「Kafka」生产者篇
「Kafka」生产者篇
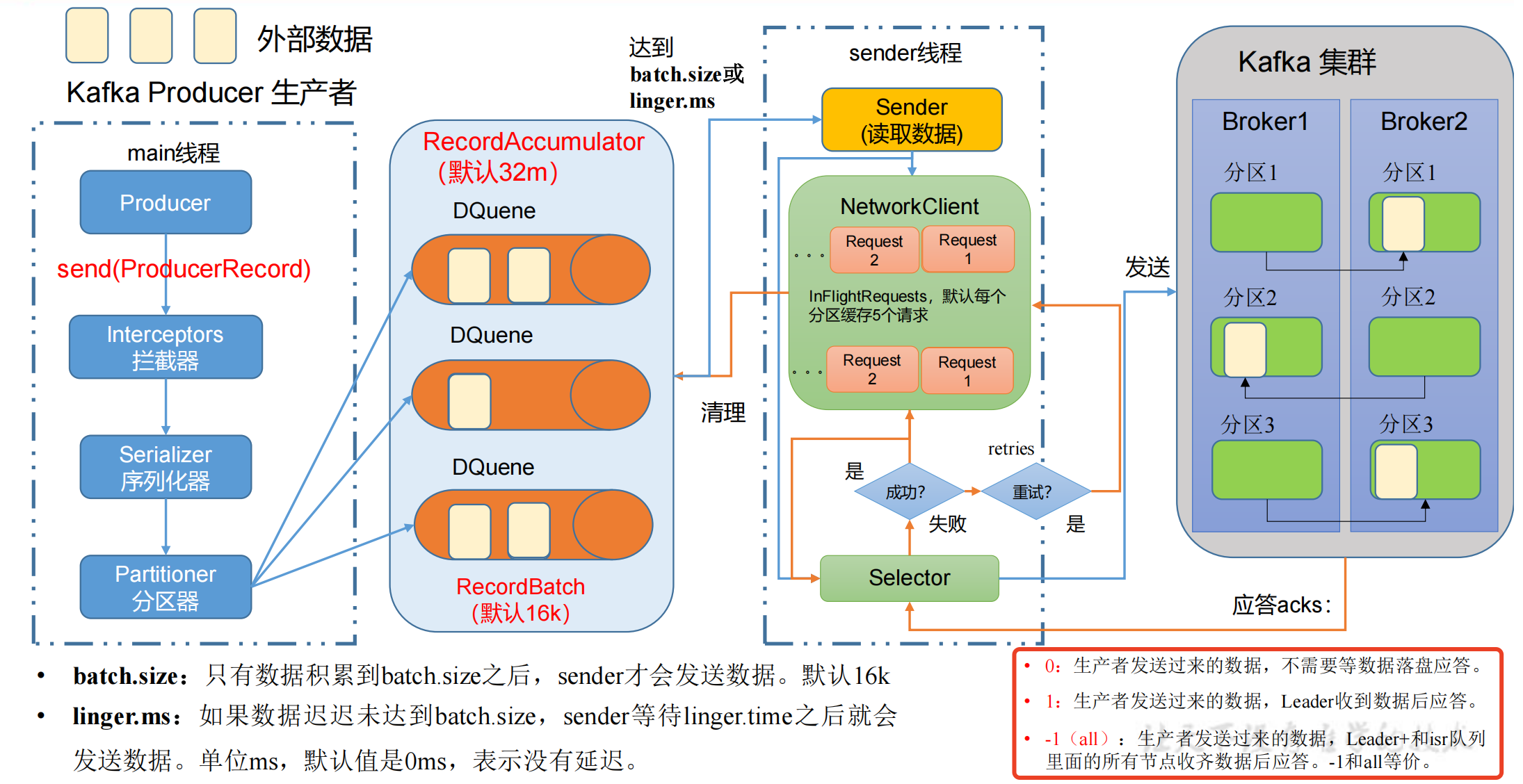
生产者发送消息流程
在消息发送的过程中,涉及到了 两个线程 ——main 线程和Sender 线程。
在 main 线程中创建了 一个 双端队列 RecordAccumulator。
main线程将消息发送给RecordAccumulator,Sender线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
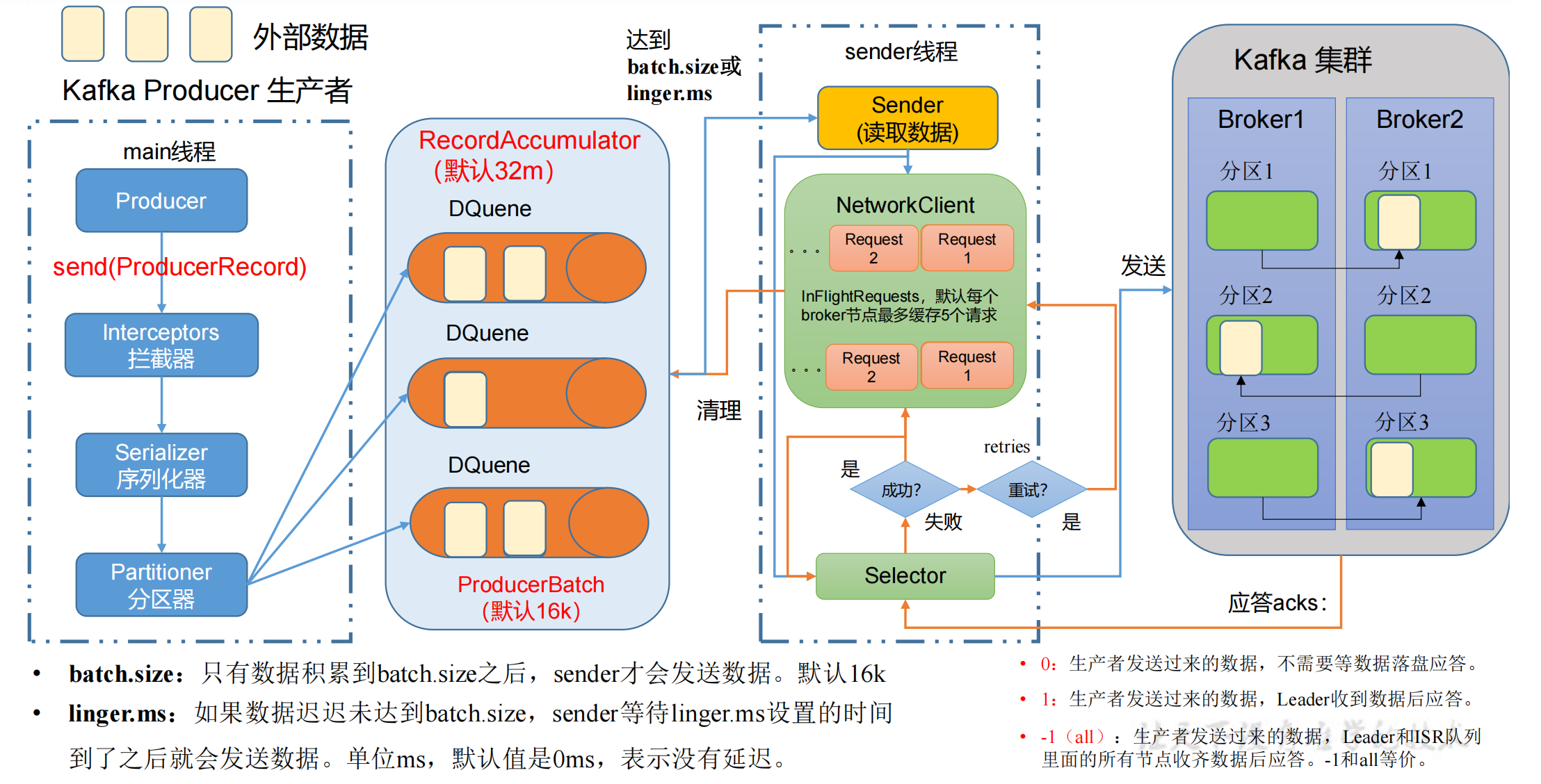
- main线程创建 Producer 对象,调用 send 函数发送消息,经过:
- 拦截器 Interceptors(可选项,扩展一些额外功能)
- 序列化器 Serializer(为什么不用Java的序列化?因为大数据传输需要更轻量的序列化方式)
- 分区器 Partitioner,需要判断发送到哪个分区
- 一个分区就会创建一个双端队列 RecordAccumulator,创建队列都是在
内存里完成的,总大小默认为32m。- 双端队列 RecordAccumulator 还有一个
内存池的概念,每次 send 数据到队列后,在存放数据的时候会从内存池中取出内存,数据发送到kafka后释放内存归还到内存池;一端创建内存,另一端释放内存,这也是它为什么设计为双端队列。
- 双端队列 RecordAccumulator 还有一个
- Sender线程从队列中拉取数据
- 每次批处理
batch.size的大小默认为16k,延迟时间linger.ms默认为0ms,没有延迟。- 这两个条件是 或 的关系,两个条件达到任意一个就可以发送数据。
- 以节点的方式,
key:value => Broker1:(队列数据...)的格式发送给对应的 kafka 服务器,如果kafka没有应答,默认每个broker节点队列最多缓存 5 个请求,后续 生产经验—数据乱序 的章节会讲这个作用。
- 每次批处理
- Selector负责打通底层的链路,IO输入流 => IO输出流,经过Selector发送到kafka集群,kafka集群进行副本的同步。
- 如果kafka集群收到数据后,会返回 ack,有3种模式,如上图。
- 如果ack返回成功,则先清理掉缓存的Request请求,然后清理到对应队列中的数据。
- 如果ack返回失败,则进行 retries 重试,默认重试次数是int的最大值(死磕),一直发Request请求,直到重试成功。
- 详细讲解请参考下文的 生产经验—数据可靠性。
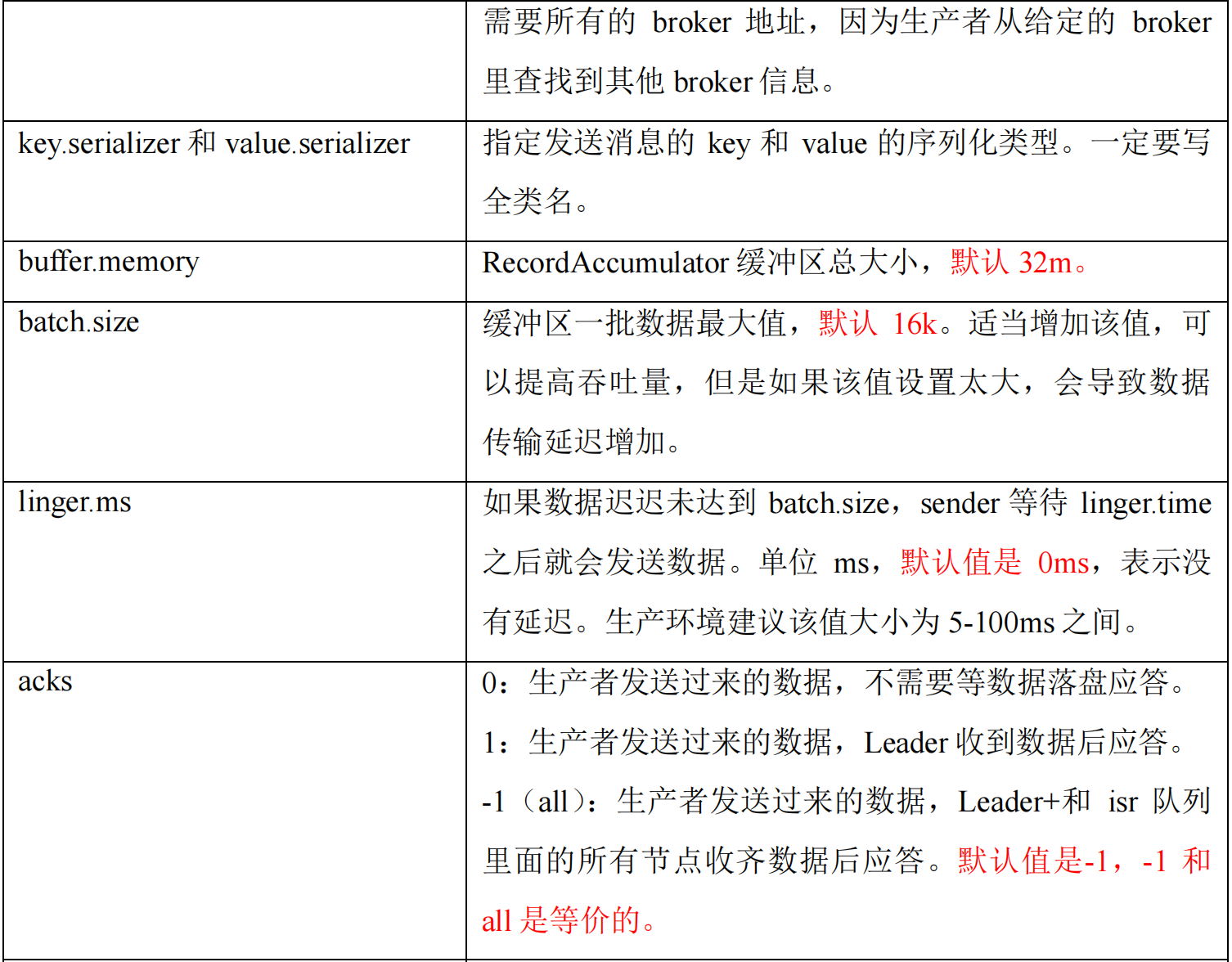
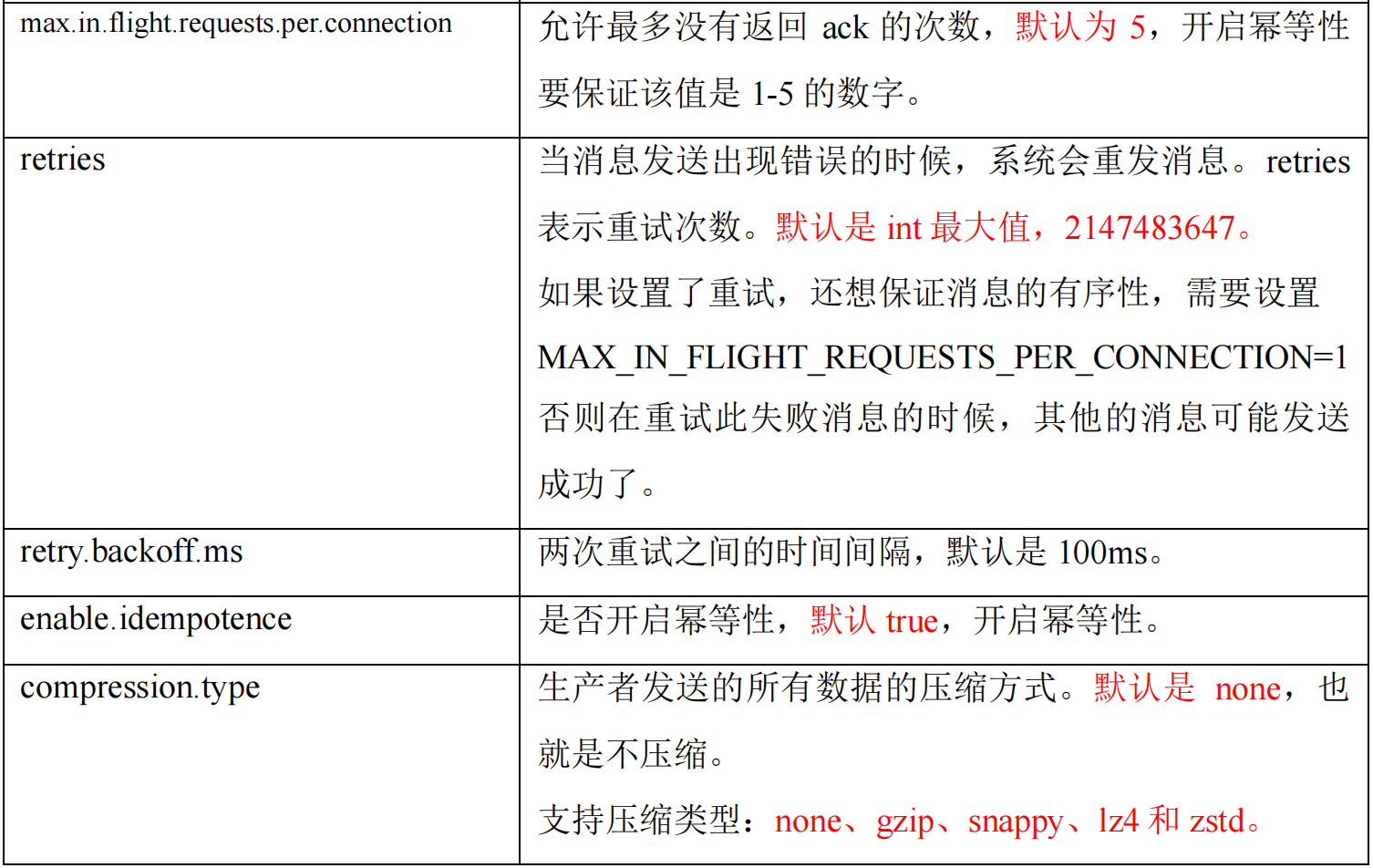
生产者重要参数列表

异步发送
- 同步发送:外部数据发送到 RecordAccumulator 队列中,等待这批数据都发送到 kafka 集群,再返回。
- 异步发送:外部数据发送到 RecordAccumulator 队列中,不管这些数据有没有发送到 kafka 集群,直接返回。
- 默认为异步发送
普通异步发送
编写不带回调函数的代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class CustomProducer {public static void main(String[] args) throws InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {// 这里只指定了topic和valuekafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i));}// 5. 关闭资源kafkaProducer.close();}
}
回调异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception)。
如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
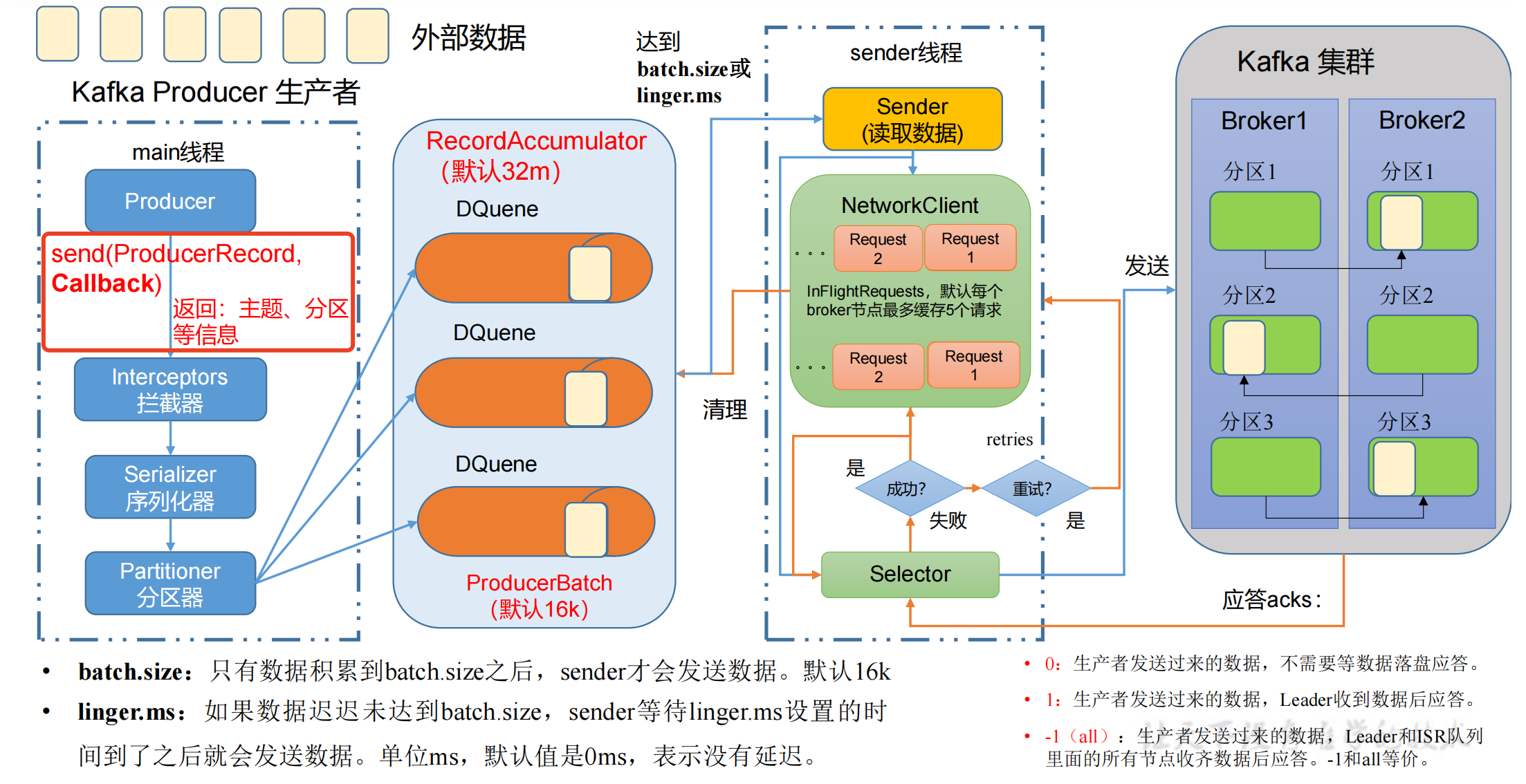
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {// 添加回调 CallbackkafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {// 该方法在 Producer 收到 ack 时调用,为异步调用@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {// 没有异常,输出信息到控制台System.out.println("主题:" + metadata.topic() + "->" +"分区:" + metadata.partition());} else {// 出现异常打印exception.printStackTrace();}}});// 延迟一会会看到数据发往不同分区Thread.sleep(2);
}
同步发送
只需在异步发送的基础上,再调用一下 get() 方法即可。

生产者分区
分区好处
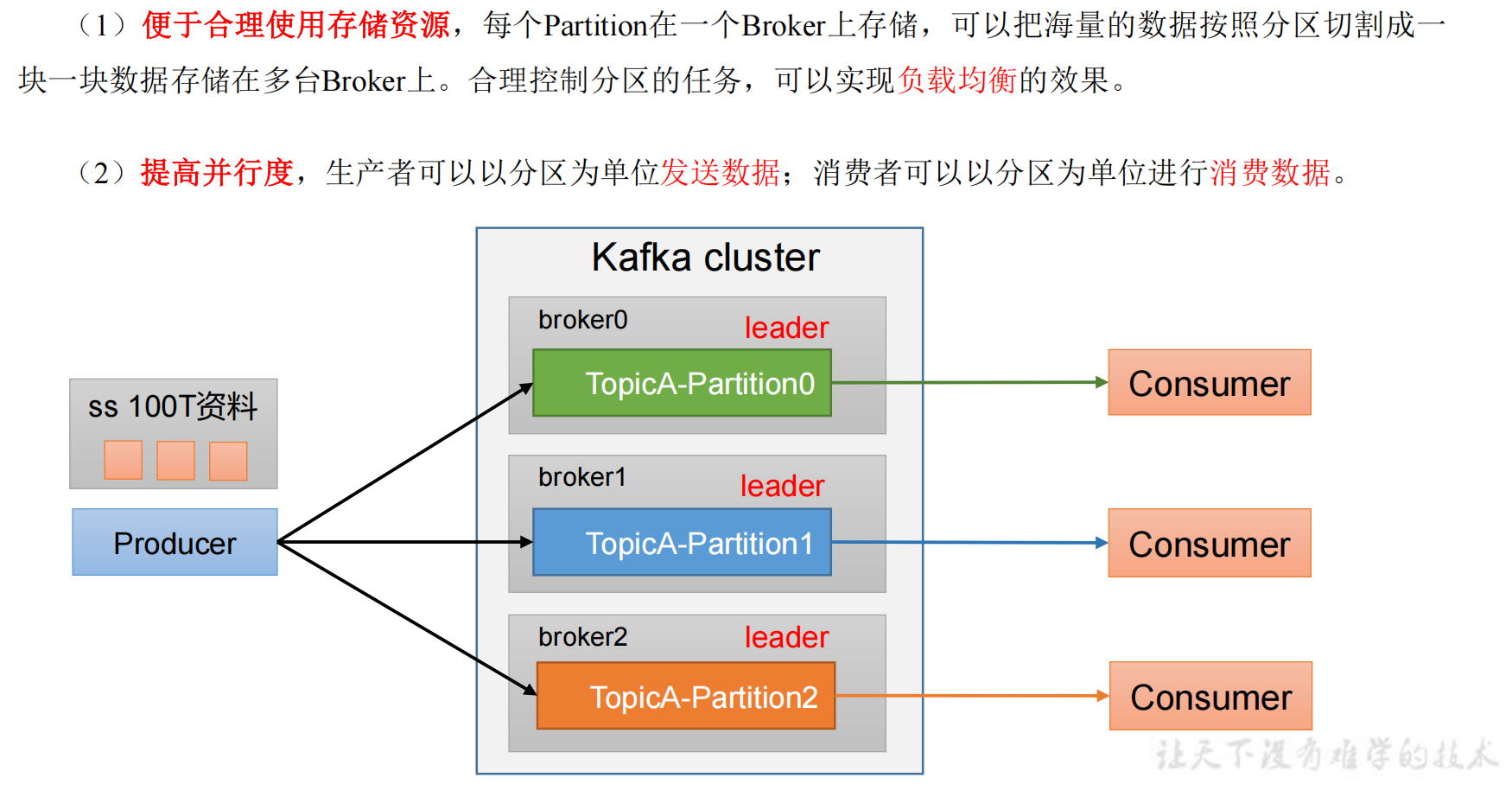
可以通过机器的存储能力自定义分区数据,比如 broker0 存储 20T 数据,broker1和2分别存储 40T 数据。
生产者发送消息的分区策略
可阅读:详解Kafka分区机制原理|Kafka 系列 二
默认的分区器 DefaultPartitioner
/*** The default partitioning strategy: 默认分区策略* 如果你指定了分区,则直接用这个分区* 如果没指定分区,但有key,则按照key的hash值 % 分区数* 如果既没指定分区也没指定key,则按照粘性分区处理。* See KIP-480 for details about sticky partitioning.*/
public class DefaultPartitioner implements Partitioner {...
}
ProducerRecord 类的构造方法就表示了这 3 种分区策略:

自定义分区器
-
定义类实现
Partitioner接口 -
重写
partition()方法import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map;/*** 1. 实现接口 Partitioner* 2. 实现3个方法: partition、close、configure* 3. 编写 partition 方法,返回分区号*/ public class MyPartitioner implements Partitioner {/*** 返回信息对应的分区* @param topic 主题* @param key 消息的 key* @param keyBytes 消息的 key 序列化后的字节数组* @param value 消息的 value* @param valueBytes 消息的 value 序列化后的字节数组* @param cluster 集群元数据可以查看分区信息* @return*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取消息String msgValue = value.toString();// 创建 partitionint partition;// 判断消息是否包含 atguiguif (msgValue.contains("atguigu")) {partition = 0;} else {partition = 1;}// 返回分区号return partition;}// 关闭资源@Overridepublic void close() {}// 配置方法@Overridepublic void configure(Map<String, ?> configs) {} } -
使用分区器的方法,在生产者的配置中添加分区器参数
import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties;public class CustomProducerCallbackPartitions {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 添加自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.atguigu.kafka.producer.MyPartitioner");KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception e) {if (e == null) {System.out.println("主题:" + metadata.topic() + "->" +"分区:" + metadata.partition());} else {e.printStackTrace();}}});}kafkaProducer.close();} }
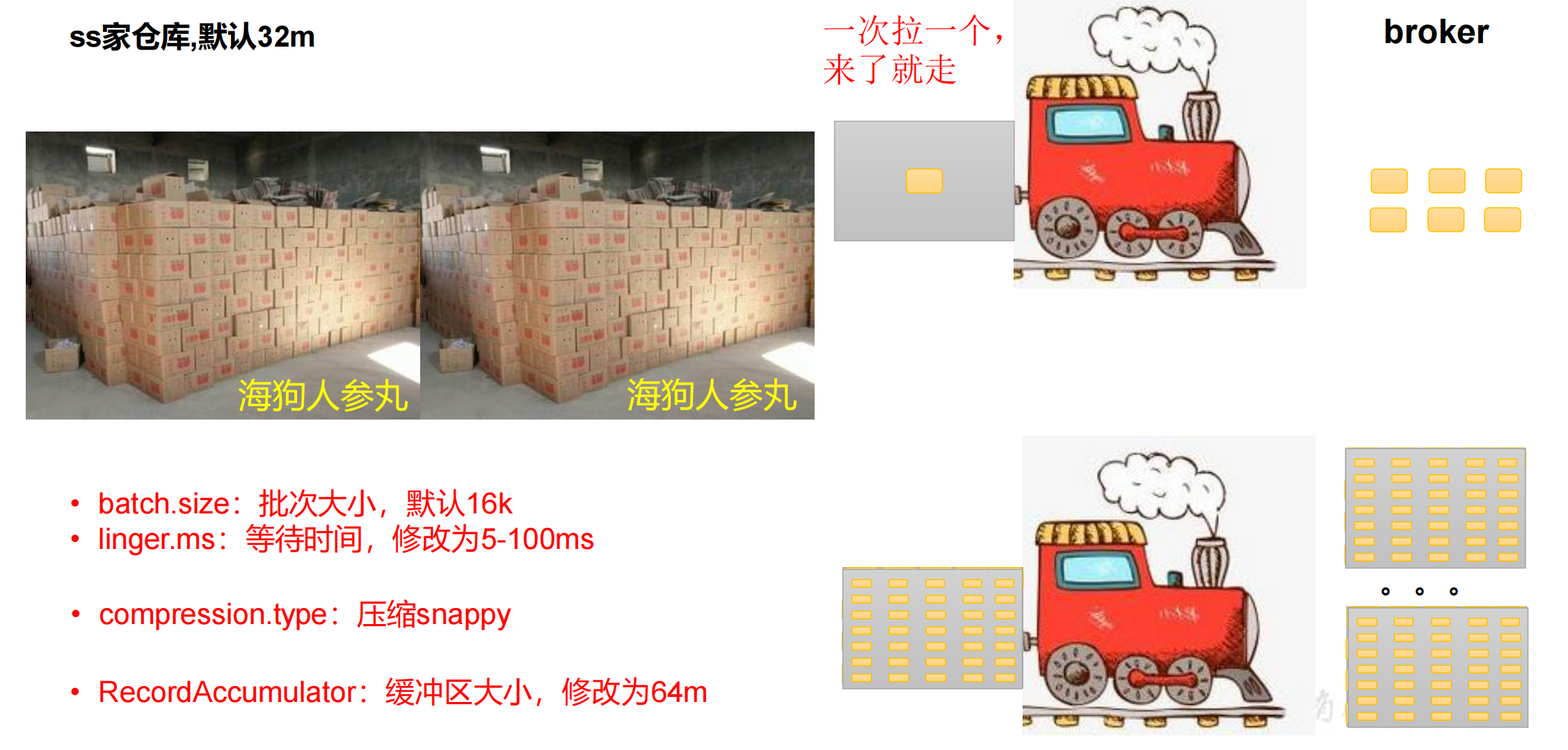
生产者如何提高吞吐量
- 合理调整
batch.size和linger.ms的参数值 - 采用数据压缩
- 调整缓冲区大小
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class CustomProducerParameters {public static void main(String[] args) {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// batch.size:批次大小,默认 16Kproperties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// linger.ms:等待时间,默认 0msproperties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// RecordAccumulator:缓冲区大小,默认 32M:buffer.memoryproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);// compression.type:压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstdproperties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i));}// 5. 关闭资源kafkaProducer.close();}
}
生产经验—数据可靠性
回顾发送流程
数据可靠性主要根据 kafka 集群返回给我们的 ack。
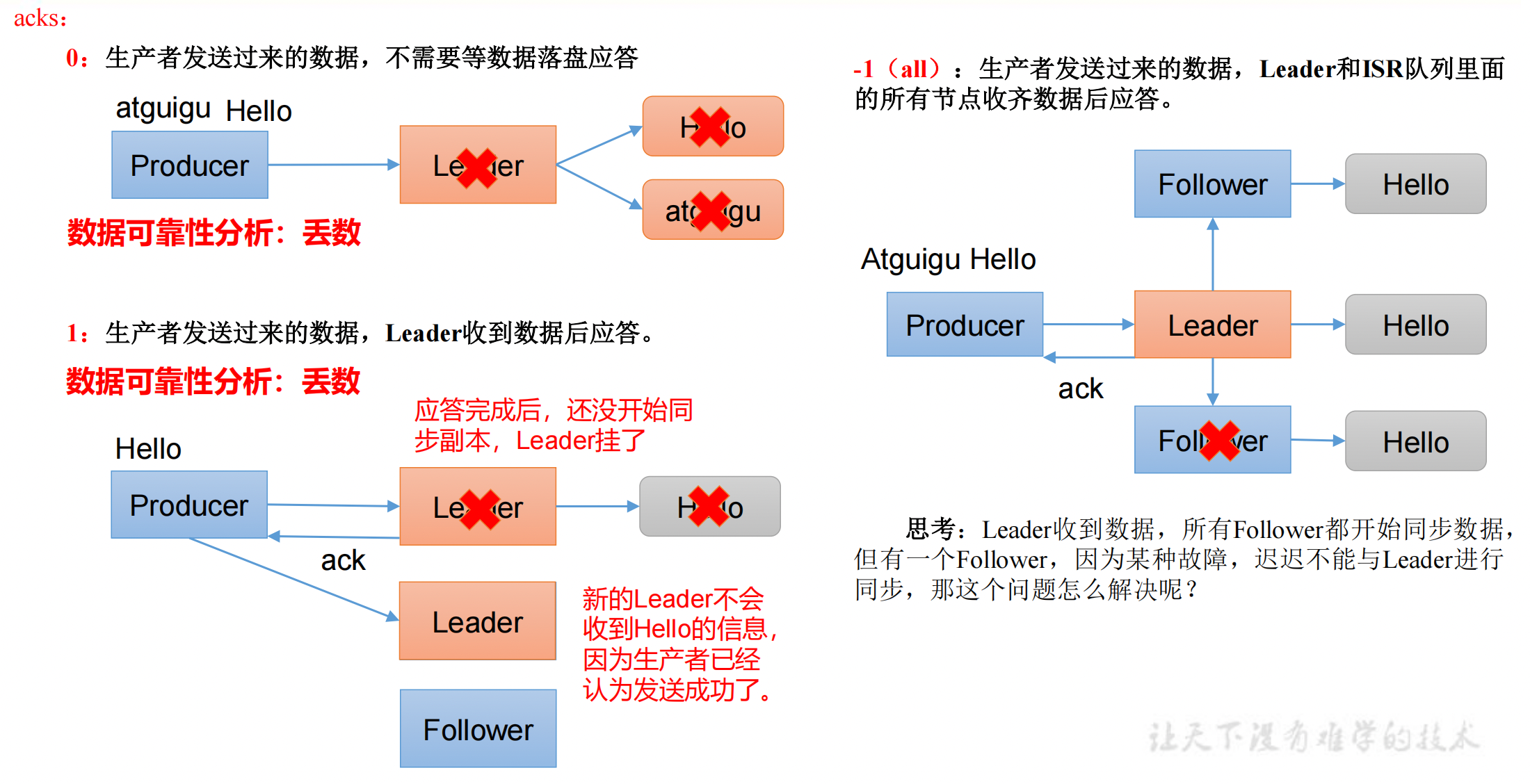
ack 应答原理
- ack=0,不需要等待数据落盘应答,一直发送给 kafka,很容易丢数据。
- 数据发送到 Leader 后,Leader 挂掉了,此时数据还在内存中,未落盘,数据丢失。
- ack=1,不需要等待 kafka 主从同步完成,Leader 收到数据落盘后应答。
- Leader 成功落盘,但还未同步给 Follower,Leader 挂了,数据丢失。
- ack=-1,需要等待 Leader 和 ISR 队列里面的所有节点收齐数据后应答。
数据完全可靠条件
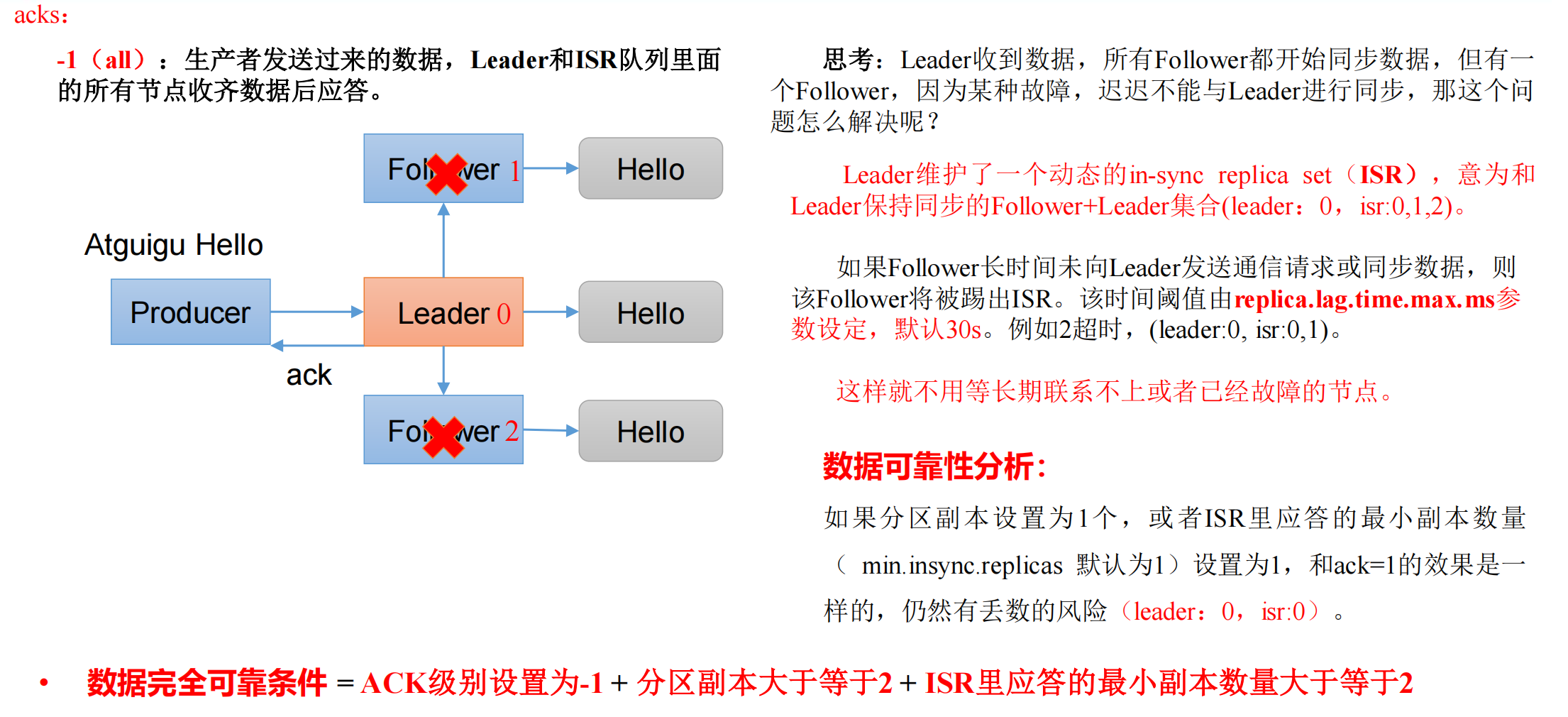
数据完全可靠条件 = ACK 级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
注意,这里的“副本”并不是指的 Follower;在 Kafka 中,副本分为 Leader 副本和 Follower 副本。Leader 副本负责处理消息,而 Follower 副本则简单地复制 Leader 副本的数据。
也就是一个分区至少要有 1 个 Leader 和 1 个 Follower,ISR 队列最少也要有 1 个 Leader 和 1 个 Follower。
一个分区至少有 1 个 Leader,所以每个 Partition 都会有一个 ISR,而且是由 Leader 动态维护。
可靠性总结
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据 Leader 应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据 Leader 和 ISR 队列里面所有 Follwer 应答,可靠性高,效率低;
- 在生产环境中,
- acks=0,很少使用;
- acks=1,一般用于传输普通日志,允许丢个别数据;
- acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
代码实现
// 设置 acks=-1
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 重试次数 retries,默认是 int 最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
拓展:
生产者将数据发送给 Leader,并且完成同步给 Follower,此时回复 ack 时,Leader 挂了,kafka 会挑一个 Follower 成为新的 Leader,因为生产者没有收到 ack,此时就会认为他的数据没有发送到 kafka,就会进行重试,导致新 Leader 重复接收了两份数据。
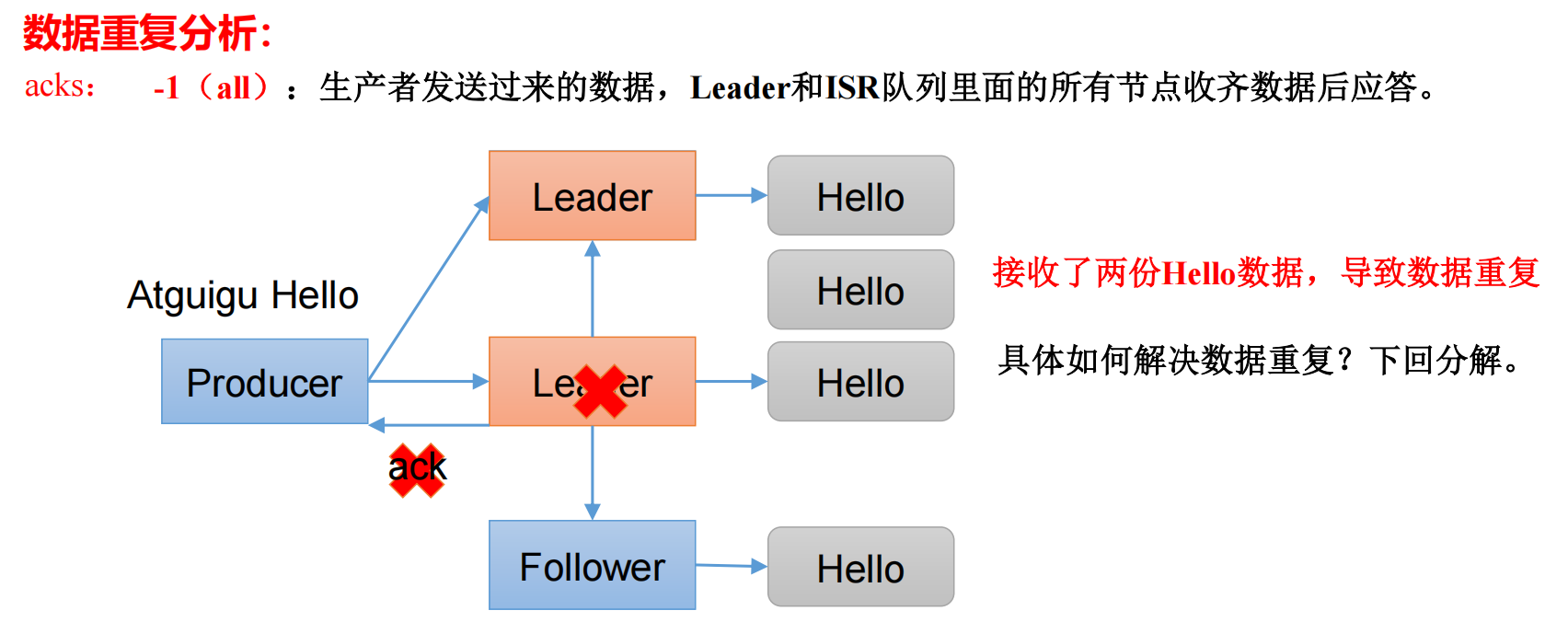
生产经验—数据去重
数据传递语义

幂等性
幂等性原理
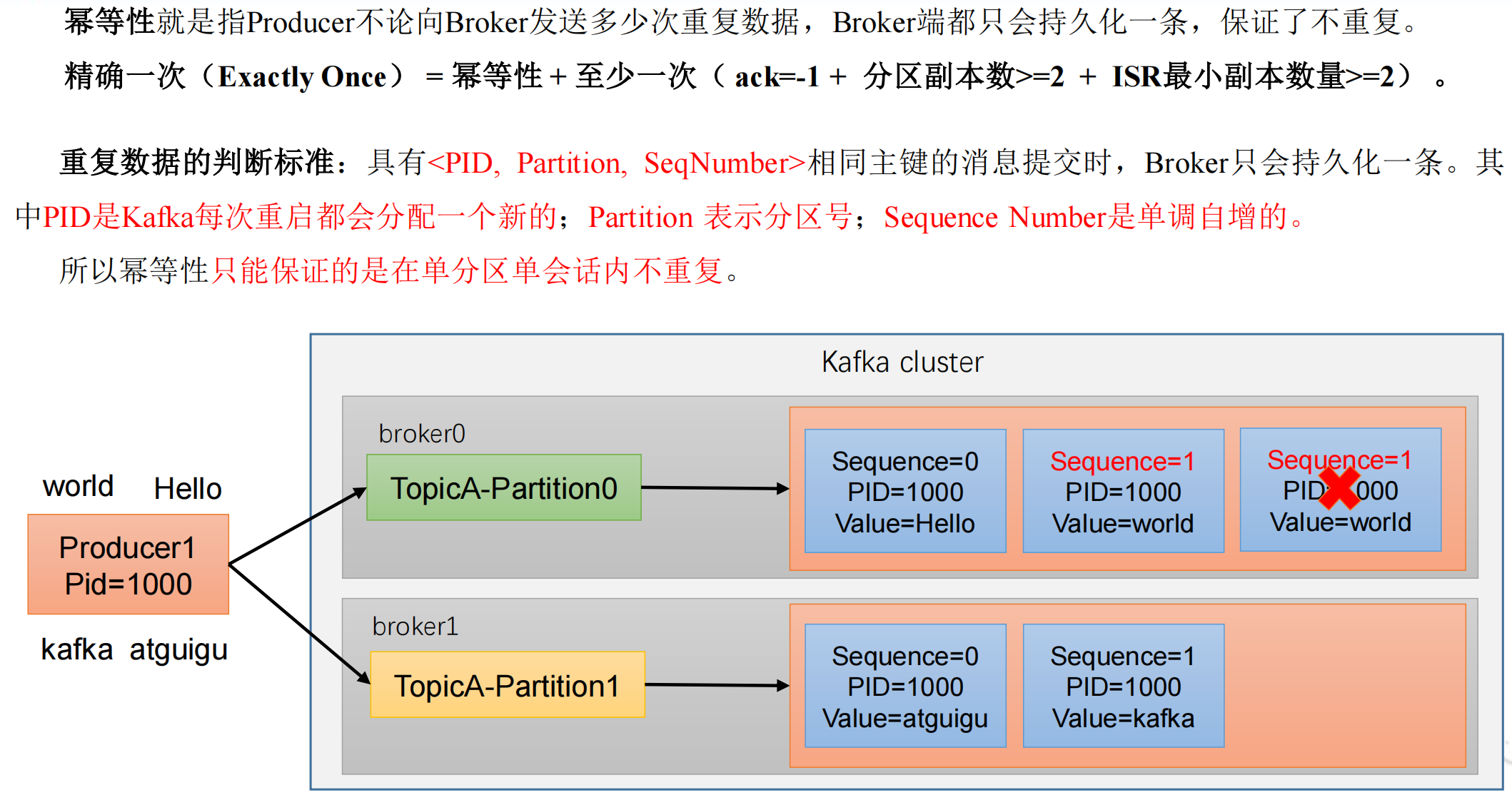
如何使用幂等性
开启参数 enable.idempotence,默认为 true(默认开启)。
生产者事务
幂等性只能保证单分区单会话的不重复,一旦 kafka 挂掉重启,还是有可能产生重复数据。如果想完全去重,就必须使用事务。
Kafka 事务原理
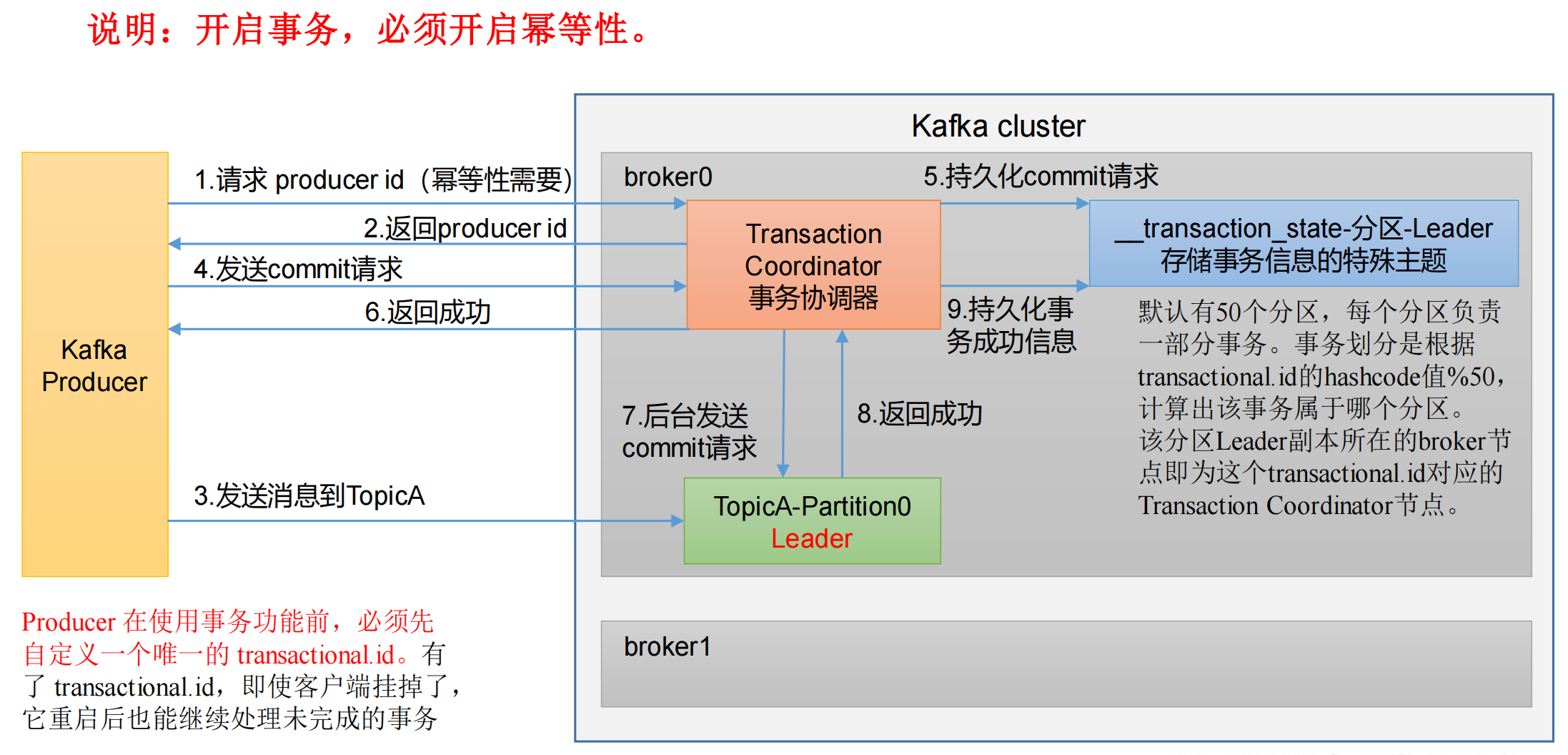
- 幂等性:如果 kafka 挂掉重启,会重新生成一个 PID,所以可能会有重复。
- 事务:kafka 根据全局唯一的
transactional.id会划分到50个分区中的某一个分区,这些分区的信息是存储在一个特殊 Topic 里的,而 Topic 的底层就是硬盘,所以即使客户端挂掉了,重启后也能继续处理未完成的事务,因为有transactional.id存在。
Kafka 的事务一共有如下 5 个 API:
// 1. 初始化事务
void initTransactions();// 2. 开启事务
void beginTransaction() throws ProducerFencedException;// 3. 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException;// 4. 提交事务
void commitTransaction() throws ProducerFencedException;// 5. 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
单个 Producer,使用事务保证消息的仅一次发送:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;public class CustomProducerTransactions {public static void main(String[] args) {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value 序列化properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 设置事务 id(必须),事务 id 任意起名,要求全局唯一properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_0");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 初始化事务kafkaProducer.initTransactions();// 开启事务kafkaProducer.beginTransaction();try {// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {// 发送消息kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i));}// int i = 1 / 0;// 提交事务kafkaProducer.commitTransaction();} catch (Exception e) {// 终止事务kafkaProducer.abortTransaction();} finally {// 5. 关闭资源kafkaProducer.close();}}
}
生产经验—数据有序
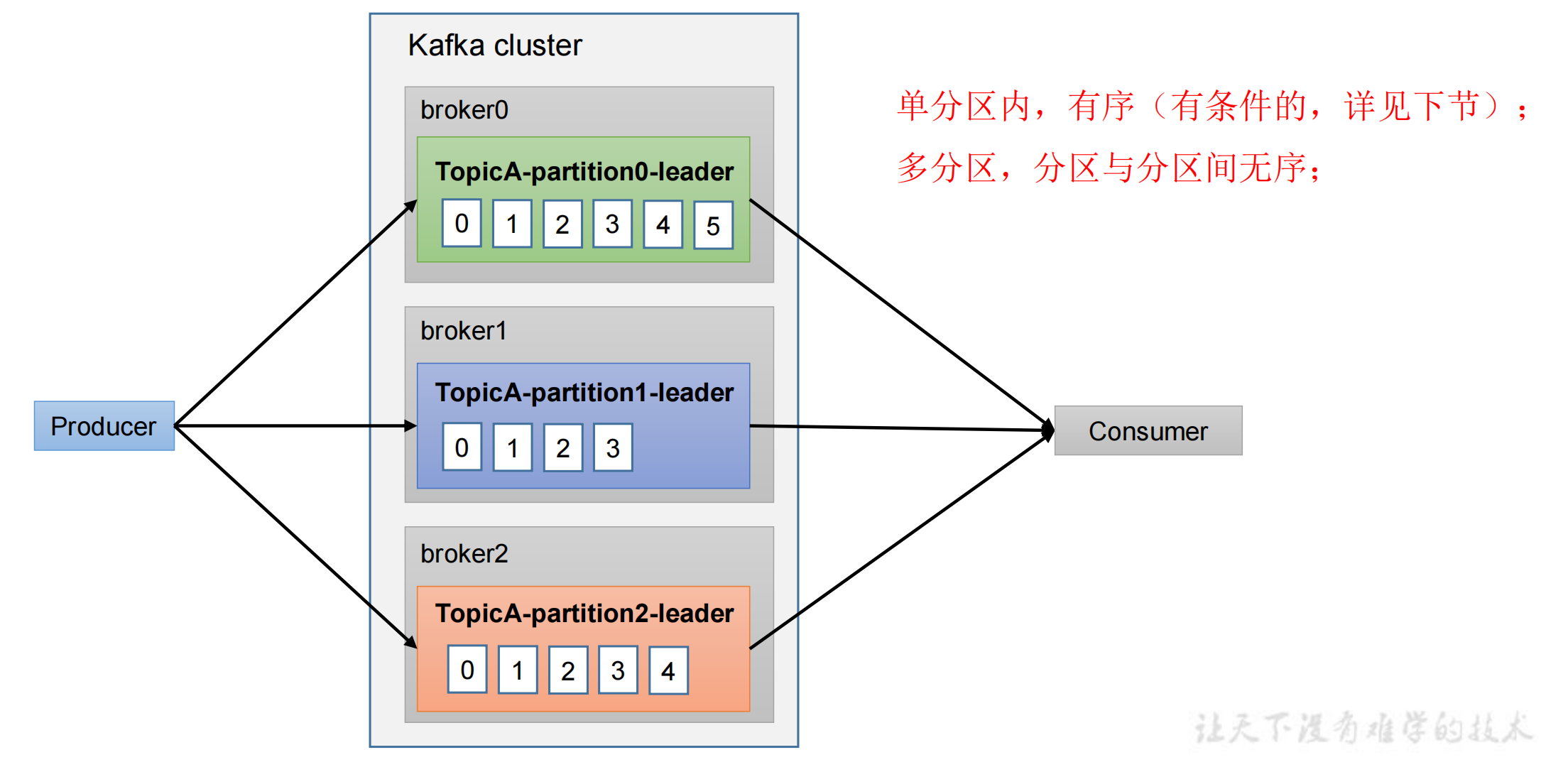
仅能保证单分区内有序,如果想保证全局有序,只能把所有分区的消息都拉到消费者端,进行一个全排序,再进行消费。
但需要等所有数据到齐了再进行排序,效率可能还不如单分区。
生产经验—数据乱序
一个 broker 可以有一个 broker 缓存队列,队列中存放的是还未收到 ack 的请求,最多能存放 5 个。
比如发送 Request1 后,对方没有应答,此时还可以发送 Request2、Request3、Request4、Request5,最多能发送 5 次请求。
假设在一个分区中,生产者发送了 Request1、Request2 请求都成功了,但 Request3 请求发送失败了,进行重试,但此时 Request4 请求发送成功了,然后 Request3 请求才发送成功,此时到达 kafka 的顺序就为 1 2 4 3,是乱序的。
- kafka在1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。- 也就是 broker 的缓存队列只允许有 1 个请求,这个请求收到 ack 后才能发送下一个。
- kafka在1.x及以后版本保证数据单分区有序,条件如下:
- 开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。
- 未开启幂等性
max.in.flight.requests.per.connection需要设置为1(和kafka在1.x版本之前一样)。
- 开启幂等性
原因说明:因为在 kafka1.x 以后,启用幂等后,kafka 服务端最多会缓存 producer 发来的最近 5 个 request 的元数据。
故无论如何,都可以保证最近 5 个 request 的数据都是有序的。
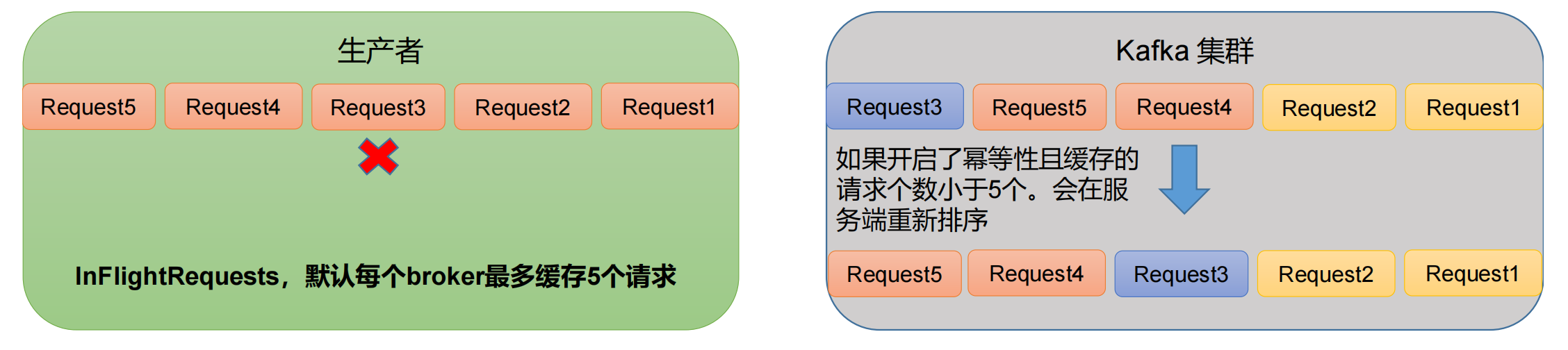
- 比如先来的 Request1、Request2,服务端根据
SeqNumber判断数据是否是单调递增的,如果符合则直接进行落盘; - 但下一个请求是 Request4,正常应该是 Request3,所以 Request4 这个请求只能在内存中放着,不能进行落盘;
- 再下一个是 Request5,同样不能进行落盘;
- 直到 Request3 来了,然后对他们进行排序,然后再依次落盘 Request3、Request4、Request5。
笔记整理自b站尚硅谷视频教程:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
相关文章:
「Kafka」生产者篇
「Kafka」生产者篇 生产者发送消息流程 在消息发送的过程中,涉及到了 两个线程 ——main 线程和Sender 线程。 在 main 线程中创建了 一个 双端队列 RecordAccumulator。 main线程将消息发送给RecordAccumulator,Sender线程不断从 RecordAccumulator…...
C语言实现RSA算法加解密
使用c语言实现了RSA加解密算法,可以加解密文件和字符串。 rsa算法原理 选择两个大素数p和q;计算n p * q;计算φ(n)(p-1)(q-1);选择与φ(n)互素的整数d;由de1 mod φ(n)计算得到e;公钥是(e, n), 私钥是(d, n);假设明…...

如何设计前后端分离的系统架构?
如何将前端页面和后端Java代码进行集成? 将前端页面和后端Java代码进行集成通常需要使用一些特定的工具和技术。以下是一些常见的方法: 使用RESTful API:REST(Representational State Transfer)是一种基于HTTP协议构…...

【强化学习】SARAS代码实现
前言 SARAS,假设环境状态和动作状态都是离散的。利用动作价值矩阵来进行行为的预测。其主要就是利用时序差分的思想,对动作价值矩阵进行更新。 代码实现 import gymnasium as gym import numpy as npclass sarsa():def __init__(self, states_n, acti…...
P1019 [NOIP2000 提高组] 单词接龙 刷题笔记
P1019 [NOIP2000 提高组] 单词接龙 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 思路来自 大佬 Chardo 的个人中心 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 匹配 : 将 第一个字符串末尾 和第二个字符串第一个开始匹配 如果 j<i这段走完了 flag还没…...

如何实现WinApp的UI自动化测试?
WinApp(WindowsAPP)是运行在Windows操作系统上的应用程序,通常会提供一个可视的界面,用于和用户交互。例如运行在Windows系统上的Microsoft Office、PyCharm、Visual Studio Code、Chrome,都属于WinApp。常见的WinApp&…...

chrome扩展程序开发之在目标页面运行自己的JS
原文地址:https://qdgithub.com/home/index/article/aid/247.html chrome 插件开发的入门介绍,实现利用 chrome 扩展实现在目标网页运行我们的 js 的功能。关于 chrome 扩展的详细内容,可以通过官网了解。 开发工具很简单,记事本…...

NLP项目之语种识别
目录 1. 代码及解读2. 知识点n-grams仅保留最常见的1000个n-grams。意思是n1000 ? 1. 代码及解读 in_f open(data.csv) lines in_f.readlines() in_f.close() dataset [(line.strip()[:-3], line.strip()[-2:]) for line in lines] print(dataset[:5])[(1 december wereld…...
)
Linux lpr命令教程:如何使用lpr命令打印文件(附案例详解和注意事项)
Linux lpr命令介绍 lpr命令在Unix-like操作系统中用于提交打印任务。如果在命令行中指定了文件名,那么这些文件将被发送到指定的打印机(如果没有指定目的地,则发送到默认目的地)。如果命令行中没有列出文件,lpr将从标…...

浅谈C语言inline关键字
对于C开发者来说,inline是个再熟悉不过的关键字,因为默认的成员函数都是inline,也是常规高校教材中宣扬C的“优势”之一。 但是C语言其实也是支持inline关键字的,而且是很早期的gcc就支持了该关键字。在Linux0.12版本内核代码中也…...
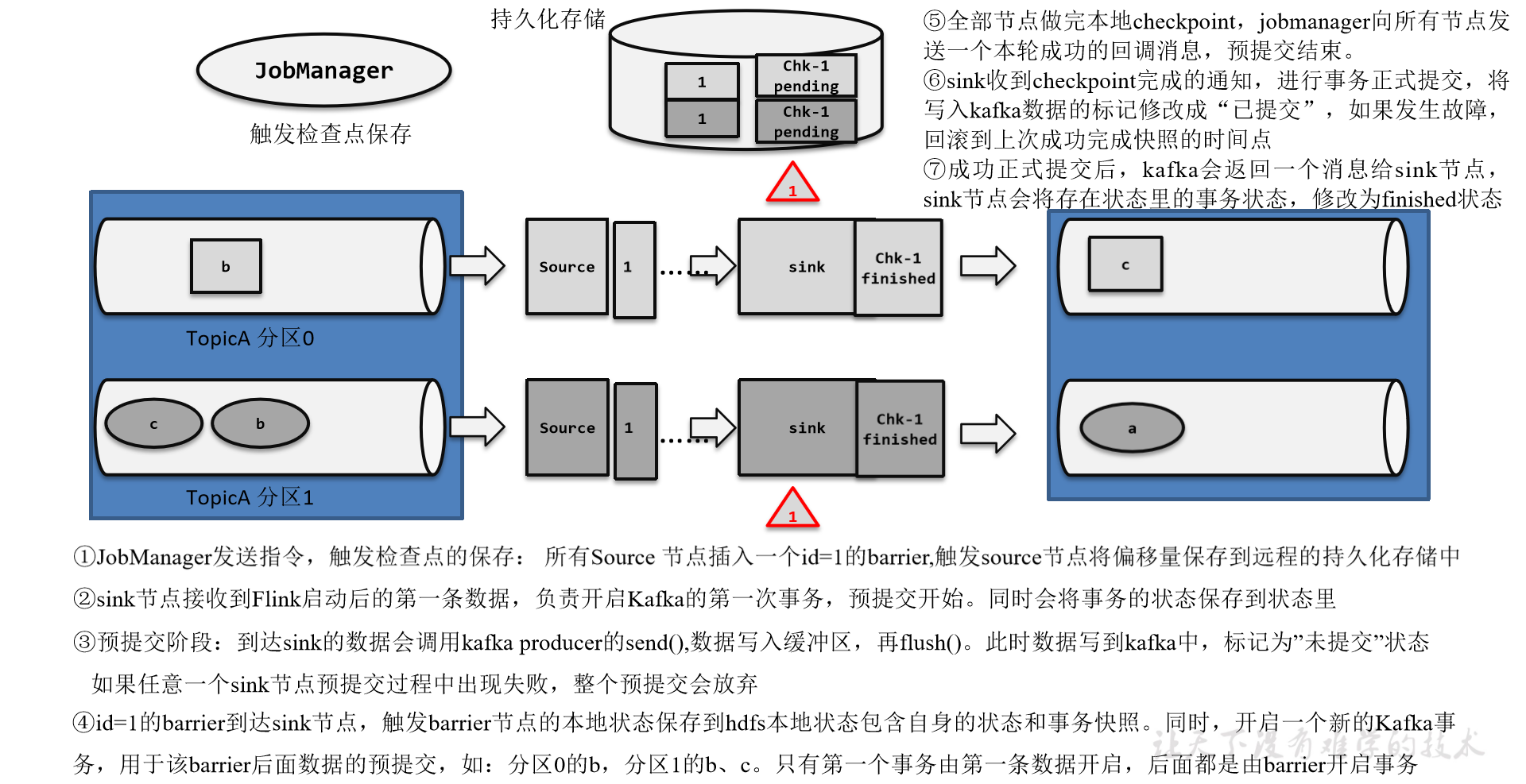
Flink1.17实战教程(第六篇:容错机制)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…...
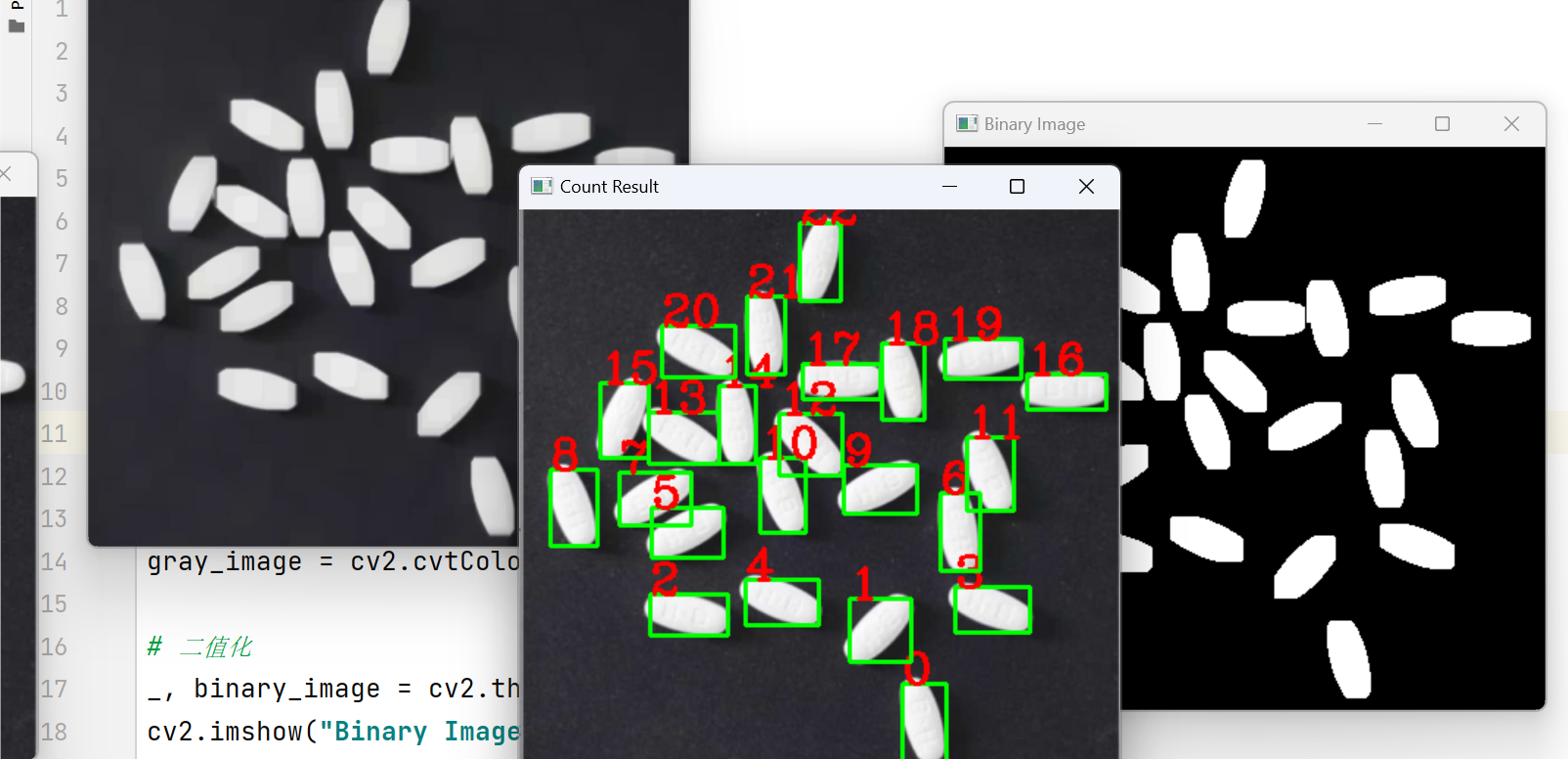
OpenCV实战 -- 维生素药片的检测记数
文章目录 检测记数原图经过操作开始进行消除粘连性--形态学变换总结实现方法1. 读取图片:2. 形态学处理:3. 二值化:4. 提取轮廓:5. 轮廓筛选和计数: 分水岭算法:逐行解释在基于距离变换的分水岭算法中&…...

【AI】注意力机制与深度学习模型
目录 一、注意力机制 二、了解发展历程 2.1 早期萌芽: 2.2 真正意义的注意力机制: 2.3 2015 年及以后: 2.4 自注意力与 Transformer: 2.5 BERT 与预训练模型: 三、基本框架 1. 打分函数(Score Fun…...
HTML5和JS实现新年礼花效果
HTML5和JS实现新年礼花效果 2023兔年再见,2024龙年来临了! 祝愿读者朋友们在2024年里,身体健康,心灵愉悦,梦想成真。 下面是用HTML5和JS实现新年礼花效果: 源码如下: <!DOCTYPE html>…...
【owt-server】一些构建项目梳理
【owt-server】清理日志:owt、srs、ffmpeg 【owt】p2p client mfc 工程梳理【m98】webrtc vs2017构建带符号的debug库【OWT】梳理构建的webrtc和owt mfc工程 m79的mfc客户端及owt-client...

Linux shell编程学习笔记38:history命令
目录 0 前言 1 history命令的功能、格式和退出状态1.1 history命令的功能1.2 history命令的格式1.3退出状态2 命令应用实例2.1 history:显示命令历史列表2.2 history -a:将当前会话的命令行历史追加到历史文件~/.bash_history中2.3 history -c…...
elasticsearch安装教程(超详细)
1.1 创建网络(单点部署) 因为我们还需要部署 kibana 容器,因此需要让 es 和 kibana 容器互联,所有先创建一个网络: docker network create es-net 1.2.加载镜像 采用的版本为 7.12.1 的 elasticsearch;…...
arkts中@Watch监听的使用
概述 Watch用于监听状态变量的变化,当状态变量变化时,Watch的回调方法将被调用。Watch在ArkUI框架内部判断数值有无更新使用的是严格相等(),遵循严格相等规范。当在严格相等为false的情况下,就会触发Watch的…...
【Jmeter】Jmeter基础9-BeanShell介绍
3、BeanShell BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法。 3.1、Jmeter中使用的BeanShell 在Jmeter中,除了配置元件,其他类型的元件中都有BeanShell。BeanShell 是一种完全符合Java语法规范的脚本语言,并且又拥…...
详解数组的轮转
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary-walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...

麒麟v10搭建rsync
1.安装启动 yum install -y rsyncrsync --versionsystemctl enable rsyncdsystemctl restart rsyncd2.修改配置文件 cat > /etc/rsyncd.conf <<-EOF # 全局设置 uid root gid root use chroot no max connections 5 log file /var/log/rsyncd.log pid file /var…...

手把手教你用HY-MT1.5-1.8B:GGUF版本Ollama部署,小白也能搞定
手把手教你用HY-MT1.5-1.8B:GGUF版本Ollama部署,小白也能搞定 1. 准备工作:了解你的翻译小助手 HY-MT1.5-1.8B是一款来自腾讯混元的轻量级翻译模型,虽然只有18亿参数,但翻译效果却能媲美那些体积大几十倍的模型。最厉…...

如何通过解谜掌握SQL?这款开源项目让学习像玩游戏
如何通过解谜掌握SQL?这款开源项目让学习像玩游戏 【免费下载链接】sql-mysteries Inspired by veltmans command-line mystery, use SQL to research clues and find out whodunit! 项目地址: https://gitcode.com/gh_mirrors/sq/sql-mysteries 项目价值定位…...
本地7分钟超简单集成教程)
【最新】2026年3月OpenClaw(Clawdbot)本地7分钟超简单集成教程
【最新】2026年3月OpenClaw(Clawdbot)本地7分钟超简单集成教程。OpenClaw是什么?OpenClaw怎么部署?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot&am…...

Hunyuan-MT Pro一文详解:Hunyuan-MT-7B模型能力边界与调优技巧
Hunyuan-MT Pro一文详解:Hunyuan-MT-7B模型能力边界与调优技巧 1. 开篇:重新认识现代翻译工具 如果你还在为语言障碍而烦恼,或者需要频繁处理多语言文档,那么今天介绍的Hunyuan-MT Pro可能会改变你的工作方式。这不是又一个简单…...

ComfyUI插件避坑指南:SeedVR2+Kontext组合安装常见报错解决方案
ComfyUI高阶插件实战:SeedVR2与Kontext联合部署的深度排错手册 当你在深夜的显示器前盯着ComfyUI的报错日志,那些红色警告文字像是一道道无法逾越的围墙——这不是你第一次尝试将SeedVR2的超分能力与Kontext的上下文理解结合,但每次都在模型加…...

ChatTTS插件全解析:如何实现高效自然语音合成与交互
在语音交互应用开发中,我们常常会遇到一个两难的局面:要么追求语音合成的自然度,牺牲响应速度,导致交互体验卡顿;要么为了实时性,使用生硬、机械的合成语音,让用户体验大打折扣。尤其是在客服机…...
)
Oracle vs MySQL:SYSDATE函数使用差异全解析(附实战避坑指南)
Oracle vs MySQL:SYSDATE函数使用差异全解析(附实战避坑指南) 数据库开发中,时间戳处理是高频操作场景。Oracle和MySQL作为两大主流关系型数据库,其SYSDATE函数的实现差异常成为跨平台迁移的"暗礁"。本文将深…...

永磁同步电机匝间短路故障Simulink仿真探索
永磁同步电机(pmsm)匝间短路故障simulink仿真。 提供文档参考说明。在电机领域,永磁同步电机(PMSM)凭借其高效、节能等诸多优点,广泛应用于工业、交通等众多领域。然而,如同所有设备一样&#x…...

5个强力方案:让老旧Mac用户的系统升级难题获得完美解决
5个强力方案:让老旧Mac用户的系统升级难题获得完美解决 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 问题导入:你的Mac被时代抛弃了吗࿱…...