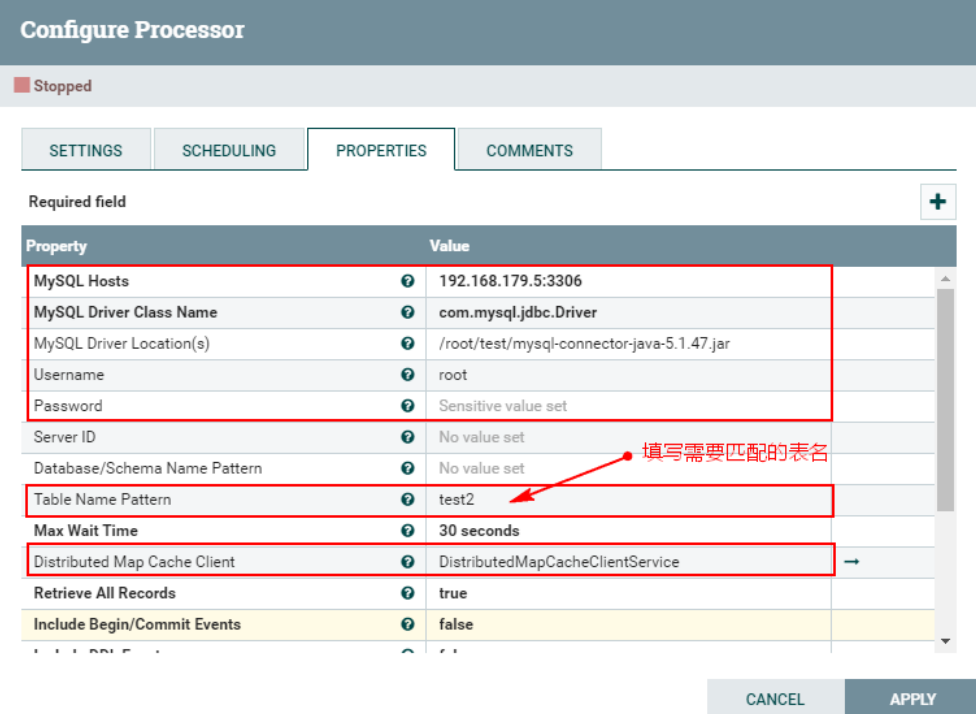
注意:以上“Table Name Pattern”这里配置对应的Value值为:test2,也可以不配置,不配置会监控所有MySQL表的变化对应的binlog事件。当后面向Hive表中插入新增和更新数据时,对应MySQL中的元数据表也会变化,也会监控到对应的binlog事件。为了避免后期出现监控到其他表的binlog日志,这里建议配置上“test2”。
5、启动MySQL,创建表“test2”测试“CaptureChangeMySQL”处理器
登录mysql ,使用“mynifi”库,创建表“test2”。暂时设置“CaptureChangeMySQL”处理器“success”事件自动终止并启动,向表中插入对应的数据查看“CaptureChangeMySQL”处理器能否正常监控事件。
在mysql中创建对应的表:
use mynifi;
create table test2 (id int,name varchar(255),age int);启动“CaptureChangeMySQL”处理器:
向表“test2”中插入以下数据:
insert into test2 values (1,"zs",18);
update test2 set name = "ls" where id = 1;
delete from test2 where id = 1;可以在“CaptureChangeMySQL”处理器中右键“View data provenance”查看捕获到的“insert”、“update”、“delete”事件:
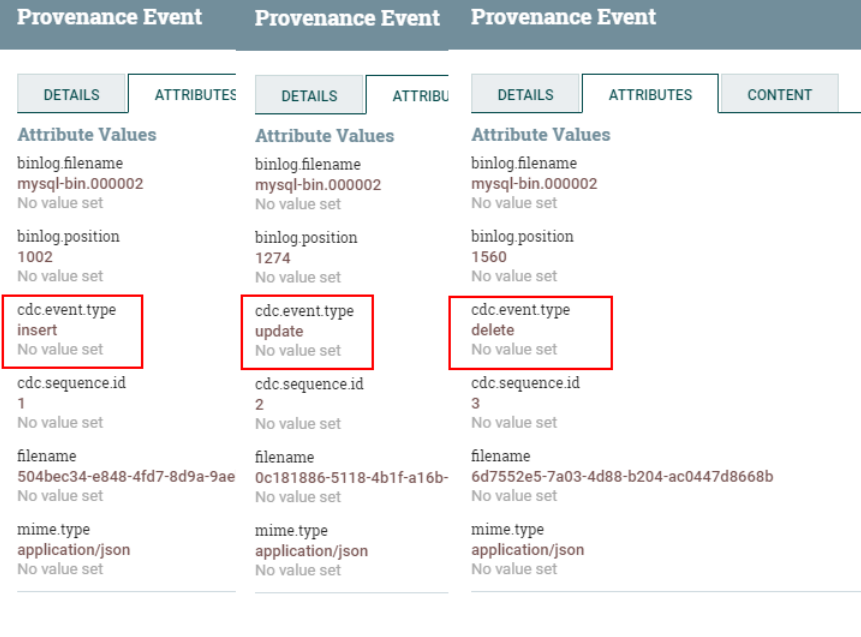
注意问题:在配置好“CaptureChangeMySQL”处理器启动后,当MySQL中有数据插入、修改、删除时当前处理器会读取MySql binlog日志,并在当前处理器中记录读取binlog的位置状态。正常来说这里关闭“CaptureChangeMySQL”处理器后再次启动,会接着保存的binlog位置继续读取(可以参照“PROPERTIES”属性中“Retrieve All Records”配置说明),但是经过测试,此NiFi版本出现以下错误(无效的binlog位置,目测是一个版本bug错误):
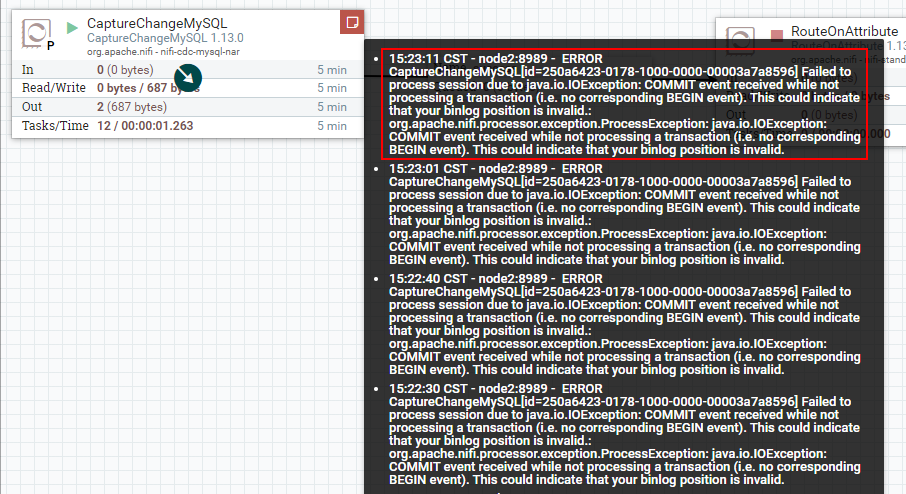
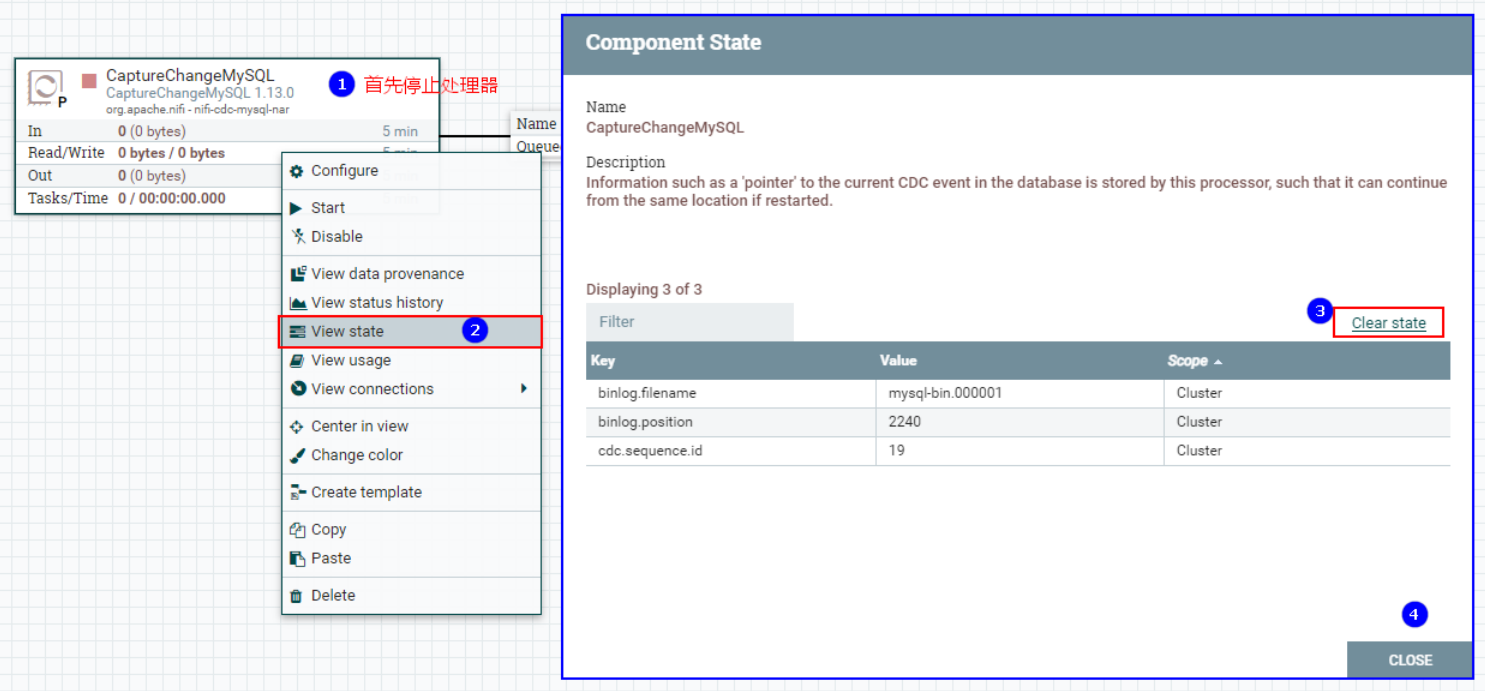
所以在之后的测试中,我们可以将“CaptureChangeMysql”处理器读取binlog的状态清空,然后再次启动即可,这里会重复读取MySQL之前已经检测到的新增、修改、删除数据。
清空“CaptureChangeMysql”读取binlog状态:
三、配置“RouteOnAttribute”处理器
“RouteOnAttribute”是根据FlowFile的属性使用属性表达式进行数据路由。
关于“RouteOnAttribute”处理器的“Properties”主要配置的说明如下:
| 配置项 | 默认值 | 描述 |
| Routing Strategy(路由策略) | Route to Property name | 指定在计算表达式语言时如何使用哪个关系。 有如下几个关系可选择: ▪Route to Property name FlowFile的副本将被路由到对应的表达式计算结果为'true'的每个关系。 ▪Route to 'matched' if all match 要求所有用户定义的表达式求值都为'true',才认为FlowFile是匹配的。 ▪Route to 'matched' if any matches 至少有一个用户定义的表达式求值为'true',才能认为FlowFile是匹配的。 |
注意:该处理器允许用户自定义属性并指定该属性的匹配表达式。属性与动态属性指定的属性表达式相匹配的FileFlow,映射到动态属性上。
配置如下:
1、创建“RouteOnAttribute”处理器
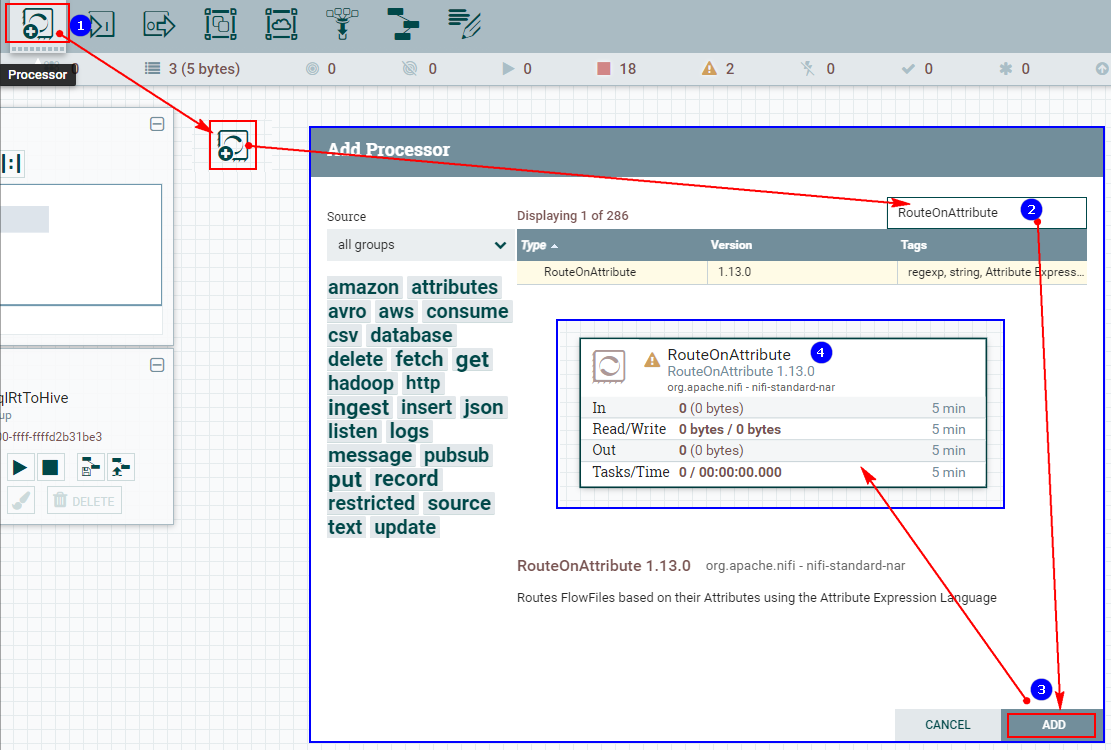
2、配置“PROPERTIES”自定义属性
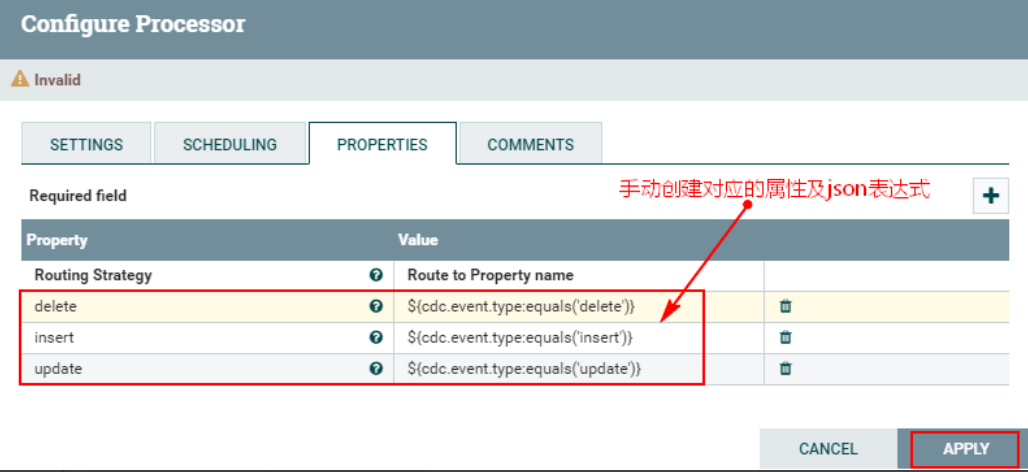
注意:以上自定义的属性中update、insert、delete对应的json 表达式写法为:${cdc.event.type:equals('delete')},代表匹配对应类型的FlowFile,“cdc.event.type”是上游FlowFile中的属性,“equales”是对应的方法,“delete”使用单引号引起,表示匹配的CDC事件。
3、连接“CaptureChangeMySQL”处理器与“RouteOnAttribute”处理器

四、配置“EvaluatejsonPath”处理器
“EvaluatejsonPath”处理器将根据上游“RouteOnAttribute”匹配的事件将内容映射成FlowFile属性,方便后期拼接SQL获取数据,上游匹配到的FlowFile中的数据格式为:

EvaluatejsonPath”处理器配置如下:
1、配置“EvaluatejsonPath”的“PROPERTIES”属性
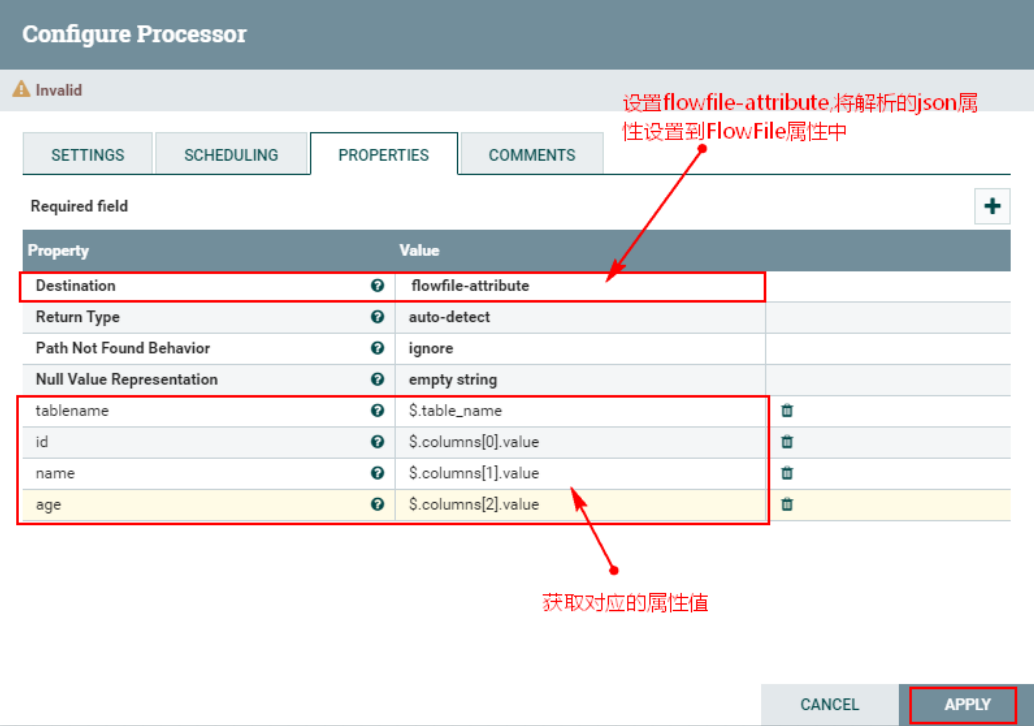
2、连接“RouteOnAttribute”处理器和“EvaluatejsonPath”处理器
连接关系中,我们这里只关注“insert”和“update”的数据,后期获取对应的属性将插入和更新的数据插入到Hive表中,对于“delete”的数据可以路由到其他关系中,例如需要将删除数据插入到另外的Hive表中,可以再设置个分支处理。这里我们将“delete”和“failure”的数据设置自动终止关系。

设置“RouteOnAttribute”处理器其他匹配路由关系为自动终止:
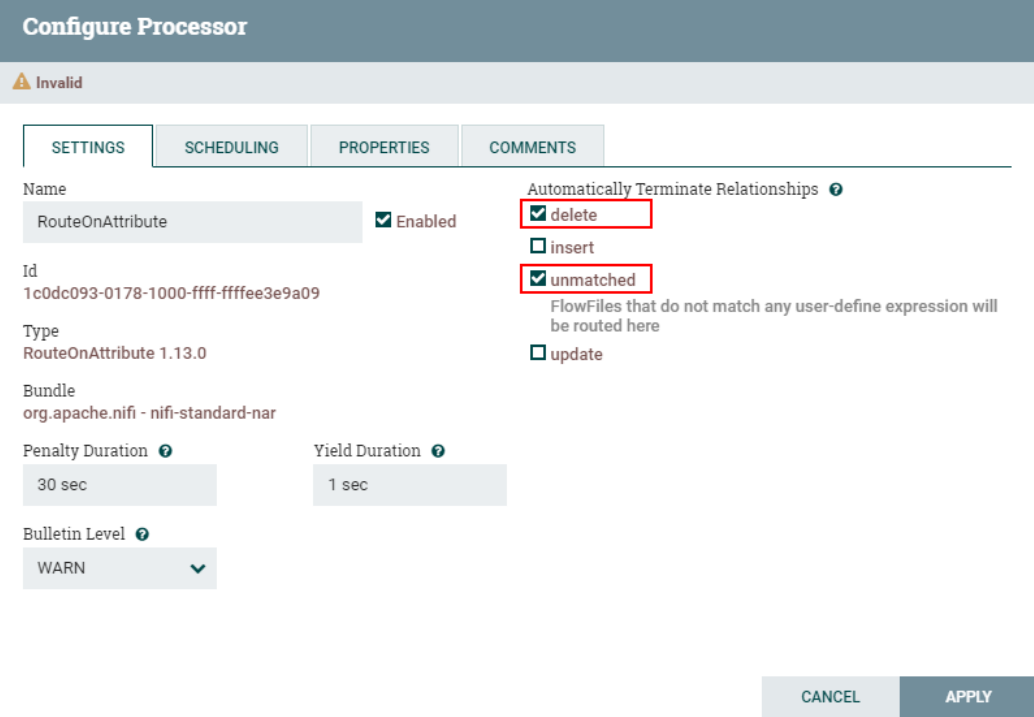
五、配置“ReplaceText”处理器
“ReplaceText”处理器可以获取“EvaluatejsonPath”转换后FlowFile中的属性来替换原有数据组成一个“insert into ... values (... ...)”语句,方便后续将数据插入到Hive中。“ReplaceText”处理器的配置如下:
1、配置“RelaceText”处理器“PROPERTIES”属性
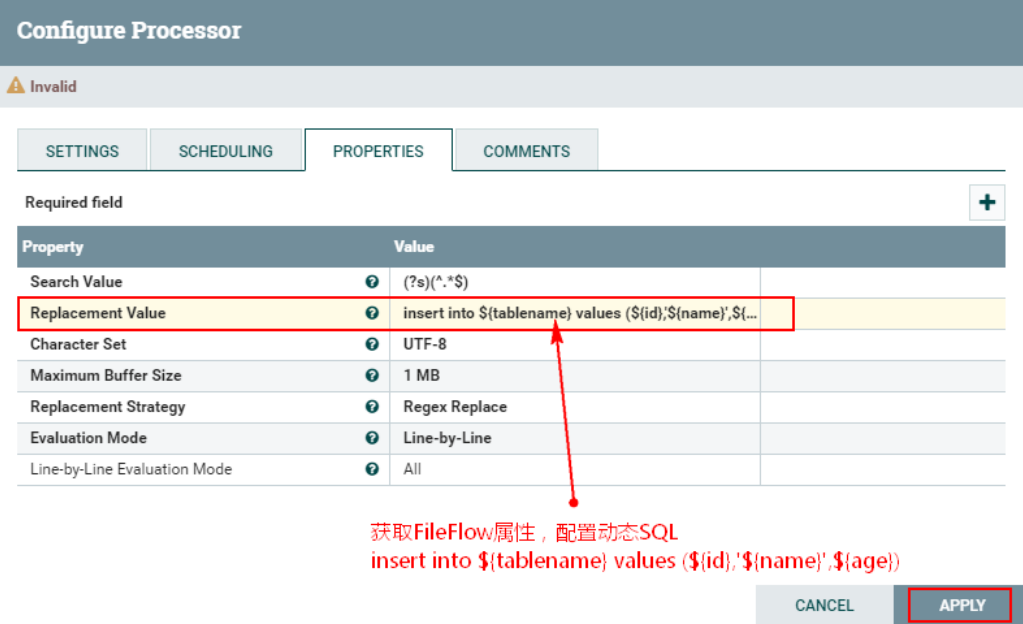
在“Replacement Value”中配置“insert into ${tablename} values (${id},'${name}',${age})”
注意:
以上获取的tablename名称为“test2”,后面这个sql是要将数据插入到Hive中的,所以这里在Hive中也应该创建“test2”的表名称,或者将表名称写成固定表,后期在Hive中创建对应的表即可。
另外,需要注意${name}在插入Hive中时对应的列为字符串,这里需要加上单引号。
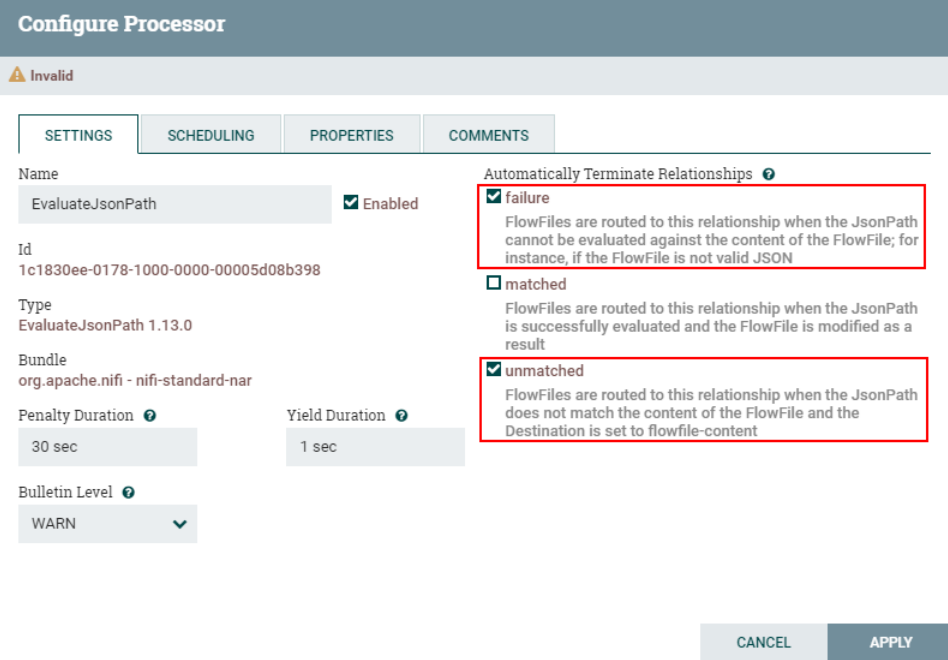
2、连接“EvaluatejsonPath”处理器与“ReplaceText”处理器

配置“EvaluatjsonPath”处理器“failure”和“unmatch”路由关系为自动终止。
六、配置Hive 支持HiveServer2
访问Hive有两种方式:HiveServer2和Hive Client,Hive Client需要Hive和Hadoop的jar包,配置环境。HiveServer2使得连接Hive的Client从Yarn和HDFS集群中独立出来,不需要每个几点都配置Hive和Hadoop的jar包和一系列环境。
NiFi连接Hive就是使用了HiveServer2方式连接,所以这里需要配置HiveServer2。
配置HiveServer2步骤如下:
1、在Hive服务端配置hive-site.xml
#在Hive 服务端 $HIVE_HOME/etc/hive-site.xml中配置:
<!-- 配置hiveserver2 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>
<property><name>hive.server2.thrift.bind.host</name><value>192.168.179.4</value>
</property>2、在每台Hadoop 节点配置core-site.xml
<!-- 配置代理访问用户 -->
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value></property>
<property> <name>hadoop.proxyuser.root.groups</name> <value>*</value>
</property>3、重启HDFS ,Hive ,在Hive服务端启动Metastore和HiveServer2服务
nohup hive --service metastore >> ./nohup.out 2>&1 &
nohup hive --service hiveserver2 >> ./nohup.out 2>&1 &4、在客户端通过beeline连接Hive
[root@node3 test]# beeline
beeline> !connect jdbc:hive2://node1:10000 root
Enter password for jdbc:hive2://node1:10000: 没有密码直接跳过即可
0: jdbc:hive2://node1:10000> show tables;
+------------------------------------+
| tab_name |
+------------------------------------+
| personinfo |
| test2 |
+------------------------------------+以上配置完成后,还需要将配置好的core-site.xml文件发送到各个NiFi节点对应的路径/root/test下替换原有的core-site.xml文件。之后重启NiFi集群,各个NiFi节点上执行命令:
service nifi restart七、配置“PutHiveQL”处理器
“PutHiveQL”主要执行HiveQL的DDL/DML命令,传入给该处理器的FlowFile内容是要执行的HiveQL命令。HiveQL命令可以使用“?”来指定参数,这种情况下,参数必须存在于FlowFile的属性中,命名约定为hiveql.args.N.type和hiveql.args.N.value,其中N为正整数。
关于“PutHiveQL”处理器的“Properties”主要配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
| Hive Database Connection Pooling Servic (Hive数据库连接池服务) | Hive Controller服务,用于获取与Hive数据库的连接。 | ||
| Batch Size (批次大小) | 100 | 一批次读取FlowFile的个数。 | |
| Character Set (编码) | UTF-8 | 指定数据的编码格式。 | |
| Statement Delimiter (语句分隔符) | ; | 语句分隔符,用于分隔多个语句脚本中的SQL语句。 | |
| Rollback On Failure (失败时回滚) | false | ▪true ▪false | 指定如何处理错误。默认false指的是如果在处理FlowFile时发生错误,则FlowFile将根据错误类型路由到“failure”或“retry”关系,处理器继续处理下一个FlowFile。 相反,可以设置为true回滚当前已处理的FlowFile,并立即停止进一步的处理。如果设置为true启用,失败的FlowFiles将停留在输入关系中并会反复处理,直到成功处理或通过其他方式将其删除为止。 可以设置足够大的“Yield Duration”避免重试次数过多。 |
“PutHiveQL”处理器的配置如下:
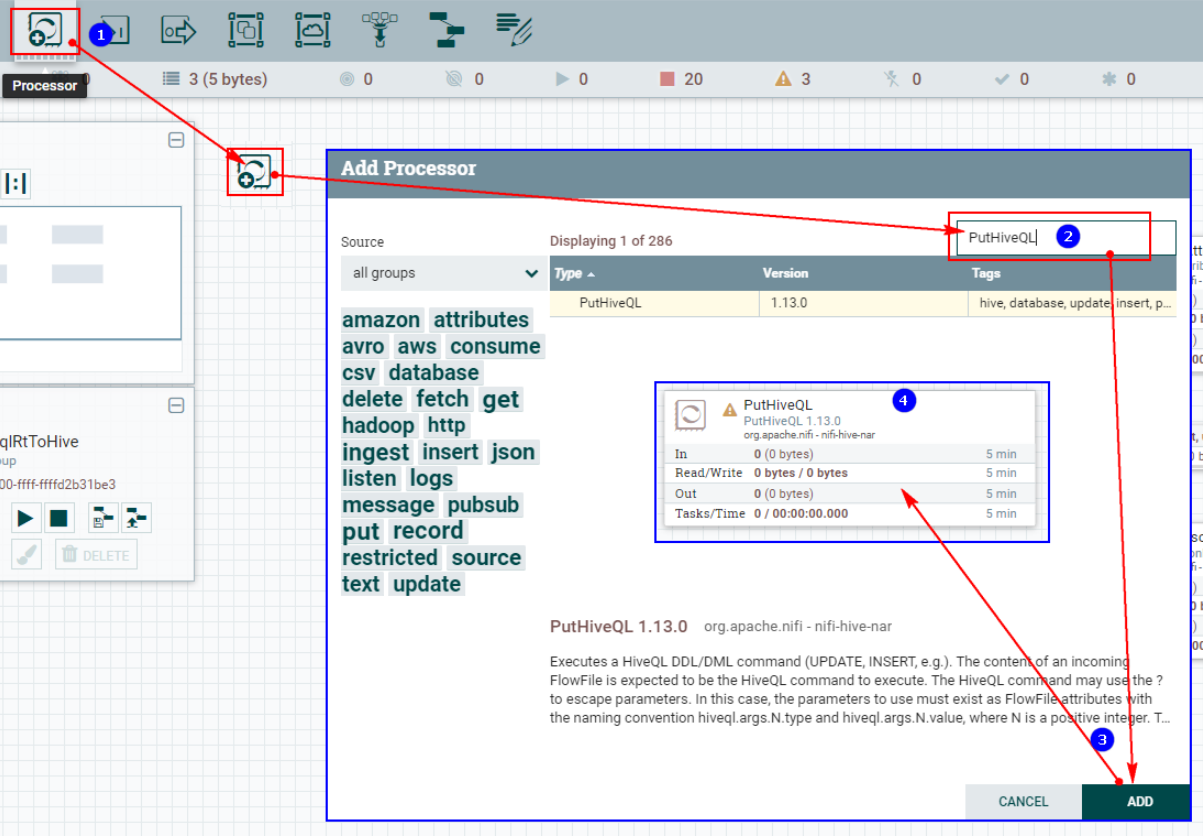
1、创建“PutHiveQL”处理器
2、 配置“PROPERTIES”
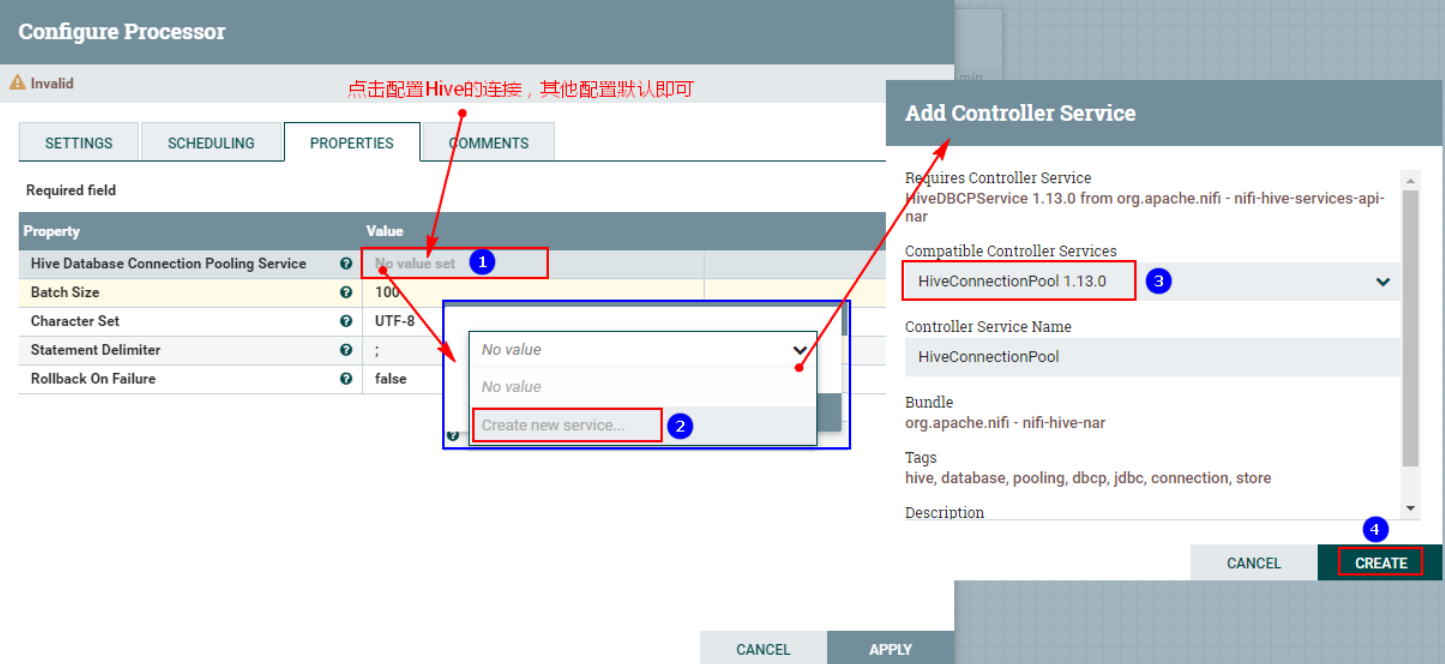
点击之后,配置“HiveConnectionPool”控制服务:
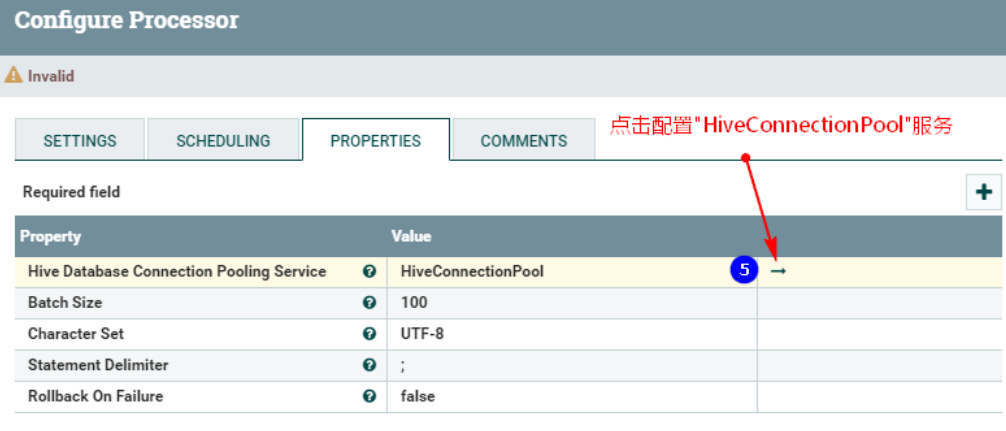
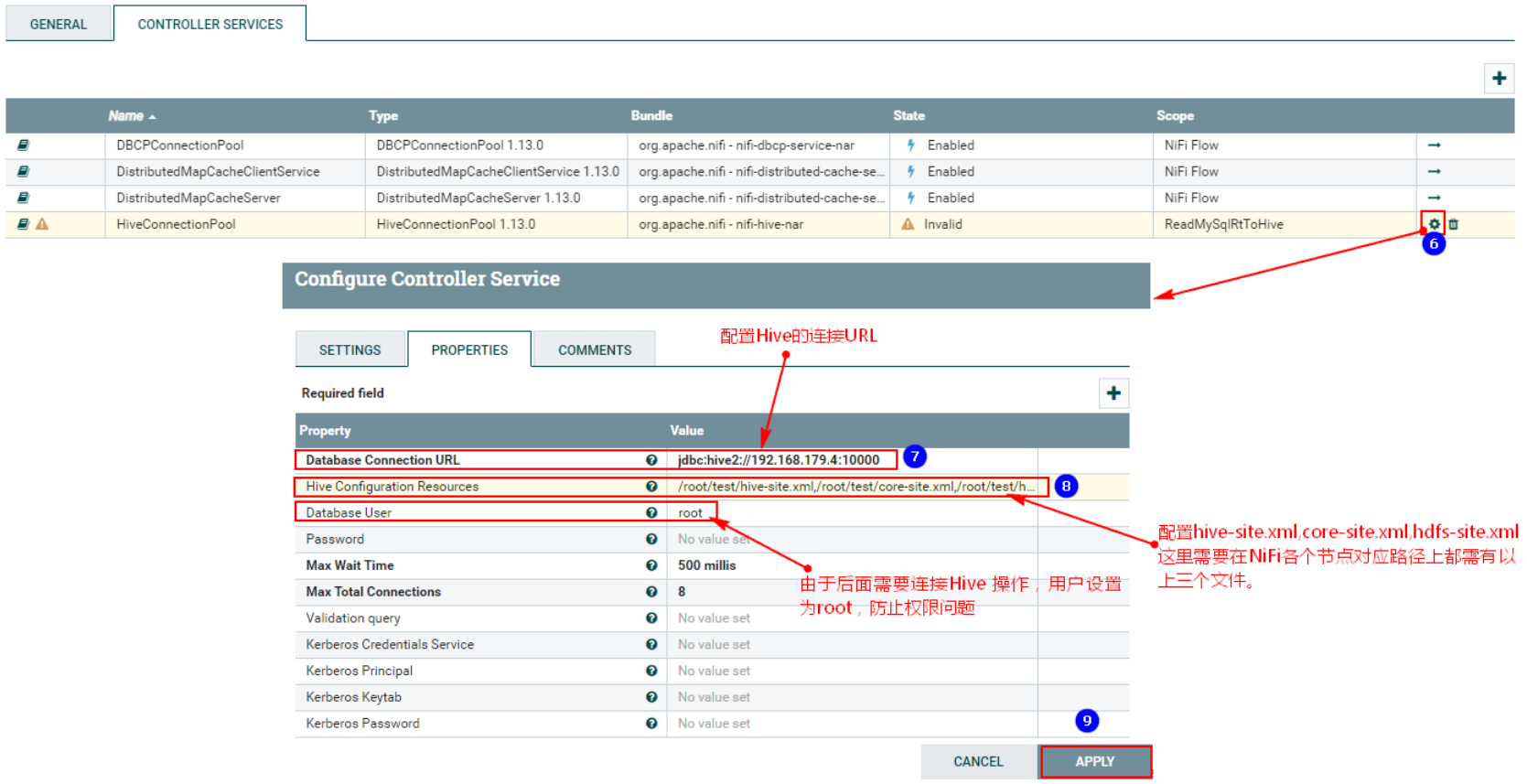
注意以上需要配置:
- “Database Connection URL” :这里是Hive的HiveServer2启动的节点,也就是服务端节点。“jdbc:hive2://192.168.179.4:10000”
- “Hive Configuration Resources”:“/root/test/hive-site.xml,/root/test/core-site.xml,/root/test/hdfs-site.xml”,这里需要将以上各个文件在NiFi集群各个节点对应位置准备好。
- “Database User”:root,这里防止操作Hive对应的HDFS时权限问题。
配置完成后,需要启用对应的“HiveConnectionPool”控制服务:

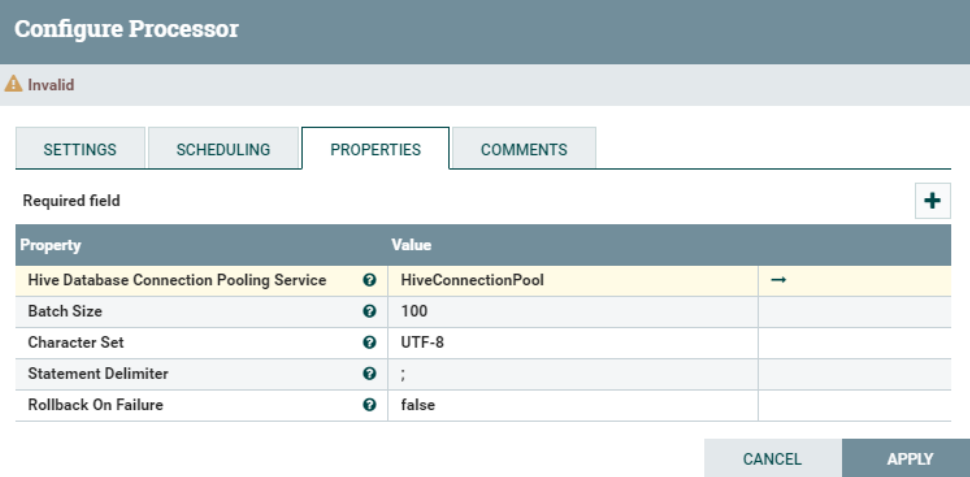
最终配置“PROPERTIES”为:
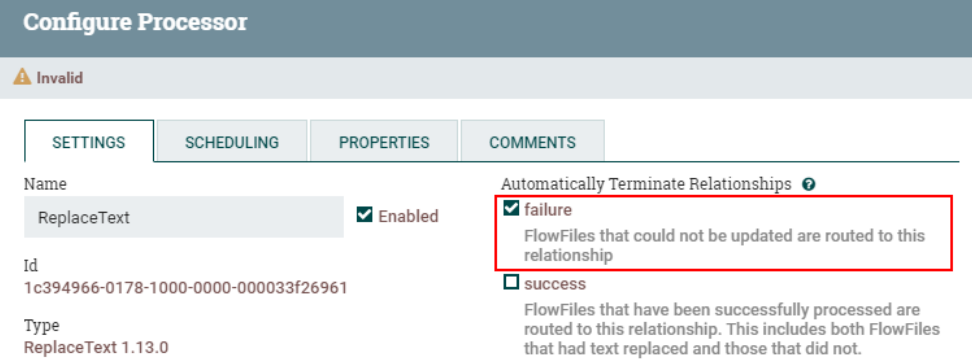
3、连接“ReplaceText”处理器与“PutHiveQL”处理器并设置关系

设置“ReplaceText”处理器“failure”路由关系为自动终止:
设置“PutHiveQL”处理器路由关系为自动终止:
八、运行测试
1、在Hive中创建表“test2”
动HDFS,启动Hive服务端和客户端,创建表“test2”
create table test2 (id int,name string,age int )row format delimited fields terminated by '\t';
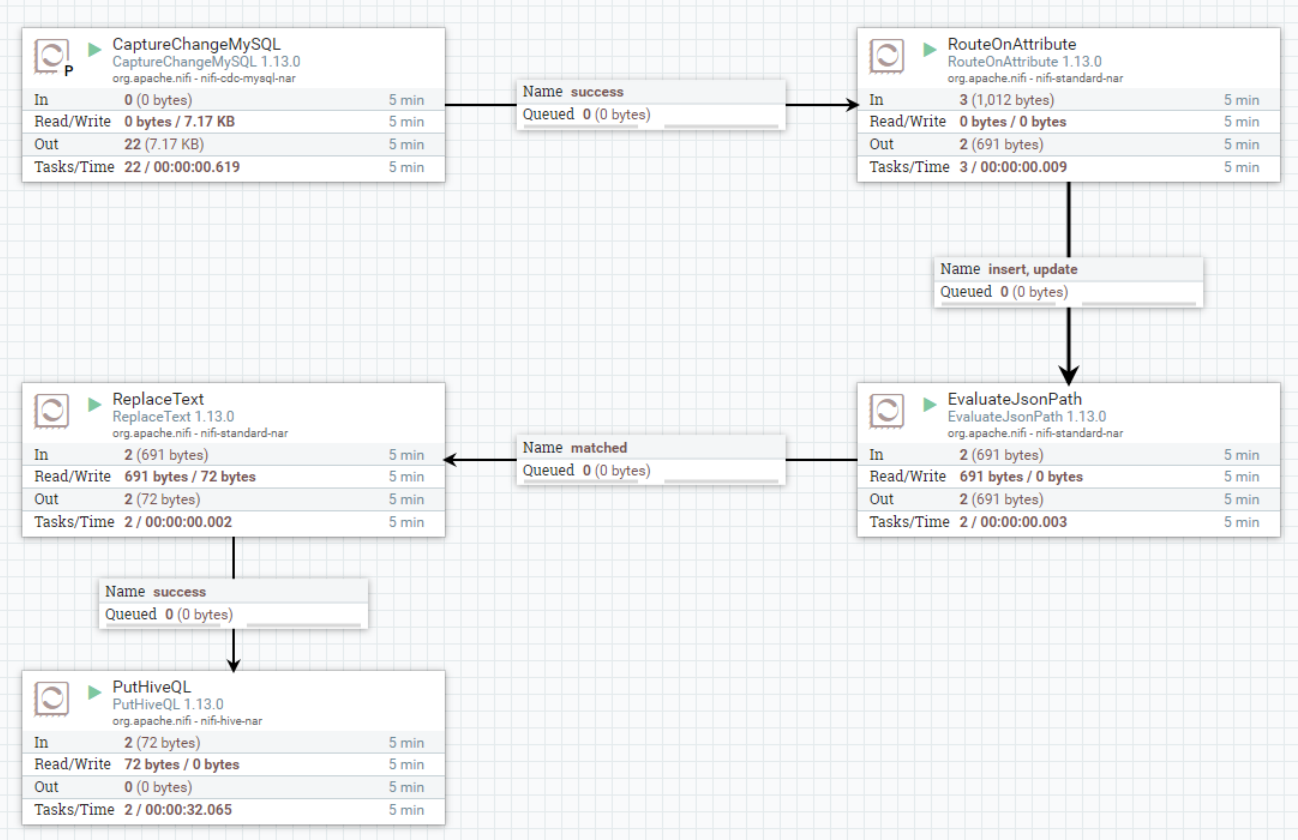
2、启动NiFi处理数据流程,向MySQL中写入数据,查看Hive中表数据
首先清空“CaptureChangeMySQL”处理器的状态,单独启动“CaptureChangeMySQL”处理器,清空重新消费的数据(以上主要就是避免此版本NiFi bug问题),启动当前案例中其他NiFi处理器。
然后向MySQL中插入以下数据:
insert into test2 values (1,"zs",18);
update test2 set name = "ls" where id = 1;
delete from test2 where id = 1;NiFi页面:
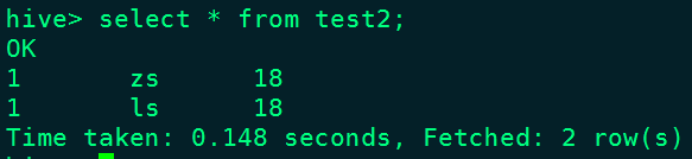
Hive表test2中的结果:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
相关文章:
大数据NiFi(二十):实时同步MySQL数据到Hive
文章目录 实时同步MySQL数据到Hive 一、开启MySQL的binlog日志 1、登录mysql查看MySQL是否开启binlog日志 2 、开启mysql binlog日志 3、重启mysql 服务,重新查看binlog日志情况 二、配置“CaptureChangeMySQL”处理器 1、创建“…...
mac 如何设置 oh my zsh 终端terminal 和添加主题powerlevel10k
Oh My Zsh 是什么 Oh My Zsh 是一款社区驱动的命令行工具,正如它的主页上说的,Oh My Zsh 是一种生活方式。它基于 zsh 命令行,提供了主题配置,插件机制,已经内置的便捷操作。给我们一种全新的方式使用命令行。 **Oh …...
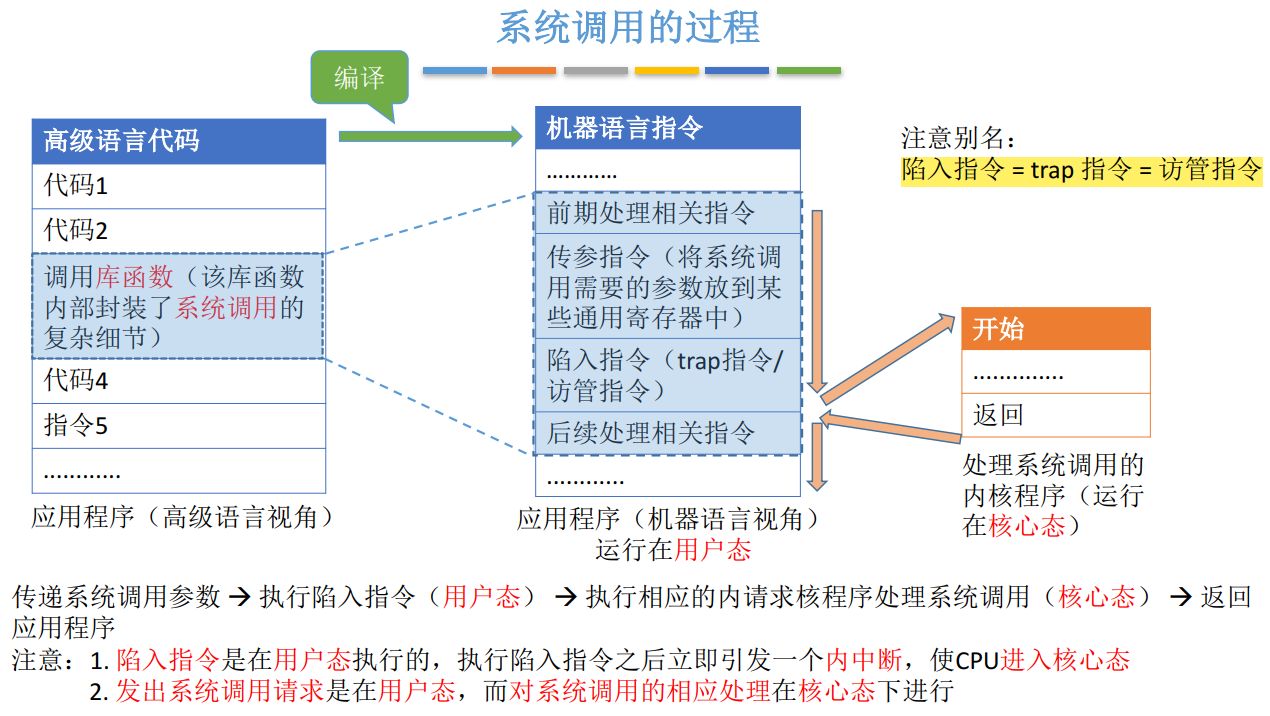
王道《操作系统》学习(一)——计算机系统概述
1.1 操作系统的概念、功能 1.1.1 操作系统的概念(定义) (1)操作系统是系统资源的管理者 (2)向上层用户、软件提供方便易用的服务 (3)是最接近硬件的一层软件 1.1.2 操作系统的功能…...

什么是自适应平台服务?
总目录链接==>> AutoSAR入门和实战系列总目录 文章目录 什么是自适应平台服务?1.1 自适应平台服务包含哪些功能簇呢?1.1.1 ara::sm 状态管理 (SM)1.1.2 ara::diag 诊断管理 (DM)1.1.3 ara::s2s 信号到服务映射1.1.4 ara::nm 网络管理 (NM)1.1.5 ara::ucm 更新和配置管…...

QML Image and Text(图像和文字)
Image(图片) 图像类型显示图像。 格式: Image {source: "资源地址" } source:指定资源的地址 自动检测文件拓展名:source中的URL 指示不存在的本地文件或资源,则 Image 元素会尝试自动检测文件…...
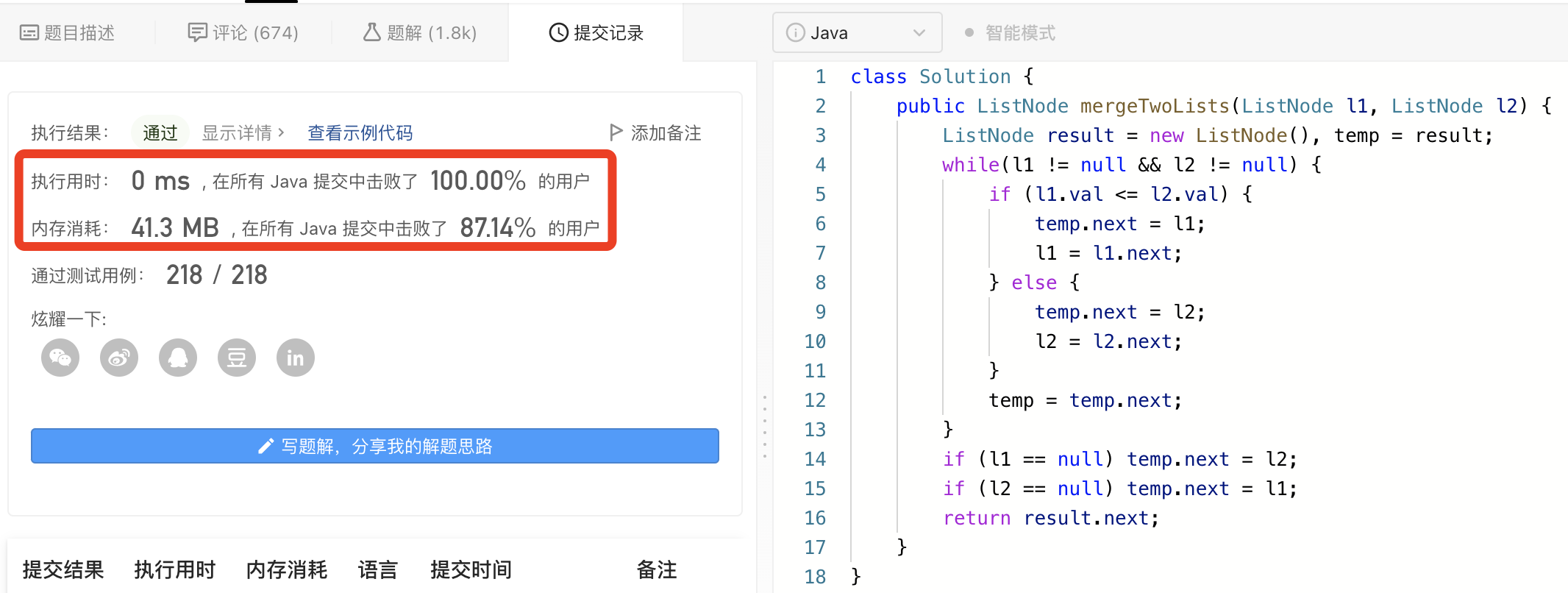
图解LeetCode——剑指 Offer 25. 合并两个排序的链表
一、题目 输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。 二、示例 2.1> 示例1: 【输入】1->2->4, 1->3->4 【输出】1->1->2->3->4->4 限制: 0 < 链表长度 < 1000 三、…...

2023年全国最新安全员精选真题及答案7
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.(单选题)进入盾构机土仓进行维修工作时,需经&am…...
TypeScript笔记-进行中
学习来源: 本笔记由尚硅谷教学视频整理而来 文章目录学习来源:一.TS简介TypeScript是什么TypeScript增加了什么二环境搭建安装nvm环境搭建二.TypeScript中的基本类型类型声明类型类型示例代码三.编译配置自动编译文件自动编译整个项目四.使用webpack打包…...
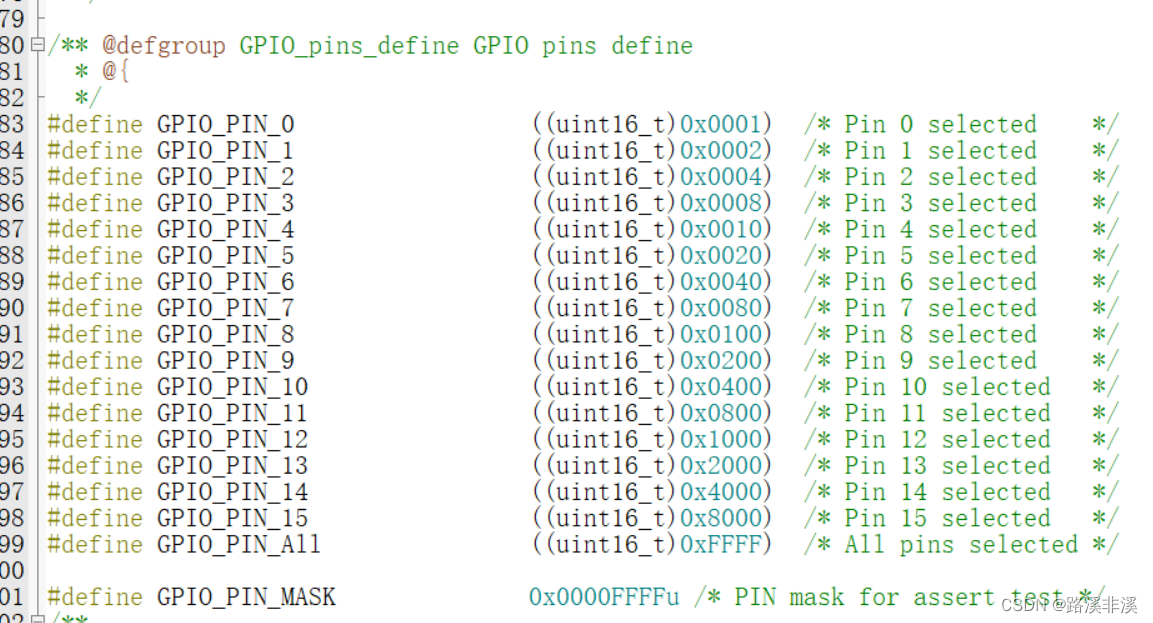
阅读HAL源码之重点总结
HAL库的封装特点 HAL封装中有如下特点(自己总结的): 特定外设要设置的参数组成一个结构体; 特定外设所有寄存器组成一个结构体; 地址基本都是通过宏来定义的,定义了各外设的起始地址,也就是对应…...

常见的http请求响应的状态码
常见的http请求响应的状态码 一些常见的状态码为: 200 – 服务器成功返回网页 404 – 请求的网页不存在 503 – 服务不可用 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码。 代码 说明 100 (继续)…...
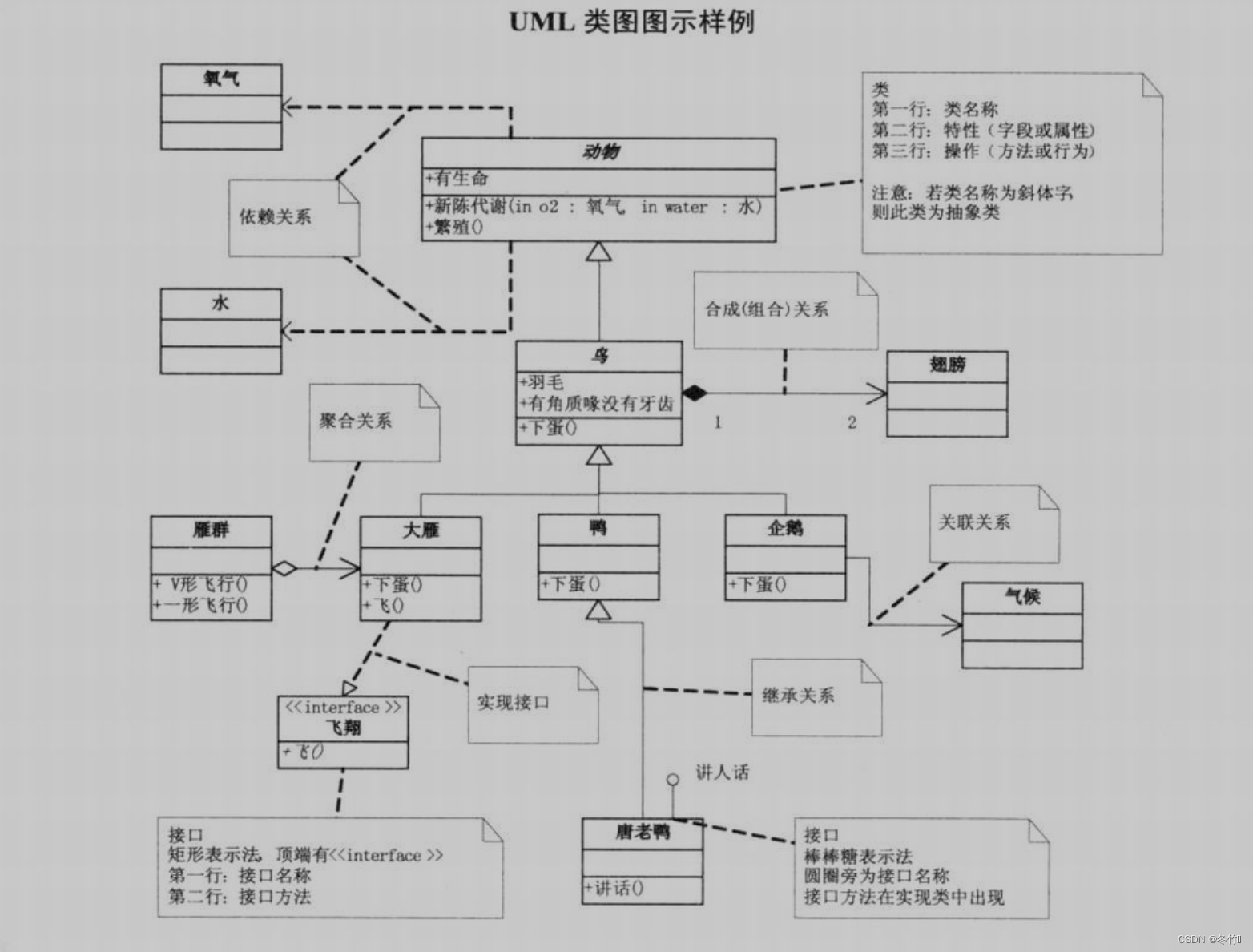
UML类图中的类图、接口图、关联、聚合、依赖、组合概念的解释
文章目录UML类图依赖和关联的主要区别UML类图 类:类有三层结构 第一层:类的名字第二层:类的属性第三层:类的方法 接口:接口跟类相似,不过多了一个<<interface>>来表示它是一个接口 第一层&a…...

【数据库】第九章 关系查询处理与优化
第九章 关系查询处理与优化 索引 索引文件是一种辅助存储结构,其存在与否不改变存储表的物理存储结 构;然而其存在,可以明显提高存储表的访问速度。 索引文件组织方式有两种:(相对照的,主文件组织有堆文件、排序文件、…...

大学物理期末大题专题训练总结-磁学大题
(事先声明指的是简单的那个磁学大题,另外一类涉及储存的磁能、磁感应强度分布下次说)求个磁通量,求个感应电动势,求个安培力大小......这个感觉是不是像你梦回高中?当然,这一块大题跟高中磁学部…...
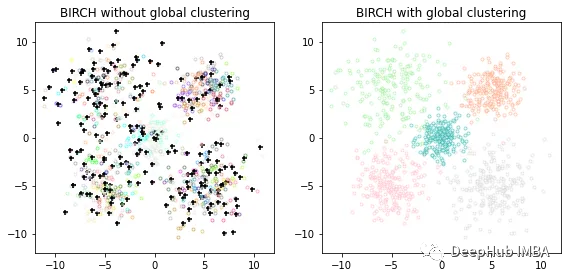
聚类算法(上):8个常见的无监督聚类方法介绍和比较
无监督聚类方法的评价指标必须依赖于数据和聚类结果的内在属性,例如聚类的紧凑性和分离性,与外部知识的一致性,以及同一算法不同运行结果的稳定性。 本文将全面概述Scikit-Learn库中用于的聚类技术以及各种评估方法。 本文将分为2个部分&…...
)
华为OD机试真题Python实现【找到它】真题+解题思路+代码(20222023)
找到它 题目 找到它是个小游戏,你需要在一个矩阵中找到给定的单词 假设给定单词HELLOWORLD,在矩阵中只要能找HELLOWORLD就算通过 注意区分英文字母大小写,并且你只能上下左右行走 不能走回头路 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD机试(Python)真题目…...

English Learning - L2 语音作业打卡 Day4 2023.2.24 周五
English Learning - L2 语音作业打卡 Day4 2023.2.24 周五💌 发音小贴士:💌 当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音 [u:]&#x…...
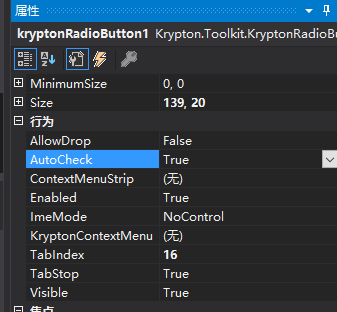
C#:Krypton控件使用方法详解(第九讲) ——kryptonRadioButton
今天介绍的Krypton控件中的kryptonRadioButton,这是一个单选按钮控件。下面开始介绍这个控件的属性:首先介绍的是外观属性,如下图所示:Cheacked属性:表示设置kryptonRadioButton控件的初始选中状态是什么样的ÿ…...
)
消失的数字(每日一题)
目录 一、题目描述 二、题目分析 2.1 方法一 2.1.1 思路 2.1.2 代码 2.2 方法二 2.2.1 思路 2.2.2 代码 2.3 方法三 2.3.1 思路 2.3.2 代码 三、完整代码 一、题目描述 oj链接:https://leetcode.cn/problems/missing-number-lcci 数组nums包含从0到n的…...

TypeScript算法基础——TS字符串的常用操作总结:substring、indexOf、slice、replace等
字符串的操作是算法题当中经常碰见的一类题目,主要考察对string类型的处理和运用。 在处理字符串的时候,我们经常会碰到求字符串长度、匹配子字符串、替换字符串内容、连接字符串、提取字符串字符等操作,那么调用一些简单好用的api可以让工作…...

Leetcode100-两数之和
参见官方题解 一、学到的知识 正面寻找两个数之和相加等于某个数,如 ab c,不如反过来寻找 a c - b 正面寻找需要两层 for 循环,把每个数都进行遍历,所以时间复杂度较高 反过来则可以通过维护一个 a 的集合,每次通过…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...