Java 某厂面试题真题合集

哈喽~大家好,这篇来看看Java 某厂面试题真题合集。
🥇个人主页:个人主页
🥈 系列专栏:【日常学习上的分享】
🥉与这篇相关的文章:
SpringCloud Sentinel 使用 SpringCloud Sentinel 使用_程序猿追的博客-CSDN博客_springcloud使用sentinel 将Nacos注册到springboot使用以及Feign实现服务调用 将Nacos注册到springboot使用以及Feign实现服务调用_程序猿追的博客-CSDN博客_nacos springboot 服务调用 微服务介绍与 SpringCloud Eureka 微服务介绍与 SpringCloud Eureka_程序猿追的博客-CSDN博客
目录
二、mysql事务怎么用
三、Oracle的如何分组去重
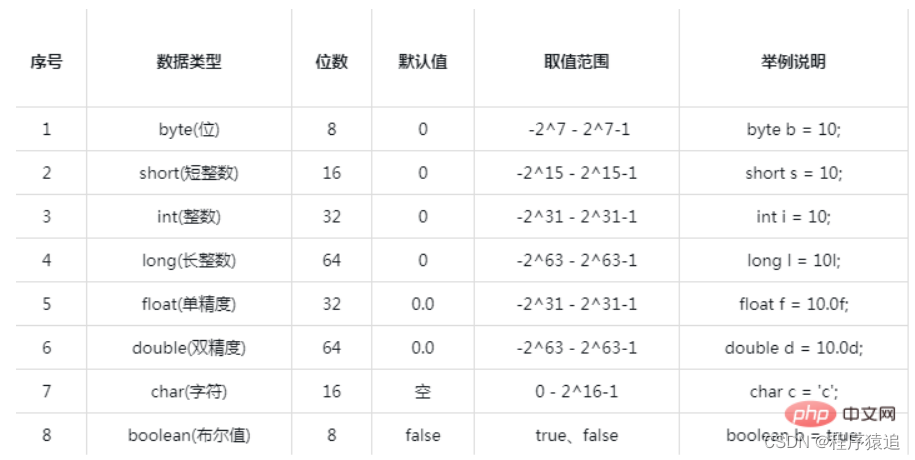
四、Java 数据类型有哪些?
五、Java 集合有哪些?
六、Java运算符有哪些?
七、SQL 查询,分组,函数,过滤(去重),内联外联查询,子查询,视图,索引
八、视图是什么?
九、面向对象特性
十、Java作用域(访问权限)
十一、JAVA程序分支结构
十二、break和continue
十三、error和exception区别
十四、ioc
十五、如何清理Tomcat缓存
十六、mybatis缓存
十七、session生命周期
十八、mysql分页查询
十九、空指针产生条件
二十、三大范式
二一、工厂模式
二二、Get 和 Post 的区别
二三、九种内置对象
二四、线程锁synchronized和lock区别
二五、线程的生命周期
二六、servlet生命周期
二七、并发和并行的区别
二八、为什么现在大多数网站使用html/htm,很少使用jsp?
二九、其他
一、session和cookie的区别
1、保存的位置不同 cookie保存在浏览器端,session保存在服务端。
2、使用方式不同 cookie如果在浏览器端对cookie进行设置对应的时间,则cookie保存在本地硬盘中,此时如果没有过期,则就可以使用,如果过期则就删除。如果没有对cookie设置时间,则默认关闭浏览器,则cookie就会删除。 session:我们在请求中,如果发送的请求中存在sessionId,则就会找到对应的session对象,如果不存在sessionId,则在服务器端就会创建一个session对象,并且将sessionId返回给浏览器,可以将其放到cookie中,进行传输,如果浏览器不支持cookie,则应该将其通过encodeURL(sessionID)进行调用,然后放到url中。
3、存储内容不同:cookie只能存储字符串,而session存储结构类似于hashtable的结构,可以存放任何类型。
4、存储大小:cookie最多可以存放4k大小的内容,session则没有限制。
5、session的安全性要高于cooKie
6、cookie的session的应用场景:cookie可以用来保存用户的登陆信息,如果删除cookie则下一次用户仍需要重新登录 session就类似于我们拿到钥匙去开锁,拿到的就是我们个人的信息,一般我们可以在session中存放个人的信息或者购物车的信息。
7、session和cookie的弊端:cookie的大小受限制,cookie不安全,如果用户禁用cookie则无法使用cookie。如果过多的依赖session,当很多用户同时登陆的时候,此时服务器压力过大。sessionId存放在cookie中,此时如果对于一些浏览器不支持cookie,此时还需要改写代码,将sessionID放到url中,也是不安全。
二、mysql事务怎么用
MySQL事务主要用于处理操作量大、复杂度高的数据。比如:在人员管理系统中删除一个人员,你既需要删除人员的基本资料,也需要删除和该人员相关的信息,这样,这些数据库操作语句就构成一个事务。InnoDB数据引擎的数据库才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的sql语句要么全部执行,要么全部不执行。事务用来处理insert、update、delete语句。
事务使用两种方法实现:
1)用begin、rollback、commit来实现。
Begin开始一个事务。
Rollback事务回滚。
Commit事务提交确认。
2)直接用set来改变MySQL的自动提交模式。
Set autocommit=0禁止自动提交。
Set autocommit=1开启自动提交。


一般来说,事务是必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
-
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
三、Oracle的如何分组去重
示例
表数据
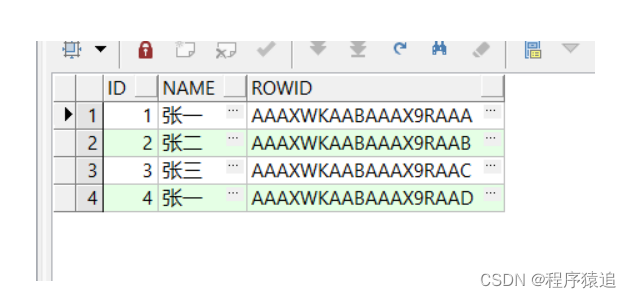
筛选出重复的数据
select name from TEST group by name having count(*) > 1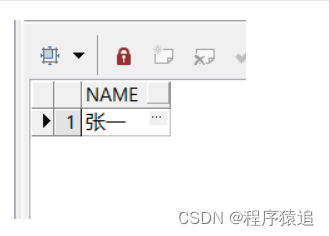
算出有多少个数量为1的数据(不重复的),将这些数据不做删除
select min(id) from TEST group by name having count(*)>1上面的"筛选出重复的数据" 作为删除条件
delete from TEST a where (a.name) in
(select name from TEST group by name having count(*) > 1)
and id not in (select min(id) from TEST group by name having count(*)>1)四、Java 数据类型有哪些?
Java的基本数据类型有8种,分别是:byte(位)、short(短整数)、int(整数)、long(长整数)、float(单精度)、double(双精度)、char(字符)和boolean(布尔值)。
五、Java 集合有哪些?
Java API中所用的集合类,都是实现了Collection接口,他的一个类继承结构如下:
Collection<–List<–VectorCollection<–List<–ArrayListCollection<–List<–LinkedListCollection<–Set<–HashSetCollection<–Set<–HashSet<–LinkedHashSetCollection<–Set<–SortedSet<–TreeSet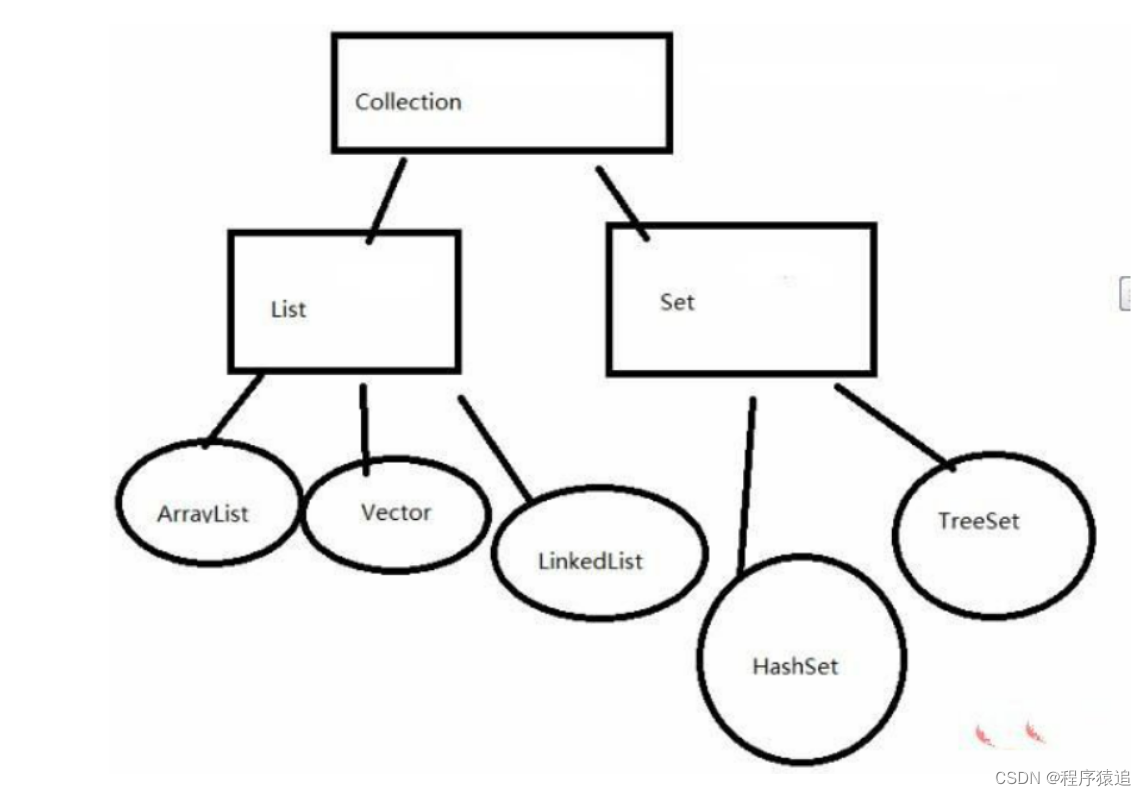
Vector
1) 底层数据结构是数组,查询快,增删慢
2)线程安全,效率低
基于Array的List,其实就是封装了Array所不具备的一些功能方便我们使用,它不可能走入Array的限制。性能也就不可能超越Array。所以,在可能的情况下,我们要多运用Array。另外很重要的一点就是Vector“sychronized”的,这个也是Vector和ArrayList的唯一的区别。
ArrayList
1).底层数据结构是数组,查找快,增删慢。
2). 线程不安全,效率高
同Vector一样是一个基于Array上的链表,但是不同的是ArrayList不是同步的。所以在性能上要比Vector优越一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。
LinkedList
1) 底层数据结构是链表,查询慢,增删快
2)线程不安全,效率高
LinkedList不同于前面两种List,它不是基于Array的,所以不受Array性能的限制。它每一个节点(Node)都包含两方面的内容:
-
节点本身的数据(data);
-
下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了。这就是LinkedList的优势。
Hashset集合:
1) 底层数据结构是哈希表,哈希表依赖两个方法hascode ()和equals()方法
2)两个方法的执行顺序:
首先判断hascode()值是否相同
是:继续执行equals()方法,看其返回值
是true:说明元素重复,不添加
是false:就直接添加元素
否:就直接添加到集合
Treeset集合:
1)底层数据结构是二叉树
总结:
-
所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ];
-
所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ];
-
所有的List中可以有null元素,例如[ tom,null,1 ];
-
基于Array的List(Vector,ArrayList)适合查询,而LinkedList(链表)适合添加,删除操作。
HashSet:虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项。
六、Java运算符有哪些?
1、算术运算符 2、赋值运算符 3、比较运算符 4、逻辑运算符 5、三目运算符 6、位运算
具体使用自行百度
七、SQL 查询,分组,函数,过滤(去重),内联外联查询,子查询,视图,索引
查询:select
分组:group by
函数:sum,max,min,avg等
过滤:上面有讲
内连接:inner join
左外连接:left join
右外连接:right join
全连接:full join
联合(合并)查询:union
(具体作用后面数据库篇会做具体讲解)
子查询是嵌套在另一个语句,如:select,insert,update、delete中的查询,就像上面的分组去重一样
八、视图是什么?
从SQL的角度来看,视图就是一张表,存在表名、字段列。在SQL语句中,也并不区分实体表和视图。
视图和实体表的区别就在与:是否保存了实际数据。
视图本身是一个不含任何数据的虚拟表,数据库中存放视图的定义(保存好的SELECT语句),而不存放视图对应的数据。
实体表中保存实际数据,使用实体表创建视图后,实体表中的数据发生变化,视图查询出的数据就会发生变化。
从视图中读取数据时,视图会在内部执行对应的SELECT语句,并创建出一张临时表。
索引
SQL 索引(Index)用于提高数据表的查询速度。一个表可以创建多个索引,一个索引可以包含一个或者多个字段。
不使用索引,数据库引擎将遍历整个表。
九、面向对象特性
面向对象的特征是:
1、“抽象”,把现实世界中的某一类东西,提取出来,用程序代码表示;
2、“封装”,把过程和数据包围起来,对数据的访问只能通过已定义的界面;
3、“继承”,一种联结类的层次模型;
4、“多态”,允许不同类的对象对同一消息做出响应。
十、Java作用域(访问权限)
访问权限控制: 指的是本类及本类内部的成员(成员变量、成员方法、内部类)对其他类的可见性,即这些内容是否允许其他类访问。
Java 中一共有四种访问权限控制,其权限控制的大小情况是这样的:public > protected > default(包访问权限) > private ,具体的权限控制看下面表格,列所指定的类是否有权限允许访问行的权限控制下的内容:
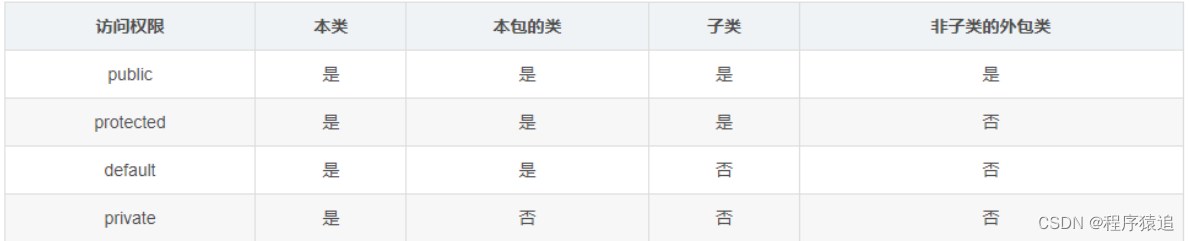
1、public: 所修饰的类、变量、方法,在内外包均具有访问权限; 2、protected: 这种权限是为继承而设计的,protected所修饰的成员,对所有子类是可访问的,但只对同包的类是可访问的,对外包的非子类是不可以访问; 3、包访问权限(default): 只对同包的类具有访问的权限,外包的所有类都不能访问; 4、private: 私有的权限,只对本类的方法可以使用;
十一、JAVA程序分支结构
Java程序中, 有3个基本结构: 顺序结构/分支结构/循环结构
十二、break和continue
1 break用于完全结束一个循环,跳出循环体,执行循环后面的语句。
2 continue是跳过当次循环中剩下的语句,执行下一次循环。9.equal和==的区别
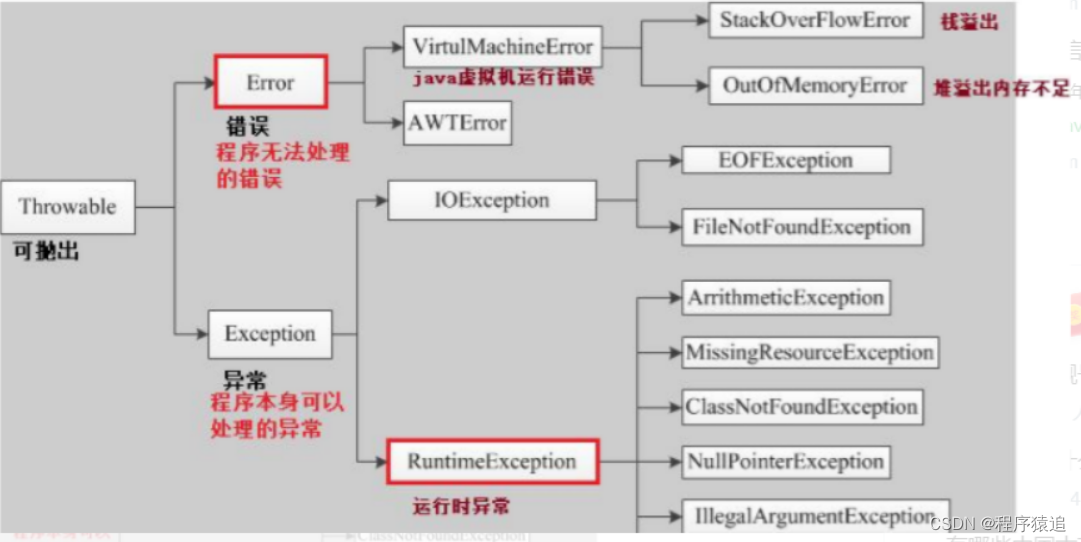
十三、error和exception区别
一、含义不同:
Error类一般是与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
二、用途不同:
Exception和Error体现了Java平台设计者对不同异常情况的分类。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error是指在正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如OutOfMemoryError之类,都是Error的子类。
十四、ioc
见【JAVAEE框架】浅谈 Spring 框架的两大核心思想 AOP 与 IOP_aop iop_程序猿追的博客-CSDN博客 这篇有具体讲解
十五、如何清理Tomcat缓存
1:关闭tomcat服务
进入到tomcat/bin目录下,执行 ./shutdown.sh
2:查看进程,tomcat是否关闭
ps -aux | grep tomcat
3:如果没有关闭,杀死进程
kill -9 #pid 来彻底关闭tomcat(#pid是tomcat的进程ID)
4:进入到tomcat/work目录
执行rm -rf Catalina 来删除缓存文件
最后进入tomcat/work目录下,执行rm -rf Catalina 来删除缓存文件
执行ls 确认是否删除,如果work目录下没有Catalina文件夹说明删除成功。
5:重新启动tomcat
十六、mybatis缓存
这篇有所介绍,【JAVAEE框架】Spring 项目构建流程_java spring项目_程序猿追的博客-CSDN博客
十七、session生命周期
session的生命周期分为创建session与销毁session
创建session:是指当用户第一次访问jsp页面时,因为jsp页面内置了session对象或Sessinon在用户访问第一次访问服务器时创建,需要注意只有访问JSP、Servlet等程序时才会创建Session。 只访问HTML、IMAGE等静态资源并不会创建Session,可调用request.getSession(true)强制生成Session。 第一次是指:浏览器访问服务器时,不带值为sessionId的cookie 销毁session(只有这两种情况): a.当session有效期到期(默认为30分钟,可手动设置) b.手动销毁session,用session.invalidate(); 情景:先第一次访问了服务器的index.jsp页面,此时服务器创建一个session,并将它的id值存入一个cookie中响应给服务器。然后将浏览器关闭重开再次访问index.jsp
第一次访问index.jsp,服务器会将这个session存入服务器内存。关闭浏览器再次访问,服务器会再给浏览器一个新的session,这是由于浏览器刚开,之前接受到的存有sessionId的cookie被清除了,再次访问浏览器时,又处于了第一次访问的状态。但是,之前的session(即第一个访问时创建的),并没有被销毁,而是保存在服务器内存中,直到有效期到了或手动销毁。
从上述表述可知,第一次访问服务器,是指访问服务器时没有携带带有sessionId的cookie或从服务器端理解,是没有对应访问用户的session
十八、mysql分页查询
分页查询公式
通过以上三个案例,我们可以总结出分页查询公式: (当前页数-1) * 每页条数,每页条数
SELECT FROM TABLE LIMIT (Page - 1) * PageSize, PageSize ;十九、空指针产生条件
-
当对象为null时,调用了其成员方法或属性。
-
在使用equals()比较两个对象是否相等时,当双方是一个常量和一个变量,把变量放在常量前且当变量为空的时候,运行时会报错。
System.out.println(“abc”.equals(str5)); // 推荐:false
System.out.println(str5.equals(“abc”)); // 不推荐:报错,空指针异常NullPointerException-
对key、value不能为null的容器put为null的key、value值。
-
自己搞的一个集合,当集合为空时,对其遍历会报空指针异常。PS:**若使用mybatis做查询返回集合时,当没查到数据时,返回的集合不是空,而是一个size为0的集合。对其遍历不会报空指针异常。**
二十、三大范式
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
其中最常使用的是第一范式(1NF)、第二范式(2NF)、第三范式(3NF),也就是所谓的三大范式
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
2NF是对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖
第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
3NF是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖
二一、工厂模式
简单工厂模式
(1)简单工厂模式时属于创建型模式,是工厂模式的一种。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式 (2)简单工厂模式:定义了一个创建对象的类,由这个类来封装实例化对象的行为(代码) (3)在软件开发中,当我们会用到大量的创建某种,某类或者某批对象时,就会使用到工厂模式
工厂模式
定义了一个创建对象的抽象方法,有子类决定要实例化的类。工厂方发模式将对象的实例化推迟到子类
抽象工厂模式
(1)定义了一个interface 用于创建相关或有依赖关系的对象簇,而无需指明具体的类 (2)抽象工厂模式可以将简单工厂模式和工厂方法模式进行整合 (3)从设计层面看,抽象工厂模式就是对简单工厂模式的改进或称为进一步的抽象。
二二、Get 和 Post 的区别
POST和GET都是向服务器提交数据,并且都会从服务器获取数据。
区别: 1、传送方式:get通过地址栏传输,post通过报文传输。 2、传送长度:get参数有长度限制(受限于url长度),而post无限制 3、GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包
长的说: 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); 而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。 也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。 因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。为什么?
-
GET与POST都有自己的语义,不能随便混用。
-
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
-
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。 建议: 1、get方式的安全性较Post方式要差些,包含机密信息的话,建议用Post数据提交方式; 2、在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式; 案例:一般情况下,登录的时候都是用的POST传输,涉及到密码传输,而页面查询的时候,如文章id查询文章,用get 地址栏的链接为:article.php?id=11,用post查询地址栏链接为:article.php, 不会将传输的数据展现出来。
增加:
get传输数据是通过URL请求,以field(字段)= value的形式,置于URL后,并用"?"连接,多个请求数据间用"&"连接,如http://127.0.0.1/Test/login.action?name=admin&password=admin,这个过程用户是可见的;post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的;
Get传输的数据量小,因为受URL长度限制,但效率较高,Post可以传输大量数据,所以上传文件时只能用Post方式;
post较get安全性较高,get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等.
get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码,post支持标准字符集,可以正确传递中文字符。
二三、九种内置对象
JSP内置对象,就是在编写JSP页面时,不需要做任何声明就可以直接使用的对象。
九大内置对象分别是:request、response、session、application、out、pageContext、config、page和exception
二四、线程锁synchronized和lock区别
区别1:Synchronized 是Java的一个关键字,而Lock是java.util.concurrent.Locks 包下的一个接口;
区别2:Synchronized 使用过后,会自动释放锁,而Lock需要手动上锁、手动释放锁。(在 finally 块中)
区别3:Lock提供了更多的实现方法,而且 可响应中断、可定时, 而synchronized 关键字不能响应中断;
区别4:synchronized关键字是非公平锁,即,不能保证等待锁的那些线程们的顺序,而Lock的子类ReentrantLock默认是非公平锁,但是可通过一个布尔参数的构造方法实例化出一个公平锁;
公平锁与非公平锁:
公平锁就是:先等待的线程,先获得锁。 非公平锁就是:不能够保证 等待锁的 那些线程们的顺序, 公平锁因为需要维护一个等待锁资源的队列,所以性能相对低下;
区别5:synchronized无法判断,是否已经获取到锁,而Lock通过tryLock()方法可以判断,是否已获取到锁;
区别6:Lock可以通过分别定义读写锁提高多个线程读操作的效率。
区别7:二者的底层实现不一样:synchronized是同步阻塞,采用的是悲观并发策略;Lock是同步非阻塞,采用的是乐观并发策略(底层基于volatile关键字和CAS算法实现)
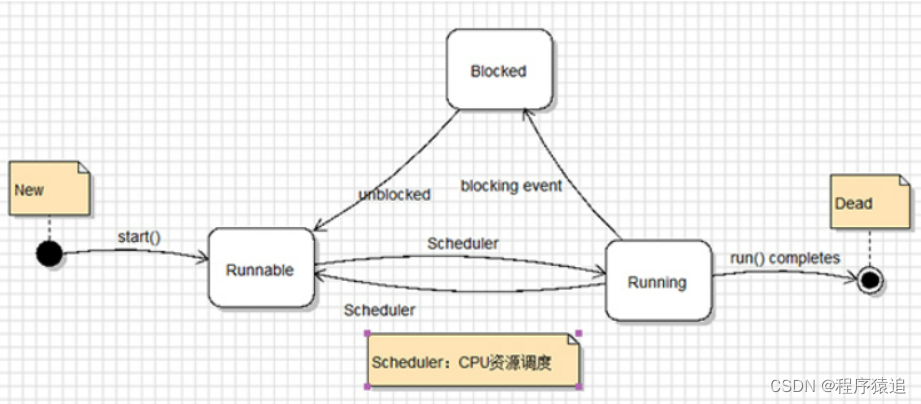
二五、线程的生命周期
线程的生命周期一共分为五个部分分别是:新建,就绪,运行,阻塞以及死亡。
二六、servlet生命周期
servlet生命周期:
1、初始化阶段,Servlet容器会创建一个Servlet实例并调用【init()】方法;
2、处理客户端请求阶段,每收到一个客户端请求,服务器就会产生一个新的线程去处理;
3、终止阶段,调用destroy方法终止。
主要有三个方法:
-
init()初始化阶段
-
service()处理客户端请求阶段
-
destroy()终止阶段
二七、并发和并行的区别
并发(Concurrent)
在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
就想前面提到的操作系统的时间片分时调度。打游戏和听音乐两件事情在同一个时间段内都是在同一台电脑上完成了从开始到结束的动作。那么,就可以说听音乐和打游戏是并发的。
并行
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
这里面有一个很重要的点,那就是系统要有多个CPU才会出现并行。在有多个CPU的情况下,才会出现真正意义上的『同时进行』。
并发,指的是多个事情,在同一时间段内同时发生了。
并行,指的是多个事情,在同一时间点上同时发生了。
并发的多个任务之间是互相抢占资源的。
并行的多个任务之间是不互相抢占资源的
二八、为什么现在大多数网站使用html/htm,很少使用jsp?
以前,jsp,asp,aspx等很流行,那是因为当时前端网页与后端代码混合开发。HTML只负责静态网页,其他的脚本负责实现动态网页。对于动态网页,写几行HTML,再插几句ASP、JSP代码,然后再写几行HTML,再写几行jsp,里面还打印几行HTML内容……很难阅读,也很难调试。写一个网页既要懂网页设计:字体、颜色、布局、动画,又要懂代码编程、数据库、业务逻辑。那时开发网站的,基本都是“全栈工程师”。
现在,有了各种前段框架(JQuery,Ajax,Angular,Vue,Bootstrap,React,……),前后端代码分开开发。前端使用HTML和js来完成各种复杂的动态效果,重新刷新和加载后端数据,而不需要向后端索要整个网页内容。前端负责html、css、js,主要是美编、设计、图片处理、js程序员进行开发。而后端只负责业务及数据处理,各种语言都能实现,以java、.net、php、python等语言为主。这些后端数据URL可以自己定义后缀名,只要后端增加一个路由解析就可以了。所以,呈现在浏览器上的URL基本都是HTML后缀的。
注:
所有面试官问的题尽量多答,最好保证一道题至少扯2分钟。 如果一道题答案只有一句话的尽量联想其他相关联的知识点,只要面试官不打断就大胆说。 如果遇到不会的,听都没听过的,如果是个关键字就反问面试官:不好意思,刚刚没听清楚,是问的框架还是原理方面的。之类的话,如果是新的概念,就抓关键字联想类似的知识点答。
eg:
面向对象的三大特性,继承可以联想重载重写,封装可以联想访问权限和空指针异常,多态可以联想通过中间类方式实现多态,继承,重写,上转型。如果只让说一个,就说除了这一个还有另外两个。
二九、其他
==和equal equal可以联想空指针,hashcode。
所有涉及线程安全的题一律往锁和多线程扯
抽象类和接口 多扯一个跟普通类的区别
问到反射就说完基础之后往用到反射的地方。
问锁相关就扯多线程和事务,问事务就扯锁和多线程。
问到集合就扯到vector或者hashtable可以加点多线程和锁进去。(stringbuild和stringbuffer同理) 如果单问一两个集合的区别,则可以说着说着扯到其他类型集合,跟问的集合的区别。
问到异常相关的trycatch throw throws,finally知道的全部扯出来,还可以举例,在什么场景用过这些方法,还可以说自定义异常和原理。
总的来说就是由简化繁,想的越多越好。
回答不上的题:不好意思,这方面的知识点我之前学习的时候没有很深入的了解,今天知道不足后会在回去之后好好理解和补充的。
不积跬步无以至千里,趁年轻,使劲拼,给未来的自己一个交代!向着明天更好的自己前进吧!
相关文章:

Java 某厂面试题真题合集
哈喽~大家好,这篇来看看Java 某厂面试题真题合集。 🥇个人主页:个人主页 🥈 系列专栏:【日常学习上的分享】 🥉与这篇相关的文章: Spr…...

很特别的5G市场,5.75亿部手机,却有11亿5G用户,这是怎么了?
中国在5G商用方面已取得了巨大的成绩,这是毋庸置疑的,不过近期公布的一份数据却相当特别,5G手机用户数为5.75亿,而开通了5G套餐的用户数却已超过11亿,这数据对比有点意思。中国在5G商用方面推进很快,建成的…...

go modules
文章目录1. 简介示例1. 示例——同一项目2. 示例——不同项目3. 示例——添加远程模块依赖库1. 简介 go module是Go1.11版本之后官方推出的版本管理工具,并且从Go1.13版本开始,go module将是Go语言默认的依赖管理工具。到今天Go1.14版本推出之后Go modu…...
Baklib客户故事:快递助手ERP
快递助手ERP以多平台多店铺订单管理为核心,集打单发货、商品、库存、采购、售后于一体,中小商家易上手的轻量级ERP,可以满足满足微商、自建商城、档口货源网、一件代发等不同类型客户的打单需求,通过开放平台API接口,自…...
MongoDB学习(java版)
MongoDB概述 结构化数据库 结构化数据库是一种使用结构化查询语言(SQL)进行管理和操作的数据库,它们的数据存储方式是基于表格和列的。结构化数据库要求数据预先定义数据模式和结构,然后才能存储和查询数据。结构化数据库通常…...

RK3568平台开发系列讲解(显示篇)什么是DRM
🚀返回专栏总目录 文章目录 一、DRM介绍二、DRM与framebuffer的区别沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍什么是DRM。 一、DRM介绍 DRM 是 Linux 目前主流的图形显示框架,相比FB架构,DRM更能适应当前日益更新的显示硬件。 比如FB原生不支…...

Python蓝桥杯训练:基本数据结构 [二叉树] 上
Python蓝桥杯训练:基本数据结构 [二叉树] 上 文章目录Python蓝桥杯训练:基本数据结构 [二叉树] 上一、前言二、有关二叉树理论基础1、二叉树的基本定义2、二叉树的常见类型3、二叉树的遍历方式三、有关二叉树的层序遍历的题目1、[二叉树的层序遍历](http…...
vuex基础之初始化功能、state、mutations、getters、模块化module的使用
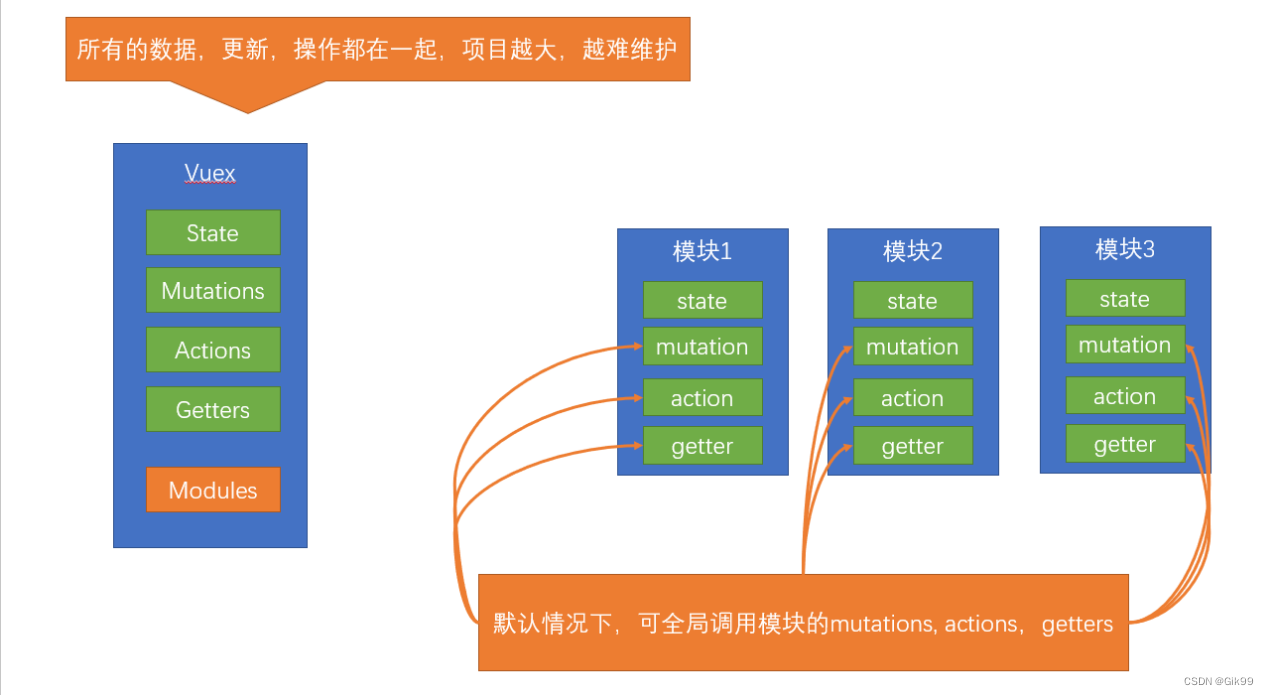
vuex基础之初始化功能、state、mutations、getters、模块化module的使用一、Vuex的介绍二、初始化功能三、state3.1 定义state3.2 获取state3.2.1 原始形式获取3.2.2 辅助函数获取(mapState)四、mutations4.1 定义mutations4.2 调用mutations4.2.1 原始形式调用($store)4.2.2 辅…...

WebSphere中间件漏洞总结
WebSphere中间件漏洞总结 一、WebSphere简介 WebSphere为SOA(面向服务架构)环境提供软件,以实现动态的、互联的业务流程,为所有业务情形提供高度有效的应用程序基础架构。WebSphere是IBM的应用程序和集成软件平台,包含所有必要的中间件基础架构(包括服务器、服务和工具)…...

Unity之ASE实现影魔灵魂收集特效
前言 我们今天来实现一下Dota中的影魔死亡后,灵魂收集的特效。效果如下: 实现原理 1.先添加一张FlowMap图,这张图的UV是根据默认UV图,用PS按照我们希望的扭曲方向修改的如下图所示: 2.通过FlowMap图,我…...

半入耳式耳机运动会不会掉、佩戴超稳固的运动耳机推荐
现在越来越多的人开始意识到运动的重要性,用运动给身体增加一道“防护墙”是最好的生活方式了,不过,日复一日做着几乎相同的动作,难免索然无味,所以很多人都会选择在运动时戴上耳机听歌解闷,这时候也有不少…...
使用Tensorflow完成一个简单的手写数字识别
Tensorflow中文手册 介绍TensorFlow_w3cschool 模型结构图: 首先明确模型的输入及输出(先不考虑batch) 输入:一张手写数字图(28x28x1像素矩阵) 1是通道数 输出:预测的数字(1x10的one…...

OpenGL三种向着色器传递数据的方法 attributes,uniform,texture以及中间产物
(1)属性,使在顶点着色器中使用的变量,用于描述顶点的属性,如位置、颜色、法向量等,attributes通常用于描述每个顶点的属性,因此在顶点缓冲对象中存储,渲染的时候,openGL会…...

详解package.json和package-lock
详解package.json和package-lockpackage.json和package-lock.json作用首先要明确一点,package.json不会自动生成,需要我们使用 npm init 创建。package-lock.json是自动生成的,我们使用 npm install 安装包后就会自动生成。在我们执行 npm in…...

02-CSS
一、emmet语法1、简介Emmet语法的前身是Zen coding,它使用缩写,来提高html/css的编写速度, Vscode内部已经集成该语法。快速生成HTML结构语法快速生成CSS样式语法2、快速生成HTML结构语法生成标签 直接输入标签名 按tab键即可 比如 div 然后tab 键, 就可以生成 <…...

JavaScript 中的类型转换机制以及==和===的区别
目录一、概述二、显示转换Number()parseInt()String()Boolean()三、隐式转换自动转换成字符串自动转换成数值四、 和 区别1、等于操作符2、全等操作符3、区别小结一、概述 我们知道,JS中有六种简单数据类型:undefined、null、boolean、string、number、…...
RocketMQ基础篇(一)
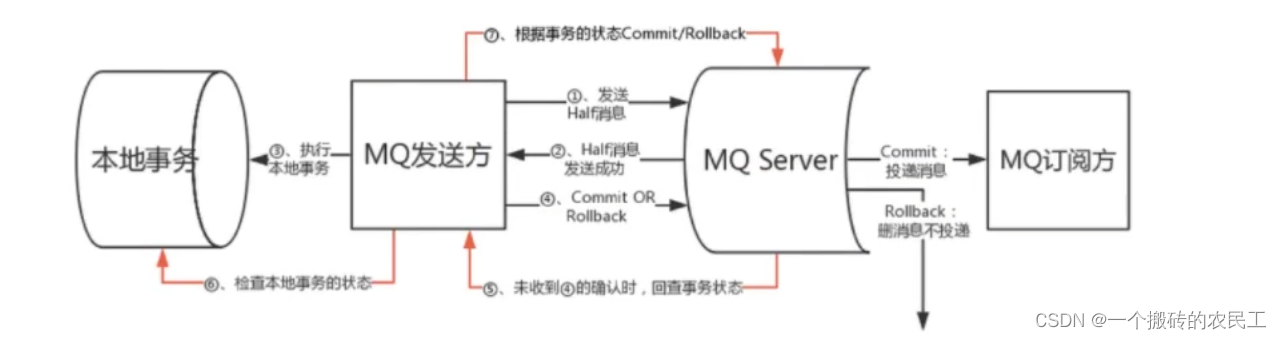
目录一、发送消息类型1、同步消息2、异步消息3、单向消息4、顺序消费5、延迟消费二、消费模式1、集群模式2、广播模式3、消费模式扩展4、如何配置三、其他用法1、事务消息2、过滤消息1)Tag过滤2)SQL方式过滤源码放到了GitHub仓库上,地址 http…...

Android前沿技术—gradle中的build script详解
build.gradle是gradle中非常重要的一个文件,因为它描述了gradle中可以运行的任务,今天本文将会带大家体验一下如何创建一个build.gradle文件和如何编写其中的内容。 project和task gradle是一个构建工具,所谓构建工具就是通过既定的各种规则…...

深入浅出PaddlePaddle函数——paddle.zeros_like
分类目录:《深入浅出PaddlePaddle函数》总目录 相关文章: 深入浅出PaddlePaddle函数——paddle.Tensor 深入浅出PaddlePaddle函数——paddle.ones 深入浅出PaddlePaddle函数——paddle.zeros 深入浅出PaddlePaddle函数——paddle.full 深入浅出Padd…...

物料-零部件分类属性
离散制造业的研发、生产跟产品零部件紧密联系在一起,从企业业务流程来说零部件涉及研发、采购、仓储、生产、质量、售后和配件等多个部门,为了更好地管理零部件,下面我们一起来看看零部件概念及分类。 1、按行业属性分类 (1&…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...