卷积神经网络之AlexNet
目录
- 概述
- AlexNet特点
- 激活函数
- sigmoid激活函数
- ReLu激活函数
- 数据增强
- 层叠池化
- 局部相应归一化
- Dropout
- Alexnet网络结构
- 网络结构分析
- AlexNet各层参数及其数量
- 模型框架形状结构
- 关于数据集
- 训练学习
- keras代码示例
概述
由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注。 知道2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷积神经网络乃至深度学习重新引起了广泛的关注。
Alex Krizhevsky等人训练了一个大型的卷积神经网络用来把ImageNet LSVRC-2010比赛中120万张高分辨率的图像分为1000个不同的类别。在测试卷上,获得很高准确率(top-1 and top-5 error rates of 37.5%and 17.0% ).。通过改进该网络,在2012年ImageNet LSVRC比赛中夺取了冠军,且准确率远超第二名(top-5 test error rate of 15.3%,第二名26.2%。这在学术界引起了很大的轰动,开启了深度学习的时代,虽然后来大量比AlexNet更快速更准确的卷积神经网络结构相继出现,但是AlexNet作为开创者依旧有着很多值得学习参考的地方,它为后续的CNN甚至是R-CNN等其他网络都定下了基调,所以下面我们将从AlexNet入手,理解卷积神经网络的一般结构。
AlexNet特点
AlexNet网络包括了6000万个参数和65000万个神经元,5个卷积层,在一些卷积层后面还有池化层,3个全连接层,输出为softmax层。
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。AlexNet的特点:
1、更深的网络结构
2、使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
3、使用Dropout抑制过拟合
4、使用数据增强Data Augmentation抑制过拟合
5、使用Relu替换之前的sigmoid的作为激活函数
6、多GPU训练
激活函数
在最初的感知机模型中,输入和输出的关系如下:
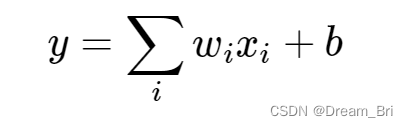
上面函数式只是单纯的线性关系,这样的网络结构有很大的局限性。即使用很多这样结构的网络层叠加,其输出和输入仍然是线性关系,无法处理有非线性关系的输入输出。

因此,对每个神经元的输出做个非线性的转换也就是,将上面就加权求和的结果输入到一个非线性函数,也就是激活函数中。 这样,由于激活函数的引入,多个网络层的叠加就不再是单纯的线性变换,而是具有更强的表现能力。
sigmoid激活函数
在最初,sigmoid和tanh函数最常用的激活函数。
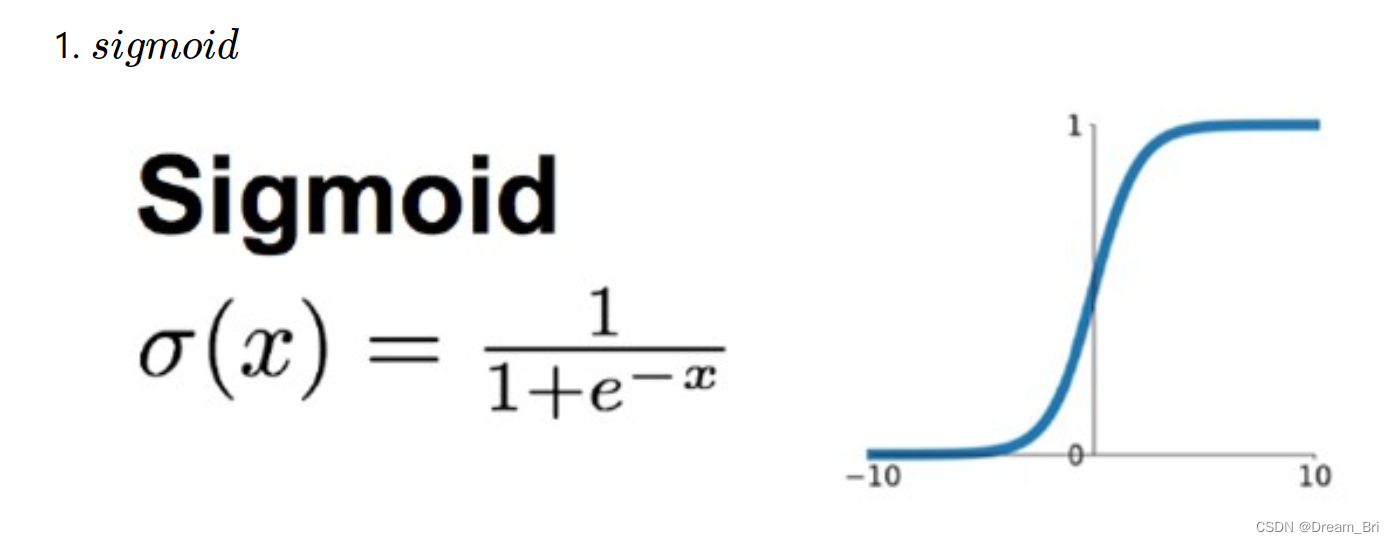
在网络层数较少时,sigmoid函数的特性能够很好的满足激活函数的作用:它把一个实数压缩至0到1之间,当输入的数字非常大的时候,结果会接近1;当输入非常大的负数时,则会得到接近0的结果。
这种特性,能够很好的模拟神经元在受刺激后,是否被激活向后传递信息(输出为0,几乎不被激活;输出为1,完全被激活)。
sigmoid一个很大的问题就是梯度饱和。 观察sigmoid函数的曲线,当输入的数字较大(或较小)时,其函数值趋于不变,其导数变的非常的小。这样,在层数很多的的网络结构中,进行反向传播时,由于很多个很小的sigmoid导数累成,导致其结果趋于零,更新速度更慢。
ReLu激活函数
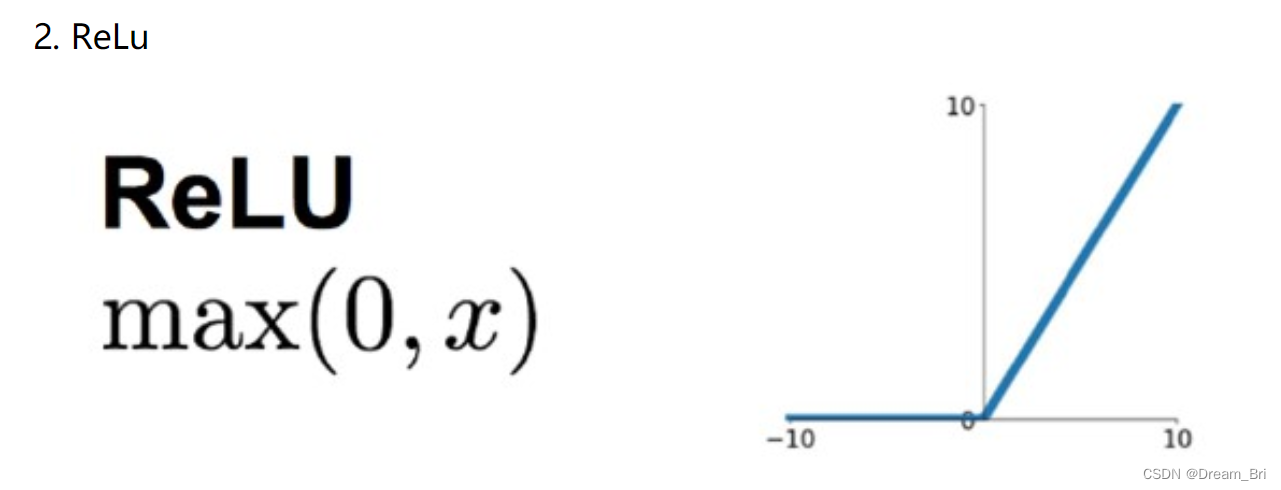
针对sigmoid梯度饱和导致训练收敛慢的问题,在AlexNet中引入了ReLU。ReLU是一个分段线性函数,小于等于0则输出为0;大于0的则恒等输出。
相比于sigmoid,ReLU有以下优点:
1、计算开销下:sigmoid的正向传播有指数运算,倒数运算,而ReLu是线性输出;反向传播中,sigmoid有指数运算,而ReLU有输出的部分,导数始终为1;
2、梯度饱和问题;
3、稀疏性:Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
这里有个问题,前面提到,激活函数要用非线性的,是为了使网络结构有更强的表达的能力。那这里使用ReLU本质上却是个线性的分段函数,是怎么进行非线性变换的。
这里把神经网络看着一个巨大的变换矩阵M,其输入为所有训练样本组成的矩阵A,输出为矩阵B,则有:B=M⋅A。这里的M是一个线性变换的话,则所有的训练样本A进行了线性变换输出为B。
那么对于ReLU来说,由于其是分段的,0的部分可以看着神经元没有激活,不同的神经元激活或者不激活,其神经玩过组成的变换矩阵是不一样的。
设有两个训练样本 a1,a2,其训练时神经网络组成的变换矩阵为M1,M2。 由于M1变换对应的神经网络中激活神经元和M2是不一样的,这样M1,M2实际上是两个不同的线性变换。也就是说,每个训练样本使用的线性变换矩阵Mi是不一样的,在整个训练样本空间来说,其经历的是非线性变换。
简单来说,不同训练样本中的同样的特征,在经过神经网络学习时,流经的神经元是不一样的(激活函数值为0的神经元不会被激活)。这样,最终的输出实际上是输入样本的非线性变换。
单个训练样本是线性变换,但是每个训练样本的线性变换是不一样的,这样整个训练样本集来说,就是非线性的变换。
数据增强
神经网络由于训练的参数多,表能能力强,所以需要比较多的数据量,不然很容易过拟合。当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。对于图像数据集来说,可以对图像进行一些形变操作:翻转、随机裁剪、平移、颜色光照的变换…
AlexNet中对数据做了以下操作:
1、随机裁剪,对256×256的图片进行随机裁剪到227×227,然后进行水平翻转。
2、测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。
3、对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
层叠池化
在LeNet中池化是不重叠的,即池化的窗口的大小和步长是相等的。
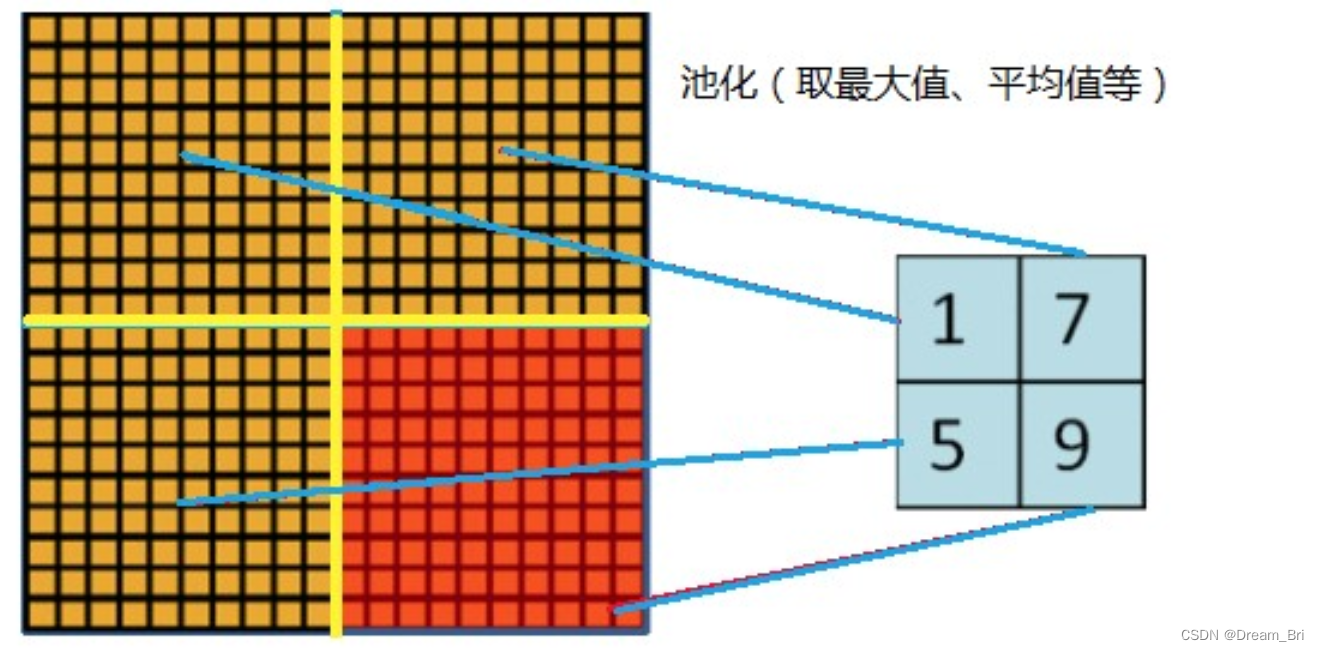
在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。与非重叠方案s=2,z=2相比,输出的维度是相等的,并且能够在一定程度上抑制过拟合。
局部相应归一化

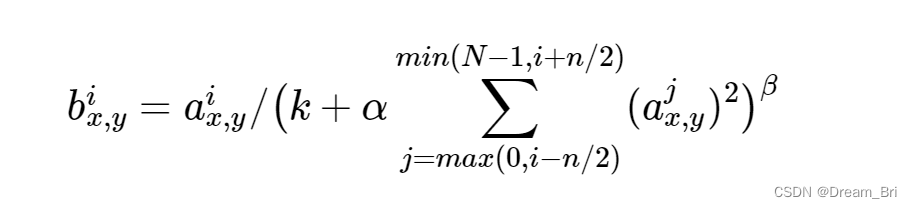

Dropout
这个是比较常用的抑制过拟合的方法了。
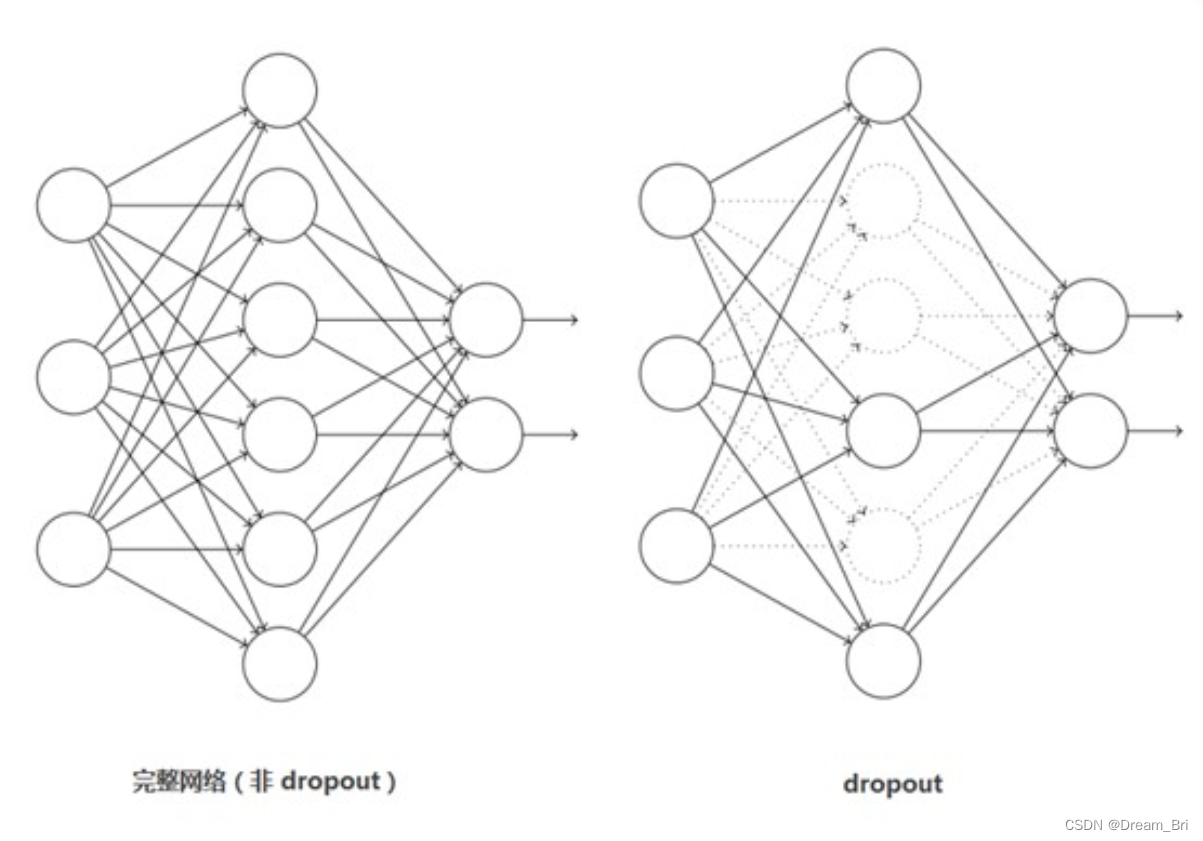
引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。如下图:
Alexnet网络结构
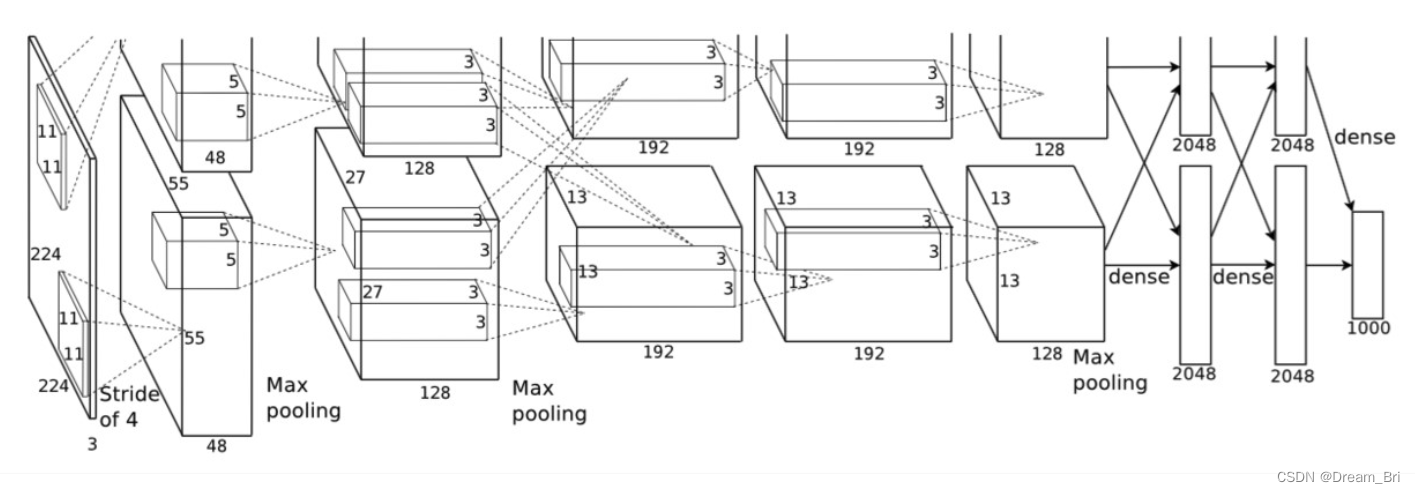
网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。
从图上可以明显看到网络结构分为上下两侧,这是因为网络分布在两个GPU上,这主要是因为NVIDIA GTX 580 GPU只用3GB内存,装不下那么大的网络。
需要说明的是,虽然AlexNet网络都用上图的结构来表示,但是其实输入图像的尺寸不是224x224x3,而应该是227x227x3,大家可以用244的尺寸推导下,会发现边界填充的结果是小数,这显然是不对的,在这里就不做推导了。
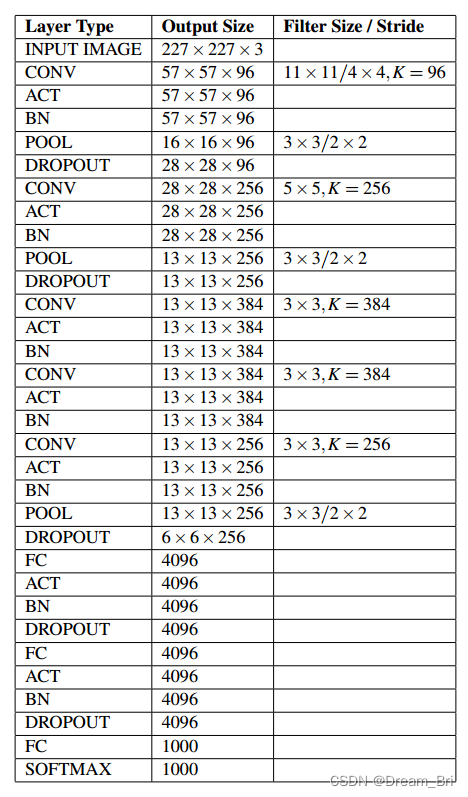
AlexNet各个层的参数和结构如下:
输入层:227x227x3
C1:96x11x11x3 (卷积核个数/高/宽/深度)
C2:256x5x5x48(卷积核个数/高/宽/深度)
C3:384x3x3x256(卷积核个数/高/宽/深度)
C4:384x3x3x192(卷积核个数/高/宽/深度)
C5:256x3x3x192(卷积核个数/高/宽/深度)
网络结构分析
1、卷积层C1
该层的处理流程是: 卷积–>ReLU–>池化–>归一化。
卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
2、卷积层C2
该层的处理流程是:卷积–>ReLU–>池化–>归一化
卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为2727128. ((27+2∗2−5)/1+1=27)
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
3、卷积层C3
该层的处理流程是: 卷积–>ReLU
卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为1313384
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
4、卷积层C4
该层的处理流程是: 卷积–>ReLU
该层和C3类似。
卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
5、卷积层C5
该层处理流程为:卷积–>ReLU–>池化
卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
6、全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
卷积->全连接: 输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
7、全连接层FC7
流程为:全连接–>ReLU–>Dropout
全连接,输入为4096的向量
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
8、输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
AlexNet各层参数及其数量
卷积层的参数 = 卷积核的数量 * 卷积核 + 偏置
C1: 96个11×11×3的卷积核,96×11×11×3+96=34848
C2: 2组,每组128个5×5×48的卷积核,(128×5×5×48+128)×2=307456
C3: 384个3×3×256的卷积核,3×3×256×384+384=885120
C4: 2组,每组192个3×3×192的卷积核,(3×3×192×192+192)×2=663936
C5: 2组,每组128个3×3×192的卷积核,(3×3×192×128+128)×2=442624
FC6: 4096个6×6×256的卷积核,6×6×256×4096+4096=37752832
FC7: 4096∗4096+4096=16781312
output: 4096∗1000=4096000
卷积层 C2,C4,C5中的卷积核只和位于同一GPU的上一层的FeatureMap相连。从上面可以看出,参数大多数集中在全连接层,在卷积层由于权值共享,权值参数较少。
模型框架形状结构
由于AlexNet是使用两块显卡进行训练的,其网络结构的实际是分组进行的。并且,在C2,C4,C5上其卷积核只和上一层的同一个GPU上的卷积核相连。 对于单显卡来说,并不适用,本文基于Keras的实现,忽略其关于双显卡的的结构,并且将局部归一化
关于数据集
实验采用的数据集是ImageNet。ImageNet是超过1500万个标记的高分辨率图像的数据集,大约有22,000个类别。这些图像是从网上收集的,并使用亚马逊的Mechanical Turk众包服务进行了标记。
从2010年开始,举办ILSVRC比赛,数据使用的是ImageNet的 一个子集,每个类别大约有1000个图像,总共有1000个类别。总共有大约120万个训练图像,50000个验证图像,以及150000个测试图像。ImageNet比赛给出两个错误率,top-1和top-5,top-5错误率是指你的模型预测的概率最高的5个类别中都不包含正确的类别。
ImageNet由可变分辨率的图像组成,而神经网络输入维度是固定的。 因此,我们将图像下采样到256×256的固定分辨率矩形图像,我们首先重新缩放图像,使短边长度为256,然后从结果图像中裁剪出中心256×256的图片。 我们没有预先处理图像以任何其他方式,我们在像素的原始RGB值上训练了我们的网络。
训练学习
该模型训练使用了随机梯度下降法,每批图片有180张,权重更新公式如下:

其中i是迭代的索引,v是动量,0.9是动量参数,ε是学习率,0.0005是权重衰减系数,在这里不仅起到正则化的作用,而且减少了模型的训练误差。
所有的权重都采用均值为0,方差为0.01的高斯分布进行初始化。第2,4,5卷积层和所有全连接层的偏置都初始化为1,其他层的偏置初始化为0.学习率ε=0.01,所有层都使用这个学习率,在训练过程中,当错误率不在下降时,将学习率除以10,在终止训练之前减少3次,我们把120万张图片训练了90遍,总过花费了5到6天。
keras代码示例
class AlexNet:@staticmethoddef build(width,height,depth,classes,reg=0.0002):model = Sequential()inputShape = (height,width,depth)chanDim = -1if K.image_data_format() == "channels_first":inputShape = (depth,height,width)chanDim = 1model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=inputShape,padding="same",kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization(axis=chanDim))model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))model.add(Dropout(0.25))model.add(Conv2D(256,(5,5),padding="same",kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization(axis=chanDim))model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))model.add(Dropout(0.25))model.add(Conv2D(384,(3,3),padding="same",kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization(axis=chanDim))model.add(Conv2D(384,(3,3),padding="same",kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization(axis=chanDim))model.add(Conv2D(256,(3,3),padding="same",kernel_regularizer=l2(reg)))model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(4096,kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization())model.add(Dropout(0.25))model.add(Dense(4096,kernel_regularizer=l2(reg)))model.add(Activation("relu"))model.add(BatchNormalization())model.add(Dropout(0.25))model.add(Dense(classes,kernel_regularizer=l2(reg)))model.add(Activation("softmax"))return model
参考:
https://blog.csdn.net/lcczzu/article/details/91991725
https://www.cnblogs.com/wangguchangqing/p/10333370.html
https://www.cnblogs.com/zyly/p/8781224.html
https://blog.csdn.net/chaipp0607/article/details/72847422
相关文章:
卷积神经网络之AlexNet
目录概述AlexNet特点激活函数sigmoid激活函数ReLu激活函数数据增强层叠池化局部相应归一化DropoutAlexnet网络结构网络结构分析AlexNet各层参数及其数量模型框架形状结构关于数据集训练学习keras代码示例概述 由于受到计算机性能的影响,虽然LeNet在图像分类中取得了…...

React中setState什么时候是同步的,什么时候是异步的?
本文内容均针对于18.x以下版本 setState 到底是同步还是异步?很多人可能都有这种经历,面试的时候面试官给了你一段代码,让你说出输出的内容,比如这样: constructor(props) {super(props);this.state {val: 0}}compo…...

优秀开源软件的类,都是怎么命名的?
日常编码中,代码的命名是个大的学问。能快速的看懂开源软件的代码结构和意图,也是一项必备的能力。 Java项目的代码结构,能够体现它的设计理念。Java采用长命名的方式来规范类的命名,能够自己表达它的主要意图。配合高级的 IDEA&…...

绘制CSP的patterns矩阵图
最近在使用FBCSP处理数据,然后就想着看看处理后的样子,用地形图的形式表现出来,但是没有符合自己需求的函数可以实现,就自己尝试的实现了一下,这里记录一下,方便以后查阅。 绘制CSP的patterns矩阵图 对数据做了FBCSP处理,但是想画一下CSP计算出来的patterns的地形图,并…...
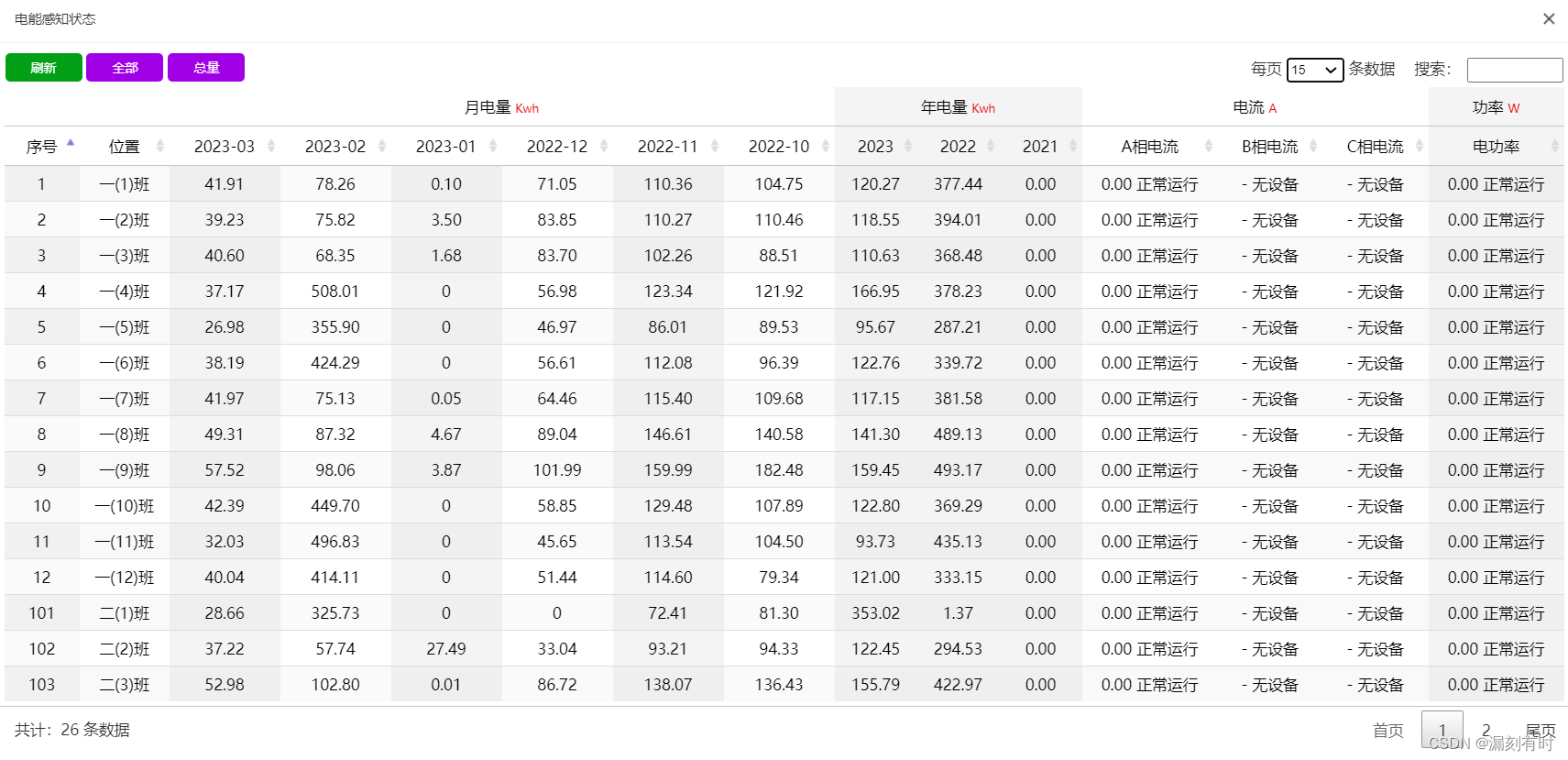
Datatables展示数据(表格合并、日期计算、异步加载数据、分页显示、筛选过滤)
系列文章目录 datatable 自定义筛选按钮的解决方案Echarts实战案例代码(21):front-endPage的CJJTable前端分页插件ajax分页异步加载数据的解决方案 文章目录系列文章目录前言一、html容器构建1.操作按钮2.表格构建二、时间日期计算三、dataTables属性配置1.调用2.过…...

Python decimal模块的使用
Python decimal 模块Python中的浮点数默认精度是15位。Decimal对象可以表示任意精度的浮点数。getcontext函数用于获取当前的context环境,可以设置精度、舍入模式等参数。#在context中设置小数的精度 decimal.getcontext().prec 100通过字符串初始化Decimal类型的变…...

pycharm常用快捷键
编辑类: Ctrl D 复制选定的区域或行 Ctrl Y 删除选定的行 Ctrl Alt L 代码格式化 Ctrl Alt O 优化导入(去掉用不到的包导入) Ctrl 鼠标 简介/进入代码定义 Ctrl / 行注释 、取消注释 Ctrl 左方括号 快速跳到代码开头 Ctrl 右方括…...

useCallback 与 useMemo 的区别 作用
useCallback 缓存钩子函数,useMemo 缓存返回值(计算结果)。 TS声明如下:type DependencyList ReadonlyArray<any>;function useCallback<T extends (...args: any[]) > any>(callback: T, deps: DependencyList)…...

Mybatis的学习
01-mybatis传统dao开发模式 概述 mybatis有两种使用模式: ①传统dao开发模式, ②dao接口代理开发模式 ①传统dao开发模式 dao接口 dao实现子类 mapper映射文件dao实现子类来决定了dao接口的方法和mapper映射文件的statement的关系 代码实现 public class StudentDaoImpl im…...
PyTorch深度学习实战 | 计算机视觉
深度学习领域技术的飞速发展,给人们的生活带来了很大改变。例如,智能语音助手能够与人类无障碍地沟通,甚至在视频通话时可以提供实时翻译;将手机摄像头聚焦在某个物体上,该物体的相关信息就会被迅速地反馈给使用者&…...
436. 寻找右区间(2023.03.10))
力扣(LeetCode)436. 寻找右区间(2023.03.10)
给你一个区间数组 intervals ,其中 intervals[i] [starti, endi] ,且每个 starti 都 不同 。 区间 i 的 右侧区间 可以记作区间 j ,并满足 startj > endi ,且 startj 最小化 。 返回一个由每个区间 i 的 右侧区间 在 interv…...
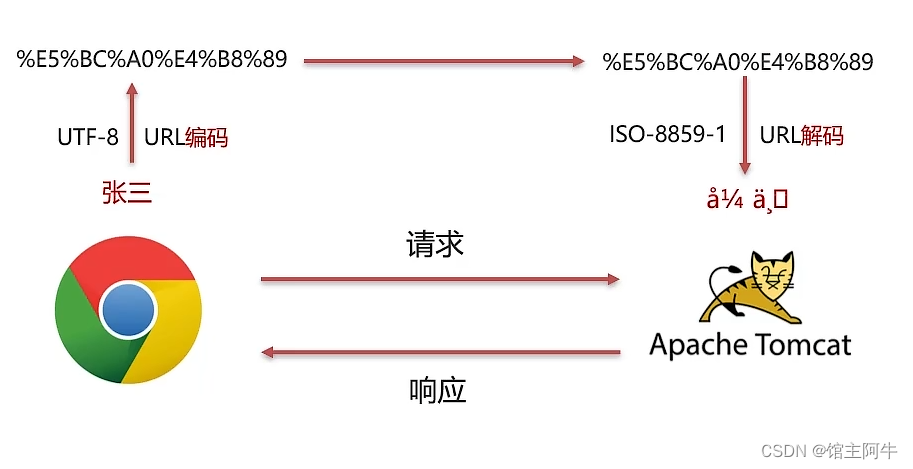
已解决Servlet中Request请求参数中文乱码的问题
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...
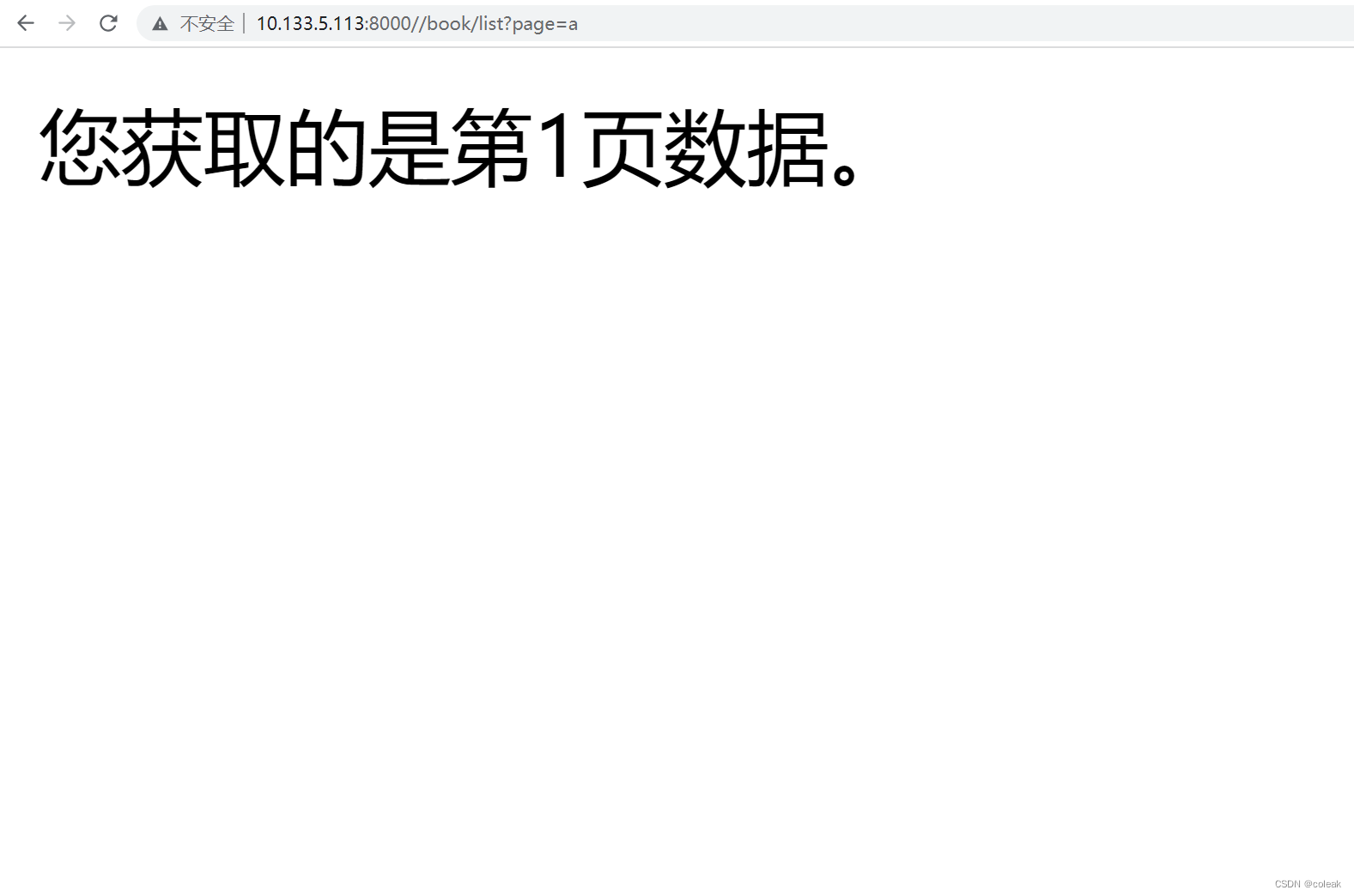
【flask】URL和视图映射
目录 首页 传参 URL数据类型 get传参 首页 url与视图函数的映射是通过app.route()装饰器实现的。 只有一个斜杠代表的是根目录——首页。 传参 URL传参是通过<参数名称>的形式进行传递。URL中有几个参数,在视图函数中也要指定几个参数 from flask im…...

Python实现性能测试(locust)
一、安装locustpip install locust -- 安装(在pycharm里面安装或cmd命令行安装都可)locust -V -- 查看版本,显示了就证明安装成功了或者直接在Pycharm中安装locust:搜索locust并点击安装,其他的第三方包也可以通过这种方式二、loc…...

【数论】试除法判断质数,分解质因数,筛质数
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 现已更新完KMP算法、排序模板,之…...
【C++】红黑树
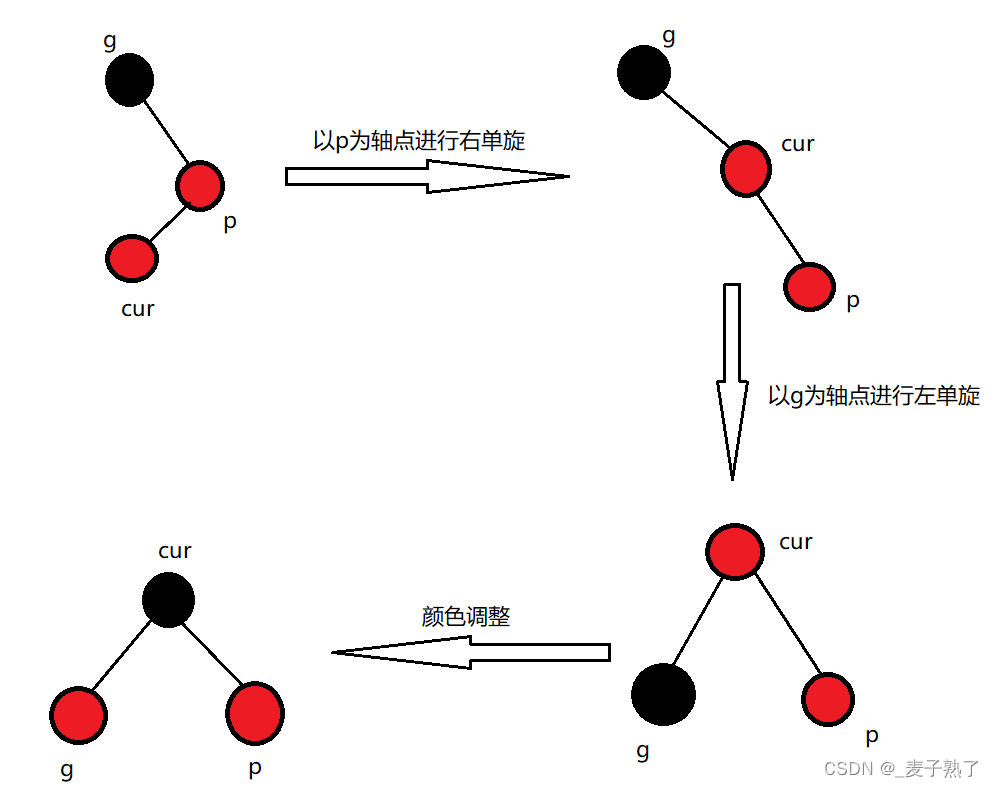
文章目录红黑树的概念红黑树的性质特征红黑树结点的定义红黑树的插入操作情况1情况2情况3特殊情况代码实现红黑树的验证红黑树的删除红黑树和AVL树的比较红黑树的应用红黑树的概念 红黑树,是一种二叉搜索树,但是每一个结点都增加一个存储位表示结点的颜…...
【剧前爆米花--爪哇岛寻宝】进程的调度以及并发和并行,以及PCB中属性的详解。
作者:困了电视剧 专栏:《JavaEE初阶》 文章分布:这是关于进程调度、并发并行以及相关属性详解的文章,我会在之后文章中更新有关线程的相关知识,并将其与进程进行对比,希望对你有所帮助。 目录 什么是进程/…...
网络的瓶颈效应
python从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129328397?spm1001.2014.3001.5501 ❤ 网络的瓶颈效应 网络瓶颈,指的是影响网络传输性能及稳定性的一些相关因素,如网络拓扑结构,网线࿰…...
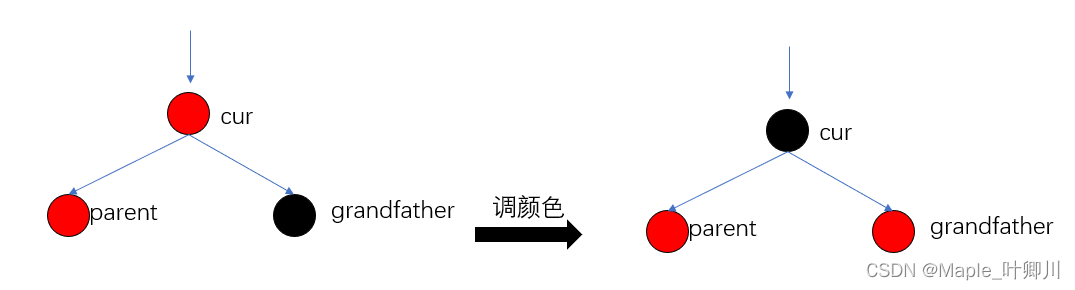
【C++进阶】四、红黑树(三)
目录 一、红黑树的概念 二、红黑树的性质 三、红黑树节点的定义 四、红黑树的插入 五、红黑树的验证 六、红黑树与AVL树的比较 七、完整代码 一、红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可…...
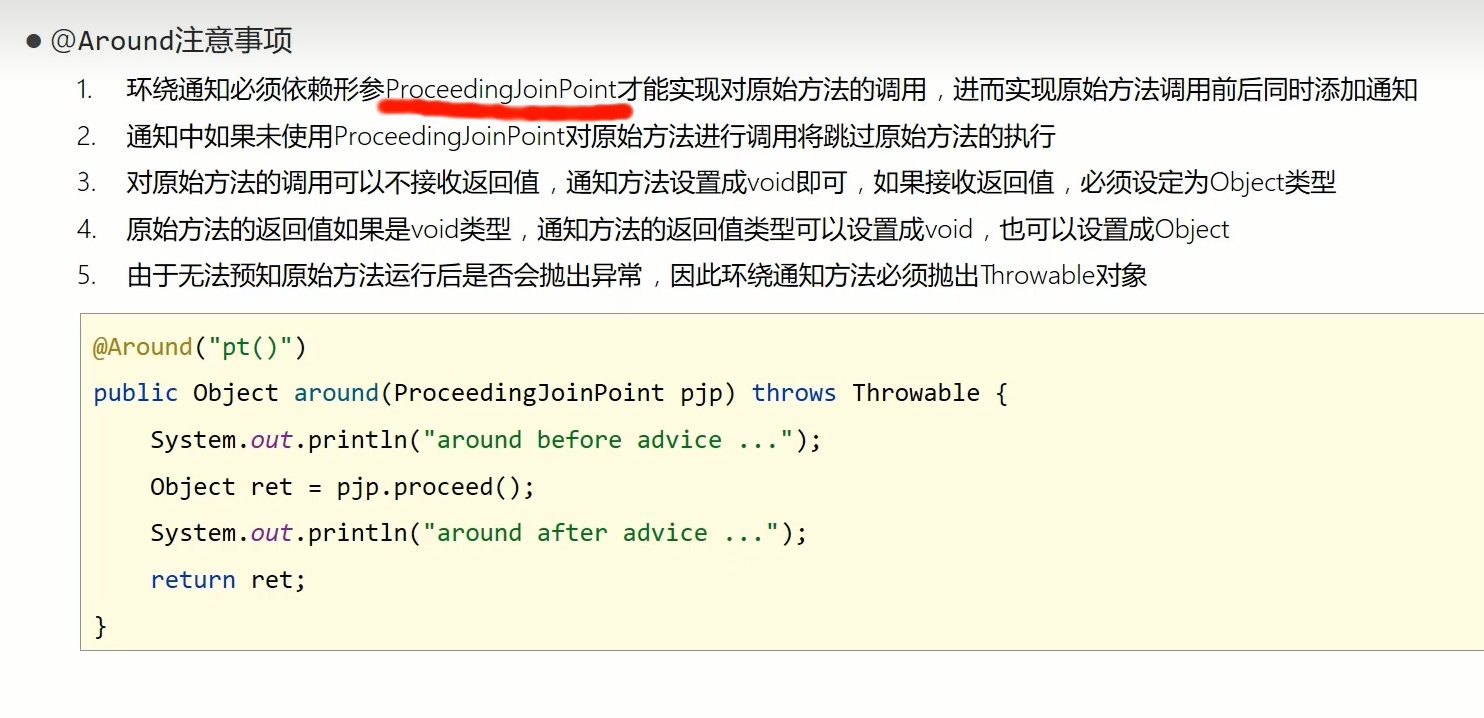
Spring——AOP切入点表达式和AOP通知类型
切入点:要进行增强的方法 切入点表达式:要进行增强的方法的描述式 第一种方法的本质是基于接口实现的动态代理(jdk) 第二种是基于cglib实现的动态代理 AOP切入点表达式 而需要加载多个切入点时,不可能每个切入点都写一个切入点表达式 例子 下面的代理描述的是匹配…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
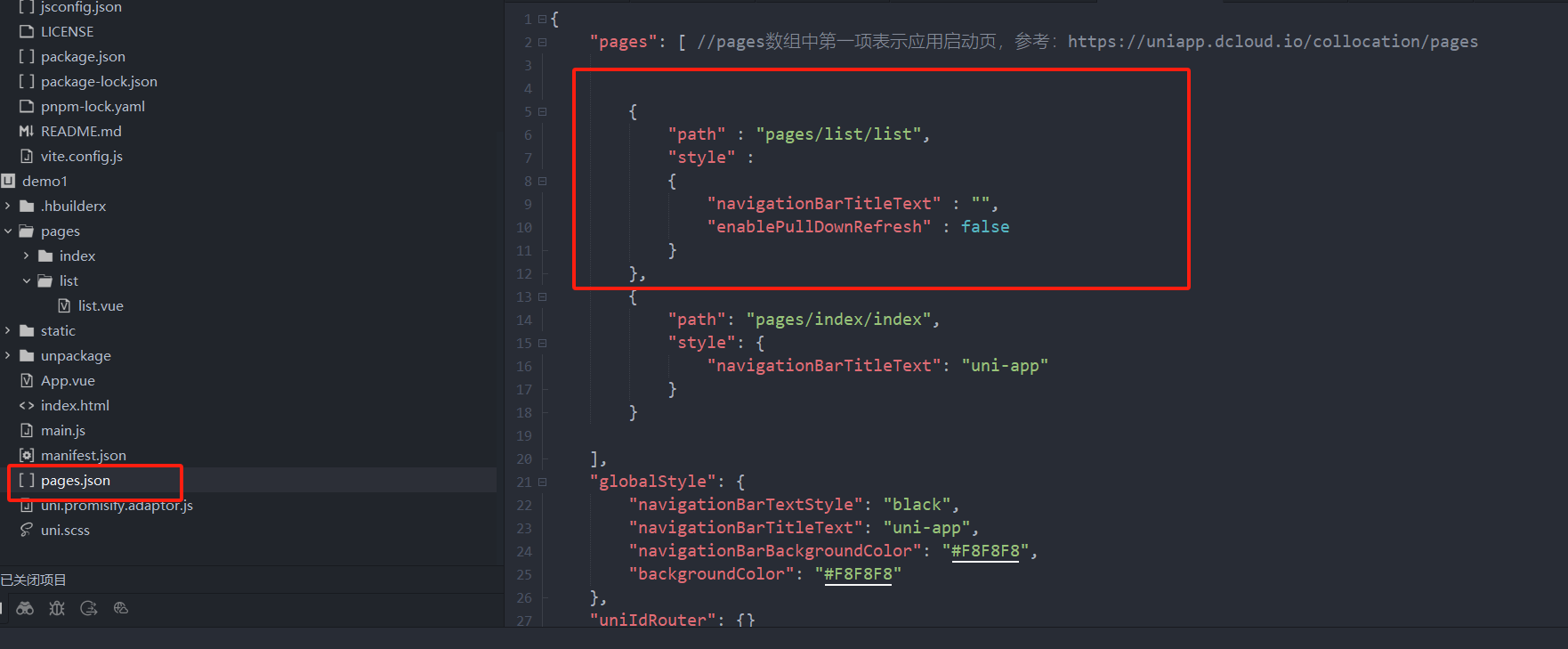
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...