面向LLM的App架构——技术维度
这是两篇面向LLM的大前端架构的第二篇,主要写我对LLM辅助开发能力的认知以及由此推演出的适合LLM辅助开发的技术架构。
LLM之于代码
商业代码对质量的要求其实对LLM是有点高的。主要是输入准确度、输出准确度(这个是绝大部分人质疑的点)、知识新鲜度和上下文长度。
现有的玩票类的代码辅助看起来非常酷炫(也证明了LLM的潜力,特别是chatdev),放到商业环境下还是不太行。Copilot简单使用了相似的线上代码,所以可用性好很多,但是LLM的参与度非常低。AutoDev、UnitMesh做了很多东西,源码上看prompt有些简单,没有真的用过,不敢评价。
简单解释一下我觉得有挑战的这几个方面:
- 输入准确度,要保证完备且精准的把需求写进prompt。而且要把边界条件、异常处理都加上,这个就比较离谱了,因为大部分人是做不了这么详细的技术设计的,或者能细致如斯那离真正代码就太近了,不太值得费心思用LLM
- 输出准确度,这个好理解,想办法规避幻觉。不论是代码本身层面的还是业务逻辑层面的
- 知识新鲜度,LLM对新知识的追加是非常困难的,而且不天然具备新知识比旧知识权重高的特点。对于大前端这种人均轮子王的技术栈,很难给出足够现代的代码
- 上下文长度,即便是最新的gpt4,面对轻松松百万行的代码处理也是有心无力的,更不要说超长上下文带来的lost in context问题。就算是想办法把业务上下文处理掉,组件、内部基建的上下文是极难搞定的
修改架构以适应LLM
核心思路:严格的SOLID和代码拆解,减少单次生成范围;不造轮子;让LLM做准确度要求不高的工作。
流程
编码只是整个开发过程的一部分,基于前面的分析,这部分提效最困难。而开发过程的其他部分反而有非常适合LLM的,有的简单调整也可以快速应用LLM。单次开发流程大概是需求分析->技术设计->写代码->自测->CR->bugfix->上线。
需求分析
主要是把业务正常、异常情况,潜在扩展点,非业务逻辑类的需求(性能、安全性等)列清楚,并且确定业务归属的子域(DDD)。
需要做的根据需求文档做问答、对上下文进行常见的扩写(异常情况、扩展点、其他要求)非常适合LLM。但是确定业务归属不太合适,不过也不太值得用LLM。
技术设计
确定模块、分层、用的技术点、核心复杂度的拆解和设计、风险评估、扩展点实现方式等。
需要做的有不少是搜索(retrieve)类的工作:技术点、风险评估、核心复杂度的拆解方式、设计模式,是非常适合LLM的,如果能对接搜索引擎的就基本完美了。
识别核心复杂度是个分类任务,还不需要特别新的知识,这个也非常适合LLM。
还有另一个大部分工作是应用规则的:模块、分层、细节设计、任务拆解和依赖梳理、相关代码梳理,这些对LLM比较难。
写代码
见下文
自测
主要是手点和UT,手点没办法,UT见下文
CR
CR其实要确定三件事是做到位的:技术使用、业务合理、多端一致。
- 技术CR,主要就是看遵循习俗、规范。只要不是有特别多内部基建和奇异写法,LLM的知识和理解力是完全胜任的
- 业务CR。这个需要有完整的业务定义的,仅靠当前的技术评审文档是不够的。和代码合到一起,上下文会非常爆炸,不太行
- 多端一致。这个其实完全可以在写代码的时候靠翻译,我们落地效果非常好。如果是硬对齐,是需要LLM分别解释代码到一个中间态,然后再用LLM做中间态的一致性判断的。这里面又涉及到了不同端基建行为的不一致,所以问题会比较多
bugfix
由于技术带来的bug一般都问题不大,由业务逻辑带来的bug一般都解不了。
上线
这部分主要是merge代码处理冲突。这个上下文会非常长,但是如果能有业务解释文档(prompt历史记录)做背景,解冲突可能会很好用。没试过,不敢保证。
新App
基建
简单一句,尽量用最流行的开源库。用hook、字节码、fork来做底层修改,但是保证api与公有知识一致。这样LLM生成的代码能非常简单的适配。
即便做不到这个,那一定要有(智能)规则来做转化,这个转换可以也利用LLM。
如果没有流行开源库,那一定按照广为流传的标准定义或者计算机基本原理中的术语(不是黑话)来定义接口。LLM的理解和近迁移还是相对厉害的,如果复杂任务+中远迁移是强模所难。
UI/业务组件
要么能用规则说明白设计稿与组件的对应关系,让LLM一次性直接生成使用组件的代码。要么就是生成原始代码,再利用RAG相反的思路去做组件替换。
前者没有试过,我司用的figma,导出的设计稿并不能包含组件信息(虽然在figma页面上能看到)。后者逻辑上可行,还没来得及试。
分层
一定要严格、规整的MVX分层,严格、规整的数据驱动(或者状态机),保证每一层的关注点是独立的,且上一层的代码只需要理解和依赖下一层。规避任何context、单例、全局变量等不受控的信息扩散。保证任何一层的代码生成只需要当层的业务描述和下一层的接口声明,且接口必须明确变化和不变字段。
分块
分块是为了尽可能减少单模块的上下文需求和迭代所需要的历史代码。
几个关键点:
- 平衡模块大小和通信,降低大小核心目的是控制上下文长度。如果通信过多的话,上下文会比业务逻辑描述还要更麻烦。
- M层用DDD拆分,按业务逻辑边界拆开
- V层用视图位置拆分,按设计稿边界拆开
- X层如果是VM的话,按V层拆分;如果是P层的话,按M层拆分。这个比较麻烦,需要实践中规范SOP。MVVM和MVI(redux)应该是更合理的选型
函数式
分块的粒度最终会是方法,不会是类。因为类会有成员变量,对生成准确性影响会比较大,所以要尽可能规避。而最好的办法就是函数式。
打包/组件化
幻觉是不可避免的,人和IDE一定是在相当长时间内作为纠错机制存在的。虽然已经有利用编译错误进行编译错误修复的功能,但是,这个的正确与否是极为客观的,修复也是极为客观的(语法规则)。而一般情况下业务的正确与否还是需要人来校准的,否则就可以通过细化步骤完全规避幻觉了(在用LLM的过程中发现,任务的核心复杂度严重影响最终结果可用性,细化步骤+ReAct来把单任务的核心复杂度降低,并且利用前序消息做chat历史效果好很多)。
那么,快速试错就是开发过程中最重要的了。换句话说,打包速度、小粒度快速运行会变得极为重要。打包又要成显学了,就…。所以,MVVM这种能把业务逻辑、交互逻辑都以UT方式验证的模式会比其他MVX模式要更适合。任何可以快速预览的UI框架也都更优于需要打包的框架。
UT
对于相对完整和独立的代码,LLM是可以给出完整的UT的。如果是白盒补UT,边界搞得比较准。但是,有一些算法会明显被网络上不靠谱但错的很普遍的代码误导,出问题。
再叠加验证速度很可能成为开发效率瓶颈,应该更多的考虑黑盒的TDD,甚至case本身会是非常好的提示词,能非常准确的描述需求。从需求到UT这个还没找到靠谱的prompt,直给的prompt效果不好,能想到的多步骤是需求->简单代码框架(翻译)->边界条件(联想)->UT(翻译)这个路径,但是我司并不写UT,暂未实践。
迭代
迭代的挑战是远高于一次性生成的,之前所以image2code的项目都选择性的无视了这个点,导致不太能落地,沦为KPI项目。
代码由于大部分源自于生成,迭代方式一定会有大量变化。无非是两种可能性:每次都重新生成和每次都带上老代码。
重新生成就必须把历史(上次)prompt和人工修改点记录下来,那么commit的规范应该是生成(记录代码和prompt)+fix bugs。这样的下次生成最理想情况下(LLM的温度和topxxx都是最稳定的那档)是可以直接重新生成+cherry-pick来形成下一个迭代结果的。但注意,很可能代码生成是一连串对话的结果,所以可能对话导出+单独文件是更明智的选择,比如codexxx.kt有一个配套的codexxx.chat.log来记录完整prompt过程。
带上次代码,这部分没有持续试过,但简单尝试发现很难正确描述代码。或者说很难把修改点让LLM弄明白。Chat效果相对好一些,不过也不是很乐观。
风格一致性和协作
这里是不是真的需要我是有一些怀疑的。如果所有代码都是生成的,那么协作规模应该是相对小的,即便是大团队,边界也会更加明确,人的作用也更多的是cr和流程管理,所以由大规模协作带来的风格一致性、规范等等问题会不会就不需要了,只要保证模型能迭代就ok了。
但是一致性带来的技术收敛就没有了,对hook、依赖管理会有更高的要求。
老App
老代码会希望演变到新App描述的状态,或者说把屎山变成稍微有条理的代码。有一些额外的工作可以试着用LLM,也有一些大概率当前的LLM不能胜任。从大到小大概是这些工作。这部分很多来自我自己的知乎回答。
模块化和业务分割
受困于上下文长度和代码理解的精准程度,这种偏全局的工作很难直接利用LLM。但是在原有静态分析工具的基础上,把结果规范化之后让LLM做全局分析应该是问题不大的。因为静态分析之后做模块化和拆分其实是根据依赖做最大流最小割,以及对代码做分类,这两个上下文要求就小很多了,分类还是LLM最强的能力之一。
整体分层
分层比单纯模块化需要更多的业务知识,是根据业务特征把分好的模块归入不同的层级。毕竟对于IDaaS和支付公司来说登录是完全不同的业务定位,代码所处的层级也是完全不同的。这个其实不太需要LLM,有个正经业务架构师正经分析一下业务情况,给一个原则性指导文件就好。但是,让LLM根据这个指导文件来指导后续代码的实施还是很有价值的,至少是可以做一个文件问答,让每个人都能更好的理解其中的原理。
冗余
发现和去掉冗余/重复代码也是去屎山的重要步骤。对于完全基于LLM的App来说,这个也是非常重要的,因为LLM上下文天然决定了除非用非常强的RAG和大量反反复复的chat,否则一定会出现大量重复或极小差异的代码。
这部分直接裸用LLM不行,但是用LLM做标注、embedding后做相似度应该是可以的,只不过做全代码聚类的成本比较高,需要有的放矢的查和改。如果能fine tune embedding,直接对代码表意,能去掉标注步骤,可以真的做全代码的聚类和修改。
局部分层
就是把BBM搞成合理分层的MVX。如果是想真的把MVX分好,这个难度很大,LLM不太能理解分层的清晰边界是啥;但是,如果是人明确规则,比如buildview、setdata、updateconstraints,这种明确的代码特征,那非常好用。有了这些方法,其实人再做分层也没那么麻烦了。
主要还是困于LLM应用原则(中距离迁移)的能力并不是很强。
老代码迁移
迁移到函数式
这个相对简单,一般这个量级的代码对gpt4来说问题不大。函数式也是一个通用概念。任务本身难度没那么大。
迁移到更通用的库
完全看现有库是不是接口非常离谱。如果老库只是实现非常蹩脚,但是还是使用业界相关命名,迁移效果非常好。如果老库取的是Eva这种不着调的名字,那很可能会大规模跑偏。因为被激活的包含了完全不同领域的部分。
性能问题
看性能来源是什么:
- 全局设计问题,这种通常是业务设计问题,LLM不太行
- 局部设计问题,这种通常是使用的技术不太对或者实现方式不合理。如果是成熟(老)技术,那问题不大,如果最好的解法是新技术可能会有点问题
梳理
或者说与代码对话。
全局搜索类的靠RAG是非常值得做的。我自己实现了一版半,效果还是可以的。如果不考虑成本,把能上的手段都上了,把embedding的ft也做了,应该会非常惊艳。
局部分析类的直接把代码丢给GPT4也是OK的,只是代码最好和正常思路是一致的,要不然代码中命名、逻辑激活的常见思路和实际情况的差异会带来大量的幻觉。
总结
LLM对于开发来说,当前情况下最大的贡献点在于非代码部分和最细节的代码部分。为了适配LLM的能力水平,流程需要识别出适合LLM的点,并且规范化输入输出,尽可能交给LLM;代码需要极限的拆解,让每一块代码都更聚焦;人需要增强cr能力和表达能力,充分利用好工具;IDE需要更好的集成和基于prompt的协作支持。
相关文章:

面向LLM的App架构——技术维度
这是两篇面向LLM的大前端架构的第二篇,主要写我对LLM辅助开发能力的认知以及由此推演出的适合LLM辅助开发的技术架构。 LLM之于代码 商业代码对质量的要求其实对LLM是有点高的。主要是输入准确度、输出准确度(这个是绝大部分人质疑的点)、知…...
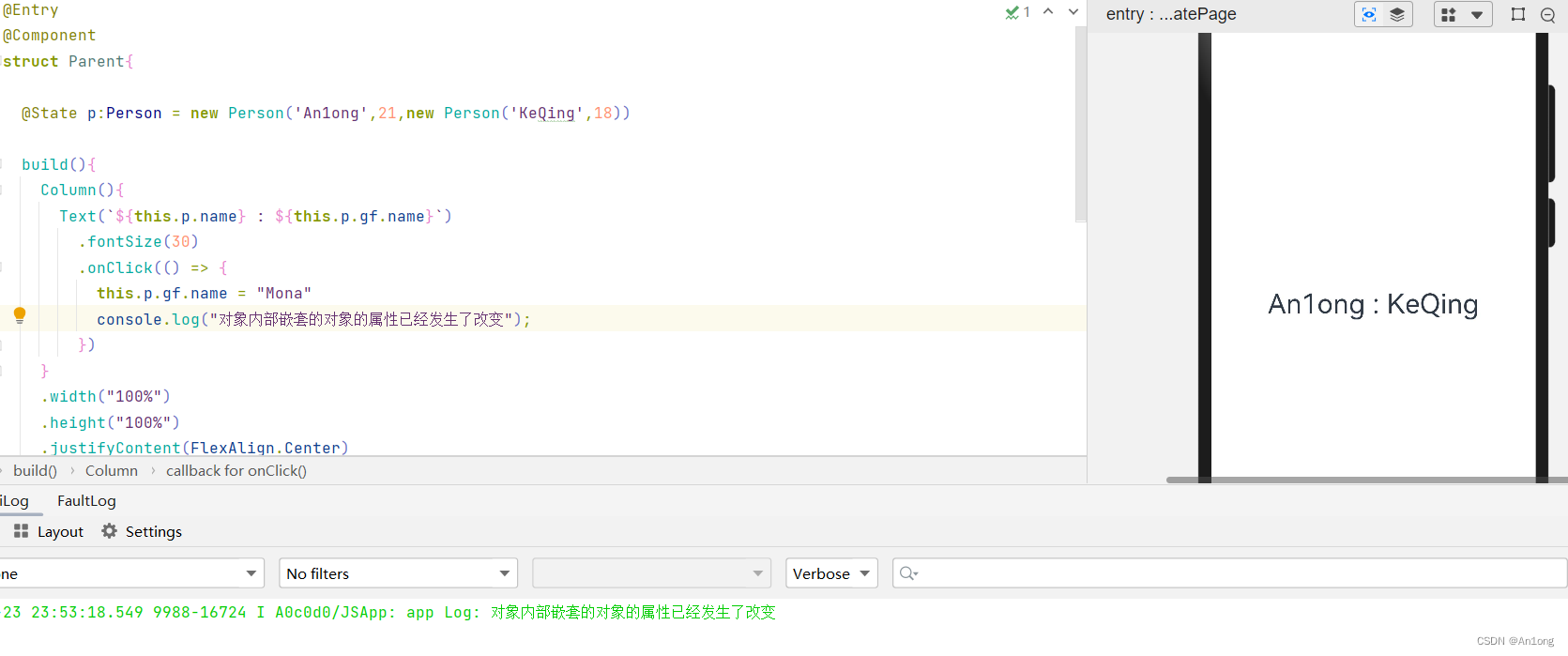
ArkUI - 状态管理
目录 一、State装饰器 二、自定义组件 三、Prop和Link、Provide和Consume 四、Observed和ObjectLink 一、State装饰器 这里涉及到两个概念 状态 和 视图 状态(State):指驱动视图更新的数据(就是被State注解标记的变量&…...

C++ 学习系列 -- C++ 中的多态行为
一 多态是什么? 多态是面向对象三大特征中重要一项,另外两项分别是封装与继承。 所谓多态,指的是多种不同的形态,也就是去完成某个具体的行为,多个不同的对象去操作同一个函数时,会产生不同的行为&…...

Spring Cloud中实现Feign声明式服务调用客户端
可以通过OpenFeign从一个服务中调用另一个服务,我们一般采用的方式就是定义一个Feign接口并使用FeignClient注解来进行标注,feign会默认为我们创建的接口生成一个代理对象。 当我们在代码中调用Feign接口的方法的时候,实际上就是在调用我们Fe…...

【网络编程】网络通信基础——简述TCP/IP协议
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【网络编程】【Java系列】 本专栏旨在分享学习网络编程的一点学习心得,欢迎大家在评论区交流讨论💌 目录 一、ip地…...

观察者模式 Observer
观察者模式属于行为型模式。在程序设计中,观察者模式通常由两个对象组成:观察者和被观察者。当被观察者状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应。 三要素:观察者(Observer&#…...
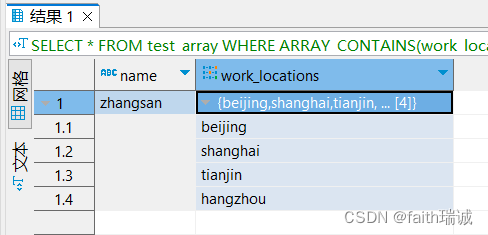
Hadoop入门学习笔记——七、Hive语法
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 七、Hive语法7.1. 数据库相关操作7.1.1. 创建数据库7.1.2…...

采用SpringBoot框架+原生HTML、JS前后端分离模式开发和部署的电子病历编辑器源码(电子病历评级4级)
概述: 电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录,是病历的一种记录形式。 医院通过电子病历以电子化方式记录患者就诊的信息,包括&…...

HTML表单
<!DOCTYPE html> <html><head><meta charset"utf-8"><title>招聘案列</title></head><body><h1>午睡操场传来蝉的声音</h1><hr /><form>昵称:<input type"text" …...

Http 请求体和响应体中重要的字段
Http 请求体 Accept:用于告诉服务器客户端能够处理哪些媒体类型。Accept 头中的值通常是一个或多个 MIME 类型,并按优先级排序。服务器会根据 Accept 头中的值来决定响应的内容类型。例如,Accept: text/plain, text/html。Content-Type&…...
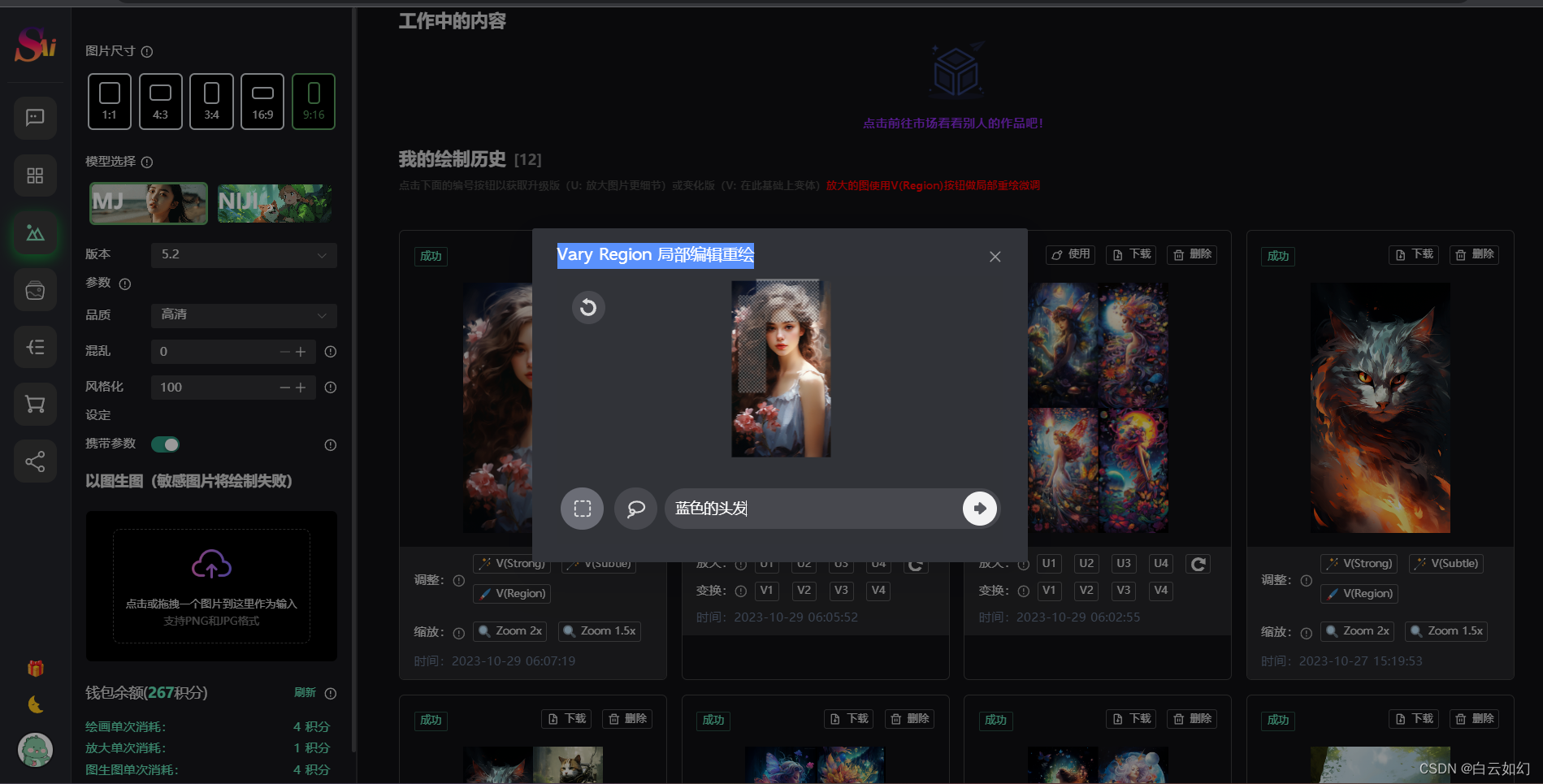
最新国内可用使用GPT4.0,GPT语音对话,Midjourney绘画,DALL-E3文生图
一、前言 ChatGPT3.5、GPT4.0、GPT语音对话、Midjourney绘画,相信对大家应该不感到陌生吧?简单来说,GPT-4技术比之前的GPT-3.5相对来说更加智能,会根据用户的要求生成多种内容甚至也可以和用户进行创作交流。 然而,GP…...
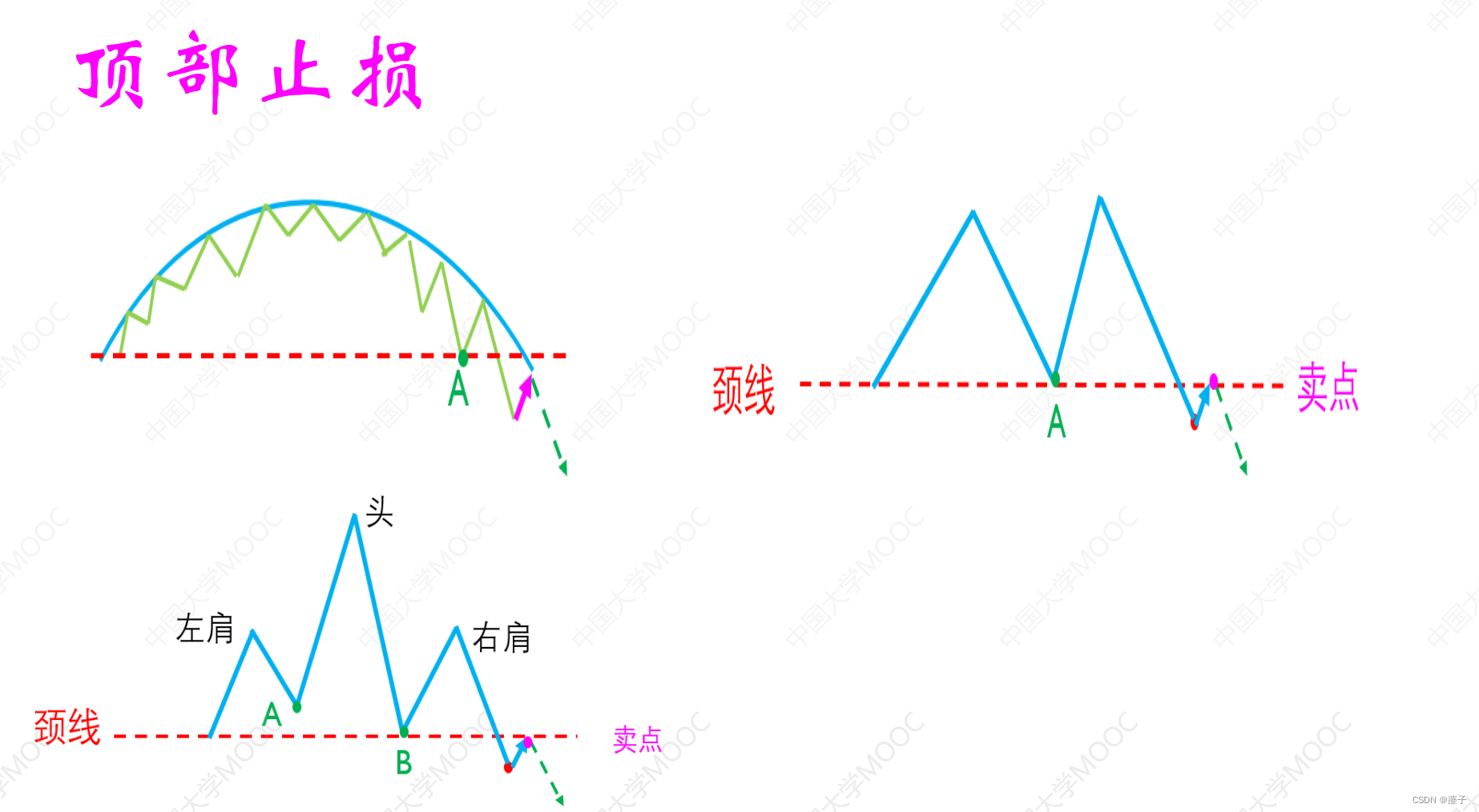
【量化金融】证券投资学
韭菜的自我修养 第一章: 基本框架和概念1.1 大盘底部形成的技术条件1.2 牛市与熊市1.3 交易系统1.3.1 树懒型交易系统1.3.2 止损止损的4个技术 第二章:证券家族4兄弟2.1 债券(1)债券,是伟大的创新(2&#x…...

【Bash】重点总结
文章目录 1. 总体认识1.1. Shell概述1.2. 第一个Shell脚本 2. 变量2.1. 定义变量2.2. 使用变量2.3. 只读变量2.4. 删除变量2.5. 变量类型2.5.1. 字符串变量 1. 总体认识 1.1. Shell概述 Shell是一个用C语言编写的程序,这个程序提供了一个界面,用户通过…...

Git安装和使用教程,并以gitee为例实现远程连接远程仓库
文章目录 1、Git简介及安装2、使用方法2.1、Git的启动与配置2.2、基本操作2.2.1、搭建自己的workspace2.2.2、git add2.2.3、git commit2.2.4、忽略某些文件不予提交2.2.5、以gitee为例实现git连接gitee远程仓库来托管代码 1、Git简介及安装 版本控制(Revision cont…...
Hadoop入门学习笔记——一、VMware准备Linux虚拟机
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 一、VMware准备Linux虚拟机1.1. VMware安装Linux虚拟机1.…...

CSS3新增特性
CSS3 CSS3私有前缀 W3C 标准所提出的某个CSS 特性,在被浏览器正式支持之前,浏览器厂商会根据浏览器的内核,使用私有前缀来测试该 CSS 特性,在浏览器正式支持该 CSS 特性后,就不需要私有前缀了。 查询 CSS3 兼容性的网…...
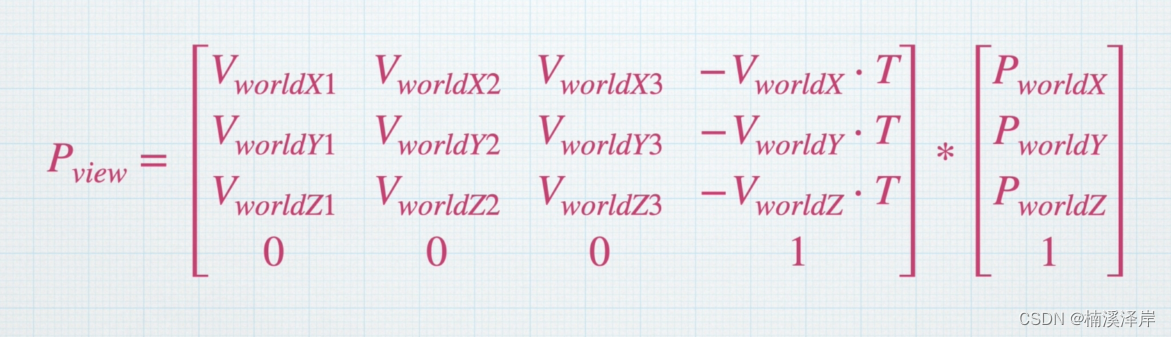
Unity中Shader观察空间推导
文章目录 前言一、本地空间怎么转化到观察空间二、怎么得到观察空间的基向量1、Z轴向量2、假设 观察空间的 Y~假设~ (0,1,0)3、X Y 与 Z 的叉积4、Y X 与 Z 的叉积 三、求 [V~world~]^T^1、求V~world~2、求[V~world~]^T^ 四、求出最后在Unity中使用的公式1、偏移坐标轴2、把…...

信息学奥赛一本通2034:【例5.1】反序输出
2034:【例5.1】反序输出 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 79280 通过数: 35643 【题目描述】 输入nn个数,要求程序按输入时的逆序把这nn个数打印出来,已知整数不超过100100个。也就是说,按输入相反顺序打印这nn个…...
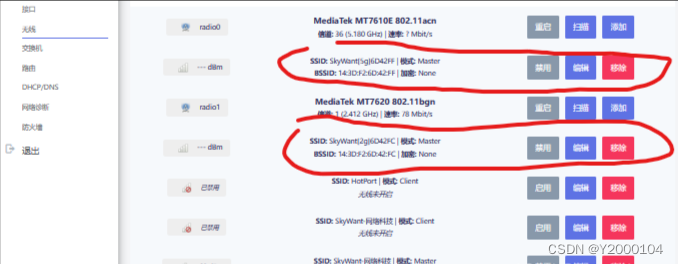
使用教程之【SkyWant.[2304]】路由器操作系统,破解移动【Netkeeper】校园网【小白篇】
许多高校目前饱受Netkeeper认证的痛苦,普通路由器无法使用, 教你利用SkyWant的Netkeeper认证软件来使你的SkyWant路由器顺利认证上网,全宿舍又可以合作共赢了! 步骤一:正确连接网线,插电开机 正确连接网…...
:梯度提升树)
模式识别与机器学习(十):梯度提升树
1.原理 提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。提升树模型可以表示为决…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...