【项目日记(二)】搜索引擎-索引制作
❣博主主页: 33的博客❣
▶️文章专栏分类:项目日记◀️
🚚我的代码仓库: 33的代码仓库🚚
🫵🫵🫵关注我带你了解更多项目内容

目录
- 1.前言
- 2.索引结构
- 2.1创捷索引
- 2.2根据索引查询
- 2.3新增文档
- 2.4内存索引保存到磁盘
- 2.5把磁盘索引加载到内存
- 3.性能优化
- 3.1多线程
- 3.2线程安全
- 3.3CountDownLatch类
- 4.总结
1.前言
在上一篇文章中,我们已经介绍了索引解析,那么接下来我们继续完善我们的项目,既然已经有了解析好的索引,那么我们就需要把解析的内容添加到倒排索引和正排索引中。
2.索引结构
创建index类,通过这个类来构建索引结构
基本步骤:
- 用ArrayList创建正排索引
- 用HashMap创建倒排索引
- 1.给定docid在正排索引中,查询详细信息
- 2.给定一个词,在倒排索引中查与这个词的关联文档
- 3.往索引中新增文档
- 4.把内存的索引保存到磁盘
- 5.把磁盘的索引结构保存到内存
2.1创捷索引
正排索引
private ArrayList<DocInfo> forwardIndex=new ArrayList<>();
倒排索引
private HashMap<String,ArrayList<Weight>> invertedIndex=new HashMap<>();
DocInfo类:
public class DocInfo {private int docID;private String title;private String url;private String content;public int getDocID() {return docID;}public void setDocID(int docID) {this.docID = docID;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}
}
Weight类:
public class Weight {private int docId;private int weight;public int getDocId() {return docId;}public void setDocId(int docId) {this.docId = docId;}public int getWeight() {return weight;}public void setWeight(int weight) {this.weight = weight;}
}
2.2根据索引查询
//1.根据docId查询文档详情,数组小标就是文档idpublic DocInfo getDocInfo(int docId){return forwardIndex.get(docId);}
//2.给定一个词,查在哪些文档中public List<Weight> getInverted(String term){return invertedIndex.get(term);}
2.3新增文档
public void addDoc(String title,String url,String content){//给正排索引新增和倒排索引都新增信息//构建正排索引DocInfo docInfo=buildForward(title,url,content);//创建倒排索引buildInverted(docInfo);}
在正排索引中添加文档:
private DocInfo buildForward(String title, String url, String content) {DocInfo docInfo=new DocInfo();docInfo.setTitle(title);docInfo.setUrl(url);docInfo.setContent(content);//巧妙设计:docInfoId的下标和数组下标一一对应docInfo.setDocID(forwardIndex.size());forwardIndex.add(docInfo);return docInfo;}
在倒排索引中新增文档
1.需要统计每一个词在文档中的出现次数,在根据次数算出权重
2.首先进行分词操作,统计每一个不同的词在标题中出现的次数
3.再进行分词操作,统计每一个词在正文出现的次数
4.设置权重为标题次数*10+正文次数
private void buildInverted(DocInfo docInfo) {class WordCnt{public int titleCount;public int contentCount;}HashMap<String,WordCnt> wordCntHashMap=new HashMap<>();//1.针对标题进行分词操作List<Term> terms= ToAnalysis.parse(docInfo.getTitle()).getTerms();//2.针对分词结果,统计每个词出现的次数for (Term term:terms){String word=term.getName();WordCnt wordCnt=wordCntHashMap.get(word);if (wordCnt==null){WordCnt newwordCnt=new WordCnt();newwordCnt.titleCount=1;newwordCnt.contentCount=0;wordCntHashMap.put(word,newwordCnt);}else {wordCnt.titleCount+=1;}}//3.针对正文进行分词操作List<Term> terms2=ToAnalysis.parse(docInfo.getContent()).getTerms();//4.遍历分词结果,统计每个词出现的次数for (Term term:terms2){String word=term.getName();WordCnt wordCnt=wordCntHashMap.get(word);if (wordCnt==null){WordCnt newWordCnt=new WordCnt();newWordCnt.titleCount=0;newWordCnt.contentCount=1;wordCntHashMap.put(word,newWordCnt);}else {wordCnt.contentCount+=1;}}//5.设置权重为:标题*10+正文//一个对象必须实现了Iterable接口才能使用for each进行遍历,而Map并没有实现该接口,但Set实现了,所以就把Map转换为Setfor(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()) { List<Weight> invertedList=invertedIndex.get(entry.getKey());if (invertedList==null){ArrayList<Weight> newInvertedList=new ArrayList<>();Weight weight=new Weight();weight.setWeight(entry.getValue().titleCount*10+entry.getValue().contentCount);weight.setDocId(docInfo.getDocID());newInvertedList.add(weight);invertedIndex.put(entry.getKey(),newInvertedList);}else {Weight weight=new Weight();weight.setDocId(docInfo.getDocID());weight.setWeight(entry.getValue().titleCount*10+entry.getValue().contentCount);invertedList.add(weight);} }}
2.4内存索引保存到磁盘
索引当前是存储在内存中的,构造索引的过程是非常耗时的,因此我们就不应该再服务器启动时才去构造索引,通常就把这些耗时的操作,单独执行完成之后,然后再让线上的服务器加载构造好的索引。
我们就把内存中构造的索引结构,给变成一个字符串,然后写入文件即可,这个操作就叫序列化。适应Jackson中的ObjectMapper来完成此操作。
private static String INDEX_PATH="D:/doc_searcher_index/";public void save(){long beg=System.currentTimeMillis();System.out.println("保存索引开始!");File indexPathFile=new File(INDEX_PATH);if(!indexPathFile.exists()){indexPathFile.mkdir();}File forwardIndexFile=new File(INDEX_PATH+"forward.txt");File invertedIndexFile=new File(INDEX_PATH+"inverted.txt");try {//利用ObjectMapperJava对象转换为JSON格式//从内存中读取forwardIndex保存到forwardIndexFileobjectMapper.writeValue(forwardIndexFile,forwardIndex);//从内存中读取nvertedIndex保存到invertedIndexFileforwardIndexFileobjectMapper.writeValue(invertedIndexFile,invertedIndex);}catch (IOException e) {e.printStackTrace();}long end=System.currentTimeMillis();System.out.println("保存索引完成!消耗时间:"+(end-beg)+"ms");}
2.5把磁盘索引加载到内存
public void load(){long beg=System.currentTimeMillis();System.out.println("加载索引开始!");File forwardIndexFile=new File(INDEX_PATH+"forward.txt");File invertedIndexFile=new File(INDEX_PATH+"inverted.txt");try {forwardIndex=objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});invertedIndex=objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});}catch (IOException e){e.printStackTrace();}long end=System.currentTimeMillis();System.out.println("加载引擎结束消耗时间:"+(end-beg)+"ms");}
parser相当于制作索引的入口,对应到一个可执行的程序
index相当于实现了索引的数据结构,提供一些Api
接下来我们就在parser里面调用对应的api
在parser类中解析完Html文件时,应添加到索引中
private void parseHTML(File f) {//1.解析HTML标题String title=parseTitle(f);//2.解析HTML的URLString url=parseUrl(f);//3.解析HTML的正文long beg=System.nanoTime();//String content=parseContent(f);String content=parseContentByRegex(f);long mid=System.nanoTime();//把解析出来的信息加载到索引index.addDoc(title,url,content); }
在添加完索引之后,应该把索引保存到磁盘
public void run() {long beg=System.currentTimeMillis();System.out.println("索引制作开始");//1.枚举出INPUT_PATH下的所有html文件ArrayList<File> fileList=new ArrayList<>();enumFile(INPUT_PATH,fileList);//2.解析文档内容for (File f:fileList){System.out.println("开始解析"+f.getAbsolutePath()+"....");parseHTML(f);}//3.把内存构造的索引保存到磁盘index.save();long end=System.currentTimeMillis();System.out.println("索引制作结束!消耗时间:"+(end-beg)+"ms");}
3.性能优化
此时我们已经完成了文档解析和索引制作模块,那么我们进行验证

文档内容正确生成:


但我们观察索引制作的时间:一个消耗了19973ms就是19s,花费的时间是比较长的,那么有什么办法提高效率呢?方法当然是有的,首先我们得清楚具体是哪一个步骤拖慢了执行效率,我们来分析代码:

可以看到解析文档的时候从磁盘读文件,循环遍历文件操作,那么显然效率是非常慢的,既然一个线程串行执行效率非常慢,那么我们就采用多线程并发执行来提高效率。
3.1多线程
我们可以使用创建一个线程池来实现并发操作。通过submit往线程池中提价任务,操作极快(只是把Runnable对象放入阻塞队列中)。
把代码改进成多线程的版本,线程池中的线程数目具体设置成多少才合适呢?最好通过实验来确定。
public void run() {long beg=System.currentTimeMillis();System.out.println("索引制作开始");//1.枚举出INPUT_PATH下的所有html文件ArrayList<File> fileList=new ArrayList<>();enumFile(INPUT_PATH,fileList);ExecutorService executorService= Executors.newFixedThreadPool(6);//2.解析文档内容for (File f:files){executorService.submit(new Runnable() {@Overridepublic void run() {System.out.println("解析:"+f.getAbsolutePath());parseHTML(f); }});}//3.把内存构造的索引保存到磁盘index.save();long end=System.currentTimeMillis();System.out.println("索引制作结束!消耗时间:"+(end-beg)+"ms");}
3.2线程安全
我们既然引入了多线程就要考虑线程安全问题,要注意修改操作和读写操作。当多个线程同时尝试修改同一个共享数据时,需要确保数据的一致性,避免出现竞态条件。读写操作:如果一个线程在读取共享数据的同时另一个线程在修改该数据,可能导致读取到不一致或无效的数据。
那么我们就需要对程序进行加锁操作:


3.3CountDownLatch类
添加锁虽然解决了线程安全问题,依然有新的问题,那就是在所有文件提交完成后就会立即执行save()操作,但是可能文件解析还没有完成。为了解决这样的问题,我们就引入 CountDownLatch类。
CountDownLatch类类似于跑步比赛的裁判,只有所有的选手都撞线了,就认为这场比赛结束了。再构造 CountDownLatch的时候指定一下比赛选手的个数,每个选手撞线都要通知一下countDown(),通过await来等待所有的选手都撞线完毕才执行save()操作。
public void runByThread(){long beg=System.currentTimeMillis();System.out.println("索引开始制作");//1.枚举出INPUT_PATH下的所有html文件ArrayList<File> files=new ArrayList<>();enumFile(INPUT_PATH,files);//2.解析文档内容CountDownLatch latch=new CountDownLatch(files.size());ExecutorService executorService= Executors.newFixedThreadPool(6);for (File f:files){executorService.submit(new Runnable() {@Overridepublic void run() {System.out.println("解析:"+f.getAbsolutePath());parseHTML(f);latch.countDown();}});}try {//await会阻塞,把所有选手都调用countDown以后才会继续执行latch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}//手动的把线程池里面的线程杀掉executorService.shutdown();//3.把内存构造的索引保存到磁盘index.save();long end=System.currentTimeMillis();System.out.println("索引制作结束!消耗时间:"+(end-beg)+"ms");System.out.println("t1:"+t1+"t2"+t2);}
4.总结
这篇文章主要完成了索引制作模块,以及进行了性能优化,在下一篇文章中将进行搜索模块的制作。
下期预告:项目日记(三)
相关文章:
【项目日记(二)】搜索引擎-索引制作
❣博主主页: 33的博客❣ ▶️文章专栏分类:项目日记◀️ 🚚我的代码仓库: 33的代码仓库🚚 🫵🫵🫵关注我带你了解更多项目内容 目录 1.前言2.索引结构2.1创捷索引2.2根据索引查询2.3新增文档2.4内存索引保存到磁盘2.5把…...

K 近邻、K-NN 算法图文详解
1. 为什么学习KNN算法 KNN是监督学习分类算法,主要解决现实生活中分类问题。根据目标的不同将监督学习任务分为了分类学习及回归预测问题。 KNN(K-Nearest Neihbor,KNN)K近邻是机器学习算法中理论最简单,最好理解的算法…...

Eclipse + GDB + J-Link 的单片机程序调试实践
Eclipse GDB J-Link 的调试实践 本文介绍如何创建Eclipse的调试配置,如何控制调试过程,如何查看修改各种变量。 对 Eclipse 的要求 所用 Eclipse 应当安装了 Eclipse Embedded CDT 插件。从 https://www.eclipse.org/downloads/packages/ 下载 Ecli…...

前端代码生成辅助工具
1,Axure Axure设计的界面如何生成HTML文件 https://blog.csdn.net/qq_43279782/article/details/112387511 Axure 生成HTML 文件,并用Chrome打开 https://blog.csdn.net/qq_30718137/article/details/80621025 2,OpenUI [开源] OpenUI …...

静态库与动态库总结
一、库文件和头文件 所谓库文件,可以将其理解为压缩包文件,该文件内部通常包含不止一个目标文件(也就是二进制文件)。 值得一提的是,库文件中每个目标文件存储的代码,并非完整的程序,而是一个…...

深入解析tcpdump:网络数据包捕获与分析的利器
引言 在网络技术日新月异的今天,网络数据包的捕获与分析成为了网络管理员、安全专家以及开发人员不可或缺的技能。其中,tcpdump作为一款强大的网络数据包捕获分析工具,广泛应用于Linux系统中。本文将从技术人的角度,详细分析tcpdu…...

【漏洞复现】科立讯通信有限公司指挥调度管理平台uploadgps.php存在SQL注入
0x01 产品简介 科立讯通信指挥调度管理平台是一个专门针对通信行业的管理平台。该产品旨在提供高效的指挥调度和管理解决方案,以帮助通信运营商或相关机构实现更好的运营效率和服务质量。该平台提供强大的指挥调度功能,可以实时监控和管理通信网络设备、…...
什么是自然语言处理(NLP)?详细解读文本分类、情感分析和机器翻译的核心技术
什么是自然语言处理? 自然语言处理(Natural Language Processing,简称NLP)是人工智能的一个重要分支,旨在让计算机理解、解释和生成人类的自然语言。打个比方,你和Siri对话,或使用谷歌翻译翻译一…...

【linux】gcc快速入门教程
目录 一.gcc简介 二.gcc常用命令 一.gcc简介 gcc 是GNU Compiler Collection(GNU编译器套件)。就是一个编译器。编译一个源文件的时候可以直接使用,但是源文件数量太多时,就很不方便,于是就出现了make 工具 二.gcc…...
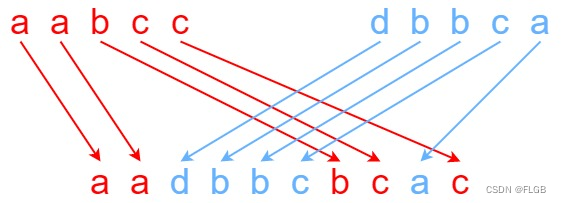
【多维动态规划】Leetcode 97. 交错字符串【中等】
交错字符串 给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。 两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串 子字符串 是字符串中连续的 非空 字符序列。 s s1 s2 … snt…...

【JavaScript脚本宇宙】精通前端开发:六大热门CSS框架详解
前端开发的利器:深入了解六大CSS框架 前言 在现代Web开发中,选择适合的前端框架和工具包是构建高效、响应式和美观的网站或应用程序的关键。本文将详细介绍六个广受欢迎的CSS框架:Bootstrap、Bulma、Tailwind CSS、Foundation、Materialize…...

开发技术-Java集合(List)删除元素的几种方式
文章目录 1. 错误的删除2. 正确的方法2.1 倒叙删除2.2 迭代器删除2.3 removeAll() 删除2.4 removeIf() 最简单的删除 3. 总结 1. 错误的删除 在写代码时,想将其中的一个元素删除,就遍历了 list ,使用了 remove(),发现效果并不是想…...

c++ 递归
递归函数是指在函数定义中调用自身的函数。C语言也支持递归函数。 下面是一个使用递归函数计算阶乘的例子: #include <iostream> using namespace std;int factorial(int n) {// 基本情况,当 n 等于 0 或 1 时,阶乘为 1if (n 0 || n…...
RedHat9 | podman容器
1、容器技术介绍 传统问题 应用程序和依赖需要一起安装在物理主机或虚拟机上的操作系统应用程序版本比当前操作系统安装的版本更低或更新两个应用程序可能需要某一软件的不同版本,彼此版本之间不兼容 解决方式 将应用程序打包并部署为容器容器是与系统的其他部分…...

边缘计算项目有哪些
边缘计算项目在多个领域得到了广泛的应用,以下是一些典型的边缘计算项目案例: 1. **智能交通系统**:通过在交通信号灯、监控摄像头等设备上部署边缘计算,可以实时分析交通流量,优化交通信号控制,减少拥堵&…...

计算fibonacci数列每一项时所需的递归调用次数
斐波那契数列是一个经典的数列,其中每一项是前两项的和,定义为: [ F(n) F(n-1) F(n-2) ] 其中,( F(0) 0 ) 和 ( F(1) 1 )。 对于计算斐波那契数列的第 ( n ) 项,如果使用简单的递归方法,其时间复杂度是…...

【教学类65-05】20240627秘密花园涂色书(中四班练习)
【教学类65-03】20240622秘密花园涂色书03(通义万相)(A4横版1张,一大 68张纸136份)-CSDN博客 背景需求: 打印以下几款秘密花园样式(每款10份)给中四班孩子玩一下,看看效果 【教学类…...
)
Python 学习之基础语法(一)
Python的语法基础主要包括以下几个方面,下面将逐一进行分点表示和归纳: 一、基本语法 1. 注释 a. 单行注释:使用#开头,例如# 这是一个单行注释。 b. 多行注释:使用三引号(可以是三个单引号或三个双引号&…...
日志分析-windows系统日志分析
日志分析-windows系统日志分析 使用事件查看器分析Windows系统日志 cmd命令 eventvwr 筛选 清除日志、注销并重新登陆,查看日志情况 Windows7和Windowserver2008R2的主机日志保存在C:\Windows\System32\winevt\Logs文件夹下,Security.evtx即为W…...

【ARM】MDK工程切换高版本的编译器后出现error A1137E报错
【更多软件使用问题请点击亿道电子官方网站】 1、 文档目标 解决工程从Compiler 5切换到Compiler 6进行编译时出现一些非语法问题上的报错。 2、 问题场景 对于一些使用Compiler 5进行编译的工程,要切换到Compiler 6进行编译的时候,原本无任何报错警告…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...