GPT-2原理-Language Models are Unsupervised Multitask Learners
文章目录
- 前言
- GPT-1优缺点回顾
- GPT-1实验结果分析
- GPT-1缺陷分析
- GPT-2
- 训练数据
- OpenAI的野心
- 预训练/微调的训练范式
- 训练数据选择
- 模型结构和参数(更大的GPT-1)
- 模型预训练
- 训练参数
- 输入数据编码
- 总结
前言
首先强调一下,在看这篇文章之前,建议去看一下我之前写的:GPT-1原理-Improving Language Understanding by Generative Pre-Training
因为GPT-2是GPT-1的延续,所以接下来我介绍的内容都是假设你看过或者了解过GPT-1。
那么我们先来提前总结一下GPT2的内容,其实GPT-2只做了3点:
- 在更大的模型上进行效果验证;
- 在更大的数据集上进行模型训练和验证;
- 改进了输入的有损编码情况
其实本质上GPT-2就是对GPT-1的缺点进行改进、对优点进行放大、为之前的实验结果找到一个自洽的解释。所以这篇论文的介绍本身也不会太多。但是值得一看,因为它对未来的训练范式具有指导意义。
GPT-1优缺点回顾
既然GPT-2是对1的一个改进,那下面就先把我在GPT-1时候的一些总结照抄过来,当做参考。
GPT-1实验结果分析
- 增加transformer的decoder层数,会对NLI的理解任务有提升。
- 零样本能力:预训练好后的模型本身不需要微调,就具有了一定的NLI解决能力。
关于第1条的结论应该属于顺理成章,而关于第2点,文章作者最开始的本意可能只是想在预训练阶段让模型学到一些词级别或者是短语级别的能力,诸如word2vec能力,而训练完之后,却发现,这个预训练的模型不仅仅具有简单的词embedding的能力,居然就已经有一些能够解决具体NLI任务的基础能力,只是效果不一定好。这应该是属于意外之喜。
GPT-1缺陷分析
- 微调阶段,是需要根据不同的NLI任务,添加不同的任务头,这其实和Bert那一套是很像的,可以想象Bert很大概率是借鉴了GPT-1的。好了话说回来,这种添加任务头的形式,无形中是改变了原有的模型的。这可以说是一个缺点吧,因为OpenAI的追求是在不改变模型的情况下得到一个通才。
- 在训练参数这一节提到,在文本输出的时候,是按照词级别进行输入的,这种有一个很大的缺点,如果有些单词没见过,那如何进行编码呢?当然可以有一些平滑处理的手段,但是这确实是一个现存的问题所在,而在minGPT中,则是用了字符级的输入,就是把单词中的字母一个一个的进行编码输入。这虽然解决了问题,但是这个计算量就很大了。所以才有了后来的字节级的编码,诸如bpe,wordpiece等。
GPT-2
训练数据
OpenAI的野心
首先我们从数据开始说起,然而训练数据的选定并不是这么简单,至少要自洽是不那么容易的,它牵扯到的问题很多,下面我们开始分析一下。
首先在GPT-1时期OpenAI就提出,当下的流行的这种有监督学习的形式,属于狭窄专家范畴,它只能解决单一的任务。而OpenAI的目标是希望探索出一个通用的可以完成多任务的模型。
但是在GPT-1中并没有做到一点,至少说是做得不彻底,因为在GPT-1中分为了两个阶段的训练:
- 预训练:这个阶段主要是在大量未标注数据上进行无监督任务的学习;
- 微调训练:这个阶段主要是在具体NLI任务上已标注好的数据上进行有监督学习;
在微调阶段,模型是需要更改的,它需要根据具体的NLI任务来添加不同的任务头,诸如情感分类任务,是需要在预训练的模型上加入一个二分类头,然后进行微调。这对于预训练阶段的模型来说,其实已经算是一个新模型了,因为一定程度上更改了模型的结构。这就是GPT-1的缺陷分析的第1点。
预训练/微调的训练范式
上一小节介绍了GPT-1在微调阶段其实是更改了模型的(根据不同的NLI任务添加任务头),这显然没有彻底满足OpenAI的野心,OpenAI希望找到一个通用的可以完成多任务的模型。
那他们该如何解决这个问题呢?其实这就归结到你的训练目标上,如果你的训练目标是一样的,那自然这个训练的方式就不用变,模型也不用变。我稍微举一个例子,如果你预训练阶段的训练目标是一个二分类,而你的微调阶段的目标也是二分类,自然模型自始至终都不用修改了,这很直觉的。那我们就要想想预训练阶段的训练目标是什么?微调阶段的训练目标是什么?他们能不能统一呢?
预训练的训练范式
我们来看一下,其实预训练阶段是可以抽象出一个通用的抽象表达的:利用输入来预测输出。
P(output | input)
而在预训练阶段,input就是之前出现的词,而output就是要预测的下一个词,以我在GPT-1中的例子来说:“你是一个打不死的码农”为例,先构建输入和输出
| 特征(feature) | 标签(label) |
|---|---|
| 你 | 是 |
| 你是 | 一 |
| 你是一 | 个 |
| 你是一个 | 打 |
| 你是一个打 | 不 |
| 你是一个打不 | 死 |
| 。。。 | 。。。 |
左侧的特征(feature)就是每一次输入到模型的input,而右边的标签(label)就是模型预测的output。当然输入的input每一次都会被padding到同一个长度,保证输入维度一样。
微调的训练范式
同样的,在微调阶段,他的训练范式是什么样子的呢?
同样的我们以GPT-1中的情感分类举例子:
| 特征(feature) | 标签(label) |
|---|---|
| 你真的狗阿 | 负面 |
| 小明的表现还是很不错的 | 负面 |
| 。。。 | 。。。 |
单从这个例子来看,其实是可以满足像预训练这样的训练范式的:
P(output | input)
左侧的特征(feature)就是每一次输入到模型的input,而右边的标签(label)就是模型预测的output。
但是你要时刻记住OpenAI的野心:通用多任务模型,这里的核心就是**通用多任务。**当从上面的单一的情感分类来看,训练范式其实已经和预训练阶段得到了统一,但是其他的任务呢?我现在来举一个例子:文本蕴含和文本问答
文本蕴含的意思就是判断一个句子是不是包含在另一个句子中,是一个二分类问题
摘要提取的意思随从一段文本中提取一小段文本,举个例子
| 句子1(feature1) | 句子2(feature2) | 标签(label) |
|---|---|---|
| 我是一个练习三年半的码农,但是干了这么多年,我还是一事无成 | 我一事无成 | 包含 |
文本问答的意思是给一段文本和给一个问题,根据文本来回答问题,举个例子
| 句子1(feature1) | 句子2(feature2) | 标签(label) |
|---|---|---|
| 我是一个练习三年半的码农,但是干了这么多年,我还是一事无成 | 你是设么职业? | 码农 |
如果还是按照预训练的训练范式做训练的话,就不可行了,因为输入都是要两段连续文本。如果不做区分,我根本不知道你要我做文本蕴含任务还是文本问答。
那该如何弄呢?或许可以添加一个条件,给模型一个不同任务的区分。
P(output | input,task)
但是这有一个问题了,多了一个task,现在就要看一下,是否可以将这个有条件的微调范式和预训练的范式做一个统一。这就要看这个task怎么加了。或许可以在每个不同任务的输入的最前面加上关于任务的提示(这应该就是prompt的雏形):
文本蕴含的输入:
文本蕴含:我是一个练习三年半的码农,但是干了这么多年,我还是一事无成 $ 我一事无成
文本问答的输入:
文本问答:我是一个练习三年半的码农,但是干了这么多年,我还是一事无成 $ 你是设么职业?
这样其实训练的范式就统一了,输入的时候利用在前面加上关于任务的提示,输出的时候就是根据输入去做词语接龙预测。范式重新统一到预训练时期的模式:
P(output | input)
那这样的话,不管是预训练还是微调,都是关于“下一个词”的预测。都满足P(output | input)的范式。这样就解决了一个最大的问题,不管是预训练还是微调阶段,模型都不用做任何更改了。同时这也指导着未来微调时你的数据该如何组织。
另外这样的训练范式的统一,也进一步验证了GPT-1阶段的实验结论:
零样本能力:预训练好后的模型本身不需要微调,就具有了一定的NLI解决能力。
训练数据选择
从上面的介绍来看,现在模型已经可以不用更改了,但是还有一个问题就是:多任务。作者通过在GPT-1的实验中得到了关于“零样本能力”的结论,这个结论表明,大模型可以通过在大量的未标记的文本数据上去进行训练,在无形中掌握多任务的处理能力,同时他们看了大量的论文发现,这个观点可靠。 所以解决多任务的办法就是增加训练数据,且数据要尽量的多样化,当然也要保证数据的质量
综合以上的种种考虑,他们放弃了以往大家都用的Common Crawl数据集,他们觉得这个数据不够干净,最终他们网上爬取了大量的数据,经过数据清洗,制造了一个数据集WebText,总共40G:
| 数据集 | 大小 |
|---|---|
| WebText | 40G |
最后总结一下,数据集的选择过程其实是在寻找一些理论来自洽现有的种种迹象,诸如零样本能力。这有一定的必要性。
模型结构和参数(更大的GPT-1)
上面已经搞定了数据选定的问题,从数据已经找到了统一的范式,自然模型就不用更改了,同时针对GPT-1实验中的第一点,在之前的实验中得到结论,transformer的decoder层数越多,对NLI的理解任务就会有所提升,那既然有这个结论,就实践呗,GPT-2就是一个更大的GPT-1,下面是具体的参数。
| 解码器块 | 多头注意力 | 词embedding | 前馈神经网络隐藏层维度 | |
|---|---|---|---|---|
| GPT-2 | 12 | 12 | 768 | 3072 |
| GPT-2-medium | 24 | 16 | 1024 | 4096 |
| GPT-2-large | 36 | 20 | 1280 | 5120 |
| GPT-2-xl | 48 | 25 | 1600 | 6400 |
在GPT-2中,给出了4个模型,一个比一个大。大力出奇迹。
模型预训练
数据搞定了,模型搞定了,接下来就是训练了,训练阶段呢,则有几个训练的数据作者更改了一下。
训练参数
在训练参数上的更改也是依据模型越大效果越好的实验结论,所以具体的训练参数只修改了两点
- 单词输入最长文本为从512更改为1024;
- batchsize从64更改为512;
其他的保持不变。
输入数据编码
最后还有一个地方是和GPT-1不一样的,那就是输入数据的编码形式,在原来GPT-1上,数据特征的embedding化是词级别的,这就会出现一个问题,那就是对于一些没有出想过的词,很难处理,只能利用有损编码的形式进行处理,所以这次GPT-2改了,在字节对级别上进行embedding化,这样就大大的减小了信息的损失,诸如interesting,在进行编码的时候,并不是一整个单词进行编码,而是先拆成字节对,诸如拆成int、erest,ing,然后对他们进行分别编码。这样其实就很少会遇到没有见过的词了。因为是在字节对这个级别进行编码的。而GPT-2是利用什么算法对单词进行字节对的拆分呢?是BPE,关于BPE的原理,后面会有专门的文章。当然了,可能有人会问,字符级的编码,信息可以实现完全的无损,理论上是这么说,但是字符级的编码,有很多的缺点:诸如计算量大,阻碍上下文长度的学习,没有捕获更高级的语义信息等,总之,字节对级的编码是在词级别和字符级别做一个折中。
最后总结一下,在数据编码上,从原来的词级别,改为字节对级别,字节对的拆分算法用BPE。这也是现在GPT4一直用的。
总结
关于GPT-2的内容大概就是这么多了,其实总结下来,就是:
- 探索更大的模型进行训练
- 探索利用更大更多样性更干净的数据进行预训练
- 利用BPE这种字节对切分形式对词进行编码,减少信息损失。
最后我想解释一点,为啥GPT-2只讲了预训练,而不讲微调,这里就要看我在训练数据那一节的讲解了。首先他已经统一了训练的范式,既然统一了范式,这样你可以认为预训练和微调阶段其实就统一了。其次是从OpenAI的野心来看,他一直都想找到一个通用的多任务模型,而这个通用多任务的模型的特征就体现在他的零样本能力,所以整个GPT-2其实就是在探索模型的零样本能力。
好了,内容到此就结束了,后面按照大模型的时间线,可能会分享一下google的T5。同样的也强烈推荐大家去阅读一下GPT-2的原文:Language Models are Unsupervised Multitask Learners
相关文章:

GPT-2原理-Language Models are Unsupervised Multitask Learners
文章目录 前言GPT-1优缺点回顾GPT-1实验结果分析GPT-1缺陷分析 GPT-2训练数据OpenAI的野心预训练/微调的训练范式训练数据选择 模型结构和参数(更大的GPT-1)模型预训练训练参数 输入数据编码 总结 前言 首先强调一下,在看这篇文章之前&#…...

逆向案例十二——看准网企业信息json格式的信息
网址:【全国公司排行|排名榜单|哪家好】-看准网 打开开发者工具——刷新——网络——XHR——下滑页面加载新的页面——找到数据包 发现参数加密,返回的数据也进行了加密 按关键字在下方搜索 kiv进入第一个js文件 ctrlf打开文件里面的搜索框继续搜kiv找到…...
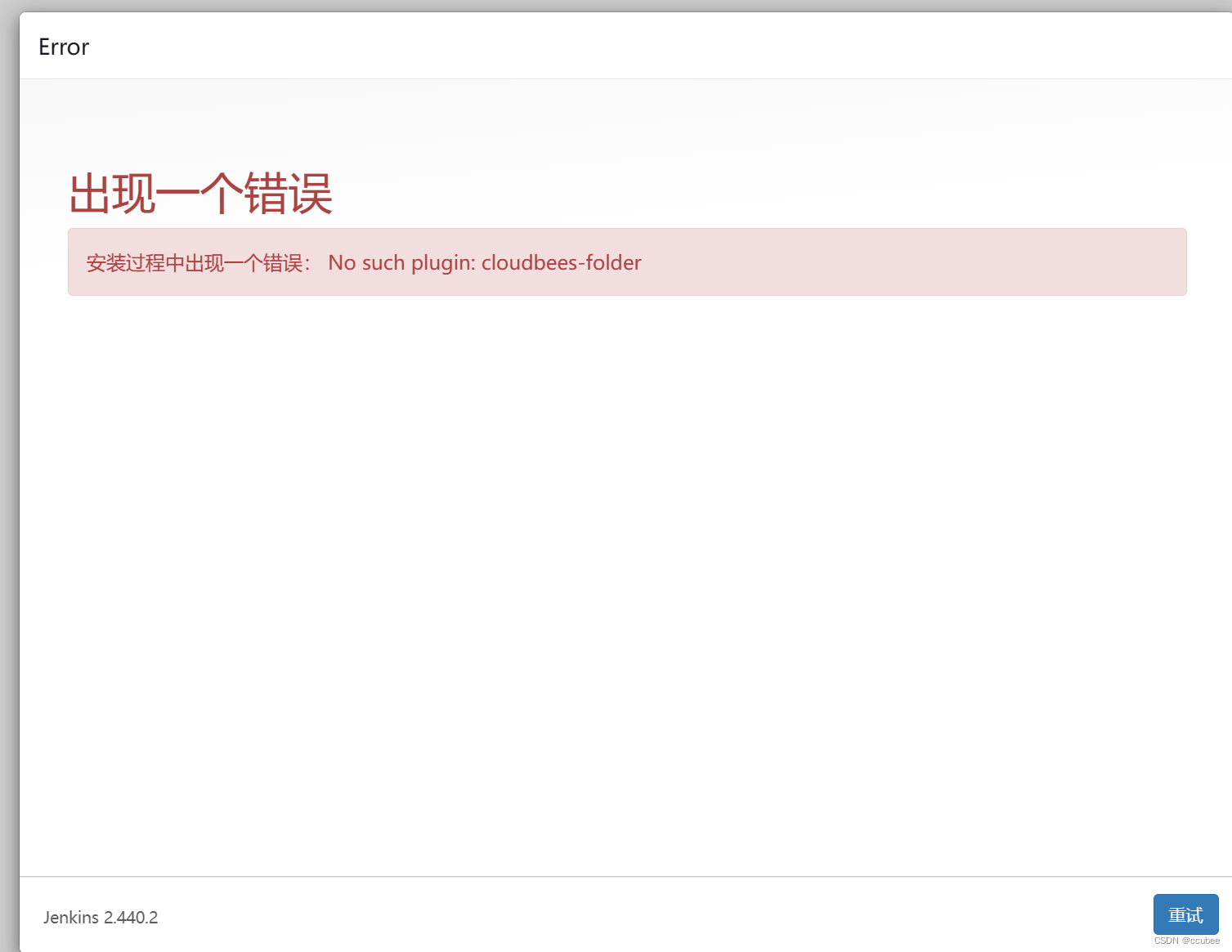
docker安装jenkins 2024版
docker 指令安装安装 docker run -d --restartalways \ --name jenkins -uroot -p 10340:8080 \ -p 10341:50000 \ -v /home/docker/jenkins:/var/jenkins_home \ -v /var/run/docker.sock:/var/run/docker.sock \ -v /usr/bin/docker:/usr/bin/docker jenkins/jenkins:lts访问…...

输入url到页面显示过程的优化
浏览器架构 线程:操作系统能够进行运算调度的最小单位。 进程:操作系统最核心的就是进程,他是操作系统进行资源分配和调度的基本单位。 一个进程就是一个程序的运行实例。启动一个程序的时候,操作系统会为该程序创建一块内存&a…...
部署hive)
Linux(centos7)部署hive
前提环境: 已部署完hadoop(HDFS 、MapReduce 、YARN) 1、安装元数据服务MySQL 切换root用户 # 更新密钥 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysqL-2022 # 安装Mysql yum库 rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm # yu…...

LeetCode | 数组 | 双指针法 | 27. 移除元素【C++】
题目链接 1. 题目描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...

【Apache Doris】周FAQ集锦:第 2 期
【Apache Doris】周FAQ集锦:第 2 期 SQL问题数据操作问题运维常见问题其它问题关于社区 欢迎查阅本周的 Apache Doris 社区 FAQ 栏目! 在这个栏目中,每周将筛选社区反馈的热门问题和话题,重点回答并进行深入探讨。旨在为广大用户和…...

jQuery(二)
文章目录 1.jQuery操作节点1.查找节点,修改属性1.基本介绍2.切换图片案例 2.创建节点1.基本介绍2.内部插入3.外部插入4.小结1.插入方法说明2.两种插入方法的区别 5.插入元素实例6.移动元素实例 3.删除节点1.基本介绍2.代码实例 4.复制节点1.基本介绍2.代码实例 5.替…...

MIT6.828 实验环境安装教程
Thanks:mit6.828环境搭建 - 人云我不亦云的文章 - 知乎 https://zhuanlan.zhihu.com/p/489921553 sudo make && make install install -d -m 0755 "/share/qemu" install: 无法创建目录 “/share”: 权限不够 make: *** [Makefile:382:…...

一文彻底搞清 Iterator(遍历器)概念及用法
目录 一、由来及意义 二、具体实现流程 三、具有默认 Iterator 接口的数据结构 四、调用 Iterator 接口的场合 五、总结 一、由来及意义 Javascript中表示“集合”的数据结构,主要是 Array、Object、Map、Set 这四种数据集合,除此之外,…...
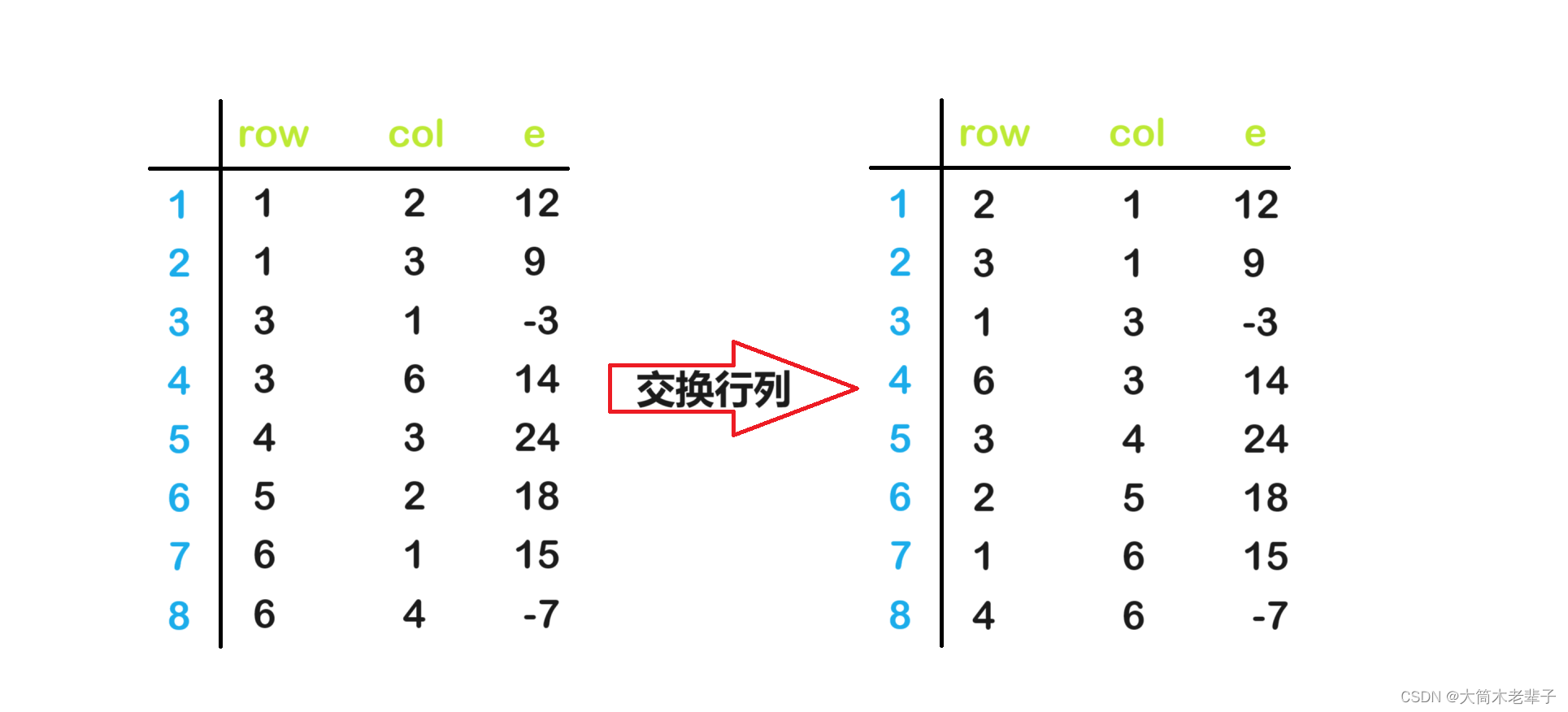
稀疏矩阵的三元组表表示法及其转置
1. 什么是稀疏矩阵 稀疏矩阵是指矩阵中大多数元素为零的矩阵。 从直观上讲,当元素个数低于总元素的30%时,这样的矩阵被称为稀疏矩阵。 由于该种矩阵的特点,我们在存储这种矩阵时,如果直接采用二维数组,就会十分浪费…...

docker安装rabbitMQ,并且创建账号
# 创建docker容器启动,挂到后台运行 docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.13-management # 打开防火墙 sudo firewall-cmd --zonepublic --add-port5672/tcp --permanent sudo firewall-cmd --zonepublic --add-port15672/tcp --permanent s…...

wireshark解析grpc/protobuf的方法
1,wireshark需要安装3.20以上 下载地址:https://www.wireshark.org/ 2,如果版本不对,需要卸载,卸载方法: sudo rm -rf /Applications/Wireshark.app sudo rm -rf $HOME/.config/wireshark sudo rm -rf /…...
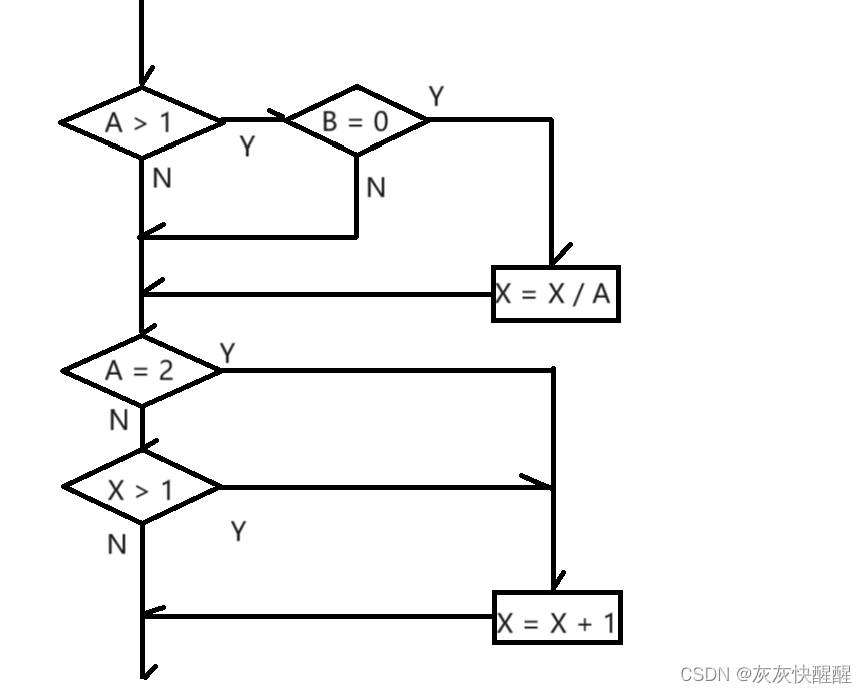
软件测试用例(2)
具体的设计方法 -- 黑盒测试 因果图 因果图是一种简化的逻辑图, 能直观地表明程序的输入条件(原因)和输出动作(结果)之间的相互关系. 因果图法是借助图形来设计测试用例的一种系统方法, 特别适用于被测试程序具有多种输入条件, 程序的输出又依赖于输入条件的各种情况. 因果图…...

集群式无人机仿真环境和数据集
仿真环境和数据集 Quick StartAcknowledgementsSwarmSim Quick Start Compiling tests passed on 20.04 with ros installed. You can just execute the following commands one by one. # Download the Simulator and run it wget https://cloud.tsinghua.edu.cn/library/34…...
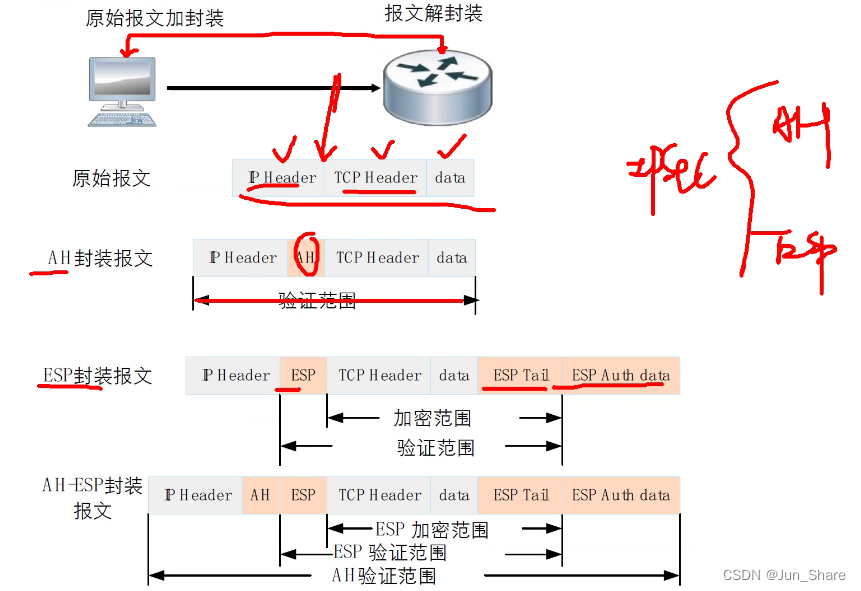
IPSec VPN
IP Security,IP安全 1、特点 L3的VPN 缺:不支持组播、配置复杂、延迟增加、资源消耗较多 优:具备访问控制、密码学四个维度、抗重放打击 2、组件 ①安全协议 1)验证头技术(AH) IP协议号51 提供数据完整性检查,身份验证,抗重放攻击 无法做数据的机密性 AH的完…...
docker部署nacos,单例模式(standalone),使用内置的derby数据库,简易安装
文章目录 前言安装创建文件夹docker指令安装docker指令安装-瘦身版 制作docker-compose.yaml文件查看页面 前言 nacos作为主流的服务发现中心和配置中心,广泛应用于springcloud框架中,现在就让我们一起简易的部署一个单例模式的nacos,版本可…...

systemd监听服务配置文件更新自动重启服务
背景&需求 需要频繁更改一个服务的配置文件进行测试 实现 配置服务的systemd文件 vim /lib/systemd/system/xxx.service [Unit] Descriptionxxx daemon, A rule-based proxy in Go.[Service] Typesimple ExecStart/opt/xxx/xxx-d /etc/xxx/ Restartalways[Install] Wan…...

【yy讲解PostCSS是如何安装和使用】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

YOLO电动车检测识别数据集:12617张图像,yolo标注完整
YOLO电动车检测识别数据集:12617张图像,电动车一类,yolo标注完整,部分图像应用增强。 适用于CV项目,毕设,科研,实验等 需要此数据集或其他任何数据集请私信...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...
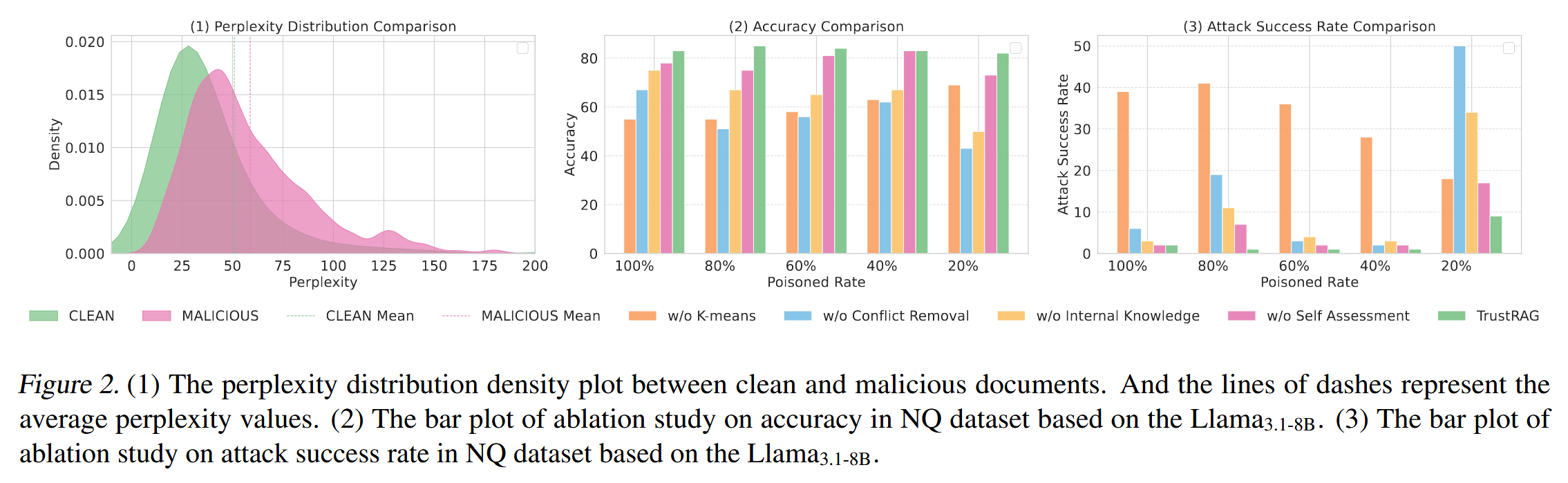
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...
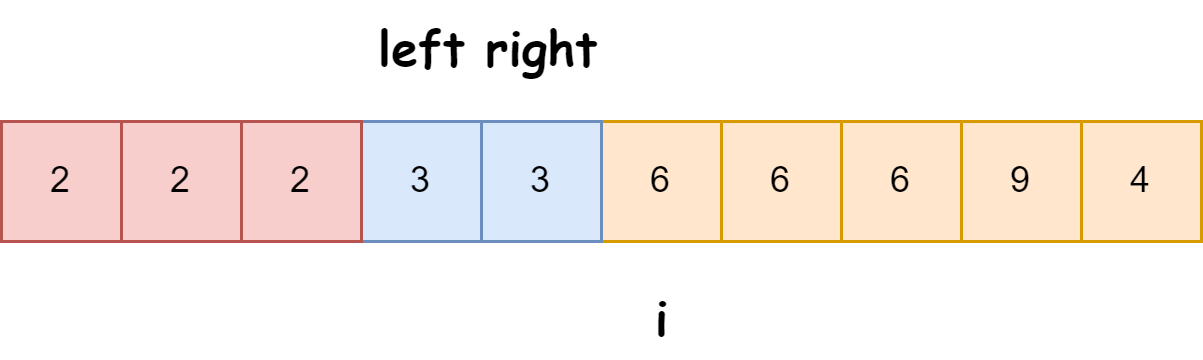
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...