2023 年中国高校大数据挑战赛赛题B DNA 存储中的序列聚类与比对-解析与参考代码
题目背景:目前往往需要对测序后的序列进行聚类与比对。其中聚类指的是将测序序列聚类以判断原始序列有多少条,聚类后相同类的序列定义为一个簇。比对则是指在聚类基础上对一个簇内的序列进行比对进而输出一条最有 可能的正确序列。通过聚类与比对将会极大地恢复原始序列的信息,但需要注意 由于DNA测序后序列众多,如何高效地进行聚类与比对则是在满足准确率基础上的另一大难点。

数据说明:
“train_reference.txt”是某次合成的目标序列,其中第一行为序号,第二行
为序列内容。
通过真实合成、测序后读取到的测序序列文件为“train_reads.txt”,我们已经对测序序列进行了分类,该文件第一行为目标序列的序号,第二行为序列内容。
基于赛题提供的数据,自主查阅资料,选择合适的方法完成如下任务:
任务1:观察数据集“train_reads.txt”、“train_reference.txt”,针对这次合成任务,进行错误率(插入、删除、替换、断链)、拷贝数方面的分析。其中错误率定义为某个碱基发生错误的概率,需要对不同类型的错误率分别进行分析。拷贝数定义为原始序列复制的数量。
·数据读取与查看:
首先需要根据题目给出的数据信息,对任务1中提到的两个数据集“train_reads.txt”、“train_reference.txt”进行读取与查看。
这里我们采用python语言,Jupiter notebook编程:
import pandas as pd
import numpy as np
#1#读取数据
df_reference = pd.read_csv('train_reference.txt', delimiter=' ',header=None)
df_reference.columns = ['序号', '序列内容'] # 替换列名
df_reference
df_train=pd.read_csv('train_reads.txt',delimiter=' ',header=None)
df_train.columns = ['序号', '序列内容'] # 替换列名
df_train
·拷贝数分析:
由于拷贝数的统计计算较为简单,我们首先对拷贝数进行统计分析。
根据题意,拷贝数定义为原始序列复制的数量,所以我们只需要计算每个序列对应的复制次数。
代码如下:
#拷贝数分析
df_copies=df_train['序号'].value_counts().sort_index()
df_copies
#可视化
import matplotlib.pyplot as plt
# 绘制柱状图
plt.bar(df_copies.index, df_copies.values)
plt.xlabel('Order')
plt.ylabel('Count')
plt.title('Order Counts')
plt.show()

从可视化结果可以直观地看出,绝大多数序列被复制的次数都在100-140之间,但是具体的复制数目参差不齐。
·错误率分析:
错误率共有四种类型:(插入、删除、替换、断链)
针对每种类型,需要我们进行人工定义相应的错误率计算方式:
- 插入错误(记为1类错误)
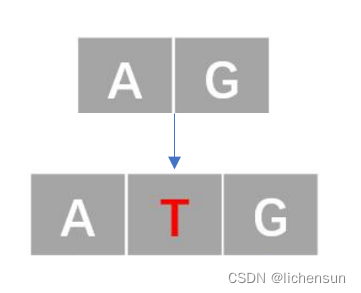
- 删除错误(记为2类错误)
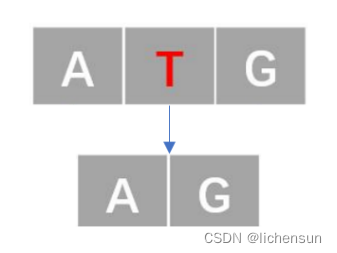
- 替换错误(记为3类错误)

-
断链(记为4类错误)
-
该类错误比较特殊,在 DNA 复制过程中,"断链"通常指的是 DNA 双螺旋的某一条链在复制时发生了断裂,形成一个或多个暂时的单链断裂。这个过程可能是由于复制过程中的各种因素引起的。
比较直观的观测方法是查看复制链的长度,如果序列长度比原定目标长度少了25%及以上,可以认为发生了断链。
如发生断链,4类错误率记为100%(1),否则记为0。
要统计从字符串 B 修改到字符串 A 所涉及的添加、删除和替换的字符个数,可以使用编辑距离(Levenshtein 距离)的概念。编辑距离是衡量两个字符串相似程度的一种方法,包括插入、删除和替换的操作。
在 Python 中,可以使用第三方库 python-Levenshtein 来计算编辑距离。
import Levenshtein
#实现代码请戳完整版获取
任务 2:设计开发一种模型用于对测序后的序列“train_reads.txt”进行聚类,
并根据“train_reads.txt”的标签验证模型准确性。模型主要从两方面评估效果:
-
聚类后准确性(包括簇的数量以及簇内纯度)、(2)聚类速度(以分钟为单位)
思路提示:标签即为文件第一行——目标序列的序号,在该任务中,我们将假设序号未知,尝试通过聚类的方法来标记各复制得到的序列可能对应哪个目标序列。
对测序后的序列进行聚类,聚类的依据即为与序列之间的相似性。
聚类是一种将相似的数据点分组的方法。在字符串的情境下,可以使用字符串之间的相似度来聚类。以下是一个示例,使用 KMeans 聚类算法进行字符串的聚类:
#代码见完整版任务 3:“test_reads.txt”是我们在另一种合成环境下合成的测序文件(与“train_reads.txt”的目标序列不相同),请用任务 2 所开发的模型对其进行聚类,给出聚类耗时以及“test_reads.txt”的目标序列数量,给出拷贝数分布图。
由于test数据不清楚分几类合适,需要进行初步的分类步长探索。这里通过设置合理的取样步长采用遍历方法,每次遍历直接套用任务2中设计好的模型(即k-means聚类方法)即可。
对于分类探索,根据实际问题背景,对每个目标序列进行的拷贝数目应该大致相同。
任务 4:聚类后能否通过比对恢复原始信息也是极为关键的,设计开发一种用于同簇序列的比对模型,该模型可以针对同簇的DNA序列进行比对并输出最有可能正确的目标序列。 请使用该工具对任务 3 中“test_reads.txt”的聚类后序列进行比对,并输出“test_reads.txt”最有可能的目标序列,并分析“test_reads.txt”的错误率。(请用一个“test_ref.txt”的文件记录“test_reads.txt”的目标序列。
观察已知数据,不难发现目标序列长度为60.
思路1:针对每个簇内的复制序列,通过相似度计算找出其中最可能与目标序列接近程度最大的序列。依据其他序列修正为长度60作为预测目标序列。
思路2:将每个簇内的复制序列进行长度切割,分别找出各片段的高频序列,将其拼接得到预测的目标序列。
思路3:直接计算公共相同片段(前缀、后缀等),将其适当拼接。
为了构造一个新字符串,使其尽可能与已知的10个字符串都具有很大的相似度,你可以考虑找到这些字符串之间的最长公共子串(Longest Common Substring)。以下是一个示例,使用动态规划来找到最长公共子串,并构造新字符串:
def longest_common_substring(str1, str2):
m, n = len(str1), len(str2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
max_len = 0
end_index = 0
for i in range(1, m + 1):
for j in range(1, n + 1):
if str1[i - 1] == str2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
if dp[i][j] > max_len:
max_len = dp[i][j]
end_index = i - 1
else:
dp[i][j] = 0
return str1[end_index - max_len + 1:end_index + 1]
def construct_string(known_strings):
common_substring = known_strings[0]
for i in range(1, len(known_strings)):
common_substring = longest_common_substring(common_substring, known_strings[i])
# 构造新字符串,将最长公共子串重复若干次
constructed_string = common_substring * 5 # 假设构造的字符串长度为5倍最长公共子串长度
return constructed_string
# 示例
known_strings = ["apple", "apricot", "appetizer", "apology", "apex", "applause", "apricot", "april", "apocalypse", "apostrophe"]
constructed_string = construct_string(known_strings)
print(f"构造的字符串: {constructed_string}")
在这个示例中,longest_common_substring 函数用于找到两个字符串的最长公共子串,然后 construct_string 函数使用这个方法找到所有字符串的最长公共子串,并将其重复若干次以构造新字符串。请注意,具体的重复次数和其他参数可能需要根据实际情况进行调整。
在获得预测的目标序列后,继续采用task1中的方法进行错误率分析即可。
完整获取请戳↓
baiduwangpan:https://pan.baidu.com/s/1BKsSgjSSnHu4433O7jf06w?pwd=ggt9 提取码:ggt9
相关文章:
2023 年中国高校大数据挑战赛赛题B DNA 存储中的序列聚类与比对-解析与参考代码
题目背景:目前往往需要对测序后的序列进行聚类与比对。其中聚类指的是将测序序列聚类以判断原始序列有多少条,聚类后相同类的序列定义为一个簇。比对则是指在聚类基础上对一个簇内的序列进行比对进而输出一条最有 可能的正确序列。通过聚类与比对将会极大…...

决策树--分类决策树
1、介绍 ① 定义 分类决策树通过树形结构来模拟决策过程,决策树由结点和有向边组成。结点有两种类型:内部结 点和叶结点。内部结点表示一个特征或属性,叶子节点表示一个类。 ② 生成过程 用决策树分类,从根结点开始ÿ…...

【2024/1/5】
2024/1/5周报 本周开展工作下周工作计划 本周开展工作 首先的话就是跟大家汇报一下上一个项目的进度,那因为一些我这边的不可控的因素暂时进行搁置,随后的话还是需要在进行做的。 因此我们最近在做一个web端的项目,这个项目的具体的就不汇报…...
CNN——VGG
1.VGG简介 论文下载地址:https://arxiv.org/pdf/1409.1556.pdf VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军ÿ…...

深入理解Java中的多线程编程与并发控制
当谈论到 Java 编程语言时,多线程编程和并发控制是其中最重要的话题之一。Java 在多线程领域有着强大的支持和丰富的工具集,允许开发人员利用并发性来提高程序性能和效率。本文将深入探讨 Java 中的多线程编程和并发控制,包括线程的创建、同步…...

提供10个mysql的实例和思路
学生信息管理系统 学生表(id, name, gender, age, class_id)班级表(id, name)思路:通过学生表和班级表进行关联,可以实现学生信息的查询、添加、修改、删除等操作。 订单管理系统 订单表(id, us…...
FPGA项目(14)——基于FPGA的数字秒表设计
1.功能设计 设计内容及要求: 1.秒表最大计时范围为99分59. 99秒 2.6位数码管显示,分辨率为0.01秒 3.具有清零、启动计时、暂停及继续计时等功能 4.控制操作按键不超过二个。 2.设计思路 所采用的时钟为50M,先对时钟进行分频,得到100HZ频率…...
)
浅谈指数移动平均(ema)
经常在各种代码中看到指数移动平均(比如我专注的网络传输领域),但却不曾想到它就是诠释世界的方法,我们每个人都在被这种方式 “平均”… 今天说说指数移动平均(或移动指数平均,Exponential Moving Average)。 能查到的资料都侧重于其数学形…...

1-并发编程线程基础
什么是线程 在讨论什么是线程前有必要先说下什么是进程,因为线程是进程中的一个实体,线程本身是不会独立存在的。 进程是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,线程则是进程的一个执行路径&#…...
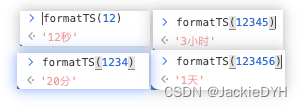
vue中动态出来返回的时间秒数,在多少范围显示多少秒,多少范围显示分,小时等等
在Vue中,你可以使用计算属性(computed property)或过滤器(filter)来根据动态返回的时间秒数来显示不同的时间单位,比如秒、分、小时等等。 下面是一个使用计算属性的示例: <template>&l…...

English: go through customs
文章目录 常见单词机场指示登机和中转降落以及公共服务签证篇出/入境卡篇入境英语会话篇 常见单词 customs: 海关 (kʌstəmz)cash: 现金 (kʃ)passport: 护照 (pspɔːt)luggage/baggage: 行李 (lʌɡɪdʒ/ˈbɡɪdʒ)Exchange: 换钱 (ɪks’tʃeɪndʒ)airport: 飞机场 (ɛ…...
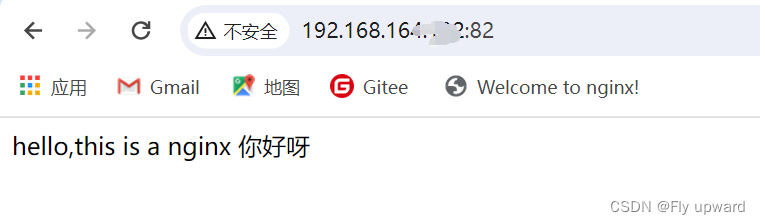
Nginx 多端口部署多站点
目录 1.进行nginx.conf 2.复制粘贴 3.修改端口及站点根目录 4. 网站上传 1.进行nginx.conf 在 nginx 主要配置文件 nginx.conf 中,server 是负责一个网站配置的,我们想要多个端口访问的话,可以复制多个 server 先进入到 nginx.conf 中 …...
从零开始配置kali2023环境:配置jupyter的多内核环境
在kali2023上面尝试用anaconda3,anaconda2安装实现配置jupyter的多内核环境时出现各种问题,现在可以通过镜像方式解决 1. 搜索镜像 ┌──(holyeyes㉿kali2023)-[~] └─$ sudo docker search anaconda ┌──(holyeyes㉿kali2023)-[~] └─$ sudo …...

Dart调用JS对10000条定位数据滤波
使用Dart调用JS,还是为了练习跨语言调用; 一、编写对应的JS代码 平时在开发时不推荐将算法放在JS里,我这里是简单的做一下数据过滤; 首先生成一些随机定位数据,在实际开发中可以使用真实数据; // 随机定…...

大模型应用实践:AIGC探索之旅
随着OpenAI推出ChatGPT,AIGC迎来了前所未有的发展机遇。大模型技术已经不仅仅是技术趋势,而是深刻地塑造着我们交流、工作和思考的方式。 本文介绍了笔者理解的大模型和AIGC的密切联系,从历史沿革到实际应用案例,再到面临的技术挑…...

【.NET Core】异步编程模式
【.NET Core】异步编程模式 文章目录 【.NET Core】异步编程模式一、概述二、基于任务的异步模式(TAP)2.1 TAP模式命名、参数和返回类型2.2 TAP初始化异步操2.3 TAP如何编译2.4 手动生成TAP方法2.5 混合方法实现TAP2.6 TAP中Await挂起执行2.7 TAP中使用Y…...

macOS通过外置驱动器备份数据
通过外置驱动器备份数据(谨慎操作) 1.将外置驱动器连接到您的 Mac。驱动器容量应等于或大于您当前的启动磁盘。驱动器还应该是您可以抹掉的。 2.使用 macOS 恢复功能 抹掉外置驱动器,然后将 macOS 安装 到外置驱动器上。确保您选择的外置驱动…...
rtsp解析视频流
这里先说一下 播放rtsp 视频流,尽量让后端转换一下其他格式的流进行播放。因为rtsp的流需要flash支持,现在很多浏览器不支持flash。 先说一下这里我没有用video-player插件,因为它需要用flash ,在一个是我下载flash后,还是无法播放…...

【物联网】手把手完整实现STM32+ESP8266+MQTT+阿里云+APP应用——第3节-云产品流转配置
🌟博主领域:嵌入式领域&人工智能&软件开发 本节目标:本节目标是进行云产品流转配置为后面实际的手机APP的接入做铺垫。云产品流转配置的目的是为了后面能够让后面实际做出来的手机APP可以控制STM32/MCU,STM32/MCU可以将数…...
)
Spring Cloud Config相关问题及答案(2024)
1、什么是 Spring Cloud Config,它解决了哪些问题? Spring Cloud Config 是一个为微服务架构提供集中化外部配置支持的项目。它是构建在 Spring Cloud 生态系统之上,利用 Spring Boot 的开发便利性,简化了分布式系统中的配置管理…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...
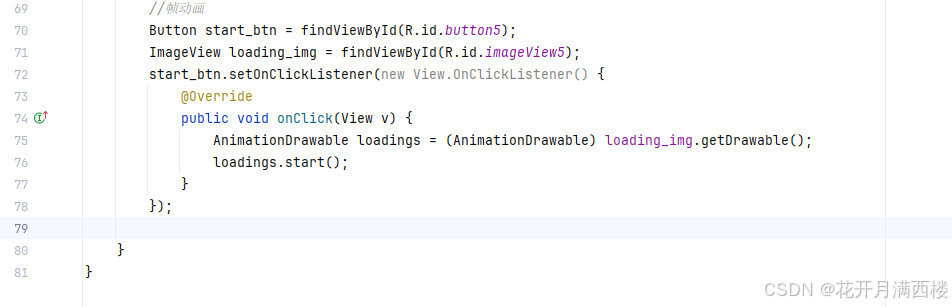
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...
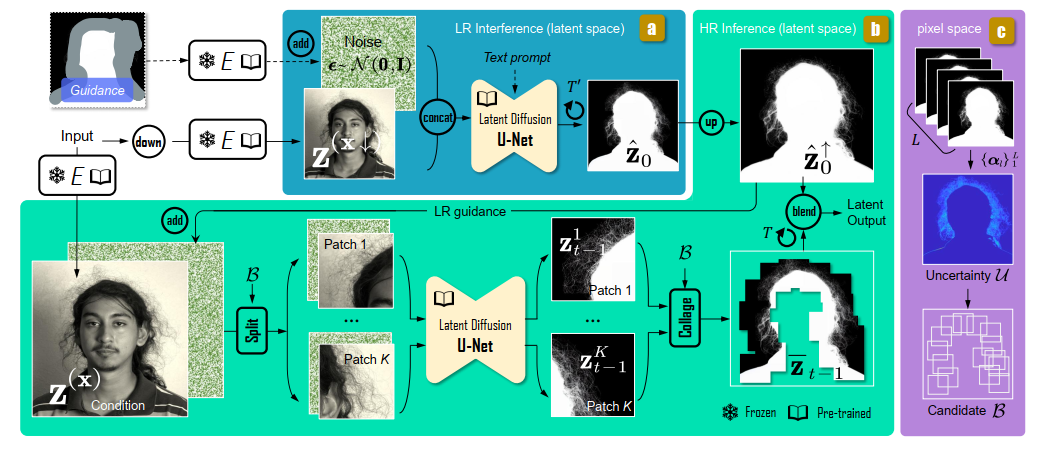
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...
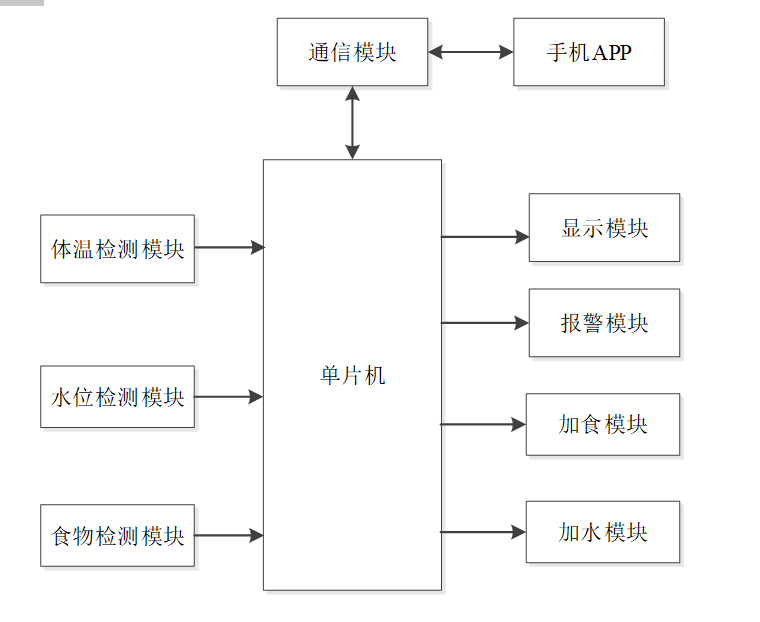
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...

Linux信号保存与处理机制详解
Linux信号的保存与处理涉及多个关键机制,以下是详细的总结: 1. 信号的保存 进程描述符(task_struct):每个进程的PCB中包含信号相关信息。 pending信号集:记录已到达但未处理的信号(未决信号&a…...