阿里后端实习一面面经
阿里后端实习一面面经
项目中使用到了es,es的作用?
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
es中的重要概念?
群集:一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
节点:属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
索引:就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。
eg: MySQL =>数据库 ElasticSearch =>索引
文档:类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。
MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
类型:是索引的逻辑类别/分区,其语义完全取决于用户。
es为什么快,相对于mysql有什么优势?
数据库在查询时,如果查询id的话,会那么直接走索引,查询速度非常快。但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
- 用户搜索数据,条件是title符合
"%手机%" - 逐行获取数据,比如id为1的数据
- 判断数据中的title是否符合用户搜索条件
- 如果符合则放入结果集,不符合则丢弃。回到步骤1
这种全表扫描的方法在数据量很多的情况下会消耗很多时间。为了解决这个问题,elesticsearch中采用了倒排索引的方法。
首先引入两个概念:
- 文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条。
- 创建表,每行数据包括词条、词条所在文档id或位置等信息。
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引。
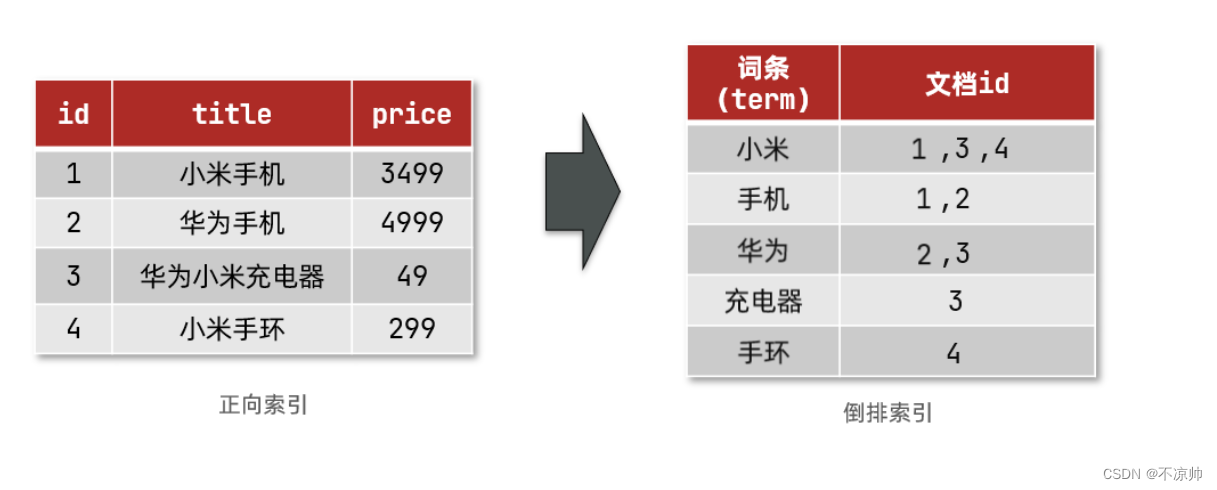
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件 "华为手机" 进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
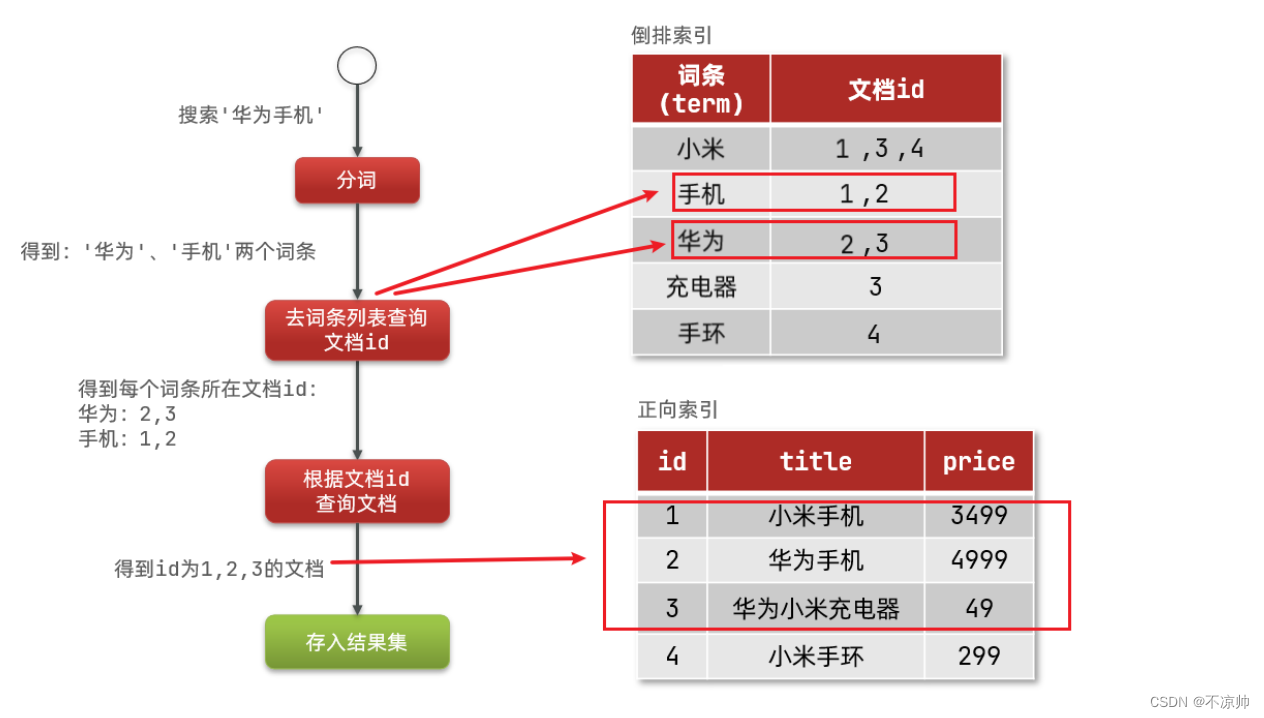
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
- 优点:根据词条搜索、模糊搜索时,速度非常快
- 缺点:只能给词条创建索引,而不是字段无法根据字段做排序
项目中有用到事务吗?讲一下事务
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成
事务的特性(ACID)
- 原子性(Atomicity):事务是应用中不可再分的最小执行体。
- 一致性(Consistency):事务执行的结果,须使数据从一个一致性状态,变为另一个一致性状态。
- 隔离性(Isolation):各个事务的执行互不干扰,任何事务的内部操作对其他的事务都是隔离的。
- 持久性(Durability):事务一旦提交,对数据所做的任何改变都要记录到永久存储器中。
常见的并发异常
第一类丢失更新 :某一个事务的回滚, 导致另外一个事务已更新的数据丢失了。
第二类丢失更新 :某一个事务的提交, 导致另外一个事务已更新的数据丢失了。
脏读 :某一个事务, 读取了另外一个事务未提交的数据
不可重复读 :某一个事务, 对同一个数据前后读取的结果不一致
幻读 :某一个事务, 对同一个表前后查询到的行数不一致
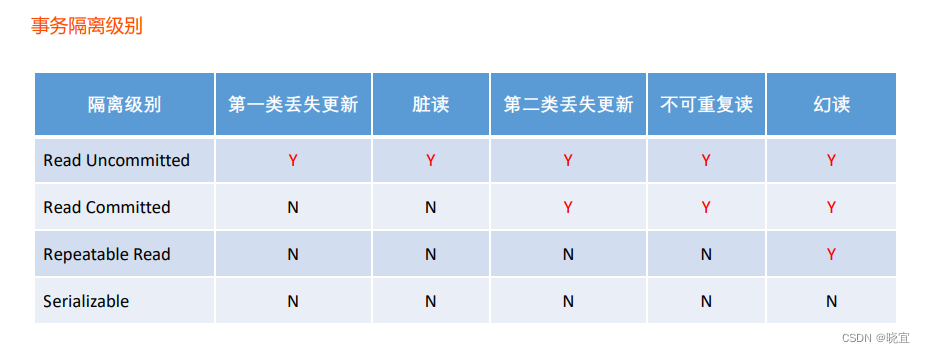
常见的隔离级别
Read Uncommitted:读取未提交的数据。
Read Committed:读取已提交的数据,就是只能读到已经commit了的内容。
Repeatable Read:可重复读。在读已提交的基础上增大锁的粒度,在事务运行中,不允许其他事物update,解决了脏读和不可重复读的问题,但是无法解决幻读。
Serializable:串行化,事务“串行化顺序执行”,也就是一个一个排队执行。
不同数据库的默认隔离级别
MySQL:
MySQL 的默认隔离级别是 "Repeatable Read"(可重复读)。这意味着在同一事务中多次读取相同的数据会得到相同的结果,并且事务期间其他事务不能修改这些数据。
Oracle:
Oracle 的默认隔离级别是 "Read Committed"(读提交)。在 "Read Committed" 隔离级别下,事务只能看到已经提交的数据。这是 Oracle 的默认行为,但 Oracle 也提供了其他隔离级别,如 "Serializable"(可串行化)等。
锁
• 悲观锁(数据库)
共享锁(S锁) 事务A对某数据加了共享锁后,其他事务只能对该数据加共享锁,但不能加排他锁。
排他锁(X锁) 事务A对某数据加了排他锁后,其他事务对该数据既不能加共享锁,也不能加排他锁。
• 乐观锁(自定义)
在更新数据前,检查版本号是否发生变化。若变化则取消本次更新,否则就更新数据(版本号+1)。
spring中使用事务
声明式事务:通过注解,声明某方法的事务特征。
在 service 类上面添加注解@Transactional,在这个注解里面可以配置事务相关参数
// REQUIRED: 支持当前事务(外部事务),如果不存在则创建新事务.required// REQUIRES_NEW: 创建一个新事务,并且暂停当前事务(外部事务).requires_new// NESTED: 如果当前存在事务(外部事务),则嵌套在该事务中执行(独立的提交和回滚),否则就会REQUIRED一样.@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED)public Object save1() {// 新增用户User user = new User();user.setUsername("alpha");user.setSalt(CommunityUtil.generateUUID().substring(0, 5));user.setPassword(CommunityUtil.md5("123" + user.getSalt()));user.setEmail("alpha@qq.com");user.setHeaderUrl("http://image.nowcoder.com/head/99t.png");user.setCreateTime(new Date());userMapper.insertUser(user);// 新增帖子DiscussPost post = new DiscussPost();post.setUserId(user.getId());post.setTitle("Hello");post.setContent("新人报道!");post.setCreateTime(new Date());discussPostMapper.insertDiscussPost(post);//这步报错,观测是否回滚Integer.valueOf("abc");return "ok";}
编程式事务:通过 TransactionTemplate 管理事务, 并通过它执行数据库的操作
public Object save2() {transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);return transactionTemplate.execute(new TransactionCallback<Object>() {@Overridepublic Object doInTransaction(TransactionStatus status) {// 新增用户User user = new User();user.setUsername("beta");user.setSalt(CommunityUtil.generateUUID().substring(0, 5));user.setPassword(CommunityUtil.md5("123" + user.getSalt()));user.setEmail("**********");user.setHeaderUrl("http://image.nowcoder.com/head/999t.png");user.setCreateTime(new Date());userMapper.insertUser(user);// 新增帖子DiscussPost post = new DiscussPost();post.setUserId(user.getId());post.setTitle("你好");post.setContent("我是新人!");post.setCreateTime(new Date());discussPostMapper.insertDiscussPost(post);//这步报错,观测是否回滚Integer.valueOf("abc");return "ok";}});
讲一下Java线程池以及相关参数?
相关流程:
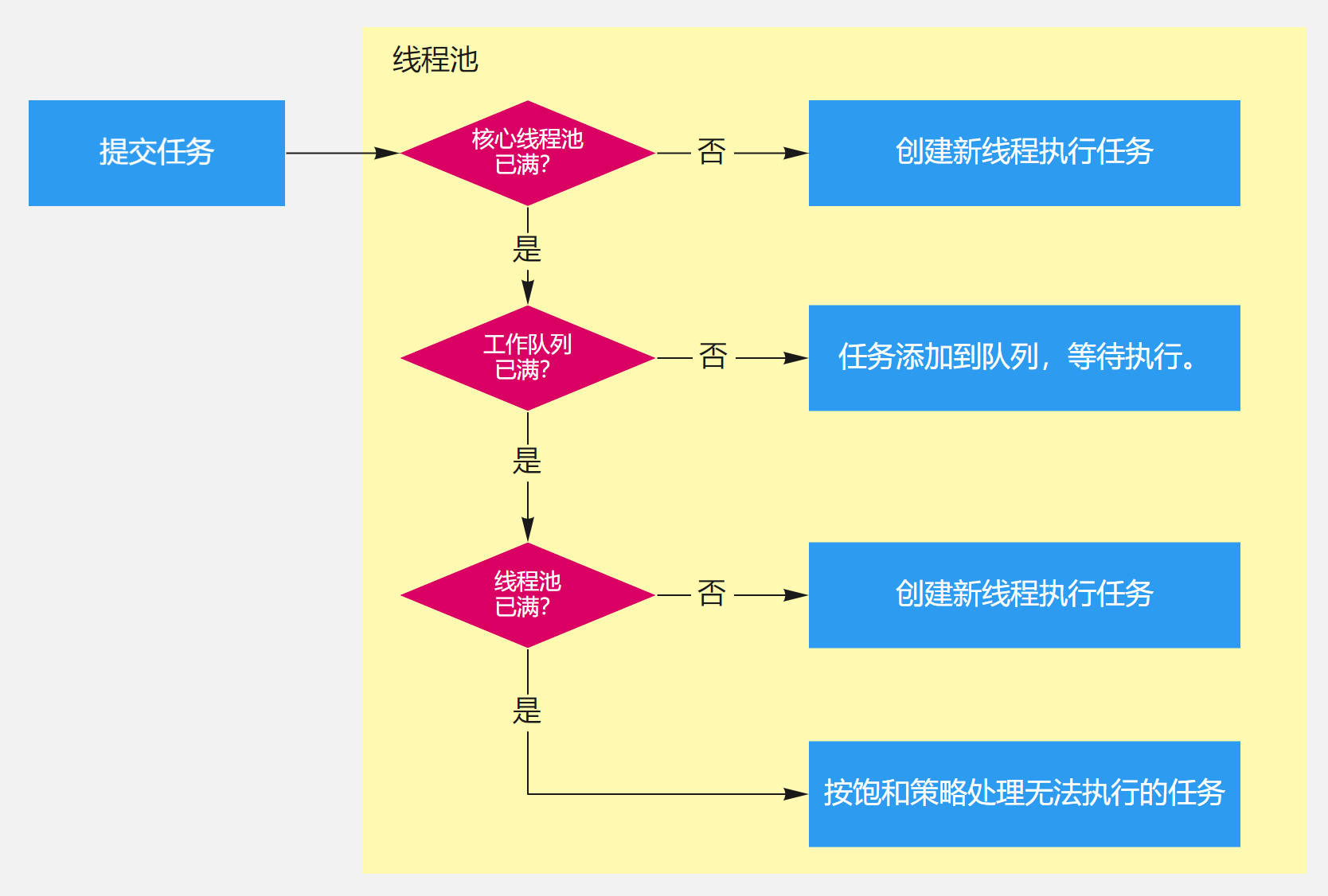
线程池主要有如下6个参数:
- corePoolSize(核心工作线程数):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时。
- maximumPoolSize(最大线程数):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
- keepAliveTime(多余线程存活时间):当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。
- workQueue(工作队列):用于传输和保存等待执行任务的阻塞队列。
- threadFactory(线程创建工厂):用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
- handler(拒绝策略):当线程池和队列都满了,再加入线程会执行此策略
四大拒绝策略
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- DiscardPolicy:也是丢弃任务,但是不抛出异常。
- DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复该过程)。
- CallerRunsPolicy:由调用线程处理被拒绝的run方法
如何创建一个线程池?
使用Executors相关函数进行创建
1.newFixedThreadPool:创建一个固定大小的线程池
public class ThreadPool1 {public static void main(String[] args) {//1.创建一个大小为5的线程池ExecutorService threadPool= Executors.newFixedThreadPool(5);//2.使用线程池执行任务一for (int i=0;i<5;i++){//给线程池添加任务threadPool.submit(new Runnable() {@Overridepublic void run() {System.out.println("线程名"+Thread.currentThread().getName()+"在执行任务1");}});}//2.使用线程池执行任务二for (int i=0;i<8;i++){//给线程池添加任务threadPool.submit(new Runnable() {@Overridepublic void run() {System.out.println("线程名"+Thread.currentThread().getName()+"在执行任务2");}});}}
}
2.newCachedThreadPool:带缓存的线程池,适用于短时间有大量任务的场景,但有可能会占用更多的资源;线程数量随任务量而定。
public class ThreadPool3 {public static void main(String[] args) {//创建线程池ExecutorService service= Executors.newCachedThreadPool();//有50个任务for(int i=0;i<50;i++){int finalI = i;service.submit(()->{System.out.println(finalI +"线程名"+Thread.currentThread().getName());//线程名有多少个,CPU就创建了多少个线程});}}
}
3.newSingleThreadExecuto:创建单个线程的线程池
public class ThreadPool4 {public static void main(String[] args) {ExecutorService service= Executors.newSingleThreadExecutor();for (int i=0;i<5;i++){int finalI = i;service.submit(()->{System.out.println(finalI +"线程名"+Thread.currentThread().getName());//CPU只创建了1个线程,名称始终一样});}}
}
4.newSingleThreadScheduledExecutor:创建执行定时任务的单个线程的线程池
public class ThreadPool5 {public static void main(String[] args) {ScheduledExecutorService service= Executors.newSingleThreadScheduledExecutor();System.out.println("添加任务:"+ LocalDateTime.now());service.schedule(new Runnable() {@Overridepublic void run() {System.out.println("执行任务:"+LocalDateTime.now());}},3,TimeUnit.SECONDS);//推迟3秒执行任务}
}
讲一下threadlocal
ThreadLocal可以解释成线程的局部变量,也就是说一个ThreadLocal的变量只有当前自身线程可以访问,别的线程都访问不了,那么自然就避免了线程竞争。
使用:
创建一个ThreadLocal对象:
private ThreadLocal<Integer> localInt = new ThreadLocal<>();
上述代码创建一个localInt变量,由于ThreadLocal是一个泛型类,这里指定了localInt的类型为整数。
下面展示了如果设置和获取这个变量的值:
public int setAndGet(){localInt.set(8);return localInt.get();
}
上述代码设置变量的值为8,接着取得这个值。
由于ThreadLocal里设置的值,只有当前线程自己看得见,这意味着你不可能通过其他线程为它初始化值。为了弥补这一点,ThreadLocal提供了一个withInitial()方法统一初始化所有线程的ThreadLocal的值:
private ThreadLocal<Integer> localInt = ThreadLocal.withInitial(() -> 6);
上述代码将ThreadLocal的初始值设置为6,这对全体线程都是可见的。
hashmap底层是如何实现的
hashmap定义:
HashMap是用数组+单链表+红黑树实现的map类。同时它的数组的默认初始容量是 16、扩容因子为 0.75,每次采用 2 倍的扩容。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。
HashMap的存储过程:
HashMap 将将要存储的值按照 key 计算其对应的数组下标,如果对应的数组下标的位置上是没有元素的,那么就将存储的元素存放上去,但是如果该位置上已经存在元素了,那么这就需要用到我们上面所说的链表存储了,将数据按照链表的存储顺序依次向下存储就可以了。
当链表长度大于 8 时,我们会对链表进行“树化”操作,将其转换成一颗红黑树。
但是要注意只有当链表的长度小于 6 的时候,我们才会将红黑树重新转化为链表,这个过程就叫做“链化”。
散列表相关的知识?
散列表(hash table),我们平时叫它哈希表。散列表是根据关键码值(Key value)而直接进行访问的数据结构。
散列函数本质就是一个函数,我们把它定义为 hash(key),key 就是元素的键值,通过 hash 函数得到的值就是散列值。
散列函数的要求
1.散列函数不能太复杂,太复杂肯定会消耗更多的时间,从而影响散列表的性能。
2.散列函数得到的散列值尽可能随机且均匀分布,这样才能减少散列冲突,即使有冲突,每个位置对应的元素也会比较平均,不会有的特别多,而有的特别少的情况。
我们在构造哈希表的时候不可避免的会产生哈希冲突,我们有两种方法去解决这个问题:
1.开放寻址法
开发寻址法就是但我们遇到了哈希冲突,我们就重新探索一个空闲位置,然后插入。常见的开放寻址法有线性探测,二次探索
2.链表法
链表法是一种更为常用的解决散列冲突的方法,比开放寻址法更加简单。在散列表中每个下标位置对应一个链表,所有经过散列函数得到的散列值相同的元素,我们都放到对应下标位置的链表中。
如何确定两个对象是不是相同的
使用equal,equal默认情况下与==功能相同,会去比较两个对象的地址是否相同,我们可以通过重写的方式实现对象的比较
讲一下设计模式中的工厂模式以及观察者模式
简单工厂模式
工厂模式有一种非常形象的描述,建立对象的类就如一个工厂,而需要被建立的对象就是一个个产品;在工厂中加工产品,使用产品的人,不用在乎产品是如何生产出来的。从软件开发的角度来说,这样就有效的降低了模块之间的耦合。
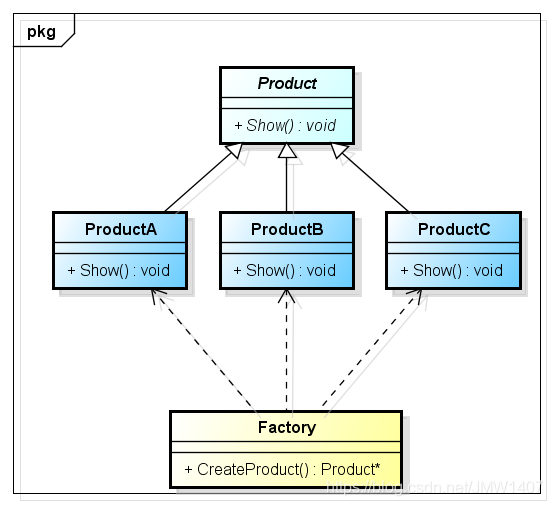
工厂模式
定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
具体过程:创建一个接口;创建实现接口的实体类;创建一个工厂,生成基于给定信息的实体类的对象;使用该工厂,通过传递类型信息来创建相应的工厂并且实体类的对象;
抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式。与工厂方法不同,奔驰的工厂不只是生产具体的某一个产品,而是一族产品
工厂模式的区别
- 简单工厂 : 使用一个工厂对象用来生产同一等级结构中的任意产品。(不支持拓展增加产品)
- 工厂方法 : 使用多个工厂对象用来生产同一等级结构中对应的固定产品。(支持拓展增加产品)
- 抽象工厂 : 使用多个工厂对象用来生产不同产品族的全部产品。(不支持拓展增加产品;支持增加产品族)
观察者模式
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
例如:拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。redis 哨兵模式监督主节点
作者:肖宜
链接:阿里一面面经_牛客网
来源:牛客网
相关文章:
阿里后端实习一面面经
阿里后端实习一面面经 项目中使用到了es,es的作用? elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容 es中的重要概念? 群集:一个或多个节点…...
element-ui组件DatePicker日期选择器移动端兼容
element-ui组件DatePicker日期选择器移动端兼容 css /** 移动端展示 **/ media screen and (max-width: 500px) {.el-picker-panel__sidebar {width: 100%;}.el-picker-panel {width: 400px!important;}.el-picker-panel__content {width: 100%;}.el-picker-panel__body{marg…...
burpsuite 爆破
靶场搭建:phpstudy的安装与靶场搭建 - junlin623 - 博客园 (cnblogs.com) 账号字典:XXTK: 一些弱口令、fuzz字典 (gitee.com) 网盘链接:https://pan.baidu.com/s/1v5pAwaTwoeCnJgkUXf3iLQ?pwd=mllm 提取码:mllm --来自百度网盘超级会员V2的分享 一、暴力破解 - 基于…...

SparkSQL基础解析(三)
1、 Spark SQL概述 1.1什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和 DataSet,并且作为分布式SQL查询引擎的作用。 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提…...
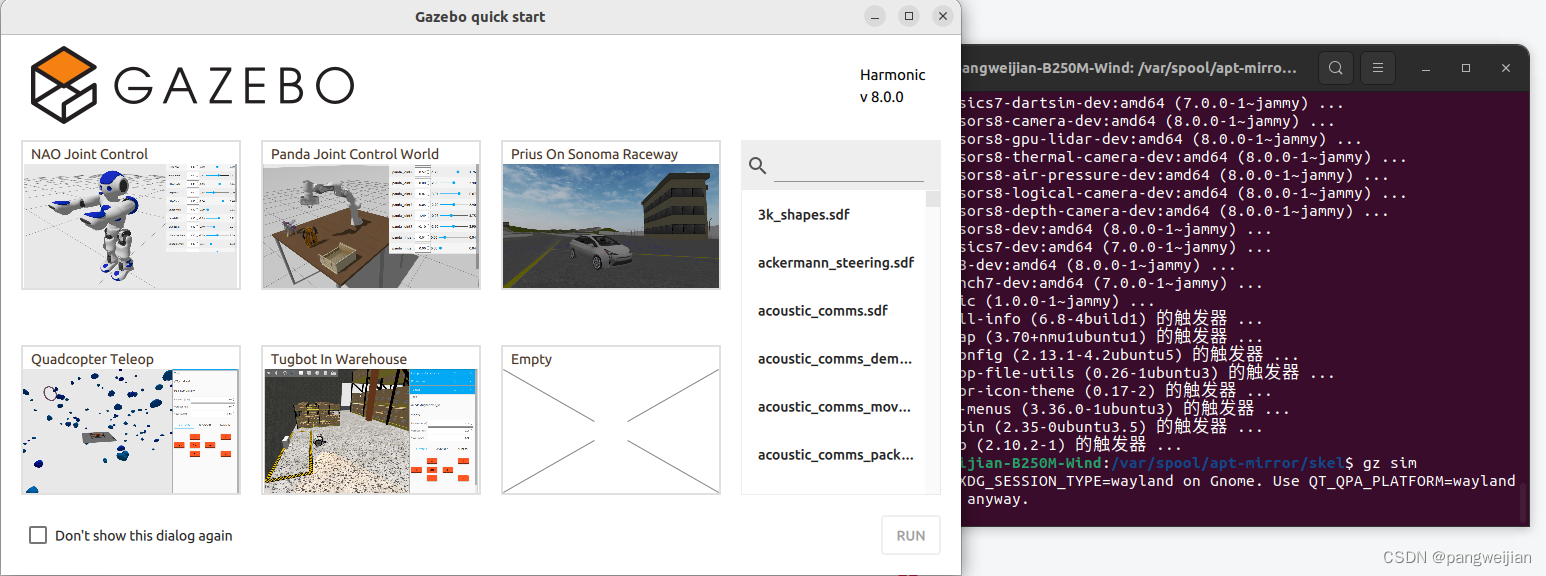
gz-hamonic 安装提示缺少许多依赖无法安装
在软件更新源中增加gz-hamonic的软件源, 点击添加,在输入框中填入如下语句: deb http://packages.osrfoundation.org/ubuntu jammy main 如图所示: 然后执行 sudo apt -get install gz-hamonic即可安装。 如下图 在终端中输入…...

新版Edge卸载
新版Edge卸载:步骤与注意事项 随着Windows 10的发布,微软推出了新版Edge浏览器。虽然新版Edge浏览器具有许多优秀的新功能和改进,但有时您可能希望卸载它并使用其他浏览器。在本文中,我们将向您介绍如何卸载新版Edge浏览器&#…...

Ansibe自动化基础
目录 一.Ansibe自动化概述 1.特点 2.工作特性 3.应用场合 二.ansibe安装即相关文件说明 1.安装 2.相关文件 3.主配置文件内容详解 4.ansibe运行机制 三.ansibe管理节点命令 1.Ansibe 四.主机组配置 1.基本配置 第一种: 第二种: 2.设置SSH…...
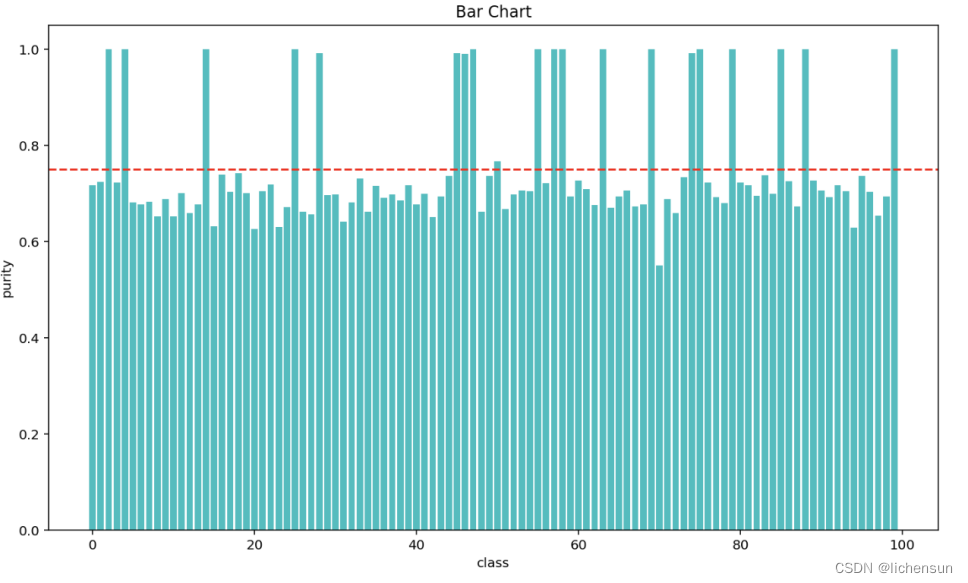
2023 年中国高校大数据挑战赛赛题B DNA 存储中的序列聚类与比对-解析与参考代码
题目背景:目前往往需要对测序后的序列进行聚类与比对。其中聚类指的是将测序序列聚类以判断原始序列有多少条,聚类后相同类的序列定义为一个簇。比对则是指在聚类基础上对一个簇内的序列进行比对进而输出一条最有 可能的正确序列。通过聚类与比对将会极大…...

决策树--分类决策树
1、介绍 ① 定义 分类决策树通过树形结构来模拟决策过程,决策树由结点和有向边组成。结点有两种类型:内部结 点和叶结点。内部结点表示一个特征或属性,叶子节点表示一个类。 ② 生成过程 用决策树分类,从根结点开始ÿ…...

【2024/1/5】
2024/1/5周报 本周开展工作下周工作计划 本周开展工作 首先的话就是跟大家汇报一下上一个项目的进度,那因为一些我这边的不可控的因素暂时进行搁置,随后的话还是需要在进行做的。 因此我们最近在做一个web端的项目,这个项目的具体的就不汇报…...
CNN——VGG
1.VGG简介 论文下载地址:https://arxiv.org/pdf/1409.1556.pdf VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军ÿ…...

深入理解Java中的多线程编程与并发控制
当谈论到 Java 编程语言时,多线程编程和并发控制是其中最重要的话题之一。Java 在多线程领域有着强大的支持和丰富的工具集,允许开发人员利用并发性来提高程序性能和效率。本文将深入探讨 Java 中的多线程编程和并发控制,包括线程的创建、同步…...

提供10个mysql的实例和思路
学生信息管理系统 学生表(id, name, gender, age, class_id)班级表(id, name)思路:通过学生表和班级表进行关联,可以实现学生信息的查询、添加、修改、删除等操作。 订单管理系统 订单表(id, us…...
FPGA项目(14)——基于FPGA的数字秒表设计
1.功能设计 设计内容及要求: 1.秒表最大计时范围为99分59. 99秒 2.6位数码管显示,分辨率为0.01秒 3.具有清零、启动计时、暂停及继续计时等功能 4.控制操作按键不超过二个。 2.设计思路 所采用的时钟为50M,先对时钟进行分频,得到100HZ频率…...
)
浅谈指数移动平均(ema)
经常在各种代码中看到指数移动平均(比如我专注的网络传输领域),但却不曾想到它就是诠释世界的方法,我们每个人都在被这种方式 “平均”… 今天说说指数移动平均(或移动指数平均,Exponential Moving Average)。 能查到的资料都侧重于其数学形…...

1-并发编程线程基础
什么是线程 在讨论什么是线程前有必要先说下什么是进程,因为线程是进程中的一个实体,线程本身是不会独立存在的。 进程是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,线程则是进程的一个执行路径&#…...
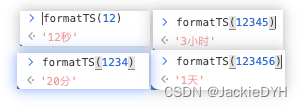
vue中动态出来返回的时间秒数,在多少范围显示多少秒,多少范围显示分,小时等等
在Vue中,你可以使用计算属性(computed property)或过滤器(filter)来根据动态返回的时间秒数来显示不同的时间单位,比如秒、分、小时等等。 下面是一个使用计算属性的示例: <template>&l…...

English: go through customs
文章目录 常见单词机场指示登机和中转降落以及公共服务签证篇出/入境卡篇入境英语会话篇 常见单词 customs: 海关 (kʌstəmz)cash: 现金 (kʃ)passport: 护照 (pspɔːt)luggage/baggage: 行李 (lʌɡɪdʒ/ˈbɡɪdʒ)Exchange: 换钱 (ɪks’tʃeɪndʒ)airport: 飞机场 (ɛ…...
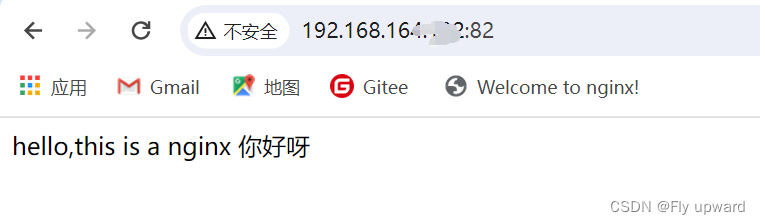
Nginx 多端口部署多站点
目录 1.进行nginx.conf 2.复制粘贴 3.修改端口及站点根目录 4. 网站上传 1.进行nginx.conf 在 nginx 主要配置文件 nginx.conf 中,server 是负责一个网站配置的,我们想要多个端口访问的话,可以复制多个 server 先进入到 nginx.conf 中 …...
从零开始配置kali2023环境:配置jupyter的多内核环境
在kali2023上面尝试用anaconda3,anaconda2安装实现配置jupyter的多内核环境时出现各种问题,现在可以通过镜像方式解决 1. 搜索镜像 ┌──(holyeyes㉿kali2023)-[~] └─$ sudo docker search anaconda ┌──(holyeyes㉿kali2023)-[~] └─$ sudo …...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...