目标检测经典模型之YOLOV5-detect.py源码解析(持续更新)
detect文件框架
- 一、导入模块包
- 二、定义run函数
- 1. 归一化操作
- 代码解析
- uint8
- 精度转换
- 归一化
- 2. 扩展维度
- 为什么扩展维度?
- 代码解释
- 3. 对检测结果类别计数
- 检查是否有检测结果
- 统计每个类别的出现次数
- 构建描述性字符串
- 三、定义命令行参数
- 四、主函数
本帖是YOLOV5推理部分代码的中文逐行注释。由于AI注释的缘故,可能与源码会有小部分出入,所以不建议复制粘贴替换源码的detect.py文件。本贴的初衷是YOLOV5源码逻辑的学习,后续会不断修正该代码和加入新的注释。
一、导入模块包
import argparse # 引入argparse库,用于解析命令行参数
import os # 引入os库,用于进行操作系统相关的操作
import platform # 引入platform库,用于获取平台信息
import sys # 引入sys库,用于操作Python运行时环境
from pathlib import Path # 引入Path库,用于处理文件和目录路径import cv2 # 引入OpenCV库,用于图像处理
import torch # 引入PyTorch库,用于深度学习
FILE = Path(__file__).resolve() # 获取当前文件的绝对路径
ROOT = FILE.parents[0] # 获取当前文件的父目录路径if str(ROOT) not in sys.path: # 如果当前文件的父目录路径不在系统路径中sys.path.append(str(ROOT)) # 将当前文件的父目录路径添加到系统路径中ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # 将ROOT路径相对于当前工作目录进行转换from ultralytics.utils.plotting import Annotator, colors, save_one_box
from models.common import DetectMultiBackend # 从models.common模块中导入DetectMultiBackend类
from utils.dataloaders import LoadImages, LoadStreams # 从utils.dataloaders模块中导入LoadImages和LoadStreams类
from utils.general import ( # 从utils.general模块中导入多个函数和类LOGGER,Profile,check_file,check_img_size,check_imshow,check_requirements,colorstr,cv2,increment_path,non_max_suppression,print_args,scale_boxes,strip_optimizer,xyxy2xywh,
)
from utils.torch_utils import select_device, smart_inference_mode # 从utils.torch_utils模块中导入select_device和time_sync和smart_inference_mode函数
二、定义run函数
@smart_inference_mode()
def run(weights='yolov5s.pt', # 模型权重文件路径,默认值为'yolov5s.pt'source='data/images', # 输入源,可以是文件、目录、URL或摄像头,默认值为'data/images'data='data/coco128.yaml', # 数据集配置文件路径,默认值为'data/coco128.yaml'imgsz=640, # 输入图像尺寸,默认值为640conf_thres=0.25, # 置信度阈值,默认值为0.25iou_thres=0.45, # 非极大值抑制的IoU阈值,默认值为0.45max_det=1000, # 每张图像的最大检测数量,默认值为1000device='', # 使用的设备,可以是'cpu'或'cuda:0',默认值为''view_img=False, # 是否显示检测结果,默认值为Falsesave_txt=False, # 是否将检测结果保存到文本文件,默认值为Falsesave_conf=False, # 是否保存置信度,默认值为Falsesave_crop=False, # 是否保存裁剪后的检测框,默认值为Falsenosave=False, # 是否保存图像/视频,默认值为Falseclasses=None, # 按类别过滤,例如0或0 2 3,默认值为Noneagnostic_nms=False, # 是否使用类别无关的NMS,默认值为Falseaugment=False, # 是否使用增强推理,默认值为Falsevisualize=False, # 是否可视化特征,默认值为Falseupdate=False, # 是否更新所有模型,默认值为Falseproject='runs/detect', # 保存结果的项目路径,默认值为'runs/detect'name='exp', # 保存结果的文件夹名称,默认值为'exp'exist_ok=False, # 是否允许现有项目名称,默认值为Falseline_thickness=3, # 边界框的厚度(像素),默认值为3hide_labels=False, # 是否隐藏标签,默认值为Falsehide_conf=False, # 是否隐藏置信度,默认值为Falsehalf=False, # 是否使用FP16半精度推理,默认值为Falsednn=False, # 是否使用OpenCV DNN进行ONNX推理,默认值为Falsevid_stride=1, # 视频帧率步幅,默认值为1
):# 将source变量转换为字符串source = str(source)# 判断是否需要保存推理后的图像,除非指定了--nosave或source是文本文件save_img = not nosave and not source.endswith(".txt") # 判断source是否是一个图像或视频文件is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)# 判断source是否是一个网络链接is_url = source.lower().startswith(("rtsp://", "rtmp://", "http://", "https://"))# 判断source是否是一个网络摄像头流或屏幕截图指令或一个有效的URLwebcam = source.isnumeric() or source.endswith(".streams") or (is_url and not is_file)# 判断source是否是一个屏幕截图指令screenshot = source.lower().startswith("screen")# 如果source是一个有效的URL并且指向一个文件,下载这个文件if is_url and is_file:source = check_file(source) # 创建保存结果的目录,如果存在则覆盖或增量命名save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # 创建用于保存标签的子目录(save_dir / "labels" if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # 加载模型并选择设备(CPU或GPU)device = select_device(device)model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)# 获取模型的步幅、类别名以及模型是否是PyTorch模型stride, names, pt = model.stride, model.names, model.pt# 检查并调整图像尺寸以适应模型的步幅imgsz = check_img_size(imgsz, s=stride) # 设置batch_size为1,因为通常推理是单张图像进行bs = 1 # 根据source类型选择数据加载方式if webcam:# 对于网络摄像头流,检查是否可以显示图像view_img = check_imshow(warn=True)# 加载网络摄像头流数据dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)# 确定batch_sizebs = len(dataset)elif screenshot:# 加载屏幕截图数据dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)else:# 加载普通图像或视频数据dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)# 初始化视频路径和视频写入器列表vid_path, vid_writer = [None] * bs, [None] * bs# 模型预热model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # 初始化计数器和时间记录器seen, windows, dt = 0, [], (Profile(device=device), Profile(device=device), Profile(device=device))# 遍历数据集中的每一张图片for path, im, im0s, vid_cap, s in dataset:# 测量预处理时间with dt[0]:# 将图像转换为Tensor并移至适当设备im = torch.from_numpy(im).to(model.device)# 调整数据类型和归一化im = im.half() if model.fp16 else im.float() im /= 255 # 扩展维度以匹配batch_sizeif len(im.shape) == 3:im = im[None] # 如果模型是XML格式且batch_size大于1,将图像拆分为多个部分if model.xml and im.shape[0] > 1:ims = torch.chunk(im, im.shape[0], 0)# 执行推理with dt[1]:# 可视化模式,保存可视化结果visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False# 如果模型是XML格式且batch_size大于1,逐个执行推理if model.xml and im.shape[0] > 1:pred = Nonefor image in ims:if pred is None:pred = model(image, augment=augment, visualize=visualize).unsqueeze(0)else:pred = torch.cat((pred, model(image, augment=augment, visualize=visualize).unsqueeze(0)), dim=0)pred = [pred, None]# 否则直接执行推理else:pred = model(im, augment=augment, visualize=visualize)# 进行非最大值抑制with dt[2]:pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)# 定义CSV文件路径csv_path = save_dir / "predictions.csv"# 定义函数将预测数据写入CSV文件def write_to_csv(image_name, prediction, confidence):"""将预测数据写入CSV文件,如果文件不存在则创建新文件。"""data = {"Image Name": image_name, "Prediction": prediction, "Confidence": confidence}with open(csv_path, mode="a", newline="") as f:writer = csv.DictWriter(f, fieldnames=data.keys())if not csv_path.is_file():writer.writeheader()writer.writerow(data)# 处理预测结果for i, det in enumerate(pred): # 遍历每一张图片的预测结果seen += 1 # 增加已处理图片的数量# 如果是网络摄像头流,获取路径、原始图像和帧号if webcam: p, im0, frame = path[i], im0s[i].copy(), dataset.counts += f"{i}: " else:p, im0, frame = path, im0s.copy(), getattr(dataset, "frame", 0)# 将路径转换为Path对象p = Path(p) # 构建保存图像的路径save_path = str(save_dir / p.name) # 构建保存标签的路径txt_path = str(save_dir / "labels" / p.stem) + ("" if dataset.mode == "image" else f"_{frame}")# 更新打印字符串s += "%gx%g " % im.shape[2:] # 计算归一化增益gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # 为保存裁剪图像复制原始图像imc = im0.copy() if save_crop else im0 # 创建Annotator对象用于在图像上绘制annotator = Annotator(im0, line_width=line_thickness, example=str(names))# 如果有检测结果if len(det):# 对每个类别进行计数for c in det[:, 5].unique():n = (det[:, 5] == c).sum() s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # 写入预测结果到CSV文件if save_csv:write_to_csv(p.name, label, confidence_str)# 将检测框坐标从模型输出大小缩放回原图大小det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()# 将检测结果写入文件或在图像上绘制for *xyxy, conf, cls in reversed(det):c = int(cls) # 整数类别label = names[c] if hide_conf else f"{names[c]}" confidence = float(conf)confidence_str = f"{confidence:.2f}"# 如果需要保存CSV文件,写入数据if save_csv:write_to_csv(p.name, label, confidence_str)# 如果需要保存文本标签文件,写入数据if save_txt: xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() line = (cls, *xywh, conf) if save_conf else (cls, *xywh) with open(f"{txt_path}.txt", "a") as f:f.write(("%g " * len(line)).rstrip() % line + "\n")# 如果需要保存图像或裁剪图像或显示图像,在图像上绘制边界框if save_img or save_crop or view_img: c = int(cls) label = None if hide_labels else (names[c] if hide_conf else f"{names[c]} {conf:.2f}")annotator.box_label(xyxy, label, color=colors(c, True))# 如果需要保存裁剪图像,保存裁剪的检测框if save_crop:save_one_box(xyxy, imc, file=save_dir / "crops" / names[c] / f"{p.stem}.jpg", BGR=True)# 绘制结果im0 = annotator.result()# 如果需要显示图像,在窗口中显示if view_img:if platform.system() == "Linux" and p not in windows:windows.append(p)cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])cv2.imshow(str(p), im0)cv2.waitKey(1) # 如果需要保存图像,保存结果if save_img:if dataset.mode == "image":cv2.imwrite(save_path, im0)else: if vid_path[i] != save_path: vid_path[i] = save_pathif isinstance(vid_writer[i], cv2.VideoWriter):vid_writer[i].release() if vid_cap: fps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))else: fps, w, h = 30, im0.shape[1], im0.shape[0]save_path = str(Path(save_path).with_suffix(".mp4")) vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))vid_writer[i].write(im0)# 输出单张图像的推理时间LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")# 输出整体速度统计t = tuple(x.t / seen * 1e3 for x in dt) LOGGER.info(f"Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}")# 输出保存结果的信息if save_txt or save_img:s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ""LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")# 如果有模型更新,清理优化器if update:strip_optimizer(weights[0])
1. 归一化操作
# 遍历数据集中的每一张图片for path, im, im0s, vid_cap, s in dataset:# 测量预处理时间with dt[0]:# 将图像转换为Tensor并移至适当设备im = torch.from_numpy(im).to(model.device)# 调整数据类型和归一化im = im.half() if model.fp16 else im.float() im /= 255
这段代码是针对深度学习模型输入预处理的一部分,特别是在使用PyTorch框架时。这里是针对YOLOv5或类似的模型,它说明了如何将输入图像从uint8格式转换为适合模型输入的格式,即fp16(半精度浮点数,16位)或fp32(单精度浮点数,32位)。
代码解析
uint8
uint8类型用于数字图像时,每个像素的颜色通道(如红、绿、蓝)通常使用uint8类型表示,每个通道的值范围从0(黑色)到255(最饱和的颜色)。
精度转换
im = im.half() if model.fp16 else im.float()
这段代码检查模型是否支持半精度(fp16)计算。如果model.fp16为True,则im.half()将图像张量从uint8转换为fp16(半精度浮点数)。如果model.fp16为False,则im.float()将图像张量转换为fp32(单精度浮点数)。
注意:uint8到fp16或fp32的转换是隐式的,即当从uint8类型转换到浮点类型时,原本的整数值会被转换为相应的浮点数值,但不会改变其数值大小。例如,uint8的255在转换为fp32后仍然是255.0。
归一化
im /= 255 # 0 - 255 to 0.0 - 1.0
这行代码将图像张量的像素值从uint8的0到255范围归一化到fp16或fp32的0.0到1.0之间。这是深度学习模型输入预处理中常见的一步,帮助模型在训练和推断时获得更好的数值稳定性,同时使不同亮度和对比度的图像在模型眼中更加“平等”。
这段代码的关键在于它确保了输入图像被适当地格式化和归一化,以供模型进行有效处理。模型是否使用半精度计算取决于模型自身的配置(model.fp16),这通常在模型训练时为了提高计算效率和减少内存使用而设定。归一化步骤则是深度学习图像处理中普遍采用的预处理步骤,确保模型输入的一致性和数值稳定性。
2. 扩展维度
# 扩展维度以匹配batch_size
if len(im.shape) == 3:im = im[None]
在深度学习中,尤其是使用卷积神经网络(CNN)进行图像处理时,通常需要处理的是一批图像而非单一图像。这是因为现代GPU架构设计为并行处理大量数据,处理一批图像比一次处理一张图像更有效率。因此,即使输入的是单张图像,也需要将其形状转换为适用于模型的批次输入格式。
为什么扩展维度?
当你的图像数据im的形状是三维的(例如,形状为(height, width, channels)),这意味着你只有一个图像。然而,大多数深度学习框架和模型期望输入数据的形状至少是四维的,即(batch_size, height, width, channels)(对于TensorFlow)或(batch_size, channels, height, width)(对于PyTorch)。
在YOLOv5的情况下,模型预期的输入是四维的,即 (batch_size, channels, height, width)。因此,如果你的im是一个单独的图像,它的形状会是 (channels, height, width),需要在前面增加一个维度来代表batch_size,这样形状就会变成 (1, channels, height, width)。这就是为什么使用im = im[None]来扩展维度,None在这里等价于np.newaxis,它会在数组中插入一个新的轴。
代码解释
if len(im.shape) == 3:im = im[None] # 扩展维度,使形状从 (channels, height, width) 变为 (1, channels, height, width)
这条语句检查im的形状,如果它只有三个维度,那么就使用None来扩展其第一个维度,从而匹配模型期望的输入形状。扩展维度是为了将单张图像转换为批次格式,以便模型能够正确处理。这是深度学习实践中一个常见的预处理步骤,尤其在使用CNN进行图像处理时。
3. 对检测结果类别计数
# 如果有检测结果if len(det):# 对每个类别进行计数for c in det[:, 5].unique():n = (det[:, 5] == c).sum() s += f"{n} {names[int(c)]}{'s' * (n > 1)}, "
这段代码是在处理YOLOv5模型输出的检测结果时,用于统计每个类别出现的次数,并生成一个描述性的字符串,用于后续的日志记录或输出。让我们逐步分解这段代码:
检查是否有检测结果
if len(det):
det是一个二维张量,包含了所有检测到的对象的信息,每一行代表一个检测到的对象,列中包含位置信息(如边界框坐标)、类别ID和置信度得分。如果det非空(即有检测结果),则执行以下操作。
统计每个类别的出现次数
for c in det[:, 5].unique():n = (det[:, 5] == c).sum()
det[:, 5]访问的是检测结果中每一行的第6个元素(索引为5,因为Python中索引从0开始),这通常对应于检测到对象的类别ID。unique()函数返回所有独特的类别ID,这样我们就可以迭代每一个类别。- 对于每一个类别
c,(det[:, 5] == c)会产生一个布尔掩码,表示哪些检测结果属于这个类别。 sum()函数计算这个布尔掩码中True的个数,即该类别在检测结果中出现的次数,结果存储在变量n中。
构建描述性字符串
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, "
f"{n} {names[int(c)]}"使用f-string(格式化字符串字面量)来构建一个描述,其中n是检测到的类别数量,names[int(c)]是从模型的类别名列表中获取该类别的名称。's' * (n > 1)检查如果n大于1,就在类别名称后面加上一个s,这样可以正确地复数化名词。- 最后,结果字符串后面加上一个逗号和空格,以便在下一个类别出现时可以继续拼接。
这段代码的结果是一个描述检测结果的字符串,其中包含了每个类别及其出现的次数。例如,如果有两个狗和一个猫被检测到,结果可能是 "2 dogs, 1 cat"。这个字符串通常用于在控制台或日志中提供一个直观的反馈,说明检测到了什么以及数量。
三、定义命令行参数
def parse_opt():parser = argparse.ArgumentParser() # 创建ArgumentParser对象parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model path(s)') # 添加权重参数parser.add_argument('--source', type=str, default='data/images', help='file/dir/URL/glob, 0 for webcam') # 添加输入源参数parser.add_argument('--data', type=str, default='data/coco128.yaml', help='(optional) dataset.yaml path') # 添加数据集参数parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)') # 添加图像大小参数parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold') # 添加置信度阈值参数parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold') # 添加IoU阈值参数parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image') # 添加最大检测数量参数parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 添加设备参数parser.add_argument('--view-img', action='store_true', help='show results') # 添加显示图像参数parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') # 添加保存文本参数parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') # 添加保存置信度参数parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes') # 添加保存裁剪框参数parser.add_argument('--nosave', action='store_true', help='do not save images/videos') # 添加不保存图像/视频参数parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3') # 添加类别过滤参数parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') # 添加类别无关的NMS参数parser.add_argument('--augment', action='store_true', help='augmented inference') # 添加增强推理参数parser.add_argument('--visualize', action='store_true', help='visualize features') # 添加可视化特征参数parser.add_argument('--update', action='store_true', help='update all models') # 添加更新模型参数parser.add_argument('--project', default='runs/detect', help='save results to project/name') # 添加项目路径参数parser.add_argument('--name', default='exp', help='save results to project/name') # 添加结果文件夹名称参数parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') # 添加允许现有项目名称参数parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)') # 添加边界框厚度参数parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels') # 添加隐藏标签参数parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences') # 添加隐藏置信度参数parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference') # 添加半精度推理参数parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference') # 添加OpenCV DNN推理参数parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride') # 添加视频帧率步幅参数opt = parser.parse_args() # 解析命令行参数return opt # 返回解析结果
四、主函数
def main(opt):check_requirements(exclude=('tensorboard', 'thop')) # 检查运行所需的库run(**vars(opt)) # 运行检测程序if __name__ == "__main__":opt = parse_opt() # 解析命令行参数main(opt) # 运行主程序相关文章:
)
目标检测经典模型之YOLOV5-detect.py源码解析(持续更新)
detect文件框架 一、导入模块包二、定义run函数1. 归一化操作代码解析uint8精度转换归一化 2. 扩展维度为什么扩展维度?代码解释 3. 对检测结果类别计数检查是否有检测结果统计每个类别的出现次数构建描述性字符串 三、定义命令行参数四、主函数 本帖是YOLOV5推理部…...

PF4J+SpringBoot
plugin-common pom.xml相关配置 <groupId>pub.qingyun</groupId> <artifactId>plugin-common</artifactId> <version>0.0.1-SNAPSHOT</version> <description>插件配置类</description><dependency><groupId>or…...

设计模式11-原型模式
设计模式11-原型模式 写在前面对象创建模式典型模式原型模式动机结构代码推导应用特点要点总结 原型模式与工厂方法模式对比工厂方法模式原型模式什么时候用什么模式 写在前面 对象创建模式 通过对象创建模式绕开动态内存分配来避免创建过程中所导致的耦合过紧的问题。从而支…...

Tomcat长连接源码解析
长连接: 客户端发送Http请求至服务端,请求发送完之后socket连接不断开,可以继续接收下一个Http请求并且解析返回。接手并解析这些Http请求的时候socket连接不断开,这种过程被称为长连接。 需要注意的点就在于,在满足什么条件的情况…...

C++编程:实现一个跨平台安全的定时器Timer模块
文章目录 0. 概要1. 设计目标2. SafeTimer 类的实现2.1 头文件 safe_timer.h源文件 safe_timer.cpp 3. 工作流程图4. 单元测试 0. 概要 对于C应用编程,定时器模块是一个至关重要的组件。为了确保系统的可靠性和功能安全,我们需要设计一个高效、稳定的定…...

PyTorch的自动微分模块【含梯度基本数学原理详解】
文章目录 1、简介1.1、基本概念1.2、基本原理1.2.1、自动微分1.2.2、梯度1.2.3、梯度求导1.2.4、梯度下降法1.2.5、张量梯度举例 1.3、Autograd的高级功能 2、梯度基本计算2.1、单标量梯度2.2、单向量梯度的计算2.3、多标量梯度计算2.4、多向量梯度计算 3、控制梯度计算4、累计…...

AI 绘画|Midjourney设计Logo提示词
你是否已经看过许多别人分享的 MJ 咒语,却仍无法按照自己的想法画图?通过学习 MJ 的提示词逻辑后,你将能够更好地理解并创作自己的“咒语”。本文将详细拆解使用 MJ 设计 Logo 的逻辑,让你在阅读后即可轻松上手,制作出…...

LeNet实验 四分类 与 四分类变为多个二分类
目录 1. 划分二分类 2. 训练独立的二分类模型 3. 二分类预测结果代码 4. 二分类预测结果 5 改进训练模型 6 优化后 预测结果代码 7 优化后预测结果 8 训练四分类模型 9 预测结果代码 10 四分类结果识别 1. 划分二分类 可以根据不同的类别进行多个划分,以…...

【BUG】已解决:java.lang.reflect.InvocationTargetException
已解决:java.lang.reflect.InvocationTargetException 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开发…...

配置kali 的apt命令在线安装包的源为国内源
目录 一、安装VMware Tools 二、配置apt国内源 一、安装VMware Tools 点击安装 VMware Tools 后,会加载一个虚拟光驱,里面包含 VMware Tools 的安装包 鼠标右键单击 VMware Tools 的安装包,点击复制到 点击 主目录,再点击选择…...

JAVA 异步编程(线程安全)二
1、线程安全 线程安全是指你的代码所在的进程中有多个线程同时运行,而这些线程可能会同时运行这段代码,如果每次运行的代码结果和单线程运行的结果是一样的,且其他变量的值和预期的也是一样的,那么就是线程安全的。 一个类或者程序…...

Golang | Leetcode Golang题解之第260题只出现一次的数字III
题目: 题解: func singleNumber(nums []int) []int {xorSum : 0for _, num : range nums {xorSum ^ num}lsb : xorSum & -xorSumtype1, type2 : 0, 0for _, num : range nums {if num&lsb > 0 {type1 ^ num} else {type2 ^ num}}return []in…...

IDEA自带的Maven 3.9.x无法刷新http nexus私服
问题: 自建的私服,配置了域名,使用http协议,在IDEA中或本地Maven 3.9.x会出现报错,提示http被blocked,原因是Maven 3.8.1开始,Maven默认禁止使用HTTP仓库地址,只允许使用HTTPS仓库地…...

56、本地数据库迁移到阿里云
现有需求,本地数据库迁移到阿里云上。 库名xy102表 test01test02test01 test023条数据。1、登录阿里云界面创建免费试用ECS实列。 阿里云登录页 (aliyun.com)](https://account.aliyun.com/login/login.htm?oauth_callbackhttps%3A%2F%2Fusercenter2.aliyun.com%…...

新时代多目标优化【数学建模】领域的极致探索——数学规划模型
目录 例1 1.问题重述 2.基本模型 变量定义: 目标函数: 约束条件: 3.模型分析与假设 4.模型求解 5.LINGO代码实现 6.结果解释 编辑 7.敏感性分析 8.结果解释 例2 奶制品的销售计划 1.问题重述 编辑 2.基本模型 3.模…...

单例模式详解
文章目录 一、概述1.单例模式2.单例模式的特点3.单例模式的实现方法 二、单例模式的实现1. 饿汉式2. 懒汉式3. 双重校验锁4. 静态内部类5. 枚举 三、总结 一、概述 1.单例模式 单例模式(Singleton Pattern)是一种创建型设计模式,确保一个类…...

WebGIS主流的客户端框架比较|OpenLayers|Leaflet|Cesium
实现 WebGIS 应用的主流前端框架主要包括 OpenLayers、Leaflet、Mapbox GL JS 和 Cesium 等。每个框架都有其独特的功能和优势,适合不同的应用场景。 WebGIS主流前端框架的优缺点 前 端 框架优点缺点OpenLayers较重量级的开源库,二维GIS功能最丰富全面…...

【LabVIEW作业篇 - 2】:分数判断、按钮控制while循环暂停、单击按钮获取book文本
文章目录 分数判断按钮控制while循环暂停按钮控制单个while循环暂停 按钮控制多个while循环暂停单击按钮获取book文本 分数判断 限定整型数值输入控件值得输入范围,范围在0-100之间,判断整型数值输入控件的输入值。 输入范围在0-59之间,显示…...
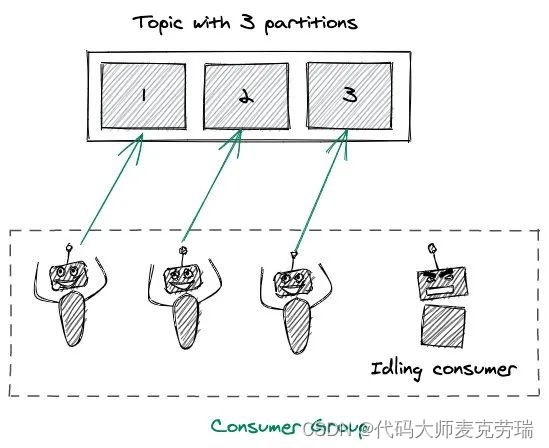
Kafka架构详解之分区Partition
目录 一、简介二、架构三、分区Partition1.分区概念2.Offsets(偏移量)和消息的顺序3.分区如何为Kafka提供扩展能力4.producer写入策略5.consumer消费机制 一、简介 Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义…...

SSM之Mybatis
SSM之Mybatis 一、MyBatis简介1、MyBatis特性2、MyBatis的下载3、MyBatis和其他持久化层技术对比 二、MyBatis框架搭建三、MyBatis基础功能1、MyBatis核心配置文件2、MyBatis映射文件3、MyBatis实现增删改查4、MyBatis获取参数值的两种方式5、MyBatis查询功能6、MyBatis自定义映…...
抽采教学视频)
瓦斯气驱(二氧化碳、氮气)抽采教学视频
瓦斯气驱(二氧化碳,氮气)抽采教学视频最近在矿上折腾瓦斯气驱,发现很多新人对着设备一脸懵。今天就拿二氧化碳和氮气这两种常见驱替气体来说说门道,咱们直接上硬货。先看个现场数据处理的Python脚本,这个比…...

3步解决B站缓存视频无法播放问题:m4s-converter技术方案详解
3步解决B站缓存视频无法播放问题:m4s-converter技术方案详解 【免费下载链接】m4s-converter 将bilibili缓存的m4s转成mp4(读PC端缓存目录) 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 当你在离线环境下打开B站缓存的教学视频,却…...

BEV分割新范式:PETRv2在车道线检测中的创新应用
BEV分割新范式:PETRv2在车道线检测中的创新应用 1. 引言 想象一下,一辆自动驾驶汽车行驶在复杂的城市道路上,突然遇到一个急转弯,车道线被部分遮挡,阳光刺眼,还有前方车辆的身影干扰。传统的视觉系统可能…...

别再瞎找了!9个降AIGC网站开源免费测评:降AI率全维度对比推荐
在学术写作日益依赖AI辅助的今天,论文中的AIGC痕迹和查重率问题成为许多学生和研究者的痛点。如何在保持原意不变的前提下,有效降低AI生成内容的痕迹,同时避免重复率过高,成为了亟需解决的难题。而AI降重工具的出现,为…...

Realistic Vision V5.1虚拟摄影棚实操:多轮迭代生成——从草图到精修人像
Realistic Vision V5.1虚拟摄影棚实操:多轮迭代生成——从草图到精修人像 1. 项目概述 Realistic Vision V5.1虚拟摄影棚是一款基于Stable Diffusion 1.5生态顶级写实模型开发的本地化工具,专为摄影级人像生成而设计。这个工具解决了普通用户在尝试使用…...

从零开始:如何为你的降压型DC-DC变换器选择合适的反馈控制模式?
降压型DC-DC变换器反馈控制模式深度解析与选型指南 在电源设计领域,选择合适的反馈控制模式往往决定着整个系统的性能上限。想象一下这样的场景:当你精心设计的电源模块在实验室测试时表现完美,却在量产阶段频繁出现输出电压振荡;…...

APatch故障诊疗指南:从现象到本质的问题解决框架
APatch故障诊疗指南:从现象到本质的问题解决框架 【免费下载链接】APatch Patching, hooking, and rooting the Android using only a stripped kernel image. 项目地址: https://gitcode.com/gh_mirrors/ap/APatch APatch作为一款结合Magisk便捷安装与Kerne…...

rx 像素编辑器 Rust 实现原理:现代图形编程的最佳实践
rx 像素编辑器 Rust 实现原理:现代图形编程的最佳实践 【免费下载链接】rx 👾 Modern and minimalist pixel editor 项目地址: https://gitcode.com/gh_mirrors/rx/rx rx 是一个采用 Rust 语言实现的现代化极简像素编辑器,专为像素艺术…...

Hazelcast微服务集成终极指南:5步实现高效服务发现与配置管理
Hazelcast微服务集成终极指南:5步实现高效服务发现与配置管理 【免费下载链接】hazelcast hazelcast - 这是一个分布式数据存储和计算平台,用于构建高性能、可扩展的应用程序。适用于实时数据处理、缓存、分布式计算等场景。特点包括高性能、可扩展 项…...

Elsevier:深度嵌入高校科研评价基础设施
一、战略逻辑:从"卖内容"到"卖基础设施" 要理解Elsevier在高校服务领域的布局,首先要理解它的战略转型逻辑。 传统意义上,学术出版社的商业模式很简单:生产内容,卖给图书馆,图书馆付…...