MySQL进阶之性能优化与调优技巧
数据库开发-MySQL
- 1. 多表查询
- 1.1 概述
- 1.1.2 介绍
- 1.1.3 分类
- 1.2 内连接
- 1.3 外连接
- 1.4 子查询
- 1.4.1 介绍
- 1.4.2 标量子查询
- 1.4.3 列子查询
- 1.4.4 行子查询
- 1.4.5 表子查询
- 2. 事务
- 2.1 介绍
- 2.2 操作
- 2.3 四大特性
- 3. 索引
- 3.1 介绍
- 3.2 结构
- 3.3 语法
1. 多表查询
1.1 概述
1.1.2 介绍
多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2;
查询用户表和部门表中的数据:
select * from tb_emp , tb_dept;
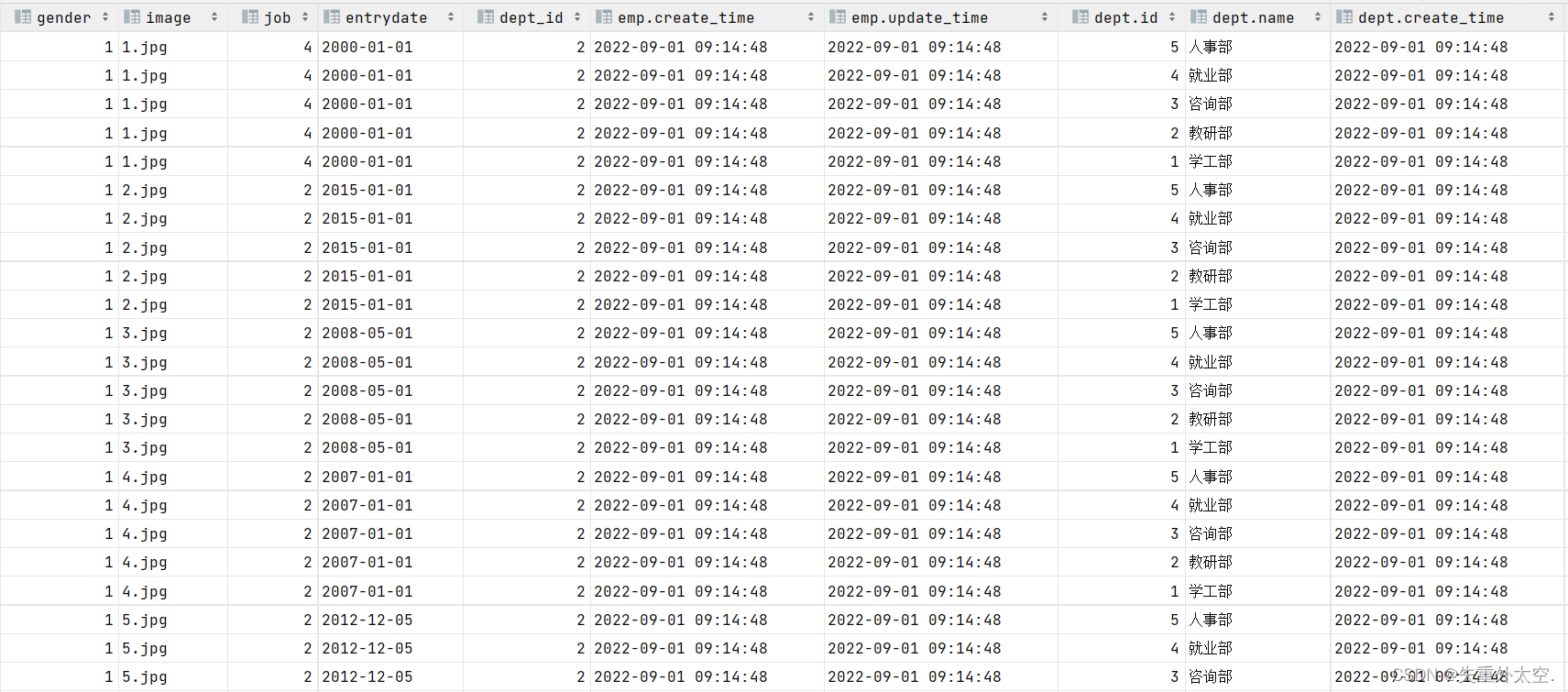
此时,我们看到查询结果中包含了大量的结果集,总共85条记录,而这其实就是员工表所有的记录(17行)与部门表所有记录(5行)的所有组合情况,这种现象称之为笛卡尔积。
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况。

在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据

在SQL语句中,如何去除无效的笛卡尔积呢?只需要给多表查询加上连接查询的条件即可。
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
1.1.3 分类
多表查询可以分为:
-
连接查询
- 内连接:相当于查询A、B交集部分数据

- 内连接:相当于查询A、B交集部分数据
-
外连接
-
左外连接:查询左表所有数据(包括两张表交集部分数据)
-
右外连接:查询右表所有数据(包括两张表交集部分数据)
-
-
子查询
1.2 内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:
-
隐式内连接
-
显式内连接
隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;
显式内连接语法:
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
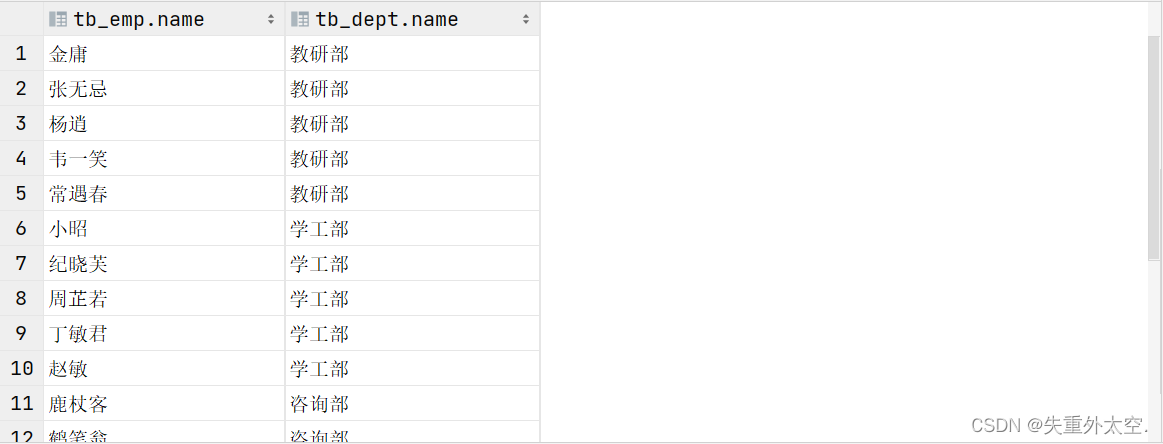
案例:查询员工的姓名及所属的部门名称
- 隐式内连接实现
select tb_emp.name , tb_dept.name -- 分别查询两张表中的数据
from tb_emp , tb_dept -- 关联两张表
where tb_emp.dept_id = tb_dept.id; -- 消除笛卡尔积
- 显式内连接实现
select tb_emp.name , tb_dept.name
from tb_emp inner join tb_dept
on tb_emp.dept_id = tb_dept.id;
多表查询时给表起别名:
-
tableA as 别名1 , tableB as 别名2 ;
-
tableA 别名1 , tableB 别名2 ;

使用了别名的多表查询:
select emp.name , dept.name
from tb_emp emp inner join tb_dept dept
on emp.dept_id = dept.id;
注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
1.3 外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
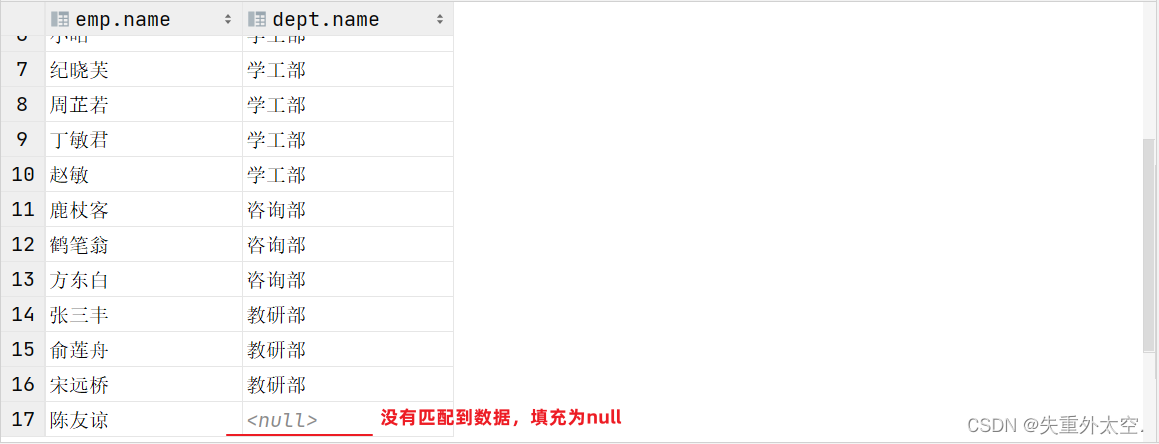
案例:查询员工表中所有员工的姓名, 和对应的部门名称
-- 左外连接:以left join关键字左边的表为主表,查询主表中所有数据,以及和主表匹配的右边表中的数据
select emp.name , dept.name
from tb_emp AS emp left join tb_dept AS dept on emp.dept_id = dept.id;
案例:查询部门表中所有部门的名称, 和对应的员工名称
-- 右外连接
select dept.name , emp.name
from tb_emp AS emp right join tb_dept AS depton emp.dept_id = dept.id;

注意事项:
左外连接和右外连接是可以相互替换的,只需要调整连接查询时SQL语句中表的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
1.4 子查询
1.4.1 介绍
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
根据子查询结果的不同分为:
-
标量子查询(子查询结果为单个值[一行一列])
-
列子查询(子查询结果为一列,但可以是多行)
-
行子查询(子查询结果为一行,但可以是多列)
-
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:
- where之后
- from之后
- select之后
1.4.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: = <> > >= < <=
案例1:查询"教研部"的所有员工信息
可以将需求分解为两步:
- 查询 “教研部” 部门ID
- 根据 “教研部” 部门ID,查询员工信息
-- 1.查询"教研部"部门ID
select id from tb_dept where name = '教研部'; #查询结果:2
-- 2.根据"教研部"部门ID, 查询员工信息
select * from tb_emp where dept_id = 2;-- 合并出上两条SQL语句
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部');

案例2:查询在 “方东白” 入职之后的员工信息
可以将需求分解为两步:
- 查询 方东白 的入职日期
- 查询 指定入职日期之后入职的员工信息
-- 1.查询"方东白"的入职日期
select entrydate from tb_emp where name = '方东白'; #查询结果:2012-11-01
-- 2.查询指定入职日期之后入职的员工信息
select * from tb_emp where entrydate > '2012-11-01';-- 合并以上两条SQL语句
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');

1.4.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
案例:查询"教研部"和"咨询部"的所有员工信息
分解为以下两步:
- 查询 “销售部” 和 “市场部” 的部门ID
- 根据部门ID, 查询员工信息
-- 1.查询"销售部"和"市场部"的部门ID
select id from tb_dept where name = '教研部' or name = '咨询部'; #查询结果:3,2
-- 2.根据部门ID, 查询员工信息
select * from tb_emp where dept_id in (3,2);-- 合并以上两条SQL语句
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');

1.4.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:查询与"韦一笑"的入职日期及职位都相同的员工信息
可以拆解为两步进行:
- 查询 “韦一笑” 的入职日期 及 职位
- 查询与"韦一笑"的入职日期及职位相同的员工信息
-- 查询"韦一笑"的入职日期 及 职位
select entrydate , job from tb_emp where name = '韦一笑'; #查询结果: 2007-01-01 , 2
-- 查询与"韦一笑"的入职日期及职位相同的员工信息
select * from tb_emp where (entrydate,job) = ('2007-01-01',2);-- 合并以上两条SQL语句
select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑');

1.4.5 表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
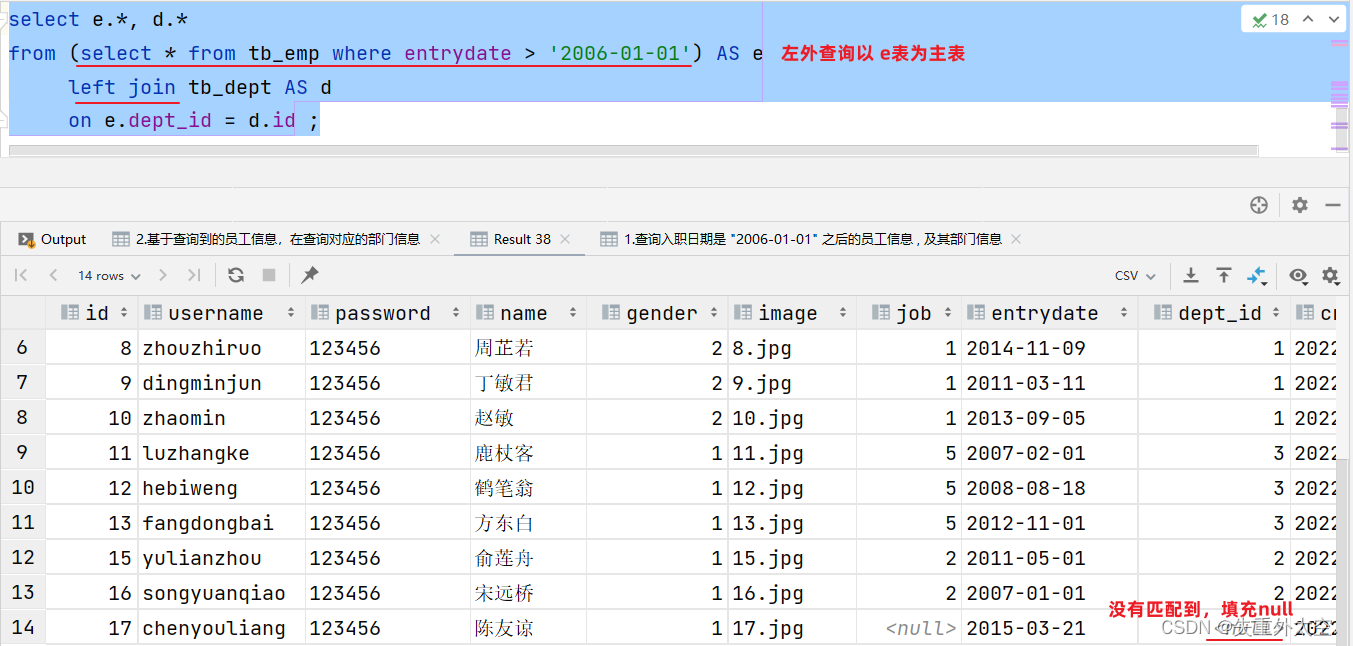
案例:查询入职日期是 “2006-01-01” 之后的员工信息 , 及其部门信息
分解为两步执行:
- 查询入职日期是 “2006-01-01” 之后的员工信息
- 基于查询到的员工信息,在查询对应的部门信息
select * from emp where entrydate > '2006-01-01';select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
2. 事务
2.1 介绍
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
2.2 操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
- 手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
使用事务控制删除部门和删除该部门下的员工的操作:
-- 开启事务
start transaction ;-- 删除学工部
delete from tb_dept where id = 1;-- 删除学工部的员工
delete from tb_emp where dept_id = 1;
- 上述的这组SQL语句,如果如果执行成功,则提交事务
-- 提交事务 (成功时执行)
commit ;
- 上述的这组SQL语句,如果如果执行失败,则回滚事务
-- 回滚事务 (出错时执行)
rollback ;
2.3 四大特性
面试题:事务有哪些特性?
- 原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
-
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
-
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
- 隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。
- 持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
3. 索引
3.1 介绍
索引(index):是帮助数据库高效获取数据的数据结构 。
- 简单来讲,就是使用索引可以提高查询的效率。
测试没有使用索引的查询:

添加索引后查询:
-- 添加索引
create index idx_sku_sn on tb_sku (sn); #在添加索引时,也需要消耗时间-- 查询数据(使用了索引)
select * from tb_sku where sn = '100000003145008';

优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
3.2 结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
在没有了解B+Tree结构前,我们先回顾下之前所学习的树结构:
二叉查找树:左边的子节点比父节点小,右边的子节点比父节点大

当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣。

可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)

但是在Mysql数据库中并没有使用二叉搜索数或二叉平衡数或红黑树来作为索引的结构。
思考:采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
答案 最大的问题就是在数据量大的情况下,树的层级比较深,会影响检索速度。因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。
下面我们来看看B+Tree(多路平衡搜索树)结构中如何避免这个问题:
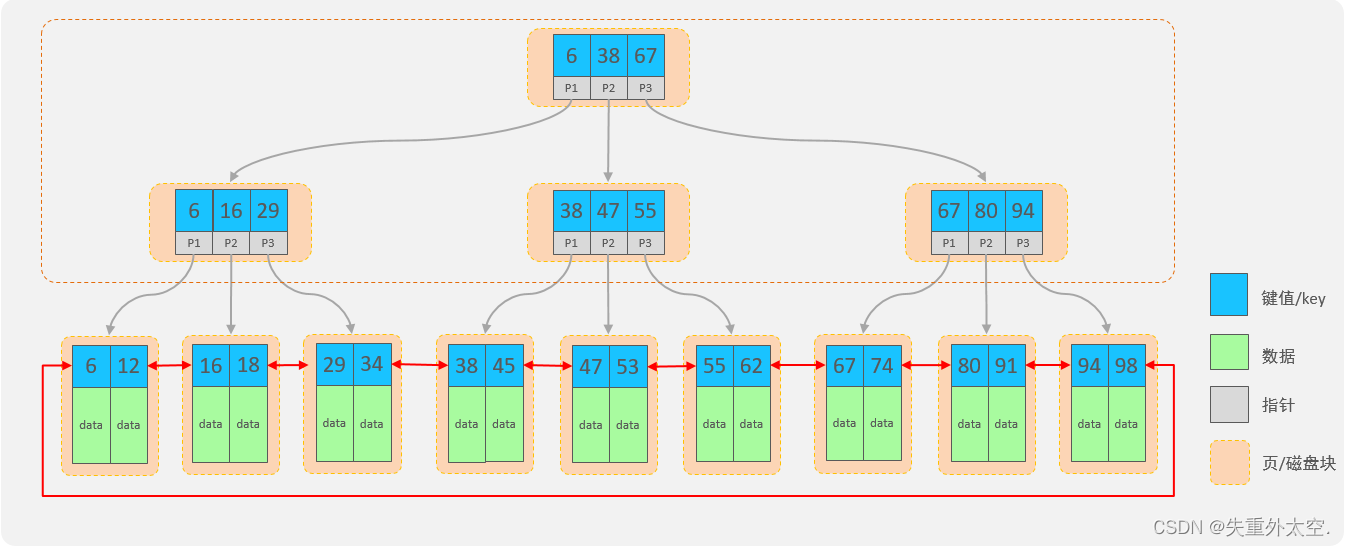
B+Tree结构:
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
拓展:
非叶子节点都是由key+指针域组成的,一个key占8字节,一个指针占6字节,而一个节点总共容量是16KB,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6)=1170个元素。
- 查看mysql索引节点大小:show global status like ‘innodb_page_size’; – 节点大小:16384
当根节点中可以存储1170个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储1170个元素,那么第二层即第二次IO的时候就会找到数据大概是:1170*1170=135W。也就是说B+Tree数据结构中只需要经历两次磁盘IO就可以找到135W条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由key+数据组成,假设key+数据总大小是1KB,而每个节点一共能存储16KB,所以一个第三层一个节点大概可以存储16个元素(即16条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是135W个元素,那么第三层总元素大小就是:135W*16结果就是2000W+的元素个数。
结合上述分析B+Tree有如下优点:
- 千万条数据,B+Tree可以控制在小于等于3的高度
- 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
3.3 语法
创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
案例:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
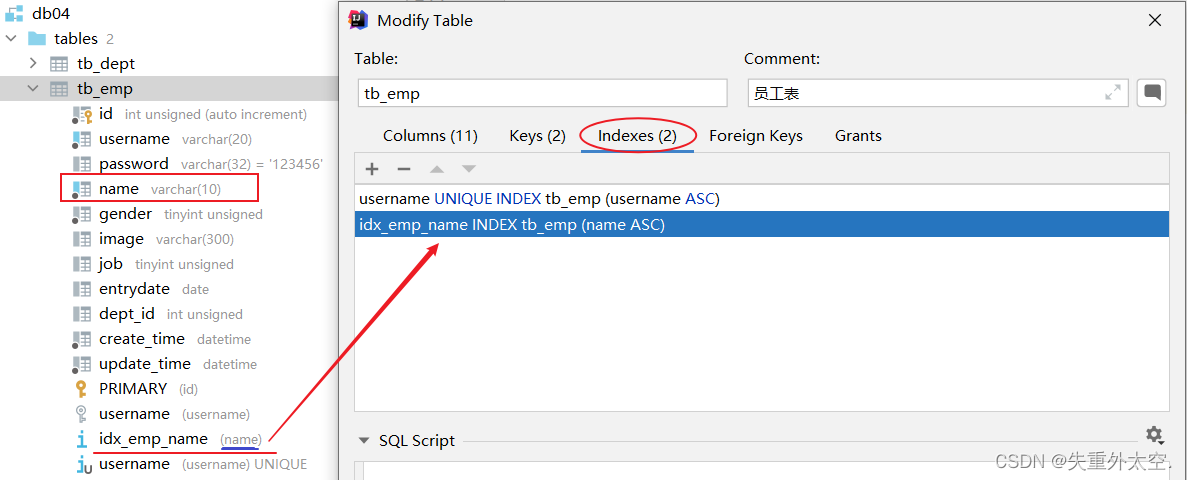
在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束

查看索引
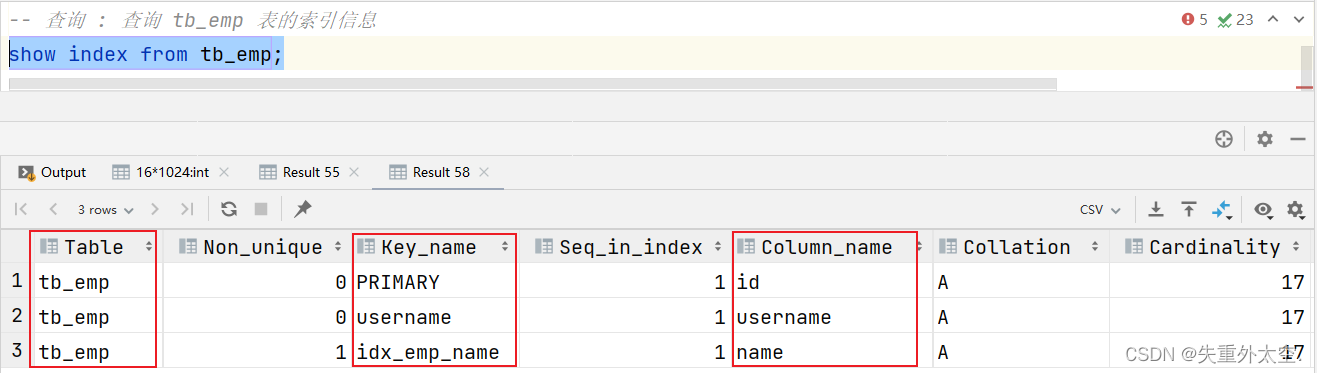
show index from 表名;
案例:查询 tb_emp 表的索引信息
show index from tb_emp;
删除索引
drop index 索引名 on 表名;
案例:删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事项:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引
后记
👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹
相关文章:
MySQL进阶之性能优化与调优技巧
数据库开发-MySQL 1. 多表查询1.1 概述1.1.2 介绍1.1.3 分类 1.2 内连接1.3 外连接1.4 子查询1.4.1 介绍1.4.2 标量子查询1.4.3 列子查询1.4.4 行子查询1.4.5 表子查询 2. 事务2.1 介绍2.2 操作2.3 四大特性 3. 索引3.1 介绍3.2 结构3.3 语法 1. 多表查询 1.1 概述 1.1.2 介绍…...
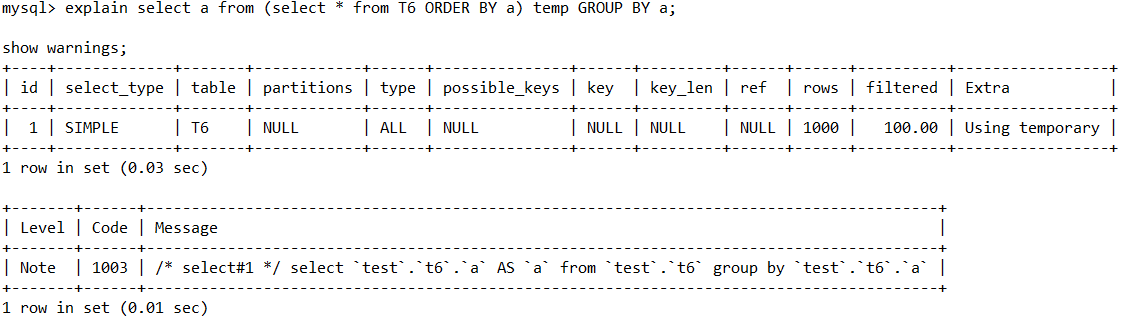
MySQL EXPLAIN查看执行计划
MySQL 执⾏计划是 MySQL 查询优化器分析 SQL 查询时⽣成的⼀份详细计划,包括表如何连 接、是否⾛索引、表扫描⾏数等。通过这份执⾏计划,我们可以分析这条 SQL 查询中存在的 问题(如是否出现全表扫描),从⽽进⾏针对优化…...
)
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(最终篇)
目录 知识储备 杂散光 结构光 ■ 被动测距 ■ 主动结构光 图像分类技巧 增强...
redis教程 二 redis客户端Jedis使用
文章目录 Redis的Java客户端-JedisJedis快速入门创建工程:引入依赖:建立连接测试:释放资源Jedis连接池创建Jedis的连接池改造原始代码 Redis的Java客户端-SpringDataRedis快速入门导入pom坐标配置文件测试代码 数据序列化器StringRedisTempla…...
【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎 大数据引擎是用于处理大规模数据的软件系统, 常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。 其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提…...
)
SOEM源码解析——ecx_init_context(初始化句柄)
0 工具准备 1.SOEM-master-1.4.0源码1 ecx_init_context函数总览 /*** @brief 初始化句柄* @param context 句柄*/ void ecx_init_context(ecx_contextt *context) {int lp;*(context->slavecount) = 0;/* clean ec_slave array */...

11.Z-Stack协议栈使用
f8wConfig.cfg文件 选择信道、设置PAN ID 选择信道 #define DEFAULT_CHANLIST 0x00000800 DEFAULT_CHANLIST 表明Zigbee模块要工作的网络,当有多个信道参数值进行或操作之后,把结果作为 DEFAULT_CHANLIST值 对于路由器、终端、协调器的意义࿱…...
设计模式—结构型模式之适配器模式
设计模式—结构型模式之适配器模式 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,适配器模式分为类结构型模式(继承)和对象结构型模式(组合)两种,前者&a…...

【LeetCode】187. 重复的DNA序列
187. 重复的DNA序列 难度:中等 题目 DNA序列 由一系列核苷酸组成,缩写为 A, C, G 和 T.。 例如,"ACGAATTCCG" 是一个 DNA序列 。 在研究 DNA 时,识别 DNA 中的重复序列非常有用。 给定一个表示 DNA序列 的字符串 …...

C++17中std::any的使用
类sdk:any提供类型安全的容器来存储任何类型的单个值。通俗地说,std::any是一个容器,可以在其中存储任何值(或用户数据),而无需担心类型安全。void*的功能有限,仅存储指针类型,被视为不安全模式。std::any可以被视为vo…...

携手ChainGPT 人工智能基础设施 波场TRON革新 Web3 版图
近日,波场TRON与 Web3 人工智能基础设施服务商 ChainGPT 正式达成合作。通过本次合作,双方将进一步推动人工智能和区块链技术的融合,在实现优势互补的同时,真正惠及日常生活。 作为一站式的加密AI中心,ChainGPT 的人工智能工具需要进行大量计算,能耗高,而波场TRON采用的创新型…...

pdfH5实现pdf预览功能
1.引入 npm install pdfh5 2.使用 <view id"pdfBox" class""></view> showPdf(url) {this.pdfh5 new Pdfh5("", {URIenable: false,zoomEnanle: true,maxZoom: 2,pdfurl: url})this.pdfh5.on("complete", function(st…...

Redis的持久化机制
多级缓存使用到了一个装饰设计模式:相当于我不影响我之前缓存本身的代码,但是我可以对我的缓存去做增强,因此多级缓存就是采用装饰模式去实现的~! 多级缓存可以采用装饰模式去重构~! Redis当中的持久化机制ÿ…...
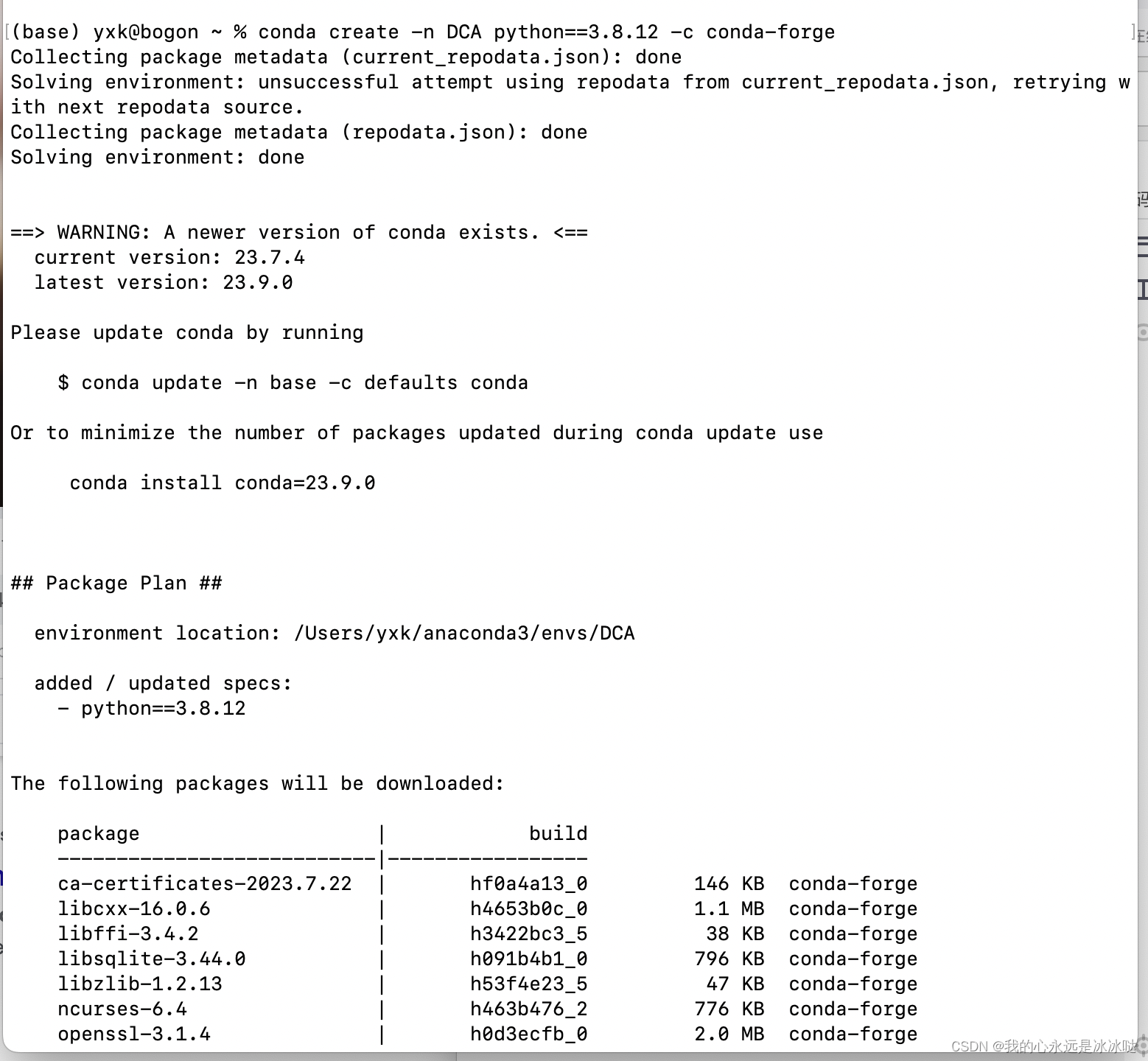
mac装不了python3.7.6
今天发现一个很奇怪的问题 但是我一换成 conda create -n DCA python3.8.12就是成功的 这个就很奇怪...

仿写知乎日报第三周
新学到的 本周新学习了FMDB数据库,并对Masonry的使用有了更近一步的了解,还了解了cell的自适应高度 FMDB数据库的介绍和使用:iOS——FMDB的介绍与使用 cell自适应高度和Mansonry自动布局 本周写了评论区,在写评论区的时候&…...

Godot Best practices
Get Forward Vector transform.x # 等价手算 var rad node.rotation var forward Vector2(cos(rad), sin(rad))Await and Unity Style Coroutine func coroutine(on_update: Callable, duration: float 1):var elapse_time 0while elapse_time < 1:elapse_time get_p…...

win10 + cmake3.17 编译 giflib5.2.1
所有源文件已经打包上传csdn,大家可自行下载。 1. 下载giflib5.2.1,解压。 下载地址:GIFLIB - Browse Files at SourceForge.net 2. 下载CMakeLists.txt 及其他依赖的文件 从github上的osg-3rdparty-cmake项目: https://github.…...

【rust/esp32】初识slint ui框架并在st7789 lcd上显示
文章目录 说在前面关于slint关于no-std关于dma准备工作相关依赖代码结果参考 说在前面 esp32版本:s3运行环境:no-std开发环境:wsl2LCD模块:ST7789V2 240*280 LCDSlint版本:master分支github地址:这里 关于s…...
-http工作机制、指令和内置变量)
精通Nginx(05)-http工作机制、指令和内置变量
http服务是Nginx最原始的服务,搞清楚其工作机制非常有利于弄懂nginx是如何工作的。 Nginx核心模块为ngx_http_core_module。 目录 http工作机制 配置结构 工作机制 http常用指令 http server listen server_name location 优先级 "/"的特殊用法 root/a…...
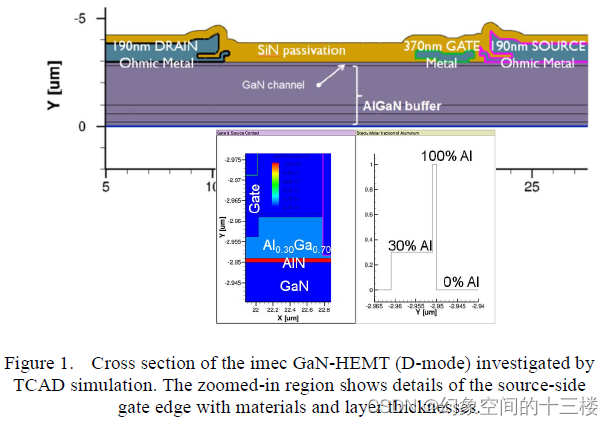
用于 GaN-HEMT 功率器件仿真的 TCAD 方法论
目录 标题:TCAD Methodology for Simulation of GaN-HEMT Power Devices来源:Proceedings of the 26th International Symposium on Power Semiconductor Devices & ICs(14年 ISPSD)GaN-HEMT仿真面临的挑战文章研究了什么文章的创新点文章的研究方法…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...