LORA概述: 大语言模型的低阶适应
LORA概述: 大语言模型的低阶适应
- LORA: 大语言模型的低阶适应
- 前言
- 摘要
- 论文十问
- 实验
- RoBERTa
- DeBERTa
- GPT-2
- GPT-3
- 结论
- 代码调用
LORA: 大语言模型的低阶适应
前言
LoRA的核心思想在于优化预训练语言模型的微调过程,通过有效地处理权重矩阵的变化(即梯度更新的累积),使其具有“低秩”结构。简而言之,这意味着可以通过低秩分解有效地表示变化矩阵。
具体来说,对于预训练权重矩阵W₀,其更新量可以表示为∆W = BA,其中B和A都是低秩矩阵(例如,秩为r,r明显小于矩阵维度d)。在训练期间,W₀被冻结,而B和A中的参数是可训练的。这明显减少了适应的可训练参数数量。
如下图所示,在原始预训练语言模型旁边添加一个旁路,执行降维再升维的操作,以模拟内在秩。在训练过程中,固定预训练语言模型的参数,只训练降维矩阵A和升维矩阵B。模型的输入输出维度保持不变,输出时将BA与预训练语言模型的参数叠加。矩阵A使用随机高斯分布进行初始化,而矩阵B则使用零矩阵进行初始化,以确保在训练开始时,该旁路矩阵仍然是零矩阵。

摘要
自然语言处理的一个重要范式包括在通用域数据上进行大规模预训练,以及针对特定任务或域进行适配。随着我们预训练更大的模型,全面微调,即重新训练所有模型参数,变得更加不可行。
以GPT-3 175B为例,单独部署经过微调的独立实例模型,每个实例拥有1750亿个参数,是极其昂贵的。我们提出了低秩适应(LoRA)方法,其中冻结预训练模型权重,并在transformer体系结构的每个层中插入可训练的低秩分解矩阵,从而大大减少下游任务的可训练参数数量。
与使用Adam微调GPT-3 175B相比,LoRA可以将可训练参数数量减少10000倍,GPU内存需求减少3倍。尽管只有更少的可训练参数和更高的训练吞吐量,但LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3上的性能优于或等同于微调。
我们还对语言模型适配中的秩缺失进行了实证研究,这解释了LoRA的功效。我们发布了一个软件包,可以方便地将LoRA与PyTorch模型集成,并为RoBERTa、DeBERTa和GPT-2提供了我们的实现和模型检查点。
论文十问
- 论文试图解决什么问题?
这篇论文试图解决大规模预训练语言模型(如GPT-3)微调(fine-tuning)所带来的巨大的存储、部署和任务切换成本的问题。
- 这是否是一个新的问题?
这不是一个全新的问题,但随着 transformer 语言模型规模的不断增长(如 GPT-3 175B 参数),这个问题的严重性在增加。论文中也提到了许多相关的已有工作。
- 这篇文章要验证一个什么科学假设?
这篇文章的主要科学假设是微调过程中模型参数的变化矩阵具有低秩结构(rank-deficient)。基于这个假设,作者提出了低秩适应(LoRA)方法来有效地适应下游任务。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关的工作包括适配器模块、prompt tuning等参数高效适应方法。
- 论文中提到的解决方案之关键是什么?
LoRA的关键是只训练插入到每个transformer层中的低秩分解矩阵,而保持预训练权重固定。这大大降低了适应的可训练参数数量。
- 论文中的实验是如何设计的?
在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 等模型上进行了大量实验比较。实验设计针对性强,测试了性能和参数数量的权衡。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的数据集包括 GLUE、WikiSQL、SAMSum 等。实验代码和模型检查点开源。
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
是的,丰富的实验验证了 LoRA 在性能、存储效率、训练速度等方面都优于或匹敌全微调基线,支持了低秩适应的有效性。
- 这篇论文到底有什么贡献?
主要贡献是提出 LoRA 方法,大幅降低大模型微调的成本,并给出可复现的实验验证。
- 下一步呢?有什么工作可以继续深入?
下一步可以考虑与其他高效适应方法(如prompt tuning)的结合,解释微调过程中模型内部表示的变化,进一步提高 LoRA 的泛化性等。
实验
评估了 LoRA 在 RoBERTa (Liu et al., 2019)、DeBERTa (He et al., 2021) 和 GPT-2 (Radford etal., b) 上的下游任务性能,然后再扩展到 GPT- 3 175B(布朗等人,2020 年)
RoBERTa
RoBERTa是Facebook AI于2019年提出的语言表示模型。相比BERT有更优化的预训练步骤,性能更好,参数规模类似,分Base和Large两个版本。实验中分别使用了1.25亿参数和3.55亿参数的RoBERTa模型。
DeBERTa
微软于2020年提出的改进型BERT模型。采用多任务预训练、增强型注意力机制等技术。实验中使用了极大规模的DeBERTa XXL,包含了1500亿参数。
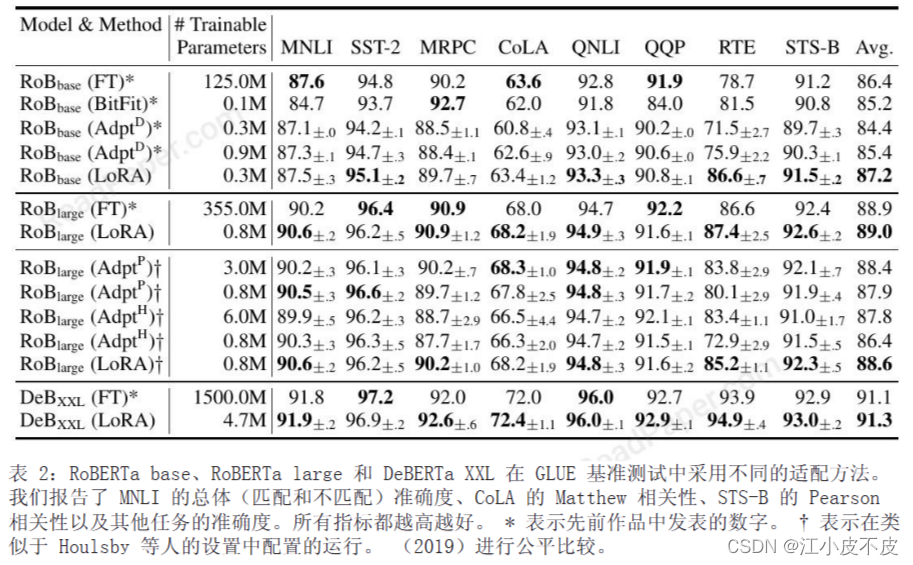
GPT-2
OpenAI于2019年提出的基于Transformer的语言生成模型GPT-2。模型架构采用了解码器,支持自回归文本生成。实验分别基于中等规模(3.54亿参数)和大规模(7.74亿参数)的GPT-2进行。
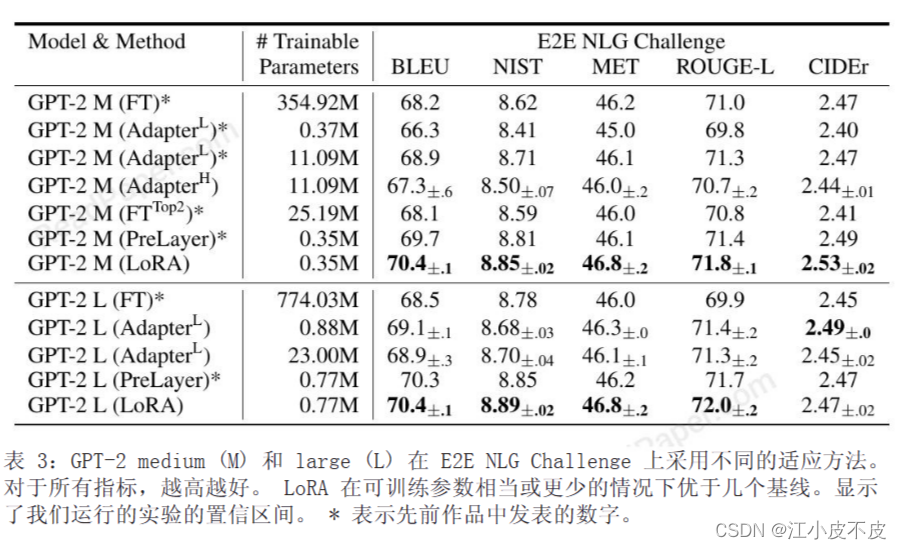
GPT-3
OpenAI于2020年发布的巨大语言模型, Transformer规模达到了1750亿参数,是当时最大的神经语言模型。论文使用了这个极具挑战性的大模型进行扩展实验。这几种模型的选择,可以让作者全面验证LoRA适配方法在不同规模的Transformer类模型中的有效性。覆盖了目前最典型和最前沿的语言表示与生成模型。
结论
实际好处:
- 内存和存储使用减少: 在使用Adam训练的大型Transformer中,通过使用LoRA,显著减少了VRAM(显存)和存储的使用量。例如,在GPT-3 175B上,将训练期间的VRAM消耗从1.2TB减少到350GB。
- 检查点大小减小: 在一定条件下,检查点大小减少了大约10,000倍,从350GB减少到35MB。这降低了GPU训练的硬件需求,并避免了I/O瓶颈。
- 任务切换成本降低: LoRA允许在任务之间进行切换,通过仅交换LoRA权重而不是所有参数,降低了部署的成本。这使得可以在机器上动态换入和换出预训练权重,创建自定义模型。
- 加速训练: 在GPT-3 175B的训练中,相较于完全微调,观察到25%的加速,因为不需要计算绝大多数参数的梯度。
局限性:
- 前向传递复杂性: 吸收不同任务的A和B到W中,以消除额外推理延迟,在单个前向传递中批量输入并不简单。需要考虑不同任务的权重合并和动态选择LoRA模块的复杂性。
- 推理延迟问题: 尽管可以动态选择LoRA模块以处理不同任务的推理延迟,但在一些场景中,合并权重可能引入不可避免的问题。
代码调用
使用 🤗 PEFT 训练您的模型
下面的示例是使用 LoRA 进行微调的情况。
from transformers import AutoModelForSeq2SeqLM
from peft import PeftModel, PeftConfigpeft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")with torch.no_grad():outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])相关文章:
LORA概述: 大语言模型的低阶适应
LORA概述: 大语言模型的低阶适应 LORA: 大语言模型的低阶适应前言摘要论文十问实验RoBERTaDeBERTaGPT-2GPT-3 结论代码调用 LORA: 大语言模型的低阶适应 前言 LoRA的核心思想在于优化预训练语言模型的微调过程,通过有效地处理权重矩阵的变化(即梯度更新…...

关于在PyTorch中使用cudnn.benchmark= True
关于在PyTorch中使用cudnn.benchmark True 在PyTorch中,cudnn.benchmark True是一个参数,用于启用或禁用cuDNN的基准测试模式。cuDNN是一个由NVIDIA开发的深度神经网络库,它为GPU提供了一个优化的计算接口。 基准测试模式是cuDNN的一个特性…...

re:Invent大会,亚马逊云科技为用户提供端到端的AI服务
11月末,若是你降落在拉斯维加斯麦卡伦国际机场,或许会在大厅里看到一排排AI企业和云厂商相关的夸张标语。走向出口的路上,你的身边会不断穿梭过穿着印有“AI21Lab”“Anthropic”等字样的AI企业员工。或许,你还会被机场工作人员主…...

23、什么是卷积的 Feature Map?
这一节介绍一个概念,什么是卷积的 Feature Map? Feature Map, 中文称为特征图,卷积的 Feature Map 指的是在卷积神经网络(CNN)中,通过卷积这一操作从输入图像中提取的特征图。 上一节用示意动图介绍了卷积算…...
安装获取mongodb
目录 本地安装 获取云上资源 获取Atlas免费数据库 本地连接数据库 在Atlas中连接数据库 本文适合初学者或mongodb感兴趣的同学来准备学习测试环境,或本地临时开发环境。mongodb是一个对用户非常友好的数据库。这种友好,不仅仅体现在灵活的数据结构和…...
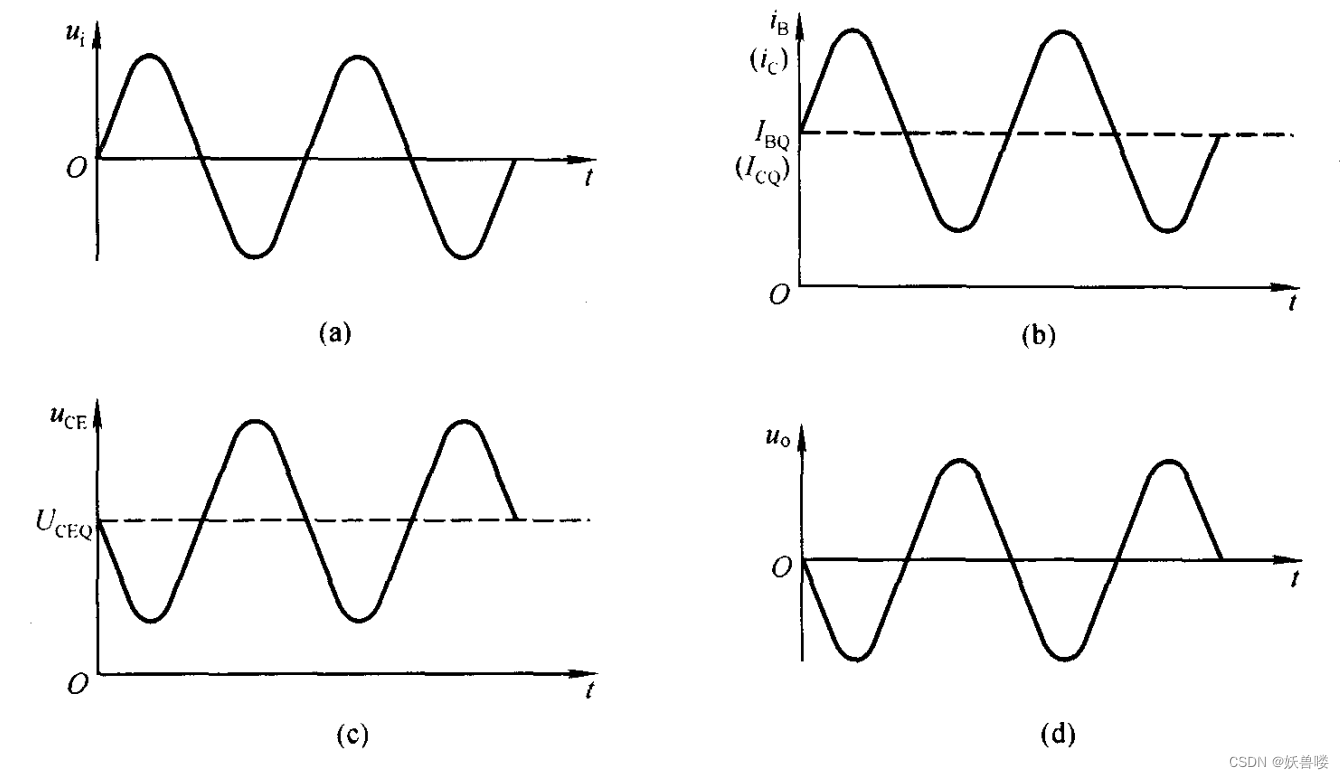
【模电】基本共射放大电路的工作原理及波形分析
基本共射放大电路的工作原理及波形分析 在上图所示的基本放大电路中,静态时的 I B Q I\tiny BQ IBQ、 I C Q I\tiny CQ ICQ、 U C E Q U\tiny CEQ UCEQ如下图( b )、( c )中虚线所标注。 ( a ) u i 的波形( b ) i B …...
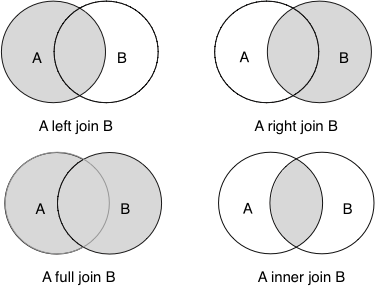
Oracle:左连接、右连接、全外连接、(+)号详解
目录 Oracle 左连接、右连接、全外连接、()号详解 1、左外连接(LEFT OUTER JOIN/ LEFT JOIN) 2、右外连接(RIGHT OUTER JOIN/RIGHT JOIN) 3、全外连接(FULL OUTER JOIN/FULL JOIN࿰…...

virtualbox上win7企业微信CPU高问题
问题 linux Opensuse上的Virtualbox安装有win7, win7中跑企业微信CPU占用很高。一杀掉它,CPU占用就立马降下来了。 定位 当cpu占用高时,打开任务管理器,可以定位到svhost.exe占用很高, 优化 右键点击计算机–管理–服务和应用…...

【华为OD题库-055】金字塔/微商-java
题目 微商模式比较典型,下级每赚100元就要上交15元,给出每个级别的收入,求出金字塔尖上的人收入。 输入描述 第一行输入N,表示有N个代理商上下级关系 接下来输入N行,每行三个数:代理商代号 上级代理商代号 代理商赚的钱…...
OpenVINO异步Stable Diffusion推理优化方案
文章目录 Stable Diffusion 推理优化背景技术讲解:异步优化方案思路:异步推理优化原理OpenVINO异步推理Python API同步和异步实现方式对比 oneflow分布式调度优化优势:实现思路 总结: Stable Diffusion 推理优化 背景 2022年&…...

51单片机的智能加湿器控制系统【含proteus仿真+程序+报告+原理图】
1、主要功能 该系统由AT89C51单片机LCD1602显示模块DHT11湿度传感器模块继电器等模块构成。主要适用于智能自动加湿器、湿度保持、湿度控制等相似项目。 可实现基本功能: 1、LCD1602液晶屏实时显示湿度信息 2、DHT11采集湿度 3、按键可以调节适宜人体湿度的阈值范围࿰…...
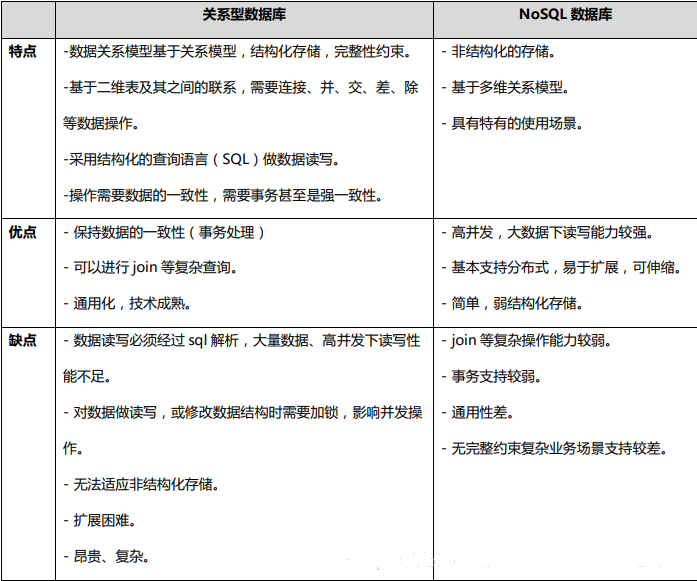
NoSql非关系型数据库
前言:Nosql not only sql,意即“不仅仅是sql”,泛指非关系型数据库。这些类型的数据存储不需要固定的模式(当然也有固定的模式),无需多余的操作就可以横向扩展。NoSql数据库中的数据是使用聚合模型来进行处…...
抖音集团面试挂在2面,复盘后,决定二战.....
先说下我基本情况,本科不是计算机专业,现在是学通信,然后做图像处理,可能面试官看我不是科班出身没有问太多计算机相关的问题,因为第一次找工作,字节的游戏专场又是最早开始的,就投递了…...

每个.NET开发都应掌握的C#处理文件系统I/O知识点
上篇文章讲述了C#多线程知识点,本文将介绍C#处理文件的知识点。在.NET开发领域,文件系统I/O是一个至关重要的主题,尤其是在处理文件、目录和数据存储方面。C#作为.NET平台的主要编程语言,提供了丰富而强大的文件系统I/O功能&#…...

vue3 中使用 sse 最佳实践,封装工具
工具 // 接受参数 export interface SSEChatParams {url: string,// sse 连接onmessage: (event: MessageEvent) > void,// 处理消息的函数onopen: () > void,// 建立连接触发的事件finallyHandler: () > void,// 相当于 try_finally 中的 finally 部分,不…...

OpenCV快速入门【完结】:总目录——初窥计算机视觉
文章目录 前言目录1. OpenCV快速入门:初探2. OpenCV快速入门:像素操作和图像变换3. OpenCV快速入门:绘制图形、图像金字塔和感兴趣区域4. OpenCV快速入门:图像滤波与边缘检测5. OpenCV快速入门:图像形态学操作6. OpenC…...
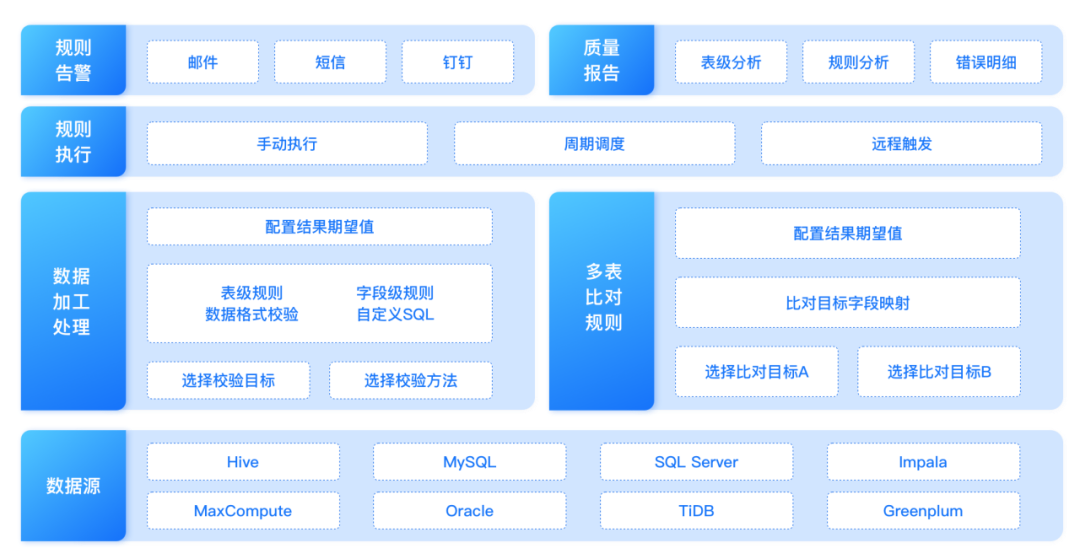
车企数据治理实践案例,实现数据生产、消费的闭环链路 | 数字化标杆
随着业务飞速发展,某汽车制造企业业务系统数量、复杂度和数据量都在呈几何级数的上涨,这就对于企业IT能力和IT架构模式的要求越来越高。加之企业大力发展数字化营销、新能源车等业务,希望通过持续优化客户体验,创造可持续发展的数…...
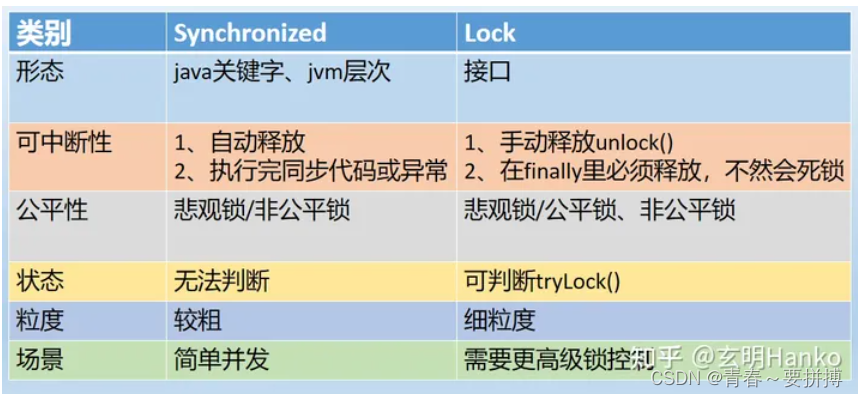
深入学习锁--Lock各种使用方法
一、什么是Lock Lock是一个接口,通常所说的可重入锁是指Lock的一个实现子类ReentrantLock 二、Lock实现步骤: ①创建锁对象Lock lock new ReentrantLock(); ②加锁lock.lock(); ③释放锁lock.unlock(); import java.util.concurrent.locks.Lock; import java.util…...
计算机毕设:基于机器学习的生物医学语音检测识别 附完整代码数据可直接运行
项目视频讲解: 基于机器学习的生物医学语音检测识别 完整代码数据可直接运行_哔哩哔哩_bilibili 运行效果图: 数据展示: 完整代码: #导入python的 numpy matplotlib pandas库 import pandas as pd import numpy as np import matplotlib.pyplot as plt #绘图 import se…...

VMware安装Ubuntu系统(Server端,Desktop端步骤一样)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

CppCon 2015 学习:REFLECTION TECHNIQUES IN C++
关于 Reflection(反射) 这个概念,总结一下: Reflection(反射)是什么? 反射是对类型的自我检查能力(Introspection) 可以查看类的成员变量、成员函数等信息。反射允许枚…...
RabbitMQ 各类交换机
为什么要用交换机? 交换机用来路由消息。如果直发队列,这个消息就被处理消失了,那别的队列也需要这个消息怎么办?那就要用到交换机 交换机类型 1,fanout:广播 特点 广播所有消息:将消息…...