【六 (2)机器学习-机器学习建模步骤/kaggle房价回归实战】
一、确定问题和目标:
1、业务需求分析:
与业务团队或相关利益方进行深入沟通,了解他们的需求和期望。
分析业务流程,找出可能的瓶颈、机会或挑战。
思考机器学习如何帮助解决这些问题或实现业务目标。
2、问题定义:
将业务需求转化为一个或多个具体的机器学习问题,例如分类、回归、聚类等。
定义问题的输入(特征)和输出(目标变量)。
明确问题的约束条件,如数据可用性、计算资源、时间限制等。
3、目标设定:
确定机器学习模型需要达到的性能指标,如准确率、召回率、F1值等。
根据业务需求,设定合理的性能阈值。
考虑模型的泛化能力,确保模型能在未知数据上表现良好。
4、数据可行性评估:
检查现有数据是否足够支持机器学习模型的训练和评估。
分析数据的质量和分布,确保数据能够反映问题的真实情况。
如果数据不足或质量不佳,考虑是否需要收集更多数据或进行数据增强。
5、资源评估:
评估可用的计算资源,如CPU、GPU和内存等,以确保能够支持模型的训练和推断。
考虑是否需要额外的工具或平台来支持建模过程,如数据预处理工具、机器学习框架等。
6、风险评估:
分析可能的风险和挑战,如数据泄露、模型过拟合、性能波动等。
制定应对策略,如加密数据、使用正则化技术、进行模型监控等。
二、数据收集:
1、明确数据需求
在开始收集数据之前,需要明确所需的数据类型、格式和数量。这取决于具体的应用场景和问题。
2、选择数据来源
数据可以从多种渠道收集,包括公共数据集、网站爬虫、传感器数据、数据库等。确保所选的数据源与问题和目标紧密相关。
3、考虑数据质量和完整性
在收集数据时,要特别注意数据的准确性和可靠性。确保数据的完整性和一致性,避免数据缺失或异常值。
三、EDA
EDA(Exploratory Data Analysis)即探索性数据分析,EDA通过可视化、统计和图形化的方法,对数据集进行全面的、非形式化的初步分析,帮助分析人员了解数据的基本特征,发现数据中的规律和模式。这有助于获取对数据的直观感受和深刻理解,为后续的数据处理和建模提供基础。
1、查看数据基本信息
# 查看数据基本信息
train_df.info()
2、查看每个特征的含义
SalePrice: 房产销售价格,以美元计价。所要预测的目标变量
MSSubClass: Identifies the type of dwelling involved in the sale 住所类型
MSZoning: The general zoning classification 区域分类
LotFrontage: Linear feet of street connected to property 房子同街道之间的距离
LotArea: Lot size in square feet 建筑面积
Street: Type of road access 主路的路面类型
Alley: Type of alley access 小道的路面类型
LotShape: General shape of property 房屋外形
LandContour: Flatness of the property 平整度
Utilities: Type of utilities available 配套公用设施类型
LotConfig: Lot configuration 配置
LandSlope: Slope of property 土地坡度
Neighborhood: Physical locations within Ames city limits 房屋在埃姆斯市的位置
Condition1: Proximity to main road or railroad 附近交通情况
Condition2: Proximity to main road or railroad (if a second is present) 附近交通情况(如果同时满足两种情况)
BldgType: Type of dwelling 住宅类型
HouseStyle: Style of dwelling 房屋的层数
OverallQual: Overall material and finish quality 完工质量和材料
OverallCond: Overall condition rating 整体条件等级
YearBuilt: Original construction date 建造年份
YearRemodAdd: Remodel date 翻修年份
RoofStyle: Type of roof 屋顶类型
RoofMatl: Roof material 屋顶材料
Exterior1st: Exterior covering on house 外立面材料
Exterior2nd: Exterior covering on house (if more than one material) 外立面材料2
MasVnrType: Masonry veneer type 装饰石材类型
MasVnrArea: Masonry veneer area in square feet 装饰石材面积
ExterQual: Exterior material quality 外立面材料质量
ExterCond: Present condition of the material on the exterior 外立面材料外观情况
Foundation: Type of foundation 房屋结构类型
BsmtQual: Height of the basement 评估地下室层高情况
BsmtCond: General condition of the basement 地下室总体情况
BsmtExposure: Walkout or garden level basement walls 地下室出口或者花园层的墙面
BsmtFinType1: Quality of basement finished area 地下室区域质量
BsmtFinSF1: Type 1 finished square feet Type 1完工面积
BsmtFinType2: Quality of second finished area (if present) 二次完工面积质量(如果有)
BsmtFinSF2: Type 2 finished square feet Type 2完工面积
BsmtUnfSF: Unfinished square feet of basement area 地下室区域未完工面积
TotalBsmtSF: Total square feet of basement area 地下室总体面积
Heating: Type of heating 采暖类型
HeatingQC: Heating quality and condition 采暖质量和条件
CentralAir: Central air conditioning 中央空调系统
Electrical: Electrical system 电力系统
1stFlrSF: First Floor square feet 第一层面积
2ndFlrSF: Second floor square feet 第二层面积
LowQualFinSF: Low quality finished square feet (all floors) 低质量完工面积
GrLivArea: Above grade (ground) living area square feet 地面以上部分起居面积
BsmtFullBath: Basement full bathrooms 地下室全浴室数量
BsmtHalfBath: Basement half bathrooms 地下室半浴室数量
FullBath: Full bathrooms above grade 地面以上全浴室数量
HalfBath: Half baths above grade 地面以上半浴室数量
Bedroom: Number of bedrooms above basement level 地面以上卧室数量
KitchenAbvGr: Number of kitchens 厨房数量
KitchenQual: Kitchen quality 厨房质量
TotRmsAbvGrd: Total rooms above grade (does not include bathrooms) 总房间数(不含浴室和地下部分)
Functional: Home functionality rating 功能性评级
Fireplaces: Number of fireplaces 壁炉数量
FireplaceQu: Fireplace quality 壁炉质量
GarageType: Garage location 车库位置
GarageYrBlt: Year garage was built 车库建造时间
GarageFinish: Interior finish of the garage 车库内饰
GarageCars: Size of garage in car capacity 车壳大小以停车数量表示
GarageArea: Size of garage in square feet 车库面积
GarageQual: Garage quality 车库质量
GarageCond: Garage condition 车库条件
PavedDrive: Paved driveway 车道铺砌情况
WoodDeckSF: Wood deck area in square feet 实木地板面积
OpenPorchSF: Open porch area in square feet 开放式门廊面积
EnclosedPorch: Enclosed porch area in square feet 封闭式门廊面积
3SsnPorch: Three season porch area in square feet 时令门廊面积
ScreenPorch: Screen porch area in square feet 屏风门廊面积
PoolArea: Pool area in square feet 游泳池面积
PoolQC: Pool quality 游泳池质量
Fence: Fence quality 围栏质量
MiscFeature: Miscellaneous feature not covered in other categories 其它条件中未包含部分的特性
MiscVal: $Value of miscellaneous feature 杂项部分价值
MoSold: Month Sold 卖出月份
YrSold: Year Sold 卖出年份
SaleType: Type of sale 出售类型
SaleCondition: Condition of sale 出售条件
3、查看目标变量分布
plt.figure()
sns.distplot(train_df['SalePrice'])
plt.title('SalePrice分布')
plt.show()
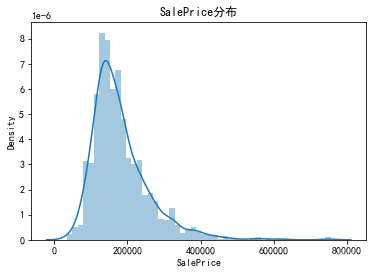
# 计算峰度和偏度
# - Kurtosis=0 与正态分布的陡缓程度相同
# - Kurtosis>0 比正态分布的高峰陡峭——尖顶峰
# - Kurtosis<0 比正态分布的高峰平缓——平顶峰
# - Skewness=0 分布形态与正态分布偏度相同
# - Skewness>0 正偏差数值较大,为正偏或右偏。长尾巴拖在右边
# - Skewness<0 负偏差数值较大,为负偏或左偏。长尾巴拖在左边
print('峰度(Kurtosis): ', train_df['SalePrice'].kurt())
print('偏度(Skewness): ', train_df['SalePrice'].skew())
峰度(Kurtosis): 6.536281860064529
偏度(Skewness): 1.8828757597682129
4、查看定量变量分布
先取出定量变量
# 特征变量按照数据类型分成定量变量和定性变量
quantitative = [feature for feature in train_df.columns if train_df.dtypes[feature] != 'object'] # 定量变量
quantitative.remove('Id')
quantitative.remove('SalePrice')
print('定量变量')
print(quantitative)
qualitative = [feature for feature in train_df.columns if train_df.dtypes[feature] == 'object'] # 定性变量
print('定性变量')
print(qualitative)
m_cont = pd.melt(train_df, value_vars=quantitative)
g = sns.FacetGrid(m_cont, col='variable', col_wrap=4, sharex=False, sharey=False)
g.map(sns.distplot, 'value')
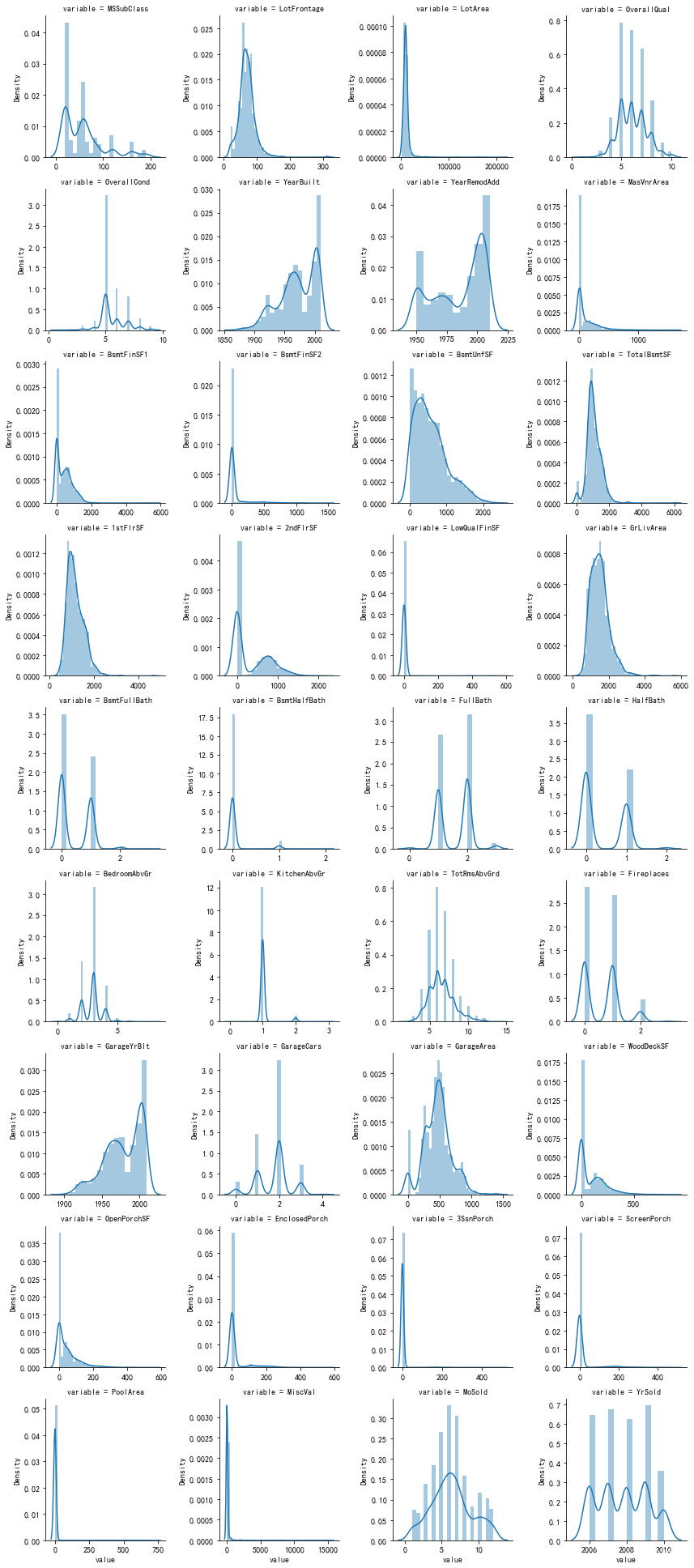
5、查看定量变量与目标变量的关系
m_cont = pd.melt(train_df, id_vars='SalePrice', value_vars=quantitative)
g = sns.FacetGrid(m_cont, col='variable', col_wrap=4, sharex=False, sharey=True)
g.map(plt.scatter, 'value', 'SalePrice')
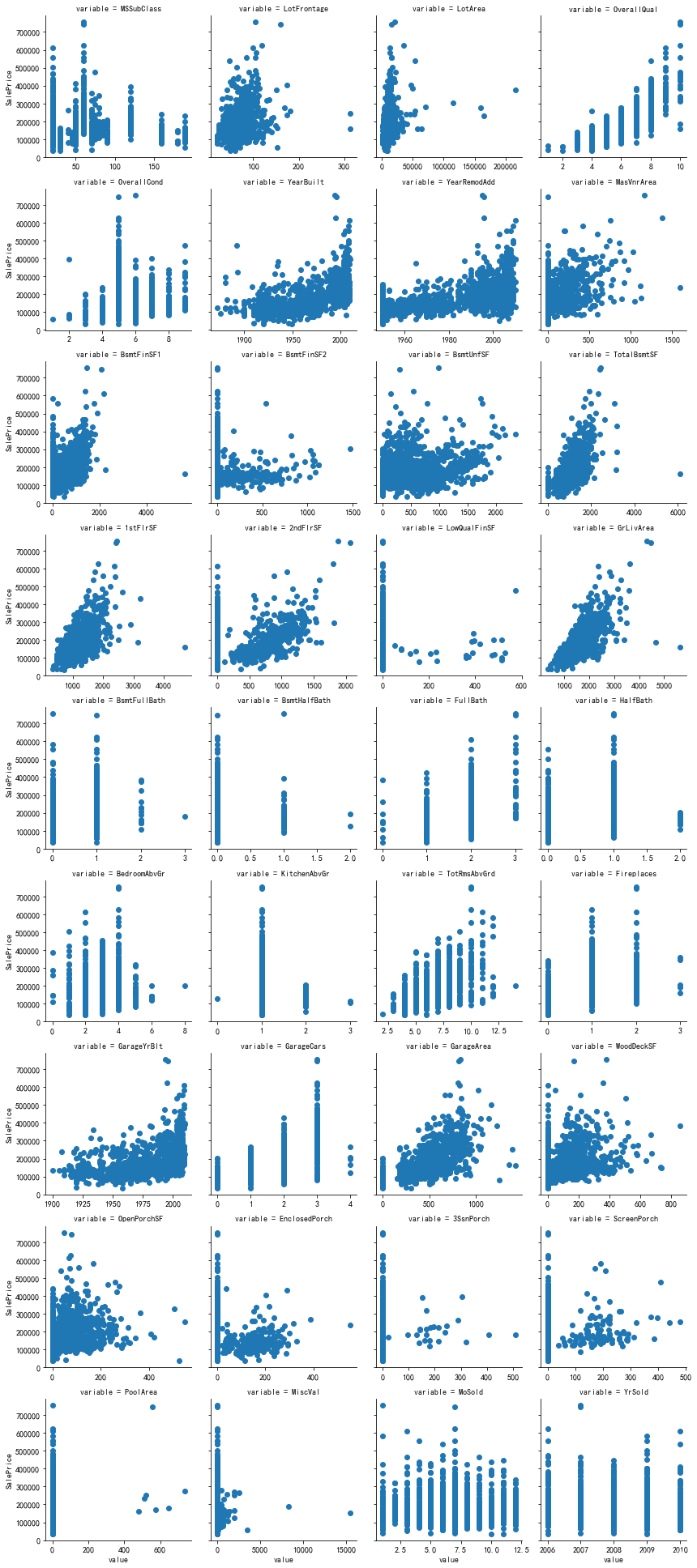
6、查看定性变量对目标变量的显著性影响程度
目标变量的显著性影响程度对机器学习建模有重要影响。这涉及到特征选择(feature selection)和特征工程(feature engineering)的过程。
特征选择是选择对目标变量具有显著影响的特征,以便在建模过程中仅使用最相关的特征。如果一个特征对目标变量的显著性影响较高,那么将其包含在模型中可能会提供更好的预测能力。
def anova(frame, qualitative):anv = pd.DataFrame()anv['feature'] = qualitativep_vals = []for fea in qualitative:samples = []cls = frame[fea].unique() # 变量的类别值for c in cls:c_array = frame[frame[fea]==c]['SalePrice'].valuessamples.append(c_array)p_val = stats.f_oneway(*samples)[1] # 获得p值,p值越小,对SalePrice的显著性影响越大p_vals.append(p_val)anv['pval'] = p_valsreturn anv.sort_values('pval')
a = anova(train_df, qualitative)
a['disparity'] = np.log(1./a['pval'].values) # 对SalePrice的影响悬殊度
plt.figure(figsize=(8, 6))
sns.barplot(x='feature', y='disparity', data=a)
plt.xticks(rotation=90)
plt.show()
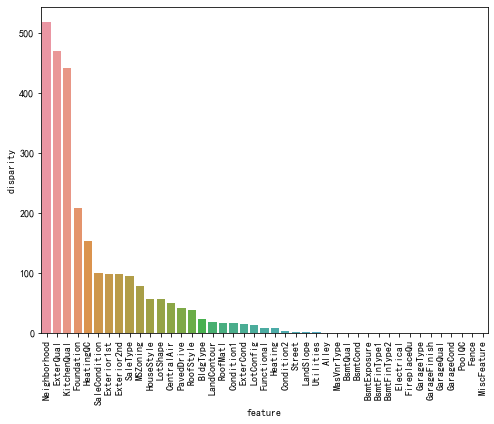
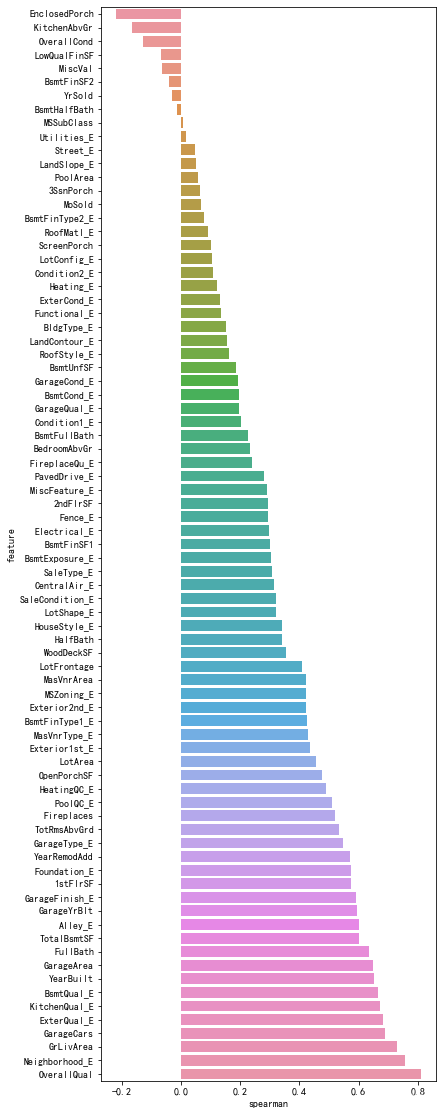
7、查看定性变量与目标变量的spearman相关系数
Spearman相关系数是一种用于衡量两个变量之间的单调关系的非参数统计指标。与皮尔逊相关系数不同,Spearman相关系数不要求变量之间的关系是线性的,而是可以捕捉到任何单调的关系,包括非线性的关系。
Spearman相关系数的取值范围为-1到1。以下是对Spearman相关系数取值的一般解释:
- 当Spearman相关系数为-1时,表示变量之间存在完全的负相关关系。即,当一个变量增加时,另一个变量会完全减小,并且变量之间的关系可以通过一个单调递减函数来描述。
- 当Spearman相关系数为0时,表示变量之间不存在单调关系。即,一个变量的值的变化并不意味着另一个变量的值会发生变化。
- 当Spearman相关系数为1时,表示变量之间存在完全的正相关关系。即,当一个变量增加时,另一个变量会完全增加,并且变量之间的关系可以通过一个单调递增函数来描述。
Spearman相关系数是基于变量的排序顺序进行计算的,而不是直接使用原始变量的值。对于定性变量(也称为分类变量),它们通常没有直接可比较的数值关系。例如,一个定性变量可能是颜色,有"红"、"绿"和"蓝"等等取值,这些取值之间没有明确的大小关系。因此,为了能够计算Spearman相关系数,我们需要将定性变量转换为数值表示。编码定性变量可以为每个不同的取值分配一个数值标签,使得不同的取值之间存在一种排序关系。常见的编码方法包括使用整数编码、独热编码(One-Hot Encoding)等。
def encode(frame, feature):ordering = pd.DataFrame()ordering['val'] = frame[feature].unique()ordering.index = ordering['val']ordering['spmean'] = frame[[feature, 'SalePrice']].groupby(feature)['SalePrice'].mean()ordering = ordering.sort_values('spmean')ordering['ordering'] = np.arange(1, ordering.shape[0]+1)ordering = ordering['ordering'].to_dict() # 返回的数据样例{category1:1, category2:2, ...}# 对frame[feature]编码for category, code_value in ordering.items():frame.loc[frame[feature]==category, feature+'_E'] = code_value
qual_encoded = []
for qual in qualitative:encode(train_df, qual)qual_encoded.append(qual+'_E')
print(qual_encoded)
# 计算特征变量与房价的spearman相关系数
def spearman(frame, features):spr = pd.DataFrame()spr['feature'] = featuresspr['spearman'] = [frame[f].corr(frame['SalePrice'], 'spearman') for f in features]spr = spr.sort_values('spearman')plt.figure(figsize=(6, 0.25*len(features)))sns.barplot(x='spearman', y='feature', data=spr)
spearman(train_df, quantitative+qual_encoded)
四、数据预处理
1、数据清洗
包括去除异常值、处理缺失数据、处理样本不平衡等。例如,缺失值可以通过填充均值、中位数或特定值来处理;异常值可以通过阈值法、IQR法等方法识别和处理。
异常值处理
查看异常值
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
plt.figure(figsize=(12,6))
plt.scatter(train['GrLivArea'], train['SalePrice'])
plt.xlabel('GrLivArea')
plt.ylabel('SalePrice')
plt.title('GrLivArea与SalePrice散点图,观察异常值')
plt.grid(b=True, ls=':')
plt.show()
异常值较少,选择删除
# 删除两个离群点
train.drop(train[(train.GrLivArea>4000) & (train.SalePrice<200000)].index, inplace=True)
# 合并训练集和测试集,便于同时对两个数据集进行数据清洗和特征工程
full = pd.concat([train, test], axis=0, ignore_index=True)
train.shape, test.shape, full.shape
缺失值处理
查看每个特征的缺失情况
def audit_missing_values(df): audit_result = {} for col in df.columns: count = df[col].isnull().sum() ratio = count / len(df) if len(df) > 0 else 0 audit_result[col] = {'缺失数量': count, '缺失百分比': ratio} return audit_resultaudit_missing_values(full)
中位数填充
房子同街道之间的距离,按照建筑面积分为10块,用每块的中位数填充
full['LotAreaCut'] = pd.qcut(full['LotArea'], 10)
full.groupby(['LotAreaCut', 'Neighborhood'])['LotFrontage'].agg(['count', 'mean', 'median'])
full['LotFrontage'] = full.groupby(['LotAreaCut', 'Neighborhood'])['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 由于某些分组没有数据,因此未填补的缺失值单独利用LotAreaCut填充
full['LotFrontage'] = full.groupby(['LotAreaCut'])['LotFrontage'].transform(lambda x: x.fillna(x.median()))
None填充
游泳池质量、车库质量、车库条件是类型特征,可以用None填充
cols = ["PoolQC" , "MiscFeature", "Alley", "Fence", "FireplaceQu", "GarageQual", "GarageCond", "GarageFinish", "GarageYrBlt", "GarageType", "BsmtExposure", "BsmtCond", "BsmtQual", "BsmtFinType2", "BsmtFinType1", "MasVnrType"]
for col in cols:full[col] = full[col].fillna('None')
0填充
装饰石材面积、地下室区域未完工面积缺失时可视为0
cols2 = ["MasVnrArea", "BsmtUnfSF", "TotalBsmtSF", "GarageCars", "BsmtFinSF2", "BsmtFinSF1", "GarageArea"]
for col in cols2:full[col] = full[col].fillna(0)
众数填充
区域分类、地下室全浴室数量、功能性评级类似特征可以用众数填充
cols3 = ["MSZoning", "BsmtFullBath", "BsmtHalfBath", "Utilities", "Functional", "Electrical", "KitchenQual", "SaleType","Exterior1st", "Exterior2nd"]
for col in cols3:full[col] = full[col].fillna(full[col].mode()[0])
默认值填充
full['GarageYrBlt'] = full['GarageYrBlt'].replace(['', ' ', 'None'], np.nan)
full['GarageYrBlt'] = full['GarageYrBlt'].fillna(-1)
full.GarageYrBlt
确认填充结果
full.isnull().sum()[full.isnull().sum()>0] # 缺失值填补完毕
只有SalePrice 有缺失,这是正常的,因为测试集没有SalePrice值
2、特征归一化
将数据特征缩放到同一尺度上,使得不同特征的权重相当,便于模型处理。
3、离散特征编码
对于类别型数据,可以通过独热编码、标签编码等方式将其转换为数值型数据。
有序编码
# 定义映射函数
def map_values(df):df['MSSubClass'] = df['MSSubClass'].map({180:1,30:2, 45:2,190:3, 50:3, 90:3, 85:4, 40:4, 160:4, 70:5, 20:5, 75:5, 80:5, 150:5,120: 6, 60:6})df['MSZoning'] = df['MSZoning'].map({'C (all)':1, 'RM':2, 'RH':2, 'RL':3, 'FV':4})df['Neighborhood'] = df['Neighborhood'].map({'MeadowV':1,'IDOTRR':2, 'BrDale':2,'OldTown':3, 'Edwards':3, 'BrkSide':3,'Sawyer':4, 'Blueste':4, 'SWISU':4, 'NAmes':4,'NPkVill':5, 'Mitchel':5,'SawyerW':6, 'Gilbert':6, 'NWAmes':6,'Blmngtn':7, 'CollgCr':7, 'ClearCr':7, 'Crawfor':7,'Veenker':8, 'Somerst':8, 'Timber':8,'StoneBr':9,'NoRidge':10, 'NridgHt':10})df['HouseStyle'] = df['HouseStyle'].map({'1.5Unf':1, '1.5Fin':2, '2.5Unf':2, 'SFoyer':2, '1Story':3, 'SLvl':3,'2Story':4, '2.5Fin':4})df['MasVnrType'] = df['MasVnrType'].map({'BrkCmn':1, 'None':1, 'BrkFace':2, 'Stone':3})df['ExterQual'] = df['ExterQual'].map({'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})df['ExterCond'] = df['ExterCond'].map({'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})df['Foundation'] = df['Foundation'].map({'Slab':1, 'BrkTil':2, 'CBlock':2, 'Stone':2, 'Wood':3, 'PConc':4})df['BsmtQual'] = df['BsmtQual'].map({'None':1, 'Po':2, 'Fa':3, 'TA':4, 'Gd':5, 'Ex':6})df['BsmtCond'] = df['BsmtCond'].map({'None':1, 'Po':2, 'Fa':3, 'TA':4, 'Gd':5, 'Ex':6})df['BsmtExposure'] = df['BsmtExposure'].map({'None':1, 'No':2, 'Mn':3, 'Av':4, 'Gd':5})df['BsmtFinType1'] = df['BsmtFinType1'].map({'None':1, 'Unf':2, 'LwQ':3, 'Rec':4, 'BLQ':5, 'ALQ':6, 'GLQ':7})df['BsmtFinType2'] = df['BsmtFinType2'].map({'None':1, 'Unf':2, 'LwQ':3, 'Rec':4, 'BLQ':5, 'ALQ':6, 'GLQ':7})df['HeatingQC'] = df['HeatingQC'].map({'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})df['KitchenQual'] = df['KitchenQual'].map({'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})df['Functional'] = df['Functional'].map({'Maj2':1, 'Maj1':2, 'Min1':2, 'Min2':2, 'Mod':2, 'Sev':2, 'Typ':3})df['FireplaceQu'] = df['FireplaceQu'].map({'None':1, 'Po':2, 'Fa':3, 'TA':4, 'Gd':5, 'Ex':6})df['GarageFinish'] = df['GarageFinish'].map({'None':1, 'Unf':2, 'RFn':3, 'Fin':4})df['GarageQual'] = df['GarageQual'].map({'None':1, 'Po':2, 'Fa':3, 'TA':4, 'Gd':5, 'Ex':6})df['GarageCond'] = df['GarageCond'].map({'None':1, 'Po':2, 'Fa':3, 'TA':4, 'Gd':5, 'Ex':6})df['PavedDrive'] = df['PavedDrive'].map({'N':1, 'P':2, 'Y':3})df['PoolQC'] = df['PoolQC'].map({'None':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})df['Fence'] = df['Fence'].map({'None':1, 'MnWw':2, 'GdWo':3, 'MnPrv':4, 'GdPrv':5})# 有序特征编码
map_values(full)
标签编码
lab = LabelEncoder()
full['YearBuilt'] = lab.fit_transform(full['YearBuilt'])
full['YearRemodAdd'] = lab.fit_transform(full['YearRemodAdd'])
full['GarageYrBlt'] = lab.fit_transform(full['GarageYrBlt'])
对数变换
full.drop(['SalePrice', 'Id'], axis=1, inplace=True)
# 数据做一备份
full_fe = full.copy()
# 对于偏度大于1的定量变量进行对数变换
full_numeric = full_fe.select_dtypes(exclude='object')
skew = full_numeric.apply(lambda x: x.skew())
skew_features = skew[abs(skew) >= 1].index
full_fe[skew_features] = np.log1p(full_fe[skew_features])
4、连续特征离散化
将连续型特征划分为不同的区间或类别,有助于处理非线性关系或简化模型。
5、特征缩放
特征缩放在机器学习中是一种常见的预处理步骤,它对特征数据进行线性变换,使得特征值落入特定的范围或分布,以便更好地满足模型的要求和优化算法的性质。并非所有机器学习算法都对特征缩放敏感,例如决策树和随机森林等基于树的算法通常不需要特征缩放。然而,对于许多线性模型、支持向量机、神经网络等模型,特征缩放通常是一个重要的步骤,有助于提升模型的性能和稳定性。
scaler = RobustScaler()
# 分离训练集和测试集
n_train = train.shape[0]
train_X = full_fe[:n_train]
test_X = full_fe[n_train:]
train_y = train['SalePrice']
# 区间缩放
# 注意事项:不能分别对训练集和测试集训练与转换,应该在训练集上训练,在测试集上转换
train_X = scaler.fit_transform(train_X)
test_X = scaler.transform(test_X)
train_y = np.log(train_y)
# robustscaler
scaler = RobustScaler()
train_X = scaler.fit_transform(train_X)
test_X = scaler.transform(test_X)
train_y = np.log(train_y)
train_X[:5]
5、特征选择
从原始特征中选择对模型有用的特征,去除冗余特征,提高模型效果。这可以通过基于统计的方法(如卡方检验、互信息法等)或基于模型的方法(如决策树、随机森林的特征重要性评分)来实现。
通过Lasso回归模型选择特征
lasso = Lasso(alpha=0.001)
lasso.fit(train_X, train_y)
Lasso(alpha=0.001, copy_X=True, fit_intercept=True, max_iter=1000,normalize=False, positive=False, precompute=False, random_state=None,selection='cyclic', tol=0.0001, warm_start=False)
lasso_fi = pd.DataFrame({'feature_importance':lasso.coef_}, index=full_fe.columns)
lasso_fi.sort_values('feature_importance', ascending=False)
plt.figure()
lasso_fi[lasso_fi['feature_importance'] != 0].sort_values('feature_importance').plot(kind='barh', figsize=(12, 25))
plt.grid()
plt.show()
6、特征构造
根据业务领域或数据背景,人工构造新的特征。例如,在电商领域,可以构造用户购买频率、购买间隔等特征。又比如从时间特征衍生出日/周/月/年/季度特征。
增加特征
def add_feature(X):X['TotalHouse'] = X['TotalBsmtSF'] + X['1stFlrSF'] + X['2ndFlrSF']X['TotalArea'] = X['TotalBsmtSF'] + X['1stFlrSF'] + X['2ndFlrSF'] + X['GarageArea']X['TotalQuality'] = X['OverallQual'] + X['OverallCond']X['TotalHouse_OverallQual'] = X['TotalHouse'] * X['OverallQual']X['GrLivArea_OverallQual'] = X['GrLivArea'] * X['OverallQual']X['MSZoning_TotalHouse'] = X['MSZoning'] * X['TotalHouse']X['MSZoning_OverallQual'] = X['MSZoning'] + X['OverallQual']X['MSZoning_YearBuilt'] = X['MSZoning'] + X['YearBuilt']X['Neighborhood_TotalHouse'] = X['Neighborhood'] * X['TotalHouse']X['Neighborhood_OverallQual'] = X['Neighborhood'] + X['OverallQual']X['Neighborhood_YearBuilt'] = X['Neighborhood'] + X['YearBuilt']X['BsmtFinSF1_OverallQual'] = X['BsmtFinSF1'] * X['OverallQual']X['Functional_TotalHouse'] = X['Functional'] * X['TotalHouse']X['Functional_OverallQual'] = X['Functional'] + X['OverallQual']X['LotArea_OverallQual'] = X['LotArea'] * X['OverallQual']X['LotArea_TotalHouse'] = X['LotArea'] + X['TotalHouse']X['Bsmt'] = X['BsmtFinSF1'] + X['BsmtFinSF2'] + X['BsmtUnfSF']X['PorchArea'] = X['OpenPorchSF'] + X['EnclosedPorch'] + X['3SsnPorch'] + X['ScreenPorch']X['TotalPlace'] = X['TotalArea'] + X['PorchArea']
# 获取原数据
full_fe1 = full.copy()full_fe1.shape
# 增加特征
add_feature(full_fe1)full_fe1.shape
# 数据转换
full_numeric1 = full_fe1.select_dtypes(exclude='object')
skew1 = full_numeric1.apply(lambda x: x.skew())
skew_features1 = skew1[abs(skew1) >= 1].index
full_fe1[skew_features1] = np.log1p(full_fe1[skew_features1])
# one-hot编码
full_fe1 = pd.get_dummies(full_fe1)
full_fe1.shape
7、特征降维
当特征维度过高时,可能导致模型复杂度增加、计算成本上升以及过拟合等问题。特征降维旨在减少特征数量,同时保留尽可能多的有用信息。常用的方法包括主成分分析(PCA)、线性判别分析(LDA)等。
pca = PCA(n_components=205)
train_X = pca.fit_transform(train_X)
test_X = pca.transform(test_X)
train_X.shape, test_X.shape五、模型选择
1、理解问题类型
首先,需要明确问题的类型,是分类、回归还是聚类等。这决定了选择哪种类型的机器学习模型。
该问题为回归
2、考虑数据特性
数据的规模、分布和特征等都会影响模型的选择。例如,对于大规模数据集,可能需要选择计算效率更高的模型;对于非线性关系的数据,可能需要选择能够处理复杂关系的模型。
3、选择常用模型
根据问题的类型和数据的特性,可以选择一些常用的模型进行尝试,如线性回归、逻辑回归、决策树、随机森林、支持向量机等。
4、考虑集成学习和深度学习
对于复杂的问题,可以考虑使用集成学习或深度学习模型。集成学习可以通过结合多个模型的预测结果来提高性能,而深度学习可以处理大规模和高维度的数据。
六、模型训练
1、数据准备
将经过预处理的数据划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的超参数,测试集用于评估模型的性能。
# 分离训练集和测试集
n_train = train.shape[0]
train_X = full_fe1[:n_train]
test_X = full_fe1[n_train:]
train_y = train.SalePrice
train_X.shape, test_X.shape, train_y.shape
2、模型初始化
选择好模型后,需要进行初始化,包括设置模型的参数和结构等。
models = [LinearRegression(),Ridge(),Lasso(alpha=0.01,max_iter=10000),RandomForestRegressor(),GradientBoostingRegressor(),SVR(),LinearSVR(),ElasticNet(alpha=0.001,max_iter=10000),SGDRegressor(max_iter=1000,tol=1e-3),BayesianRidge(),KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5),ExtraTreesRegressor(),XGBRegressor()]
names = ["LR", "Ridge", "Lasso", "RF", "GBR", "SVR", "LinSVR", "Ela","SGD","Bay","Ker","Extra","Xgb"]
cv_results = []
for name, model in zip(names, models):score = rmse_cv(model, train_X, train_y)cv_results.append(score)print('%s: %f (%f)' % (name, score.mean(), score.std()))
LR: 20981998087.207458 (36234568672.259140)
Ridge: 0.118677 (0.004891)
Lasso: 0.124334 (0.006086)
RF: 0.136326 (0.006123)
GBR: 0.129313 (0.005787)
SVR: 0.143337 (0.012095)
LinSVR: 0.121567 (0.005950)
Ela: 0.113721 (0.004883)
SGD: 0.133089 (0.009391)
Bay: 0.113197 (0.004988)
Ker: 0.110177 (0.005107)
Extra: 0.132725 (0.006600)
Xgb: 0.146359 (0.005729)
3、训练模型
使用训练集对模型进行训练。在训练过程中,模型会学习数据的特征和规律,并不断优化自身的参数以减小预测误差。
4、验证和调整
使用验证集对训练好的模型进行验证,并根据验证结果调整模型的超参数。这个过程可能需要进行多次迭代,以找到最优的超参数组合。
七、模型评估
1、选择评估指标
根据问题的类型和需求,选择合适的评估指标。对于分类问题,常用的评估指标包括准确率、精确率、召回率和F1分数等。对于回归问题,常用的指标有均方误差(MSE)、均方根误差(RMSE)和决定系数(R2)等。
回归模型,这里选择rmse作为评价指标
def rmse_cv(model, X, y):rmse = np.sqrt(-cross_val_score(model, X, y, scoring='neg_mean_squared_error', cv=5))return rmse
2、计算评估指标
使用测试集对模型进行预测,并根据预测结果计算评估指标。确保测试集与训练集和验证集完全独立,以准确评估模型的泛化能力。
# 创建模型并训练
models = [LinearRegression(),Ridge(),Lasso(alpha=0.01,max_iter=10000),RandomForestRegressor(),GradientBoostingRegressor(),SVR(),LinearSVR(),ElasticNet(alpha=0.001,max_iter=10000),SGDRegressor(max_iter=1000,tol=1e-3),BayesianRidge(),KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5),ExtraTreesRegressor(),XGBRegressor()]
names = ["LR", "Ridge", "Lasso", "RF", "GBR", "SVR", "LinSVR", "Ela","SGD","Bay","Ker","Extra","Xgb"]
cv_results = []
for name, model in zip(names, models):score = rmse_cv(model, train_X, train_y)cv_results.append(score)print('%s: %f (%f)' % (name, score.mean(), score.std()))
3、解读评估结果
分析评估指标的值,了解模型在不同方面的性能表现。例如,准确率可以反映模型整体预测正确的比例,而精确率和召回率则可以帮助了解模型在不同类别上的表现。
LR: 0.116180 (0.005230)
Ridge: 0.115855 (0.005188)
Lasso: 0.124334 (0.006086)
RF: 0.134958 (0.007572)
GBR: 0.128602 (0.004423)
SVR: 0.142950 (0.011931)
LinSVR: 0.116312 (0.004945)
Ela: 0.113806 (0.004936)
SGD: 0.134785 (0.007010)
Bay: 0.113186 (0.005027)
Ker: 0.110572 (0.004634)
Extra: 0.132237 (0.006353)
Xgb: 0.139968 (0.005361)
从结果看核岭回归表现最好,平均值为0.110572,标准差为0.004634
八、模型验证
1、交叉验证
采用交叉验证方法,如k折交叉验证,来评估模型的稳定性和泛化能力。将数据集分成k个子集,每次使用k-1个子集进行训练,剩下的一个子集进行验证。重复这个过程k次,得到k个验证结果,最后取平均值作为最终的评估结果。
def rmse_cv(model, X, y):rmse = np.sqrt(-cross_val_score(model, X, y, scoring='neg_mean_squared_error', cv=5))return rmse
# 创建模型并训练
models = [LinearRegression(),Ridge(),Lasso(alpha=0.01,max_iter=10000),RandomForestRegressor(),GradientBoostingRegressor(),SVR(),LinearSVR(),ElasticNet(alpha=0.001,max_iter=10000),SGDRegressor(max_iter=1000,tol=1e-3),BayesianRidge(),KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5),ExtraTreesRegressor(),XGBRegressor()]
names = ["LR", "Ridge", "Lasso", "RF", "GBR", "SVR", "LinSVR", "Ela","SGD","Bay","Ker","Extra","Xgb"]
cv_results = []
for name, model in zip(names, models):score = rmse_cv(model, train_X, train_y)cv_results.append(score)print('%s: %f (%f)' % (name, score.mean(), score.std()))
2、绘制学习曲线
通过绘制学习曲线,可以观察模型随着训练样本数量的增加,其性能的变化趋势。这有助于判断模型是否存在过拟合或欠拟合的问题。
3、比较不同模型
如果有多个候选模型,可以通过比较它们在测试集上的评估指标,选择性能最优的模型。
LR: 0.116180 (0.005230)
Ridge: 0.115855 (0.005188)
Lasso: 0.124334 (0.006086)
RF: 0.134958 (0.007572)
GBR: 0.128602 (0.004423)
SVR: 0.142950 (0.011931)
LinSVR: 0.116312 (0.004945)
Ela: 0.113806 (0.004936)
SGD: 0.134785 (0.007010)
Bay: 0.113186 (0.005027)
Ker: 0.110572 (0.004634)
Extra: 0.132237 (0.006353)
Xgb: 0.139968 (0.005361)
从结果看核岭回归表现最好,平均值为0.110572,标准差为0.004634
九、模型优化
1、理解超参数
超参数是模型训练前需要设定的参数,如学习率、正则化系数、树的数量等。它们对模型的性能有很大影响。
2、网格搜索与随机搜索
使用网格搜索或随机搜索来系统地探索超参数空间,找到最佳的超参数组合。
def grid(model, X, y, params):grid_search = GridSearchCV(model, params, scoring='neg_mean_squared_error', cv=5)grid_search.fit(X, y)print(grid_search.best_params_, np.sqrt(-grid_search.best_score_))
params_lasso = {'alpha': [0.0004,0.0005,0.0007,0.0009], 'max_iter':[10000]}
grid(Lasso(), train_X, train_y, params_lasso)
params_lasso = {'alpha': [0.0004,0.0005,0.0007,0.0009], 'max_iter':[10000]}
grid(Lasso(), train_X, train_y, params_lasso)
params_svr = {'C':[11,13,15],'kernel':["rbf"],"gamma":[0.0003,0.0004],"epsilon":[0.008,0.009]}
grid(SVR(), train_X, train_y, params_svr)
params_ker = {'alpha':[0.2,0.3,0.4], 'kernel':["polynomial"], 'degree':[3],'coef0':[0.8,1]}
grid(KernelRidge(), train_X, train_y, params_ker)
params_ela = {'alpha':[0.0008,0.004,0.005],'l1_ratio':[0.08,0.1,0.3],'max_iter':[10000]}
grid(ElasticNet(), train_X, train_y, params_ela)
使用搜索后的参数重新训练模型
lasso = Lasso(alpha=0.0009, max_iter=10000)
ridge = Ridge(alpha=65)
svr = SVR(C=15, epsilon=0.009, gamma= 0.0004, kernel='rbf')
ker = KernelRidge(alpha=0.4, coef0=1, degree=3, kernel='polynomial')
ela = ElasticNet(alpha=0.005,l1_ratio=0.1,max_iter=10000)
bay = BayesianRidge()
3、贝叶斯优化
对于复杂的模型,如深度学习模型,贝叶斯优化是一种有效的超参数调整方法。
十、模型融合
1、平均融合
将多个模型的预测结果进行加权平均或简单平均,以得到最终的预测结果。对于分类问题,还可以将预测结果转化为概率分布后再求平均。这种方法的优点是简单易实现,不需要训练额外的模型,但缺点是每个模型都被平等对待,无法充分利用模型之间的差异性。
class AverageWeight(BaseEstimator, RegressorMixin):def __init__(self, mods, weight):self.mods = modsself.weight = weightdef fit(self, X, y):self.models_ = [clone(x) for x in self.mods]for model in self.models_:model.fit(X, y)return selfdef predict(self, X):results = [model.predict(X) for model in self.models_]# 各个模型预测结果加权平均pre = np.dot(np.array(self.weight), np.array(results))return pre
model_weight = [0.05, 0.2, 0.3, 0.35, 0.03, 0.07]
models = [lasso, ridge, svr, ker, ela, bay]
avg_w = AverageWeight(models, model_weight)
avg_score = rmse_cv(avg_w, train_X, train_y)
print(avg_score.mean())
0.1090625412907696
avg_w2.fit(train_X, train_y)
y_pred = np.exp(avg_w2.predict(test_X))
result = pd.DataFrame({'Id':test['Id'], 'SalePrice':y_pred})
result.to_csv('submission_avg.csv', index=False)
2、投票融合
对于分类问题,每个模型都给出一个预测结果,最终预测结果取多数投票。这也是一种简单直接的方法,能够综合考虑多个模型的意见。
3、堆叠融合
这是一种更为复杂的融合方式,将多个模型的预测结果作为输入,再训练一个元模型来得到最终的预测结果。这种方法能够充分利用各个模型的优点,但训练过程相对复杂,且可能增加过拟合的风险。
class stacking(BaseEstimator, RegressorMixin):def __init__(self, base_models, stack_model):self.base_models = base_modelsself.stack_model = stack_modelself.kf = KFold(n_splits=5, random_state=42, shuffle=True)def fit(self, X, y):# 注:这里要把数据转换成数组类型,避免传入的数据不是数组类型时报错X = np.array(X)y = np.array(y)self.saved_models = [list() for model in self.base_models]oof_train = np.zeros((X.shape[0], len(self.base_models)))for i, model in enumerate(self.base_models):for train_idx, val_idx in self.kf.split(X, y):fit_model = clone(model) fit_model.fit(X[train_idx], y[train_idx])self.saved_models[i].append(fit_model)oof_train[val_idx, i] = fit_model.predict(X[val_idx])self.stack_model.fit(oof_train, y)return selfdef predict(self, X):X = np.array(X)oof_test = np.zeros((X.shape[0], len(self.base_models)))for i, model in enumerate(self.saved_models):model_pred = np.column_stack([fit_model.predict(X) for fit_model in model])oof_test[:, i] = model_pred.mean(1)return self.stack_model.predict(oof_test)stack_model = stacking(base_models=[lasso, ridge, svr, ker, ela, bay], stack_model=ker)
stack_score = rmse_cv(stack_model, train_X, train_y)
print(stack_score.mean())
0.1081483570026502
stack_model.fit(train_X, train_y)
stack_pred =np.exp(stack_model.predict(test_X))
result_s = pd.DataFrame({'Id':test['Id'], 'SalePrice':stack_pred})
result_s.to_csv('submmision_stack.csv', index=False)
十一、完整代码
通过百度网盘分享的文件:房价预测-回归算…
链接:https://pan.baidu.com/s/1NCHAgKefth5BTuGyPNmDYA?pwd=4349
提取码:4349
复制这段内容打开「百度网盘APP 即可获取」
相关文章:
【六 (2)机器学习-机器学习建模步骤/kaggle房价回归实战】
一、确定问题和目标: 1、业务需求分析: 与业务团队或相关利益方进行深入沟通,了解他们的需求和期望。 分析业务流程,找出可能的瓶颈、机会或挑战。 思考机器学习如何帮助解决这些问题或实现业务目标。 2、问题定义:…...
vue源码解析——vue如何将template转换为render函数
Vue 将模板(template)转换为渲染函数(render function)是 Vue 编译器的核心功能,它是 Vue 实现响应式和虚拟 DOM 的关键步骤。在 Vue 中,模板(template)是开发者编写的类似 HTML 的代…...

深入理解zookeeper
如果是zookeeper的初学者,可以看: zookeeper快速入门(合集)-CSDN博客 如果想要深入理解zookeeper,并在面试中取得更好的表现,可以看下面的文章,都是偏面试向的角度写的。 三分钟明白zookeeper…...
【漏洞复现】WordPress Plugin LearnDash LMS 敏感信息暴漏
漏洞描述 WordPress和WordPress plugin都是WordPress基金会的产品。WordPress是一套使用PHP语言开发的博客平台。该平台支持在PHP和MySQL的服务器上架设个人博客网站。WordPress plugin是一个应用插件。 WordPress Plugin LearnDash LMS 4.10.2及之前版本存在安全漏洞&#x…...
phpmyadmin页面getshell
0x00 前言 来到phpmyadmin页面后如何getshell呢?下面介绍两种方法 0x01 select into outfile直接写入 1、利用条件 对web目录需要有写权限能够使用单引号(root) 知道网站绝对路径(phpinfo/php探针/通过报错等) secure_file_priv没有具体值 2、查看secure_file…...

题目:学习static定义静态变量的用法
题目:学习static定义静态变量的用法 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheate…...

【C++】编程规范之函数规则
对所有函数入参进行合法性检查 在编写函数时,应该始终对所有传入的参数进行合法性检查,以防止出现意外的错误或异常情况。这包括但不限于检查指针是否为空、整数是否在有效范围内、数组是否越界等等。通过对参数进行严格的合法性检查,可以避免…...
HTML常用的图片标签和超链接标签
目录 一.常用的图片标签和超链接标签: 1.超链接标签: 前言: 超链接的使用: target属性: 1)鼠标样式: 2)颜色及下划线: 总结: 2.图片标签: 前言: img的使用: 设置图片: 1.设置宽度和高度: 2.HTM…...

浏览器工作原理与实践--WebAPI:XMLHttpRequest是怎么实现的
在上一篇文章中我们介绍了setTimeout是如何结合渲染进程的循环系统工作的,那本篇文章我们就继续介绍另外一种类型的WebAPI——XMLHttpRequest。 自从网页中引入了JavaScript,我们就可以操作DOM树中任意一个节点,例如隐藏/显示节点、改变颜色、…...
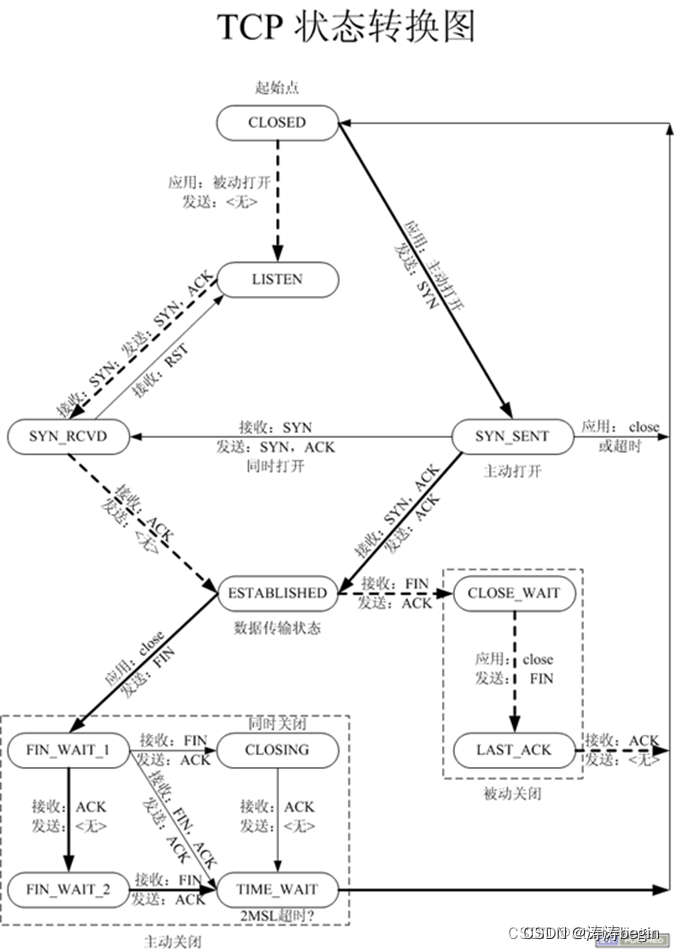
TCP网络协议栈和Posix网络部分API总结
文章目录 Posix网络部分API综述TCP协议栈通信过程TCP三次握手和四次挥手(看下图)三次握手常见问题?为什么是三次握手而不是两次?三次握手和哪些函数有关?TCP的生命周期是从什么时候开始的? 四次挥手通信状态…...
》)
《解释器模式(极简c++)》
本文章属于专栏- 概述 - 《设计模式(极简c版)》-CSDN博客 模式说明 方案: 对每个data建立一个单点解释器对象X,dataA和dataB之间的关系,建立一个关系解释器对象Y,这里的Y处理的是X1和X2。这样,…...

c#仿ppt案例
画曲线 namespace ppt2024 {public partial class Form1 : Form{public Form1(){InitializeComponent();}//存放所有点的位置信息List<Point> lstPosition new List<Point>();//控制开始画的时机bool isDrawing false;//鼠标点击开始画private void Form1_MouseD…...

10.图像高斯滤波的原理与FPGA实现思路
1.概念 高斯分布 图像滤波之高斯滤波介绍 图像处理算法|高斯滤波 高斯滤波(Gaussian filter)包含很多种,包括低通、高通、带通等,在图像上说的高斯滤波通常是指的高斯模糊(Gaussian Blur),是一种高斯低通滤波。通常这个算法也可以用来模…...

WebGIS 地铁交通线网 | 图扑数字孪生
数字孪生技术在地铁线网的管理和运维中的应用是一个前沿且迅速发展的领域。随着物联网、大数据、云计算以及人工智能技术的发展,地铁线网数字孪生在智能交通和智慧城市建设中的作用日益凸显。 图扑软件基于 HTML5 的 2D、3D 图形渲染引擎,结合 GIS 地图…...
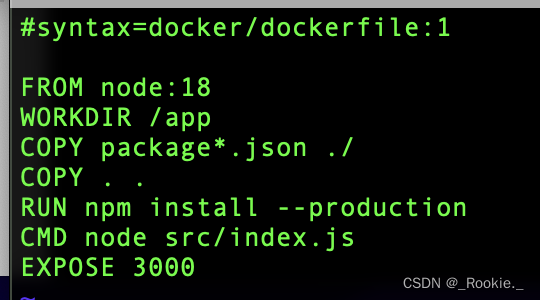
Docker 哲学 - push 本机镜像 到 dockerhub
注意事项: 1、 登录 docker 账号 docker login 2、docker images 查看本地镜像 3、注意的是 push镜像时 镜像的tag 需要与 dockerhub的用户名保持一致 eg:本地镜像 express:1 直接 docker push express:1 无法成功 原因docker不能识别 push到哪里 …...
大数据学习第十二天(hadoop概念)
1、服务器之间数据文件传递 1)服务器之间传递数据,依赖ssh协议 2)http协议是web网站之间的通讯协议,用户可已通过http网址访问到对应网站数据 3)ssh协议是服务器之间,或windos和服务器之间传递的数据的协议…...
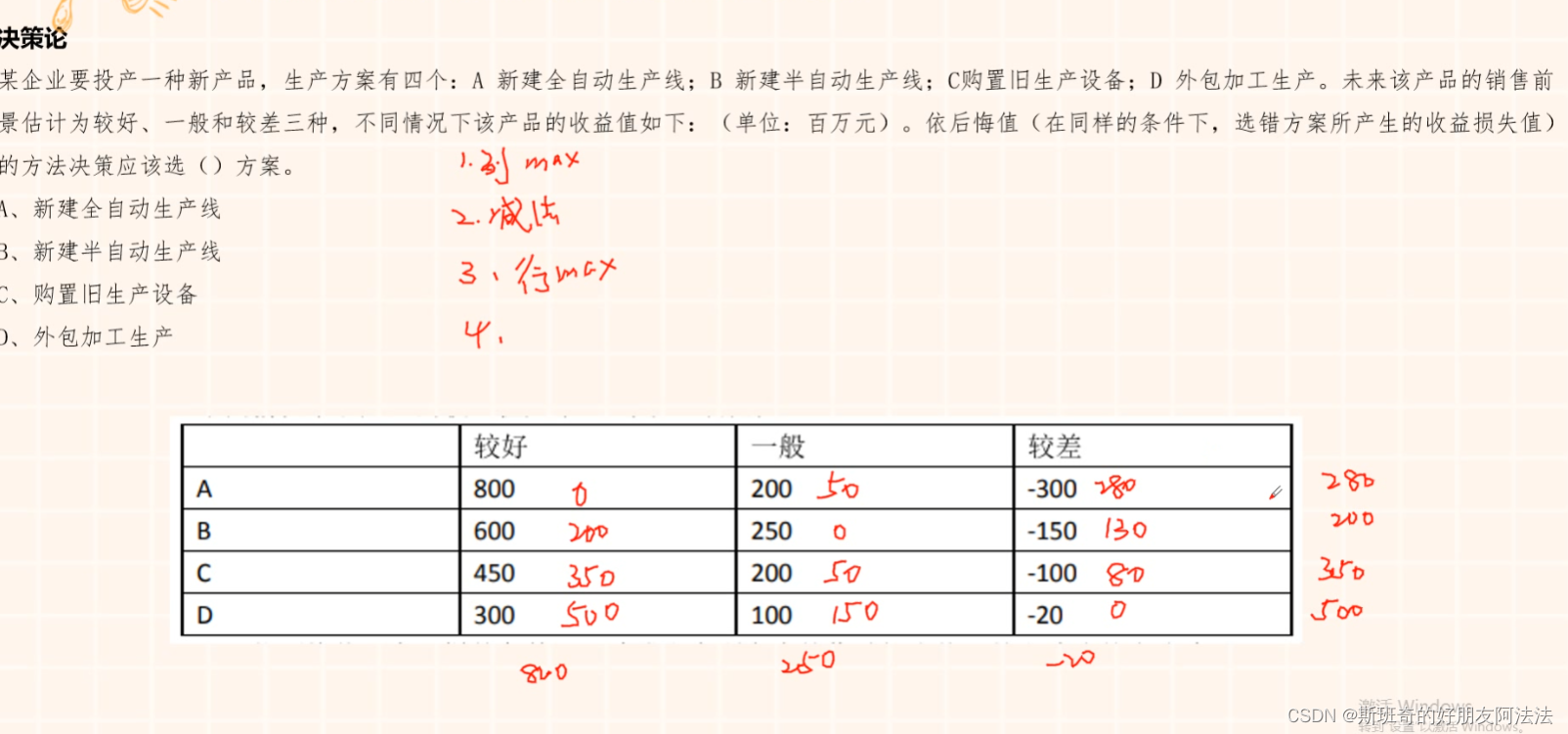
管理科学笔记
1.线性规划 画出区域,代入点计算最大最小值 2.最小生成树 a.断线法,从大的开始断 b.选择法,从小的开始选 3.匈牙利法 维度数量直线覆盖所有的0 4.一直选最当前路线最短路径 5.线性规划 6.决策论...

WebKit结构简介
WebKit是一款开源的浏览器引擎,用于渲染网页内容。它负责将HTML、CSS和JavaScript等网络资源转换为用户在屏幕上看到的图形界面。WebKit是一个跨平台的引擎,可以在多种操作系统上运行,如Windows、macOS、Linux等。 以下是一篇关于WebKit结构…...

Kaggle:收入分类
先看一下数据的统计信息 import pandas as pd # 加载数据(保留原路径,但在实际应用中建议使用相对路径或环境变量) data pd.read_csv(r"C:\Users\11794\Desktop\收入分类\training.csv", encodingutf-8, encoding_errorsrepl…...
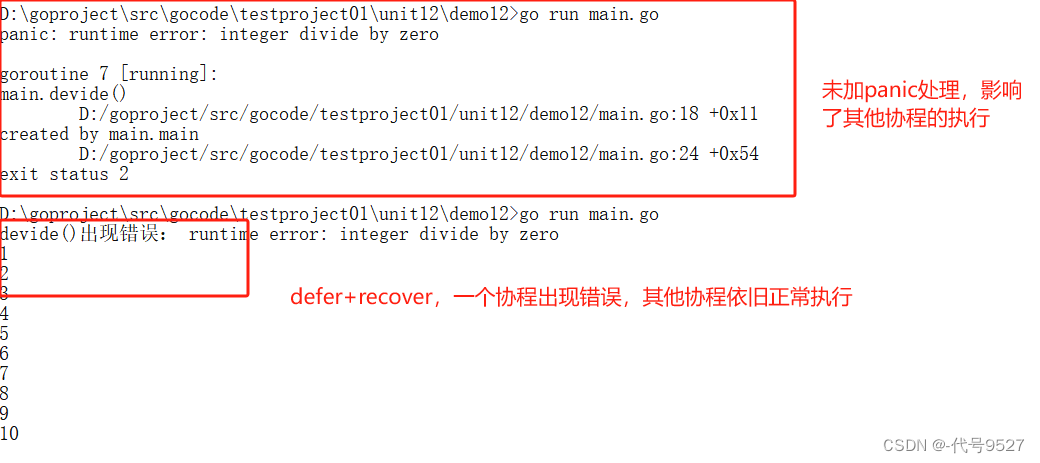
【Go】十七、进程、线程、协程
文章目录 1、进程、线程2、协程3、主死从随4、启动多个协程5、使用WaitGroup控制协程退出6、多协程操作同一个数据7、互斥锁8、读写锁9、deferrecover优化多协程 1、进程、线程 进程作为资源分配的单位,在内存中会为每个进程分配不同的内存区域 一个进程下面有多个…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...