弱监督参考图像分割:Learning From Box Annotations for Referring Image Segmentation论文阅读笔记
弱监督参考图像分割:Learning From Box Annotations for Referring Image Segmentation论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- A、全监督参考图像分割
- B、基于 Box 的实例分割
- C、带有噪声标签的学习
- 四、提出的方法
- A、概述
- B、伪标签生成
- 目标轮廓预测
- Proposal 选择
- 对抗边界损失 Ladv\mathcal{L}_{\text{adv}}Ladv 和MIL损失
- C、从噪声标签中学习
- 五、实验
- A、数据集和评估指标
- B、实施细节
- C、性能比较
- 定量评估
- 定性评估
- D、消融实验
- Ltight\mathcal{L}_{\text tight}Ltight 和 Lce\mathcal{L}_{\text ce}Lce
- 对抗边界损失的有效性:
- 自训练策略 Self-T 和共同训练策略 Co-T:
- N1+N2N_1 + N_2N1+N2 的结果:
- 与全监督算法的比较:
- 参数敏感性:
- Bounding box 没有严格标注限制的结果:
- 目标到 Box 区域的保留比例分析:
- E、失败的案例
- 六、结论
写在前面
最近一直在找论文看咩,奈何很多都是“花里胡哨”,嗯,就是结构设计的挺巧妙,没法通用呀~
这是一篇弱监督 Box 监督下的参考图像分割论文,最主要是提出了一个边界损失函数~
- 论文地址:Learning From Box Annotations for Referring Image Segmentation
- 代码地址:https://github.com/fengguang94/Weakly-Supervised-RIS,尚未完全发布
- 收录于 TNNLS 2022
一、Abstract
参考图像分割 Referring image segmentation (RIS) 的方法需要大量像素级别的标注数据,而本文提出一种基于 Box 标注的弱监督 RIS 方法。首先,设计一个边界对抗损失来提取 Bounding Box (BB) 中的目标轮廓;而这些轮廓用于选择合适的区域 Proposal 来生成 Pseudoground-truth (PGT);其次,设计一种共同训练 (Co-T) 策略来对伪标签进行过滤,具体来说,训练两个网络并迭代的引导彼此挑选出干净的标签,目的是弱化噪声标签对模型训练的影响,实验结果表明能以 63 帧/秒的速度来产生高质量的 masks。
二、引言

首先讲一下参考图像分割的定义,接下来指出之前基于全监督的 RIS 方法耗时且费力,因此提及弱监督实例分割方法,但是 RIS 的弱监督方法还未被考虑,因此本文着手解决这一任务。
接下来是对一些弱监督实例分割方法的介绍,有基于 BB 的,基于伪标签的,但是基于伪标签的方法并不能捕捉目标区域的一般形状,只能确保所选择的 Proposal 尽可能属于 BB。但由于目标尺寸、外观的不同,因此很难选择类似 GT 的 BB。有一些基于全局限定的端到端模型缺乏对目标轮廓的描述,因此可能会存在混淆的边界像素点。
好的 Proposals 能够提供重要的目标级别先验,但是不能感知前景的具体形状。一个合理的假设是如果前景轮廓可以从 BB 中推理得出,那么就能使用其作为一个强先验信息来滤除区域 Proposal。于是本文根据这一思想提出一种对抗边界损失,其包含两个构件,一个用于促进目标主干区域有着高度的激活值,另外一个用于抑制高度激活值。在这种对抗作用下,目标的主体部分被抑制,而轮廓被突出,接下来利用学习到的轮廓来挑选出少量的 Proposal 来生成 PGT (伪标签)。
伪标签包含有噪声信息,会损坏模型的泛化能力,因此本文设计一种基于共同训练 Co-T 策略来过滤噪声标签。具体来说,使用 Cross-entropy 损失作为偏置来决定伪标签的置信度,之后选择小损失的像素用于反向传播,并且同时采用两个网络来相互引导彼此间的反向传播。本文主要贡献如下:
- 设计了一种基于 Box 标注的对抗边界损失来捕捉前景目标轮廓,这些轮廓用于过滤proposal从而获得精确的伪标签;
- 引入一种 Co-T 策略来过滤伪标签,促进两个网络来引导彼此,这能减小错误标签像素在反向传播中的影响;
- 实验效果很好,速度很快。
三、相关工作
A、全监督参考图像分割
介绍下概念,指出其难点,列举之前的方法,指出缺点:获得像素级别的 masks 费时费力,相比之下,本文提出的方法只依赖 BB 的标注。
B、基于 Box 的实例分割
弱监督方法一般分为两类,一类是采用无监督的方法生成伪标签,然后来训练分割网络;一类是利用 BB 来得出全局限制并直接建立一个新的损失函数。
接下来是举例。指出缺点:所有的方法没有确切考虑目标的边界信息。相比之下,本文提出的方法定义了一个对抗边界损失来预测粗糙的目标轮廓,然后结合 BB 以及预测的轮廓作为先验来滤除候选的 Proposal,这使得剩下的 Proposals 能够和目标有着高度的重合。
C、带有噪声标签的学习
一些基于 box 监督的方法将分割任务作为一个噪声标签的学习任务,缺点:由样本选择时的偏置导致的误差会一直积累下去。本文采用两个网络来迭代地挖掘出有用的标签来训练彼此,能够提供不同的视角,过滤不同类别的噪声及避免误差的积累。
四、提出的方法

A、概述
本文提出的框架建立在 BRINet 之上,核心为 BCAM,由一个视觉引导的语言注意力模块 VLAM 和一个语言引导的视觉注意力模块 LVAM 构成。
采用编码器融合策略,以一种残差连接的方式将 BCAM 嵌入到 ResNet101 内,解码器采用 FPN 结构。本文提出的方法主要分成两个阶段:第一阶段采用对抗边界损失来捕捉目标轮廓,之后联合 BB 选择合适的 Proposals 作为伪标签用于接下来的训练。第二阶段同时训练两个新的分割网络,彼此间引导着来阻止虚假标签的反向传播,从而缓解噪声伪标签的影响。
BRINet: Z. Hu, G. Feng, J. Sun, L. Zhang, and H. Lu, “Bi-directional relationship inferring network for referring image segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2020, pp. 4424–4433.
B、伪标签生成
讲述一下动机:对于弱监督 RIS,常规做法是利用无监督的区域提议方法和网格式的目标提议来生成一系列的分割 masks,然后采用 box 级别的标注作为先验来选择高质量的候选 mask。然而 BB 仅仅能提供目标的位置信息,而不能用来描述目标。因此对于目标边界来说,目标 mask 和选择的 proposal 之间的匹配概率不能保证,从而影响模型的训练。于是本文尝试捕捉目标的轮廓并将其作为先验从而选出高质量的 Proposal。步骤如下:
目标轮廓预测
首先,轮廓先验假设:目标区域充分靠近 Box 标注的边缘,因此至少 BB mask 的每一行或者每一列属于前景。对于 RIS 的前景/背景分类器来说,设 C∈[0,1]H×WC\in{[0,1]^{H\times W}}C∈[0,1]H×W 为模型在第一阶段的输出特征图,其中 0,1 分别表示非轮廓点和轮廓点,CrowiC_{row}^{i}Crowi 和 CcoljC_{col}^{j}Ccolj 为预测特征图的第 iii 行和第 jjj 列。定义 Prow(i)=max(Crowi)P_{row}(i)=\max(C_{row}^{i})Prow(i)=max(Crowi), Pcol(j)=max(Ccolj)P_{col}(j)=\max(C_{col}^{j})Pcol(j)=max(Ccolj) 分别计算 CCC 上第 iii 行和第 jjj 列的最大值。
当 box 跨越第 iii 行或者第 jjj 列时,这一行或列穿过了前景区域,于是 Prow(i)P_{row}(i)Prow(i) 或者 Pcol(j)P_{col}(j)Pcol(j) 的预测值应该接近 1,反之接近 0。基于这一先决条件,定义损失函数如下:
Ltight =∑Crow i,Ccol j∩B∉∅−[log(Prow(i))+log(Pcol(j))]+∑Cfow i,Ccol j∩B∈∅−[log(1−Prow(i))+log(1−Pcol(j))]\mathcal{L}_{\text {tight }}= \sum_{C_{\text {row }}^{i}, C_{\text {col }}^{j} \cap \mathcal{B} \notin \varnothing}-\left[\log \left(P_{\mathrm{row}}(i)\right)+\log \left(P_{\mathrm{col}}(j)\right)\right] +\sum_{C_{\text {fow }}^{i}, C_{\text {col }}^{j} \cap \mathcal{B} \in \varnothing}-\left[\log \left(1-P_{\mathrm{row}}(i)\right)+\log \left(1-P_{\mathrm{col}}(j)\right)\right] Ltight =Crow i,Ccol j∩B∈/∅∑−[log(Prow(i))+log(Pcol(j))]+Cfow i,Ccol j∩B∈∅∑−[log(1−Prow(i))+log(1−Pcol(j))]其中 B\mathcal{B}B 为 BB 包围的矩形区域,上式右边第一项和第二项确保了最大激活区域能够定位到与 BB 相交的行或列。因此这一损失函数 Ltight \mathcal{L}_{\text {tight }}Ltight 能够驱动网络去预测 BB 内的前景。之后定义一个 0 限制条件,目的是使得预测的特征图倾向于全为0:
Laro =∑i=1H∑j=1W−log(1−Ci,j)\mathcal{L}_{\text {aro }}=\sum_{i=1}^{H} \sum_{j=1}^{W}-\log \left(1-C_{i, j}\right) Laro =i=1∑Hj=1∑W−log(1−Ci,j)于是结合这两个损失来构成对抗边界损失:
Ladv=Ltight+λ⋅Lzero\mathcal{L}_{\text{adv}}=\mathcal{L}_{\text{tight}}+\lambda\cdot\mathcal{L}_{\text{zero}} Ladv=Ltight+λ⋅Lzero其中 λ\lambdaλ 设为 0.05,目的是缩小比重,Ltight\mathcal{L}_{\text{tight}}Ltight 为全局限制,Lzero\mathcal{L}_{\text{zero}}Lzero 为局部限制。
下图展示了这些损失函数的可视化:

Proposal 选择
首先选择一种无监督 proposal 方法来生成一些区域 proposals,之后预测的轮廓 mask 可以用来选择一些合适的 proposals。定义目标函数如下:
argmaxy{C∩b(⋃pi∈Pyi⋅pi)}s.t. yi=0or 1,P⊆box \arg \max _{y}\left\{\mathcal{C} \cap b\left(\bigcup_{p_{i} \in \mathcal{P}} y_{i} \cdot p_{i}\right)\right\} \text { s.t. } y_{i}=0 \quad \text { or } \quad 1, \mathcal{P} \subseteq \text { box } argymax⎩⎨⎧C∩bpi∈P⋃yi⋅pi⎭⎬⎫ s.t. yi=0 or 1,P⊆ box 其中 C\mathcal{C}C 为轮廓点像素的集合,可以通过对预测的特征图 CCC 二值化获得。P\mathcal{P}P 为 proposals 的集合,bbb 为边界提取器。
接下来利用膨胀和腐蚀操作分别处理得到的 mask,然后就可以从膨胀后 mask 中抽取出腐蚀的 mask,从而得到边界框。如果 proposal pip_ipi 被选择上,那么设置其标签 yi=1y_i=1yi=1,否则 yi=0y_i=0yi=0。所有被选择出的 proposal 都作为 PGT mask,而 NP 难样本的构建可以通过下面的贪婪算法获得:

首先以一个种子 proposal sp 开始,其边界和目标轮廓 C\mathcal{C}C 有着最大的交集。接下来利用 sp 作为偏置来添加或移除集合 SSS 中的 proposal,直到 SSS 中的边界有着和目标轮廓最大的交集。
对抗边界损失 Ladv\mathcal{L}_{\text{adv}}Ladv 和MIL损失
MIL 损失建立在局部交集之上,并不会捕捉区域之外的信息,而 Ladv\mathcal{L}_{\text{adv}}Ladv 建立在全局预测特征图之上,从而避免采样正负样本的过程。MIL 损失直接用于训练分割网络,而 Ladv\mathcal{L}_{\text{adv}}Ladv,Ltight\mathcal{L}_{\text{tight}}Ltight 和 Lzero\mathcal{L}_{\text{zero}}Lzero 损失一起来强制捕捉目标的轮廓信息。之后利用这些学习到的轮廓来得到一个更加精确的伪标签。
C、从噪声标签中学习
为了减轻伪标签中噪声对训练的影响,本文提出选择高置信度的像素级标签来参与监督。思路来源:一个模型容易积累误差,而两个模型可以彼此监督从而减小误差。于是本文建立两个网络来迭代地决定哪些标签是有用的。

算法流程:首先对于两个网络 N1N_1N1 和 N2N_2N2,基于伪标签 MMM 来计算一个 batch 内每个像素的 cross-entropy 损失,然后基于损失值对这些像素进行排序。于是有着最小损失的像素很有可能是正确的标签。之后记录每个网络中最小 R(t)%R(t)\%R(t)% 比率损失的像素点索引,最后根据这些索引来控制反向传播过程中彼此网络的对应位置。(注意,两个网络仅仅在初始化参数上不同。)
保留比例:模型一开始学习简单且通用的数据类型,然后逐渐地拟合噪声数据。因此在训练开始时采用一个更大的保留比例 R(t)%R(t)\%R(t)%,实际设置为:R(t)=1−η⋅(t/T)R(t)=1-\eta\cdot(t/T)R(t)=1−η⋅(t/T),其中 ttt 为迭代步,最大迭代次数 TTT 设置为 50K,噪声水平 η\etaη 设置为 0.1。
五、实验
A、数据集和评估指标
数据集:UNC、UNC+、Google-Ref、ReferIt;
评估指标:IoU、Prec@X。
B、实施细节
SGD 优化器,初始学习率 0.002,50K 次迭代之后 ×10%\times 10\%×10%,最大迭代 90K,batch_size 16,权重衰减 0.0005,输入图像尺寸 320×320320\times 320320×320,最大句子词数 20,
C、性能比较
定量评估


定性评估

D、消融实验
消融实验在 UNC 数据集上进行。
Ltight\mathcal{L}_{\text tight}Ltight 和 Lce\mathcal{L}_{\text ce}Lce

对抗边界损失的有效性:
同表 Ⅲ。
自训练策略 Self-T 和共同训练策略 Co-T:
同表 Ⅲ。
N1+N2N_1 + N_2N1+N2 的结果:
同表 Ⅲ。
与全监督算法的比较:
同表 Ⅲ。
参数敏感性:
同表 Ⅲ 及表 Ⅳ。

Bounding box 没有严格标注限制的结果:
同表 Ⅲ。
目标到 Box 区域的保留比例分析:
同表 Ⅲ。
E、失败的案例

六、结论
本文提出一种两阶段训练方法用于 box 级别的 RIS 弱监督分割。第一阶段用对抗边界损失捕捉前景区域的轮廓,然后利用这些轮廓作为先验挑选出合适的 proposal 作为伪标签。第二阶段采用 Co-T 策略来促进两个网络过滤包含噪声的伪标签以及避免误差积累。实验效果牛批。
写在后面
感觉下吧,相比于三大顶会确实差了点意思,而且作者的写作水平不敢恭维,只能说可以做个 Baseline,mark 一下 😁。
相关文章:
弱监督参考图像分割:Learning From Box Annotations for Referring Image Segmentation论文阅读笔记
弱监督参考图像分割:Learning From Box Annotations for Referring Image Segmentation论文阅读笔记一、Abstract二、引言三、相关工作A、全监督参考图像分割B、基于 Box 的实例分割C、带有噪声标签的学习四、提出的方法A、概述B、伪标签生成目标轮廓预测Proposal 选…...

Linux进程和任务管理和分析和排查系统故障
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

【满分】【华为OD机试真题2023 JAVA】最多几个直角三角形
华为OD机试真题,2023年度机试题库全覆盖,刷题指南点这里 最多几个直角三角形 知识点递归深搜 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 有N条线段,长度分别为a[1]-a[N]。现要求你计算这N条线段最多可以组合成几个直角三角形,每条线段只能使用一次,每个三…...
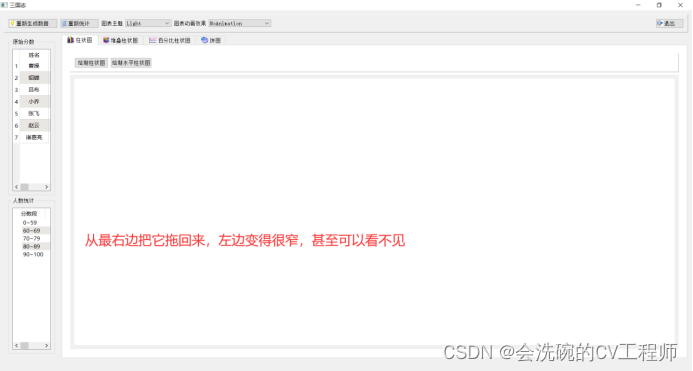
PyQt5可视化 7 饼图和柱状图实操案例 ②建表建项目改布局
目录 一、数据库建表 1 建表 2 插入数据 3 查看表数据 二、建立项目 1 新建项目 2 appMain.py 3 myMainWindow.py 4 myChartView.py 2.4.1 提升的后果 2.4.2 QmyChartView类说明 2.4.3 添加代码 三、修改myMainWindow.py程序,添加功能 1 打开数据库 …...
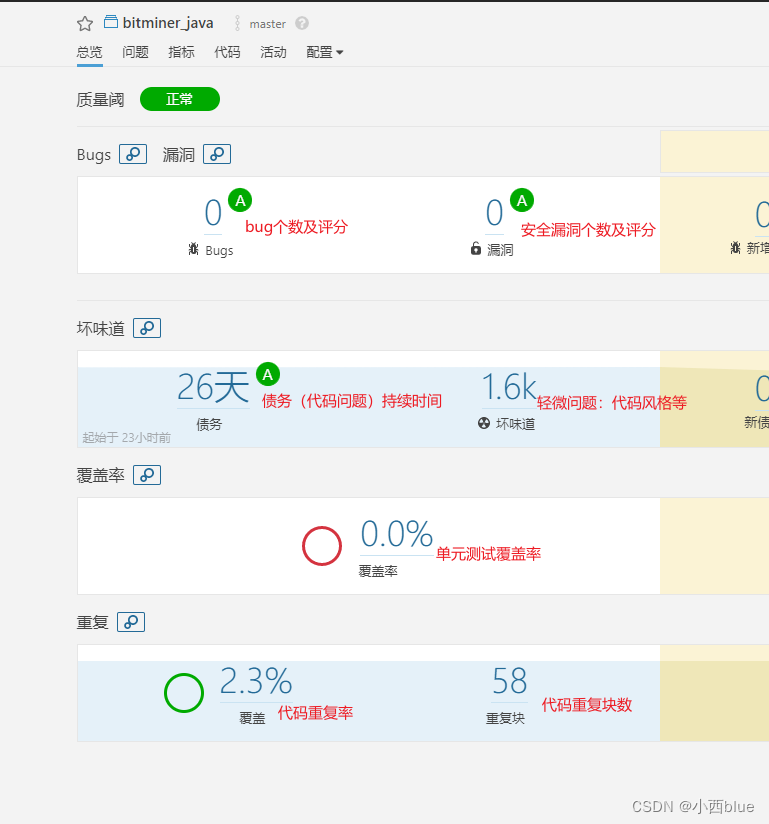
sonarqube指标详解
最近公司引入了sonar,作为代码质量检测工具,以期提高研发同学的代码质量,但是结果出来后,有些同学不清楚相应的指标内容,不知道应该重点关注哪些指标,于是查询了一下相关的资料,加以总结同时也分…...

耳机 喇叭接线分析
1 注意 1 首先必须接地 2 接某一个声道 2 分析 从三段式耳机结构可以得出: 模拟数据 必须的 结构 1 地 2 左or右信号 附加 我们要注意 耳机也是分左声道 右声道的 参考:耳机插头3.5与2.5三段与四段i版与n版等详解 在iPhone还没现在这么NB的时候&a…...

SpaceNet 建筑物检测
SpaceNet 建筑物检测 该存储库提供了一些 python 脚本和 jupyter 笔记本来训练和评估从SpaceNet卫星图像中提取建筑物的卷积神经网络。 用法...

蓝桥杯刷题第六天
第一题:星期计算问题描述本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。已知今天是星期六,请问 20的22次方天后是星期几?注意用数字 1 到 7 表示星期一到星期日。运行限制最大运行时间:1s最…...

Linux C++ 多线程高并发服务器实战项目一
文章目录1、项目介绍2、项目流程2.1、环境变量搬家2.2、设置进程title2.3、信号初始化2.4、开始监听端口2.5、创建守护进程2.6、创建子进程1、项目介绍 1、按照包头包体的格式收发数据包,解决粘包的问题 2、非常完整的多线程高并发服务器 3、根据收到数据包执行&…...

QML ComboBox简介
1.简介 ComboBox是一个组合按钮和弹出列表。它提供了一种以占用最小屏幕空间的方式向用户显示选项列表的方法。 ComboBox用数据模型填充。数据模型通常是JavaScript数组、ListModel或整数,但也支持其他类型的数据模型。 常用属性: count : int&#x…...

uniapp使用webview嵌入vue页面及通信
最近刚做的一个需求,web端(Vue)使用了FormMaking库,FormMaking是一个拖拉拽的动态设计表单、快速开发的一个东西,拖拽完之后最终可以导出一个很长的json,然后通过json再进行回显,快速开发&#…...
: CUDA RunTime API-2.1内存管理)
深度学习部署笔记(九): CUDA RunTime API-2.1内存管理
1. 前言 主要理解pinned memory、global memory、shared memory即可 2. 主机内存 主机内存很多名字: CPU内存,pinned内存,host memory,这些都是储存在内存条上的Pageable Memory(可分页内存) Page lock Memory(页锁定内存) 共同组成内存你…...

Idea+maven+spring-cloud项目搭建系列--11-2 dubbo鉴权日志记录数据统一封装
前言:使用dubbo做为通信组件,如果接口需要鉴权,和日志记录需要怎样处理; 1 鉴权: 1.1 在bootstrap.yml 中定义过滤器: dubbo.provider.filter: 过滤器的名字: 1.2 resources 目录下创建配置文…...
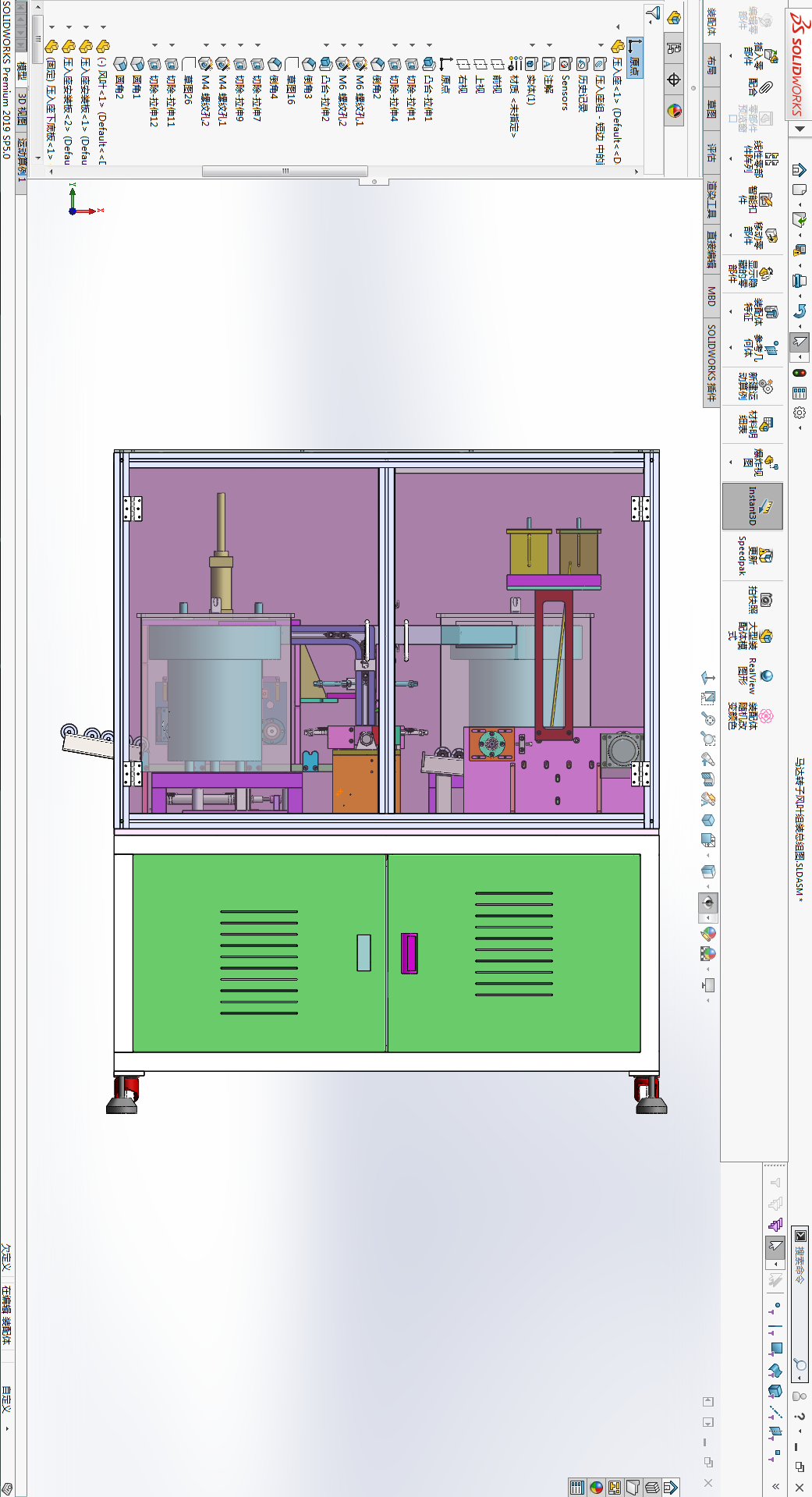
SOLIDWORKS免费培训 SW大型装配体模式课程
在SOLIDWORKS的使用过程中,大家经常会遇到大型装配体的处理问题,微辰三维的培训课程中也包含了一些大型装配体的技术培训,下面整理一些常见问题,供参考:大型装配体模式1.当我们打开一个大的装配体时,可能会…...

xxl-job registry fail
解决方法: 1、检查nacos是否正确,一定要注意格式,一般都是addersses的地址问题,一定的要加/不然找不到,本机就不要使用ip了,用localhost。 xxl: job: admin: addresses: http://localhost:8080/xxl-job-ad…...
【C#进阶】C# 反射
序号系列文章11【C#基础】C# 预处理器指令12【C#基础】C# 文件与IO13【C#进阶】C# 特性文章目录前言1,反射的概念2,使用反射访问特性3,反射的用途4,反射的优缺点比较4.1 优点:4.2 缺点:5,System…...
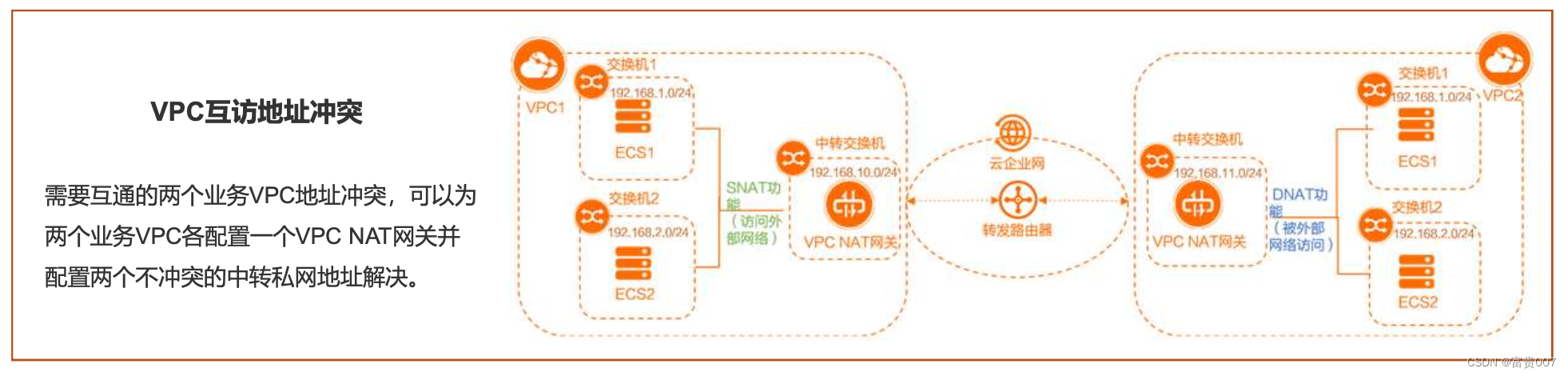
公网NAT网关与VPC NAT网关介绍与实践
NAT网关介绍 NAT网关是一种网络地址转换服务,提供NAT代理(SNAT和DNAT)能力。 公有云NAT分为公网NAT网关和VPC NAT网关。 1)公网NAT网关:提供公网地址转换服务。 2)VPC NAT网关:提供私网地址转换…...
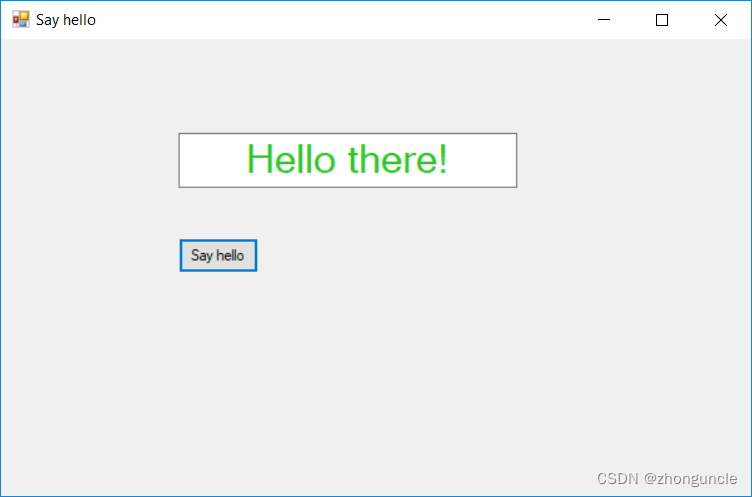
Windows中UWP、WPF和Windows窗体的区别
Windows 中开发应用(或者可以说客户端)有三种方法: UWP(Universal Windows Platform)、WPF(Windows Presentation Foundation)和 Windows 窗体(Win Forms)。这三种方法在…...
Flink从入门到精通系列(一)
1、Flink概述 Apache Flink 是一个框架和分布式处理引擎,用于在, 无边界和有边界数据流上进行有状态的计算 ,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 Apache Flink 功能强大,支持开发…...

云原生应用风险介绍
本博客地址:https://security.blog.csdn.net/article/details/129303616 一、传统风险 传统风险主要是注入、敏感数据泄露、跨站脚本、配置错误等等,这些传统的安全风险在云原生应用中也是存在的,这里就不具体展开说了。 二、云原生应用架…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...