【数据结构】链表的大概认识及单链表的实现
目录
一、链表的概念及结构
二、链表的分类
三、单链表的实现
建立链表的节点:
尾插——尾删:
头插——头删:
查找:
指定位置之后删除——插入:
指定位置之前插入——删除指定位置:
销毁链表:
打印:
四、链表面试题
五、总体代码
一、链表的概念及结构
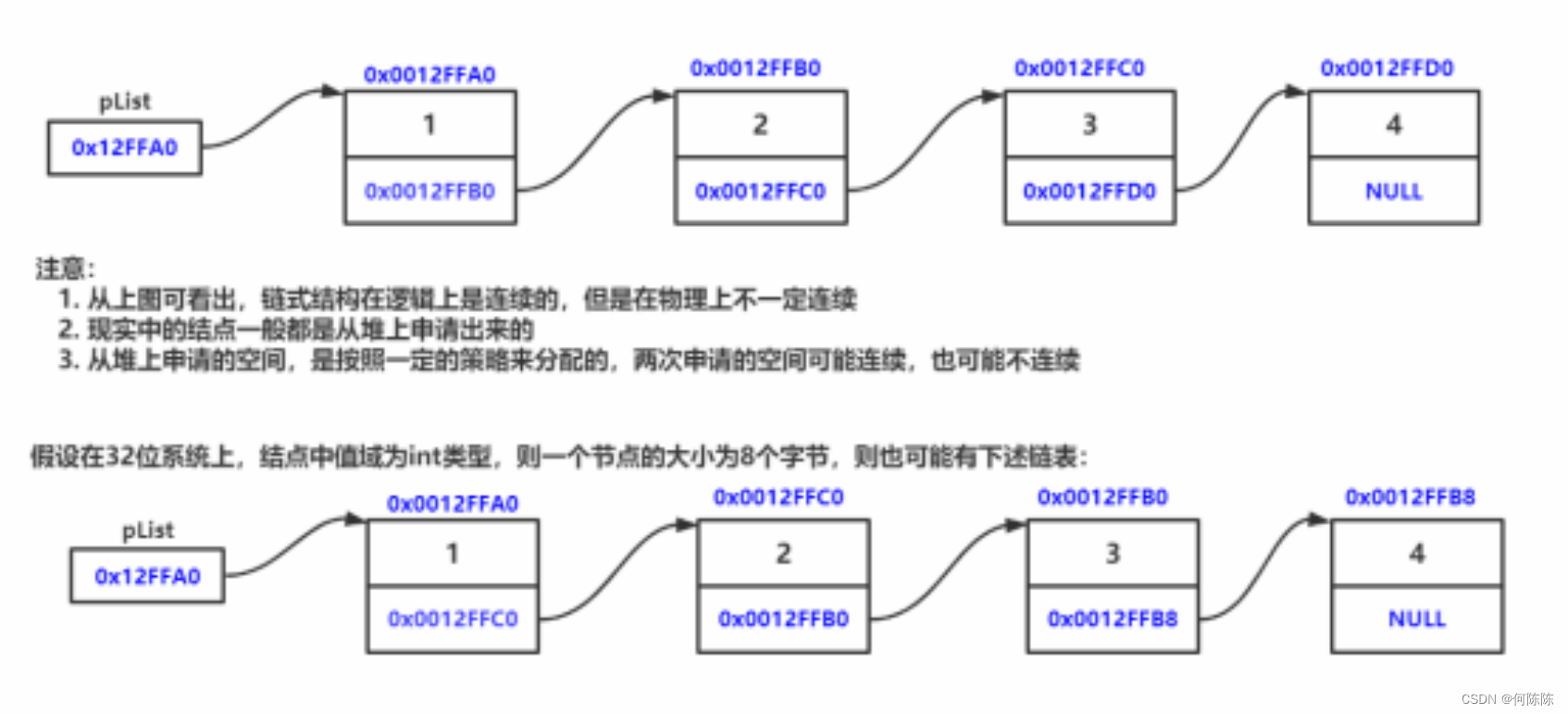
二、链表的分类
实际中链表的结构非常多样,以下情况组合起来就有 8 种链表结构:
1. 单向或者双向
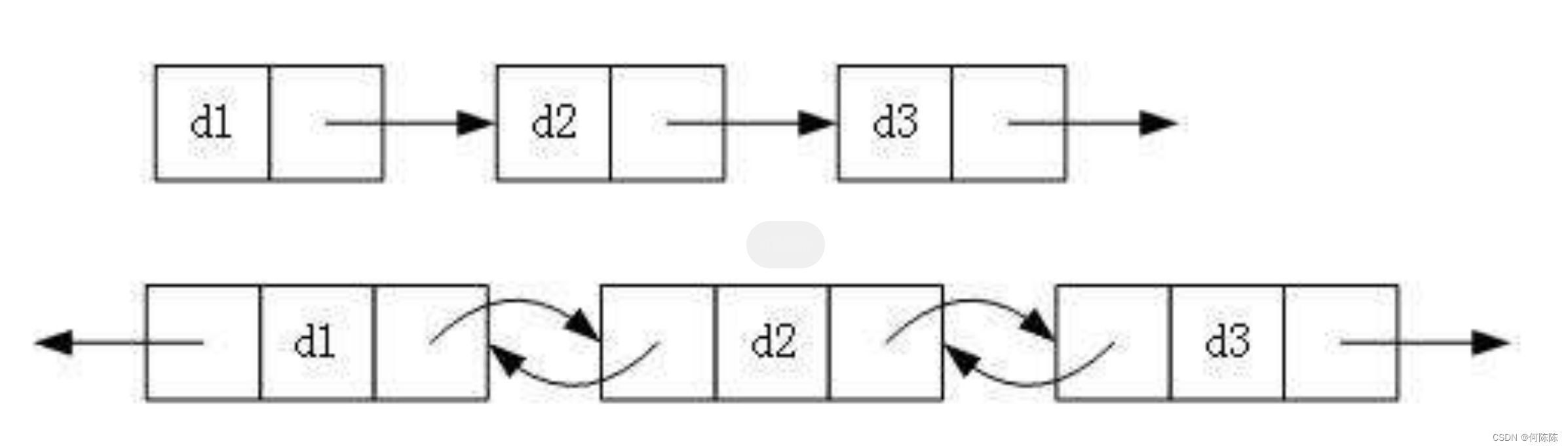
2. 带头或者不带头
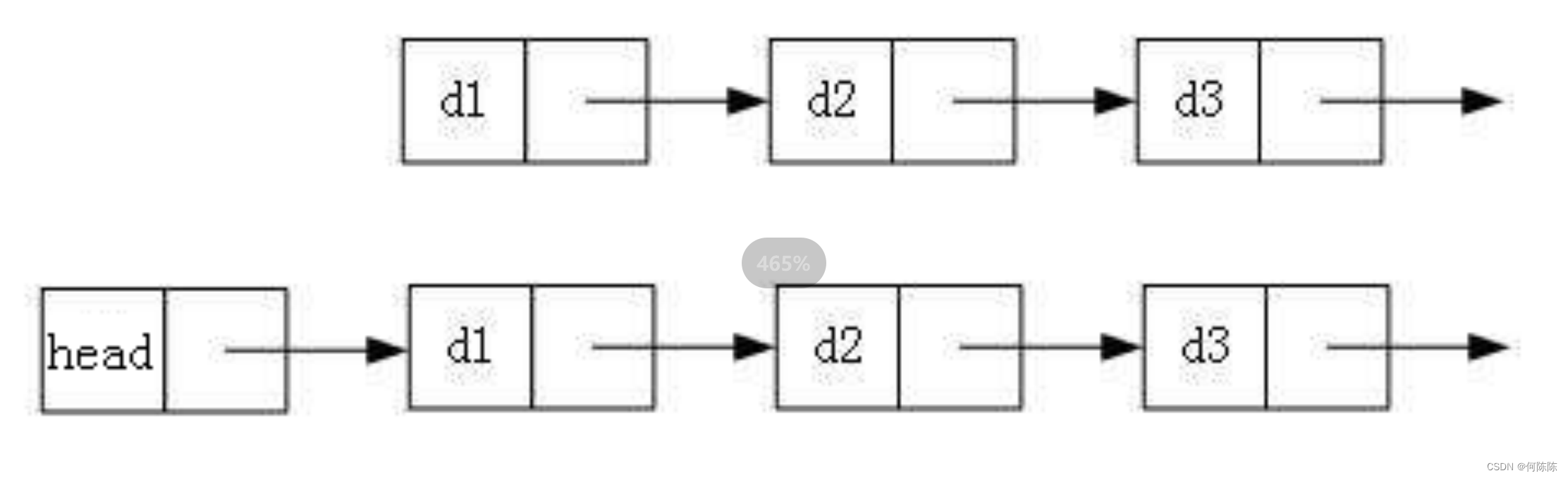
3. 循环或者非循环
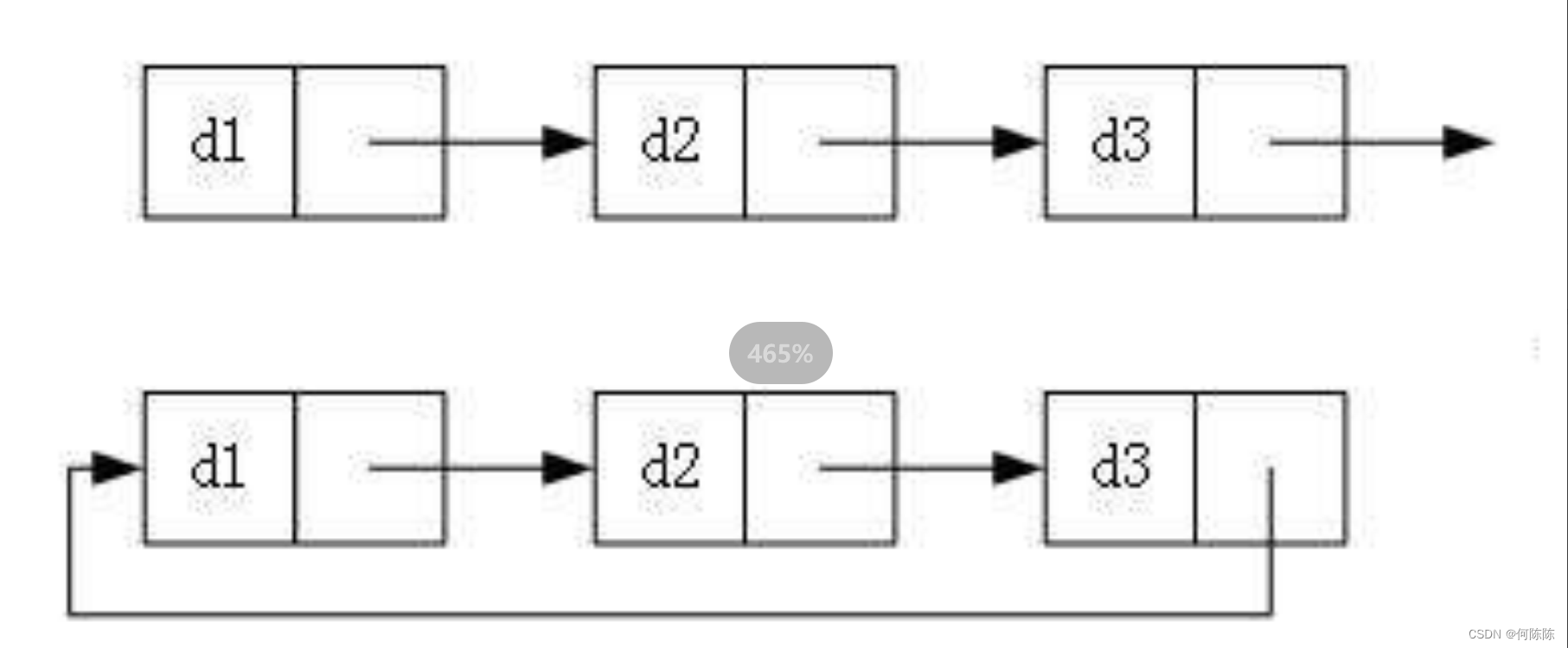
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
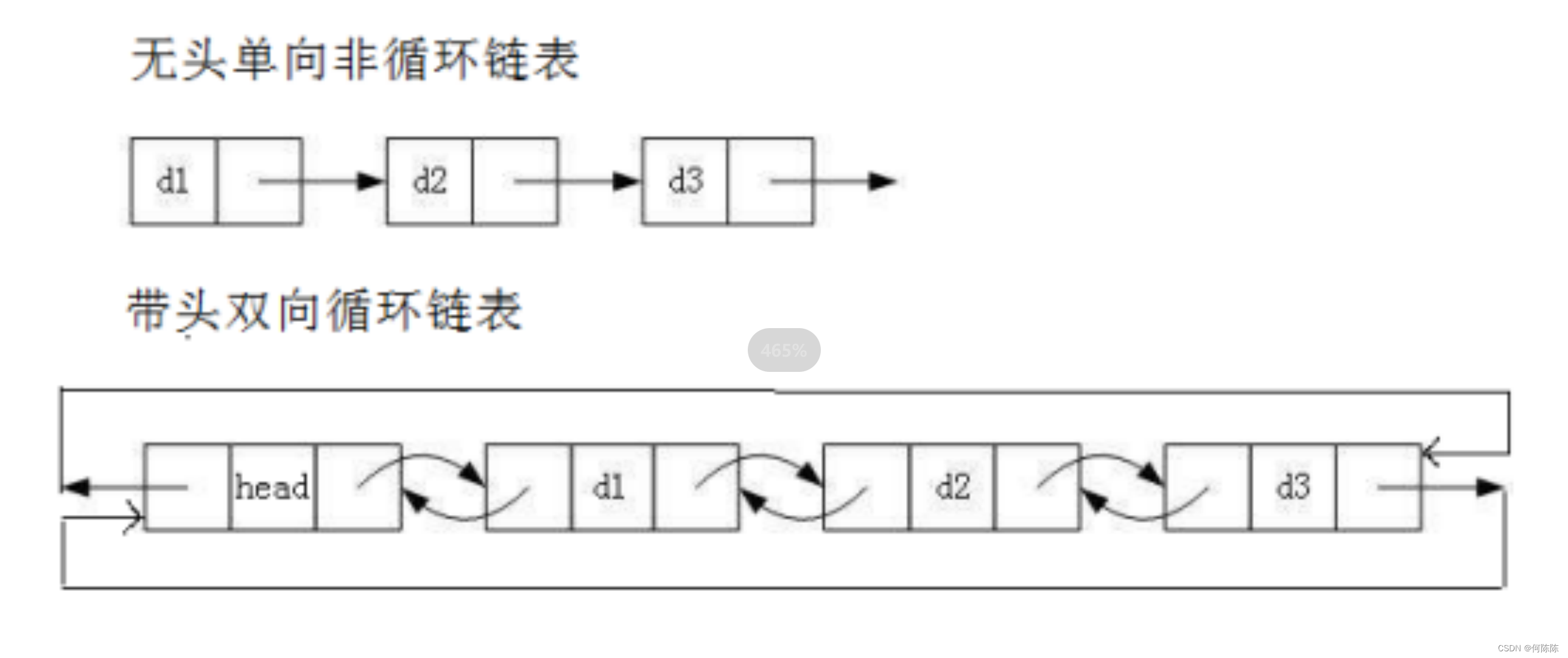
1. 无头单向非循环链表: 结构简单 ,一般不会单独用来存数据。实际中更多是作为 其他数据结 构的子结构 ,如哈希桶、图的邻接表等等。另外这种结构在 笔试面试 中可能出现比较多。2. 带头双向循环链表: 结构最复杂 ,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
三、单链表的实现
建立链表的节点:
链表中的节点结构体大概有这些内容:节点数据,下一个节点的地址
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType data;struct SListNode* next;
}SListNode;尾插——尾删:
不管是尾插还头插还是任意位置插入,我们都需要先创建一个新节点。
尾插和尾删都需要注意一些点:
用二级指针接收:
因为我们这个是无头的链表,在链表没有一个节点的时候,我们需要创建一个节点。然后将链表的头指向这个新节点,这个时候就涉及到需要修改一级结构体的一级指针。一级指针类型的变量需要修改的话,就要用到二级指针。
尾插:是否链表一个数据都没有,这个时候我们要特殊处理一下,检查链表有效性
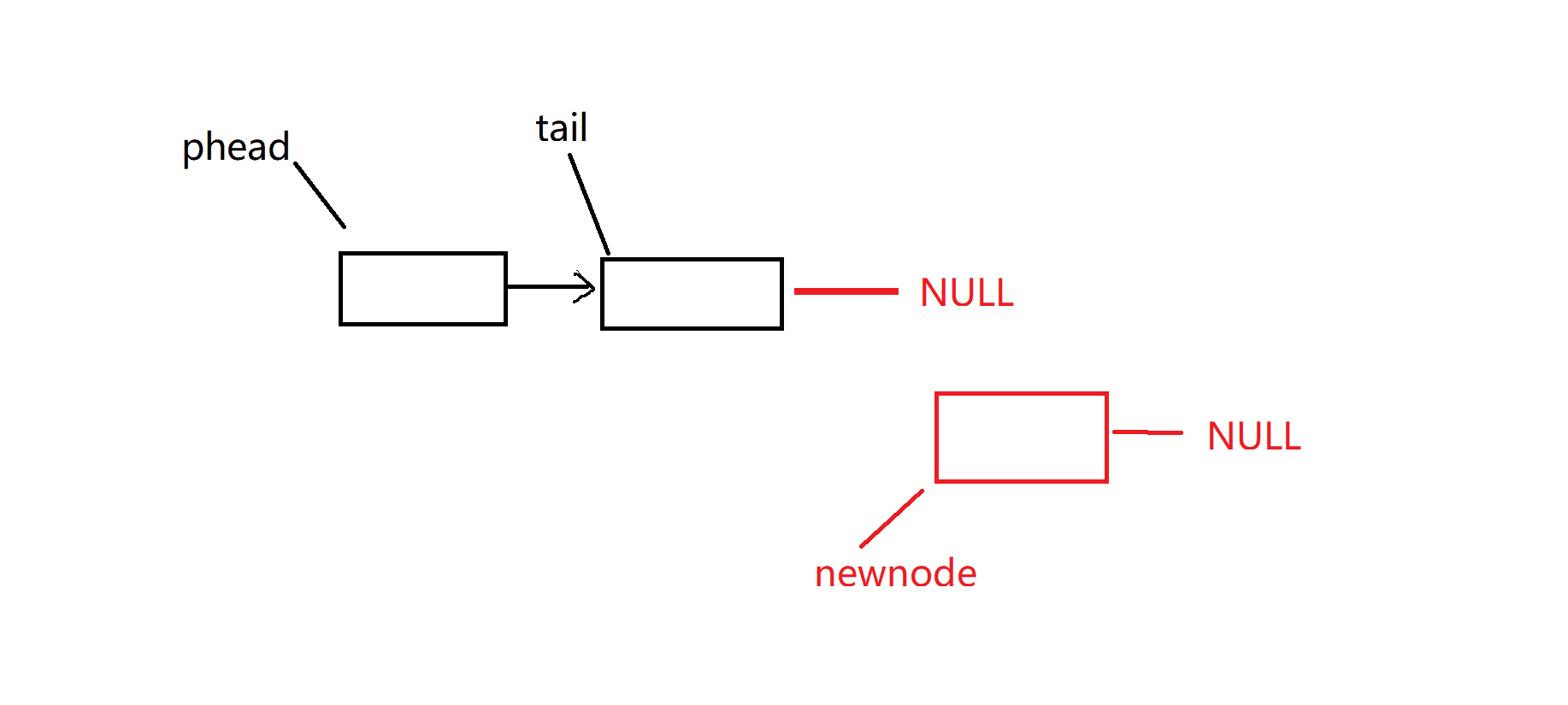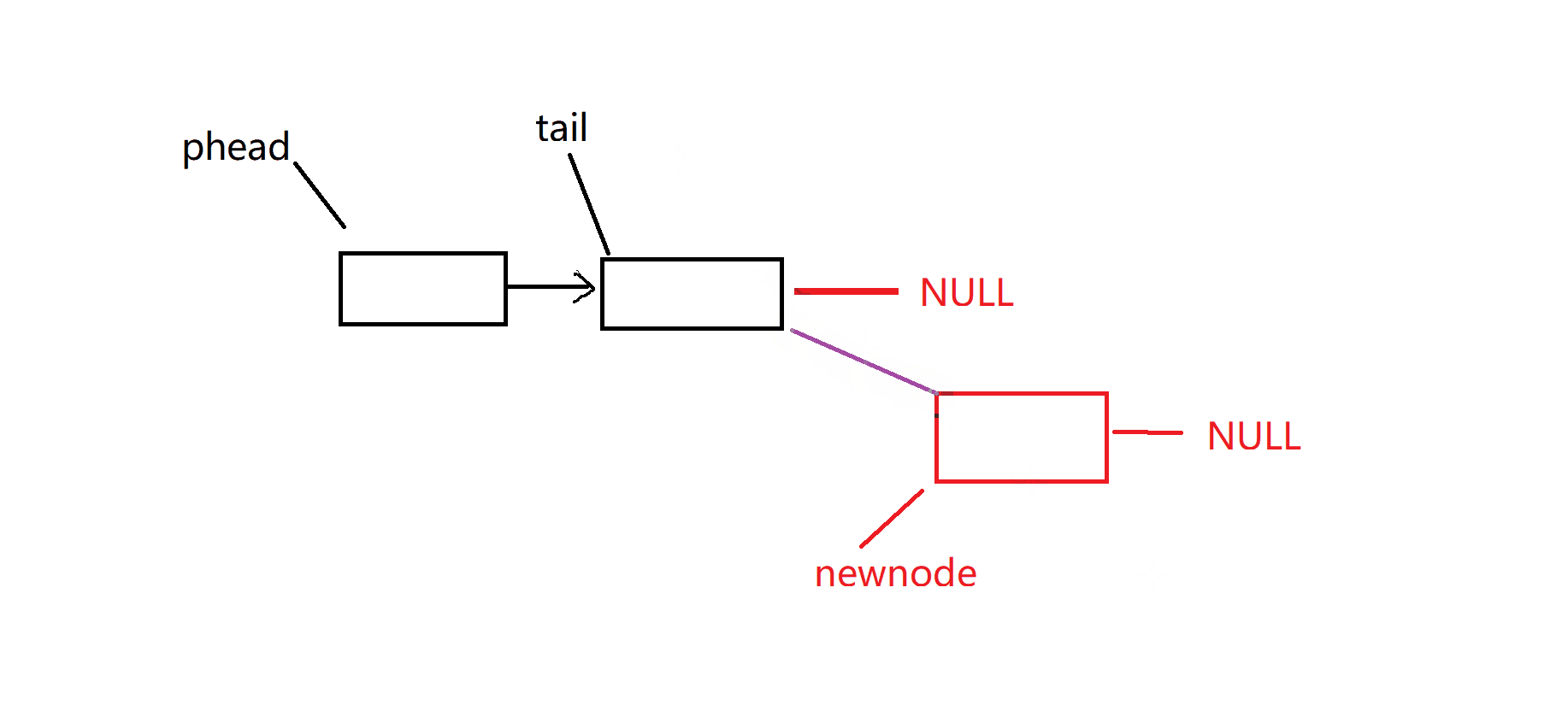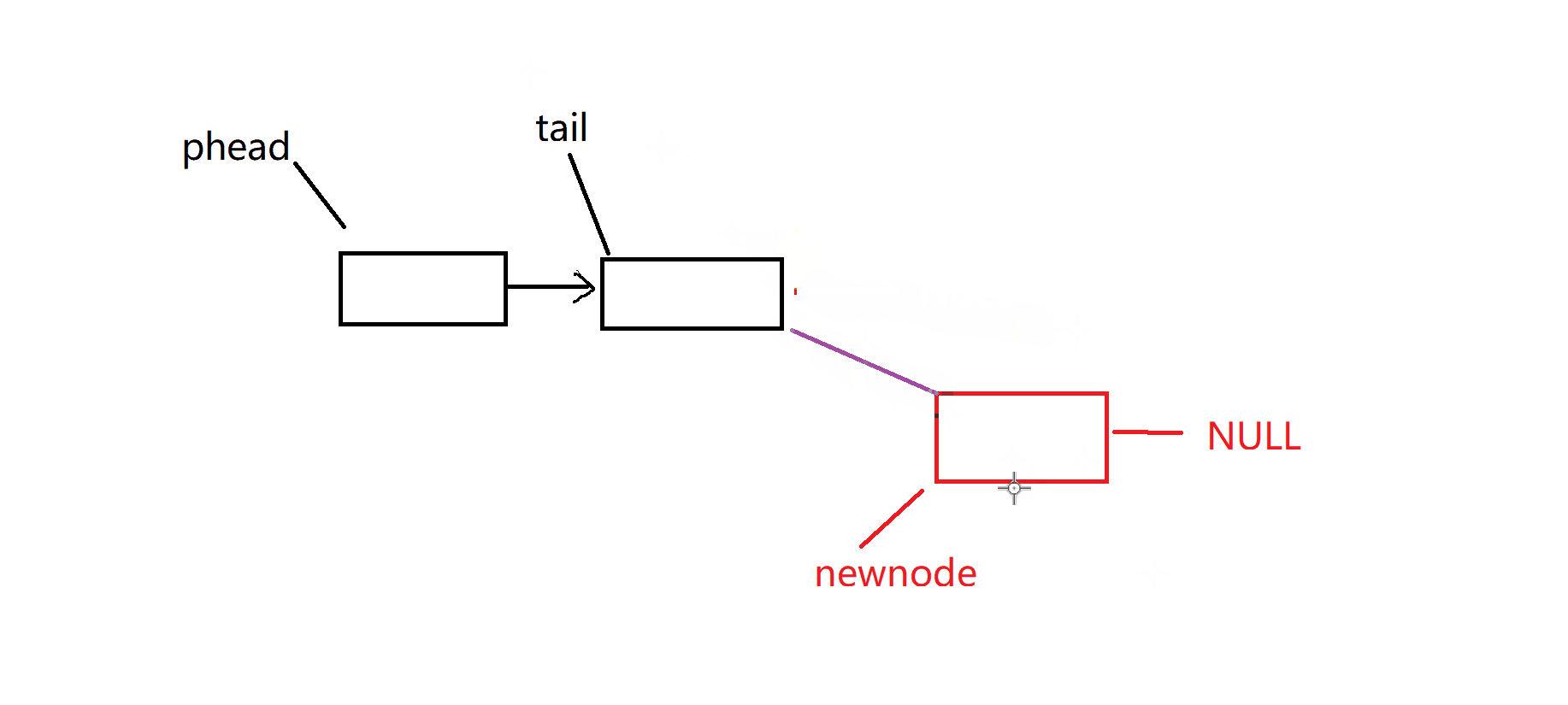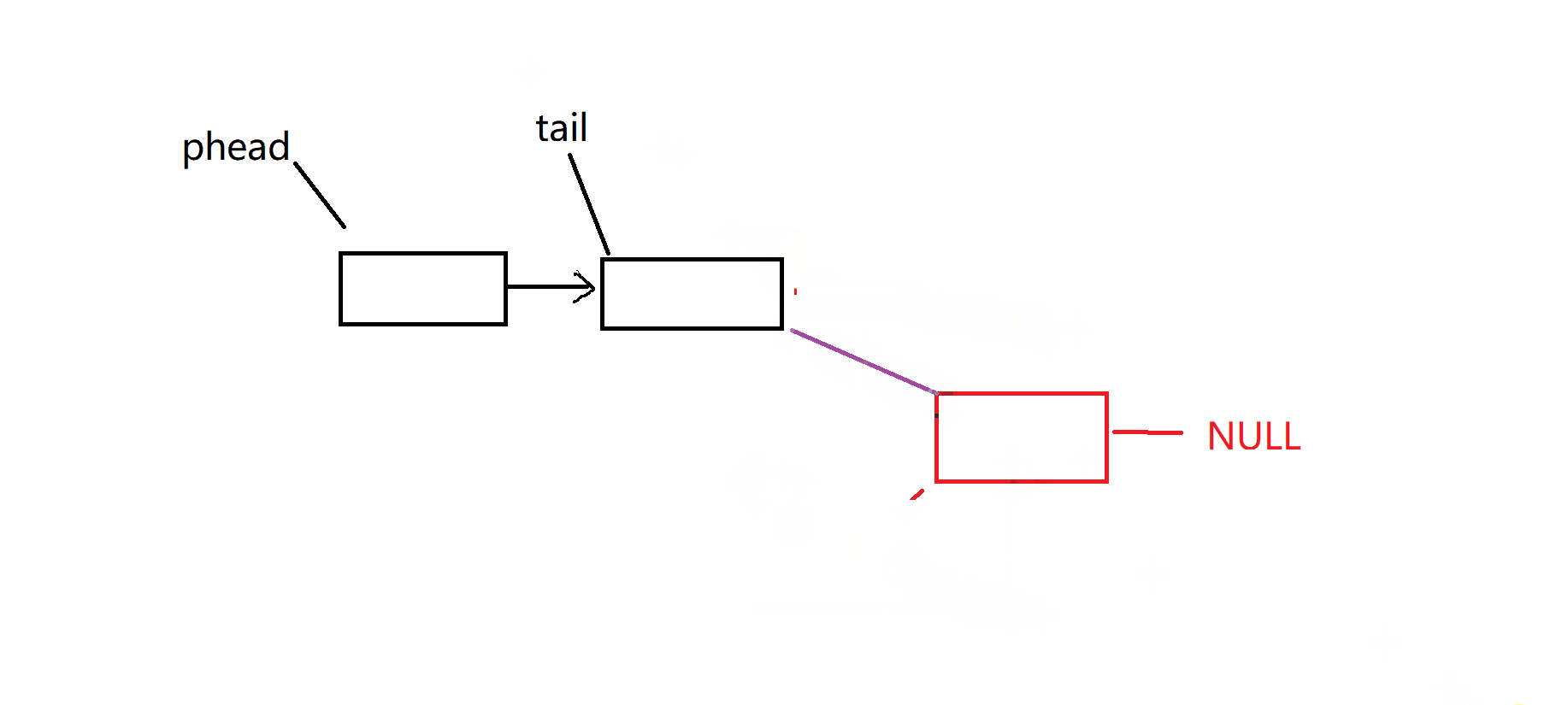
尾删:是否链表只有一个数据 ,检查是否有数据可以删除,检查链表有效性
// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x)
{SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));if (newnode == NULL){perror("malloc fail");}newnode->data = x;newnode->next = NULL;return newnode;
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{assert(pplist);SListNode* newnode = BuySListNode(x);if (*pplist == NULL){*pplist = newnode;return;}//找尾巴SListNode* tail = *pplist;while (tail->next != NULL)tail = tail->next;tail->next = newnode;
}
// 单链表的尾删
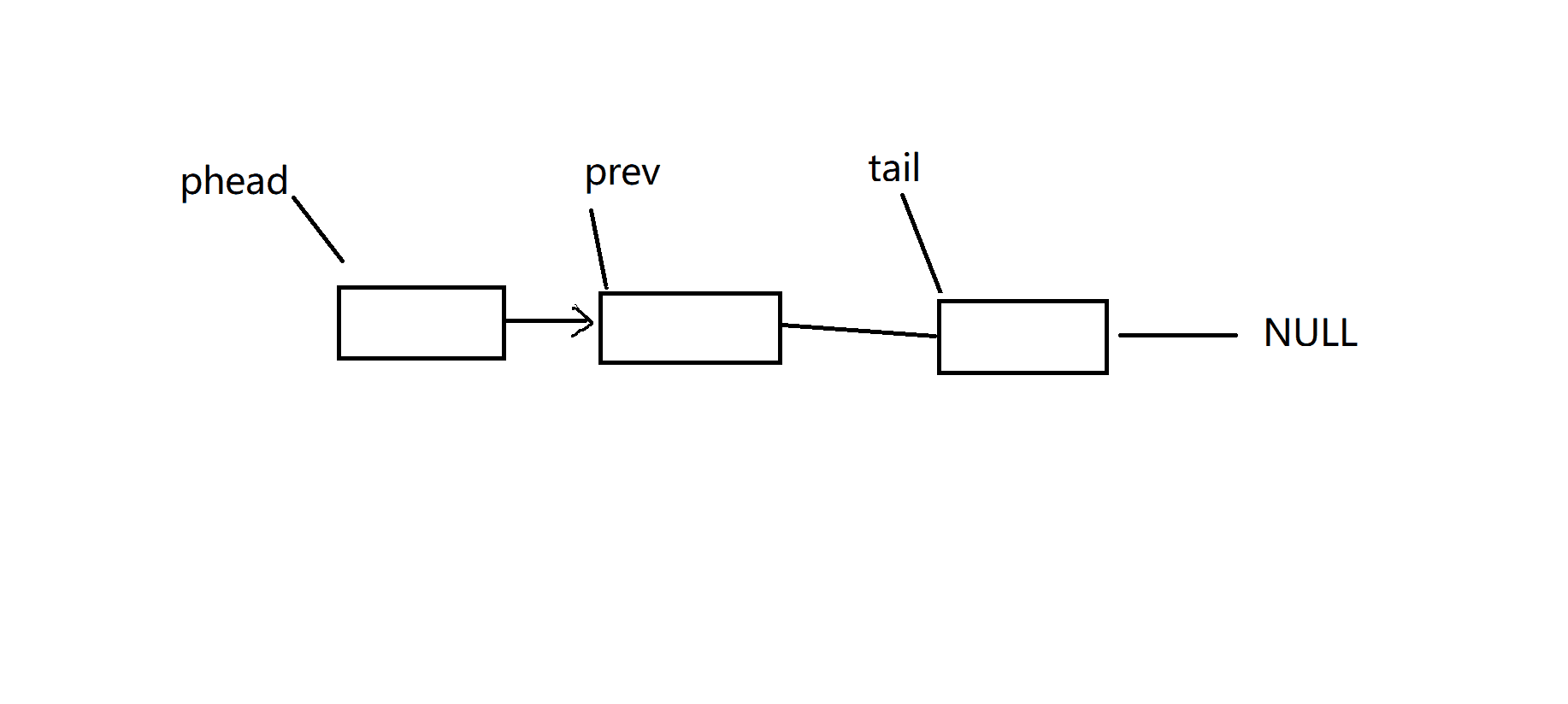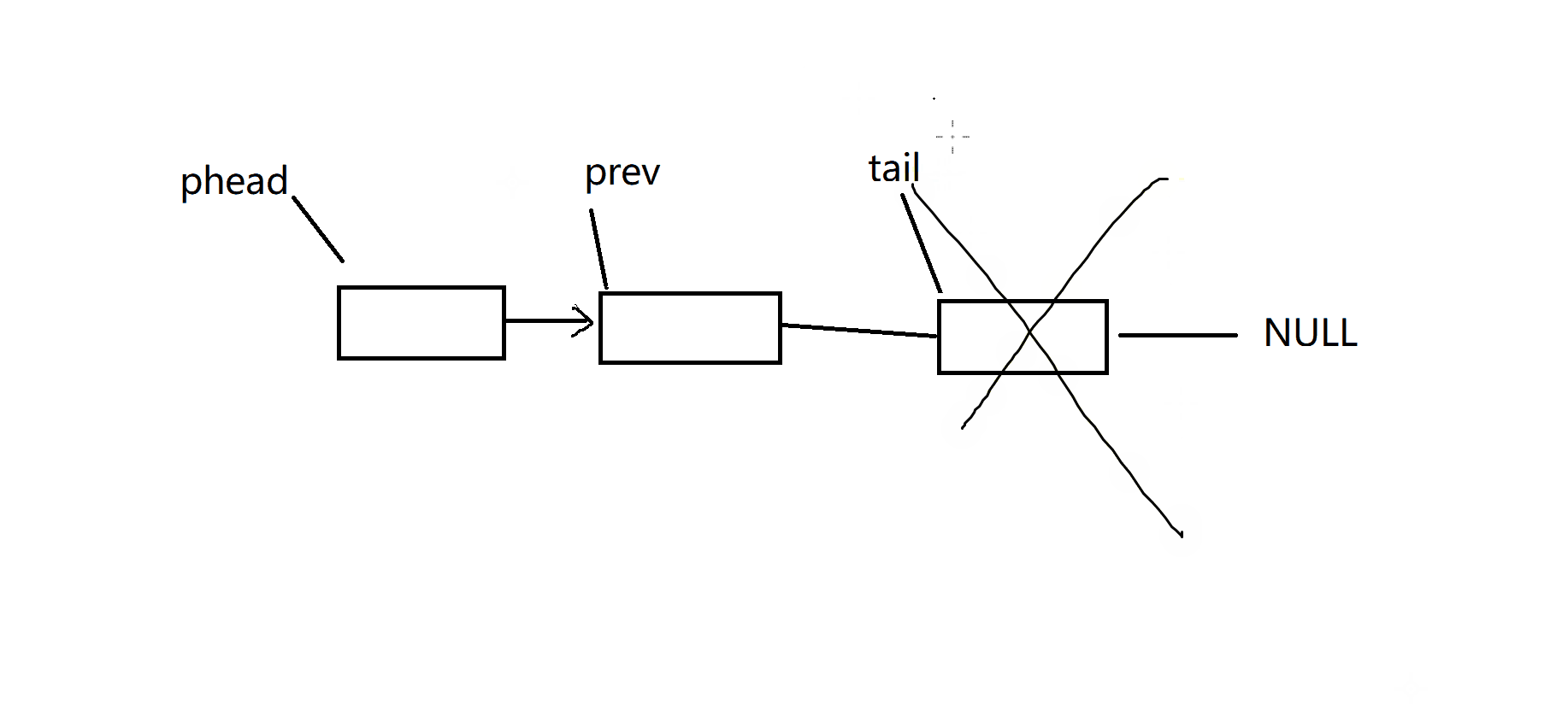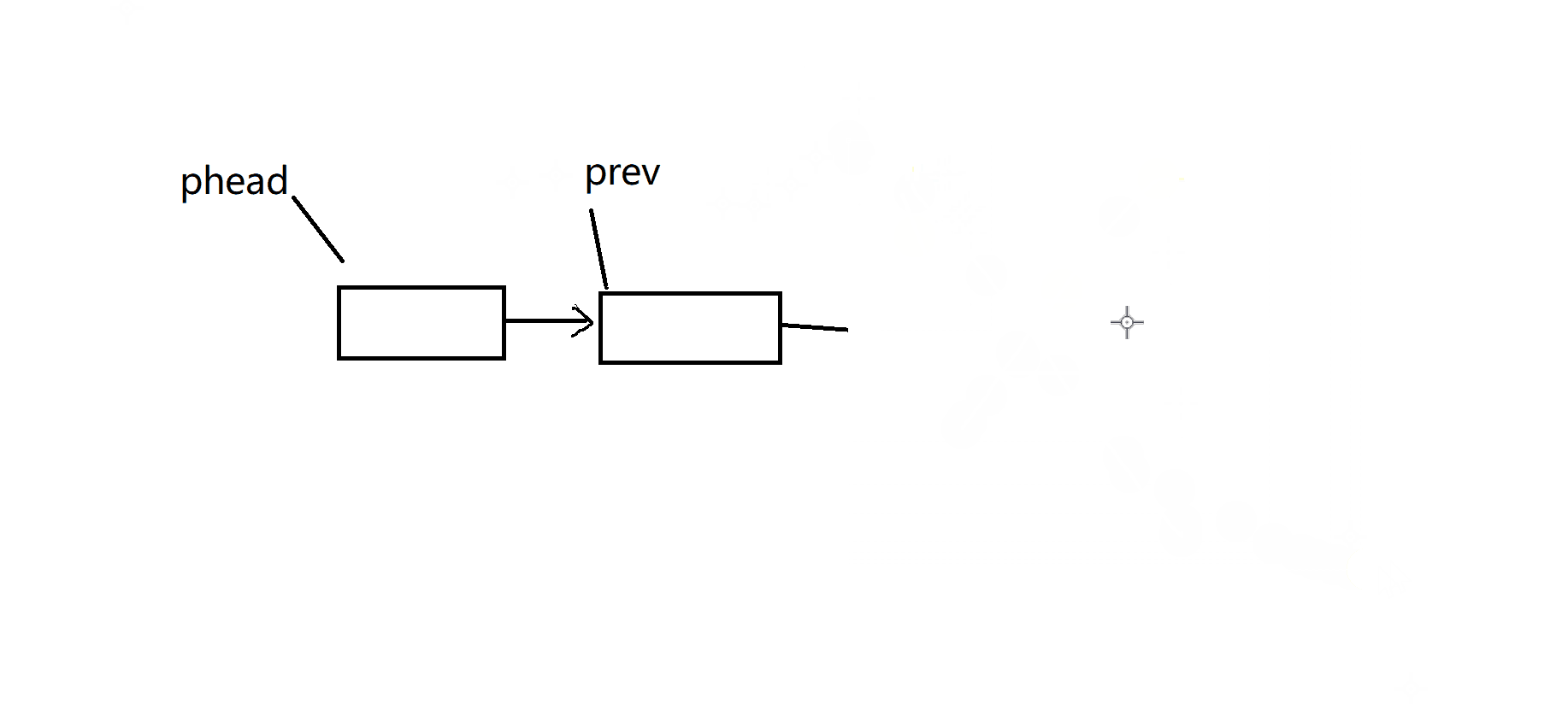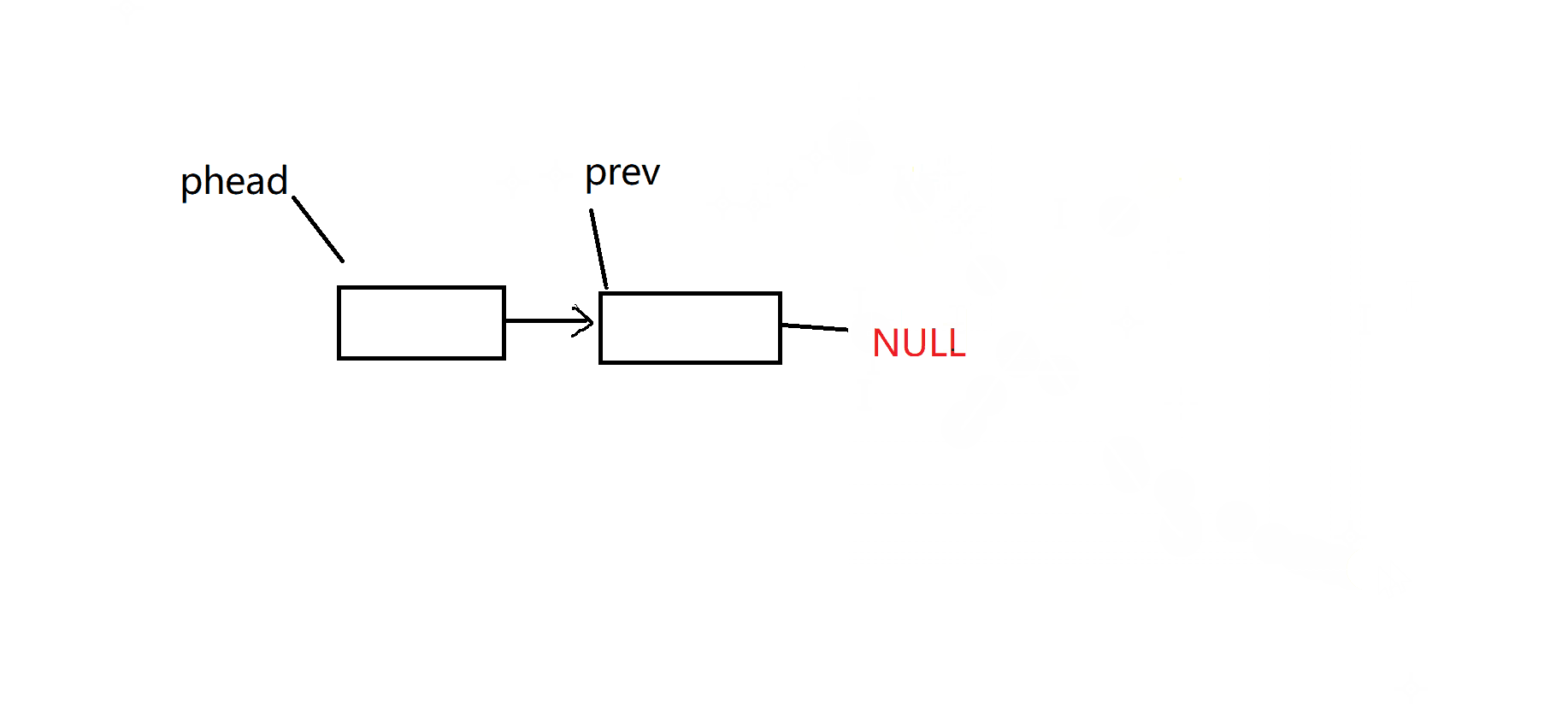
void SListPopBack(SListNode** pplist)
{assert(pplist);assert(*pplist);//有数据才能删,没有数据不删,至少有一个及其以上节点if ((*pplist)->next == NULL){free(*pplist);*pplist = NULL;}else{//找尾巴SListNode* prev = NULL;SListNode* tail = *pplist;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
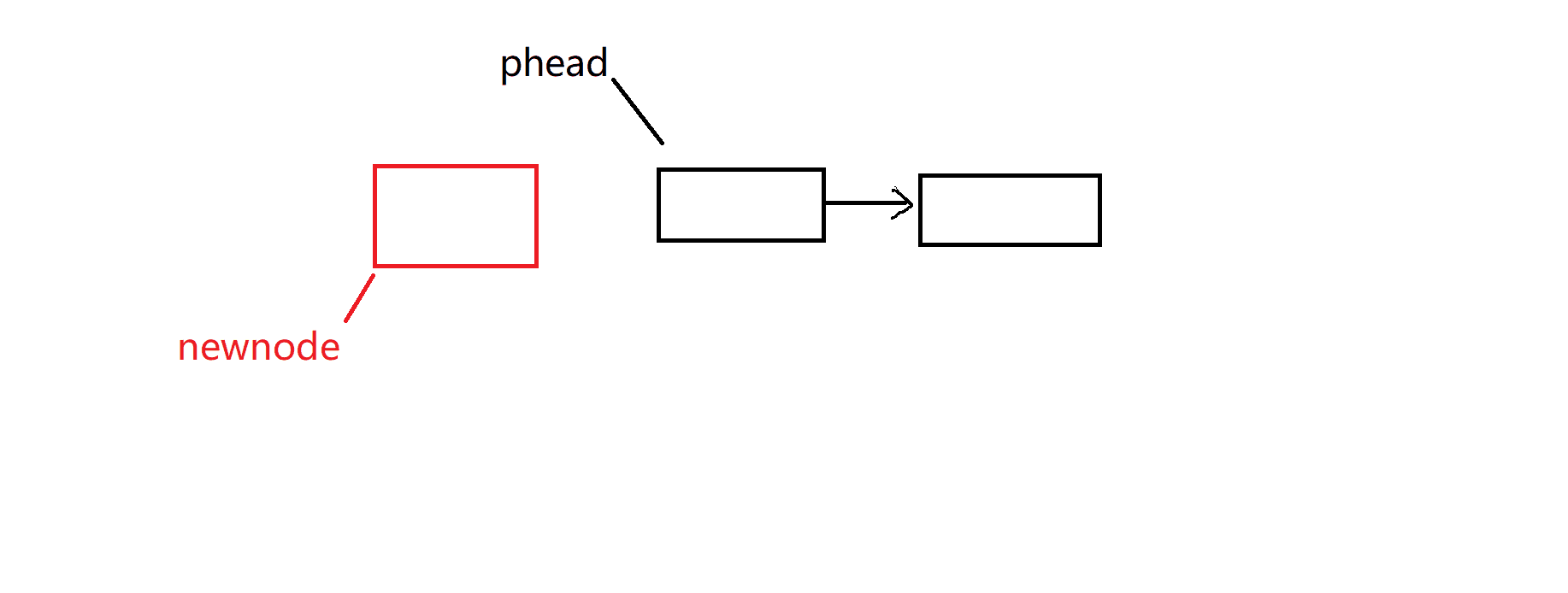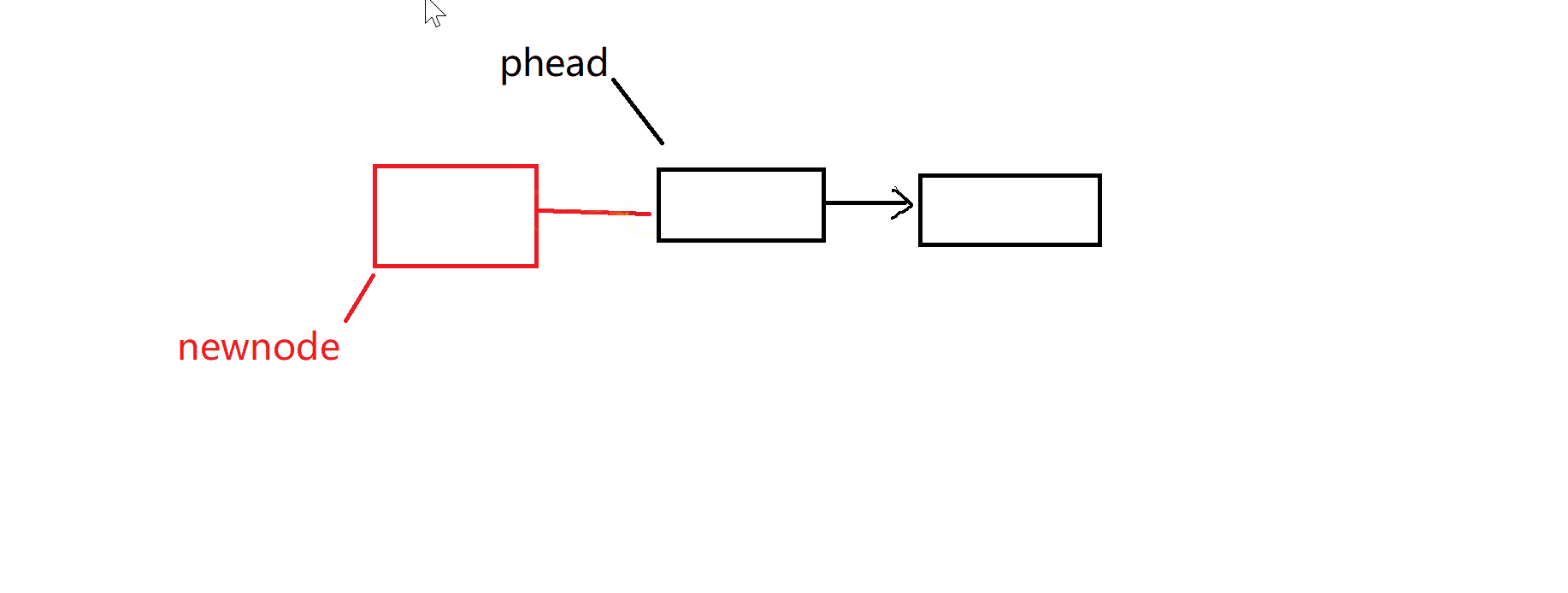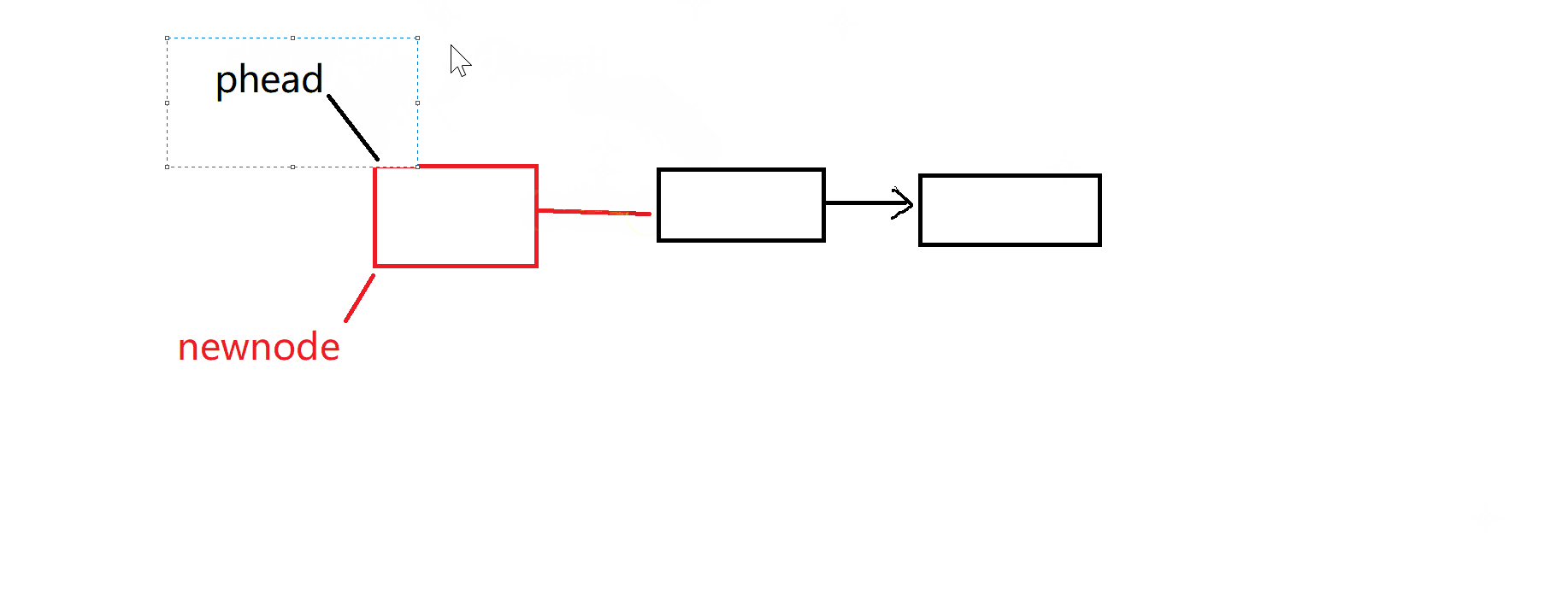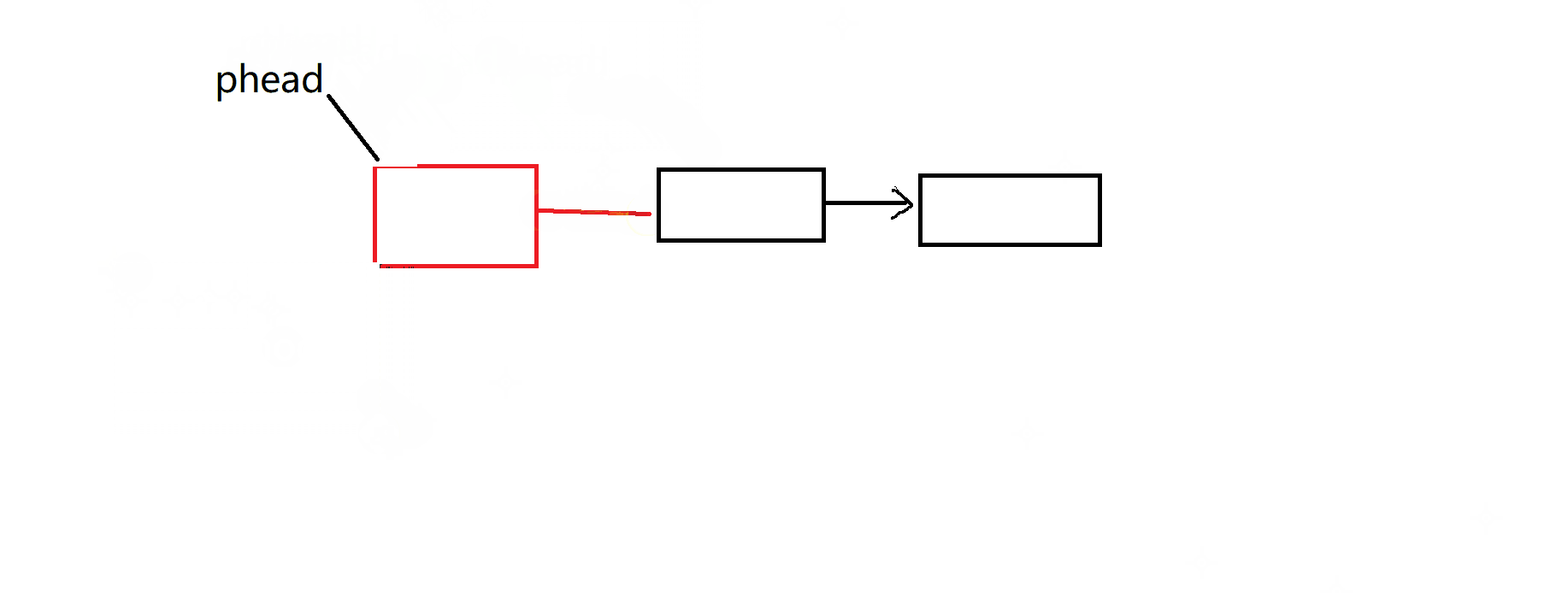
}头插——头删:
头插和头删在链表中还是比较简单,一个是把头节点保存起来,另一个是头节点的下一个节点保存起来,然后进行删除就行了。
头插:注意需要检查链表有效性
头删:注意这里需要检查数据个数,有数据才能删除;
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{assert(pplist);SListNode* newnode = BuySListNode(x);newnode->next = *pplist;*pplist = newnode;
}
// 单链表头删
void SListPopFront(SListNode** pplist)
{assert(pplist);assert(*pplist);SListNode* next = (*pplist)->next;free(*pplist);*pplist = next;
}查找:
通过简单遍历就行了,注意返回的是节点的指针;
我们在外面定义的是一个链表节点的指针,打印的时候按照传值的方式传递变量,他会把变量的内容(链表中首节点的地址)拷贝过来,最终返回的也是链表节点的地址
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x)
{assert(plist);SListNode* cur = plist;while (cur){if (cur->data == x)return cur;cur = cur->next;}return NULL;
}指定位置之后删除——插入:
注意:写这两个接口,我们首先就要想到的是检查 指定位置的有效性 还有检查 链表有效性。
代码还是很简单的,这里的删除要检查是不是最后一个节点;
// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDateType x)
{assert(pos);SListNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}
// 单链表删除pos位置之后的值void SListEraseAfter(SListNode* pos)
{assert(pos);assert(pos->next);//检查是不是最后一个SListNode* next = pos->next;pos->next = next->next;free(next);
}指定位置之前插入——删除指定位置:
这两个接口:我们需要像尾插那个样子 遍历找到指定位置前的位置:然后进行插入,删除,同时也要注意检查链表有效性,
注意: 如果链表只有一个位置或者指定位置为第一个节点,那删除就变成了头删,可以复用原来的头删接口。尾删则没有必要,我们已经遍历一遍找到尾了,不需要调用尾删接口再遍历一遍了,直接像尾删一样删除就行了。
// 在pos的前面插入
void SLTInsert(SListNode** pphead, SListNode* pos, SLTDateType x)
{assert(pphead);assert((!pos&&!(*pphead))||(pos&&(*pphead)))//这里我们让他都为空(头插)或者都不为空//我们想暴露出一个问题,不允许乱位置插入 限定pos一定是有效节点if (pos == *pphead){SListPushFront(pphead, x);return;}SListNode* prev = *pphead;while (prev->next!=pos){prev = prev->next;}SListNode* newnode = BuySListNode(x);newnode->next = pos;prev->next = newnode;
}
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos)
{assert(pphead);assert(*pphead);assert(pos);//这里进行检查pos,必须有这个节点才能删除if (pos == *pphead){SListPopFront(pphead);return;}SListNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}销毁链表:
这个按照遍历的同时free就行了。
注意:遍历完了,全部空间释放了把链表置空
void SLTDestroy(SListNode** pphead)
{assert(pphead);assert(*pphead);SListNode* cur = *pphead;while (cur){SListNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}打印:
为了好测试写的接口是否正确,我们还是写一个打印接口,方便我们观察:同样的,循环遍历打印就行了;这里不需要检查链表是否为空,空链表也可以打印
// 单链表打印
void SListPrint(SListNode* plist)
{SListNode* cur = plist;while (cur){printf("%d-> ", cur->data);cur = cur->next;}printf("\n");
}四、链表面试题
1. 删除链表中等于给定值 val 的所有结点。 203. 移除链表元素 - 力扣(LeetCode)
1:链表为空2:需要删除头(需要循环删除,因为有可能连续好几个都需要删)
参考代码:
struct ListNode* removeElements(struct ListNode* head, int val) {//处理链表为空if(!head) return NULL;//处理链表第一个就是该删的元素if(head->val==val){while(head&&head->val==val){struct ListNode* next=head->next;free(head);head=next;}}struct ListNode* cur=head;struct ListNode* prev=NULL;while(cur){if(cur->val==val){prev->next=cur->next;free(cur);cur=prev->next;}else{prev=cur;cur=cur->next;}}return head;
}2. 反转一个单链表。 206. 反转链表 - 力扣(LeetCode)
这个题,就是一个简单头插就行了
当然我们也可以用三个指针将链表的指向反转(注意检查链表是否为空),这里我们用两种方法实现,两种方法任选其一都能通过,
struct ListNode* reverseList(struct ListNode* head) {//头插处理// struct ListNode* newhead=NULL;// while(head)// {// struct ListNode* next=head->next;// head->next=newhead;// newhead=head;// head=next;// }// return newhead;//直接反转if(!head)return head;struct ListNode* n1=NULL,*n2=head,*n3=head->next;while(n2){n2->next=n1;n1=n2;n2=n3;if(n3)n3=n3->next; }return n1;
}3. 给定一个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。 876. 链表的中间结点 - 力扣(LeetCode)
值得注意的是:我们判断条件是快指针为NULL或者快指针的下一个节点为NULL,他们在循环中判断的先后为先判断自己再判断下一个,因为先判断下一个的话,有可能出现野指针问题。

struct ListNode* middleNode(struct ListNode* head) {//快慢指针法struct ListNode* fast=head;struct ListNode* slow=head;while(fast&&fast->next){fast=fast->next->next;slow=slow->next;}return slow;
}4. 输入一个链表,输出该链表中倒数第k个结点。 面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode)
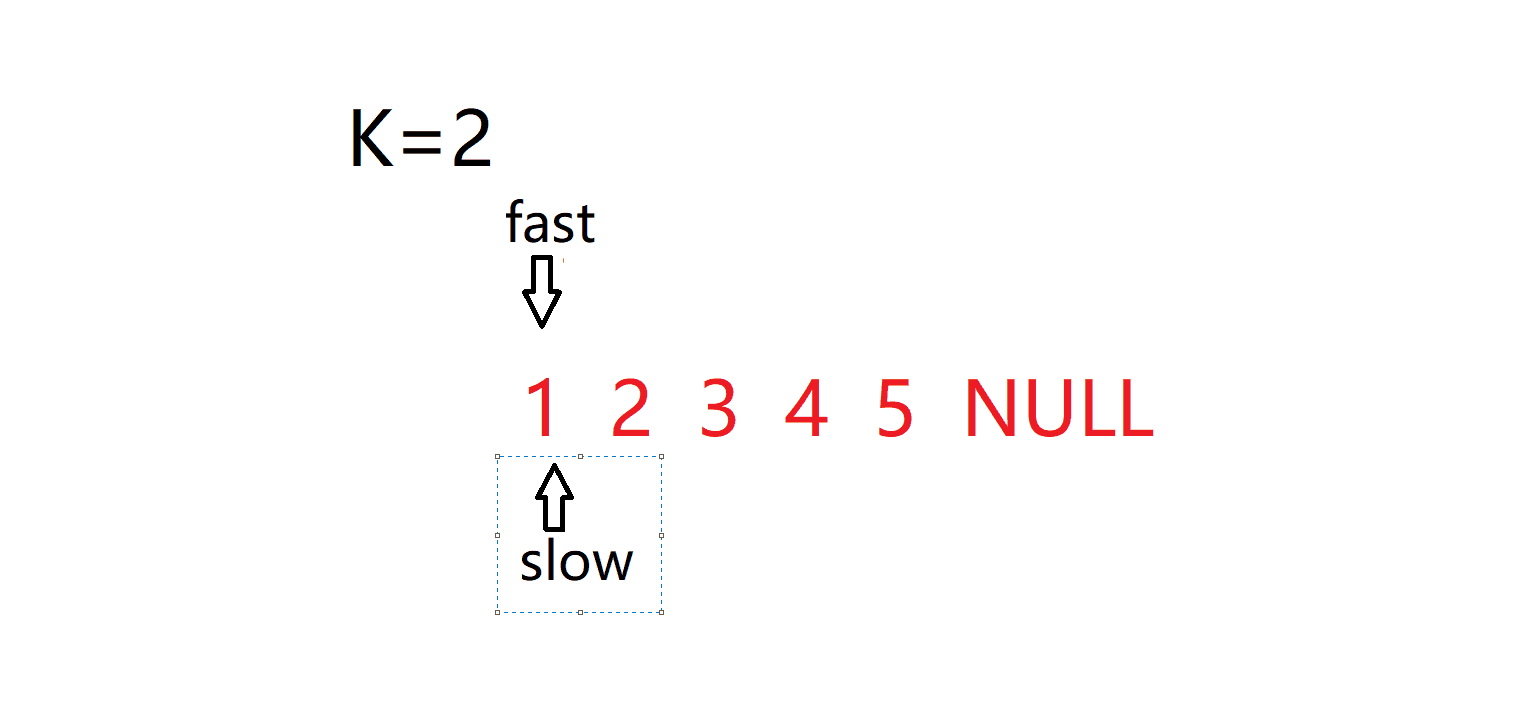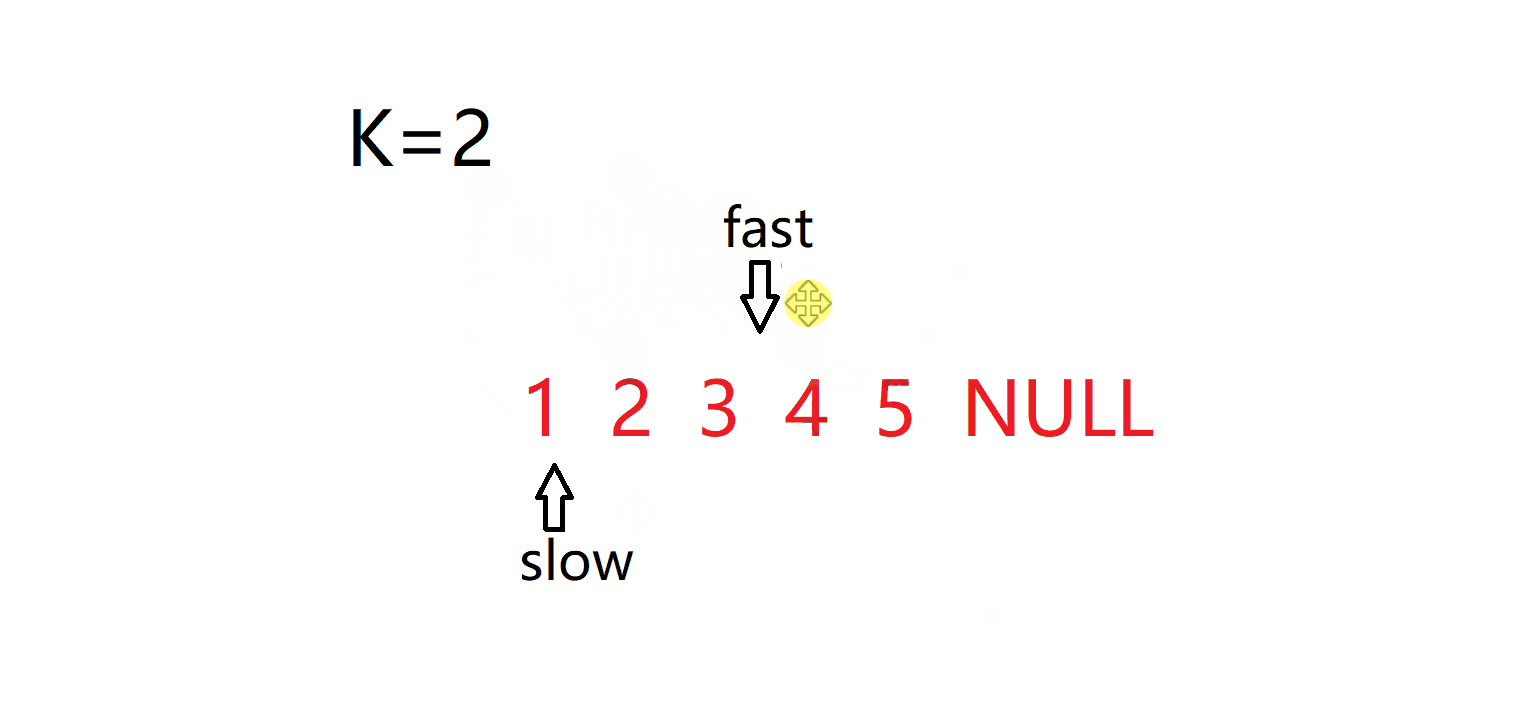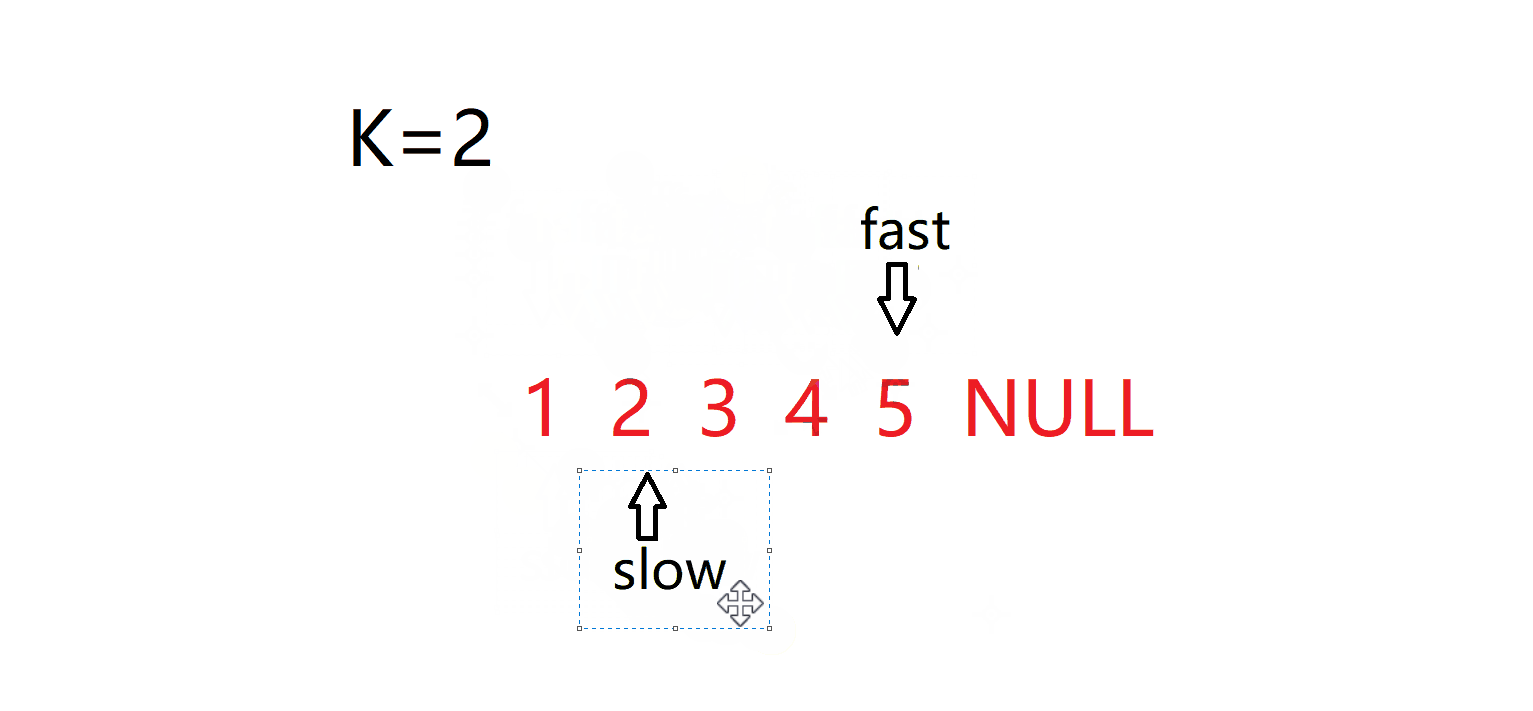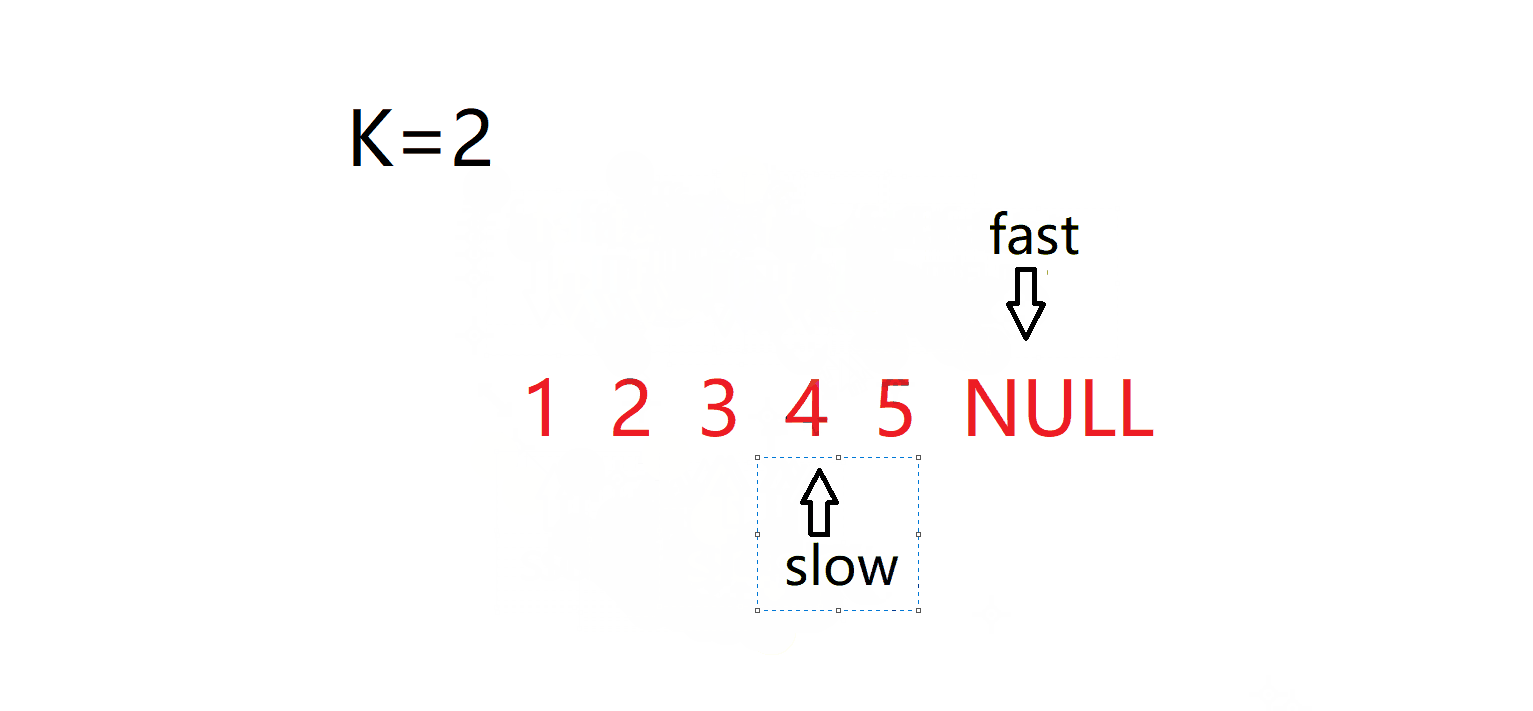
int kthToLast(struct ListNode* head, int k){struct ListNode* fast=head;struct ListNode* slow=head;while(k--)fast=fast->next;while(fast){fast=fast->next;slow=slow->next;}return slow->val;
}5. 将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有结点组成的。 21. 合并两个有序链表 - 力扣(LeetCode)
这个题就要用到并归和尾插了,选择小的尾插到新链表里面,这个尾插是移动他的链表节点到我们新的链表里面。
需要注意的是:1.需要处理空链表情况,一个为空或者两个为空
2.处理头节点

struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {//处理为空的情况 if(!list1)return list2;if(!list2)return list1;struct ListNode* head=NULL;struct ListNode* tail=NULL;while(list1&&list2){if(list1->val<list2->val){struct ListNode* next=list1->next;if(head==NULL)//处理头节点head=tail=list1;else{tail->next=list1;tail=tail->next;tail->next=NULL;//这个可以不处理,后面剩余节点的尾巴也一定是NULL}list1=next;}else{struct ListNode*next=list2->next;if(head==NULL)//处理头节点head=tail=list2;else{tail->next=list2;tail=tail->next;tail->next=NULL;}list2=next;}}if(list1==NULL)//处理剩余未插入的节点tail->next=list2;elsetail->next=list1;return head;
}6. 编写代码,以给定值 x 为基准将链表分割成两部分,所有小于 x 的结点排在大于或等于 x 的结点之前 。 链表分割_牛客题霸_牛客网 (nowcoder.com)
class Partition {public:ListNode* partition(ListNode* pHead, int x) {ListNode* head1, *tail1, *head2, *tail2;head1 = tail1 = (ListNode*)malloc(sizeof(ListNode));//第一条链表head2 = tail2 = (ListNode*)malloc(sizeof(ListNode));//第二条链表tail1->next = tail2->next = NULL;while (pHead) {if (pHead->val < x) {ListNode* next = pHead->next;tail1->next = pHead;tail1 = tail1->next;tail1->next = NULL;pHead = next;} else {ListNode* next = pHead->next;tail2->next = pHead;tail2 = tail2->next;tail2->next = NULL;pHead = next;}}tail1->next=head2->next;ListNode* re=head1->next;free(head2);free(head1);return re;}
};7. 链表的回文结构。OJ链接
class PalindromeList {
public:bool chkPalindrome(ListNode* A) {if(!A) return true;int count=0;ListNode* cur=A;while(cur){cur=cur->next;count++;}count=(count+1)/2;int i=count;ListNode*head=NULL;while(i--){ListNode*next=A->next;A->next=head;head=A;A=next;}while(head&&A){if(head->val!=A->val)return false;head=head->next;A=A->next;}return true;}
};8. 输入两个链表,找出它们的第一个公共结点。 160. 相交链表 - 力扣(LeetCode)
这个题我们可以首先想到暴力解法:先在定一条链表中的某个节点,然后再另一个链表中找该节点,如果找到了有返回该节点,不过这样的解法时间复杂度太高了
第二种方法是我们先遍历各自链表,找出其中个数,先让长的那一条链表先走他们的节点个数差,然后两条链表同时遍历,找出相交节点;
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {int cnt1=0,cnt2=0;struct ListNode* cur1=headA;while(cur1){cur1=cur1->next;cnt1++;}struct ListNode* cur2=headB;while(cur2){cur2=cur2->next;cnt2++;}if(cur2!=cur1)//如果链表到最后都不相等,说明不相交,没有交点return NULL;//假定A比B长struct ListNode* ha=headA;struct ListNode* hb=headB;if(cnt1<cnt2){ha=headB;hb=headA;}int cnt=abs(cnt1-cnt2);while(cnt--)//让长的先走个数差ha=ha->next;while(ha)//两条链表同时遍历{if(ha==hb)//注意两个节点相等,不是节点值相等 !!!!!!!return ha;ha=ha->next;hb=hb->next;}return NULL;
}9.给定一个链表,判断链表中是否有环。141. 环形链表 - 力扣(LeetCode)
这是一个经典快慢指针:
bool hasCycle(struct ListNode *head) {struct ListNode* fast=head;struct ListNode* slow=head;while(fast&&fast->next){fast=fast->next->next;slow=slow->next;if(fast==slow)return true;}return false;
}10.给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULL142. 环形链表 II - 力扣(LeetCode)
这个题需要我么用到简单的数学知识:
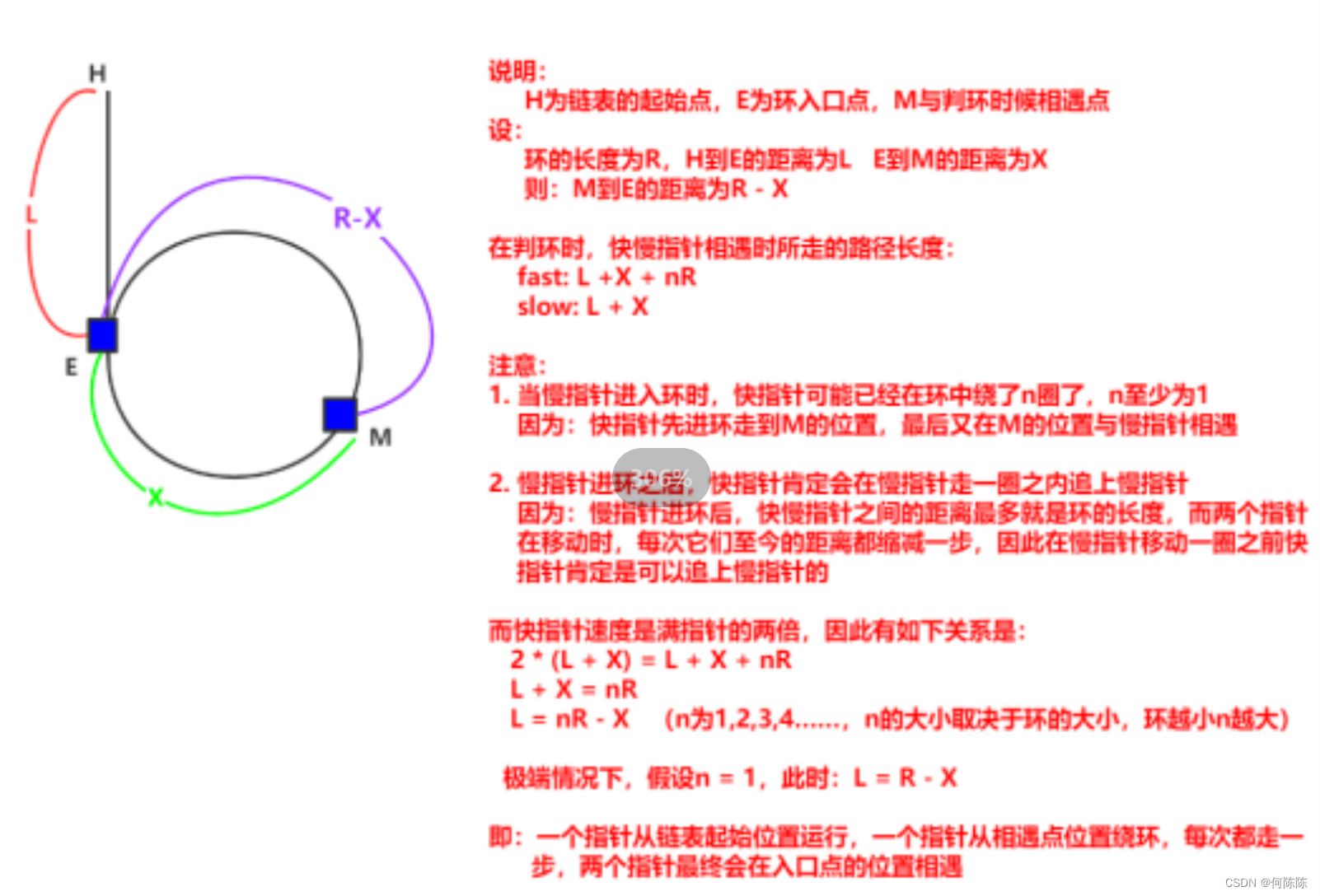
struct ListNode *detectCycle(struct ListNode *head) {struct ListNode* fast=head;struct ListNode* slow=head;while(fast&&fast->next){fast=fast->next->next;slow=slow->next;if(fast==slow){struct ListNode* cur=head;while(cur!=fast){cur=cur->next;fast=fast->next;}return cur;}}return NULL;
}11. 给定一个链表,每个结点包含一个额外增加的随机指针,该指针可以指向链表中的任何结点或空结点。 要求返回这个链表的深度拷贝。 138. 随机链表的复制 - 力扣(LeetCode)
这个题我们可以用这个方法: 在原链表中,每个节点都复制一个节点插入在自己的后面,
然后进行random处理,如果原节点的random存在,则新节点的random指向原节点的random的下一个。最后,将两条链表分离即可。
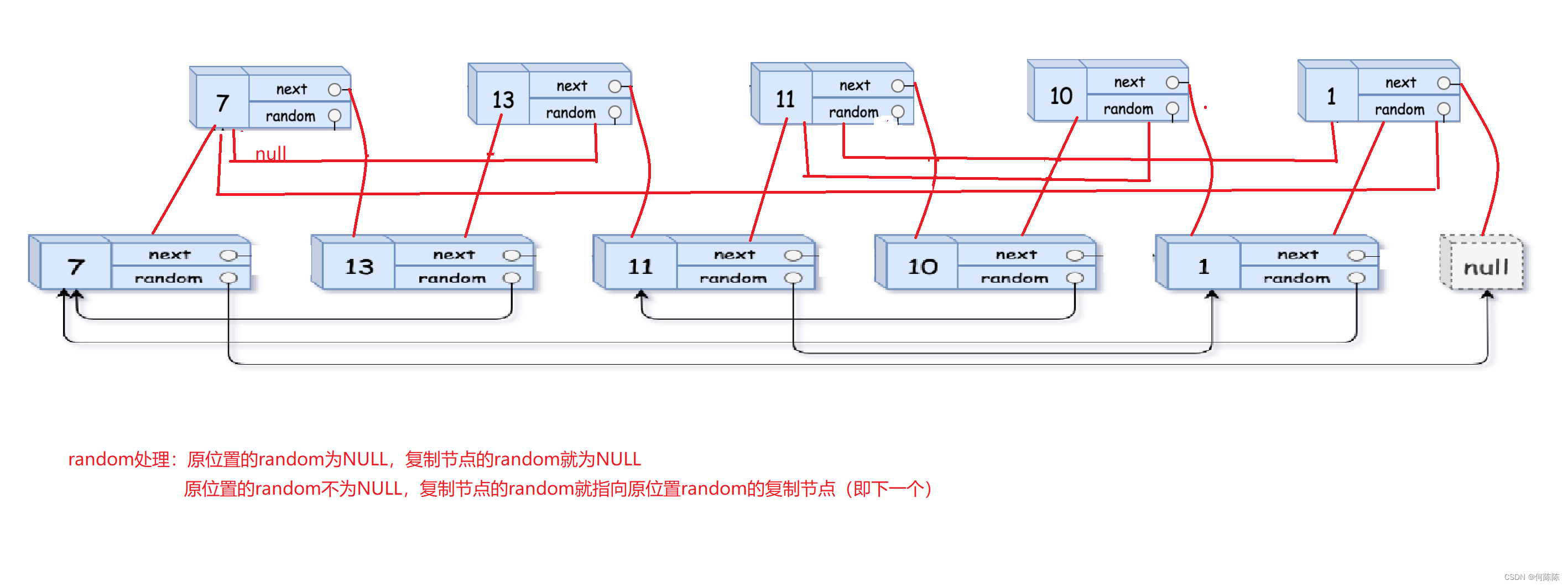
struct Node* copyRandomList(struct Node* head) {if(!head) return NULL;struct Node* cur=head;while(cur){struct Node* newnode=(struct Node*)malloc(sizeof(struct Node));newnode->next=cur->next;newnode->val=cur->val;newnode->random=NULL;cur->next=newnode;cur=newnode->next;}cur=head;while(cur){struct Node* new=cur->next;if(cur->random)new->random=cur->random->next;cur=new->next;}cur=head;struct Node* newhead=cur->next;struct Node* tail=cur->next;while(cur){cur->next=tail->next;cur=cur->next;if(cur)tail->next=cur->next;tail=tail->next;}return newhead;
}五、总体代码
SList.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
// slist.h
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType data;struct SListNode* next;
}SListNode;// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?
void SListEraseAfter(SListNode* pos);// 在pos的前面插入
void SLTInsert(SListNode** pphead, SListNode* pos, SLTDateType x);
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos);
void SLTDestroy(SListNode** pphead);
SList.h
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x)
{SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));if (newnode == NULL){perror("malloc fail");}newnode->data = x;newnode->next = NULL;return newnode;
}
// 单链表打印
void SListPrint(SListNode* plist)
{assert(plist);SListNode* cur = plist;while (cur){printf("%d-> ", cur->data);cur = cur->next;}printf("\n");
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{assert(pplist);SListNode* newnode = BuySListNode(x);if (*pplist == NULL){*pplist = newnode;return;}//找尾巴SListNode* tail = *pplist;while (tail->next != NULL)tail = tail->next;tail->next = newnode;
}
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{assert(pplist);SListNode* newnode = BuySListNode(x);newnode->next = *pplist;*pplist = newnode;
}
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{assert(pplist);assert(*pplist);//有数据才能删,没有数据不删if ((*pplist)->next == NULL){free(*pplist);*pplist = NULL;}else{//找尾巴SListNode* prev = NULL;SListNode* tail = *pplist;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}
// 单链表头删
void SListPopFront(SListNode** pplist)
{assert(pplist);assert(*pplist);SListNode* next = (*pplist)->next;free(*pplist);*pplist = next;
}
// 单链表查找
//plist是一个变量,保存的是地址,传的时候也是地址,传过去就是将变量里面的地址拷贝一份传过去了
SListNode* SListFind(SListNode* plist, SLTDateType x)
{assert(plist);SListNode* cur = plist;while (cur){if (cur->data == x)return cur;cur = cur->next;}return NULL;
}
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
void SListInsertAfter(SListNode* pos, SLTDateType x)
{assert(pos);SListNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?
void SListEraseAfter(SListNode* pos)
{assert(pos);assert(pos->next);//检查是不是最后一个SListNode* next = pos->next;pos->next = next->next;free(next);
}// 在pos的前面插入
void SLTInsert(SListNode** pphead, SListNode* pos, SLTDateType x)
{assert(pphead);assert(*pphead);//这里没有检查pos是否为NULL,我认为在最后一个节点之后插入也是可以的if (pos == *pphead){SListPushFront(pphead, x);return;}SListNode* prev = *pphead;while (prev->next!=pos){prev = prev->next;}SListNode* newnode = BuySListNode(x);newnode->next = pos;prev->next = newnode;
}
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos)
{assert(pphead);assert(*pphead);assert(pos);//这里进行检查pos,必须有这个节点才能删除if (pos == *pphead){SListPopFront(pphead);return;}SListNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}
void SLTDestroy(SListNode** pphead)
{assert(pphead);assert(*pphead);SListNode* cur = *pphead;while (cur){SListNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"
void test1()
{SListNode* SL = NULL;SListPushBack(&SL, 1);SListPushBack(&SL, 2);SListPushBack(&SL, 3);SListPushBack(&SL, 4);SListPushBack(&SL, 5);SListPrint(SL);SListPushFront(&SL, 6);SListPushFront(&SL, 7);SListPushFront(&SL, 8);SListPushFront(&SL, 9);SListPushFront(&SL, 10);SListPushFront(&SL, 99);SListPushFront(&SL, 88);SListPushFront(&SL, 77);SListPrint(SL);SListPopBack(&SL);SListPopBack(&SL);SListPopBack(&SL);SListPopBack(&SL);SListPrint(SL);SListPopFront(&SL);SListPopFront(&SL);SListPopFront(&SL);SListPrint(SL);SListInsertAfter(SListFind(SL, 1), 99);SListInsertAfter(SListFind(SL, 10), 99);SListPrint(SL);SListEraseAfter(SListFind(SL, 1));SListEraseAfter(SListFind(SL, 10));//printf("%d\n", SListFind(SL, 1)->data);SListPrint(SL);SLTInsert(&SL, SListFind(SL, 10), 99);SLTInsert(&SL, NULL, 99);SListPrint(SL);SLTErase(&SL, SListFind(SL, 99));SLTErase(&SL, SListFind(SL, 99));SListPrint(SL);SLTDestroy(&SL);}
int main()
{test1();return 0;
}相关文章:
【数据结构】链表的大概认识及单链表的实现
目录 一、链表的概念及结构 二、链表的分类 三、单链表的实现 建立链表的节点: 尾插——尾删: 头插——头删: 查找: 指定位置之后删除——插入: 指定位置之前插入——删除指定位置: 销毁链表&am…...
国企:2024年6月中国移动相关招聘信息 二
在线营销服务中心-中国移动通信有限公司在线营销服务中心 硬件工程师 工作地点:河南省-郑州市 发布时间 :2024-06-18 截至时间: 2024-06-30 学历要求:本科及以上 招聘人数:1人 工作经验:3年 岗位描述 1.负责公司拾音器等音视频智能硬件产品全过程管理,包括但…...

Elasticsearch:智能 RAG,获取周围分块(二)
在之前的文章 “Elasticsearch:智能 RAG,获取周围分块(一) ” 里,它介绍了如何实现智能 RAG,获取周围分块。在那个文章里有一个 notebook。为了方便在本地部署的开发者能够顺利的运行那里的 notebook。在本…...

华为---RIP路由协议的汇总
8.3 RIP路由协议的汇总 8.3.1 原理概述 当网络中路由器的路由条目非常多时,可以通过路由汇总(又称路由汇聚或路由聚合)来减少路由条目数,加快路由收敛时间和增强网络稳定性。路由汇总的原理是,同一个自然网段内的不同子网的路由在向外(其他…...

Python基础——字符串常见用法:切片、去空格、替换、拼接
文章目录 专栏导读1、拼接字符串2、获取字符串长度3、字符串切片4、字符串替换:5、字符串分割6、字符串查找7、字符串大小写转换8、字符串去除空白9、字符串格式化:10、字符串编码与解码:11、字符串判断12、字符串填充与对齐总结 专栏导读 &a…...

LeetCode.51N皇后详解
问题描述 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案…...

计算机网络之奇偶校验码和CRC冗余校验码
今天我们来看看有关于计算机网络的知识——奇偶校验码和CRC冗余校验码,这两种检测编码的方式相信大家在计算机组成原理当中也有所耳闻,所以今天我就来跟大家分享有关他们的知识。 奇偶校验码 奇偶校验码是通过增加冗余位使得码字中1的个数恒为奇数或偶数…...
二叉树经典OJ练习
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 二叉树经典OJ练习 收录于专栏【数据结构初阶】 本专栏旨在分享学习数据结构学习的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 前置说…...

【OpenHarmony4.1 之 U-Boot 2024.07源码深度解析】008 - make distclean 命令解析
【OpenHarmony4.1 之 U-Boot 2024.07源码深度解析】008 - make distclean 命令解析 一、make V=1 distclean 命令解析系列文章汇总:《【OpenHarmony4.1 之 U-Boot 源码深度解析】000 - 文章链接汇总》 本文链接:《【OpenHarmony4.1 之 U-Boot 2024.07源码深度解析】008 - mak…...
QTreeView双击任意列展开
一.效果 二.原理 重点是如何通过其他列的QModelIndex(假设为index),获取第一列的QModelIndex(假设为firstColumnIndex)。代码如下所示: QModelIndex firstColumnIndex = model->index(index.row(), 0, index.parent()); 这里要注意index函数的第三个参数,第三个参…...
Linux入门攻坚——26、Web Service基础知识与httpd配置-2
http协议 URL:Uniform Resource Locator,统一资源定位符 URL方案:scheme,如http://,https:// 服务器地址:IP:port 资源路径: 示例:http://www.test.com:80/bbs/…...

相由心生与事出反常必有妖
从端午节之日生病起,已就医三次,快半个月了。医检的结论是老病复发—— 上呼吸道感染 。原本并无大碍,加之“水不在深,有龙则灵”的张龙医生处方得当,现已病情好转。只是“800727”趁人之危,兴灾乐祸地欲从…...

微信小程序---支付
一、判断是否登录 如果没有登录,走前端登录流程,不再赘述 二、获取订单编号 跟自己的后端商议入参,然后获取订单编号 三、通过订单编号获取wx.requestPayment()需要的参数 获取订单编号再次请求后端接口,拿到wx.requestPayme…...
Git学习2 -- VSCode中的Git
看了下,主要的插件有3个。自带的Source Control。第1个是Gitlens,第2个是Git Graph。第三个还有个git history。 首先是Source Control。界面大概是这样的。 还是挺直观的。在第一栏source control,可以进行基本的git操作。主要的git操作都是…...

VC++支持断点续下或续传的功能
VC使用多线程和Socket实现断点续下 一、断点续下的基本原理: 1.断点续传的理解可以分为两部分:一部分是断点,一部分是续传。断点的由来是在下载过程中,将一个下载文件分成了多个部分,同时进行多个部分一起的下载&…...
机器学习数学原理专题——线性分类模型:损失函数推导新视角——交叉熵
目录 二、从回归到线性分类模型:分类 3.分类模型损失函数推导——极大似然估计法 (1)二分类损失函数——极大似然估计 (2)多分类损失函数——极大似然估计 4.模型损失函数推导新视角——交叉熵 (1&#x…...

windows和linux路径斜杆转换脚本,打开即用
前言: windows和linux的目录路径斜杆是相反的,在ssh或者其他什么工具在win和ubuntu传文件时候经常需要用到两边的路径,有这个工具就不用手动去修改斜杆反斜杠了。之前有个在线网站,后来挂了,就想着自己搞一个脚本来用。…...

在Android系统中,查看apk安装路径
在Android系统中,应用通常安装在内部存储的特定目录下。要找到已安装应用的路径,可以通过ADB(Android Debug Bridge)工具来查询。以下是一些步骤和命令,可以帮助你找到应用的安装路径: 使用pm list package…...

管理不到位,活该执行力差?狠抓这4点要素,强化执行力
管理不到位,活该执行力差?狠抓这4点要素,强化执行力 一:强化制度管理 1、权责分明,追责管理 要知道,规章制度其实就是一种“契约”。 在制定制度和规则的时候,民主一点,征求团队成员…...

应届毕业之本科简历制作
因为毕设以及编制岗位面试,最近好久没有更新了,刚好有同学问如何制作简历,我就准备将我自己制作简历的流程分享给各位,到此也算是一个小的结束,拿了工科学位证书毕业去做🐂🐎了。 简历主要包含内…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...