MR实战:网址去重
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、创建Maven项目
- 2、添加相关依赖
- 3、创建日志属性文件
- 4、创建网址去重映射器类
- 5、创建网址去重归并器类
- 6、创建网址去重统计驱动器类
- 7、启动应用,查看结果
- 四、实战总结
一、实战概述
-
本实战项目主要利用Hadoop MapReduce框架对多个文本文件中的IP地址进行整合并去除重复项。首先,在虚拟机上创建了三个包含IP地址列表的文本文件(ips01.txt、ips02.txt、ips03.txt),并将这些文件上传至HDFS上的/deduplicate/input目录作为原始数据。
-
接着,通过IntelliJ IDEA创建了一个Maven项目MRDeduplicateIPs,并添加了hadoop-client和junit相关依赖。在项目中定义了三个关键类:DeduplicateIPsMapper、DeduplicateIPsReducer和DeduplicateIPsDriver。
-
DeduplicateIPsMapper类作为Map阶段的处理单元,读取每行输入文本数据(表示一个IP地址),将IP地址作为新的键输出,并使用NullWritable类型的空值,以准备后续去重操作。
-
DeduplicateIPsReducer类则负责Reduce阶段的逻辑,它接收Mapper阶段输出的所有具有相同IP地址的键值对,并通过不遍历值迭代器的方式实现键(即IP地址)的去重,确保每个唯一IP地址仅被写入一次。
-
最后,DeduplicateIPsDriver类作为整个任务的驱动程序,负责配置和启动MapReduce作业。它设置了作业的输入与输出路径、Mapper和Reducer类,以及它们的键值类型。作业完成后,该类会遍历输出目录下的文件,读取并打印去重后的IP地址列表到控制台。
-
通过运行DeduplicateIPsDriver类启动应用,最终实现了从多个文本文件中提取并整合出一份仅包含唯一IP地址的结果集。
二、提出任务
- 三个包含IP地址列表的文本文件(ips01.txt、ips02.txt、ips03.txt)
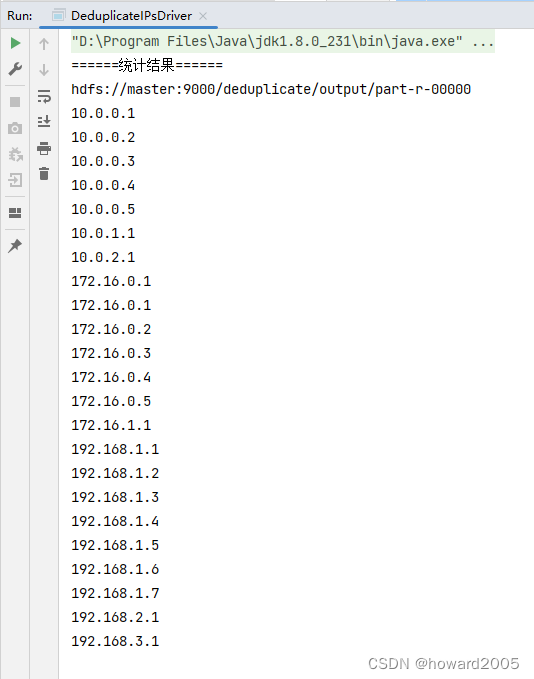
- ips01.txt
192.168.1.1
172.16.0.1
10.0.0.1
192.168.1.2
192.168.1.3
172.16.0.2
10.0.0.2
192.168.1.1
172.16.0.1
10.0.0.3
- ips02.txt
192.168.1.4
172.16.0.3
10.0.0.4
192.168.1.5
192.168.2.1
172.16.0.4
10.0.1.1
192.168.1.1
172.16.0.1
10.0.0.1
- ips03.txt
192.168.1.6
172.16.1.1
10.0.2.1
192.168.1.7
192.168.3.1
172.16.0.5
10.0.0.5
192.168.1.1
172.16.0.1
10.0.0.3
- 使用MR框架,实现网址去重
三、完成任务
(一)准备数据
1、在虚拟机上创建文本文件
- 在master虚拟机上使用文本编辑器创建三个文件:
ips01.txt,ips02.txt,ips03.txt,并确保每个文件内存储的是纯文本格式的IP地址列表。
2、上传文件到HDFS指定目录
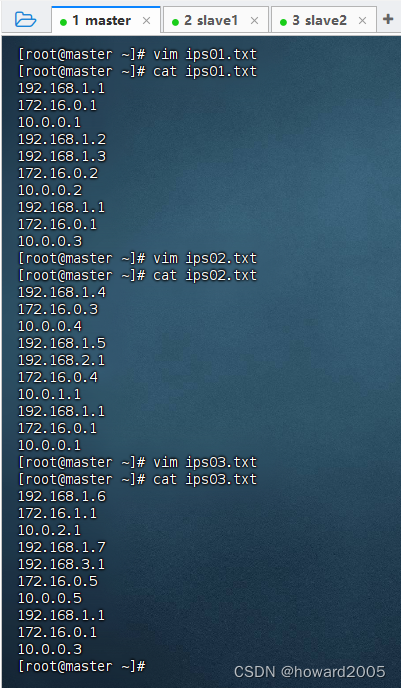
- 在master虚拟机上创建HDFS上的
/deduplicate/input目录,用于存放待处理的原始数据文件。 - 执行命令:
hdfs dfs -mkdir -p /deduplicate/input
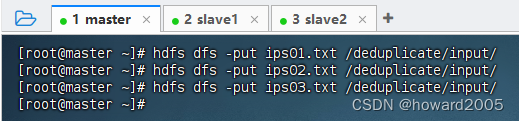
- 将本地创建的三个文本文件上传至HDFS的
/deduplicate/input目录hdfs dfs -put ips01.txt /deduplicate/input/ hdfs dfs -put ips02.txt /deduplicate/input/ hdfs dfs -put ips03.txt /deduplicate/input/ - 执行上述命令
(二)实现步骤
- 说明:集成开发环境IntelliJ IDEA版本 -
2022.3
1、创建Maven项目
-
Maven项目 -
MRDeduplicateIPs,设置了JDK版本 -1.8,组标识 -net.huawei.mr
-
单击【Create】按钮,得到初始化项目
2、添加相关依赖
- 在
pom.xml文件里添加hadoop-client和junit依赖
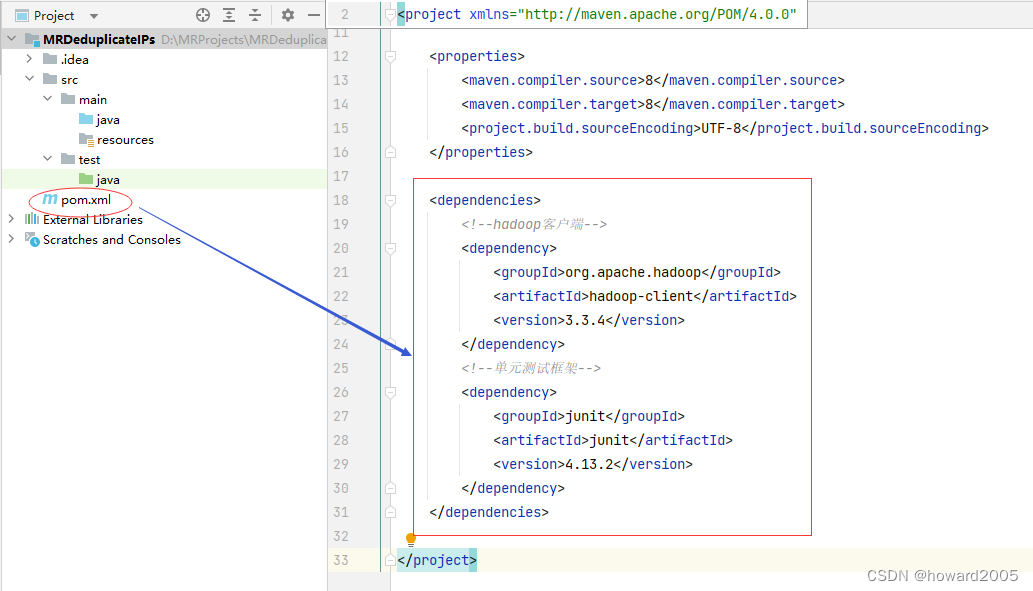
<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
- 刷新项目依赖
3、创建日志属性文件
- 在
resources目录里创建log4j.properties文件
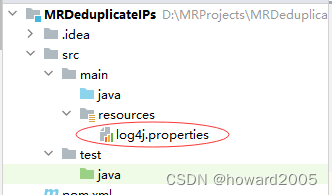
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/deduplicateips.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、创建网址去重映射器类
- 创建
net.huawei.mr包,在包里创建DeduplicateIPsMapper类
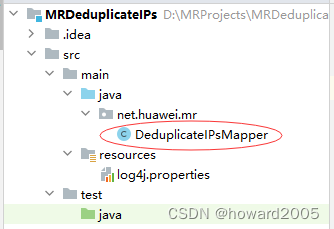
package net.huawei.mr;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 功能:网址去重映射器类* 作者:华卫* 日期:2024年01月05日*/
public class DeduplicateIPsMapper extends Mapper<LongWritable, Text, Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 获取行内容String ip = value.toString();// 将<ip,null>键值对写入中间结果context.write(new Text(ip), NullWritable.get());}
}
-
这段代码是Hadoop MapReduce编程框架中的一个Mapper类实现,名为
DeduplicateIPsMapper,用于处理URL去重问题。虽然注释中提到的是“网址去重”,但实际代码逻辑仅针对IP地址进行操作。 -
在Map阶段,该类继承自
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, NullWritable> -
输入键类型为
LongWritable,通常表示文本行号; -
输入值类型为
Text,存储一行原始数据(在这里应是IP地址); -
输出键类型为
Text,用于输出去重后的IP地址; -
输出值类型为
NullWritable,由于此处仅需去重并不需要具体值,所以使用空值。 -
map()方法是Mapper的主体逻辑部分,在每次调用时接收一行输入数据(键和值)。它首先将输入值(即每行文本内容)转换成字符串类型的IP地址,然后将这个IP地址作为新的键输出,并与NullWritable类型的空值一起写入到中间结果中。通过这种方式,Map阶段结束后,相同的IP地址会被归并到一起,以便后续Reducer阶段进一步处理以达到去重的目的。
5、创建网址去重归并器类
- 在
net.huawei.mr包里创建DeduplicateIPsReducer
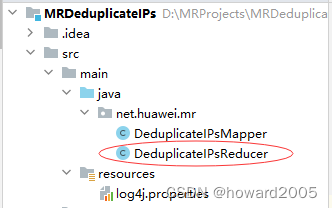
package net.huawei.mr;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** 功能:网址去重归并器类* 作者:华卫* 日期:2024年01月05日*/
public class DeduplicateIPsReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {// 不遍历值迭代器,就可以实现键去重context.write(key, NullWritable.get()); }
}
-
这段代码是Hadoop MapReduce编程框架中的一个Reducer类实现,名为
DeduplicateIPsReducer,用于处理URL去重问题。尽管注释中提到的是“网址去重”,但实际代码逻辑只针对IP地址进行操作。 -
在Reduce阶段,该类继承自
org.apache.hadoop.mapreduce.Reducer<Text, NullWritable, Text, NullWritable> -
输入键类型为
Text,存储Map阶段输出的去重后的IP地址; -
输入值类型为
Iterable<NullWritable>,由于Mapper阶段输出的值为NullWritable,因此这里接收一组空值; -
输出键类型仍为
Text,保持与Mapper阶段一致,输出去重后的唯一IP地址; -
输出值类型也仍为
NullWritable,表示在这个任务中我们仅关注IP地址的去重,不需要额外信息。 -
reduce()方法是Reducer的核心逻辑部分,在此场景下,当多个相同的IP地址(键)被归并到一起时,无需遍历值迭代器(因为所有值都是NullWritable的空值),只需将接收到的每个唯一的IP地址作为键输出即可,从而达到去除重复IP的目的。通过这种方式,Reduce阶段结束后,输出结果中每个IP地址都只出现一次。
6、创建网址去重统计驱动器类
- 在
net.huawei.mr包里,创建DeduplicateIPsDriver类
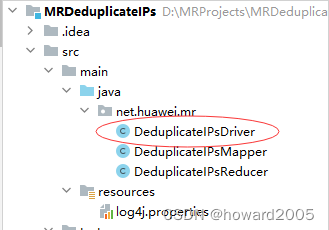
package net.huawei.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 功能:网址去重驱动器类* 作者:华卫* 日期:2024年01月05日*/
public class DeduplicateIPsDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置客户端使用数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(DeduplicateIPsDriver.class);// 设置Mapper类job.setMapperClass(DeduplicateIPsMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(NullWritable.class);// 设置Reducer类job.setReducerClass(DeduplicateIPsReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(Text.class);// 设置reduce任务输出值类型job.setOutputValueClass(NullWritable.class);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/deduplicate/input");// 创建输出目录Path outputPath = new Path(uri + "/deduplicate/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
- 这段代码是Hadoop MapReduce框架下的一个驱动器类(Driver)实现,名为
DeduplicateIPsDriver,用于处理URL去重问题。它主要负责设置MapReduce作业的相关配置信息,并启动整个作业流程。
-
首先创建一个Hadoop Configuration对象并设置相关属性,如“dfs.client.use.datanode.hostname”,以便正确连接到HDFS数据节点。
-
初始化Job实例,并通过
job.setJarByClass()方法指定作业的主类(即该驱动器类),使得Hadoop能够找到运行作业所需的JAR包。 -
设置作业的Mapper和Reducer类分别为
DeduplicateIPsMapper和DeduplicateIPsReducer,同时设定它们的输入输出键值类型。 -
定义HDFS上输入与输出目录的URI路径,并使用FileSystem API获取文件系统实例,删除预先存在的输出目录以确保每次运行时结果都是新的。
-
将输入目录添加到作业中,设置唯一的输出目录。
-
调用
job.waitForCompletion(true)方法启动并等待作业完成。 -
作业完成后,遍历输出目录下的所有文件(除成功标志文件外),打开每个文件并将其内容读取并打印到控制台,从而展示去重后的结果。
- 总之,此驱动器类将配置、初始化及执行一个完整的MapReduce作业,该作业的主要功能是对存储在HDFS上的IP地址进行去重处理。
7、启动应用,查看结果
- 运行
DeduplicateIPsDriver类,查看结果
四、实战总结
- 本实战项目利用Hadoop MapReduce框架,通过自定义的DeduplicateIPsMapper和DeduplicateIPsReducer类处理三个文本文件中的IP地址数据。Mapper阶段读取每行IP并作为键输出,Reducer阶段对相同键(IP)进行归并去重。在DeduplicateIPsDriver驱动类中配置了作业属性、输入输出路径以及Map和Reduce阶段所使用的类,并成功执行了任务。最终,从原始文本数据中提取出一份不重复的IP地址集合。整个过程展示了MapReduce框架高效处理大规模数据集及实现特定业务逻辑的能力。
相关文章:
MR实战:网址去重
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、创建Maven项目2、添加相关依赖3、创建日志属性文件4、创建网址去重映射器类5、创建网址去重归并…...

linux 内核编译安装
一、配置 默认配置 make ARCHarm CROSS_COMPILEarm-linux-gnueabihf- omap2plus_defconfig原配置 make ARCHarm CROSS_COMPILEarm-linux-gnueabihf- oldconfig 重新配置 make ARCHarm CROSS_COMPILEarm-linux-gnueabihf- menuconfig二 kernel zImage make ARCHarm CRO…...
)
hash基础知识(算法村第五关青铜挑战)
一、Hash的概念和基本特征 哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。 二、碰撞处理方法(2种) 在上面的例子中,我们发现有些在Hsh中很多位置可能要存两个甚…...
Linux第8步_USB设置
学习完设置“虚拟机的电源”后,接着学习通过鼠标点击操作U盘,目的是了解USB设置。 1、在桌面,双击“VMware Workstation Pro”图标,得到下图: 2、点击“编辑虚拟机”,得到下图: 只要点击编辑虚…...

第五节 强制规范commit提交 .husky/commit-msg: no-such file or directory问题解决办法
系列文章目录 目录 系列文章目录 前言 操作方法 总结 前言 在每次Git提交时,强制严格执行制定的规范。 操作方法 npm 安装commitlist 进行校验 npm install --save-dev @commitlint/config-conventional@12.1.4 @commitlint/cli@12...
2024年了,难道还不会使用谷歌DevTools么?
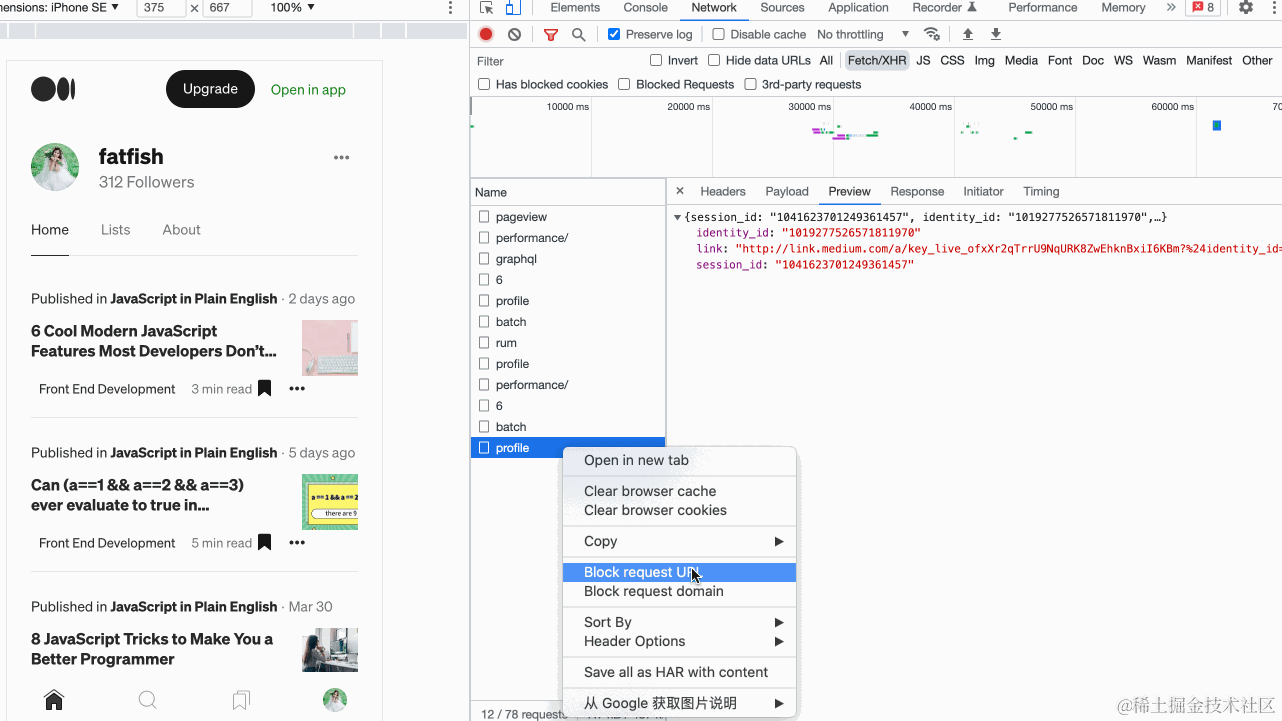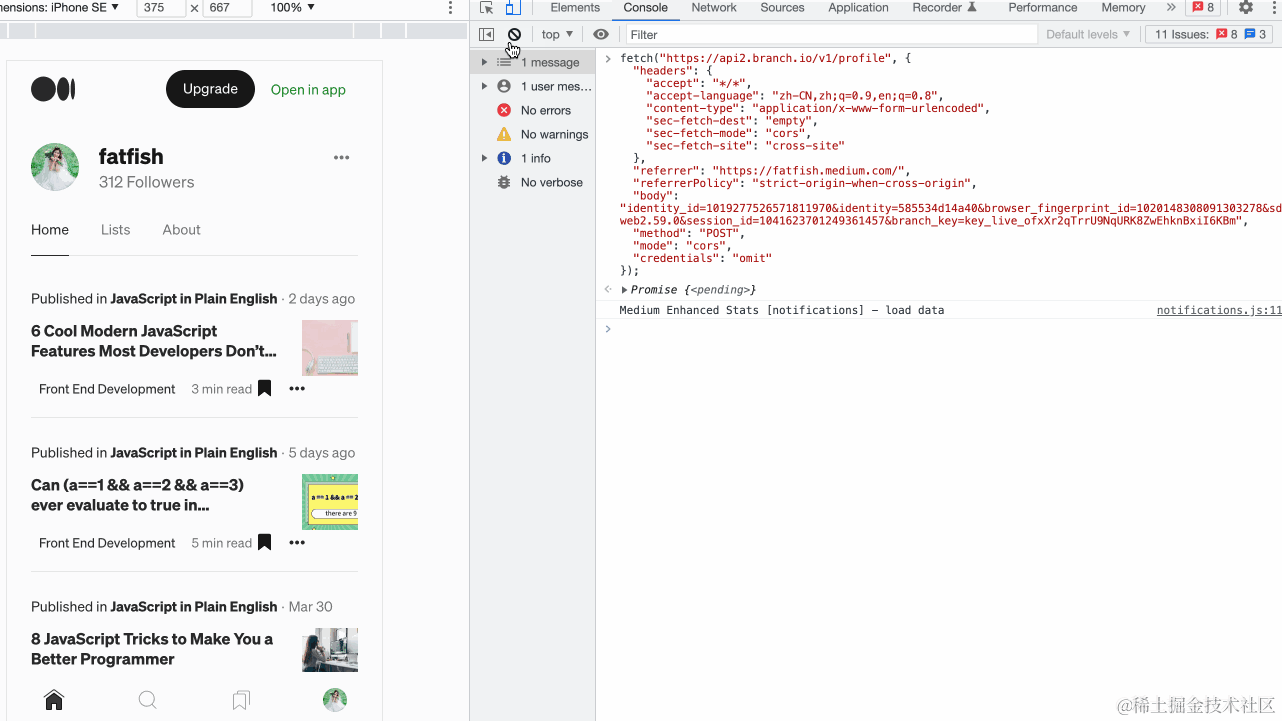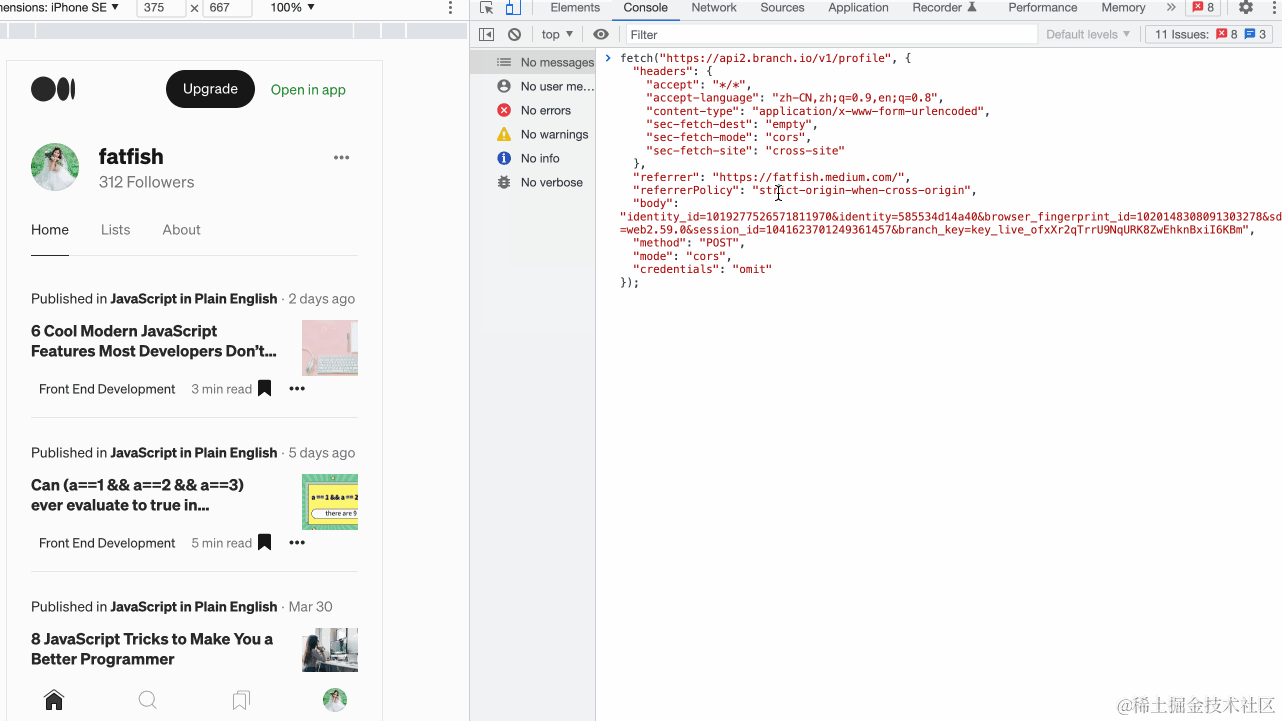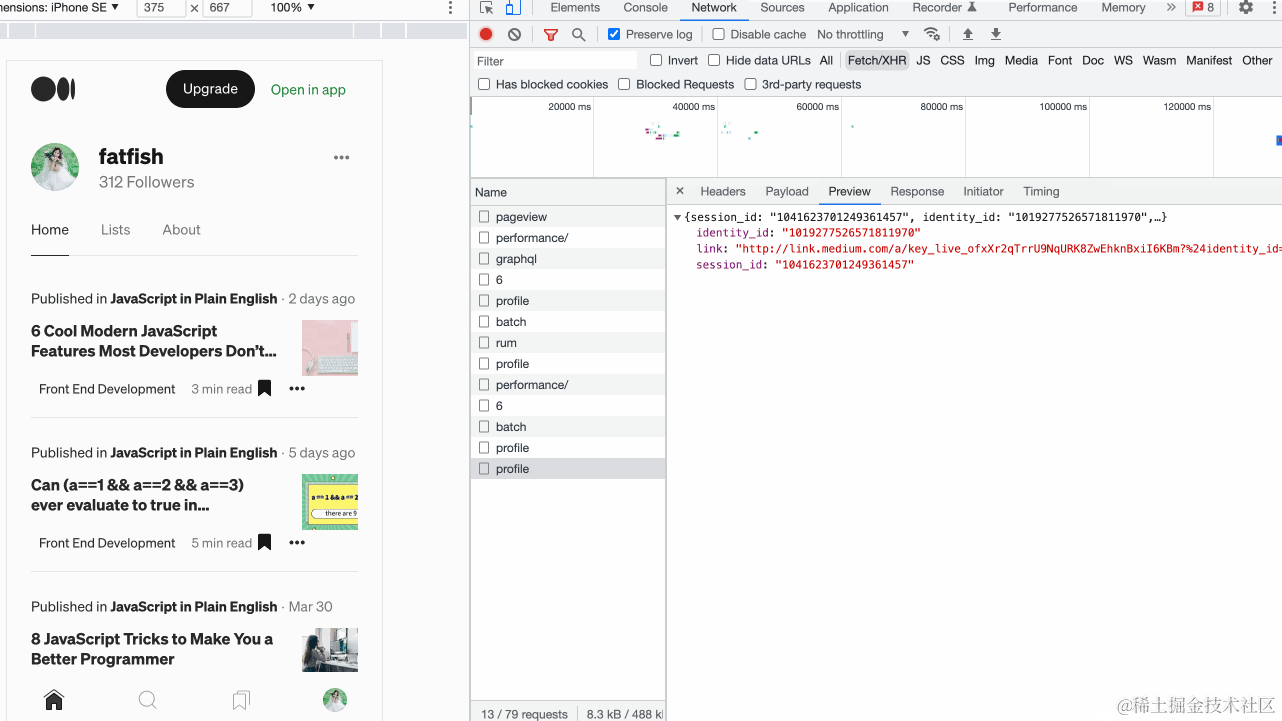
我相信您一定对Chrome浏览器非常熟悉,因为它是前端开发者最亲密的伙伴。我们可以使用它查看网络请求、分析网页性能以及调试最新的JavaScript功能。 除此之外,它还提供了许多功能强大但不常见的功能,这些功能可以大大提高我们的开发效率。 让我们来看看。 1. 重新发送XHR…...

springboot(ssm生产管理ERP系统 wms出入库管理系统Java系统
springboot(ssm生产管理ERP系统 wms出入库管理系统Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0)…...
通过使用别名让 SQL 更简短-数据库教程shulanxt.com-帆软软件有限公司
MySQL视频教程导航 https://www.shulanxt.com/database/mysqlvideo/p1 SQL 别名 SQL 别名 通过使用 SQL,可以为表名称或列名称指定别名。 基本上,创建别名是为了让列名称的可读性更强。 列的 SQL 别名语法 SELECT column_name AS alias_name FROM …...

最优化理论分析复习--最优性条件(一)
文章目录 上一篇无约束问题的极值条件约束极值问题的最优性条件基本概念只有不等式约束时 下一篇 上一篇 最优化理论复习–对偶单纯形方法及灵敏度分析 无约束问题的极值条件 由于是拓展到向量空间 R n R^n Rn, 所以可由高数中的极值条件进行类比 一阶必要条件 设函数 f (…...

基于WIFI指纹的室内定位算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1WIFI指纹定位原理 4.2 指纹数据库建立 4.3定位 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 .....................................…...
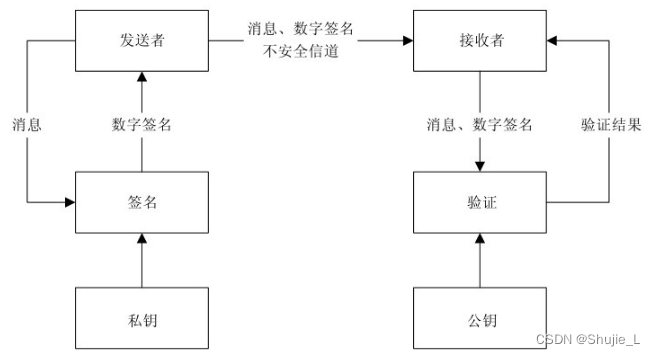
密码学:一文读懂非对称密码体制
文章目录 前言非对称密码体制的保密通信模型私钥加密-公钥解密的保密通信模型公钥加密-私钥解密的保密通信模型 复合式的非对称密码系统散列函数数字签名数字签名满足的三个基本要求先加密还是先签名?数字签名成为公钥基础设施以及许多网络安全机制的基础什么是单向…...
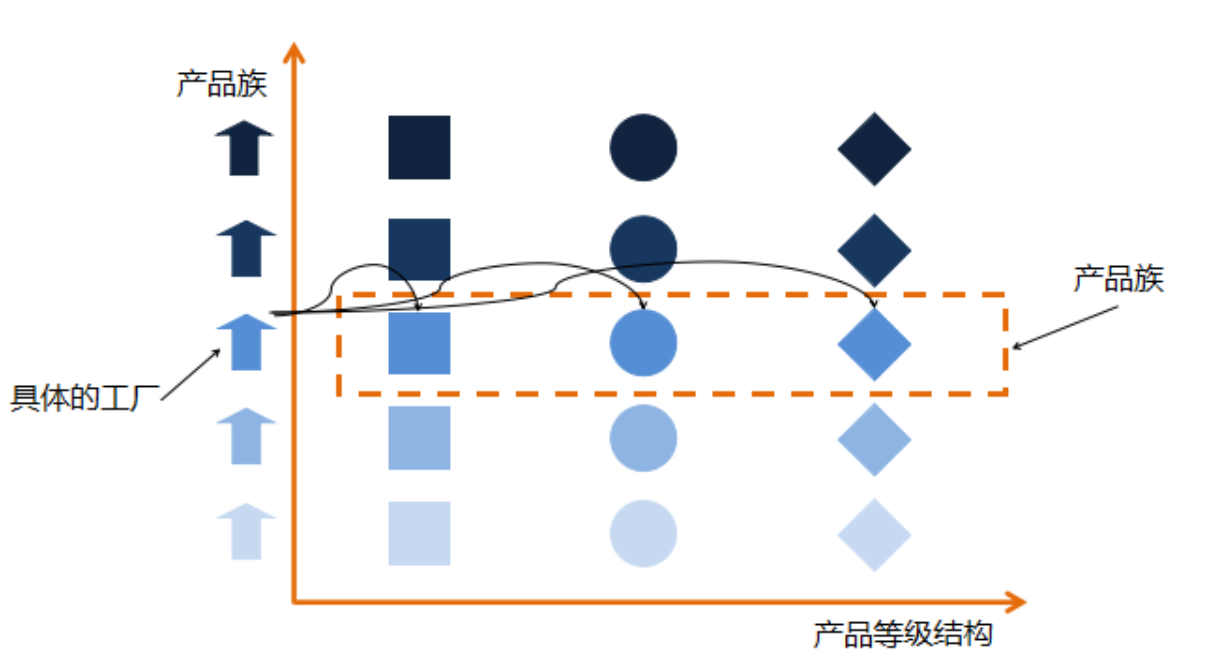
2_工厂设计_工厂方法和抽象工厂
工厂设计模式-工厂方法 1.概念 工厂方法模式(Fatory Method Pattern ) 是指定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类,工厂方法让类的实例化推迟到子类中进行。 在工厂方法模式中用户只需要关心所需产品对应的工厂,…...

k8s之pod进阶
1.k8s的pod重启策略 Always :不论正常退出还是非正常退出都重启deployment的yaml文件只能是always pod的yaml三种模式都可以。 OnFailure:只有状态码非0才会重启,正常退出不重启 Never:正常退出和非正常退出都不重启 容器的退…...
)
RTTI(运行时类型识别)
RTTI(运行时类型识别) 实验介绍 RTTI 全称 Run Time Type Identification,中文称为 “运行时类型识别”,在程序中使用 typeid 和 dynamic_cast 实现。RTTI 技术允许程序在运行时识别对象的类型。 知识点 typeiddynamic_castRTTI 技术typeid typeid 是 C++ 关键字,用于…...

19.Linux Shell任务控制
文章目录 Linux Shell任务控制1)信号通过键盘生成信号trap 命令捕获信号 2)在后台运行脚本命令后加 & 符使用nohub命令 3)作业控制4)调度优先级nice命令renice 命令 5)定时运行作业at定期执行命令reference 欢迎访问个人网络日志🌹🌹知行空间&#x…...

域名流量被劫持怎么办?如何避免域名流量劫持?
随着互联网不断发展,流量成为线上世界的巨大财富。然而一种叫做域名流量劫持的网络攻击,将会在不经授权的情况下控制或重定向一个域名的DNS记录,导致用户在访问一个网站时,被引导到另一个不相关的网站,从而劫持走原网站…...

java案例知识点
一.会话技术 概念 技术 二.跨域 三.过滤器 四.拦截器...

Arrays 的使用
Arrays 概述 提供了数组操作的相关方法,连接数组和集合 asList 返回指定数组的列表列表和数组的引用位置相同 Integer[] arrs new Integer[] {1,2,3,4,5,6,7,8,9};List<Integer> list Arrays.asList(arrs);System.out.println(list);arrs[5] 100;Syste…...
IDEA中怎么用Postman?这款插件你试试
Postman是大家最常用的API调试工具,那么有没有一种方法可以不用手动写入接口到Postman,即可进行接口调试操作?今天给大家推荐一款IDEA插件:Apipost Helper,写完代码就可以调试接口并一键生成接口文档!而且还…...
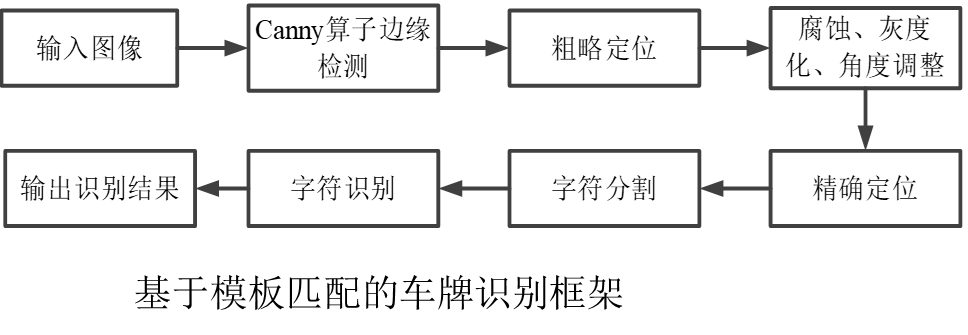
基于机器视觉的车牌检测-边缘检测因子的选择
车牌检测概述 车牌识别在检测报警、汽车出入登记、交通违法违章以及移动电子警察方面应用广泛。车牌识别过程为:首先通过摄像头获取包含车牌的彩色图像;然后进行车牌边缘检测,先粗略定位到车牌位置,再精细定位;最后根…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...