PySpark本地开发环境搭建
一.前置事项
请注意,需要先实现Windows的本地JDK和Hadoop的安装。
二.windows安装Anaconda
资源:Miniconda3-py38-4.11.0-Windows-x86-64,在window使用的Anaconda资源-CSDN文库
右键以管理员身份运行,选择你的安装路径,但是请注意最好文件路径不要有空格或者中文,并且要自己找得到。
然后傻瓜式安装即可。
三.Anaconda中安装PySpark
进入黑窗口,操作如下:
进入base环境中:
conda activate base
安装pyspark [此时的pyspark和pyspark命令不是一会儿事儿]
pip install pyspark==3.1.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/也可以使用阿里云的源:https://mirrors.aliyun.com/pypi/simple中间如果遇到输入y或者n,就输入y
检查是否安装成功:
可以通过conda list或者pip list检查是否包含:py4j和 pyspark两个包。
四.Pycharm中创建工程
如图:
大概介绍一下目前为止都在干什么:
Annaconda : 这个软件它包含了Python,并且可以安装各种环境,比如pyspark
PySpark : pip install pyspark==3.1.2 首先这个是pyspark的开发环境,这个软件安装在了 Annaconda里面,所以Annaconda 安装在了哪个盘,你这个pyspark 就在哪个盘。
pycharm: 这个是一个IDE工具,IDE工具关联了 本地的Annaconda,你这个Annaconda 里面有什么工具,pycharm 中就可以使用什么工具。
假如我没有在黑窗口安装这个pyspark ,就关联了pycharm ,请问,这个pycharm 如何才能有pyspark的环境?
那么继续,创建项目后来检查一下:
看一下如下文件夹里面是否有py4j和pyspark:
有的话恭喜没有问题,那么继续下一步:

创建四个文件夹:
main :用于存放每天开发的一些代码文件
resources :用于存放程序中需要用到的配置文件
datas :用于存放每天用到的一些数据文件
test :用于存放测试时的一些代码文件
main和resource的创建后:
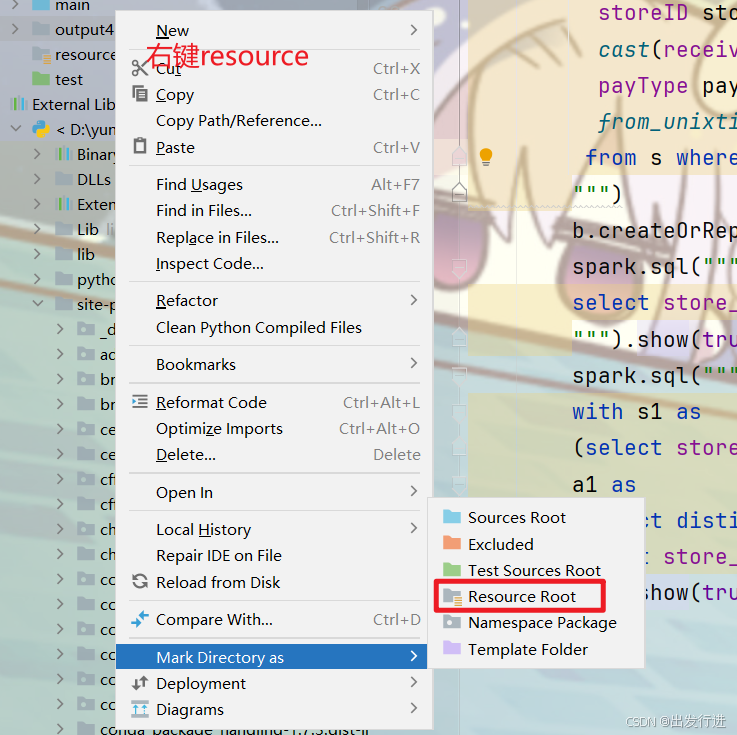
同理test选择test sources root,一样的操作不再放图了。
好的,那么准备工作已经完成,来写一个代码测试一下:
在main里新建一个Python文件然后:
import osif __name__ == '__main__':print("你好")os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'# 配置Hadoop的路径,就是前面解压的那个路径os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'# 配置base环境Python解析器的路径os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
请改成自己电脑里的配置。
获取SparkContext对象:
Spark中的核心类,任何一个Spark的程序都必须包含一个SparkContext类的对象
import os
# 导入pyspark模块
from pyspark import SparkContext,SparkConfif __name__ == '__main__':# 配置环境os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'# 配置Hadoop的路径,就是前面解压的那个路径os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'# 配置base环境Python解析器的路径os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'# 获取 conf 对象# setMaster 按照什么模式运行,local bigdata01:7077 yarn# local[2] 使用2核CPU * 你本地资源有多少核就用多少核# appName 任务的名字conf = SparkConf().setMaster("local[*]").setAppName("第一个Spark程序")# 假如我想设置压缩# conf.set("spark.eventLog.compression.codec","snappy")# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字sc = SparkContext(conf=conf)print(sc)# 使用完后,记得关闭sc.stop()运行结果如下:
可见非常明显的问题,每次都要写入这固定的环境配置,非常麻烦,那么我们将它模板化:
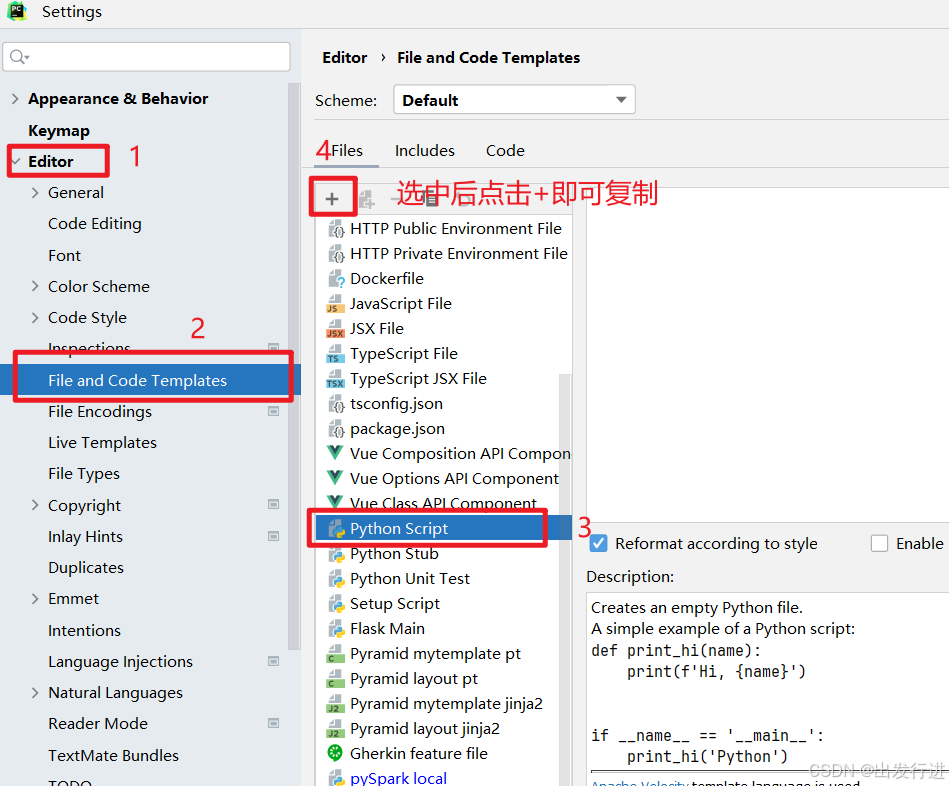
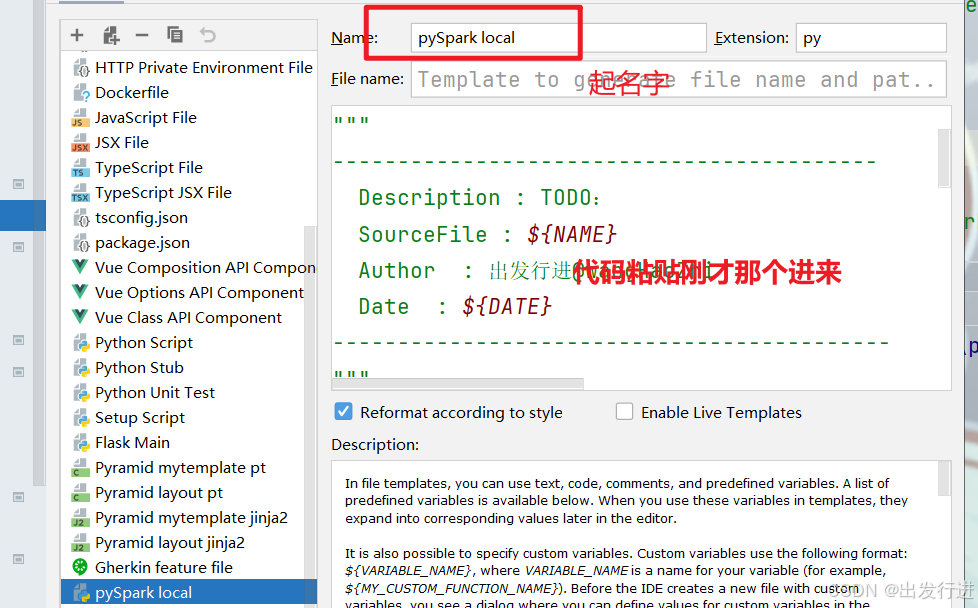
配置完成后记得是要点击:![]()
再退出,否则没有保存的话肯定用不了,
然后再次进行新建的时候:
就可以直接选择我们的模板了。非常的方便。
相关文章:
PySpark本地开发环境搭建
一.前置事项 请注意,需要先实现Windows的本地JDK和Hadoop的安装。 二.windows安装Anaconda 资源:Miniconda3-py38-4.11.0-Windows-x86-64,在window使用的Anaconda资源-CSDN文库 右键以管理员身份运行,选择你的安装路径&#x…...

【进阶】Stable Diffusion 插件 Controlnet 安装使用教程(图像精准控制)
Stable Diffusion WebUI 的绘画插件 Controlnet 最近更新了 V1.1 版本,发布了 14 个优化模型,并新增了多个预处理器,让它的功能比之前更加好用了,最近几天又连续更新了 3 个新 Reference 预处理器,可以直接根据图像生产…...

调试、发布自己的 npm 包
查看 npm 的配置 npm config ls登录 whoami 查看当前登录的用户 npm whoamiaduser 登录 adduser 有以下参数: –scope 作用域–registry 注册地址 默认地址:https://registry.npmjs.org/,也可通过.npmrc文件配置 npm login 是 …...

拓扑学与DNA双螺旋结构的奇妙连接:从算法到分子模拟
拓扑的形变指的是通过连续地拉伸、弯曲或扭曲物体而不进行撕裂或粘合来改变其形状的一种数学变换。拓扑形变属于拓扑学的一个分支,研究在这些操作下保持不变的性质。简单来说,它关注的是物体“形状的本质”,而不是具体的几何形状。 拓扑形变…...
单表查询)
mysql数据库(四)单表查询
单表查询 文章目录 单表查询一、单表查询1.1 简单查询1.2where1.3group by1.4having1.5order by1.6limit 一、单表查询 记录的查询语法如下: SELECT DISTINCT(去重) 字段1,字段2… FROM 表名 WHERE 筛选条件 GROUP BY 分组 HAVING 分组筛选 ORDER BY 排序 LIMIT 限…...
JavaEE初阶---properties类+反射+注解
文章目录 1.配置文件properities2.快速上手3.常见方法3.1读取配置文件3.2获取k-v值3.3修改k-v值3.4unicode的说明 4.反射的引入4.1传统写法4.2反射的写法(初识)4.3反射的介绍4.4获得class类的方法4.5所有类型的class对象4.6类加载过程4.7类初始化的过程4…...

HarmonyOS一次开发多端部署三巨头之功能级一多开发和工程级一多开发
功能级一多开发与工程级一多开发 引言功能级一多开发SysCaps机制介绍能力集canlUse接口 工程级一多开发三层架构规范 引言 一次开发多端部署 定义:一套代码工程,一次开发上架,多端按需部署 目标:支撑开发者快速高效的开发多终端设…...

STL常用遍历算法
概述: 算法主要是由头文件<algorithm> <functional> <numeric>组成。 <algorithm>是所有STL头文件中最大的一个,范围涉及到比较、 交换、查找、遍历操作、复制、修改等等 <numeric>体积很小,只包括几个在序列上面进行简…...

前端开发中常见的ES6技术细节分享一
var、let、const之间有什么区别? var: 在ES5中,顶层对象的属性和全局变量是等价的,用var声明的变量既是全局变量,也是顶层变量 注意:顶层对象,在浏览器环境指的是window对象,在 Node 指的是g…...

行业类别-智慧城市-子类别智能交通-细分类别自动驾驶技术-应用场景城市公共交通优化
1.大纲分析 针对题目“8.0 行业类别-智慧城市-子类别智能交通-细分类别自动驾驶技术-应用场景城市公共交通优化”的大纲分析,可以从以下几个方面进行展开: 一、引言 简述智慧城市的概念及其重要性。强调智能交通在智慧城市中的核心地位。引出自动驾驶…...

[High Speed Serial ] Xilinx
Xilinx 高速串行数据接口 收发器产品涵盖了当今高速协议的方方面面。GTH 和 GTY 收发器提供要求苛刻的光互连所需的低抖动,并具有世界一流的自适应均衡功能,具有困难的背板操作所需的 PCS 功能。 Versal™ GTY (32.75Gb/s)&…...

Unity学习笔记(3):场景绘制和叠层设置 Tilemap
文章目录 前言开发环境规则瓦片绘制拐角 动态瓦片总结 前言 这里学一下后面的场景绘制和叠层技巧。 开发环境 Unity 6windows 11vs studio 2022Unity2022.2 最新教程《勇士传说》入门到进阶|4K:https://www.bilibili.com/video/BV1mL411o77x/?spm_id_from333.10…...

不吹不黑,客观理性深入讨论中国信创现状
1. 题记: 随着美国大选尘埃落定,特朗普当选美国新一任总统,参考他之前对中国政策的风格,个人预计他将进一步限制中国半导体产业和信创产业的发展。本篇博文不吹不黑,客观理性深入探讨中国信创现状。文中数据来自权威媒…...
NoSQL数据库的基本原理)
NoSQL大数据存储技术测试(2)NoSQL数据库的基本原理
写在前面:未完成测试的同学,请先完成测试,此博文供大家复习使用,(我的答案)均为正确答案,大家可以放心复习 单项选择题 第1题 NoSQL的主要存储模式不包括 键值对存储模式 列存储模式 文件…...

「QT」几何数据类 之 QPoint 整型点类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...

植物明星大乱斗5
能帮到你的话,就给个赞吧 😘 文章目录 timer.htimer.cppcamera.hcamera.cppmenuScene.cpp timer.h #pragma once #include <functional>class Timer {public:void reStart();void setTimer(int timerMs);void setIsOneShot(bool isOneShot);void …...

每日算法练习
各位小伙伴们大家好,今天给大家带来几道算法题。 题目一 算法分析 首先,我们应该知道什么是完全二叉树:若一颗二叉树深度为n,那么前n-1层是满二叉树,只有最后一层不确定。 给定我们一棵完全二叉树,我们查看…...

把握鸿蒙生态崛起机遇:开发者如何在全场景操作系统中脱颖而出
把握鸿蒙生态崛起机遇:开发者如何在全场景操作系统中脱颖而出 随着鸿蒙系统的逐步成熟和生态体系的扩展,其与安卓、iOS 形成了全新竞争格局,为智能手机、穿戴设备、车载系统和智能家居等领域带来了广阔的应用前景。作为开发者,如…...

字符串类型排序,通过枚举进行单个维度多个维度排序
字符串类型进行排序通过定义枚举值实现 1.首先创建一个测试类,并实现main方法 2.如果是单个维度的排序,则按照顺序定义一个枚举 public enum Risk {高风险,中风险,一般风险,低风险 } public static void main(String[] args) { }3.main方法里实现如下…...

figma的drop shadow x:0 y:4 blur:6 spread:0 如何写成css样式
figma的drop shadow x:0 y:4 blur:6 spread:0 如何写成css样式 在CSS中,我们可以使用box-shadow属性来模拟Figma中的Drop Shadow效果。box-shadow属性接受的值分别是:横向偏移、纵向偏移、模糊半径、扩展半径和颜色。 但是,Figma的Drop Sha…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...