MySQL知识点全面总结3:Mysql高级篇
三.MySQL知识点全面总结3:mysql高级篇
1.mysql语句的执行过程?
2.myesql事务详解?
3.mysql日志详解?
4.mysql的索引功能详解?
5.mysql的存储引擎详解?
6.mysql事务提交后数据与硬盘如何交互存储?回滚呢?
未更新
三.MySQL知识点全面总结3:mysql高级篇
1.mysql语句的执行过程?
①两个架构
- 客户端层
- 服务器层:
连接器:身份认证
分析器:语法分析:检查sql语句正确性。提取查询的表,查询条件等。
缓存:缓存select语句的结果集
优化器:多个索引时选择索引
执行器:调用引擎接口返回结果 - 引擎层:
存储引擎:具体执行存储操作。
②执行更新语句和查询语句
- 在存储引擎中过程不同
- 对于查询语句返回结果即可
- 对于更新语句:
引擎将数据保存在内存中,记录redo log(预提交)
通知执行器,执行器记录bin log,然后调用引擎提交redo log(提交)
2.myesql事务详解?
①为什么出现mysql事务?
- 因为假如插入多条相关联数据,中间宕机,则插入一般结果很差
- 引入事务,要么都执行,要么都不执行
②数据库事务执行过程
- start transaction
- sql1 sql2
- commit
- 执行过程分析
为了提升性能,不会每次提交数据都写入磁盘。
事务提交的数据先写入缓冲池,然后使用后台线程来更新缓存和硬盘一致性。
如果没来得及同步,则通过redo log日志恢复一致性。
事务提交了一半数据,还没来得及提交另一半,则通过undo log回滚数据。
③事务的属性
- ACID
原子性,隔离性,持久性—>一致性
原子性:要么都执行要么都不执行
隔离性:事务之间互不影响
持久性:事务提交的数据永久保留
一致性:事务的结果前后一致(借了100块我有100块,加起来保证总共200块)
④事务产生的问题
- 脏读:A事务读到B事务未提交的数据(mysql读取内存的数据还未提交)
- 丢失修改:A事务和B事务同时读到同样数据,都加10,最后写入内存只是加了一次10。
- 不可重复读:A事务两次读A,第二次读到的被别人修改了的数据。
- 幻读:A事务读两次,第二次读入的多了几条数据。
⑤解决产生的问题的隔离级别
- 读未提交:什么都没解决(可以读到未提交的数据)
- 读已提交:解决脏读(只能读已提交的数据)
- 可重复读:解决脏读和不可重复度
- 可串行化:全部解决
⑤如何设置的隔离级别(锁+MVCC)
- 锁:悲观
按读写分:读锁和写锁。读锁允许共享,写锁:排斥其他锁。也就是允许读读并行,不允许读写并行和写写并行。
按表行分:表锁和行锁。 - MVCC:乐观
隐藏字段+read view来查看当前数据的可见性
undo log记录某行的版本数据
⑥解决事务的ACID
- 原子性:undo日志回滚实现
- 持久性:redo日志崩溃恢复数据实现
- 隔离性:锁+MVCC实现
- 最终保障一致性
3.mysql日志详解?
①redo log
- 不断写入
- 是InnoDB独有的,为了解决崩溃恢复能力
②bin log
- 事务提交时写入
- 为了保证集群架构一致性
③undo log
- 异常发生,记录所有事务的修改记录,出现异常回滚
④redolog 和binlog联合工作保证数据库的崩溃恢复能力,保证集群架构一致性。
- 为什么不用一个日志?
mysql原来没有InnoDB引擎,InnoDB引擎是专门为了恢复崩溃数据的。 - 为什么redolog要引入prepare和commit状态?
如果不引入,redolog写完后未提交给binlog前系统崩溃,则发生数据不一致。
引入后,崩溃后发现redolog是prepare状态,那么就回滚事务。
4.mysql的索引功能详解?
①为什么引入索引?
- 索引能够帮助mysql高效的获取数据。目的为了加速数据库的查询时间。
②索引怎么实现的?
- 以空间换时间。
- 优点:大大增加了数据的检索速度。
缺点:索引需要存储浪费空间,索引在数据修改时也会修改降低执行效率。
③索引底层的数据结构是什么?
- 索引的数据结构需要满足什么?
空间局部访问性原理。
减少IO次数。
能够实现顺序查找。 - hash表
数组+链地址 - 平衡二叉树
二叉树 - B树
索引和数据都在树中。平衡多叉树+每个节点有多个子节点 - B+树
关键字只存储在叶子节点,非叶子结点不存储data,所有叶子节点都用链表相连。 - 为什么不用hash表结构呢?
因为Hash表结构不支持顺序和范围查询。 - 为什么不用平衡二叉树呢?
因为平衡二叉树每个节点一次IO过度浪费资源,且看似很近的数据存储离得很远,满足不了空间局部访问原理,实现不了顺序查找。(树的高度为IO次数) - 为什么不用B树呢?
空间局部性原理无法更好的利用。 - 为什么用B+树呢?
由于节点不存储数据,故索引存储的范围更大更精确。即B+树相对于B树同样的IO能获得更多的索引即更精确的数据。
由于B+树有链表连接叶子节点故可以实现空间局部性原理。 - B+树的不同使用
聚簇索引:InnoDB引擎。叶子节点直接存放的是数据。
优点:速度快
缺点:依赖于有序数据, 更新代价大
非聚簇索引:MyISM引擎。叶子节点存放数据记录地址(数据文件和索引文件分离)。
优点:更新代价小。
缺点:依赖于有序数据,二次查询(即查到记录地址还需再去查文件)。
④索引分级
- 从数据结构分
B-Tree索引
哈希索引 - 从底层存储方式分
聚簇索引
非聚簇索引 - 从应用维度分:
主键索引
普通索引
全文索引 - 从级别分
一级索引:直接根据主键查到数据
辅助索引 :查到的是数据的主键(再去一级索引查) - 其他索引
覆盖索引:包含所有需要查的字段值(查主键)
联合索引:表中多个字段联合创建的索引
⑤索引的使用
- 正确选字段:不选Null的值,选择频繁查询的字段
- 不选择频繁更新的字段(还需更新索引)
- 限制每张表的索引:影响插入更新效率,可能影响查找效率
因为优化器选择优查询时会选择对应的索引表,索引表太多选择也会慢。
5.mysql的存储引擎详解?
①存储引擎使用
- mysql采用的是插件式架构,支持多种存储引擎。
- 存储引擎是基于表的,而不是数据库,即每一个表都可以有一个存储引擎。
②主流存储引擎对比
- InnoDB 行级锁+表级锁, 实现四个隔离级别, 支持外键, 数据库崩溃后能安全恢复redo log,数据文件本身即是索引文件
- MyISAM 表级锁, 不支持事务, 不支持外键,无安全恢复,索引文件和数据文件分离。
6.mysql事务提交后数据与硬盘如何交互存储?
①write和fsyc操作
- write操作:从buffer(缓冲区)中写入到page cache(操作系统文件缓冲区)
- fsyc操作:从page cache(操作系统文件缓冲区)写入到硬盘
②update更新流程
- CURD操作到达执行器。
- 判断BufferPool中是否有该数据(没有则从磁盘中调入,有则直接更改BufferPool的数据)。
- 事务执行过程中,会记录更改过程到 bin log buffer 。
- redo log buffer记录更新操作。
- 如果事务提交了
(mysql默认配置事务自动提交) - redo log buffer的更新操作进入prepare状态
- 同时告诉执行器 bin log buffer执行write操作。
默认参数为0 只执行write操作prepare状态
参数为1 执行write + fsyc - 然后redo log buffer 执行write + fsyc操作。
默认参数为1 执行write + fsyc操作
参数为0 不执行(等待后台线程一秒后自动write操作)
参数为2 write
③示例
- 如果redo为0 mysql挂了或者宕机 损失1秒数据。
- 如果redo为1 不损失任何数据。
- 如果redo为2 mysql挂了不损失任何数据,宕机损失一秒的数据。
③为什么不直接将bufferPool的数据写入磁盘?
- 因为bufferPool的数据过大,刷盘耗时,利用redo.file刷盘,bufferPool也会通过IO线程写入磁盘的(合适的时机)
④事务回滚机制
- 进行更新操作前,都会记录一条undo buffer(相反操作,如果是delete 则是add,如果是add,则是delete),然后undo buffer会持久化到 undo log文件中
- 事务提交了(利用binlog和redolog),则undo log日志删除,事务未提交而回滚,只需要执行undo log日志的内容即可。
- undo log会持久化到磁盘上,如果数据库宕机,那么数据库可以通过查undo log回滚未完成的事务。
- 注意点:
优点:
undo log会先于数据持久化到磁盘上,即数据持久化到磁盘上,此时undo log一定已经在磁盘中了。这样能够保证事务的原子性,即如果mysql挂了,则可以通过undo log来回滚事务。
缺点:
每个事务提交前将undo log写入磁盘,这样会导致大量的磁盘IO,因此性能较差。
未更新
相关文章:

MySQL知识点全面总结3:Mysql高级篇
三.MySQL知识点全面总结3:mysql高级篇 1.mysql语句的执行过程? 2.myesql事务详解? 3.mysql日志详解? 4.mysql的索引功能详解? 5.mysql的存储引擎详解? 6.mysql事务提交后数据与硬盘如何交互存储&…...

Spring注解开发之组件注册(二)
Spring注解开发之组件注册(一) 5.Import 给容器导入一个组件 给容器中注册组件 一、包扫描 组件标注注解(Controller/Service/Repository/Component) [自己写的类] 二、Bean [导入的第三包里面的组件] 三、Import [快速给容器中导入组件] (Import{…...

【web前端开发】CSS最常用的11种选择器
文章目录1.CSS介绍2.CSS的语言规则3.CSS的引入方式4.选择器标签选择器类选择器id选择器通配符选择器复合选择器后代选择器子代选择器并集选择器交集选择器伪类选择器hover伪类选择器active伪类选择器结构伪类选择器结语1.CSS介绍 CSS (Cascading Style Sheets,层叠样…...

微电影广告发展的痛点
微电影广告以不可阻挡之势进入大众生活中,企业利用微电影广告来进行企业形象塑造的例子比比皆是。于是乎,微电影广告在为企业塑造品牌形象方面上取得了可喜的效果,但也不可忽视,在这个发展过程中,微电影广告所面临的问…...
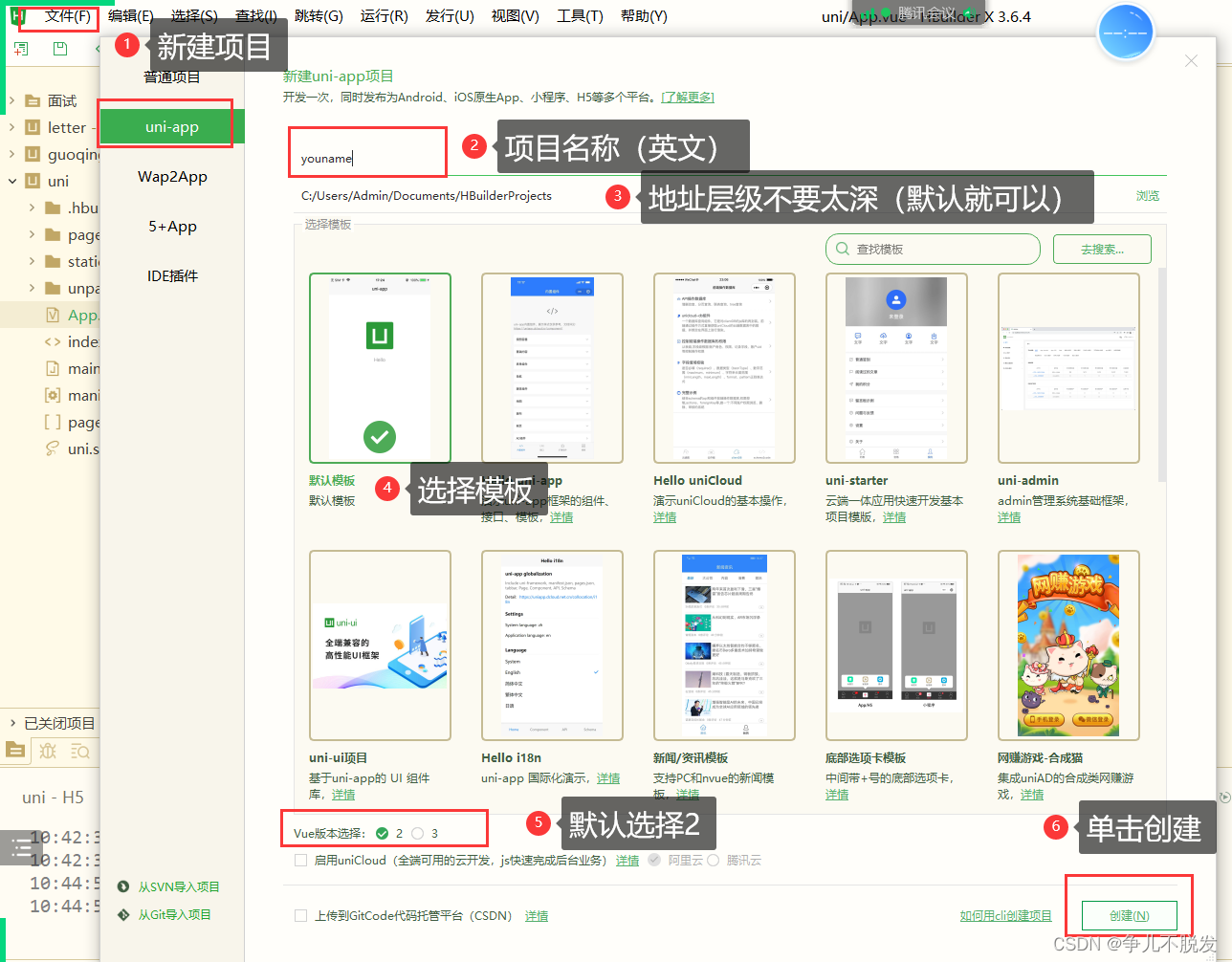
uniapp新手入门
前言: 这篇文章主要写的是uniapp的基础知识,可以让大家快速上手uniapp,同时避掉一些可能踩到的坑。 一. 什么是uniapp uniapp是由dcloud 公司开发的多端融合框架。uniapp的出现让我们的开发更为方便,一次开发,多端运行…...

linux segfault at 问题定位实践
问题:程序崩溃,打印为:app[13016]: segfault at 7fb668d29930 ip 00007fb668d3c23c sp 00007fb668e7de20 error 7 in mydefine.so[7fb668d3400011000]定位步骤:基础分析数据,大概了解反馈信息(根据chatGPT&…...

SpringCloud+SpringCloudAlibaba
架构的演进1.1单体架构将所有业务场景的表示层、业务逻辑层和数据访问层放在一个工程中,最终经过编译、打包,部署在一台服务器上。◆ 1.1.1单体架构的优点1)部署简单: 由于是完整的结构体,可以直接部署在一个服务器上即可。2&…...
【独家】)
华为OD机试 - 路灯照明(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:路灯照明…...
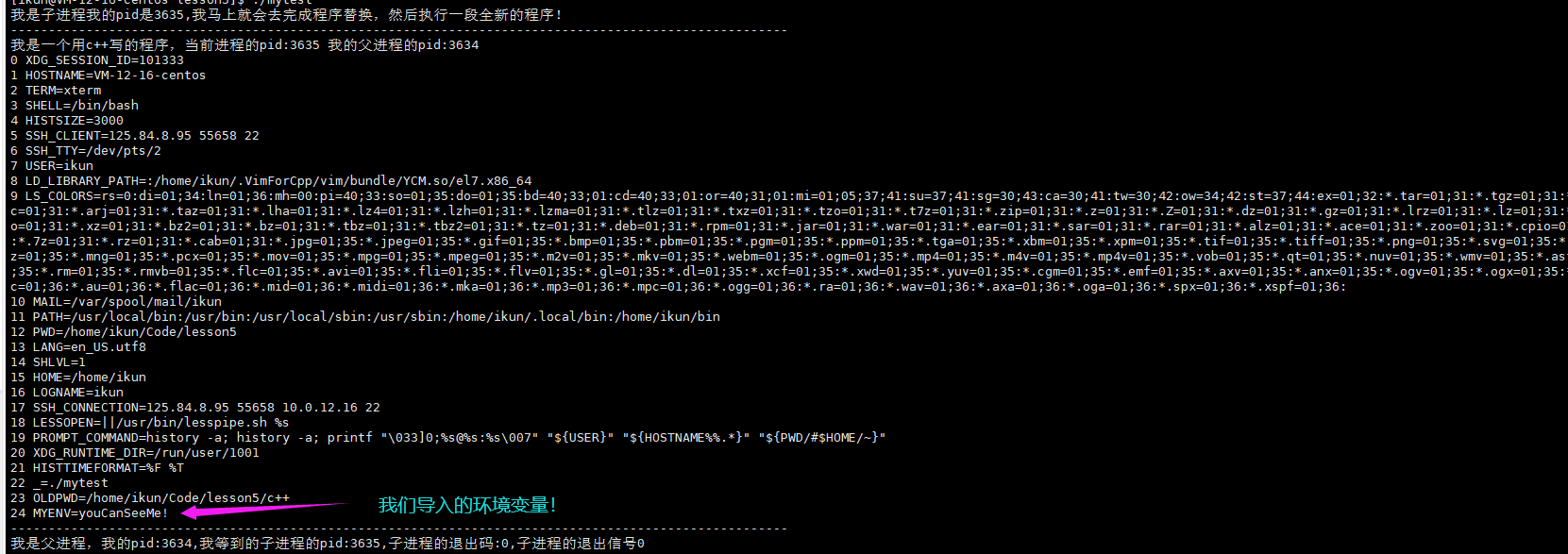
Linux程序替换
Linux程序替换创建子进程的目的?程序替换如何实现程序替换?什么是程序替换?先见一见单进程版本的程序替换程序替换原理多进程版本的程序替换execl函数组简易版Shell创建子进程的目的? 目的:为了帮助父进程完成一些特定的任务&…...

@JsonFormat @DataTimeFormat 时间格式
省流:用JsonFormat即可有时候会看到入参dto里,在时间类型的变量上用DateTimeFormat,代码如下。public class XXXdto{DateTimeFormat(pattern "yyyy-MM-dd hh:mm:ss")private Date startDate; }这是为了入参传日期格式的值。即前端…...
带你玩转modbusTCP通信
modbus TCP Modbus TCP是一种基于TCP/IP协议的Modbus通信协议,它是Modbus协议的一种变体,用于在以太网上进行通信。Modbus TCP协议是一种开放的通信协议,它支持多种编程语言和操作系统,并且可以在不同的硬件和软件平台上进行通信…...
T2交替)
2021牛客OI赛前集训营-提高组(第三场)T2交替
2021牛客OI赛前集训营-提高组(第三场) 题目大意 一个长度为nnn的数组aaa,每秒都会变成一个长度为n−1n-1n−1的新数组a′aa′,其变化规则如下 如果当前数组aaa的大小nnn为偶数,则对于新数组a′aa′的每一个位置i(1≤…...

论文投稿指南——中文核心期刊推荐(金融)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
【独家】)
华为OD机试 - 不等式(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:不等式题…...
90后老板用低代码整顿旅行社,创2000万年收,他是怎么做到的?(真实)
热爱旅游的92年成都小伙猴哥,大学毕业后开了一家旅行社,主要从事川藏、云南定制游服务。 从今年春节开始,国内各地旅游业开始复苏,向旅行社打电话咨询的人越来越多。 旅游的人多是好事,也是一种烦恼,因为…...

Apache Dubbo 存在反序列化漏洞(CVE-2023-23638)
漏洞描述 Apache Dubbo 是一款轻量级 Java RPC 框架 该项目受影响版本存在反序列化漏洞,由于Dubbo在序列化时检查不够全面,当攻击者可访问到dubbo服务时,可通过构造恶意请求绕过检查触发反序列化,执行恶意代码 漏洞名称Apache …...

【YOLO】YOLOv8训练自定义数据集(4种方式)
YOLOv8 出来一段时间了,继承了分类、检测、分割,本文主要实现自定义的数据集,使用 YOLOV8 进行检测模型的训练和使用 YOLOv8 此次将所有的配置参数全部解耦到配置文件 default.yaml,不再类似于 YOLOv5,一部分在配置文件…...

linux重置root用户密码
重置root密码 法一:rd.break 第 1 步:重启系统编辑内核参数 第 2 步:找到 linux 这行,在此行末尾空格后输入rd.break (End键也可直接进入行尾) 成功后显示页面为: 第 3 步:查看。…...
【DBC专题】-10-CAN DBC转换C语言代码Demo_接收Rx报文篇
案例背景(共15页精讲): 该篇博文将告诉您,CAN DBC转换C语言代码Demo,只需传递对应CAN信号关联参数,无需每个信号"左移"和"右移",并举例介绍:在CANoe/Canalyzer中CAPL中的应用ÿ…...

AtCoder292 E 思维
题意: 给定一副n(n≤3000)n(n\leq 3000)n(n≤3000)个顶点,mmm条有向边的图,可以在图中添加有向边,求添加的最少边数,使得这副图满足:如果顶点aaa到顶点bbb有边,顶点bbb到ccc右有边,…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...