【深度学习】注意力机制
https://blog.csdn.net/weixin_43334693/article/details/130189238
https://blog.csdn.net/weixin_47936614/article/details/130466448
https://blog.csdn.net/qq_51320133/article/details/138305880
注意力机制:在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
注意力机制可以使模型在处理序列数据时更加准确和有效。在传统的神经网络中,每个神经元的输出只依赖于前一层的所有神经元的输出,而在注意力机制中,每个神经元的输出不仅仅取决于前一层的所有神经元的输出,还可以根据输入数据的不同部分进行加权,即对不同部分赋予不同的权重。这样可以使模型更加关注输入序列中的关键信息,从而提高模型的精度和效率。
注意力机制原理
1.计算注意力权重:注意力机制的第一步是计算每个输入位置的注意力权重。这个权重可以根据输入数据的不同部分进行加权,即对不同部分赋予不同的权重。权重的计算通常是基于输入数据和模型参数的函数,可以使用不同的方式进行计算,比如点积注意力、加性注意力、自注意力等。
2.加权求和输入表示:计算出注意力权重之后,下一步就是将每个输入位置的表示和对应的注意力权重相乘,并对所有加权结果进行求和。这样可以得到一个加权的输入表示,它可以更好地反映输入数据中重要的部分。
3.计算输出:注意力机制的最后一步是根据加权的输入表示和其他模型参数计算输出结果。这个输出结果可以作为下一层的输入,也可以作为最终的输出。
需要注意的是,注意力机制并不是一种特定的神经网络结构,而是一种通用的机制,可以应用于不同的神经网络结构中。比如,可以在卷积神经网络中使用注意力机制来关注输入图像中的重要区域,也可以在循环神经网络中使用注意力机制来关注输入序列中的重要部分。
查询(Query): 指的是查询的范围,自主提示,即主观意识的特征向量
键(Key): 指的是被比对的项,非自主提示,即物体的突出特征信息向量
值(Value) : 则是代表物体本身的特征向量,通常和Key成对出现
注意力机制是通过Query与Key的注意力汇聚(给定一个 Query,计算Query与 Key的相关性,然后根据Query与Key的相关性去找到最合适的 Value)实现对Value的注意力权重分配,生成最终的输出结果。
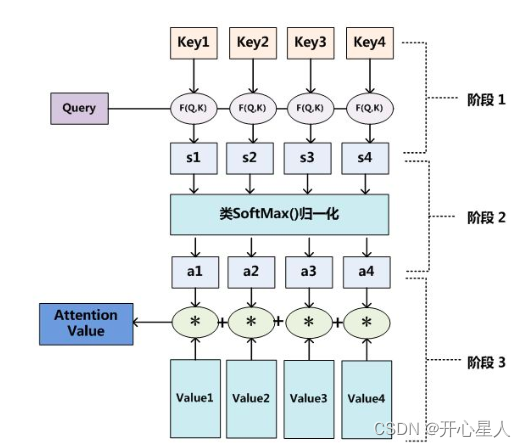
注意力机制计算过程:
阶段1、根据Query和Key计算两者之间的相关性或相似性(常见方法点积、余弦相似度,MLP网络),得到注意力得分

阶段2、对注意力得分进行缩放scale(除以维度的根号),再softmax函数,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重。一般采用如下公式计算
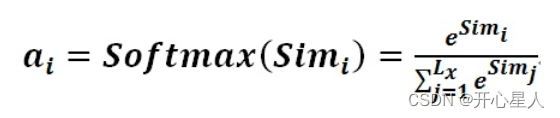
阶段3、根据权重系数对Value值进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了)
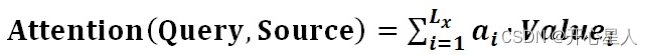
自注意力机制
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译(序列到序列的问题,机器自己决定多少个标签),词性标注(Pos tagging一个向量对应一个标签),语义分析(多个向量对应一个标签)等文字处理问题。
自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。不是输入语句和输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制。
自注意力机制原理
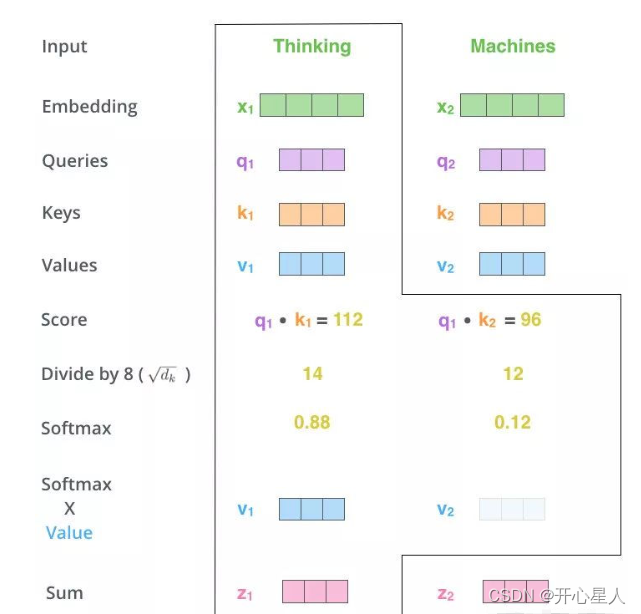
1、得到Q,K,V的值
对于每一个向量x,分别乘上三个系数 Wq,Wk,Wv,得到的Q,K和V分别表示query,key和value (这三个W就是我们需要学习的参数)
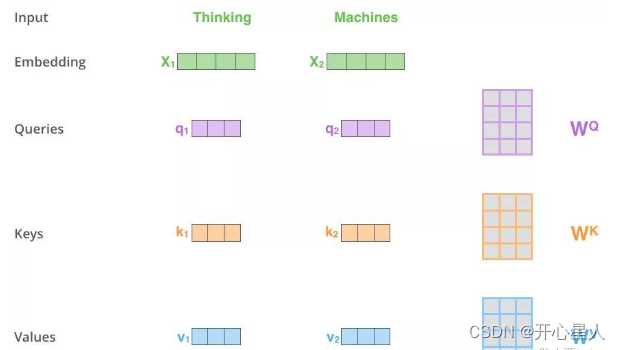
2、计算注意力权重
利用得到的Q和K计算每两个输入向量之间的相关性,一般采用点积计算
3、Scale+Softmax
将刚得到的相似度除以 d k \sqrt{d~k~} d k (dk 表示键向量的维度),再进行Softmax。经过Softmax的归一化后,每个值是一个大于0且小于1的权重系数,且总和为1,这个结果可以被理解成一个权重矩阵。
4、使用刚得到的权重矩阵,与V相乘,计算加权求和。
自注意力机制问题:
1、自注意力机制的原理是筛选重要信息,过滤不重要信息。这就导致自注意力机制无法完全利用图像本身具有的尺度,平移不变性,以及图像的特征局部性。这就导致自注意力机制只有在大数据的基础上才能有效地建立准确的全局关系
2、自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。在实际的文字处理问题中,可能在不同位置词语具有不同的性质(可通过位置编码解决:对每一个输入向量加上一个位置向量e,位置向量的生成方式有多种,通过e来表示位置信息带入self-attention层进行计算)
多头注意力机制:Multi-Head Self-Attention
多头注意力机制在自注意力的基础上,通过增加多个注意力头来并行地对输入信息进行不同维度的注意力分配,从而捕获更丰富的特征和上下文信息。
第1步:定义多组W,生成多组Q、K、V
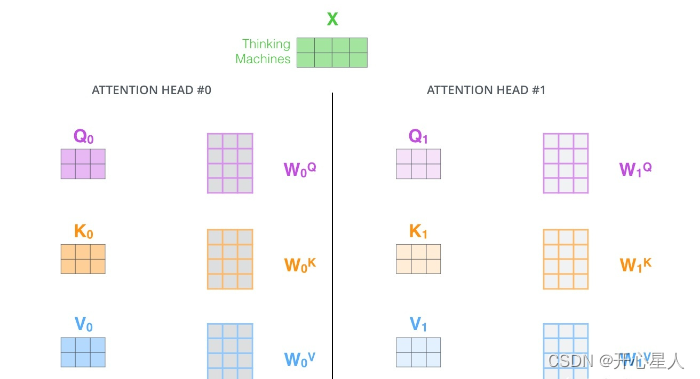
线性变换:首先,对输入序列中的每个位置的向量分别进行三次线性变换(即加权和偏置),生成查询矩阵Q, 键矩阵K, 和值矩阵V。在多头注意力中,这一步骤实际上会进行h次(其中h为头数),每个头拥有独立的权重矩阵,从而将输入向量分割到h个不同的子空间。
第2步:
并行注意力计算:对每个子空间,应用自注意力机制计算注意力权重,并据此加权求和值矩阵V,得到每个头的输出。公式上表现为:
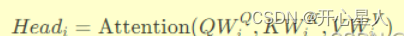
第3步:
合并与最终变换:将所有头的输出拼接起来,再经过一个最终的线性变换和层归一化,得到多头注意力的输出。这一步骤整合了不同子空间学到的信息,增强模型的表达能力。
import torch
from torch.nn import Module, Linear, Dropout, LayerNormclass MultiHeadAttention(Module):def __init__(self, d_model, num_heads, dropout=0.1):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"self.d_head = d_model // num_headsself.num_heads = num_headsself.linear_q = Linear(d_model, d_model)self.linear_k = Linear(d_model, d_model)self.linear_v = Linear(d_model, d_model)self.linear_out = Linear(d_model, d_model)self.dropout = Dropout(dropout)self.layer_norm = LayerNorm(d_model)def forward(self, q, k, v, mask=None):batch_size = q.size(0)# 线性变换q = self.linear_q(q).view(batch_size, -1, self.num_heads, self.d_head)k = self.linear_k(k).view(batch_size, -1, self.num_heads, self.d_head)v = self.linear_v(v).view(batch_size, -1, self.num_heads, self.d_head)# 转置以便于计算注意力q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)# 计算注意力权重scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_head)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)attn_weights = torch.softmax(scores, dim=-1)attn_weights = self.dropout(attn_weights)# 加权求和得到输出outputs = torch.matmul(attn_weights, v)# 转换回原始形状并进行最终线性变换outputs = outputs.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)outputs = self.linear_out(outputs)outputs = self.layer_norm(outputs + q)return outputs
相关文章:
【深度学习】注意力机制
https://blog.csdn.net/weixin_43334693/article/details/130189238 https://blog.csdn.net/weixin_47936614/article/details/130466448 https://blog.csdn.net/qq_51320133/article/details/138305880 注意力机制:在处理信息的时候,会将注意力放在需要…...

安卓开发自定义时间日期显示组件
安卓开发自定义时间日期显示组件 问题背景 实现时间和日期显示,左对齐和对齐两种效果,如下图所示: 问题分析 自定义view实现一般思路: (1)自定义一个View (2)编写values/attrs.…...

IT行业入门,如何假期逆袭,实现抢跑
目录 前言 1.IT行业领域分类 2.基础课程预习指南 3.技术学习路线 4.学习资源推荐 结束语 前言 IT(信息技术)行业是一个非常广泛和多样化的领域,它包括了许多不同的专业领域和职业路径。如果要进军IT行业,我们应该要明确自己…...

Pyramid 中混合认证策略
1. 问题背景 在一个使用 Pyramid 框架开发的应用程序中,需要同时处理 HTML 内容的显示和 JSON API 的请求。对于 HTML 内容,使用了 AuthTktAuthenticationPolicy 进行身份验证和 ACLAuthorizationPolicy 进行授权。当用户成功登录后,会在浏览…...
深度学习经典检测方法概述
一、深度学习经典检测方法 two-stage(两阶段):Faster-rcnn Mask-Rcnn系列 one-stage(单阶段):YOLO系列 1. one-stage 最核心的优势:速度非常快,适合做实时检测任务! 但是…...
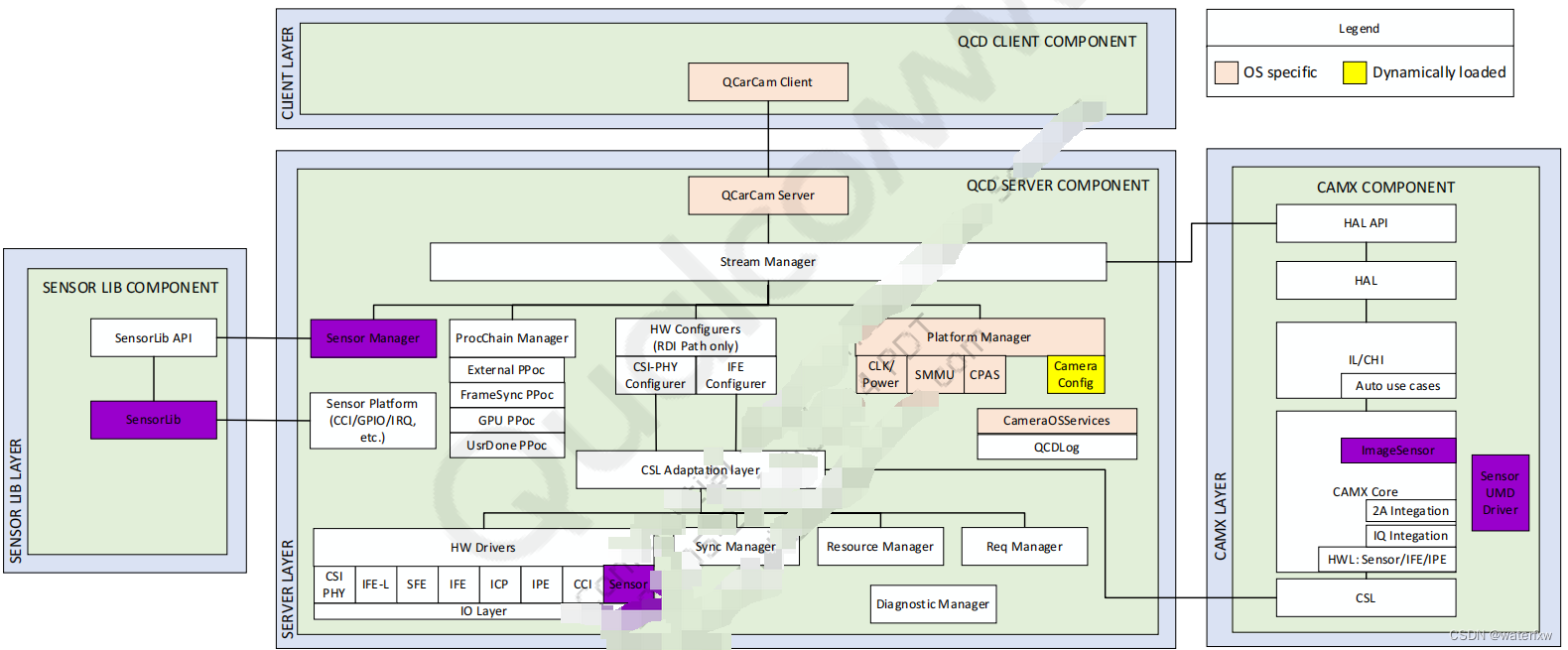
<sa8650>sa8650 qcxserver-之-摄像头传感器VB56G4A驱动开发<1>
<sa8650>sa8650 qcxserver-之-摄像头传感器VB56G4A驱动开发 <1> 一、前言二、QCX架构三、QCX 传感器驱动程序定制开发3.1 sensor硬件接口3.2 sensor配置文件3.2.1 cameraconfig.c3.2.2 cameraconfigsa8650_water.c3.2.3 新增编译MK3.2.4 参数解析3.2.4.1 struct Camera…...
推荐8款超实用的ComfyUI绘画插件,帮助我们的AI绘画质量和效率提升几个档次!
前言 大家在使用SD绘画过程中,想必见识到了插件的强大功能,本身纯净版的SD界面是相对简洁的,但是搭配了各种插件后,界面标签栏会增加很多,相应的功能也增加了。 从简单的中文界面翻译插件,到强大的contro…...

MATLAB-振动问题:两自由度耦合系统自由振动
一、基本理论 二、MATLAB实现 以下是两自由度耦合系统自由振动质量块振动过程动画显示的MATLAB程序。 clear; clc; close allx0 1; D1 40; D12 8; D2 D1; m1 1; omega0 sqrt(D1/m1); k1 D12 / D1; k2 D12 / D2; k sqrt(k1 * k2); omegazh omega0 * sqrt(1 k); omeg…...
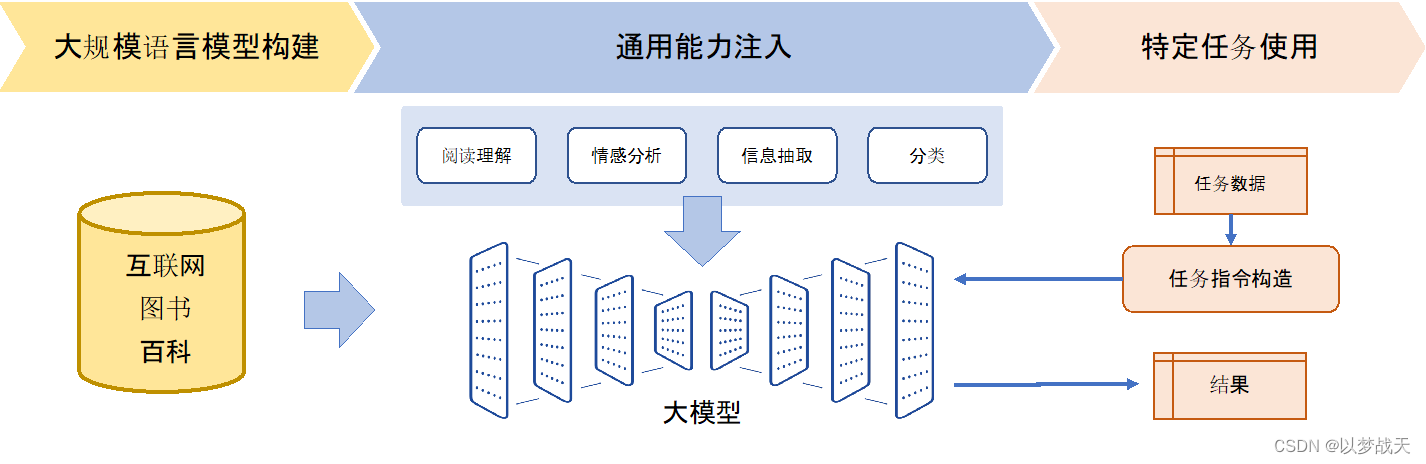
人工智能-NLP简单知识汇总01
人工智能-NLP简单知识汇总01 1.1自然语言处理的基本概念 自然语言处理难点: 语音歧义句子切分歧义词义歧义结构歧义代指歧义省略歧义语用歧义 总而言之:!!语言无处不歧义 1.2自然语言处理的基本范式 1.2.1基于规则的方法 通…...

Spring Boot中的异步编程技巧
Spring Boot中的异步编程技巧 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨在Spring Boot应用程序中如何使用异步编程技巧,以提升性…...

深度解密Spark性能优化之道
课程介绍 课程通过实战案例解析和性能调优技巧的讲解,帮助学员提升大数据处理系统的性能和效率。课程内容涵盖了Spark性能调优的各个方面,包括内存管理、并行度设置、数据倾斜处理、Shuffle调优、资源配置等关键技术和策略。学员将通过实际案例的演示和…...

在U盘/移动硬盘上安装热插拔式Ubuntu系统,并将Docker目录挂载到NTFS硬盘
Windows10的WSL2的确给开发人员带来了很多方便,但是仍然有很多缺点。比如:太占系统内存;有些软件无法在WSL2中编译成功;相当于虚拟机,性能不如原装系统。 装双系统,相信大家都不陌生,但它会占用…...

商城小程序论文(设计)开题报告
一、课题的背景和意义 近些年来,随着移动互联网巅峰时期的来临,互联网产业逐渐趋于“小、轻、微”的方向发展,符合轻应用时代特点的各类技术受到了不同领域的广泛关注。在诸多产品中,被誉为“运行着程序的网站”之名的微信小程序…...

15. Java的 CAS 操作原理
1. 前言 本节内容主要是对 CAS 操作原理进行讲解,由于 CAS 涉及到了并发编程包的使用,本节课程只对 CAS 的原理问题进行讲解,有助于同学后续对并发编程工具使用的学习。本节具体内容点如下: 了解 CAS 的概念,这是本节…...

修改element-ui日期下拉框datetimePicker的背景色样式
如图: 1、修改背景色 .el-date-picker.has-sidebar.has-time { background: #04308D; color: #fff; border: 1px solid #326AFF } .el-date-picker__header-label { color: #ffffff; } .el-date-table th { color: #fff; } .el-icon-d-arrow-left:before { color: …...

Linux—— 逻辑运算符,压缩和解压缩
- -a: and 逻辑与 - -o: or 逻辑或 - -not: not 逻辑非 - 优先级:与>或>非 shell [rootserver ~]# find / -size 10k -a -size -50k [rootserver ~]# find /etc -name "e*" -o -name "f*"…...
——FFmpeg源码:从H.264码流中提取NALU Header、EBSP、RBSP和SODB)
音视频入门基础:H.264专题(6)——FFmpeg源码:从H.264码流中提取NALU Header、EBSP、RBSP和SODB
音视频入门基础:H.264专题系列文章: 音视频入门基础:H.264专题(1)——H.264官方文档下载 音视频入门基础:H.264专题(2)——使用FFmpeg命令生成H.264裸流文件 音视频入门基础&…...

STM32实现按键单击、双击、长按、连按功能,使用状态机,无延时,不阻塞
常见的按键判定程序,如正点原子按键例程,只能判定单击事件,对于双击、长按等的判定逻辑较复杂,且使用main函数循环扫描的方式,容易被阻塞,或按键扫描函数会阻塞其他程序的执行。使用定时器设计状态机可以规…...

C#之Delta并联机械手的视觉同步分拣
本文导读 前面两节课程我们介绍了怎么建立Delta并联机械手的正逆解以及如何通过视觉进行匹配定位。本节课程给大家分享如何通过C#语言开发正运动Delta并联机械手传送带同步的视觉分拣。 VPLC711硬件介绍 VPLC711是正运动推出的一款基于x86平台和Windows操作系统的高性能机器…...
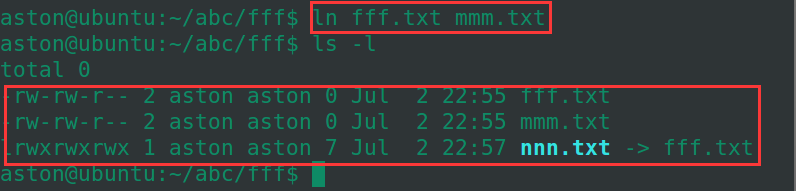
01:Linux的基本命令
Linux的基本命令 1、常识1.1、Linux的隐藏文件1.2、绝对路径与相对路径 2、基本命令2.1、ls2.2、cd2.3、pwd / mkdir / mv / touch / cp / rm / cat / rmdir2.4、ln2.5、man2.6、apt-get 本教程是使用的是Ubuntu14.04版本。 1、常识 1.1、Linux的隐藏文件 在Linux中…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...