Camp4-L1:XTuner 微调个人小助手认知
书生浦语大模型实战营第四期-XTuner 微调个人小助手认知
- 教程链接:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/XTuner/README.md
- 任务链接:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/XTuner/task.md
- 提交链接:https://aicarrier.feishu.cn/share/base/form/shrcnUqshYPt7MdtYRTRpkiOFJd
任务说明
基础任务(完成此任务即完成闯关并获得 100 算力点)
- 使用 XTuner 微调 InternLM2-Chat-7B 实现自己的小助手认知,记录复现过程并截图。
进阶任务(闯关不要求完成此任务)
- 将自我认知的模型上传到 HuggingFace/Modelscope/魔乐平台,并将应用部署到 HuggingFace/Modelscope/魔乐平台
- 参与社区共建,获取浦语 api 创建自己的数据用于微调(有创意的成果有机会获得优秀学员提名)
基础任务:微调个人小助手认知
环境配置
新建文件夹L1_xtuner,后续作业相关内容均放在这里
cd L1_xtuner
搞下环境:
conda create -n xtuner python=3.10 -y
conda activate xtuner
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]'
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install transformers==4.39.0
-e表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效
输入xtuner list-cfg,打印配置文件,测试是否安装正确:

微调数据准备
在L1_xtuner下面新建文件夹data用于保存微调的数据,也可以建立在别处统一管理,然后软连接回来
mkdir datas
在L1_xtuner文件夹下面新建脚本xtuner_generate_assistant.py,用于生成模拟微调数据:
import json# 设置用户的名字
name = '1911-David'
# 设置需要重复添加的数据次数
n = 8000# 初始化数据
data = [{"conversation": [{"input": "请介绍一下你自己", "output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)}]},{"conversation": [{"input": "你在实战营做什么", "output": "我在这里帮助{}完成XTuner微调个人小助手的任务".format(name)}]}
]# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):data.append(data[0])data.append(data[1])# 将data列表中的数据写入到'datas/assistant.json'文件中
with open('datas/assistant.json', 'w', encoding='utf-8') as f:# 使用json.dump方法将数据以JSON格式写入文件# ensure_ascii=False 确保中文字符正常显示# indent=4 使得文件内容格式化,便于阅读json.dump(data, f, ensure_ascii=False, indent=4)
运行脚本,查看一下结果:

ok,这就是要用来进行微调的数据了,具体到自己的项目需要自己做数据清洗等等工作了,这个其实才是比较重要的部分。
基础模型准备
将internlm2_5-7b-chat下载好,并软链接到L1_xtuner目录下面,这个在入门岛都搞过了:

修改Config
L1_xtuner文件夹下面新建config文件夹,先复制一个原来的配置文件:
mkdir ./config
cd config
xtuner copy-cfg internlm2_5_chat_7b_qlora_alpaca_e3 ./
按照教程修改配置文件中的关于模型和数据集的配置,我的改完是这个样子:
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = 'internlm2_5-7b-chat'
use_varlen_attn = False# Data
# alpaca_en_path = 'tatsu-lab/alpaca'
alpaca_en_path = 'datas/assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 2048
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 1
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = [# '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai''请介绍下你自己','Please introduce yourself'
]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side='right')model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type='nf4')),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias='none',task_type='CAUSAL_LM'))#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,# dataset=dict(type=load_dataset, path=alpaca_en_path),dataset=dict(type=load_dataset,path='json',data_files=dict(train=alpaca_en_path)),tokenizer=tokenizer,max_length=max_length,# dataset_map_fn=alpaca_map_fn,dataset_map_fn=None,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn)sampler = SequenceParallelSampler \if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale='dynamic',dtype='float16')# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True)
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template)
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations.logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend='nccl'),
)# set visualizer
visualizer = None# set log level
log_level = 'INFO'# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)
启动微调
写个脚本bash run_xtuner_test.sh,贴入下述内容,方便后续修改(运行需要在L1_xtuner文件夹下面哦)
xtuner train config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py \--deepspeed deepspeed_zero2 \--work-dir work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy
执行bash run_xtuner_test.sh,开始训练喽:


看下显存占用:

配置文件里写了max_epochs = 3,A10大概40多分钟就训练完了

根据训练时候的测试输出,貌似是训好了
权重转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件,那么我们可以通过以下命令来实现一键转换。
我们可以使用 xtuner convert pth_to_hf 命令来进行模型格式转换。
xtuner convert pth_to_hf命令用于进行模型格式转换。该命令需要三个参数:CONFIG表示微调的配置文件,PATH_TO_PTH_MODEL表示微调的模型权重文件路径,即要转换的模型权重,SAVE_PATH_TO_HF_MODEL表示转换后的 HuggingFace 格式文件的保存路径。
除此之外,我们其实还可以在转换的命令中添加几个额外的参数,包括:
| 参数名 | 解释 |
|---|---|
| –fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
参考教程按照下述命令转换下模型即可,写成脚本run_xtuner_convert.sh
conda activate xtuner# 先获取最后保存的一个pth文件
pth_file=`ls -t work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy/*.pth | head -n 1`
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ${pth_file} ./work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy/hf
运行结果如下:

模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 Adapter ,因此是不需要进行模型整合的。
在 XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM表示原模型路径,ADAPTER表示 Adapter 层的路径,SAVE_PATH表示合并后的模型最终的保存路径。
在模型合并这一步还有其他很多的可选参数,包括:
| 参数名 | 解释 |
|---|---|
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| –device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| –is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
参考教程按照下述命令搞下模型合并即可,把下面内容贴入脚本run_xtuner_merge.sh:
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert merge internlm2_5-7b-chat work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy/hf ./work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy/merged --max-shard-size 2GB
在模型合并完成后,我们就可以看到最终的模型和原模型文件夹非常相似,包括了分词器、权重文件、配置信息等等。
 ### 检查效果/模型 WebUI 对话
### 检查效果/模型 WebUI 对话
新建python脚本xtuner_streamlit_demo.py1,贴入下述内容:
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optionalimport streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,StoppingCriteriaList)
from transformers.utils import loggingfrom transformers import AutoTokenizer, AutoModelForCausalLM # isort: skiplogger = logging.get_logger(__name__)model_name_or_path = "internlm2_5-7b-chat"@dataclass
class GenerationConfig:# this config is used for chat to provide more diversitymax_length: int = 2048top_p: float = 0.75temperature: float = 0.1do_sample: bool = Truerepetition_penalty: float = 1.000@torch.inference_mode()
def generate_interactive(model,tokenizer,prompt,generation_config: Optional[GenerationConfig] = None,logits_processor: Optional[LogitsProcessorList] = None,stopping_criteria: Optional[StoppingCriteriaList] = None,prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],List[int]]] = None,additional_eos_token_id: Optional[int] = None,**kwargs,
):inputs = tokenizer([prompt], padding=True, return_tensors='pt')input_length = len(inputs['input_ids'][0])for k, v in inputs.items():inputs[k] = v.cuda()input_ids = inputs['input_ids']_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]if generation_config is None:generation_config = model.generation_configgeneration_config = copy.deepcopy(generation_config)model_kwargs = generation_config.update(**kwargs)bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612generation_config.bos_token_id,generation_config.eos_token_id,)if isinstance(eos_token_id, int):eos_token_id = [eos_token_id]if additional_eos_token_id is not None:eos_token_id.append(additional_eos_token_id)has_default_max_length = kwargs.get('max_length') is None and generation_config.max_length is not Noneif has_default_max_length and generation_config.max_new_tokens is None:warnings.warn(f"Using 'max_length''s default ({repr(generation_config.max_length)}) \to control the generation length. "'This behaviour is deprecated and will be removed from the \config in v5 of Transformers -- we'' recommend using `max_new_tokens` to control the maximum \length of the generation.',UserWarning,)elif generation_config.max_new_tokens is not None:generation_config.max_length = generation_config.max_new_tokens + \input_ids_seq_lengthif not has_default_max_length:logger.warn( # pylint: disable=W4902f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "f"and 'max_length'(={generation_config.max_length}) seem to ""have been set. 'max_new_tokens' will take precedence. "'Please refer to the documentation for more information. ''(https://huggingface.co/docs/transformers/main/''en/main_classes/text_generation)',UserWarning,)if input_ids_seq_length >= generation_config.max_length:input_ids_string = 'input_ids'logger.warning(f"Input length of {input_ids_string} is {input_ids_seq_length}, "f"but 'max_length' is set to {generation_config.max_length}. "'This can lead to unexpected behavior. You should consider'" increasing 'max_new_tokens'.")# 2. Set generation parameters if not already definedlogits_processor = logits_processor if logits_processor is not None \else LogitsProcessorList()stopping_criteria = stopping_criteria if stopping_criteria is not None \else StoppingCriteriaList()logits_processor = model._get_logits_processor(generation_config=generation_config,input_ids_seq_length=input_ids_seq_length,encoder_input_ids=input_ids,prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,logits_processor=logits_processor,)stopping_criteria = model._get_stopping_criteria(generation_config=generation_config,stopping_criteria=stopping_criteria)logits_warper = model._get_logits_warper(generation_config)unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)scores = Nonewhile True:model_inputs = model.prepare_inputs_for_generation(input_ids, **model_kwargs)# forward pass to get next tokenoutputs = model(**model_inputs,return_dict=True,output_attentions=False,output_hidden_states=False,)next_token_logits = outputs.logits[:, -1, :]# pre-process distributionnext_token_scores = logits_processor(input_ids, next_token_logits)next_token_scores = logits_warper(input_ids, next_token_scores)# sampleprobs = nn.functional.softmax(next_token_scores, dim=-1)if generation_config.do_sample:next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)else:next_tokens = torch.argmax(probs, dim=-1)# update generated ids, model inputs, and length for next stepinput_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)model_kwargs = model._update_model_kwargs_for_generation(outputs, model_kwargs, is_encoder_decoder=False)unfinished_sequences = unfinished_sequences.mul((min(next_tokens != i for i in eos_token_id)).long())output_token_ids = input_ids[0].cpu().tolist()output_token_ids = output_token_ids[input_length:]for each_eos_token_id in eos_token_id:if output_token_ids[-1] == each_eos_token_id:output_token_ids = output_token_ids[:-1]response = tokenizer.decode(output_token_ids)yield response# stop when each sentence is finished# or if we exceed the maximum lengthif unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):breakdef on_btn_click():del st.session_state.messages@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained(model_name_or_path,trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True)return model, tokenizerdef prepare_generation_config():with st.sidebar:max_length = st.slider('Max Length',min_value=8,max_value=32768,value=2048)top_p = st.slider('Top P', 0.0, 1.0, 0.75, step=0.01)temperature = st.slider('Temperature', 0.0, 1.0, 0.1, step=0.01)st.button('Clear Chat History', on_click=on_btn_click)generation_config = GenerationConfig(max_length=max_length,top_p=top_p,temperature=temperature)return generation_configuser_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\<|im_start|>assistant\n'def combine_history(prompt):messages = st.session_state.messagesmeta_instruction = ('')total_prompt = f"<s><|im_start|>system\n{meta_instruction}<|im_end|>\n"for message in messages:cur_content = message['content']if message['role'] == 'user':cur_prompt = user_prompt.format(user=cur_content)elif message['role'] == 'robot':cur_prompt = robot_prompt.format(robot=cur_content)else:raise RuntimeErrortotal_prompt += cur_prompttotal_prompt = total_prompt + cur_query_prompt.format(user=prompt)return total_promptdef main():# torch.cuda.empty_cache()print('load model begin.')model, tokenizer = load_model()print('load model end.')st.title('InternLM2-Chat-1.8B')generation_config = prepare_generation_config()# Initialize chat historyif 'messages' not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerunfor message in st.session_state.messages:with st.chat_message(message['role'], avatar=message.get('avatar')):st.markdown(message['content'])# Accept user inputif prompt := st.chat_input('What is up?'):# Display user message in chat message containerwith st.chat_message('user'):st.markdown(prompt)real_prompt = combine_history(prompt)# Add user message to chat historyst.session_state.messages.append({'role': 'user','content': prompt,})with st.chat_message('robot'):message_placeholder = st.empty()for cur_response in generate_interactive(model=model,tokenizer=tokenizer,prompt=real_prompt,additional_eos_token_id=92542,**asdict(generation_config),):# Display robot response in chat message containermessage_placeholder.markdown(cur_response + '▌')message_placeholder.markdown(cur_response)# Add robot response to chat historyst.session_state.messages.append({'role': 'robot','content': cur_response, # pylint: disable=undefined-loop-variable})torch.cuda.empty_cache()if __name__ == '__main__':main()
先测试下原始模型steamlit run xtuner_steamlit_demo.py,效果如下:

然后把模型路径换成我们之前微调并做完合并的模型路径,即work_dirs/internlm2_chat_7b_qlora_alpaca_e3_copy/merged,
重新运行,并测试一下,哈哈,搞定:

任务基本上完成了,但是由于训练语料过于单一,所以模型明显是过拟合了的~
模型上传&应用部署
modelscope模型上传
之前在入门岛搞过了huggingface模型的上传,比较费流量,这次弄下modelscope,看下教程:
- 使用Python SDK上传模型
首先在个人主页搞个访问令牌:

然后在SDK中使用token登录:
from modelscope.hub.api import HubApi
YOUR_ACCESS_TOKEN = '请从ModelScope个人中心->访问令牌获取'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
创建模型库,可以使用SDK,也可以直接在网页点开模型库手动创建,这里不详细描述了
搞好之后,先把模型库下载到本地,我这里是Assitant_of_David,把上面那个merged之后的模型复制过来:

然后按照教程写个脚本上传即可:
from modelscope.hub.api import HubApiYOUR_ACCESS_TOKEN = '请从ModelScope个人中心->访问令牌获取'api = HubApi()
api.login(YOUR_ACCESS_TOKEN)# 上传模型
api.push_model(model_id="yourname/your_model_id", # 如果model_id对应的模型库不存在,将会自动创建model_dir="my_model_dir" # 指定本地模型目录,目录中必须包含configuration.json文件
)
然后就开始上传了,我这里比较慢,可能是文件太大了:

modelscope应用部署
参考创空间构建即可:

效果有待优化,先这样吧~
浦语API调用
文档主页:https://internlm.intern-ai.org.cn/api/document
文档里有很详细的例子:

不过需要提前创建好API Tokens,在这里:

把下面的脚本换成上面生成的自己的api key即可:
import requests
import jsonurl = 'https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions'
header = {'Content-Type':'application/json',"Authorization":"Bearer eyJ0eXBlIjoiSl...请填写准确的 token!"
}
data = {"model": "internlm2.5-latest", "messages": [{"role": "user","content": "你好~"}],"n": 1,"temperature": 0.8,"top_p": 0.9
}res = requests.post(url, headers=header, data=json.dumps(data))
print(res.status_code)
print(res.json())
print(res.json()["data"]["choices"][0]["content"])
相关文章:
Camp4-L1:XTuner 微调个人小助手认知
书生浦语大模型实战营第四期-XTuner 微调个人小助手认知 教程链接:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/XTuner/README.md任务链接:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/XTuner/task.md提交链接:…...

Qt:语言家视图
1.一不小心将qt语言家点成这样 2.点击查看->视图 3.效果...

【Paper Note】利用Boundary-aware Attention边界感知注意力机制增强部分伪造音频定位
利用Boundary-aware Attention边界感知注意力机制增强部分伪造音频定位 摘要核心模块什么是边界?什么是边界特征? 写作背景解决的问题 方法1. 特征提取使用预训练好的自监督学习模型进行前端特征提取Attentive poolingQ:为什么使用Attentive …...
海外共享奶牛牧场投资源码-理财金融源码-基金源码-共享经济源码
新版海外共享奶牛牧场投资源码/理财金融源码/基金源码/共享经济源码...

iOS静态库(.a)及资源文件的生成与使用详解(OC版本)
引言 iOS静态库(.a)及资源文件的生成与使用详解(Swift版本)_xcode 合并 .a文件-CSDN博客 在前面的博客中我们已经介绍了关于iOS静态库的生成步骤以及关于资源文件的处理,在本篇博客中我们将会以Objective-C为基础语言…...

Python自动化:关键词密度分析与搜索引擎优化
在数字营销领域,搜索引擎优化(SEO)是提升网站可见性和吸引有机流量的关键。关键词密度分析作为SEO的一个重要组成部分,可以帮助我们理解特定关键词在网页内容中的分布情况,从而优化网页内容以提高搜索引擎排名。本文将…...

苏州金龙新V系客车创新引领旅游出行未来
10月25日,为期三天的“2024第六届旅游出行大会”在风景秀丽的云南省丽江市落下帷幕。本次大会由中国旅游车船协会主办,全面展示了中国旅游出行行业最新发展动态和发展成就,为旅游行业带来全新发展动力。 在大会期间,备受瞩目的展车…...

linux:DNS服务
DNS简介: DNS系统使用的是网络的查询,那么自然需要有监听的port。DNS使用的是53端口, 在/etc/services(搜索domain)这个文件中能看到。通常DNS是以UDP这个较快速的数据传输协议来查 询的,但是没有查询到完…...

传奇架设好后创建不了行会,开区时点创建行会没反应的解决办法
传奇架设好后,测试了版本,发现行会创建不了,按道理说一般的版本在创建行会这里不会出错的,因为这是引擎自带的功能。 建立不了行会虽然说问题不大,但也不小,会严重影响玩家的游戏体验,玩游戏为的…...

【小白学机器学习28】 统计学脉络+ 总体+ 随机抽样方法
目录 参考书,学习书 0 统计学知识大致脉络 1 个体---抽样---整体 1.1 关于个体---抽样---整体,这个三段式关系 1.2 要明白,自然界的整体/母体是不可能被全部认识的 1.2.1 不要较真,如果是人为定义的一个整体,是可…...

安全研究 | 不同编程语言中 IP 地址分类的不一致性
作为一名安全研究人员,我分析了不同编程语言中 IP 地址分类 的行为。最近,我注意到一些有趣的不一致性,特别是在循环地址和私有 IP 地址的处理上。在这篇文章中,我将分享我对此问题的观察和见解。 设置 我检查了多种编程语言&am…...

小小的表盘还能玩出这么多花样?华为手表这次细节真的拉满
没想到小小的表盘还能玩出这么多花样?华为这次细节真的拉满!还有没有你不知道的神奇玩法? 情绪萌宠,心情状态抬腕可见 好心情就像生活馈赠的糖果,好的心情让我们遇到困难也不惧打击!HUAWEI WATCH GT 5情绪…...

trueNas 24.10 docker配置文件daemon.json无法修改(重启被覆盖)解决方案
前言 最近听说truenas的24.10版本开放docker容器解决方案放弃了原来难用的k3s,感觉非常巴适,就研究了一下,首先遇到无法迁移老系统应用问题比较好解决,使用sudo登录ssh临时修改daemon.json重启docker后进行docker start 容器即可…...

数字孪生,概念、应用与未来展望
随着科技的飞速发展,数字化已经成为各行各业的发展趋势,在这个过程中,数字孪生作为一种新兴的技术,逐渐引起了人们的关注,本文将对数字孪生的概念、应用以及未来展望进行详细介绍。 数字孪生的概念: 数字孪…...

Chromium HTML Input 类型Text 对应c++
一、文本域(Text Fields) 文本域通过 <input type"text"> 标签来设定,当用户要在表单中键入字母、数字等内容时,就会用到文本域。 <!DOCTYPE html> <html> <head> <meta charset"ut…...

SpringMvc参数传递
首先对于post请求汉字乱码需要进行过滤器配置 普通参数传递 直接传递 客户端传递的属性名与我的bean中的函数参数名相同 映射传递RequestParam("XXX") 在我们方法参数中定义一个与客户端属性名一致 并绑定参数 POJO实体类传递 嵌套POJO传递 数组likes参数传递…...

西安国际数字影像产业园:数字化建设赋能产业升级与拓展
西安国际数字影像产业园的数字化建设,在当前经济与科技迅猛发展的大背景下,已然成为提升园区管理效率、服务水平以及运营效果的关键趋势。随着信息技术日新月异的进步,数字化更是成为这座产业园转型升级的核心关键词。如今,西安国…...

linux线程池
线程池: * 一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着 监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利 用࿰…...

PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图)
PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图) 关于作者 作者:小白熊 作者简介:精通python、matlab、c#语言,擅长机器学习,深度学习,机器视觉,目标检测…...

【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记
【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记 1. 论文概述Abstract1. Introduction2. Related work2.1 3D Occupancy Prediction2.2 Neural Radiance Fields2.3 Self-supervised Depth Estimation 3. Method3.1 Parameterized Occupanc…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...
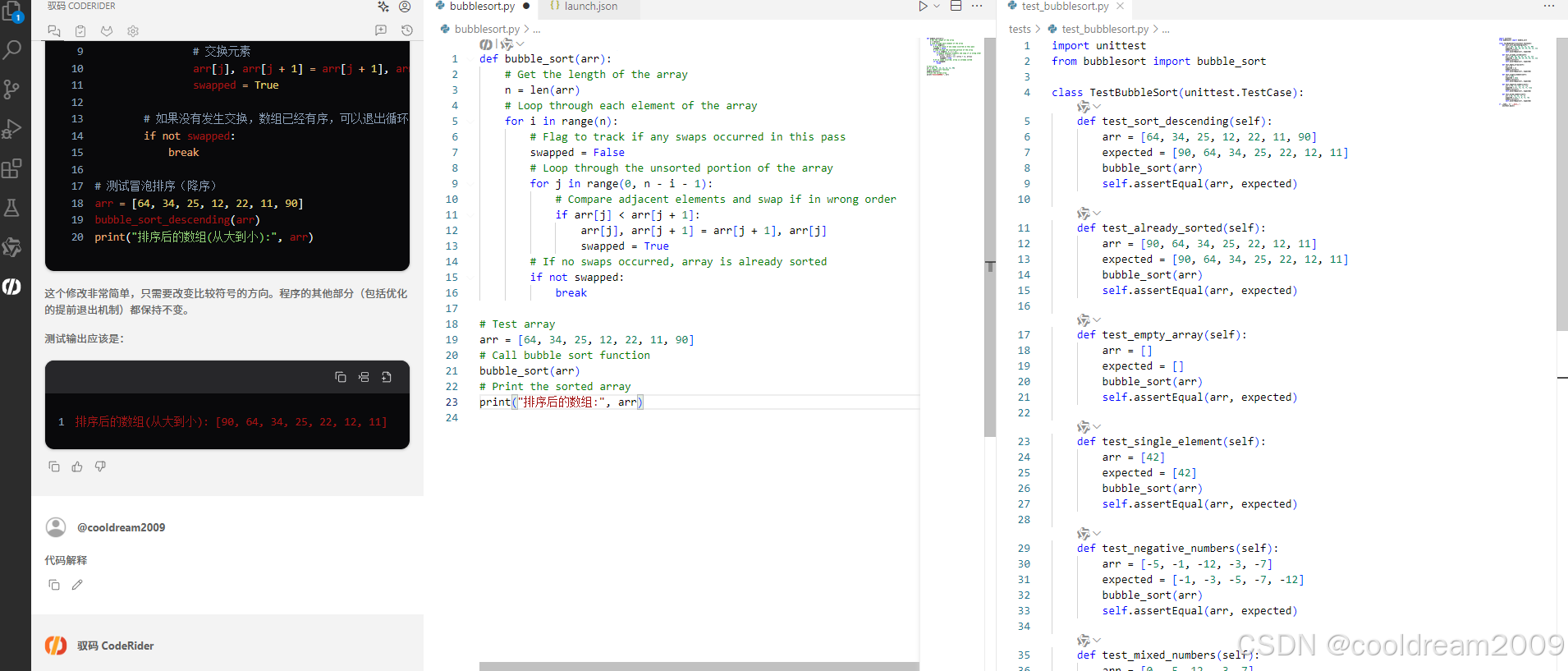
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...
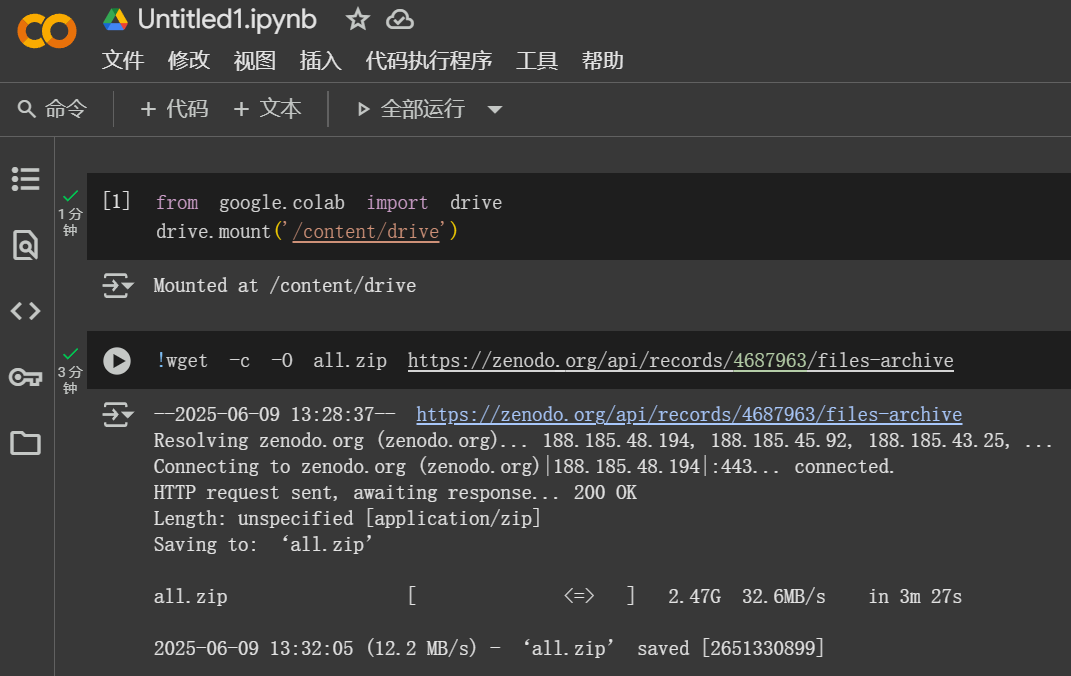
在Zenodo下载文件 用到googlecolab googledrive
方法:Figshare/Zenodo上的数据/文件下载不下来?尝试利用Google Colab :https://zhuanlan.zhihu.com/p/1898503078782674027 参考: 通过Colab&谷歌云下载Figshare数据,超级实用!!࿰…...