优化算法3D可视化
编程实现优化算法,并3D可视化
1. 函数3D可视化
分别画出 和
的3D图
import numpy as np from matplotlib import pyplot as plt import torch# 画出x**2 class Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)def forward(self, inputs):raise NotImplementedErrordef backward(self, outputs_grads):raise NotImplementedErrorclass OptimizedFunction3D1(Op):def __init__(self):super(OptimizedFunction3D1, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]def backward(self):x = self.params['x']gradient1 = 2 * x[0] + x[1]gradient2 = 2 * x[1] + 3 * x[1] ** 2 + x[0]grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])class OptimizedFunction3D2(Op):def __init__(self):super(OptimizedFunction3D2, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn x[0] * x[0] / 20 + x[1] * x[1] / 1def backward(self):x = self.params['x']gradient1 = 2 * x[0] / 20gradient2 = 2 * x[1] / 1grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-3, 3, 0.1) x2 = np.arange(-3, 3, 0.1) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2])) model1 = OptimizedFunction3D1() model2 = OptimizedFunction3D2()# 绘制 f_3d 函数的三维图像,分别在两个子图中绘制 fig = plt.figure()# 绘制第一个子图 ax1 = fig.add_subplot(121, projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z1 = model1(init_x).numpy() ax1.plot_surface(X, Y, Z1, cmap='rainbow') ax1.set_xlabel('x1') ax1.set_ylabel('x2') ax1.set_zlabel('f(x1, x2)') ax1.set_title('Function 1')# 绘制第二个子图 ax2 = fig.add_subplot(122, projection='3d') Z2 = model2(init_x).numpy() ax2.plot_surface(X, Y, Z2, cmap='rainbow') ax2.set_xlabel('x1') ax2.set_ylabel('x2') ax2.set_zlabel('f(x1, x2)') ax2.set_title('Function 2')plt.show()

2.加入优化算法,画出轨迹
import torch import numpy as np import copy from matplotlib import pyplot as plt from matplotlib import animation from itertools import zip_longest from nndl.op import Opclass Optimizer(object): # 优化器基类def __init__(self, init_lr, model):"""优化器类初始化"""# 初始化学习率,用于参数更新的计算self.init_lr = init_lr# 指定优化器需要优化的模型self.model = modeldef step(self):"""定义每次迭代如何更新参数"""passclass SimpleBatchGD(Optimizer):def __init__(self, init_lr, model):super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)def step(self):# 参数更新if isinstance(self.model.params, dict):for key in self.model.params.keys():self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]class Adagrad(Optimizer):def __init__(self, init_lr, model, epsilon):"""Adagrad 优化器初始化输入:- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数"""super(Adagrad, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.epsilon = epsilondef adagrad(self, x, gradient_x, G, init_lr):"""adagrad算法更新参数,G为参数梯度平方的累计值。"""G += gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class RMSprop(Optimizer):def __init__(self, init_lr, model, beta, epsilon):"""RMSprop优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta:衰减率- epsilon:保持数值稳定性而设置的常数"""super(RMSprop, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.beta = betaself.epsilon = epsilondef rmsprop(self, x, gradient_x, G, init_lr):"""rmsprop算法更新参数,G为迭代梯度平方的加权移动平均"""G = self.beta * G + (1 - self.beta) * gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class Momentum(Optimizer):def __init__(self, init_lr, model, rho):"""Momentum优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- rho:动量因子"""super(Momentum, self).__init__(init_lr=init_lr, model=model)self.delta_x = {}for key in self.model.params.keys():self.delta_x[key] = 0self.rho = rhodef momentum(self, x, gradient_x, delta_x, init_lr):"""momentum算法更新参数,delta_x为梯度的加权移动平均"""delta_x = self.rho * delta_x - init_lr * gradient_xx += delta_xreturn x, delta_xdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],self.model.grads[key],self.delta_x[key],self.init_lr) class Nesterov(Optimizer):def __init__(self, init_lr, model, rho):"""Nesterov优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- rho:动量因子"""super(Nesterov, self).__init__(init_lr=init_lr, model=model)self.delta_x = {}for key in self.model.params.keys():self.delta_x[key] = 0self.rho = rhodef nesterov(self, x, gradient_x, delta_x, init_lr):"""Nesterov算法更新参数,delta_x为梯度的加权移动平均"""delta_x_prev = delta_xdelta_x = self.rho * delta_x - init_lr * gradient_xx += -self.rho * delta_x_prev + (1 + self.rho) * delta_xreturn x, delta_xdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.delta_x[key] = self.nesterov(self.model.params[key],self.model.grads[key],self.delta_x[key],self.init_lr)class Adam(Optimizer):def __init__(self, init_lr, model, beta1, beta2, epsilon):"""Adam优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta1, beta2:移动平均的衰减率- epsilon:保持数值稳定性而设置的常数"""super(Adam, self).__init__(init_lr=init_lr, model=model)self.beta1 = beta1self.beta2 = beta2self.epsilon = epsilonself.M, self.G = {}, {}for key in self.model.params.keys():self.M[key] = 0self.G[key] = 0self.t = 1def adam(self, x, gradient_x, G, M, t, init_lr):"""adam算法更新参数输入:- x:参数- G:梯度平方的加权移动平均- M:梯度的加权移动平均- t:迭代次数- init_lr:初始学习率"""M = self.beta1 * M + (1 - self.beta1) * gradient_xG = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2M_hat = M / (1 - self.beta1 ** t)G_hat = G / (1 - self.beta2 ** t)t += 1x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hatreturn x, G, M, tdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],self.model.grads[key],self.G[key],self.M[key],self.t,self.init_lr)class OptimizedFunction3D(Op):def __init__(self):super(OptimizedFunction3D, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]def backward(self):x = self.params['x']gradient1 = 2 * x[0] + x[1]gradient2 = 2 * x[1] + 3 * x[1] ** 2 + x[0]grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])class Visualization3D(animation.FuncAnimation):""" 绘制动态图像,可视化参数更新轨迹 """def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=600, blit=True, **kwargs):"""初始化3d可视化类输入:xy_values:三维中x,y维度的值z_values:三维中z维度的值labels:每个参数更新轨迹的标签colors:每个轨迹的颜色interval:帧之间的延迟(以毫秒为单位)blit:是否优化绘图"""self.fig = figself.ax = axself.xy_values = xy_valuesself.z_values = z_valuesframes = max(xy_value.shape[0] for xy_value in xy_values)self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]for _, label, color in zip_longest(xy_values, labels, colors)]super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,interval=interval, blit=blit, **kwargs)def init_animation(self):# 数值初始化for line in self.lines:line.set_data([], [])# line.set_3d_properties(np.asarray([])) # 源程序中有这一行,加上会报错。 Edit by David 2022.12.4return self.linesdef animate(self, i):# 将x,y,z三个数据传入,绘制三维图像for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values):line.set_data(xy_value[:i, 0], xy_value[:i, 1])line.set_3d_properties(z_value[:i])return self.linesdef train_f(model, optimizer, x_init, epoch):x = x_initall_x = []losses = []for i in range(epoch):all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.loss = model(x)losses.append(loss)model.backward()optimizer.step()x = model.params['x']return torch.Tensor(np.array(all_x)), losses# 构建6个模型,分别配备不同的优化器 model1 = OptimizedFunction3D() opt_gd = SimpleBatchGD(init_lr=0.01, model=model1)model2 = OptimizedFunction3D() opt_adagrad = Adagrad(init_lr=0.5, model=model2, epsilon=1e-7)model3 = OptimizedFunction3D() opt_rmsprop = RMSprop(init_lr=0.1, model=model3, beta=0.9, epsilon=1e-7)model4 = OptimizedFunction3D() opt_momentum = Momentum(init_lr=0.01, model=model4, rho=0.9)model5 = OptimizedFunction3D() opt_adam = Adam(init_lr=0.1, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)model6 = OptimizedFunction3D() opt_Nesterov = Nesterov(init_lr=0.1, model=model6, rho=0.9)models = [model1, model2, model3, model4, model5, model6] opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam, opt_Nesterov]x_all_opts = [] z_all_opts = []# 使用不同优化器训练for model, opt in zip(models, opts):x_init = torch.FloatTensor([2, 3])x_one_opt, z_one_opt = train_f(model, opt, x_init, 150) # epoch# 保存参数值x_all_opts.append(x_one_opt.numpy())z_all_opts.append(np.squeeze(z_one_opt))# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-3, 3, 0.1) x2 = np.arange(-3, 3, 0.1) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2]))model = OptimizedFunction3D()# 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4 ax.plot_surface(X, Y, Z, cmap='rainbow')ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)')labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam', 'Nesterov'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax) ax.legend(loc='upper left')plt.show() animator.save('animation.gif') # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
import torch
import numpy as np
import copy
from matplotlib import pyplot as plt
from matplotlib import animation
from itertools import zip_longest
from matplotlib import cmclass Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)# 输入:张量inputs# 输出:张量outputsdef forward(self, inputs):# return outputsraise NotImplementedError# 输入:最终输出对outputs的梯度outputs_grads# 输出:最终输出对inputs的梯度inputs_gradsdef backward(self, outputs_grads):# return inputs_gradsraise NotImplementedErrorclass Optimizer(object): # 优化器基类def __init__(self, init_lr, model):"""优化器类初始化"""# 初始化学习率,用于参数更新的计算self.init_lr = init_lr# 指定优化器需要优化的模型self.model = modeldef step(self):"""定义每次迭代如何更新参数"""passclass SimpleBatchGD(Optimizer):def __init__(self, init_lr, model):super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)def step(self):# 参数更新if isinstance(self.model.params, dict):for key in self.model.params.keys():self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]class Adagrad(Optimizer):def __init__(self, init_lr, model, epsilon):"""Adagrad 优化器初始化输入:- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数"""super(Adagrad, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.epsilon = epsilondef adagrad(self, x, gradient_x, G, init_lr):"""adagrad算法更新参数,G为参数梯度平方的累计值。"""G += gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class RMSprop(Optimizer):def __init__(self, init_lr, model, beta, epsilon):"""RMSprop优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta:衰减率- epsilon:保持数值稳定性而设置的常数"""super(RMSprop, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.beta = betaself.epsilon = epsilondef rmsprop(self, x, gradient_x, G, init_lr):"""rmsprop算法更新参数,G为迭代梯度平方的加权移动平均"""G = self.beta * G + (1 - self.beta) * gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class Momentum(Optimizer):def __init__(self, init_lr, model, rho):"""Momentum优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- rho:动量因子"""super(Momentum, self).__init__(init_lr=init_lr, model=model)self.delta_x = {}for key in self.model.params.keys():self.delta_x[key] = 0self.rho = rhodef momentum(self, x, gradient_x, delta_x, init_lr):"""momentum算法更新参数,delta_x为梯度的加权移动平均"""delta_x = self.rho * delta_x - init_lr * gradient_xx += delta_xreturn x, delta_xdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],self.model.grads[key],self.delta_x[key],self.init_lr)class Adam(Optimizer):def __init__(self, init_lr, model, beta1, beta2, epsilon):"""Adam优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta1, beta2:移动平均的衰减率- epsilon:保持数值稳定性而设置的常数"""super(Adam, self).__init__(init_lr=init_lr, model=model)self.beta1 = beta1self.beta2 = beta2self.epsilon = epsilonself.M, self.G = {}, {}for key in self.model.params.keys():self.M[key] = 0self.G[key] = 0self.t = 1def adam(self, x, gradient_x, G, M, t, init_lr):"""adam算法更新参数输入:- x:参数- G:梯度平方的加权移动平均- M:梯度的加权移动平均- t:迭代次数- init_lr:初始学习率"""M = self.beta1 * M + (1 - self.beta1) * gradient_xG = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2M_hat = M / (1 - self.beta1 ** t)G_hat = G / (1 - self.beta2 ** t)t += 1x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hatreturn x, G, M, tdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],self.model.grads[key],self.G[key],self.M[key],self.t,self.init_lr)class OptimizedFunction3D(Op):def __init__(self):super(OptimizedFunction3D, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn x[0] * x[0] / 20 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]def backward(self):x = self.params['x']gradient1 = 2 * x[0] / 20gradient2 = 2 * x[1] / 1grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])class Visualization3D(animation.FuncAnimation):""" 绘制动态图像,可视化参数更新轨迹 """def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):"""初始化3d可视化类输入:xy_values:三维中x,y维度的值z_values:三维中z维度的值labels:每个参数更新轨迹的标签colors:每个轨迹的颜色interval:帧之间的延迟(以毫秒为单位)blit:是否优化绘图"""self.fig = figself.ax = axself.xy_values = xy_valuesself.z_values = z_valuesframes = max(xy_value.shape[0] for xy_value in xy_values)self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]for _, label, color in zip_longest(xy_values, labels, colors)]self.points = [ax.plot([], [], [], color=color, markeredgewidth=1, markeredgecolor='black', marker='o')[0]for _, color in zip_longest(xy_values, colors)]# print(self.lines)super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,interval=interval, blit=blit, **kwargs)def init_animation(self):# 数值初始化for line in self.lines:line.set_data_3d([], [], [])for point in self.points:point.set_data_3d([], [], [])return self.points + self.linesdef animate(self, i):# 将x,y,z三个数据传入,绘制三维图像for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values):line.set_data_3d(xy_value[:i, 0], xy_value[:i, 1], z_value[:i])for point, xy_value, z_value in zip(self.points, self.xy_values, self.z_values):point.set_data_3d(xy_value[i, 0], xy_value[i, 1], z_value[i])return self.points + self.linesdef train_f(model, optimizer, x_init, epoch):x = x_initall_x = []losses = []for i in range(epoch):all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.loss = model(x)losses.append(loss)model.backward()optimizer.step()x = model.params['x']return torch.Tensor(np.array(all_x)), losses# 构建5个模型,分别配备不同的优化器
model1 = OptimizedFunction3D()
opt_gd = SimpleBatchGD(init_lr=0.95, model=model1)model2 = OptimizedFunction3D()
opt_adagrad = Adagrad(init_lr=1.5, model=model2, epsilon=1e-7)model3 = OptimizedFunction3D()
opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)model4 = OptimizedFunction3D()
opt_momentum = Momentum(init_lr=0.1, model=model4, rho=0.9)model5 = OptimizedFunction3D()
opt_adam = Adam(init_lr=0.3, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)models = [model1, model2, model3, model4, model5]
opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam]x_all_opts = []
z_all_opts = []# 使用不同优化器训练for model, opt in zip(models, opts):x_init = torch.FloatTensor([-7, 2])x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch# 保存参数值x_all_opts.append(x_one_opt.numpy())z_all_opts.append(np.squeeze(z_one_opt))# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值
x1 = np.arange(-10, 10, 0.01)
x2 = np.arange(-5, 5, 0.01)
x1, x2 = np.meshgrid(x1, x2)
init_x = torch.Tensor(np.array([x1, x2]))model = OptimizedFunction3D()# 绘制 f_3d函数 的 三维图像
fig = plt.figure()
ax = plt.axes(projection='3d')
X = init_x[0].numpy()
Y = init_x[1].numpy()
Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4
surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm)
# fig.colorbar(surf, shrink=0.5, aspect=1)
# ax.set_zlim(-3, 2)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1,x2)')labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam']
colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax)
ax.legend(loc='upper right')plt.show()
# animator.save('teaser' + '.gif', writer='imagemagick',fps=10) # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
# save不好用,不费劲了,安装个软件做gif https://pc.qq.com/detail/13/detail_23913.html 这段代码我试了老师给的代码,不对劲,不能动,而且没有轨迹,更过分就是一会儿就自动关闭了,还有再优化优化
这段代码我试了老师给的代码,不对劲,不能动,而且没有轨迹,更过分就是一会儿就自动关闭了,还有再优化优化
改了一上午,终于好了,我修改了
class Visualization3D(animation.FuncAnimation)函数和图形显示部分
以下是我的代码:
import torch
import numpy as np
import copy
from matplotlib import pyplot as plt
from matplotlib import animation
from itertools import zip_longest
from matplotlib import cmclass Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)# 输入:张量inputs# 输出:张量outputsdef forward(self, inputs):# return outputsraise NotImplementedError# 输入:最终输出对outputs的梯度outputs_grads# 输出:最终输出对inputs的梯度inputs_gradsdef backward(self, outputs_grads):# return inputs_gradsraise NotImplementedErrorclass Optimizer(object): # 优化器基类def __init__(self, init_lr, model):"""优化器类初始化"""# 初始化学习率,用于参数更新的计算self.init_lr = init_lr# 指定优化器需要优化的模型self.model = modeldef step(self):"""定义每次迭代如何更新参数"""passclass SimpleBatchGD(Optimizer):def __init__(self, init_lr, model):super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)def step(self):# 参数更新if isinstance(self.model.params, dict):for key in self.model.params.keys():self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]class Adagrad(Optimizer):def __init__(self, init_lr, model, epsilon):"""Adagrad 优化器初始化输入:- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数"""super(Adagrad, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.epsilon = epsilondef adagrad(self, x, gradient_x, G, init_lr):"""adagrad算法更新参数,G为参数梯度平方的累计值。"""G += gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class RMSprop(Optimizer):def __init__(self, init_lr, model, beta, epsilon):"""RMSprop优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta:衰减率- epsilon:保持数值稳定性而设置的常数"""super(RMSprop, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.beta = betaself.epsilon = epsilondef rmsprop(self, x, gradient_x, G, init_lr):"""rmsprop算法更新参数,G为迭代梯度平方的加权移动平均"""G = self.beta * G + (1 - self.beta) * gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class Momentum(Optimizer):def __init__(self, init_lr, model, rho):"""Momentum优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- rho:动量因子"""super(Momentum, self).__init__(init_lr=init_lr, model=model)self.delta_x = {}for key in self.model.params.keys():self.delta_x[key] = 0self.rho = rhodef momentum(self, x, gradient_x, delta_x, init_lr):"""momentum算法更新参数,delta_x为梯度的加权移动平均"""delta_x = self.rho * delta_x - init_lr * gradient_xx += delta_xreturn x, delta_xdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],self.model.grads[key],self.delta_x[key],self.init_lr)class Adam(Optimizer):def __init__(self, init_lr, model, beta1, beta2, epsilon):"""Adam优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta1, beta2:移动平均的衰减率- epsilon:保持数值稳定性而设置的常数"""super(Adam, self).__init__(init_lr=init_lr, model=model)self.beta1 = beta1self.beta2 = beta2self.epsilon = epsilonself.M, self.G = {}, {}for key in self.model.params.keys():self.M[key] = 0self.G[key] = 0self.t = 1def adam(self, x, gradient_x, G, M, t, init_lr):"""adam算法更新参数输入:- x:参数- G:梯度平方的加权移动平均- M:梯度的加权移动平均- t:迭代次数- init_lr:初始学习率"""M = self.beta1 * M + (1 - self.beta1) * gradient_xG = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2M_hat = M / (1 - self.beta1 ** t)G_hat = G / (1 - self.beta2 ** t)t += 1x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hatreturn x, G, M, tdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],self.model.grads[key],self.G[key],self.M[key],self.t,self.init_lr)class OptimizedFunction3D(Op):def __init__(self):super(OptimizedFunction3D, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn x[0] * x[0] / 20 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]def backward(self):x = self.params['x']gradient1 = 2 * x[0] / 20gradient2 = 2 * x[1] / 1grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])class Visualization3D(animation.FuncAnimation):""" 绘制动态图像,可视化参数更新轨迹 """def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):"""初始化3d可视化类输入:xy_values:三维中x,y维度的值z_values:三维中z维度的值labels:每个参数更新轨迹的标签colors:每个轨迹的颜色interval:帧之间的延迟(以毫秒为单位)blit:是否优化绘图"""self.fig = figself.ax = axself.xy_values = xy_valuesself.z_values = z_valuesframes = max(xy_value.shape[0] for xy_value in xy_values)self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]for _, label, color in zip_longest(xy_values, labels, colors)]self.points = [ax.plot([], [], [], color=color, markeredgewidth=1, markeredgecolor='black', marker='o')[0]for _, color in zip_longest(xy_values, colors)]# print(self.lines)super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,interval=interval, blit=blit, **kwargs)def init_animation(self):# 数值初始化for line in self.lines:line.set_data([], [])line.set_3d_properties([])for point in self.points:point.set_data([], [])point.set_3d_properties([])return self.points + self.linesdef animate(self, i):# 将x,y,z三个数据传入,绘制三维图像for line, xy_value, z_value, point in zip(self.lines, self.xy_values, self.z_values, self.points):line.set_data(xy_value[:i, 0], xy_value[:i, 1])line.set_3d_properties(z_value[:i])point.set_data(xy_value[i, 0], xy_value[i, 1])point.set_3d_properties(z_value[i])return self.points + self.linesdef train_f(model, optimizer, x_init, epoch):x = x_initall_x = []losses = []for i in range(epoch):all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.loss = model(x)losses.append(loss)model.backward()optimizer.step()x = model.params['x']return torch.Tensor(np.array(all_x)), losses
# 构建5个模型,分别配备不同的优化器
model1 = OptimizedFunction3D()
opt_gd = SimpleBatchGD(init_lr=0.95, model=model1)model2 = OptimizedFunction3D()
opt_adagrad = Adagrad(init_lr=1.5, model=model2, epsilon=1e-7)model3 = OptimizedFunction3D()
opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)model4 = OptimizedFunction3D()
opt_momentum = Momentum(init_lr=0.1, model=model4, rho=0.9)model5 = OptimizedFunction3D()
opt_adam = Adam(init_lr=0.3, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)models = [model1, model2, model3, model4, model5]
opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam]x_all_opts = []
z_all_opts = []# 使用不同优化器训练
for model, opt in zip(models, opts):x_init = torch.FloatTensor([-7, 2])x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch# 保存参数值x_all_opts.append(x_one_opt.numpy())z_all_opts.append(np.squeeze(z_one_opt))# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-10, 10],以0.01为间隔的数值
x1 = np.arange(-10, 10, 0.01)
x2 = np.arange(-5, 5, 0.01)
x1, x2 = np.meshgrid(x1, x2)
init_x = torch.Tensor(np.array([x1, x2]))model = OptimizedFunction3D()fig = plt.figure()
ax = plt.axes(projection='3d')
X = init_x[0].numpy()
Y = init_x[1].numpy()
Z = model(init_x).numpy()surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1,x2)')# 添加轨迹图
labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam']
colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']for x_opt, z_opt, label, color in zip(x_all_opts, z_all_opts, labels, colors):ax.plot(x_opt[:, 0], x_opt[:, 1], z_opt, label=label, color=color)ax.legend(loc='upper right')
# 修改下面这行,将Visualization3D的初始化参数中的fig和ax改为ax.figure和ax
animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=ax.figure, ax=ax)plt.show()

用网页做的竟然还带水印 不在意水印的推荐
不在意水印的推荐
3.复现CS231经典动画
import torch import numpy as np import copy from matplotlib import pyplot as plt from matplotlib import animation from itertools import zip_longest from matplotlib import cmclass Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)# 输入:张量inputs# 输出:张量outputsdef forward(self, inputs):# return outputsraise NotImplementedError# 输入:最终输出对outputs的梯度outputs_grads# 输出:最终输出对inputs的梯度inputs_gradsdef backward(self, outputs_grads):# return inputs_gradsraise NotImplementedErrorclass Optimizer(object): # 优化器基类def __init__(self, init_lr, model):"""优化器类初始化"""# 初始化学习率,用于参数更新的计算self.init_lr = init_lr# 指定优化器需要优化的模型self.model = modeldef step(self):"""定义每次迭代如何更新参数"""passclass SimpleBatchGD(Optimizer):def __init__(self, init_lr, model):super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)def step(self):# 参数更新if isinstance(self.model.params, dict):for key in self.model.params.keys():self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]class Adagrad(Optimizer):def __init__(self, init_lr, model, epsilon):"""Adagrad 优化器初始化输入:- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数"""super(Adagrad, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.epsilon = epsilondef adagrad(self, x, gradient_x, G, init_lr):"""adagrad算法更新参数,G为参数梯度平方的累计值。"""G += gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class RMSprop(Optimizer):def __init__(self, init_lr, model, beta, epsilon):"""RMSprop优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta:衰减率- epsilon:保持数值稳定性而设置的常数"""super(RMSprop, self).__init__(init_lr=init_lr, model=model)self.G = {}for key in self.model.params.keys():self.G[key] = 0self.beta = betaself.epsilon = epsilondef rmsprop(self, x, gradient_x, G, init_lr):"""rmsprop算法更新参数,G为迭代梯度平方的加权移动平均"""G = self.beta * G + (1 - self.beta) * gradient_x ** 2x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_xreturn x, Gdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],self.model.grads[key],self.G[key],self.init_lr)class Momentum(Optimizer):def __init__(self, init_lr, model, rho):"""Momentum优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- rho:动量因子"""super(Momentum, self).__init__(init_lr=init_lr, model=model)self.delta_x = {}for key in self.model.params.keys():self.delta_x[key] = 0self.rho = rhodef momentum(self, x, gradient_x, delta_x, init_lr):"""momentum算法更新参数,delta_x为梯度的加权移动平均"""delta_x = self.rho * delta_x - init_lr * gradient_xx += delta_xreturn x, delta_xdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],self.model.grads[key],self.delta_x[key],self.init_lr)class Adam(Optimizer):def __init__(self, init_lr, model, beta1, beta2, epsilon):"""Adam优化器初始化输入:- init_lr:初始学习率- model:模型,model.params存储模型参数值- beta1, beta2:移动平均的衰减率- epsilon:保持数值稳定性而设置的常数"""super(Adam, self).__init__(init_lr=init_lr, model=model)self.beta1 = beta1self.beta2 = beta2self.epsilon = epsilonself.M, self.G = {}, {}for key in self.model.params.keys():self.M[key] = 0self.G[key] = 0self.t = 1def adam(self, x, gradient_x, G, M, t, init_lr):"""adam算法更新参数输入:- x:参数- G:梯度平方的加权移动平均- M:梯度的加权移动平均- t:迭代次数- init_lr:初始学习率"""M = self.beta1 * M + (1 - self.beta1) * gradient_xG = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2M_hat = M / (1 - self.beta1 ** t)G_hat = G / (1 - self.beta2 ** t)t += 1x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hatreturn x, G, M, tdef step(self):"""参数更新"""for key in self.model.params.keys():self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],self.model.grads[key],self.G[key],self.M[key],self.t,self.init_lr)class OptimizedFunction3D(Op):def __init__(self):super(OptimizedFunction3D, self).__init__()self.params = {'x': 0}self.grads = {'x': 0}def forward(self, x):self.params['x'] = xreturn - x[0] * x[0] / 2 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]def backward(self):x = self.params['x']gradient1 = - 2 * x[0] / 2gradient2 = 2 * x[1] / 1grad1 = torch.Tensor([gradient1])grad2 = torch.Tensor([gradient2])self.grads['x'] = torch.cat([grad1, grad2])class Visualization3D(animation.FuncAnimation):""" 绘制动态图像,可视化参数更新轨迹 """def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):"""初始化3d可视化类输入:xy_values:三维中x,y维度的值z_values:三维中z维度的值labels:每个参数更新轨迹的标签colors:每个轨迹的颜色interval:帧之间的延迟(以毫秒为单位)blit:是否优化绘图"""self.fig = figself.ax = axself.xy_values = xy_valuesself.z_values = z_valuesframes = max(xy_value.shape[0] for xy_value in xy_values)# , marker = 'o'self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]for _, label, color in zip_longest(xy_values, labels, colors)]print(self.lines)super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,interval=interval, blit=blit, **kwargs)def init_animation(self):# 数值初始化for line in self.lines:line.set_data([], [])# line.set_3d_properties(np.asarray([])) # 源程序中有这一行,加上会报错。 Edit by David 2022.12.4return self.linesdef animate(self, i):# 将x,y,z三个数据传入,绘制三维图像for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values):line.set_data(xy_value[:i, 0], xy_value[:i, 1])line.set_3d_properties(z_value[:i])return self.linesdef train_f(model, optimizer, x_init, epoch):x = x_initall_x = []losses = []for i in range(epoch):all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.loss = model(x)losses.append(loss)model.backward()optimizer.step()x = model.params['x']return torch.Tensor(np.array(all_x)), losses# 构建5个模型,分别配备不同的优化器 model1 = OptimizedFunction3D() opt_gd = SimpleBatchGD(init_lr=0.05, model=model1)model2 = OptimizedFunction3D() opt_adagrad = Adagrad(init_lr=0.05, model=model2, epsilon=1e-7)model3 = OptimizedFunction3D() opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)model4 = OptimizedFunction3D() opt_momentum = Momentum(init_lr=0.05, model=model4, rho=0.9)model5 = OptimizedFunction3D() opt_adam = Adam(init_lr=0.05, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)models = [model5, model2, model3, model4, model1] opts = [opt_adam, opt_adagrad, opt_rmsprop, opt_momentum, opt_gd]x_all_opts = [] z_all_opts = []# 使用不同优化器训练for model, opt in zip(models, opts):x_init = torch.FloatTensor([0.00001, 0.5])x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch# 保存参数值x_all_opts.append(x_one_opt.numpy())z_all_opts.append(np.squeeze(z_one_opt))# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-1, 2, 0.01) x2 = np.arange(-1, 1, 0.05) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2]))model = OptimizedFunction3D()# 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4 surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm) # fig.colorbar(surf, shrink=0.5, aspect=1) ax.set_zlim(-3, 2) ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)')labels = ['Adam', 'AdaGrad', 'RMSprop', 'Momentum', 'SGD'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax) ax.legend(loc='upper right')plt.show() # animator.save('animation.gif') # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
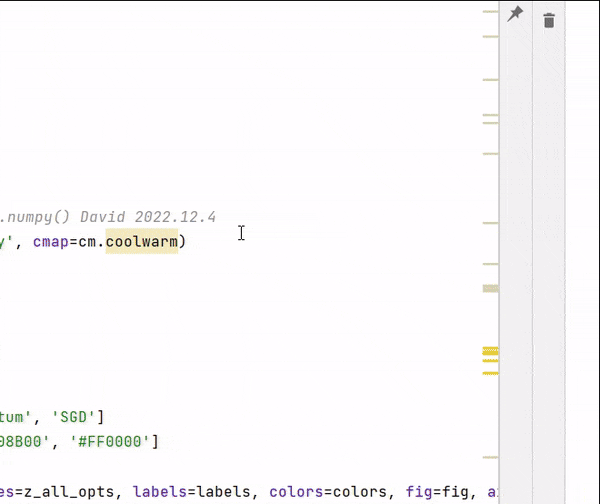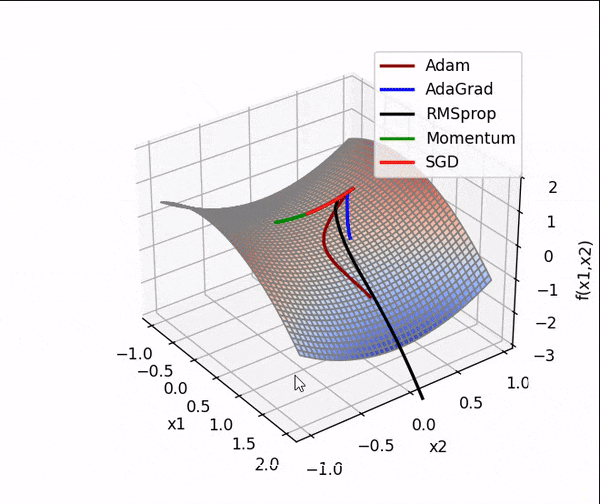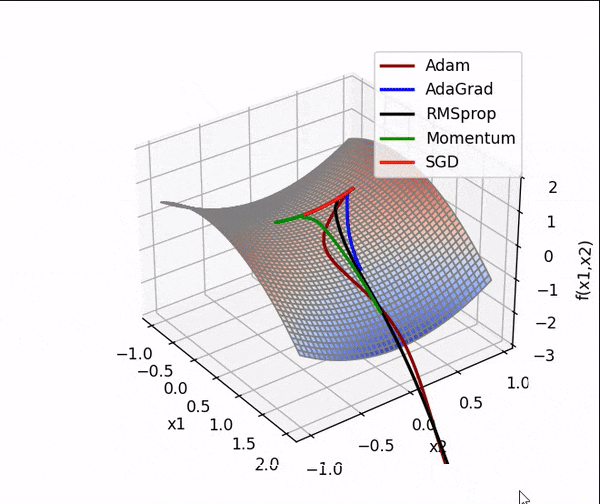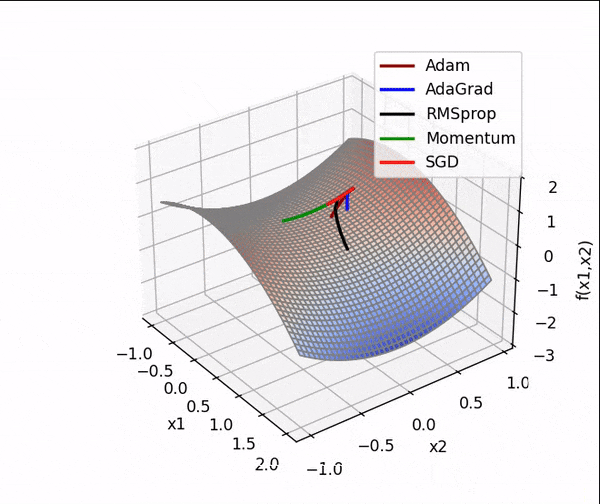
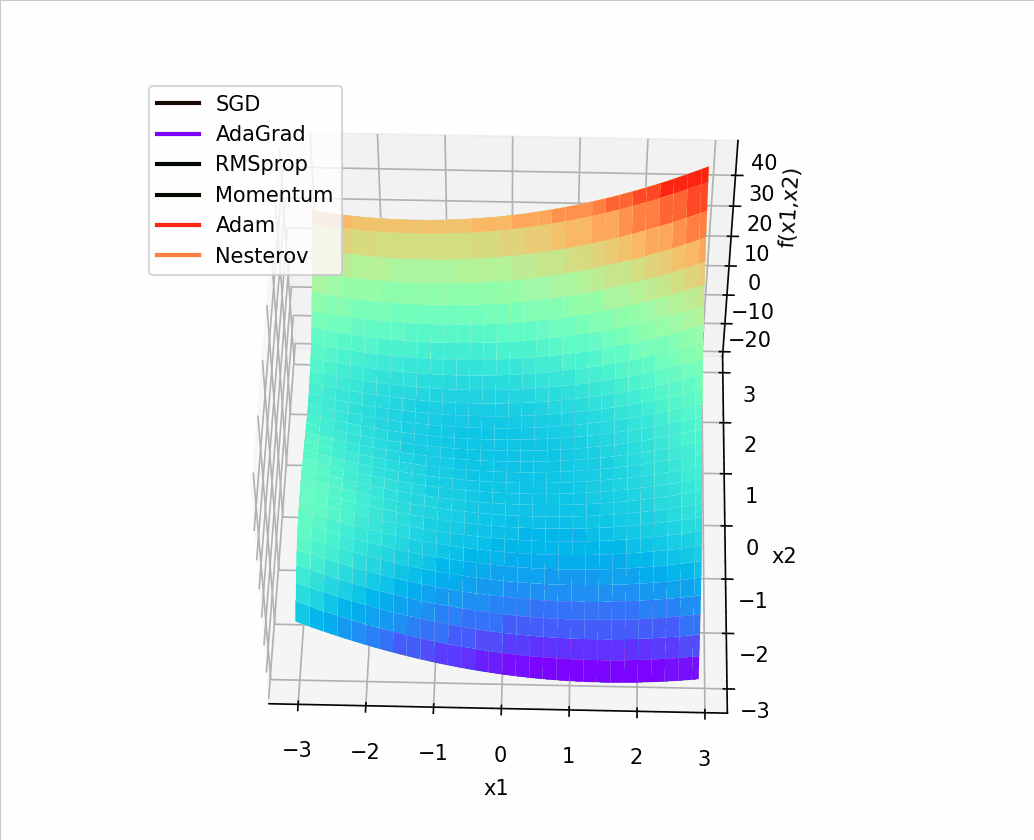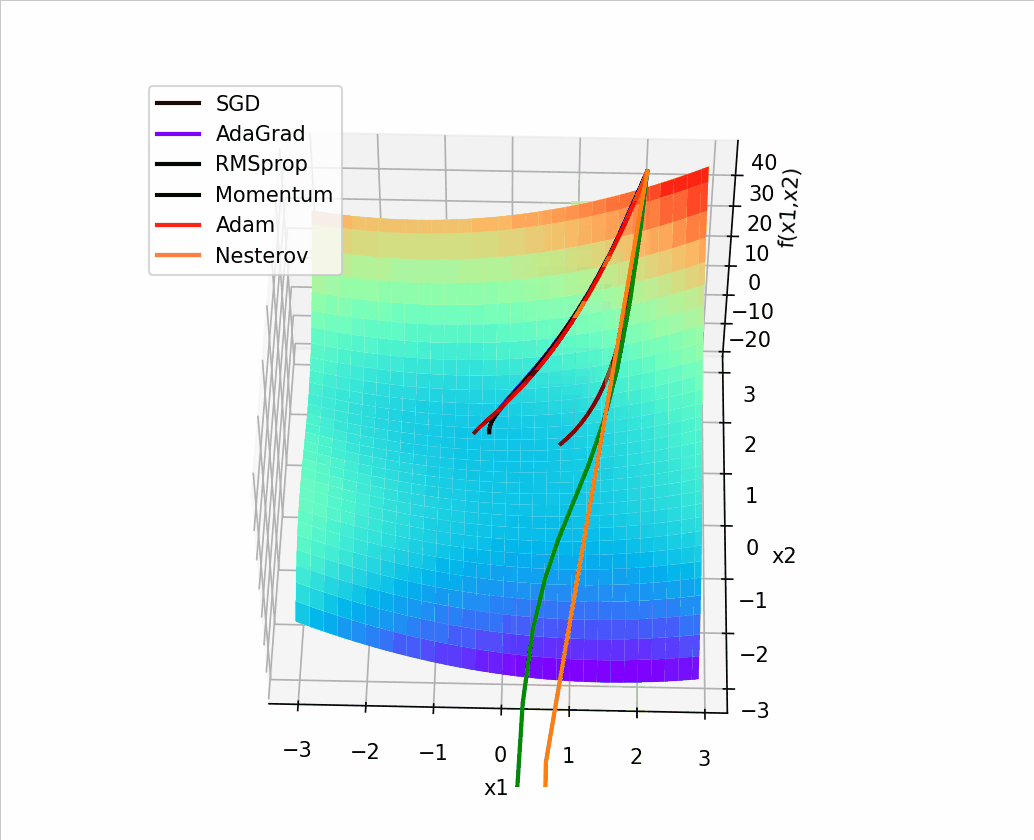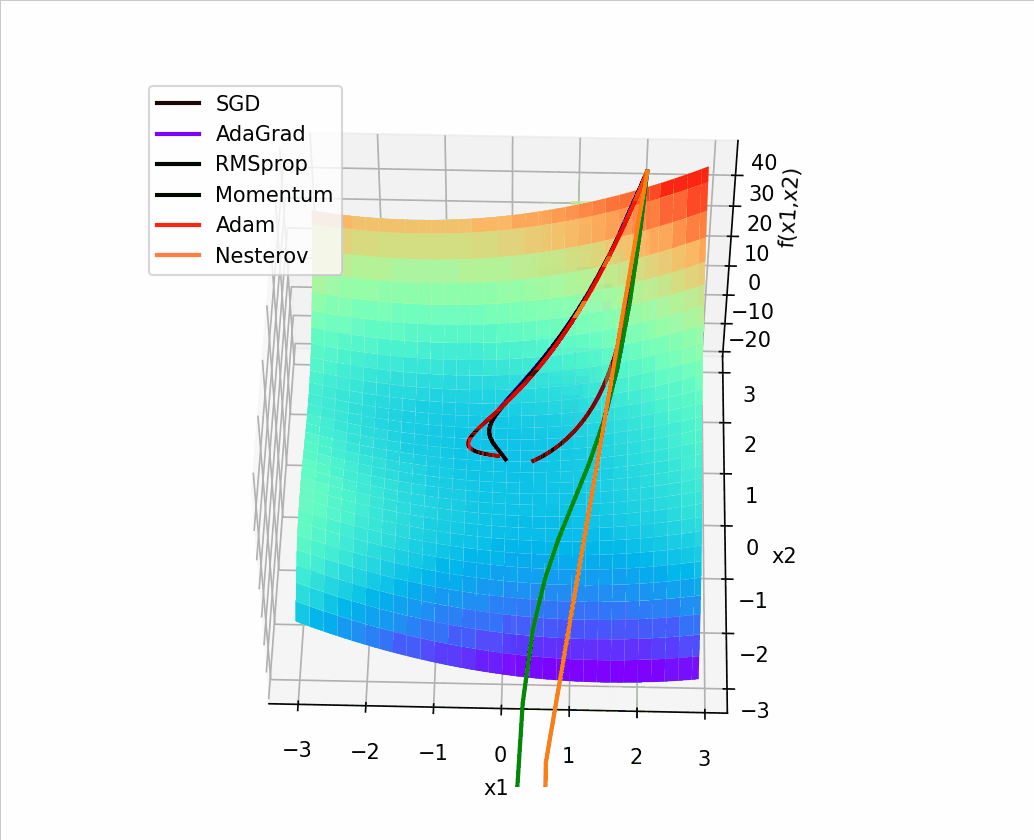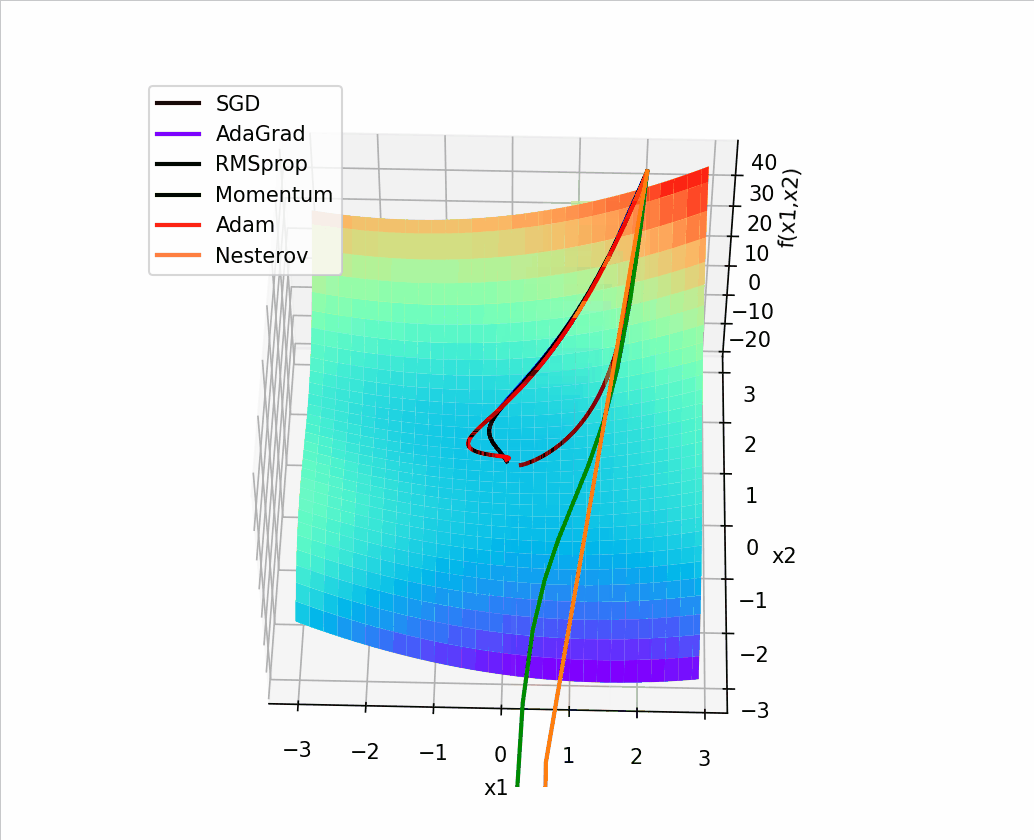
4. 结合3D动画,用自己的语言,从轨迹、速度等多个角度讲解各个算法优缺点
1、SGD
SGD从图像上来看,呈现“之”字形,路径不够平滑,而且在刚才那个图中,就陷入了局部最小值,而且还出不来。
优点:1、对于大的数据集来说,速度比较快,因为每次就算一个数据的梯度就可以了。
2、计算复杂度也低,因为就算一个数据的梯度
缺点:1、震荡的很,呈现“之”字型
2、容易陷入局部极小值
3、容易受噪声的影响,如果碰巧选择噪声点来进行更新,那就偏了。
4、需要调节成合适的学习率
2、AdaGrad
从上面看出 蓝色线(AdaGrad)一开始更新的很快,然后后面逐渐变慢,但是也能看出来最平滑了
优点: 1、Adagrad的速度受益于自适应学习率的特性,可以根据每个参数的历史梯度动态调整学习率,更有效地更新参数。
2、对于具有梯度稀疏性的问题,Adagrad可能更为有效,因为它可以根据每个参数历史梯度的信息来调整学习率。(根据公式就可以知道)
缺点: 1、随着时间推移,Adagrad累积的历史梯度平方可能导致学习率逐渐减小,可能导致训练后期学习率过小,使得模型参数更新幅度过小,难以收敛。
2、衰减的过快,可能会早停
3、RMSprop
从轨迹上看 整体上虽然没有AdaGrad平滑,但是依然比其他的要平滑,并且整体上速度很块,由于学习率的自适应性,RMSprop的路径可能在优化过程中逐渐收敛,呈现出更为平稳的特点。
优点: 1、RMSprop同样有自适应学习率,它通过梯度平方的移动平均来调整学习率,能够在不同参数之间适应性地选择学习率。
2、因为有自适应学习率,所以路径平滑,此外,历史梯度逐渐削弱,速度会块,解决了早停的问题。
缺点: 1、类似于Adagrad,RMSprop可能随着时间推移导致学习率逐渐减小,这可能使得在训练后期模型参数更新幅度过小,难以收敛。
4、Momentum
从路径上来看,速度很快,但是会找错路,并且,它是这几个算法里对一个方向的更新时间最持续的并且很直
优点: 1、Momentum算法通过积累动量,能够更快地加速收敛,尤其是在具有平坦或弯曲路径的情况下,相对于SGD具有更好的表现。
2、引入动量有助于平滑更新路径,减轻震荡,使得模型更为稳定。(不走错路还挺平滑的,走错了会有“之”)
缺点: 1、非凸优化问题中,动量算法可能使得路径过于迅速地越过全局最优点,导致无法稳定地收敛。
5、Nesterov
从路径上看,也会走错,但是是最先纠正路径的,速度最快,改路最快可能是Nesterov先用当前的速度v更新一遍参数,在用更新的临时参数计算梯度。
优点: 1、有前瞻性(改路最快)能够更快速地收敛,特别是在梯度较为复杂的情况下,相对于标准Momentum表现更好。
2、路径平滑,对于训练更稳定。
3、块
缺点:
调参复杂,参数多
6、Adam
从路径来看 不像动量法那样会走错,既没走错,也不慢,中间的样子,还是比较平滑的。
优点: 1、其自适应学习率机制,能够根据每个参数的历史梯度信息动态调整学习率,适应不同参数的特点。
2、方向性比较好,速度也不慢
缺点: 1、Adam算法需要维护每个参数的一阶矩和二阶矩的历史信息,导致内存需求较高,尤其是在参数较多的情况下。




总结:
1、第一个实验,就出师未捷身先死,用的同学的代码复现打算,结果一直只有第一张图,第二张图片出不来,左一那样,我看了看代码,感觉没啥毛病,于是,我按照我自己的想法开始改,结果两张图出是出来了,就是出现在一张图上,而且第二个函数的图还有点怪怪的,我瞅着代码上看没啥毛病,我猜测是因为度量衡的问题,于是,我又把两张图分开看,就长最下面那样,嘿,成了!



原因就是,我一开始就用来一个画布,后面加了一个画布就好了

2、第二个代码一开始出现的图像,我不能动,而且没有轨迹,最狗的就是一会儿就自己关了,我修改了一部分,终于和小伙伴们一样拥有了自己的动图,太不容易了,看其他同学貌似也有同样问题奉上我的修改过程:
class Visualization3D(animation.FuncAnimation):# ... (不变)def init_animation(self):# 数值初始化for line in self.lines:line.set_data([], [])line.set_3d_properties([])for point in self.points:point.set_data([], [])point.set_3d_properties([])return self.points + self.linesdef animate(self, i):# 将x,y,z三个数据传入,绘制三维图像for line, xy_value, z_value, point in zip(self.lines, self.xy_values, self.z_values, self.points):line.set_data(xy_value[:i, 0], xy_value[:i, 1])line.set_3d_properties(z_value[:i])point.set_data(xy_value[i, 0], xy_value[i, 1])point.set_3d_properties(z_value[i])return self.points + self.lines # (后面的代码不变)# 构建5个模型,分别配备不同的优化器 # ... (不变)# 使用不同优化器训练 # ... (不变)# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-10, 10],以0.01为间隔的数值 # ... (不变)# 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy()surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm) ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)')# 添加轨迹图 labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']for x_opt, z_opt, label, color in zip(x_all_opts, z_all_opts, labels, colors):ax.plot(x_opt[:, 0], x_opt[:, 1], z_opt, label=label, color=color)ax.legend(loc='upper right')# 修改下面这行,将Visualization3D的初始化参数中的fig和ax改为ax.figure和ax animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=ax.figure, ax=ax)plt.show()我是这样修改的,原因如下:
在原始的代码中,
Visualization3D类的init_animation和animate方法的实现存在一些问题,这有可能导致轨迹图无法正确显示。原始实现中使用了set_data_3d方法,但是这个方法可能没有正确地设置Z轴的值,导致轨迹图在三维空间中无法正确显示。
Visualization3D类的初始化参数中有fig和ax,而在动画的过程中,我注意到ax在这个类中被用作动画的轴。在原始代码中,fig和ax的值分别传递给了Visualization3D类,但是在动画的过程中,ax的figure属性才是正确的Figure对象。所以,我对
Visualization3D的初始化参数进行了修改,将fig和ax改为ax.figure和ax,以确保Visualization3D正确连接到已有的ax上。此外,我还更新了init_animation和animate方法。在init_animation方法中,我修改了对line.set_data_3d和point.set_data_3d的调用,将其分别改为line.set_data和point.set_data,同时添加了set_3d_properties来设置Z轴的值。在animate方法中,也做了类似的修改,以确保在动画过程中正确更新轨迹图的数据。
参考链接:
NNDL 作业13 优化算法3D可视化-CSDN博客
NNDL实验 优化算法3D轨迹 复现cs231经典动画_深度学习 优化算法 动画展示-CSDN博客
【23-24 秋学期】NNDL 作业13 优化算法3D可视化-CSDN博客
3、又是美好的一天过去了,学了不少知识,希望睡一觉不会忘记!!
NNDL结束了,完结!撒花!!

给老师一个,真是辛苦了,看了我写了一学期的学术垃圾

相关文章:
优化算法3D可视化
编程实现优化算法,并3D可视化 1. 函数3D可视化 分别画出 和 的3D图 import numpy as np from matplotlib import pyplot as plt import torch# 画出x**2 class Op(object):def __init__(self):passdef __call__(self, inputs):return self.forward(inputs)def for…...
魔术表演Scratch-第14届蓝桥杯Scratch省赛真题第1题
1.魔术表演(20分) 评判标准: 4分:满足"具体要求"中的1); 8分:满足"具体要求"中的2); 8分,满足"具体要求"中的3)…...
LLM 中的长文本问题
近期,随着大模型技术的发展,长文本问题逐渐成为热门且关键的问题,不妨简单梳理一下近期出现的典型的长文本模型: 10 月上旬,Moonshot AI 的 Kimi Chat 问世,这是首个支持 20 万汉字输入的智能助手产品; 10 月下旬,百川智能发布 Baichuan2-192K 长窗口大模型,相当于一次…...

深入了解Swagger注解:@ApiModel和@ApiModelProperty实用指南
在现代软件开发中,提供清晰全面的 API 文档 至关重要。ApiModel 和 ApiModelProperty 这样的代码注解在此方面表现出色,通过增强模型及其属性的元数据来丰富文档内容。它们的主要功能是为这些元素命名和描述,使生成的 API 文档更加明确。 Api…...

Linux学习第48天:Linux USB驱动试验:保持热情,保持节奏,持续学习是作为一个技术人员应有的基本素质和要求
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 最近更新的速度和频率大不如以前,主要原因还是自己有些懈怠了。学习是一个持续努力的过程,一旦中断,再想保持以往的状态可能要…...

数据库索引简析
文章目录 前言一、索引是什么二、索引的有什么用三、索引的分类四、索引的数据结构总结 前言 在我们使用数据库的过程中,往往会碰到一个叫做索引的东西,不管是表的设计,还是数据库性能的优化往往都会涉及到索引。那么他是个什么东西ÿ…...
leetcode贪心(单调递增的数字、监控二叉树)
738.单调递增的数字 给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。 (当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。ÿ…...

如何在win7同样支持Webview2 在 WPF 中使用本地 Webview2 ,如何不依赖系统 Runtime
项目运行环境: .Net Framework 4.5.2 Windows 7 x64 Service Pack 1 WebView2 Microsoft.WebView2.FixedVersionRuntime.120.0.2210.91.x64 考虑到很多老项目,本项目使用的是.Net Framework 4.5.2,.Net 更高版本的其实也是可以支持的。 …...

【docker】网络模式管理
目录 一、Docker网络实现原理 二、Docker的网络模式 1、host模式 1.1 host模式原理 1.2 host模式实操 2、Container模式 2.2 container模式实操 3、none模式 4、bridger模式 4.1 bridge模式的原理 4.2 bridge实操 5、overlay模式 6、自定义网络模式 6.1 为什么需要…...
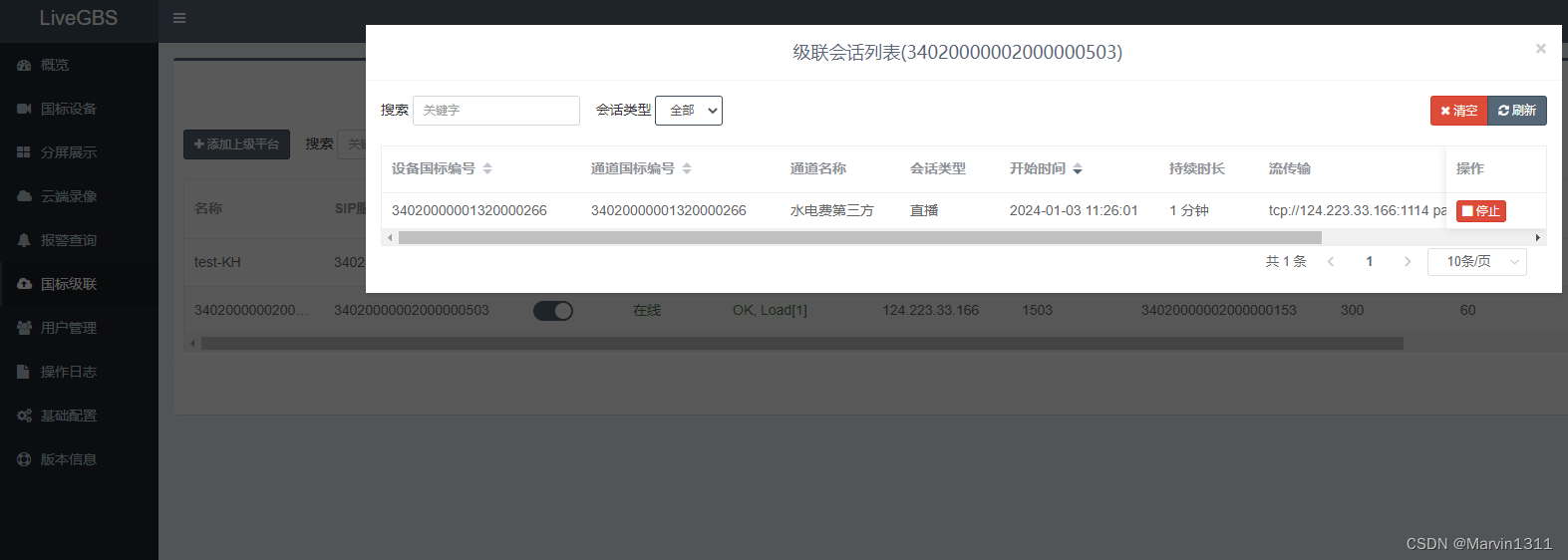
LiveGBS国标GB/T28181流媒体平台功能-国标级联中作为下级平台对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话
LiveGBS国标级联中作为下级平台对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话 1、GB/T28181级联是什么2、搭建GB28181国标流媒体平台3、获取上级平台接入信息3.1、如何提供信息给上级3.2、上级国标平台如何添加下级域3.2、接入LiveGBS示例 4、配置国标…...

技术发展驱动编程语言走向
未来编程语言的走向可能会受到多种因素的影响,包括技术进步、市场需求、开发人员的偏好和生态系统的演变等。以下是一些可能的发展趋势: 简洁性和易用性 随着技术的进步,编程语言可能会变得越来越简洁和易于使用。一些语言可能会引入更高级的…...
tp5+workman(GatewayWorker) 安装及使用
一、安装thinkphp5 1、宝塔删除php禁用函数putenv、pcntl_signal_dispatch、pcntl_wai、pcntl_signal、pcntl_alarm、pcntl_fork,执行安装命令。 composer create-project topthink/think5.0.* tp5 --prefer-dist 2、配置好站点之后,浏览器打开访问成…...

vscode安装Prettier插件,对vue3项目进行格式化
之前vscode因为安装了Vue Language Features (Volar)插件,导致Prettier格式化失效,今天有空,又重新设置了一下 1. 插件要先安装上 2. 打开settings.json {"editor.defaultFormatter": "esbenp.prettier-vscode","…...

macOS跨进程通信: XPC 创建实例
一:简介 XPC 是 macOS 里苹果官方比较推荐和安全的的进程间通信机制。 集成流程简单,但是比较绕。 主要需要集成 XPC Server 这个模块,这个模块最终会被 apple 的根进程 launchd 管理和以独立进程的方法唤起和关闭, 我们主app 进…...

Ubuntu18.04 升级Ubuntu20.04
文章目录 背景升级方法遇到的问题 背景 因项目环境需要,欲将Ubuntu18.04升级至Ubuntu20.04,参考网上其他小伙伴的方法,也遇到了一个问题,特此记录一下,希望能帮助其他有同样问题的小伙伴。 升级方法 参考:…...
自动化测试怎么做?看完你就懂了。。。
前言 我想应该有很多测试人员应该有这样的疑虑,自动化测试要怎么去做,现在我把自己的一些学习经验分享给大家,希望对你们有帮助,有说的不好的地方,还请多多指教! 对于测试人员来说,不管进行功…...

小秋SLAM入门实战opencv所有文章汇总
opencv_core和 opencv_imgcodecs是 OpenCV(开源计算机视觉库)的两个主要模块 【如何使用cv::erode()函数对图像进行腐蚀操作】 头文件用途 用OpenCV创建一张类型为CV_8UC1的单通道随机灰度图像 用OpenCV创建一张灰度黑色图像并设置某一列为白色 OpenCV创…...

2023年终总结(脚踏实地,仰望星空)
回忆录 2023年,经历非常多的大事情,找工作、实习、研究生毕业、堂哥结婚、大姐买车、申博、读博、参加马拉松,有幸这一年全家人平平安安,在稳步前进。算是折腾的一年,杭州、赣州、武汉、澳门、珠海、遵义来回跑。完成…...

Transforer逐模块讲解
本文将按照transformer的结构图依次对各个模块进行讲解: 可以看一下模型的大致结构:主要有encode和decode两大部分组成,数据经过词embedding以及位置embedding得到encode的时输入数据 输入部分 embedding就是从原始数据中提取出单词或位置&…...

macOS进程间通信的常用技术汇总
macOS进程间通信的常用技术汇总 命令行传参。yyds管道(pipe), 匿名管道, c的技术,可以跨平台使用 只能在父子进程间通信,由于是单向的管道,只能单方面传输数据。 如果需要双向传输,需要建立双向的两条管道才行 匿名管…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...