Spark RDD持久化
RDD Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

1)代码实现
object cache01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}//3.5 cache操作会增加血缘关系,不改变原有的血缘关系println(wordToOneRdd.toDebugString)//3.4 数据缓存。wordToOneRdd.cache()//3.6 可以更改存储级别// wordToOneRdd.persist(StorageLevel.MEMORY_AND_DISK_2)//3.2 触发执行逻辑wordToOneRdd.collect()println("-----------------")println(wordToOneRdd.toDebugString)//3.3 再次触发执行逻辑wordToOneRdd.collect()//4.关闭连接sc.stop()}
}2)源码解析
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)object StorageLevel {val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = new StorageLevel(true, false, false, false)val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)val MEMORY_ONLY = new StorageLevel(false, true, false, true)val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)val OFF_HEAP = new StorageLevel(true, true, true, false, 1)注意:默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上“_2”表示持久化的数据存为两份。

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
3)自带缓存算子
Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
object cache02 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}// 采用reduceByKey,自带缓存val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)//3.5 cache操作会增加血缘关系,不改变原有的血缘关系println(wordByKeyRDD.toDebugString)//3.4 数据缓存。//wordByKeyRDD.cache()//3.2 触发执行逻辑wordByKeyRDD.collect()println("-----------------")println(wordByKeyRDD.toDebugString)//3.3 再次触发执行逻辑wordByKeyRDD.collect()//4.关闭连接sc.stop()}
}访问http://localhost:4040/jobs/页面,查看第一个和第二个job的DAG图。说明:增加缓存后血缘依赖关系仍然有,但是,第二个job取的数据是从缓存中取的。
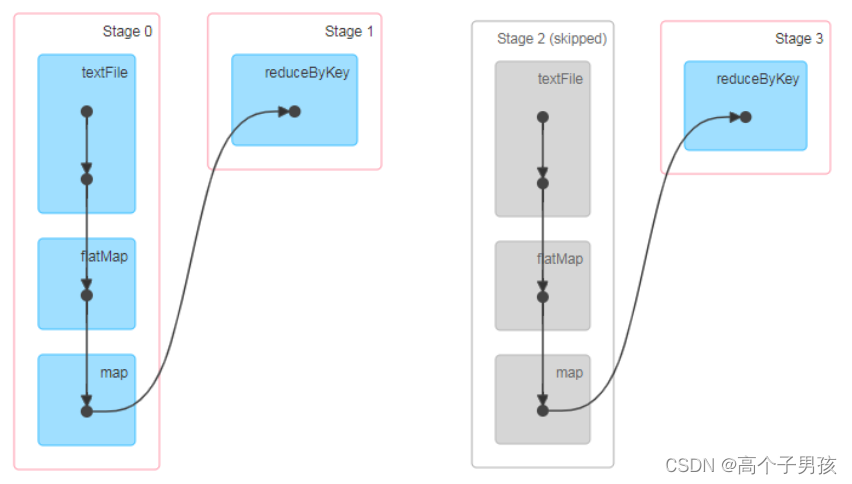
RDD CheckPoint检查点
1)检查点:是通过将RDD中间结果写入磁盘。
2)为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
3)检查点存储路径:Checkpoint的数据通常是存储在HDFS等容错、高可用的文件系统
4)检查点数据存储格式为:二进制的文件
5)检查点切断血缘:在Checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。
6)检查点触发时间:对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍
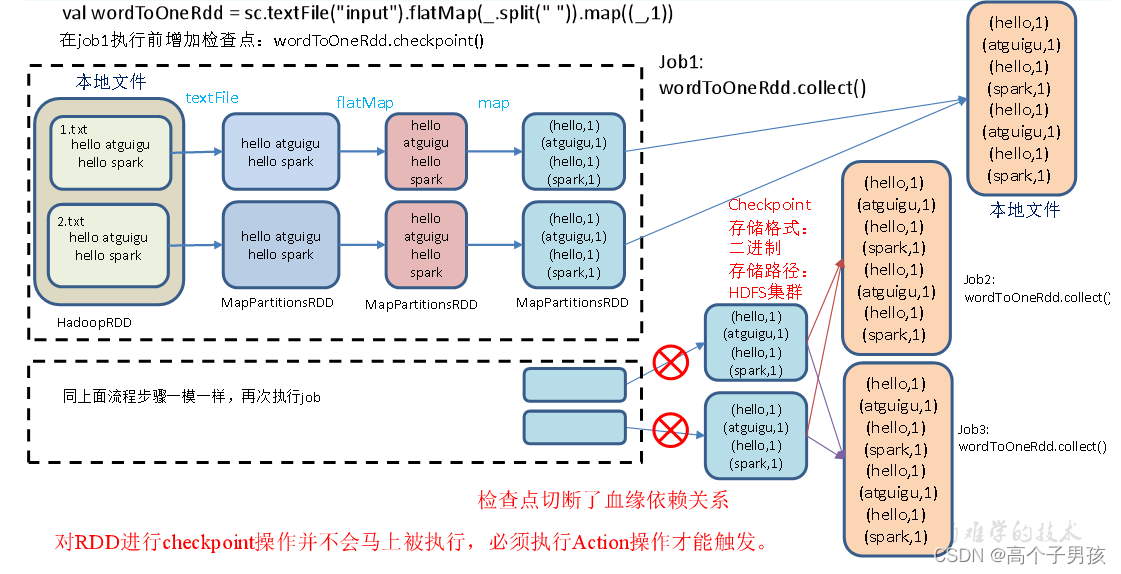
7)设置检查点步骤
(1)设置检查点数据存储路径:sc.setCheckpointDir("./checkpoint1")
(2)调用检查点方法:wordToOneRdd.checkpoint()
8)代码实现
object checkpoint01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径,否则抛异常:Checkpoint directory has not been set in the SparkContextsc.setCheckpointDir("./checkpoint1")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.5 增加缓存,避免再重新跑一个job做checkpoint
// wordToOneRdd.cache()//3.4 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)// 会立即启动一个新的job来专门的做checkpoint运算//3.3 再次触发执行逻辑wordToOneRdd.collect().foreach(println)wordToOneRdd.collect().foreach(println)Thread.sleep(10000000)//4.关闭连接sc.stop()}
}9)执行结果
访问http://localhost:4040/jobs/页面,查看4个job的DAG图。其中第2个图是checkpoint的job运行DAG图。第3、4张图说明,检查点切断了血缘依赖关系。
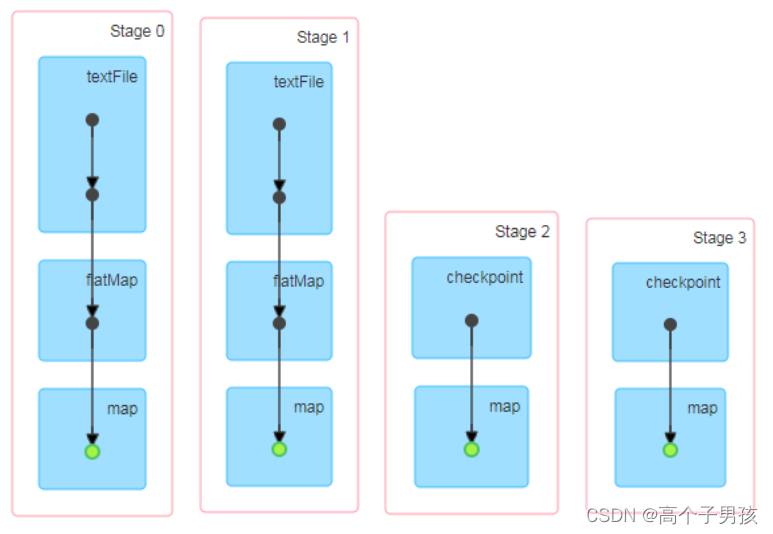
(1)只增加checkpoint,没有增加Cache缓存打印
第1个job执行完,触发了checkpoint,第2个job运行checkpoint,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。
(hadoop,1577960215526)
。。。。。。
(hello,1577960215526)
(hadoop,1577960215609)
。。。。。。
(hello,1577960215609)
(hadoop,1577960215609)
。。。。。。
(hello,1577960215609)
(2)增加checkpoint,也增加Cache缓存打印
第1个job执行完,数据就保存到Cache里面了,第2个job运行checkpoint,直接读取Cache里面的数据,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。
(hadoop,1577960642223)
。。。。。。
(hello,1577960642225)
(hadoop,1577960642223)
。。。。。。
(hello,1577960642225)
(hadoop,1577960642223)
。。。。。。
(hello,1577960642225)
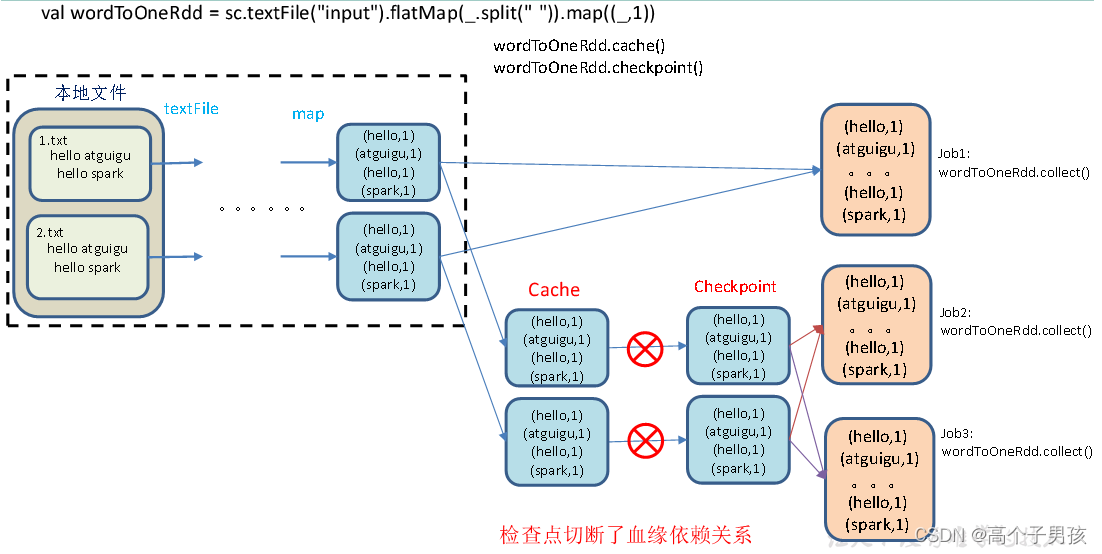
缓存和检查点区别
1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
4)如果使用完了缓存,可以通过unpersist()方法释放缓存
检查点存储到HDFS集群
如果检查点数据存储到HDFS集群,要注意配置访问集群的用户名。否则会报访问权限异常。
object checkpoint02 {def main(args: Array[String]): Unit = {// 设置访问HDFS集群的用户名System.setProperty("HADOOP_USER_NAME","atguigu")//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径.需要提前在HDFS集群上创建/checkpoint路径sc.setCheckpointDir("hdfs://hadoop102:9000/checkpoint")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.4 增加缓存,避免再重新跑一个job做checkpointwordToOneRdd.cache()//3.3 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)//4.关闭连接sc.stop()}
}相关文章:
Spark RDD持久化
RDD Cache缓存 RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供…...

【Linux】Linux系统安装Python3和pip3
1.说明 一般来说Linux会自带Python环境,可能是Python3或者Python2,可能有pip也可能没有pip,所以有时候需要自己安装指定的Python版本。Linux系统下的安装方式都大同小异,基本上都是下载安装包然后编译一下,再创建好软…...

用java进行base64加密
首先定义一组密钥,加密和解密使用同一组密钥private final String key "hahahahahaha";也可以随机生成密钥/*** 生成随机密钥* param keySize 密钥大小推荐128 256* return* throws NoSuchAlgorithmException*/public static String generateSecret(int keySize) th…...
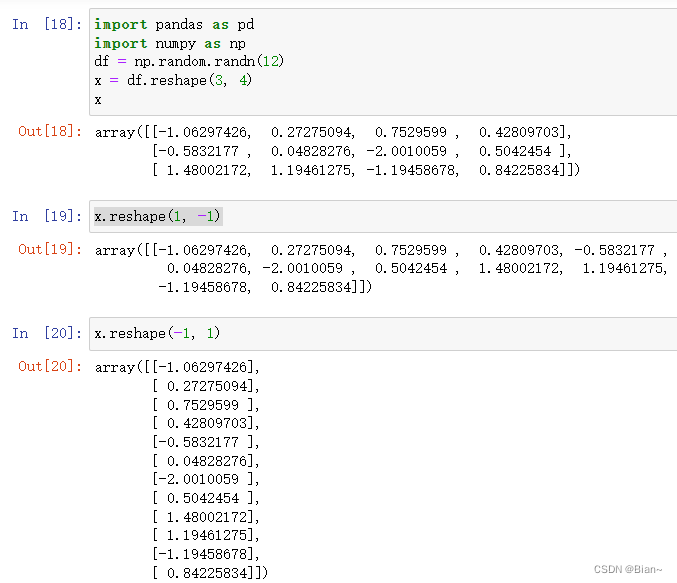
torch函数合集
torch.tensor() 原型:torch.tensor(data, dtypeNone, deviceNone, requires_gradFalse) 功能:其中data可以是:list,tuple,NumPy,ndarray等其他类型,torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应类型的torch.Tenso…...

AcWing算法提高课-3.1.2信使
宣传一下算法提高课整理 <— CSDN个人主页:更好的阅读体验 <— 题目传送门点这里 题目描述 战争时期,前线有 nnn 个哨所,每个哨所可能会与其他若干个哨所之间有通信联系。 信使负责在哨所之间传递信息,当然,…...

Paddle OCR Win 11下的安装和简单使用教程
Paddle OCR Win 11下的安装和简单使用教程 对于中文的识别,可以考虑直接使用Paddle OCR,识别准确率和部署都相对比较方便。 环境搭建 目前PaddlePaddle 发布到v2.4,先下载paddlepaddle,再下载paddleocr。根据自己设备操作系统进…...

杂谈:数组index问题和对象key问题
面试题一: var arr [1, 2, 3, 4] 问:arr[1] ?; arr[1] ?答:arr[1] 2; arr[1] 2 这里可以再分为两个问题: 1、数组赋值 var arr [1, 2, 3, 4]arr[1] 10; // 数字场景 arr[10] 1; // 字符串场景 arr[a] 1; // 字符串…...
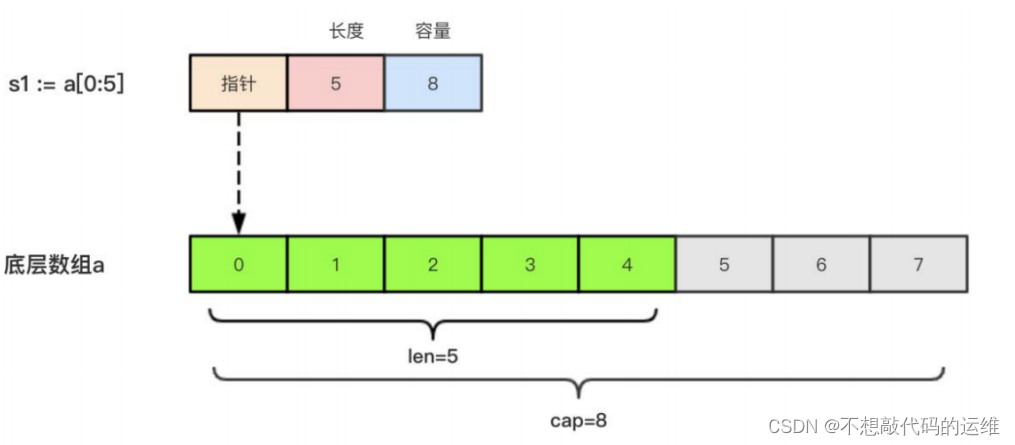
三天Golang快速入门—Slice切片
三天Golang快速入门—Slice切片Slice切片切片原理切片遍历append函数操作切片append添加append追加多个切片中删除元素切片合并string和slice的联系Slice切片 切片原理 由三个部分构成,指针、长度、容量指针:指向slice第一个元素对应的数组元素的地址长…...
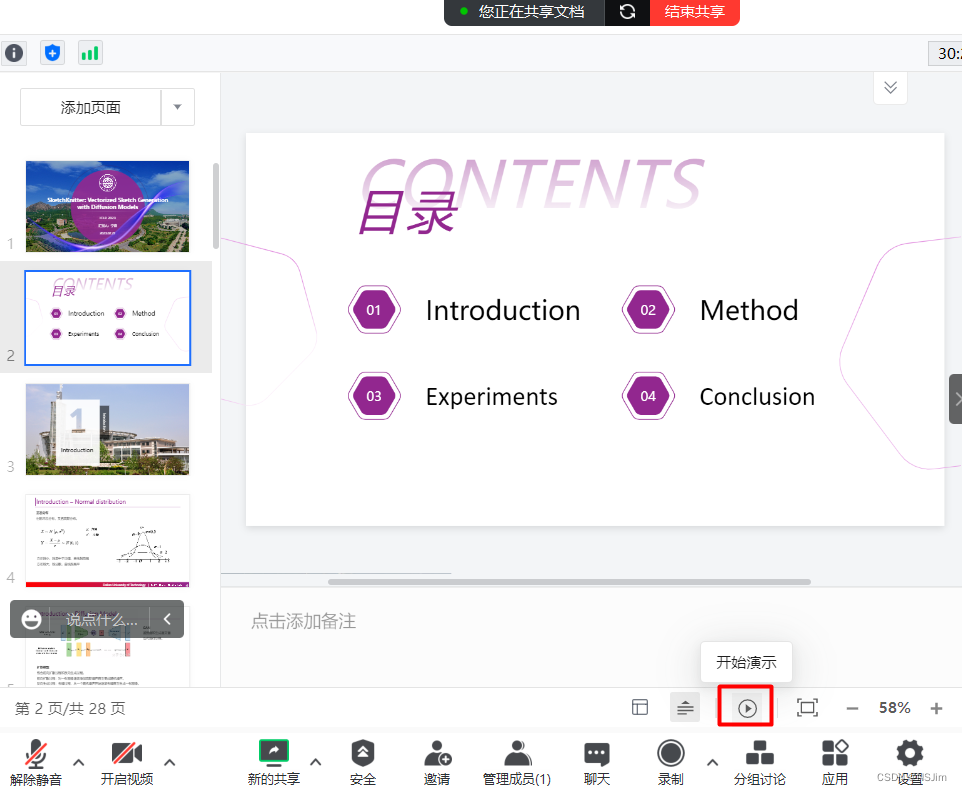
腾讯会议演示者视图/演讲者视图
前言 使用腾讯会议共享PPT时,腾讯会议支持共享用户使用演示者视图/演讲者视图,而会议其他成员可以看到正常的放映视图。下面以Win10系统和Office为例,介绍使用步骤。值得一提的是,该方法同时适用于单显示屏和多显示屏。 腾讯会议…...
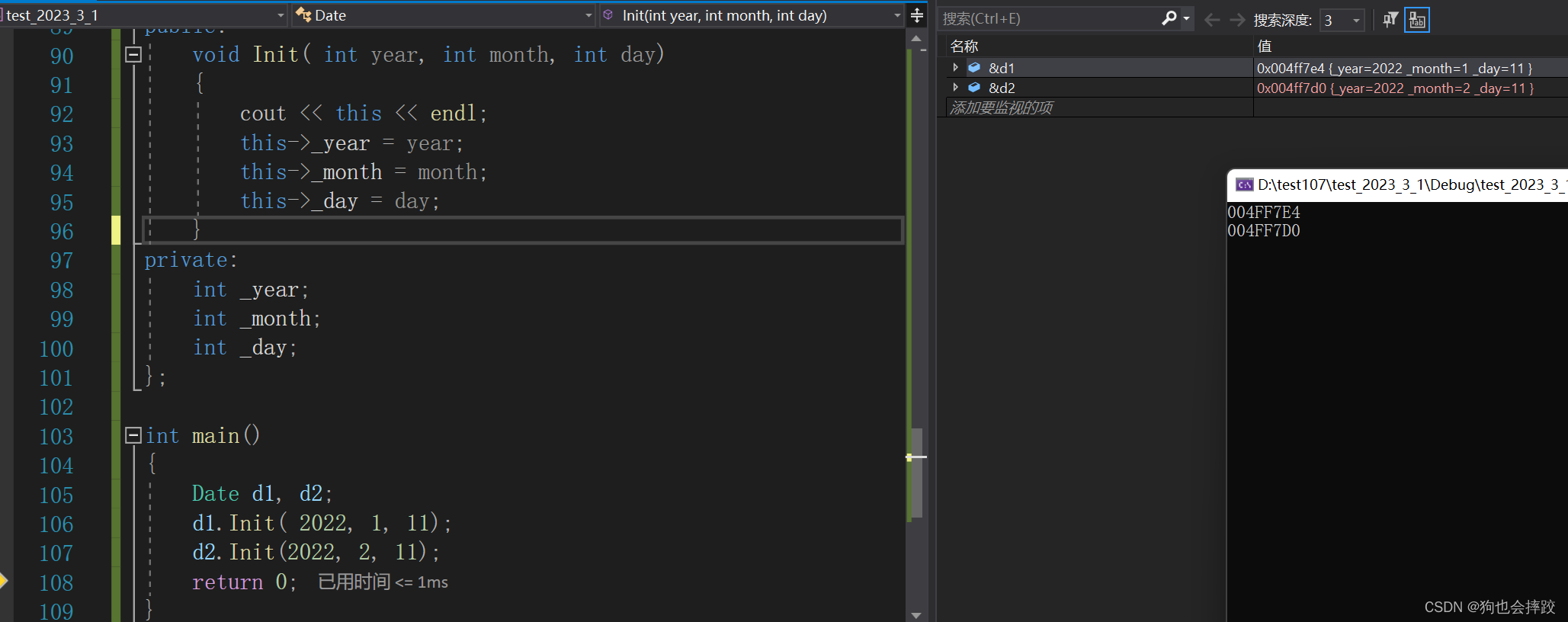
【C++】类与对象(一)
文章目录1、面向过程和面向对象初步认识2、类的引入3、类的定义4、类的访问限定符5、类的作用域6、类的实例化7、计算类对象的大小8、this指针9、 C语言和C实现Stack的对比1、面向过程和面向对象初步认识 C语言是面向过程的,关注的是过程,分析出求解问题…...

JavaScript基本语法
本文提到的绝大多数语法都是与Java不同的语法,相同的就不会赘述了.JavaScript的三种引入方式内部js<body><script>alert(hello);</script> </body>行内js<body><div onclick"alert(hello)">这是一个div 点击一下试试</div>…...

OpenCV4.x图像处理实例-道路车辆检测(基于背景消减法)
通过背景消减进行道路车辆检测 文章目录 通过背景消减进行道路车辆检测1、车辆检测思路介绍2、BackgroundSubtractorMOG23、车辆检测实现在本文中,将介绍如何使用简单但有效的背景-前景减法方法执行车辆检测等任务。本文将使用 OpenCV 中使用背景-前景减法和轮廓检测,以及如何…...
pwnlab通关流程
pwnlab通关 关于文件包含,环境变量劫持的一个靶场 信息收集 靶机ip:192.168.112.133 开放端口 根据开放的端口信息决定从80web端口入手 目录信息 在images和upload路径存在目录遍历,config.php被渲染无法查看,upload.php需…...

面向过程与面向对象的区别与联系
目录 什么是面向过程 什么是面向对象 区别 各自的优缺点 什么是面向过程 面向过程是一种以事件为中心的编程思想,编程的时候把解决问题的步骤分析出来,然后用函数把这些步骤实现,在一步一步的具体步骤中再按顺序调用函数。 什么是面向对…...
主机状态(查看资源占用情况、查看网络占用情况)
1. 查看资源占用情况 【1】可以通过top命令查看cpu、内存的使用情况,类似windows的任务管理器 默认5s刷新一次 语法:top 可 Ctrl c 退出 2.磁盘信息监控 【1】使用df命令,查看磁盘信息占用情况 语法:df [ -h ] 以更加人性化…...
代码随想录算法训练营第四十一天 | 01背包问题-二维数组滚动数组,416. 分割等和子集
一、参考资料01背包问题 二维 https://programmercarl.com/%E8%83%8C%E5%8C%85%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%8001%E8%83%8C%E5%8C%85-1.html 视频讲解:https://www.bilibili.com/video/BV1cg411g7Y6 01背包问题 一维 https://programmercarl.com/%E8%83%8C%E5…...

VMware NSX 4.1 发布 - 网络安全虚拟化平台
请访问原文链接:VMware NSX 4 - 网络安全虚拟化平台,查看最新版。原创作品,转载请保留出处。 作者主页:www.sysin.org VMware NSX 提供了一个敏捷式软件定义基础架构,用来构建云原生应用程序环境。NSX 专注于为具有异…...

计算理论 复杂度预备知识
文章目录计算理论 复杂度预备知识符号递归表达式求解通项公式主方法Akra-Bazzi 定理计算理论 复杂度预备知识 符号 f(n)o(g(n))f(n)o(g(n))f(n)o(g(n)) :∃c\exists c∃c ,当 nnn 足够大时, f(n)<cg(n)f(n)\lt cg(n)f(n)<cg(n) &#…...
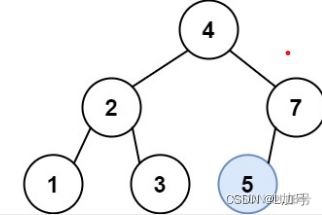
二叉树——二叉搜索树中的插入操作
二叉搜索树中的插入操作 链接 给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。 注意,…...

C# if break,if continue,if return的区别和使用
故事部分: 现在你肚子饿了,想要去: 1.吃个三菜一汤。 2.吃个蛋糕。 3.喝个奶茶。 结果,你吃饭的时候,吃到一个虫子。 你会有几种做法? 1.把有虫子这道菜拿走,继续吃下一道菜 。 2.算了ÿ…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...