kaggle RSNA 比赛过程总结
引言
算算时间,有差不多两年多没在打kaggle了,自20年最后一场后(其实之前也就打过两场,一场打铁,一场表格赛是金是银不太记得,当时相当于刺激战场,过拟合lb大赛太刺激了,各种trick只有敢想就敢做,但最近发现账号都忘了),RSNA开赛那段时期,有个群里正好有人说要参加,具体啥情况忘了,然后我正值年底,阳了后又恍恍惚惚参加了一场考试,转阴后方觉大梦一场,梦醒茶凉(当然,这只是我现在的说辞,从11月发生了太多意料之外的事情,我现在也只能用一梦黄粱来搪塞),需要做一些事情排解一下新年的迷茫与惆怅,于是顺势就加入开整。不过这一整,又收获了更多煎熬,但也把我过剩的精神内耗挥霍了一部分,这不得不说也算另一种buff转移了。关于最后拿到了bronze medal,我只能说很遗憾,又比较幸运,因为整个比赛过程期间我都苦于算力,很多想法没有付诸于行动,做了Rashaad,虽然我并不想。比赛最后几天,我将lb中0.52的方案融进了自己的base里,然后就没有跑了,可能我离我心中的成功就差两张3090或者4080的距离,但这距离,已经形如沟壑(PS:其实应该去用云平台的,中途也看到几个不错的),所以本篇主题,算是对之前的一个回忆帖,也算一个总结帖。
赛题数据分析
赛题说明为:
The goal of this competition is to identify breast cancer. You’ll train your model with screening mammograms obtained from regular screening.
Your work improving the automation of detection in screening mammography may enable radiologists to be more accurate and efficient, improving the quality and safety of patient care. It could also help reduce costs and unnecessary medical procedures.
赛题图像数据为:
one fold only.
train images :num_patient = 9530num_image = 43771cancer0 = 42854 (0.979)cancer1 = 917 (0.021)
validation images :num_patient = 2383num_image = 10935cancer0 = 10694 (0.978)cancer1 = 241 (0.022)
即总共加起来5w多张,可视化为:
def has_cancer(l):return len(l) == 2 or (len(l) == 1 and l[0] == 1)patient_cancer_map = train.groupby('patient_id').cancer.unique().apply(lambda l: has_cancer(l))fig, ax = plt.subplots(1,2,figsize=(20,5))sns.countplot(patient_cancer_map, palette='Paired', ax=ax[0]);
ax[0].set_title('Number of patients with cancer');sns.countplot(train.groupby('patient_id').size(), ax=ax[1])
ax[1].set_title('Number of images per patient')
ax[1].set_xlabel('Number of images')
ax[1].set_ylabel('Counts of patients');

我们能得出来的信息为:
- 数据样本是高度不平衡的,比例差距接近50:1
- 而在大多数情况下,患者的样本数一般为4张,但有些患者的picture提供了10张,这很奇怪
进一步针对target分析为:
biopsy_counts = train.groupby('cancer').biopsy.value_counts().unstack().fillna(0)
biopsy_perc = biopsy_counts.transpose() / biopsy_counts.sum(axis=1)fig, ax = plt.subplots(1,2,figsize=(20,5))
sns.countplot(train.cancer, palette='Reds', ax=ax[0])
ax[0].set_title('Number of images displaying cancer');
sns.heatmap(biopsy_perc.transpose(), ax=ax[1], annot=True, cmap='Oranges');

这里可以获得的insight为:
- 显示癌症的图像数量非常少。这应该比癌症患者的人数还要少。
- 从活检特征来看,我们可以说所有癌症患者都进行了活检。但只有大约3%的没有癌症的图像进行了后续活检。也许我们应该在患者层面上了解一下这一功能。
这也是后续我将介绍的一个trick,这里先按下不提。
至于更详细的EDA,可以查看public公开的gold medal notebooks,以及discussion,这里不再详述。
该赛题的评价函数为:
pF1=2pPrecision⋅pRecallpPrecision+pRecallpF_1 = 2\frac{pPrecision \cdot pRecall}{pPrecision+pRecall}pF1=2pPrecision+pRecallpPrecision⋅pRecall
其中 pPrecision=pTPpTP+pFPpPrecision = \frac{pTP}{pTP+pFP}pPrecision=pTP+pFPpTP, pRecall=pTPTP+FNpRecall = \frac{pTP}{TP+FN}pRecall=TP+FNpTP
这就是常说的pf1值了,但是在这种高度不平衡类别下,用pf1值是有很大波动情况的,所以这里也算是一个不稳定的trick,好用是真好用,但过拟合可能也是真过拟合。介绍完赛题,下面是我的一个心路历程。
初期——摇摇乐环节
为什么取这个名字,是因为可能相当多人,如果不是非常纯小白,都算是有自己的一个弹药库的,即或多或少看过以及会去找之前的方案,然后直接套用,就简单过一下数据,先用之前方案跑了再说,生死有命富贵在天,一人得道鸡犬升天。这个时期,public是混乱的,但也是文艺复兴,不管专业不专业,先提出自己见解,有人觉得不对就delete,emmm。。。
然后我这边也是豪言壮语,各路大神各显神通,有位老板直接说上efficientb8,batchsize为128,参数拉大(但往往,越带有别样激情的,被拷打后,也是越容易放弃的),我的另一个高中生队友,直接给了一个large_kernel,为:
class LargeKernel_debias(nn.Conv2d):def forward(self, input: torch.Tensor):finput = input.flatten(0, 1)[:, None]target = abs(self.weight)target = target / target.sum((-1, -2), True)joined_kernel = torch.cat([self.weight, target], 0)reals = target.new_zeros([1, 1] + [s + p * 2 for p, s in zip(self.padding, input.shape[-2:])])reals[[slice(None)] * 2 + [slice(p, -p) if p != 0 else slice(None) for p in self.padding]].fill_(1)output, power = torch.nn.functional.conv2d(finput, joined_kernel, padding=self.padding).chunk(2, 1)ratio = torch.div(*torch.nn.functional.conv2d(reals, joined_kernel).chunk(2, 1))power_ = torch.mul(power, ratio)output = torch.sub(output,power_)out = output.unflatten(0, input.shape[:2]).flatten(1, 2)return out
听说在上一个比赛是好用的,但这个比赛因为前期没做好预处理,300G数据我这服务器磁盘空间都不够,根本处理不了,就直接使用public公开的512 * 512的数据集,顺带加了个二阶优化器,结果就是代码没什么问题,数据问题很大,一个epochs用我的rtx 5000单卡就三小时一个,跑得我惊了,直接惊为天人,还是改回了adam,后续老板机跑得咋样我忘了,因为模型就没给我了。
当然,中间还发生了很多事情,做了很多奇思妙想以及胡思乱想式编码,因为我也是两年多没学套路了,顺带把没走过的坑再重新走一遍,当成一种学习与修炼(大雾)?紧接着就到了新的一年。
baseline前——无序转有序
如果说为什么在队友全躺的时候,我连算力都没有,但还依然坚持走完全程,大概就是有青蛙佬hengck23的方案公开吧,从前期到最后,他的大部分工作都出于分享式的,算是在这个比赛对我影响最大的,我也学会了很多,在1月的时候,发觉不能这样毫无方向实验了,于是开始看他的实验记录:


上述只是截取的两张表格数据,他还分享了很多point of view,好的或者不好的,以及论文。我也是顺着思路,找到了LMFLOSS(论文地址:https://arxiv.org/pdf/2212.12741.pdf),以及Global Objectives For PyTorch(https://github.com/Shlomix/global_objectives_pytorch/),其中LMFLoss在paper with code中是没代码的,但是它表达的意思很简单,就是对focal loss和LDAM做了一个加权,我中途在kaggle上找了一个脑部的小数据集上试着调了下参,但效果差不多,所以就选择了后者。相比于BCEloss这种通用公式,在不平衡样本集上,PRLoss效果更佳显著。
这里确定了baseline的基本模型为efficient-v2,因为够小,并且在青蛙佬和前排的discuss上看,没有必要用太大的模型(依照赛后我现在的理解上看,就是小模型针对大图像,而大模型针对小图像,防止过拟合),另外,发现了之前读数据的方式是不对的,没有使用StratifiedGroupKFold,那我做k折交叉反而是无序的,这里也是转为有序的一个地方,即:
train_data['fold']= -1
cv = StratifiedGroupKFold(n_splits=CFG.n_splits, shuffle=CFG.shuffle, random_state=CFG.random_state)for fold, (_, valid_idx) in enumerate(cv.split(X=train_data["image_id"], y=train_data["cancer"], groups=train_data["patient_id"])):train_data.loc[valid_idx, "fold"] = foldassert train_data.groupby(['fold', 'cancer']).size().sum() == train_data.shape[0]
仅仅只是加了这一步,先对Excel进行了分组,就提高了2个十分位,是巨大的,虽然我的分辨率还是低于1024的,但显然让模型学习到了更精确的东西。修改完了两个大方向问题,以及一些小方向后,重新调参,排名也终于变得好看了些,可好看的结果就是后续一直被爆,倒地不起了。
产生baseline——开始佛系
这时候是过年前夕吧,我发现了一个根本问题,我没有机器没法跑1024分辨率以上的模型,public已经上升到这个高度了,虽然不能说明这个分辨率就一定好,还看见很多1384,1536的,但至少我已经跑不动了,我高中生队友已经转去打NLP了,因为没思路没机器,我也接近放弃,但看到public公开了一个0.47的方案,非常的简单,连带着train和inference一起公开的,这时候我心态就变了,从目标银牌,转变为了体验比赛过程。
开源的0.47方案非常简单,我感觉就是在规则允许的9小时内通过非常多的数据增强以及集成来达到最高,这里使用了monai包,也是我该场比赛才知道,发现非常好用的一个医疗图像包,它使用的还是基础的efficientv2,但增强代码为:
cfg.train_transforms = Compose([LoadImaged(keys="image", image_only=True),EnsureChannelFirstd(keys="image"),RepeatChanneld(keys="image", repeats=3),Transposed(keys="image", indices=(0, 2, 1)),Resized(keys="image", spatial_size=cfg.img_size, mode="bilinear"),Lambdad(keys="image", func=lambda x: x / 255.0),RandFlipd(keys="image", prob=0.5, spatial_axis=[1]),]
)cfg.val_transforms = Compose([LoadImaged(keys="image", image_only=True),EnsureChannelFirstd(keys="image"),RepeatChanneld(keys="image", repeats=3),Transposed(keys="image", indices=(0, 2, 1)),Resized(keys="image", spatial_size=cfg.img_size, mode="bilinear"),Lambdad(keys="image", func=lambda x: x / 255.0),]
)该参数一度在我做512 * 512训练的时候,发现epochs在5个左右就接近巅峰,我加入了wandb后观察图像,基本验证集的loss也就和train一样,在4到5个左右epochs就涨不动了,然后大概训练了4折,然后做集成:
all_fold_preds = []
for weights in glob.glob(weights_path + f"fold*.pth"):model = timm.create_model(cfg.backbone,pretrained=False,num_classes=cfg.num_classes,drop_rate=cfg.drop_rate,drop_path_rate=cfg.drop_path_rate,)model = torch.nn.DataParallel(model)model.to("cuda")model.load_state_dict(torch.load(weights)["model"])model = model.modulemodel.eval()torch.set_grad_enabled(False)all_ids = []all_preds = []for batch in infer_dataloader:# print(batch["image"].shape,".....image")inputs = batch["image"].to("cuda")outputs = model(inputs)
这个idea给了我很大的启发,因为我之前提交线上评估的时候,感觉时间都很长,让我产生了一种错觉,觉得kaggle给的空间太小,时间太少。但这波增强下去,我发现我错了,因为该方案的加速,主要用到了Dali,根据事后我看discuss,dali自带的提升让整个过程时间提升了接近30%,特别是在比赛截止还有一个月的时候,因为有个很吊的nvidia工程师也在这场打,并且很长时间的第一,他直接针对这个比赛数据集的图像格式,对dali进行了再次升级,加入了jpeg2000 decode,我想说,不愧是nvidia,为了比赛改了一个版本,牛批!
中间也尝试了很多其它的方案,但发现不如该方案给我的感觉直观,主要可扩展性大,所以我直接就定为了baseline,但跑了一个512 * 512分辨率后发现跟1024的差距是真大啊,1024的分数是0.47,而我跑512就已经到0.25了。
这时候过年,看着漫天烟火,我不经陷入了沉思,这一思考,就到了年后。
baseline后——automl
年后工作忙起来了,也有了一些规划,颓废感因为没有足够时间精神内耗而少了许多,我因为没有机器的原因,天天就只是上discuss区看看,没有再过多尝试了,因为卡在模型训练上,发现后续的事情都变得毫无意义,有idea但不想付出实践,而开始忙于其它事情,比如我想开的区块链系列,openmmlab训练营以及各种琐碎缠身。
省略中间过程,直到前20天,nvidia工程师大佬修改了dali版本,以及开源了它的SE-ResNeXt50 full GPU decoding方案,顺势跑了一波,发现效果非常不错,该方案中的trick我也觉得非常多,比如说一通道升维:
class CustomDataset(Dataset):def __init__(self, df, cfg, aug):passdef __getitem__(self, idx):label = self.labels[idx]img = self.load_one(idx)if self.aug:img = self.augment(img)img = self.normalize_img(img)torch_img = torch.tensor(img).float().permute(2,0,1)feature_dict = {"input": torch_img,"target": torch.tensor(label),}return feature_dictdef __len__(self):return len(self.fns)def load_one(self, idx):path = self.data_folder + self.fns[idx]try:img = cv2.imread(path, cv2.IMREAD_UNCHANGED)shape = img.shapeif len(img.shape) == 2:img = img[:,:,None]except Exception as e:print(e)return img
以及gempool:
def gem(x, p=3, eps=1e-6):return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1.0 / p)class GeM(nn.Module):def __init__(self, p=3, eps=1e-6, p_trainable=False):super(GeM, self).__init__()if p_trainable:self.p = Parameter(torch.ones(1) * p)else:self.p = pself.eps = epsdef forward(self, x):ret = gem(x, p=self.p, eps=self.eps)return retdef __repr__(self):return (self.__class__.__name__ + f"(p={self.p.data.tolist()[0]:.4f},eps={self.eps})")
后者这个pooling的对比avg_pool我不知道,方案作者是说better,具体的在论文中有体现:https://arxiv.org/pdf/1711.02512.pdf
我想聊的是前者,可能我接触医学图像不多,按常理来讲,一般都是读成三维三通道图像再去升tensor,很少有说直接按一通道来转格式,即使在这里,它是正确的,跟前面的dali和后面的batch一起,又将速度提升了。我于是将这个方案嵌入进了我的baseline中,但那时候已经是最后几天了,简单跑了跑,发现比原efficientv2确实有提升,并且能集成的模型又多了一个,但很可惜,最终怠惰了,想申请个云平台,嫖一波a100,还是没有付诸于实践。
所以标题中的automl,auto指的是lb,我直接不训练了,通过嫖公开的model,然后加入我之前的调参、预处理和TTA作为了最终成绩,事后这时候想想,很遗憾,很幸运。
公开的各种trick
这节是我赛后看了很多前排的方案,感觉可以做一个分类,做一个笔记,针对我看的这几个,我每个方向选一个觉得比较适合我,有代表性的。
dataset上
dataset理论上,能做的操作就三种,一种是删,一种是augment,一种是直接扩充。这里我考虑没有修改的原因是原数据是dcm格式,每个方案修改数据只是针对后续的模型,以及还有用metamodel对数据做进一步修改的,所以放在后续的model上来讨论。
删减
这个trick其实很容易想到,但是想做好比较难,根据评价指标是pf1,那我们需要删的目标为假阴性,但是怎么从这5w张图像中找到基模型分类错误的假阴性呢?这里赛后第26th的方案让我有了一种大道至简的感觉。原文为:
I realized that all the label tagged for laterality + patient_id is the same. That means the label is actually for patient + laterality, not image. So the easiest way to deal with this, is to train OOF and drop False Negatives with high confidence( e.g. the label is 1 but model predict probability is like 0.1 or 0.01). The CV score boost huge after this is done( about 0.03 to 0.04 ).
我当初也想了很多方式,但其实最简单的方案也是最直接有效的就藏在了train.csv中,既然图像方式很难走通,为什么不更上一级,通过病患呢?然后我去看了一下作者公开的github,大致找到删的规则为:
for patient_id, laterality in itertools.product(train_df.loc[(train_df.cancer == 1) & (train_df.fold < 10)].patient_id.unique(), ("0", "1")
):sub_df = train_df.loc[(train_df.patient_id == patient_id)& (train_df.laterality == laterality)& (train_df.cancer == 1)]if sub_df.shape[0] == 0:continueto_delete_index = sub_df.loc[sub_df.oof_prob < tao.args.fp_threshold].indexif len(to_delete_index) == sub_df.shape[0]:to_delete_index = sub_df.loc[sub_df.oof_prob != sub_df.oof_prob.max()].indextrain_df.drop(to_delete_index, inplace=True)// An highlighted block
var foo = 'bar';
作者的github为:https://github.com/louis-she/rsna-2022-public
增强
这里的增主要只数据增强,而增强方案就太多了,这里贴出8th公开的方案:
def mixup_augmentation(x:torch.Tensor, yc:torch.Tensor, alpha:float = 1.0):"""Function which performs Mixup augmentation"""assert alpha > 0, "Alpha must be greater than 0"assert x.shape[0] > 1, "Need more than 1 sample to apply mixup"lam = np.random.beta(alpha, alpha)rand_idx = torch.randperm(x.shape[0])mixed_x = lam * x + (1 - lam) * x[rand_idx, :]yc_j, yc_k = yc, yc[rand_idx]return mixed_x, yc_j, yc_k, lamdef get_transforms_16bit(data, img_size, normalize_mean, normalize_std):if data == 'train':return Compose([ToFloat(max_value=65535.0),RandomResizedCrop(img_size[0], img_size[1], scale=(0.8, 1), ratio=(0.45, 0.55), p=1), HorizontalFlip(p=0.5),VerticalFlip(p=0.5),ShiftScaleRotate(rotate_limit=(-5, 5), p=0.3),RandomBrightnessContrast(brightness_limit=(-0.1,0.1), contrast_limit=(-0.1, 0.1), p=0.5),JpegCompression(quality_lower=80, quality_upper=100, p=0.3),Affine(p=0.3),ToTensorV2(),])elif data == 'valid':return Compose([ToFloat(max_value=65535.0),Resize(img_size[0], img_size[1]),ToTensorV2(),])
扩增
即使用外部数据,比赛规则并没有禁止,但基本要kaggle内公开的吧,比如20th的方案:
Likewise my timm backbones were pretrained on VinDr by predicting BIRADS. I used CBIS, Vindr PL as external data (boosted my CV by ~0.02).
后面我看到还用了纽约大学的预训练模型,但不知道啥原因被kaggle禁止了,这里可以去看原discussion,主要是VinDr数据集,介绍为:
- FFDM / Full Field Digital Mammography / similar to RSNA dataset
- 5000 patients / 337.8 GB dataset
- All 20K images are marked with density classification
- Findings annotations with bounding boxes around various types of marked regions.
- 241 of these findings are marked BIRADS 5 (very high probability of malignancy)
- 995 of the findings are marked BIRADS 4 (about 30% chance of cancer)
- Remainder of bbox findings are BIRADS 3, so 2254 images have been annotated- I traded emails with who I reasonably believe is the author of the dataset (Nguyễn Quý Hà), and he said it would be OK to use this data with this RSNA Kaggle competition. Still waiting to hear back from physionet. It goes without saying of course, that you can’t rely on anything I say here as any type of legal guarantee.
看完介绍我就感觉非常适合rsna,作者这里说提升了0.02,我感觉应该是没有做什么清洗针对负样本,以及我上面所提trick清除 false negatives,应该还能比0.02高一点。我比赛期间也去找了external data,但扩增的是CMMD(The Chinese Mammography Database)2022,结果发现不太好,跟没扩差不多,但那是在baseline之前了,那时候因为跑一次时间太久,对结果没有啥提升的我一般都是不再看了,赛后发现这其实很不好,玄学了,但不能太玄学,emmm。
model上
这里除了上述我的baseline中提到的外,还包括几个方面吧。
分辨率(image size)
这个我看到很多用的size闻所未闻,比如1536x960,1536x768等等,我很想学学这些宽高比是怎么搞出来的,我猜测可能是根据使用的模型一次次试验从而得到的?我确实玩不起。。。
这里顺便补充crop裁剪策略,在这个比赛中,有非常多的ROI方式,比如说66th的非模型方式为:
frame_org = copy.copy(frame)thres1 = np.min(frame)+68 #Adjustments were made while viewing the crop image.np.place(frame, frame < thres1, 0)thres2 = frame_org.sum() / (h*w)vertical_not_zero = [True if frame[:,idx].sum() > thres2 else False for idx in range(w)]horizontal_not_zero = [True if frame[idx,:].sum() > thres2 else False for idx in range(h)]crop = frame_org[horizontal_not_zero,:]crop = crop[:,vertical_not_zero]
而再前排的,选择了yolo进行crop,特别是青蛙佬早早开源了裁剪模型,6th的说明是:
- YOLOX model was trained to generate breast bbox
- Compared to simple rule-based breast extraction, YOLOX cropped images usually have a smaller region, which seemed to prevent our models from overfitting
- In order to shorten inference time, we used simple rule-based crop during inference
- Images were cropped with a random margin during training as augmentation
- Bbox mix (YOLOX crop + rule-based crop) were also used as augmentation
- Cropped images are resized to an aspect ratio of 2:1 (1024 x 512 or 1536 x 768)
采样
这里有Negative sampling 和 versampling,但这个是个仁者见仁智者见智的idea,因为这两种方法都不能保证模型的泛化能力,它们只改变了训练集的分布,而不是真实的数据分布,所以拟合程度需要手动调调,这里贴出蛙哥的采样器:
class Balancer(torch.utils.data.Sampler):def __init__(self, pos_cases, neg_cases, ratio = 3):self.r = ratio - 1self.pos_index = pos_casesself.neg_index = neg_casesself.length = self.r * int(np.floor(len(self.neg_index)/self.r))self.ds_len = self.length + (self.length // self.r)def __iter__(self):pos_index = self.pos_indexneg_index = self.neg_indexnp.random.shuffle(pos_index)np.random.shuffle(neg_index)neg_index = neg_index[:self.length].reshape(-1,self.r)#pos_index = np.random.choice(pos_index, self.length//self.r).reshape(-1,1)pos_index_len = len(pos_index)pos_index = np.tile(pos_index, ((len(neg_index) // pos_index_len) + 1, 1))pos_index = np.apply_along_axis(np.random.permutation, 1, pos_index)pos_index = pos_index.reshape(-1,1)[:len(neg_index)]index = np.concatenate([pos_index,neg_index], -1).reshape(-1)return iter(index)def __len__(self):return self.ds_len
以及github上一个针对不平衡样本,在cifar100上做的实验:
Validation error on Long-Tailed CIFAR100:
| Imbalance | 200 | 100 | 50 | 20 | 10 | 1 |
|---|---|---|---|---|---|---|
| Baseline | 64.21 | 60.38 | 55.09 | 48.93 | 43.52 | 29.69 |
| Over-sample | 66.39 | 61.53 | 56.65 | 49.03 | 43.38 | 29.41 |
| Focal | 64.38 | 61.31 | 55.68 | 48.05 | 44.22 | 28.52 |
| CB | 63.77 | 60.40 | 54.68 | 47.41 | 42.01 | 28.39 |
| LDAM-DRW | 61.73 | 57.96 | 52.54 | 47.14 | 41.29 | 28.85 |
| Baseline+RS | 59.59 | 55.65 | 51.91 | 45.09 | 41.45 | 29.80 |
| WVN+RS | 59.48 | 55.50 | 51.80 | 46.12 | 41.02 | 29.22 |
链接为:https://github.com/feidfoe/AdjustBnd4Imbalance
model策略
这里就各种神仙打架了,比如6th的方案:

以及4th的stage 1:

第一种我没看懂,第二种我看懂了,但我都大受震撼。但所幸,前者提供了源代码,到时候去研究一波。其它还有很多牛皮的架构图就不再这里展示了
图像嵌入
我不知道该不该取这个名字,主要最近在看cs224w,管它,直接扯了。这里可以理解成,语义分割、背景建模或者图像嵌入,具体比如66th的方案:
Background noise reduction (kmeans)
I apply kmeans-clustering into each image using pixel values, then the pixel values of a cluster which has the lowest summation change into zero.
To save time, I used the kmeans-pytorch

以及我看有几个方案提到的原模型:
Metamodel - SVM and XGBoost on image enbeddings.
这个很有意思,但我暂时没找到开源方案,所以去找到一篇论文,即:
Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles
之后会回过头来再研究一下,我还看见一个用xgboost做二折,针对前特征,做一波多分类,即31th的方案:
The idea here was to take use of all other information META etc and together with vision model feed features to a XGB model, which is SOTA in handling imbalanced and mix of feature information. We also had information for the negative clas that could be used for smoothing the imbalanced situation, like create more classes.
The features for the XGB training and inference where:
'‘site_id’,‘laterality’,‘view’,‘age’,‘implant’,‘n_images’,‘image_size’ + extracted information from the last dense layer from every model instead of embeddings to minimize the size if the vision information and features to 32 vs 64 features.
I created a total of 9 classes from the information in the traindata, “neg”, “pos”, “diffneg”, “rneg”, “negA”, “negB” etc. Data not seen in test data, but it doesn’t matter as you only need to train the XGB to classify them instead which help sort the total information within the negative class region of information, leaving it less imbalanced.
我直接惊为天人,我确实没有尝试过,很可惜,代码也没开源。
Optimizer
这里抛出这个东西,主要是最近出lion了,看论文说远远超过adamw,但该比赛中的一次discussion,使用lion的选手好像都没有特别理想,很多人说线上掉分了,我引出这个只是想在这里Mark一下,方便后续回头看。
lion的paper为:https://arxiv.org/abs/2302.06675
inference上
这里也有非常多种方式,在我看来,而赛后很多前排大佬也都用了,但好不好用,也是一个不稳定的过程,比如说中后期热度很高的转tensorrt模型加速,但主要都是青蛙佬提出的字节跳动的nextvit,但这个模型太复杂了,我在复现过程中就发现很慢,还有batch操作等等,这里不再过多提及,因为我后期没事做就是各种琢磨推理了,而其实很多都常见方式,不能算trick,这里唯一一个比较重要的trick就是阈值了。
阈值(threshold)
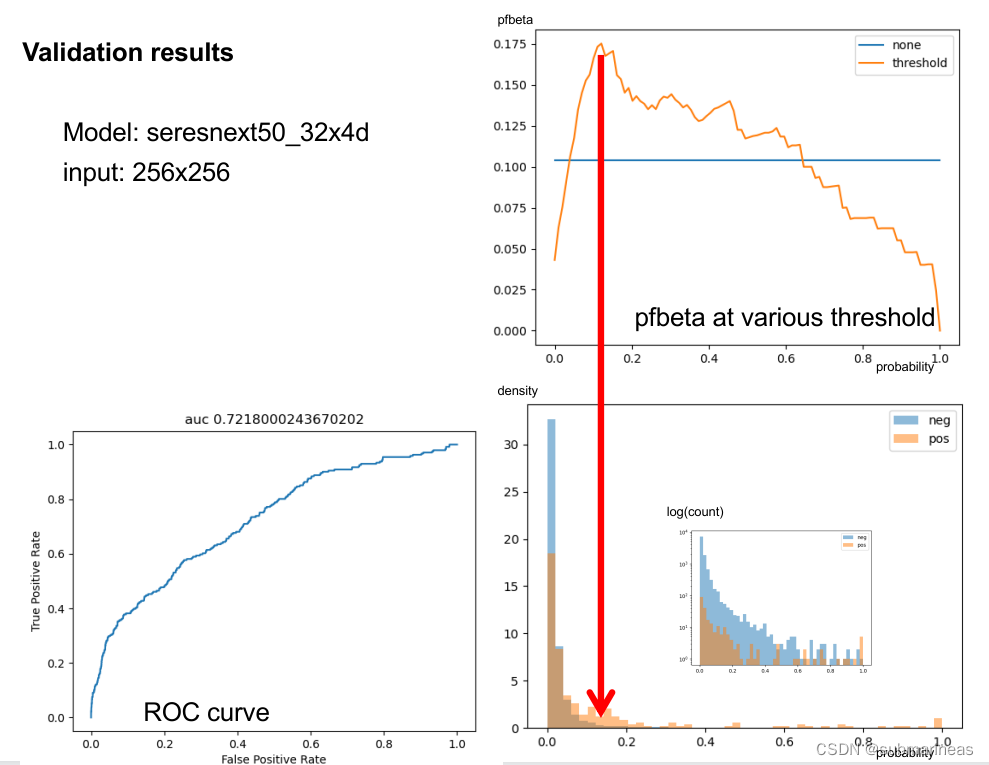
这是青蛙哥所做的一张图像,我们可以从图中看到,因为样本极度不平衡,而采取pf1值,那么很显然,训练一个模型使用多视图输入进行预测,结果会比平均值(和/或最大值)更好,即集成。
但还有一种方案更直接,就是限制阈值,比如最后我是直接写了:
# binarize predictions
th = np.quantile(sub['cancer_raw'].values,0.98)
sub['cancer'] = (sub['cancer_raw'].values > th).astype(int)
因为统计值是0.97935:
df['label'].value_counts(normalize=True), df['label'].value_counts(normalize=False), (0.0 0.979351.0 0.02065Name: label, dtype: float64,0.0 233341.0 492Name: label, dtype: int64)
当然这里,还能根据每折模型的不同预测参数去动态调整阈值,即我初始设置一个0.9的threshold,然后对模型预测进行一个采样,再加上初始值,这或许也有比较好的分数。
结尾
该说的都差不多说了,这里我只能说,过程是曲折的,人的心情都在一次次commit上动态调整,结果或遗憾,或欣喜,但最终,我只能说,不虚此行。
相关文章:
kaggle RSNA 比赛过程总结
引言 算算时间,有差不多两年多没在打kaggle了,自20年最后一场后(其实之前也就打过两场,一场打铁,一场表格赛是金是银不太记得,当时相当于刺激战场,过拟合lb大赛太刺激了,各种trick只…...

51单片机入门————LED灯的控制
LED的电路图通过原理图看出,LED灯是接单片机芯片的P20~P27的一共有8个LED,51单片机也是8字节的P20x010xFE————1111 1110P20xFE可以表示把在P2端的第一个灯点亮1 表示高电平0表示低电平当为0的时候形成一个完整回路,电流从高电平流向低电平…...

J - 二进制与、平方和(线段树 + 维护区间1的个数)
2023河南省赛组队训练赛(二) - Virtual Judge (vjudge.net) 请你维护一个长度为 n 的非负整数序列 a1, a2, ..., an,支持以下两种操作: 第一种操作会将序列 al, al 1, ..., ar 中的每个元素,修改为各自和 x…...
)
BertTokenizer的使用方法(超详细)
导入 from transformers import BertTokenizer from pytorch_pretrained import BertTokenizer以上两行代码都可以导入BerBertTokenizer,transformers是当下比较成熟的库,pytorch_pretrained是google提供的源码(功能不如transformers全面) 加载 tokenizer BertT…...
:编译过程中遇到的问题总结)
深度学习编译器CINN(3):编译过程中遇到的问题总结
目录 问题一:No module named XXXX 问题描述 分析与解决方案 问题二:catastrophic error: cannot open source file "float16.h"...

yum 安装mysql8数据全过程
mysql8安装方式:(使用官方yum仓库) 1. wget https://dev.mysql.com/get/mysql80-community-release-el7-4.noarch.rpm 安装 yum install mysql80-community-release-el7-4.noarch.rpm 2、生成yum源缓存 每次当我们编写了,…...
内网vCenter部署教程一
PS:因为交换机链路为trunk,安装先登录ESXI,将端口组改为管理vlan ID(1021) 一、双击镜像,打开文件夹,目录为F:\vcsa-ui-installer\win32,双击installer.exe 二、先设置语言为中文 三、点击下一步 四、选择需要安装esxi的主机。 五、设置Vcenter虚拟机的密码...

java 进阶—线程的常用方法
大家好,通过java进阶—多线程,我们知道的什么是进程,什么是线程,以及线程的三种创建方式的选择 今天,我们来看看线程的基础操作 start() 开启线程 public class Demo implements Runnable {Overridepublic void run…...
hadoop的运行模式
作者简介:大家好我是小唐同学(๑><๑),好久不见,为梦想而努力的小唐又回来了,让我们一起加油!!! 个人主页:小唐同学(๑><๑)的博客主页 目前…...

服务器(centos7.6)已经安装了宝塔面板,想在里面安装一个SVN工具(subversion),应该如何操作呢?
首先,在登录进入宝塔面板,然后点击左侧终端,进入终端界面,如下图:------------------------------------------如果是第一次使用会弹出输入服务器用户名和密码,此时输入root账号和密码,即可进入…...

从智能进化模型看用友BIP的AI平台化能力
随着人工成本的上升,智能和自动化技术的成熟,企业在越来越多的场景开始应用自动化技术来替代相对标准及有规则的工作,同时利用智能算法来优化复杂工作及决策,获得竞争优势。 不同于阅读、聊天、搜索等面向终端用户的应用场景&…...
项目管理的主要内容包括哪些?盘点好用的项目管理系统软件
阅读本文您将了解:1、项目管理的主要内容包括哪些2、好用的项目管理软件 项目管理是为了实施一个特定目标,所实施的一系列针对项目要素的管理过程,包括过程、手段以及技术等。 通过项目管理,我们能够提前安排和控制项目的时间、…...
Allegro如何查看PCB上器件的库路径操作指导
Allegro如何查看PCB上器件的库路径操作指导 在做PCB设计的时候,有时需要检查PCB上器件使用的库的路径是否正确,Allegro支持快速将PCB上所有器件的库路径都列出来 如下图 如何显示这个报表,具体操作如下 点击Tools点击Report...

笔记【尚硅谷】大数据Canal教程丨Alibaba数据实时同步神器
视频教程:【尚硅谷】大数据Canal教程丨Alibaba数据实时同步神器教程资料:https://pan.baidu.com/s/1VhGBcqeywM6jyXJxtytd1w?pwd6666,提取码:6666本套教程以Canal的底层原理展开讲解,细致地介绍了Canal的安装部署及常…...

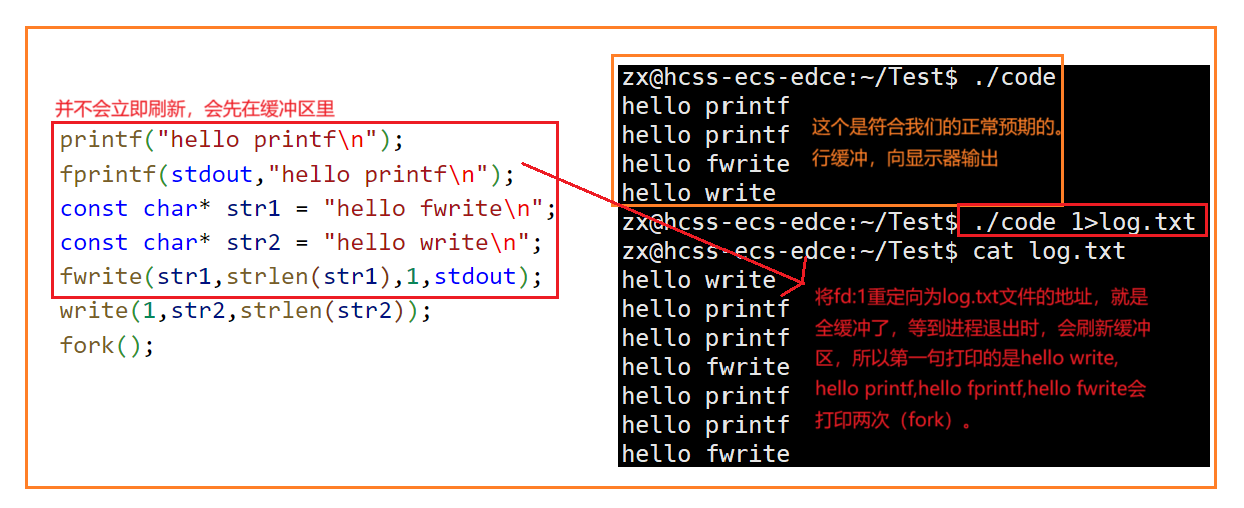
如何重定向命令行日志信息到指定txt文件?
如果你想把命令行的输出重定向到指定的txt文件,你可以使用一些符号来实现。例如,你可以在命令后面加上>或>>符号,然后指定文件名。例如: command > output.txt 这样就会把command的标准输出保存到output.txt文件中&…...

物理机不能访问虚拟机kali的web服务解决方案记录
目录 环境 问题描述 解决方案 知识补充 效果测试 其他思路 环境 kali(nat模式),物理机,可互ping 问题描述 kali的web服务器不能在物理机上访问。 1.本机能ping通虚拟机 2.虚拟机也能ping通本机 3.虚拟机能访问自己的web …...
服务器配置 | 在Windows本地显示远程服务器绘图程序
文章目录方法1:在MobaXterm的终端输入指令方法2:在Pycharm中运行前提概要,需要在本地Windows端显示点云的3d可视化界面 对于点云的3d可视化一般有两种方法,open3d显示或者是mayavi显示。这两个库都可以使用pip install来实现安装…...

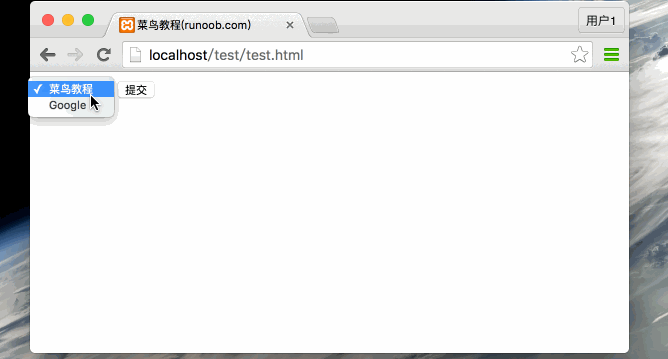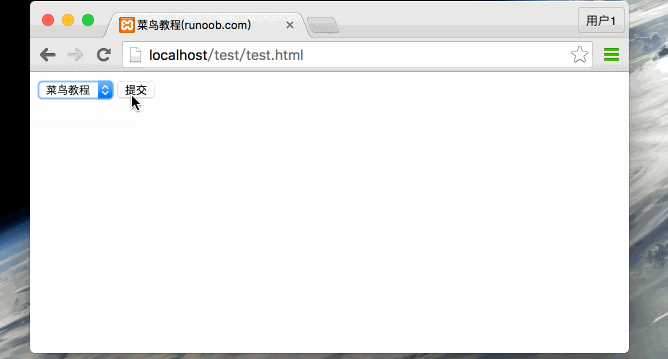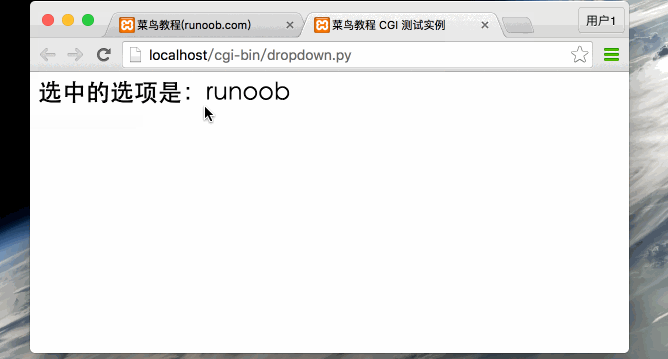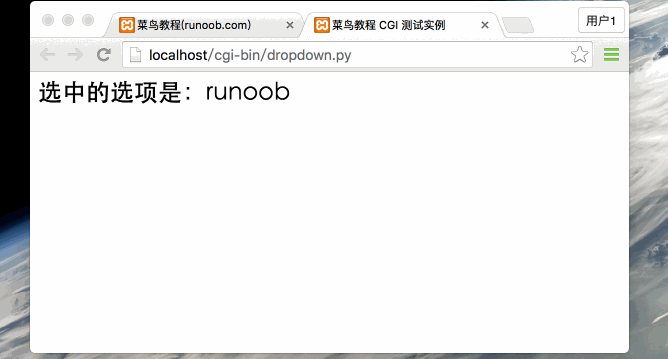
从0开始学python -47
Python CGI编程 -2 GET和POST方法 浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。 使用GET方法传输数据 GET方法发送编码后的用户信息到服务端,数据信息包含在请求页面的URL上,以"?"号分割…...
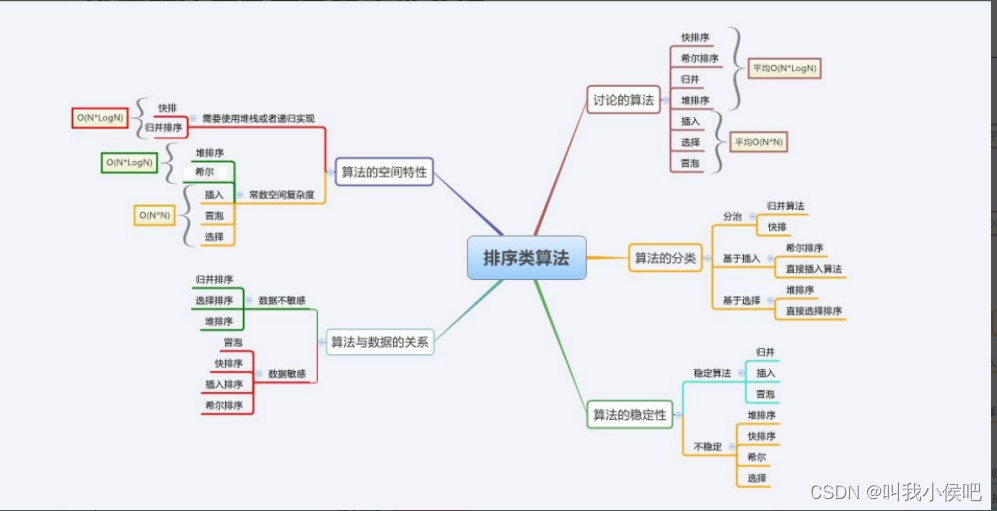
【数据结构】八大经典排序总结
文章目录一、排序的概念及其运用1.排序的概念2.常见排序的分类3.排序的运用二、常见排序算法的实现1.直接插入排序1.1排序思想1.2代码实现1.3复杂度及稳定性1.4特性总结2.希尔排序2.1排序思想2.3复杂度及稳定性2.4特性总结3.直接选择排序3.1排序思想3.2代码实现3.3复杂度及稳定…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...