基于机器学习的地震预测(Earthquake Prediction with Machine Learning)
基于机器学习的地震预测(Earthquake Prediction with Machine Learning)
- 一、地震是什么
- 二、数据组
- 三、使用的工具和库
- 四、预测要求
- 五、机器学习进行地震检测的步骤
- 六、总结
一、地震是什么
地震几乎是每个人都听说过或经历过的事情。地震基本上是一种自然发生的事件,当地壳中突然释放能量导致地面振动或晃动时,就会发生地震。在地球表面之下,有很大一部分被称为构造板块,它们构成了地球的外层。这些部分经常移动并相互作用。由于这种相互作用和运动,这些板块可能会因摩擦而锁定,这反过来又会导致压力增加。
随着时间的推移,随着压力的不断积累,在某一点上,它达到了一个点,沿着板块边界的岩石破裂,释放出大量储存的能量。这种释放出来的能量以地震波的形式在地壳中传播,从而导致地面震动和颤抖。地震的强度和强度都是用里氏震级来测量的。
二、数据组
地震数据集包含2001年1月1日至2023年1月1日在世界各地发生的各种地震的详细信息。它是与地震事件相关的结构化数据。这些数据是由地震研究所、研究机构等组织收集和维护的。这个数据集可以用来建立和训练各种机器学习模型,这些模型可以预测地震,这将有助于拯救人们的生命,并采取必要的措施来减少造成的损害。
数据集可以使用此此链接下载: dataset
该数据集总共包含782行和19个属性(列)。属性的简要描述如下:
标题: 指给地震起的名称/标题
震级: 用来描述地震的强度或强度
日期: 地震发生的日期和时间
cdi: cdi表示给定地震记录的最高烈度
mmi: mmi代表修正Mercalli烈度,表示地震的最大仪器报告烈度
alert: 此属性指的是与特定地震相关的可能威胁或风险的警报级别
tsunami: 表示本次地震是否引起海啸
震级: 用来描述地震的严重程度。地震的重要性与这个数字成正比
net: 表示采集数据的源的id。
nst: 此属性用于描述用于确定地震位置的地震台站的总数。
dmin: 表示离震中最近的监测站的水平距离。
缺口: 用于确定地震的水平位置。数值越小,表明确定地震水平位置的可靠性越高
magType: 这是指用于计算地震震级的算法类型
深度: 表示地震开始破裂的深度
纬度,经度: 用坐标系统表示地震发生的位置
location: 该国家的具体位置
大陆: 指发生地震的大陆
country: 表示受地震影响的国家
三、使用的工具和库
该项目使用了以下Python库:
● Numpy
● Matplotlib
● Seaborn
● Pandas
● Scikit-learn
四、预测要求
先决条件是:
NumPy:
-
理解数组和矩阵运算。
-
能够有效地进行数值计算。
Pandas:
-
熟练处理和分析结构化数据。
-
了解数据框架和系列。
-
能够处理和预处理地震数据,包括清理、过滤和转换数据。
Matplotlib:
-
掌握基本的绘图技术,包括线形图、散点图和直方图。
-
理解子图,以便在单个图中创建多个图。
-
熟悉高级绘图类型,如热图、等高线图和地理可视化。
Seaborn:
-
了解统计数据可视化技术。
-
Seaborn功能的知识,创建视觉吸引力和信息丰富的情节。
Scikit-learn:
-
熟悉机器学习概念,如监督学习和无监督学习。
-
了解模型选择、培训和评估程序。
五、机器学习进行地震检测的步骤
- 导入所需的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns- 导入所需库后,可以读取和显示数据集。可以使用**read_csv()**函数读取数据集,并且可以使用head()函数显示数据集的前5行。
data = pd.read_csv('earthquake_data.csv')
data.head()
输出:
输出显示数据集的前5行。
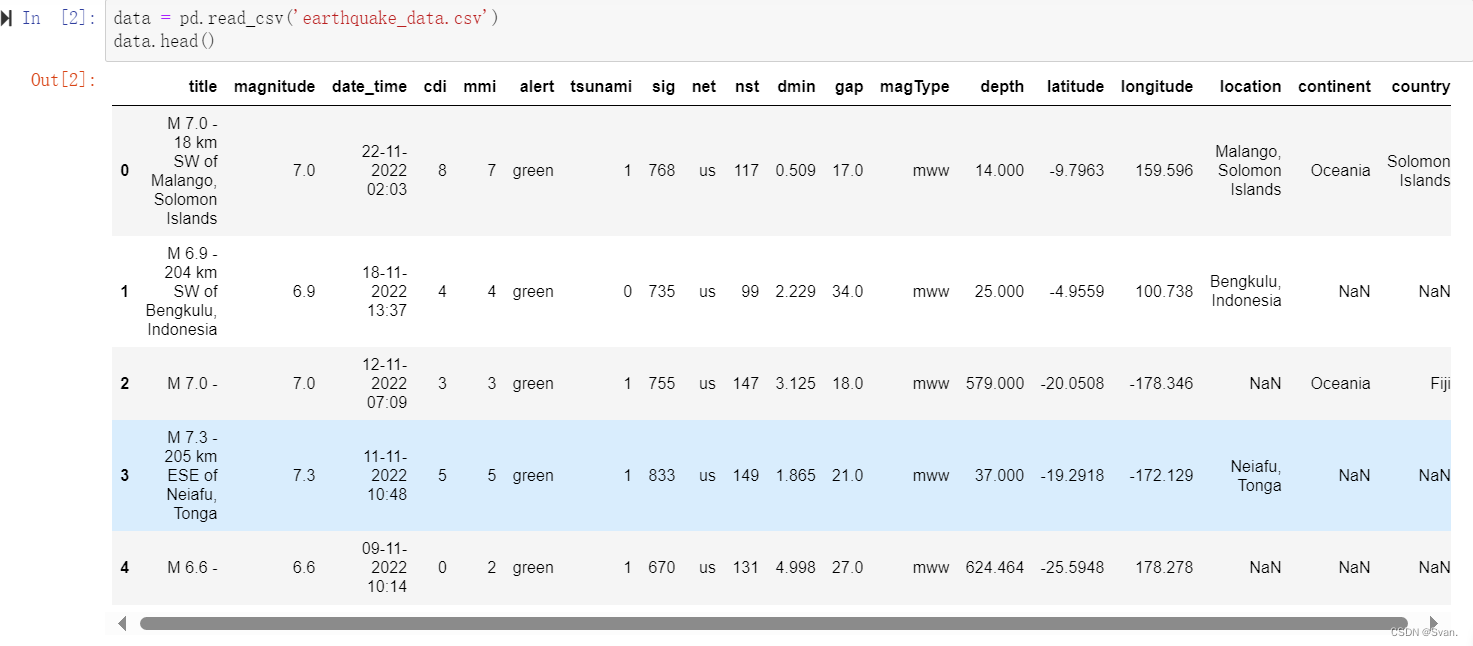
3. 一旦数据被读取,就可以对数据进行一些基本的探索性数据分析,以获得对数据的一些见解,并对数据有更多的了解。
data.info()
输出:
info()函数用于获取有关数据集中存在的属性、数据集中的行数、每个属性中缺失值的数量、每个属性的数据类型等信息。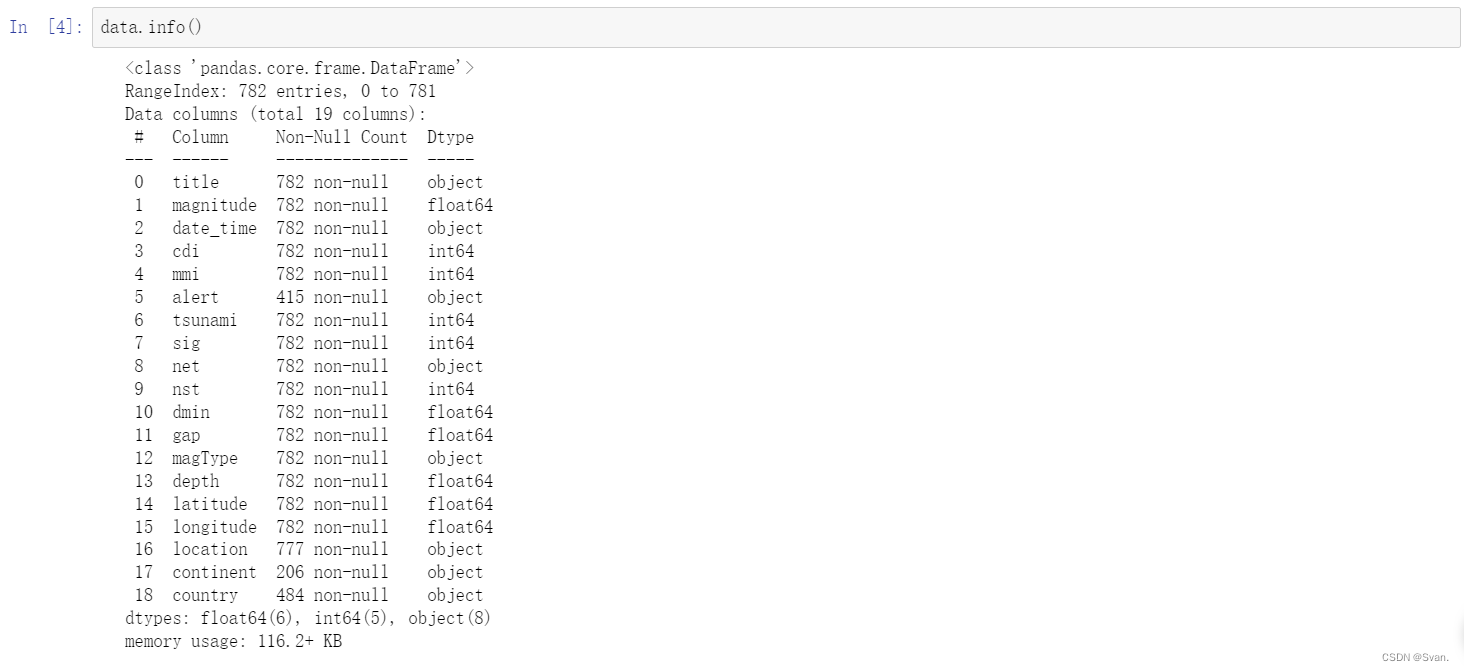
4. 除了info()函数,description()函数还可用于获取数据集的统计信息。
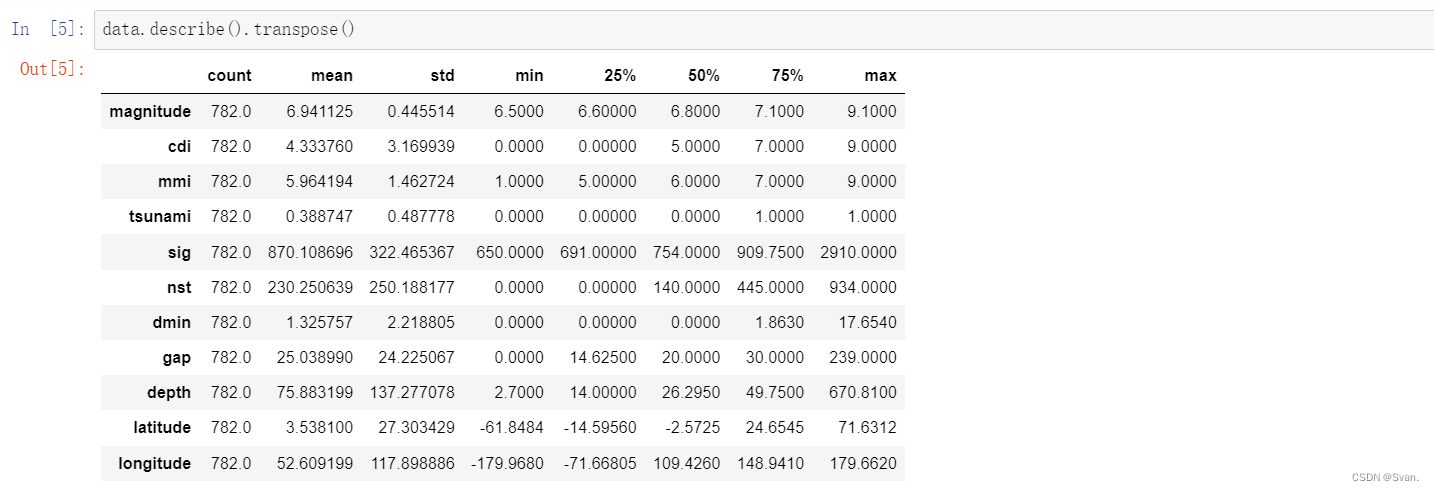
data.describe().transpose()
输出:
description()函数为属于数据集的所有属性提供最小值,最大值,平均值,标准差等统计见解。
5. isnull()函数可用于查找数据集中是否存在任何空值,聚合函数sum()用于获取数据集中每个属性中空值的总数。
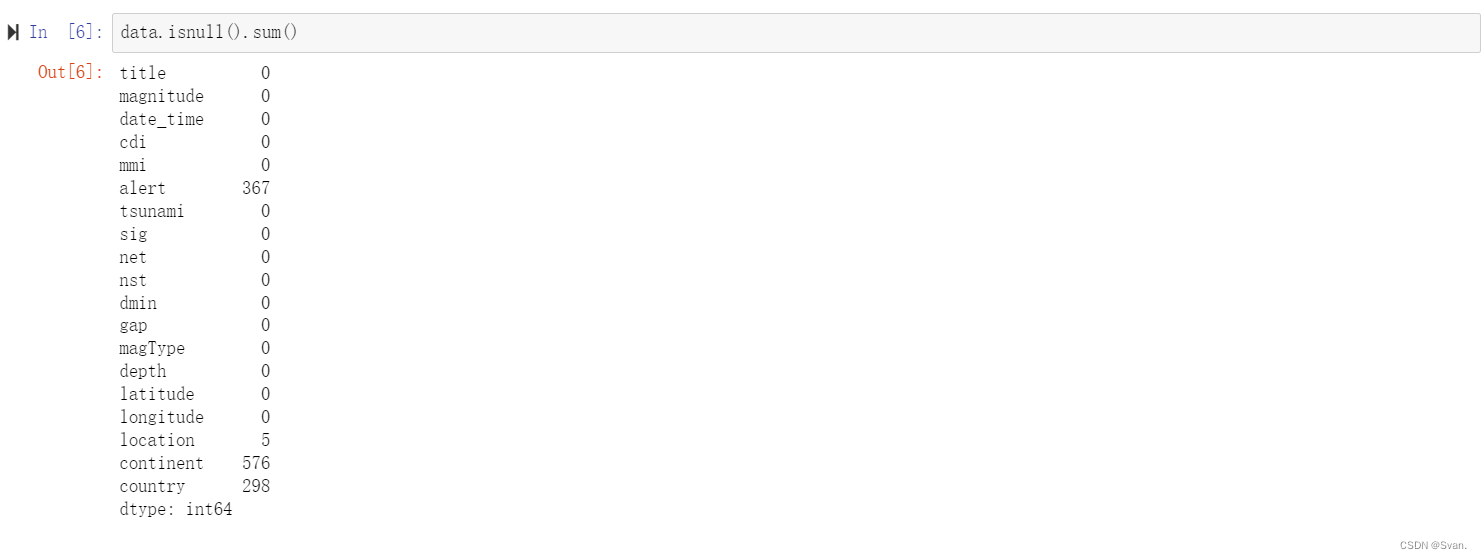
data.isnull().sum()
输出:
输出图像显示数据集所有属性中空值的总数。列alert、continent和country分别有367,576和298个空值。
6. 在获得关于数据的一些基本见解之后,我们可以继续清理数据集。清理数据集将有助于将其转换为更好的形式,以便以后用于训练各种机器学习模型。
features = ["magnitude", "depth", "cdi", "mmi", "sig"]
target = "alert"
data = data[features + [target]]
data.head()输出:
在上面给出的代码中,我们创建了一个名为features的列表,其中包含名为震级,深度,cdi, mmi, sig。我们将使用机器学习模型来预测警报属性。
警报属性存储在一个名为target的变量中。在下一步中,我们将创建一个数据框架,并只选择功能列表中提到的列/属性以及目标变量。
新数据框的前10行可以使用head()函数显示。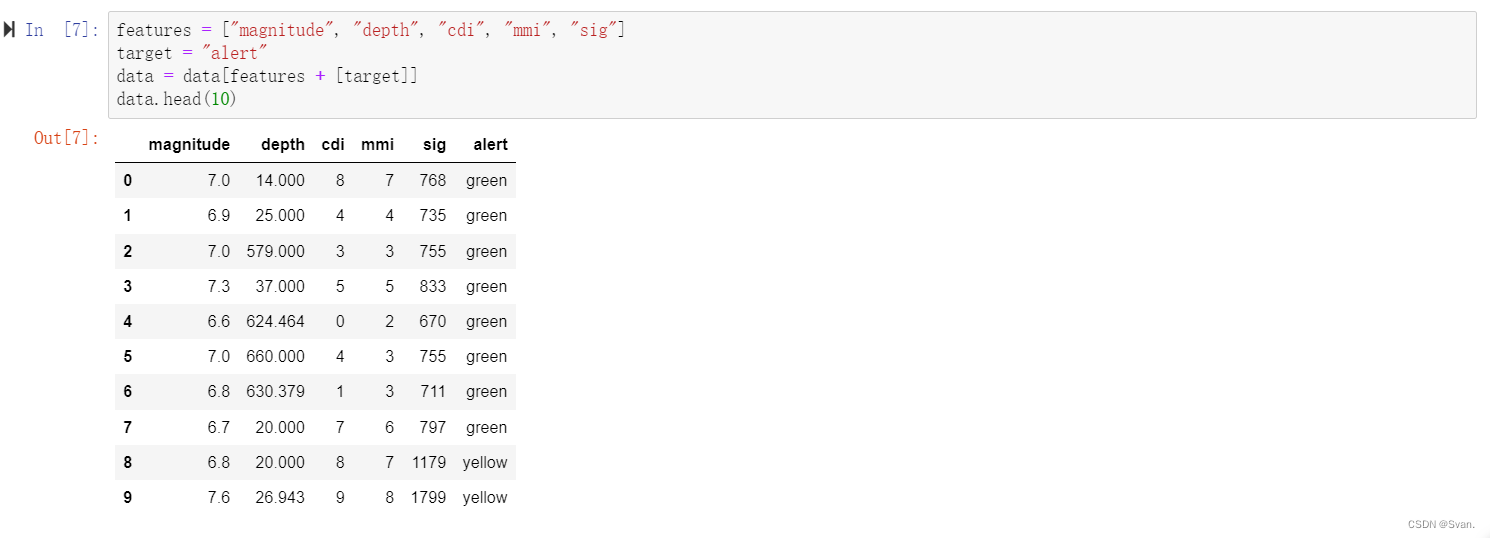
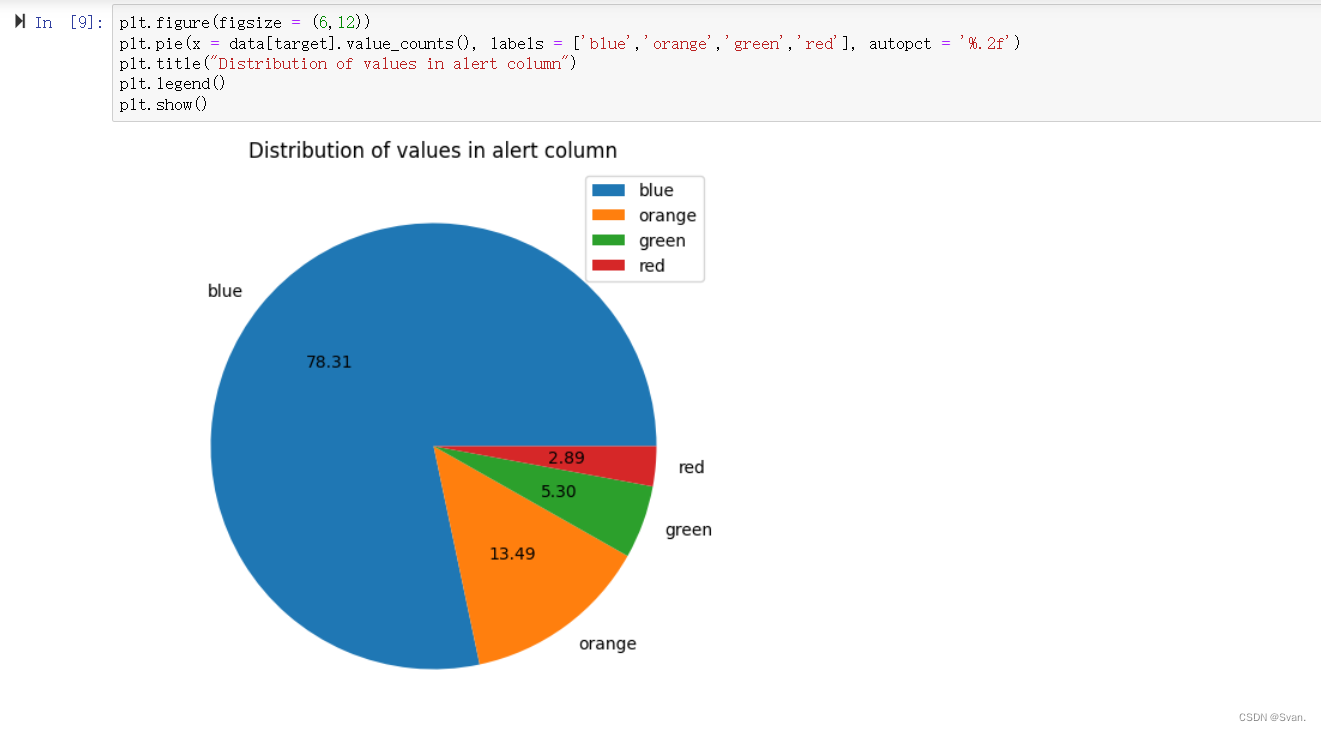
- 警报属性中所有值的计数可以使用饼图显示。
plt.figure(figsize = (6,12))
plt.pie(x = data[target].value_counts(), labels = ['blue','orange','green','red'], autopct = '%.2f')
plt.title("Distribution of values in alert column")
plt.legend()
plt.show()输出:
饼状图显示警报列中出现的各种值的分布。各种值出现的百分比为:蓝色= 78.31%,橙色= 13.49%,绿色= 5.30%,红色= 2.89%。
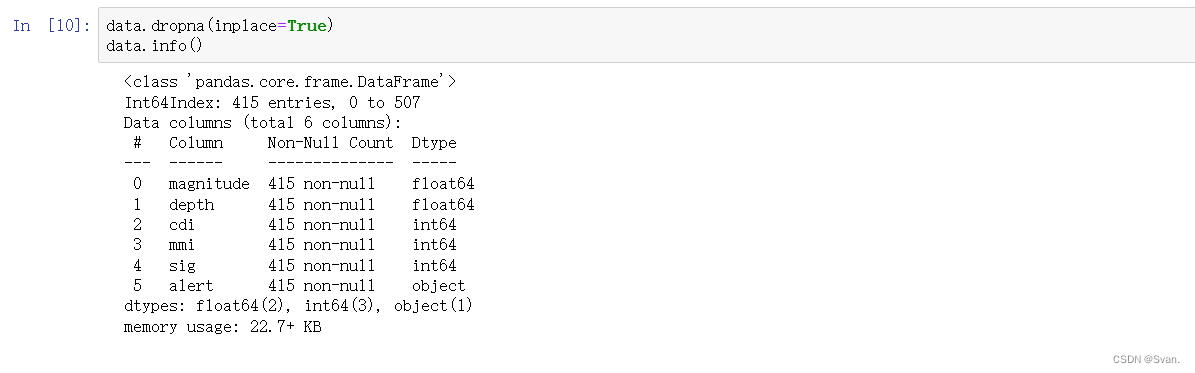
8. 前面我们已经看到数据集中的一些属性包含某些空值。由于空值不多,因此可以使用dropna()函数从数据集中删除这些值。
data.dropna(inplace=True)
data.info()输出:
使用dropna()函数删除空值,在下一行中,使用info()函数获取有关数据集的一些基本信息。
9. 在下一步中,我们将对数据进行预处理。在此步骤中,将更改某些属性的数据类型。代码中将属性cdi、mmi、sig从int64类型转换为int8类型,将属性depth从float64类型转换为int16类型。属性警报也从类型对象转换为类别。这些转换主要是为了内存优化。转换数据类型的其他原因是,使用整数而不是浮点数以更好的方式表示数据。
data = data.astype({'cdi': 'int8', 'mmi': 'int8', 'sig': 'int8', 'depth': 'int16', 'alert': 'category'})
data.info()输出:一旦转换了属性的数据类型,就可以使用info()函数来显示属性关于属性及其数据类型的信息。

10. 现在,让我们检查目标(警报)列中出现的各种值的计数。我们可以使用条形图来实现这个目的。
data[target].value_counts().plot(kind='bar', title='Count (target)', color=['green', 'yellow', 'orange', 'red']);
输出:输出图像是一个条形图,显示alert属性中所有值的计数。的值是绿色,黄色,橙色,红色。大多数值是绿色的,其次是黄色、橙色和红色。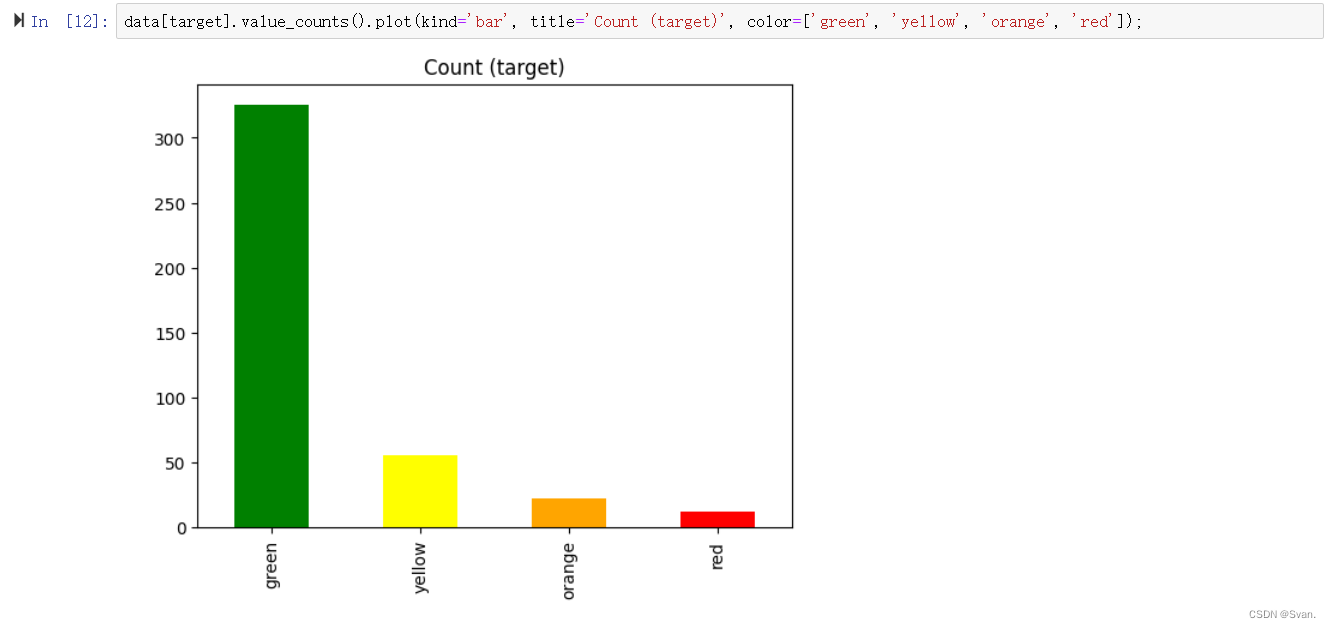
11. 在前面的步骤中,可以看到alert属性中最常出现的值是绿色的价值。这表明alert属性是不平衡的,即alert属性中的值没有相同的出现次数。为了克服alert属性不平衡的问题,我们可以执行over-sampling过采样也有助于模型表现良好,因为它消除了被偏向于出现次数最高的值的可能性。
X = data[features]
y = data[target]X = X.loc[:,~X.columns.duplicated()]sm = SMOTE(random_state=42)
X_res, y_res= sm.fit_resample(X, y,)y_res.value_counts().plot(kind='bar', title='Count (target)', color=['green', 'orange', 'red', 'yellow']);在前两行中,变量X被初始化为名为data的数据框。这是一个功能列表先前指定的属性。变量y是用数据框架的目标(警报)列初始化的。在下一行中,代码从X值中删除所有重复的列。只有那些列不会重复,并将存储在X中。完成此操作后,我们将创建SMOTE算法的一个新实例。SMOTE代表合成少数过采样技术。这是一种常用的解决问题的技术机器学习中的类不平衡。创建SMOTE算法的实例后,可以使用该实例应用SMOTE算法对变量X和y进行重采样,应用SMOTE算法得到的值为分别存储在x_res和y_res变量中。完成后,我们可以使用条形图绘制y_res变量中的值。
输出:从柱状图中可以明显看出,y_res变量中存在的所有值具有相同数量的出现了。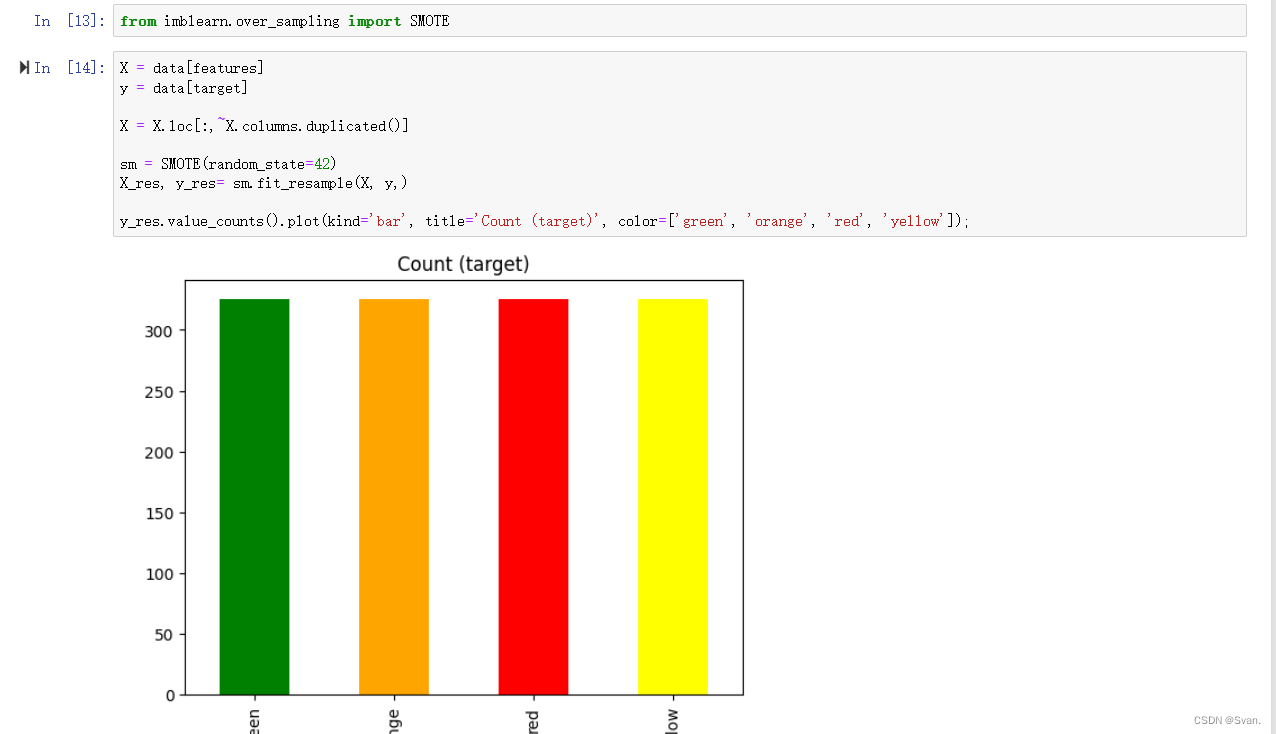
12. 接下来,我们可以使用train_test_split()将数据分割为训练数据和测试数据函数。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.2, random_state=42)注意,在上面的代码中,我们使用变量X_res和y_res作为独立变量和因变量分别为。我们使用X_res和y_res,因为它没有问题alert属性不平衡。原始数据帧在告警中面临着不平衡的问题属性。
- 在我们开始在数据集上实现模型之前,我们必须使数据符合标准这将最终帮助机器学习模型以更好的方式理解数据。这可以使用StandardScaler()函数来完成。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)- 我们可以绘制出数据集中存在的各种值之间的相关性。相关矩阵表示数据集中存在的各种变量之间的关系,以及每个变量如何受到其他变量的影响。也可以使用下面的代码绘制它。
plt.figure(figsize = (10,6))
sns.heatmap(data.corr(), annot=True, fmt=".2f")
plt.plot()输出:
相关矩阵表示数据集中存在的各种值之间的相关系数。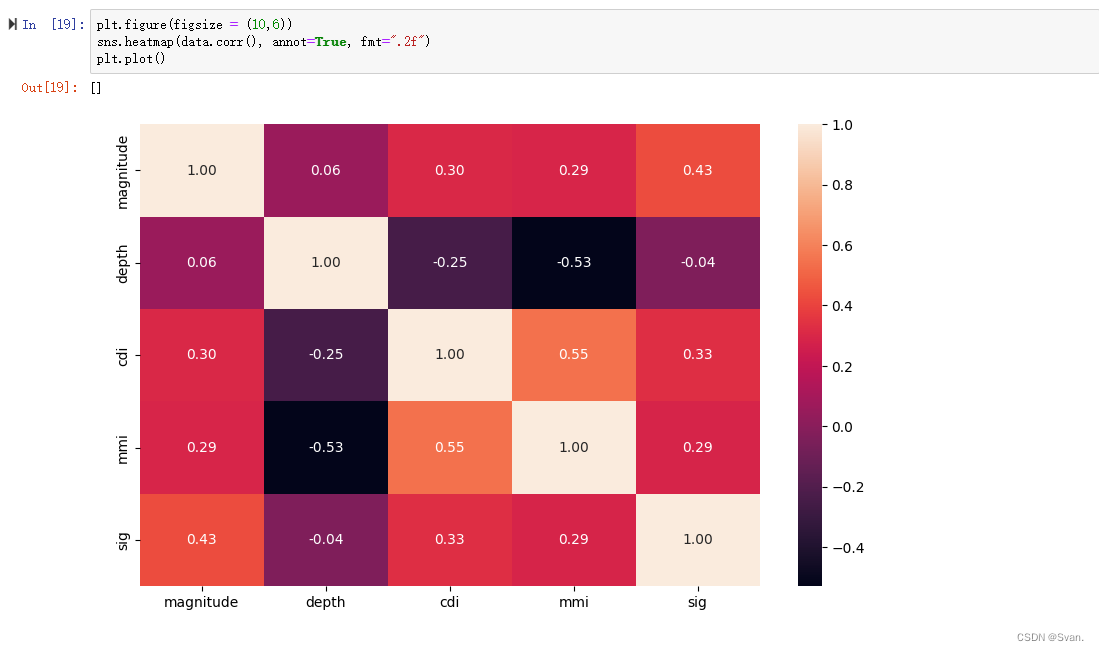
15. 下一步,我们可以在训练数据集上训练各种机器学习模型这些模型的性能可以使用测试数据集进行评估。
models = []
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train, y_train)可以使用predict()方法对模型进行预测。模型的性能可以使用指标accuracy_score、classification_report、confusion_matrix。
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
dt_pred = dt.predict(X_test)
print(accuracy_score(dt_pred,y_test)*100)
print(classification_report(dt_pred, y_test))
sns.heatmap(confusion_matrix(dt_pred, y_test), annot = True)
plt.plot()输出:出现在混淆矩阵对角线上的值(54,64,60,51)表示被模型正确分类的数据点的数量。从准确性来看得分,显然决策树分类器的准确率为88.07%。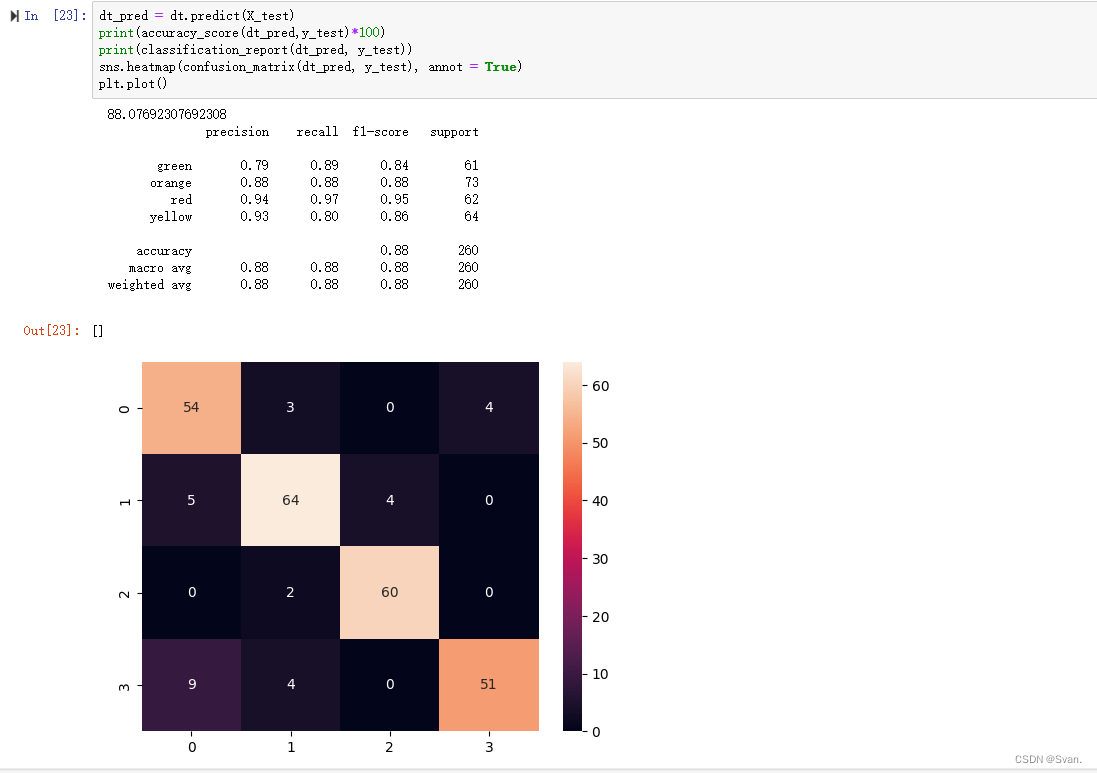
16. 我们要实现的下一个模型是KNN。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)该模型的预测方式与之前的预测方式相似
knn_pred = knn.predict(X_test)
print(accuracy_score(knn_pred, y_test)*100)
print(classification_report(knn_pred, y_test))
sns.heatmap(confusion_matrix(knn_pred, y_test), annot = True)
plt.plot()输出:
混淆矩阵和准确度分数可以像前面一样显示。从输出可以明显看出KNN的准确率为89.23%。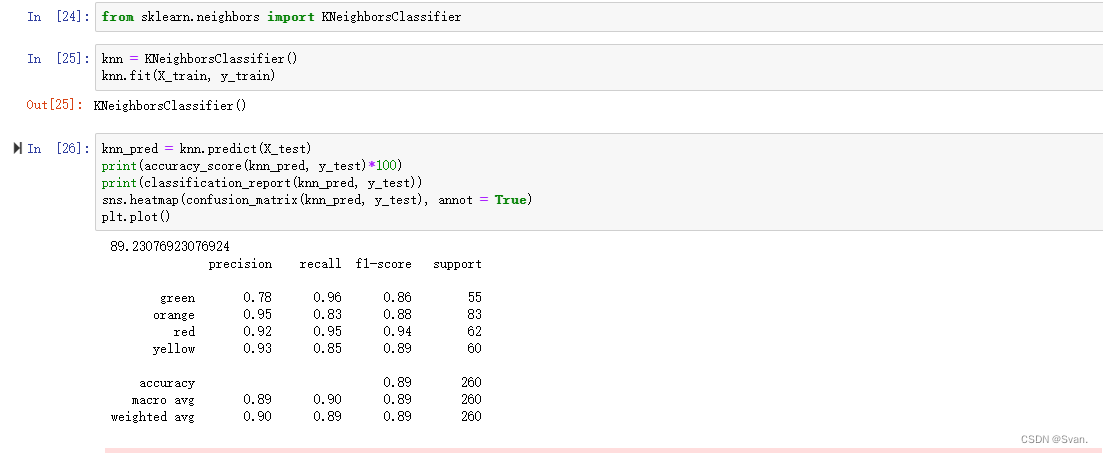
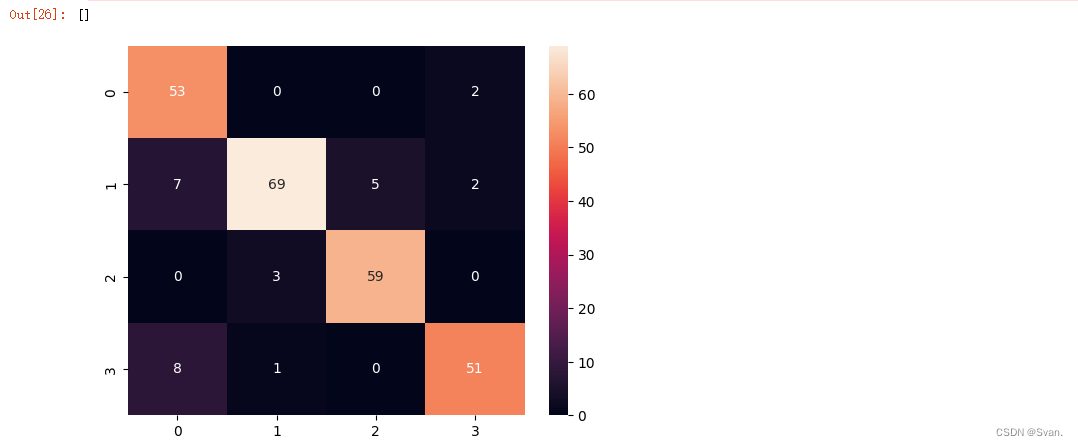
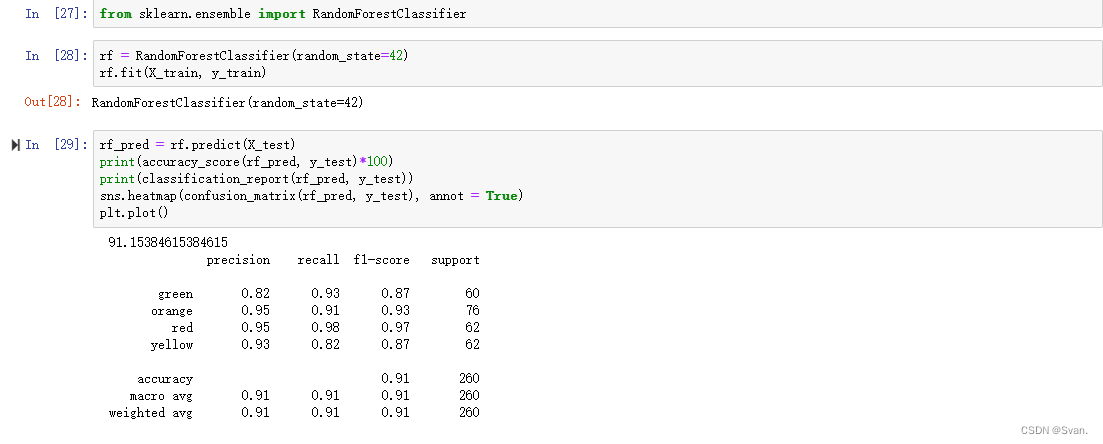
17. 在使用KNN算法之后,我们可以在数据集上使用随机森林分类器。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)来自随机森林分类器的预测可以使用predict()方法进行。混淆矩阵和准确性评分可以像前面一样显示。
rf_pred = rf.predict(X_test)
print(accuracy_score(rf_pred, y_test)*100)
print(classification_report(rf_pred, y_test))
sns.heatmap(confusion_matrix(rf_pred, y_test), annot = True)
plt.plot()输出:可以看出随机森林分类器的准确率为91.15%。
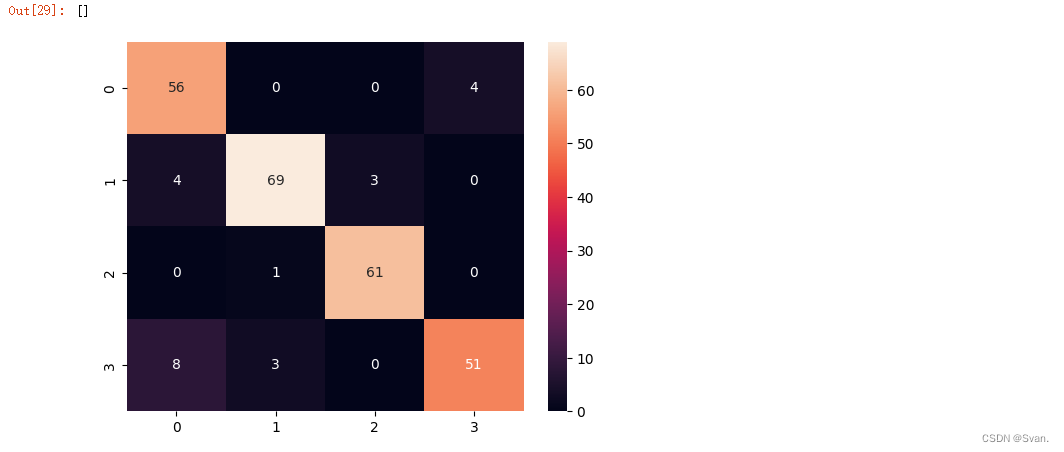
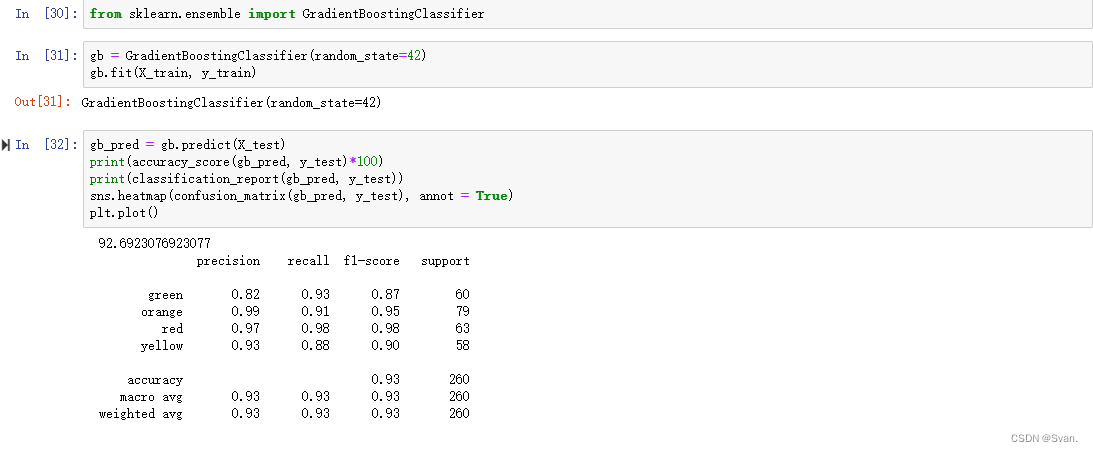
18. 我们将实现的最后一个模型是梯度增强分类器。
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
gb.fit(X_train, y_train)混淆矩阵和精度可以像前面那样显示。
gb_pred = gb.predict(X_test)
print(accuracy_score(gb_pred, y_test)*100)
print(classification_report(gb_pred, y_test))
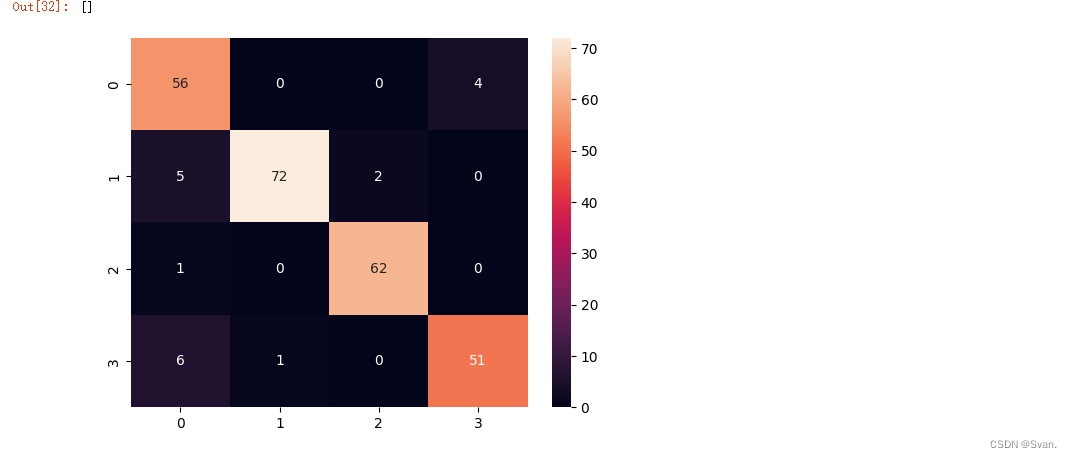
sns.heatmap(confusion_matrix(gb_pred, y_test), annot = True)
plt.plot()输出:梯度增强算法的准确率为92.69%。
六、总结
总之,机器学习技术在地震预测方面显示出了很好的结果。通过分析各种数据源,如地震记录、地理空间信息等,机器学习模型可以学习模式、趋势和关系,这些可以帮助识别潜在的地震发生。
虽然机器学习模型可以帮助预测地震,但重要的是要注意,这是一个正在进行的研究领域,实现可靠和准确的预测仍然是一项复杂的任务。领域专家和机器学习工程师之间的合作努力对于推进该领域和开发可以帮助早期检测地震的强大模型至关重要。
相关文章:
基于机器学习的地震预测(Earthquake Prediction with Machine Learning)
基于机器学习的地震预测(Earthquake Prediction with Machine Learning) 一、地震是什么二、数据组三、使用的工具和库四、预测要求五、机器学习进行地震检测的步骤六、总结 一、地震是什么 地震几乎是每个人都听说过或经历过的事情。地震基本上是一种自…...

《30天自制操作系统》 第一周(D1-D7) 笔记
前言:这是我2023年5月份做的一个小项目,最终是完成了整个OS。笔记的话,只记录了第一周。想完善,却扔在草稿箱里许久。最终决定,还是发出来存个档吧。 一、汇编语言 基础指令 MOV: move赋值,数据传送指令…...

SQL注入:报错注入
SQL注入系列文章:初识SQL注入-CSDN博客 SQL注入:联合查询的三个绕过技巧-CSDN博客 目录 什么是报错注入? 报错注入常用的3个函数 UpdateXML ExtractValue Floor rand(随机数) floor(向上取整&…...

K8s 安装部署-Master和Minion(Node)文档
K8s 安装部署-Master和Minion(Node)文档 操作系统版本:CentOS 7.4 Master :172.20.26.167 Minion-1:172.20.26.198 Minion-2:172.20.26.210(后增加节点) ETCD:172.20.27.218 先安装部署ETC…...
OpenAI 降低价格并修复拒绝工作的“懒惰”GPT-4,另外ChatGPT 新增了两个小功能
OpenAI降低了GPT-3.5 Turbo模型的API访问价格,输入和输出价格分别降低了50%和25%。这对于使用API进行文本密集型应用程序的用户来说是一个好消息。 OpenAI官网:OpenAI AIGC专区:aigc 教程专区:AI绘画,AI视频&#x…...

springboot+value静态属性获取配置文件中的值的操作方法
1.配置类需要让spring管理 2.set方法不要加static 3.如果静态属性是private修饰,则在使用的时候,需要 类名.getXXX方法 如果静态属性是public修饰,则在使用的时候,需要 类名.属性名 import org.springframework.beans.factory.an…...
Prometheus 架构全面解析
在本指南中,我们将详细介绍 Prometheus 架构。 Prometheus 是一个用 Golang 编写的开源监控和告警系统,能够收集和处理来自各种目标的指标。您还可以查询、查看、分析指标,并根据阈值收到警报。 此外,在当今世界,可观…...
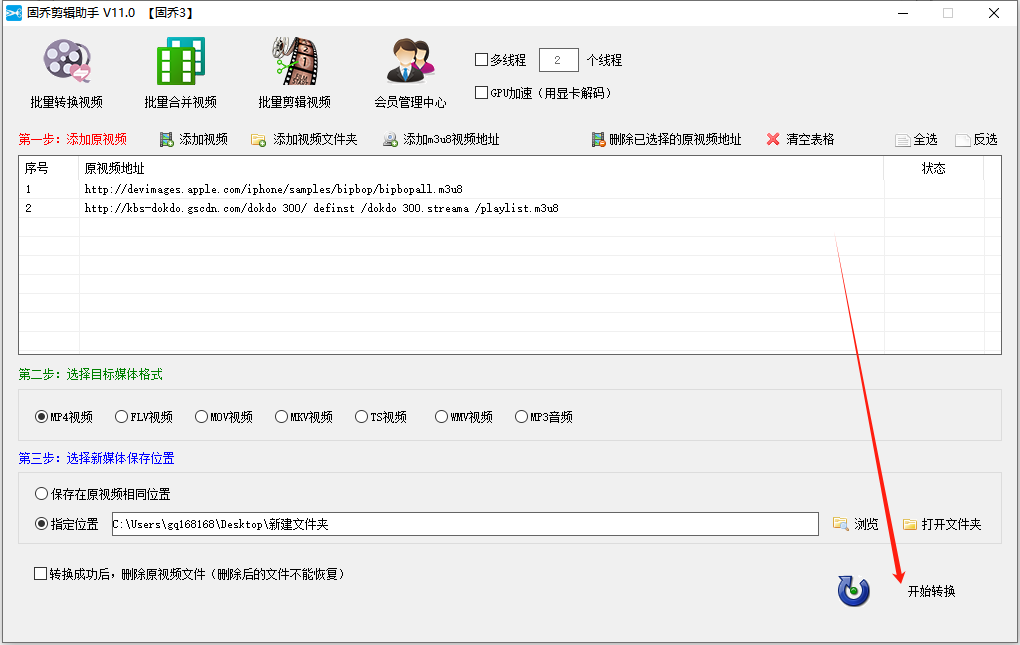
把批量M3U8网络视频地址转为MP4视频
在数字媒体时代,视频格式的转换已成为一项常见的需求。尤其对于那些经常处理网络视频的用户来说,将M3U8格式的视频转换为更常见的MP4格式是一项必备技能。幸运的是,现在有了固乔剪辑助手这款强大的工具,这一过程变得异常简单。下面…...

联合 Maxlinear 迈凌 与 Elitestek 易灵思 - WPI 世平推出基于 FPGA 芯片的好用高效电源解决方案
近期 WPI 世平公司联合 Maxlinear 迈凌电源产品搭配 Elitestek 易灵思 FPGA 共同合作推出基于 FPGA 芯片的好用高效电源解决方案。 Elitestek 易灵思 FPGA 核心产品有 2 大系列 : Trion 系列与钛金系列。Trion 系列主要特点是 : 1. 40nm 工艺 2. 超低功耗 ( 可低至竞争对手的 …...

Keycloak - docker 运行 前端集成
Keycloak - docker 运行 & 前端集成 这里的记录主要是跟我们的项目相关的一些本地运行/测试,云端用的 keycloak 版本不一样,不过本地我能找到的最简单的配置是这样的 docker 配置 & 运行 keycloak keycloak 有官方(Red Hat Inc.)的镜像&#…...

架构篇27:如何设计计算高可用架构?
文章目录 主备主从集群小结计算高可用的主要设计目标是:当出现部分硬件损坏时,计算任务能够继续正常运行。因此计算高可用的本质是通过冗余来规避部分故障的风险,单台服务器是无论如何都达不到这个目标的。所以计算高可用的设计思想很简单:通过增加更多服务器来达到计算高可…...

Python 有用的库模块
简介 Python中有许多常用的库或者模块,在写代码的时候或多或少会遇到,本文对其进行总结,方便日后查阅。 pprint Python中的pprint模块是用于打印数据结构(如字典,列表等)的模块,提供了一种以…...

vivado DDS学习
实现DDS通常有两种方式,一种是读取ROM存放的正弦/余弦信号的查表法,另一种是用DDS IP核。这篇学习笔记中,我们要讲解说明的是VIVADO DDS IP核的应用。 目前本篇默认Phase Generator and SIN/COS LUT(DDS)的standard模式…...

微信小程序(十六)slot插槽
注释很详细,直接上代码 上一篇 温馨提醒:此篇需要自定义组件的基础,如果不清楚请先看上一篇 新增内容: 1.单个插槽 2.多个插槽 单个插糟 源码: myNav.wxml <view class"navigationBar custom-class">…...

gtest 单元测试
文章目录 前言一、Google Test介绍1.1 gtest源码下载编译1.2 常用API介绍1.3 gtest运行参数介绍 二、Google Mock参考资料 前言 Google Test(简称gtest)是一个开源的C单元测试框架。和常见的测试工具一样,gtest提供了单体测试常见的工具和组…...

掌握assert的使用:断言在错误检查和调试中不可或缺
断言在错误检查和调试中不可或缺 一、简介二、断言的基本语法和用法三、错误检查与断言四、 调试与断言五、避免滥用断言六、总结 一、简介 断言是一种在程序中用于检查特定条件是否满足的工具。一般用于验证开发者的假设,如果条件不成立,就会导致程序报…...
)
概念杂记--到底啥是啥?(数据库篇)
文章目录 1.聚集索引(clustered index)2.非聚集索引(Non-clustered index)3.聚集索引和非聚集索引区别?4.覆盖索引(covering index)5、复合索引 (Composite Index)6.索引…...

Ubuntu20.4 Mono C# gtk 编程习练笔记(四)
连续实时绘图 图看上去不是很清晰,KAZAM录屏AVI尺寸80MB, 转换成gif后10MB, 按CSDN对GIF要求,把它剪裁缩小压缩成了上面的GIF,图像质量大不如原屏AVI,但应该能说明原意:随机数据随时间绘制在 gtk 的 drawin…...

1 月 26日算法练习
文章目录 九宫幻方穿越雷区走迷宫 九宫幻方 小明最近在教邻居家的小朋友小学奥数,而最近正好讲述到了三阶幻方这个部分,三阶幻方指的是将1~9不重复的填入一个33的矩阵当中,使得每一行、每一列和每一条对角线的和都是相同的。 三阶幻方又被称…...
今日AI大热潮,明日智能风向标
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...