二叉树(二)
二叉树——堆存储
- 1.堆的初始化
- 2. 堆的销毁
- 3.堆的插入
- 4.堆的删除
- 5.堆的打印
- 6.取堆顶的数据
- 7.堆的数据个数
- 8.堆的判空
- 9.堆的构建
- 10.向上调整
- 11.向下调整
- 12.使用堆进行排序
- 13.交换
- 14.完整代码
🌟🌟hello,各位读者大大们你们好呀🌟🌟
🚀🚀系列专栏:【数据结构的学习】
📝📝本篇内容:使用数组实现二叉树堆的存储
⬆⬆⬆⬆上一篇:二叉树(一)
💖💖作者简介:轩情吖,请多多指教(> •̀֊•́ ) ̖́-
使用数组来存储,一般使用数组只适合完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一棵二叉树。
大堆:树中所有的父亲都大于等于孩子
小堆:树中的所有父亲都小于等于孩子
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆
任何一个数组,可以看做完全二叉树,但不一定是堆
1.堆的初始化
void HeapInit(Heap* hp)// 堆的初始化
{assert(hp);hp->arr = NULL;hp->capacity = 0;hp->size = 0;
}
2. 堆的销毁
void HeapDestory(Heap* hp)// 堆的销毁
{assert(hp);free(hp->arr);//先得把开辟的动态空间释放掉,不然会造成内存泄露hp->capacity = hp->size = 0;//重新设置为0
}
3.堆的插入
void HeapPush(Heap* hp, Type x)//堆的插入
{assert(hp);if (hp->size == hp->capacity)//如果大小相同则需要扩容{int new = hp->arr == NULL ? 4 : hp->capacity * 2;//如果是NULL就开辟4个空间,否则就翻倍Type* tmp =(Type*)realloc(hp->arr, sizeof(Type)*new);//当第一个参数是NULL时,realloc的作用相等于mallocif (tmp == NULL)//判断realloc是否开辟成功{perror("realloc fail");exit(-1);}hp->capacity = new;hp->arr = tmp;}hp->arr[hp->size] = x;hp->size++;AdjustUp(hp->arr, hp->size - 1);//向上调整}
4.堆的删除
void HeapPop(Heap* hp)// 堆的删除
{hp->arr[0] = hp->arr[hp->size - 1];//把最后一个结点(指的是数组里最后一个元素)赋给根节点,就能删除大根堆hp->size--;AdjustDown(hp->arr,hp->size,0);//向下调整(但必须要做一些调整,不然堆就会出现问题)
}
5.堆的打印
void HeapPrint(Heap* hp)//堆的打印
{ for (int i = 0; i < hp->size; i++){printf("%d ",hp->arr[i]);}printf("\n");
}
6.取堆顶的数据
Type HeapTop(Heap* hp)//取堆顶的数据
{assert(hp);assert(hp->size>0);return hp->arr[0];
}
7.堆的数据个数
int HeapSize(Heap* hp)// 堆的数据个数
{assert(hp);return hp->size;}
8.堆的判空
bool HeapEmpty(Heap* hp)//堆的判空
{assert(hp);return hp->size ==0;
}
9.堆的构建
void HeapCreate(Heap* hp, Type* a, int n)//堆的构建
{HeapInit(hp);hp->arr = malloc(sizeof(Type) * n);if (hp->arr == NULL){perror("malloc fail");exit(-1);}memcpy(hp->arr,a,sizeof(Type)*n);hp->size += n;hp->capacity += n;//向上调整/*for (int i = 0; i < n; i++){AdjustUp(hp->arr, i);}*///向下调整int i = (n - 1 - 1) / 2;for (; i >= 0; i--){AdjustDown(hp->arr,n,i);}
}
10.向上调整
void AdjustUp(Type* arr,int child)//向上调整
{while (child>0)//当child为0的时候。说明已经没有父节点了,到了根节点{int parent = (child - 1) / 2;//算出父节点if (arr[parent] > arr[child])//判断是否父节点小于孩子节点{swap(&arr[parent],&arr[child]);//交换child = parent;//把父节点的下标赋给孩子节点,继续判断}else{break;}}
}
11.向下调整
AdjustDown(Type* arr, int size, int parent)//向下调整
{
int child = parent * 2 + 1;//先求出孩子结点的下标,并假设左子树的值比右子树的大while (child<size){//要小心右子树可能没有,所以需要判断if (child+1<size&&arr[child] > arr[child + 1])//如果不是,调换,右子树正好是左子树的下标+1{child++;}if (arr[parent]>arr[child]){swap(&arr[parent], &arr[child]);parent = child;child = parent * 2 + 1;}else{break;}}}
12.使用堆进行排序
void HeapSort(Type* arr, int n)//使用堆进行排序
{//升序//大堆来实现//向下调整int end = n - 1;while (end > 0){swap(&arr[0], &arr[end]);//先交换AdjustDown(arr, end, 0);end--;}
}
13.交换
void swap(Type* s1,Type* s2)//交换
{Type tmp = *s1;//先保存一下s1*s1 = *s2;*s2 = tmp;
}
14.完整代码
//头文件
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
#include <string.h>
typedef int Type;
typedef struct Heap//在现实使用中只有堆才会使用数组来存储
{Type* arr;int size;int capacity;
}Heap;
void HeapInit(Heap* hp);// 堆的初始化
void HeapDestory(Heap* hp);// 堆的销毁
void HeapPush(Heap* hp,Type x);//堆的插入
void HeapPop(Heap* hp);// 堆的删除
void HeapPrint(Heap* hp);//堆的打印
Type HeapTop(Heap* hp);//取堆顶的数据
int HeapSize(Heap* hp);// 堆的数据个数
bool HeapEmpty(Heap* hp);// 堆的判空
void HeapCreate(Heap* hp,Type* a, int n);//堆的构建
void AdjustUp(Type* arr, int child);//向上调整
AdjustDown(Type* arr, int size, int parent);//向下调整
void HeapSort(Type* arr, int n);//使用堆进行排序
void swap(Type* s1, Type* s2);//交换//函数实现
#define _CRT_SECURE_NO_WARNINGS 1
#include "Heap.h"
void HeapInit(Heap* hp)// 堆的初始化
{assert(hp);hp->arr = NULL;hp->capacity = 0;hp->size = 0;
}
void HeapDestory(Heap* hp)// 堆的销毁
{assert(hp);free(hp->arr);//先得把开辟的动态空间释放掉,不然会造成内存泄露hp->capacity = hp->size = 0;//重新设置为0
}void swap(Type* s1,Type* s2)//交换
{Type tmp = *s1;//先保存一下s1*s1 = *s2;*s2 = tmp;
}void AdjustUp(Type* arr,int child)//向上调整
{while (child>0)//当child为0的时候。说明已经没有父节点了,到了根节点{int parent = (child - 1) / 2;//算出父节点if (arr[parent] > arr[child])//判断是否父节点小于孩子节点{swap(&arr[parent],&arr[child]);//交换child = parent;//把父节点的下标赋给孩子节点,继续判断}else{break;}}
}
void HeapPush(Heap* hp, Type x)//堆的插入
{assert(hp);if (hp->size == hp->capacity)//如果大小相同则需要扩容{int new = hp->arr == NULL ? 4 : hp->capacity * 2;//如果是NULL就开辟4个空间,否则就翻倍Type* tmp =(Type*)realloc(hp->arr, sizeof(Type)*new);//当第一个参数是NULL时,realloc的作用相等于mallocif (tmp == NULL)//判断realloc是否开辟成功{perror("realloc fail");exit(-1);}hp->capacity = new;hp->arr = tmp;}hp->arr[hp->size] = x;hp->size++;AdjustUp(hp->arr, hp->size - 1);//向上调整}AdjustDown(Type* arr, int size, int parent)//向下调整
{
int child = parent * 2 + 1;//先求出孩子结点的下标,并假设左子树的值比右子树的大while (child<size){//要小心右子树可能没有,所以需要判断if (child+1<size&&arr[child] > arr[child + 1])//如果不是,调换,右子树正好是左子树的下标+1{child++;}if (arr[parent]>arr[child]){swap(&arr[parent], &arr[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void HeapPop(Heap* hp)// 堆的删除
{hp->arr[0] = hp->arr[hp->size - 1];//把最后一个结点(指的是数组里最后一个元素)赋给根节点,就能删除大根堆hp->size--;AdjustDown(hp->arr,hp->size,0);//向下调整(但必须要做一些调整,不然堆就会出现问题)
}void HeapPrint(Heap* hp)//堆的打印
{ for (int i = 0; i < hp->size; i++){printf("%d ",hp->arr[i]);}printf("\n");
}void HeapCreate(Heap* hp, Type* a, int n)//堆的构建
{HeapInit(hp);hp->arr = malloc(sizeof(Type) * n);if (hp->arr == NULL){perror("malloc fail");exit(-1);}memcpy(hp->arr,a,sizeof(Type)*n);hp->size += n;hp->capacity += n;//向上调整/*for (int i = 0; i < n; i++){AdjustUp(hp->arr, i);}*///向下调整int i = (n - 1 - 1) / 2;for (; i >= 0; i--){AdjustDown(hp->arr,n,i);}
}Type HeapTop(Heap* hp)//取堆顶的数据
{assert(hp);assert(hp->size>0);return hp->arr[0];
}int HeapSize(Heap* hp)// 堆的数据个数
{assert(hp);return hp->size;}bool HeapEmpty(Heap* hp)//堆的判空
{assert(hp);return hp->size ==0;
}void HeapSort(Type* arr, int n)//使用堆进行排序
{//升序//大堆来实现//向下调整int end = n - 1;while (end > 0){swap(&arr[0], &arr[end]);//先交换AdjustDown(arr, end, 0);end--;}
}
🌸🌸二叉树(二)的知识大概就讲到这里啦,博主后续会继续更新更多数据结构的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!你们的支持是博主坚持创作的动力!💪💪
相关文章:
)
二叉树(二)
二叉树——堆存储1.堆的初始化2. 堆的销毁3.堆的插入4.堆的删除5.堆的打印6.取堆顶的数据7.堆的数据个数8.堆的判空9.堆的构建10.向上调整11.向下调整12.使用堆进行排序13.交换14.完整代码🌟🌟hello,各位读者大大们你们好呀🌟&…...

爬虫知识简介
爬虫简介 爬虫与网络请求 网络爬虫是一个自动提取网页的程序,一般都分为3步:数据爬取,数据解析,数据存储。数据爬取就是模拟浏览器发送请求,所以需要对网络请求HTTP/HTTPS有一定了解 相关概念: H…...

2023年全国最新会计专业技术资格精选真题及答案6
百分百题库提供会计专业技术资格考试试题、会计考试预测题、会计专业技术资格考试真题、会计证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.下列各项中,企业根据本月“工资费用分配汇总表”分配所列财务部门…...

同时学习C++语言和C#语言好吗?
同时学习两门编程语言并不是不好的选择,尤其是对于初学者而言,这样做能够帮助你更好地理解编程语言的基本概念和原则。C和C#都是常用的编程语言,它们都有各自的优点和用途。同时学习这两门语言能够让你更好地理解它们之间的异同点,…...

Android8,source与lunch流程解析
source 流程 # build/make/envsetup.sh ---- # Execute the contents of any vendorsetup.sh files we can find. for f in test -d device && find -L device -maxdepth 4 -name vendorsetup.sh 2> /dev/null | sort \ test -d vendor && find -L vendo…...
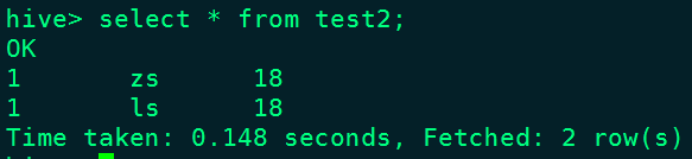
大数据NiFi(二十):实时同步MySQL数据到Hive
文章目录 实时同步MySQL数据到Hive 一、开启MySQL的binlog日志 1、登录mysql查看MySQL是否开启binlog日志 2 、开启mysql binlog日志 3、重启mysql 服务,重新查看binlog日志情况 二、配置“CaptureChangeMySQL”处理器 1、创建“…...
mac 如何设置 oh my zsh 终端terminal 和添加主题powerlevel10k
Oh My Zsh 是什么 Oh My Zsh 是一款社区驱动的命令行工具,正如它的主页上说的,Oh My Zsh 是一种生活方式。它基于 zsh 命令行,提供了主题配置,插件机制,已经内置的便捷操作。给我们一种全新的方式使用命令行。 **Oh …...
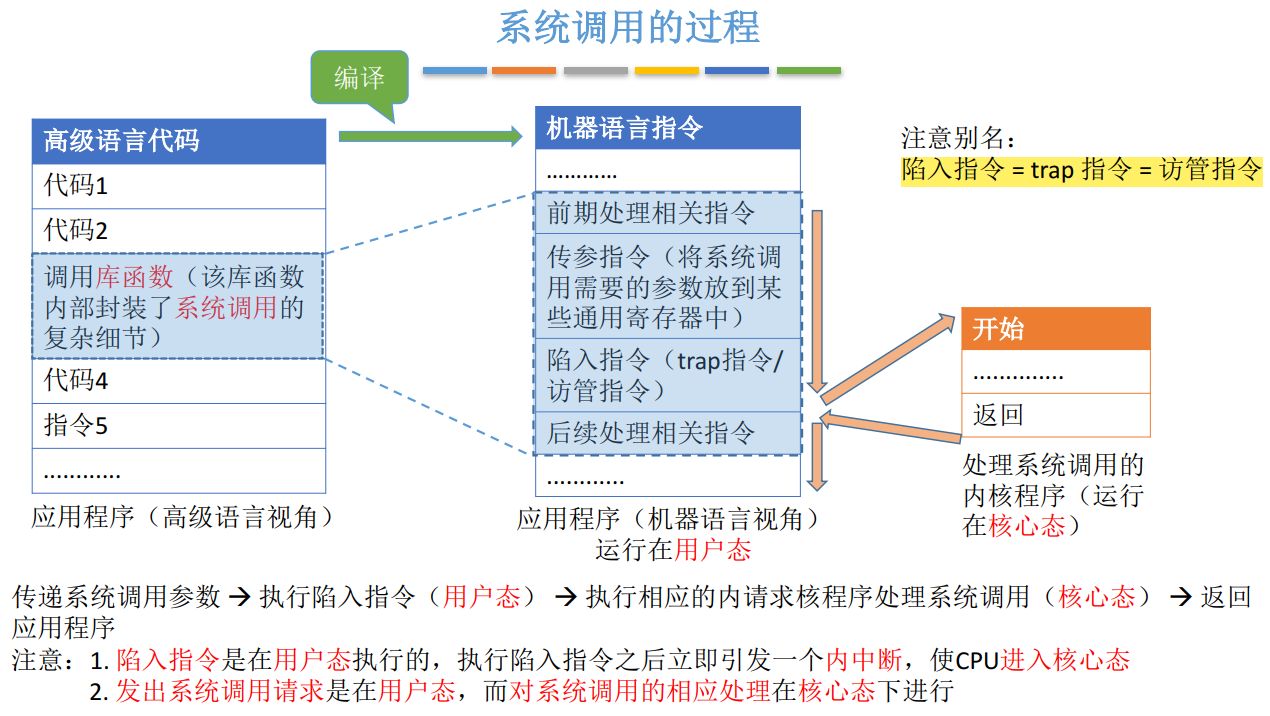
王道《操作系统》学习(一)——计算机系统概述
1.1 操作系统的概念、功能 1.1.1 操作系统的概念(定义) (1)操作系统是系统资源的管理者 (2)向上层用户、软件提供方便易用的服务 (3)是最接近硬件的一层软件 1.1.2 操作系统的功能…...

什么是自适应平台服务?
总目录链接==>> AutoSAR入门和实战系列总目录 文章目录 什么是自适应平台服务?1.1 自适应平台服务包含哪些功能簇呢?1.1.1 ara::sm 状态管理 (SM)1.1.2 ara::diag 诊断管理 (DM)1.1.3 ara::s2s 信号到服务映射1.1.4 ara::nm 网络管理 (NM)1.1.5 ara::ucm 更新和配置管…...

QML Image and Text(图像和文字)
Image(图片) 图像类型显示图像。 格式: Image {source: "资源地址" } source:指定资源的地址 自动检测文件拓展名:source中的URL 指示不存在的本地文件或资源,则 Image 元素会尝试自动检测文件…...
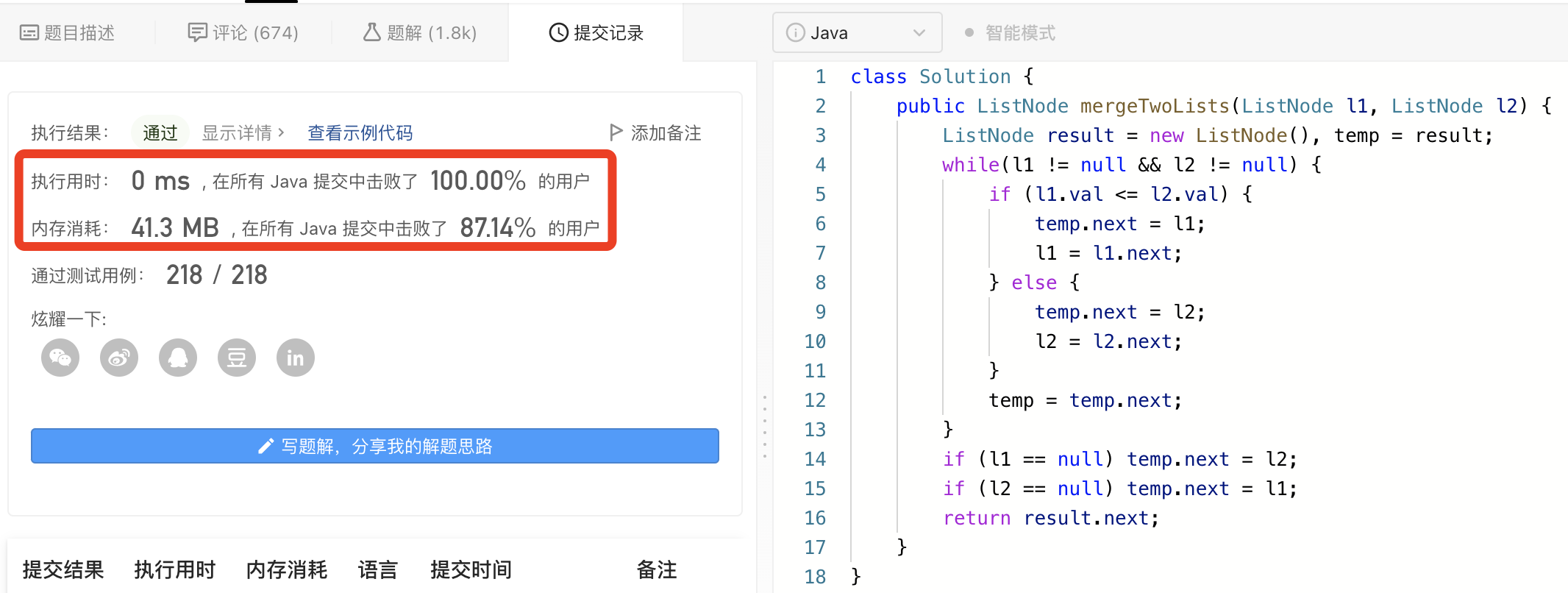
图解LeetCode——剑指 Offer 25. 合并两个排序的链表
一、题目 输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。 二、示例 2.1> 示例1: 【输入】1->2->4, 1->3->4 【输出】1->1->2->3->4->4 限制: 0 < 链表长度 < 1000 三、…...

2023年全国最新安全员精选真题及答案7
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.(单选题)进入盾构机土仓进行维修工作时,需经&am…...
TypeScript笔记-进行中
学习来源: 本笔记由尚硅谷教学视频整理而来 文章目录学习来源:一.TS简介TypeScript是什么TypeScript增加了什么二环境搭建安装nvm环境搭建二.TypeScript中的基本类型类型声明类型类型示例代码三.编译配置自动编译文件自动编译整个项目四.使用webpack打包…...
阅读HAL源码之重点总结
HAL库的封装特点 HAL封装中有如下特点(自己总结的): 特定外设要设置的参数组成一个结构体; 特定外设所有寄存器组成一个结构体; 地址基本都是通过宏来定义的,定义了各外设的起始地址,也就是对应…...

常见的http请求响应的状态码
常见的http请求响应的状态码 一些常见的状态码为: 200 – 服务器成功返回网页 404 – 请求的网页不存在 503 – 服务不可用 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码。 代码 说明 100 (继续)…...
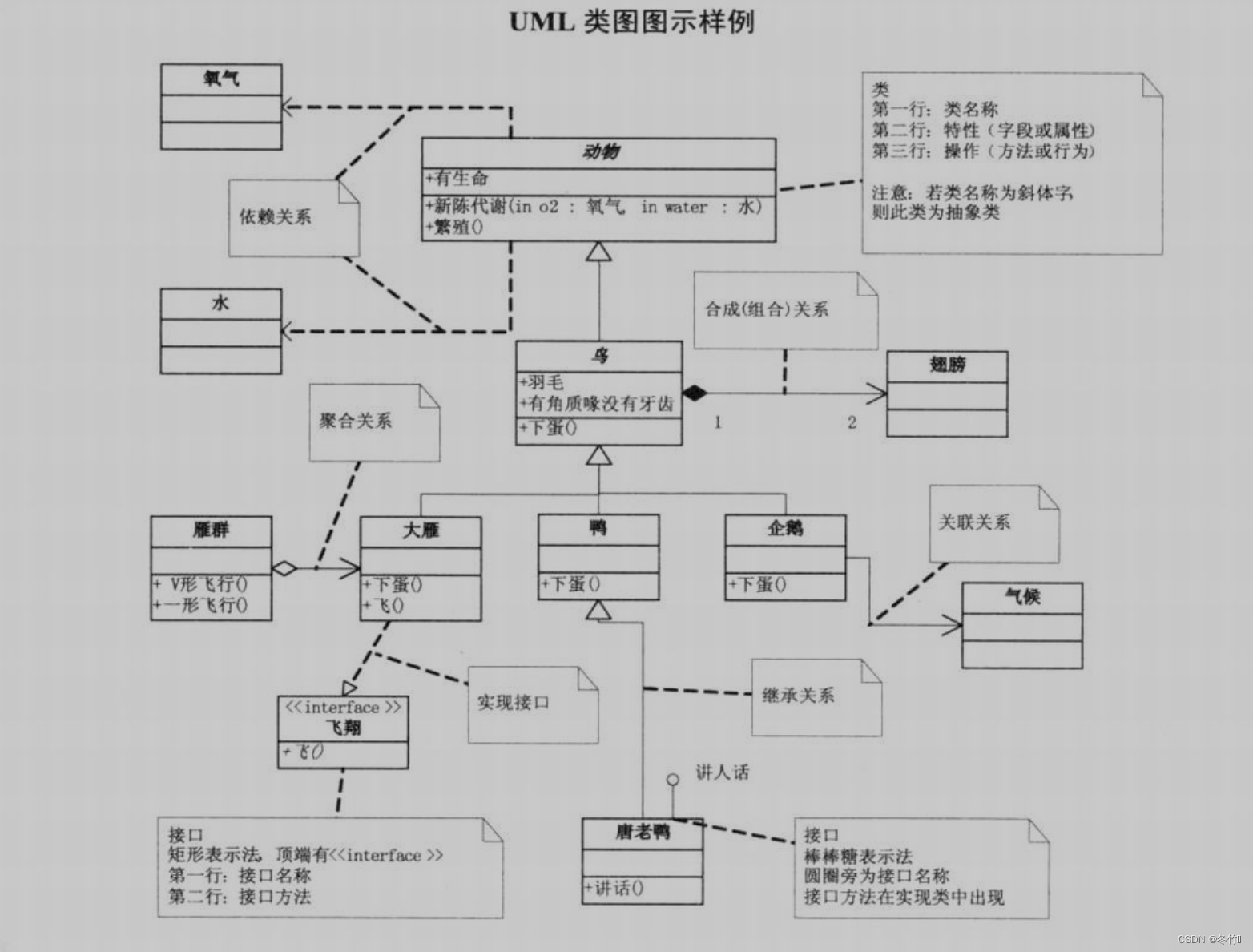
UML类图中的类图、接口图、关联、聚合、依赖、组合概念的解释
文章目录UML类图依赖和关联的主要区别UML类图 类:类有三层结构 第一层:类的名字第二层:类的属性第三层:类的方法 接口:接口跟类相似,不过多了一个<<interface>>来表示它是一个接口 第一层&a…...

【数据库】第九章 关系查询处理与优化
第九章 关系查询处理与优化 索引 索引文件是一种辅助存储结构,其存在与否不改变存储表的物理存储结 构;然而其存在,可以明显提高存储表的访问速度。 索引文件组织方式有两种:(相对照的,主文件组织有堆文件、排序文件、…...

大学物理期末大题专题训练总结-磁学大题
(事先声明指的是简单的那个磁学大题,另外一类涉及储存的磁能、磁感应强度分布下次说)求个磁通量,求个感应电动势,求个安培力大小......这个感觉是不是像你梦回高中?当然,这一块大题跟高中磁学部…...
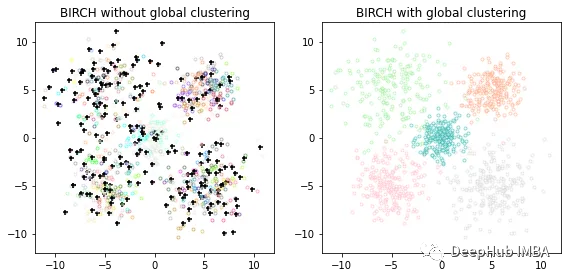
聚类算法(上):8个常见的无监督聚类方法介绍和比较
无监督聚类方法的评价指标必须依赖于数据和聚类结果的内在属性,例如聚类的紧凑性和分离性,与外部知识的一致性,以及同一算法不同运行结果的稳定性。 本文将全面概述Scikit-Learn库中用于的聚类技术以及各种评估方法。 本文将分为2个部分&…...
)
华为OD机试真题Python实现【找到它】真题+解题思路+代码(20222023)
找到它 题目 找到它是个小游戏,你需要在一个矩阵中找到给定的单词 假设给定单词HELLOWORLD,在矩阵中只要能找HELLOWORLD就算通过 注意区分英文字母大小写,并且你只能上下左右行走 不能走回头路 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD机试(Python)真题目…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

0x-3-Oracle 23 ai-sqlcl 25.1 集成安装-配置和优化
是不是受够了安装了oracle database之后sqlplus的简陋,无法删除无法上下翻页的苦恼。 可以安装readline和rlwrap插件的话,配置.bahs_profile后也能解决上下翻页这些,但是很多生产环境无法安装rpm包。 oracle提供了sqlcl免费许可,…...
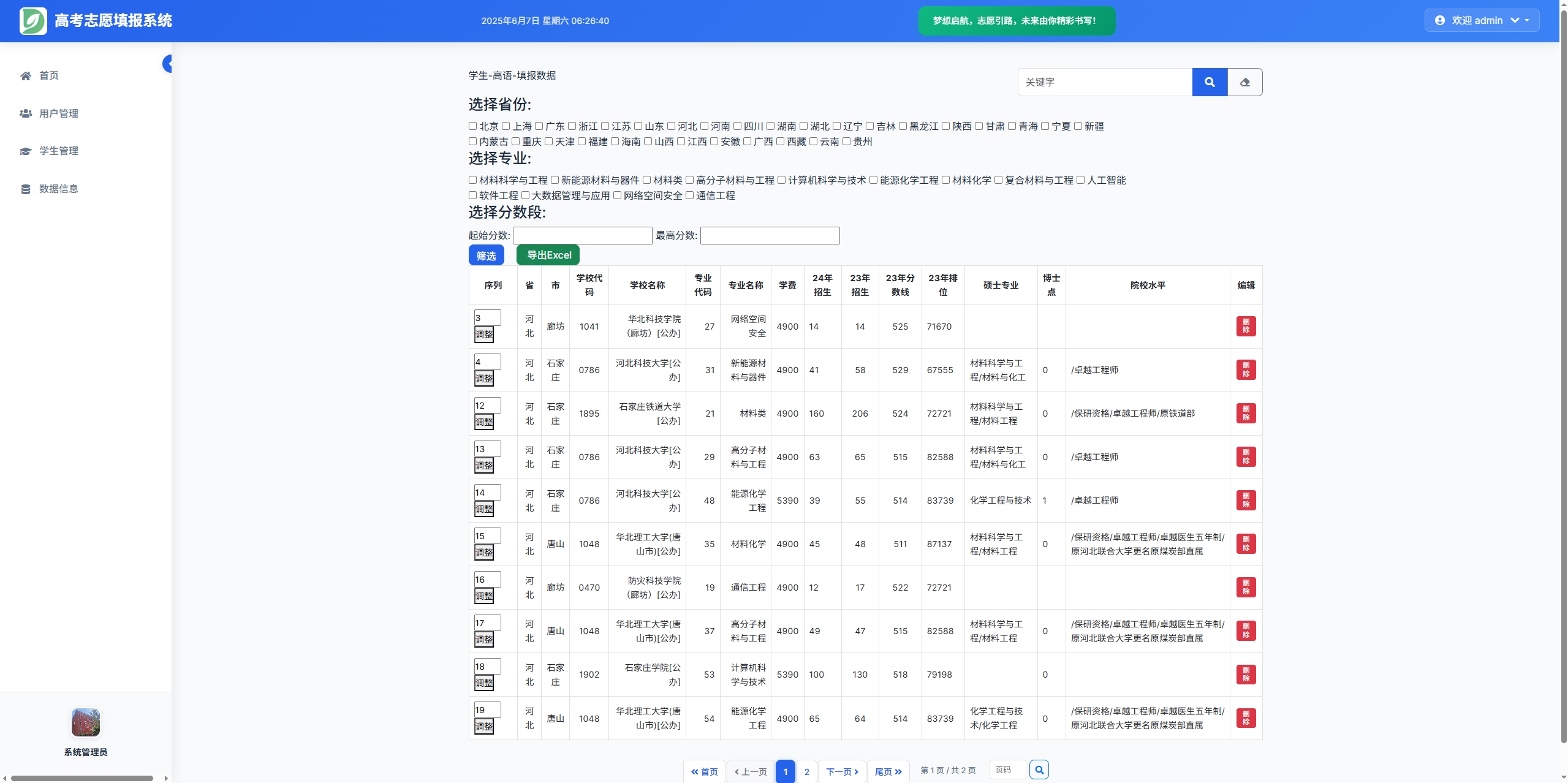
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...

VASP软件在第一性原理计算中的应用-测试GO
VASP软件在第一性原理计算中的应用 VASP是由维也纳大学Hafner小组开发的一款功能强大的第一性原理计算软件,广泛应用于材料科学、凝聚态物理、化学和纳米技术等领域。 VASP的核心功能与应用 1. 电子结构计算 VASP最突出的功能是进行高精度的电子结构计算ÿ…...