CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
0x0 背景
相信大家都使用或者听说过github copilot这个高效的代码生成工具。CodeGeeX类似于github copilot,是由清华大学,北京智源研究院,智谱AI等机构共同开发的一个拥有130亿参数的多编程语言代码生成预训练模型。它在vscode上也提供了插件,可以直接安装使用,我个人体验了一下代码生成的功能还不错。此外除了代码生成,CodeGeeX还可以做代码加注释,不同语言翻译(比如把c++代码翻译为python)等,感兴趣的读者可以体验一下。并且可以在 https://models.aminer.cn/codegeex/blog/index_zh.html 这个官方博客上查看更多详细信息。
为了说明oneflow在大模型训练和推理上的高效性,继上次对glm10b模型的训练优化工作 之后,我们对CodeGeeX模型的推理进行优化。在oneflow团队的优化下,CodeGeeX可以使用oneflow的后端进行推理并且在FP16和INT8模式的推理速度均可以超过CodeGeeX团队基于FasterTransformer的方案(基于NVIDIA A100显卡进行测试)。oneflow的推理方案已经upstream CodeGeeX的主分支,欢迎小伙伴查看。需要指出的是本文用到的大多数cuda优化手段均由oneflow的柳俊丞大佬提供,在此致敬。本着开源精神,本文将展示一下我们的优化结果并且解析一下我们的优化手段,和大家共同探讨学习。介于篇幅原因,在解析优化手段时,我们会简单介绍一下优化的原理并给出代码链接。但不会详细阅读优化涉及到的cuda kernel,感兴趣的小伙伴可以留言,后续我再推出更详细的解读。
- CodeGeeX代码链接:https://github.com/THUDM/CodeGeeX (点击右下角BBuf的头像就可以找到oneflow的pr)
- OneFlow代码链接:https://github.com/Oneflow-Inc/oneflow
0x1. 优化后的结果
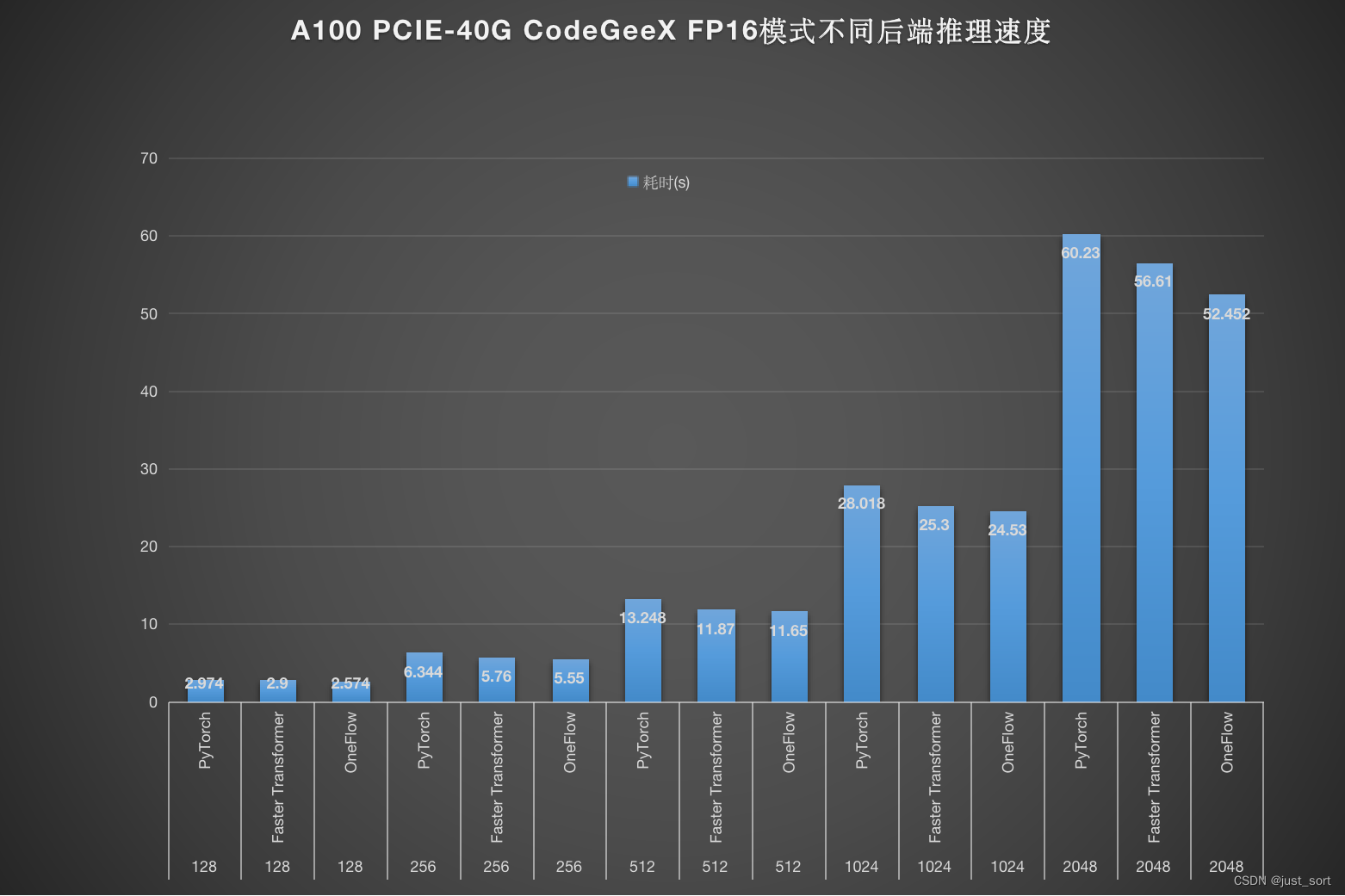
我们在A100 PCIE-40G上对比了分别使用PyTorch,FasterTransformer以及Oneflow推理CodeGeeX模型的耗时情况,FP16模式推理速度结果如下:
 INT8模式的推理速度如下:
INT8模式的推理速度如下:
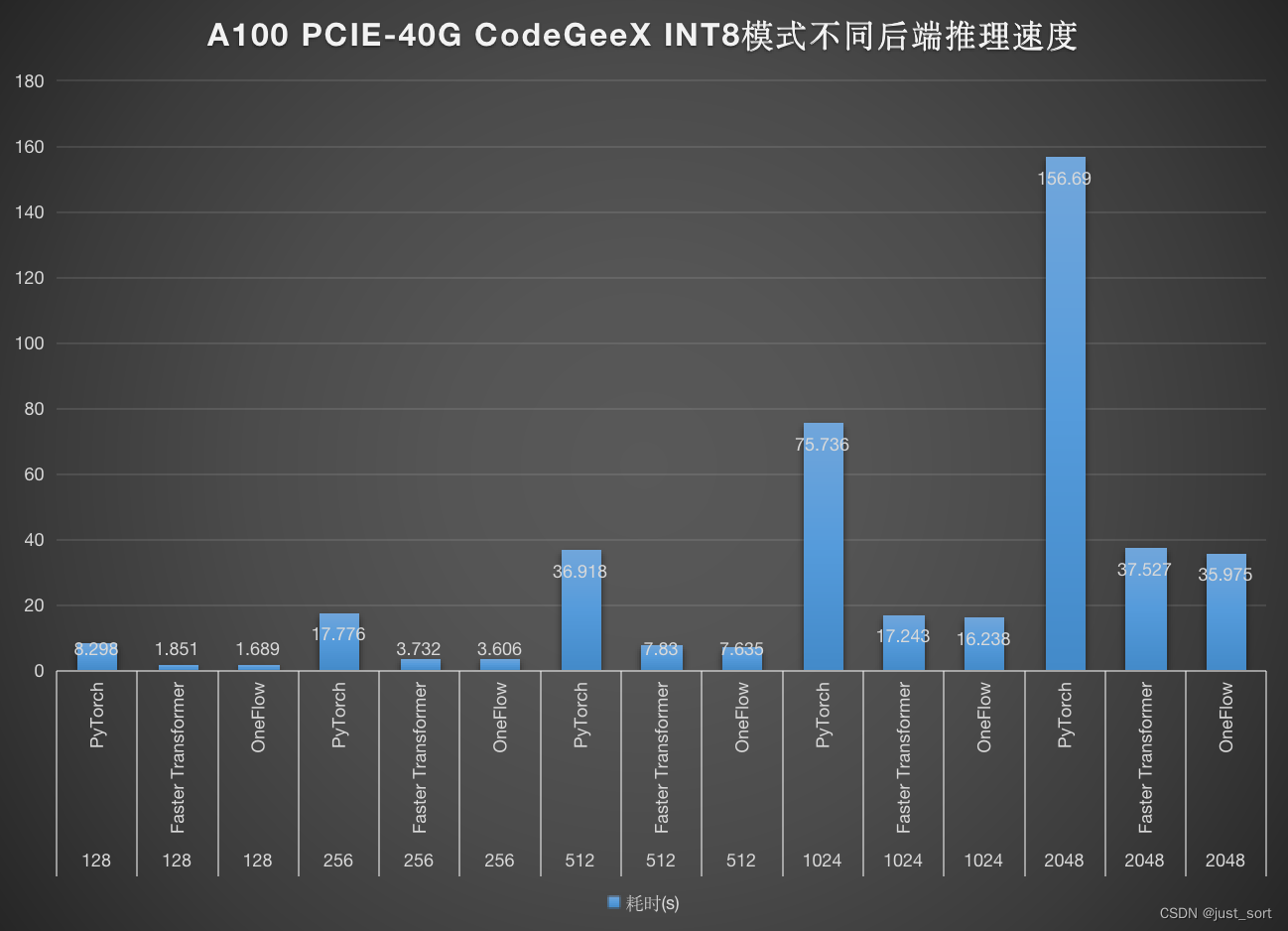
可以看到无论是在FP16模式还是INT8模式,OneFlow均取得了最好的性能结果。也许有些读者会提出似一个疑问,似乎OneFlow的性能并没有超越FasterTransformer太多,选择OneFlow的好处是?我个人认为由于C++以及手动插入集合通信的原因FasterTransformer的适配难度是相对比较大的,特别是多卡模式,而OneFlow不仅拥有和PyTorch一模一样的用户体验并且扩展到多卡时不需要用户手动管理集合通信的问题,用户体验拉满。
除了性能优势,OneFlow也可以节省一些显存资源消耗,详细的信息可以点击这个链接查看:https://github.com/THUDM/CodeGeeX/pull/87 。
0x2. 优化手段解析
针对CodeGeeX大模型的推理,OneFlow做了什么优化可以超越NVIDIA FasterTransformer库的推理速度呢?
- quick_gelu融合优化。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L7-L11 指的是将
x / (1 + torch.exp(-1.702 * torch.abs(x))) * torch.exp(0.851 * (x - torch.abs(x)))这个elementwise操作组合成的pattern融合成一个算子,在oneflow中为flow._C.quick_gelu。 - grouped_matmul_bias优化。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L101-L108 指的是将一堆同时执行并且数据没有前后依赖关系的matmul+bias_add算子融合成一个cuda kernel,降低kernel launch的开销。https://github.com/Oneflow-Inc/oneflow/pull/9413。
- 更高效的fused attention kernel(在oneflow中使用
flow._C.fused_multi_head_attention_inference_v2调用)。在oneflow中引入了cutlass的fmha以及TensorRT的FlashAttention实现,可以在不同的数据规模调用最优的fmha实现。在此基础上oneflow针对Q,K,V可能存在的不同数据排布进行优化,具体来说oneflow的fused_multi_head_attention_inference_v2接口支持手动配置Q,K,V这三个输入tensor的数据排布。比如在CodeGeeX里面,Q,K,V的shape是[seq_lenght, batch_size, num_heads * hidden_size_per_attention_head],我们就可以直接把Q,K,V的数据排布配置成MB(HK),并且输出的数据排布也配置成MB(HK),这样就可以避免在把Q,K,V传入fused_multi_head_attention_inference_v2之前需要额外做的reshape带来的开销了,同样输出Tensor的reshape开销也可以避免。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L253-L264 。这部分的cuda实现分成很多pr,这里指一下路:https://github.com/Oneflow-Inc/oneflow/pull/9950 & https://github.com/Oneflow-Inc/oneflow/pull/9933。 - CodeGeeX和大多数的自回归模型一样有一个增量推理阶段,需要把当前的key,value和上一轮的key,value concat起来,也就是:https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L135-L140 。针对这个特殊的操作,我们也开发了一个可以配置输入输出数据排布的fuse kernel,把两个concat操作融合起来降低kernel launch以及reshape的开销。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L239 。在oneflow中对应https://github.com/Oneflow-Inc/oneflow/pull/9963 。
- fused matmul+bias。https://github.com/THUDM/CodeGeeX/blob/main/tests/test_inference_oneflow.py#L14 。具体来说就是将Linear中的matmul和bias_add融合在一起。https://github.com/Oneflow-Inc/oneflow/pull/9369。
上述优化既适用于FP16模式,也适用于INT8模式,接下来我们聊一下INT8 weight only quantization的motivation以及优化。经过调研,FasterTransformer的INT8模式采用了weight only quantization的方式,也就是只对Linear层的权重进行量化,但是在计算的时候仍然要反量化回FP16和Activation进行矩阵乘计算。按道理来说,加入了反量化之后速度应该变慢才对,为什么这里使用了INT8 weight quantization之后反而能加速最终的推理速度呢?这是因为在这个网络中,推理时的batch_size以及seq_length都是1,这个时候的矩阵乘法退化到了一个向量和一个矩阵相乘的情况,实际上类似于卷积神经网络中的全连接层,是一个典型的访存密集型算子。所以这里对weight进行反量化和矩阵乘法可以fuse到一起来进行加速(原因是减少了访存)。在oneflow中的实现对应:https://github.com/Oneflow-Inc/oneflow/pull/9900 。然后我基于这个算子在CodeGeeX中实现了OneFlow INT8版本的推理脚本:https://github.com/THUDM/CodeGeeX/blob/main/codegeex/quantization/quantize_oneflow.py
0x3. 总结
至此,我分享完了我们团队最近加速CodeGeeX百亿参数大模型推理的所有优化技巧,相信对要做LLM大模型的推理的小伙伴会有帮助。本着开源精神,请给oneflow点击star再研究相关优化。此外,更多的优化解读我也会放到个人仓库:https://github.com/BBuf/how-to-optim-algorithm-in-cuda ,欢迎大家关注。
相关文章:
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
0x0 背景 相信大家都使用或者听说过github copilot这个高效的代码生成工具。CodeGeeX类似于github copilot,是由清华大学,北京智源研究院,智谱AI等机构共同开发的一个拥有130亿参数的多编程语言代码生成预训练模型。它在vscode上也提供了插件…...

Linux驱动之并发与竞争
文章目录并发与竞争的概念原子操作原子整形操作 API 函数原子位操作 API 函数自旋锁自旋锁简介自旋锁结构体自旋锁 API 函数自旋锁的注意事项读写自旋锁读写自旋锁的API顺序锁顺序锁的APIRCU(Read-Copy-Update)RCU的API信号量信号量API互斥体互斥体的API完成量(Completion)完成…...

【密码学复习】第四讲分组密码(三)
AES算法的整体结构 AES算法的轮函数 1)字节代换(SubByte) 2)行移位(ShiftRow) 3)列混合(MixColumn) 4)密钥加(AddRoundKey)1-字节代换…...

JVM(内存划分,类加载,垃圾回收)
JVMJava程序,是一个名字为Java 的进程,这个进程就是所说的“JVM”1.内存区域划分JVM会先从操作系统这里申请一块内存空间,在这个基础上再把这个内存空间划分为几个小的区域在一个JVM进程中,堆和方法区只有一份;栈和程序…...

工作中遇到的问题 -- 你见过哪些写的特别好的代码
strPtr : uintptr((*(*stringStruct)(unsafe.Pointer(&str))).str)代码解析: 这是一段 Go 代码,它的作用是获取一个字符串变量 str 的底层指针,即字符串数据的起始地址。 这段代码涉及到了 Go 语言中的指针、类型转换和内存布局等概念&…...

基于chatGPT设计卷积神经网络
1. 简介 本文主要介绍基于chatGPT,设计一个针对骁龙855芯片设计的友好型神经网络。 提问->跑通总共花了5min左右,最终得到的网络在Cifar100数据集上与ResNet18的精度对比如下。 模型flopsparamstrain acc1/5test acc1/5ResNet18(timm)1.8211.18~98…...

java.sql.Date和java.util.Date的区别
参考答案 java.sql.Date 是 java.util.Date 的子类java.util.Date 是 JDK 中的日期类,精确到时、分、秒、毫秒java.sql.Date 与数据库 Date 相对应的一个类型,只有日期部分,时分秒都会设置为 0,如:2019-10-23 00:00:0…...
动态规划---线性dp和区间dp
动态规划(三) 目录动态规划(三)一:线性DP1.数字三角形1.1数字三角形题目1.2代码思路1.3代码实现(正序and倒序)2.最长上升子序列2.1最长上升子序列题目2.2代码思路2.3代码实现3.最长公共子序列3.1最长公共子序列题目3.2代码思路3.3代码实现4.石子合并4.1题目如下4.2代…...

常见的2D与3D碰撞检测算法
分离轴分离轴定理(Separating Axis Theorem)是用于解决2D或3D物体碰撞检测问题的一种方法。其基本思想是,如果两个物体未发生碰撞,那么可以找到一条分离轴(即一条直线或平面),两个物体在该轴上的…...

STM32 10个工程篇:1.IAP远程升级(二)
一直提醒自己要更新CSDN博客,但是确实这段时间到了一个项目的关键节点,杂七杂八的事情突然就一涌而至。STM32、FPGA下位机代码和对应Labview的IAP升级助手、波形设置助手上位机代码笔者已经调试通过,因为不想去水博客、凑数量,复制…...
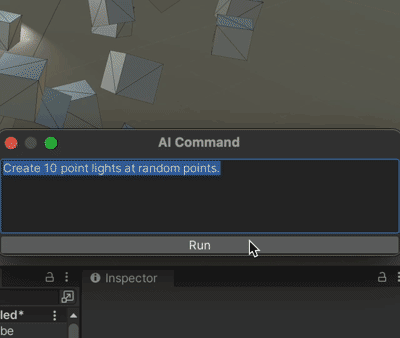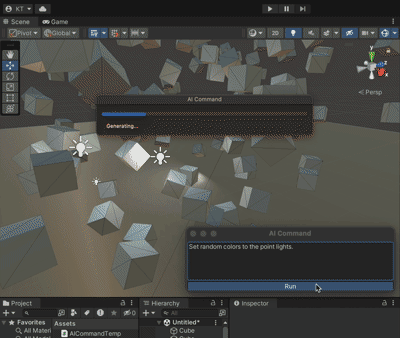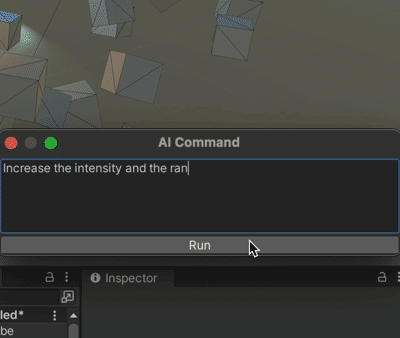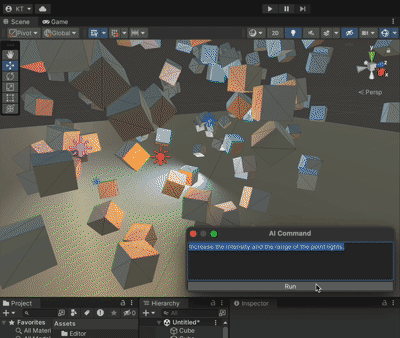
Unity+ChatGpt的联动 AICommand
果然爱是会消失的,对吗 chatGpt没出现之前起码还看人家的文章,现在都是随便你。 本着师夷长技以制夷的思路,既然打不过,那么我就加入 github地址:https://github.com/keijiro/AICommand 文档用chatGpt翻译如下&#…...
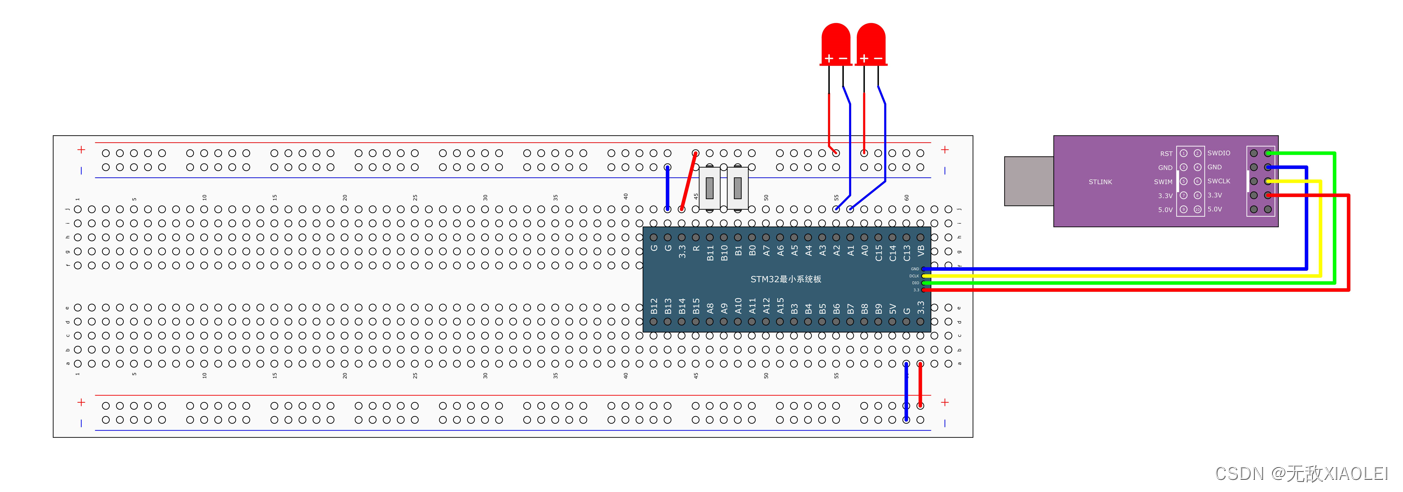
STM-32:按键控制LED灯 程序详解
目录一、基本原理二、接线图三、程序思路3.1库函数3.2程序代码注:一、基本原理 左边是STM322里电路每一个端口均可以配置的电路部分,右边部分是外接设备 电路图。 配置为 上拉输入模式的意思就是,VDD开关闭合,VSS开关断开。 浮空…...
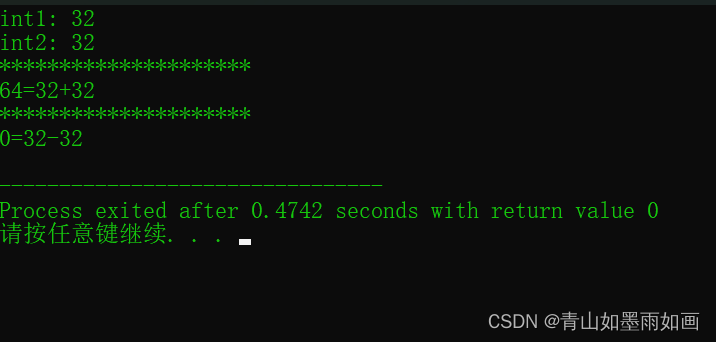
北邮22信通:(8)实验1 题目五:大整数加减法(搬运官方代码)
北邮22信通一枚~ 跟随课程进度每周更新数据结构与算法的代码和文章 持续关注作者 解锁更多邮苑信通专属代码~ 上一篇文章: 北邮22信通:(7)实验1 题目四:一元多项式(节省内存版)_青山如…...

Fiddler抓取https史上最强教程
有任何疑问建议观看下面视频 2023最新Fiddler抓包工具实战,2小时精通十年技术!!!对于想抓取HTTPS的测试初学者来说,常用的工具就是fiddler。 但是初学时,大家对于fiddler如何抓取HTTPS难免走歪路ÿ…...
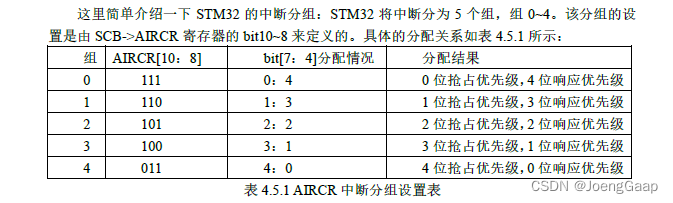
STM32开发基础知识入门
C语言基础 位操作 对基本类型变量可以在位级别进行操作。 1) 不改变其他位的值的状况下,对某几个位进行设值。 先对需要设置的位用&操作符进行清零操作,然后用|操作符设值。 2) 移位操作提高代码的可读性。 3) ~取反操作使用技巧 可用于对某…...

学习操作系统的必备教科书《操作系统:原理与实现》| 文末赠书4本
使用了6年的实时操作系统,是时候梳理一下它的知识点了 摘要: 本文简单介绍了博主学习操作系统的心路历程,同时还给大家总结了一下当下流行的几种实时操作系统,以及在工程中OSAL应该如何设计。希望对大家有所启发和帮助。 文章目录…...
)
大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学…...
【数据结构】详解二叉树与堆与堆排序的关系
🌇个人主页:平凡的小苏 📚学习格言:别人可以拷贝我的模式,但不能拷贝我不断往前的激情 🛸C语言专栏:https://blog.csdn.net/vhhhbb/category_12174730.html 🚀数据结构专栏ÿ…...
【Pandas】数据分析入门
文章目录前言一、Pandas简介1.1 什么是Pandas1.2 Pandas应用二、Series结构2.1 Series简介2.2 基本使用三、DataFrame结构3.1 DataFrame简介3.2 基本使用四、Pandas-CSV4.1 CSV简介4.2 读取CSV文件4.3 数据处理五、数据清洗5.1 数据清洗的方法5.2 清洗案例总结前言 大家好&…...
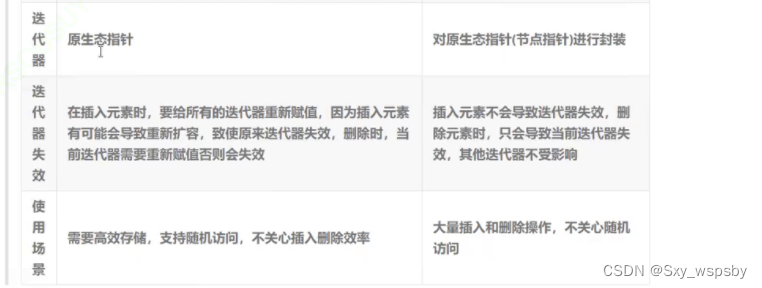
【c++】:list模拟实现“任意位置插入删除我最强ƪ(˘⌣˘)ʃ“
文章目录 前言一.list的基本功能的使用二.list的模拟实现总结前言 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中࿰…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...