Flink:快速掌握批处理数据源的创建方法
Flink 社区最近 “基于FLIP-27” 设计了新的 Source 框架 。一些连接器(API)已迁移到这个新框架。本文介绍了如何使用这个新框架创建批处理源。 它是在为Cassandra实现Flink 批处理源时构建的。如果您有兴趣贡献或迁移连接器,这篇文章非常适合!
1.实现Source组件
Source架构如图:


1.1 Source框架
Cassandra 源示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/CassandraSource.java源接口仅在所有其他组件之间起“粘合”作用。它的作用是实例化所有这些并定义源Boundedness 。我们还在这里进行源配置以及用户配置验证。
1.2 SourceReader
Cassandra SourceReader 示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/reader/CassandraSourceReader.java如上图所示,SourceReader 的实例( 在本文的后续部分中我们将其简称为阅读器)在任务管理器中并行运行,以读取划分为Split 的实际数据。阅读器从SplitEnumerator请求拆分,并将生成的拆分结果返回给它们。
Flink 提供了负责所有线程的SourceReaderBase实现。对于大多数情况,Flink 还为此类提供了有用的扩展:
SingleThreadMultiplexSourceReaderBase :
https://nightlies.apache.org/flink/flink-docs-master/api/java/org/apache/flink/connector/base/source/reader/SingleThreadMultiplexSourceReaderBase.html该类已配置了线程模型:每个SplitReader 实例使用一个线程读取拆分(但任务管理器中存在多个 SplitReader 实例)。
我们在 SourceReader 类中接下来要做的事情是:
-
提供 SplitReader 供应者;
-
创建一个记录发射器;
-
为 SplitReaders 创建共享资源(会话等)。由于 SplitReader 供应者是在 super() 调用的 SourceReader 构造函数中创建的,因此使用 SourceReader 工厂创建共享资源并将它们传递给供应者是一个好主意;
-
实现start():这里我们应该要求枚举器进行第一次分割;
-
重写SourceReaderBase 父类中的close() 以释放任何创建的资源(例如共享资源);
-
实现initializedState(),以从Split 创建可变的SplitState;
-
实现toSplitType() ,以从可变的 SplitState 创建 Split;
-
实现onSplitFinished():这里,因为它是一个批处理源(有限数据),我们应该要求Enumerator进行下一次分割。
1.3 Split和SplitState
Cassandra Split示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/split/CassandraSplit.javaSourceSplit表示源数据的一个分区。拆分的定义取决于我们正在读取的后端。例如,它可以是(分区开始,分区结束)元组或(偏移量,分割大小)元组。
在任何情况下,Split对象都应该被视为不可变对象:对它的任何更新都应该在相关的SplitState上完成。拆分状态是将存储在Flink检查点内的状态。一个检查点可能发生在两次获取一次分裂之间。因此,如果我们正在读取拆分,我们必须在拆分状态中存储读取进程的当前状态。这个当前状态需要是可序列化的(因为它将成为检查点的一部分),并且后端源可以从中恢复。这样,在故障转移的情况下,读取可以从中断的地方恢复。因此,我们确保不会有重复或丢失的数据。
例如,如果记录的读取顺序在后端是确定的,那么拆分状态可以存储n条已经读取的记录,以便在故障转移后在n+1处重新启动。
1.4 SplitEnumerator和SplitEnumeratorState
SplitEnumerator负责创建拆分并将其提供给阅读器。只要有可能,最好是惰性地生成分割,这意味着每次读取器向枚举数请求分割时,枚举数都会按需生成一个并将其分配给阅读器。
为此,我们实现了SplitEnumerator handleSplitRequest() 方法。延迟拆分生成比拆分发现更可取,在拆分发现中,我们预先生成所有拆分并存储它们,等待将它们分配给阅读器。实际上,在某些情况下,分割的数量可能非常大,并且会消耗大量内存,这可能会在分散阅读器的情况下产生问题。该框架通过实现addReader()提供了对阅读器注册进行操作的能力。但是,由于我们要进行延迟分割生成,因此在那里我们没有什么可做的。在某些情况下,生成拆分的成本太高,因此我们可以预先生成一批(不是全部)拆分来分摊这个成本。需要考虑批处理分割的 数量/大小,以避免消耗过多的内存。
长话短说,Source实现的棘手部分是拆分源数据。最好的平衡是不要有太多的分割(这会导致太多的内存消耗),也不要太少(这会导致次优的并行性)。满足这种平衡的一个好方法是预先评估源数据的大小,并允许用户指定拆分将占用的最大内存。这样他们就可以根据任务管理器上的可用内存配置此参数。这个参数是可选的,所以Source程序需要提供一个默认值。此外,源代码需要控制用户提供的max-split-size不能太小,否则会导致太多的分割。一般的经验法则是给用户一些自由,来保护他们免受不必要的行为。对于这些安全措施,刚性阈值不能很好地工作,因为当突然超过阈值时,Source可能开始失效。
例如,如果我们强制分割的数量低于并行度的两倍,如果作业经常在一个不断增长的表上运行,那么在某个时刻,将会有越来越多的max-split-size的分割,并且将超过阈值。当然,需要在不读取实际数据的情况下评估源数据的大小。Cassandra连接器就是这样做的。
另一个重要的话题是状态。如果作业管理器失败,则拆分枚举器需要恢复。对于分割,我们需要为枚举器提供一个状态,它将成为检查点的一部分。恢复后,将重建枚举数并接收一个枚举数状态,以恢复其先前的状态。在检查点上,当调用SplitEnumerator snapshotState()时,枚举数返回其状态。状态必须包含恢复故障转移后枚举器停止的位置所需的所有内容。在延迟分割生成场景中,状态将包含生成下一个分割所需的所有内容。例如,它可以是下一个分裂的开始偏移量,分裂大小,仍然生成的分裂的数量等等,但是SplitEnumeratorState也必须包含一个分裂的列表,不是发现的分裂的列表,而是要重新分配的分裂的列表。实际上,每当reader失败时,如果它在最后一个检查点之后被分配了分片,那么检查点就不会包含这些分片。因此,在恢复时,阅读器将不再分配分片。有一个回调来处理这种情况:addSplitsBack()。在这里,分配给故障读取器的分片可以放回枚举器状态,以便以后重新分配给阅读器。这里没有内存大小风险,因为要重新分配的分片数量非常低。
以上是关于分裂的更重要的话题。还有两个方法需要实现:用于资源创建/处置的常用start() /close()方法。关于start()的实现,Flink连接器框架提供了enumeratorContext callAsync()实用程序来异步运行长时间的处理,比如拆分准备或拆分发现(如果不可能生成延迟拆分)。实际上,start()方法在源协调器线程中运行,我们不希望长时间阻塞它。
1.5 SplitReader
Cassandra SplitReader示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/reader/CassandraSplitReader.java这个类负责读取框架调用handleSplitsChanges()时接收到的实际分片。拆分阅读器的主要部分是fetch()实现,我们读取接收到的所有分片,并将读取的记录作为RecordsBySplits对象返回。该对象包含分割id到所属记录的映射,以及已完成分割的id。需要考虑的要点:
-
fetch调用必须是非阻塞的。如果其代码中的任何调用是同步的并且可能很长,则必须提供fetch()的转义。当框架调用wakeUp()时,我们应该通过设置一个AtomicBoolean来中断获取。
-
Fetch调用需要是可重入的:一个已经读过的分片不能被重读。我们应该将其从分割列表中删除,并在返回的RecordsBySplits中将其id添加到已完成的分割(以及空分割)中。
实现者提前退出fetch()方法是完全可以的。此外,失败可能会中断获取。在这两种情况下,框架稍后都会再次调用fetch()。在这种情况下,fetch方法必须使用已经讨论过的拆分状态从停止读取的位置恢复读取。如果由于后端约束而无法恢复对分割的读取,那么唯一的解决方案就是自动读取分割(要么根本不读取分割,要么完全读取分割)。这样,在读取中断的情况下,不会输出任何内容,并且可以在下一次读取调用时从开始重新读取分割,从而没有重复。但是,如果完全读取分割,则需要考虑以下几点:
-
我们应该确保总的拆分内容(来自源的记录)适合内存,例如通过指定以字节为单位的最大拆分大小(请参阅SplitEnumarator)。
-
分裂状态变得无用,只需要一个分裂类。
1.6 RecordEmitter
Cassandra RecordEmitter示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/reader/CassandraRecordEmitter.javaSplitReader以实现者为每条记录提供的中间记录格式的形式读取记录。它可以是后端返回的原始格式,也可以是允许事后提取实际记录的任何格式。该格式不是源程序期望的最终输出格式。它包含转换为记录输出格式所需的所有内容。我们需要实现RecordEmitter#emitRecord()来完成这个转换。一个好的模式是用一个映射函数初始化RecordEmitter。实现必须是幂等的。实际上,这种方法可能会在中途中断。在这种情况下,稍后将再次将同一组记录传递给记录发射器。
1.7 Serializers
Cassandra SplitSerializer和SplitEnumeratorStateSerializer示例:
https://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/split/CassandraSplitSerializer.javahttps://github.com/apache/flink-connector-cassandra/blob/d92dc8d891098a9ca6a7de6062b4630079beaaef/flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/enumerator/CassandraEnumeratorStateSerializer.java
我们需要为以下情况提供单例序列化器:
-
拆分:当将拆分从枚举器发送到读取器时,以及当检查读取器的当前状态时,拆分被序列化
-
SplitEnumeratorState:序列化器用于SplitEnumerator#snapshotState()的结果。
对于两者,我们都需要实现SimpleVersionedSerializer。在一些重要的地方需要注意:
-
在Flink中禁止使用Java序列化,主要是出于迁移考虑。我们应该使用ObjectOutputStream手动编写对象的字段。当一个类不被ObjectOutputStream(不是String, Integer, Long…)支持时,我们应该将对象的大小以字节为单位写入Integer,然后写入转换为byte[]的对象。类似的方法用于序列化集合。首先写入集合的元素数量,然后序列化所有包含的对象。当然,对于反序列化,我们以相同的顺序进行完全相同的读取。
-
可能会有很多拆分,所以我们应该缓存SplitSerializer中使用的OutputStream。我们可以使用。
ThreadLocal<DataOutputSerializer> SERIALIZER_CACHE = ThreadLocal. withinitial (() -> new DataOutputSerializer(64));初始流大小取决于拆分的大小。
2.测试&&总结
本文收集了实现领域的反馈,因为javadoc无法涵盖高性能和可维护源的所有实现细节。希望你喜欢这篇文章,并且它给了你为Flink项目贡献一个新连接器的愿望!
Flink:快速掌握批处理数据源的创建方法
相关文章:
Flink:快速掌握批处理数据源的创建方法
Flink 社区最近 “基于FLIP-27” 设计了新的 Source 框架 。一些连接器(API)已迁移到这个新框架。本文介绍了如何使用这个新框架创建批处理源。 它是在为Cassandra实现Flink 批处理源时构建的。如果您有兴趣贡献或迁移连接器,这篇文章非常适合…...

基于cubeMX的正点原子miniSTM32对W25Q64的存储使用
一、实现目标 使用cubeMX建立项目工程,结合正点原子提供的hal库对W25Q64闪存调用的例程,实现W25Q64的读写。 二、实现过程 1、首先建立cubeMX工程,其他项设置不再叙述,只看连接W25Q64的SPI设置,这里使用SPI1…...
)
C++笔记(三)
封装意义: 在设计类的时候,属性和行为写在一起,表现事物 类在设计时,可以把属性和行为放在不同的权限下,加以控制。 访问权限有三种: public 公共 类内 类外都可以访问, protected保护 类内可以访问…...

c语言不定参数
时间记录:2024/1/22 一、不定参数的函数定义和使用到的c函数 (1)定义 void fun1(参数类型 argName,...); 示例: void fun1(int count,...);(2)获取不定参数的值 #include <stdarg.h> //包含头文件…...

云手机与实体手机的对比
在数字化时代,云手机作为一种虚拟手机在云端服务器上运行,与传统的实体手机相比存在诸多差异。让我们深入探讨云手机与实体手机之间的区别,以便更好地了解它们的特点和优势。 外观上的差异 实体手机具有实际的外观和重量,占据一定…...

diffusion 和 gan 的优缺点对比
sample速度GAN更快,Diffusion需要迭代更多次。 训练难度GAN 的训练可能是不稳定的,容易出现模式崩溃和训练振荡等问题。Diffusion 训练loss收敛性好,比较平稳。 模拟分布连续性Diffusion相较于GAN可以模拟更加复杂,更加非线性的分…...
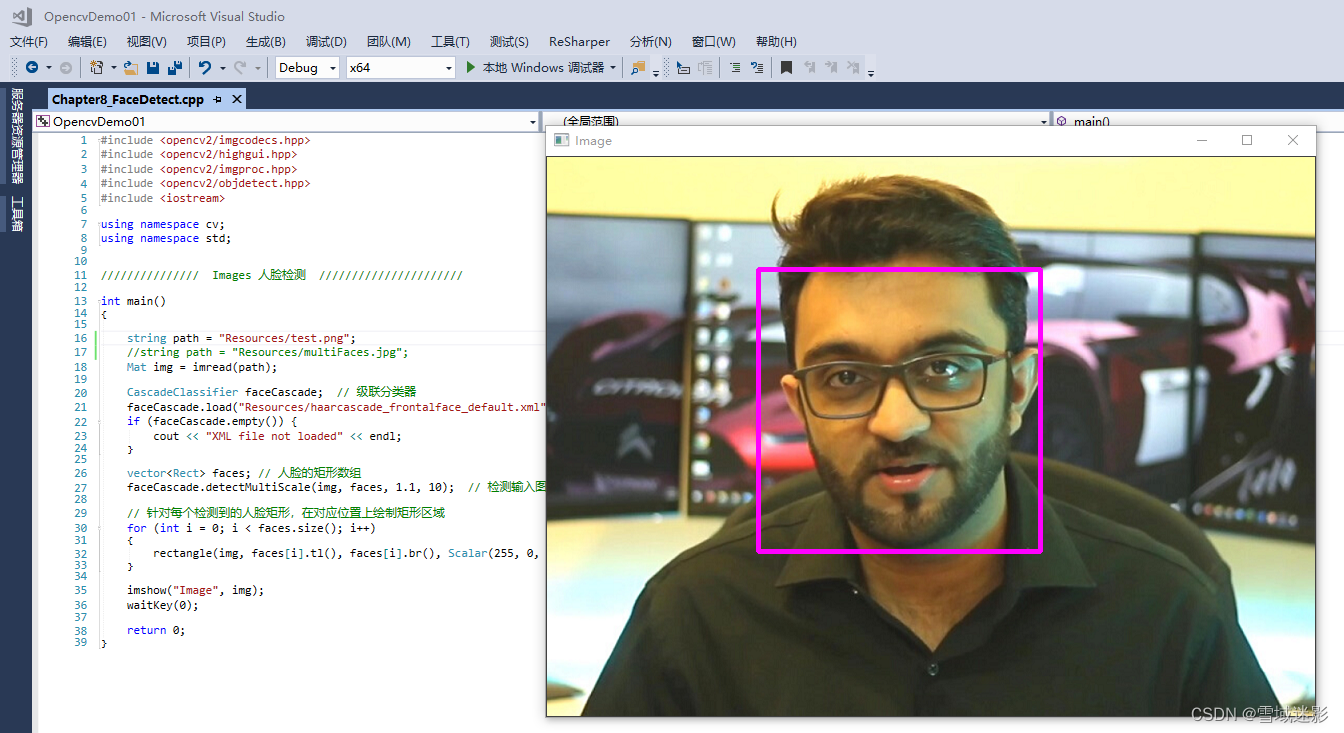
VC++中使用OpenCV进行人脸检测
VC中使用OpenCV进行人脸检测 对于上面的图像,如何使用OpenCV进行人脸检测呢? 使用OpenCV进行人脸检测十分简单,OpenCV官网给了一个Python人脸检测的示例程序, objectDetection.py代码如下: from __future__ import p…...

11Docker数据持久化
Docker数据持久化 容器中数据持久化主要有两种方式: 数据卷(Data Volumes)数据卷容器(Data Volumes Dontainers) 数据卷 数据卷是一个可供一个或多个容器使用的特殊目录,可以绕过UFS(Unix F…...
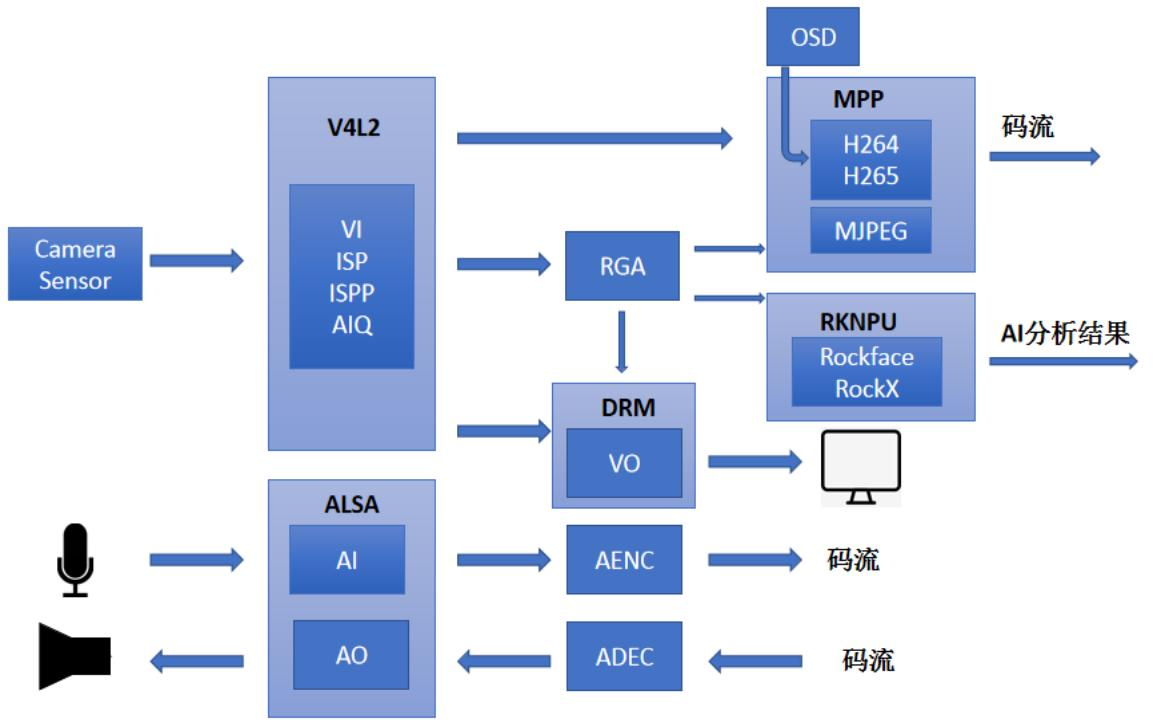
RK3588平台开发系列讲解(视频篇)RKMedia框架
文章目录 一、 RKMedia框架介绍二、 RKMedia框架API三、 视频处理流程四、venc 测试案例沉淀、分享、成长,让自己和他人都能有所收获!😄 📢RKMedia是RK提供的一种多媒体处理方案,可实现音视频捕获、音视频输出、音视频编解码等功能。 一、 RKMedia框架介绍 功能: VI(输…...
Vue3 Teleport 将组件传送到外层DOM位置
✨ 专栏介绍 在当今Web开发领域中,构建交互性强、可复用且易于维护的用户界面是至关重要的。而Vue.js作为一款现代化且流行的JavaScript框架,正是为了满足这些需求而诞生。它采用了MVVM架构模式,并通过数据驱动和组件化的方式,使…...
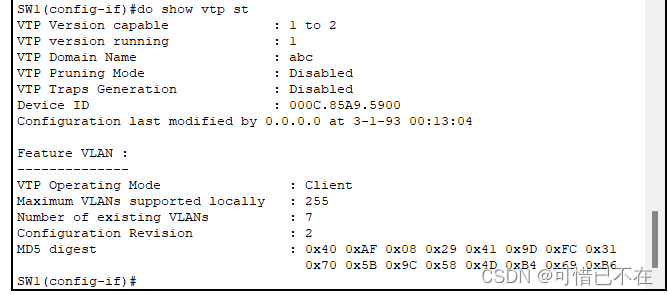
【学网攻】 第(5)节 -- Cisco VTP的使用
文章目录 【学网攻】 第(1)节 -- 认识网络【学网攻】 第(2)节 -- 交换机认识及使用【学网攻】 第(3)节 -- 交换机配置聚合端口【学网攻】 第(4)节 -- 交换机划分Vlan 前言 网络已经成为了我们生活中不可或缺的一部分,它连接了世界各地的人们,让信息和资…...

uniapp复选框 实现排他选项
选择了排他选项之后 复选框其他选项不可以选择 <view class"reportData" v-for"(val, index) in obj" :key"index"> <view v-if"val.type 3" ><u-checkbox-group v-model"optionValue" placement"colu…...

openssl3.2/test/certs - 004 - cross root and root cross cert
文章目录 openssl3.2/test/certs - 004 - cross root and root cross cert概述笔记END openssl3.2/test/certs - 004 - cross root and root cross cert 概述 索引贴 openssl3.2 - 官方demo学习 - test - certs 笔记 // \file my_openssl_linux_log_doc_004.txt // openssl…...
图像分类】【深度学习】【轻量级网络】【Pytorch版本】EfficientNet_V2模型算法详解
【图像分类】【深度学习】【轻量级网络】【Pytorch版本】EfficientNet_V2模型算法详解 文章目录 【图像分类】【深度学习】【轻量级网络】【Pytorch版本】EfficientNet_V2模型算法详解前言EfficientNet_V2讲解自适应正则化的渐进学习(Progressive Learning with adaptive Regul…...

05.Elasticsearch应用(五)
Elasticsearch应用(五) 1.目标 咱们这一章主要学习Mapping(映射) 2.介绍 Mapping是对索引库中文档的约束,类似于数据表结构,作用如下: 定义索引中的字段的名称定义字段的数据类型ÿ…...

npm更换镜像
大家好!今天给大家分享的知识是如何更换npm镜像 前言 有时候在加载npm时有时会很慢,那是由于node安装插件是从国外服务器下载,受网络影响大,速度慢且可能出现异常,这时候就需要更换镜像,使插件的安装快捷&…...
)
野指针(C语言)
野指针 //概念:野指针就是指针指向的位置是不可知的(随机的,不正确的 //,没有明确限制的,空间还属于操作系统而不属于程序的) //野指针成因: //1.指针未初始化 #include <stdio.h> int main() { int* p;//局部变量指针未初始化,默认为随机值 //此时p指向的空间不…...

动物姿态识别(数据集+代码)
动物姿态识别是指利用计算机视觉和深度学习技术来识别动物的姿态,即确定动物身体的姿态、方向和位置等信息。这种技术可应用于动物行为研究、动物健康监测、智能养殖等领域。 动物姿态识别的关键技术包括图像处理、特征提取和分类器设计。首先,需要对动…...
JSON-handle工具安装及使用
目录 介绍下载安装简单操作 介绍 JSON-Handle 是一款非常好用的用于操作json的浏览器插件,对于开发人员和测试人员来说是一款很好用的工具,如果你还没有用过,请赶紧下载安装吧,下面是安装过程和具体使用。 下载安装 点击下载JSON…...
kali安装LAMP和DVWA
LANMP简介 LANMP是指一组通常用来搭建动态网站或者服务器的开源软件,本身都是各自独立的程序,但是因为常被放在一起使用,拥有了越来越高的兼容度,共同组成了一个强大的Web应用程序平台。 L:指Linux,一类Unix计算机操作…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...