LLMs模型选择,LLMs复读机问题,LLMs长文本处理方案
为什么会出现 LLMs 复读机问题?
LLMs 复读机问题(LLMs Parroting Problem)是指大型语言模型(LLMs)在生成文本时可能出现的重复或重复先前输入内容的现象。出现LLMs复读机问题可能有以下几个原因:
- 数据偏差:大型语言模型通常是通过预训练阶段使用大规模无标签数据进行训练的。如果训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。
- 训练目标的限制:大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。
- 缺乏多样性的训练数据:虽然大型语言模型可以处理大规模的数据,但如果训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
- 模型结构和参数设置:大型语言模型的结构和参数设置也可能对复读机问题产生影响。例如,模型的注意力机制和生成策略可能导致模型更倾向于复制输入的文本。
如何缓解 LLMs 复读机问题?
为了缓解LLMs复读机问题,可以尝试以下方法:
- 多样性训练数据:在训练阶段,使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。这可以包括从不同领域、不同来源和不同风格的文本中获取数据。
- 引入噪声:在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现。
- 温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性。较高的温度值会增加随机性,从而减少复读机问题的出现。
- Beam搜索调整:在生成文本时,可以调整Beam搜索算法的参数。Beam搜索是一种常用的生成策略,它在生成过程中维护了一个候选序列的集合。通过调整Beam大小和搜索宽度,可以控制生成文本的多样性和创造性。
- 后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。可以使用文本相似度计算方法或规则来检测和去除重复的文本。
- 人工干预和控制:对于关键任务或敏感场景,可以引入人工干预和控制机制,对生成的文本进行审查和筛选,确保生成结果的准确性和多样性。
需要注意的是,缓解LLMs复读机问题是一个复杂的任务,没有一种通用的解决方案。不同的方法可能适用于不同的场景和任务,需要根据具体情况进行选择和调整。此外,解决复读机问题还需要综合考虑数据、训练目标、模型架构和生成策略等多个因素,需要进一步的研究和实践来提高大型语言模型的生成文本多样性和创造性。
llama 输入句子长度理论上可以无限长吗?
理论上来说,LLMs(大型语言模型)可以处理任意长度的输入句子,但实际上存在一些限制和挑战。下面是一些相关的考虑因素:
- 计算资源:生成长句子需要更多的计算资源,包括内存和计算时间。由于LLMs通常是基于神经网络的模型,计算长句子可能会导致内存不足或计算时间过长的问题。
- 模型训练和推理:训练和推理长句子可能会面临一些挑战。在训练阶段,处理长句子可能会导致梯度消失或梯度爆炸的问题,影响模型的收敛性和训练效果。在推理阶段,生成长句子可能会增加模型的错误率和生成时间。
- 上下文建模:LLMs是基于上下文建模的模型,长句子的上下文可能会更加复杂和深层。模型需要能够捕捉长句子中的语义和语法结构,以生成准确和连贯的文本。
尽管存在这些挑战,研究人员和工程师们已经在不断努力改进和优化LLMs,以处理更长的句子。例如,可以采用分块的方式处理长句子,将其分成多个较短的片段进行处理。此外,还可以通过增加计算资源、优化模型结构和参数设置,以及使用更高效的推理算法来提高LLMs处理长句子的能力。
值得注意的是,实际应用中,长句子的处理可能还受到应用场景、任务需求和资源限制等因素的影响。因此,在使用LLMs处理长句子时,需要综合考虑这些因素,并根据具体情况进行选择和调整。
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型?
选择使用哪种大模型,如Bert、LLaMA或ChatGLM,取决于具体的应用场景和需求。下面是一些指导原则:
Bert模型:Bert是一种预训练的语言模型,适用于各种自然语言处理任务,如文本分类、命名实体识别、语义相似度计算等。如果你的任务是通用的文本处理任务,而不依赖于特定领域的知识或语言风格,Bert模型通常是一个不错的选择。Bert由一个Transformer编码器组成,更适合于NLU相关的任务。
LLaMA模型:LLaMA(Large Language Model Meta AI)包含从 7B 到 65B 的参数范围,训练使用多达14,000亿tokens语料,具有常识推理、问答、数学推理、代码生成、语言理解等能力。Bert由一个Transformer解码器组成。训练预料主要为以英语为主的拉丁语系,不包含中日韩文。所以适合于英文文本生成的任务。
ChatGLM模型:ChatGLM是一个面向对话生成的语言模型,适用于构建聊天机器人、智能客服等对话系统。如果你的应用场景需要模型能够生成连贯、流畅的对话回复,并且需要处理对话上下文、生成多轮对话等,ChatGLM模型可能是一个较好的选择。ChatGLM的架构为Prefix decoder,训练语料为中英双语,中英文比例为1:1。所以适合于中文和英文文本生成的任务。
在选择模型时,还需要考虑以下因素:
- 数据可用性:不同模型可能需要不同类型和规模的数据进行训练。确保你有足够的数据来训练和微调所选择的模型。
- 计算资源:大模型通常需要更多的计算资源和存储空间。确保你有足够的硬件资源来支持所选择的模型的训练和推理。
- 预训练和微调:大模型通常需要进行预训练和微调才能适应特定任务和领域。了解所选择模型的预训练和微调过程,并确保你有相应的数据和时间来完成这些步骤。
最佳选择取决于具体的应用需求和限制条件。在做出决策之前,建议先进行一些实验和评估,以确定哪种模型最适合你的应用场景。
各个专业领域是否需要各自的大模型来服务?
各个专业领域通常需要各自的大模型来服务,原因如下:
- 领域特定知识:不同领域拥有各自特定的知识和术语,需要针对该领域进行训练的大模型才能更好地理解和处理相关文本。例如,在医学领域,需要训练具有医学知识的大模型,以更准确地理解和生成医学文本。
- 语言风格和惯用语:各个领域通常有自己独特的语言风格和惯用语,这些特点对于模型的训练和生成都很重要。专门针对某个领域进行训练的大模型可以更好地掌握该领域的语言特点,生成更符合该领域要求的文本。
- 领域需求的差异:不同领域对于文本处理的需求也有所差异。例如,金融领域可能更关注数字和统计数据的处理,而法律领域可能更关注法律条款和案例的解析。因此,为了更好地满足不同领域的需求,需要专门针对各个领域进行训练的大模型。
- 数据稀缺性:某些领域的数据可能相对较少,无法充分训练通用的大模型。针对特定领域进行训练的大模型可以更好地利用该领域的数据,提高模型的性能和效果。
尽管需要各自的大模型来服务不同领域,但也可以共享一些通用的模型和技术。例如,通用的大模型可以用于处理通用的文本任务,而领域特定的模型可以在通用模型的基础上进行微调和定制,以适应特定领域的需求。这样可以在满足领域需求的同时,减少模型的重复训练和资源消耗。
如何让大模型处理更长的文本?
要让大模型处理更长的文本,可以考虑以下几个方法:
- 分块处理:将长文本分割成较短的片段,然后逐个片段输入模型进行处理。这样可以避免长文本对模型内存和计算资源的压力。在处理分块文本时,可以使用重叠的方式,即将相邻片段的一部分重叠,以保持上下文的连贯性。
- 层次建模:通过引入层次结构,将长文本划分为更小的单元。例如,可以将文本分为段落、句子或子句等层次,然后逐层输入模型进行处理。这样可以减少每个单元的长度,提高模型处理长文本的能力。
- 部分生成:如果只需要模型生成文本的一部分,而不是整个文本,可以只输入部分文本作为上下文,然后让模型生成所需的部分。例如,输入前一部分文本,让模型生成后续的内容。
- 注意力机制:注意力机制可以帮助模型关注输入中的重要部分,可以用于处理长文本时的上下文建模。通过引入注意力机制,模型可以更好地捕捉长文本中的关键信息。
- 模型结构优化:通过优化模型结构和参数设置,可以提高模型处理长文本的能力。例如,可以增加模型的层数或参数量,以增加模型的表达能力。还可以使用更高效的模型架构,如Transformer等,以提高长文本的处理效率。
需要注意的是,处理长文本时还需考虑计算资源和时间的限制。较长的文本可能需要更多的内存和计算时间,因此在实际应用中需要根据具体情况进行权衡和调整。
相关文章:

LLMs模型选择,LLMs复读机问题,LLMs长文本处理方案
为什么会出现 LLMs 复读机问题? LLMs 复读机问题(LLMs Parroting Problem)是指大型语言模型(LLMs)在生成文本时可能出现的重复或重复先前输入内容的现象。出现LLMs复读机问题可能有以下几个原因: 数据偏差…...

LeetCode.144. 二叉树的前序遍历
题目 144. 二叉树的前序遍历 分析 这道题目是比较基础的题目,我们首先要知道二叉树的前序遍历是什么? 就是【根 左 右】 的顺序,然后利用递归的思想,就可以得到这道题的答案,任何的递归都可以采用 栈 的结构来实现…...
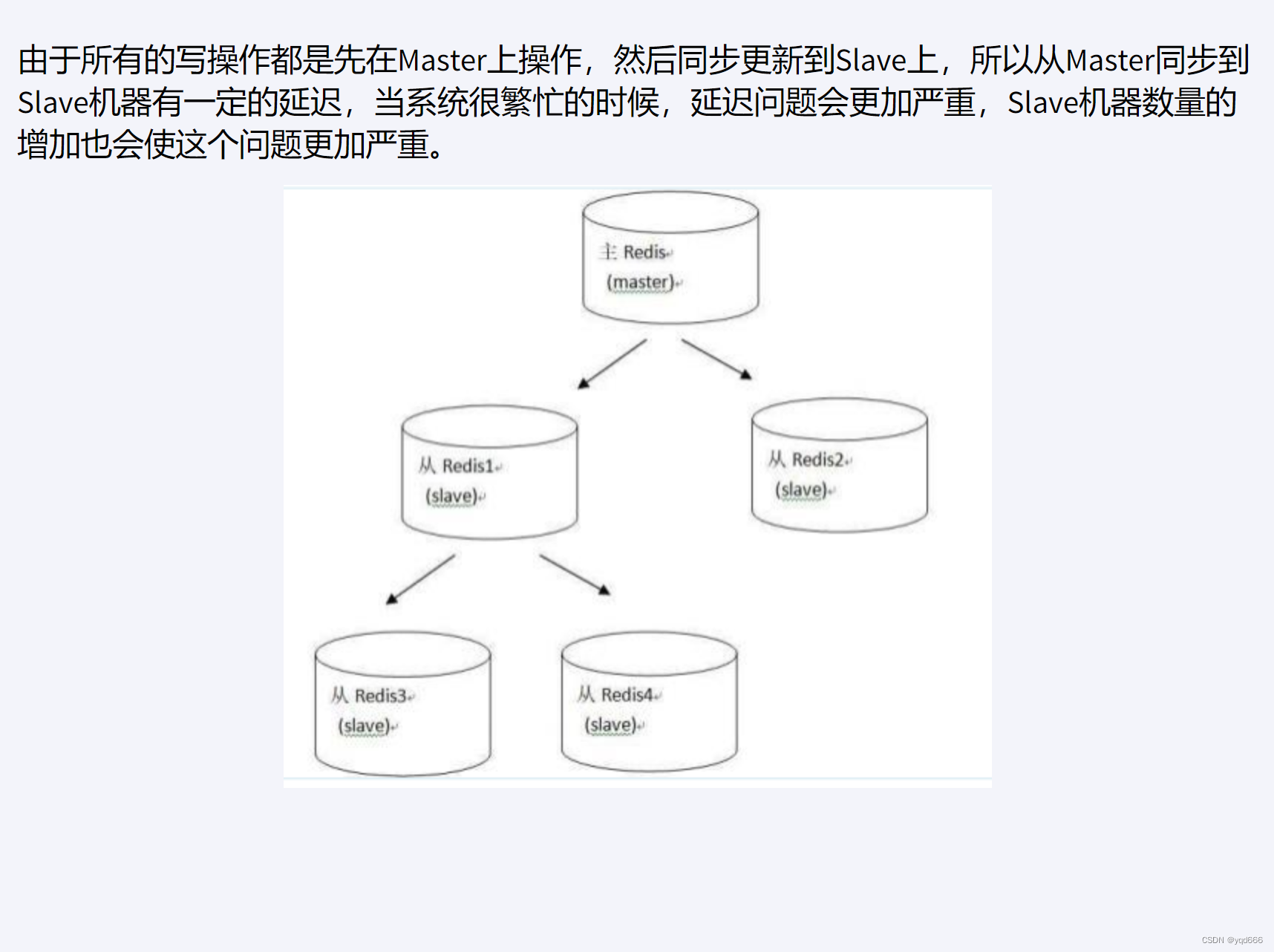
Redis复制
文章目录 1.Redis复制是什么2.Redis能干嘛3.权限细节4.基本操作命令5.常用三招5.1 一主二仆5.2 薪火相传5.3 反客为主 6.复制原理和工作流程7.复制的缺点 1.Redis复制是什么 就是主从复制,master以写为主,Slave以读为主。当master数据变化的时候&#x…...
C++入门学习(二十七)跳转语句—break语句
1、与switch语句联合使用 C入门学习(二十三)选择结构-switch语句-CSDN博客 #include <iostream> #include <string> using namespace std;int main() { int number;cout<<"请为《斗萝大路》打星(1~5※):" &…...
Spark安装(Yarn模式)
一、解压 链接:https://pan.baidu.com/s/1O8u1SEuLOQv2Yietea_Uxg 提取码:mb4h tar -zxvf /opt/software/spark-3.0.3-bin-hadoop3.2.tgz -C /opt/module/spark-yarn mv spark-3.0.3-bin-hadoop3.2/ spark-yarn 二、配置环境变量 vim /etc/profile…...

1.4 Binance_interface API U本位合约行情
Binance_interface API U本位合约行情 Github地址PyTed量化交易研究院 1. API U本位合约行情接口总览 方法解释Pathget_ping测试服务器连通性 PING/fapi/v1/pingget_time获取服务器时间/fapi/v1/timeget_exchangeInfo获取交易规则和交易对/fapi/v1/exchangeInfoget_depth深度…...
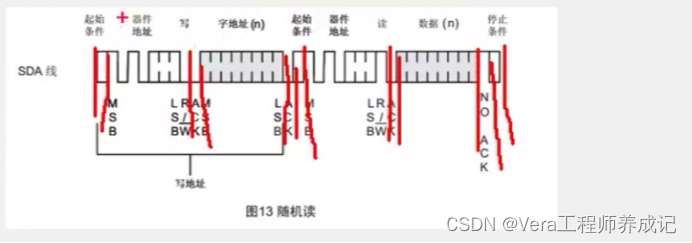
单片机学习笔记---AT24C02(I2C总线)
目录 有关储存器的介绍 存储器的简介 存储器简化模型 AT24C02介绍 AT24C02引脚及应用电路 I2C总线介绍 I2C电路规范 开漏输出模式和弱上拉模式 其中一个设备的内部结构 I2C通信是怎么实现的 I2C时序结构 起始条件和终止条件 发送一个字节 接收一个字节 发送应答…...

c++恶魔轮盘制造第1期输赢
小常识,恶魔叫DEALER。 赢了很简单 void sheng() { cout<<"你获胜了!";MessageBox(NULL,TEXT("你的钱~~~~~~给你"),TEXT("DEALER"),MB_OK);system("pause");system("cls"); } 输了我用了个选…...

60-JS-Ajax
ajax取数据的一种手段,局部刷新,例如弹幕 1.ajax的使用,创建ajax对象,发起对服务器请求 2.核心对象XMLHttpRequest对象(简称XHR) CSS:Cascading Style Sheets(层叠样式表) HTML:Hypertext Markup Language(超文本标记语言) 3.发起对服务器的请求 浏览器方式请求:打…...

C# Avalonia 折线图
线图开发在C# Avalonia框架中可以通过多种方式实现。由于Avalonia旨在成为跨平台的UI框架,您可以利用多种库和方法来绘制折线图。以下是一个简单的例子,展示了如何在Avalonia应用程序中创建一个基本的折线图。 首先,您需要在Avalonia项目中包…...
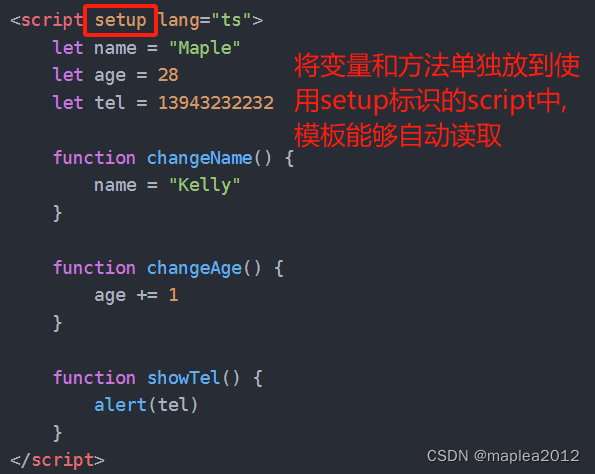
Vue3中Setup概述和使用(三)
一、引入Setup 1、Person.Vue 与Vue3编写简单的App组件(二) 中的区别是:取消data、methods等方法,而是将数据和方法定义全部放进setup中。 <template><div class"person"><h1>姓名:{{name}}</h1><h1>年龄:{{age}}</h…...

hexo 博客搭建以及踩雷总结
搭建时的坑 文章置顶 安装一下这个依赖 npm install hexo-generator-topindex --save然后再文章的上面设置 top: number,数字越大,权重越大,也就是越靠顶部 hexo 每次推送 nginx 都访问不到 宝塔自带的 nginx 的 config 里默认的角色是 …...
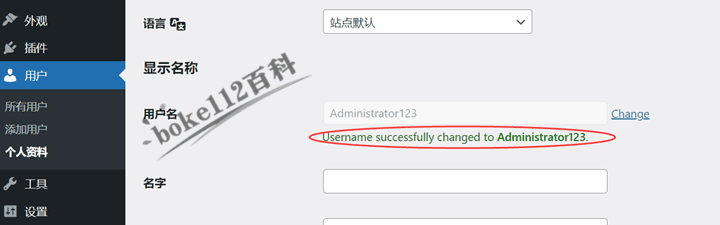
WordPress后台编辑个人资料页面直接修改用户名插件Change Username
前面跟大家介绍了『如何修改WordPress后台管理员用户名?推荐2种简单方法』一文,但是对于新站长或者有很多用户的站长来说,操作有点复杂,所以今天向大家推荐一款可以直接在WordPress后台编辑个人(用户)资料页…...
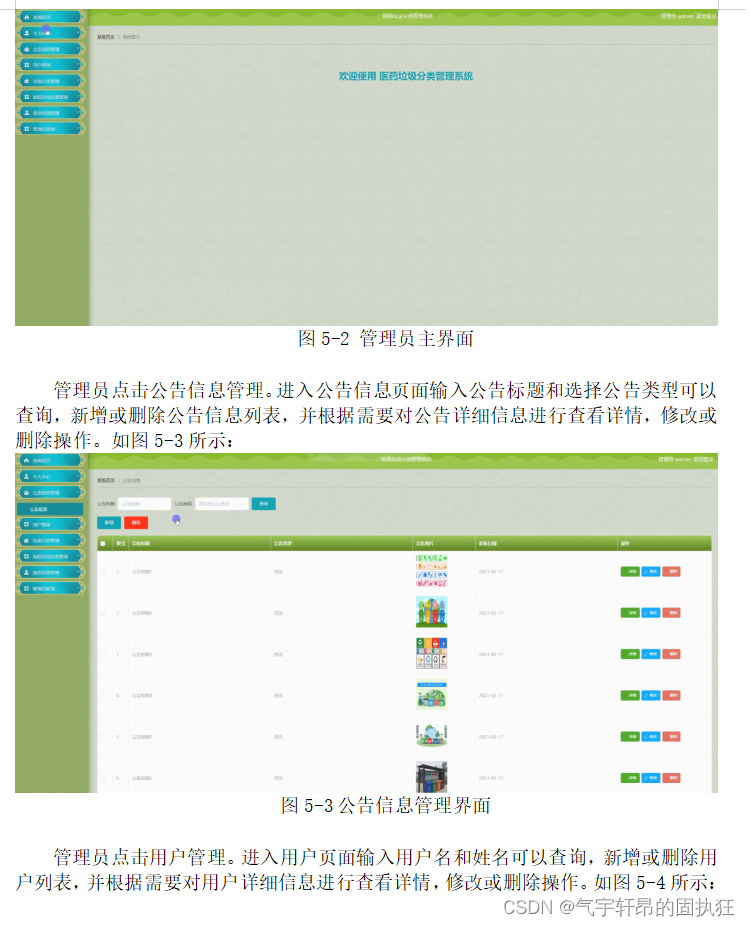
ssm+vue的医药垃圾分类管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。
演示视频: ssmvue的医药垃圾分类管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结…...
)
LLM大模型基本概念,及其相关问题汇总(1)
什么是涌现?为什么会出现涌现? "大模型的涌现能力"这个概念可能是指大型神经网络模型在某些任务上表现出的出乎意料的能力,超出了人们的预期。出现的原因从结论上来看,是模型不够好,导致的原因主要是&#…...

【已解决】pt文件转onnx后再转rknn时得到推理图片出现大量锚框变花屏
前言 环境介绍: 1.编译环境 Ubuntu 18.04.5 LTS 2.RKNN版本 py3.8-rknn2-1.4.0 3.单板 迅为itop-3568开发板 一、现象 采用yolov5训练并将pt转换为onnx,再将onnx采用py3.8-rknn2-1.4.0推理转换为rknn,rknn模型能正常转换,…...

DevOps文章之 操作手册用户使用说明书
前言 最近主导了几个项目操作手册的编写。有新开发的项目,要重新编写操作手册;有中途接手别的项目,后来功能迭代,需要更新原操作手册;有客户对操作手册有意见,需要调整;零零散散写了数万字的手…...

【RT-DETR进阶实战】利用RT-DETR进行视频划定区域目标统计计数
👑欢迎大家订阅本专栏,一起学习RT-DETR👑 一、本文介绍 Hello,各位读者,最近会给大家发一些进阶实战的讲解,如何利用RT-DETR现有的一些功能进行一些实战, 让我们不仅会改进RT-DETR,也能够利用RT-DETR去做一些简单的小工作,后面我也会将这些功能利用PyQt或者是…...

2.11学习总结
有效点对https://www.acwing.com/problem/content/description/5472/ 给定一个 n� 个节点的无向树,节点编号 1∼n1∼�。 树上有两个不同的特殊点 x,y�,�,对于树中的每一个点对 (u,v)(u≠v)(�,…...
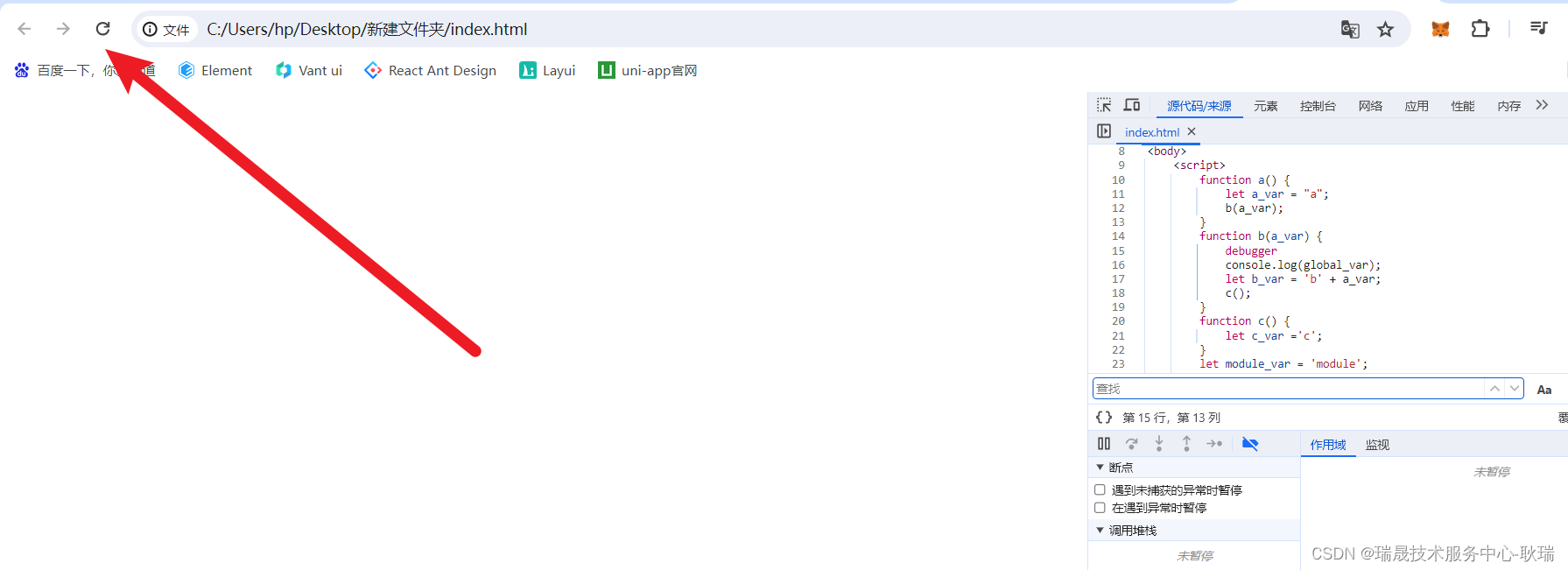
以谷歌浏览器为例 讲述 JavaScript 断点调试操作用法
今天来说个比较实用的东西 用浏览器开发者工具 对 javaScript代码进行调试 我们先创建一个index.html 编写代码如下 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content&…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...
鸿蒙Navigation路由导航-基本使用介绍
1. Navigation介绍 Navigation组件是路由导航的根视图容器,一般作为Page页面的根容器使用,其内部默认包含了标题栏、内容区和工具栏,其中内容区默认首页显示导航内容(Navigation的子组件)或非首页显示(Nav…...

基于 HTTP 的单向流式通信协议SSE详解
SSE(Server-Sent Events)详解 🧠 什么是 SSE? SSE(Server-Sent Events) 是 HTML5 标准中定义的一种通信机制,它允许服务器主动将事件推送给客户端(浏览器)。与传统的 H…...