中文大模型基准测评2024上半年报告
中文大模型基准测评2024上半年报告
原创 SuperCLUE CLUE中文语言理解测评基准 2024年07月09日 18:09 浙江

SuperCLUE团队
2024/07
背景
自2023年以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。进入2024年,全球大模型竞争态势日益加剧,随着GPT-4o、Claude3.5、Gemini1.5-pro和Llama3的发布,国内大模型同样在2024年上半年内进行了波澜壮阔的大模型追逐赛。中文大模型测评基准SuperCLUE持续对国内外大模型的发展趋势和综合效果进行了实时跟踪。
基于此,我们发布了《中文大模型基准测评2024上半年报告》,在AI大模型发展的巨大浪潮中,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。
点击文章底部【阅读原文】查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_24h1
![]()
报告核心内容摘要
摘要1:国内外大模型差距进一步缩小
国内外大模型差距进一步缩小:OpenAI最新模型GPT-4o依然是全球表现最好的模型,但国内大模型已将差距缩小至5%以内。
摘要2:国内开源模型崛起
本次登顶SuperCLUE的国内大模型为开源模型Qwen2-72B-Instruct,并且超过了众多国内外闭源模型。
摘要3:国内开源模型崛起
在文科、理科和Hard任务中,GPT-4o综合最佳,Claude-3.5在Hard任务表现突出,Qwen2-72B在文科任务表现优异。
摘要4:端侧小模型表现惊艳
端侧小模型进展迅速,部分小尺寸模型表现要好于上一代的稍大尺寸模型,极大提升了落地的可行性。
详情请查看#正文或完整报告。
目录
一、国内大模型关键进展
1. 2023-2024年大模型关键进展
2. 2024年值得关注的中文大模型全景图
3. 2023-2024年度国内外大模型技术发展趋势
二、SuperCLUE通用能力测评
1. 中文大模型基准SuperCLUE介绍
2. SuperCLUE测评体系及数据集说明
3. 测评模型列表
4. SuperCLUE通用能力测评:一级总分
5. SuperCLUE通用能力测评:二级维度分数
6. SuperCLUE通用能力测评:三级细粒度分数
7. SuperCLUE模型象限
8. 国内大模型SuperCLUE历届Top3
9. 理科测评
10. 文科测评
11. Hard测评
12. SuperCLUE开源榜单
13. SuperCLUE端侧小模型榜单
14. 大模型对战胜率分布图
15. SuperCLUE成熟度指数
16. 评测与人类一致性验证
三、SuperCLUE多模态能力测评
1.AIGVBench视频生成测评
2.SuperCLUE-Image文生图测评
3.SuperCLUE-V多模态理解测评
四、SuperCLUE专项与行业测评
1. 专项基准:SuperCLUE-Math6数学推理
2. 专项基准:SuperCLUE-Coder代码助手
2. 专项基准:SuperCLUE-RAG检索增强生成
3. 专项基准:SuperCLUE-Code3代码生成
4. 专项基准:SuperCLUE-Agent智能体
5. 专项基准:SuperCLUE-Safety安全
6. 专项基准:SuperCLUE-200K超长文本
7. 专项基准:SuperCLUE-Role角色扮演
8. 专项基准:SuperCLUE-Video文生视频
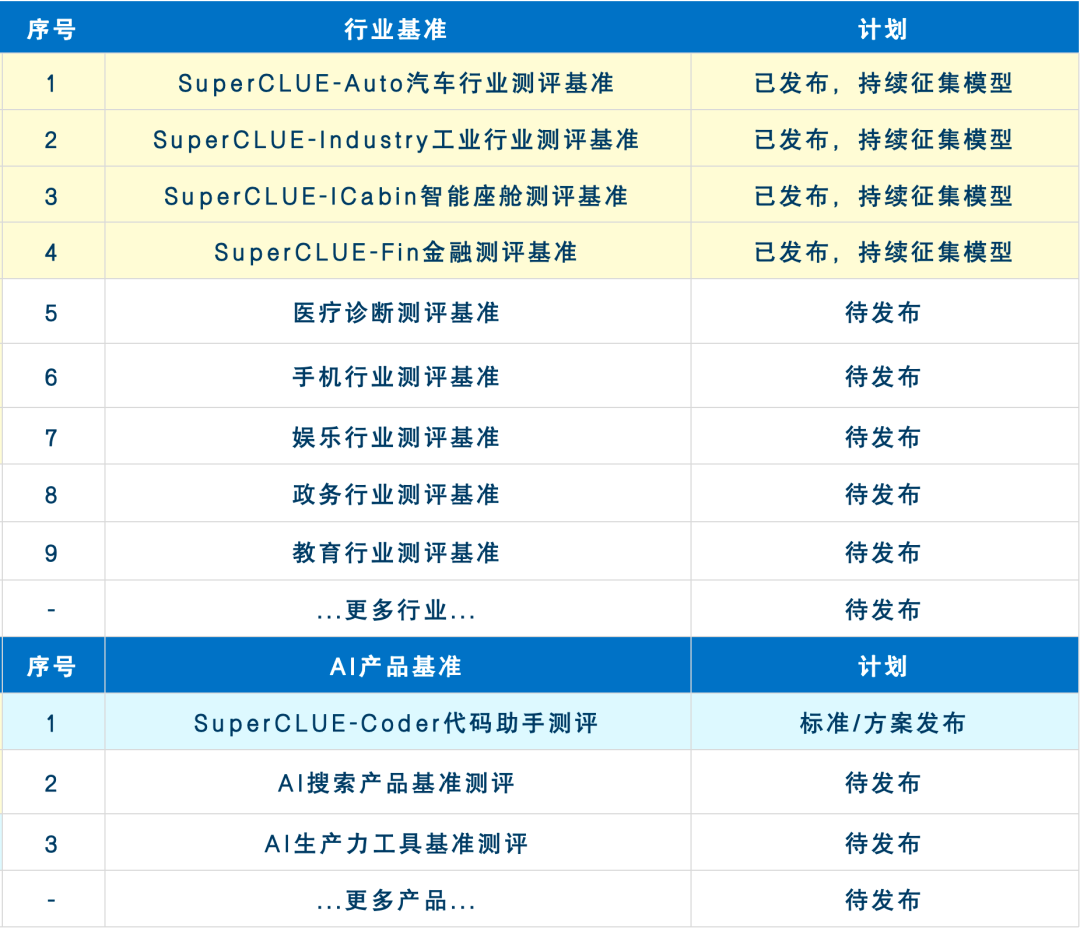
9. 行业基准:SuperCLUE-Auto汽车
11. 行业基准:SuperCLUE-Fin金融
12. 行业基准:SuperCLUE-Industry工业
13. 行业基准:SuperCLUE-ICabin智能座舱
14. 竞技场:琅琊榜对战结果及分析
15. 未来两个月基准发布计划
五、优秀模型案例介绍
1. 优秀模型案例介绍
正文
一、国内大模型关键进展
1. 2023年大模型关键进展与中文大模型全景图
国内学术和产业界在过去一年半也有了实质性的突破。大致可以分为三个阶段,即准备期(ChatGPT发布后国内产学研迅速形成大模型共识)、成长期(国内大模型数量和质量开始逐渐增长)、爆发期(各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势)。

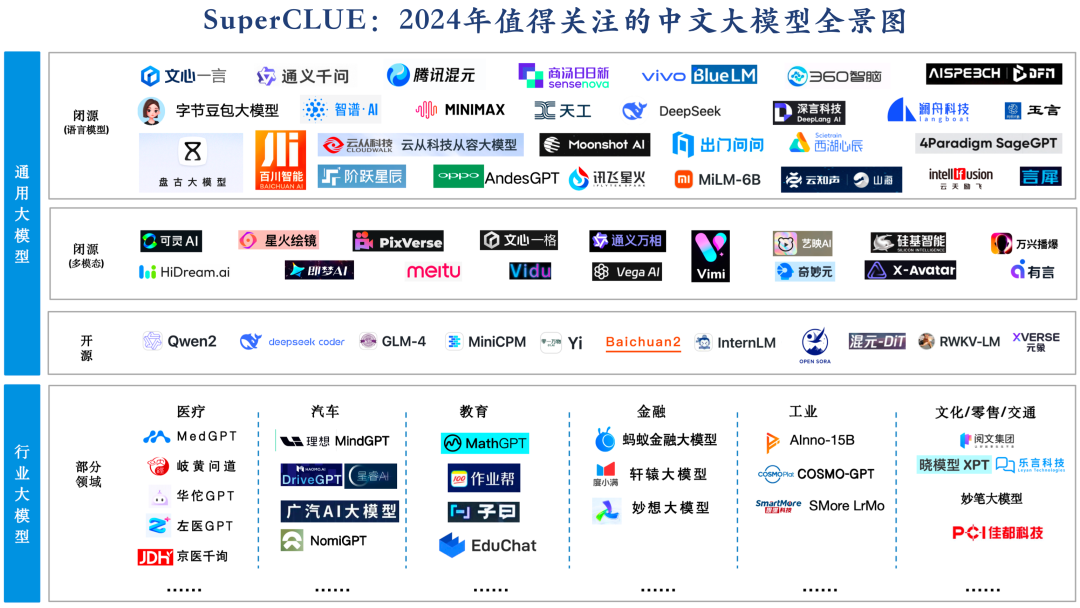
2. 2024年值得关注的中文大模型全景图
截止目前为止,国内已发布开源、闭源通用大模型及行业大模型已有上百个,SuperCLUE梳理了2024年值得关注的大模型全景图。
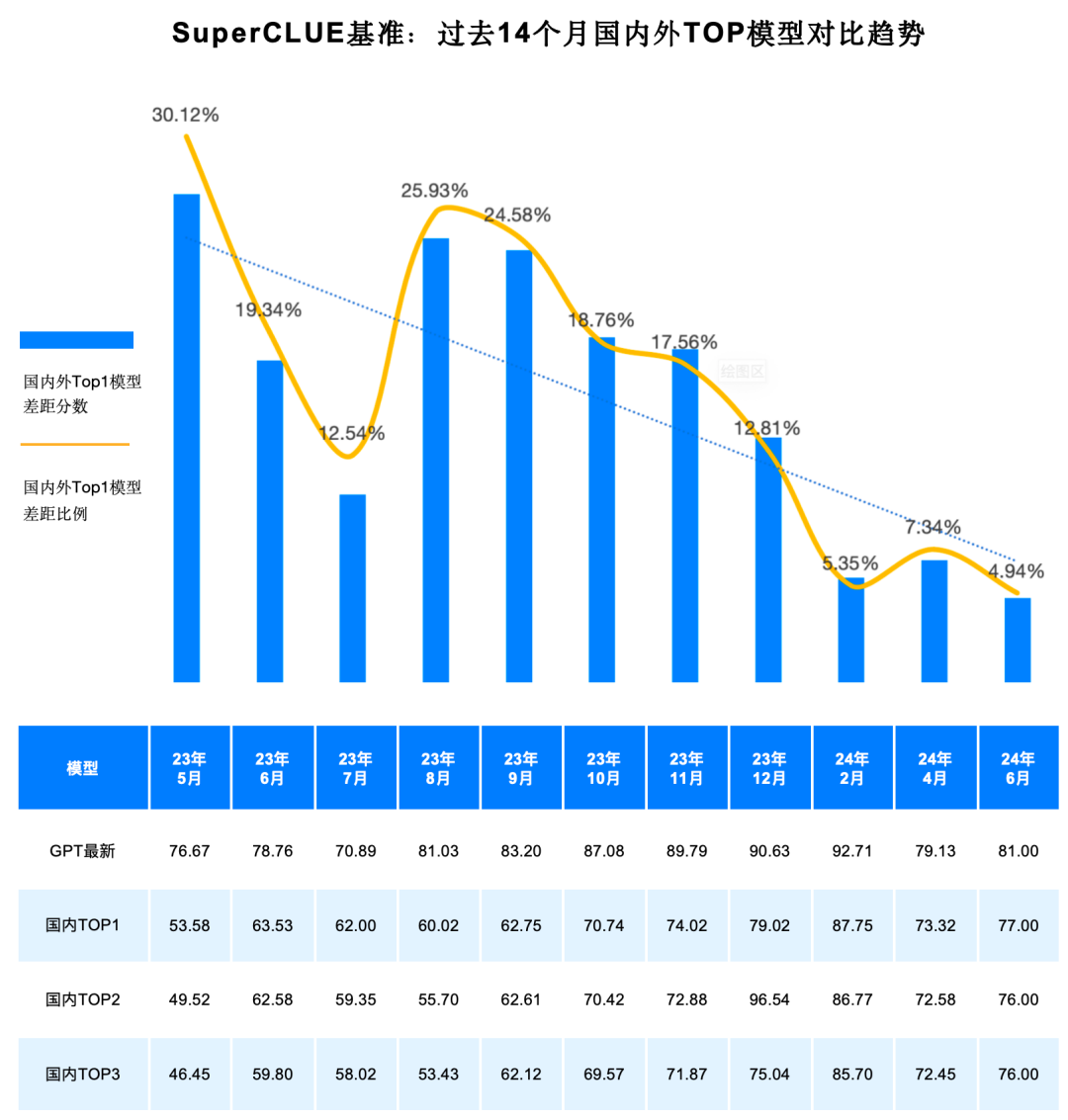
3. 2023-2024年度国内外大模型技术发展趋势
2023年5月至今,国内外大模型能力持续发展。其中GPT系列模型为代表的海外最好模型经过了从GPT3.5、GPT4、GPT4-Turbo、GPT4o的多个版本的迭代升级。国内模型也经历了波澜壮阔的14个月的迭代周期,其中Top1的模型经历了8次易主,不断提升国内模型的最强战力。
总体趋势上,国内外第一梯队大模型在中文领域的通用能力差距在持续缩小,从2023年5月的30.12%的差距,缩小至2024年6月的4.94%。
来源:SuperCLUE,2024年7月9日
二、SuperCLUE通用能力测评
1. 中文大模型基准SuperCLUE介绍
中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)是致力于科学、客观、中立的语言模型评测基准,发起于2019年。陆续推出CLUE、FewCLUE、KgCLUE、DataCLUE等广为引用的测评基准。
SuperCLUE是大模型时代CLUE基准的发展和延续。聚焦于通用大模型的综合性测评。SuperCLUE根据多年的测评经验,基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准。
传统测评与SuperCLUE的区别
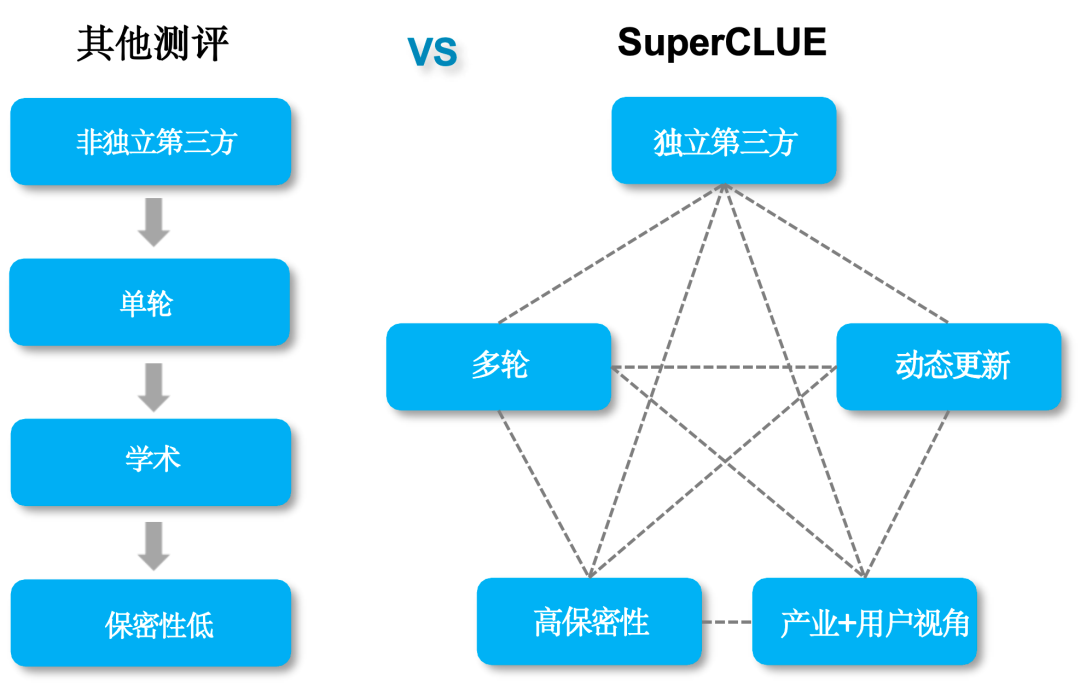
SuperCLUE三大特征
1) 独立第三方测评,非大模型方主导
随着国内外大模型的竞争日益激烈,模型开发方主导的评测可能存在偏向自家产品的风险。与之形成鲜明对比的是,SuperCLUE作为一个完全独立的第三方评测机构,承诺提供无偏倚的客观评测结果。SuperCLUE采用先进的自动化评测技术,有效消除人为因素带来的不确定性,确保每一项评测都公正无私。
2) 测评方式与真实用户体验目标一致
不同于传统测评通过选择题形式的测评,SuperCLUE目标是与真实用户体验目标保持一致,所以纳入了开放主观问题的测评。通过多维度多视角多层次的评测体系以及对话的形式,模拟大模型的应用场景,真实有效的考察模型生成能力。
3) “live”更新,测评体系/方法与时俱进
不同于传统学术领域的评测,SuperCLUE根据全球的大模型技术发展趋势,不断升级迭代测评体系、测评维度和方法,以保证尽可能精准量化大模型的技术演进程度。
2. SuperCLUE测评体系及数据集说明
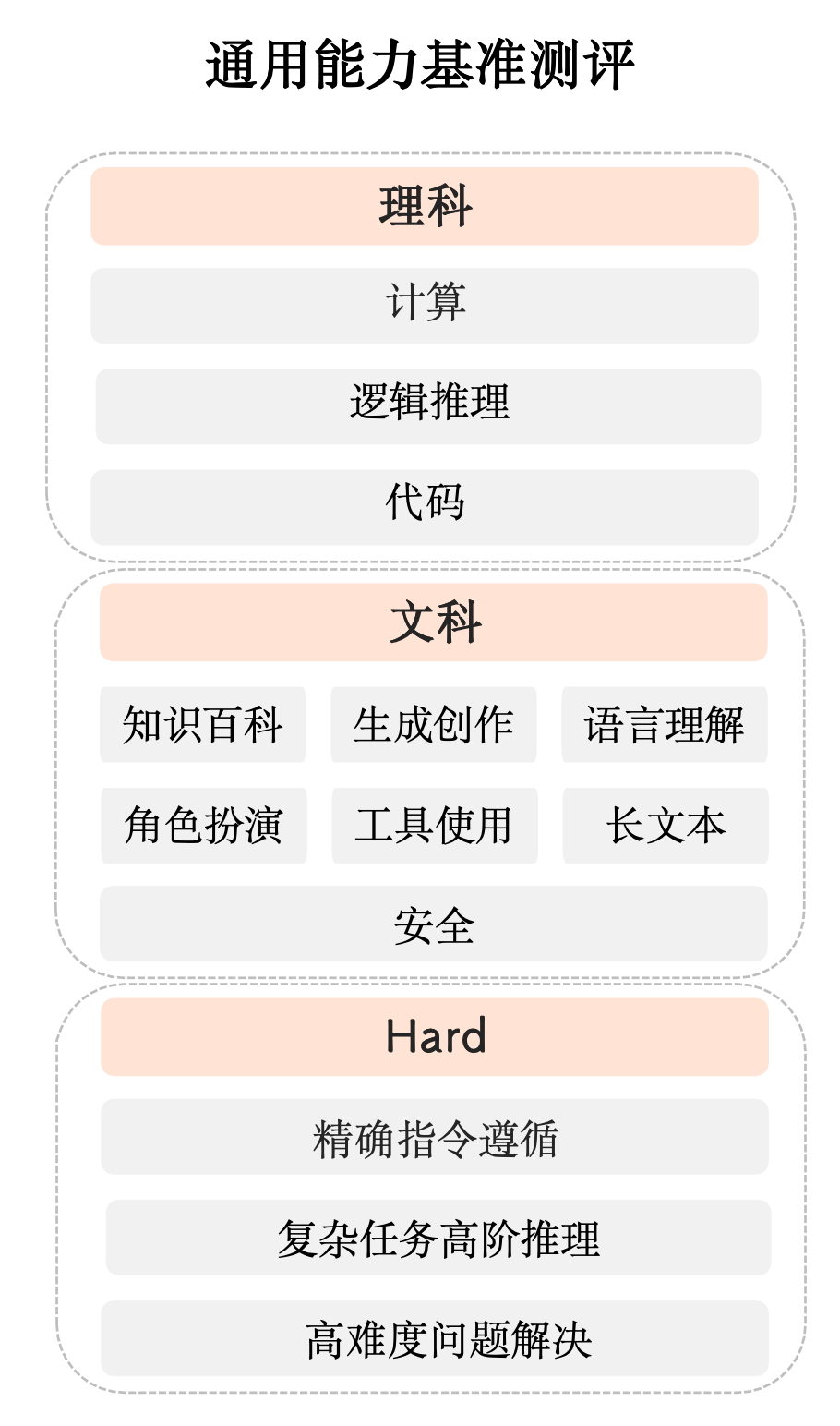
为进一步真实反应大模型能力,本次半年度测评采用多维度、多层次的综合性测评方案,由理科、文科和Hard三大维度构成。
【理科任务】分为计算、逻辑推理、代码测评集;
【文科任务】分为知识百科、语言理解、长文本、角色扮演、生成与创作、安全和工具使用七大测评集;
【Hard任务】本次测评首次纳入精确指令遵循测评集,另外复杂多步推理和高难度问题解决Hard测评集后续陆续推出。

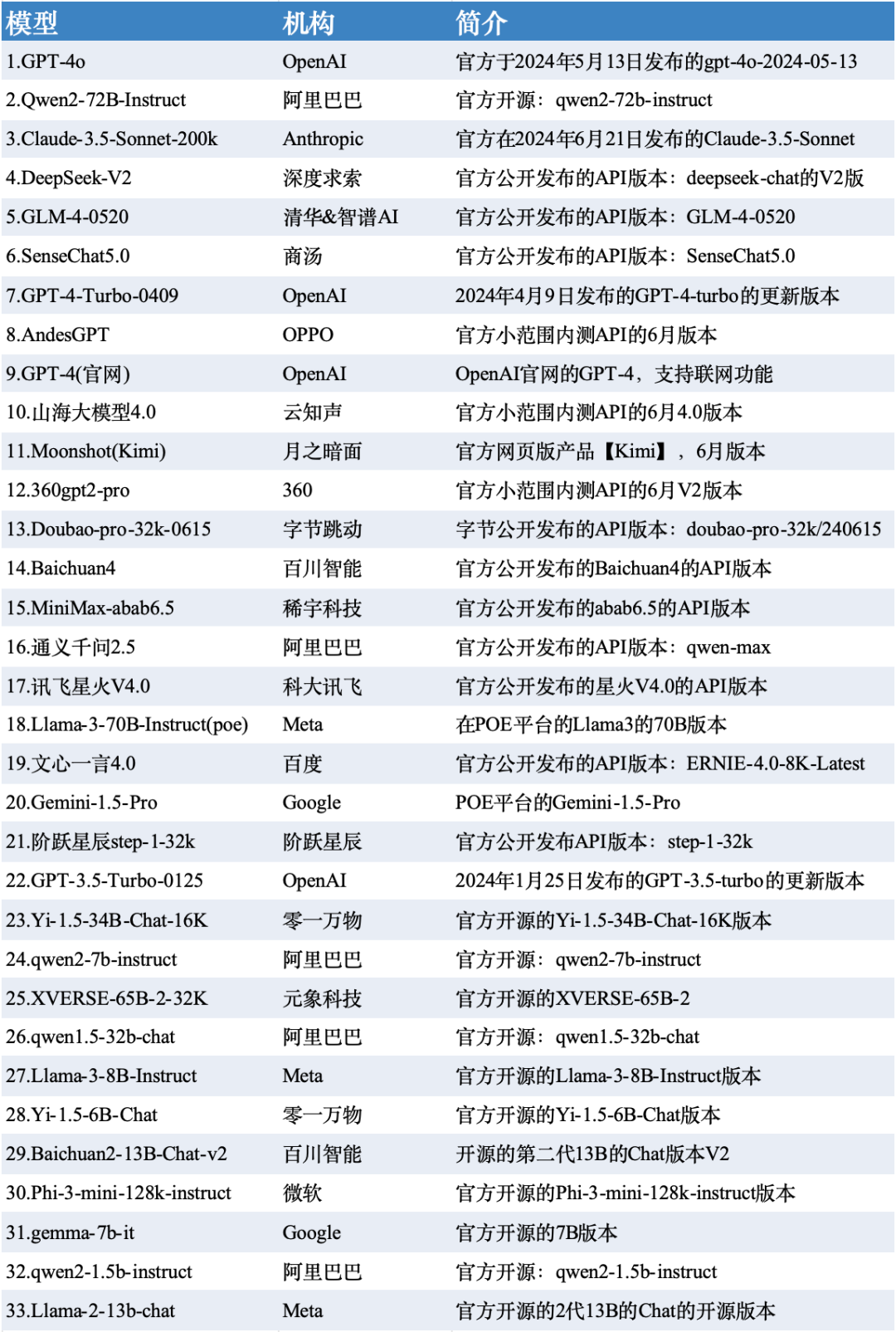
3. 测评模型列表
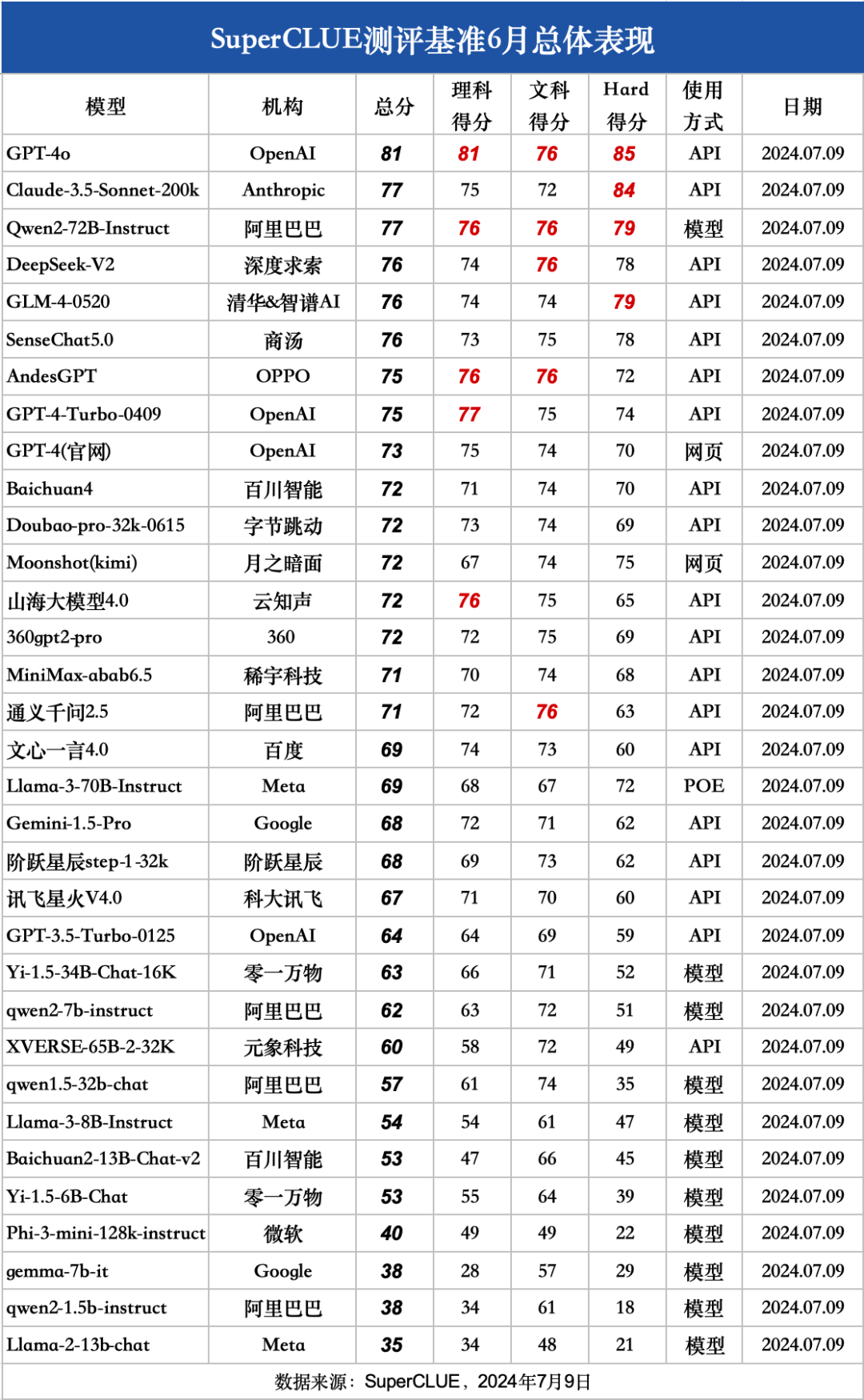
本次测评数据选取了SuperCLUE-6月测评结果,模型选取了国内外有代表性的33个大模型在6月份的版本。
4.SuperCLUE通用能力测评:一级总分
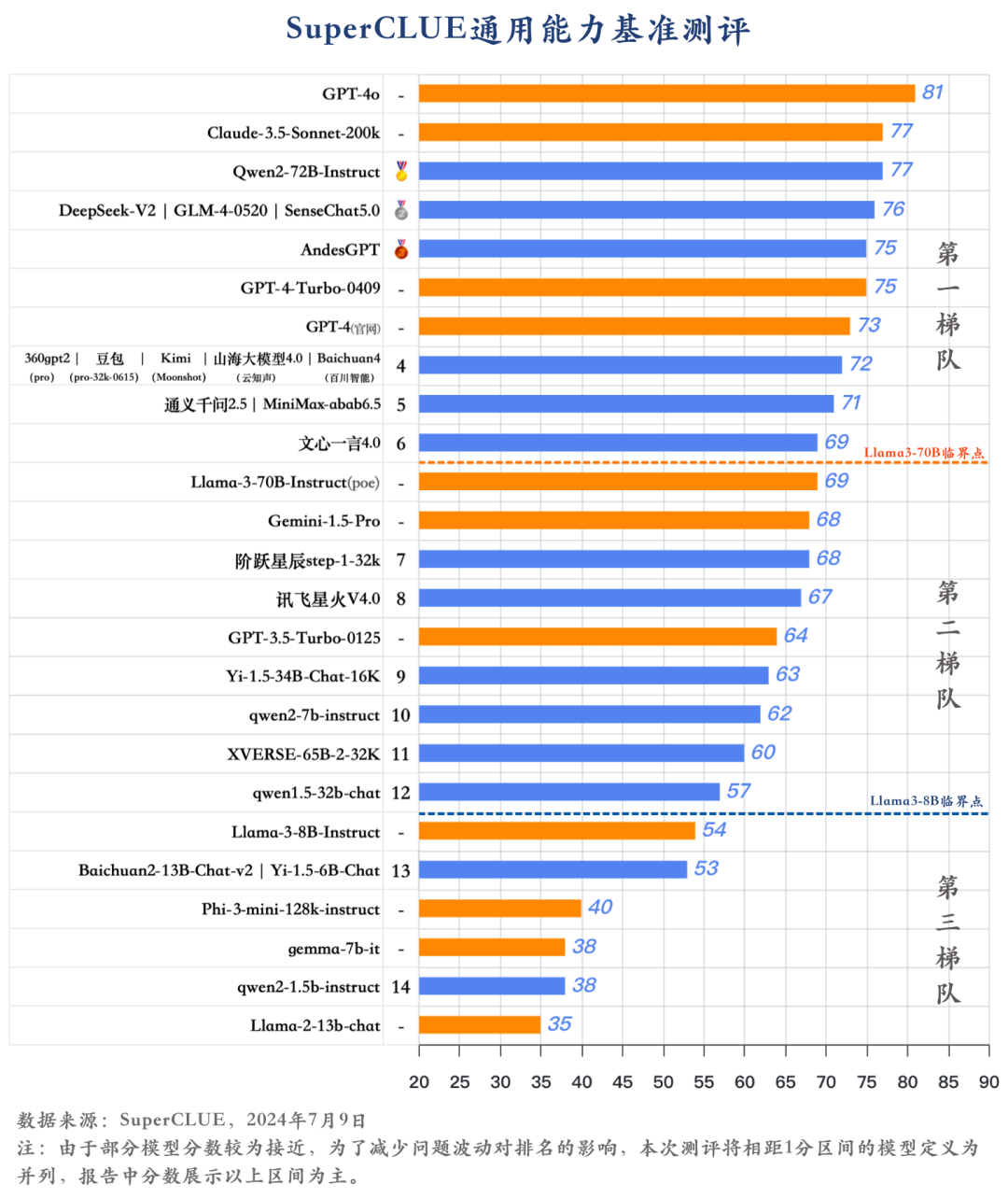
1)GPT-4o领跑,国内大模型进展迅速
-
GPT-4o以81分的绝对优势领跑 SuperCLUE基准测试,是全球模型中唯一超过80分的大模型。展现出强大的语言、数理和指令遵循能力。
-
国内大模型上半年发展非常迅速,其中有6个国内大模型超过GPT-4-Turbo-0409。绝大部分闭源模型已超过GPT-3.5-Turbo-0125。
2)国内大模型形成三大梯队,头部企业引领发展
-
国内大模型市场形成多梯队格局,头部企业凭借快速迭代、技术积累或资源优势,引领国内大模型发展。例如大厂模型以阿里的Qwen2-72B、商汤的SenseChat5.0等均以 75+的分数位居国内大模型第一梯队。
-
大模型创业公司的代表如GLM-4、Baichuan4、Kimi、MiniMax-abab6.5均有超过70分的表现,位列国内大模型第一梯队。
3)开源模型极大发展,有超出闭源模型趋势
-
开源模型Qwen2-72B在SuperCLUE基准中表现非常出色,超过众多国内外闭源模型,与Claude-3.5持平,与GPT-4o仅差4分。
-
零一万物推出的Yi-1.5-34B在开源领域表现不俗,有超过60分的表现,较为接近部分闭源模型。
随着技术进步和应用场景拓展,2024年下半年国内外大模型市场竞争将持续加剧,推动技术创新和产业升级。
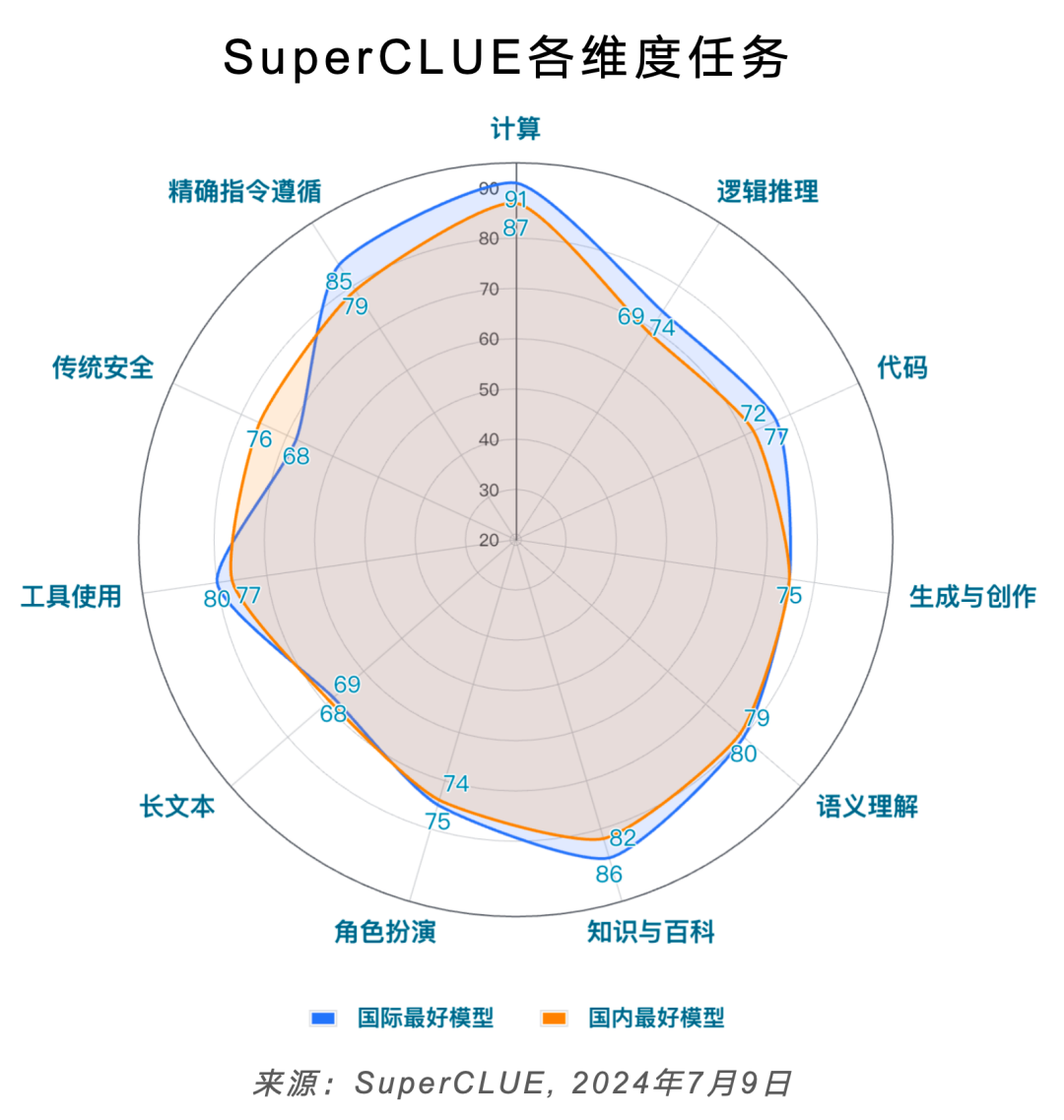
5.SuperCLUE通用能力测评:二级维度分数
6.SuperCLUE通用能力测评:三级细粒度分数
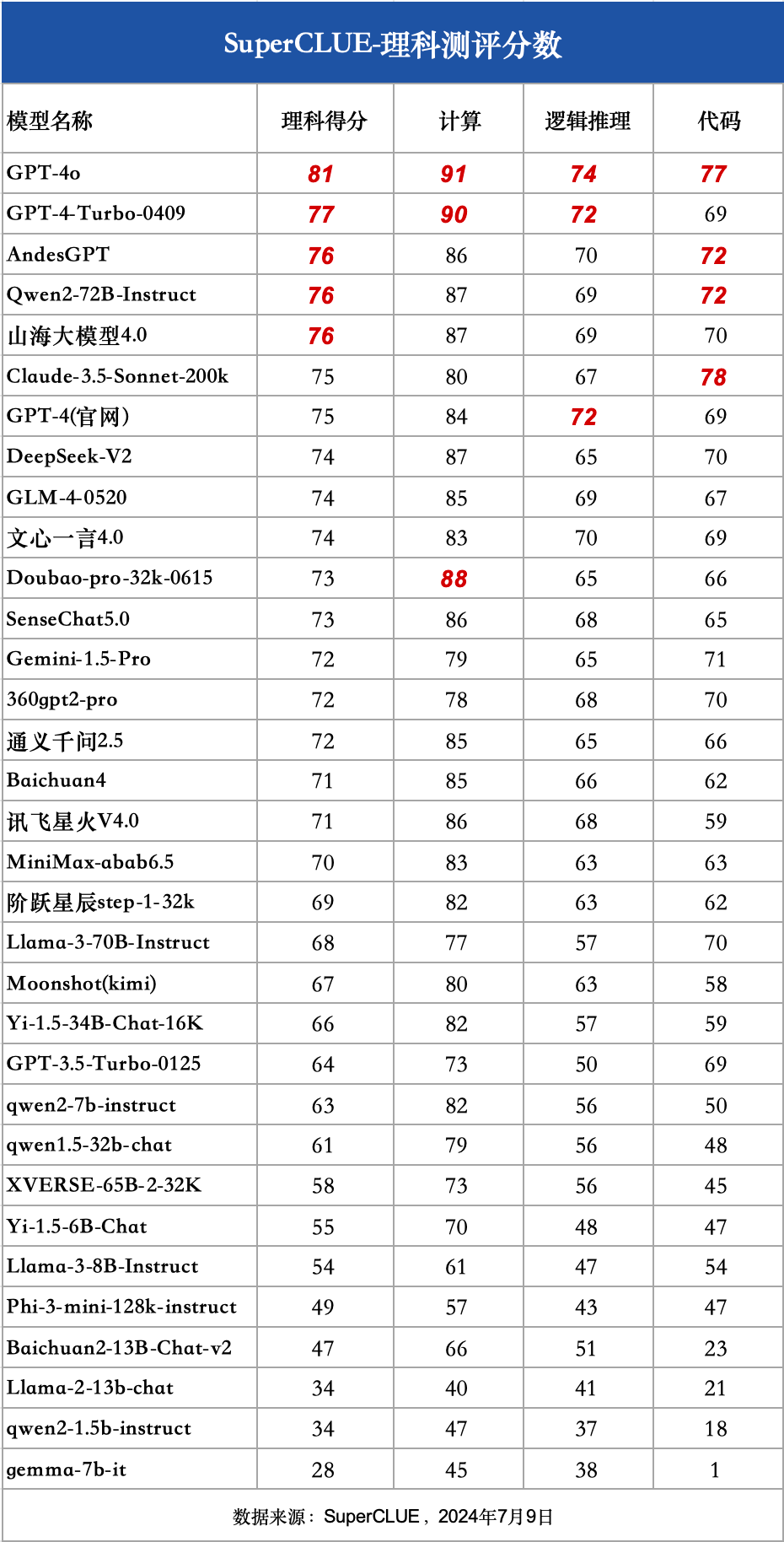
1)理科细粒度分数
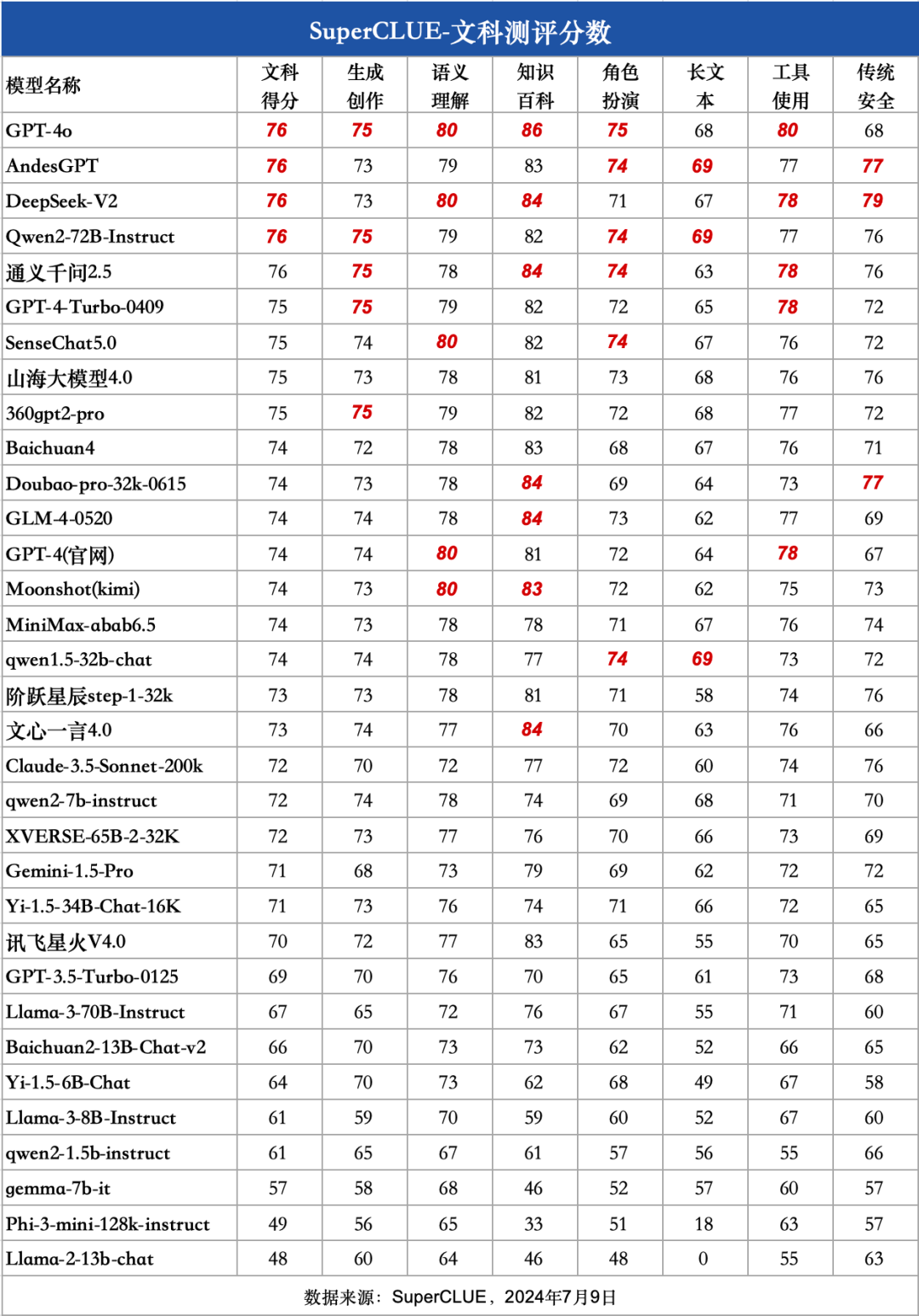
2)文科细粒度分数
3)SuperCLUE细粒度全局分数
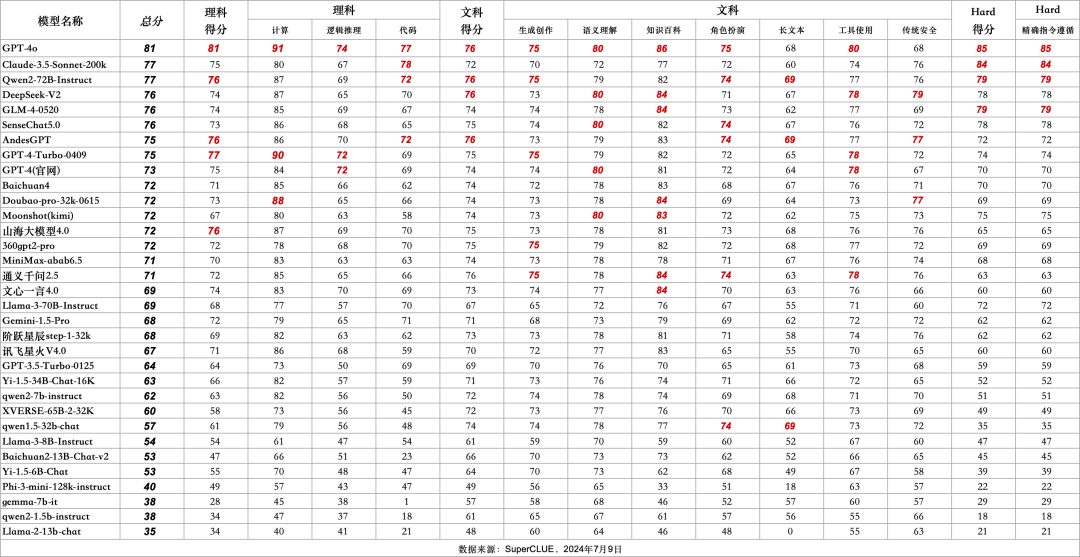
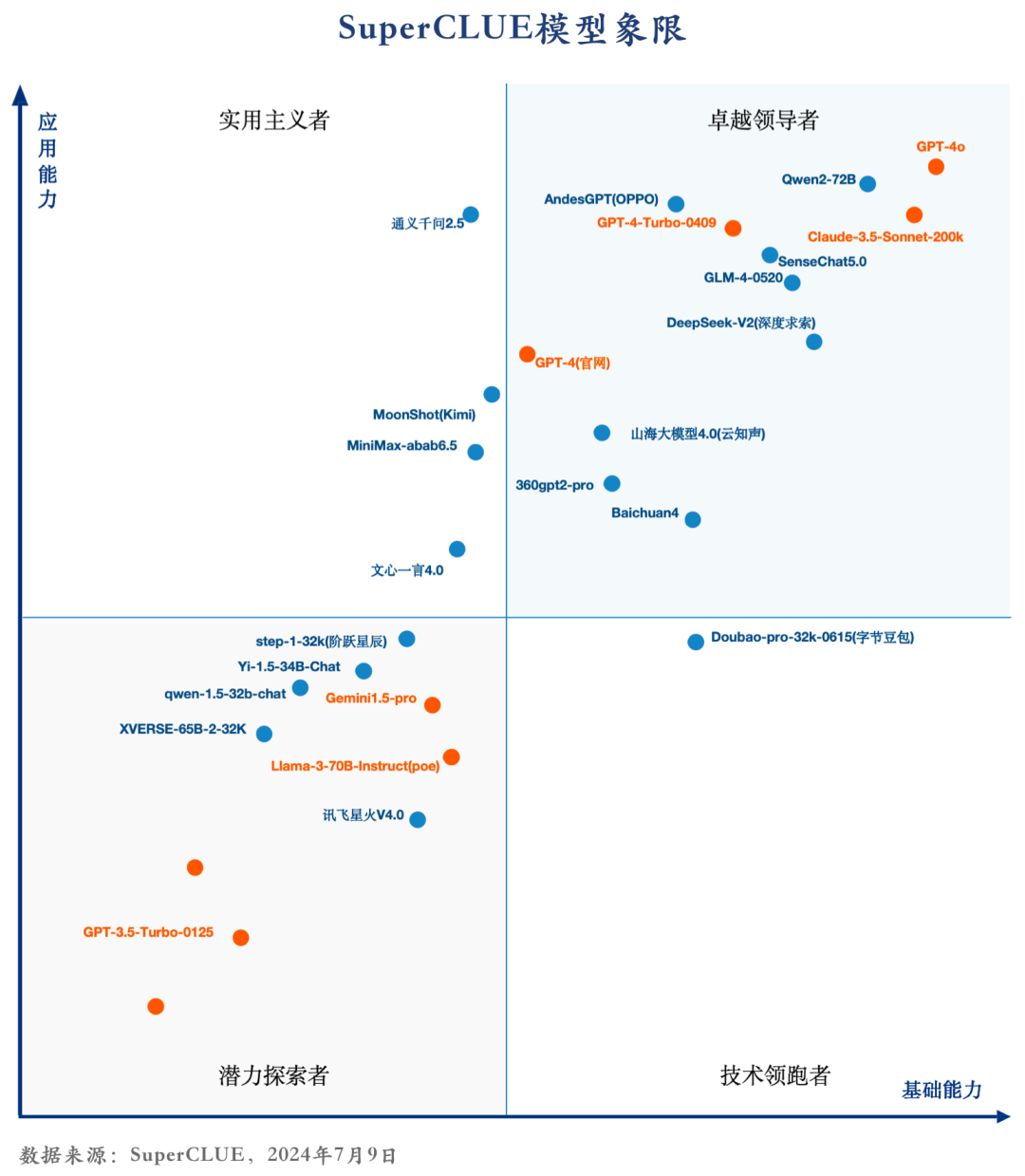
7.SuperCLUE模型象限
SuperCLUE评测任务可划分为基础能力和应用能力两个维度。
基础能力,包含:计算、代码、传统安全等能力。
应用能力,包括:工具使用、角色扮演等能力。
基于此,SuperCLUE构建了大模型四个象限,它们代表大模型所处的不同阶段与定位,其中【潜力探索者】代表模型正在技术探索阶段拥有较大潜力;【技术领跑者】代表模型聚焦基础技术研究;【实用主义者】代表模型在场景应用上处于领先定位;【卓越领导者】代表模型在基础和场景应用上处于领先位置,引领国内大模型发展。
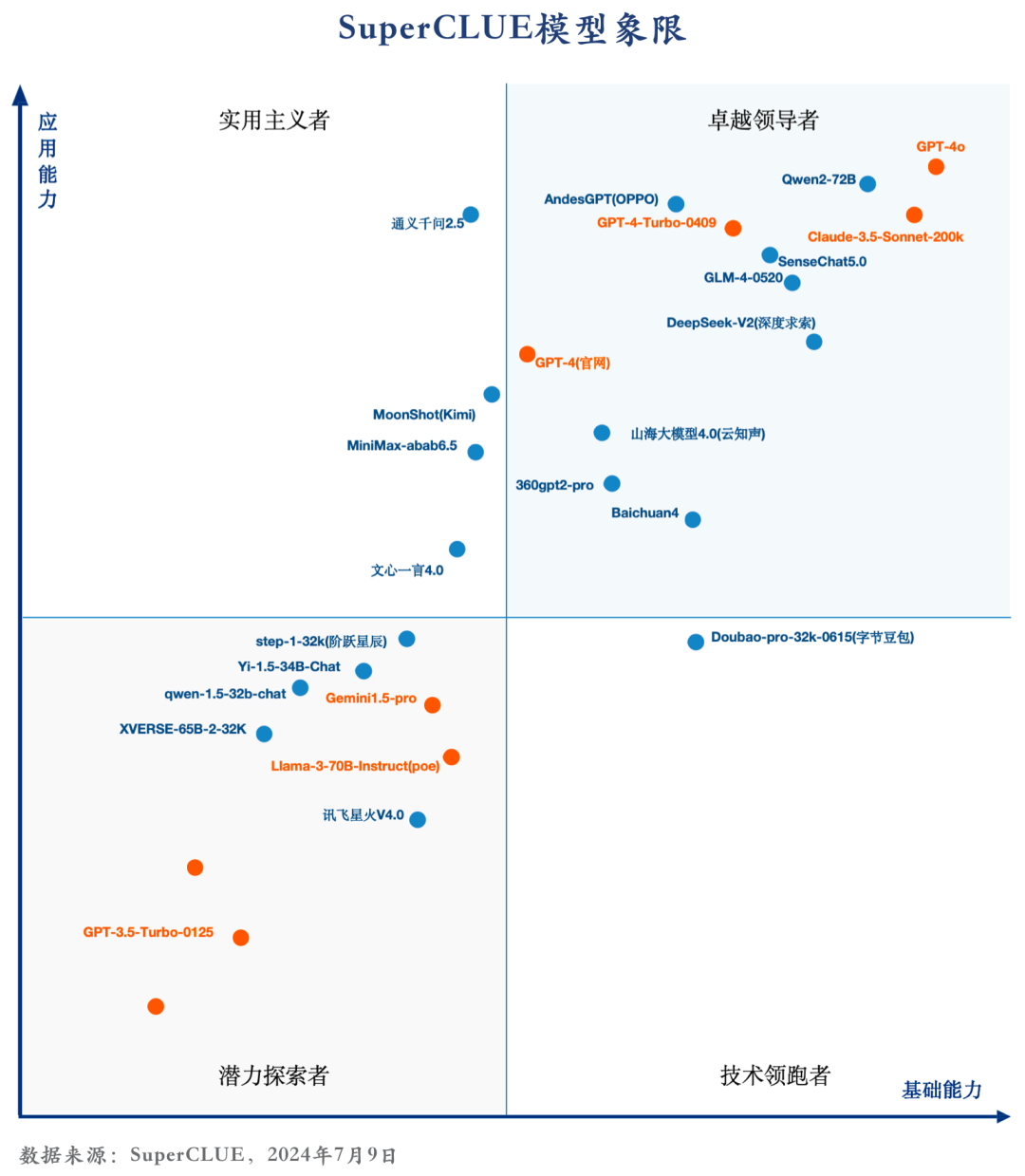
8. 国内大模型SuperCLUE历届Top3
过去十一个月国内模型在SuperCLUE基准上的前三名。
9. SuperCLUE理科测评
1)测评数据集及方法说明


2)SuperCLUE理科成绩
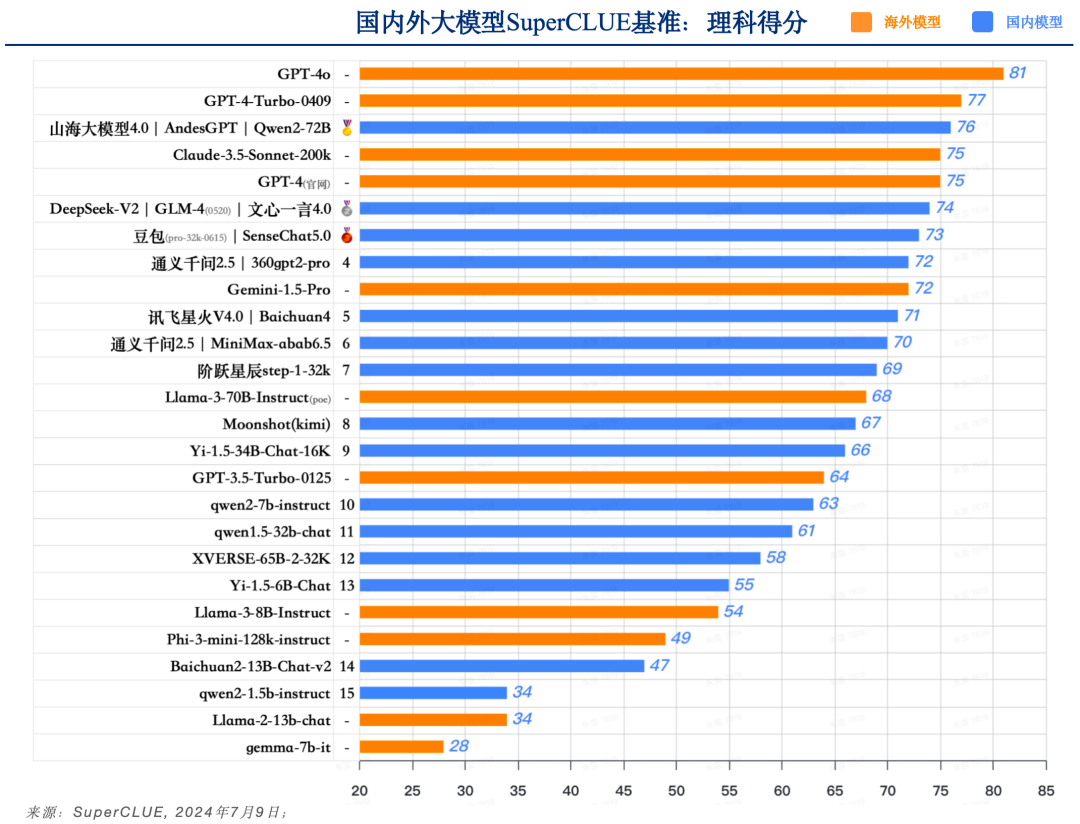
a. GPT-4o领先,国内外有一定差距
-
GPT-4o以81分的绝对优势领跑SuperCLUE基准理科测试,是全球模型中唯一超过80分的大模型。GPT-4-Turbo-0409得分77分,紧随其后。
-
国内大模型理科表现优异的模型,如Qwen2-72B、AndesGPT和山海大模型4.0稍落后于GPT-4-Turbo-0409,均取得76分的高分。但与GPT-4o还有较大差距。
b. 理科任务具有较高的挑战难度,区分度明显
-
理科任务有较高难度,我们可以发现,GPT-4o和GPT3.5-Turbo有17分的差距,Llama-3-70B比Llama-2-13B有34分的差距。
-
在国内闭源模型中,表现最高的模型(76分)和表现最差模型(58分)有18分的区分度。可见在理科任务上较能反应大模型之间的能力差距。
c. 小参数量模型在理科能力上表现不足
-
参数量较小的模型在SuperCLUE理科测评中,基本均为达到60分及格线,可见在难度较高任务上,参数量依然是影响较大的因素。
理科任务上主要包括计算、逻辑推理和代码任务,这几项将是国内外大模型在下半年重点突破的方向。
10. SuperCLUE文科测评
1)测评数据集及方法说明
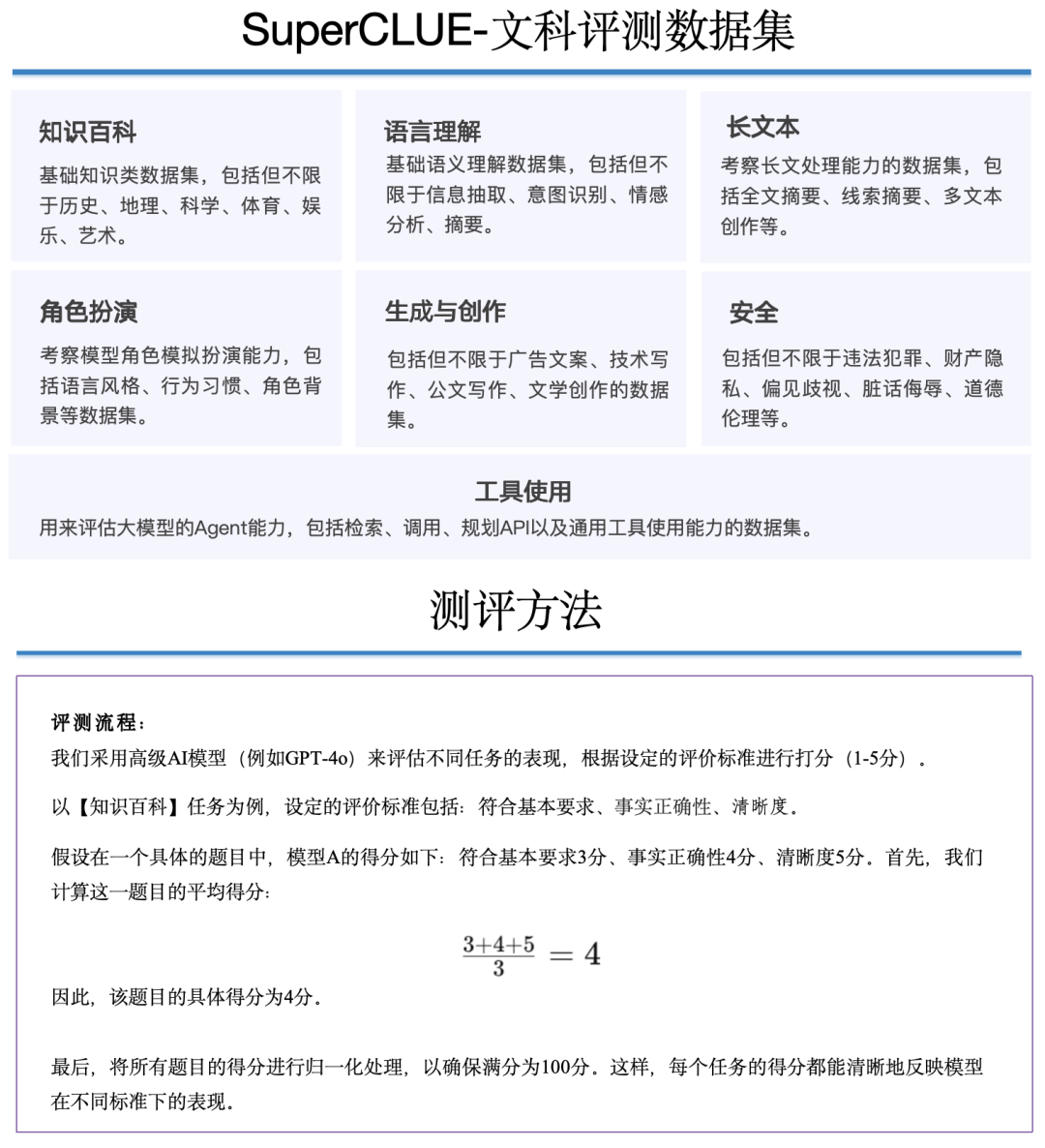

2)SuperCLUE文科成绩
a. 国内外头部模型处于同一水平,均未达到80分良好线
-
GPT-4o在文科任务上取得76分,并未超过80分,说明文科任务上实现高质量处理依然有较大提升空间。国内擅长文科的模型如Qwen2-72B、AndesGPT、通义千问2.5和 DeepSeek-V2同样取得76分,与GPT-4o处于同一水平。
-
另外国内大模型如SenseChat5.0、山海大模型4.0和360gpt2-pro取得75分,表现不俗。与GPT-4-Turbo-0409表现相当。
b. 文科任务模型间的区分度不明显,表现“中规中矩”
-
本次测评所有国内模型得分分布较为集中,没有较大的区分性,均处于及格线(60分)-良好线(80分)之间。
-
国内外闭源模型得分均处于70-80分,表现“中规中矩”,处理能力较为相似。
-
国内开源模型得分大部分处于60-70分,表现“基本可用”,但在质量上还有较大提升空间。
c. 模型参数量在文科能力上不是模型的决定性因素
-
本次测评中参数量最小的模型qwen2-1.5b(15亿参数量),依然有超过60分的表现,而qwen2-7b有超过70分的表现,与文心一言4.0表现接近。
文科任务上如何提高语言处理质量,增加内容生成和理解的优秀水平,是国内外大模型需要进一步优化的方向。
11. SuperCLUE-Hard测评
1)测评数据集及方法说明


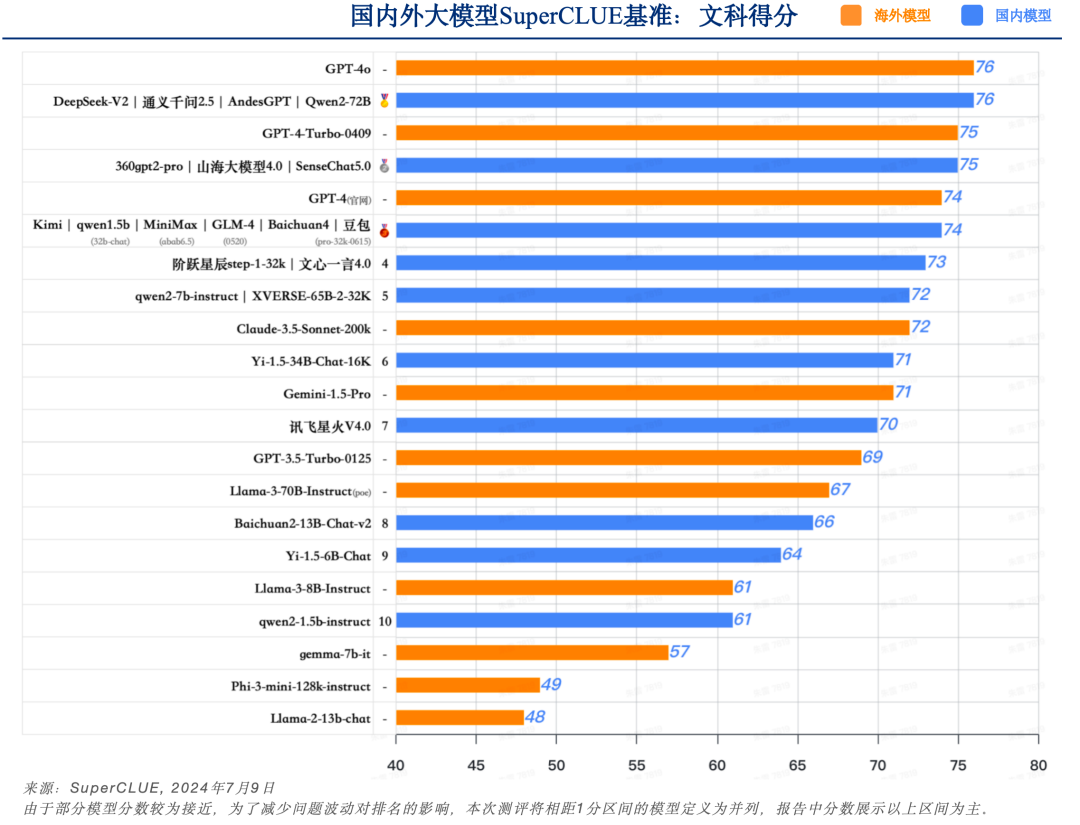
2)SuperCLUE-Hard成绩
a. 国内外模型在精确指令遵循能力上有一定差距
-
GPT-4o在Hard任务(精确指令遵循)任务上取得85分,领跑全球大模型。Claude-3.5-Sonnet-200k仅随其后取得84分,表现同样不俗。是国内外模型中唯二超过80分的大模型。
-
国内表现最好的模型是GLM-4-0520和Qwen2-72B,取得79分,较GPT-4o低6分,还有一定的提升空间。
b. 精确指令遵循有较大区分度
-
本次测评所有模型得分的差异性较大,超出80分只有2个模型,且与排名第三的模型有5分差距。
-
国内仅有4个模型超过了75分,分别为GLM-4-0520、Qwen2-72B、SenseChat5.0和DeepSeek-V2。在国内大模型中较为领先。
-
国内闭源模型中得分最低的仅有60分,这说明高难度任务可以进一步区分模型之间的能力差距。
c. 小模型普遍不擅长精确指令遵循
-
本次测评中参数量最小的开源模型qwen2-1.5b在精确指令遵循任务上仅有18分,并且小于10B的模型均为达到60分及格线,是端侧小模型后续需要重点提升的能力。
Hard任务如精确指令遵循,可以很好的考察大模型的极限能力,后续将陆续增加复杂任务高阶推理和高难度问题解决等Hard任务,会进一步发现大模型的优化方向。
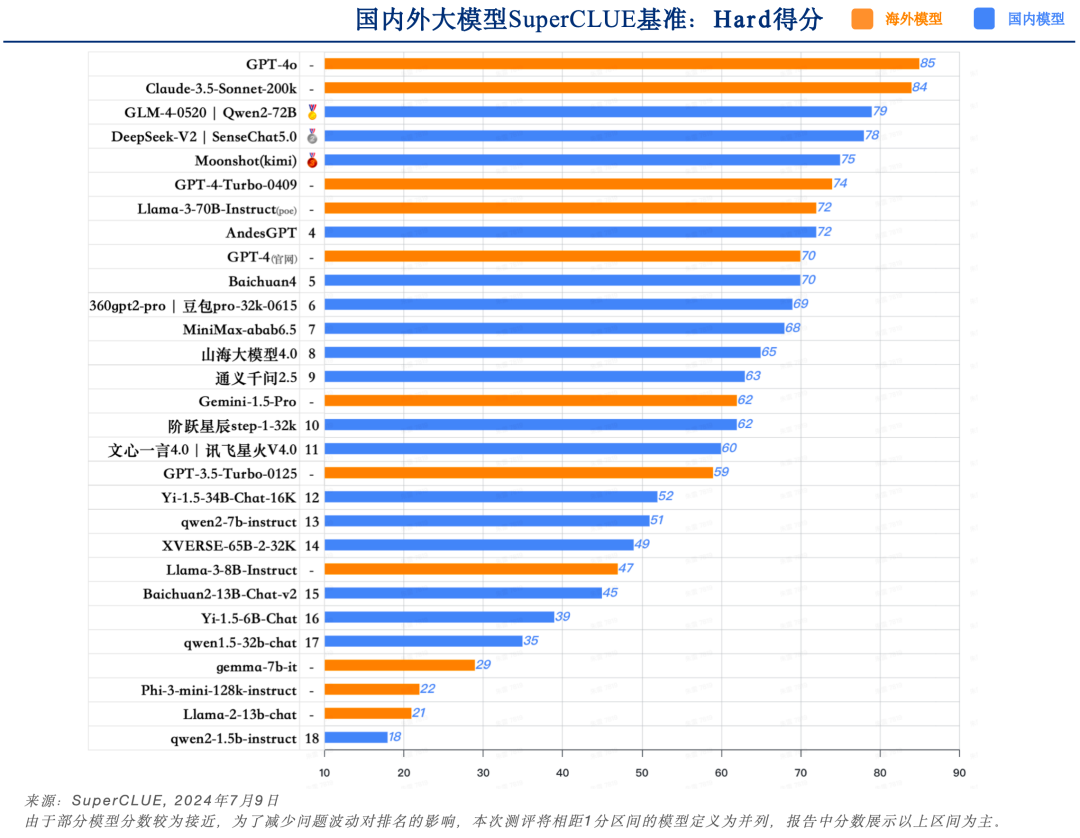
12. SuperCLUE开源榜单
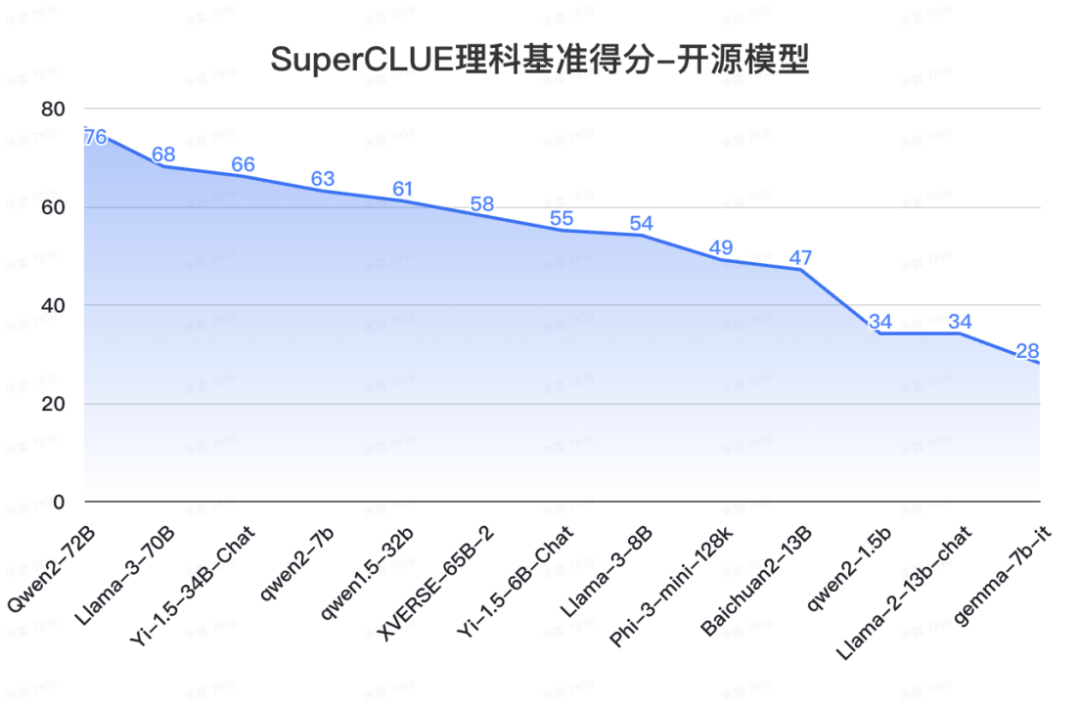
来源:SuperCLUE,2024年7月9日
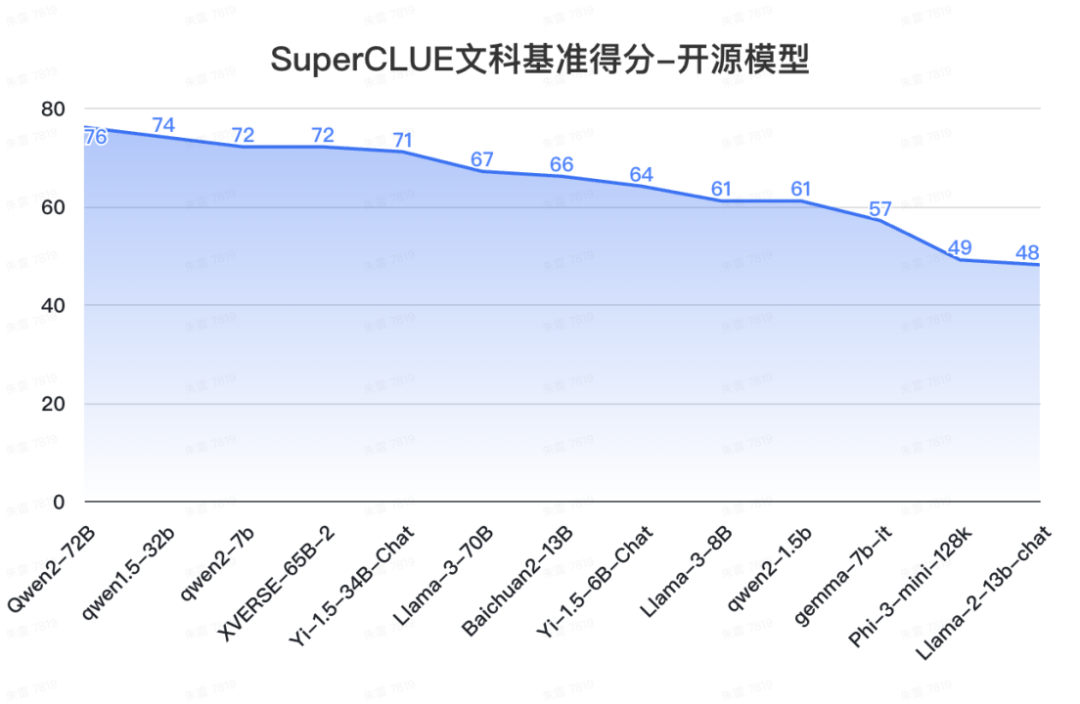
来源:SuperCLUE,2024年7月9日
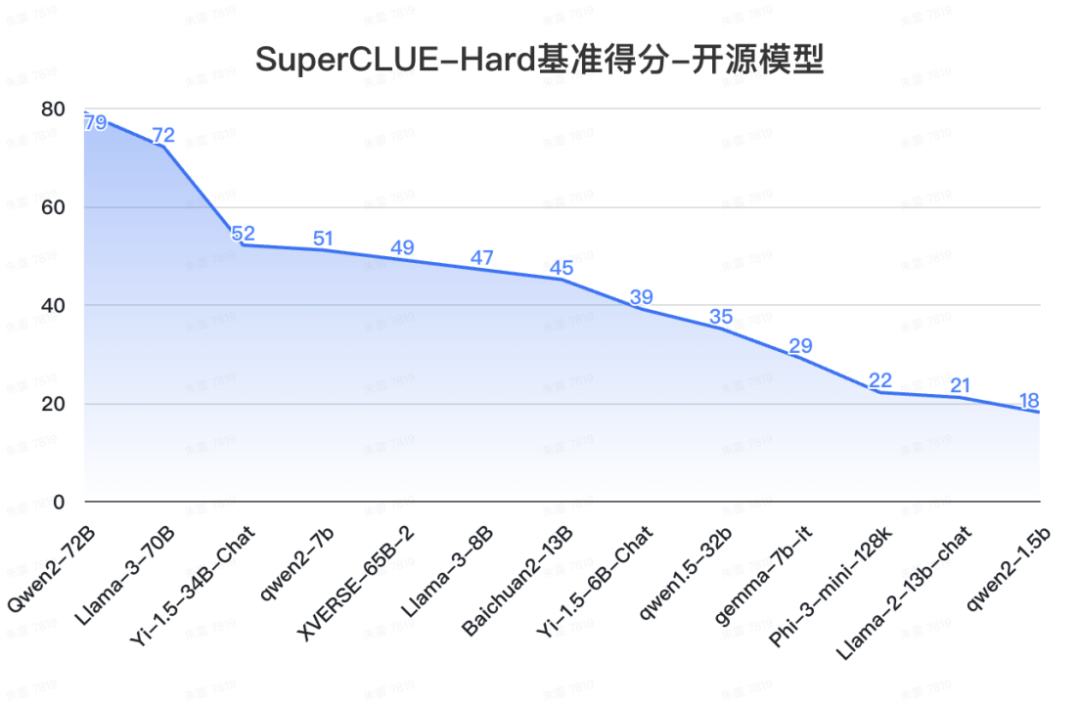
来源:SuperCLUE,2024年7月9日
a. 中文场景国内开源模型具备较强竞争力
-
Qwen2-72B领跑全球开源模型,较Llama-3-70B在中文能力上有较大领先性。
-
Yi-1.5系列模型同样有不俗的表现,其中34B版本有超过60分的表现。
-
小参数量的模型发展迅速,如qwen2-1.5b与gemma-7b表现相当。
b. 在高难度任务上,不同的开源模型区分度较大。
-
在Hard任务中,Qwen2-72B和Llama-3-70B领先幅度很大,均有超出70分的表现。其他开源模型均未达到及格线。
Hard任务如精确指令遵循,可以很好的考察大模型的极限能力,后续将陆续增加复杂任务高阶推理和高难度问题解决等Hard任务,会进一步发现大模型的优化方向。
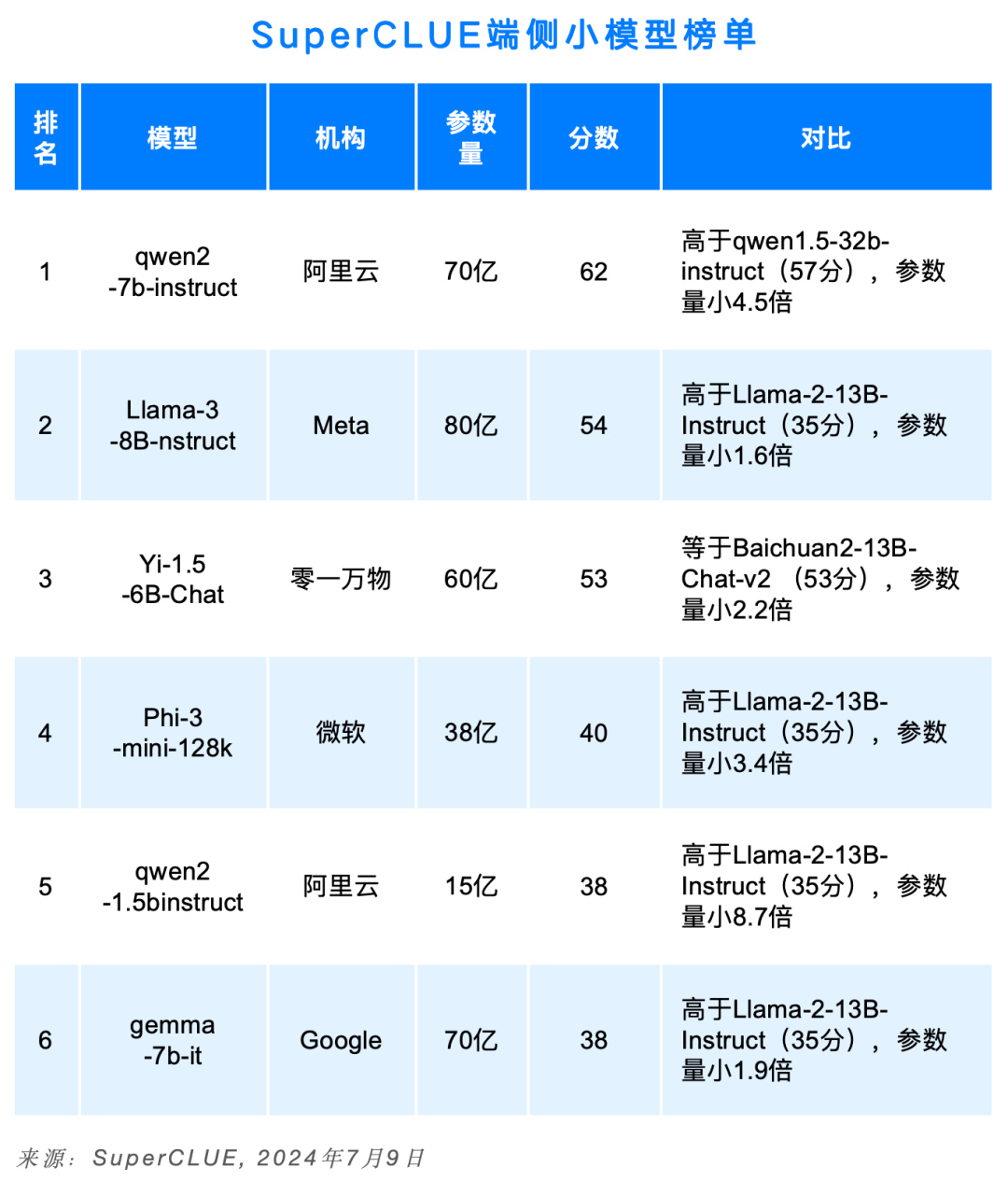
13. SuperCLUE端侧小模型榜单
2024年上半年小模型快速发展,可在设备端侧(非云)上本地运行,落地在不需要大量推理或需要快速响应的场景。
国内以qwen和Yi系列开源模型为代表,上半年进行了多次迭代。其中qwen2-7b(70亿参数)取得62分,打败了上一代版本的qwen1.5-32b(320亿参数),qwen2-1.5b(15亿参数)打败了Llama-2-13B-Instruct(130亿参数),展现了更小尺寸的模型的极致性能。
14. 大模型对战胜率分布图
我们统计了所有大模型在测评中与GPT4-Turbo-0409的对战胜率。模型在每道题上的得分与GPT4-Turbo-0409相比计算差值,得到胜(差值大于0.5分)、平(差值在-0.5~+0.5分之间)、负(差值低于-0.5)。
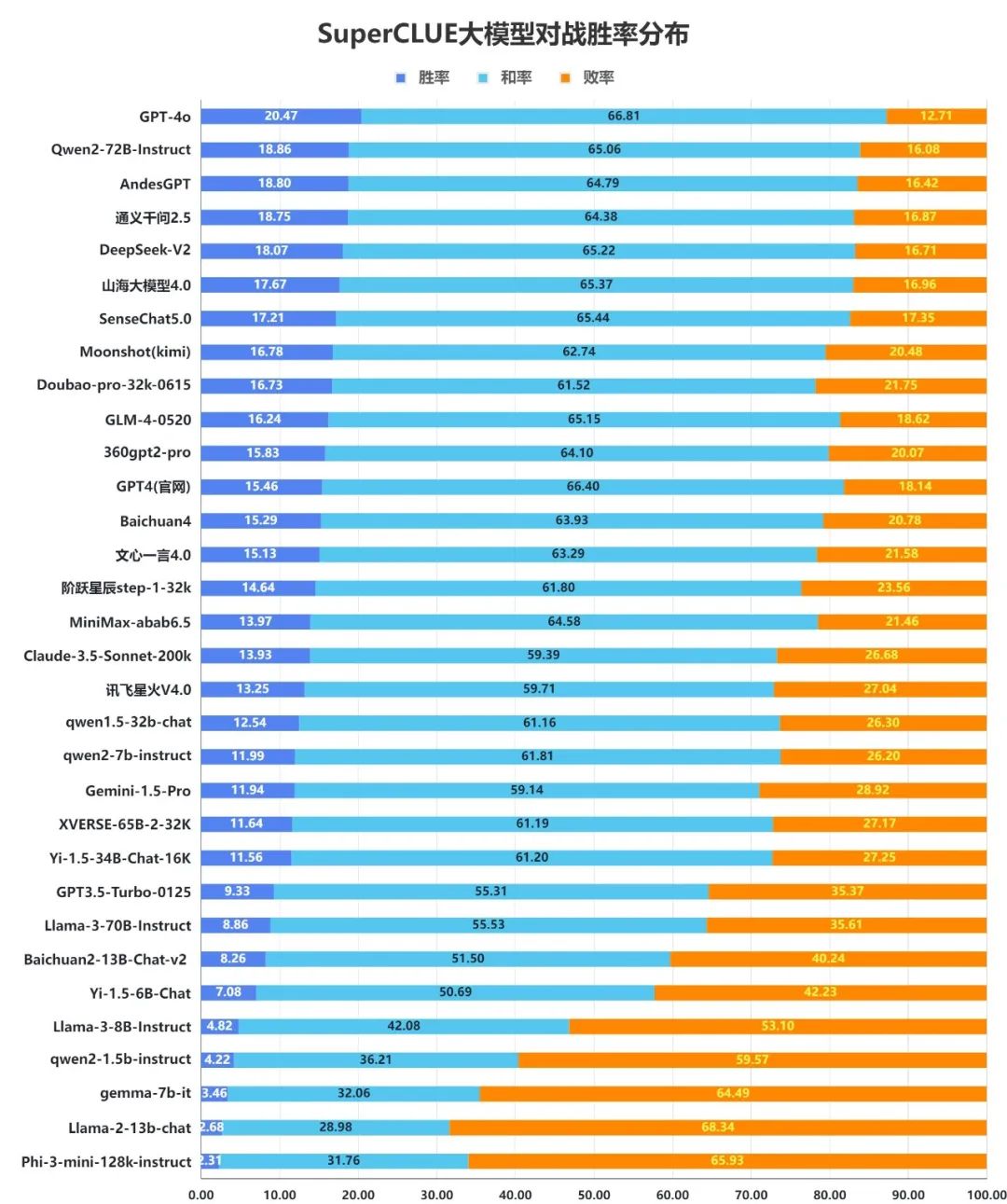
来源:SuperCLUE,2024年7月9日
1)整体胜率表现
从整体对战来看,国外领先模型GPT-4o以20.47%的胜率,66.81%的和率占据第一位,显示出其强大的整体能力。紧随其后的是Qwen2-72B-Instruct,胜率为18.86%,和率为65.06%,也展现出优于GPT4-Turbo-0409的实力。同样有着较强实力的模型还有AndesGPT、通义千问2.5、DeepSeek-V2、山海大模型4.0和SenseChat5.0等模型。
2)小模型胜率情况
在200亿以内参数的模型中qwen-2-7b的胜率排在首位,展现出不俗能力。排在2至3位的是Baichuan2-13B-Chat-v2、Yi-1.5-6B-Chat,同样有50%以上的胜和率,表现可圈可点。
3)在基础题目上与GPT-4-Turbo-0409差距有限
从胜率分布数据可以发现,大部分模型的和率都在50%以上。这说明国内外大部分模型在基础题目上与GPT-4-Turbo-0409的水平相近,随着任务难度的提升,不同模型的表现会有一定区分度。
15. SuperCLUE成熟度指数
SuperCLUE成熟度指数用以衡量国内大模型在SuperCLUE能力上是否成熟。
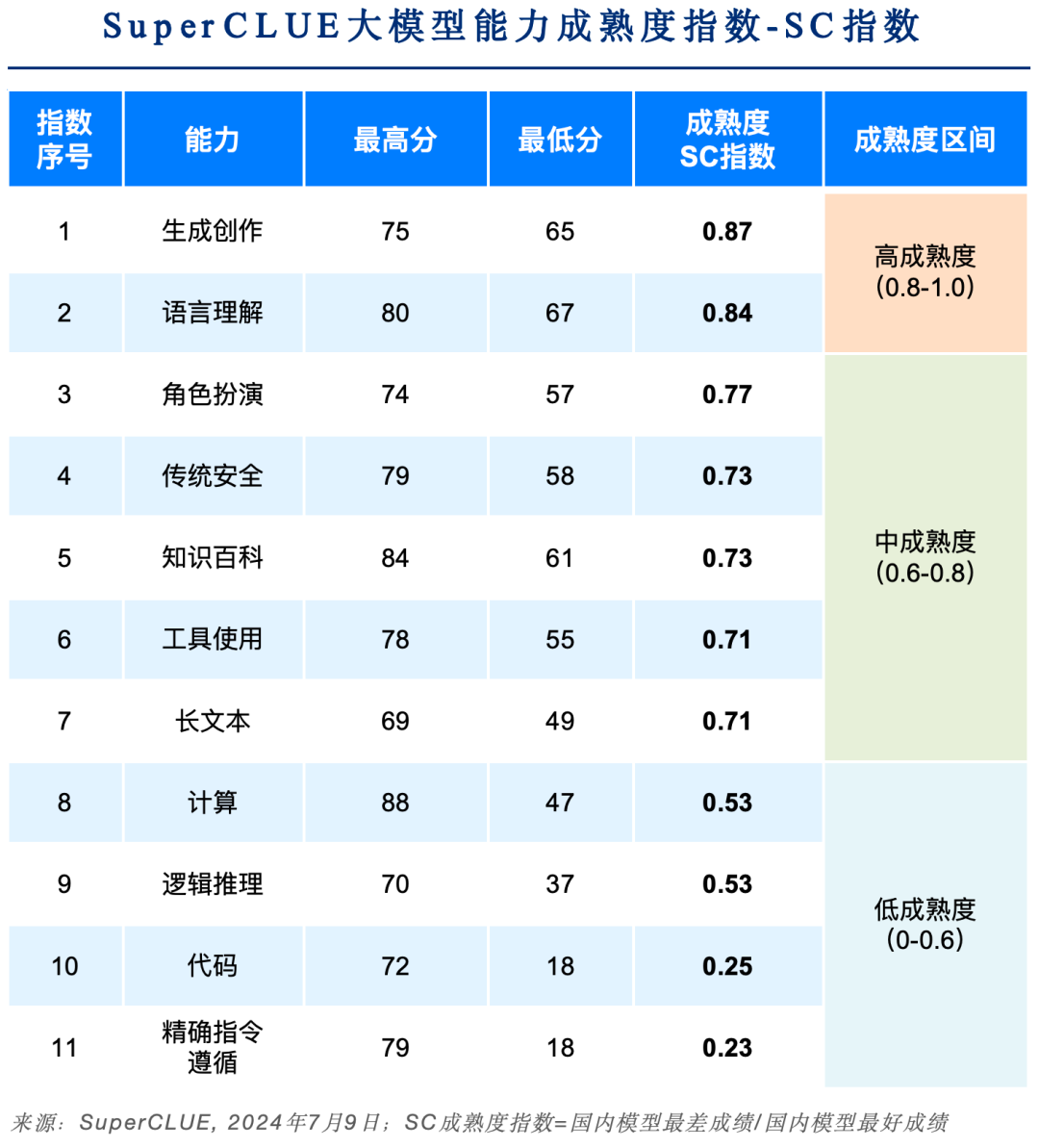
1)高成熟度能力
-
高成熟度指大部分大模型普遍擅长的能力,SC成熟度指数在0.8至1.0之间。
-
当前国内大模型成熟度较高的能力是【生成创作】和 【语言理解】,也是目前产业和用户侧大模型的重点应用场景。
2)中成熟度能力
-
中成熟度指的是不同大模型能力上有一定区分度,但不会特别大。SC成熟度指数在0.6至0.8之间。
-
当前国内大模型中成熟度的能力是【角色扮演】、【传统安全】、【知识百科】、【工具使用】、【长文本】,还有一定优化空间。
3)低成熟度能力
-
低成熟度指的是少量大模型较为擅长,很多模型无法胜任。SC成熟度指数在0.6以下。
-
当前国内大模型低成熟度的能力是【计算】、【逻辑推理】、【代码】、【精确指令遵循】。尤其在Hard任务的精确指令遵循的成熟度仅有0.23,是非常有挑战性的大模型应用能力。
16. 评测与人类一致性验证
1) SuperCLUE VS Chatbot Arena
Chatbot Arena是当前英文领域较为权威的大模型排行榜,由LMSYS Org开放组织构建, 它以公众匿名投票的方式,对各种大型语言模型进行对抗评测。其中,皮尔逊相关系数:0.90,P值:1.22e-5;斯皮尔曼相关系数:0.85,P值:1.12e-4 ;说明SuperCLUE基准测评的成绩,与人类对模型的评估(以大众匿名投票的Chatbot Arena为典型代表),具有高度一致性。
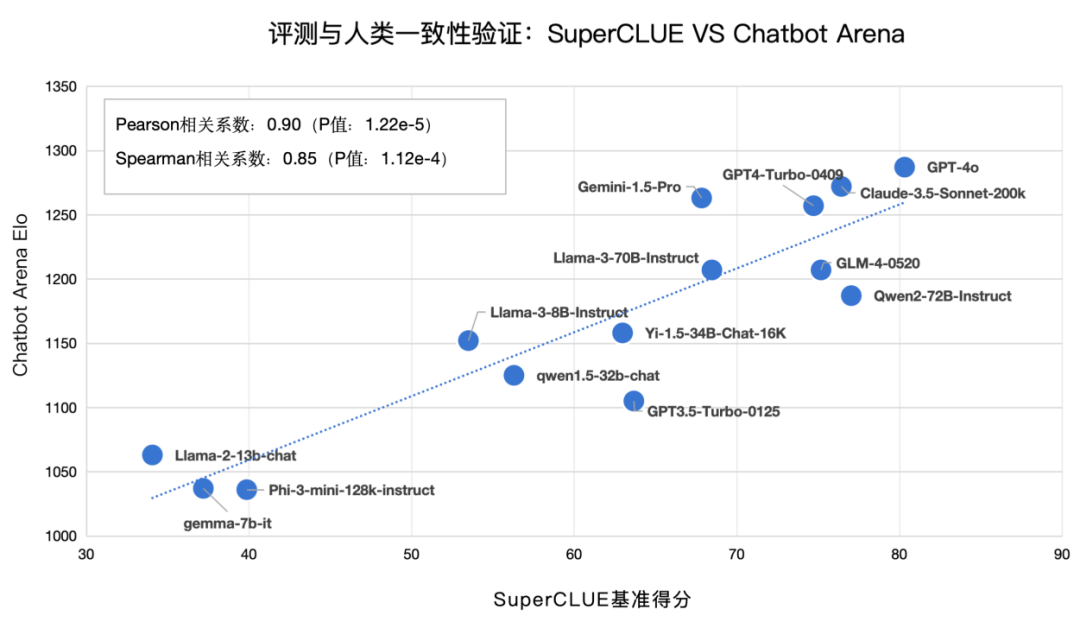
来源:SuperCLUE,2024年7月9日
2) 评测与人类一致性验证2:自动化评价可靠性的人工评估
为验证自动化评价的可靠性,SuperCLUE团队在进行正式测评之前,从2000+道题目中针对4个模型,每个模型随机抽取了100道题目进行人工复审。
审核内容及标准包括:
评价质量分为:优秀,良好 ,及格,不及格
完全不符合自己的判断:不及格(60以下)
基本符合自己的判断:及格(60或以上)或良好(75或以上)
特别符合自己的判断:评价的特别好:优秀(85或以上)
最后统计可靠性指标,将基本符合、特别符合的结果认定为是可靠性较高的评价。
最终各模型可靠性指标结果如下:

通过4个模型的可靠性分析验证,我们发现可靠性数据分别为91%、90%、99%、90%,其中可靠性最低有90%,最高为模型的99.00%。平均有92.5%的可靠性。
所以,经过验证,SuperCLUE自动化评价有较高的可靠性。
多模态测评、行业、专项测评、优秀案例介绍以及更详细测评数据分析,请查看完整PDF报告。
点击文章底部【阅读原文】查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_24h1
未来两个月基准发布计划
未来2-3个月SuperCLUE会持续完善大模型专项能力及行业能力的测评基准。现针对于所有专项及行业测评基准征集大模型,欢迎申请。有意愿参与测评的厂商可发送邮件至contact@superclue.ai,标题:SuperCLUE专项/行业测评,请使用单位邮箱,邮件内容包括:单位信息、大模型简介、联系人和所属部门、联系方式。
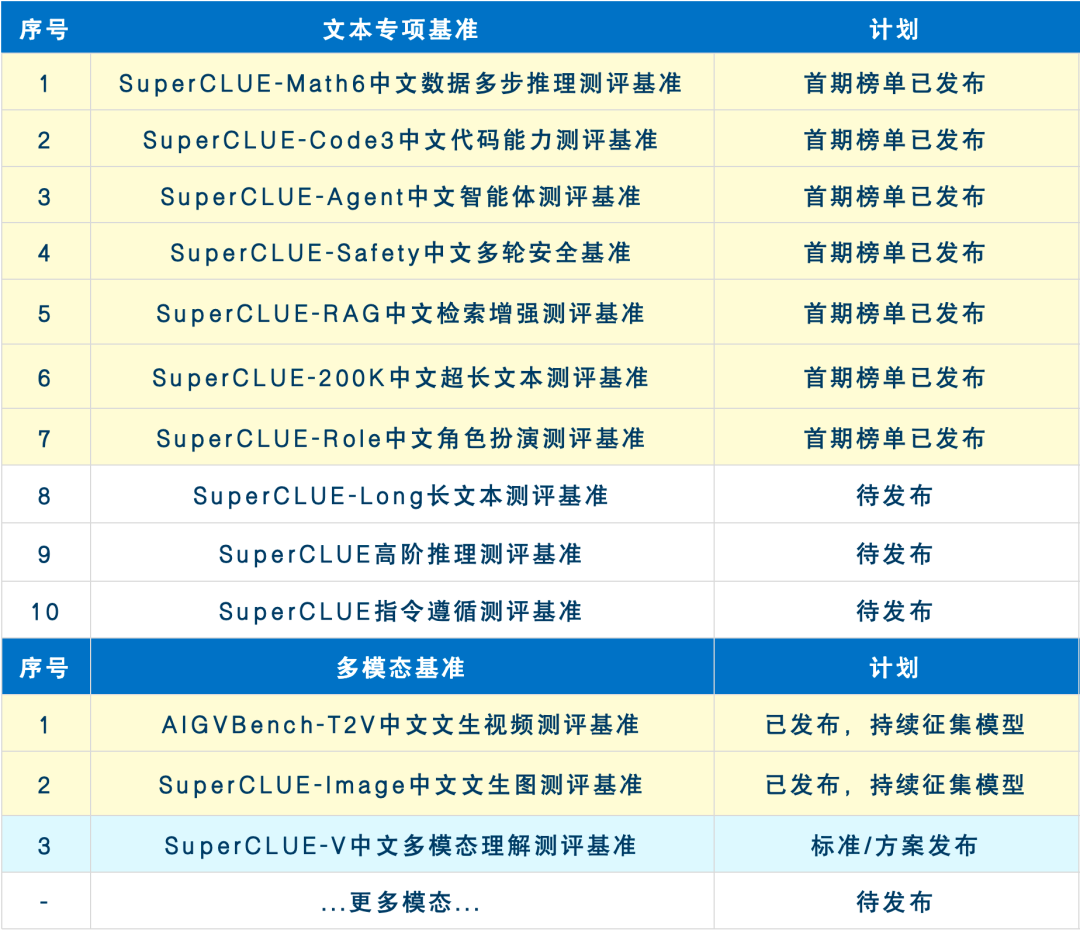
预告:SuperCLUE通用基准测评8月报告将在2024年8月27日发布,欢迎反馈意见、参与测评。
欢迎加入【2024上半年报告】交流群。


扩展阅读

[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE
[4] 在线报告地址:www.cluebenchmarks.com/superclue_24h1
相关文章:
中文大模型基准测评2024上半年报告
中文大模型基准测评2024上半年报告 原创 SuperCLUE CLUE中文语言理解测评基准 2024年07月09日 18:09 浙江 SuperCLUE团队 2024/07 背景 自2023年以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。进入2024年,全球大模型竞争态势日益加…...

新火种AI|OpenAI的CEO又有新动作?这次他成立了AI健康公司
作者:一号 编辑:美美 AI技术即将改变医疗健康市场。 就在前两天,人工智能和医疗健康领域迎来了一个重要时刻。OpenAI的CEO萨姆阿尔特曼(Sam Altman)与Thrive Global的CEO阿里安娜赫芬顿(Arianna Huffing…...

中介子方程五十
XXFXXaXnXaXXαXLXyXXWXuXeXKXXiXyXΣXXΣXXVXuXhXXWXηXXiXhXXpXXhXiXXηXWXXhXuXVXXΣXXΣXyXiXXKXeXuXWXXyXLXαXXaXnXaXXFXXaXnXaXXαXLXyXXWXuXeXKXXiXyXΣXXΣXXVXuXhXXWXηXXiXhXXpXXhXiXXηXWXXhXuXVXXΣXXΣXyXiXXKXeXuXWXXyXLXαXXaXnXaXXFXXuXXWXXuXXdXXrXXαXXuXpX…...

如何借助社交媒体影响者的力量,让品牌影响力倍增?
一、引言:为何社交媒体影响者如此关键? 在信息爆炸的今天,社交媒体已成为塑造消费者行为与品牌认知的重要渠道。社交媒体影响者,凭借其在特定领域的专业知识、庞大的粉丝基础及高度的互动性,成为了品牌传播不可忽视的…...

Python面试题:Python 中的 `property` 函数有什么用?
在 Python 中,property 函数用于创建和管理类中的属性。它允许你将方法转换为属性,这样你可以像访问变量一样访问这些方法。这对于控制属性的访问和修改非常有用,因为它允许你在属性访问时执行额外的逻辑(如验证或计算)…...
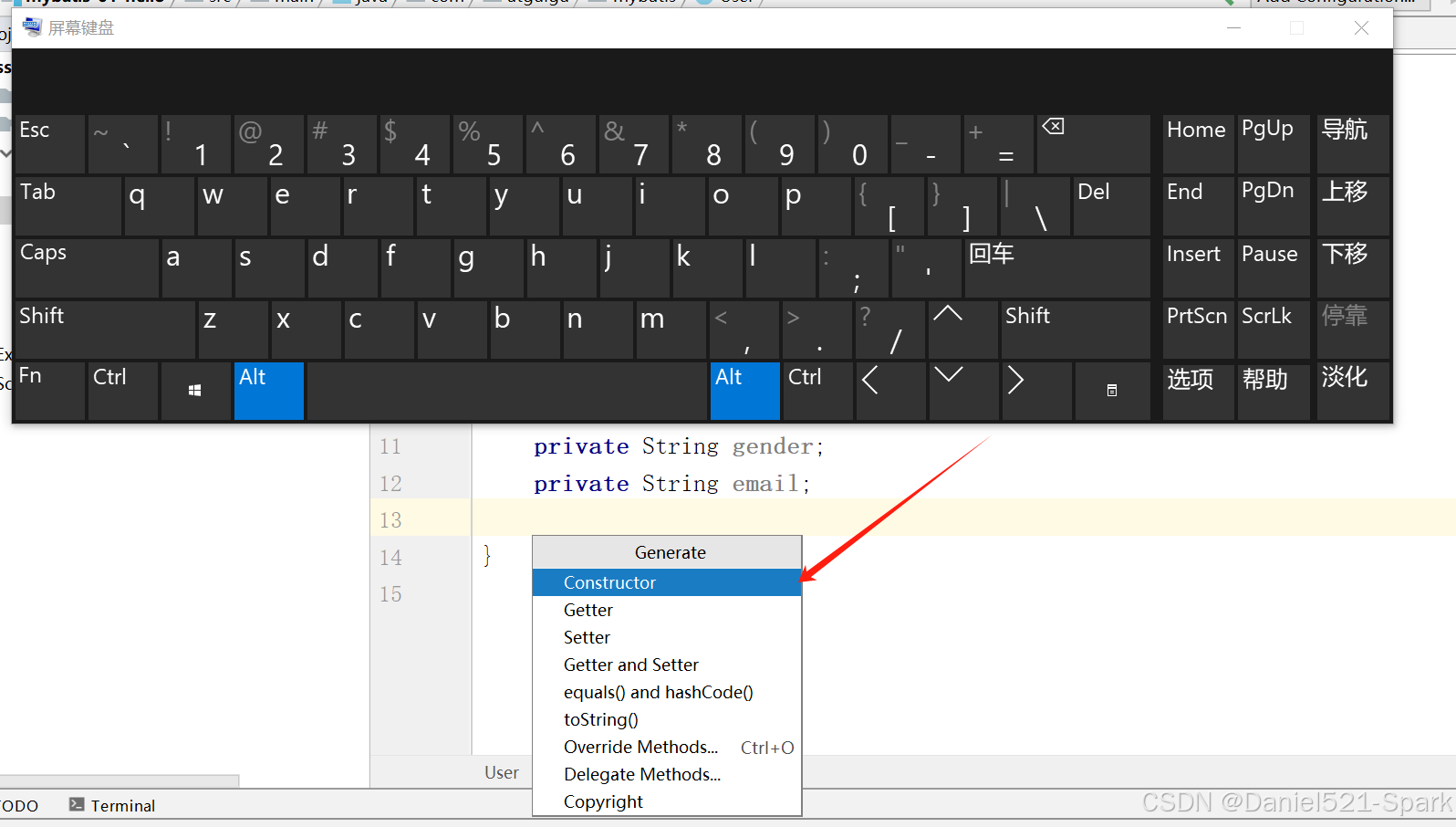
十五、小型电脑没有数字键及insert,怎么解决IDEA快速插入getset构造这些方法
🌻🌻目录 一、小型电脑没有数字键及insert,怎么解决IDEA快速插入getset构造这些方法 一、小型电脑没有数字键及insert,怎么解决IDEA快速插入getset构造这些方法 解决: 1.winR打开搜索 2.osk回车 屏幕就出现了这样的一…...
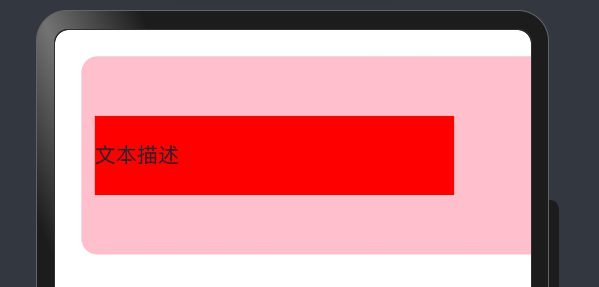
【鸿蒙学习笔记】属性学习迭代笔记
这里写目录标题 TextImageColumnRow Text Entry Component struct PracExample {build() {Row() {Text(文本描述).fontSize(40)// 字体大小.fontWeight(FontWeight.Bold)// 加粗.fontColor(Color.Blue)// 字体颜色.backgroundColor(Color.Red)// 背景颜色.width(50%)// 组件宽…...

工具推荐:滴答清单
官网地址:DIDA:Todo list, checklist and task manager app for Android, iPhone and Web 使用近一个月,特别方便,使用感受非常棒,功能全面。 我主要用了以下功能: 1、每日事项提醒:写作,背字…...
阶段三:项目开发---大数据开发运行环境搭建:任务4:安装配置Spark集群
任务描述 知识点:安装配置Spark 重 点: 安装配置Spark 难 点:无 内 容: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop …...

SDIO CMD 数据部分 CRC 计算规则
使用的在线 crc 计算工具网址:http://www.ip33.com/crc.html CMD CRC7 计算 如下图为使用逻辑分析仪获取的SDIO读写SD卡时,CMD16指令发送的格式,通过逻辑分析仪总线分析,可以看到,该部分的CRC7校验值得0x05,大多数情况…...

每日一编程,早点拿offer
计算字符串最后一个单词的长度,单词以空格隔开 输入描述: 输入一行,代表要计算的字符串,非空 输出描述: 输出一个整数,表示输入字符串最后一个单词的长度。 输入:hello world输出:…...

https创建证书
需要下载httpd模块:yum install httpd -y 前提需要先搭建一个虚拟主机来测试证书创建的效果,以下面www.hehe.com为例,可以参考创建: [rootlocalhost conf.d]# vim vhost.conf <directory /www> allowoverride none requi…...

C++ 是否变得比 C 更流行了?
每年都会出现一种新的编程语言。创造一种新语言来解决计算机科学中的挑战的诱惑很难抗拒。一些资料表明,目前有多达 2,500 种语言,这并不奇怪! 对于我们嵌入式软件开发人员来说,这个列表并不长。事实上,我们可以用一只…...

Redis-Jedis连接池\RedisTemplate\StringRedisTemplate
Redis-Jedis连接池\RedisTemplate\StringRedisTemplate 1. Jedis连接池1.1 通过工具类1.1.1 连接池:JedisConnectionFactory:1.1.2 test:(代码其实只有连接池那里改变了) 2. SpringDataRedis(lettuce&#…...

Obsidian 文档编辑器
Obsidian是一款功能强大的笔记软件 Download - Obsidian...

Spring Boot项目中JPA操作视图会改变原表吗?
一直有一种认识就是:使用JPA对视图操作,不会影响到原表。 直观的原因就是视图是一种数据库中的虚拟表,它由一个或多个表中的数据通过SQL查询组成。视图不包含数据本身,而是保存了一条SQL查询,这条查询是用来展示数据的。 但是在实际项目种的一个场景颠覆和纠正了这个认识…...

C++之goto陈述
关键字 goto用于控制程式执行的顺序,使程式直接跳到指定标签(lable) 的地方继续执行。 形式如下 标签可以是任意的识别字,后面接一个冒号。 举例如下 #include <iostream>int main() {goto label_one;label_one: {std::cout << "Lab…...

ChatGPT提问提示指南PDF下载经典分享推荐书籍
ChatGPT提问提示指南PDF,在本书的帮助下,您将学习到如何有效地向 ChatGPT 提出问题,以获得更准确和有用的回答。我们希望这本书能够为您提供实用的指南和策略,帮助您更好地与 ChatGPT 交互。 ChatGPT提问提示指南PDF下载 无论您是…...
云原生架构与实例部署)
架构设计(2)云原生架构与实例部署
云原生架构 云原生架构是一种面向云环境设计和构建应用程序的方法论,旨在充分利用云计算的优势,如弹性、自动化和可扩展性,以实现更高效、可靠和灵活的应用部署和管理。以下是云原生架构的核心理念和关键特点: 核心理念…...

《UDS协议从入门到精通》系列——图解0x84:安全数据传输
《UDS协议从入门到精通》系列——图解0x84:安全数据传输 一、简介二、数据包格式2.1 服务请求格式2.2 服务响应格式2.2.1 肯定响应2.2.2 否定响应 Tip📌:本文描述中但凡涉及到其他UDS服务的,均提供专栏内文章链接跳转方式以便快速…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...