建模杂谈系列211 ADBS的取数模式以及衔接
说明
这应该是进一步的完善ADBS的工作模式。
之所以做A系列的架构工具,就是为了可以实现大型的数据处理、存储。从应用上说,是为了提高效率,并达到超高的效果。
为了达到这个目的,就必须从数据架构上、任务调度上、逻辑架构上作出好的设计,并将之实现。逻辑架构主要对应的就是Core的设计,目前初步的实现了ETL,模型的还没有去实现,但有了Core和ETL的经验,那么模型只是另一种形态和时间问题。
但无论如何,数据架构一定是所有应用的基础,所以第一步也就是实现了数据架构。ADBS是基于Mongo和Redis搭建的一套可适应高并发并支持多Worker并行执行的数据库流转体系,目前看来效果是很理想的,单核日吞吐可以达到3000万条数据以上。
因为单步的ADBS已经包含了包括流转、监控、分发在内的一系列程序(sniffer, io型),单个ADBS已经具备了很强的独立服务能力,而如果要进行定制化修改会略显麻烦。 所以从应用于结构可靠性的角度上考虑,我倾向于使用「简单结构,多层迭代」。这也是从计算机发展史里得到的教训,简单的结构(迭代/叠加)才可能实现真正复杂的功能。
本次的内容就是在进行ADBS之间连接时,sniffer的动作。
内容
1 Sniffer的取数场景
广义上来说,ADBS里除了Worker,其他都是Sniffer。不过这里特指进行取数衔接的程序部分。
我大致想了一下,Sniffer可能有几个取数场景:
- 1 从数据库取数。这在之前的项目服务类场景下常见,需要我向数据库发起Range或者Set查询,来获取要处理的数据。
- 2 文件取数。例如这次,我会手动下载510300的离线文件,然后由Sniffer驱动取到第一个ADBS
- 3 ADBS取数。也就是本次讨论的内容,从ADBS取数。本质上也是从数据库取数,但是由于ADBS存在一些规范,所以取数的模式可以比较固定。另外就是未来ADBS之间衔接必然是不可少的一部分,所以特殊独立出来。
2 取数模式
某个step_out的数据如下
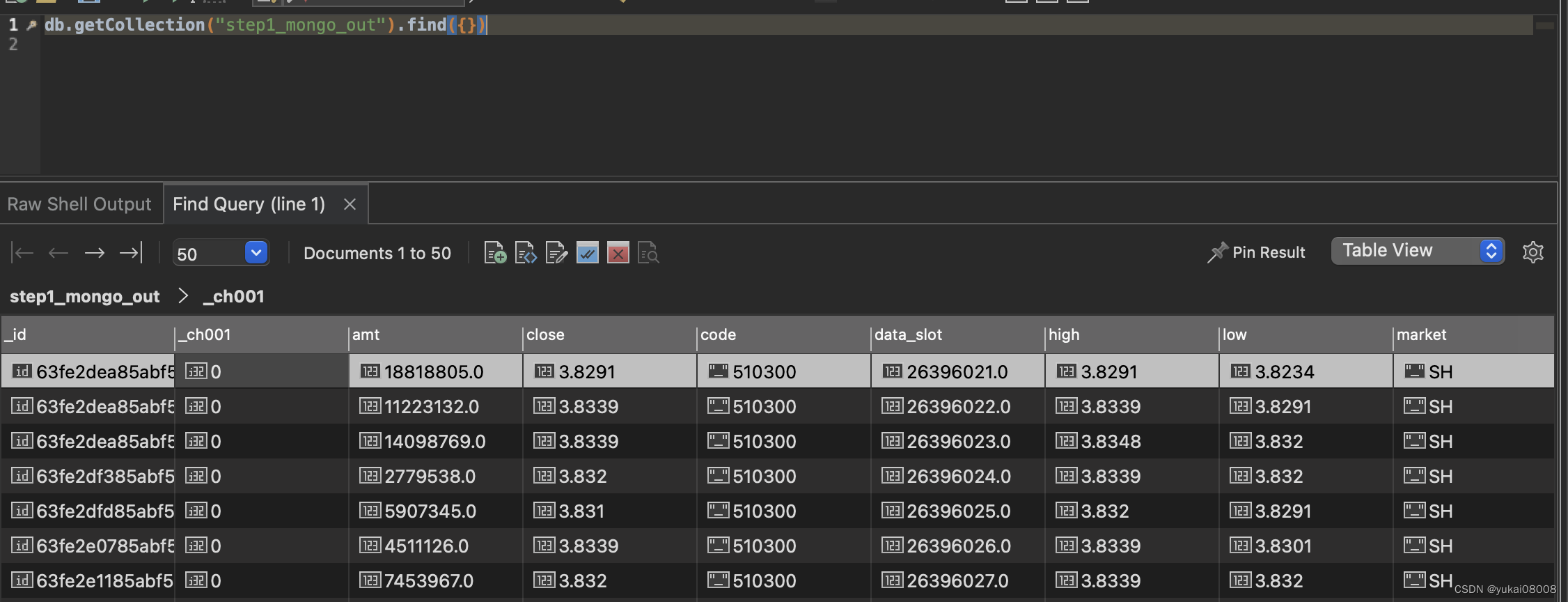
step_out提供了默认的任务通道_ch001,在sniffer取数时需要根据这个通道的状态进行查询、ACK。
一般情况下,Sniffer取数后要立即ACK状态1,这样避免其他Sniffer重复的获取数据;在最后一步的时候ACK2或者3表示任务的完成状态。有时候,数据不满足条件,这样会导致计算失败。此时会有再次巡查Sniffer,检查到超时会将任务重启初始化。当然,超时重试也有次数限制。
初次请求:
- 1 请求数据【是否为空】【是否满足可用条件】
- 2 * 回应【ACK】【如果是数据库取数】
- 3 根据规则判断下一步可行性【队列是否溢出】
- 4 执行具体操作 【增删改】
- 5 进行回应【ACK】【异常上报】
再次巡查:
- 1 检查数据是否认领+超时
- 2 将数据的通道字段翻回0
在这里加入一个限定:只有一个Sniffer向Step Out(Mongo)发起取数。
加入这个限定后,请求过程会得到简化,但是这样合理吗?
在ADBS中,任务的分发是通过Redis的Stream完成的,天然的分发方式。所以Sniffer的这个变化不影响并发处理。
并且对于IO来说,单个Sniffer可以吞吐的速度已经足够快了。每秒1万条就已经超过单核ADBS一天吞吐量的好几倍了。
所以,结论是可行。
加入限定后,流程变得简单:
-
1 请求数据
- 执行两个判定:数据是否为空、数据是否满足特定要求(基础要求)
-
2 判断目标队列是否会溢出
-
3 根据2的结果决定是否执行操作
-
4 根据3的结果决定是否ACK
这样就不用考虑并行时的抢占,也不必考虑考虑巡检重置超时的问题。
具体的做法其实可以参考StreamsIO.M2S的方法,当时只是考虑在本ADBS中将Mongo数据拉到工作队列并记录日志。现在的差别是读取数据和日志不是同一个ADBS。
实例:
这个Sniffer运行在MyQuantBaseStep2Signals,向MyQuantBase.step1_mongo_out发起取数。
- 1 Sniffer实际运行的ADBS是MyQuantBaseStep2Signals。
- 2 Sniffer请求的源是MyQuantBase.step1_mongo_out
- 3 Sniffer记录的log是在MyQuantBaseStep2Signals
- 4 Sniffer的目标是 MyQuantBaseStep2Signals.
需要的一些参数
- 1 redis服务地址
- 2 超时设置
- 3 批次取数量
- 4 源mongo的tier1和tier2
- 5 当前mongo记录日志的tier1和tier2
- 6 当前所使用的通道
- 7 目标队列的最大长度
代码:
from funcs_apifunc_database_model1_6810f9d37e89e5e1f33e1b8f4defa22e import *from configs_base import redis_agent_host,project_name,cur_w
from configs_base import color_print,step1_stream_in# 判断队列是否可以插入
def is_q_available(stream_name, maxlen = 100000, new_task_len = 10000, redis_agent = None,connection_hash =None ):cur_redis_agent = redis_agentcur_len_resp = req.post(cur_redis_agent + 'len_of_queue/',json ={'stream_name':stream_name,'connection_hash':connection_hash}).json()if cur_len_resp['status']:cur_len = cur_len_resp['data']if cur_len + new_task_len >=maxlen:return False else:return True else:print('Connection Error')return False # 基于并发方法,向数据库存数【队列Write相关-写入消息】- 其实是使用pipeline - 最好单次一万左右
def parrallel_write_msg(stream_name, data_listofdict = None ,maxlen = None, time_out = None,redis_agent = None,connection_hash =None,is_return_msg_id_list=False):cur_redis_agent = redis_agentcur_maxlen = maxlen or 100000# 默认十秒超时time_out = time_out or 30print('>>> 并发写Stream')tick11 = time.time()resp_dict = req.post(cur_redis_agent + 'batch_add_msg/',json ={'connection_hash':connection_hash,'stream_name':stream_name,'msg_dict_list':data_listofdict,'maxlen':cur_maxlen,'is_return_msg_id_list':is_return_msg_id_list},timeout=time_out).json()tick13 = time.time()print('写入任务数据 {:.2f}'.format(tick13 -tick11))return resp_dict# 回应
def ack_mongo(w = None,tier1 = None, tier2 = None, key_list = None,keyname = None, channel_name = None, channel_val = None ):cur_w = w or self.w var_list =[tier1, tier2, key_list, keyname, channel_name, channel_val]assert all(var_list), ','.join(var_list)+'参数不可为空'filter_list = [{keyname:{'$in':key_list}}]attr_list = [{channel_name:channel_val}]inc_list = [{channel_name+ '_cnt': 1}]return cur_w.update_with_inc(tier1 = tier1, tier2 = tier2, filter_list= filter_list, attr_list = attr_list, inc_list = inc_list)# ============== Modify 2023.01.10
# 【基础定义区-常变】
cur_machine = get_machine_name()
print('Current Machine', cur_machine)redis_agent_host = 'http://172.17.0.1:24021/'
redis_connection_hash =None# 这个sniffer盯的是上一个ADBS的输出
# source
source_server = 'm7.24065'
source_tier1 = 'MyQuantBase'
source_tier2 = 'step1_mongo_out'
gs_id = 'rec_id'current_tier1 = project_namemarket = 'SH'
code ='510300'
start_slot = 26299291# 这个可以自由定义,这里我用了24000最大周期 + 之前有一部分误写入的部分
burnt_slots = 20000
batch_num = 10000
# 目标队列允许的最大长度
target_q_max_len = 100000
target_q_name = '%s.%s' % (current_tier1, step1_stream_in)
sniffer_name = 'sniffer01_query_step1_result'
keyname = gs_id
channel_name = '_ch001'
custom_filter_list = [{'market':market,'code':code}]
default_filter_list = [{'_is_enable':1, channel_name:0}]
# 数据连接操作不得超过30秒
db_connect_ttl = 30try:source_w = from_pickle('source_w_' + source_tier1)color_print('【Loading source_w】from pickle')
except:w = WMongo('w')source_w = w.TryConnectionOnceAndForever(server_name =source_server)to_pickle(source_w, 'source_w_' +source_tier1)# ============================ 操作
msg =''
log_tier1 = current_tier1
log_tier2 = 'log_sniffer'tick1 = time.time()# 判断队列是否可以写入
is_target_q_available = is_q_available(target_q_name,maxlen = target_q_max_len, new_task_len = batch_num, redis_agent = redis_agent,connection_hash =redis_connection_hash)cur_len_resp = req.post(redis_agent + 'len_of_queue/',json ={'stream_name':target_q_name,'connection_hash':redis_connection_hash}).json()q_len = cur_len_resp['data']
print('{} Q has {} Messages' .format(target_q_name,q_len))# 如果目标队列满
if not is_target_q_available:msg = 'target q is full {} ,{}'.format(q_len, qname)if is_target_q_available:tick100 = time.time()color_print('>>> fetching from Mongo ')recs = source_w.query_recs(tier1 = source_tier1, tier2 = source_tier2, filter_dict= {'$and':default_filter_list + custom_filter_list}, silent=True, limits = batch_num, sort_tuple_list=[(channel_name,1)])print('Spends {:.2f}' .format(time.time()-tick100))rec_num = len(recs['data'])if rec_num:data_listofdict = recs['data']tick101 = time.time()color_print('>>> Writing To Stream ')write_resp = parrallel_write_msg(target_q_name, data_listofdict = data_listofdict ,maxlen = target_q_max_len, time_out = db_connect_ttl,redis_agent = redis_agent,connection_hash =redis_connection_hash, is_return_msg_id_list=True)print('Spends {:.2f}' .format(time.time()-tick101))# 假设全部成功,如果有失败的最终会被发现超时successful_keyname = list(pd.DataFrame(data_listofdict)[keyname]) # ack - 成功ack_res = ack_mongo( w = source_w,tier1 = source_tier1 , tier2 = source_tier2, key_list =successful_keyname ,keyname = keyname, channel_name = channel_name, channel_val = 2 )if ack_res['status']:msg ='ok,{} of {} , {}' .format(len(successful_keyname),rec_num, target_q_name)else:msg ='error,ack mongo {} recs of {}' .format(rec_num, target_q_name)else:msg ='no source data {}' .format(target_q_name)tick2 = time.time()
duration = round(tick2 -tick1,2)
# -- log
log_dict = {'sniffer': sniffer_name,'duration':duration,'msg': msg }cur_w.insert_recs(tier1=log_tier1, tier2=log_tier2, data_listofdict =[log_dict])
# ============================ 操作 ENDsource mongo:
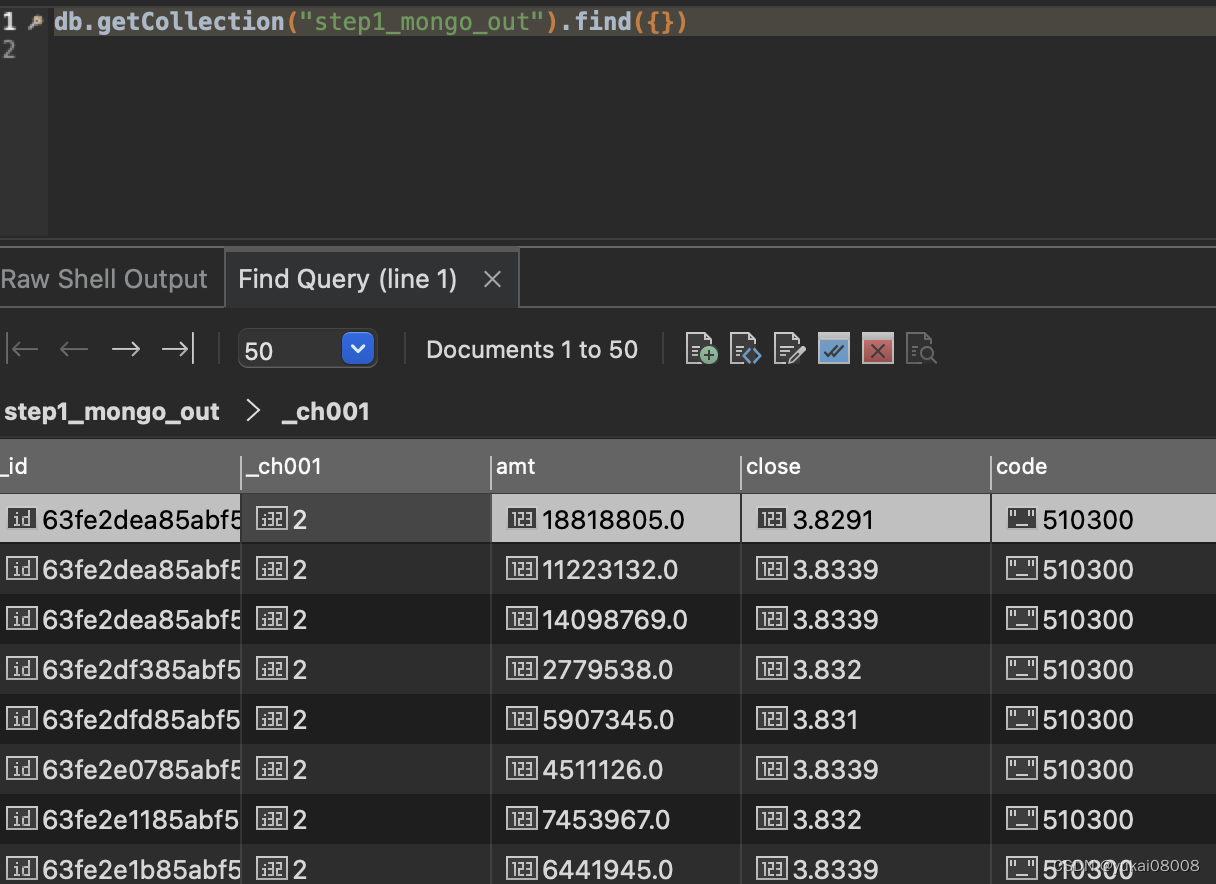
目标队列

代码比较长,改造成本还可以(花费的时间比较少)。能够越来越多的基于简单复用肯定是好的,我的Web编辑平台搞好后,应该可以让这种复用更容易(最好再加个问答+推荐系统)。
改造的部分包括:
- 1 将
is_q_available、parrallel_write_msg、ack_mongo从对象里抽出来,改造为普通函数 - 2 匹配并校准源和当前(日志)WMongo连接
- 3 将 M2S的流程从对象里抽出来,写在sniffer的程序体内
之后其他的ADBS均可以仿照此例连接。
相关文章:
建模杂谈系列211 ADBS的取数模式以及衔接
说明 这应该是进一步的完善ADBS的工作模式。 之所以做A系列的架构工具,就是为了可以实现大型的数据处理、存储。从应用上说,是为了提高效率,并达到超高的效果。 为了达到这个目的,就必须从数据架构上、任务调度上、逻辑架构上作…...

易基因:RRBS揭示晚年锻炼可以减缓骨骼肌表观遗传衰老(甲基化年龄)|新研究
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。2021年12月21日,美国阿肯色大学、德克萨斯大学和肯塔基大学的研究人员合作在《Aging Cell》杂志发表了题为“Late-life exercise mitigates skeletal muscle epigenetic aging”…...
JVM的基本知识
JVM JVM是java的虚拟机,是一个十分复杂的东西,所以掌握的要求比较高.本文主要是研究JVM的三大话题 JVM内存划分JVM类加载JVM的垃圾回收 JVM内存划分 java程序要执行的时候,JVM会先申请一块空间,这里就涉及到JVM的内存划分 堆 : 放的是new 出来的对象栈: 放的是方法之间的调…...

STM32移植FreeRTOS操作系统
一、FreeRTOS源码下载(1)移植钱得准备前菜对吧,我们先来去官网瞄一瞄网址:https://freertos.org/zh-cn-cmn-s/ 第一步:点击下载FreeRTOS第二步:选择版本下载(我选择稳定版本)注&…...

【专项训练】泛型递归、树的递归
递归和循环没有明显的边界! 不要进行人肉递归! 找最近重复子问题,直接写递归! 数学归纳法思维:1,2,…… 70. 爬楼梯 https://leetcode.cn/problems/climbing-stairs/ 互斥,且加在一起是全部答案! 动态规划法:用数组做递推,就是动态规划!!! class Solution...

React18 setState是同步还是异步?
相信大家对于react的setState肯定是不陌生了, 这是一个用于更新状态的函数. 但是在之前有一道非常经典的面试题就是关于setState是同步还是异步的问题, 具体可以参考我之前写的一篇文章: 一篇文章彻底理解setState是同步还是异步!. 对于react 18之前的版本, 上文说的…...

Kafka消费者 TCP管理
Kafka消费者 TCP管理创建 TCPFindCoordinator连接协调者消费数据TCP 连接数关闭 TCP 连接消费者的程序入口类是 KafkaConsumer 构建 KafkaConsumer 时 ,不会创建任何 TCP 连接TCP 连接是用 KafkaConsumer.poll 创建 创建 TCP poll 创建 TCP 的地方 : 发起 FindC…...

软考高级备考哪一个类型好些?
软考高级是比中级和初级难,科目就要考三科,选择题基础知识简答题案例分析写作论文 软考高级科目有:信息系统项目管理师、系统分析师、系统架构设计师、网络规划师、系统规划与管理师。如下: 软考高级中高项信息系统项目管理师师比…...

2023 HBU 天梯赛第一次测试 题目集
目录 1 建校日期 2 发射小球 3 背上书包去旅行 4 吉利的数字 5 向前走 6 热水器 7 走方格 8 朋友圈 9 交保护费 10 走方格 11 和与积 12 缩短字符串 13 买木棒 1 建校日期 在2022 ICPC沈阳站上,东北大学命题组给参赛的选手们出了一道签到题࿰…...

华为OD机试题,用 Java 解【子序列长度】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...
内网环境解决SSL证书问题
本来这个没什么好写的,但是坑实在有点多,不得不写个文章记录下来。 创建证书看这里!!! 很多知识点要结合这个页面内容来看。 创建证书已经看过相关文章,然后用unity跑的时候发现连不上,完全没…...

数据分析方法01对比分析法
对比分析法 1、概念 基于相同的数据标准下,把两个及以上相互联系的指标数据进行比较,准确量化的分析他们的差异,说明研究对象在规模大小,水平高低,速度快慢等的不同表现,目的是为了找到差异的原因&#x…...
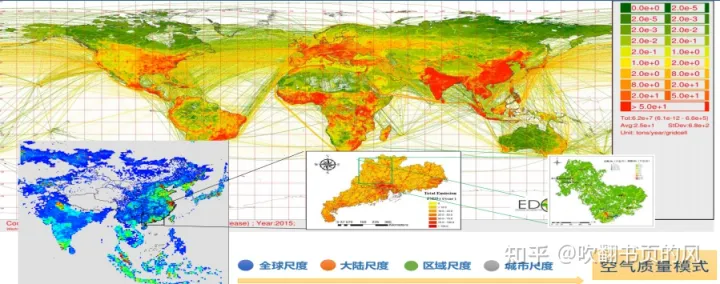
基于SMOKE多模式排放清单处理技术及EDGAR/MEIC清单制作与VOCs排放量核算
查看原文>>>基于SMOKE多模式排放清单处理技术及EDGAR/MEIC清单制作与VOCs排放量核算 (qq.com)随着我国经济快速发展,我国面临着日益严重的大气污染问题。近年来,严重的大气污染问题已经明显影响国计民生,引起政府、学界和人们越来越…...

CSS流动布局-页面自适应
项目中经常会碰到页面自适应的问题,例如:商城的列表展示、分类列表展示等页面,如下: 该页面会随着页面的放大缩小而随之发生变化,这种自适应的页面布局在大屏幕、小屏幕、不同的浏览器设备上都应该呈现出与设计匹配的…...

3.Elasticsearch初步进阶
3.Elasticsearch初步进阶[toc]1.文档批量操作批量获取文档数据批量获取文档数据是通过_mget的API来实现的在URL中不指定index和type请求方式:GET请求地址:_mget功能说明:可以通过ID批量获取不同index和type的数据请求参数docs:文档数组参数_index:指定index_type:指定type_id:指…...

优思学院|六西格玛管理的核心理念是什么?
六西格玛管理是一种基于数据分析的质量管理方法,旨在通过降低过程的变异性来达到质量稳定和优化的目的。该方法以希腊字母“σ”为名,代表标准差,是衡量过程变异性的重要指标。 六西格玛管理的核心理念是“以客户为中心、以数据为基础、追求…...

第十七节 多态
多态 什么是多态? ●同类型的对象,执行同一个行为,会表现出不同的行为特征。 多态的常见形式 父类类型 对象名称new子类构造器; 接口 对象名称new 实现类构造器; 多态中成员访问特点 ●方法调用:编译看左边,运行看右边。 ●变量调用:编译看…...

[vue]提供一种网站底部备案号样式代码
演示 vue组件型(可直接用) 组件代码:copyright-icp.vue <template><div class"icp">{{© ${year} ${author} }}<a href"http://beian.miit.gov.cn/" target"_blank">{{ record }}</a…...
python第四天作业~函数练习
目录 作业4、判断以下哪些不能作为标识符 A、a B、¥a C、_12 D、$a12 E、false F、False 作业5: 输入数,判断这个数是否是质数(要求使用函数 for循环) 作业6:求50~150之间的质数是…...
linux安装influxdb-rpmyum方式
一、influxdb的安装InfluxDB简介时序数据库InfluxDB版是一款专门处理高写入和查询负载的时序数据库,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、应用指标和IoT传感器上的数据主要特点:专为时间序列数据量身订造高性能数据存…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...