【PyTorch】记一次卷积神经网络优化过程
记一次卷积神经网络优化过程
前言
在深度学习的世界中,图像分类任务是一个经典的问题,它涉及到识别给定图像中的对象类别。CIFAR-10数据集是一个常用的基准数据集,包含了10个类别的60000张32x32彩色图像。在上一篇博客中,我们已经探讨如何使用PyTorch框架创建一个简单的卷积神经网络(CNN)来对CIFAR-10数据集中的图像进行分类。

引用
关于卷积神经网络的原理,感兴趣的请参阅我的另一篇博客,里面只使用numpy和基础函数组建了一个卷积神经网络模型,并完成训练和测试
【手搓深度学习算法】从头创建卷积神经网络
在这片文章中,我们将使用上一篇博客里面组建的模型和参数作为基线,一步一步检查问题和优化点,尝试提高准确率和性能。
背景
卷积神经网络是深度学习中用于图像识别和分类的一种强大工具。它们能够自动从图像中提取特征,并通过一系列卷积层、池化层和全连接层来学习图像的复杂模式。
CIFAR-10数据集包含了飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车等10个类别的图像。每个类别有6000张图像,其中50000张用于训练,10000张用于测试。
基线主要模块
数据预处理
我们首先定义了unpickle函数来加载CIFAR-10数据集的批次文件。read_data函数用于读取数据,将其转换为适合卷积网络输入的格式,并进行归一化处理。我们还提供了一个选项来将图像转换为灰度。
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dictdef read_data(file_path, gray = False, percent = 0, normalize = True):data_src = unpickle(file_path)np_data = np.array(data_src["data".encode()]).astype("float32")np_labels = np.array(data_src["labels".encode()]).astype("float32").reshape(-1,1)single_data_length = 32*32 image_ret = Noneif (gray):np_data = (np_data[:, :single_data_length] + np_data[:, single_data_length:(2*single_data_length)] + np_data[:, 2*single_data_length : 3*single_data_length])/3image_ret = np_data.reshape(len(np_data),32,32)else:image_ret = np_data.reshape(len(np_data),32,32,3)if(normalize):mean = np.mean(np_data)std = np.std(np_data)np_data = (np_data - mean) / stdif (percent != 0):np_data = np_data[:int(len(np_data)*percent)]np_labels = np_labels[:int(len(np_labels)*percent)]image_ret = image_ret[:int(len(image_ret)*percent)]num_classes = len(np.unique(np_labels))np_data, np_labels = convert_to_conv_input(np_data, np_labels)return np_data, np_labels, num_classes, image_ret 网络结构
Conv类定义了我们的CNN模型,它包含一个卷积层、一个最大池化层、一个ReLU激活函数和一个全连接层。在forward方法中,我们指定了数据通过网络的流程。
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv = th.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)self.pool = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear = th.nn.Linear(16*15*15, 10)self.softmax = th.nn.Softmax(dim=1)def forward(self, x):x = self.conv(x) #32,16,30,30x = self.pool(x) #32,16,15,15x = self.relu(x)x = x.view(x.size(0), -1)x = self.linear(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x
损失函数和优化器
交叉熵损失函数
交叉熵损失函数(Cross Entropy Loss)是一种常用的损失函数,特别是在多分类问题中。它的主要目标是最小化真实标签和模型预测的概率分布之间的差异。
交叉熵损失函数的基本思想是:对于每个样本,计算其真实标签和模型预测的概率分布之间的交叉熵。交叉熵是信息论中的一个概念,表示两个概率分布之间的差异。在这个情况下,我们希望模型的预测概率分布与真实的标签分布越接近,所以我们希望交叉熵越小。
具体来说,对于一个多分类问题,我们有 K 个类别,每个样本属于其中一个类别。模型会对每个类别都预测一个概率,形成一个 K 维的向量。真实的标签也是一个 K 维的向量,只不过真实的标签向量中,对应正确类别的位置为 1,其他位置为 0。
那么,对于一个样本,其交叉熵损失就是真实标签向量和模型预测向量之间的交叉熵。对于所有样本,我们取平均,得到整个数据集的交叉熵损失。
在 PyTorch 中,可以使用 torch.nn.CrossEntropyLoss() 来创建一个交叉熵损失函数。
随机梯度下降优化函数
SGD,即随机梯度下降(Stochastic Gradient Descent),是一种广泛使用的优化算法,用于求解机器学习模型的参数。
SGD的基本原理是:在每次迭代时,只使用当前批次的数据来计算梯度,然后根据这个梯度来更新模型的参数。这种方法的优点是计算速度快,因为它只需要处理一部分数据;缺点是可能会震荡,因为每次迭代的梯度都是基于一部分数据的,可能会导致模型在最优解附近震荡而无法收敛。
SGD的主要步骤如下:
- 初始化模型的参数。
- 对于每个批次的数据:
- 计算梯度:使用反向传播算法计算损失函数关于模型参数的梯度。
- 更新参数:根据计算出的梯度和学习率,更新模型的参数。
- 重复第二步,直到满足停止条件(例如,达到最大迭代次数或者损失值变化非常小)。
在 PyTorch 中,可以使用 torch.optim.SGD() 来创建一个 SGD 优化器。
loss_function = th.nn.CrossEntropyLoss()
optimizer = th.optim.SGD(conv_model.parameters(), lr = lr)
超参数
学习率(lr) = 0.01
批量大小(batch_size) = 32
最大训练轮次(max_epoch) = 1000
在这里,我们使用了早停机制,在训练过程中不断去检查测试集的准确率指标,当发现测试集准确率连续N个epoch出现上升,将会提前停止测试
test_acc_turn_to_bad_count = 0start loopif (acc > best_test_acc):best_test_acc = acctest_acc_turn_to_bad_count = 0else:test_acc_turn_to_bad_count += 1if (test_acc_turn_to_bad_count > 50):break...
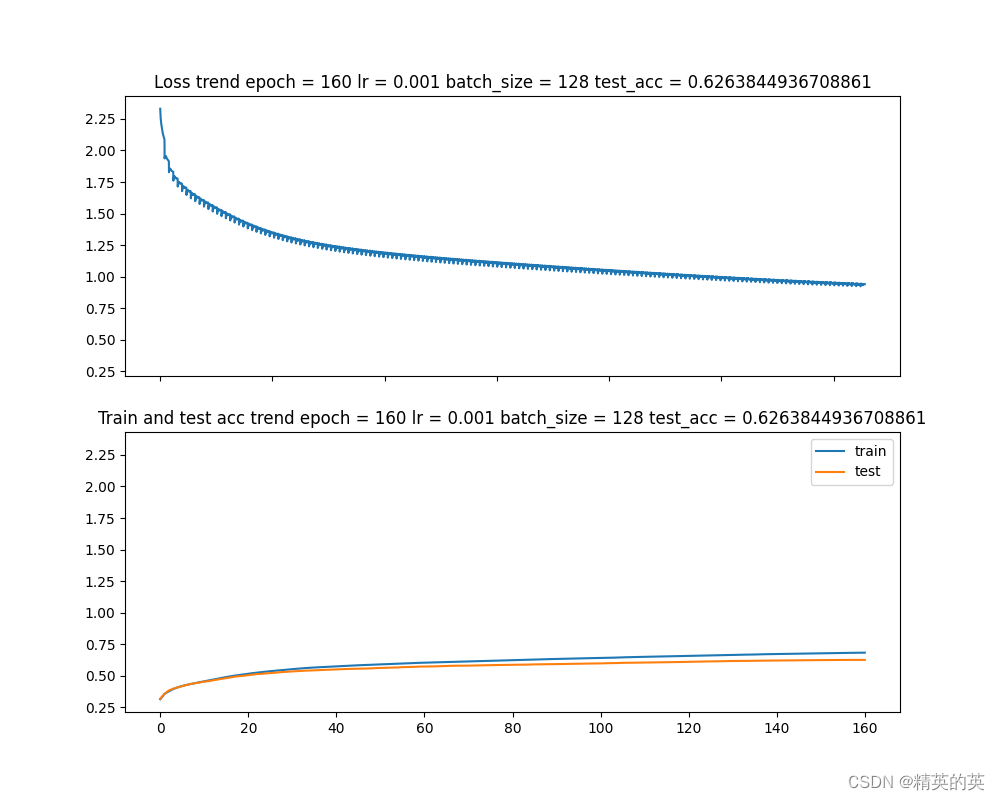
运行结果
准确率=52% (当前图上没有显示,后面我会加上显示)
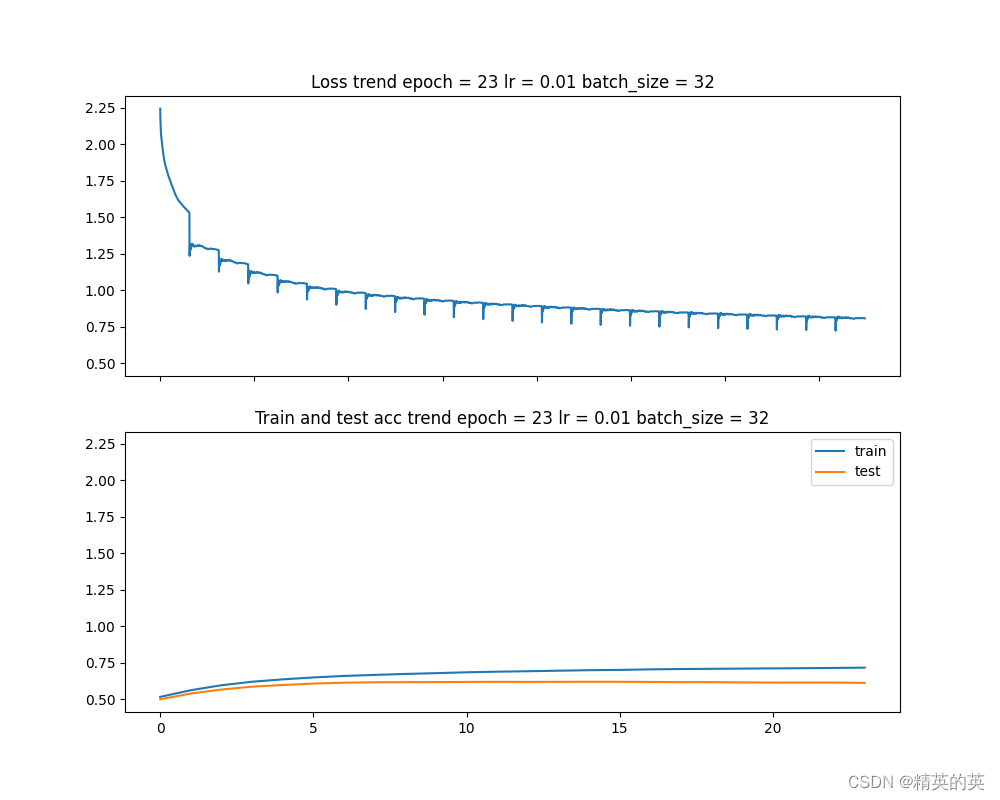
第一次实验:增大batch_size减少震荡
在基线版本的测试中,发现一个问题,损失值震荡较大
于是便考虑损失震荡的原因和可能的解决方法
为什么训练过程中损失值曲线出现震荡可能是batch_size太小的原因,以及为什么增大batch_size可能会减少损失值震荡
在深度学习的训练过程中,损失值曲线出现震荡可能是由于批次大小(batch size)太小引起的。这是因为当批次大小较小时,每次迭代的梯度更新都是基于一小部分数据的,这可能会导致模型在最优解附近震荡而无法收敛。
增大批次大小可能会减少损失值震荡的原因是,当批次大小增大时,每次迭代的梯度更新都是基于更多的数据的,这可以帮助模型更准确地估计梯度,从而更有效地朝着最优解的方向移动。
解决方法
因为CIFAR-10数据集单个图片都比较小(32*32),所以大胆选用了512的batch_size
超参数
学习率(lr) = 0.01
批量大小(batch_size) = 32 -> 512
最大训练轮次(max_epoch) = 1000
模型 不变
运行结果
可以看到震荡减小了很多,准确率也略有上升,非常nice
准确率变化 52% -> 53%
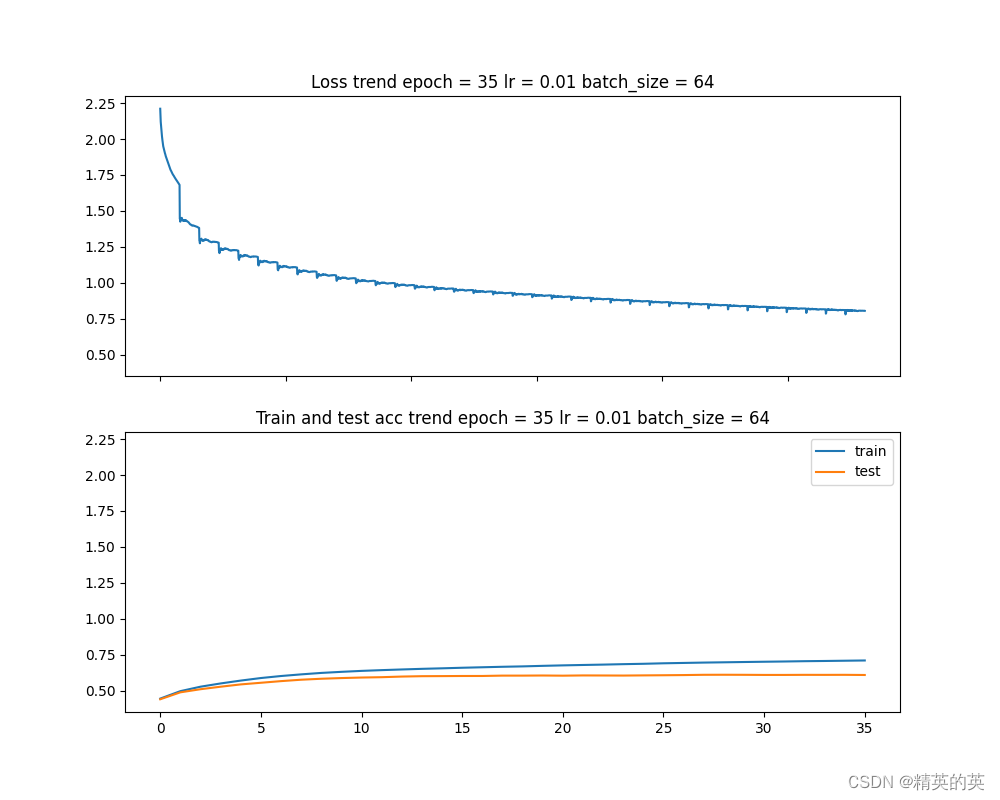
第二次实验,通过减小学习率尝试提高准确率
虽然经过上一轮实验,损失值震荡减小了,准确率也略有上升,但是53%的准确率还是太低了,于是就考虑进一步增加准确率的方法
为什么调节学习率有可能提高准确率
学习率(learning rate)是一个非常重要的超参数,它决定了模型在每次迭代时,如何更新参数以减少损失函数的值
如果学习率设置得过大,模型可能会在最优解附近震荡,无法收敛到最优解。这是因为每次迭代的梯度更新都会使模型的参数跳跃较大的距离,可能会错过最优解。
相反,如果学习率设置得过小,模型可能会收敛得过慢,甚至可能陷入局部最优解。这是因为每次迭代的梯度更新都会使模型的参数移动较小的距离,可能会在最优解附近震荡,无法找到更好的解。
因此,选择合适的学习率是一个需要权衡的问题。一般来说,学习率设置得过大可能会导致模型收敛得过快,而学习率设置得过小可能会导致模型收敛得过慢。在实践中,我们通常会通过实验来调整学习率,以找到最优的学习率值。
解决方法
因为基线版本的学习率是0.01,中规中矩,但还可以更小,所以大胆改成0.001
超参数
学习率(lr) = 0.01 -> 0.001
批量大小(batch_size) = 512
最大训练轮次(max_epoch) = 1000
模型 不变
运行结果
果然损失曲线变得更平滑了,准确率也得到了显著提升,但是收敛轮次从 35 涨到了 160,果然有利也有弊
准确率变化 53% -> 62%
第三次实验,增加网络层数
经过上一次实验,感觉超参数已经折腾的差不多了,于是便打起了模型的注意
为什么对简单的网络增加层数有可能提高准确率
对于简单的网络,增加层数可能会提高准确率的原因主要有以下几点:
-
更多的参数:增加网络的层数意味着增加了更多的参数。更多的参数可以使模型更好地拟合训练数据,从而提高准确率。
-
更复杂的模型:增加网络的层数意味着模型变得更复杂。复杂的模型可以学习到更复杂的模式,从而提高准确率。
-
更好的泛化能力:增加网络的层数可以使模型更好地泛化到未见过的数据。这是因为复杂的模型可以学习到更多的特征,从而更好地区分不同的类别。
解决方法
因为基线版本的网络结构是1层卷积层加上一层全连接层,也太简单了,所以这次同时添加两个卷积层和两个全连接层
超参数
学习率(lr) = 0.01
批量大小(batch_size) = 128
最大训练轮次(max_epoch) = 1000
模型
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv1 = th.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)self.conv2 = th.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3)self.conv3 = th.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)self.pool = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(256, 128)self.linear2 = th.nn.Linear(128, 64)self.linear3 = th.nn.Linear(64, 10)self.softmax = th.nn.Softmax(dim=1)self.drop = th.nn.Dropout(0.2)def forward(self, x):x = self.conv1(x) #32,16,30,30x = self.pool(x) #32,16,15,15x = self.relu(x)x = self.conv2(x)x = self.pool(x)x = self.relu(x)x = self.conv3(x)x = self.pool(x)x = self.relu(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.relu(x)x = self.linear2(x)x = self.relu(x)x = self.linear3(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x运行结果
果然更多的层数带来了更高的准确率,非常的nice
准确率 62% -> 69%
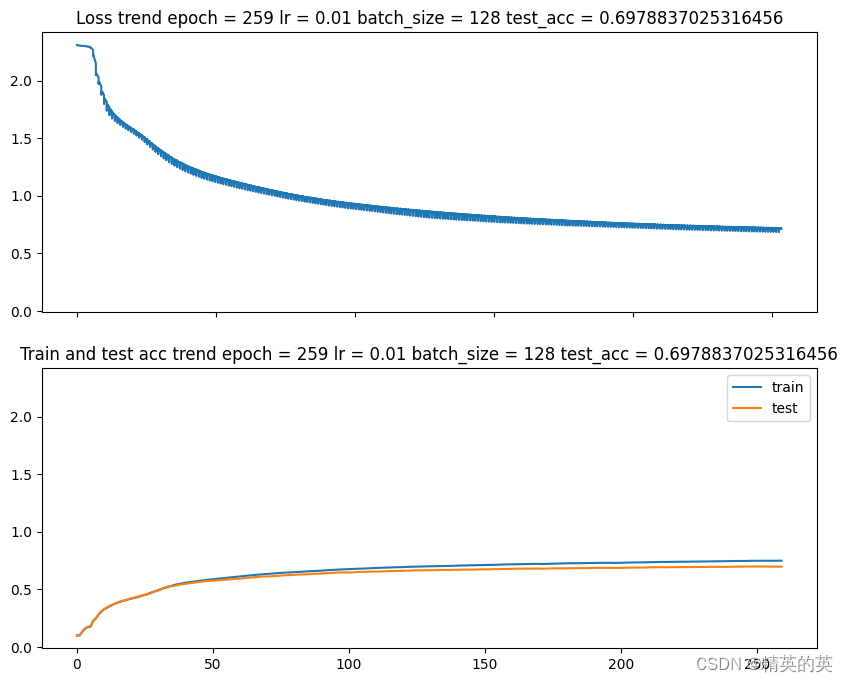
第四次实验,数据随机和数据增强
前面的实验已经得到了不错的成果,但是我发现我的数据没有做任何处理,老话说:数据决定上限,模型只是逼近上限,那么,数据随机和数据增强是必须的
为什么数据随机和数据增强可能提高准确率
数据随机和数据增强是两种常用的数据增强技术,它们可以提高模型的泛化能力,从而提高准确率。
-
数据随机:在训练过程中,我们通常会随机打乱数据集,然后按照一定的批次大小进行批次训练。这样做的目的是为了使模型在每次迭代时都能看到不同的数据样本,从而避免模型在训练过程中过拟合到某些特定的数据样本。
-
数据增强:数据增强是一种通过对原始数据进行一些随机变换(例如旋转、缩放、平移、翻转等)来生成新的数据样本的技术。这样做的目的是为了增加数据集的多样性,使模型能够学习到更多的特征,从而提高模型的泛化能力。
解决方法
因为我们的数据是从文件中读取的,所以我们新增两个函数分别执行数据随机和数据增强
超参数
学习率(lr) = 0.001
批量大小(batch_size) = 512
最大训练轮次(max_epoch) = 1000
网络 不变
数据增强代码
其实pytorch中有现成的transform类可以更简单的执行数据增强,这里手动处理只是为了更直观
def transform_data(data, is_test = False):# 将NumPy数组转换为PIL Imagemean = [0.4914, 0.4822, 0.4465]std = [0.247, 0.243, 0.261]data_ret = []for image in data:image = Image.fromarray((image).astype(np.uint8))_rand = random.randint(1,100)if (_rand > 0): #支持部分随机增强# 应用每个单独的变换#image = transforms.ToPILImage()(image)if not (is_test):#测试集不做处理image = transforms.RandomRotation(10)(image)#随机旋转+-10度image = transforms.RandomAutocontrast(0.5)(image)#随机自动对比度调整,概率为50%image = transforms.RandomHorizontalFlip(0.5)(image)#随机水平翻转,概率为50%image = transforms.ToTensor()(image)image = transforms.Normalize(mean=mean, std=std)(image)data_ret.append(image)data_ret = th.stack(data_ret)return data_retdef convert_to_conv_input(data : np.ndarray, labels : np.ndarray, is_test = False, batch_size = 32):if not (is_test):random_permutation = th.randperm(data.size(0)) data = data[random_permutation] labels = labels[random_permutation] _3d_data_list = split_into_batches(data, batch_size)labels = split_into_batches(labels, batch_size)return _3d_data_list, labels
运行结果
可以看到准确率再一次得到提升,而且可以清楚的看到随着每次数据随机和数据增强(每50个epoch),损失值出现正常波动
准确率变化:69% -> 73%
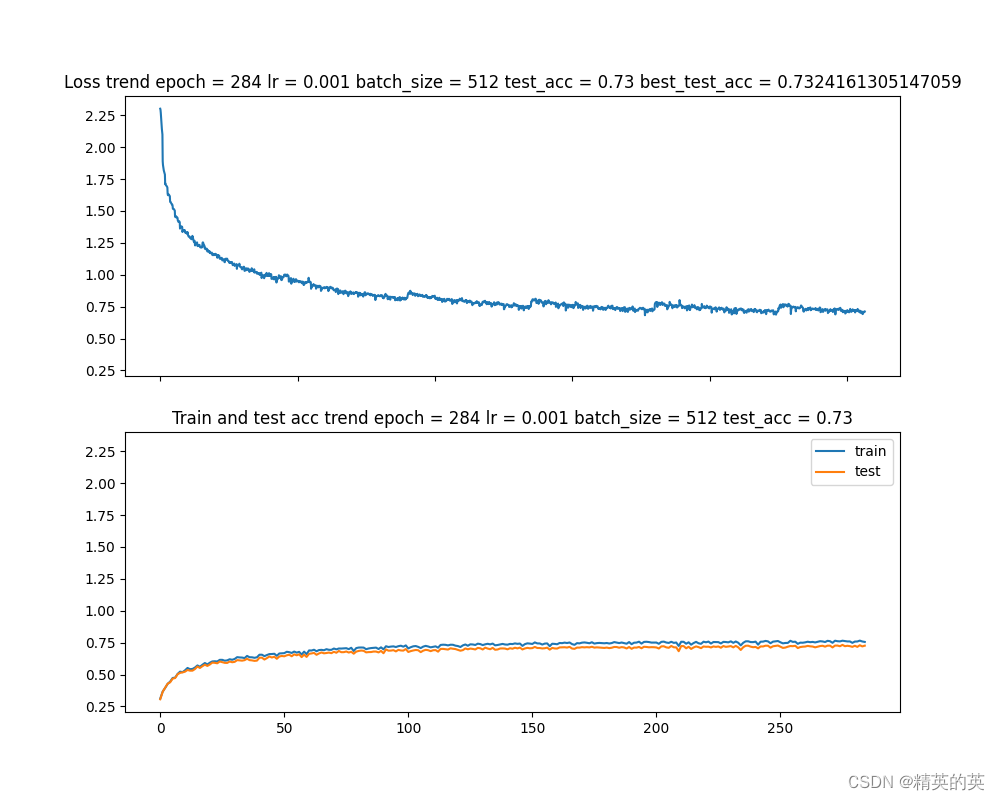
第五次实验,使用残差特征提取
残差特征提取是深度学习中的一个概念,它源自残差网络(Residual Networks,简称ResNets)的设计。残差网络通过引入残差模块(residual blocks)来解决深度神经网络训练中的退化问题,即随着网络层数的增加,网络的性能往往会饱和甚至下降。
作用:
残差特征提取的主要作用是允许训练更深的神经网络,同时避免梯度消失或梯度爆炸的问题。这使得网络能够学习到更复杂的特征表示,从而提高模型的准确率和泛化能力。
原理:
残差网络的核心思想是引入一个“跳跃连接”(skip connection),它允许输入直接跳过一个或多个层次连接到后面的层。这样,网络不是学习完整的输出特征,而是学习输入与输出之间的残差(即差异)。如果输入和输出相同,理想的残差就是零。
数学上,如果我们将 ( H(x) ) 定义为一个层(或一系列层)的期望输出,而 ( x ) 是输入,那么残差就是 ( H(x) - x )。残差网络通过优化 ( F(x) = H(x) - x ) 来学习这个残差,然后输出 ( H(x) = F(x) + x ),其中 ( F(x) ) 是网络层的学习目标。
这种设计允许梯度在训练过程中直接通过跳跃连接传播,从而减轻了梯度消失的问题,并使得网络能够有效地训练更深的层次。
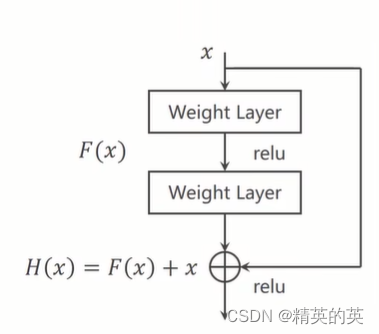
解决方法
创建一个残差块,然后在每次卷积之后附加这个残差层,就达到了增加网络层数,同时避免网络退化的目的
超参数
学习率(lr) = 0.001
批量大小(batch_size) = 512
最大训练轮次(max_epoch) = 1000
网络
#残差块
class ResidualBlock(th.nn.Module):def __init__(self, channels) -> None:super(ResidualBlock, self).__init__()self.channels = channelsself.conv1 = th.nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.conv2 = th.nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.relu = th.nn.ReLU()def forward(self, x):y = self.relu(self.conv1(x))y = self.conv2(x)return self.relu(x + y)#网络模型
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv1 = th.nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5)self.conv2 = th.nn.Conv2d(in_channels=88, out_channels=20, kernel_size=3)self.incep1 = InceptionA(in_channels = 10)self.incep2 = InceptionA(in_channels=20)#output_features = ((input_features - filter_size + 2*padding) / stride) + 1self.pool1 = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(3168, 1280)self.linear2 = th.nn.Linear(1280, 128)self.linear3 = th.nn.Linear(128, 10)self.softmax = th.nn.Softmax(dim=1)self.drop = th.nn.Dropout(0.2)self.res_block1 = ResidualBlock(10)self.res_block2 = ResidualBlock(20)def forward(self, x):x = self.conv1(x) #32,16,30,30x = self.pool1(x) #32,16,15,15x = self.relu(x)x = self.res_block1(x)x = self.incep1(x)#512,88,14,14x = self.conv2(x)x = self.pool1(x)x = self.relu(x)#512,20,6,6x = self.res_block2(x)x = self.incep2(x)x = x.reshape(x.size(0), -1)#512,88,6,6x = self.linear1(x)x = self.relu(x)x = self.drop(x)x = self.linear2(x)x = self.relu(x)x = self.linear3(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x运行结果
残差块果然不负众望,再次取得了+3分的好成绩
准确率变化:73% -> 76%
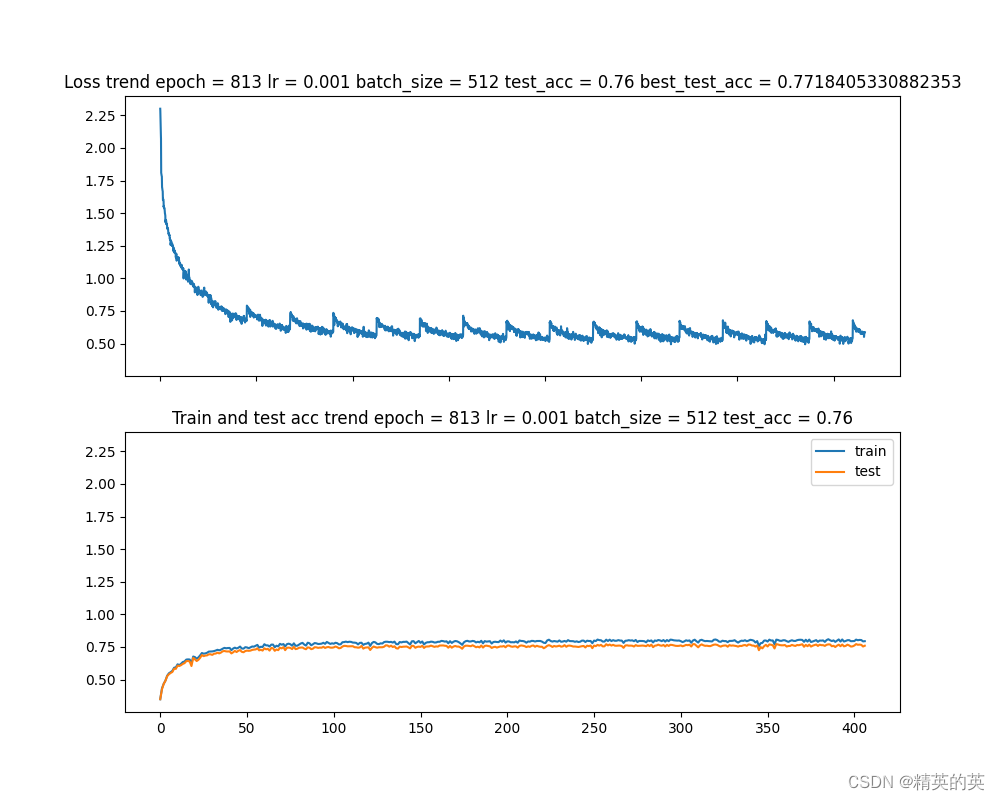
结论
通过本博客,我们尝试了在基线模型上进行模型微调,实现了测试集准确率 从52% 到 76% 的显著提升,虽然和成熟分类网络的成绩还存在较大差距,但实际工作中很少会有重新造轮子的机会,重要的是学习模型调优的方法和思想。
完整代码(数据集在绑定资源里,也可以自己下载)
import torch as th
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torchvision as tvdata_buffer = {}
def unpickle(file_list):import picklenp_data = np.array([])np_labels = np.array([])for file in file_list:if (data_buffer.get(file) != None):np_data_tmp = data_buffer[file]["data"]np_labels_tmp = data_buffer[file]["labels"]else:single_file_data = {}with open(file, 'rb') as fo:np_data_tmp = np.array([])np_labels_tmp = np.array([])dict = pickle.load(fo, encoding='bytes')np_data_tmp = np.array(dict["data".encode()]).astype("float32")np_labels_tmp = np.array(dict["labels".encode()]).astype("float32").reshape(-1,1)single_file_data["data"]= np_data_tmpsingle_file_data["labels"]= np_labels_tmpdata_buffer[file]=single_file_dataif (np_data.size == 0):np_data = np_data_tmpnp_labels = np_labels_tmpelse:np_data = np.concatenate((np_data, np_data_tmp), axis=0)np_labels = np.concatenate((np_labels, np_labels_tmp), axis=0)return np_data, np_labelsfrom PIL import Image
import torchvision.transforms as transforms
import random
def transform_data(data, is_test = False):# 将NumPy数组转换为PIL Imagemean = [0.4914, 0.4822, 0.4465]std = [0.247, 0.243, 0.261]data_ret = []for image in data:image = Image.fromarray((image).astype(np.uint8))_rand = random.randint(1,100)if (_rand > 0):# 应用每个单独的变换#image = transforms.ToPILImage()(image)if not (is_test):image = transforms.RandomRotation(10)(image)image = transforms.RandomAutocontrast(0.5)(image)image = transforms.RandomHorizontalFlip(0.5)(image)image = transforms.ToTensor()(image)image = transforms.Normalize(mean=mean, std=std)(image)data_ret.append(image)data_ret = th.stack(data_ret)return data_retdef read_data(file_path, batch_size = 32, is_test = False, gray = False, percent = 0, normalize = True):np_data, np_labels = unpickle(file_path)num_samples = len(np_data)single_data_length = 32*32 image_ret = Noneif (gray):np_data = (np_data[:, :single_data_length] + np_data[:, single_data_length:(2*single_data_length)] + np_data[:, 2*single_data_length : 3*single_data_length])/3image_ret = np_data.reshape(len(np_data),32,32)else:#image_ret = np_data.reshape(len(np_data),32,32,3)r_data = np_data[:, :single_data_length].reshape(num_samples,32,32)g_data = np_data[:, single_data_length:(2*single_data_length)].reshape(num_samples,32,32)b_data = np_data[:, 2*single_data_length : 3*single_data_length].reshape(num_samples,32,32)rgb_data = np.stack((r_data, g_data, b_data), axis = -1)image_ret = rgb_datanp_data = image_ret#np_data = np_data.permute(0,2,3,1)np_data = transform_data(np_data, is_test = is_test)if (percent != 0):np_data = np_data[:int(len(np_data)*percent)]np_labels = np_labels[:int(len(np_labels)*percent)]image_ret = image_ret[:int(len(image_ret)*percent)]num_classes = len(np.unique(np_labels))return np_data, np_labels, num_classes, image_ret def split_into_batches(original_array, n):sub_array_size = nbatches_count = int(len(original_array) / n)sub_arrays = []last_pos = 0for i in range(batches_count):start = i * sub_array_sizeend = start + sub_array_sizesub_array = original_array[start:end]sub_arrays.append(sub_array)last_pos = endsub_arrays.append(original_array[last_pos:])return sub_arraysdef convert_to_conv_input(data : np.ndarray, labels : np.ndarray, is_test = False, batch_size = 32):if not (is_test):random_permutation = th.randperm(data.size(0)) data = data[random_permutation] labels = labels[random_permutation] _3d_data_list = split_into_batches(data, batch_size)labels = split_into_batches(labels, batch_size)return _3d_data_list, labelsclass Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv = th.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)self.pool = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(16*15*15, 512)self.linear2 = th.nn.Linear(512, 10)self.softmax = th.nn.Softmax(dim=1)self.res_block1 = ResidualBlock(16)def forward(self, x):x = self.conv(x) #32,16,30,30x = self.pool(x) #32,16,15,15x = self.relu(x)x = self.res_block1(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.relu(x)x = self.linear2(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x'''
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv1 = th.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)self.conv2 = th.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3)self.conv3 = th.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)#output_features = ((input_features - filter_size + 2*padding) / stride) + 1self.pool1 = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(256, 128)self.linear2 = th.nn.Linear(128, 64)self.linear3 = th.nn.Linear(64, 10)self.softmax = th.nn.Softmax(dim=1)self.drop = th.nn.Dropout(0.1)def forward(self, x):x = self.conv1(x) #32,16,30,30x = self.pool1(x) #32,16,15,15x = self.relu(x)x = self.conv2(x)x = self.pool1(x)x = self.relu(x)x = self.conv3(x)x = self.pool1(x)x = self.relu(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.relu(x)x = self.drop(x)x = self.linear2(x)x = self.relu(x)x = self.linear3(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x
'''
class ResidualBlock(th.nn.Module):def __init__(self, channels) -> None:super(ResidualBlock, self).__init__()self.channels = channelsself.conv1 = th.nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.conv2 = th.nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.relu = th.nn.ReLU()def forward(self, x):y = self.relu(self.conv1(x))y = self.conv2(x)return self.relu(x + y)class InceptionA(th.nn.Module):def __init__(self, in_channels) -> None:super(InceptionA, self).__init__()self.branch1x1 = th.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_1 = th.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_2 = th.nn.Conv2d(16, 24, kernel_size=5, padding=2)self.branch3x3_1 = th.nn.Conv2d(in_channels, 16, kernel_size=1)self.branch3x3_2 = th.nn.Conv2d(16,24,kernel_size=3, padding=1)self.branch3x3_3 = th.nn.Conv2d(24,24,kernel_size=3,padding=1)self.branch_pool = th.nn.Conv2d(in_channels, 24, kernel_size=1)self.avg_pool = th.nn.AvgPool2d(kernel_size=3, stride=1, padding=1)def forward(self,x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = self.avg_pool(x)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return th.cat(outputs, dim=1)'''
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv1 = th.nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5)self.conv2 = th.nn.Conv2d(in_channels=88, out_channels=20, kernel_size=3)self.incep1 = InceptionA(in_channels = 10)self.incep2 = InceptionA(in_channels=20)#output_features = ((input_features - filter_size + 2*padding) / stride) + 1self.pool1 = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(3168, 1280)self.linear2 = th.nn.Linear(1280, 128)self.linear3 = th.nn.Linear(128, 10)self.softmax = th.nn.Softmax(dim=1)self.drop = th.nn.Dropout(0.2)self.res_block1 = ResidualBlock(10)self.res_block2 = ResidualBlock(20)def forward(self, x):x = self.conv1(x) #32,16,30,30x = self.pool1(x) #32,16,15,15x = self.relu(x)x = self.res_block1(x)x = self.incep1(x)#512,88,14,14x = self.conv2(x)x = self.pool1(x)x = self.relu(x)#512,20,6,6x = self.res_block2(x)x = self.incep2(x)x = x.reshape(x.size(0), -1)#512,88,6,6x = self.linear1(x)x = self.relu(x)x = self.drop(x)x = self.linear2(x)x = self.relu(x)x = self.linear3(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x
'''
'''
class Conv(th.nn.Module):def __init__(self, *args, **kwargs) -> None:super(Conv, self).__init__()self.conv1 = th.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)self.conv2 = th.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3)self.conv3 = th.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)self.res_block1 = ResidualBlock(16)self.res_block2 = ResidualBlock(32)self.res_block3 = ResidualBlock(64)#output_features = ((input_features - filter_size + 2*padding) / stride) + 1self.pool1 = th.nn.MaxPool2d(kernel_size=2,stride=2)#.self.relu = th.nn.ReLU()self.linear1 = th.nn.Linear(256, 128)self.linear2 = th.nn.Linear(128, 64)self.linear3 = th.nn.Linear(64, 10)self.softmax = th.nn.Softmax(dim=1)self.drop = th.nn.Dropout(0.2)def forward(self, x):x = self.conv1(x) #32,16,30,30x = self.pool1(x) #32,16,15,15x = self.relu(x)x = self.res_block1(x)x = self.conv2(x)x = self.pool1(x)x = self.relu(x)x = self.res_block2(x)x = self.conv3(x)x = self.pool1(x)x = self.relu(x)x = self.res_block3(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.relu(x)x = self.drop(x)x = self.linear2(x)x = self.relu(x)x = self.linear3(x)return xdef predict(self,x):x = self.forward(x)x = self.softmax(x)return x
'''def main():batch_size = 512cuda_valid = th.cuda.is_available()print("CUDA avaliable: {}".format(cuda_valid))'''transform_train = tv.transforms.Compose([tv.transforms.ToPILImage(),tv.transforms.RandomRotation(10),tv.transforms.RandomAutocontrast(0.5),tv.transforms.RandomHorizontalFlip(0.5),tv.transforms.ToTensor(),tv.transforms.Normalize(mean, std)])transform_test = tv.transforms.Compose([tv.transforms.ToPILImage(),tv.transforms.ToTensor(),tv.transforms.Normalize(mean, std)])''''''train_file_path = ["J:\\MachineLearning\\数据集\\cifar-10-batches-py\\data_batch_1","J:\\MachineLearning\\数据集\\cifar-10-batches-py\\data_batch_2","J:\\MachineLearning\\数据集\\cifar-10-batches-py\\data_batch_3","J:\\MachineLearning\\数据集\\cifar-10-batches-py\\data_batch_4","J:\\MachineLearning\\数据集\\cifar-10-batches-py\\data_batch_5",]'''train_file_path = ["ubuntu/data/data_batch_1","ubuntu/data/data_batch_2","ubuntu/data/data_batch_3","ubuntu/data/data_batch_4","ubuntu/data/data_batch_5",]train_data=train_labels=Nonenum_classes = 10'''train_data, train_labels, num_classes, image_data = read_data(train_file_path, batch_size)train_data, train_labels = convert_to_conv_input(train_data, train_labels, batch_size)print(type(train_data))print(type(train_labels))print(train_data[0].shape)print(train_labels[0].shape)print(image_data.shape)# 随机选择9张图片indices = np.random.choice(image_data.shape[0], size=9, replace=False)selected_images = image_data[indices]plt.imshow(image_data[0]/255)plt.show()# 创建一个3x3的子图fig, axes = plt.subplots(3, 3)# 在每个子图中显示一张图片for i, ax in enumerate(axes.flat):img = selected_images[i]# 由于imshow期望输入的数据在0-1之间,我们需要将图像数据归一化img = img / 255.0ax.imshow(img)ax.axis('off') # 关闭坐标轴plt.show()int_labels = train_labels[0].flatten()print(int_labels[:10])print (train_data[0].shape)print (train_data[0][:2])'''epochs = 1000best_loss = 100lr = 0.001conv_model = Conv(num_classes)device = th.device("cuda" if cuda_valid else "cpu")conv_model = conv_model.to(device)loss_function = th.nn.CrossEntropyLoss()#optimizer = th.optim.SGD(conv_model.parameters(), lr = lr, weight_decay=0.01)optimizer = th.optim.Adam(params=conv_model.parameters(), lr = lr, weight_decay=0.01)turn_to_bad_loss_count = 0loss_history = []test_acc_history = []train_acc_history = []#test_file_path = ["J:\\MachineLearning\\数据集\\cifar-10-batches-py\\test_batch"]test_file_path = ["ubuntu/data/test_batch"]test_buffer = {}def test(file_path):test_data = Nonetest_labels = Noneif (test_buffer.get(file_path[0]) == None):test_data_src, test_labels_src, num_classes, image_data = read_data(file_path, batch_size, is_test = True)test_data, test_labels = convert_to_conv_input(test_data_src, test_labels_src, is_test=True, batch_size=batch_size)test_buffer[file_path[0]] = {"data":test_data, "labels":test_labels}else:test_data = test_buffer[file_path[0]]["data"]test_labels = test_buffer[file_path[0]]["labels"]with th.no_grad():test_accuracies = []for index,batch_test_data in enumerate(test_data):#batch_test_data = th.from_numpy(batch_test_data).type(th.float32)batch_test_data = batch_test_data.to(device)test_result = conv_model.predict(batch_test_data)#print(test_result[:10])result_index = test_result.argmax(dim=1)accuracy=(result_index.cpu().numpy().reshape(-1,1) == test_labels[index].reshape(-1,1)).sum() / len(test_labels[index])test_accuracies.append(accuracy)return np.mean(test_accuracies)best_test_acc = 0test_acc_turn_to_bad_count = 0for epoch in range(epochs):if (epoch % 50 == 0):train_data_src, train_labels_src, num_classes, image_data = read_data(train_file_path, batch_size) train_data, train_labels = convert_to_conv_input(train_data_src, train_labels_src, is_test=False, batch_size=batch_size)batch_loss = []for index, batch_data in enumerate(train_data):batch_data = batch_data.to(device)int_labels = train_labels[index].flatten()tensor_labels = th.from_numpy(int_labels).type(th.long) tensor_labels = tensor_labels.to(device)#batch_train_data = th.from_numpy(batch_data)optimizer.zero_grad()y_pred = conv_model(batch_data)#print(y_pred)#print(y_pred.shape)loss = loss_function(y_pred, tensor_labels)batch_loss.append(loss.item())if (float(loss.item()) > best_loss):turn_to_bad_loss_count += 1else:best_loss = float(loss.item())#if (turn_to_bad_loss_count > 10000):#breakif (index % 10 == 9):ten_batch_loss = np.mean(batch_loss)print("epoch {} batch iter {} / {} 10 batch mean loss is {}".format(epoch, index, len(train_data), ten_batch_loss))loss_history.append(float(ten_batch_loss))loss.backward()optimizer.step()if (epoch % 2 == 1):acc = test(train_file_path)print("epoch {} train accuracy is {}".format(epoch, acc))train_acc_history.append(acc)acc = test(test_file_path)print("epoch {} test accuracy is {}".format(epoch, acc))test_acc_history.append(acc)if (acc > best_test_acc):best_test_acc = acctest_acc_turn_to_bad_count = 0else:test_acc_turn_to_bad_count += 1if (test_acc_turn_to_bad_count > 50):break# 创建一个2x1的子图网格,并选择第(0,0)位置的子图绘制第一个折线图 fig, ax1 = plt.subplots(2, 1, figsize=(10, 8), sharey=True) # 1行2列的子图网格 ax1[0].plot(loss_history) ax1[0].set_title('Loss trend epoch = {} lr = {} batch_size = {} test_acc = {} best_test_acc = {}'.format(epoch, lr, batch_size, round(test_acc_history[-1],2), best_test_acc)) # 设置标题 ax1[0].label_outer() # 显示y轴标签 # 在同一张图上并排显示第二个折线图,选择第(1,0)位置的子图绘制第二个折线图 ax1[1].plot(train_acc_history, label = "train")ax1[1].legend() ax1[1].set_title('Train and test acc trend epoch = {} lr = {} batch_size = {} test_acc = {}'.format(epoch, lr, batch_size, round(test_acc_history[-1],2))) # 设置标题 ax1[1].label_outer() # 显示y轴标签 ax1[1].plot(test_acc_history, label = "test")ax1[1].legend() plt.show()from datetime import datetime # 获取当前时间 # 获取当前时间 current_time = datetime.now() # 将当前时间格式化为 YYYY_MM_DD_HH_MM_SS 格式 formatted_time = current_time.strftime("%Y_%m_%d_%H_%M_%S")plt.savefig("test.png")file_name = "result_lr_{}_batch_size_{}_time_{}.png".format(lr, batch_size, formatted_time)plt.savefig("result_pic/{}".format(file_name))if (__name__ == "__main__"):main()相关文章:
【PyTorch】记一次卷积神经网络优化过程
记一次卷积神经网络优化过程 前言 在深度学习的世界中,图像分类任务是一个经典的问题,它涉及到识别给定图像中的对象类别。CIFAR-10数据集是一个常用的基准数据集,包含了10个类别的60000张32x32彩色图像。在上一篇博客中,我们已…...

C++面试宝典第24题:袋鼠过河
题目 一只袋鼠要从河这边跳到河对岸,河很宽,但是河中间打了很多桩子。每隔一米就有一个桩子,每个桩子上都有一个弹簧,袋鼠跳到弹簧上就可以跳得更远。每个弹簧力量不同,用一个数字代表它的力量,如果弹簧力量为5,就代表袋鼠下一跳最多能够跳5米;如果为0,就会陷进去无法…...

2401vim,vim标号
标号简介 提供高亮,快速告诉用户有用信息.如,调试器在左侧列中有个表示断点的图标. 另一例可能是表示(PC)程序计数器的箭头.标号功能允许在窗口左侧放置标号或图标,并定义应用行的高亮. 此外,调试器还支持8到10种不同的标号和高亮颜色,见|NetBeans|. 使用标号有两个步骤: 1…...

Web开发中HTTP请求、响应等相关知识
目录 params和data区别? post请求可以使用params吗? put、delete请求应该使用params还是data? get和post的区别? 常用注解使用 params和data区别? 在使用Ajax时,"params" 和 "data" 通常用于不同的上下文。 "params…...

[Android] Android文件系统中存储的内容有哪些?
文章目录 前言root 文件系统/system 分区稳定性:安全性: /system/bin用来提供服务的二进制可执行文件:调试工具:UNIX 命令:调用 Dalvik 的脚本(upall script):/system/bin中封装的app_process脚本 厂商定制的二进制可执行文件: /system/xbin/system/lib[64]/system/…...
透明拼接屏在汽车领域的应用
随着科技的进步,透明拼接屏作为一种新型的显示技术,在汽车领域的应用越来越广泛。尼伽小编将围绕透明拼接屏在汽车本身、4S店、展会、工厂等方面的应用进行深入探讨,并展望未来的设计方向。 一、透明拼接屏在汽车本身的应用 车窗显示&#x…...

“深入理解RabbitMQ交换机的原理与应用“
深入理解RabbitMQ交换机的原理与应用 引言1. RabbitMQ交换机简介介绍1.1 什么是RabbitMQ?1.1.1 消息中间件的作用1.1.2 RabbitMQ的特点和优势 1.2 RabbitMQ的基本概念1.2.1 队列1.2.2 交换机1.2.3 路由键 1.3 交换机的作用和分类1.3.1 直连交换机(direct…...

Programming Abstractions in C阅读笔记:p248-p253
《Programming Abstractions in C》学习第69天,p248-p253总结,总计6页。 一、技术总结 “A generalized program for two-player games”如标题所示,该小节强调要学会从一个复杂的程序中抽象出通用的内容——这也是本书的主旨——“Program…...

面试题目,你对前端工程化的了解
前端工程化是通过工具和流程来提高软件开发效率、降低维护成本以及改善项目可维护性的方法。在前端领域,前端工程化通常包括以下方面内容 版本控制 使用 git 来管理代码的版本,追踪变更,协作开发等项目脚手架 使用项目的脚手架进行项目的初始…...

2023年春秋杯网络安全联赛冬季赛 Writeup
文章目录 Webezezez_phppicup Misc谁偷吃了外卖modules明文混淆 Pwnnmanagerbook Reupx2023 CryptoCF is Crypto Faker 挑战题勒索流量Ezdede 可信计算 Web ezezez_php 反序列化打redis主从复制RCE:https://www.cnblogs.com/xiaozi/p/13089906.html <?php c…...
docker安装Rabbitmq教程(详细图文)
目录 1.下载Rabbitmq的镜像 2.创建并运行rabbitmq容器 3.启动web客户端 4.访问rabbitmq的微博客户端 5.遇到的问题 问题描述:在rabbitmq的web客户端发现界面会弹出如下提示框Stats in management UI are disabled on this node 解决方法 (1&#…...

java web mvc-05-JSF JavaServer Faces 入门例子
拓展阅读 Spring Web MVC-00-重学 mvc mvc-01-Model-View-Controller 概览 web mvc-03-JFinal web mvc-04-Apache Wicket web mvc-05-JSF JavaServer Faces web mvc-06-play framework intro web mvc-07-Vaadin web mvc-08-Grails 开源 The jdbc pool for java.(java …...

yolov8 训练voc数据集
yolov8训练 from ultralytics import YOLO# 加载模型 # model YOLO(yolov8n.yaml) # 从YAML构建新模型 # model YOLO(yolov8n.pt) # 加载预训练模型(推荐用于训练) model YOLO(yolov8n.yaml).load(yolov8n.pt) # 从YAML构建并转移权重# 训练模型…...

Python笔记12-多线程、网络编程、正则表达式
文章目录 多线程网络编程正则表达式 多线程 现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统。 进程: 就是一个程序,运行在系统之上,那么便称之这个程序为一个运…...

X射线中关于高频高压发生器、高清晰平板探测器、大热容量X射线球管、远程遥控系统的解释
高频高压发生器(High Frequency High Voltage Generator) 在医用诊断X射线设备中扮演着关键角色,它主要用于产生并控制用于X射线成像的高压电能。 这种发生器采用高频逆变技术,通过将输入的低电压、大电流转换为高电压、小电流&am…...

【算法】最短路计数(搜索)复习
题目 给出一个 N 个顶点 M 条边的无向无权图,顶点编号为 1 到 N。 问从顶点 1 开始,到其他每个点的最短路有几条。 输入格式 第一行包含 2 个正整数 N,M,为图的顶点数与边数。 接下来 M 行,每行两个正整数 x,y,表…...
html火焰文字特效
下面是代码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>HTML5火焰文字特效DEMO演示</title><link rel"stylesheet" href"css/style.css" media"screen" type&quo…...
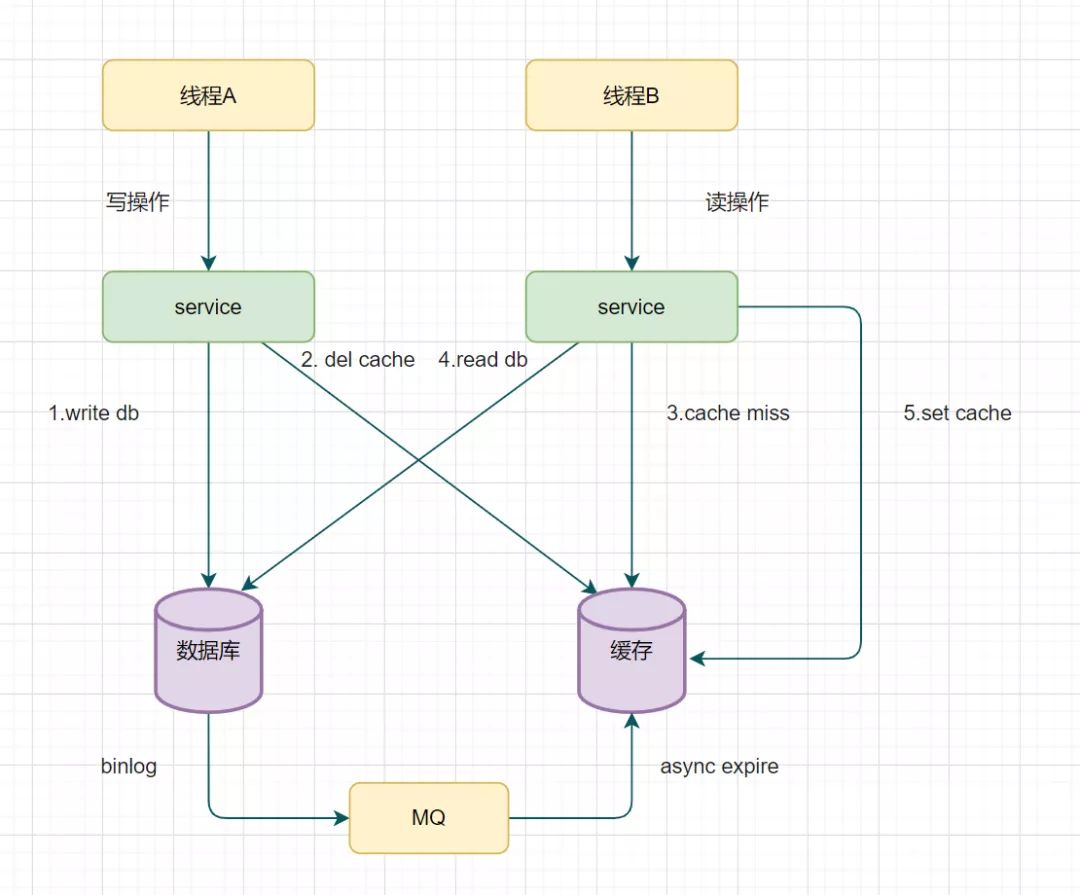
Redis双写一致性
所有的情况都是再并发情况下存在温蒂 一、先更新数据库,再更新缓存场景-不推荐 当有两个线程A、B,同时对一条数据进行操作,一开始数据库和redis的数据都为1,当线程A去修改数据库,将1改为2,然后线程A在修改…...

html+css+javascript实现贪吃蛇游戏
文章目录 一、贪吃蛇游戏二、JavaScript三、HTML四、CSS五、热门文章 一、贪吃蛇游戏 这是一个简单的用HTML、CSS和JavaScript实现的贪吃蛇游戏示例。 HTML部分: <!DOCTYPE html> <html> <head><title>贪吃蛇游戏</title><styl…...

【K8S】Kubernetes 中滚动发布由浅入深实战
目录 一、Kubernetes中滚动发布的需求背景1.1 滚动发布1.2 滚动发布、蓝绿发布、金丝雀发布的区别 二、Kubernetes中实现滚动发布2.1 定义Kubernetes中的版本2.2 创建 Deployment 资源对象2.2.1 在 Yaml 中定义 Deployment 资源对象2.2.2 执行命令创建 Deployment 资源对象 三、…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...
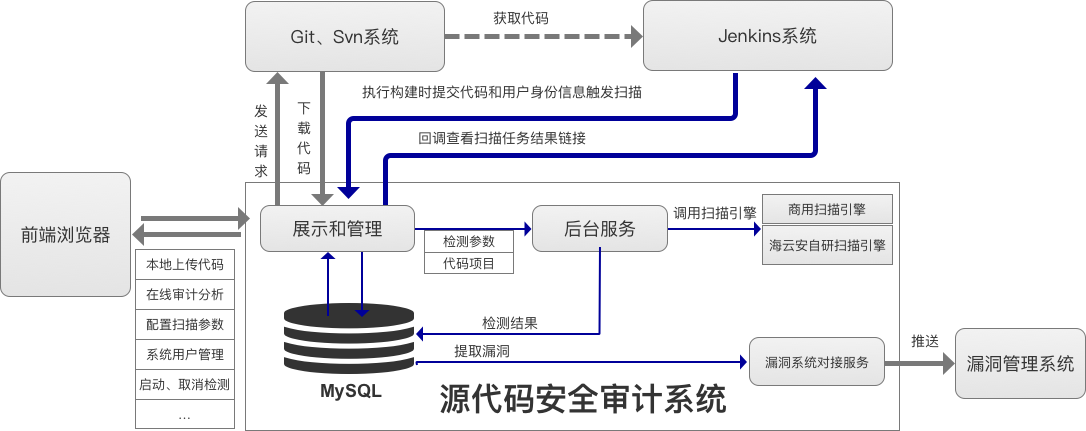
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...
机器学习复习3--模型评估
误差与过拟合 我们将学习器对样本的实际预测结果与样本的真实值之间的差异称为:误差(error)。 误差定义: ①在训练集上的误差称为训练误差(training error)或经验误差(empirical error&#x…...

第2篇:BLE 广播与扫描机制详解
本文是《BLE 协议从入门到专家》专栏第二篇,专注于解析 BLE 广播(Advertising)与扫描(Scanning)机制。我们将从协议层结构、广播包格式、设备发现流程、控制器行为、开发者 API、广播冲突与多设备调度等方面,全面拆解这一 BLE 最基础也是最关键的通信机制。 一、什么是 B…...

python打卡day47
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import D…...
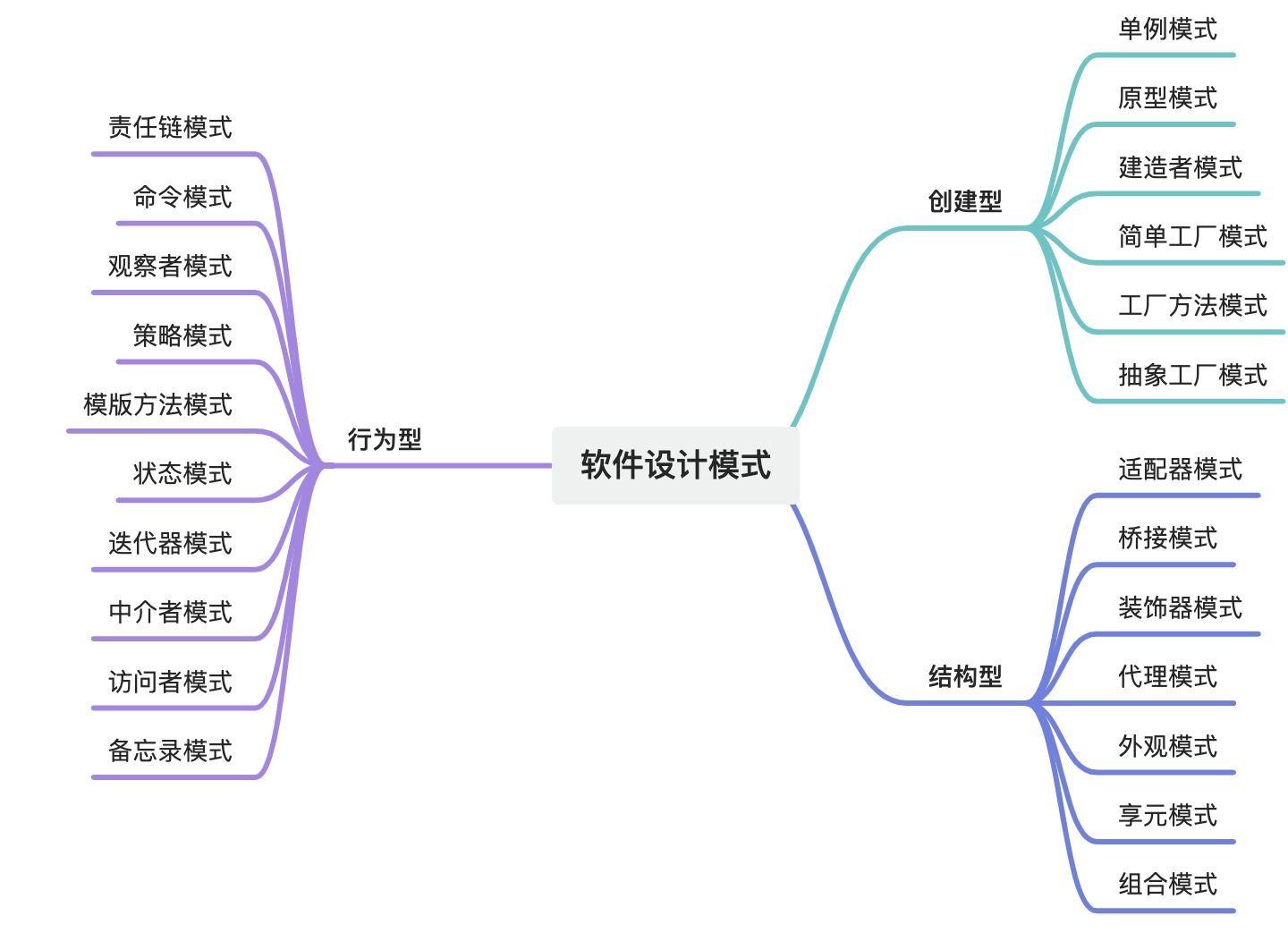
设计模式域——软件设计模式全集
摘要 软件设计模式是软件工程领域中经过验证的、可复用的解决方案,旨在解决常见的软件设计问题。它们是软件开发经验的总结,能够帮助开发人员在设计阶段快速找到合适的解决方案,提高代码的可维护性、可扩展性和可复用性。设计模式主要分为三…...