kibana搭建(windowslinux)
1.说明
搭建kibana方便查询es库,本文分别对windows和linux版本进行安装,因为es集群版本是7.4.1,所以配套的kibana也是选择相同版本
2.下载
https://artifacts.elastic.co/downloads/kibana/kibana-7.4.1-windows-x86_64.zip
https://artifacts.elastic.co/downloads/kibana/kibana-7.4.1-linux-x86_64.tar.gz
3.windows安装
下载zip包,解压文件到固定目录,进入解压目录的config目录,编辑kibana.yml
elasticsearch.hosts配置集群位置,最后一行开启汉化
/bin/kibana.bat 双击启动即可,默认端口5601,访问地址http://localhost:5601
# Kibana is served by a back end server. This setting specifies the port to use. #server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. #server.host: "localhost"# Enables you to specify a path to mount Kibana at if you are running behind a proxy. # Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath # from requests it receives, and to prevent a deprecation warning at startup. # This setting cannot end in a slash. #server.basePath: ""# Specifies whether Kibana should rewrite requests that are prefixed with # `server.basePath` or require that they are rewritten by your reverse proxy. # This setting was effectively always `false` before Kibana 6.3 and will # default to `true` starting in Kibana 7.0. #server.rewriteBasePath: false# The maximum payload size in bytes for incoming server requests. #server.maxPayloadBytes: 1048576# The Kibana server's name. This is used for display purposes. #server.name: "your-hostname"# The URLs of the Elasticsearch instances to use for all your queries. elasticsearch.hosts: ["http://192.168.72.184:9200"]# When this setting's value is true Kibana uses the hostname specified in the server.host # setting. When the value of this setting is false, Kibana uses the hostname of the host # that connects to this Kibana instance. #elasticsearch.preserveHost: true# Kibana uses an index in Elasticsearch to store saved searches, visualizations and # dashboards. Kibana creates a new index if the index doesn't already exist. #kibana.index: ".kibana"# The default application to load. #kibana.defaultAppId: "home"# If your Elasticsearch is protected with basic authentication, these settings provide # the username and password that the Kibana server uses to perform maintenance on the Kibana # index at startup. Your Kibana users still need to authenticate with Elasticsearch, which # is proxied through the Kibana server. #elasticsearch.username: "kibana" #elasticsearch.password: "pass"# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively. # These settings enable SSL for outgoing requests from the Kibana server to the browser. #server.ssl.enabled: false #server.ssl.certificate: /path/to/your/server.crt #server.ssl.key: /path/to/your/server.key# Optional settings that provide the paths to the PEM-format SSL certificate and key files. # These files validate that your Elasticsearch backend uses the same key files. #elasticsearch.ssl.certificate: /path/to/your/client.crt #elasticsearch.ssl.key: /path/to/your/client.key# Optional setting that enables you to specify a path to the PEM file for the certificate # authority for your Elasticsearch instance. #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]# To disregard the validity of SSL certificates, change this setting's value to 'none'. #elasticsearch.ssl.verificationMode: full# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of # the elasticsearch.requestTimeout setting. #elasticsearch.pingTimeout: 1500# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value # must be a positive integer. #elasticsearch.requestTimeout: 30000# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying. #elasticsearch.startupTimeout: 5000# Logs queries sent to Elasticsearch. Requires logging.verbose set to true. #elasticsearch.logQueries: false# Specifies the path where Kibana creates the process ID file. #pid.file: /var/run/kibana.pid# Enables you specify a file where Kibana stores log output. #logging.dest: stdout# Set the value of this setting to true to suppress all logging output. #logging.silent: false# Set the value of this setting to true to suppress all logging output other than error messages. #logging.quiet: false# Set the value of this setting to true to log all events, including system usage information # and all requests. #logging.verbose: false# Set the interval in milliseconds to sample system and process performance # metrics. Minimum is 100ms. Defaults to 5000. #ops.interval: 5000# Specifies locale to be used for all localizable strings, dates and number formats. # Supported languages are the following: English - en , by default , Chinese - zh-CN . #i18n.locale: "en" i18n.locale: "zh-CN"
4.linux安装
下载tar.gz包
解压文件,体验差,解压等待时间太久,不如windows版本解压速度快
tar -zxvf -C /opt/
其中server.host: "0.0.0.0" 类似访问白名单,配置允许的ip即可,访问地址http://虚拟机IP或服务器IP:5601
linux启动方式,我直接配成了开机自启
vi /etc/rc.d/rc.local
sh /opt/kibana-7.4.1-linux-x86_64/bin/kibana --allow-root
#授可执行权限
chmod +x /etc/rc.d/rc.local
参考linux配置文件
# Kibana is served by a back end server. This setting specifies the port to use. #server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. server.host: "0.0.0.0"# Enables you to specify a path to mount Kibana at if you are running behind a proxy. # Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath # from requests it receives, and to prevent a deprecation warning at startup. # This setting cannot end in a slash. #server.basePath: ""# Specifies whether Kibana should rewrite requests that are prefixed with # `server.basePath` or require that they are rewritten by your reverse proxy. # This setting was effectively always `false` before Kibana 6.3 and will # default to `true` starting in Kibana 7.0. #server.rewriteBasePath: false# The maximum payload size in bytes for incoming server requests. #server.maxPayloadBytes: 1048576# The Kibana server's name. This is used for display purposes. #server.name: "your-hostname"# The URLs of the Elasticsearch instances to use for all your queries. elasticsearch.hosts: ["http://192.168.72.184:9200"]# When this setting's value is true Kibana uses the hostname specified in the server.host # setting. When the value of this setting is false, Kibana uses the hostname of the host # that connects to this Kibana instance. #elasticsearch.preserveHost: true# Kibana uses an index in Elasticsearch to store saved searches, visualizations and # dashboards. Kibana creates a new index if the index doesn't already exist. #kibana.index: ".kibana"# The default application to load. #kibana.defaultAppId: "home"# If your Elasticsearch is protected with basic authentication, these settings provide # the username and password that the Kibana server uses to perform maintenance on the Kibana # index at startup. Your Kibana users still need to authenticate with Elasticsearch, which # is proxied through the Kibana server. #elasticsearch.username: "kibana" #elasticsearch.password: "pass"# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively. # These settings enable SSL for outgoing requests from the Kibana server to the browser. #server.ssl.enabled: false #server.ssl.certificate: /path/to/your/server.crt #server.ssl.key: /path/to/your/server.key# Optional settings that provide the paths to the PEM-format SSL certificate and key files. # These files validate that your Elasticsearch backend uses the same key files. #elasticsearch.ssl.certificate: /path/to/your/client.crt #elasticsearch.ssl.key: /path/to/your/client.key# Optional setting that enables you to specify a path to the PEM file for the certificate # authority for your Elasticsearch instance. #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]# To disregard the validity of SSL certificates, change this setting's value to 'none'. #elasticsearch.ssl.verificationMode: full# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of # the elasticsearch.requestTimeout setting. #elasticsearch.pingTimeout: 1500# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value # must be a positive integer. #elasticsearch.requestTimeout: 30000# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying. #elasticsearch.startupTimeout: 5000# Logs queries sent to Elasticsearch. Requires logging.verbose set to true. #elasticsearch.logQueries: false# Specifies the path where Kibana creates the process ID file. #pid.file: /var/run/kibana.pid# Enables you specify a file where Kibana stores log output. #logging.dest: stdout# Set the value of this setting to true to suppress all logging output. #logging.silent: false# Set the value of this setting to true to suppress all logging output other than error messages. #logging.quiet: false# Set the value of this setting to true to log all events, including system usage information # and all requests. #logging.verbose: false# Set the interval in milliseconds to sample system and process performance # metrics. Minimum is 100ms. Defaults to 5000. #ops.interval: 5000# Specifies locale to be used for all localizable strings, dates and number formats. # Supported languages are the following: English - en , by default , Chinese - zh-CN . #i18n.locale: "en"i18n.locale: "zh-CN"
相关文章:

kibana搭建(windowslinux)
1.说明 搭建kibana方便查询es库,本文分别对windows和linux版本进行安装,因为es集群版本是7.4.1,所以配套的kibana也是选择相同版本 2.下载 https://artifacts.elastic.co/downloads/kibana/kibana-7.4.1-windows-x86_64.zip https://artifact…...
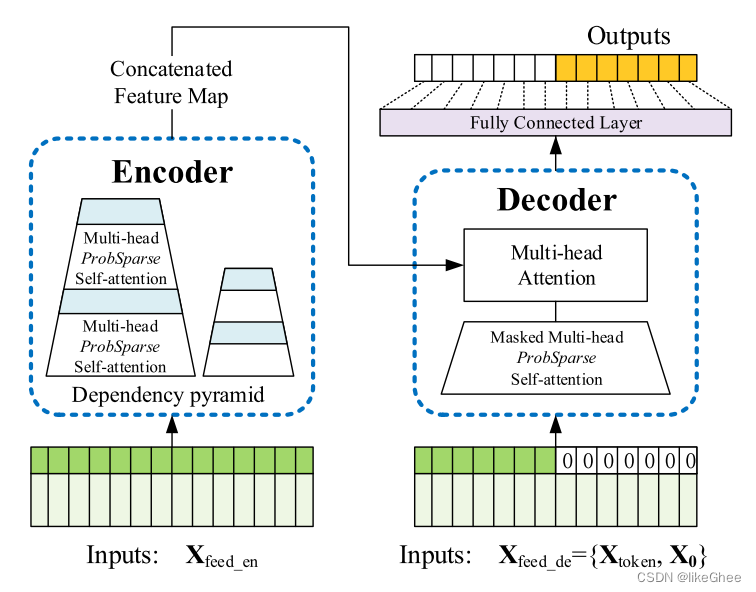
(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper) 看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧 论文作者也很良心的…...
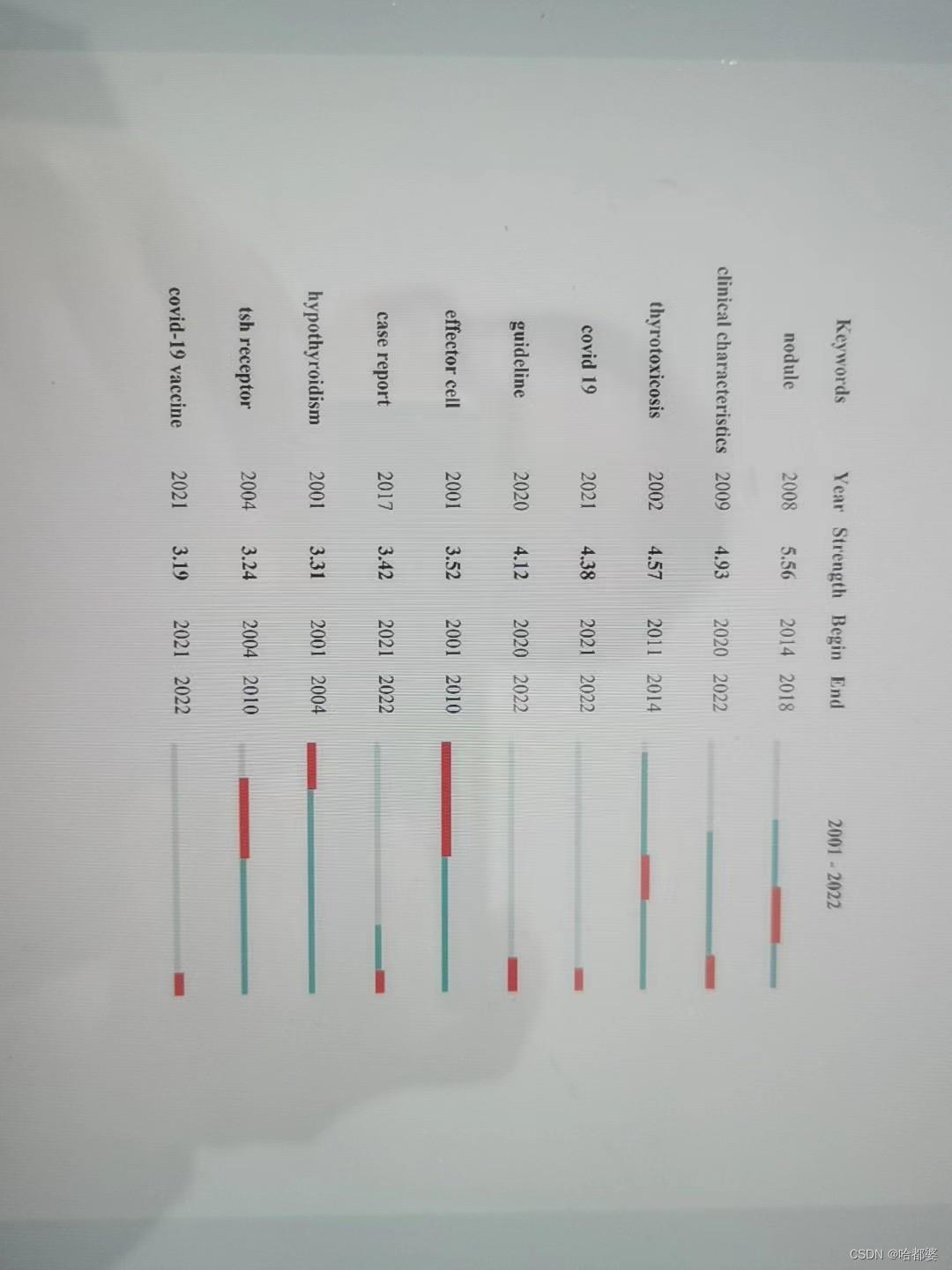
关键词聚类和凸现分析-实战1——亚急性甲状腺炎的
审稿人问题第8页第26行-请指出#是什么意思,并解释为什么亚急性甲状腺炎在这里被列为#8。我认为在搜索亚急性甲状腺炎相关文章时,关键词共现分析应该提供关键词共现的数据。这些结果的实际用途是什么?亚急性甲状腺炎是一种较为罕见但重要的甲状腺疾病&am…...

二叉树——二叉搜索树中的众数
二叉搜索树中的众数 链接 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定…...
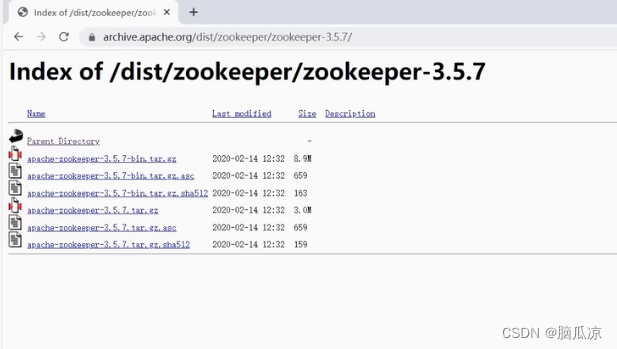
安装_配置参数解读_集群安装配置_启动选举_搭建启停脚本---大数据之ZooKeeper工作笔记004
这里首先下载zookeeper安装包,可以看到官网地址 找到download 点击下载 找到老一点的,我们找3.5.7 in the archive 点击 然后这里找到3.5.7这一个 然后下载这个-bin.tar.gz这个...
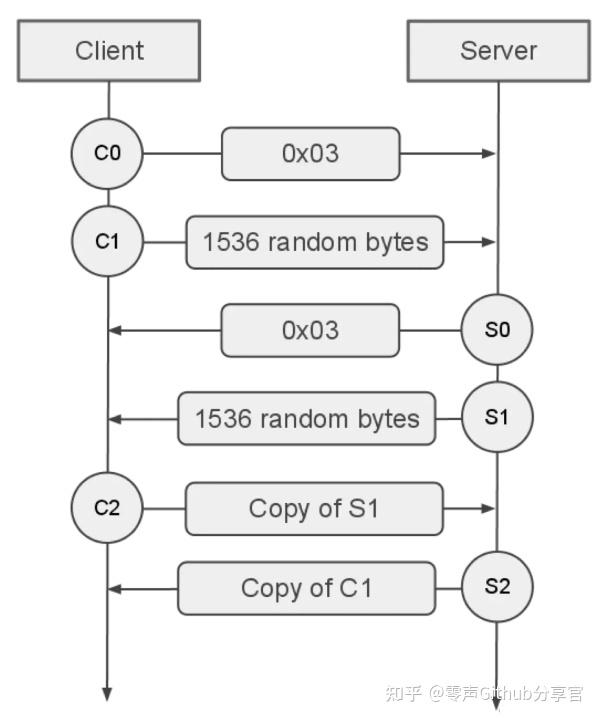
RTMP的工作原理及优缺点
一.什么是RTMP?RTMP(Real-Time Messaging Protocol,实时消息传输协议)是一种用于低延迟、实时音视频和数据传输的双向互联网通信协议,由Macromedia(后被Adobe收购)开发。RTMP的工作原理是&#…...

【数据结构与算法】——第八章:排序
文章目录1、基本概念1.1 什么是排序1.2 排序算法的稳定性1.3 排序算法的分类1.4 内排序的方法2、插入排序2.1 直接插入排序2.2 直接插入排序2.3 希尔排序3、交换排序3.1 冒泡排序3.2 快速排序4、选择排序4.1 简单选择排序4.2 树形选择排序4.3 堆排序4.4 二路归并排序5、基数排序…...

在linux中web服务器的搭建与配置
以下涉及到的linux命令大全查阅 https://www.runoob.com/linux/linux-command-manual.htmlvim命令查阅 https://www.runoob.com/linux/linux-vim.htmlscp命令https://www.runoob.com/linux/linux-comm-scp.html首先要有一个请求的服务地址用ssh 进入到linux系统中ssh 请求的服务…...
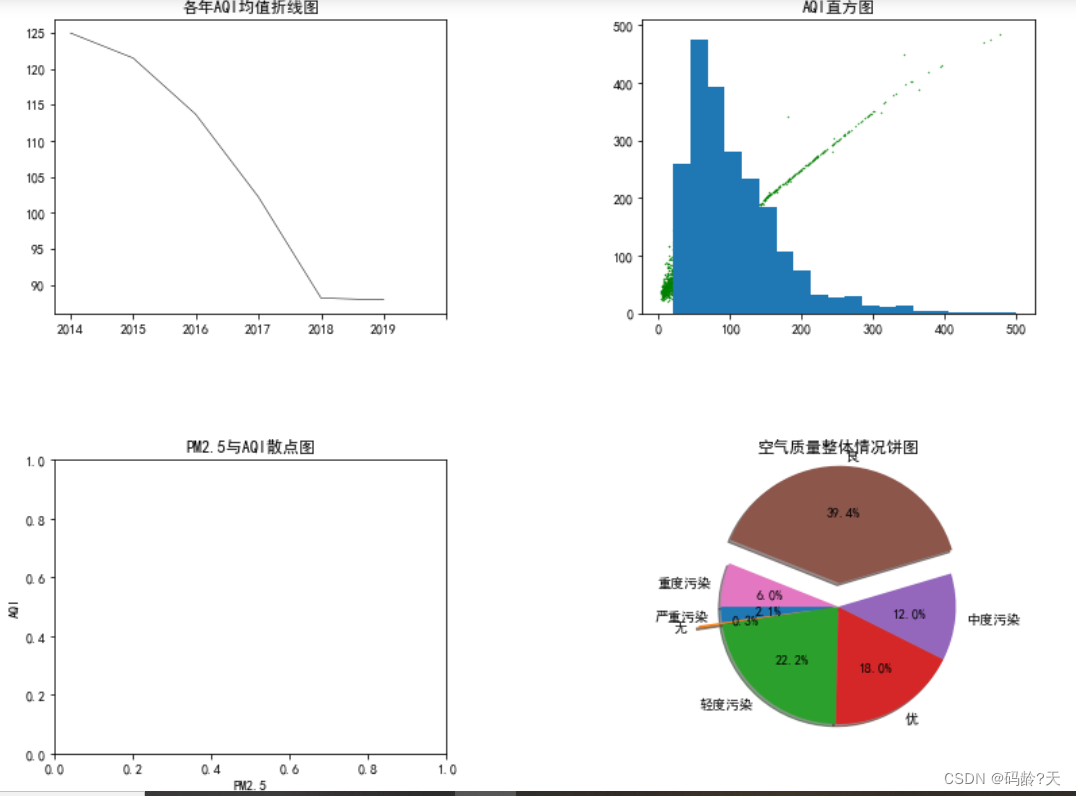
《Python机器学习》基础代码2
👂 逝年 - 夏小虎 - 单曲 - 网易云音乐 目录 👊Matplotlib综合应用:空气质量监测数据的图形化展示 🌼1,AQI时序变化特点 🌼2,AQI分布特征 相关性分析 🌼3,优化图形…...

如何基于MLServer构建Python机器学习服务
文章目录前言一、数据集二、训练 Scikit-learn 模型三、基于MLSever构建Scikit-learn服务四、测试模型五、训练 XGBoost 模型六、服务多个模型七、测试多个模型的准确性总结参考前言 在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行…...

9.1 IGMPv1实验
9.4.1 IGMPv1 实验目的 熟悉IGMPv1的应用场景掌握IGMPv1的配置方法实验拓扑 实验拓扑如图9-7所示: 图9-7:IGMPv1 实验步骤 (1)配置IP地址 MCS1的配置 MCS1的IP地址配置如图9-8所示: 图9-8:MCS1的配置 …...

软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用
软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用 一、摘要二、正文三、总结一、摘要 近年来,在应用需求的强大驱动下,我国通信业有了长足的进步。现有通信行业中的许多企业单位,如电信公司或移动集团,其信息系统的主要特征之一是对线路的…...
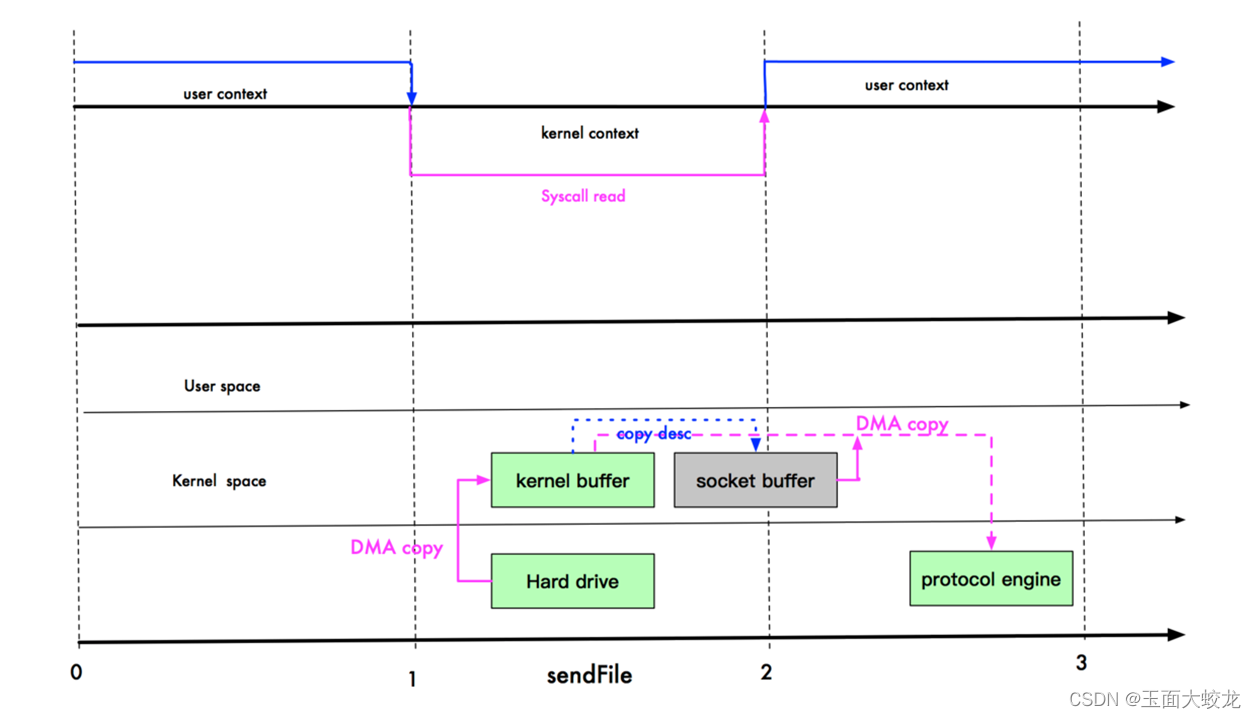
NIO与零拷贝
目录 一、零拷贝的基本介绍 二、传统IO数据读写的劣势 三、mmap优化 四、sendFile优化 五、 mmap 和 sendFile 的区别 六、零拷贝实战 6.1 传统IO 6.2 NIO中的零拷贝 6.3 运行结果 一、零拷贝的基本介绍 零拷贝是网络编程的关键,很多性能优化都离不开。 在…...
)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分) 前言 Problem:1151 LCA in a Binary Tree (30 分) Tags:树的遍历 并查集 LCA Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1151 LCA in a Binary Tree (30 分…...

Android 获取手机语言环境 区分简体和繁体,香港,澳门,台湾繁体
安卓和IOS 系统语言都是准守:ISO 639 ISO 代码表IOS:plus.os.language ios正常,安卓下简体和繁体语言,都是zh安卓获取系统语言方法:Locale.getDefault().language手机切换到繁体(台湾,香港&…...

一文搞懂Python时间序列
Python时间序列1. datetime模块1.1 datetime对象1.2 字符串和datatime的相互转换2. 时间序列基础3. 重采样及频率转换4. 时间序列可视化5. 窗口函数5.1 移动窗口函数5.2 指数加权函数5.3 二元移动窗口函数时间序列(Time Series)是一种重要的结构化数据形…...
GeoServer发布数据进阶
GeoServer发布数据进阶 GeoServer介绍 GeoServer是用于共享地理空间数据的开源服务器。 它专为交互操作性而设计,使用开放标准发布来自任何主要空间数据源的数据。 GeoServer实现了行业标准的 OGC 协议,例如网络要素服务 (WFS)…...
Docker离线部署
Docker离线部署 目录 1、需求说明 2、下载docker安装包 3、上传docker安装包 4、解压docker安装包 5、解压的docker文件夹全部移动至/usr/bin目录 6、将docker注册为系统服务 7、重启生效 8、设置开机自启 9、查看docker版本信息 1、需求说明 大部份公司为了服务安全…...
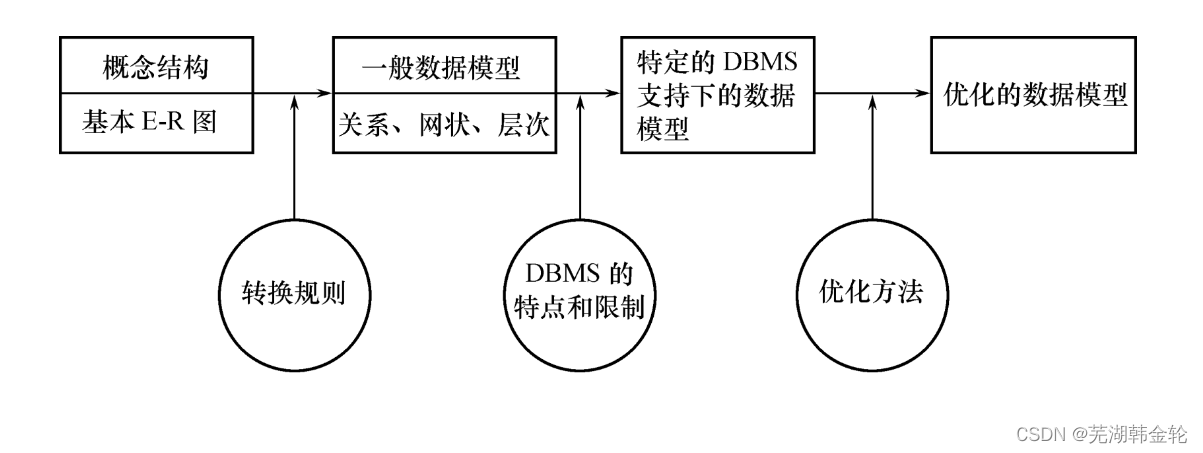
《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊) 这一章概念比较多。最重点就是7.4节。 7.1 数据库设计概述 数据库设计定义: 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构&#x…...

【Datawhale图机器学习】半监督节点分类:标签传播和消息传递
半监督节点分类:标签传播和消息传递 半监督节点分类问题的常见解决方法: 特征工程图嵌入表示学习标签传播图神经网络 基于“物以类聚,人以群分”的Homophily假设,讲解了Label Propagation、Relational Classificationÿ…...
)
实操指南|安科士ANBR-1414TZ光模块替换与调试全流程(附故障排查)
在上一篇博客中,我们解析了安科士ANBR-1414TZ光模块的核心技术亮点,其与AVAGO安华高HFBR-1414/2412系列的全兼容设计,让进口模块替换变得简单高效。但在实际操作中,不少用户仍会遇到替换后无法正常工作、传输不稳定等问题。今天&a…...

Code Agent 到头了?把 Token 成本打到地板,把并发效率拉到天花板——Auto-Coder.Chat 的暴力美学
当前 Code Agent 赛道的三座大山:第一,好的模型太贵了。 Cursor Ultra 订阅 $200/月,平台额外补贴了 $200-300 的 API 用量,相当于在每个用户身上倒贴钱,即便如此重度使用五六天就见底。Claude Code 更夸张——经常有用…...
Wi-Fi6与星闪SLE实战开发)
小熊派BearPi-Pico H3863(二)Wi-Fi6与星闪SLE实战开发
1. Wi-Fi6开发实战:从零搭建物联网连接 第一次拿到BearPi-Pico H3863开发板时,最让我惊喜的就是它内置的Wi-Fi6模块。相比传统Wi-Fi4,Wi-Fi6的传输效率提升了近3倍,实测在智能家居多设备场景下延迟能控制在20ms以内。下面分享几个…...

Step3-VL-10B-Base模型环境配置详解:从Anaconda虚拟环境到依赖安装
Step3-VL-10B-Base模型环境配置详解:从Anaconda虚拟环境到依赖安装 想试试那个能看懂图片又能聊天的Step3-VL-10B-Base模型?第一步,也是最关键的一步,就是把它的“家”给搭好。这个“家”就是它的运行环境。很多朋友卡在这一步&a…...
)
U盘误删视频别慌!用DiskGenius v5.5专业版5分钟找回(附ChipGenius验盘防坑)
U盘误删视频急救指南:从应急恢复到长效防护 U盘作为移动存储的"老将",依然是许多人传输视频、照片的首选工具。但当你发现误删了重要视频时,那种瞬间的慌乱感恐怕不少人都体验过——上周拍摄的客户演示视频、孩子第一次登台的珍贵录…...

Windows驱动垃圾终极清理指南:Driver Store Explorer帮你轻松释放数十GB空间
Windows驱动垃圾终极清理指南:Driver Store Explorer帮你轻松释放数十GB空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer [RAPR] 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾经疑惑,为什么Windo…...

Firejail终极性能优化指南:10个技巧在不牺牲安全性的前提下提升运行效率
Firejail终极性能优化指南:10个技巧在不牺牲安全性的前提下提升运行效率 【免费下载链接】firejail Linux namespaces and seccomp-bpf sandbox 项目地址: https://gitcode.com/gh_mirrors/fi/firejail Firejail是一款基于Linux namespaces和seccomp-bpf的沙…...

探索C++标准库中的算法:<algorithm> 头文件概览
探索C标准库中的算法: 头文件概览 在C编程的广阔天地里,标准库犹如一座宝库,为开发者提供了丰富多样的工具和组件,极大地简化了开发流程,提升了代码效率与质量。本文将带您走进<algorithm>的世界,一窥…...
WSL2 中部署 Pixel Mind Decoder:Windows 开发者的 Linux 模型测试方案
WSL2 中部署 Pixel Mind Decoder:Windows 开发者的 Linux 模型测试方案 1. 为什么选择WSL2进行AI模型测试 对于Windows开发者来说,直接在原生系统上部署和测试Linux环境下的AI模型往往面临诸多挑战。依赖关系复杂、环境配置繁琐、性能损耗大等问题常常…...

别再只用RSA了!手把手教你用Java SM2国密算法给接口数据加个密
Java开发者必看:从RSA到SM2国密算法的平滑迁移实战 当我们需要在API接口或数据传输中实现非对称加密时,RSA往往是大多数Java开发者的默认选择。但你可能不知道的是,在相同安全强度下,国密SM2算法的计算速度比RSA快得多,…...