Phoenix基本使用
1、Phoenix简介
1.1 Phoenix定义
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
1.2 Phoenix特点
- 容易集成:如Spark,Hive,Pig,Flume和Map Reduce。
- 性能好:直接使用HBase API以及协处理器和自定义过滤器,可以为小型查询提供毫秒级的性能,或者为数千万行提供数秒的性能。
- 操作简单:DML命令以及通过DDL命令创建表和版本化增量更改。
- 安全功能: 支持GRANT和REVOKE 。
- 完美支持Hbase二级索引创建。
1.3 Phoenix架构
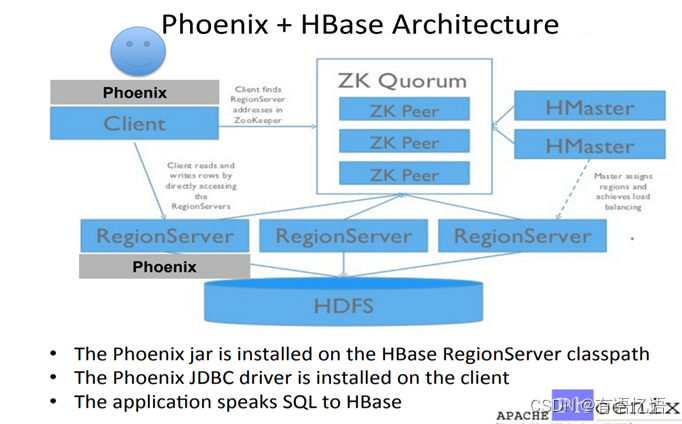
1.4 Phoenix的作用
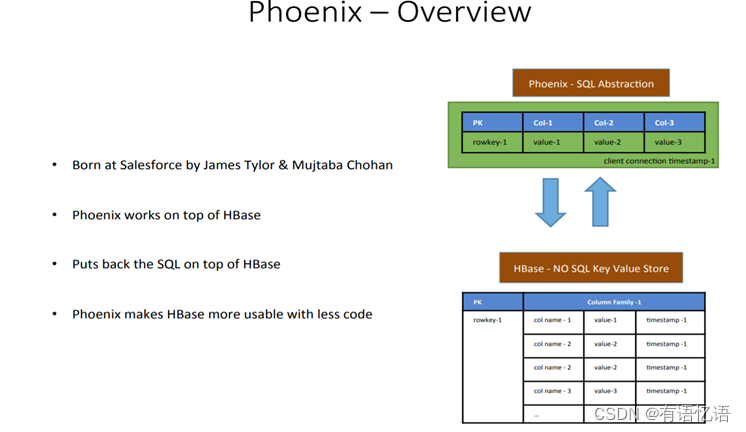
2、Phoenix快速入门
2.1 Phoenix安装部署
2.1.1官方网址: http://phoenix.apache.org/index.html
2.1.2 上传jar包到/opt/software/
解压到/opt/module 改名为phoenix
[ybb@hadoop101 module]$ tar -zxvf /opt/software/apache-phoenix-4.14.1-HBase-1.3-bin.tar.gz -C /opt/module [ybb@hadoop101 module]$ mv apache-phoenix-4.14.1-HBase-1.3-bin phoenix
2.1.3 复制server和client这俩个包拷贝到各个节点的hbase/lib
在phoenix目录下
[ybb@hadoop101 module]$ cd /opt/module/phoenix/
向每个节点发送server jar
[ybb@hadoop101 phoenix]$ cp phoenix-4.14.1-HBase-1.3-server.jar /opt/module/hbase-1.3.1/lib/
[ybb@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-server.jar hadoop102:/opt/module/hbase-1.3.1/lib/
[ybb@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-server.jar hadoop103:/opt/module/hbase-1.3.1/lib/向每个节点发送client jar
[ybb@hadoop101 phoenix]$ cp phoenix-4.14.1-HBase-1.3-client.jar /opt/module/hbase-1.3.1/lib/
[ybb@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-client.jar hadoop102:/opt/module/hbase-1.3.1/lib/
[ybb@hadoop101 phoenix]$ scp phoenix-4.14.1-HBase-1.3-client.jar hadoop103:/opt/module/hbase-1.3.1/lib/
2.1.4在root权限下给/etc/profile 下添加如下内容
#phoenixexport PHOENIX_HOME=/opt/module/phoenixexport PHOENIX_CLASSPATH=$PHOENIX_HOMEexport PATH=$PATH:$PHOENIX_HOME/bin
2.1.5启动Zookeeper,Hadoop,Hbase
2.1.6启动Phoenix
[ybb@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
2.2 phoenix表操作
2.2.1 显示所有表
!table 或 !tables
2.2.2 创建表
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
如下显示:

在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
2.2.3 插入记录
upsert into us_population values(‘NY’,‘NewYork’,8143197);
2.2.4 查询记录
select * from us_population ;
select * from us_population wherestate=‘NY’;
2.2.5 删除记录
delete from us_population wherestate=‘NY’;
2.2.6 删除表
drop table us_population;
2.2.7 退出命令行
!quit
2.3 phoenix表映射
2.3.1 Phoenix和Hbase表的关系
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的。如图1和图2,US_POPULATION是在phoenix中直接创建的,而kylin相关表是在hbase中直接创建的,在phoenix中是查看不到kylin等表的。

hbase命令行中查看所有表:

如果要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
2.3.2 Hbase命令行中创建表test
Hbase 中test的表结构如下,两个列簇name、company.

启动Hbase shell
[ybb@hadoop101 ~]$ /opt/module/hbase-1.3.1/bin/hbase shell
创建Hbase表test
hbase(main):001:0> create ‘test’,‘name’,‘company’
创建表,如下图:

2.3.3 视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。
在phoenix中创建视图test表
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create view "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
删除视图
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> drop view "test";
2.3.3 表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create table "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
2) 当HBase中不存在表时,可以直接使用create table指令创建需要的表,系统将会自动在Phoenix和HBase中创建person_infomation的表,并会根据指令内的参数对表结构进行初始化。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create table "test"(empid varchar primary key,"name"."firstname" varchar,"name"."lastname" varchar,"company"."name" varchar,"company"."address" varchar);
2.3.4 使用spark对phoenix的读写
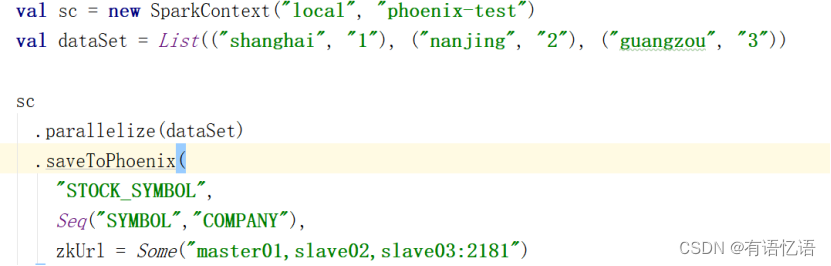
在Phoenix中查看数据
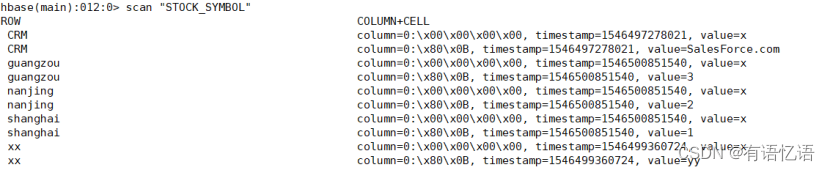
select * from STOCK_SYMBOL
如下显示:
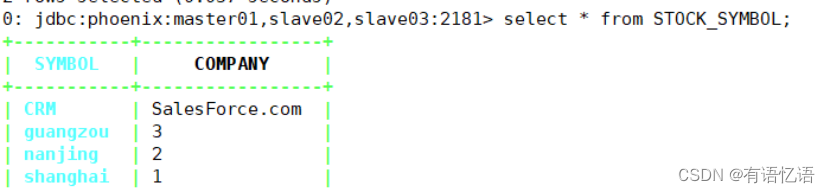
在Hbase中查看数据
scan “STOCK_SYMBOL”
更多使用详情,请参考http://phoenix.apache.org/phoenix_spark.html
2.3.5 视图映射和表映射的对比与总结:
相比于直接创建映射表,视图的查询效率会低,原因是:创建映射表的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
3、Phoenix创建Hbase二级索引
3.1 配置Hbase支持Phoenix创建二级索引
3.1.1 添加如下配置到Hbase的Hregionserver节点的hbase-site.xml
<!-- phoenix regionserver 配置参数 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property><property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property><property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>3.1.2 添加如下配置到Hbase中Hmaster节点的hbase-site.xml中
<!-- phoenix master 配置参数 -->
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property><property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>
3.1.3 常见问题汇总:
1)注意:网上配置文档里有这一条,但在实际测试中(测试环境hbase-1.3.1,网上0.98.6),加入该条的regionserver会在hbase启动时失败,对应节点上没有HregionServer进程,去掉该配置后正常启动,且能正常创建local index。
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>
2)hbase-site.xml的zookeeeper的配置信息不能加2181,否则在创建local index的时候会报以下异常:
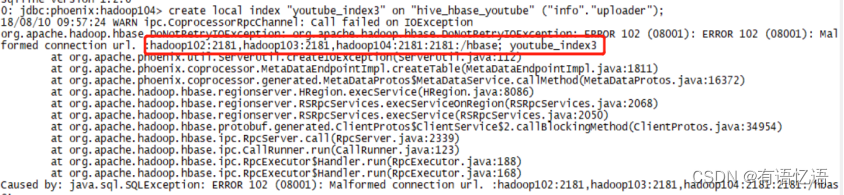
正常配置:
<property><name>hbase.zookeeper.quorum</name><value>hadoop101,hadoop102,hadoop103</value>
</property>
3.2创建索引
3.2.1 phoenix的索引分类
1)global index是默认的索引格式。适用于多读少写的业务场景。写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
CREATE INDEX my_index ON my_table (my_index)
2)Local index适用于写操作频繁的场景。索引数据和数据表的数据是存放在相同的服务器中的,避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升。
CREATE LOCAL INDEX my_index ON my_table (my_index)
3.2.2 三种提升效率查询方式
1) CREATE INDEX my_index ON my_table (v1) INCLUDE (v2)
2) SELECT /*+ INDEX(my_table my_index) */ v2 FROM my_table WHERE v1 = ‘foo’
3) CREATE LOCAL INDEX my_index ON my_table (v1)
3.2.3 如何删除索引
DROP INDEX my_index ON my_table
4、 Squirrel可视化连接Phoenix
4.1 下载Squirrel的jar包官方网址
http://squirrel-sql.sourceforge.net/
4.2 在Windows环境下安装Squirrel程序
- 选择Java方式打开安装
- 自定义安装目录
3) 一直Next到安装完成

4.3 配置Squirrel连接到Phoenix
1) 复制Phoenix的client.jar包到D:\work\squirrel\lib的lib下
2) 启动Squirrel
3) 配置Driver
4) 添加Driver具体配置信息

配置信息:
Name=Phoenix
Example URL = jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181
Java Class Path 选择D:\work\squirrel\lib\phoenix-4.14.1-HBase-1.3-client.jar
Class Name = org.apache.phoenix.jdbc.PhoenixDriver
5)配置Aliases

6)添加Aliases具体配置信息
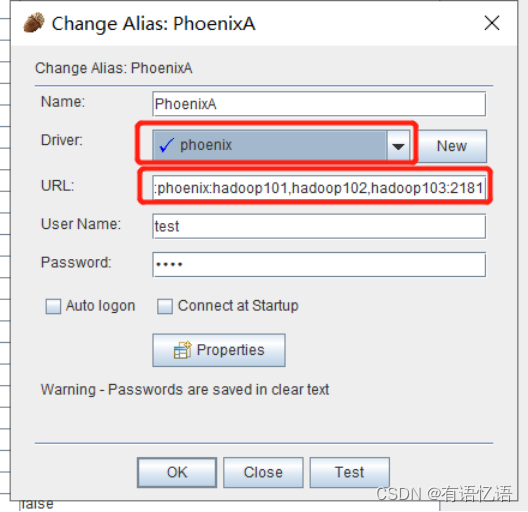
配置信息:
Name=任意
Driver选择刚才添加的Phoenix
URL= jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181
User Name = 任意
Password = 任意
7)测试连接是否成功

双击连接Phoenix
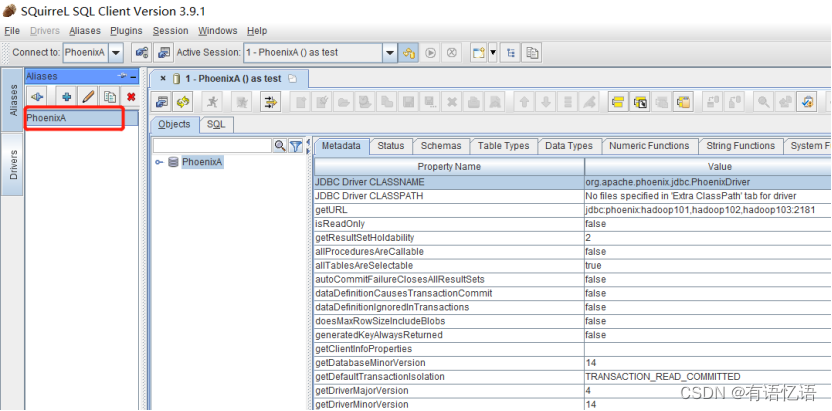
8)使用Squirrel查询数据

查询sql(WEB_STAT表要提前建好并导入数据)
[ybb@hadoop101 bin]$ psql.py …/examples/STOCK_SYMBOL.sql
[ybb@hadoop101 bin]$ psql.py …/examples/STOCK_SYMBOL.csv
select * from WEB_STAT;
相关文章:
Phoenix基本使用
1、Phoenix简介 1.1 Phoenix定义 Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。 1.2 Phoenix特点 容易集成:如Spark,Hive,Pig,Flume和Map Reduce。性能…...

31-35.玩转Linux操作系统
玩转Linux操作系统 说明:本文中对Linux命令的讲解都是基于名为CentOS的Linux发行版本,我自己使用的是阿里云服务器,系统版本为CentOS Linux release 7.6.1810。不同的Linux发行版本在Shell命令和工具程序上会有一些差别,但是这些差…...
windows下载官方正版notepad++
一、前言 notepad是一款非常好用的编辑器,简洁、快速、高效。可是很多时候我们想去官网下载时,百度出来的都是一堆第三方下载地址,捆绑流氓软件,要么就是付费,作为一款优秀开源软件,我们必须要知道正确的下…...

Jmeter+ant+jenkins持续集成
一、环境准备 1、 jdk环境 要求JDK1.8以上,命令行输入:java -version,出现如下提示说明安装成功。 2、 Jmeter环境 下载Jmeter最新版本,解压即可,添加bin目录到环境变量。 3、 Ant环境 设置ant环境变量࿰…...

利用邮件发送附件来实现一键巡检,附件是通过调用zabbix api生成的word和Excel
HTML部分: <!DOCTYPE html> <html> <head><title>自动巡检</title><!-- 加入CSS样式 --> </head> <body><form id"inspectionForm"><label for"email">邮箱地址:</label>&…...

Linux 常用指令汇总
Linux 常用指令汇总 文章目录 Linux 常用指令汇总[toc]前言一、文件目录指令pwd 指令ls 指令cd 指令mkdir 指令rmdir 指令tree 指令cp 指令rm 指令mv 指令cat 指令more 指令less 指令head 指令tail 指令echo 指令> 指令>> 指令 二、时间日期指令date 指令cal 指令 三、…...
)
SpringBoot 注解超全详解(整合超详细版本)
使用注解的优势: 采用纯java代码,不在需要配置繁杂的xml文件 在配置中也可享受面向对象带来的好处 类型安全对重构可以提供良好的支持 减少复杂配置文件的同时亦能享受到springIoC容器提供的功能 1注解详解(配备了完善的释义)…...
Redis:原理速成+项目实战——Redis实战9(秒杀优化)
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:Redis:原理速成项目实战——Redis实战8(基于Redis的分布式锁及优化) 📚订阅专栏&…...
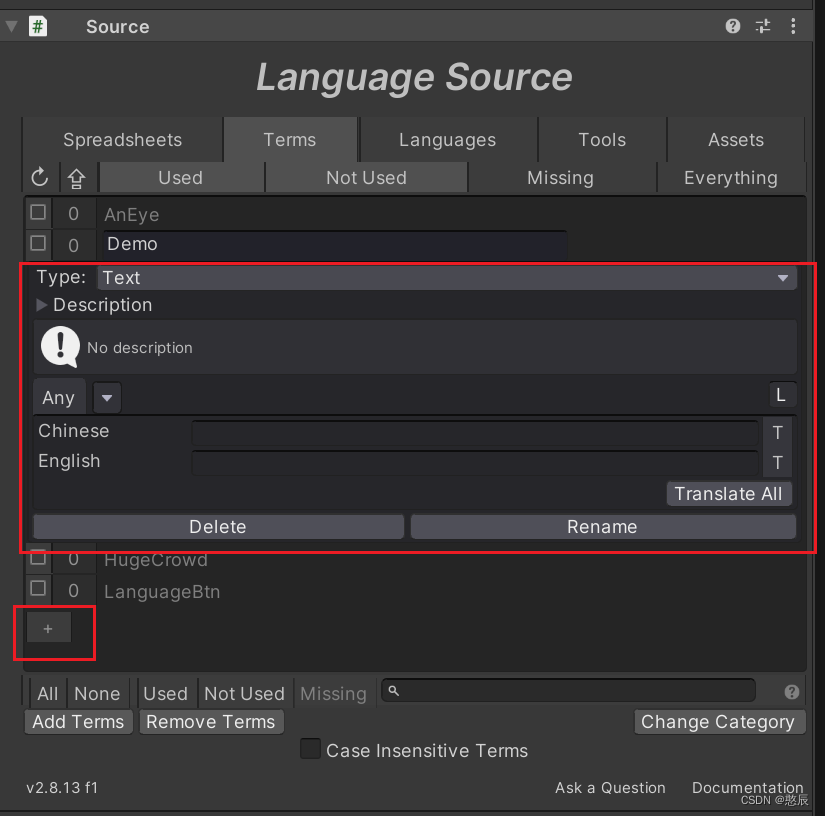
【I2多语言】多语言快速上手
简介 官方API:http://www.inter-illusion.com/assets/I2LocalizationManual/I2LocalizationManual.html意义:更改游戏语言(多语言支持) 快速上手 插件安装: 直接拖拽进Unity即可 创建语言源(Creating a …...
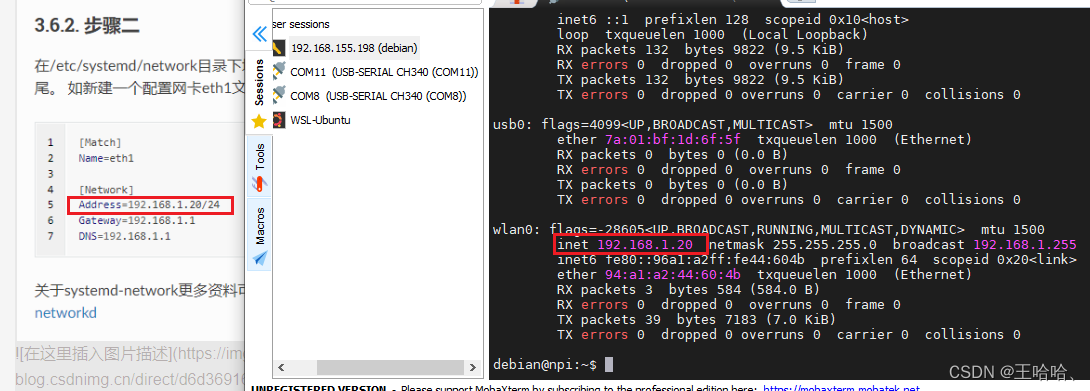
【野火i.MX6ULL开发板】开发板连接网络(WiFi)与 SSH 登录、上电自动登录、设置静态IP、板子默认参数
0、前言 参考之前自己写的: http://t.csdnimg.cn/g60P8 参考资料: [野火]《Linux基础与应用开发实战指南——基于i.MX6ULL开发板》_20230323 从野火官网下载 参考博客: http://t.csdnimg.cn/8uh4O 参考官方文档: https://doc.…...

【数据库原理】(10)数据定义功能
SQL 数据定义功能包括定义模式、定义表、定义索引和定义视图,其语句如表所示。 一.创建、删除模式 1.创建模式 (Create Schema) 用途:创建模式是为了在数据库中定义一个新的命名空间,它可以包含多个数据库对象。 语法: CREATE SCHEMA &…...
: The TLS connection was non-properly terminated.)
GnuTLS recv error (-110): The TLS connection was non-properly terminated.
bug 解决方案:参考 GnuTLS recv error (-110): The TLS connection was non-properly terminated. 解决方案: apt-get install gnutls-bin git config --global http.sslVerify false git config --global http.postBuffer 1048576000参考...

hive sql 和 spark sql的区别
Hive SQL 和 Spark SQL 都是用于在大数据环境中处理结构化数据的工具,但它们有一些关键的区别: 底层计算引擎: Hive SQL:Hive 是建立在 Hadoop 生态系统之上的,使用 MapReduce 作为底层计算引擎。因此,它的…...

SparkStreaming基础解析(四)
1、 Spark Streaming概述 1.1 Spark Streaming是什么 Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、…...
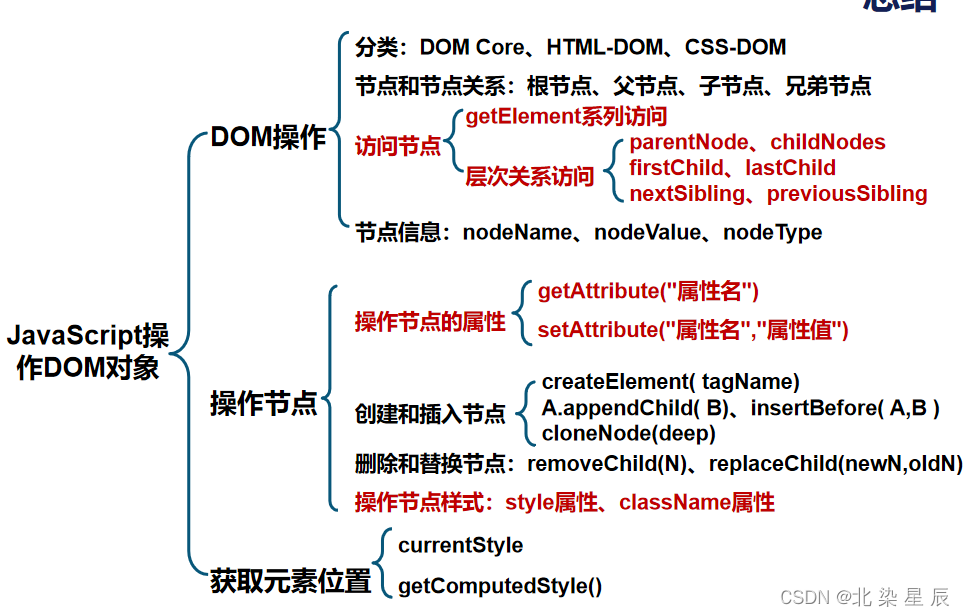
HTML---JavaScript操作DOM对象
目录 文章目录 本章目标 一.DOM对象概念 二.节点访问方法 常用方法: 层次关系访问节点 三.节点信息 四.节点的操作方法 操作节点的属性 创建节点 删除替换节点 五.节点操作样式 style属性 class-name属性 六.获取元素位置 总结 本章目标 了解DOM的分类和节点间的…...
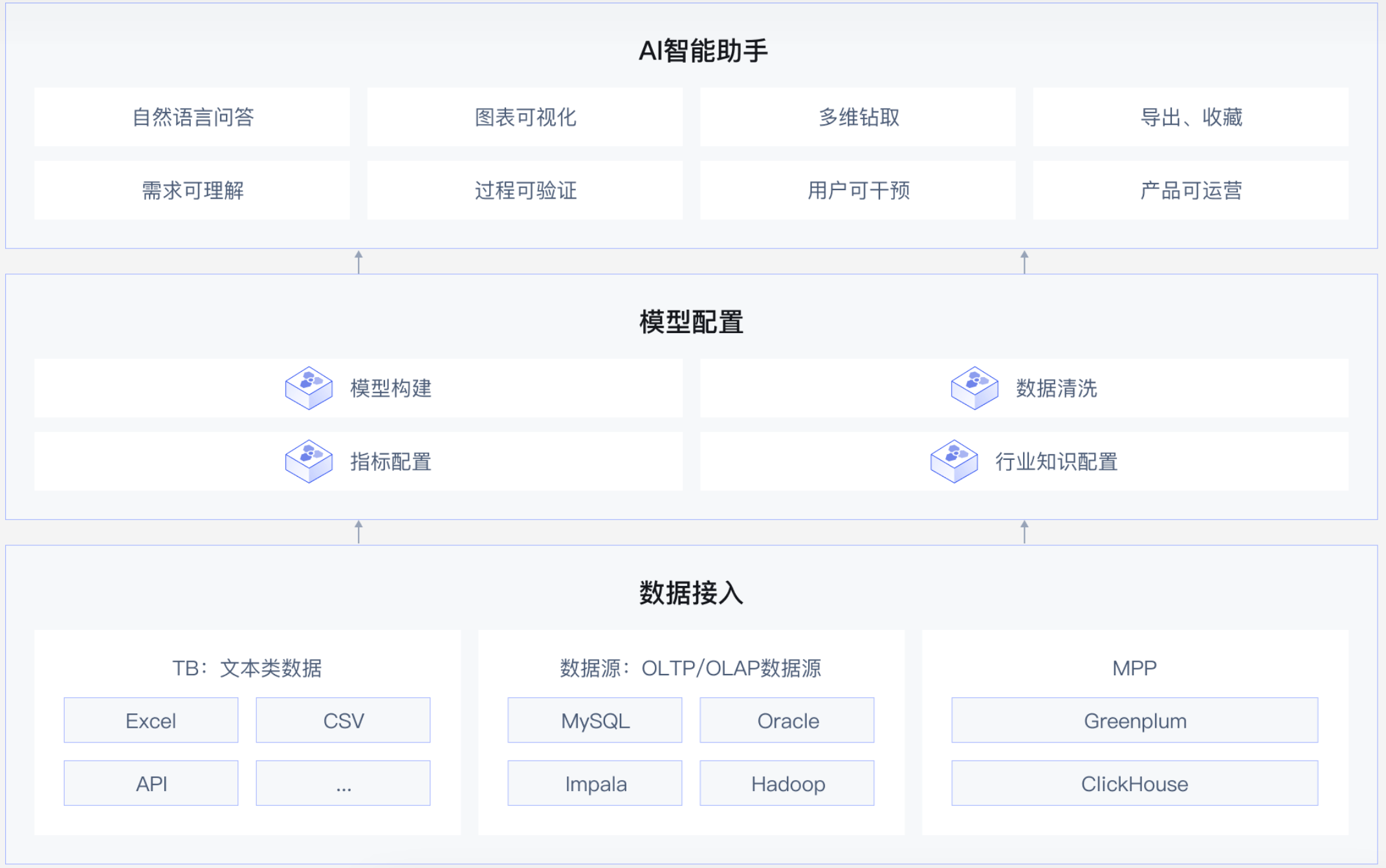
ChatGPT扩展系列之网易数帆ChatBI
在当今数字化快速发展的时代,数据已经成为业务经营与管理决策的核心驱要素。无论是跨国大企业还是新兴创业公司,正确、迅速地洞察数据已经变得至关重要。然而,传统的BI工具往往对用户有一定的技术门槛,需要熟练的操作技能和复杂的查询语句,这使得大部分的企业员工难以深入…...
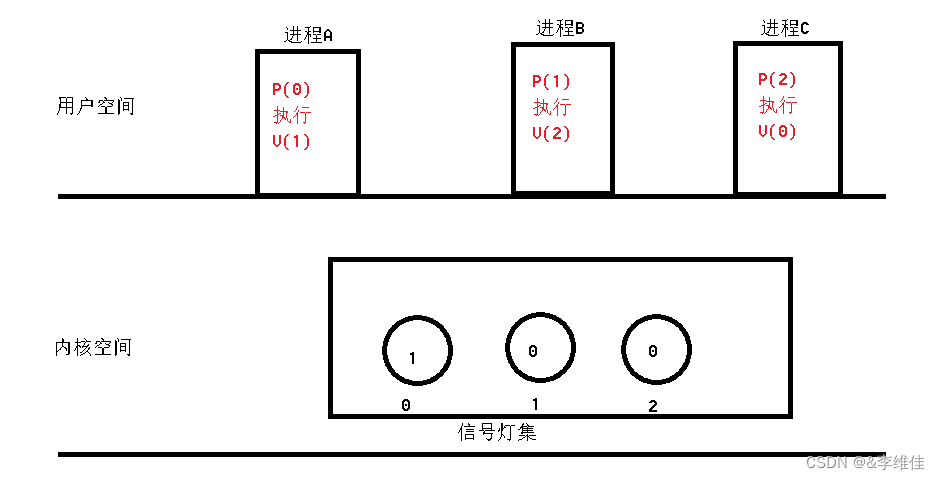
1.10号io网络
信号量(信号灯集) 1> 信号灯集主要完成进程间同步工作,将多个信号灯,放在一个信号灯集中,每个信号灯控制一个进程 2> 每个灯维护了一个value值,当value值等于0时,申请该资源的进程处于阻…...
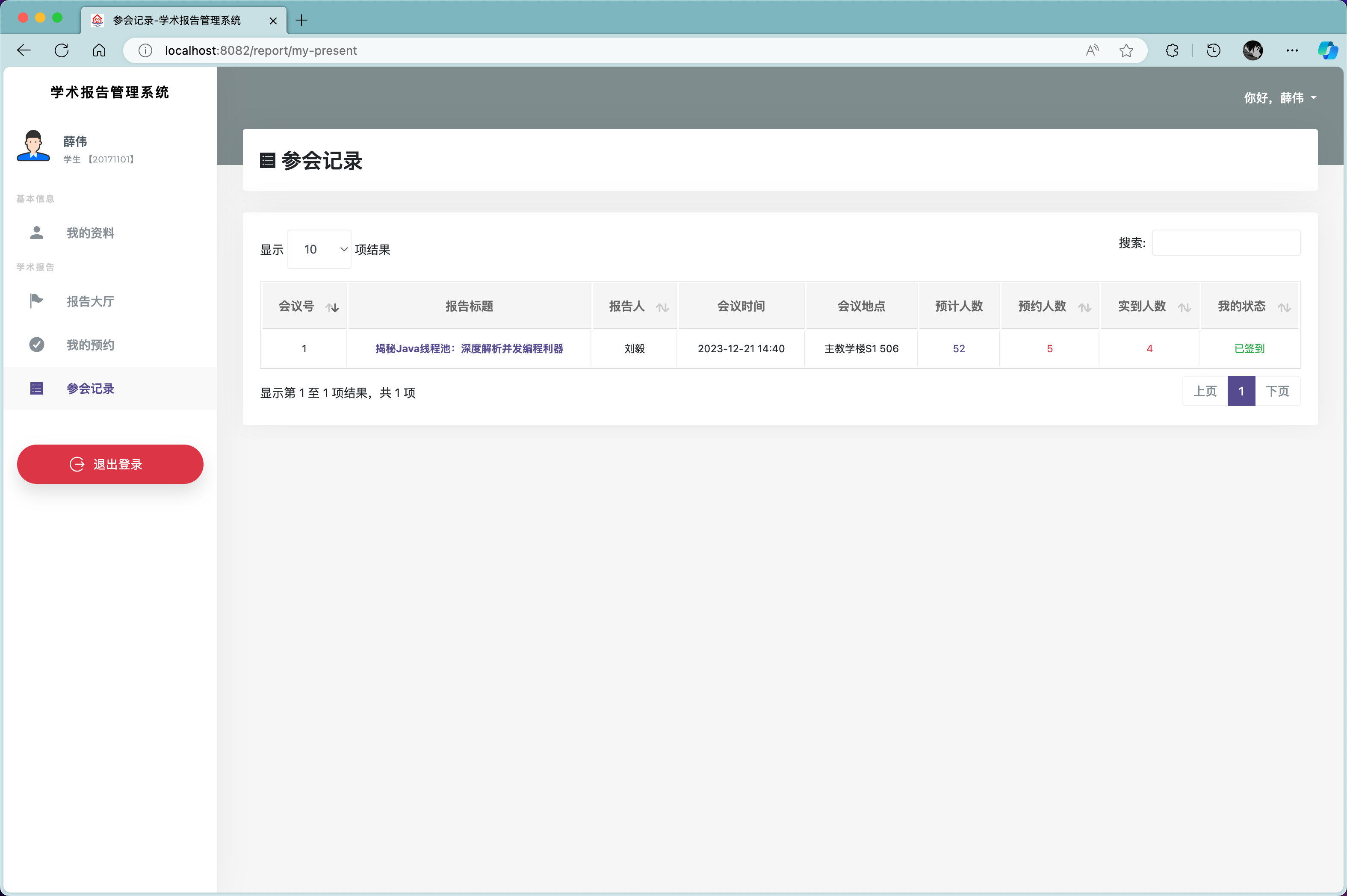
基于JAVA+SpringBoot的高校学术报告系统
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 智慧高校学术报告系统…...

单机部署Rancher
上次已经安装完毕了k8s了,但是想要界面化的管理,离不开界面工具,首推就是rancher,本文介绍安装rancher的安装,也可以将之前安装的k8s管理起来。 已经安装完毕docker和docker-ce的可以直接从第三部分开始。 一、基础准…...
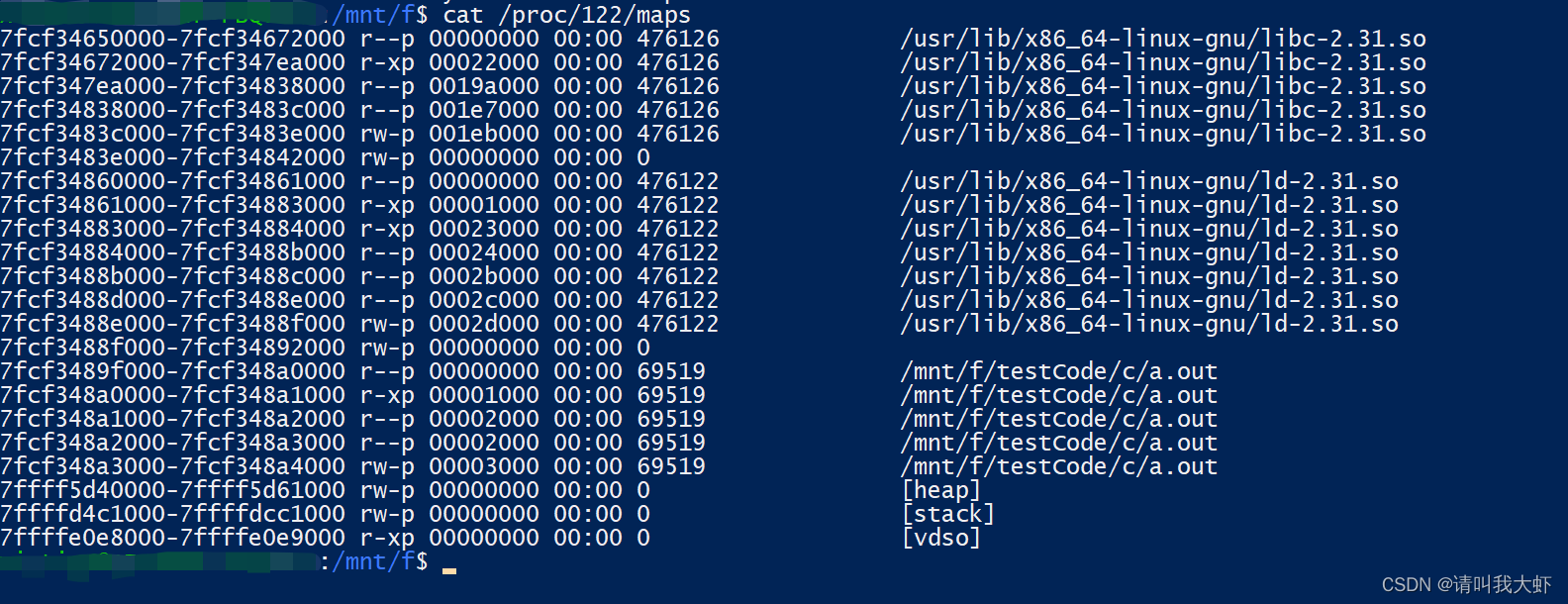
linux 命令
ps: 命令用来查看系统上的进程信息。 查看内存 cat /proc/进程id/maps...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...