Elasticsearch:创建一个简单的 “你的意思是?” 推荐搜索
“你的意思是” 是搜索引擎中一个非常重要的功能,因为它们通过显示建议的术语来帮助用户,以便他可以进行更准确的搜索。比如,在百度中,我们进行搜索时,它通常会显示一些更为常用推荐的搜索选项来供我们选择:
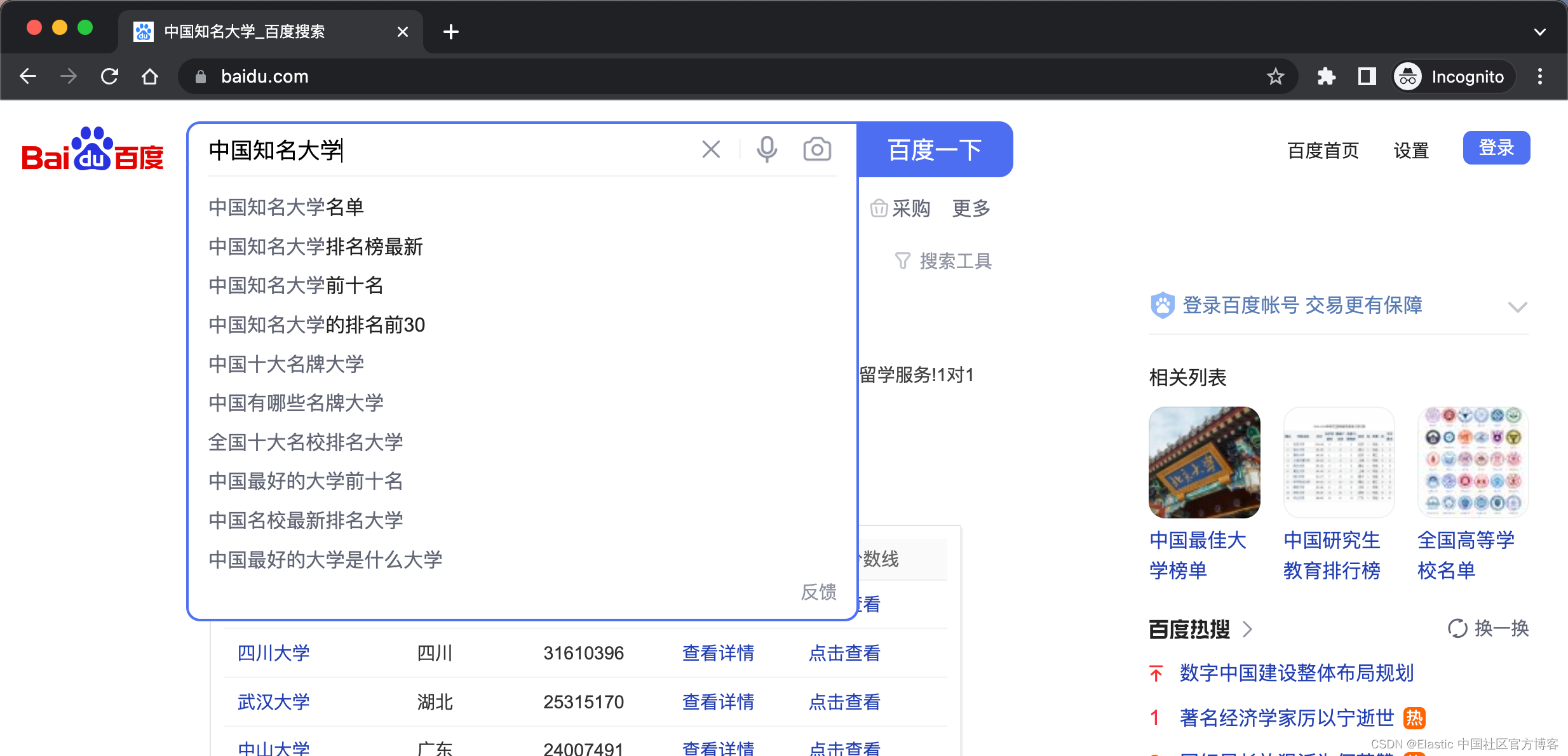
为了创建 “你的意思是”,我们将使用 phrase suggester,因为通过它我们将能够建议句子更正,而不仅仅是术语。在我之前的文章 “Elasticsearch:如何实现短语建议 - phrase suggester”,我有涉及到这个问题。
首先,我们将使用一个 shingle 过滤器,因为它将提供一个分词,短语建议器将使用该标记来进行匹配并返回更正。有关 shingle 过滤器的描述,请阅读之前的文章 “Elasticsearch: Ngrams, edge ngrams, and shingles”。
准备数据
我们首先来定义映射:
PUT movies
{"settings": {"analysis": {"analyzer": {"en_analyzer": {"tokenizer": "standard","filter": ["lowercase","stop"]},"shingle_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","shingle_filter"]}},"filter": {"shingle_filter": {"type": "shingle","min_shingle_size": 2,"max_shingle_size": 3}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "en_analyzer","fields": {"suggest": {"type": "text","analyzer": "shingle_analyzer"}}},"actors": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"description": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"director": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"genre": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"metascore": {"type": "long"},"rating": {"type": "float"},"revenue": {"type": "float"},"runtime": {"type": "long"},"votes": {"type": "long"},"year": {"type": "long"},"title_suggest": {"type": "completion","analyzer": "simple","preserve_separators": true,"preserve_position_increments": true,"max_input_length": 50}}}
}我们接下来使用 _bulk 命令来写入一些文档到这个索引中去。我们使用这个链接中的内容。我们使用如下的方法:
POST movies/_bulk
{"index": {}}
{"title": "Guardians of the Galaxy", "genre": "Action,Adventure,Sci-Fi", "director": "James Gunn", "actors": "Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana", "description": "A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.", "year": 2014, "runtime": 121, "rating": 8.1, "votes": 757074, "revenue": 333.13, "metascore": 76}
{"index": {}}
{"title": "Prometheus", "genre": "Adventure,Mystery,Sci-Fi", "director": "Ridley Scott", "actors": "Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron", "description": "Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.", "year": 2012, "runtime": 124, "rating": 7, "votes": 485820, "revenue": 126.46, "metascore": 65}....在上面,为了说明的方便,我省去了其它的文档。你需要把整个 movies.txt 的文件拷贝过来,并全部写入到 Elasticsearch 中。它共有1000 个文档。
搜索数据
现在让我们运行一个基本查询来查看 suggest 的结果:
GET movies/_search?filter_path=suggest
{"suggest": {"text": "transformers revenge of the falen","did_you_mean": {"phrase": {"field": "title.suggest","size": 5}}}
}上面命令显示的结果为:
{"suggest": {"did_you_mean": [{"text": "transformers revenge of the falen","offset": 0,"length": 33,"options": [{"text": "transformers revenge of the fallen","score": 0.004467494},{"text": "transformers revenge of the fall","score": 0.00020402104},{"text": "transformers revenge of the face","score": 0.00006419608}]}]}
}请注意,在几行中你已经获得了一些有希望的结果。
现在让我们通过使用更多短语建议功能来增加我们的查询。让我们使用 max_errors = 2,这样我们希望句子中最多有两个术语。 添加了 highlight 显示以突出显示建议的术语。
GET movies/_search?filter_path=suggest
{"suggest": {"text": "transformer revenge of the falen","did_you_mean": {"phrase": {"field": "title.suggest","size": 5,"confidence": 1,"max_errors":2,"highlight": {"pre_tag": "<strong>","post_tag": "</strong>"}}}}
}上面命令返回的结果为:
{"suggest": {"did_you_mean": [{"text": "transformer revenge of the falen","offset": 0,"length": 32,"options": [{"text": "transformers revenge of the fallen","highlighted": "<strong>transformers</strong> revenge of the <strong>fallen</strong>","score": 0.004382903},{"text": "transformers revenge of the fall","highlighted": "<strong>transformers</strong> revenge of the <strong>fall</strong>","score": 0.00020015794},{"text": "transformers revenge of the face","highlighted": "<strong>transformers</strong> revenge of the <strong>face</strong>","score": 0.00006298054},{"text": "transformers revenge of the falen","highlighted": "<strong>transformers</strong> revenge of the falen","score": 0.00006159308},{"text": "transformer revenge of the fallen","highlighted": "transformer revenge of the <strong>fallen</strong>","score": 0.000048000533}]}]}
}我们再改进一点好吗? 我们添加了 “collate”,我们可以对每个结果执行查询,改进建议的结果。 我使用了带有 “and” 运算符的匹配项,以便在同一个句子中匹配所有术语。 如果我仍然想要不符合查询条件的结果,我使用 prune = true。
GET movies/_search?filter_path=suggest
{"suggest": {"text": "transformer revenge of the falen","did_you_mean": {"phrase": {"field": "title.suggest","size": 5,"confidence": 1,"max_errors":2,"collate": {"query": { "source" : {"match": {"{{field_name}}": {"query": "{{suggestion}}","operator": "and"}}}},"params": {"field_name" : "title"}, "prune" :true},"highlight": {"pre_tag": "<strong>","post_tag": "</strong>"}}}}
}现在的结果是:

请注意,答案已更改,我有一个新字段 “collate_match”,它指示结果中是否匹配整理规则(这是因为 prune = true)。
让我们设置 prune 为 false:
GET movies/_search?filter_path=suggest
{"suggest": {"text": "transformer revenge of the falen","did_you_mean": {"phrase": {"field": "title.suggest","size": 5,"confidence": 1,"max_errors":2,"collate": {"query": { "source" : {"match": {"{{field_name}}": {"query": "{{suggestion}}","operator": "and"}}}},"params": {"field_name" : "title"}, "prune" :false},"highlight": {"pre_tag": "<strong>","post_tag": "</strong>"}}}}
}这次我们得到的结果是:

我们可以看到只有一个结果是最相关的建议。
相关文章:
Elasticsearch:创建一个简单的 “你的意思是?” 推荐搜索
“你的意思是” 是搜索引擎中一个非常重要的功能,因为它们通过显示建议的术语来帮助用户,以便他可以进行更准确的搜索。比如,在百度中,我们进行搜索时,它通常会显示一些更为常用推荐的搜索选项来供我们选择:…...
urllib之ProxyHandler代理以及CookieJar的cookie内存传递和本地保存与读取的使用详解
处理更高级操作时(Cookies处理,代理设置),需要一个强大的工具Handler,可以理解成各种处理器,有处理登录认证的、有处理Cookies的、有处理代理设置的。利用这些几乎可以做到HTTP请求中所有事情。当中urllib.request模块里的 BaseHa…...

华为造车锚定智选模式, 起点赢家赛力斯驶入新能源主航道
文|螳螂观察 作者| 易不二 近日,赛力斯与华为的一纸联合业务深化合作协议,给了频频猜测赛力斯与华为之间关系的舆论一个明确的定调:智选模式已成为华为与赛力斯共同推动中国新能源汽车产业高质量发展的坚定选择。 自华为智能汽车业务开启零…...
[oeasy]python0096_游戏娱乐行业_雅达利_米洛华_四人赛马_影视结合游戏
游戏娱乐行业 回忆上次内容 游戏机行业从无到有 雅达利 公司 一枝独秀并且带领 行业 发展起来 雅达利公司 优秀员工 乔布斯 在 朋友 帮助下完成了《pong》 Jobs 黑了 Woz 一部分收入 然后拿着钱 去印度禅修了 游戏行业 会如何继续 呢??🤔 灵修 乔布…...

使用python测试框架完成自动化测试并生成报告-实例练习
练习一: 使用unittest 完成自动化测试并使用HttpTestRunner生成报告 1、写个简单的计算器功能,大小写转换功能,随机生成字符串功能 2、编写测试用例,不同的数据(你能想到的所有测试用例),并进行断言。除0的…...
JavaWeb 实战 01 - 计算机是如何工作的
计算机是如何工作的1. 计算机发展史2. 计算机的基本组成2.1 冯诺依曼体系结构2.2 CPU的内部结构2.3 指令2.3.1 指令表2.3.1.1 寄存器2.3.2 CPU的工作流程2.4 小结3. 操作系统3.1 核心功能3.2 操作系统的软硬件结构3.3 什么是进程 / 任务3.4 进程管理3.4.1 管理3.4.2 PCB : 进程…...
线性代数学习-1
线性代数学习-1行图像和列图像行图像列图像总结本文转载于https://herosunly.blog.csdn.net/article/details/88698381 该文章本人认为十分有用,便自己敲一遍笔记加固印象原文链接 原文这个笔记感觉比我老师讲的更加透彻,清晰。很好的展示了线性代数的原…...

人工智能写的十段代码,九个通过测试了
“抢走你工作的不会是 AI ,而是先掌握 AI 能力的人” 编程测试 1. 我想用golang实现二叉树前序,请你帮我写一下代码。 // 定义二叉树节点 type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode }// 前序遍历 func PreOrderTraversal(root *Tre…...

巴塞尔问题数值逼近方法
巴塞尔问题:计算所有平方数的导数和 ∑n1∞1n2limn→∞(112122⋯1n2)\sum_{n1}^{\infty} \frac{1}{n^{2}}\lim _{n \rightarrow\infty}\left(\frac{1}{1^{2}}\frac{1}{2^{2}}\cdots\frac{1}{n^{2}}\right)n1∑∞n21n→∞lim(121221⋯n21) 其理论解为…...

【深度学习环境】Docker
1. Docker 相关安装配置 1.1 docker 安装 参考:https://www.runoob.com/docker/ubuntu-docker-install.html 1.2 nvidia-docker 安装 参考:https://zhuanlan.zhihu.com/p/37519492 1.3 代理加速 参考:https://yeasy.gitbook.io/docker_…...
基于vscode开发vue项目的详细步骤教程 2 第三方图标库FontAwesome
1、Vue下载安装步骤的详细教程(亲测有效) 1_水w的博客-CSDN博客 2、Vue下载安装步骤的详细教程(亲测有效) 2 安装与创建默认项目_水w的博客-CSDN博客 3、基于vscode开发vue项目的详细步骤教程_水w的博客-CSDN博客 目录 六、第三方图标库FontAwesome 1 安装FontAwesome 解决报…...

今天面了个腾讯拿25K出来的软件测试工程师,让我见识到了真正的天花板...
今天上班开早会就是新人见面仪式,听说来了个很厉害的大佬,年纪还不大,是上家公司离职过来的,薪资已经达到中高等水平,很多人都好奇不已,能拿到这个薪资应该人不简单,果然,自我介绍的…...

OSG三维渲染引擎编程学习之六十九:“第六章:OSG场景工作机制” 之 “6.9 OSG数据变量”
目录 第六章 OSG场景工作机制 6.9 OSG数据变量 第六章 OSG场景工作机制 作为一个成熟的三维渲染引擎,需要提供快速获取场景数据、节点等信息,具备自定义数据或动画更新接口,能接收应用程序或窗口等各类消息。OSG三维渲染引擎能较好地完成上述工作,OSG是采用什么方式或工作…...

Tektronix泰克TDP3500差分探头3.5GHz
附加功能: 带宽:3.5 GHz 差分输入电容:≤0.3 pF 差分输入电阻:100 kΩ DC pk 交流输入电压:15 V >60 dB 在 1 MHz 和 >25 dB 在 1 GHz CMRR 出色的共模抑制——减少较高共模环境中的测量误差 低电容和电阻负载…...
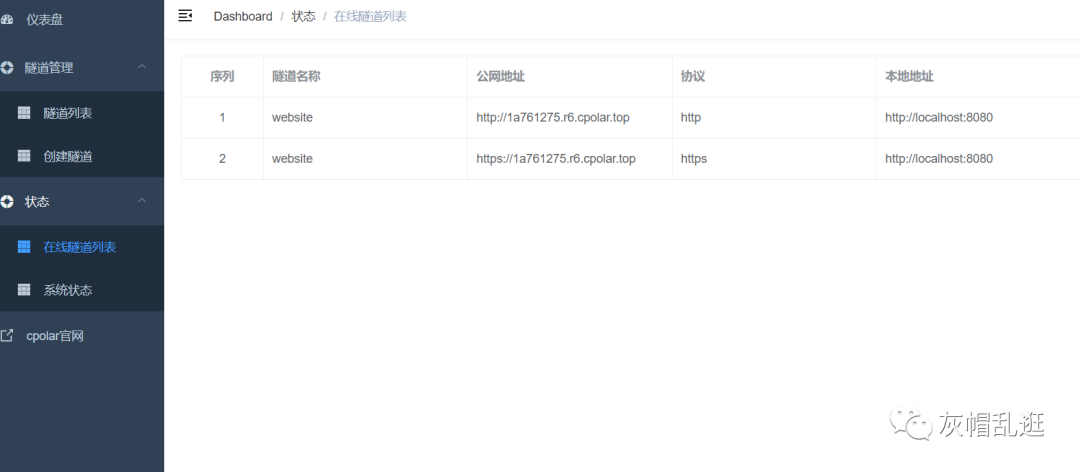
轻松实现内网穿透:实现远程访问你的私人网络
导语:内网穿透是什么?为什么我们需要它?今天我们将介绍这个令人惊叹的技术,让你实现远程访问你的私人网络。 使用内网穿透,轻松实现外网访问本地部署的网站 第一部分:什么是内网穿透? 通俗解释…...

MySQL长字符截断
MySQL超长字符截断又名"SQL-Column-Truncation",是安全研究者Stefan Esser在2008 年8月提出的。 在MySQL中的一个设置里有一个sql_mode选项,当sql_mode设置为default时,即没有开启STRICT_ALL_TABLES选项时(MySQLsql_mo…...

python计算量比指标
百度百科是这么写的:量比定义:股市开市后平均每分钟的成交量与过去5个交易日平均每分钟成交量之比。计算公式:量比(现成交总手数 / 现累计开市时间(分) )/ 过去5日平均每分钟成交量。这里公式没有问题,但是…...
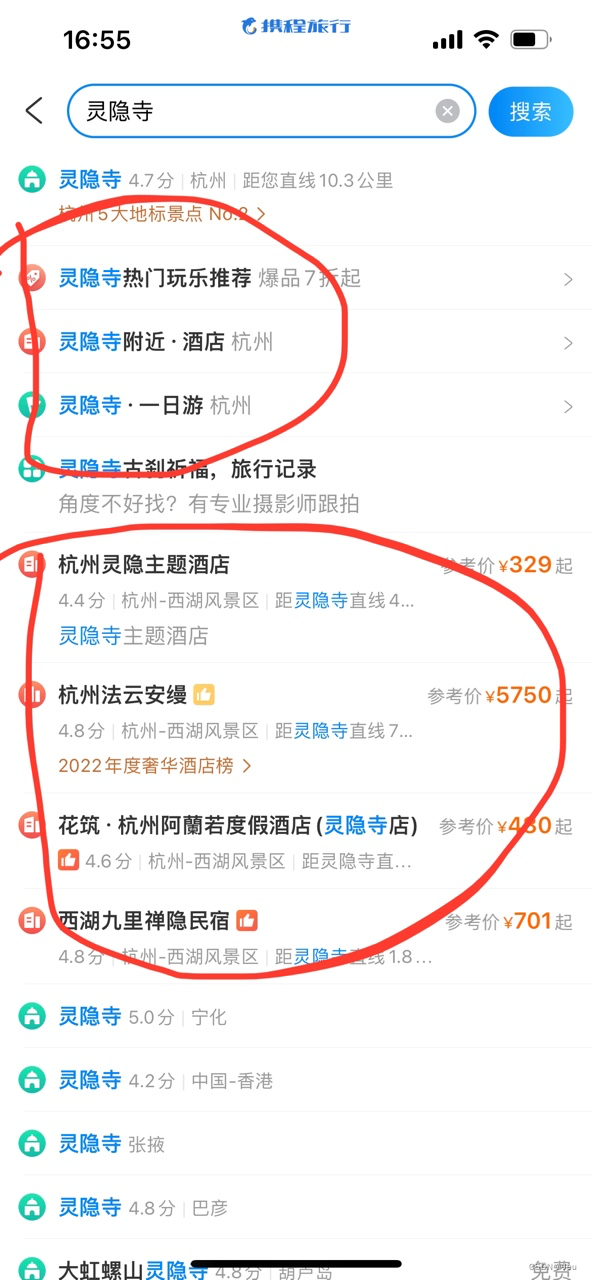
下拉框推荐-Suggest-SUG
什么是下拉框推荐 在我们使用各种app(飞猪)想要搜索我们想要的东西,假设我想要上海迪士尼的门票,那么精确的query是“上海迪士尼门票”,要打7个字,如果在你输入“上海”的时候app就推荐了query“上海迪士尼…...

Nmap的几种扫描方式以及相应的命令
Nmap是一款常用的网络扫描工具,它可以扫描目标网络上的主机和服务,帮助安全研究员了解目标网络的拓扑结构和安全情况。以下是Nmap的几种扫描方式以及相应的命令: 1.Ping扫描 Ping扫描可以用来探测网络上响应的主机,可以使用“-sn…...
Qt::QOpenGLWidget 渲染天空壳
在qt窗口中嵌入opengl渲染天空壳和各种立方体一 学前知识天空壳的渲染学前小知识1 立方体贴图 天空壳的渲染就是利用立方体贴图来实现渲染流程2 基础光照 光照模型3 opengl帧缓冲 如何自定义帧缓冲实现后期特效4 glsl常见的shader内置函数 glsl编程常用的内置函数二 shader代码…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

数据库——redis
一、Redis 介绍 1. 概述 Redis(Remote Dictionary Server)是一个开源的、高性能的内存键值数据库系统,具有以下核心特点: 内存存储架构:数据主要存储在内存中,提供微秒级的读写响应 多数据结构支持&…...
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...