【威胁情报综述阅读3】Cyber Threat Intelligence Mining for Proactive Cybersecurity Defense
【威胁情报综述阅读1】Cyber Threat Intelligence Mining for Proactive Cybersecurity Defense: A Survey and New Perspectives
- 写在最前面
- 一、介绍
- 二、网络威胁情报挖掘方法和分类
- A. 研究方法
- 1) 第 1 步 - 网络场景分析:
- 2) 第 2 步 - 数据收集:
- 3) Step 3 - CTI相关信息蒸馏:
- 4) 第 4 步 - CTI 知识获取:
- 5) 第 5 步 - 绩效评估:
- 6) 第 6 步 - 决策:
- B. 网络威胁情报挖掘定义和分类
- 1) 网络安全相关实体和事件:
- 2) 网络攻击策略、技术和程序:
- 3)黑客的个人资料:
- 4) 妥协指标:
- 5) 漏洞利用和恶意软件实施:
- 6)威胁搜寻:
- 三、最新研究:积极主动的防御视角
- A. 网络安全相关实体和事件
- 1)代表工作总结:
- 2)讨论:
- B. 网络攻击策略、技术和程序
- 1)代表工作总结:
- 2)讨论:
- C. 黑客概况
- 1)代表工作总结:
- 2)讨论:
- D. 妥协指标
- 1)代表工作总结:
- 2)讨论:
- E. 漏洞利用和恶意软件实施
- 1)代表工作总结:
- 2)讨论:
- F. 威胁搜寻
- 1)代表工作总结:
- 2)讨论:
- 四、挑战与未来方向
- A. 感知
- 1)未来方向1(从组合数据源中挖掘CTI):
- 2)未来方向(质量评估,以最大限度地发挥CTI的影响):
- 3)未来方向3(具有领域特异性的上下文处理):
- B. 理解
- 1) 未来方向 4(迈向可理解、稳健和可操作的 CTI 提取):
- 2) 未来方向 5(CTI 发现不断变化的威胁):
- C. 投影
- 1)未来方向6(实际CTI实施):
- 2) 未来方向 7(CTI 威胁初步缓解应用):
- 3)未来方向8(CTI攻击预防应用):
- 五、结束语
- A. 经验教训
- B. 结语

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
承接上文
【威胁情报综述阅读1】引言 + 开源威胁情报挖掘框架 + 开源威胁情报采集与识别提取
【威胁情报综述阅读2】综述:高级持续性威胁智能分析技术 Advanced Persistent Threat intelligent profiling technique: A survey
Cyber Threat Intelligence Mining for Proactive Cybersecurity Defense: A Survey and New Perspectives
论文链接:https://ieeexplore.ieee.org/document/10117505
同名的机器学习项目,非论文参考代码
https://www.youtube.com/watch?v=NmDsFe5JzYo

一、介绍
在 2020 年代 COVID 驱动的社会、经济和技术变革造成大规模破坏之后,网络安全对手已经改进了他们的交易技巧,使其变得更加复杂。一系列备受瞩目的攻击接踵而至,例如SolarWinds供应链攻击[1],它震撼了许多组织,标志着网络安全的转折点。作为收集、处理和分析有关威胁行为者动机、目标和攻击行为的信息的过程,网络威胁情报 (CTI) 帮助组织、政府和个人互联网用户做出更快、更明智、数据支持的安全决策并改变他们的行为,以对抗威胁行为者从被动到主动。
CTI 有几种定义。CTI被定义为“基于证据的知识,包括关于现有或新出现的资产威胁或危害的背景、机制、指标、影响和可操作的建议,可用于为有关主体对该威胁或危害的反应的决策提供信息”[2]。在[3]中,CTI指的是“收集、评估和应用的关于安全威胁、威胁行为者、漏洞利用、恶意软件、漏洞和妥协指标的数据集”。Dalziel [4] 将 CTI 描述为“经过提炼、分析或处理的数据,使其具有相关性、可操作性和价值”。一般来说,CTI管道的输入是关于网络安全的原始数据,而输出是可以帮助未来主动网络安全防御决策的知识,包括限制网络攻击的范围和预防策略。
通过使用 CTI 来观察网络风险,各种形式和规模的组织都可以更好地了解他们的攻击者,更快地响应事件,并主动领先于威胁行为者在不久的将来会采取的行动。对于中小型企业来说,CTI数据对他们有很大的好处,因为它使他们能够获得以前无法达到的保护级别。同时,拥有大型安全团队的企业可以通过利用外部CTI来降低成本并提高分析师的效率。
随着人们越来越意识到积极努力实现网络弹性,我们进行了一些研究工作来审查相关工作。现有调查CTI总结在表二中。具体而言,研讨会工作[5]提出了一项关于暗网的研究,作为监控网络活动和网络安全攻击的实用方法。这项研究[5]将暗网数据组件定义为扫描、反向散射和错误配置流量,并使用大量数据对协议、应用程序和威胁进行了详细分析。Conficker 蠕虫、Sality SIP 扫描僵尸网络和最大的 DRDoS 攻击等案例研究用于表征和定义暗网。该论文还通过分析从中提取的数据(包括网络威胁和事件)以及与暗网相关的已识别技术,回顾了暗网测量的贡献。此外,Robertson等[6]提出了一个由爬虫、解析器和分类器组成的系统,用于定位安全分析师可以收集信息的站点,以及一个基于博弈论的框架,用于模拟CTI挖掘过程中的攻击者和防御者,并将其分析为涉及过去攻击和安全专家的安全博弈。
表二 我们在网络威胁情报挖掘方面的新贡献以及它们与以前的调查有何不同。在主要议题类别下,“●”、“◑”、“○”分别代表综合审查、部分审查和不审查

此外,Tounsi和Rais[7]将现有的威胁情报类型分为战略威胁情报、作战威胁情报和战术威胁情报。该工作[7]主要关注主要由妥协指标(IOC)生成的战术威胁情报(TTI),对TTI问题、新兴研究趋势和标准进行了全面研究。随着人工智能 (AI) 的进步,Ibrahim 等人简要讨论了如何应用 AI 和机器学习 (ML) 方法来利用 CTI 阻止数据泄露。Rahman等[11],[12]进一步全面讨论了ML和自然语言处理(NLP)领域的各种技术,用于从文本描述中自动提取CTI。由于CTI的使用是最大限度地提高其有效性的关键步骤之一,Wagner等[8]报告了对共享CTI的最新方法的调查,以及自动化共享过程的相关挑战,包括技术和非技术挑战。Abu等[9]对CTI的定义、问题和挑战进行了全面调查。Ramsdale等[14]总结了共享CTI的可用格式和语言的现状。他们还分析了 CTI 提要的样本,包括它们包含的数据以及与聚合和共享这些数据相关的挑战。
除了对CTI的研究工作外,CTI的使用和实施是政府组织和企业的普遍做法,反映了人们对网络安全至关重要性的日益认识。这两方都有专门的团队负责收集、分析和传播威胁情报信息,通常通过专门的 CTI 平台和工具。例如,信息共享和分析中心 (ISAC) 是集中的非营利组织,旨在促进其成员之间共享 CTI 和其他与安全相关的信息。ISAC 服务于各种行业和部门,包括关键基础设施、金融服务、医疗保健、技术等。它们将来自特定行业或部门的组织聚集在一起,共享威胁情报和最佳实践,并在事件响应和缓解工作方面进行协作。ISAC 通常得到政府机构和其他组织的支持,它们通常遵循严格的安全和隐私协议,以确保敏感信息仅在授权个人之间受到保护和共享。
根据 2022 年 Crowdstrike 威胁情报报告,CTI 越来越被视为一种有价值的资产,72% 的人计划在 2022 年的未来三个月内花更多钱 [15]。政府组织和企业都在投入大量资源来增强其 CTI 能力,因为他们认识到在不断变化的威胁形势中保持领先地位需要不断改进和适应。这些努力包括发展内部专业知识,与其他组织和行业领导者建立伙伴关系,以及使用尖端技术和方法。政府组织和企业为提高CTI能力所做的努力表明了保护其关键资产和防范网络威胁带来的风险的承诺。CTI是全面网络安全战略的重要组成部分,也是为组织和企业保护数字系统和网络的持续努力中的重要工具。此外,根据 Brown 和 Stirparo [13] 进行的 2022 年 SANS CTI 调查,75% 的参与者认为 CTI 改善了组织的安全预测、威胁检测和响应。调查还显示,52%的受访者认为详细和及时的信息是CTI未来最重要的特征。
由于近年来网络攻击的激增,大量攻击工件已被公共在线资源广泛报道,并被不同组织积极收集[16],[17]。通过挖掘 CTI,组织可以通过检测威胁的早期迹象并不断改进其安全控制来发现基于证据的威胁并改善其安全状况。挖掘CTI的源数据可以从私人渠道(如公司内部网络日志)以及公共渠道(如技术博客或公开的网络安全报告)中检索。特别是,用自然语言编写的网络安全信息占CTI的大部分。与网络安全相关的数据可以从各种来源收集,这为挖掘CTI提供了垫脚石。然而,在跟上快速增长的网络安全相关信息的同时,挖掘强大、可操作和真正的 CTI 具有挑战性。尽管 CTI 的背景、分析和相关性水平呈上升趋势,但在 2022 年 SANS CTI 调查中,21% 的参与者 [13] 认为 CTI 并未改善其组织的整体安全状况。目前,许多组织专注于基本使用方案,这些方案涉及将威胁数据源与其当前的网络和防火墙系统、入侵防御系统以及安全信息和事件管理系统 (SIEM) 合并。然而,他们没有充分利用这种新情报可以提供的宝贵知识。因此,以细粒度研究CTI采矿消耗以开发有效的工具非常重要。具体来说,就是要调查通过CTI挖矿可以获得什么样的CTI,实现CTI的方法,以及如何利用获取的工件作为主动的网络安全防御。基于上述动机,我们对如何从各种数据源获取CTI进行了全面的文献综述,特别是从各种数据源中以自然语言文本形式编写的信息中获取CTI,以主动防御网络安全攻击。尽管在之前的文献综述中已经广泛研究了CTI,但现有的调查工作并未探讨这一观点。
本文的主要重点是回顾近年来关于CTI采矿的研究。特别是,我们的工作总结了CTI采矿技术和CTI知识获取分类法。我们的文章介绍了一种分类法,该分类法根据其目标对CTI采矿研究进行分类。此外,我们还对CTI采矿的最新研究进行了全面分析。我们还研究了CTI采矿研究中遇到的挑战,并提出了解决这些问题的未来研究方向。以下是本文重点介绍的贡献摘要:
-
我们的综述总结了一种六步方法,该方法通过感知、理解和预测,将网络安全相关信息转化为基于证据的知识,从而使用 CTI 挖矿进行主动网络安全防御。
-
我们收集并审查了最先进的解决方案,并根据CTI消费对收集到的工作进行了深入分析,特别是通过攻击者的眼睛来主动防御网络威胁。
-
作为我们努力扩大其他研究人员和 CTI 社区观点的一部分,我们讨论挑战和开放研究问题,并确定新趋势和未来方向。
以下是本次调查的概述。首先,第二部分概述了CTI采矿,包括CTI采矿的方法和分类。第三节根据我们提出的分类法,对CTI采矿领域的现有工作进行了全面回顾。第四节讨论了这一领域的挑战和未来方向。最后,第五节结束了本文。表一列出并描述了本文中使用的缩略语。
二、网络威胁情报挖掘方法和分类
在调查论文的基础上,我们总结了CTI挖掘的方法和CTI知识获取的分类法。CTI挖矿的过程逐渐演变出人们对网络安全的见解,从对环境中数据的感知到对数据含义的理解,最后演变为对未来决策的预测。此外,该分类法总结了CTI挖矿各种目的的最有价值的信息,并为CTI挖矿提供了新的视角。
A. 研究方法
如图1所示,该方法由六个步骤组成:网络场景分析、数据收集、CTI相关信息提炼、CTI知识获取、绩效评估和决策。网络场景分析和数据收集可以跨时空感知特定环境。数据蒸馏和 CTI 知识获取通过定位目标和获取有用信息来帮助理解前面步骤中感知的数据。最后两个步骤,即评估和决策,构成了预测阶段,在这个阶段,决策是高效和有效的。
1) 第 1 步 - 网络场景分析:
CTI 挖掘是一个将原始数据转化为可操作情报以进行决策并根据需要立即采取行动的过程。作为威胁情报生命周期的第一步,网络场景分析阶段至关重要,因为它为未来将要进行的特定威胁情报操作设定了路线图。在所审查的研究中,有各种主要的网络场景,包括金融科技安全、物联网安全、关键基础设施安全和基于云的CTI即服务。将有一个规划阶段,团队将根据网络场景的要求,与参与项目的各种利益相关者就目标以及情报计划的方法达成一致。团队可能会发现以下内容:(1)攻击者是什么,他们的动机是什么,以及他们在特定网络场景中是谁?(2) 是否有容易受到攻击的表面积?(3)如果将来发生攻击,如何加强他们的防御?我们回顾的研究中的主要网络场景示例:金融科技安全、物联网安全、关键基础设施和 CTI 即服务。
2) 第 2 步 - 数据收集:
作为保护组织和安全社区免受快速发展的网络威胁的一种方式,已经为共享威胁情报做出了许多努力。毫无疑问,公共资源是CTI的重要贡献者,无论使用什么平台访问它。为了共享未分类的 CTI,已经建立了一些方法,例如 AlienVault OTX [18]、OpenIOC DB [19]、IOC Bucket [20] 和 Facebook ThreatExchange [21]。这些平台上共享的信息可以帮助组织识别和减轻安全风险,确定其安全工作的优先级,并更有效地应对网络威胁。作为众包平台的一个例子,Facebook ThreatExchange [21] 对任何组织开放,并允许参与者共享实时威胁情报信息,包括有关恶意软件、网络钓鱼活动和其他类型的网络攻击的信息。CTI 数据一旦在在线平台上发布,通常可用于 Web 爬虫。例如,我们可以从国家漏洞数据库(NVD)[22]中获取漏洞记录,以及Verizon年度数据泄露调查报告(DBIR)[23]中的历史数据泄露报告。技术来源(即安全工具和系统)生成的数据,包括日志文件、网络流量和系统警报,被用作预测网络安全事件的宝贵来源[24]。此外,各种社交媒体(如 Twitter)都提供 API,用于分析这些社交媒体站点中的数据并收集个人和组织共享的威胁信息。对于受限制的评估CTI,已经创建了诸如国防工业基地(DIB)自愿信息共享计划[25]之类的平台,以帮助组织更好地保护自己和客户免受网络威胁。这些平台为认证参与者之间交换威胁情报信息提供了一个安全的协作环境。例如,仅限于 DIB 参与者的 DIB 自愿信息共享计划是专门为国防工业基地设计的,旨在提高 DIB 抵御网络威胁的安全性和弹性。该计划允许 DIB 参与者共享威胁情报信息,并共同努力增强 DIB 的安全性,以应对网络威胁、外国干扰和其他安全风险。最后但并非最不重要的一点是,值得一提的是,通过暗网来源的非法在线市场和论坛可以提供有关正在进行的网络威胁的信息。
3) Step 3 - CTI相关信息蒸馏:
收集数据后,重要的是要提炼出与 CTI 相关的信息(即文章、段落或句子),以便为 CTI 知识获取做好准备。分类是对与CTI相关或无关的目标信息进行分类的广泛采用的方法之一。研究人员使用来自各种注释类(例如,CTI 相关或非 CTI 相关)的示例,构建了机器学习分类模型来预测看不见的数据的类别。无监督机器学习算法可以被认为是一种基于聚类数据内容之间的相似性来提取与CTI相关的信息的替代方法。
4) 第 4 步 - CTI 知识获取:
在完成CTI相关信息提炼后,需要以CTI知识获取的形式进行数据分析,根据用户的要求,精确定位和定位相关、准确的信息。研究人员和 CTI 社区采用 NLP 和 ML 技术从文本数据中提取 CTI。图 2 显示了基于收集的文献对 CTI 知识获取的六个特定类别的详细分类,分别是与网络安全相关的实体和事件、网络攻击策略、技术和程序、黑客概况、入侵指标、漏洞利用和恶意软件实施以及威胁搜寻。
5) 第 5 步 - 绩效评估:
在第五步中,我们根据预期目标评估提取的CTI的性能。它通常根据各种指标进行衡量,以评估性能。大多数分类或聚类任务都涉及使用一些标准指标,包括准确率、召回率、精确率、误报率 (FPR) 和 F1 分数。为了描述收益和成本之间的权衡,使用了图形图,例如在 y 轴上绘制 TPR 和 x 轴上绘制 FPR 的受试者工作特征 (ROC) 曲线。ROC 曲线下方的面积表示 ROC 曲线的累积强度。此外,人们期望通过实时 CTI 体验减少提取所需信息所花费的时间。网络安全任务(包括 CTI 知识获取)的一个主要挑战通常是 FPR,因为误报会导致与手动验证相关的成本过高,这在许多情况下是误报的结果。以一种前所未有的方式,新兴的CTI有望首次发现,追求性能的目标通常是在最小化FPR的同时最大化TPR。通过利用综合评估指标,可以确定特定的 CTI 知识获取方法是否产生令人满意的结果。如果结果不令人满意,建议重复该过程并进行所需的交替。
6) 第 6 步 - 决策:
根据CTI在不同类别中的提取方式,它可以用于各种决策目的。以下是获得CTI在决策过程中的关键应用总结,包括CTI共享、警报生成、威胁态势、搜索引擎、教育和对策。
CTI华测检测共享:这是一种共享与网络安全相关的各种信息的做法,以识别风险、漏洞、威胁和内部安全问题,并分享这方面的良好做法。在各种类别下提取的CTI预计将在多个组织之间共享,包括政府机构,IT安全公司,网络安全研究人员等。 CTI共享通常由法律和监管因素(例如,通用数据保护条例(GDPR)[26])以及经济因素(例如,降低解决数据泄露后果的成本)驱动。
警报生成:根据美国国家标准与技术研究院(NIST)[27]的定义,针对组织信息系统的特定攻击的信息称为网络安全警报。有关当前漏洞、漏洞利用和其他安全问题的警报,这些安全问题通常是人类可读的,可以直接从提取的 CTI 中生成各种类别。可以生成多个输出,包括漏洞说明、公告和建议。
威胁态势:威胁态势是指在特定时期内影响特定行业、组织或用户组的所有潜在和公认的网络安全威胁。随着每天都有新的网络威胁出现,威胁形势也在不断变化。使用从文本中提取的 CTI,安全专家可以根据提取的 CTI 更深入地了解威胁态势。
网络安全域名搜索引擎:提取的CTI可以作为网络安全搜索引擎的基础。一般来说,信息检索是指从文本、图像和声音中查找信息的科学,以及从描述正在搜索的数据的元数据中查找信息的科学[28]。通过搜索引擎,可以在互联网上找到信息。网络安全领域搜索引擎越来越关注可解释的网络安全上下文,以强调用户消化的信息量不取决于返回的数量,而是取决于他们对返回信息的理解。例如,Shodan [29] 是用于互联网连接设备的网络安全搜索引擎。
教育与培训:目前,全球范围内缺乏合格的网络安全专业人员。根据 AustCyber 的数据,到 2023 年,澳大利亚的这种短缺可能达到 18,000 人。通过提供网络安全背景的可解释和结构化说明,提取的CTI将有助于网络安全教育和培训。一方面,教育系统通过建立行业内熟练的专业人员管道,帮助解决熟练网络专业人员的短缺问题。另一方面,网络安全教育也有望帮助对网络安全领域知识缺乏深入了解的人提高对网络安全事件和威胁的认识。
风险管理:通过使用 CTI,组织可以增强其风险管理程序,获得有关最新漏洞、攻击方法和漏洞利用的宝贵情报。及时了解新出现的风险和漏洞可以使组织采取先发制人的措施,在风险被利用之前识别和管理风险,最终降低安全事件的潜在成本和影响。
B. 网络威胁情报挖掘定义和分类
据我们所知,网络威胁情报挖掘没有正式的定义。然而,计算机科学、统计学和数据分析领域的一些研究人员和从业者已经提出了数据挖掘的定义。根据 IBM 的定义,数据挖掘,也称为数据中的知识发现,是从大型数据集中发现模式和其他有价值信息的过程。作为Fayyad等人[30]提供的最广泛引用的定义之一,“数据挖掘是应用特定算法从数据中提取模式”。Chakrabarti等[31]进一步将Fayyad等[30]的定义解释为“在大型数据集中提取和发现模式的过程,涉及机器学习、统计学和数据库系统交叉的方法”。通过限制数据挖掘概念中的数据范围,在本次调查中,我们将网络威胁情报挖掘定义为收集和分析来自各种网络威胁情报数据源的大量信息,以识别与网络威胁、攻击和有害事件相关的信息。
如第II-A节所述,如图1所示,CTI挖矿方法基本上将与网络安全广泛相关的数据转化为易于理解的CTI,以便做出最终决策。作为连接感知和投射阶段的桥梁,理解阶段在提炼与CTI相关的信息和根据各种目标定位有用信息方面发挥着作用。如图2所示,以CTI理解阶段为起点,根据CTI知识获取的目的,对CTI挖掘的综述工作进行分类。为了更清楚地阐明已确定的六类CTI采矿背后的基本原理,在下文中,我们将CTI采矿与通用疾病治疗过程进行了类比。
1) 网络安全相关实体和事件:
CTI挖矿中与网络安全相关的实体和事件的识别就像一个诊断步骤,可以识别特定疾病或疾病的性质。在网络安全实体和事件提取中,非结构化文本中的命名实体被定位并分类为预定义的网络安全类别,例如受影响的组织、位置、漏洞等,而事件则被分类为预定义的网络攻击类别,例如网络钓鱼、分布式拒绝服务 (DDoS) 攻击等。
2) 网络攻击策略、技术和程序:
在此任务类别中,目标是通过分析网络威胁参与者和黑客的战术、技术和程序 (TTP) 来确定网络威胁参与者和黑客如何准备和执行网络攻击。这类似于医疗保健中的病理学研究,旨在了解疾病或伤害的原因和影响。
3)黑客的个人资料:
CTI挖矿分类法中的第三类称为黑客档案,用于追踪网络攻击的来源。建立黑客档案旨在发现威胁行为者的来源和资源,包括网络威胁归因和黑客资产。这类似于生物学中病原体的鉴定,后者是指发现任何可能产生疾病的生物体或病原体(例如细菌或病毒)的步骤。
4) 妥协指标:
IoC 的提取旨在查找提供组织系统上潜在恶意活动证据的取证数据,例如恶意软件的名称、签名和哈希值。IOC 类似于身体或精神症状,表明疾病状况。
5) 漏洞利用和恶意软件实施:
此类别包括有关研究分析文档的文献,例如文献和用户手册,以发现特定产品或服务下的漏洞、预测漏洞利用以及查找有关恶意软件实施的信息以预测软件特征。与潜在疾病的并发症一样,利用漏洞和实施恶意软件与网络威胁的后果高度相关。
6)威胁搜寻:
此类任务的目的是识别组织网络中以前未知或正在进行的未修正威胁。这一过程可以类似于在一般疾病治疗过程中进行的基因检测,后者可以预测健康个体未来患特定疾病的可能性[32]。
三、最新研究:积极主动的防御视角
A. 网络安全相关实体和事件
网络安全攻击和事件很普遍,具有广泛的后果和影响,从数据泄露到潜在的生命损失和关键基础设施的中断[24]。根据媒体报道的网络事件的权威记录及其关键维度(例如,被利用的漏洞、受影响的系统、事件的持续时间)来开发网络防御至关重要。以精细粒度记录的网络安全事件详细信息可以帮助各种分析工作,包括识别网络攻击、开发攻击预测指标、跟踪时间和空间上的网络攻击,并将其集成到网络安全图中以协助自动分析。在本节中,我们回顾了通过CTI挖矿获取网络安全相关实体和事件知识的相应作品。
1)代表工作总结:
NLP 中的实体提取技术会自动从非结构化文本中提取特定数据,并根据预定义的类别对其进行分类。此外,对句子中存在的实体的了解可以提供有助于确认事件类别和预测事件触发器的信息。研究人员正在研究用于CTI挖掘的网络安全相关实体和事件提取,这是处理异构数据源和大量网络安全相关信息的关键。代表性研究的调查摘要列于表三。
表三 挖矿网络安全相关实体和事件的最新作品
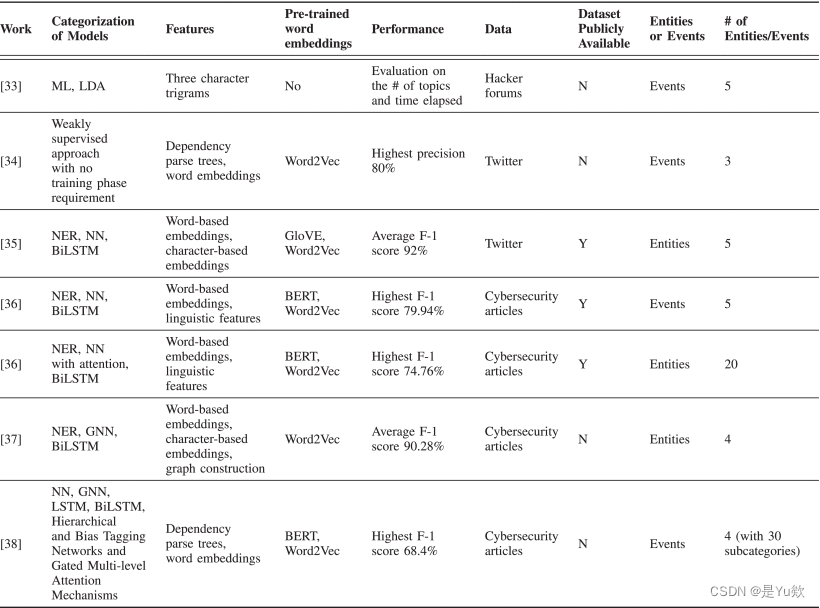
作为一项初步研究,提出了几种方法[33],[34]来快速提取网络安全事件,而无需为训练过程添加标记数据。[34]提出了一种弱监督的ML方法,没有训练阶段要求从Twitter流数据中快速提取事件。该研究[34]重点关注三类高影响的网络安全攻击,包括数据泄露、DDoS和账户劫持,以演示如何基于卷积内核和依赖解析来识别网络安全事件。在这项工作中,成功检测网络安全相关事件的最高精度可以达到80%[34]。此外,工作[33]利用无监督ML模型(即潜在狄利克雷分配(LDA))对黑客论坛中的相关帖子进行聚类,展示了一种可以在网络安全事件方面有效提取CTI的方法。尽管Deliu等[33]仅评估了估计的网络安全事件在主题数量和经过时间上的性能,但该工作展示了快速提取相关网络安全主题和事件的方法。
随着带有注释的数据集的引入以及 NLP 和深度学习技术的发展,自动识别的网络安全相关实体和事件的类别也在增长。Dionísio等[35]用5类实体(如表III所示)注释了与网络安全相关的Twitter数据,并考虑了欧洲网络和信息安全局(ENISA)风险管理词汇表[39]的描述。在这项工作[35]中,实现了双向长短期记忆(BiLSTM)神经网络(NN)用于名称实体识别。预训练词嵌入是指在一个特定任务中学习的嵌入,用于解决另一个类似任务,包括 GloVE [40] 和 Word2Vec [41],用于为语义值提供起点。BiLSTM 模型在识别六类网络安全相关实体方面的平均 F1 得分为 92%。工作中内置的注释数据(即网络安全相关实体)[35]可通过其GitHub网站公开获得,1该网站为CTI域中的名称实体识别提供了基本事实。Satyapanich等[36]进一步扩展了其他与网络安全相关的实体和事件,创建了一个包含1000篇英文新闻文章的语料库2,这些文章标有丰富的、基于事件的注释,涵盖了网络攻击和与漏洞相关的网络安全攻击。除了BiLSTM层,这项工作[36]还应用了注意力机制,这些机制在NLP中得到了极大的应用,并被证明用于学习文本中突出显示的重要部分。此外,该工作[36]在词嵌入层中使用了Word2Vec[41]和BERT[42]嵌入,并进一步将嵌入语言学特征串联起来形成嵌入层,包括词性(PoS)、词的位置等。总共定义了20个网络安全相关实体(例如文件、设备、软件)和5个事件(例如网络钓鱼),并且可以通过所提出的方法自动检测[36]。
图神经网络(GNN)将数据表示为图,旨在从图级学习特征以对节点进行分类,这开始应用于信息提取领域[43]。网络安全领域实体的复杂性使得在名称实体识别中难以捕获非本地和非顺序的依赖关系[37]。因此,最近的研究[37],[38]提出使用GNN提取的本地上下文和图级非本地依赖关系来进行网络安全实体识别。在[37]的工作中,Fang等人旨在从网络安全文章中识别出四种类型的实体,分别由人员(PER)、组织(ORG)、位置(LOC)和安全(SEC)组成。在图构建过程中,图中的每个节点代表每个句子中的一个单词,每个边构造了局部上下文依赖和非局部依赖。此外,还应用了词级嵌入(即Word2Vec [41])和字符级嵌入,以捕获句子中单词的上下文信息。工作[37]中提出的CyberEyes模型最终可以获得四种网络安全实体的F1得分为90.28%。Trang等[38]对一个大型数据集进行了注释,该数据集包括网络攻击四个不同阶段下的30个子类别网络安全事件,分别是DISCOVER、PATCH、ATTACK和IMPACT。基于多阶图注意力网络的事件检测(MOGANED)和注意力[44]方法应用于Word2Vec [41]和BERT [42]嵌入。尽管通过使用文档嵌入增强型双向递归神经网络 (RNN) 的带注释数据集 [38] 实现的网络安全事件提取的最高 F1 分数为 68.4%。当MOGANED with BERT应用于[36]提出的网络安全实体数据集时,F1得分提高了6.56%,达到86.5%。
2)讨论:
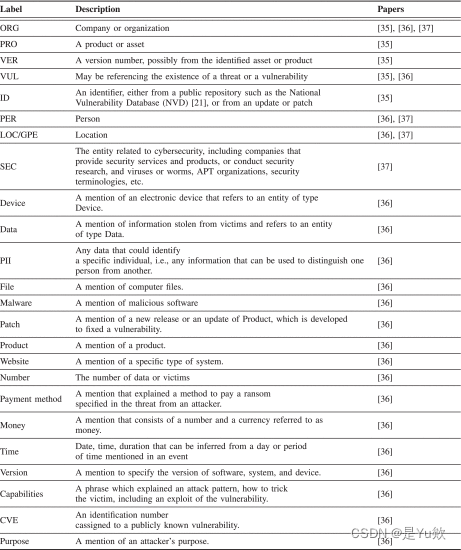
上一节回顾了七项具有代表性的研究,这些研究与网络安全相关的实体和事件。表III列出了调查研究的摘要,其中我们显示了每项工作的关键差异。具体而言,表四和表五总结了这些研究中定义的网络安全相关实体和事件。
表四 代表作品中的网络安全相关主体
表五 代表作品中的网络安全相关事件
在我们回顾的研究中,用于挖掘网络安全实体和事件的主要技术分为以下几类:(1)无监督学习方法,其中使用无监督算法而没有手工标记的训练示例;(2)将特征工程与监督学习算法结合使用的监督学习方法。大多数被审查的工作都采用了基于深度学习(DL)的方法,通过神经网络中的多个层学习数据的分层表示来自动发现分类表示。基于深度学习的方法在检测与网络安全相关的实体和事件方面特别有效,并且发展迅速。传统的基于特征的方法需要大量的特征工程技能和领域专业知识,但基于深度学习的数据挖掘可以有效地从原始数据中学习有用的表示和潜在因素。借助 DL,可以更高效地设计实体识别功能。此外,非线性激活函数使基于深度学习的模型能够从数据中学习复杂而复杂的特征。与线性模型(例如线性链条件随机场 (CRF)相比,非线性映射是从输入到输出生成的,这有利于网络安全实体和事件识别。
对评论作品的比较研究表明,它们都依赖于非结构化文本,例如推文、安全文章和黑客论坛。这表明迫切需要一个结构化的数据库来存储CTI数据。在使用的不同模型中,采用名称实体识别 (NER) 方法、神经网络和 BiLSTM 的模型表现更好。这是因为NER可以识别和提取句子中的实体,确保不相关的单词不被视为CTI实体,从而获得更好的性能。此外,F-1得分最高的两部作品[35]和[36]利用基于字符的嵌入来补充基于单词的嵌入的不足。基于字符的嵌入可以捕获前缀和后缀等形态信息,这些信息在基于单词的嵌入中可能会丢失,从而获得更准确和更强大的性能。总体而言,这些发现表明,使用NER和基于字符的嵌入可以显着提高CTI模型在识别和缓解网络威胁方面的准确性和有效性。
在自然语言处理的背景下,词嵌入技术被广泛认为是深度学习的重大突破。向量可以转换为相对低维的空间,称为嵌入。在处理大型输入(例如表示单词的稀疏向量)时,使用嵌入可以更轻松地进行机器学习。通过在嵌入空间中将语义相似的输入放在一起,嵌入可以捕获输入的一些语义。可以在模型之间学习和重用嵌入。在本小节调查的论文中,七分之六的工作使用了预训练的词嵌入,包括 Word2Vec [41]、GloVE [40] 和 BERT [42]。此外,一些网络安全实体以灵活的方式使用单词。例如,单词 Gh0st 是指同时包含大写和小写字母的远程访问木马。使标识更加复杂的是实体内的不规则缩写和嵌套问题。为了解决上述挑战,基于字符的嵌入被应用并在工作[35]中得到证明,以提高实体提取性能。单词的最终表示通常基于单词级和字符级表示,以及附加信息(例如,语言特征[36]和语言依赖性[34],然后将其输入上下文编码层。
值得注意的是,大多数被审查的工作只关注与网络相关的实体和事件的提取,而不是实体之间的关系的提取。在事件标注过程中,遇到了许多挑战,包括标注实体、事件以及事件之间的共指关系。例如,在网络攻击的描述中可以包含几个不同的操作。在执行信息提取任务(如名称识别、关系提取、事件提取和共指解析)时,跨句子合并全局上下文或考虑短语之间的非局部依赖关系是有益的[45]。例如,对共指关系的了解可以深入了解所提到的难以分类的实体类型。此外,句子的实体可以用作事件提取的输入,这可以导致有关事件触发器的有用信息。作为未来的方向,实体、事件和事件共指关系将被组合起来,通过挖掘相同或相邻句子中的实体之间的挖掘来挖掘联合CTI潜力,而动态更新将对长期跨句子关系进行建模。
B. 网络攻击策略、技术和程序
战术、技术和程序 (TTP) 的概念对 CTI 至关重要。识别 TTP 的目标是识别可用于防御恶意行为者采用的特定威胁和策略的行为模式。TTP 是指网络威胁行为者和黑客用来准备和执行网络攻击的行为,包括方法、工具和策略。根据美国国家标准与技术研究院(NIST)[46]的定义,策略是对这种行为的最高级别的描述,技术在策略的上下文中给出了更详细的解释,而程序在技术的上下文中提供了更详细的描述。本节回顾了关于网络攻击策略、技术和程序的 CTI 挖掘工作。
1)代表工作总结:
在网络威胁情报中,TTP描述了与特定威胁行为者相关的攻击行为[53]。收集此类信息后,可以有效地识别、缓解和应对网络威胁。图 3 显示了结构化威胁信息压缩 (STIX) 模式 [54] 中的 TTP 示例。如表六所示,针对挖掘TTP的工作是有限的,但由于TTP在识别网络威胁方面发挥着强大的作用,因此正在出现。
表六 关于采矿策略、技术和程序的代表性著作
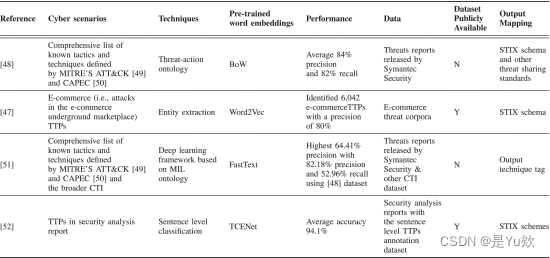
图 3.[47] 中 STIX 模式中的 TTP 示例。

Husari等[48]的研究使用名为TTPDrill的威胁行动本体描述了网络威胁的攻击模式和技术。该本体基于MITRE的CAPEC [50]和ATT&CK [49]威胁存储库构建,涵盖了利用前和利用后恶意操作的过程。从微观层面(例如,删除日志文件)到宏观层面(例如,防御规避)捕获了威胁行动和相应的战术和技术杀伤链上下文。他们的工作提出了一种基于已建立本体的方法,该方法以结构化方式将提取的非结构化数据源中的TTP映射到已建立的本体,例如CTI中广泛使用的STIX攻击模式模式[54]。一个名为Stanford类型依赖解析器[55]的NLP工具用于识别和提取候选威胁操作。此外,还为开发的本体中的常见对象构建了一组正则表达式,以解析威胁报告中使用的特殊术语(例如,字符串fil_1.exe),从而混淆了NLP工具。应用候选威胁操作生成词袋查询,并基于相似度分数的计算映射到本体中的威胁操作。
You等[52]提出了一种新的威胁情境增强TTP情报挖掘(TIM)框架,用于从非结构化威胁数据中提取TTP情报。TIM 框架利用 TCENet(即威胁上下文增强网络)从文本数据中识别和分类 TTP 描述,定义为三个连续的句子。You等[52]在描述中利用TTP的元素特征,进一步提高了TCENet的TTP分类精度。评价结果表明,所提方法在6个TTP类别中的平均分类准确率为94.1%。此外,与仅使用文本特征相比,添加 TTP 元素特征可提高分类准确性。TCENet 优于以前的文档级 TTP 分类工作和其他流行的文本分类方法,即使在少量训练样本的情况下也是如此。由此产生的 TTP 情报和规则可帮助防御者部署有效的长期威胁检测并执行更真实的攻击模拟以加强防御。
Ge 和 Wang 提出了 SeqMask 作为使用多实例学习 (MIL) 方法识别和提取 CTI TTP 的解决方案。SeqMask 使用来自 CTI 的行为关键字,通过条件概率预测 TTP 标签。为了保证提取关键词的有效性,SeqMask采用了两种机制,一种是专家经验验证,另一种是屏蔽现有关键词,以评估其对分类准确性的影响。使用 SeqMask 进行的实验结果表明,TTP 分类的 F1 得分很高(即 86.07%),并且从全尺寸 CTI 和恶意软件中提取 TTP 的能力有所提高。
尽管基于本体的TTP挖掘能够涵盖MITRE的CAPEC [50]和ATT&CK [49]威胁存储库中定义的策略和技术的综合列表,但很难适应各种网络场景,例如电子商务策略。如研究[47]所示,当应用TTPDrill发现电子商务TTP时,召回率、准确率和F1得分分别下降到50.25%、22.38%和30.97%。TTPDrill 在网络攻击的传统步骤(即网络杀伤链阶段)捕获了 TTP。由于攻击发生在购买过程之前、期间和之后,电子商务地下市场无法完全映射到传统的杀伤链。为了应对这一挑战,Wu等[47]建立了一个TTP半自动生成器(即TAG),该生成器结合了NLP技术,包括主题词提取和名称实体识别,用于识别电子商务TTP。根据TTP中主题术语通常具有相似的语义和词汇结构的观察结果,新出现的主题术语是基于语义和结构与[47]中流行主题术语的相似性来捕获的。此外,第III-A节中介绍的名称实体识别技术与规则学习(即一组基于语法结构的TTP实体识别规则)相结合,用于从非结构化数据源中自动提取TTP实体。在识别TTP术语后,[47]提出的STIX TTP生成器将从非结构化数据中提取的TTP术语转换为STIX模式[54]。TAG共识别了6,042个TTP,准确率为80%,通过分析识别出的TTP,为以前未知的电子商务CTI趋势提供了新的线索。
2)讨论:
表六总结了所审查的工作,表七列出了网络攻击策略、技术和程序。由于改变攻击策略、技术和程序对对手来说代价高昂,因此 TTP 被认为比 IOC 更强大、更持久。例如,对手使用IOC(例如,不同的恶意域)比更改其TTP(例如,防弹托管基础设施)更容易[47]。IOC 是显示系统已被攻击渗透的取证工件之一,而 TTP 是与单个或一组攻击者关联的模式或活动组之一。通过提供 TTP,可以在各种情况下使用特定 TTP 调查网络攻击下的非法活动。在最近的电子商务繁荣时期,出现了许多攻击模式(例如订单剥头皮),这些模式已被公共在线资源广泛报道。通过快速分析威胁并将TTP部署到各种安全系统,可以实现对不同类型的安全威胁的检测、响应和遏制。为了使 TTP 易于处理,需要标准化和结构化的表示。
表七 代表著作中的网络攻击策略、技术和程序
与开放领域语料库相比,网络安全语料库缺乏注释,这意味着 NLP 社区需要投入更多的注意力和精力。Husari等[48]利用基于本体的方法,根据网络杀伤链对TTP相关术语进行梳理。在工作[47]中,NER与人工验证一起使用,以保证电子商务TTP领域下关键输出的质量。通过使用机器学习,TTP可以从以前的TTP自动生成,作为基本事实,新的上下文不断提高TTP的精度。从[48]和[47]中提取的TTP涉及不同的语言,分别是英文和中文。依赖分析和语言处理在很大程度上依赖于语言模式。例如,语言处理的一个关键先决条件是单词的分割。在亚洲语言(如中文、日语和泰语)中,单词不像英语那样用空格分隔。然而,TTP也可以从英语以外的语言中提取。人们非常期待在该领域跨语言提取和转换 TTP。
尽管基于ML的方法在发现TTP方面表现不错,但由于其黑盒性质,这些方法在提高准确性和解释结果方面面临挑战。目前的提取方法存在三个主要局限性,即数据不足、验证不完整和过程复杂。虽然识别方法决定了分类的准确性,但它们并不能提供其预测背后的推理。需要一种简单而全面的方法,将数据解释和高精度相结合,以获得TTP标签和证据的完整图片。
C. 黑客概况
这是网络安全攻击者和防御者之间永无止境的游戏。通过利用各种资源,攻击者在执行黑客活动时变得更加高效和智能。为了更好地计算黑客攻击企图,重要的是要确定威胁参与者的来源和资源。本节回顾了挖掘CTI以识别黑客档案的工作,包括网络威胁归因和黑客资产。
1)代表工作总结:
识别对攻击负责的实体很复杂,通常需要有经验的安全专家的协助[61]。根据Hettema[62]的说法,由于互联网的技术架构和地理环境,归因是与新兴领域相关的最棘手的问题之一。如表八所示,在不同的网络场景(如移动恶意软件、金融科技安全)下,对应的攻击者档案与归属和资产相得益彰。
表八 挖矿黑客简介代表著作
Grisham等[60]以移动恶意软件威胁行为者为出发点,使用长短期记忆(LSTM)RNN架构在在线黑客论坛中识别CTI的移动恶意软件附件。此外,本研究还进一步利用了社会网络分析[60],通过了解威胁行为者的社会群体和能力来识别关键威胁行为者。通过使用网络和图论,社会网络分析研究了社会结构[63]。网络结构的特征是节点(即单个参与者)和它们之间的边缘(即关系或相互作用)。特别是,在工作[60]中,对于论坛上下文,包含两种不同类型节点的双模式网络(即与事件节点相关的参与者节点)被转移到单模式网络,参与者通过共享线程中的帖子相互链接。因此,计算威胁行为者网络的潜在中心性度量(例如,紧密性、中介性)并进一步识别工作中的关键威胁行为者是适应性的[60]。但是,同一恶意软件有可能被多个参与者重复使用。使用恶意软件进行攻击的参与者可能与恶意软件的作者不同。除了使用的恶意软件外,还可以从事件期间收集的信息中收集有关攻击者身份的许多线索。Perry等[58]提出了一种基于CTI报告的名为SMOBI(即SMOthed BInary向量)的攻击归因识别方法,以识别以前未见过的新型威胁行为者以及已知威胁行为者之间的相似性。基于词嵌入的网络安全相关文档的向量表示(即基于20,630篇网络安全文章和帖子生成的特定领域词嵌入)[58]以增强算法并充分发挥所提出的攻击归因识别方法的潜力。
为了防御数据泄露,工作[56]利用直接来自地下黑客社区的黑客源代码、教程和附件来识别恶意资产,如加密器、键盘记录器、SQL注入和密码破解程序,以开发主动CTI。在他们的工作[56]中,实现了分类模型,如支持向量机(SVM),对编码语言进行分类。之后,LDA被用来分析论坛的代码,以及评论、帖子内容和附件,以识别恶意话题。作为最后一步,与恶意主题相关的元数据用于构建社交网络,以识别已识别恶意主题的归属(即关键黑客)。
银行和金融部门通常是出于财务动机的网络威胁行为者(CTA)的“首选目标”[64]。因此,确保金融科技 (FinTech) 受到保护并免受来自不同 CTA 的复杂网络攻击,包括国家支持或国家附属行为者,是必要和紧迫的。Noor等[57]开发了一个基于机器学习的金融科技CTA框架。在他们的工作[57]中,根据通过自然语言处理从CTI报告中提取的高级攻击模式(例如,从ATT&CK [49] MITRE [49]中提取的策略,技术和程序)对网络威胁行为者进行了分析。具有深度学习的分类模型的准确率为94%。
2)讨论:
建立黑客档案具有挑战性,因为他们总是试图隐藏自己的身份和他们在黑客攻击中使用的资产。为了对黑客进行分析,对来自各种CTI的数据源进行了混合分析,包括代码分析、恶意软件附件分析、文档(例如,地下论坛中的帖子和评论)和网络分析,如表八所示。
为了有效,可操作的CTI不仅应包括传统的内部方法,还应包括外部的开放信息[65]。这使 CTI 能够更加主动地识别威胁,在威胁发生之前识别威胁,帮助了解攻击者并识别黑客策略。有必要将数据与上下文信息相结合,以提供相关的威胁(即具有外部知识的内部事件)。特别是,在线黑客论坛是一个丰富的外部数据源,可用于开发主动式 CTI。黑客使用许多场所进行交流和共享信息,包括互联网中继聊天(IRC)、梳理店、暗网市场和黑客论坛[66]。地下论坛或黑客论坛是黑客可以自由分享恶意工具(例如恶意附件)的方式之一[67],它为了解威胁行为者的运作方式和建立黑客档案提供了实用资源。研究人员发现,关键黑客(例如,论坛版主或高级成员)对他们的社区做出了重大贡献[68]。因此,通过与其他黑客的互动找到关键威胁参与者并识别他们的团体至关重要。
D. 妥协指标
入侵指标 (IOC) 可作为系统或网络潜在入侵的取证证据。信息安全专业人员和研究界可以使用这些工件来检测入侵企图或其他恶意活动。此外,IOC 还提供可在社区内共享的可操作威胁情报,以提高事件响应和补救效率。本节回顾了挖掘CTI以提取IOC及其关系的工作。
1)代表工作总结:
年,网络攻击正在广泛蔓延并造成严重后果,包括数据泄露、经济损失、硬件损坏等[76]。鉴于网络攻击的传播速度很快,必须根据记录的网络攻击事件报告和日志文件,主动制定预防方法。IOC 是用于识别组织系统上潜在恶意活动(例如系统日志条目或文件)的取证数据。IOC的示例包括攻击者名称、漏洞、IP/域、哈希(MD5、SHA1等)、文件名和地址以及服务器[69]。IOC 的使用有助于信息安全和 IT 专业人员检测数据泄露、恶意软件感染和其他威胁。在表IX中,我们总结了基于IOC获得CTI的最新工作。
表九 关于妥协的采矿指标的代表性著作
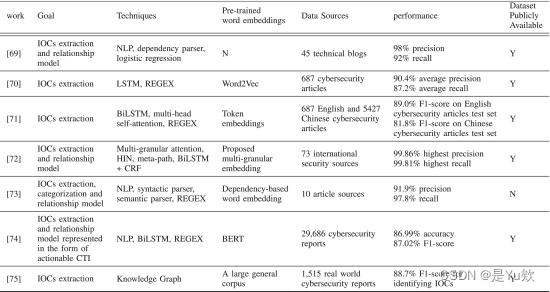
工作[69]提出了从非结构化文本中自动提取IOC。Liao等[69]提出了一种方法,首先抓取博客并删除不相关的文章。在将每篇文章拆分为多个句子后,该方法应用上下文术语和正则表达式来查找这些句子可能具有 IOC。这项工作[69]首先提出了一种方法,将IOC候选者及其之间的关系转换为图挖掘问题,以便根据图相似性检测关系。对于这两部作品,查找 IOC 文章和提取 IOC 和关系的精度最高可达 98%。
双向长短期记忆神经网络 (BiLSTM) 和条件随机场 (BiLSTM-CRF) 旨在处理名称实体识别任务,这些任务已被证明应用于 IOC 识别领域。周等[70]是第一个将BiLSTM-CRF应用于攻击报告中的IOC提取的人。所提出的方法[70]使用基于注意力和Word2Vec嵌入对输入序列进行编码。这项工作[70]即使使用一些标记拼写功能限制了训练数据的数量,也能很好地发挥作用。自动提取和标记IOC的平均工作精度[70]为90.4%。基于周等[70]的工作,Long等[71]使用BiLSTM方法改进了神经网络模型,使用了多头自注意力模块以及更多特征,并将其方法应用于英文和中文数据集。该模型[71]具有更多的标记特征,用于提高有限数量数据的性能,包括拼写特征、上下文特征和特征的使用(即拼写特征和上下文特征的连接)。该模型在从英文和中文数据集中识别IOC的工作中的平均精度得分分别为93.1%和82.9%。此外,工作[72]提出了一种多粒度注意力Bi-LSTM-CRF模型,用于从多源威胁文本中提取不同粒度的IOC,并使用异构信息网络(HIN)对IOC的上下文进行建模。该研究[72]手动定义了元路径,以呈现多个IOC之间的关系,以便更好地探索上下文,重点关注六种常见的IOC类别,包括攻击者、漏洞、设备、平台、恶意文件和攻击类型。在IOC提取工作中,最高精度为99.86%,尽管提取不同的项目精度不同。在所有试验方法中,多粒度模型的威胁实体识别精度为98.72%。
鉴于网络攻击中使用的多阶段和多样的技术,知识图谱在全面描述整个攻击过程和识别与其他攻击的相似之处方面具有明显的优势。例如,Li等[75]提出了AttacKG,这是一种新方法,用于聚合来自多个CTI报告的威胁情报,并创建一个攻击图,在技术层面总结攻击工作流程。他们[75]引入了技术知识图谱(TKG)的概念,通过总结攻击图中的因果技术来描述CTI报告中的完整攻击链。Li等[75]解析了CTI报告,以提取与攻击相关的实体和依赖关系,并使用了基于MITRE ATT&CK [49]知识库中的过程示例构建的技术模板。然后设计了一个修订后的图形对齐算法,以匹配攻击图中的技术模板,对齐和优化实体,并构建 TKG。该技术模板在 CTI 报告中聚合来自真实世界攻击场景的新情报,攻击图利用这些知识创建 TKG,以增强知识介绍报告。
从CTI数据中提取整个攻击过程具有挑战性,尽管这是了解黑客活动和制定防御策略的先决条件。幸运的是,可以通过识别 IOC 及其关系来预测攻击过程。Zhu 和 Dumitras [73] 以及 Liu 等人 [74] 将恶意软件传播活动分为不同的阶段,以便更好地分析攻击过程。Zhu和Dumitras[73]采用自然语言工具包(Natural Language ToolKit,NTLK)和Stanford CoreNLP将句子表示为有向图,以描述IOC之间的行动。采用Word2Vec计算语义相似度,采用命名实体识别(NER)技术定位IOC候选者。设计了四个二元神经网络来对 IOC 进行分类并确定候选者是否是 IOC。STIX [54]的四个阶段(即诱饵、开发、安装和命令与控制)将该过程定义为一组指标和工作阶段[73]。总之,研究[73]在检测IOC方面取得了91.9%的最高精度得分,在对活动阶段进行分类方面的平均精度为78.2%。类似地,Liu等[74]设计了一个触发增强系统,从非结构化文本中生成CTI,提取IOC,并描述IOC和活动之间的联系。特别是,在抓取报告和预处理后,系统[74]利用正则表达式和微调BERT模型来识别IOC。这项工作[74]重点研究了六种常见的IOC(即IP地址、域名、URL、哈希、电子邮件地址和CVE)。通过IOC和相关句子,触发向量可以高度解释竞选阶段。该系统在对活动阶段进行分类的工作中可以达到的最高精度为 86.55%。
2)讨论:
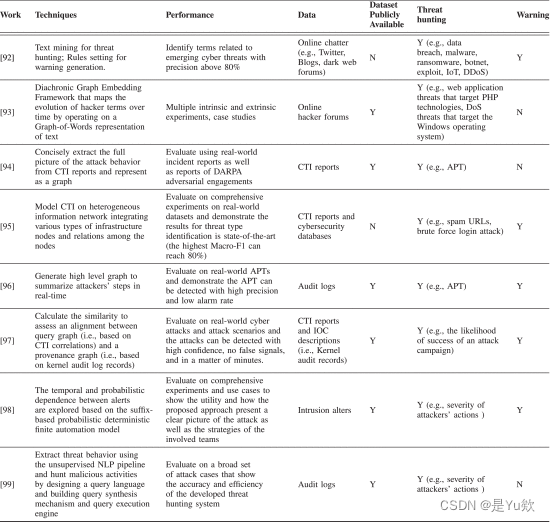
如表X所示,调查研究中的所有六项研究都采用了数据预处理(例如,将图像转换为文本,将文本分解为句子等),IOC候选物识别以及IOCs之间关系提取的方法。
表十 挖掘关键步骤总结:入侵指标及其关系
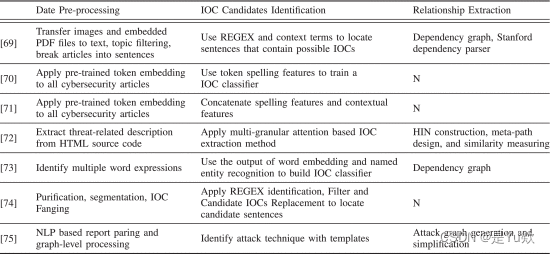
表十一 漏洞挖掘和恶意软件实施的代表性著作
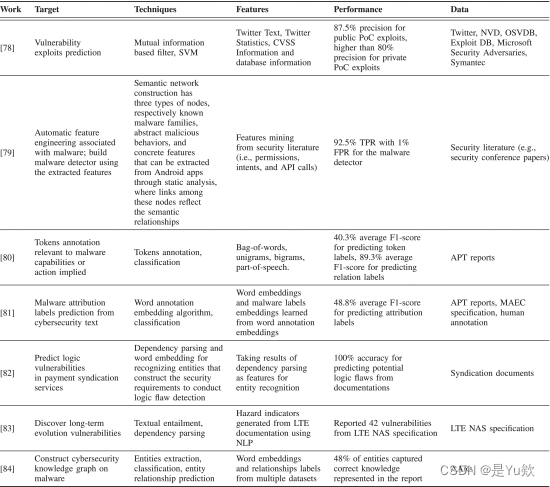
表十二 威胁搜寻代表性著作
在国际奥委会候选人的识别中,所有六项研究都使用REGular EXpression(即REGEX)作为一种快速有效的方法,搜索具有特定格式的单词或模式作为标记拼写特征,以选择国际奥委会候选人。设计一组好的 REGEX 有助于快速识别 IOC 候选术语并提高模型的性能。
在这六项著作中,关系提取的方法可以分为以下几类:1.将IOC句子转换为依赖图或树,并发现IOC之间的关系[69],[73]。2.将那些能够呈现相邻词特征的词视为上下文关键词,并从IOC候选词的关键词中生成上下文特征[70],[71]。3. 创建元路径来描述多个 IOC 之间的关系链 [72]。依赖关系树是一个有向图,可以表示句子中所有单词之间的关系。但是,依赖关系树可以表示句子中的每个单词,包括无用的单词。上下文功能捕获每个 IOC 周围的上下文,但是,在某些情况下,它需要找到难以与 IOC 术语区分开来的关键字。元路径方法可以很容易地提取IOC之间的关系,但元路径需要手动定义,并且元路径的数量会随着IOC类型数量的增加而呈指数增长[77]。预计这些方法将被组装成一种有效的方法,可以推广到各种类型的IOC关系提取。
值得一提的是,大多数综述研究主要集中在IOC识别上,少数研究集中在关系提取上。未来研究的一个可能方向是根据提取的 IOC 及其关系预测可能损坏我们的硬件或软件的网络攻击。提取攻击的详细信息和特征,包括但不限于攻击类型、漏洞利用和目标受害者,可以生成攻击报告,供网络安全专家预测网络攻击并制定防御策略。例如,使用 IOC 和关系定期构建一系列知识图谱,然后通过挖掘图之间的变化并预测下一个可能的事件来学习进化图谱是一个可行的解决方案。
E. 漏洞利用和恶意软件实施
暴露于网络安全风险和恶意软件威胁变得越来越普遍和危险。有各种各样的漏洞可能导致数据泄露,威胁代理可以利用它们来破坏安全网络。尽管使用代码语义对漏洞和恶意软件检测给予了极大的关注,但在发现有关漏洞利用和恶意软件实施的实用信息方面,挖掘代码之外的 CTI 源是有限的。在本节中,我们全面回顾了通过CTI挖掘成功识别可能被利用的漏洞和恶意软件实施的代表性作品。
1)代表工作总结:
最近,被利用的软件漏洞数量有所增加。漏洞是网络犯罪分子可以利用的弱点,以未经授权访问计算机系统。利用漏洞可导致恶意代码被运行、恶意软件安装以及敏感数据被网络攻击窃取。因此,有必要通过评估哪些漏洞可能被利用并排除那些没有被利用的漏洞来优先应对新的披露。此外,恶意软件检测越来越依赖于专注于代码语义的机器学习技术,以便将恶意软件与良性软件区分开来。例如,人类的直觉和知识是这些技术有效性的关键。鉴于攻击者试图逃避检测,以及有关在线恶意软件行为的可用资源越来越多,特征工程可能会利用这些来源的一小部分。因此,预计将查阅多个数据源,以获取有关代码本身之外的漏洞利用和恶意软件实施的知识。
在工作[78]中,Sabottke等人研究了野外与漏洞相关的信息,以便在漏洞公开披露之前进行早期漏洞检测。该研究挖掘了Twitter上传播的大量包含网络安全漏洞信息的信息,并构建了一个机器学习模型,以检测哪个漏洞在现实世界中更有可能被利用。除了挖掘推文文本的单词特征和Twitter流量的统计特征外,还收集了来自国家漏洞数据库(NVD)[22]和开源漏洞数据库(OSVDB)[85]的信息,并将其用于漏洞检测器。据我们所知,这项工作[78]是第一个使用社交媒体早期检测现实世界漏洞的技术。此外,Nunes等[86]开发了一个操作系统,用于收集和识别来自暗网和深网讨论的漏洞利用和恶意软件开发信息,特别是来自黑客论坛和市场的信息。在实时从网页中提取和构建信息后,他们[86]结合了监督和半监督方法,以发现与恶意黑客相关的产品和主题。这提供了有关尚未在网络攻击中部署的新开发的恶意软件和漏洞利用的威胁警告。由于暗网和深网上可用的标记数据有限,所提出的方法需要更少的专业知识和成本,从而达到了 80% 的精度。
为了检测恶意软件,研究人员提出了越来越多的源自人类知识和直觉的特征,这些特征用于表征恶意软件行为。由于攻击者努力逃避检测和有关恶意软件行为的出版物不断增加,特征工程过程可能会利用一小部分可用数据。为了从大量关于恶意软件行为的CTI中获得更大的收益,Zhu和Dumitraş提出的FeatureSmith[79]采用科学论文作为信息来源,自动发现和收集恶意软件检测功能。通过数据收集、文献行为提取、行为过滤和加权、语义网络构建、特征生成和解释生成等管道,FeatureSmith 识别了与恶意软件相关的抽象行为,然后将它们呈现为恶意软件检测的具体特征。作为概念验证,FeatureSmith 的自动设计功能在检测真实世界的 Android 恶意软件方面没有性能损失,与手动生成的最先进的功能集相比,真阳性率为 92.5%,误报率为 1%。
最近的文献探讨了 NLP 如何显着提高人类对网络安全环境的理解。在漏洞利用和恶意软件实施领域,工作[80]引入了一种注释恶意软件报告的方法,该方法提供了文本的语义级信息,并帮助研究人员快速了解特定恶意软件的功能。Lim 等人使用恶意软件属性枚举和表征 (MAEC) 词汇表中的属性标签注释了高级持续威胁 (APT) 报告,作为 NLP 任务的基本事实。他们首先对句子是否与恶意软件相关进行分类,然后根据描述恶意软件的文本预测标记、标记之间的关系、属性标签和恶意软件签名。此外,[81]的工作利用了各种资源,包括未标记的文本、人工注释和关于恶意软件属性的规范(即MAEC词汇)来进行恶意软件归属识别。WAE(Word Annotation Embedding)用于对异构信息进行编码。在SemEval SecureNLP分类任务[87]上测试的结果表明,在所提出的注释方法生成的特征上训练的模型优于[80]提出的注释方法以及[88]学习的嵌入特征。
在最近的研究中,已经表明软件文档可用于预测软件漏洞,而无需完全依赖程序代码。Chen等[82]开发了一种工具,可以自动检查系统安全规范文档,而不是依靠程序代码分析(例如模型检查)来预测支付联合服务中的逻辑漏洞。他们根据支付模型和支付服务的安全要求,探索了使用NLP从联合开发人员指南中发现逻辑漏洞。他们扩展了有限状态机(FSM),该机通常是手动提取的,用于评估支付服务,方法是使用开发人员指南中的依赖关系解析树来提取参与流程的各方以及他们之间传输的内容。针对所提出的方法对特定于软件文档的 NLP 技术进行了微调。此外,Chen等[83]不断应用NLP技术,包括文本蕴涵和依赖解析,来分析地窖网络的长期演化(LTE)文档,以查找危害指标(HIs)。在LTE非接入层文档中共发现了42个漏洞,并通过Chen等[83]提出的方法向授权方报告,证明了这种漏洞查找方法的有效性。
此外,知识图谱 (KG) 有助于将自由文本网络安全转换为更具结构化的格式,并具有语义丰富的知识表示见解。Piplai等[84]提出了一个基于恶意软件后行动报告(AAR)的网络安全KG示例,其中包含对网络安全事件的深刻分析,并因此向安全分析师提供可靠的信息。AAR 可以通过将模式与预定义事件进行匹配来帮助处理未识别的网络安全事件,因为它们提供了有关检测和缓解技术的关键数据。具体来说,在工作[84]中,基于Stanford NER [89]的恶意软件实体提取器是为构建网络安全KG而创建的,并且它基于CVE和安全博客的数据进行训练,以识别网络安全KG所需的实体。
2)讨论:
面对庞大的源代码和技术的进步,自动化漏洞分析和检测已成为当前的研究热点。对漏洞和恶意软件检测的研究预计将从分析源代码扩展到从多个数据源挖掘 CTI。如果可以挖掘有关漏洞利用和恶意软件实施的见解知识,它将显着增强识别、优先排序和修复漏洞的能力。
及早识别漏洞可以防止与其利用漏洞相关的灾难性后果。有关漏洞和恶意软件的信息可在各种来源获得,包括开源和机密数据。有几个关于漏洞和恶意软件的结构化和半结构化信息存储库,包括 NVD [22]、IBM 的 XFORCE [90]、US-CERT 的漏洞说明数据库 [91] 等。非正式来源,如计算机论坛、黑客博客、社交媒体等,也为这些知识库做出了贡献。虽然这些非结构化来源嘈杂、冗余,并且通常包含错误信息,但它们可以被挖掘和汇总,以跟踪新恶意软件和漏洞的传播,并提醒安全专家采取行动。ML 和 NLP 技术使强大的自动特征提取技术能够从文档中挖掘特征,使其成为更可行和及时的策略,以识别相关语义信息并了解多个数据源中的漏洞,从而取代手动检测。
F. 威胁搜寻
威胁搜寻是主动搜索潜伏在网络中未被发现的网络威胁的做法。根据IBM的定义,威胁搜寻是一种主动方法,用于识别组织网络中以前未知的或正在进行的未修复威胁[59]。在威胁搜寻期间,将检查可能被视为已解决但未解决或已遗漏的可疑活动模式。本节回顾了挖掘CTI以进行威胁搜寻的工作。
1)代表工作总结:
威胁搜寻的重要性在于,复杂的威胁可以通过自动化的网络安全系统[100]。准备充分的攻击者将能够渗透任何网络,并平均避免检测长达280天[59]。攻击者可以通过利用有效的威胁搜寻来减少入侵和发现之间的时间,从而减少损害。有关网络安全威胁(例如,APT 活动中使用的恶意软件)的知识包含在各种 CTI 资源中,并以各种格式呈现,包括自然语言、结构化、半结构化和非结构化形式。由于黑客通常在网上开会讨论最新的黑客技术或工具[101],工作[92]应用文本挖掘来识别与在线聊天中出现的网络威胁相关的术语,例如Twitter和暗网论坛。此外,[93]提出了一个历时图嵌入框架,该框架有助于动态捕获黑客术语随时间的演变。
然而,网络威胁的碎片化视图可以通过专注于提取与新兴威胁相关的术语的方法进行提取,例如签名(例如,工件的哈希值)、文件名、IP 地址和时间戳。使用预定义的规则,例如使用启发式方法关联可疑威胁,我们可以发现新出现的威胁。很难且缺乏精确度,无法全面了解威胁是如何演变的,尤其是在很长一段时间内。因此,最近的研究工作致力于关联威胁术语(即 IOC 工件)之间的关系,并以图表的形式表示攻击者的步骤,其中包括有关攻击行为的线索。在这种情况下,即使黑客更新了他们的策略(例如,签名)来进行攻击,与仅专注于威胁术语相比,威胁搜寻仍然有效。Satvat等[94]从CTI报告中提取了攻击行为的全貌,并将其表示为一个组来识别APT。通过所提出的方法[94],CTI报告中的复杂描述被处理为一个来源图,其中节点表示实体(例如,域名,用户名和文件),边缘指向系统调用(例如,写入,发送,解码和记录)。此外,Milajerdi等[96]通过在低级系统调用视图和高级APT杀伤链视图之间构建中间层,弥合了它们之间的差距。中间层是基于 MITRE 的 ATT&CK [49] 威胁存储库建立的,该存储库描述了数百种定义为 TTP 的行为模式,该存储库总结了来自来源图中节点和边缘的观察结果。
预计威胁情报将从多个来源收集信息,以提供更多见解。Gao等[95]提出了一种方法,描述了涉及不同类型的威胁基础设施节点(即域名、IP地址、恶意软件哈希和电子邮件地址)和边缘(即节点之间的关系矩阵)的CTI实例。通过利用开源CTI(如CVE)[102]来发现利用同一漏洞的关系,可以发现两个恶意软件哈希之间的更多信息。使用异构图卷积网络,提出了一种基于威胁基础设施相似度量的方法,用于建模和识别CTI中涉及的威胁(例如恶意代码、僵尸网络和未经授权的访问)[95]。在工作[95]中定义了元路径和元图,以从各种语义意义中捕获节点之间的高级关系。Milajerdi等[97]采用一种新的相似性指标来评估从IOC开放标准中提取的攻击行为图与从内核审计日志中提取的系统行为图之间的一致性。此外,GAO等人[99]创建的THREATRAPTOR系统通过使用开源网络威胁情报(OSCTI)实现了威胁搜寻过程。该系统通过开发一个无监督的 NLP 管道来实现这一点,该管道从非结构化的开源 CTI 中提取有组织的操作。可以使用建议的特定于域的查询语言、查询综合机制和查询执行引擎毫不费力地搜索这些有组织的操作。
2)讨论:
随着企业努力领先于最新威胁,跟上网络威胁并快速响应潜在攻击变得越来越重要[103]。有效的威胁搜寻策略是主动搜索潜伏在网络中未被发现的网络威胁的策略。威胁搜寻深入挖掘目标环境,以查找绕过其端点安全措施的恶意行为者。潜入网络后,攻击者可以访问数据、机密信息或登录凭据,从而允许以后移动。一旦对手逃避检测并穿透其防御,组织通常缺乏高级检测功能来检测高级持续性威胁。因此,威胁搜寻是任何防御策略的重要组成部分。因此,威胁搜寻是任何防御策略的重要组成部分。
在企业内部进行威胁搜寻存在一些挑战:(1)攻击者通常会在很长一段时间内执行攻击步骤,例如,在发现之前潜伏数月[59]。通过这种方式,可以通过窃取数据并暴露足够的机密信息来进一步访问,从而引发重大数据泄露。因此,由于攻击活动在很长一段时间内发生,因此需要一种将相关IOC链接在一起的方法[104]。(2) 有效的威胁搜寻必须能够识别攻击活动是否会影响系统,即使攻击者修改了文件哈希和 IP 地址等工件以避免检测。因此,稳健的方法应该发现整个威胁场景,而不是孤立地寻找匹配的IOC[24]。(3)为了让网络分析师及时分析和响应威胁事件,该方法必须有效且不会产生许多误报,以便可以启动适当的网络响应操作[97]。
为了克服上述限制并构建强大的威胁搜寻检测系统,重要的是要考虑入侵指标之间的相关性。CTI 报告以各种形式提供有关网络安全威胁的信息,例如自然语言、结构化和半结构化。安全社区采用了 STIX [54] 和 OpenIOC [19] 等开放标准,以促进 IOC 形式的 CTI 交换并实现 TTP 的表征。标准对指标或可观察对象的描述通常说明了它们之间的关系,以便更好地感知攻击[7]。IOC工件之间的关系为受感染系统内部的攻击提供了重要线索,这些线索与攻击者的目标有关,因此很难改变[97]。
四、挑战与未来方向
如第三节所述,许多调查提倡使用CTI挖矿来实现主动的网络安全防御,但仍有许多挑战需要解决。本节将深入探讨该领域遇到的困难。为了应对这些挑战,将根据第二节和图 4 中描述的感知、理解和预测过程管道概述潜在的未来方向。
图 4.网络威胁情报挖掘的未来方向,用于主动安全防御。
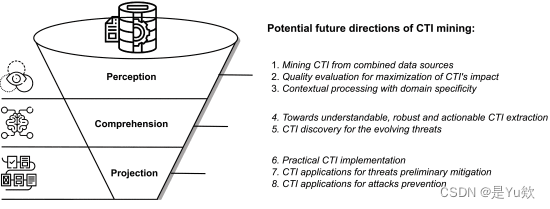
A. 感知
1)未来方向1(从组合数据源中挖掘CTI):
近年来,在与公共数据相关的网络安全事件规模不断扩大和备受瞩目的影响下,我们已经看到理解和防御不断变化的网络威胁的范式转变,从主要是被动检测到主动预测[24]。来自多个来源的网络安全信息量正在迅速增加,包括开源网络威胁情报和受限访问的机密信息。
虽然大量的信息源使得挖掘比以往任何时候都更有价值的CTI成为可能,但威胁报告通常包含大量不相关的文本[105]。换句话说,报告中只有一小部分专门用于描述攻击行为。例如,描述攻击者的地理来源是有意义的。但是,如果未提供该信息,则无助于澄清攻击活动中的攻击行为。此外,在以前的研究中,大多数工作只使用一种数据来源,即使不同的研究使用不同的来源。例如,表III总结了最近在挖掘网络安全相关实体和事件方面的工作,其中大多数工作仅使用来自单一来源的数据。
预计未来将通过聚合来自这些不同资源的信息,从多个数据源中提取 CTI。此外,预计将调查这些数据源之间的关系,以便通过使用有关CTI的多级信息(例如借助异构知识图谱)来提供攻击活动的整体情况。此外,在提取 CTI 时,检查与质量相关的问题也很重要,例如误报和一致性。
2)未来方向(质量评估,以最大限度地发挥CTI的影响):
CTI 可以从各种来源获得,包括但不限于政府机构、安全供应商、研究组织和开源信息。挑战在于确定可信和可靠的CTI来源,因为信息的质量可能差异很大。此外,CTI 的动态特性意味着信息在不断变化和发展,因此在尝试了解和预测潜在的网络威胁时,仔细评估信息及其来源的质量至关重要。收集高质量的CTI是一项挑战,需要对信息来源有透彻的了解,并采用系统的方法来评估信息的可信度和可靠性,最终决定CTI的影响。
近年来,关于获取CTI及其来源的质量进行了一些研究[106],[107],[108]。例如,Schaberreiter等[106]和Griffioen等[107]提出了参数的定量评估,以评估CTI的质量,如广泛性、维护性、合规性、及时性、完整性等。Schlette等[108]提出了一系列质量维度,并展示了如何使质量评估透明化。网络安全领域在不断发展,对CTI及其质量的探索是一个持续的追求。随着对 CTI 动态和影响其质量的因素的了解越来越多,组织可以更好地评估他们收到的 CTI,并就其安全态势做出更明智的决策。持续开发评估 CTI 质量的方法和框架将有助于确保组织能够有效地使用 CTI 来改善其安全态势。
此外,考虑CTI对评估其质量和来源质量的影响至关重要。CTI质量的评估应基于确凿的证据,而不是主观意见。例如,在Liao等[69]的一项研究中,作者利用IOC跟踪新出现的网络威胁,并通过评估其IOC的全面性、及时性和可靠性来确定高质量的情报来源。这种既考虑信息质量又考虑其影响的综合方法提供了对CTI的更全面的评估。开发一种系统和基于证据的方法来评估CTI及其来源的质量,对于确保信息准确可靠并可有效用于防范网络攻击至关重要。
3)未来方向3(具有领域特异性的上下文处理):
此外,所评价研究的假设之一是CTI报告的文本结构遵循相对简单的结构[109]。例如,在语法上遵循特定的模式,假设网络安全相关术语可以通过正则表达式捕获,同时考虑到句子中主语、动词和宾语形式的稳定语法关系。事实上,CTI报告通常比大多数其他报告包含更复杂的特定领域上下文[110]。由于 CTI 报告的句法和语义结构复杂、技术术语的普遍存在以及这些报告中缺乏适当的标点符号,这些因素很容易影响报告的解释方式和攻击行为的提取方式。
一些研究工作致力于创建网络安全领域地面实况数据集。Satyapanich等[36]创建并发布了一个包含5种网络安全攻击类型1000个注释的语料库,从而为简化从原始数据中提取网络安全相关信息的过程和促进特定领域基础事实的发展奠定了基础。Behzadan等[111]手动标记了21,000条与网络安全相关的推文,以备将来使用。此外,与一般的预训练模型(例如,word2vec [88],手套[40])相比,网络安全特定的NER模型和词嵌入(例如,由EmTaggeR [113]修改的sec2vec [112])被证明可以提高处理复杂领域特定上下文的性能[36],[114]。
B. 理解
1) 未来方向 4(迈向可理解、稳健和可操作的 CTI 提取):
近年来,研究人员在从多个数据源提取CTI的自动化方面做出了重大贡献[12]。然而,仍有一些挑战需要克服:(1)由于经验丰富的专业人员严重短缺,许多组织无法处理大量的CTI提要,导致他们负担沉重。(2)由于攻击者生成的虚假CTI,可能会发生误报。此外,攻击者可以利用虚假的 CTI 来破坏网络防御系统。(3) 提取的 CTI 可能难以用于可操作的建议,例如,优先考虑以下网络安全防御行动。为了克服这些挑战,下一代CTI必须易于理解、稳健和可操作。首先,易于理解的CTI为没有强大网络安全领域知识的人提供了对关键安全要素的解释。例如,在工作[115]中,通过基于神经网络的监督方法从文本中提取和索引了15类与网络安全事件相关的实体。提取与网络安全相关的信息,例如安全事件的受影响日期、时间和组织,并用于解释特定的网络安全事件。通过对注释实体的解释,CTI 变得更容易访问和理解,以便进行进一步分析。CTI 的可解释性可以通过包含更多的实体和多样性来提高,这些实体和多样性将通过扩大真实数据和嵌入补充语义特征来扩展实体以与词嵌入连接起来,从而促进 CTI 的解释。此外,由于网络安全事件与语言无关,因此预计将研究将来自不同语言来源的非结构化文本转换为结构化格式。
其次,强大的CTI确保提取的数据是真实的,而不是对手伪造的。伪造的CTI示例被用作腐败网络防御系统的输入,攻击者通过对错误输入的训练模型来实现恶意需求[116]。最近的研究[116]表明,GPT-2转换器生成的大多数虚假CTI样本甚至被网络安全专业人员和威胁猎人标记为真实。生成转换器通常产生的语言错误和不流畅性,但很少被期望作为提炼真正 CTI 的关键特征进行探索和利用。为了检测虚假的CTI样本,通过分析用户对真实和虚假网络新闻的传播和感知[117],确定的美学、可读性、来源可信度、新颖性和传播性等方面值得研究。
最后但并非最不重要的一点是,可操作的 CTI 提供与消费组织相关且值得信赖的完整准确信息。如果CTI与组织的运营相关且值得信赖,提供完整准确的信息,并且可以摄取到CTI共享平台中,则CTI可以称为可操作的[12]。CTI挖矿的输出旨在提供可操作的建议,包括风险缓解、安全实践建议以及提取的CTI之间的关系建立。例如,在公开可用的安全数据集、建议和知识图谱的帮助下,应向用户提供可操作的 CTI 输出,这些数据集、建议和知识图谱代表了各种 CTI 之间的关系。
2) 未来方向 5(CTI 发现不断变化的威胁):
网络防御工具不断更新,变得越来越复杂[118]。然而,我们仍然面临着对不断演变的网络威胁的缓慢反应,例如窃取我们信息的网络钓鱼、加密我们的数据并要求赎金作为交换的勒索软件,以及破坏我们关键基础设施的恶意软件。确保及时、自动地发现来自公开来源(如黑客论坛和威胁报告)的不断变化的威胁,对于帮助组织跟上不断变化的威胁形势至关重要。然而,现有的威胁情报提取技术忽略了网络威胁不断变化的性质。人工智能的最新发展通过利用能够适应攻击、生成变体和逃避检测的对手来使问题复杂化:“这个进攻性人工智能的新时代利用各种形式的机器学习来增强网络攻击,导致不可预测的、情境化的、更快的和更隐蔽的攻击,这可能会削弱未受保护的组织”,Forrester Consulting [119]。
目前提取开源CTI的方法,使用各种NLP和机器学习ML技术,例如文本记忆、信息提取、命名实体识别、决策树和神经网络,来了解不同网络攻击的手段和后果。然而,目前的CTI工作有三个主要局限性:(1)静态和孤立的CTI很难描述威胁攻击的动态和威胁事件的广阔景观;(2)CTI的碎片化视图,如可疑域名和工件哈希值,很难帮助安全分析师追踪企业中高级持续性威胁的目标;(3)CTI之间的相互依赖性,这可以帮助我们揭示威胁行为如何被探索的大图景。此外,人工智能驱动的自适应网络攻击带来了更多的挑战,这些不同的攻击变体可能会发展,多种网络攻击甚至可以合作导致大规模的有组织犯罪。总的来说,CTI提取对企业和个人来说都是一项重大且具有挑战性的任务,目前的工作无法解决这一日益严重的国家情报和安全问题。因此,为了开发从异构开源中自动提取相互关联和不断发展的CTI的重点理论和技术,构建动态CTI知识图谱,以揭示网络攻击如何演变以及多种网络攻击如何协调渗透系统,有望在复杂系统中实现及时响应的网络威胁搜寻。
C. 投影
1)未来方向6(实际CTI实施):
CTI采矿研究面临的挑战是将研究转化为CTI的实际实施和应用,并最大限度地展示其实际意义。市场上有许多 CTI 工具,有助于收集、分析和共享 CTI 数据。在对现有CTI工具的回顾中,我们将其归纳为四类:(1)可以访问威胁情报并提供高级管理选项(例如,包括过滤、分析、查找相关性、搜索在内的功能)的开源和企业工具。(2) CTI 协议集是一组用于描述和共享 CTI 信息的语言。(3)CTI的共享平台。(4)根据收集的CTI进行事件响应系统。
尽管许多组织希望共享他们的 CTI,但预计 CTI 交换的格式会得到普遍接受。例如,为了促进CTI交换,MITRE开发了STIX方案[54],该方案被研究和CTI应用广泛采用。重要的是,数据格式必须与利益攸关方的不同系统兼容。为了及时交换CTI,必须避免不必要的数据转换。
CTI共享背后的核心思想是,通过在利益相关者之间共享有关最新威胁和漏洞的信息,以及尽快实施补救措施,利益相关者将了解情况[8]。CTI 共享提供了一种在共享利益相关者之间建立态势感知的新方法。此外,人们认为有必要为未来的攻击做好准备,以便先发制人,而不是像目前的做法那样对它们作出反应。CTI共享有望成为未来组织共享信息的主动网络安全的一个组成部分。以及时消费和传播信息的方式实施CTI共享方式将对行业大有裨益,其未来取决于对CTI的理解和补救措施的实施程度。
2) 未来方向 7(CTI 威胁初步缓解应用):
通过从一开始就采取更积极主动、更具前瞻性的方法,公司可以应对和减轻未来的中断和网络威胁[120]。积极预防威胁可以促进对网络安全战略的完全控制。这有助于确定风险的优先级并相应地解决它们。通过及早识别漏洞,并提前为最坏的情况做好准备,我们将能够在网络事件中迅速果断地采取行动。虽然主动措施有助于防止违规行为,但如果发生违规行为,则会采取被动措施。2020年,主动安全市场价值2081万美元,预计到2026年将增长到4567万美元[121]。
威胁缓解是降低来自 IT 系统的物理、软件、硬件等威胁严重性的过程。从CTI挖矿应用的角度来看,我们说明了如何以主动的方式缓解威胁。首先,收购的 CTI 可以协助制定涉及物理安全措施、培训和教育的组织战略。其次,在使用技术实现来缓解威胁的网络策略方面,从CTI监控网络活动和预测网络攻击是潜在的未来方向。例如,Shen等[122]通过使用来自商业入侵防御系统的安全事件数据,预测了攻击者将采取的执行网络攻击的具体步骤。对为组织定制的特殊安全解决方案的需求也在上升。预计组织可以获得专门的安全专业知识,这些专业知识可以轻松分析系统并在短时间内将其安全性从零转变为重要级别。例如,在最近的研究工作中[123]提出了一种将异构数据集成到定制和可理解的网络安全信息中的创新方法,该方法可以应用于网络安全咨询和专业化的安全解决方案。
3)未来方向8(CTI攻击预防应用):
最近,网络威胁的数量不断增加。现在的恶意软件数量是十年前的十倍。越来越多的安全组织开始收集威胁详细信息并采取措施防止它们。因此,威胁预测对于检测和防止潜在的攻击和损失至关重要。
通过从外部来源收集大量CTI报告和论坛,并提取有用的信息,包括攻击名称、特征、攻击可能探索的漏洞、对象等,可以预测威胁是否可能攻击特定设备[72]。例如,如果有攻击报告说明攻击通过探索漏洞破坏了设备,并且组织的设备中存在相同的漏洞,则该攻击也可能损坏组织设备。因此,安全专家能够在可能发生的未发生攻击之前应用防御措施。
但是,此方法只能预测发生的攻击,这意味着只能预测收集的文本中出现的攻击和威胁。如何预测未发生的攻击一直是一个问题和挑战。
五、结束语
A. 经验教训
网络威胁情报 (CTI) 挖掘是一种强大的工具,可以为潜在的网络威胁和攻击提供有价值的见解,从而采取主动防御措施。为了生成强大且可操作的情报,我们需要使用不同的数据源进行 CTI 挖掘,包括开源和机密信息。这涉及各种技术,例如数据收集、预处理、特征提取和机器学习算法,必须仔细选择和优化这些技术才能获得准确可靠的结果。然而,CTI挖矿也有其挑战。数据量大、复杂性高、需要实时分析,以及难以区分真正的威胁和误报,都可能造成重大障碍。质量控制在CTI挖掘中至关重要,以确保提取的情报的准确性和一致性,避免根据不完整或不准确的信息做出决策的风险。CTI挖矿是一个持续的过程,需要不断监控和调整,以跟上快速发展的威胁形势。尽管如此,它对学术界和工业界都有重大好处。这些措施包括改进威胁检测和响应、增强网络安全态势以及提高对新出现的威胁和趋势的认识。总体而言,我们对CTI挖矿的最新作品的回顾表明,该领域是复杂且具有挑战性的,但最终是有价值的,能够增强我们抵御网络攻击的能力。
B. 结语
在本次调查中,我们详细回顾了迄今为止发表的关于CTI采矿的最重要著作。在本文中,我们提出了一种基于CTI知识获取目的对现有研究工作进行组织和分类的分类方案,并强调了现有研究所采用的方法。根据拟议的分类方案,我们彻底审查和讨论当前的工作,包括网络安全相关实体和事件、网络攻击策略、技术和程序、黑客概况、入侵指标、漏洞利用和恶意软件实施以及威胁追踪。此外,我们还讨论了当前的挑战和未来的研究方向。在过去的几十年里,人们对CTI挖矿产生了极大的兴趣,特别是用于主动网络安全防御。许多人已经注意到,每年都有大量的新技术和模型被开发出来。希望这项调查能帮助读者了解该领域的关键方面,澄清最显着的进展,并为未来的研究提供启示。
相关文章:
【威胁情报综述阅读3】Cyber Threat Intelligence Mining for Proactive Cybersecurity Defense
【威胁情报综述阅读1】Cyber Threat Intelligence Mining for Proactive Cybersecurity Defense: A Survey and New Perspectives 写在最前面一、介绍二、网络威胁情报挖掘方法和分类A. 研究方法1) 第 1 步 - 网络场景分析:2) 第 2 步 - 数据…...
在编程中使用中文到底该不该??
看到知乎上有个热门问题,为什么很多人反对中文在编程中的使用? 这个问题有几百万的浏览热度,其中排名第一的回答非常简洁,我深以为然: 在国内做开发,用中文写注释、写文档,是非常好的习惯&…...

PyQt6从入门到放弃
PyQt6从入门到放弃 安装PyQt6 pip install PyQt6# 查看QT和PyQT的版本 from PyQt6.QtCore import QT_VERSION_STR from PyQt6.QtCore import PYQT_VERSION_STR print(QT_VERSION_STR) print(PYQT_VERSION_STR)PyQt6模块 PyQt6类由一系列模块组成包括QtCore、QtGui、QtWidgets…...

PhpWord导入试卷
规定word导入格式 1、[单选题][2024][一般]题目1 A.选项1 B.选项2 C.选项3 D.选项4 答案:D 试题图片(上传多媒体图片): 分数:2 答案解析: 2、[多选题][2024][困难]题目2 A.选项1 B.选项2 C.选项3 D.选项4 E…...

C# 运算符重载 之前的小总结
C# 中支持运算符重载,所谓运算符重载就是我们可以使用自定义类型来重新定义 C# 中大多数运算符的功能。运算符重载需要通过 operator 关键字后跟运算符的形式来定义的,我们可以将被重新定义的运算符看作是具有特殊名称的函数,与其他函数一样&…...
XenCenter 2024 创建一个虚拟机
前言 实现,创建一个虚拟机,内存,cpu,磁盘,名称,网卡,配置 Xen Center 2024 download 创建虚拟机 选择系统类型 定义虚拟机名称 选择ISO镜像库 选择主服务器 分配虚拟机内存,cpu资源…...

tomcat 知多少
Tomcat的缺省端口: 默认端口为8080,可以通过在tomcat安装包conf目录下,service.xml中的Connector元素的port属性来修改端口。 tomcat 常见 Connector 运行模式(优化): 这三种模式的不同之处如下: BIO : 一…...

【详细讲解语言模型的原理、实战与评估】
🌈个人主页:程序员不想敲代码啊🌈 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家🏆 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提…...
Predict the Next “X” ,第四范式发布先知AIOS 5.0
今天,第四范式发布了先知AIOS 5.0,一款全新的行业大模型平台。 大语言模型的原理是根据历史单词去不断预测下一个单词,换一句常见的话:Predict the Next “Word”。 当前对于行业大模型的普遍认知就是沿用这种逻辑,用大…...

PCL使用4PCS配准
一、代码 C++ #include <pcl/registration/ia_fpcs.h> // 4PCS算法 #include <pcl/point_types.h> #include <pcl/point_cloud.h> #include <pcl/io/pcd_io.h> #include <pcl/io/ply_io.h> #include <boost/thread/thread.hpp> #include…...
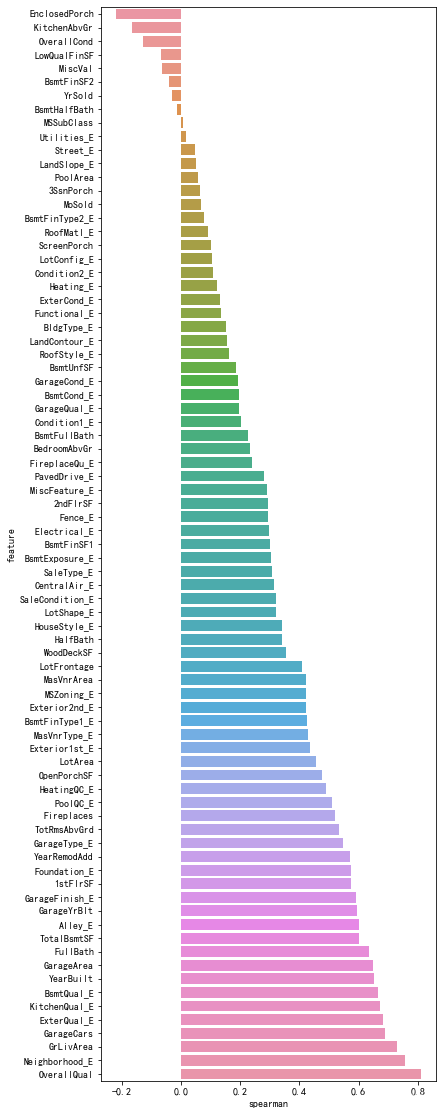
【六 (2)机器学习-机器学习建模步骤/kaggle房价回归实战】
一、确定问题和目标: 1、业务需求分析: 与业务团队或相关利益方进行深入沟通,了解他们的需求和期望。 分析业务流程,找出可能的瓶颈、机会或挑战。 思考机器学习如何帮助解决这些问题或实现业务目标。 2、问题定义:…...
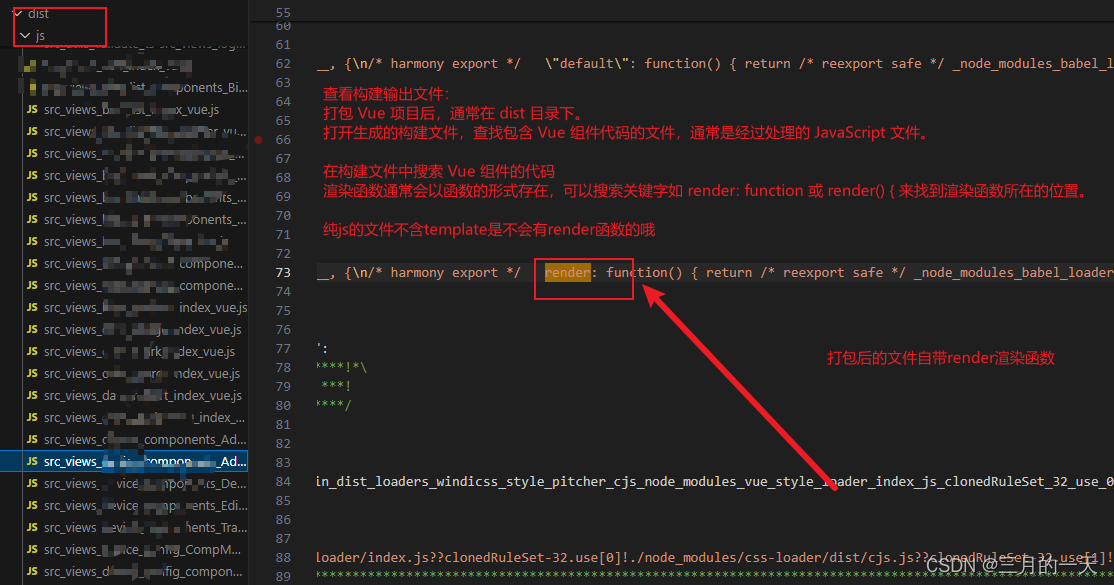
vue源码解析——vue如何将template转换为render函数
Vue 将模板(template)转换为渲染函数(render function)是 Vue 编译器的核心功能,它是 Vue 实现响应式和虚拟 DOM 的关键步骤。在 Vue 中,模板(template)是开发者编写的类似 HTML 的代…...

深入理解zookeeper
如果是zookeeper的初学者,可以看: zookeeper快速入门(合集)-CSDN博客 如果想要深入理解zookeeper,并在面试中取得更好的表现,可以看下面的文章,都是偏面试向的角度写的。 三分钟明白zookeeper…...
【漏洞复现】WordPress Plugin LearnDash LMS 敏感信息暴漏
漏洞描述 WordPress和WordPress plugin都是WordPress基金会的产品。WordPress是一套使用PHP语言开发的博客平台。该平台支持在PHP和MySQL的服务器上架设个人博客网站。WordPress plugin是一个应用插件。 WordPress Plugin LearnDash LMS 4.10.2及之前版本存在安全漏洞&#x…...
phpmyadmin页面getshell
0x00 前言 来到phpmyadmin页面后如何getshell呢?下面介绍两种方法 0x01 select into outfile直接写入 1、利用条件 对web目录需要有写权限能够使用单引号(root) 知道网站绝对路径(phpinfo/php探针/通过报错等) secure_file_priv没有具体值 2、查看secure_file…...

题目:学习static定义静态变量的用法
题目:学习static定义静态变量的用法 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheate…...

【C++】编程规范之函数规则
对所有函数入参进行合法性检查 在编写函数时,应该始终对所有传入的参数进行合法性检查,以防止出现意外的错误或异常情况。这包括但不限于检查指针是否为空、整数是否在有效范围内、数组是否越界等等。通过对参数进行严格的合法性检查,可以避免…...
HTML常用的图片标签和超链接标签
目录 一.常用的图片标签和超链接标签: 1.超链接标签: 前言: 超链接的使用: target属性: 1)鼠标样式: 2)颜色及下划线: 总结: 2.图片标签: 前言: img的使用: 设置图片: 1.设置宽度和高度: 2.HTM…...

浏览器工作原理与实践--WebAPI:XMLHttpRequest是怎么实现的
在上一篇文章中我们介绍了setTimeout是如何结合渲染进程的循环系统工作的,那本篇文章我们就继续介绍另外一种类型的WebAPI——XMLHttpRequest。 自从网页中引入了JavaScript,我们就可以操作DOM树中任意一个节点,例如隐藏/显示节点、改变颜色、…...
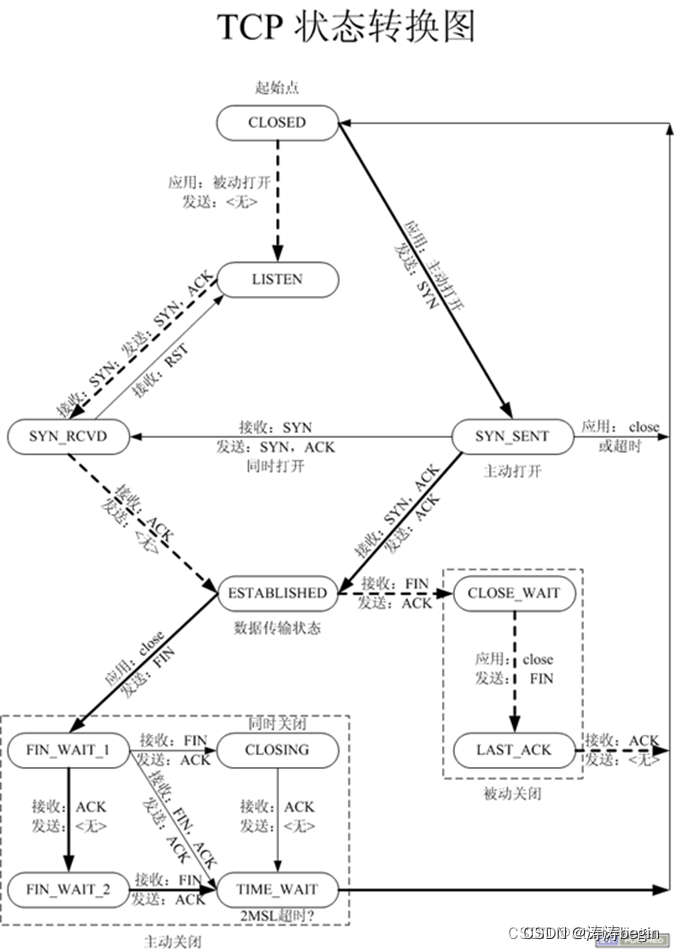
TCP网络协议栈和Posix网络部分API总结
文章目录 Posix网络部分API综述TCP协议栈通信过程TCP三次握手和四次挥手(看下图)三次握手常见问题?为什么是三次握手而不是两次?三次握手和哪些函数有关?TCP的生命周期是从什么时候开始的? 四次挥手通信状态…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...