流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换
pyflink 处理 kafka数据

1 DataStream API 示例代码
从非空集合中读取数据,并将结果写入本地文件系统。
from pyflink.common.serialization import Encoder
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import StreamingFileSinkdef tutorial():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)ds = env.from_collection(collection=[(1, 'aaa'), (2, 'bbb')],type_info=Types.ROW([Types.INT(), Types.STRING()]))ds.add_sink(StreamingFileSink.for_row_format('output', Encoder.simple_string_encoder()).build())env.execute("tutorial_job")if __name__ == '__main__':tutorial()
(1)DataStream API应用程序首先需要声明一个执行环境
StreamExecutionEnvironment,这是流式程序执行的上下文。
后续将通过它来设置作业的属性(例如默认并发度、重启策略等)、创建源、并最终触发作业的执行。
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
(2)声明数据源
一旦创建了 StreamExecutionEnvironment 之后,可以使用它来声明数据源。
数据源从外部系统(如Apache Kafka、Rabbit MQ 或 Apache Pulsar)拉取数据到Flink作业里。
为了简单起见,本次使用元素集合作为数据源。
这里从相同类型数据集合中创建数据流(一个带有 INT 和 STRING 类型字段的ROW类型)。
ds = env.from_collection(collection=[(1, 'aaa'), (2, 'bbb')],type_info=Types.ROW([Types.INT(), Types.STRING()]))
(3)转换操作或写入外部系统
现在可以在这个数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
本次使用StreamingFileSink将数据写入output文件目录中。
ds.add_sink(StreamingFileSink.for_row_format('output', Encoder.simple_string_encoder()).build())
(4)执行作业
最后一步是执行真实的 PyFlink DataStream API作业。
PyFlink applications是懒加载的,并且只有在完全构建之后才会提交给集群上执行。
要执行一个应用程序,只需简单地调用env.execute(job_name)。
env.execute("tutorial_job")

2 自定义转换函数的三种方式
三种方式支持用户自定义函数。
2.1 Lambda函数[简便]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(lambda x: x + 1, output_type=Types.INT())mapped_stream.print()
env.execute("tutorial_job")
2.2 python函数[简便]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentdef my_map_func(value):return value + 1def main():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())mapped_stream = data_stream.map(my_map_func, output_type=Types.INT())mapped_stream.print()env.execute("tutorial_job")if __name__ == '__main__':main()
2.3 接口函数[复杂]
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, MapFunctionclass MyMapFunction(MapFunction):def map(self, value):return value + 1def main():env = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(1)data_stream = env.from_collection([1, 2, 3, 41, 5], type_info=Types.INT())mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())mapped_stream.print()env.execute("tutorial_job")if __name__ == '__main__':main()3 常用算子
参考官网算子
3.1 map【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(lambda x: x + 1, output_type=Types.INT())mapped_stream.print()
env.execute("tutorial_job")
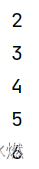
3.2 flat_map【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=['hello apache flink', 'streaming compute'])
out = data_stream.flat_map(lambda x: x.split(' '), output_type=Types.STRING())out.print()
env.execute("tutorial_job")
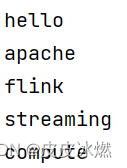
3.3 filter【DataStream->DataStream】
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件def my_func(value):if value % 2 == 0:return valuedata_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
filtered_stream = data_stream.filter(my_func)filtered_stream.print()
env.execute("tutorial_job")
3.4 window_all【DataStream->AllWindowedStream】
根据某些特征(例如,最近 100毫秒秒内到达的数据)对所有流事件进行分组。
所有的元素。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
all_window_stream = data_stream.window_all(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
3.4.1 apply【AllWindowedStream->DataStream】
将通用 function 应用于整个窗口。
from typing import Iterablefrom pyflink.common import Time
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import AllWindowFunction
from pyflink.datastream.window import TumblingProcessingTimeWindows, TimeWindowenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyAllWindowFunction(AllWindowFunction[tuple, int, TimeWindow]):def apply(self, window: TimeWindow, inputs: Iterable[tuple]) -> Iterable[int]:sum = 0for input in inputs:sum += input[0]yield sumdata_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
all_window_stream = data_stream.window_all(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
out = all_window_stream.apply(MyAllWindowFunction())out.print()
env.execute("tutorial_job")
3.5 key_by【DataStream->KeyedStream】
需要结合reduce或window算子使用。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
3.6 reduce【KeyedStream->DataStream】增量
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
out = key_stream.reduce(lambda a, b: (a[0]+b[0], a[1]))out.print()
env.execute("tutorial_job")
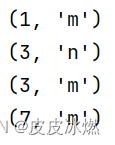
在相同 key 的数据流上“滚动”执行 reduce。
将当前元素与最后一次 reduce 得到的值组合然后输出新值。
3.7 window【KeyedStream->WindowedStream】
在已经分区的 KeyedStreams 上定义 Window。
data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
3.7.1 apply【WindowedStream->DataStream】
将通用 function 应用于整个窗口。
from typing import Iterablefrom pyflink.common import Time, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import WindowFunction
from pyflink.datastream.window import TumblingProcessingTimeWindows, TimeWindowenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyWindowFunction(WindowFunction[tuple, int, int, TimeWindow]):def apply(self, key: int, window: TimeWindow, inputs: Iterable[tuple]) -> Iterable[int]:sum = 0for input in inputs:sum += input[0]yield key, sumdata_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.apply(MyWindowFunction())out.print()
env.execute("tutorial_job")
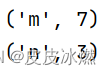
3.7.2 reduce【WindowedStream->DataStream】
from pyflink.common import Time
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.window import TumblingEventTimeWindows,TumblingProcessingTimeWindowsenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.reduce(lambda a, b: (a[0]+b[0], a[1]))out.print()
env.execute("tutorial_job")

方式二
from pyflink.common import Time
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
from pyflink.datastream.window import TumblingProcessingTimeWindowsenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件class MyReduceFunction(ReduceFunction):def reduce(self, value1, value2):return value1[0] + value2[0], value1[1]data_stream = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
key_stream = data_stream.key_by(lambda x: x[1], key_type=Types.STRING())
window_stream = key_stream.window(TumblingProcessingTimeWindows.of(Time.milliseconds(10)))
out = window_stream.reduce(MyReduceFunction())out.print()
env.execute("tutorial_job")
3.8 union【DataStream*->DataStream】
将两个或多个数据流联合来创建一个包含所有流中数据的新流。
注意:如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次。
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
out = data_stream2.union(data_stream1)out.print()
env.execute("tutorial_job")
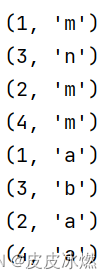
3.9 connect【DataStream,DataStream->ConnectedStream】
stream_1 = ...
stream_2 = ...
connected_streams = stream_1.connect(stream_2)
3.9.1 CoMap【ConnectedStream->DataStream】
from pyflink.datastream import StreamExecutionEnvironment, CoMapFunctionenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
connected_stream = data_stream1.connect(data_stream2)class MyCoMapFunction(CoMapFunction):def map1(self, value):return value[0] *100, value[1]def map2(self, value):return value[0], value[1] + 'flink'out = connected_stream.map(MyCoMapFunction())out.print()
env.execute("tutorial_job")

3.9.2 CoFlatMap【ConnectedStream->DataStream】
from pyflink.datastream import StreamExecutionEnvironment, CoFlatMapFunctionenv = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 将输出写入一个文件data_stream1 = env.from_collection(collection=[(1, 'm'), (3, 'n'), (2, 'm'), (4,'m')])
data_stream2 = env.from_collection(collection=[(1, 'a'), (3, 'b'), (2, 'a'), (4,'a')])
connected_stream = data_stream1.connect(data_stream2)class MyCoFlatMapFunction(CoFlatMapFunction):def flat_map1(self, value):for i in range(value[0]):yield value[0]*100def flat_map2(self, value):yield value[0] + 10out = connected_stream.flat_map(MyCoFlatMapFunction())out.print()
env.execute("tutorial_job")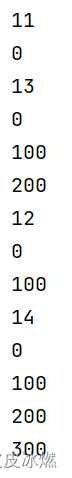
4 对接kafka输入json输出json
输入{“name”:“中文”}
输出{“name”:“中文结果”}
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer, KafkaSink, \KafkaRecordSerializationSchema
import jsonenv = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)brokers = "IP:9092"# 读取kafka
source = KafkaSource.builder() \.set_bootstrap_servers(brokers) \.set_topics("flink_source") \.set_group_id("my-group") \.set_starting_offsets(KafkaOffsetsInitializer.latest()) \.set_value_only_deserializer(SimpleStringSchema()) \.build()ds1 = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
ds1.print()# 处理流程
def process_fun(line):data_dict = json.loads(line)result_dict = {"result": data_dict.get("name", "无")+"结果"}return json.dumps(result_dict, ensure_ascii=False)ds2 = ds1.map(process_fun, Types.STRING())
ds2.print()
相关文章:
流批一体计算引擎-10-[Flink]中的常用算子和DataStream转换
pyflink 处理 kafka数据 1 DataStream API 示例代码 从非空集合中读取数据,并将结果写入本地文件系统。 from pyflink.common.serialization import Encoder from pyflink.common.typeinfo import Types from pyflink.datastream import StreamExecutionEnviron…...
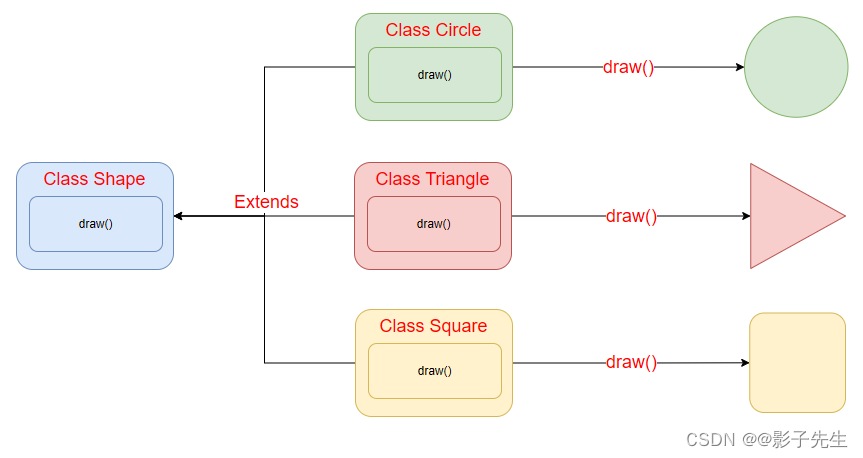
Java进阶_多态特性
生活中的多态 多态是同一个行为具有多个不同表现形式或形态的能力。多态就是同一个接口,使用不同的实例而执行不同操作,如图所示: 现实中,比如我们按下 F1 键这个动作,同一个事件发生在不同的对象上会产生不同的结果。…...
一个热门的源码整站数据打包完整代码(开箱即用),集成了最新有效数据和完美wordpress主题。
分享一个资源价值几千元的好代码资源网整站打包代码,这个wordpress网站基于集成了ripro9.1完全明文无加密后门版本定制开发,无需独立服务器,虚拟主机也可以完美运营,只要主机支持php和mysql即可。整合了微信登录和几款第三方的主题…...

操作系统真象还原-第3章 完善MBR
继续学习第三章,MBR这个引导程序上一次只是打印一个字符串,没有起到引导作用,这一章估计是要做引导了,我设想一个扇区应该不够,会再load一段代码,然后跳到这段代码执行。 开始吧: 3.1 地址/se…...

翻转链表-链表题
LCR 141. 训练计划 III - 力扣(LeetCode) 非递归 class Solution { public:ListNode* trainningPlan(ListNode* head) {if(head ! nullptr && head->next ! nullptr){ListNode* former nullptr;ListNode* mid head;ListNode* laster nul…...

【Android面试八股文】volatile和synchronize有什么区别?
volatile和synchronize有什么区别? 在 Java 多线程编程中,volatile 和 synchronized 是两个重要的关键字,它们分别用于处理并发访问共享变量的问题。尽管它们都可以用于确保多线程环境下的数据一致性,但在实际应用中却有着明显的区别和适用场景。 作用范围: volatile 只能…...

linux flask | 接口保持在后台一直运行、python后端接口长期调用、python后台持续运行方法、python提供后端接口
文章目录 一、flask接口二、长期运行接口2.1、nohup与&后台运行 实际项目中我们需要用python提供一个后端接口,并在linux上持续运行这个程序,以供其他项目调用。下面就用个简单示例讲解下怎么写python后端接口,以及如何将程序长期运行在l…...
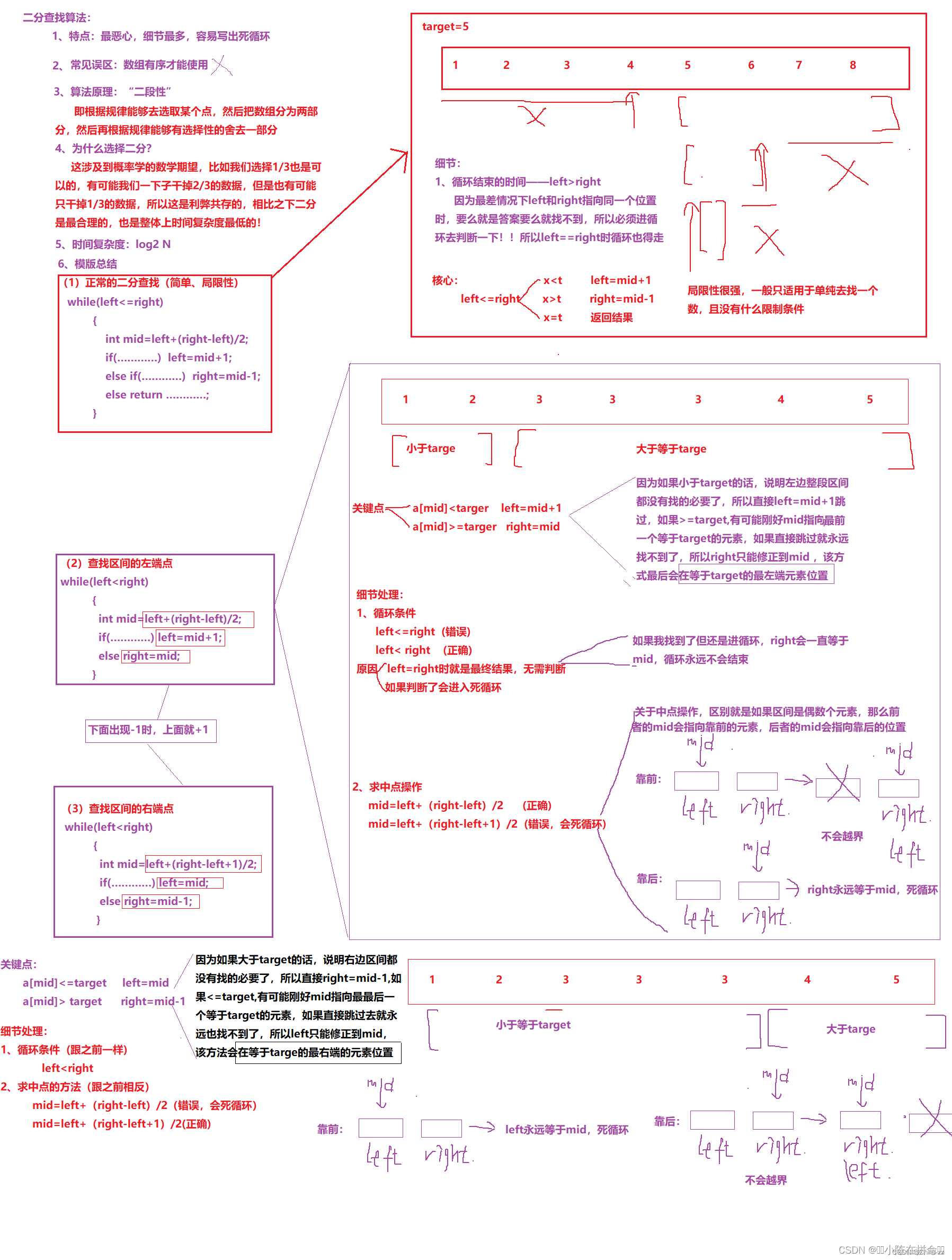
二分查找算法:穿越算法迷宫的指南
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 目录 前言 一. 二分查找算法介绍 二 二分查找的题目解析 2.1 二分查找 2.2 在排序数组中查找元素的第一个位置和最后一个位置 2.3 搜索插入位置 2.4 x的平方根 2.5 山峰数组峰顶的索引 2.6 寻找峰值 2.7 寻找旋转数…...
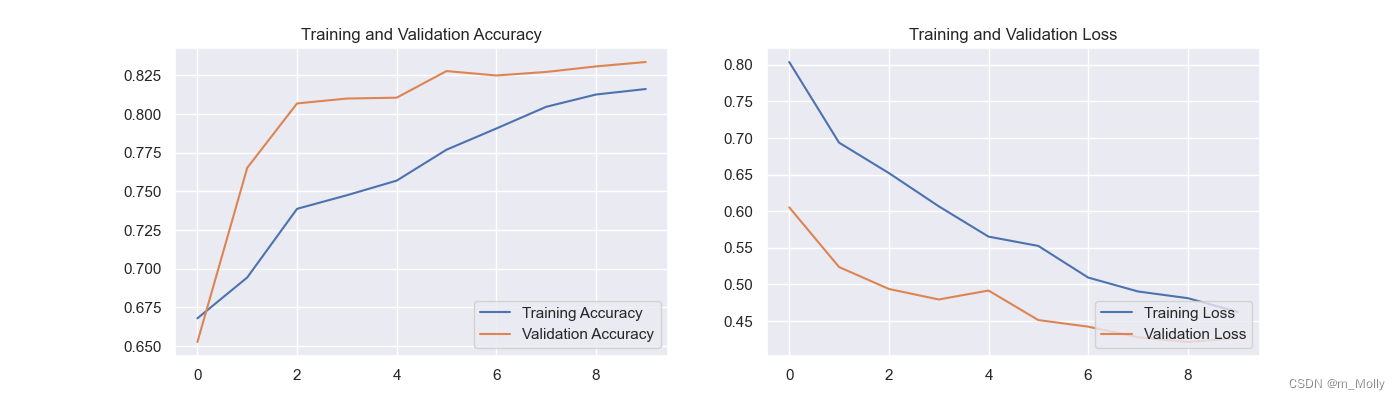
【Week-R3】天气预测,引入探索式数据分析方法(EDA)
文章目录 1. 导入模块2. 导入数据3.探索式数据分析方法(EDA)3.1 数据相关性探索3.2 是否会下雨3.3 地理位置与下雨的关系3.4 湿度和压力对下雨的影响3.5 气温对下雨的影响 4.数据预处理4.1 处理缺损值4.2 构建数据集 5 预测是否会下雨5.1 构建神经网络5.…...
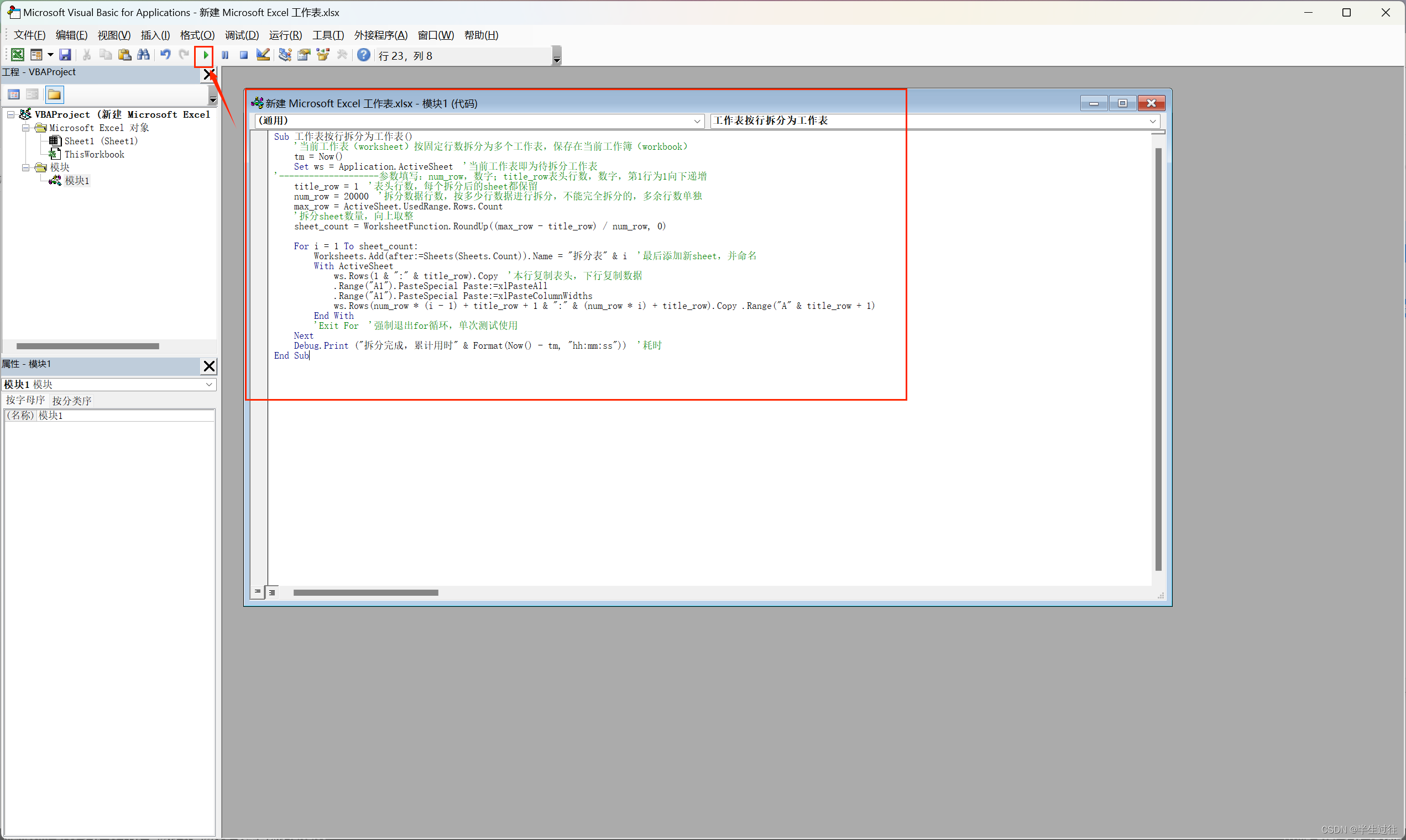
VBA excel 表格将多行拆分成多个表格或 文件 或者合并 多个表格
excel 表格 拆分 合并 拆分工作表按行拆分为工作表工作表按行拆分为工作薄 合并操作步骤 拆分 为了将Excel中的数万行数据拆分成多个个每个固定行数的独立工作表,并且保留每个工作表的表头,你可以使用以下VBA脚本。这个脚本会复制表头到每个新的工作表&…...

利用Redis的队列模式实现消息的发送和订阅,适合分布式场景,Java实现代码
在Redis中,通常使用发布/订阅模式(Pub/Sub)来进行消息的实时通信。然而,标准的Redis发布/订阅模式并不直接支持确保一条消息只被一台机器消费。在这种模式下,所有订阅了特定频道的客户端都会收到发布的消息。 但是&…...

软件下载安装【汇总】
软件下载安装【汇总】 前言版权推荐软件安装【汇总】最后 前言 2024-5-12 21:38:34 以下内容源自《【汇总】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是https://jsss-1.blog.csdn.net 禁止其他平台发布…...
重定向文件访问(Redirect file access)
重定向文件访问 重定向文件访问是指通过修改文件系统的路径,使对某个文件或目录的访问请求被转到另一个文件或目录。这在系统管理、测试和开发中非常有用,因为它允许您在不修改应用程序或服务配置的情况下,改变文件的实际存储位置。 proot …...
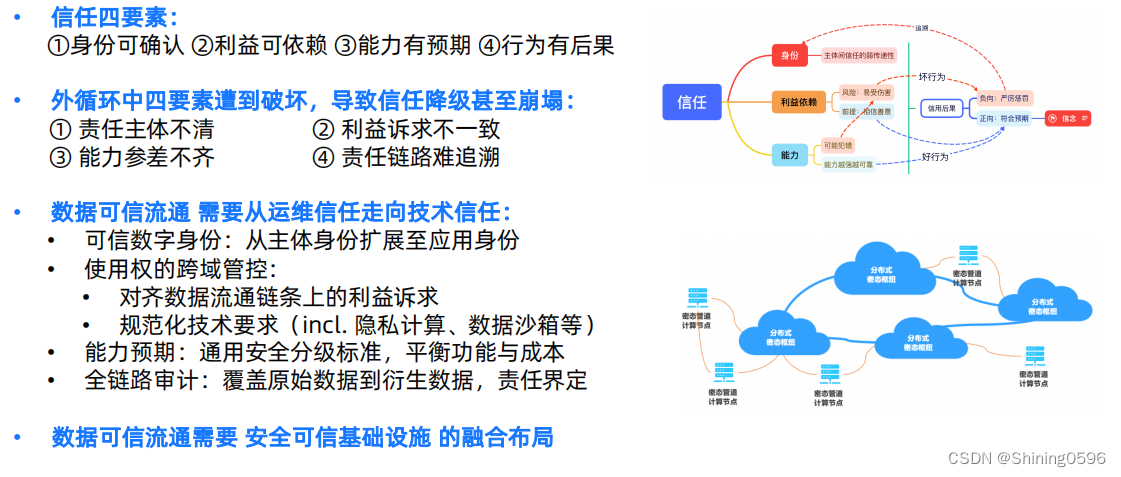
隐私计算(1)数据可信流通
目录 1. 数据可信流通体系 2. 信任的基石 3.数据流通中的不可信风险 可信链条的级联失效,以至于崩塌 4.数据内循环与外循环:传统数据安全的信任基础 4.1内循环 4.2外循环 5. 技术信任 6. 密态计算 7.技术信任 7.1可信数字身份 7.2 使用权跨域…...

果汁机锂电池充电,5V升压12.7V 升压恒压芯片SL1571B
在现代化的日常生活中,果汁机已经逐渐成为了许多家庭厨房的必备电器。随着科技的不断进步,果汁机的性能也在不断提升,其中锂电池的应用更是为果汁机带来了前所未有的便利。而5V升压12.7V升压恒压芯片SL1571B,作为果汁机锂电池充电…...

多个线程多个锁:如何确保线程安全和避免竞争条件
目录 前言 一、确定需要多个锁的场景 1.独立资源保护 2.部分依赖资源 二、避免死锁 三、锁粒度与并发性能 1. 粗粒度锁定 2.细粒度锁定 四、设计策略:减少资源依赖 1.资源分离 2.无锁设计 3.锁合并 五、Demo讲解 总结: 前言 当多个线程需要…...

Linux-笔记 设备树插件
目录 前言: 设备树插件的书写规范: 设备树插件的编译: 内核配置: 应用背景: 举例: 前言: 设备树插件(Device Tree Blob Overlay,简称 DTBO)是Linux内核和嵌入式系统…...

【排序算法】总结篇
✨✨这些 排序算法都是指的 需要进行比较的排序算法 ✨✨下面都是略微讲解一下思路,如果需要详细了解哪一个排序,点击👉链接即可 ✨✨对于时间、空间复杂度、稳定性,希望你🧑🎓能够理解记忆🧑…...

鸿蒙开发文件管理:【@ohos.fileio (文件管理)】
文件管理 该模块提供文件存储管理能力,包括文件基本管理、文件目录管理、文件信息统计、文件流式读写等常用功能。 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 impor…...

硬件工程师学习规划
背景介绍 当前电子行业中,互联网因为中国人口基数大,得到很快的发展,一越成为世界第一梯队,互联网软件薪资要高于传统制造业硬件的薪资,从各大招聘软件上就能看到,那么为什么软件发展要好于硬件࿱…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...