【打卡】图分析与节点嵌入
背景介绍
图(Graphs)是一种对物体(objects)和他们之间的关系(relationships)建模的数据结构,物体以结点(nodes)表示,关系以边(edges)表示。图是复杂系统中常用的信息载体,可以表示现实中许多复杂关系,如社交网络、犯罪网络、交通网络等。
环境配置
实践环境建议以Python3.7+,且需要安装如下库:
numpy
pandas
networkx
igraph
gensim
Task1: 图属性与图构造
Task1.1 导入network
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
Task1.2 加载数据集
# 两列,分别为节点id,节点类别
group = pd.read_csv('DATA/group.txt.zip', sep='\t', header=None)
#查看节点个数
print('节点个数:{}, 节点类别:{}'.format(group[0].nunique(), group[1].nunique()))
# 两列,分别为出发节点id,目的节点id
graph = pd.read_csv('DATA/graph.txt.zip', sep='\t', header=None)
#查看边的个数
print("边的个数:{},起始节点个数:{}, 终止节点个数:{}".format(graph.shape[0], graph[0].nunique(), graph[1].nunique()))

Task1.3 使用network构造有向图
# 创建 图
G1 = nx.Graph() # 创建:无向图
G2 = nx.DiGraph() #创建:有向图
G3 = nx.MultiGraph() #创建:多图
G4 = nx.MultiDiGraph() #创建:有向多图

#创建有向图,nx在2.5.0以上才会有指向自身的箭头
g = nx.DiGraph()
# 只添加前100条边
g.add_edges_from(graph.values[:100])
nx.draw_spring(g)# 添加所有数据
g = nx.DiGraph()
g.add_edges_from(graph.values[:])
Task2: 图查询与遍历
步骤1:使用networkx对Wiki数据集进行如下统计
节点个数、边个数
dir(g) 查看graph的属性

print('节点个数{}, 边的个数{}'.format(g.number_of_nodes(), g.number_of_edges()))

节点度平均
1.查看节点的度,是个dict类型,key是node,value是入度+出度
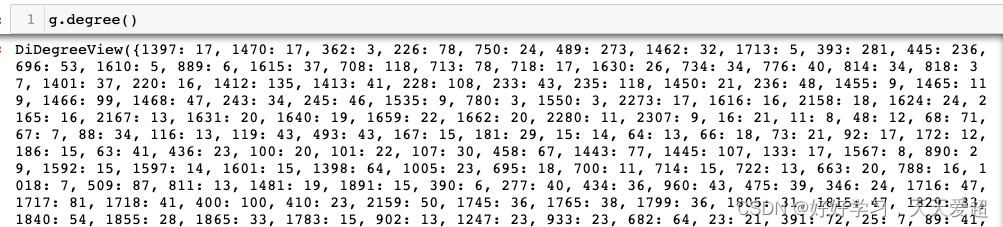
2.求度的均值
#节点度平均
np.mean([x[1] for x in list(g.degree)])

存在指向自身节点的个数
指向自身节点,就是边的起始点一样,edge[0]==edge[1]

步骤2:对节点1397进行深度和广度遍历,设置搜索最大深度为5
dir(nx)查看nx属性
# 对节点1397的深度5内进行深度和广度遍历
nx.dfs_tree(g, 1397, 5).nodes()
nx.bfs_tree(g, 1397, 5).nodes()
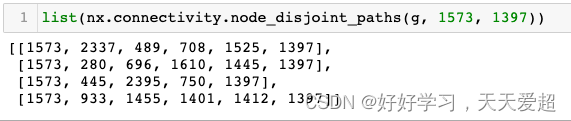
步骤3:判断节点1573与节点1397之间是否存在联通性
list(nx.connectivity.node_disjoint_paths(g, 1573, 1397))
Task3: 节点中心性与应用
步骤1:筛选度最大的Top10个节点,并对节点深度1以内的节点进行可视化;
步骤2:使用PageRank筛选Top10个节点,并对节点深度1以内的节点进行可视化;
步骤3:文本关键词提取算法RAKE
使用jieba对文本进行分词
单词作为节点,距离2以内的单词之间存在边
计算单词打分 wordDegree (w)/ wordFrequency (w)
按照打分统计每个文章Top10关键词
步骤4:文本关键词提取算法TextRank
使用jieba对文本进行分词
单词作为节点,距离2以内的单词之间存在边
使用PageRank对单词进行打分
按照打分统计每个文章Top10关键词
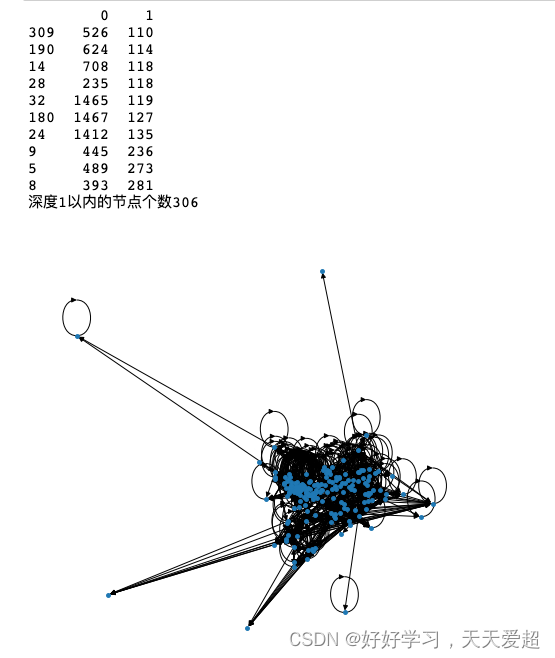
#步骤1:筛选度最大的Top10个节点,并对节点深度1以内的节点进行可视化;
g_degree = pd.DataFrame(g.degree()).sort_values(by=1)
g_degree = g_degree.iloc[-10:]
#对深度1以内的节点进行可视化
selected_nodes = []
for node in g_degree[0].values:selected_nodes += list(nx.dfs_tree(g, node, 1).nodes())
print('深度1以内的节点个数{}'.format(len(selected_nodes)))
#设置图片大小
plt.rcParams['figure.figsize']= (10, 10)
nx.draw_spring(g.subgraph(selected_nodes), node_size=15)
# 步骤2:使用PageRank筛选Top10个节点,并对节点深度1以内的节点进行可视化;
g_pagerank = pd.DataFrame.from_dict(nx.pagerank(g), orient='index')
g_pagerank = g_pagerank.sort_values(by=0)g_pagerank = g_pagerank.iloc[-10:]
print(g_pagerank)
selected_nodes = []
for node in g_pagerank[0].index:selected_nodes += list(nx.dfs_tree(g, node, 1).nodes())
print('深度1以内的节点个数{}'.format(len(selected_nodes)))
nx.draw_spring(g.subgraph(selected_nodes), node_size=15)

contents=[
# 文章1
'''
一纸四季报,令芯片巨头英特尔一夜间股价重挫近6.5%,市值蒸发80亿美元,再度被AMD反超。这份严重缩水的财报显示,英特尔在去年四季度营收大降32%至140亿美元,是2016年以来最低单季收入;净利润由三季度的10.2亿美元转为近7亿美元净亏损;毛利率更从2021年四季度的53.6%大幅下降至39.2%。此番业绩“跳水”并非英特尔一家的一时失利,在全球PC出货量整体下滑的背景下,包括英特尔、AMD、英伟达、高通在内的芯片企业,均在过去一年里出现不同程度的收入与利润下滑,但英特尔的确是其中的重灾区。
'''
,
# 文章2
'''
2021年,成都地区生产总值已经超过1.99万亿元,距离2万亿门槛仅咫尺之间。在去年遭受多轮疫情冲击及高温限电冲击的不利影响下,2022年,成都市实现地区生产总值20817.5亿元,按可比价格计算,比上年增长2.8%。成都因此成为第7个跨过GDP2万亿门槛的城市。目前,GDP万亿城市俱乐部中形成了4万亿、3万亿、2万亿和万亿这四个梯队。上海和北京在2021年跨过了4万亿,深圳2021年跨过了3万亿,重庆、广州、苏州和成都则是2万亿梯队。在排名前十的城市中,预计武汉将超过杭州。武汉市政府工作报告称,预计2022年武汉地区生产总值达到1.9万亿元左右。而杭州市统计局公布的数据显示,杭州2022年地区生产总值为18753亿元。受疫情影响,武汉在2020年GDP排名退居杭州之后。
''',
# 文章3
'''
据报道,美国证券交易委员会(SEC)与特斯拉首席执行官埃隆·马斯克之间又起波澜。SEC正对马斯克展开调查,主要审查内容是,马斯克是否参与了关于特斯拉自动驾驶软件的不恰当宣传。据知情人士透露,该机构正在调查马斯克是否就驾驶辅助技术发表了不恰当的前瞻声明。特斯拉在2014年首次发布了其自动驾驶辅助功能,公司声称该功能可以让汽车在车道内自动转向、加速和刹车。目前所有特斯拉车辆都内置了该软件。
'''
]
步骤3:文本关键词提取算法RAKE
import jieba
from collections import Counter
for content in contents:g2 = nx.Graph()words = jieba.lcut(content)words = [x for x in words if len(x) > 1]for i in range(len(words)-2):for j in range(i-2, i+2):if i == j:continueg2.add_edge(words[i], words[j])g2_node_gree = dict(g2.degree())word_counter = dict(Counter(words))g2_node_gree = pd.DataFrame.from_dict(g2_node_gree, orient='index')g2_node_gree.columns = ['degree']g2_node_gree['freq'] = g2_node_gree.index.map(word_counter)g2_node_gree['score'] = g2_node_gree['degree'] / g2_node_gree['freq']print(list(g2_node_gree.sort_values(by='score').index[-10:]))g2.clear()

文本关键词提取算法TextRank
for content in contents:g2 = nx.Graph()words = jieba.lcut(content)words = [x for x in words if len(x) > 1]for i in range(len(words)-2):for j in range(i-2, i+2):if i == j:continueg2.add_edge(words[i], words[j])g2_node_gree = pd.DataFrame.from_dict(nx.pagerank(g2), orient='index')g2_node_gree.columns = ['degree']g2_node_gree = g2_node_gree.sort_values(by='degree')print(list(g2_node_gree.sort_values(by='degree').index[-10:]))g2.clear()

Task4: 图节点嵌入算法:DeepWalk/node2vec
步骤1:使用DeepWalk对Wiki数据集节点嵌入,维度为50维
步骤2:每个group中20%的节点作为验证集,剩余的作为训练集
步骤3:使用节点嵌入向量 + 逻辑回归进行训练,并记录验证集准确率
步骤4:使用node2vec重复上述操作
步骤5:使用t-SNE将节点的DeepWalk/node2vec特征降维,绘制散点图,节点颜色使用group进行区分
2014 DeepWalk: Online Learning of Social Representations, PDF
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
相关文章:
【打卡】图分析与节点嵌入
背景介绍 图(Graphs)是一种对物体(objects)和他们之间的关系(relationships)建模的数据结构,物体以结点(nodes)表示,关系以边(edges)…...
python元编程详解
什么是元编程 软件开发中很重要的一条原则就是“不要重复自己的工作(Don’t repeat youself)”,也就是说当我们需要复制粘贴代码时候,通常都需要寻找一个更加优雅的解决方案,在python中,这类问题常常会归类…...
为什么文档对 SaaS 公司至关重要?
在过去十年左右的时间里,SaaS的兴起使全球数百家公司成为家喻户晓的公司。但他们并不是仅仅依靠产品的力量到达那里的。客户服务和支持是使一切在幕后顺利进行的原因——其中很大一部分是文档。以正确的风格和正确的位置在您的网站上找到适当的用户文档对于将浏览器…...

Echarts 实现电池效果的柱状图
第022个点击查看专栏目录本示例是解决显示电池电量状态的柱状图,具体的核心代码请参考源代码。 文章目录示例效果示例源代码(共102行)相关资料参考专栏介绍示例效果 示例源代码(共102行) /* * Author: 还是大剑师兰特…...
计算机网络高频知识点(一)
目录 一、http状态码 二、浏览器怎么数据缓存 三、强缓存与协商缓存 1、强缓存 2、协商缓存 四、简单请求与复杂请求 五、PUT 请求类型 六、GET请求类型 七、GET 和 POST 的区别 八、跨域 1、什么时候会跨域 2、解决方式 九、计算机网络的七层协议与五层协议分别指…...

JavaScript split()方法
JavaScript split()方法 目录JavaScript split()方法一、定义和用法二、语法三、参数值四、返回值五、更多实例5.1 省略分割参数5.2 使用limit参数5.3 使用一个字符作为分割符一、定义和用法 split() 方法用于把一个字符串分割成字符串数组。 二、语法 string.split(separat…...

前端面试题 —— 性能优化
目录 一、CDN的作用 二、CDN的使用场景 三、懒加载的概念 四、懒加载与预加载的区别 五、documentFragment 是什么?用它跟直接操作 DOM 的区别是什么? 六、常见的图片格式及使用场景 七、懒加载的特点 八、如何优化动画? 九、如何提⾼…...
我的周刊(第080期)
我的信息周刊,记录这周我看到的有价值的信息,主要针对计算机领域,内容主题极大程度被我个人喜好主导。这个项目核心目的在于记录让自己有印象的信息做一个留存以及共享。🎯 项目stable-diffusion-webui-docker[1]基于 Docker 的一…...
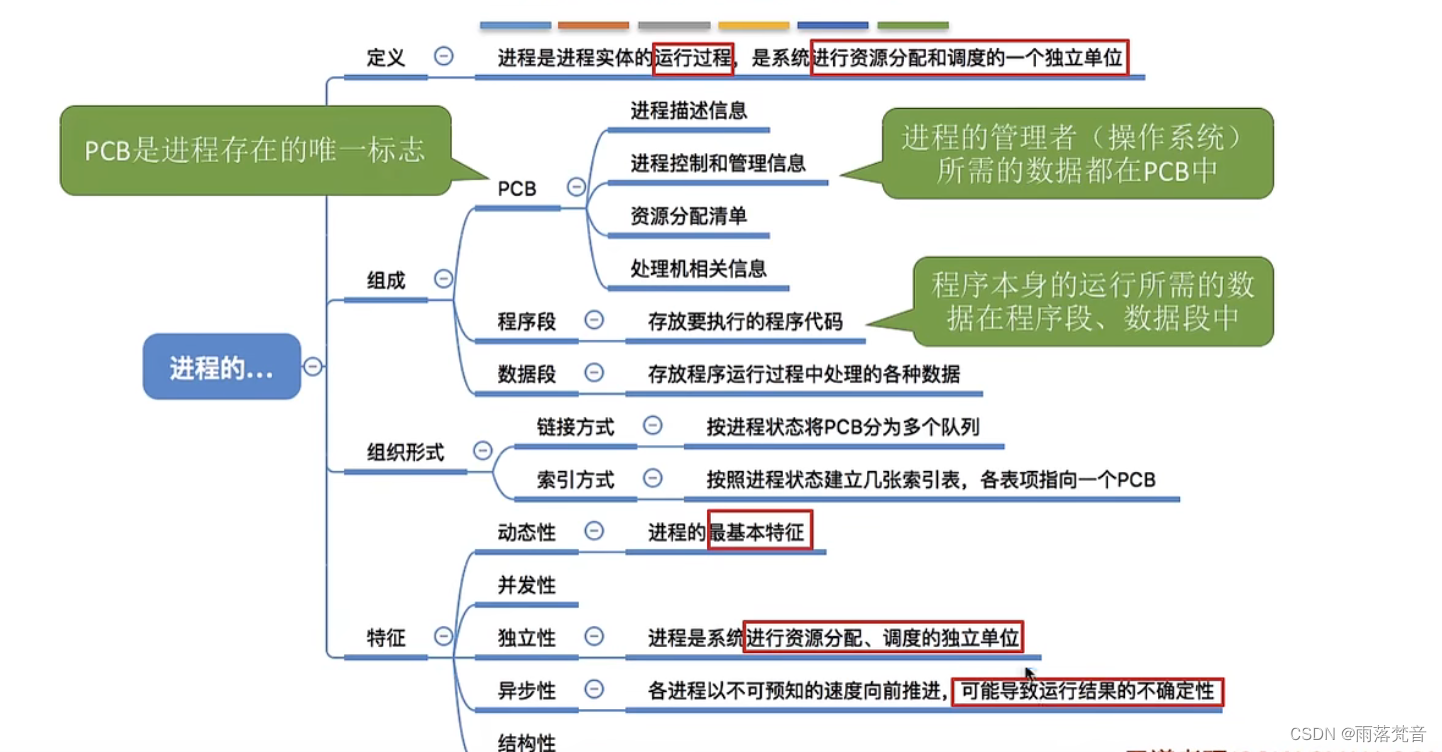
操作系统——7.进程的定义,组成,组成方式和特征
目录 1.概述 编辑2.定义 2.1单道程序 2.2多道程序 2.3进程定义 3.进程的组成 3.1进程的组成内容 3.2 PCB中的内容 4.进程的组织 4.1进程的两种组织方式 4.2链接方式 4.3索引方式 5.进程的特征 6.小结 这篇文章,我们主要来学习一下进程的定义࿰…...
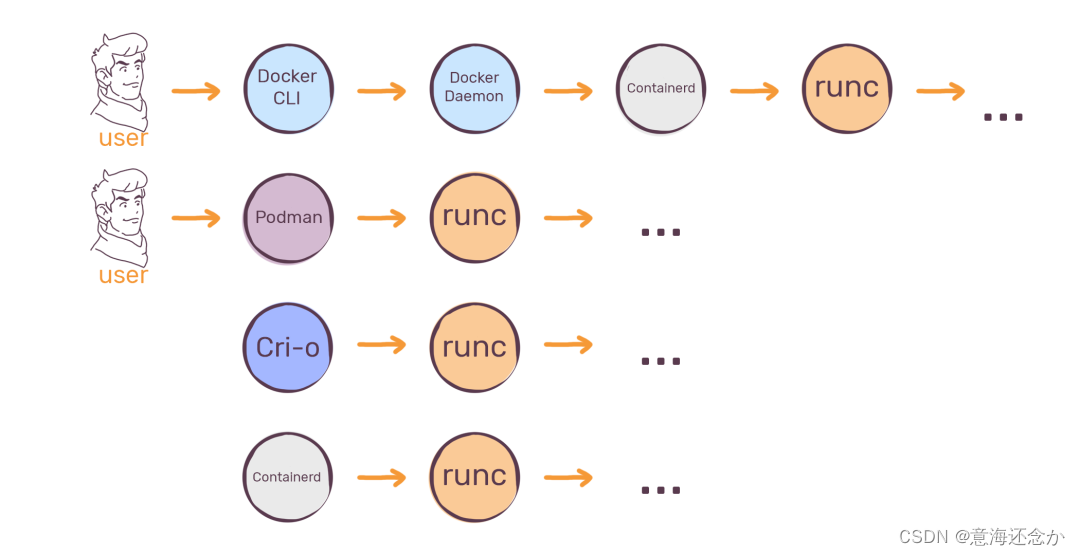
CRI-O, Containerd, Docker, Postman等概念介绍
参考:Docker,containerd,CRI,CRI-O,OCI,runc 分不清?看这一篇就够了Docker, containerd, CRI-O and runc之间的区别? Docker、Podman、Containerd 谁才是真正王者?CRI-O …...
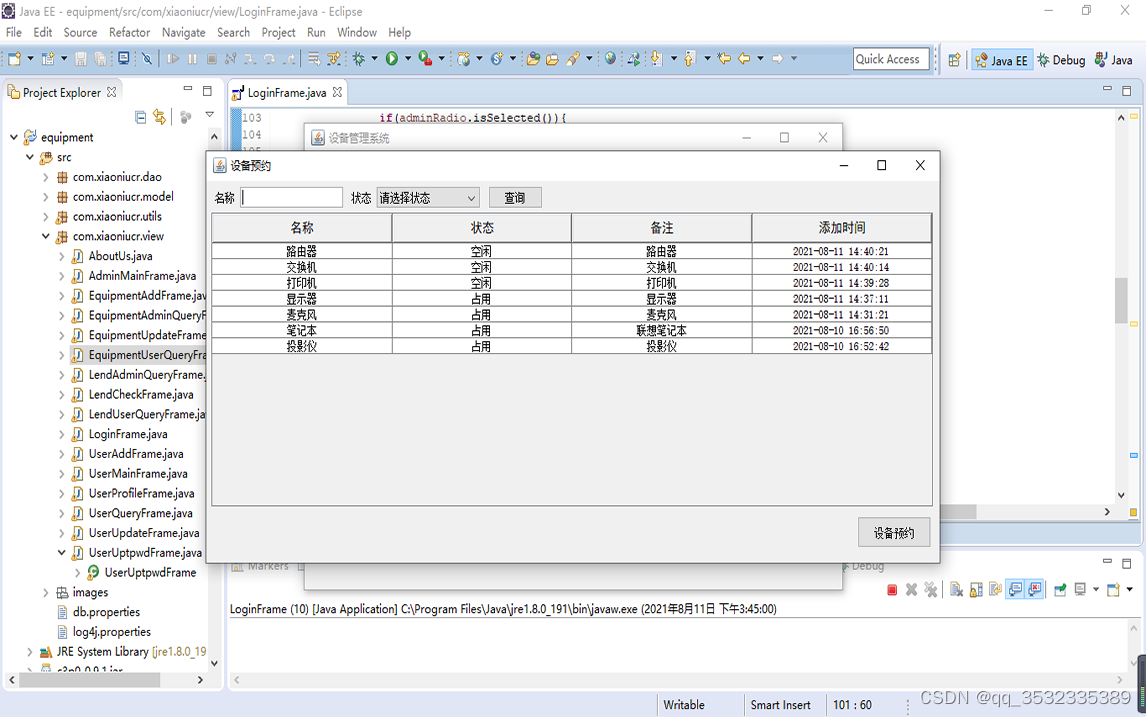
【原创】java+swing+mysql设备预约管理系统设计与实现
我们在办公室或者学校实验室的,经常需要使用一些设备,因此需要提前租借。今天我们主要介绍如何使用javaswing和mysql数据库去完成一个设备预约管理系统,方便用户进行设备管理和预约。 功能分析: 设备预约管理系统主要是为了方便…...
Dashboard 安装)
7、kubernetes(k8s)Dashboard 安装
本文内容以语雀为准 说明 Kubernetes Dashboard 是一个通用的、基于Web的UI,用于Kubernetes集群管理。 它允许用户管理群集中运行的应用程序并对其进行故障排除,以及管理群集本身。 不同 Kubernetes Dashboard 支持的 Kubernetes 版本不同,…...
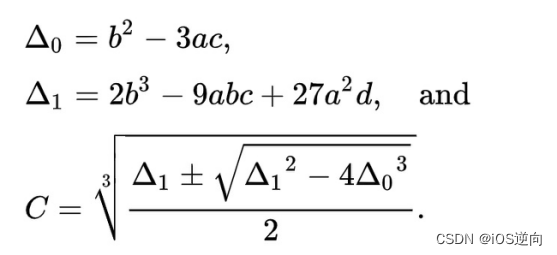
数学小课堂:虚数的媒介工具作用(虚构一个现实中不存在的概念,来解决现实问题)
文章目录 引言I 预备知识1.1 平方根1.2 三次方程1.3 极坐标II 虚数2.1 虚数的来源2.2 理解虚数存在的必要性2.3 虚数的影响III 复数3.1 人类认知升级的过程3.2 数字的扩展历史3.3 复数的用途引言 虚数的来源和存在的必要性:三次方程是一定有实数解的,因此根号里面负数的问题…...
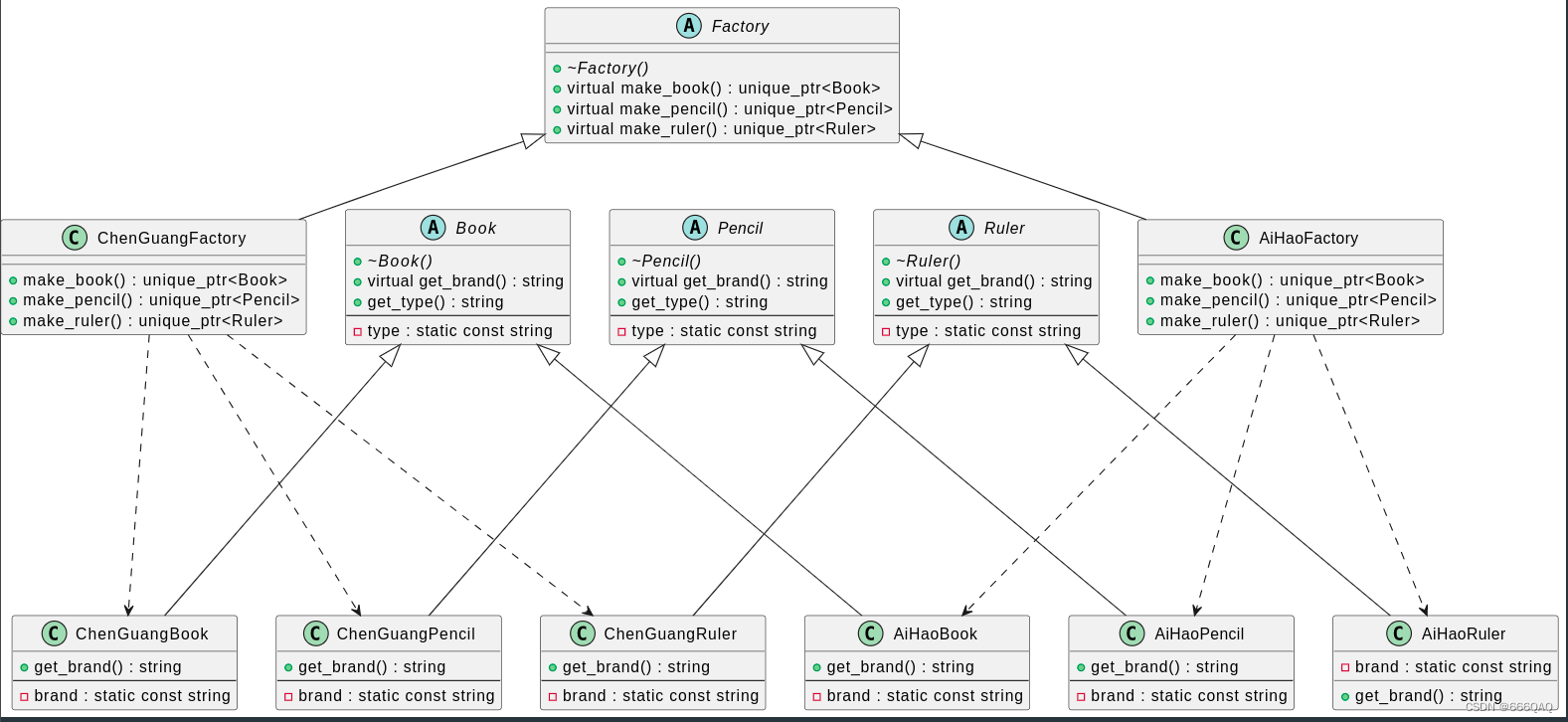
3.抽象工厂模式(Abstract Factory)
与工厂模式对比 工厂模式 工厂模式是类创建模式。在工厂模式中,只需要生产同一种产品,只不过是生产厂家不同。 所以产品类的设计: 抽象的产品类Product具体的产品类Product_A,Product_B, Product_C, Product_D…… 工厂的设计…...

synchronized底层如何实现?什么是锁的升级、降级?
第16讲 | synchronized底层如何实现?什么是锁的升级、降级? 我在上一讲对比和分析了 synchronized 和 ReentrantLock,算是专栏进入并发编程阶段的热身,相信你已经对线程安全,以及如何使用基本的同步机制有了基础&#…...
node环境搭建以及接口的封装
node环境搭建 文章目录node环境搭建1.在cmd中输入命令安装express(全局)2.在自己的项目下安装serve3.测试接口4.连接mysql4.1 创建数据表4.2 在serve目录下建db下的sql.js4.3 sql.js4.4 在serve路径下安装mysql4.5 在routes 中引入并发送请求4.6 请求到数…...
第七天)
跟着我从零开始入门FPGA(一周入门系列)第七天
7、设计一个只有4条指令的CPU我们要设计一个简单的CPU既然做CPU,我们要做流水线的,要简单,做2级流水线就够了。为了实例的简单,我们选择设计一个8bit的MCU的内核仍然我们要简单,所以选择RISC的内核,类似PIC…...

Synopsys Sentaurus TCAD系列教程之--Sde概述
Sde 方便处理rule check相关的问题。同时也能让使用者进一步了解器件结构、掺杂和引线等基本操作。Sde用于搭建结构,重新优化网格,提供.mesh文件供后面Sdevice仿真,主要包含以下几部分: 第一部分: Scheme BasicsDefi…...

计算结构体大小
计算结构体大小 目录计算结构体大小一. 结构体内存对齐1. 简介2. 嵌套结构体二. offsetof三. 内存对齐的意义四. 修改默认对齐数一. 结构体内存对齐 以字节(bety)为单位 1. 简介 对于结构体成员在内存里的存储,存在结构体的对齐规则&#…...

第二十一篇 数据增强
文章目录 摘要1、数据增强的作用2、常用的图像增强方法2.1、一些辅助函数ToTensorToPILImageNormalizeResize2.2、中心裁剪2.3、亮度、对比度和颜色的变化2.4、随机裁剪2.5、随机灰度与灰度2.6、水平/竖直翻转2.6.1、水平翻转2.6.2、垂直旋转2.7、随机角度旋转2.8、随机仿射变换…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...