Python 有用的库模块
简介
Python中有许多常用的库或者模块,在写代码的时候或多或少会遇到,本文对其进行总结,方便日后查阅。
pprint
Python中的pprint模块是用于打印数据结构(如字典,列表等)的模块,提供了一种以更可读的方式打印数据结构的方法。pprint在输出时会自动缩进和对齐数据,并且能够递归处理嵌套的数据结构,确保整个结构都以一致的格式打印出来。
pprint模块主要包含以下两个函数:
pprint.pprint(object, stream=None, indent=1, width=80, depth=None, compact=False):这个函数打印出一个对象的可读形式。它与内置的print()函数类似,但是打印的结果更易读,并且适用于任何Python对象。
参数说明:
object:要打印的对象。stream:指定打印的输出流,默认为标准输出。indent:每个嵌套级别的缩进空格数,默认为1。width:每行的最大字符宽度,默认为80个字符。depth:递归打印的最大深度,默认为None(没有限制)。compact:如果为True,则使用紧凑格式打印数据,默认为False。
pprint.pformat(object, indent=1, width=80, depth=None, compact=False):该函数返回一个对象的可读字符串,而不是打印到标准输出。它与pprint()函数类似,但是返回的是一个字符串。
参数说明:
object:要格式化的对象。indent:每个嵌套级别的缩进空格数,默认为1。width:每行的最大字符宽度,默认为80个字符。depth:递归格式化的最大深度,默认为None(没有限制)。compact:如果为True,则使用紧凑格式格式化数据,默认为False。
使用pprint模块示例:
import pprintdata = {'name': 'John', 'age': 30, 'city': 'New York'}# 使用pprint函数打印对象
pprint.pprint(data)# 使用pformat函数返回对象的可读字符串
formatted_data = pprint.pformat(data)
print(formatted_data)
输出结果:
{'age': 30, 'city': 'New York', 'name': 'John'}
{'age': 30, 'city': 'New York', 'name': 'John'}
import pprintdata = ("My name is Daniel", [1, 2, 3, 4, 5], ("more tuples", 1.4, 2.8, 5.7), "welcome to my blog!")
输出结果:
('My name is Daniel',[1, 2, 3, 4, 5],('more tuples', 1.4, 2.8, 5.7),'welcome to my blog!')
从上述示例可以看出,使用pprint模块打印的对象更易读,并且字典的键值对顺序与原始字典一致,当打印复杂的嵌套数据结构时该模块十分有用。
pickle
Python中的pickle模块是一种用于序列化和反序列化Python对象的工具。pickle模块可以将Python对象转化为字节流,以便可以在文件中保存或在网络上传输,并且可以将字节流反序列化为原始对象。
pickle模块提供了四个主要的函数:
pickle.dump(obj, file):将对象序列化并保存到文件中。pickle.load(file):从文件中读取序列化的对象并反序列化为原始对象。pickle.dumps(obj):将对象序列化为字节流。pickle.loads(bytes):将字节流反序列化为原始对象。
pickle模块的特点:
- 支持几乎所有的Python数据类型,包括自定义类和函数。
- 序列化后的字节流是二进制格式,无法直接阅读和编辑。
- 序列化的对象包含对象的数据和类的信息,可以在不同的Python解释器中进行反序列化。
使用pickle模块保存和加载Python对象示例:
import pickle# 将对象保存到文件中
data = {"name": "Alan", "age": 25}
with open("data.pkl", "wb") as f:pickle.dump(data, f)# 从文件中加载对象
with open("data.pkl", "rb") as f:data = pickle.load(f)
print(data) # {"name": "Alan", "age": 25}# 将对象序列化为字节流
data_bytes = pickle.dumps(data)
print(data_bytes)# 将字节流反序列化为对象
data = pickle.loads(data_bytes)
print(data) # {"name": "Alan", "age": 25}
pickle模块对于保存和加载Python对象的状态非常有用,例如在数据持久化、缓存和进程间通信时使用。值得注意的是,pickle模块存在安全性风险,因为反序列化过程中可以执行任意代码,需谨慎使用。
json
Python中的json模块用于处理JSON(JavaScript Object Notation)格式的数据。JSON是一种轻量级的数据交换格式,常用于前后端数据的传输。
json模块提供了四个主要的功能:
- 将Python对象转换为JSON字符串(序列化)
- 将JSON字符串转换为Python对象(反序列化)
- 读取或写入JSON文件
- 解析和生成复杂的JSON数据结构
下面列举json模块的一些基本操作:
- 将Python对象转换为JSON字符串(序列化)
import jsondata = {'name': 'John','age': 30,'city': 'New York'
}json_data = json.dumps(data)
print(json_data)
输出结果:
{"name": "John", "age": 30, "city": "New York"}
- 将JSON字符串转换为Python对象(反序列化)
import jsonjson_data = '{"name": "John", "age": 30, "city": "New York"}'data = json.loads(json_data)
print(data)
输出结果:
{'name': 'John', 'age': 30, 'city': 'New York'}
- 读取或写入JSON文件
import json# 读取JSON文件
with open('data.json', 'r') as file:data = json.load(file)# 写入JSON文件
with open('data.json', 'w') as file:json.dump(data, file)
- 解析和生成复杂的JSON数据结构
import jsondata = {'name': 'Daniel','age': 30,'city': 'New York','friends': [{'name': 'Alan', 'age': 28},{'name': 'Bob', 'age': 32}]
}json_data = json.dumps(data)
print(json_data)
输出结果:
{"name": "Daniel","age": 30,"city": "New York","friends": [{"name": "Alan", "age": 28},{"name": "Bob", "age": 32}]
}
注意:python的json模块默认对字典中的键进行排序再进行序列化,如果想保持原来的顺序可以使用json.dumps(data, sort_keys=False)。
glob
Python的glob模块是用于文件路径的通配符匹配的工具,可用于查找匹配特定模式的文件名,并返回匹配的文件名列表。glob模块提供了一个函数glob,接受一个模式参数,返回与该模式匹配的文件名列表。
下面是一些常用的模式匹配字符:
*:匹配任意字符序列(不包括路径分隔符)。?:匹配任意单个字符。[...]:匹配指定字符集中的任意一个字符。[!...]:匹配不在指定字符集中的任意一个字符。
使用示例:
import glob# 查找当前目录下的所有py文件
py_files = glob.glob('*.py')
print(py_files)# 查找当前目录及子目录下的所有txt文件
txt_files = glob.glob('**/*.txt', recursive=True)
print(txt_files)# 查找当前目录及子目录下的所有以a开头的py文件
py_files_starting_with_a = glob.glob('**/a*.py', recursive=True)
print(py_files_starting_with_a)# 查找当前目录及子目录下的所有以数字开头的文件夹
numbered_folders = glob.glob('[0-9]*', recursive=True)
print(numbered_folders)
glob模块返回的文件名列表是按照文件系统的默认顺序排序的,可能是任意顺序,如果需要按字母顺序排序,可以使用sorted函数对列表进行排序。
# 按字母顺序排序文件名列表
sorted_files = sorted(py_files)
print(sorted_files)
此外,glob模块还提供了一些其他函数,如iglob函数用于生成一个迭代器,escape函数用于转义特殊字符等。
shutil
Python的shutil模块提供了一组高级文件操作函数,可以方便地完成文件和文件夹的复制、移动、删除等操作。
-
shutil.copy(src, dst, *, follow_symlinks=True):
复制文件从源路径src到目标路径dst。如果目标路径是一个文件夹,则将文件复制到该文件夹下,并保持原文件名。如果目标路径已存在同名文件,则会将其覆盖。如果源文件是一个符号链接并且follow_symlinks为True,则会复制符号链接指向的文件而不是符号链接本身。 -
shutil.copy2(src, dst, *, follow_symlinks=True):
类似于copy()方法,但是在复制文件时,会连同文件的元数据(如权限、时间戳等)一起复制到目标文件。 -
shutil.copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False):
递归地复制整个文件夹从源路径src到目标路径dst。如果目标路径已存在,则会引发FileExistsError异常。可以通过设置symlinks为True来复制符号链接(默认为False)。可以通过设置ignore参数为一个函数来过滤需要复制的文件或文件夹。可以通过设置copy_function参数来指定复制文件的方法。 -
shutil.move(src, dst, copy_function=copy2):
移动文件或文件夹从源路径src到目标路径dst。如果目标路径已存在同名文件或文件夹,则会引发FileExistsError异常。可以通过设置copy_function参数来指定在移动文件时使用的复制方法。 -
shutil.rmtree(path, ignore_errors=False, onerror=None):
递归地删除整个文件夹,包括文件夹下的所有文件和文件夹。如果设置ignore_errors为True,则删除时会忽略错误。可以通过设置onerror参数为一个函数来处理删除过程中的错误。 -
shutil.make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, dry_run=False, owner=None, group=None, logger=None):
创建一个归档文件,可以选择不同的格式。base_name是归档文件名的前缀,format是归档文件的类型(如zip、tar等)。root_dir参数可以指定在归档文件中包含的根目录,默认为当前工作目录。base_dir参数可以指定在归档文件中包含的文件夹,默认为root_dir。 -
shutil.unpack_archive(filename, extract_dir=None, format=None):
解包归档文件,将归档文件解压缩到指定的目录中。filename是归档文件的路径,extract_dir是解压缩的目标路径。format参数可以指定解包的格式,如果没有指定,则根据文件的后缀名自动选择。
shutil模块还提供了其他一些方法和常量,可以用于操作文件权限、文件名转换等。使用shutil模块可以方便地处理文件和文件夹的复制、移动和删除操作,提高了文件操作的效率和便捷性。
logging
Python的logging模块是Python中标准的日志记录工具,可以使用该模块在代码中添加日志记录,以便在程序运行时捕获和显示信息。logging模块提供了灵活且易于使用的接口,可以根据需要配置日志记录的级别、格式和目标。
logging模块包含了四个主要的组件:日志器(Logger)、处理器(Handler)、过滤器(Filter)和格式化器(Formatter)。
-
日志器(Logger):日志器是logging模块中的顶级接口,用于向应用程序代码暴露日志记录功能。通过创建和配置日志器,我们可以控制日志记录的级别、输出位置等。日志器通常使用名称进行标识,不同名称的日志器可以用于不同模块或功能的日志记录。
-
处理器(Handler):处理器是日志器的辅助组件,用于将日志消息发送到指定的目标。常见的处理器包括将日志消息输出到控制台、写入到文件、发送电子邮件等。可以根据需要创建不同的处理器,并将它们添加到日志器中。
-
过滤器(Filter):过滤器用于对日志消息进行筛选,只输出符合指定条件的日志消息。通过创建过滤器并将其添加到处理器或者日志器中,可以实现对日志消息的精确控制。
-
格式化器(Formatter):格式化器用于定义输出日志消息的格式。可以自定义格式化器的样式,例如日期时间格式、日志级别、日志消息等。
使用logging模块进行日志记录的基本步骤:
-
导入logging模块:使用import语句导入logging模块。
-
创建和配置日志器:使用logging.getLogger()方法创建一个日志器,并设置日志级别。
-
创建和配置处理器:使用logging.handler()方法创建一个处理器,并设置日志级别和输出格式。
-
创建和配置格式化器:使用logging.Formatter()方法创建一个格式化器,并设置输出格式。
-
将处理器和格式化器添加到日志器中:使用日志器的addHandler()方法将处理器和格式化器添加到日志器中。
-
在代码中添加日志记录:使用日志器的不同方法(例如debug()、info()、error()等)在代码中添加需要记录的日志信息。
-
运行程序并观察日志输出:运行程序时,日志器会根据配置的级别和处理器将日志信息输出到指定的目标上。
Python的logging模块提供了一个灵活且易用的日志记录工具,便于输出和管理日志信息。通过配置日志器、处理器、过滤器和格式化器,可以根据需求对日志进行精确控制,调试和优化程序。
string
Python中的字符串是一种数据类型,用于存储和操作文本数据。在Python中,字符串是由一系列字符组成的,可以包含字母、数字、符号等字符。
- 创建字符串:
可以使用单引号或双引号来创建字符串。例如:
str1 = 'Hello World'
str2 = "Python is fun"
-
字符串的索引和切片:
可以使用索引来访问字符串中的单个字符,索引从0开始。例如,使用str[i]来访问第i个字符。还可以使用切片操作来获取字符串的子串,例如str[start:end]会返回从start位置到end位置之间的字符子串。 -
字符串的拼接:
可以使用加号(+)来拼接字符串。例如:
str1 = 'Hello'
str2 = 'World'
str3 = str1 + str2
print(str3) # HelloWorld
- 字符串的长度:
可以使用len()函数来获取字符串的长度。例如:
str1 = 'Hello World'
print(len(str1)) # 11
- 字符串的分割:
可以使用split()函数将字符串按照指定的分隔符分割成多个子串。例如:
str1 = 'Hello World'
words = str1.split(' ')
print(words) # ['Hello', 'World']
- 字符串的替换:
可以使用replace()函数将字符串中的指定字符或子串替换成新的字符或子串。例如:
str1 = 'Hello World'
new_str = str1.replace('World', 'Python')
print(new_str) # Hello Python
- 字符串的格式化:
可以使用格式化操作符%来格式化字符串。例如:
name = 'John'
age = 25
print('My name is %s and I am %d years old' % (name, age)) # My name is John and I am 25 years old
collections
Python的collections模块是Python标准库中的一个模块,它提供了一些方便的数据结构,这些数据结构可以用来替代Python内置的数据结构,或者是对它们进行扩展。
collections模块中的一些常用数据结构包括:
-
namedtuple:namedtuple提供了一种创建具有命名字段的元组的方法。与普通元组不同的是,可以通过字段名来访问元组的元素,这样就不需要使用索引来访问。 -
deque:deque是一个双端队列,可以在队列的两端进行添加和删除操作。与列表相比,deque在插入和删除元素时速度更快,特别是在队列的开头进行操作时。 -
Counter:Counter是一个简单的计数器,用于统计可哈希对象的出现次数。它可以接收可迭代对象作为输入,并返回一个字典,其中键是对象,值是对象在可迭代对象中出现的次数。 -
OrderedDict:OrderedDict是一个有序的字典,它保持插入元素的顺序。与普通字典不同的是,OrderedDict可以按照插入元素的顺序进行迭代,这对于需要有序访问字典的场景非常有用。 -
defaultdict:defaultdict是一个字典的子类,它可以指定一个默认的值,当访问不存在的键时,返回指定的默认值。这样可以避免了判断键是否存在的烦恼。
collections模块还提供了其他一些数据结构,如ChainMap、Counter、UserDict等,使用collections模块可以提高代码的可读性和效率,避免了手动实现一些常用的数据结构和操作。
requests
Python的requests库是一个用于发送HTTP请求的第三方库。它提供了简单且易于使用的接口,使得发送HTTP请求变得非常方便。以下是对requests库的详细介绍:
-
安装:可以在命令行中使用
pip install requests命令来安装requests库。 -
导入:在Python脚本中,使用
import requests语句来导入requests库。 -
发送GET请求:可以使用
requests.get()函数来发送一个GET请求。例如,response = requests.get('https://api.github.com')将发送一个GET请求到https://api.github.com并将响应保存在变量response中。 -
发送POST请求:可以使用
requests.post()函数来发送一个POST请求。例如,response = requests.post('https://httpbin.org/post', data={'key': 'value'})将发送一个POST请求到https://httpbin.org/post,并将data参数中的数据作为请求体发送。 -
设置请求头:可以使用
headers参数来设置请求头。例如,headers = {'User-Agent': 'Mozilla/5.0'}将设置请求头中的User-Agent字段为Mozilla/5.0。 -
获取响应内容:可以使用
response.text属性来获取响应内容的文本形式。例如,content = response.text将获取响应内容的文本形式,并将其保存在变量content中。 -
获取响应状态码:可以使用
response.status_code属性来获取响应的状态码。例如,status_code = response.status_code将获取响应的状态码,并将其保存在变量status_code中。 -
异常处理:可以使用
try-except语句来处理异常。例如,以下代码将捕获所有requests库可能抛出的异常,并打印错误信息:try:response = requests.get('https://api.github.com') except requests.exceptions.RequestException as e:print(e)
使用requests库可以轻松发送HTTP请求,并方便地处理响应数据。
总结
本文所列举的库或者模块都是平时代码中比较常见的,属于基础知识,还有更多的用法我在文中没有赘述。平时多写写代码,留意这些tools的细节就好,需要的时候就拿来用。
相关文章:

Python 有用的库模块
简介 Python中有许多常用的库或者模块,在写代码的时候或多或少会遇到,本文对其进行总结,方便日后查阅。 pprint Python中的pprint模块是用于打印数据结构(如字典,列表等)的模块,提供了一种以…...

vivado DDS学习
实现DDS通常有两种方式,一种是读取ROM存放的正弦/余弦信号的查表法,另一种是用DDS IP核。这篇学习笔记中,我们要讲解说明的是VIVADO DDS IP核的应用。 目前本篇默认Phase Generator and SIN/COS LUT(DDS)的standard模式…...

微信小程序(十六)slot插槽
注释很详细,直接上代码 上一篇 温馨提醒:此篇需要自定义组件的基础,如果不清楚请先看上一篇 新增内容: 1.单个插槽 2.多个插槽 单个插糟 源码: myNav.wxml <view class"navigationBar custom-class">…...

gtest 单元测试
文章目录 前言一、Google Test介绍1.1 gtest源码下载编译1.2 常用API介绍1.3 gtest运行参数介绍 二、Google Mock参考资料 前言 Google Test(简称gtest)是一个开源的C单元测试框架。和常见的测试工具一样,gtest提供了单体测试常见的工具和组…...

掌握assert的使用:断言在错误检查和调试中不可或缺
断言在错误检查和调试中不可或缺 一、简介二、断言的基本语法和用法三、错误检查与断言四、 调试与断言五、避免滥用断言六、总结 一、简介 断言是一种在程序中用于检查特定条件是否满足的工具。一般用于验证开发者的假设,如果条件不成立,就会导致程序报…...
)
概念杂记--到底啥是啥?(数据库篇)
文章目录 1.聚集索引(clustered index)2.非聚集索引(Non-clustered index)3.聚集索引和非聚集索引区别?4.覆盖索引(covering index)5、复合索引 (Composite Index)6.索引…...

Ubuntu20.4 Mono C# gtk 编程习练笔记(四)
连续实时绘图 图看上去不是很清晰,KAZAM录屏AVI尺寸80MB, 转换成gif后10MB, 按CSDN对GIF要求,把它剪裁缩小压缩成了上面的GIF,图像质量大不如原屏AVI,但应该能说明原意:随机数据随时间绘制在 gtk 的 drawin…...

1 月 26日算法练习
文章目录 九宫幻方穿越雷区走迷宫 九宫幻方 小明最近在教邻居家的小朋友小学奥数,而最近正好讲述到了三阶幻方这个部分,三阶幻方指的是将1~9不重复的填入一个33的矩阵当中,使得每一行、每一列和每一条对角线的和都是相同的。 三阶幻方又被称…...
今日AI大热潮,明日智能风向标
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
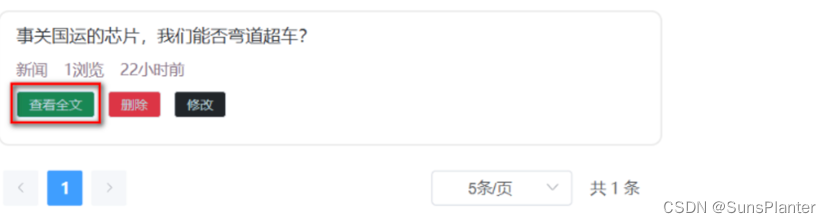
03 SB实战 -微头条之首页门户模块(跳转某页面自动展示所有信息+根据hid查询文章全文并用乐观锁修改阅读量)
1.1 自动展示所有信息 需求描述: 进入新闻首页portal/findAllType, 自动返回所有栏目名称和id 接口描述 url地址:portal/findAllTypes 请求方式:get 请求参数:无 响应数据: 成功 {"code":"200","mes…...

Abaqus许可分析工具
在当今的知识产权保护和许可管理领域,一款高效、精准的许可分析工具对于企业来说至关重要。Abaqus许可分析工具凭借其强大的功能和卓越的性能,成为了企业优化知识产权许可管理的得力助手。 一、Abaqus许可分析工具的核心优势 1.全面性:Abaqus…...

【开发工具】从eclipse到idea的过度
背景 随着eclipse相比以前性能慢了不少,idea在开发工具领域越战越猛,市场份额也逐年增加,其体验得了软件工程师的热爱。 概要 本文只是做了一个简要的记录,简单描述下本人从eclipse到idea的过度的心态。 正文 在大厂都会研发自…...

【QT+QGIS跨平台编译】之十一:【libzip+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、libzip介绍二、文件下载三、文件分析四、pro文件五、编译实践一、libzip介绍 libzip是一个开源C库,用于读取,创建和修改zip文件。 libzip可以从数据缓冲区,文件或直接从其他zip归档文件直接复制的压缩数据中添加文件。在不关闭存档的情况下所做的更改可以还原…...
openlayers+vue实现缓冲区
文章目录 前言一、准备二、初始化地图1、创建一个地图容器2、引入必须的类库3、地图初始化4、给地图增加底图 三、创建缓冲区1、引入需要的工具类库2、绘制方法 四、完整代码总结 前言 缓冲区是地理空间目标的一种影响范围或服务范围,是对选中的一组或一类地图要素(点、线或面…...
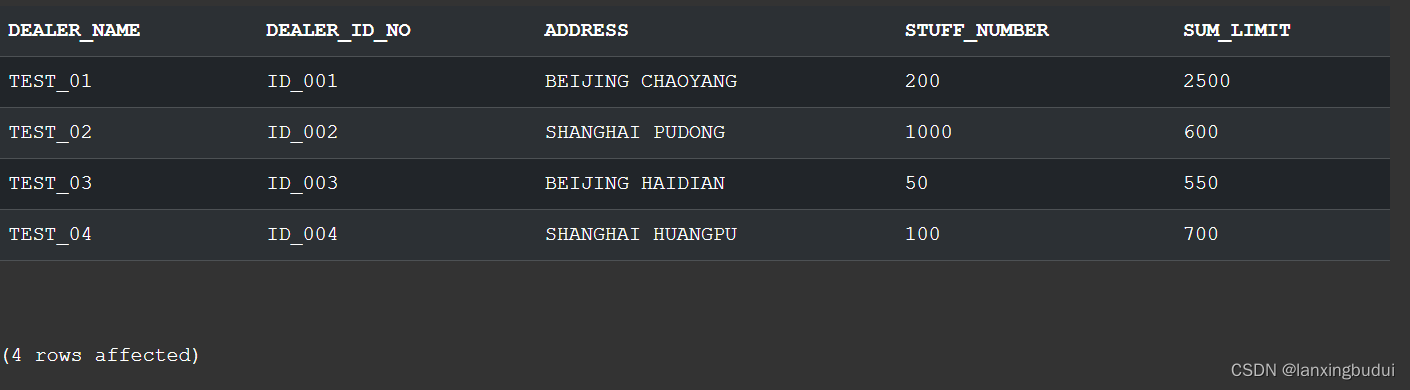
(大众金融)SQL server面试题(3)-客户已用额度总和
今天,面试了一家公司,什么也不说先来三道面试题做做,第三题。 那么,我们就开始做题吧,谁叫我们是打工人呢。 题目是这样的: DEALER_INFO经销商授信协议号码经销商名称经销商证件号注册地址员工人数信息维…...

c语言笔记
1. c语言部分算法列举 1.1 找数 二分查找(前提是数据必须有序) 1.2 求极值 1.3 数组逆序 1.4 排序法(***重点***) 1.4.1 选择排序法 1.4.2 冒泡排序法 1.4.3 插入排序法 2. 字符型数组 2.1 使用格式 char s[10]; …...

6轴机器人运动正解-逆解控制【1】——三种控制位姿的方式
概览: 通过运动学正解控制机器人运动通过运动学逆解控制机器人运动一个简单的物体搬运(沿轨迹运动) 后续会陆续更新(本例仅供学习交流用) 一、6轴机器人 二、运动正解控制 通过修改各个轴的角度,实现末…...

c# Microsoft UI Automation
Microsoft UI Automation(UIA)是一种用于自动化Windows应用程序用户界面(UI)的框架。它允许开发人员编写自动化测试脚本、辅助技术应用程序和其他需要与应用程序交互的工具。以下是一些关于Microsoft UI Automation的重要信息&…...
C#-前后端分离连接mysql数据库封装接口
C#是世界上最好的语言 新建项目 如下图所示选择框红的项目 然后新建 文件夹 Common 并新建类文件 名字任意 文件内容如下 因为要连接的是mysql数据库 所以需要安装 MySql.Data.MySqlClient 依赖; using MySql.Data.MySqlClient; using System.Data;namespace WebApplication1.…...

yolov8 opencv dnn部署自己的模型
源码地址 本人使用的opencv c github代码,代码作者非本人 使用github源码结合自己导出的onnx模型推理自己的视频 推理条件 windows 10 Visual Studio 2019 Nvidia GeForce GTX 1070 opencv4.7.0 (opencv4.5.5在别的地方看到不支持yolov8的推理,所以只使用opencv…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...