Python使用方式介绍
1.安装与版本和IDE
1.1 python2.x和python3.x区别
python2在2020已经不再维护,目前主流开发使用python3. 二者语法上略有区别:输入输出、数据处理、异常和默认编码等,如:python3中字符串为Unicode字符串,使用UTF-8编码,而python2默认使用ASCII编码。python2和python3对应的包管理工具分别是pip和pip3. 另外,Python3引入了一些高级解释器特性,如协程、类型提示、异步编程等。
软件升级过程中,设计时不考虑向下相容(减少累赘),因此python3不完全兼容python2. 可通过Python3自带的工具2to3对python文件进行转换,类似前端的ES6转ES5。
linux系统默认自带python2, python3一般需要手动安装, 可以参考: Python3安装教程。
说明:以下以python3为例进行介绍。
1.2 python的IDE
个人推荐 PyCharm和Spyder, 其中: Spyder是免费的,Pycharm的社区办是免费,而专业版收费。
2.工具包管理工具的使用和配置
python3使用pip3包管理工具处理依赖问题,类似java开发者用到的Maven.
2.1 配置三方包的镜像源和下载路径
镜像源配置:
镜像源配置可以通过命令(pip3 config set)或者配置文件方式进行修改,本文以配置文件方式进行说明。
windows系统中, 通过echo %APPDATA%查看pip文件夹所在路径,修改%APPDATA%/pip/pip.ini配置文件:
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
修改完成后,可通过pip命令查看是否修改成功:
D:\demo>pip3 config list
global.index-url='https://pypi.tuna.tsinghua.edu.cn/simple'
global.timeout='6000'
global.trusted-host='pypi.tuna.tsinghua.edu.cn'
Linux系统中, 通过修改~/.pip/pip.conf配置文件:
[root@seong bin]# cat ~/.pip/pip.conf
[global]
index-url = http://mirrors.tencentyun.com/pypi/simple
trusted-host = mirrors.tencentyun.com
修改完成后,可通过pip命令查看是否修改成功:
[root@seong bin]# ./pip3 config list
global.index-url='http://mirrors.tencentyun.com/pypi/simple'
global.trusted-host='mirrors.tencentyun.com'
下载路径配置:
配置文件中通过target指定依赖包存放的地址.
[root@seong bin]# cat ~/.pip/pip.conf
[global]
index-url = http://mirrors.tencentyun.com/pypi/simple
trusted-host = mirrors.tencentyun.com
target = D:\xxx\Lib\site-packages
或者:
pip3 config set global.target D:\xxx\Lib\site-packages
2.2 IDE配置镜像源和安装路径
这里以pycharm进行介绍,使用pycharm管理项目时,可以选择Project venv或者Custom environment或者使用Conda环境。
Project venv(Virtual Environment)是一种基于Python的虚拟环境,可为每个项目创建独立的Python环境, 确保依赖包与其他项目相互隔离,避免版本冲突,较为常用。此时依赖包存放于项目根路径的.venv/Lib/site-packages目录下。
Custom environment支持手动指定Python解释器的路径。可以使用系统中已经安装的Python解释器或者虚拟环境。此时共用指定python环境的依赖包(而不需要单独维护一份)。
2.3 使用requirements.txt文件
requirements.txt 文件用于记录项目的依赖包以及版本信息, 用于项目的依赖管理。在一台机器上将某个项目的依赖导出为requirements.txt ,在另一台机器上可以根据requirements.txt 下载该项目的所有依赖包。
格式如下所示:
s
a>=1.0
b>=1.0, <1.1
c==2.0
可以用==精确指定版本号,也可以使用 >= 或 < 或完全不指定,由python根据依赖关系确定。
生成requirements.txt
# pip freeze会把当前环境(或虚拟环境)下所依赖的所有包信息写入到requirements.txt文件中
# pip list会比pip freeze多几个包(pip , wheel , setuptools等)
pip freeze > requirements.txt# 推荐使用pipreqs导出依赖包
# pipreqs仅导出程序所用到的包, 通过python3 -m pip install pipreqs 安装pipreqs
pipreqs ./ --encoding=utf8
使用requirements.txt导入依赖
#根据requirements.txt配置下载依赖项
pip install -r requirements.txt
2.4 pip3常用操作命令
#1.查看已安装的三方包列表
pip list#2.安装包
pip install 包名
pip install 包名==版本号
pip install .whl安装包名 #通过.whl安装包安装
pip install -r requirements.txt #通过requirements.txt配置文件安装#3.卸载包
pip uninstall 包名#4.升级包
pip install -U 包名#5.查看包信息
pip show 包名
其中,通过pip install安装包时,可以通过 -i 指定使用的镜像源,如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ django
2.5 离线依赖包使用方式
#1.准备requirements.txt文件
pipreqs ./ --encoding=utf8#2.生成离线依赖包
# -r 指定requirements.txt文件(生成的离线包中包含requirements.txt指定的依赖项)
# -d 指定离线包的保存路径
# 最终会生成很多.whl文件
pip download -r requirements.txt -d packages/#3.指定从离线依赖包中安装依赖项
# -r 需要安装的依赖项
# --no-index 禁止从PyPI索引依赖包
# -find-links指定索引依赖包的路径
pip install -r ./requirements.txt --no-index --find-links=./packages
在步骤2中生成的.whl文件,可以导入至无法联网的机器后,可以通过.whl文件安装依赖包。
3.脚本运行原理
python类似java使用解释器+虚拟机的方式实现跨平台:python源码经过解释器和编译器生成 pyc 字节码文件,有PVM虚拟机读取pyc文件并执行。对于不同的平台有不同的PVM,将pyc文件的指令翻译为CPU指令执行。
4.包和模块的概念
4.1 包的概念
包可以将多个模块和子包组成在一起,每个包下需要有一个_ _init_ _.py文件,否则包会被当做普通目录对待。
包下的多个模块构成一个整体,可通过同一个包导入其他代码中。
4.2 模块的概念
每个python文件是一个模块,模块用于对逻辑进行封装,减少代码的耦合度。python中存在3种类型的模块:内置模块、三方模块、自定义模块;
[1] 内置模块:python自带的模块,如os提供操作系统的IO访问功能,math数学运算, random随机数,json解析json文件,datetime处理日期和时间相关;
[2] 三方模块:第三方开发的模块,可以通过pip安装后,再导入使用;如django提供web能力;
[3] 自定义模块:自己开发的py文件。
4.3 导入模块
#导入模块,可通过as 进行别名
import 模块
import 模块 as m1# 从模块中导入类、函数、变量等,可通过as进行别名
from 模块 import 函数
from 模块 import 函数1, 函数2
from 模块 import 函数1 as f1, 函数2 as f2
4.3 import机制
当你导入一个模块时,Python会执行该模块的代码,从而创建该模块的命名空间。这个命名空间包含了模块中定义的所有函数、类、变量等。 本质上,就是将导入的模块复制到当前文件中,但是会通过命名空间进行封装。import语句导入指定的模块时会执行三个步骤:[1] 找到模块文件;[2] 编译成字节码;[3] 依次执行
说明:模块仅初始导入时才会执行上述步骤, 后续的导入会从内存中加载的模块对象。
4.4 案例介绍
1.同级目录下,可以直接导入
-- a.py
-- b.py#在a.py中导入b模块
import b
2.模块a位于上一层级
-- a.py
-- pkg-- __init__.py-- b.py#在a.py中导入b模块
import pkg.b #或者 from pkg import b
3.其他场景
sys.path是一个列表数据结构,包含了解释器搜索模块的路径。当导入一个模块时,解释器会按照sys.path中的顺序逐个搜索模块的位置,都找不到会报错。 sys.path包含当前目录、python标准库所在目录、第三方库所在目录。其他场景时(如模块a位于模块b的下一层级),sys.path因不包含模块b的路径而找不到模块,因此需要手动将路径加入到sys.path列表中。
case1:模块a位于下一层级
-- b.py
-- pkg-- __init__.py-- a.py# 此时,可通过添加父路径完成
sys.path.append(str(Path(__file__).resolve().parents[1]))
# 或者
import os
sys.path.append(os.getcwd())import b
此时,模块a导入模块b需要两个步骤:
[1] 将模块b所在路径添加到解析器的模块搜索路径sys.path;
[2] 导入模块b.
case2:嵌套导入
--root__init__.pyroot.py--pkg1__init__.py model1.py--pkg2__init__.pymodel2.py--pkg3__init__.pymodel3.py
root.py导入pkg1.model1模块,pkg1.model1导入pkg1.pkg2.model2模块,pkg1.pkg2.model2导入pkg1.pkg2.pkg3.model3模块。
代码如下:
#root.py
from pkg1.model1 import action1print("root model name is " + __name__)
action1()-------------------------------------------------------#model1.py
import sys
from pathlib import Pathsys.path.append(str(Path(__file__).resolve().parents[0]))
from pkg2.model2 import action2def action1():print("model-1 name is " + __name__)action2()-------------------------------------------------------#model2.py
import sys
from pathlib import Pathsys.path.append(str(Path(__file__).resolve().parents[0]))
from pkg3.model3 import action3def action2():print("model-2 name is " + __name__)action3()-------------------------------------------------------#model3.py
def action3():print("model-3 name is " + __name__)
执行结果如下:
root model name is __main__
model-1 name is pkg1.model1
model-2 name is pkg2.model2
model-3 name is pkg3.model3
上述使用相对路径时,在每个文件通过sys.path.append(str(Path(__file__).resolve().parents[0]))将当前所在目录进入了sys.path路径。
5.变量和基本类型
Python中定义变量不需要指定变量类型,函数和类的属性也不需要指定类型。python中变量只能使用字母数字和下划线组成,一般使用小写字母加下划线组成,常量使用大些字母和下划线组成。
5.1 基本变量类型
python中常用的变量类型包括:数值类型、布尔类型、字符串类型、列表类型、元组类型、集合和字典类型。 其中,布尔的字面量为True和False。
5.2 空对象
python使用None表示空对象。
a = None
b = None
print(a is None)
print(b is not None)
print(a==b)#代码运行结果如下:
True
False
True
5.3 查看对象类型
可以通过type(obj) 查看对象的类型,如下所示:
a = None
print("None is: %s" % type(a))b = 1
print("1 is: %s" % type(b))c = 'hello'
print("'hello' is: %s" % type(c))
d = []
print("[] is: %s" % type(d))
e = ()
print("() is: %s" % type(e))#代码运行结果如下:
None is: <class 'NoneType'>
1 is: <class 'int'>
'hello' is: <class 'str'>
[] is: <class 'list'>
() is: <class 'tuple'>
6.字符串
python中字符串可以用单引号或者双引号包含,为不可变类型,常用操作如下:
str = "abc123"
#字符串长度
len(str)#字符串切片
str[startIndex:endIndex] 从开始索引截取到结束索引,前开后闭
str[-3:] 最后3个字符
str[:3] 前3个字符
str[:] 整个字符串#数组转字符串
arr = ["a", "b", "c"]
"_".join(arr) 得到 “a_b_c”字符串
#任何对象转字符串
str(obj)#是否已特定字符串开头或者结尾
str.startswith('abc')
str.endswith('abc')
#删除前缀
str.removeprefix(“ss”)#字符串删除左右空格(返回的是处理后的字符串,但是原始字符串不变)
str.strip() 删除左右空格
str.lstrip()删除左边空格
str.rstrip()删除右边空格#f表达式
f"{变量名}{表达式}"#字符串替换
"test%stest%stest%s" % ("1","2","3") 得到 "test1test2test3"
#也可以直接使用+对字符串进行拼接,需要注意整数等非字符需要使用str(int_temp)转字符串后才可以拼接,而使用%s替换不需要
7.集合类型
7.1 列表
列表中可以存多个不同类型的数据, 常用方法如下:
arr = [1, 2, "ss", True]#根据下标获取数据
arr[0]
#遍历方式
for item in arr:print(item)
#列表长度
len(arr)
#判断是否在数组中
print("ss" in arr)
print("ss" not in arr)#在列表尾部添加一个元素
arr.append("ss")
#在指定的小标位置插入数据
arr.insert(0,"s1")#remove删除数据
arr.remove("ss")
#clear情况列表, 此时列表等于[]
arr.clear();#分片,前开后闭地截取
arr[startIndex,endIndex]
arr[0:3] 获取前3个,即arr[0],arr[1],arr[2]
arr[:]截取全部
arr[:3]前3个
arr[-3:]最后三个
7.2 元组
元组的使用方式与列表相同,区别在于元组创建后不可修改。
tuple_temo = (1, 2, "ss", True)#根据下标获取数据
tuple_temo[0]#遍历方式
for item in tuple_temo:print(item)#获取元组长度
len(tuple_temo)#判断是否在元组中
print("ss" in tuple_temo)
print("ss" not in tuple_temo)#分片,前开后闭地截取
tuple_temo[startIndex,endIndex]
tuple_temo[0:3] 获取前3个,tuple_temo[0],tuple_temo[1],tuple_temo[2]
tuple_temo[:]截取全部
tuple_temo[:3]前3个
tuple_temo[-3:]最后三个
7.3 字典
由多个键值对组成:键必须为不可变类型,如字符串、数值、元组等;值可以是数字、字符串、列表、字典。
#字典用{}表示
dict_temp={}#根据键获取值
dict_temp.get("key") 或者 dict_temp['key']
#获取key列表
dict_temp.keys()
#获取value列表
dict_temp.values()
#获取(键, 值) 元组列表
dict_temp.items()for key,value in dict_temp.items():print(f"key is {key}, value is {value}.")# 根据Key删除元素
del dict_temp['key']#修改和添加
dict_temp['key1'] = "value1"
8.条件判断和循环逻辑
8.1 条件判断
python使用 == 和 != 表示是否相等和是否不等,使用 and 和 or 和 not表示与或非逻辑;python中只有if语句,没有switch-case语句。
int score = 99;
if score >=80:print("优秀")
elif score >= 70:print("良")
elif score >= 60:print("及格")
else if score >0:print("不及格")
else:pass
由于python使用缩进的方式替代了{},当处理逻辑为空时,可以使用pass语句占位。
8.2 循环逻辑
for循环
#循环10次
for i in range(0,10):pass#遍历列表
arr = [1, 2, 3, 's']
for item in arr:print(arr)
while循环, 在python中没有do-while循环, while用法案例如下:
while 条件:语句#案例
num = 10
while num > 0:num = num -1;
另外,继续下次循环语句continue和中断循环语句break的用法同java.
9.异常处理与自定义异常
9.1 try-except逻辑
try:#语句1
except:#语句2
当语句1执行过程中遇到异常时,会执行语句2.
注意,不建议这么使用,会将异常信息吞掉,需要指定异常对象,如下所示:
try:#语句1
except 异常类型 as exception:print(exception)#语句2
当需要处理所有的异常类型时, 执行Exception(是所有异常类的父对象):
try:#语句1
except Exception as exception:print(exception)#语句2
9.2 try-except-else逻辑
try:#语句1
except Exception as exception:print(exception)#语句2
else:#不发生异常执行的逻辑
9.3 try-except-else-finally逻辑
try:#语句1
except Exception as exception:print(exception)#语句2
else:#不发生异常执行的逻辑
finally:#无论是否有异常都执行的语句
9.4 自定义异常
自定义异常需要继承Exception类:
class MyException(Exception):def __init__(self, msg):self.msg = msg# 设置抛出异常的描述信息def __str__(self):return f'MyException occured, msg is {self.msg}'
使用raise抛出异常(类似java的throw),使用案例如下:
def main():try:raise MyException("消息异常")except Exception as exception:print(exception)main()
运行结果如下:
MyException occured, msg is 消息异常
10.方法的定义和使用
10.1函数使用方式
将功能相似的函数一般放在一个模块里,在使用的地方通过导入的方式使用函数, 从而提高代码的可维护性。
函数的定义
命名规范:函数用小写字母加下划线命名。
def print_name():print("ewen seong")#带有参数的函数名
def print_name(first_name, last_name):print(f"{first_name}{last_name}")#函数可以有返回语句,用于返回一个或多个结果
def print_name(first_name, last_name):name = f"{first_name}{last_name}"print(name)return name#函数定义时,可以指定参数的默认值
def print_name(first_name, last_name="seong"):print(f"{last_name}{first_name}")
函数的调用
#通过参数的顺序进行传参调用
print_name("ewen", "seong")#通过指定形参名进行调用,不需要按照顺序
print_name(first_name="ewen", last_name="seong")
#等价于
print_name(last_name="seong",first_name="ewen")
10.2 main函数
python与java和C不同,没有固定的main函数格式(按顺序解析执行)。可以手动指定main方法,并作为程序的执行入口,使代码组织更加清晰、易于维护。
if __name__ == "__main__":#main函数执行逻辑
此时,只有当前文件作为运行文件(被导入则不会执行),才会执行main函数内部的逻辑。
11.类的定义和使用
11.1 类的定义
类名使用首字母大写的驼峰格式,同java;
class MyClass(object):def __init__(self, id, name):self.__id = idself.name = namedef get_id(self):return self.__iddef __set_id(self, id):self.__id = id
[1] 使用class关键字定义python类,所有类的基类为object对象,因此class MyClass(object)等价于class MyClass;
[2] 以双下划线__开头的方法和属性为私有属性,不能使用对象直接访问;否则,可以通过对象直接访问;
[3] 类中存在一个__init__方法,当通过类构造对象时,会调用该方法,初始化对象;
[4] 类中定义的方法中包含一个self对象,指代当前对象本身;方法被调用时,不需要用户传递。
11.2 类的使用
#直接通过类名以及__init__方法的入参进行构造类对象
myObj1 = MyClass(110, "name-110")#通过对象调用公有方法
print(myObj1.get_id())#通过对象获取公有属性
print(myObj1.name)
运行得到结果如下:
110
name-110
当强行访问私有方法或者私有属性时,会报错:
myObj1 = MyClass(110, "name-110")
#通过对象获取私有属性,报错
print(myObj1.__id)Traceback (most recent call last):File "E:\Data\2024\4\4.7-4.12\48\V5pythonDemo\V5pythonDemo\test\other_module.py", line 17, in <module>print(myObj1.__id)^^^^^^^^^^^
AttributeError: 'MyClass' object has no attribute '__id'myObj1 = MyClass(110, "name-110")
#通过对象调用私有方法,报错
myObj1.__set_id(111)
Traceback (most recent call last):File "E:\Data\2024\4\4.7-4.12\48\V5pythonDemo\V5pythonDemo\test\other_module.py", line 18, in <module>myObj1.__set_id(111)^^^^^^^^^^^^^^^
AttributeError: 'MyClass' object has no attribute '__set_id'
11.3 继承
子类继承父类时,拥有父类所有的属性和方法。注意:需要在子类的初始化函数中,调用父类的初始化方法。
class MySubClass(MyClass):def __init__(self, id, name, age):super().__init__(id, name)self.age = agedef get_age(self):return self.agedef print_msg(self):print(f"id is {super().get_id()}, name is {self.name}, age is {self.age}")mySubClass = MySubClass(110,"sy",100)
print(mySubClass.get_id())
print(mySubClass.name)
mySubClass.print_msg()
运行结果如下所示:
110
sy
id is 110, name is sy, age is 100
说明: 子类继承父类后,拥有了所有父类的属性和方法,但是只能访问公有的属性和方法;
12.日志框架
12.1 配置日志格式
log_config.py中定义日志格式、日志级别、日志文件路径等信息
import loggingdef init_log(log_filename='app.log', level=logging.INFO):# 设置日志格式log_format = logging.Formatter('%(asctime)s - %(module)s - %(levelname)s - %(message)s',datefmt='%Y-%m-%d %H:%M:%S')# 配置根日志记录器logger = logging.getLogger()logger.setLevel(level)# 文件处理器file_handler = logging.FileHandler(log_filename)file_handler.setLevel(level)file_handler.setFormatter(log_format)# 流处理器(控制台输出)console_handler = logging.StreamHandler()console_handler.setLevel(level)console_handler.setFormatter(log_format)# 为根日志记录器添加处理器logger.addHandler(file_handler)logger.addHandler(console_handler)# 返回根日志记录器实例return logger
12.2 在入口函数中引用setup_logging方法
from log_config import init_logif __name__ == "__main__":init_log()
12.3 在其他模块中直接使用logging日志对象
import loggingdef print_log():logging.info("日志信息")
打印结果如下:
2024-04-14 15:49:26 - other_module - INFO - 这是other_module.py中的日志信息
13.读写文件
python程序常需要从json和yaml、properties文件中读取数据,本章节仅读取json文件为例介绍python读取文件的方式。
从指定路径读取json文件, 返回字典类型
import json
import loggingdef read_json_file(file_path):try:data = Nonelogging.debug("Begin to read json data from file %s", file_path)with open(file_path, 'r') as file:data = json.load(file)except Exception as exception:logging.info("Exception occurs during read json data, file is %s, exception is %s", file_path, exception)finally:return dataresult = read_json_file("a.json")
logging.info("result is %s, type is %s.",result,type(result))
运行结果如下:
DEBUG - Begin to read json data from file a.json
INFO - result is {'name': 'sy', 'id': '110'}, type is <class 'dict'>.
说明: python使用open函数与文件建立关联,可以选择’r’ 读操作,'w’写操作。案例中使用with open ... as ... 形式与java的try-with-resource相似,执行完毕后会自动关闭文件。
14.执行shell命令
python中执行shell命令是python脚本的一个重要功能,该功能依赖于python提供的subprocess模块。
将python执行shell命令的逻辑封装在utils模块下:
#utils.py文件
import logging
import subprocessdef shell_execute(cmd, need_log=True):p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)if need_log:logging.debug('pid(%s) cmd = %s' % (p.pid, cmd))data = b''for c in iter(lambda: p.stdout.read(1), b''):if c != b'\n':data = data + celse:try:logging.debug('pid(%s) %s' % (p.pid, data.decode('utf-8')))except:passdata = b''p.wait()if need_log:logging.debug('pid(%s) returncode = %s' % (p.pid, p.returncode))return p.returncode == 0def shell_execute_with_output(cmd, need_log=True):p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)logging.debug('pid(%s) cmd = %s' % (p.pid, cmd))output = []data = b''for c in iter(lambda: p.stdout.read(1), b''):if c != b'\n':data = data + celse:if need_log:try:logging.debug('pid(%s) %s' % (p.pid, data.decode('utf-8')))except:passoutput.append(data.decode('utf-8'))data = b''p.wait()logging.debug('pid(%s) returncode = %s' % (p.pid, p.returncode))return p.returncode == 0, output
上述shell_execute方法仅执行命令,无返回值;shell_execute_with_output返回一个长度为2的列表对象,第一个元素为命令是否执行成功(True表示命令执行成功),第二个命令表示执行命令得到的结果。
使用案例:
from utils import shell_execute, shell_execute_with_outputdef action():shell_execute("mkdir -p /test/test/test1")shell_execute("mkdir -p /test/test/test2")result = shell_execute_with_output("ls -al /test/test/")print("cmd execute: %s" % result[0])for each_item in result[1]:print(each_item)if __name__ == "__main__":action()
执行结果如下:
[root@seong bin]# python application.py
cmd execute: True
总用量 0
drwxr-xr-x 4 root root 30 4月 9 09:20 .
drwxr-xr-x 3 root root 17 4月 9 09:20 ..
drwxr-xr-x 2 root root 6 4月 9 09:20 test1
drwxr-xr-x 2 root root 6 4月 9 09:20 test2
相关文章:

Python使用方式介绍
1.安装与版本和IDE 1.1 python2.x和python3.x区别 python2在2020已经不再维护,目前主流开发使用python3. 二者语法上略有区别:输入输出、数据处理、异常和默认编码等,如:python3中字符串为Unicode字符串,使用UTF-8编码ÿ…...

浅述python中NumPy包
NumPy(Numerical Python)是Python的一种开源的数值计算扩展,提供了多维数组对象ndarray,是一个快速、灵活的大数据容器,可以用来存储和处理大型矩阵,支持大量的维度数组与矩阵运算,并针对数组运…...

jvm的面试回答
1、jvm由本地方法栈、虚拟机栈、方法区、程序计数器、堆组成,其中堆和方法区是线程间共享的,程序计数器、虚拟机栈和本地方法栈是线程私有的。 2、虚拟机栈: 保存每个java方法的调用、保存局部变量表、等 栈可能出现内存溢出,如果…...

打不动的蓝桥杯
打不动的蓝桥杯 2024-4-13 今天的蓝桥杯打得很烂,8题写了4题,100分可能有20来分吧。我写了的题好像都很简单,没什么竞争力。又觉得我知道的东西不止这么点,没能发挥。 这次比赛,首先,有强烈的陌生感。pytho…...
)
学习笔记——C语言基本概念文件——(13)
1、文件操作 1.1、文件概念 文件:实现数据存储的载体 1.2、文件的分类 按照数据的组织形式分类: 1.字符文件/文本文件 2.二进制文件 按照用途分类: 1.系统文件 2.库文件--标准库文件/非标准库文件(第三方库) 3.用…...
【MySQL】事务篇
SueWakeup 个人主页:SueWakeup 系列专栏:学习技术栈 个性签名:保留赤子之心也许是种幸运吧 目录 本系列专栏 1. 什么是事务 2. 事务的特征 原子性(Atomicity) 一致性(Consistency) 隔离性&…...
tsconfig.json文件常用配置
最近在学ts,因为tsconfig的配置实在太多啦,所以写此文章用作记录,也作分享 作用? tsconfig.jsono是ts编译器的配置文件,ts编译器可以根据它的信息来对代码进行编译 初始化一个tsconfig文件 tsc -init配置参数解释 …...

【Linux】tcpdump P1 - 网络过滤选项
文章目录 选项 -D选项 -c X选项 -n选项 -s端口捕获 port选项 -w总结 tcpdump 实用程序用于捕获和分析网络流量。系统管理员可以使用它来查看实时流量或将输出保存到文件中稍后分析。本文将演示在日常使用 tcpdump时可能想要使用的几种常见选项。 选项 -D 使用-D 选项的 tcpdu…...
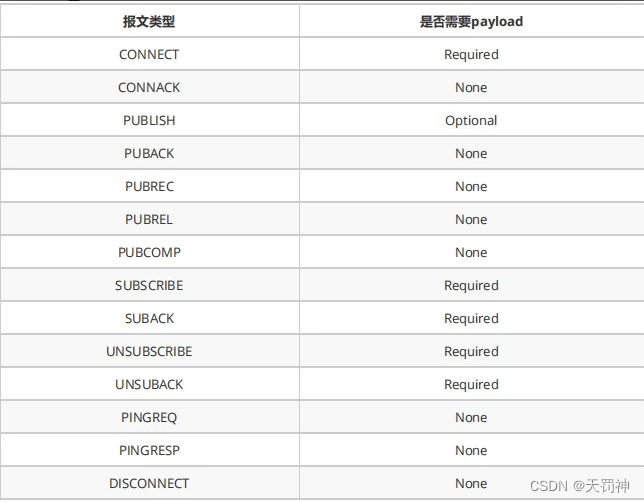
网络篇04 | 应用层 mqtt(物联网)
网络篇04 | 应用层 mqtt(物联网) 1. MQTT协议介绍1.1 MQTT简介1.2 MQTT协议设计规范1.3 MQTT协议主要特性 2 MQTT协议原理2.1 MQTT协议实现方式2.2 发布/订阅、主题、会话2.3 MQTT协议中的方法 3. MQTT协议数据包结构3.1 固定头(Fixed header…...

Transformer模型-decoder解码器,target mask目标掩码的简明介绍
今天介绍transformer模型的decoder解码器,target mask目标掩码 背景 解码器层是对前面文章中提到的子层的包装器。它接受位置嵌入的目标序列,并将它们通过带掩码的多头注意力机制传递。使用掩码是为了防止解码器查看序列中的下一个标记。它迫使模型仅使用…...

All in One:Prometheus 多实例数据统一管理最佳实践
作者:淡唯(啃唯)、阳其凯(逸陵) 引言 Prometheus 作为目前最主流的可观测开源项目之一,已经成为云原生监控的事实标准,被众多企业广泛应用。在使用 Prometheus 的时候,我们经常会遇…...
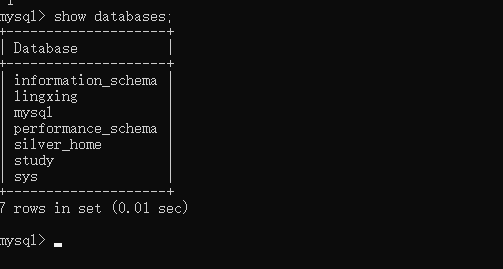
mysql报错-mysql服务启动停止后,某些服务在未由其他服务或程序使用时将自动停止和数据恢复
启动mysql服务时出现该错误: 本地计算机上的mysql服务启动停止后,某些服务在未由其他服务或程序使用时将自动停止。 我的mysql版本是8.0.18 系统:win10 如何安装mysql,可以看我这一篇文章:mysql的安装 ---必会 - bigbigbrid - 博客园 (cn…...

Java开发从入门到精通(二十):Java的面向对象编程OOP:File文件操作的增删改查
Java大数据开发和安全开发 (一)Java的文件操作1.1 Java的File和IO流概念1.2 File类的使用1.2.1 创建File类的对象1.2.2 常用方法1:判断文件类型、获取文件信息1.2.3 常用方法2:创建文件、删除文件1.2.4 常用方法3:遍历文件夹 1.3 java File的方法递归1.3…...
)
10.list的模拟实现(普通迭代器和const迭代器的类模板)
1. list的介绍及使用 1.1 list的介绍 list的文档介绍 list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过…...
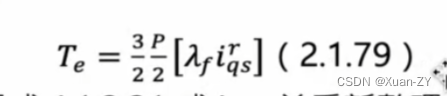
【电控笔记5】电流环速度环三环参数整定
旋转坐标系下的电压方程,由id和iq计算出ud和uq Lq:q轴电感 Ld:d轴电感 输入是电流,输出是电压? 内嵌式pmsm(ipmsm)模型建立: 其中: λf是转子磁场在定子绕组所产生的磁通链,为一常数,在psms中转子磁场非常稳定几乎不变。 ipmsm转矩方程式: 对永磁同步马达而言,使…...

AI克隆语音(基于GPT-SoVITS)
概述 使用GPT-SoVITS训练声音模型,实现文本转语音功能。可以模拟出语气,语速。如果数据质量足够高,可以达到非常相似的结果。相比于So-VITS-SVC需要的显卡配置更低,数据集更小(我的笔记本NVIDIA GeForce RTX 4050 Lap…...

小蚕爬树问题
小蚕爬树问题 问题描述: 编写一个函数 int day(int k,int m,int n),其功能是:返回小蚕需要多少天才能爬到树顶(树高 k 厘米,小蚕每天白天向上爬 m 厘米,每天晚上下滑 n 厘米,爬到树顶后不再下滑࿰…...
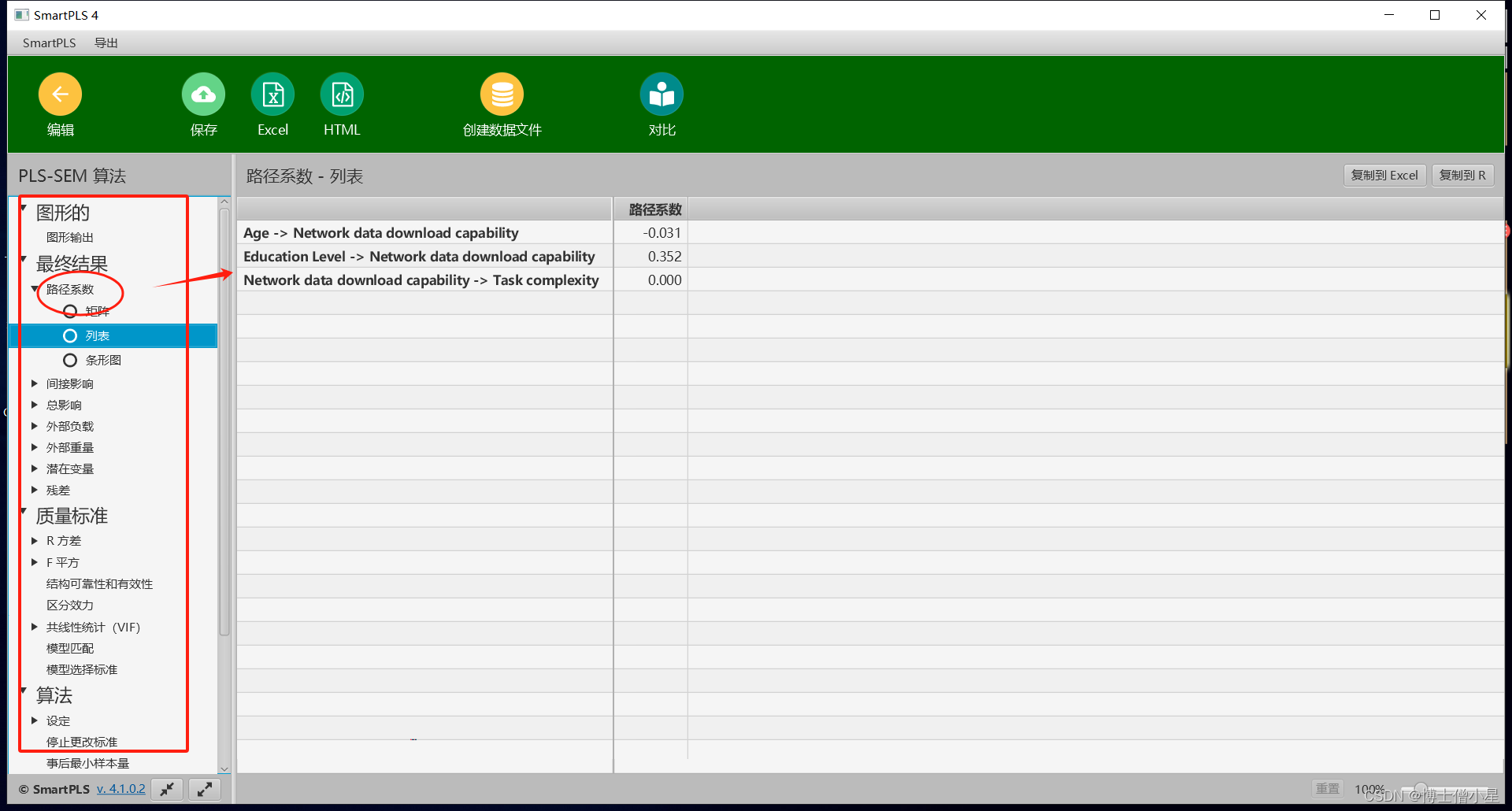
科研学习|科研软件——如何使用SmartPLS软件进行结构方程建模
SmartPLS是一种用于结构方程建模(SEM)的软件,它可以用于定量研究,尤其是在商业和社会科学领域中,如市场研究、管理研究、心理学研究等。 一、准备数据 在使用SmartPLS之前,您需要准备一个符合要求的数据集。…...
实用工具系列-ADB使用方式
作者持续关注 WPS二次开发专题系列,持续为大家带来更多有价值的WPS开发技术细节,如果能够帮助到您,请帮忙来个一键三连,更多问题请联系我(WPS二次开发QQ群:250325397),摸鱼吹牛嗨起来࿰…...

计算机网络书籍--《网络是怎样连接的》阅读笔记
第一章 浏览器生成信息 1.1 生成HTTP请求信息 1.1.1 URL Uniform Resource Locator, 统一资源定位符。就是网址。 不同的URL能够用来判断使用哪种功能来访问相应的数据,比如访问Web服务器就要用”http:”,而访问FTP服务器用”ftp:”。 FTPÿ…...

5道题通关离散数学复试:从谓词逻辑到克鲁斯卡尔算法的保姆级拆解
离散数学复试五大高频题型精讲:从逻辑符号化到图论实战 离散数学作为计算机专业复试的核心科目,其考察重点往往集中在逻辑、集合、关系与图论四大模块。通过对近十年真题的统计分析发现,超过80%的院校会从谓词逻辑符号化、集合恒等式证明、关…...

如何用Gyroflow实现专业级视频防抖?创作者必备的4大核心技巧
如何用Gyroflow实现专业级视频防抖?创作者必备的4大核心技巧 【免费下载链接】gyroflow Video stabilization using gyroscope data 项目地址: https://gitcode.com/GitHub_Trending/gy/gyroflow 在视频创作领域,抖动问题一直是影响作品质量的关键…...

大数据领域的金融应用剖析
大数据领域的金融应用剖析 一、引言 (Introduction) 钩子 (The Hook) 想象一下,你是一位银行的信贷经理,每天面对堆积如山的贷款申请,如何在短时间内准确判断申请人是否有能力按时还款,同时还要避免误拒潜在的优质客户?…...

YOLOv5s训练的1类道路裂缝数据集和代码 该项目包含YOLOv5代码 包括3857张道路裂...
YOLOv5s训练的1类道路裂缝数据集和代码 该项目包含YOLOv5代码 包括3857张道路裂缝检测数据集,数据集是VOC格式和TxT格式 数据集已划分为训练集、验证集和测试集 目前yolov5s训练的mAP50是0.850 代码和数据集在该项目下面 开箱即可使用,开箱即可使用&…...

别再直接拔电源了!聊聊Ubuntu里shutdown、halt、reboot这几个命令到底有啥区别
别再直接拔电源了!深入解析Ubuntu关机命令的底层逻辑与最佳实践 每次看到有人直接按下电源键强制关闭Ubuntu系统,我的心脏都会漏跳一拍。这就像在高速行驶时突然拉手刹——数据可能丢失,文件系统可能损坏,而这一切本可以通过几个简…...

STEP3-VL-10B多模态模型5分钟快速上手:WebUI一键部署,小白也能玩转图片推理
STEP3-VL-10B多模态模型5分钟快速上手:WebUI一键部署,小白也能玩转图片推理 1. 引言:为什么选择STEP3-VL-10B? 如果你正在寻找一个既强大又容易上手的多模态AI模型,STEP3-VL-10B绝对是你的理想选择。这个由阶跃星辰开…...

Youtu-Parsing模型单片机项目文档处理:自动化生成数据手册摘要
Youtu-Parsing模型单片机项目文档处理:自动化生成数据手册摘要 每次启动一个新的单片机项目,你是不是也经历过这样的“痛苦时刻”?面对动辄上百页、密密麻麻全是英文和复杂图表的数据手册,光是找到自己需要的关键信息——比如核心…...

SJTUThesis终极实战:3种高效集成方案深度解析
SJTUThesis终极实战:3种高效集成方案深度解析 【免费下载链接】SJTUThesis 上海交通大学 LaTeX 论文模板 | Shanghai Jiao Tong University LaTeX Thesis Template 项目地址: https://gitcode.com/gh_mirrors/sj/SJTUThesis 作为上海交通大学官方LaTeX论文模…...

黑神话悟空内置实时地图:告别迷路,沉浸探索东方神话世界
黑神话悟空内置实时地图:告别迷路,沉浸探索东方神话世界 【免费下载链接】wukong-minimap 黑神话内置实时地图 / Black Myth: Wukong Built-in real-time map 项目地址: https://gitcode.com/gh_mirrors/wu/wukong-minimap 在《黑神话:…...
用C++实现信奥题 P6273 [eJOI 2017] 魔法)
打卡信奥刷题(3009)用C++实现信奥题 P6273 [eJOI 2017] 魔法
P6273 [eJOI 2017] 魔法 题目描述 给定一个长度为 nnn 的字符串 SSS。设 SSS 中不同的字符数为 kkk 。 定义字符串的子串为该字符串某一连续段。 而 有魔法的子串 被定义为 SSS 的某一非空子串,满足该子串中不同的字符数为 kkk ,且每个字符的出现的次…...