Kafka零拷贝技术与传统数据复制次数比较
读Kafka技术书遇到困惑:
"对比传统的数据复制和“零拷贝技术”这两种方案。假设有10个消费者,传统复制方式的数据复制次数是4×10=40次,而“零拷贝技术”只需1+10= 11次(一次表示从磁盘复制到页面缓存,另外10次表示10个消费者各自读取一次页面缓存)。显然,“零拷贝技术”比传统复制方式需要的复制次数更少。 "
困惑我的有两个问题:
1. 传统一次数据传输为什么需要4次拷贝
2. 为什么零拷贝下10个消费者只需要11次
第一个问题:传统一次数据传输为什么需要4次拷贝?
传统数据传输在实现上包含两个操作, read 和write,都是由用户程序来发起, 其中read和write中各有两次复制操作. read负责将数据从磁盘加载到内存空间中, 由于用户程序没有直接读取磁盘或写入网卡等操作系统资源的的权限, 因此每次调用时, 上下文都需要从用户态切换到内核态.
在read中, 首先由系统交由DMA(direct memory access)做第一次复制, 将数据从磁盘搬运到内核空间的文件系统的页面缓存中; 然后再交由CPU执行数据的第二次复制, 将数据从页面缓存拷贝到用户内存空间中.
在write时, 首先cpu会将数据将用户空间拷贝到内核空间(文件系统缓冲区,pagecache), 放在socket缓存区中,完成第一次复制; 然后再由DMA将数据从socket缓存区搬运到网卡接口, 由网卡将数据传输到到网络中.
在此过程中发生了4次用户态与内核态的上下文切换(一次系统调用会发生两次上下文切换)、4次拷贝, 其中CPU复制两次、 DMA复制两次, 在其中很多复制步骤是非必要的, 如何进行优化?
常见优化手段有两种:
- mmap + write
- sendfile
mmap是个共享缓存方案, 即把内核空间缓存去中的数据映射到用户空间中, 可被用户程序直接使用, 进行共享, 就不用将数据从内核空间搬到用户空间了, 在write时还是需要由CPU将数据从共享区复制到socket缓存区中.
这种做法还是会有4次上下文切换, 但少了一次数据拷贝. 做了优化, 但不多.
再看另外一种sendfile, sendfile可以看成是对mmap + write操作的一种封装, 只需要指定下文件描述符和数据长度, 将两次系统调用减少为一次, 可以做到在内核态时将数据从磁盘复制到网卡, 但其中还是会经过三次数据复制:
- 磁盘->内核缓存
- 内核缓存-> socket缓存
- socket缓存->网卡
这种不是实际意义上的零拷贝, 但不在发生从内核空间到用户空间的拷贝了, 所以我理解所谓零拷贝指的是不发生从内核空间到用户空间的拷贝了。
第二个问题: 为什么零拷贝下10个消费者只需要11次拷贝?
那第二个问题"为什么零拷贝下10个消费者只需要11次拷贝?"怎么理解?
这是使用了更牛逼的SG-DMA(The Scatter-Gather Direct Memory Access)技术, SG-DMA是一种特殊的DMA, 通过sendfile指定的文件描述符和数据长度, 实现了将内核中页缓存数据直接搬运到网卡中, 中间不需要经过socket缓存区, 且中间拷贝操作全程无cpu参与.
在这种意义下, 零拷贝指的是零cpu拷贝技术.
SG-DMA实现了仅需两次拷贝就完成了一次磁盘数据的网络传输操作, 而对于10个消费者则需要10次使用SG-DMA将数据从内核页缓存拷贝到网卡的动作, 页缓存顾名思义是数据在内核空间的缓存, 对于同一条数据从磁盘拷贝到内核空间后就缓存起来, 后面再使用时就可无需再重新拷贝了.
所以1条消息发送给10个消费者, kafka做到了仅需通过11次拷贝就完成了, 越少的数据复制, 就越能更快的读取的数据, 延迟越少, 消费者性能就越好, 你说他的文件传输效率高不高.
其他使用零拷贝技术的还有Nginx系统.
其他:
chatgpt的答案:
零拷贝技术与传统数据复制次数比较解释
传统数据复制
在传统的数据复制方法中,数据在从磁盘到达消费者之前会经历多次复制。这个过程通常包括以下步骤:
- 从磁盘读取数据到内核空间的文件系统缓冲区(页缓存)。
- 从文件系统缓冲区复制数据到用户空间的应用程序缓冲区。
- 从应用程序缓冲区复制数据回内核空间的socket缓冲区。
- 从socket缓冲区将数据发送到网络。
如果有10个消费者,这个过程需要为每个消费者重复进行,导致数据被复制了4次(磁盘到文件系统缓冲区,文件系统缓冲区到用户空间,用户空间到socket缓冲区,socket缓冲区到网络)。因此,总的数据复制次数是4×10=40次。
零拷贝技术
零拷贝技术通过减少数据在用户空间和内核空间之间的不必要复制,来降低CPU的负载和提高数据传输效率。在零拷贝的情况下,数据传输过程如下:
- 从磁盘读取数据到内核空间的文件系统缓冲区(页缓存),这是唯一的一次数据复制。
- 使用零拷贝技术(如Linux的sendfile系统调用),直接从文件系统缓冲区传输数据到网络,避免了数据到用户空间的复制。
每个消费者直接从文件系统缓冲区读取数据,所以对于10个消费者,数据复制次数为1(磁盘到文件系统缓冲区)加上10(每个消费者读取一次文件系统缓冲区),总共是1+10=11次。
结论
零拷贝技术显著减少了数据复制次数,从40次降低到了11次。这减少了CPU的工作负担,提高了数据传输的效率,并且减少了延迟。在处理大量数据或者高速网络传输时,零拷贝技术的优势尤为明显
参考:
- chatgpt
- 原来 8 张图,就可以搞懂「零拷贝」了
 https://www.cnblogs.com/xiaolincoding/p/13719610.html
https://www.cnblogs.com/xiaolincoding/p/13719610.html
相关文章:
Kafka零拷贝技术与传统数据复制次数比较
读Kafka技术书遇到困惑: "对比传统的数据复制和“零拷贝技术”这两种方案。假设有10个消费者,传统复制方式的数据复制次数是41040次,而“零拷贝技术”只需110 11次(一次表示从磁盘复制到页面缓存,另外10次表示10个消费者各自…...

npm ERR! network This is a problem related to network connectivity.
遇到 ETIMEDOUT 错误时,这表明npm尝试连接到npm仓库时超时了,这通常是由网络连接问题引起的。这可能是因为网络不稳定、连接速度慢、或者你的网络配置阻止了对npm仓库的访问。以下是一些解决这个问题的步骤: 1. 检查网络连接 首先ÿ…...

【SQL高频基础题】619.只出现一次的最大数字
题目: MyNumbers 表: ------------------- | Column Name | Type | ------------------- | num | int | ------------------- 该表可能包含重复项(换句话说,在SQL中,该表没有主键)。 这张表的每…...
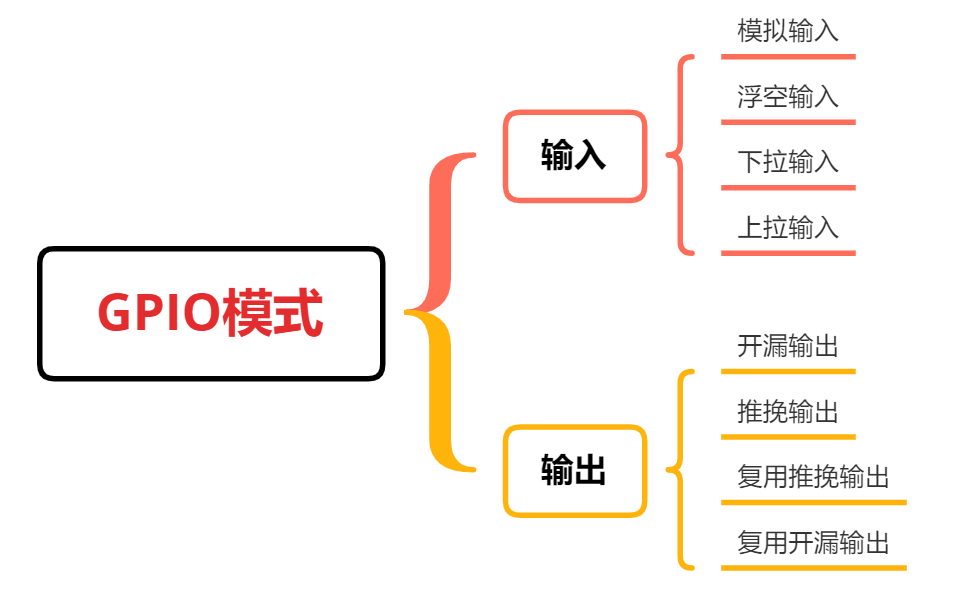
STM32F1 - GPIO外设
GPIO 1> 硬件框图2> 工作模式 1> 硬件框图 2> 工作模式 C语言描述 /** * brief Configuration Mode enumeration */typedef enum { GPIO_Mode_AIN 0x0, // Analog Input 模拟输入 GPIO_Mode_IN_FLOATING 0x04, // input floating 浮空输入GPIO_Mode_I…...

新增同步管理、操作日志模块,支持公共链接分享,DataEase开源数据可视化分析平台v2.3.0发布
2024年2月5日,DataEase开源数据可视化分析平台正式发布v2.3.0版本。 这一版本的功能升级包括:新增“同步管理”功能模块,用户可通过此模块,将传统数据库中的数据定时同步到Apache Doris中,让数据分析更快速࿱…...

跟着pink老师前端入门教程-day19
一、移动WEB开发之流式布局 1、 移动端基础 1.1 浏览器现状 PC端常见浏览器:360浏览器、谷歌浏览器、火狐浏览器、QQ浏览器、百度浏览器、搜狗浏览器、IE浏览器。 移动端常见浏览器:UC浏览器,QQ浏览器,欧朋浏览器࿰…...

ChatGPT学习第一周
📖 学习目标 掌握ChatGPT基础知识 理解ChatGPT的基本功能和工作原理。认识到ChatGPT在日常生活和业务中的潜在应用。 了解AI和机器学习的基本概念 获取人工智能(AI)和机器学习(ML)的初步了解。理解这些技术是如何支撑…...
爬爬爬——今天是浏览器窗口切换和给所选人打钩(自动化)
学习爬虫路还很长,第一阶段花了好多天了,还在底层,虽然不是我专业要学习的语言,和必备的知识,但是我感觉还挺有意思的。加油,这两天把建模和ai也不学了,唉过年了懒了! 加油坚持就是…...
Netty应用(五) 之 Netty引入 EventLoop
目录 第三章 Netty 1.什么是Netty? 2.为什么需要使用Netty? 3.Netty的发展历程 4.谁在使用Netty? 5.为什么上述这些分布式产品都使用Netty? 6.第一个Netty应用 7.如何理解Netty是NIO的封装 8.logback日志使用的加强 9.Ev…...
【c++基础】国王的魔镜
说明 国王有一个魔镜,可以把任何接触镜面的东西变成原来的两倍——只是,因为是镜子嘛,增加的那部分是反的。 比如一条项链,我们用AB来表示,不同的字母表示不同颜色的珍珠。如果把B端接触镜面的话,魔镜会把…...
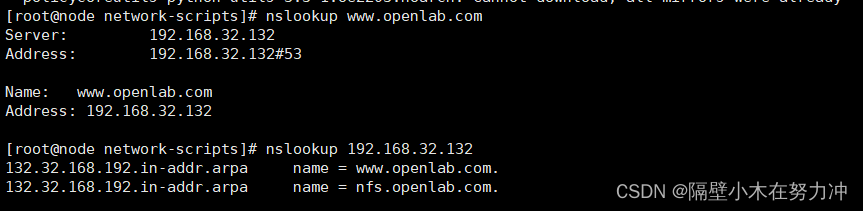
配置DNS正反向解析服务!!!!
一.准备工作 #关闭防火墙和selinux,或者允许服务通过 [rootnode ~]# nmcli c mod ens32 ipv4.method manual ipv4.address 192.168.32.133/24 ipv4.gateway 192.168.32.2 ipv4.dns 192.168.32.132 [rootnode ~]# nmcli c reload [rootnode ~]# nmcli c up ens32[rootnode ~]# …...

大模型2024规模化场景涌现,加速云计算走出第二增长曲线
导读:2024,大模型第一批规模化应用场景已出现。 如果说“百模大战”是2023年国内AI产业的关键词,那么2024年我们将正式迈进“应用为王”的新阶段。 不少业内观点认为,2024年“百模大战”将逐渐收敛甚至洗牌,而大模型在…...
)
Gitlab和Jenkins集成 实现CI (三)
Gitlab和Jenkins集成 实现CI (一) Gitlab和Jenkins集成 实现CI (二) Gitlab和Jenkins集成 实现CI (三) 自动部署 配置免密ssh 进入http服务器 生成ssh密钥 ssh-keygen -t rsa进入jenkins(容器) 拷贝公钥 ssh-copy-id http服务器用户名http服务器ip #输入http服务器密码配…...

随机过程及应用学习笔记(二)随机过程的基本概念
随机过程论就是研究随时间变化的动态系统中随机现象的统计规律的一门数学学科。 目录 前言 一、随机过程的定义及分类 1、定义 2、分类 二、随机过程的分布及其数字特征 1、分布函数 2、数字特征 均值函数和方差函数 协方差函数和相关函数 3、互协方差函数与互相关函…...

【机器学习】Kmeans如何选择k值
确定 K 值是 K-means 聚类分析的一个重要步骤。不同的 K 值可能会产生不同的聚类结果,因此选择合适的 K 值非常重要。 以下是一些常见的方法来选择 K 值: 手肘法:该方法基于绘制聚类内误差平方和(SSE)与 K 值之间的关系图。随着 K 值的增加,SSE会逐渐降低,但降低幅度逐…...
)
LeetCode 热题 100 | 链表(下)
目录 1 148. 排序链表 2 23. 合并 K 个升序链表 3 146. LRU 缓存 3.1 解题思路 3.2 详细过程 3.3 完整代码 菜鸟做题第三周,语言是 C 1 148. 排序链表 解题思路: 遍历链表,把每个节点的 val 都存入数组中用 sort 函数对数组进…...

Ubuntu搭建计算集群
计算机硬件和技术的发展使得高性能模拟和计算在生活和工作中的作用逐渐显现出来,无论是计算化学,计算物理和当下的人工智能都离不开高性能计算。笔者工作主要围绕计算化学和物理开展,亦受限于自身知识和技术所限,文中只是浅显地尝…...

数据结构~~树(2024/2/8)
目录 树 1、定义: 2、树的基本术语: 3、树的表示 树 1、定义: 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树&…...
【教学类-48-03】202402011“闰年”(每4年一次 2月有29日)世纪年必须整除400才是闰年)
2000-2099年之间的闰年有25次, 背景需求: 已经制作了对称年月的数字提取,和年月日相等的年份提取 【教学类-48-01】20240205对称的“年”和“月日”(如2030 0302)-CSDN博客文章浏览阅读84次。【教学类-48-01】202402…...

如何开发一个属于自己的人工智能语言大模型?
要开发一个属于自己的人工智能语言模型,你需要遵循以下步骤: 数据收集:首先你需要大量的文本数据来训练你的模型。这些数据可以来自于各种来源,例如书籍、网站、新闻文章等。你需要确保这些数据足够多样化,以便模型能学…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...