HDFS如何解决海量数据存储及解决方案详解
HDFS组件
HDFS组件的基准测试
说明
一般在搭建完集群之后,运维人员需要对集群进行压力测试,对于HDFS来讲,主要是读写测试
写入测试
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
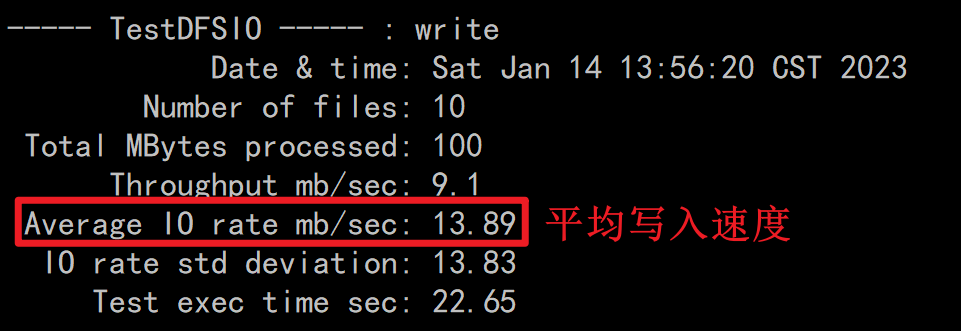
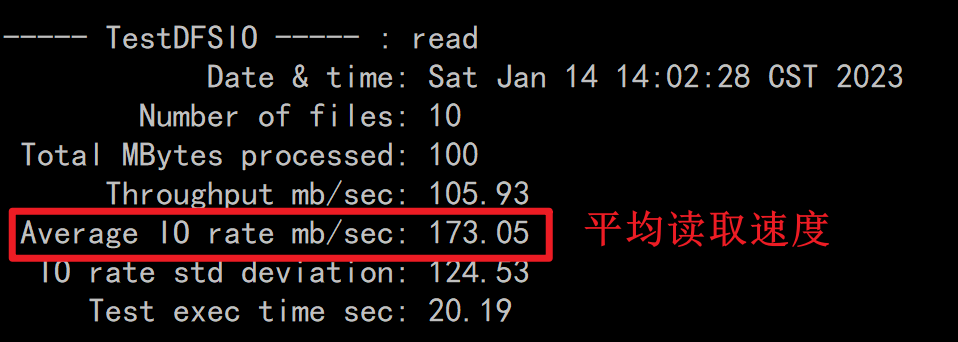
读取测试
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
Hadoop的MapReduce历史服务查看
说明
如果你开启了历史服务器组件,则你跑过的所有的MapReduce任务都可以在19888端口查看,同时可以通过后台的日志先查看任务详细的执行流程,以便排查错误http://node1:19888
打开方式
http://node1:19888/
文件系统
概念
文件系统是一个软件,通过这个软件,用户不用关系具体的文件内容存储在磁盘的什么位置,直接就可以对文件操作
文件系统的分类
-
本地磁盘文件系统
类Windows文件系统:盘符体系(D盘,E盘)NTFS 类Unix文件系统: /目录 -
光盘文件系统
ISO镜像文件 -
网络文件系统
NFS: 使用网络来远程访问其他主机的文件,就像访问本机文件一样方便 -
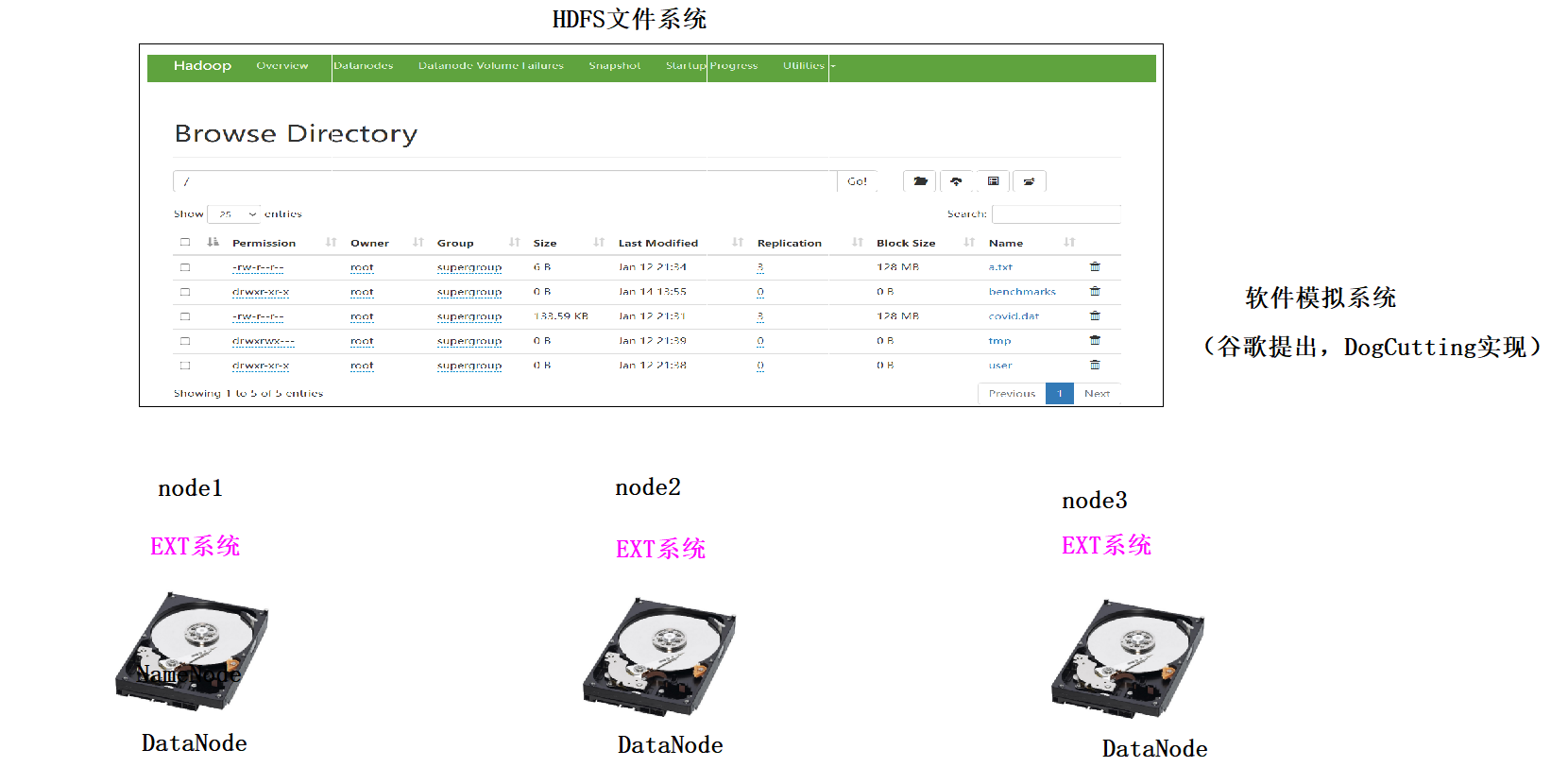
分布式文件系统
1、分布式文件系统是由多态主机模拟出来的一个文件系统,文件是分散存储在不同的主机上 2、分布式文件系统有很多种: 1)、GFS GFS(Google File System)是Google公司为满足公司需求而开发的基于Linux的可扩展的分布式文件系统,用于大型的、分布式的、对大数据进行访问和应用,成本低,应用于廉价的普通硬件上,但不开源,暂不考虑。2)、TFS TFS(Taobao File System)是阿里巴巴为满足了淘宝对小文件存储的需求而开发的一个可扩展、高可用、高性能、面向互联网服务、开源的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,这个也暂不考虑。3)、HDFS HDFS(Hadoop Distributed File System)。Hadoop分布式文件系统,适合运行在通用硬件上做分布式存储和计算,因为它具有高容错性和可扩展性的特点,可部署在廉价的机器上,适合大数据的处理,在离线批量处理大数据上有先天的优势。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。4)、MooseFS MooseFS 是来自波兰的开源且具备冗余容错功能的分布式 POSIX 文件系统,也是参照了 GFS 的架构,实现了绝大部分 POSIX 语义和 API,它支持通过FUSE方式将文件挂载操作,同时其提供的web管理界面非常方便查看当前的文件存储状态,对master服务器有单点依赖,用perl编写,用于中、大型文件应用,但性能相对较差,由于可能会实时访问所以暂不考虑。 备注:POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准5)、FastDFS 由淘宝的余庆先生所开发的一个开源分布式文件系统。它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。适合以文件为载体的在线服务,如相册网站、视频网站等等。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS搭建一套高性能的文件服务器集群提供文件上传、下载等服务。但是FastDFS部署有点麻烦,且它的SKD是不全的。6)、MogileFS MogileFS是一套高效开源的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。支持多节点冗余,可实现自动的文件复制。不需要RAID,应用层可以直接实现RAID,不共享任何东西,通过集群接口提供服务工作于应用层,没有特殊的组件要求。使用HTTP方式通信。7)、GridFS MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等),是文件存储的一种方式,但是它是存储在MonoDB的集合中。它可以直接利用已建立的复制或分片机制,所以对于文件存储来说故障恢复和扩展都容易,且GridFS不产生磁盘碎片。8)、MinIO MinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。它也是一个非常轻量的服务,可以很简单的和其他应用的结合。MinIO的特色在于简单、轻量级,对开发者友好,学习成本低,安装运维简单,开箱即用。9)、SeaweedFS SeaweedFS是基于go语言开发高度可扩展开源的分布式存储系统,能存储数十亿文件(最终受制于你的硬盘大小)、并且速度快,内存占用小。上手使用比fastDFS要简单很多,自带Rest API。对于中小型文件效率非常高,但是单卷最大容量被程序限制到30G,建议存储文件以100MB以内为主。10)、Ceph Ceph是Red Hat旗下一个成熟的分布式文件系统,而且还是一个有企业级功能的对象存储生态环境。该系统具备高性能、高可用性、高可扩展性、实时存储性等特点。虽然ceph很强大,但是学习成本高、安装运维复杂。Ceph用C++编写,存储容量可轻松达到PB级别。11)、GlusterFS GlusterFS 是由美国的 Gluster 公司开发的 POSIX 分布式文件系统(以 GPL 开源),它主要应用在集群系统中,具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。该系统主要是为中大型文件设计的,存储容量可轻松达到PB。它存在扩容缩容影响服务器较多、遍历目录下文件耗时、小文件性能较差的缺点。
HDFS如何解决海量数据问题
存储方式
1、传统单机存储是纵向扩展存储空间(不断加硬盘),这种扩展是有限的
2、分布式存储是横向扩展存储空间(不断加主机),这种扩展几乎是无限的
文件查询问题
NameNode: 存储HDFS的文件的元数据,NodeName工作时,这些元数据会被加载到内存中,同时也会被持久化存储到硬盘上#元数据:类似派出所的户籍信息,描述文件除内容之外的额数据(文件的权限,大小,存储路径,Block信息)DataNode: 具体存储文件数据的,这些数据最后分散在不同主机的硬盘上
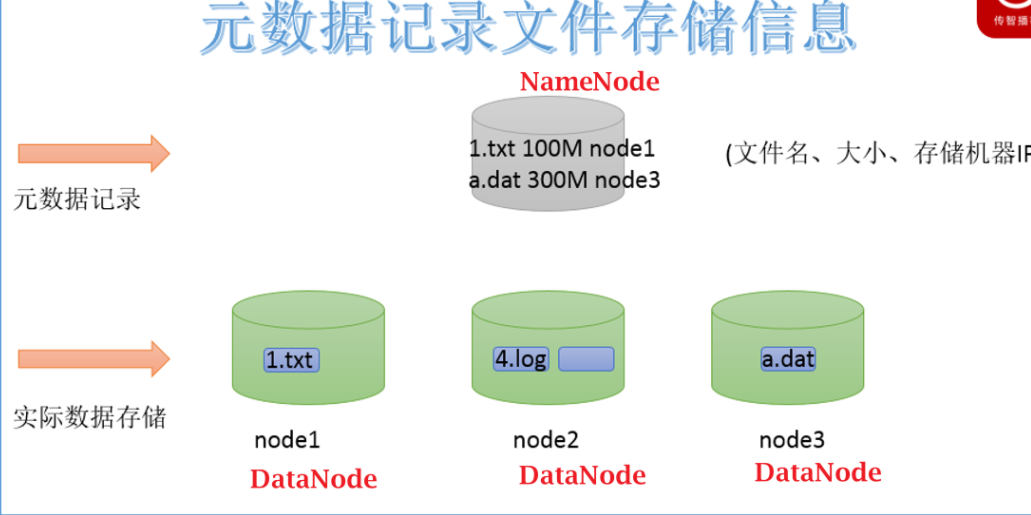
HDFS的简介
1、HDFS(Hadoop Distributed File System) 是Hadoop分布式文件系统
2、HDFS主要是存储TB和PB,EB级别文件
3、HDFS上存储的文件只能追加写入(在尾部加入内容),不能随机修改(在中间修改),HDFS除了最后一个Bock之外,前边的所有的Block一旦定型,永远不能修改4、HDFS的读写速度有延迟,不能保证实时,如果你对时效性要求比较高,则不要使用HDFS
5、HDFS适合存储大文件,不适合存储小文件:5.1)一个文件,不管大小,都会占用一条元数据,一条元数据大概是150字节5.2)在工作时,元数据是保存在NameNode主机的内存中,内存如果有限的情况下,保存的元数据数量也是有限的,NameNode主机内存固定的情况下,能存多少条元数据是固定的5.3)如果你存储太多的小文件,这些小文件会占用大量的元数据,会占用namenode大量的内存空间,会导致 NameNode内存空间不够用的问题。6、由于HDFS强调的是集群整体的性能,单机的性能可以很弱,机器可以很廉价(蚂蚁多了,力量也很强大)
HDFS的切片问题
1、默认情况下,HDFS是以Block为单位进行存储,每一个Block最大是128M,如果一个文件不足128M,则默认也是一个Block,所以Block是一个逻辑单位
2、举例:1.txt 300M Block1 128M Block2 128M Block3 44M
3、我们可以去修改每个Block的大小:dfs.blocksize 134217728 字节 在hdfs-site.xml中做如下配置:
<property><name>dfs.blocksize</name><value>268435456</value>
</property>在node1修改完之后,要将这个配置文件分发给node2和node3,然后重启hadoop
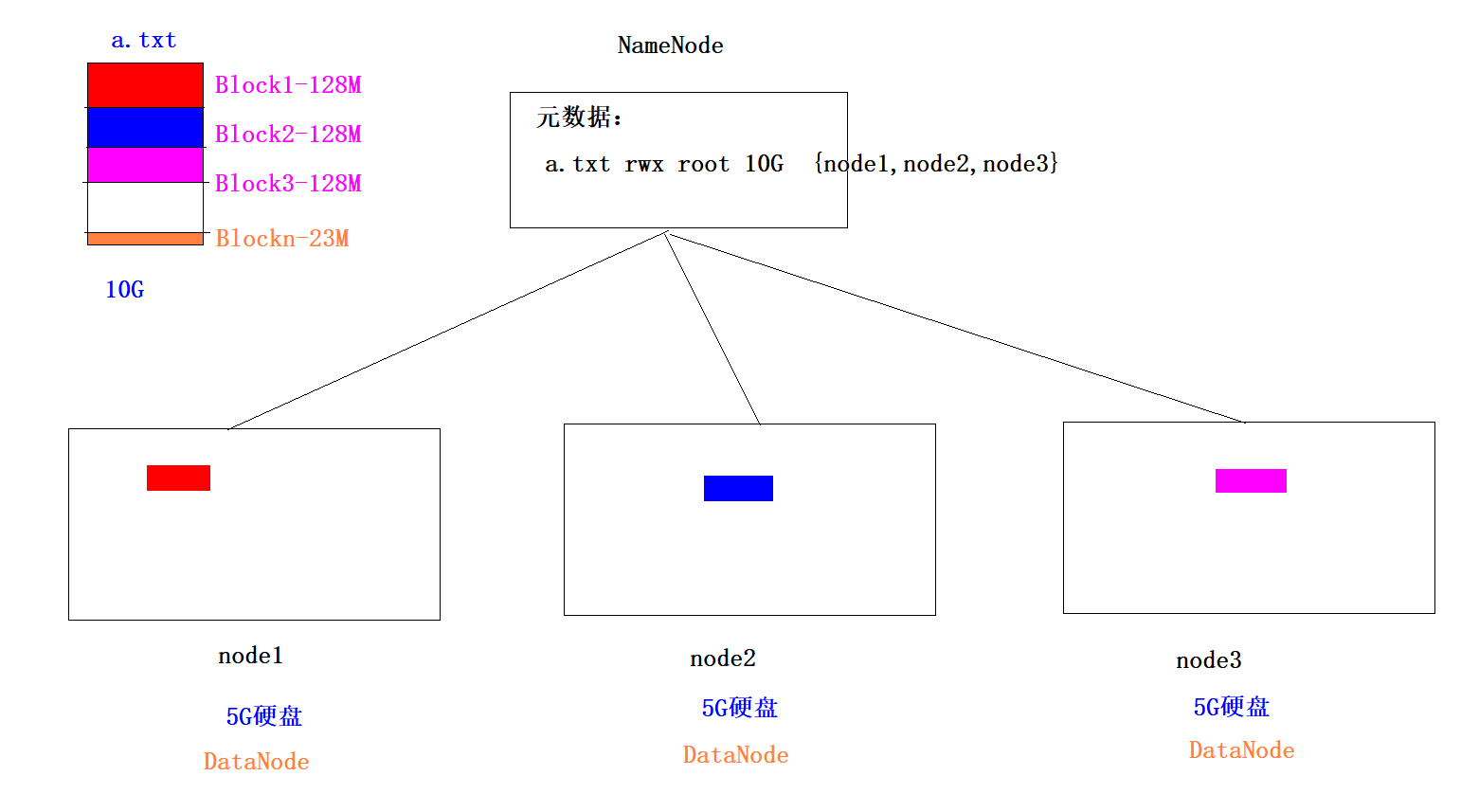
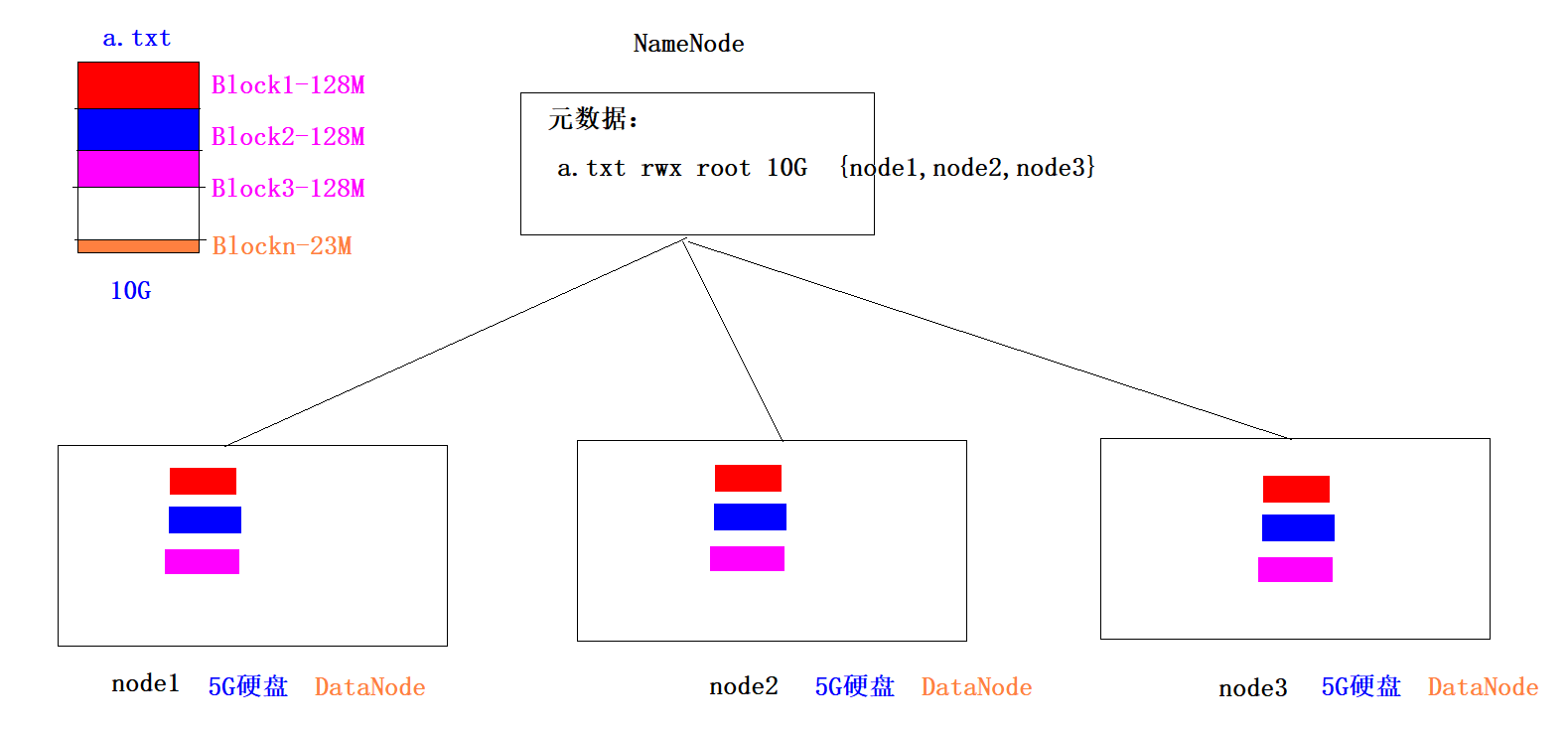
HDFS如何解决数据丢失问题-副本机制
1、每一个Block切片都会存储多个副本(默认是3个)
2、副本机制就是通过牺牲空间来换取数据的安全可靠性
3、我们可以通过dfs.replication参数来修改副本数量,在hdfs-site.xml中做如下配置:<property><name>dfs.replication</name><value>2</value>
</property>在node1修改完之后,要将这个配置文件分发给node2和node3,然后重启hadoop#在Linux如何造一个任意大小的测试文件
dd if=/dev/zero of=my_file bs=1M count=300 #300M文件
dd if=/dev/zero of=my_file bs=1G count=1 #1G文件
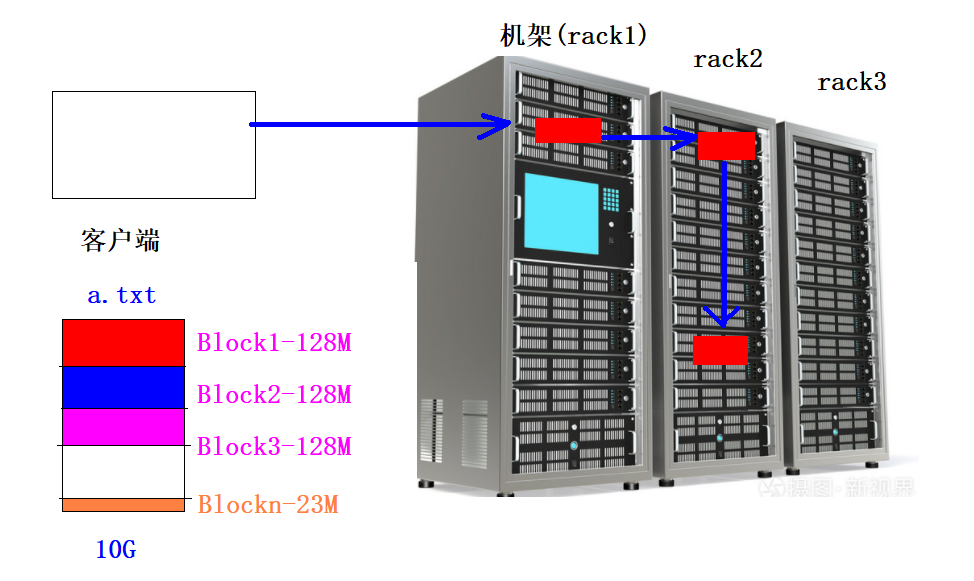
HDFS的机架感知
-
概念
1、一个Block默认有3个副本,当存一个BLock的时候,每一个副本应该存放到哪一台主机有一定的策略,这个策略就被称为机架感知/*** The class is responsible for choosing the desired number of targets* for placing block replicas.* The replica placement strategy is that if the writer is on a datanode,* the 1st replica is placed on the local machine, * otherwise a random datanode. The 2nd replica is placed on a datanode* that is on a different rack. The 3rd replica is placed on a datanode* which is on a different node of the rack as the second replica.*/ @InterfaceAudience.Private public class BlockPlacementPolicyDefault extends BlockPlacementPolicy {2、机架感知策略第一个副本如果客户端就是集群内部的某台主机,则第一个副本直接本地存储放在客户端主机上,否则随机选择一台主机第二个副本放在和第一个副本不同的机架上第三个副本放在和第二个副本同一个机架不同主机上
HDFS文件如何让用户访问-名称空间
1、为了让客户不去关心HDFS文件复杂的元数据管理,我们只需要给用户暴露一个唯一的目录树结构的访问路径鸡即可,这个被称为名称空间。
访问的主机本身就在集群内部:/benchmarks/TestDFSIO/io_data/test_io_0
访问的主机本身就在集群外部:hdfs://node1:8020/benchmarks/TestDFSIO/io_data/test_io_02、HDFS的路径和Linux主机的本地路径没有关系
HDFS的元数据
1、元数据是描述文件特征的数据,不是文件内容
2、元数据包含的信息:2.1)文件自身属性信息文件名称、权限,修改时间,文件大小,副本数,Block大小。-rw-r--r-- root supergroup 6 B Jan 12 21:34 3 128 MB a.txt2.2) 文件块位置映射信息记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。a.txt 300M------------------------------{blk1:node2,node1,node3blk2:node3,node1,node2blk3:node1,node2,node3}
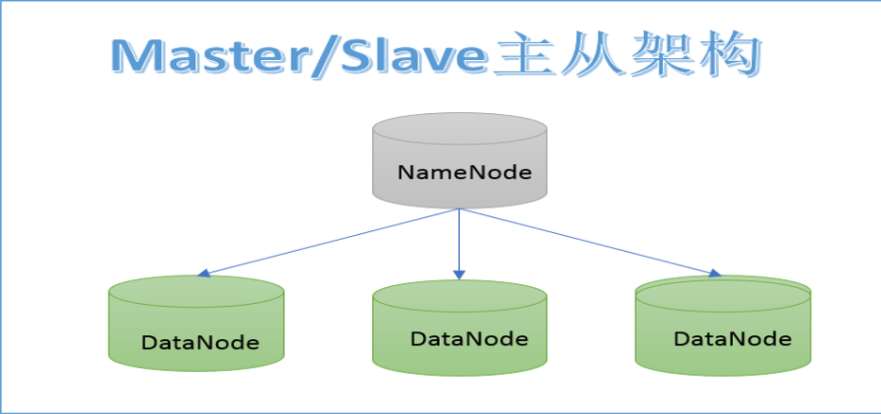
HDFS的架构
NameNode: 1、存储HDFS的文件的元数据,NodeName工作时,这些元数据会被加载到内存中,同时也会被持久化存储到硬盘2、NameNode接受客户端读写请求,因为NameNode知道每一个文件都存在哪个DataNode上3、NameNode接受各个DataNode的心跳信息、Block汇报信息、资源使用情况(硬盘)4、如果NameNode一旦挂掉,整个集群将不能工作DataNode: 1、存具体的文件数据2、定时向NameNode汇报心跳信息、Block汇报信息、资源使用情况3、如果某个DataNode挂掉,只要丢失Block的信息其他主机有,则不影响集群运行
HDFS的Shell命令
介绍
1、HDFS的网页页面在2.x版本时是没有任何操作菜单,只能查看,则必须使用Shell命令来操作
2、学习HDFS的Shell命令可以在不查看页面的情况下对HDFS上的文件进行增删改查
语法
hadoop fs 参数 #该方式可以操作任何文件系统:磁盘文件系统、HDFS文件系统
hdfs dfs 参数 #该方式只能操作HDFS文件系统
操作
#1、查看指定路径的当前目录结构
hadoop fs -ls /
hdfs dfs -ls /#2、递归查看指定路径的目录结构
hadoop fs -lsr / #已淘汰
hadoop fs -ls -R / #用这个#3、查看目录下文件的大小
hadoop fs -du -h /#4、文件移动(HDFS之间)
hadoop fs -mv /a.txt /dir1#5、文件复制(HDFS之间)
hadoop fs -cp /dir1/a.txt /dir1/b.txt#6、删除操作 !!!!!!!!!!!!!!!!!!
hadoop fs -rm /dir1/b.txt #删文件
hadoop fs -rm -r /dir1 #删目录 #7、文件上传(本地文件系统到HDFS文件系统) --- 复制操作 !!!!!!!!!!!!
hadoop fs -put a.txt /dir1 #8、文件上传(本地文件系统到HDFS文件系统) --- 剪切操作
hadoop fs -moveFromLocal test1.txt /#8、文件下载(HDFS文件系统到本地文件系统) !!!!!!!!!!!
hadoop fs -get /aaa.txt /root #9、文件下载(HDFS文件系统到本地文件系统)
hadoop fs -getmerge /dir/*.txt /root/123.txt #10、将小文件进行合并,然后上传到HDFS
hadoop fs -appendToFile *.txt /hello.txt
hadoop fs -appendToFile 1.txt 2.txt 3.txt /hello.txt
hadoop fs -appendToFile /root/* /hello.txt #11、查看HDFS文件内容
hadoop fs -cat /dir1/1.txt#12、在HDFS创建文件夹 !!!!!!!!!!!!
hadoop fs -mkdir /my_dir#13、修改HDFS文件的权限
hadoop fs -chmod -R 777 /dir1#14、修改HDFS的所属用户和用户组useradd hadoop
passwd hadoophadoop fs -chown -R hadoop:hadoop /dir
回收站配置
#在每个节点的core-site.xml上配置为1天,1天之后,回收站的资源自动
<property><name>fs.trash.interval</name><value>1440</value><description>minutes between trash checkpoints</description>
</property>#需要重启Hadoop
HDFS的安全模式
-
介绍
1、在HDFS启动时,HDFS会自动的进入安全模式,在该模式下进行Block数量的检测和自我修复,当BLock数量完整率达到99.9%时,会自动的离开安全模式2、安全模式停留多长时间不固定,你的Block数量越多,检测的时间越长,安全模式停留时间越长3、在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。 -
操作命令
hdfs dfsadmin -safemode get #查看安全模式状态 hdfs dfsadmin -safemode enter #进入安全模式 hdfs dfsadmin -safemode leave #离开安全模式hdfs dfsadmin -safemode forceExit #强制离开安全模式
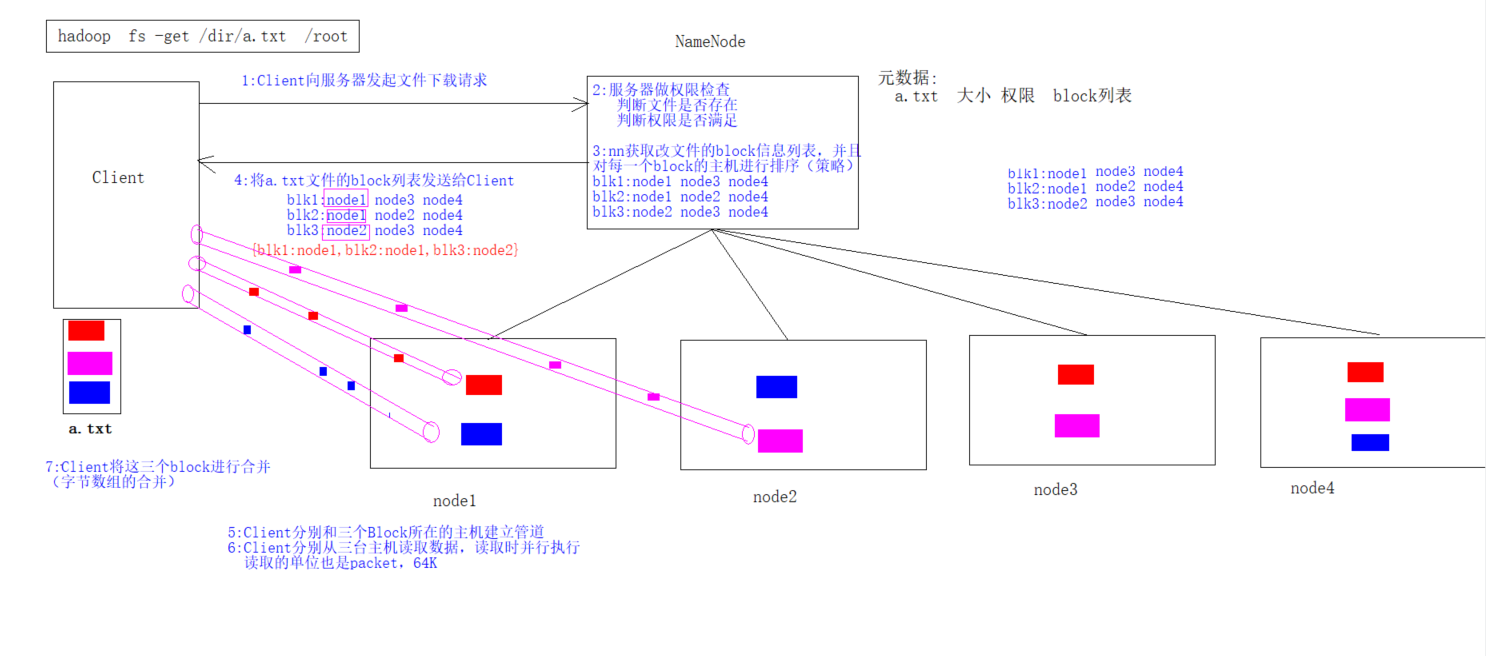
HDFS的读写流程
写入流程

读取流程
HDFS的元数据管理
- 原理
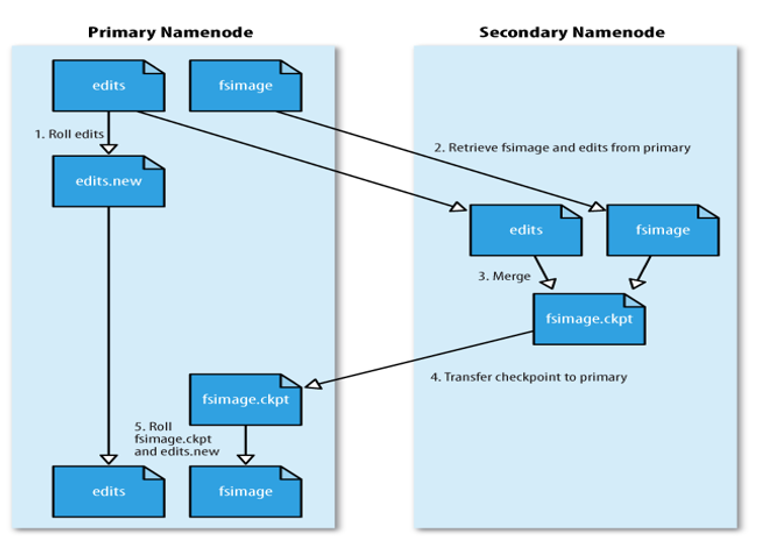
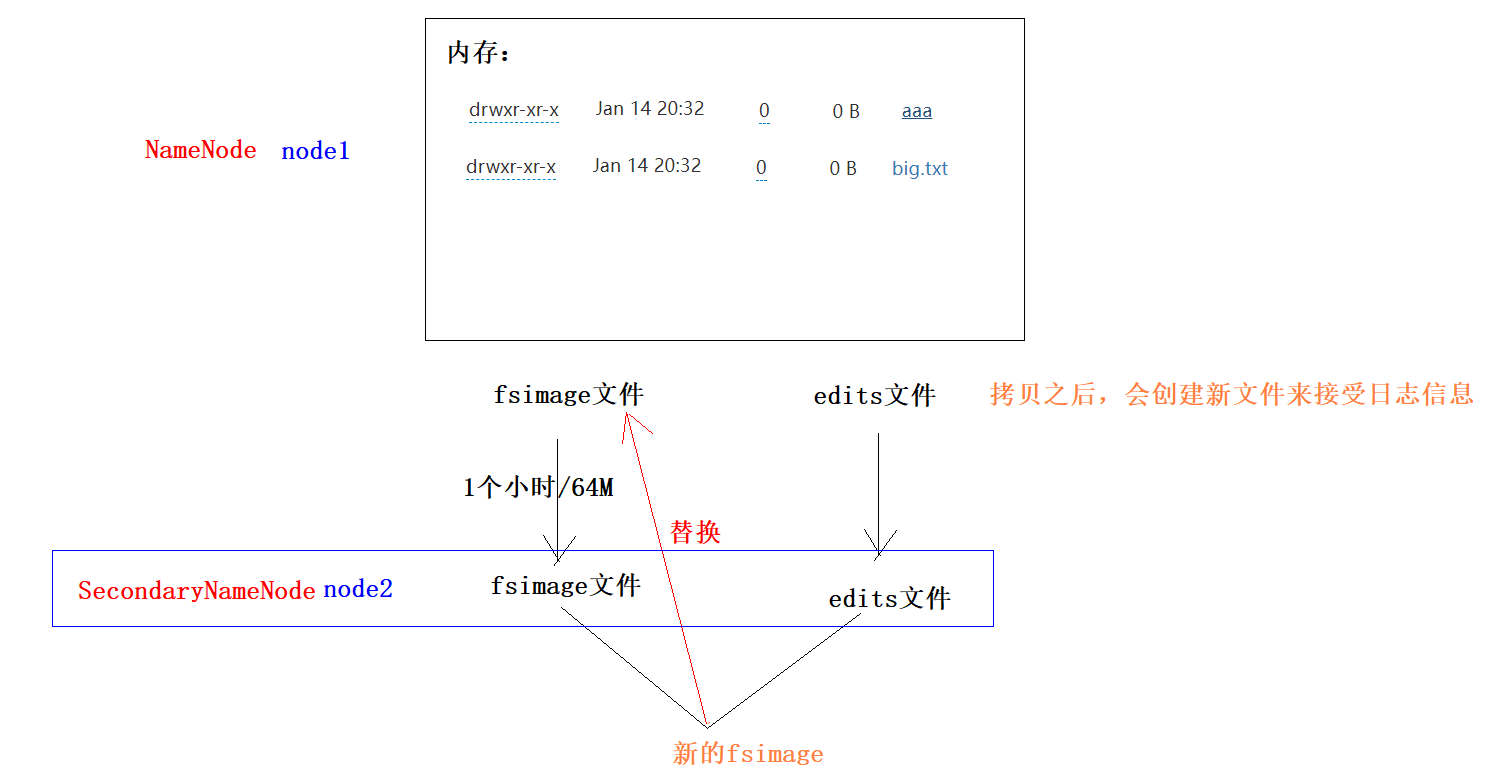
1)当触发checkpoint操作条件(每隔一个小时,或者edits文件达到64M)时,SNN发生请求给NN滚动edits log。然后NN会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
2)同时SNN会将edits文件和fsimage复制到本地(使用HTTP GET方式)。
3)SNN首先将fsimage载入到内存,然后一条一条地执行edits文件中的操作,使得内存中的fsimage不断更新,这个过程就是edits和fsimage文件合并。合并结束,SNN将内存中的数据dump生成一个新的fsimage文件。
3)SNN将新生成的Fsimage new文件复制到NN节点。
4)至此刚好是一个轮回,等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
-
查看日志文件内容
hdfs oev -i edits_0000000000000000011-0000000000000000025 -o edits.xml
HDFS的JavaAPI操作(重点)
-
介绍
使用Java提供的API来对HDFS上的文件进行增删查,相当于实现9870页面的鼠标操作和Shell命令操作 -
核心类
FileSystem Configuration -
代码
package pack01_hdfs;import org.apache.commons.compress.utils.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.Test; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.net.URI; import java.net.URISyntaxException; import java.util.Arrays;public class Test1HDFS {//文件的合并上传-方式2@Testpublic void test9AppendToFile()throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:获取HDFS目标文件的输出流-写FSDataOutputStream outputStream = fileSystem.create(new Path("/append2.txt"));//3:获取本地每一个小文件的输入流File file = new File("E:\\input");File[] files = file.listFiles();for (File file1 : files) {FileInputStream inputStream = new FileInputStream(file1);//4:实现文件的合并IOUtils.copy(inputStream,outputStream);IOUtils.closeQuietly(inputStream);}//5:关流IOUtils.closeQuietly(outputStream);}//文件的合并上传-方式1@Testpublic void test8AppendToFile()throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:获取HDFS目标文件的输出流-写FSDataOutputStream outputStream = fileSystem.create(new Path("/append.txt"));//3:获取本地每一个小文件的输入流FileInputStream inputStream1 = new FileInputStream("E:\\input\\a.txt");FileInputStream inputStream2 = new FileInputStream("E:\\input\\b.txt");FileInputStream inputStream3 = new FileInputStream("E:\\input\\c.txt");//4:实现文件的合并IOUtils.copy(inputStream1,outputStream);IOUtils.copy(inputStream2,outputStream);IOUtils.copy(inputStream3,outputStream);//5:关流IOUtils.closeQuietly(inputStream3);IOUtils.closeQuietly(inputStream2);IOUtils.closeQuietly(inputStream1);IOUtils.closeQuietly(outputStream);}//文件的下载-方式2@Testpublic void test7Upload()throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:文件的上传fileSystem.copyFromLocalFile(new Path("E:\\big.txt"),new Path("/bigg.txt"));}//文件的下载-方式2@Testpublic void test6Download2()throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:文件的下载fileSystem.copyToLocalFile(new Path("/big.txt"),new Path("E:\\big2.txt"));}//文件的下载-方式1@Testpublic void test5Download1()throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:获取HDFS文件的输入流-读FSDataInputStream inputStream = fileSystem.open(new Path("/big.txt"));//3:获取目标文件的输出流-写FileOutputStream outputStream = new FileOutputStream("E:\\big.txt");/*//4:完成文件的复制byte[] bytes = new byte[1024];while (true){int len = inputStream.read(bytes);if(len == -1){break;}outputStream.write(bytes,0,len);}//5:关流outputStream.close();inputStream.close();*///4:完成文件的复制IOUtils.copy(inputStream,outputStream);//5:关流IOUtils.closeQuietly(inputStream);IOUtils.closeQuietly(outputStream);}//从HDFS删除文件@Testpublic void test4Delete() throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:从HDFS删除文件fileSystem.delete(new Path("/itcast"),true);}//在HDFS上创建目录(递归创建)@Testpublic void test3Mkdir() throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:在HDFS创建目录fileSystem.mkdirs(new Path("/itcast/ky7/hdfs"));}//遍历HDFS的文件信息@Testpublic void test2ListFiles() throws Exception{//1:获取FileSystem对象FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());//2:获取指定目录下的所有文件元数据信息RemoteIterator<LocatedFileStatus> iterator =fileSystem.listFiles(new Path("/"), true);//3:遍历集合while (iterator.hasNext()){//4、获取每一个文件的元数据信息LocatedFileStatus fileStatus = iterator.next();//5、打印每一个文件的元数据信息-文件绝对路径System.out.print(fileStatus.getPath());//6、Block信息//6.1 获取每一个BLock信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println("----"+blockLocations.length); //输出每个文件的Block数 3for (BlockLocation blockLocation : blockLocations) {//6.2获取每一个Block的副本存储主机位置String[] hosts = blockLocation.getHosts();System.out.println(Arrays.toString(hosts));}}}@Testpublic void test1GetFileSytem() throws Exception {FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());System.out.println(fileSystem);} }
HDFS的远程拷贝命令
-
集群内部拷贝
#推数据 scp -r /root/test/ root@192.168.88.161:/root/#拉数据 scp root@192.168.88.162:/root/test.txt /root/test.txt -
集群之间拷贝
hadoop distcp hdfs://node1:8020/a.txt hdfs://hadoop1:8020/
HDFS的归档机制(面试题)
-
介绍
如果HDFS上有很多的小文件,会占用大量的NameNode元数据的内存空间,需要将这些小文件进行归档(打包),归档之后,相当于将多个文件合成一个文件,而且归档之后,还可以透明的访问其中的每一个文件 -
操作
#数据准备 hadoop fs -mkdir /config hadoop fs -put /export/server/hadoop-3.3.0/etc/hadoop/*.xml /config#创建归档文件 hadoop archive -archiveName test.har -p /config /outputdir hadoop fs -rm -r /config#查看合并后的小文件全部内容 hadoop fs -cat /outputdir/test.har/part-0#查看归档中每一个小文件的名字 hadoop fs -ls har://hdfs-node1:8020/outputdir/test.har#查看归档中其中的一个小文件内容 hadoop fs -cat har:///outputdir/test.har/core-site.xml#还原归档文件 hadoop fs -mkdir /config hadoop fs -cp har:///outputdir/test.har/* /config -
注意点
1. Hadoop archives是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。Hadoop archive的扩展名是*.har; 2. 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令,要提前启动Yarn集群; 3. 创建archive文件要消耗和原文件一样多的硬盘空间; 4. archive文件不支持压缩,尽管archive文件看起来像已经被压缩过; 5. archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日; 6. 当创建archive时,源文件不会被更改或删除;
HDFS的权限问题
- 操作
hadoop fs -chmod 750 /user/itcast/foo //变更目录或文件的权限位
hadoop fs -chown :portal /user/itcast/foo // 变更目录或文件的所属用户
hadoop fs -chgrp itcast _group1 /user/itcast/foo //变更用户组
-
原理
1、HDFS的权限有一个总开关,在hdfs-site.xml中配置,只有该参数的值为true,则HDFS的权限才可以起作用dfs.permissions.enabled #在Hadoop3.3.0中该值默认是 true -
Java代码权限问题
//如果在通过JavaAPI来访问HDFS,遇到权限问题,有3中解决方案 1、关闭HDFS权限的总开关,设置 dfs.permissions.enabled 为 false 2、使用 hadoop fs -chmod -R 777 /tmp 修改权限 3、使用root用户的身份去获取FileSystem对象FileSystem fileSystem =FileSystem.get(new URI("hdfs://node1:8020"), new Configuration(),"root");
HDFS的动态上下线
动态扩容
纵向扩容:加硬盘
横向扩容:加主机
-
介绍
1、当集群的存储容量达到上限时,我们可以通过添加主机的方式来扩展DataNode节点,来横向增加集群的存储空间 2、我们在动态扩容时,不要一影响当前集群的正常工作 -
操作
==================1、基础环境配置==================== 1、从node1克隆一台主机:node4 2、修改node4的Mac地址、IP地址为164,主机名为node4 3、关闭node4的防火墙、安装JDK,关闭Selinux (已做)4、node1、node2、node3、node4要修改域名映射 192.168.88.161 node1 node1.itcast.cn 192.168.88.162 node2 node2.itcast.cn 192.168.88.163 node3 node3.itcast.cn 192.168.88.164 node4 node4.itcast.cn5、node1、node2、node3、node4重新构建免密登录 5.1)在node4上,生成一个密钥对:ssh-keygen -t rsa 5.2)在node4上,将node4的公钥发送给node1:ssh-copy-id node1 5.3)将node1上,将所有公钥发送给:node2,node3,node4scp /root/.ssh/authorized_keys node2:/root/.sshscp /root/.ssh/authorized_keys node3:/root/.sshscp /root/.ssh/authorized_keys node4:/root/.ssh6、在node4上,删除Hadoop的所有痕迹6.1)删除Hadoop安装包: rm -fr /export/server/hadoop-3.3.0/6.2)删除Hadoop数据: rm -fr /export/data/hadoop-3.3.0/6.3)删除Hadoop的环境变量:vim /etc/profile==================1、Hadoop上线核心配置====================7、在node1上修改namenode(node1)节点workers配置文件,增加新节点主机名vim /export/server/hadoop-3.3.0/etc/hadoop/workers node1node2node3node4 8、在node1上,将Hadoop分发给node4scp -r /export/server/hadoop-3.3.0 node4:/export/server9、在node4上,新机器上配置hadoop环境变量 vim /etc/profileexport HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin最后:source /etc/profile10、在node4上启动datanode hdfs --daemon start datanode 11、通过页面查看 http://node1:9870/dfshealth.html#tab-datanode#---------------设置负载均衡--------------- #设置在负载均衡期间DataNode在数据搬移时,能够使用的最大带宽(100M) hdfs dfsadmin -setBalancerBandwidth 104857600#当不同主机之间存储的比率超过5%时,会自动进行负载均衡操作 hdfs balancer -threshold 5
动态缩容
1、在node1上,保证你的hdfs-site.xml文件中有以下黑名单配置
<property><name>dfs.hosts.exclude</name><value>/export/server/hadoop-3.3.0/etc/hadoop/excludes</value>
</property>2、在node1上,将你要退役的主机的主机名加入黑名单,编辑以下文件,加入node4vim /export/server/hadoop-3.3.0/etc/hadoop/excludes3、在ndoe1上,刷新集群hdfs dfsadmin -refreshNodes4、通过datanode页面查看node4的退役状态http://node1:9870/dfshealth.html#tab-datanode#---------------设置负载均衡---------------
#设置在负载均衡期间DataNode在数据搬移时,能够使用的最大带宽(100M)
hdfs dfsadmin -setBalancerBandwidth 104857600#当不同主机之间存储的比率超过5%时,会自动进行负载均衡操作
hdfs balancer -threshold 5
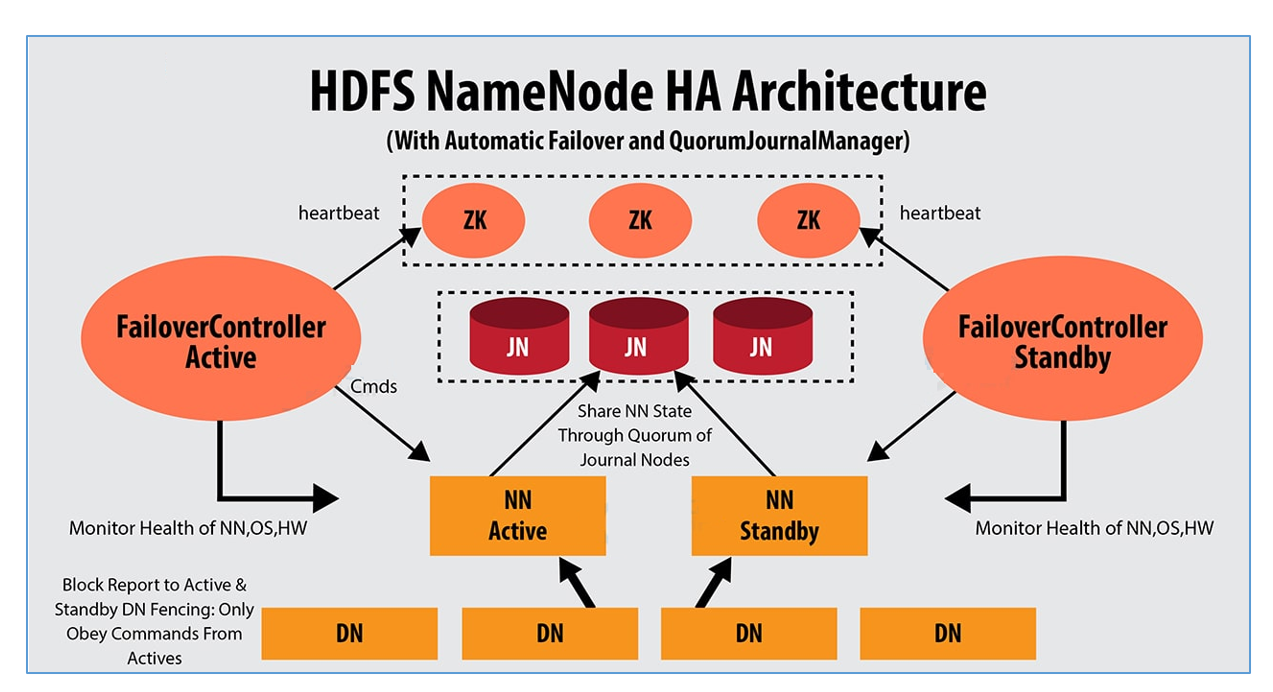
HDFS的高可用
介绍
1、HDFS的高可用是由NameNode组成,一个是Active状态的NameNode,一个是Standby状态的NameNode
2、Journal Node集群两个NamNode之间元数据的同步,同步的数据是日志文件Edits,由NameNode自己完成fsimage文件的生成,没有SecondaryNameNode
3、两个NameNode的主备切换,是由ZKFC和Zookeeper集群共同来完成3.1 正常情况下由ZKFC来监控 Active NameNode的健康状态,一旦发现主NameNode健康不良,则立刻通知Zookeeper,Zookeeper会通知备ZKFC,然后备ZKFC会改变备NameNode状态由Standby改为Active,备NameNode成为新的主节点
脑裂问题
-
原因
由于极端情况下,主NameNode发生了假死现象,临时假死,后来又复活,这样原来的主NameNode状态是Active,后来的备用NameNode状态也改为Active,这样就会有两个Active状态的NameNode,会造成元数据的管理混乱,就相当于一个大脑被拆分了。 -
解决方案
方案1:调用旧Active状态的RPC接口中的相关方法,将其状态由Active强制改为StandBy 方案2:如果方案1没有实现,则ZK会远程登录到旧Active的NameNode主机上,将NameNode进程杀死
环境搭建
- 搭建方案

-
操作步骤
-
1、备份单节点Hadoop
#在node1,node2,node3主机上,分别执行以下操作:mv /export/server/hadoop-3.3.0 /export/server/hadoop-3.3.0_bak -
2、解压Hadoop
tar -xvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /export/server/ -
3、配置环境变量(可以不做)
#在node1,node2,node3主机上,分别执行以下操作: vim /etc/profileexport HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile -
4、配置hadoop-env.sh文件
cd /export/server/hadoop-3.3.0/etc/hadoopvim hadoop-env.shexport JAVA_HOME=/export/server/jdk1.8.0_241export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root -
5、core-site.xml
<configuration><!-- HA集群名称,该值要和hdfs-site.xml中的配置保持一致 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- hadoop本地磁盘存放数据的公共目录 --><property><name>hadoop.tmp.dir</name><value>/export/data/ha-hadoop</value></property><!-- ZooKeeper集群的地址和端口--><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property> </configuration> -
6、配置 hdfs-site.xml
<configuration><!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- mycluster下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:9870</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:9870</value></property><!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/export/data/journaldata</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 指定该集群出故障时,哪个实现类负责执行故障切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制方法--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property> </configuration> -
配置mapred-site.xml
<configuration> <!-- 指定mr框架为yarn方式 --> <property><name>mapreduce.framework.name</name><value>yarn</value> </property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> </configuration> -
配置yarn-site.xml
<configuration> <!-- 开启RM高可用 --> <property><name>yarn.resourcemanager.ha.enabled</name><value>true</value> </property><!-- 指定RM的cluster id --> <property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value> </property><!-- 指定RM的名字 --> <property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value> </property><!-- 分别指定RM的地址 --> <property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value> </property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node2</value> </property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node1:8088</value> </property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node2:8088</value> </property><!-- 指定zk集群地址 --> <property><name>yarn.resourcemanager.zk-address</name><value>node1:2181,node2:2181,node3:2181</value> </property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property><!-- 是否将对容器实施物理内存限制 --> <property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value> </property><!-- 是否将对容器实施虚拟内存限制。 --> <property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value> </property> </configuration> -
配置workers
node1 node2 node3 -
分发
cd /export/server scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
-
启动集群
#为防止主备切换失败,在node1,node2,node3安装以下软件包,保证不会发生脑裂
yum install psmisc -y
-
HA集群的初始化(只在第一次执行)
-
启动zk集群
#在node1,node2,node3分别执行以下的命令 /export/server/zookeeper-3.4.6/bin/zkServer.sh start -
手动提前启动JN进程(node1 node2 node3分别启动)
hdfs --daemon start journalnode -
初始化namenode
#在node1初始化namenode hdfs namenode -format#把node1初始化的数据完整复制一份给node2 保证两个nn初始化状态及数据是一致的 #hdfs namenode –bootstrapStandbyscp -r /export/data/ha-hadoop/ root@node2:/export/data/ -
格式化ZKFC(在node1上执行即可)
首次启动谁是active取决于在哪台机器执行该命令
相当于首次选举是用户指定谁是老大
hdfs zkfc -formatZK
-
-
HA集群的启动
-
在node1上,启动hdfs集群
start-dfs.sh -
在node1上,启动yarn集群
start-yarn.sh
-
在node1上,启动历史任务
mapred --daemon start historyserver
-
-
后续启动和关闭
1、以上的启动至用于刚搭建完集群的第一次启动使用 2、以后高可用集群的启动和关闭直接使用以下命令:start-all.shstop-all.sh
验证
-
验证HDFS高可用
1、网页访问NameNode http://node1:9870/ http://node2:9870/2、文件上传 hadoop fs -put a.txt /3、杀死主NameNode,观察备用NameNode是否称为主节点kill -9 9024 -
验证Yarn高可用
1、网页访问NameNode http://node1:8088/ http://node2:8088/#1、查看两个ResourceManager的状态 yarn rmadmin -getServiceState rm1 #active yarn rmadmin -getServiceState rm2 #standby#2、在状态为active的主机中,杀死ResourceManager进程 kill -9 ResourceManager进程号#3、查看ResourceManager状态 yarn rmadmin -getServiceState rm1/rm2#4、求PI值hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 10000#19888和8088的区别?8088页面: Yarn集群的信息 + 正在运行的任务 + 已经执行完成的任务 19888页面: 已经执行完成的任务#8020和9870的区别? 8020端口: 是HDFS客户端和NameNode之间的内部数据通信端口 9870端口: 是浏览器和网页服务器之间的访问端口
如何还原单节点
1:在node1中
stop-all.sh
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.02:在node2中
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.03:在node3中
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.04:在node1中
start-all.sh#可以将之前动态添加的node4的信息删除
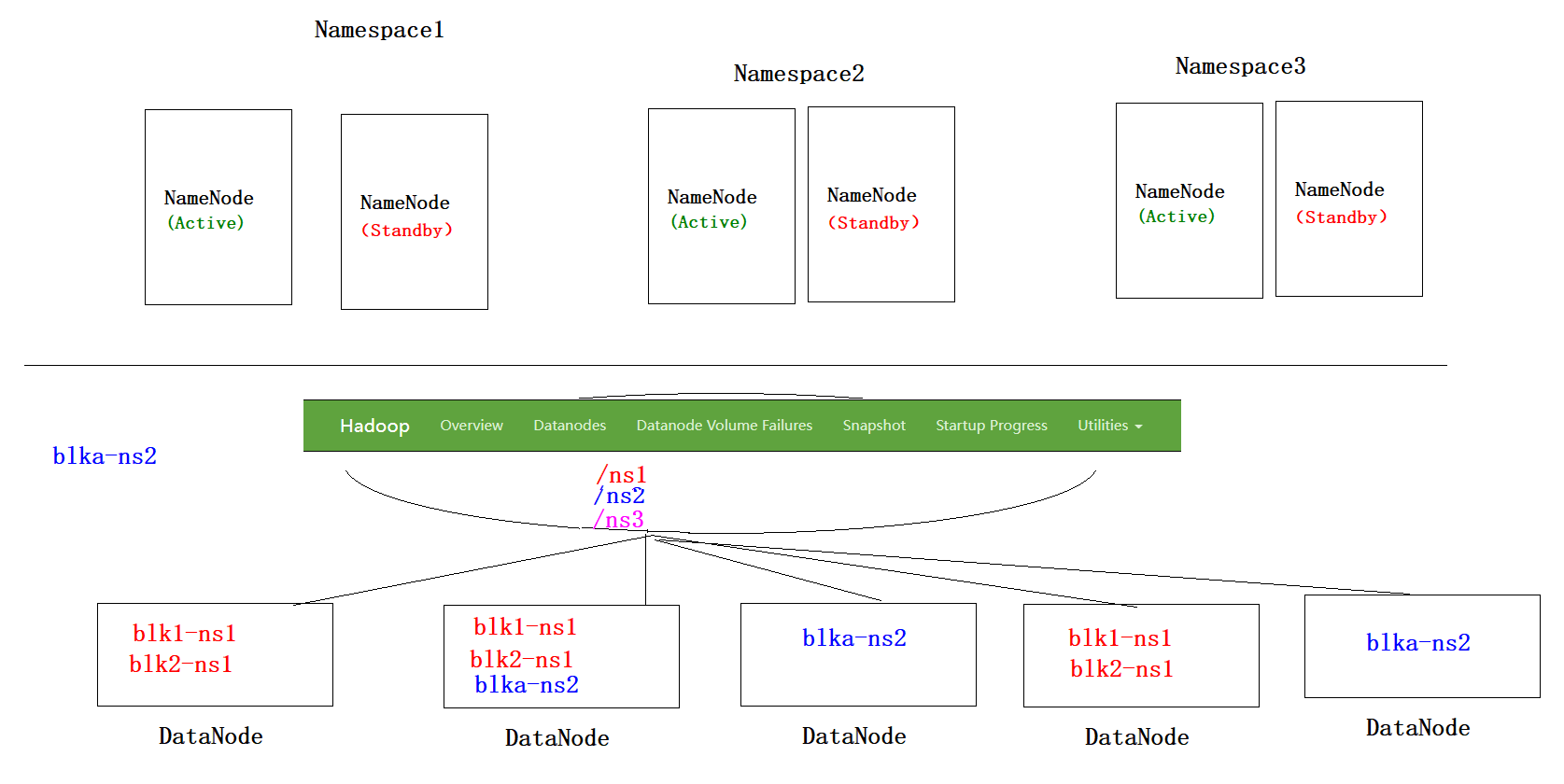
HA(高可用) + Federation*(联邦)
相关文章:
HDFS如何解决海量数据存储及解决方案详解
HDFS组件 HDFS组件的基准测试 说明 一般在搭建完集群之后,运维人员需要对集群进行压力测试,对于HDFS来讲,主要是读写测试写入测试 hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.…...
认识CSS值如何提高写前端代码的效率
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...

MySQL知识点全面总结3:Mysql高级篇
三.MySQL知识点全面总结3:mysql高级篇 1.mysql语句的执行过程? 2.myesql事务详解? 3.mysql日志详解? 4.mysql的索引功能详解? 5.mysql的存储引擎详解? 6.mysql事务提交后数据与硬盘如何交互存储&…...

Spring注解开发之组件注册(二)
Spring注解开发之组件注册(一) 5.Import 给容器导入一个组件 给容器中注册组件 一、包扫描 组件标注注解(Controller/Service/Repository/Component) [自己写的类] 二、Bean [导入的第三包里面的组件] 三、Import [快速给容器中导入组件] (Import{…...

【web前端开发】CSS最常用的11种选择器
文章目录1.CSS介绍2.CSS的语言规则3.CSS的引入方式4.选择器标签选择器类选择器id选择器通配符选择器复合选择器后代选择器子代选择器并集选择器交集选择器伪类选择器hover伪类选择器active伪类选择器结构伪类选择器结语1.CSS介绍 CSS (Cascading Style Sheets,层叠样…...

微电影广告发展的痛点
微电影广告以不可阻挡之势进入大众生活中,企业利用微电影广告来进行企业形象塑造的例子比比皆是。于是乎,微电影广告在为企业塑造品牌形象方面上取得了可喜的效果,但也不可忽视,在这个发展过程中,微电影广告所面临的问…...
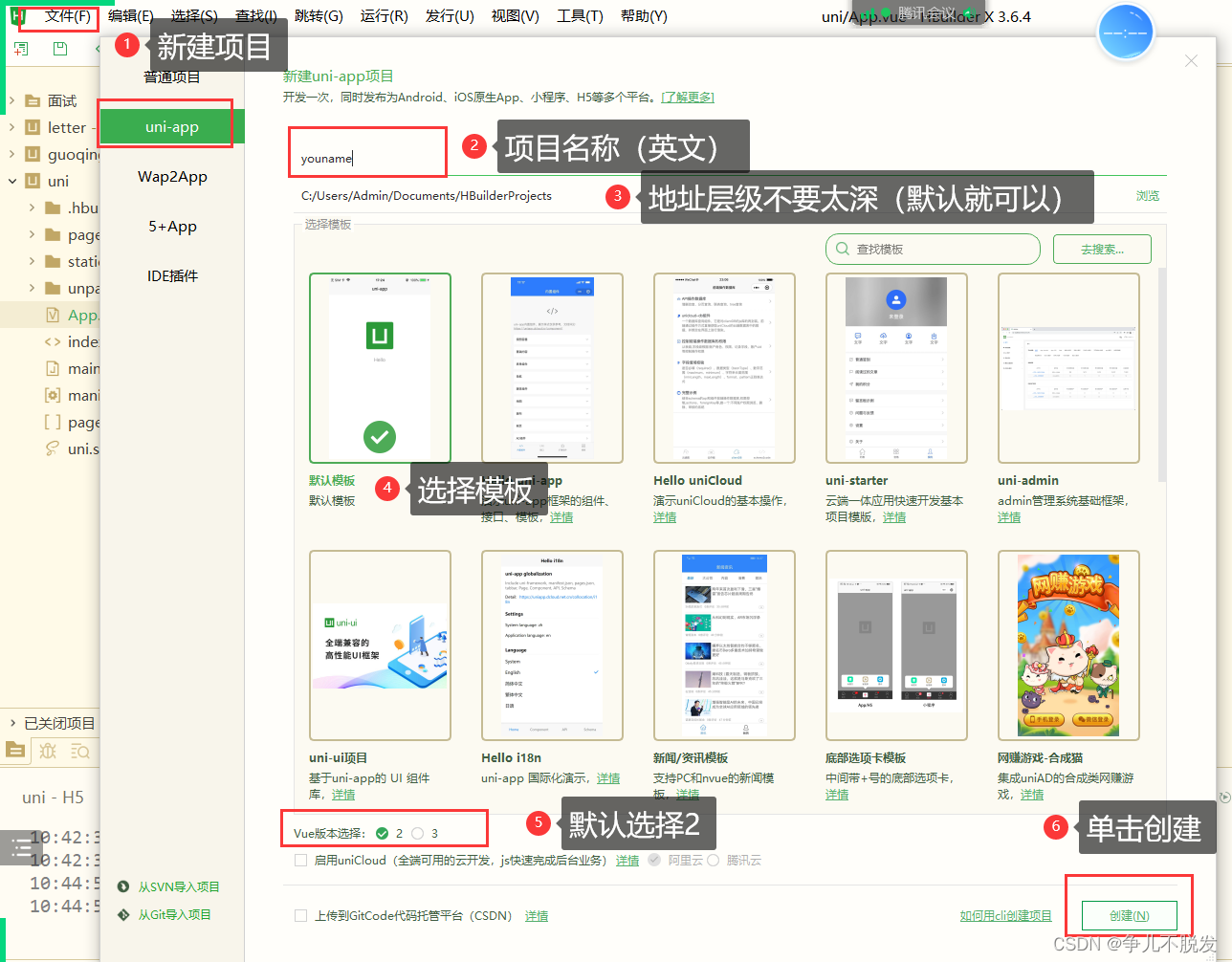
uniapp新手入门
前言: 这篇文章主要写的是uniapp的基础知识,可以让大家快速上手uniapp,同时避掉一些可能踩到的坑。 一. 什么是uniapp uniapp是由dcloud 公司开发的多端融合框架。uniapp的出现让我们的开发更为方便,一次开发,多端运行…...

linux segfault at 问题定位实践
问题:程序崩溃,打印为:app[13016]: segfault at 7fb668d29930 ip 00007fb668d3c23c sp 00007fb668e7de20 error 7 in mydefine.so[7fb668d3400011000]定位步骤:基础分析数据,大概了解反馈信息(根据chatGPT&…...

SpringCloud+SpringCloudAlibaba
架构的演进1.1单体架构将所有业务场景的表示层、业务逻辑层和数据访问层放在一个工程中,最终经过编译、打包,部署在一台服务器上。◆ 1.1.1单体架构的优点1)部署简单: 由于是完整的结构体,可以直接部署在一个服务器上即可。2&…...
【独家】)
华为OD机试 - 路灯照明(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:路灯照明…...
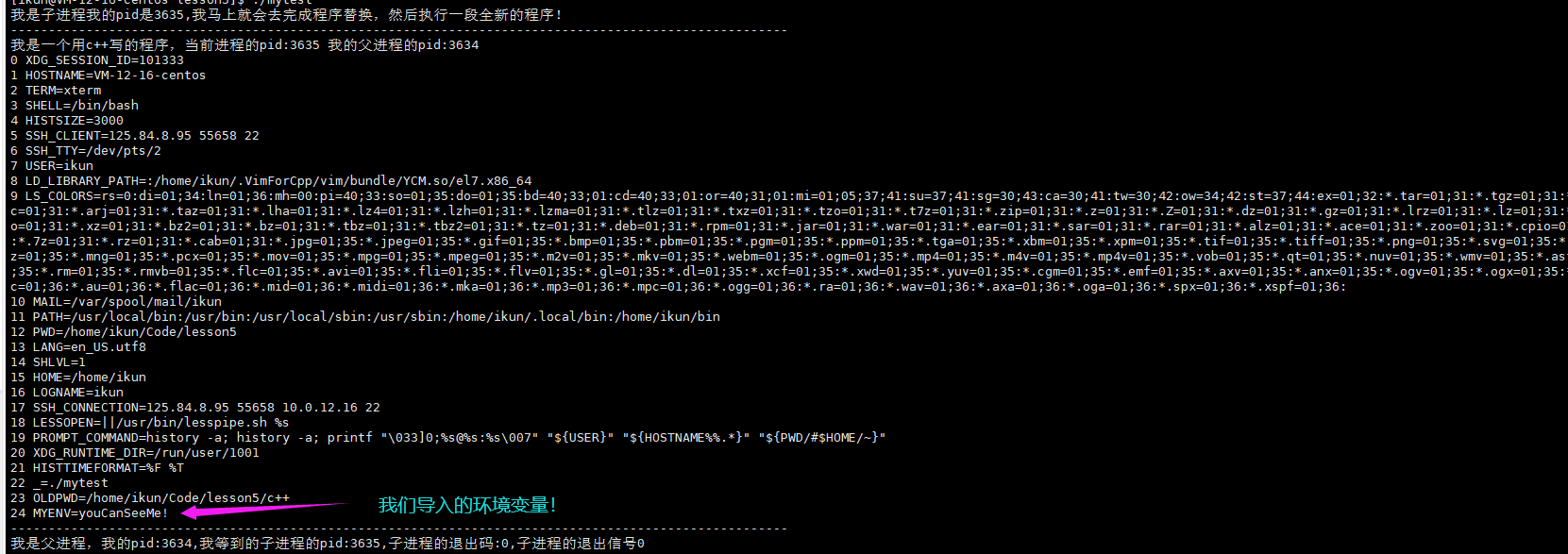
Linux程序替换
Linux程序替换创建子进程的目的?程序替换如何实现程序替换?什么是程序替换?先见一见单进程版本的程序替换程序替换原理多进程版本的程序替换execl函数组简易版Shell创建子进程的目的? 目的:为了帮助父进程完成一些特定的任务&…...

@JsonFormat @DataTimeFormat 时间格式
省流:用JsonFormat即可有时候会看到入参dto里,在时间类型的变量上用DateTimeFormat,代码如下。public class XXXdto{DateTimeFormat(pattern "yyyy-MM-dd hh:mm:ss")private Date startDate; }这是为了入参传日期格式的值。即前端…...
带你玩转modbusTCP通信
modbus TCP Modbus TCP是一种基于TCP/IP协议的Modbus通信协议,它是Modbus协议的一种变体,用于在以太网上进行通信。Modbus TCP协议是一种开放的通信协议,它支持多种编程语言和操作系统,并且可以在不同的硬件和软件平台上进行通信…...
T2交替)
2021牛客OI赛前集训营-提高组(第三场)T2交替
2021牛客OI赛前集训营-提高组(第三场) 题目大意 一个长度为nnn的数组aaa,每秒都会变成一个长度为n−1n-1n−1的新数组a′aa′,其变化规则如下 如果当前数组aaa的大小nnn为偶数,则对于新数组a′aa′的每一个位置i(1≤…...

论文投稿指南——中文核心期刊推荐(金融)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
【独家】)
华为OD机试 - 不等式(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:不等式题…...
90后老板用低代码整顿旅行社,创2000万年收,他是怎么做到的?(真实)
热爱旅游的92年成都小伙猴哥,大学毕业后开了一家旅行社,主要从事川藏、云南定制游服务。 从今年春节开始,国内各地旅游业开始复苏,向旅行社打电话咨询的人越来越多。 旅游的人多是好事,也是一种烦恼,因为…...

Apache Dubbo 存在反序列化漏洞(CVE-2023-23638)
漏洞描述 Apache Dubbo 是一款轻量级 Java RPC 框架 该项目受影响版本存在反序列化漏洞,由于Dubbo在序列化时检查不够全面,当攻击者可访问到dubbo服务时,可通过构造恶意请求绕过检查触发反序列化,执行恶意代码 漏洞名称Apache …...

【YOLO】YOLOv8训练自定义数据集(4种方式)
YOLOv8 出来一段时间了,继承了分类、检测、分割,本文主要实现自定义的数据集,使用 YOLOV8 进行检测模型的训练和使用 YOLOv8 此次将所有的配置参数全部解耦到配置文件 default.yaml,不再类似于 YOLOv5,一部分在配置文件…...

linux重置root用户密码
重置root密码 法一:rd.break 第 1 步:重启系统编辑内核参数 第 2 步:找到 linux 这行,在此行末尾空格后输入rd.break (End键也可直接进入行尾) 成功后显示页面为: 第 3 步:查看。…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...